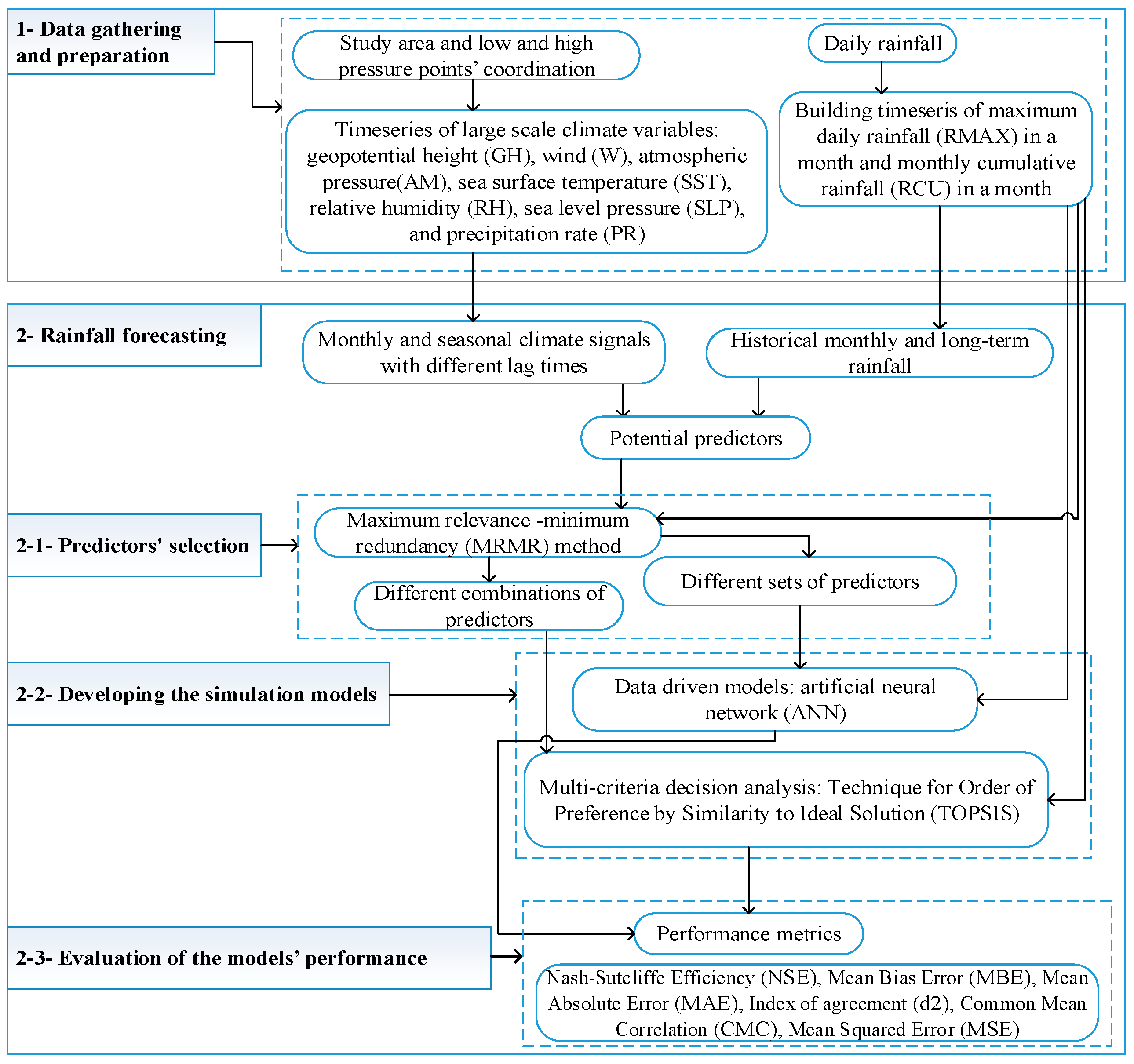
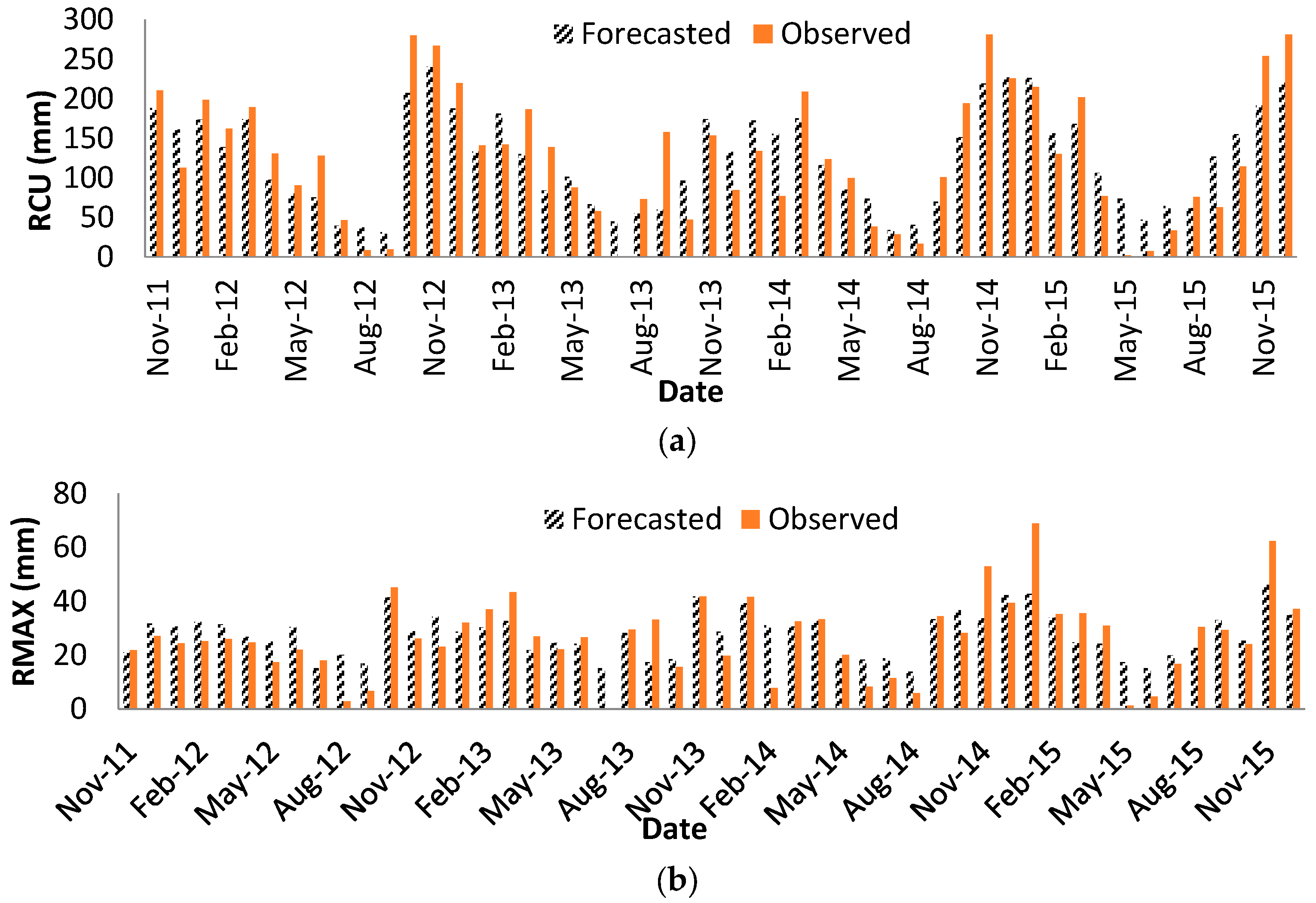
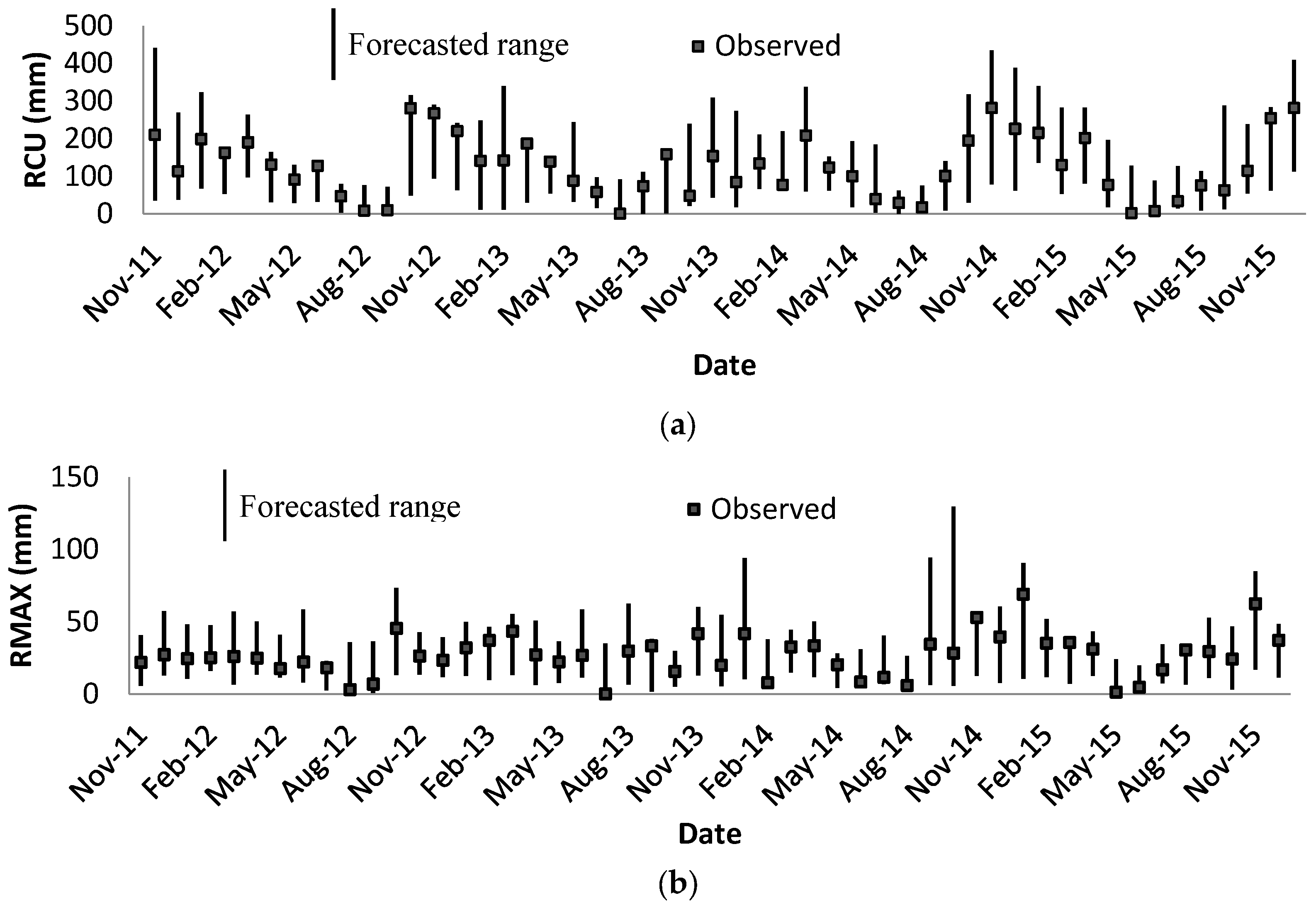
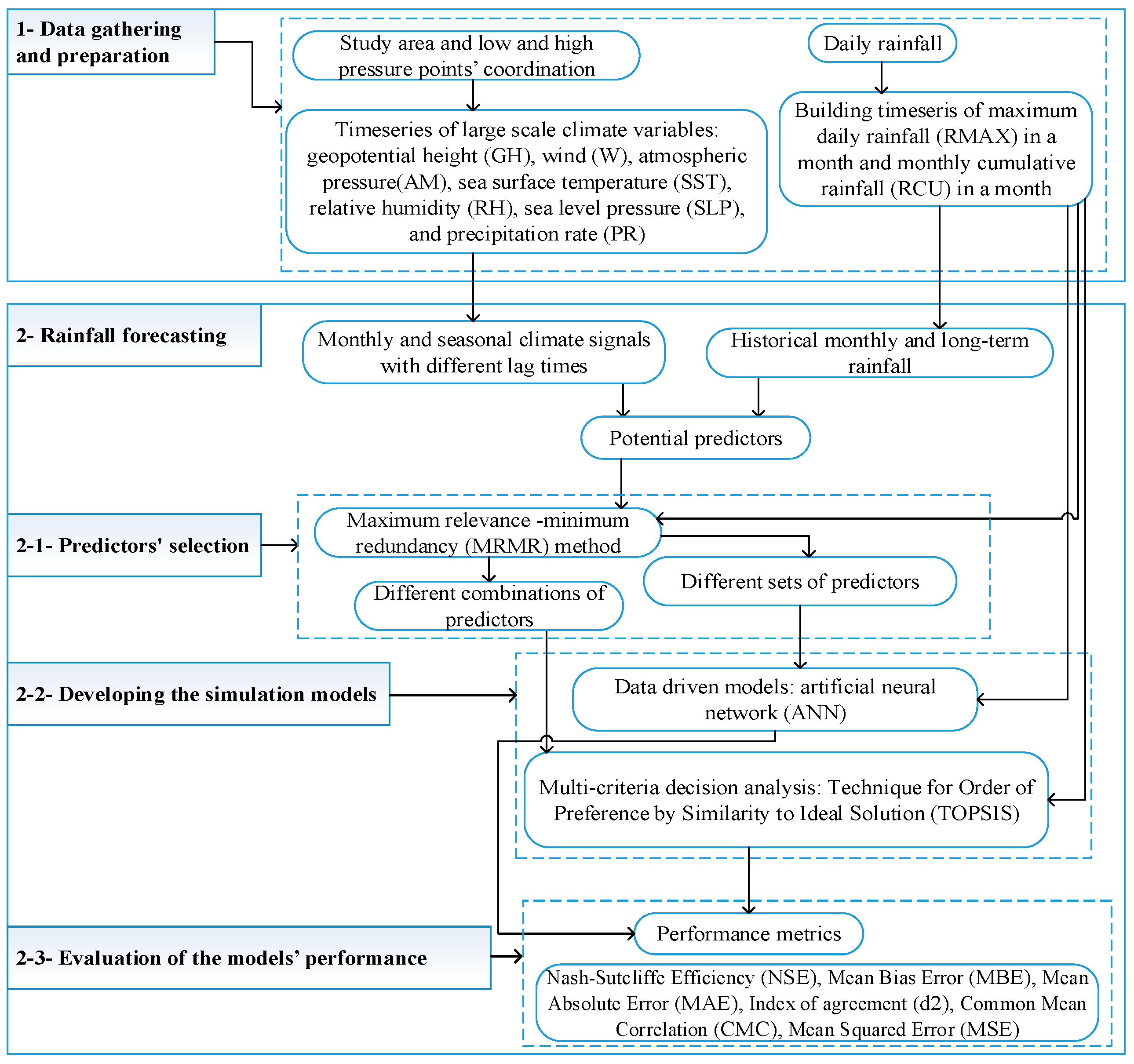
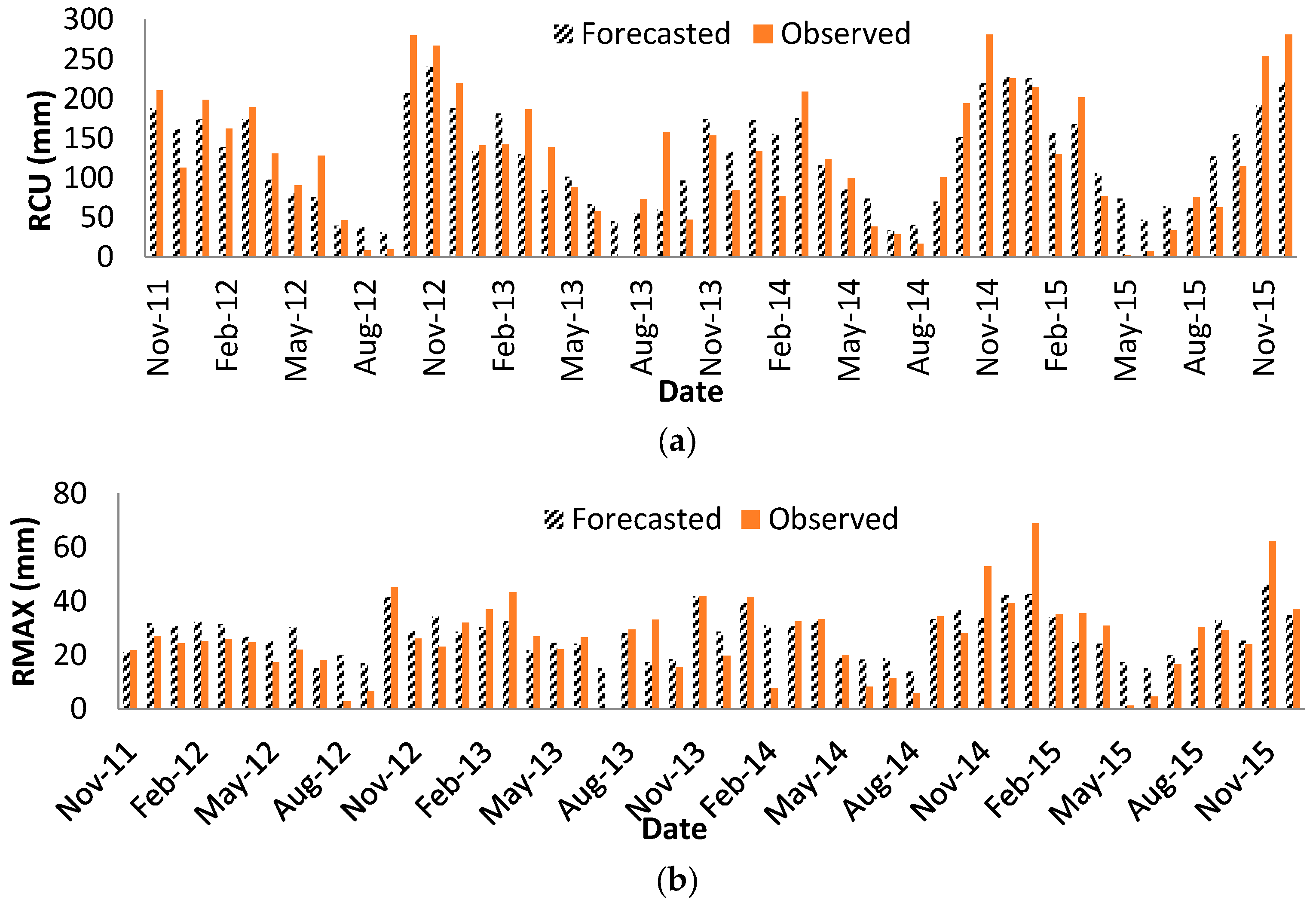
Two rainfall values are considered to be forecasted: monthly maximum daily rainfall (RMAX) (the maximum value of daily rainfall in a month) and monthly cumulative value of rainfall (RCU) (cumulative values of daily rainfalls for a month).
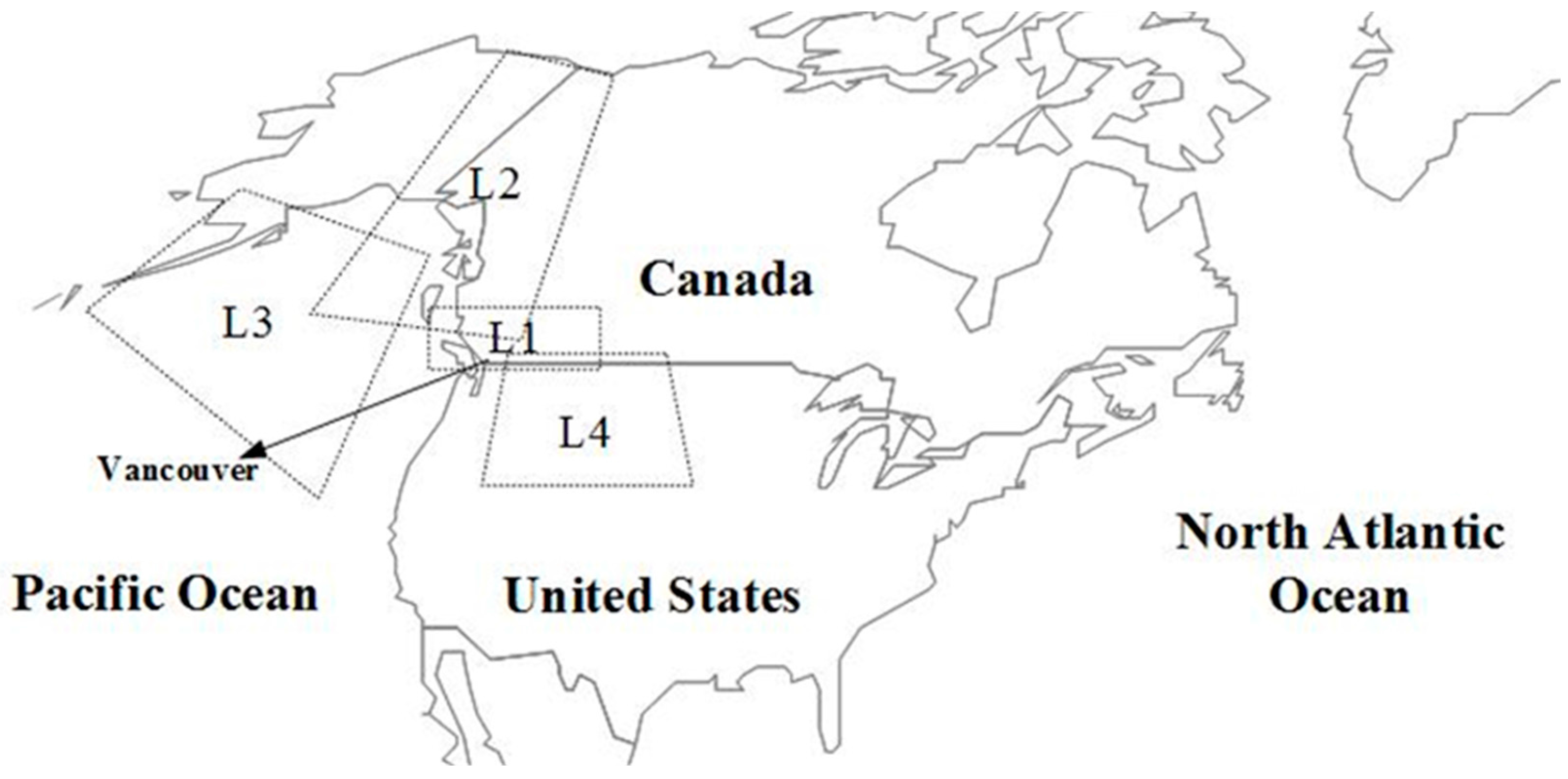
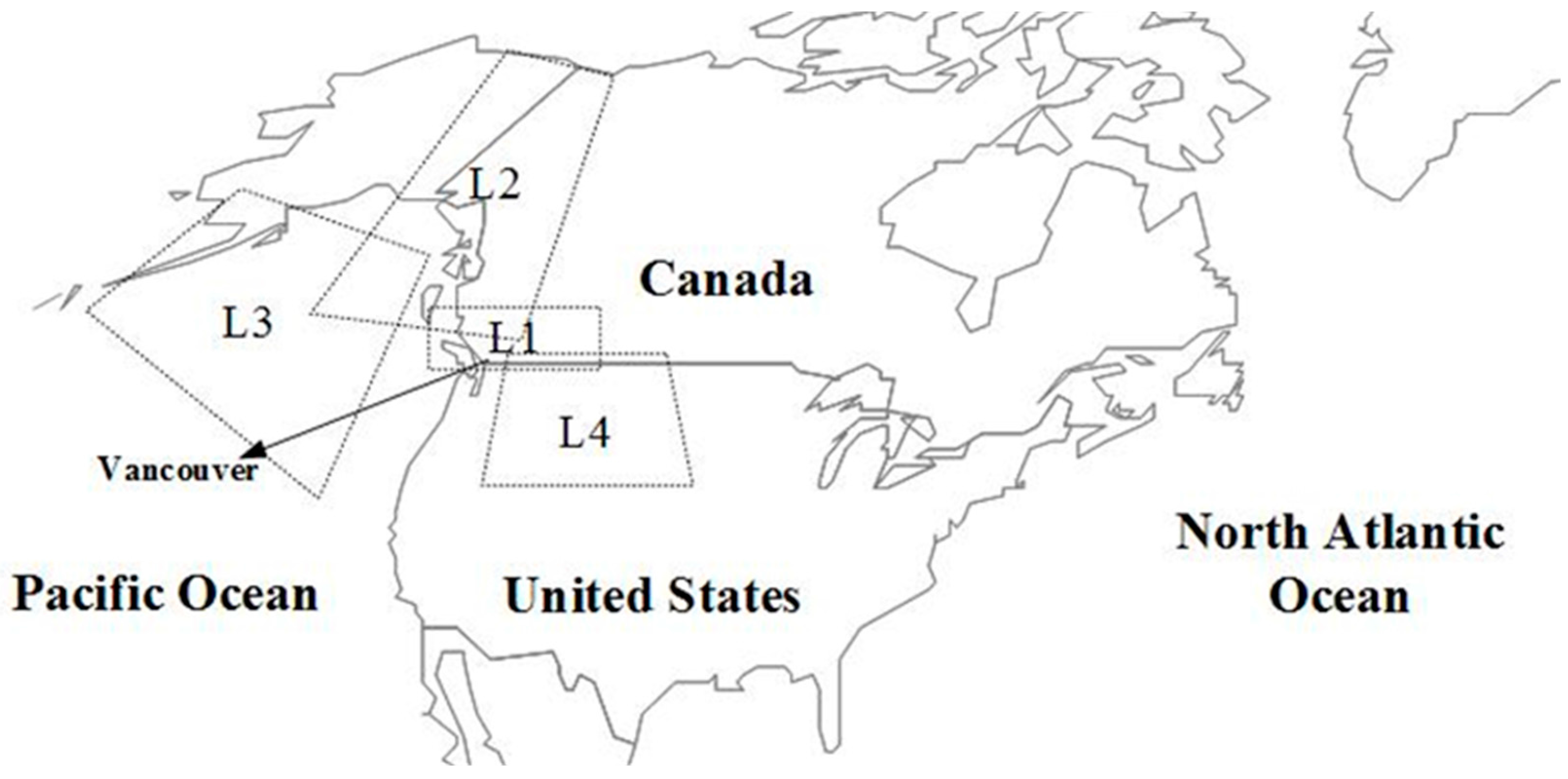
One of the main issues in developing predictive tools is to select the most appropriate set of predictors. Taking into account four locations (L
1–L
4), and monthly and seasonal climate signals with different lag times (1, 2, 3 and 12 months), a large set of possible combinations of predictors can be built. Different feature selection methods, such as Mutual Information [
45], stepwise regression [
46] and Max-Relevance and Min-Redundancy [
45,
47] can be used for selecting the optimal input variables. Considering the findings of the previous studies and the efficiency of these methods, in this study Max-Relevance and Min-Redundancy (MRMR) method is employed to select the most appropriate predictors’ set with efficient number of climate signals. MRMR considers the correlation between input variables (predictors) and rainfall (predictant), as well as inter-correlation between the inputs. The forecasting models use the identified variables by MRMR as input (predictors) and, RMAX and RCU as target (predictant).
3.2.1. Predictors’ Selection for Rainfall Forecasting: Application of MRMR Method
For data driven models, inputs have substantial effect on the model simulation performance. Mutual information (MI)-based methods are tools used to select the most suitable inputs. MRMR is an example of these methods. It selects a set of predictors among a large number of predictors (features) that are related to a predictant. This method can pick out a set of appropriate inputs based on the desired number of predictor variables. The selected predictors have the highest MI with predictant (target) and the lowest MI among themselves.
MI for two random variables of
and
is shown by
.
is defined based on their probabilistic density functions represented by
,
, and
, respectively:
The purpose of MI is to find a set of predictors (called
A) with
k features that jointly have the largest dependency on the target class
:
MRMR is represented by the criteria of maximum relevance (Max-R) and minimum redundancy (Min-R). In Max-R, selected features (
) among the predictors are required to individually have the largest MI with predictant (
c). This reflects a large dependency with the target. Max-R means to find predictors satisfying Equation (3). This equation approximates
with the mean value of all MI’s between
(the
ith feature) and
:
In the feature selection, selecting combinations of individually good features do not necessarily lead to a good performance for the classification. This is due to the redundancy among features. Therefore, the following Min-R condition is added to select mutually exclusive features with minimum redundancy:
MRMR merges the above two max and min constraints. Then, the Φ operator combines
and
to maximize
and minimize
simultaneously:
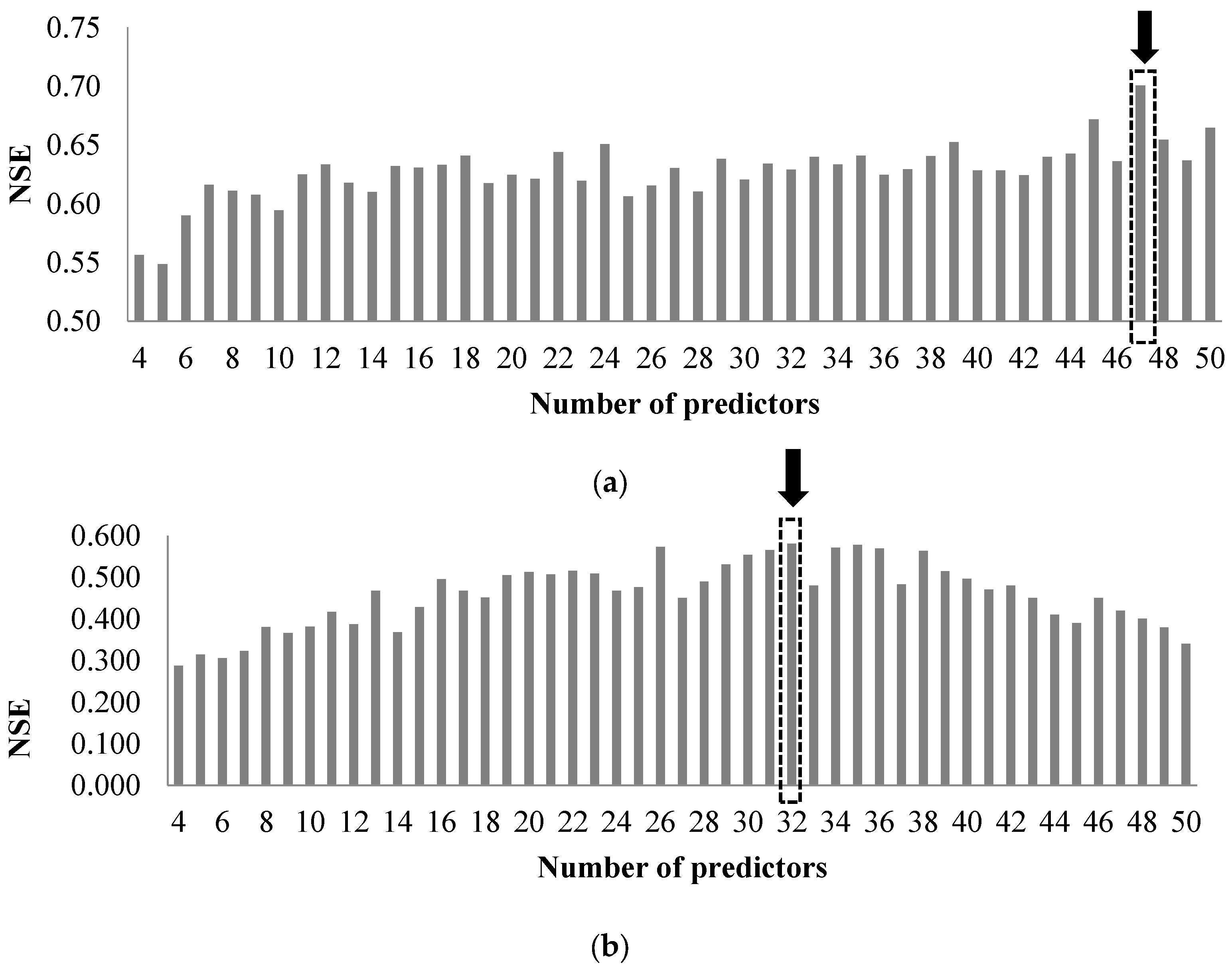
Here, the maximum number of features (k) in the predictors’ set is considered to be 50 (i.e., 4 ≤ k ≤ 50). In the MRMR method, predictors are selected based on their order of correlation with the predictant. In other words, by increasing the value of k, a new predictor is added to the previous set of inputs.
3.2.2. Models’ Development
Two modeling approaches are employed for rainfall simulation and forecasting. The first approach is based on the application of artificial neural network (ANN) machine learning method. The second model uses a multi-criteria decision analysis method, called Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS).
● Data driven models for rainfall forecasting: application of artificial neural network (ANN)
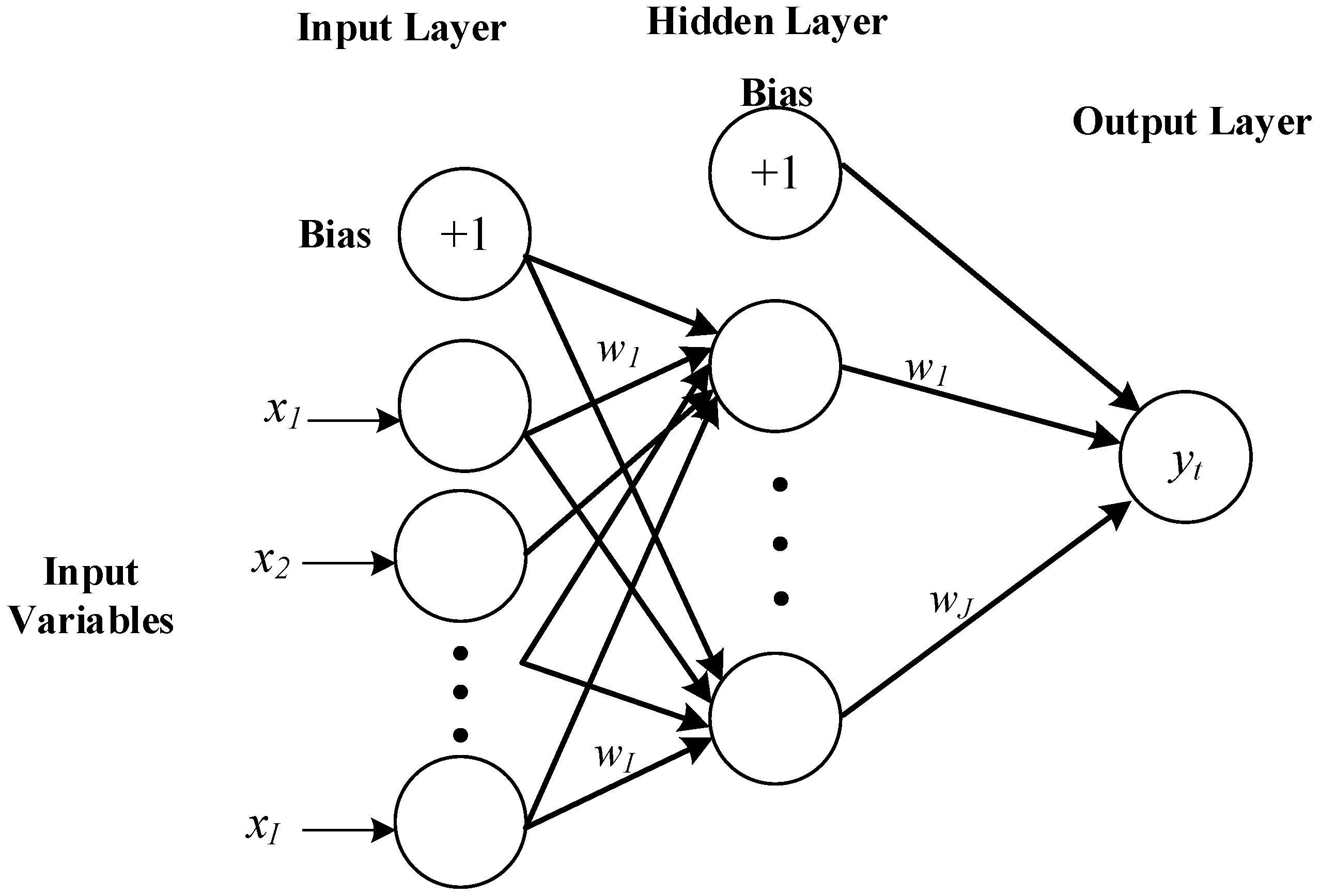
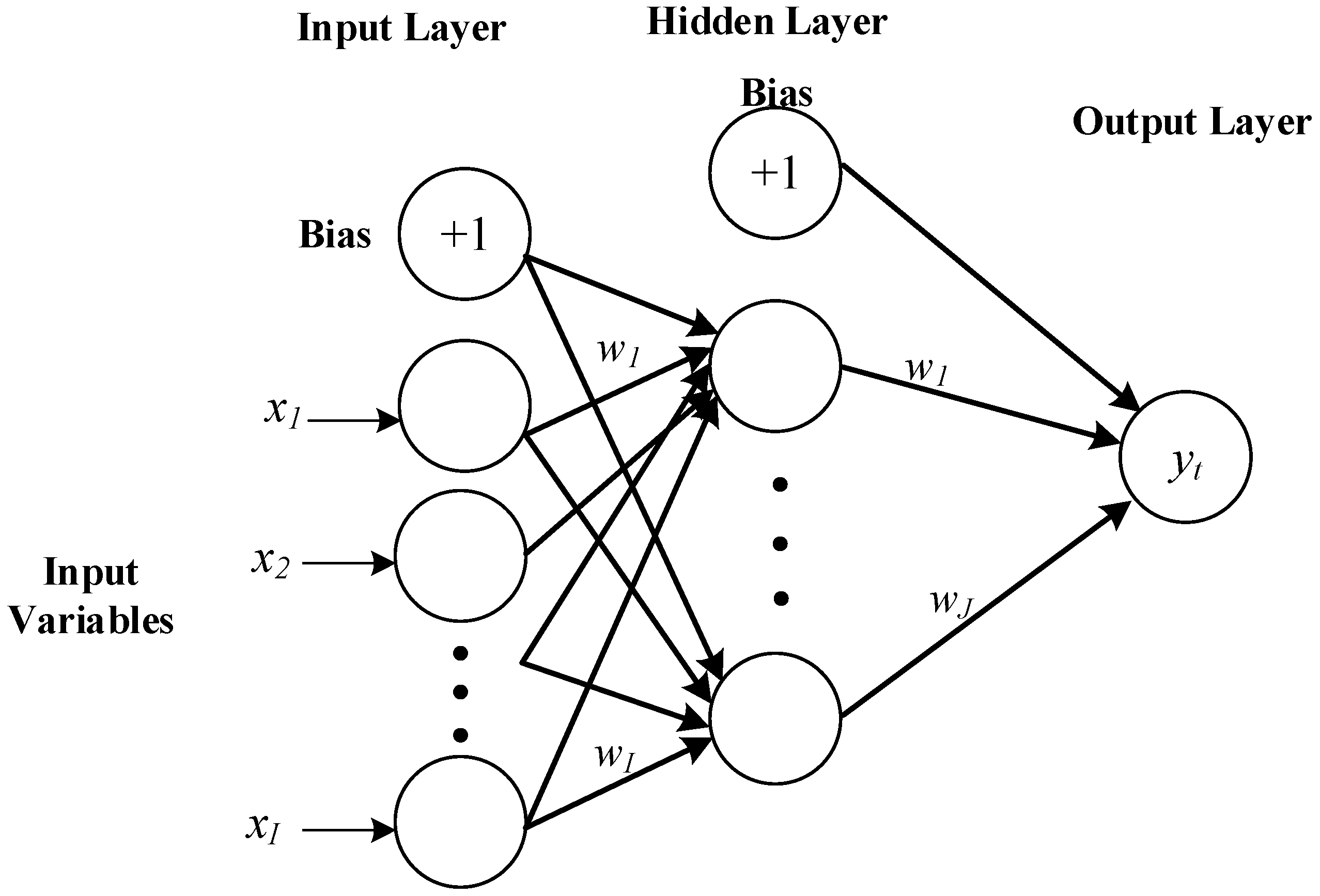
ANNs are composed of a system of interconnected neurons that fed by predictors (inputs) and compute outputs by feeding information through layers of neurons in the network (
Figure 3).
In this study, Multi-Layer Perceptron (MLP) neural network models (feedforward networks that consists of the input layer, the hidden layers and the output layer, and process the information from the input layer to the hidden layer and then the output layer) with various structures are tested:
where
is the output,
is the input, and
and
are the weights between neurons of the input and hidden layer and between the hidden layer and output, respectively.
and
are the bias vectors for the input and hidden layers, and
and
are the activation functions for the output layer and the hidden layer, respectively. Also,
I and
J signify the number of nodes in the input and hidden layer [
28].
Networks with 1 hidden layer with the number of neurons allowed to vary between 2 and 40 are built [
48]. To test if the network simulation performance could be improved, models are checked with logsig (Log-sigmoid) and tansig (Hyperbolic tangent sigmoid) non-linear transfer functions for the hidden layer (
in Equation (7)). Moreover, different training functions including traingdm (Gradient descent with momentum backpropagation), trainlm (Levenberg-Marquardt backpropagation) and traingdx (Gradient descent with momentum and adaptive learning rate backpropagation) are also examined. For the MLP networks, output unit is selected to be the linear purelin (pure linear) function (
In Equation (8)). The number of inputs in each time step is equal to the number of the selected predictors by MRMR. The initial weights are randomly selected, and then to obtain the best simulation, weights are adjusted during the network training. More information about the application of artificial neural networks can be found in [
49]. A vector composed of historical observed rainfall is used for supervised network training using the back propagation algorithms. 70% of data is used for calibration, 20% for validation, and 10% for forecasting.
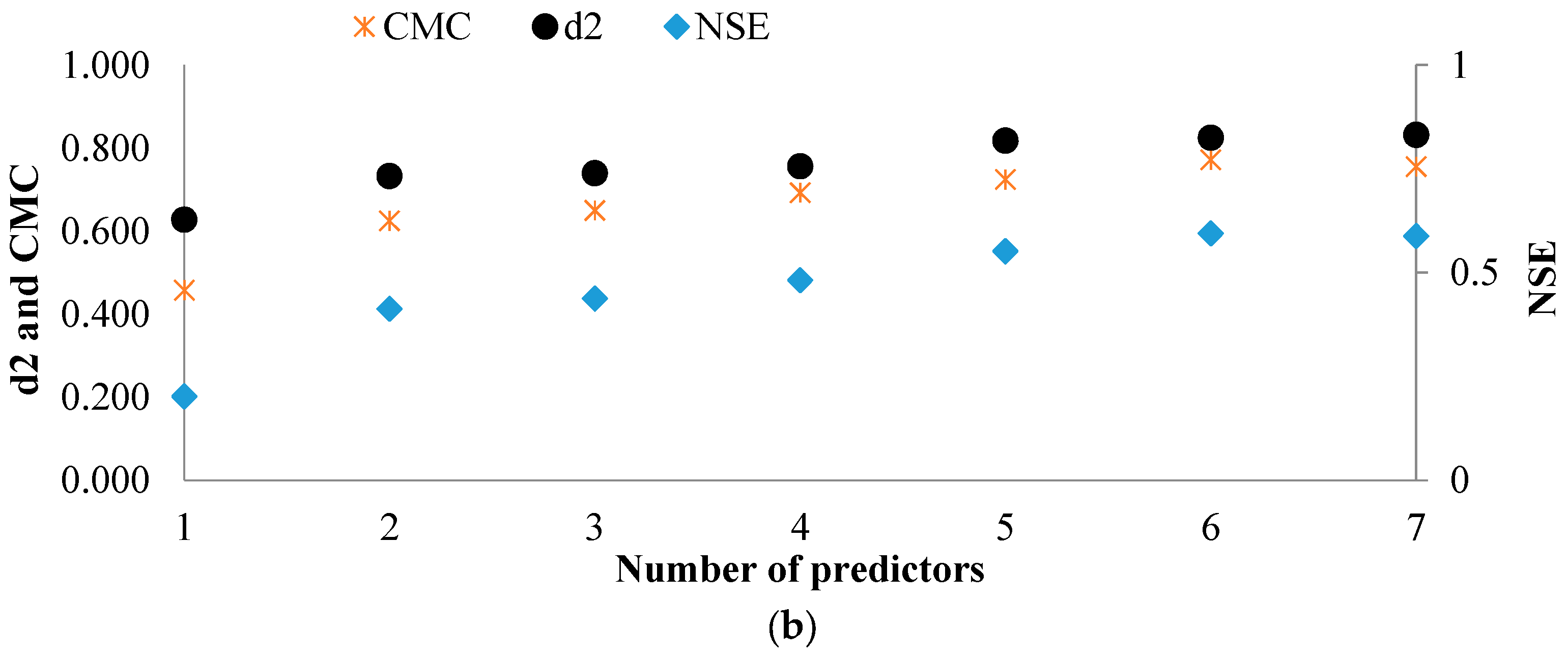
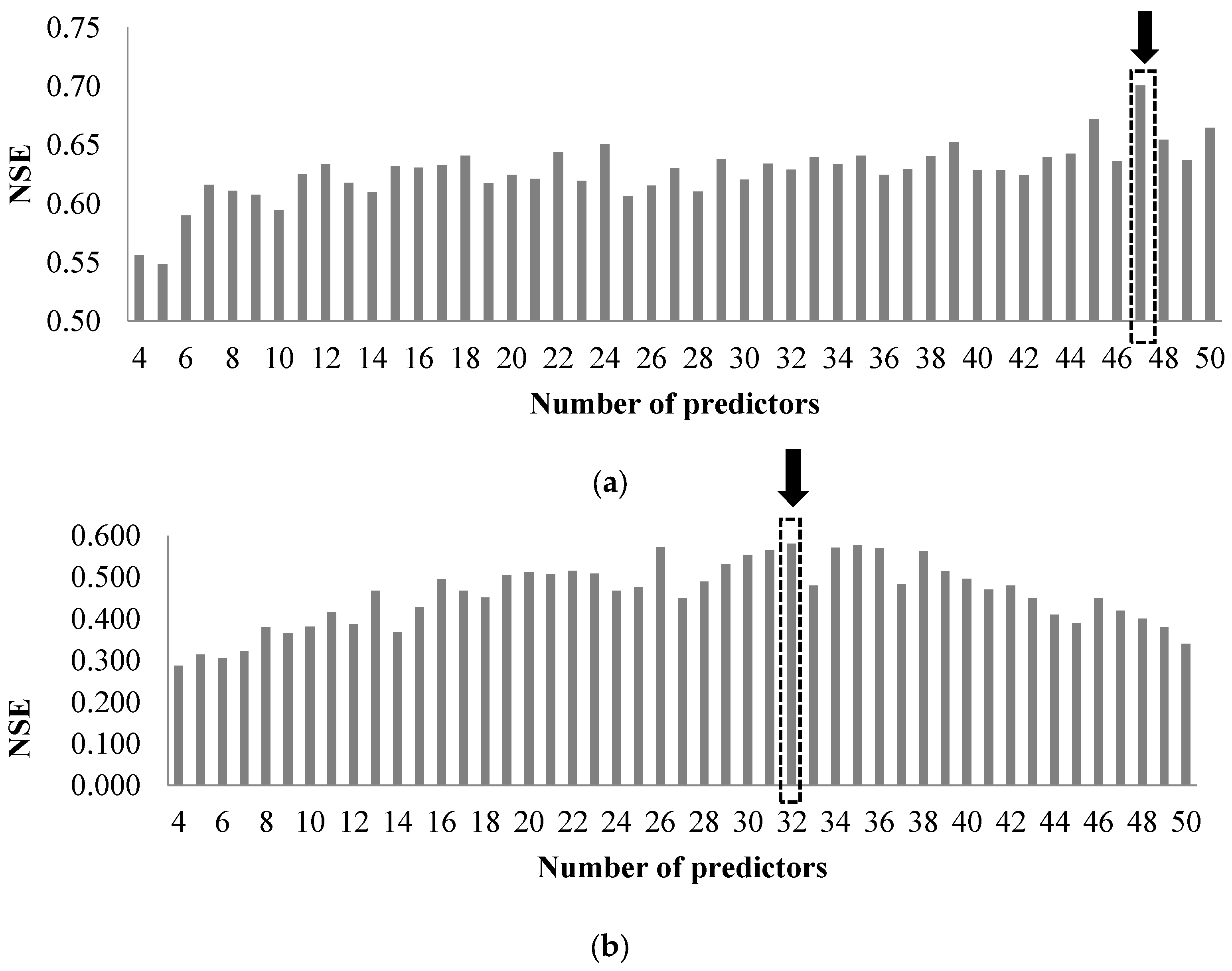
Set of the input data for the networks is built by choosing predictors from the first 50 variables selected among the 198 predictors by MRMR. The minimum number of predictors in the input set is 4 and the maximum number of predictors is 50. To automate the process of constructing the models (with different structures and number of input predictors) and find the model with the highest simulation performance, the whole process is scripted in MATLAB. Several metrics (Equations (17)–(22)) are used to evaluate the goodness of fit of the models’ performance, and finally choose the ANN model with an optimized structure.
● Multi-criteria decision analysis method for rainfall forecasting: Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS)
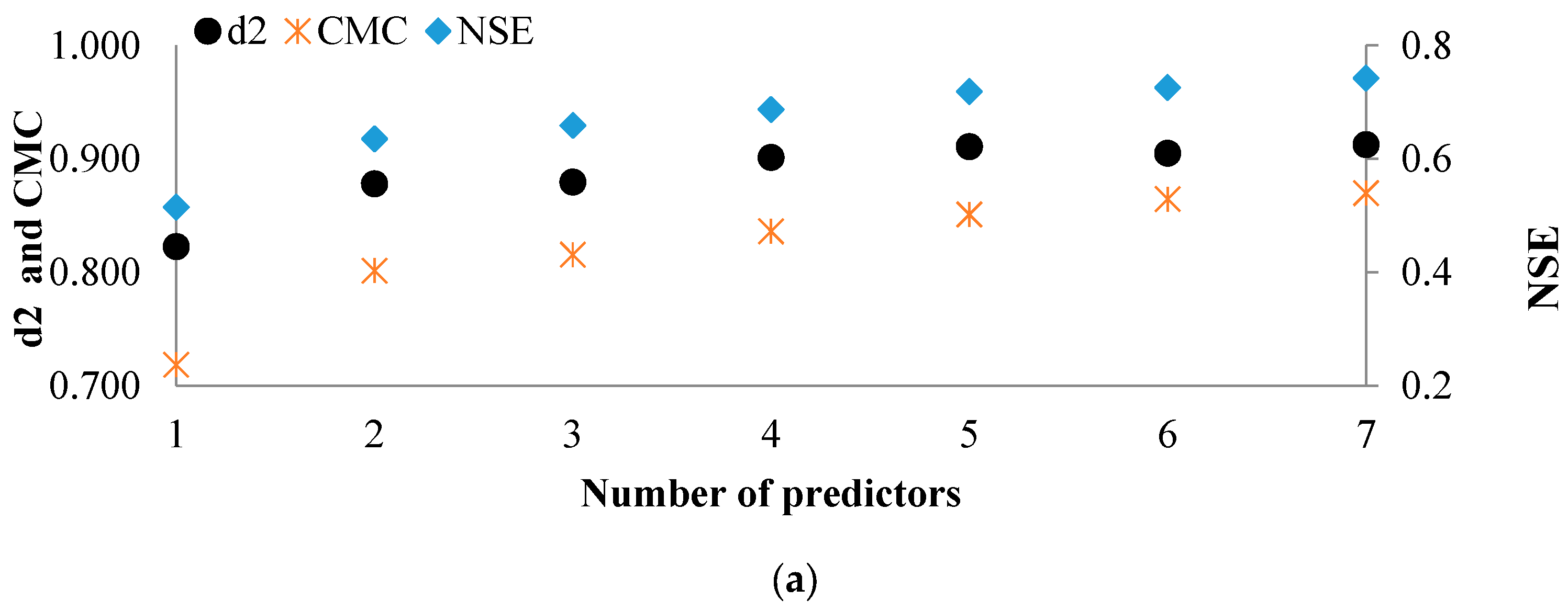
TOPSIS is a multi-criteria decision analysis ranking technique. The efficiency of TOPSIS method to forecast rainfall is investigated in this study. In this technique, the chosen alternative (here is the rainfall event) should have the shortest and longest distances from the positive ideal and negative ideal solutions (selected among the historical rainfall events), respectively. With m alternatives (number of the events in the time series of historical rainfall) and n criteria (number of the selected predictors), a decision matrix () should be built. Given the large number of identified variables (i.e., 198), MRMR method is employed for the selection of the variables to form the predictors’ set (MRMR is set up to select the first 50 most relevant variables). It is decided to test different sets of criteria by letting n changes between 1 and 50. Then, all possible combinations of variables based on the selection of n criteria among 50 variables are checked (i.e., where 1 ≤ n ≤ 50). Consequently, with different values of n, a large number of decision matrices could be developed. Developed modeling approach based on TOPSIS is applied for both timeseries of rainfall, i.e., RMAX and RCU.
Based on
n criteria and
m alternatives, the decision matrix
can be transformed to a non-dimensional normalized decision matrix (
):
Thereafter, the weighted normalized decision matrix (
) is built:
where
, which is the weight given to each predictor (criteria), is considered to be 1. Then, the worst and the best alternatives (negative ideal and positive ideal solutions),
and
respectively, are determined:
where
and
are associated with the criteria having a positive and negative impact, respectively. In the following, distances between alternative
and
and
, (shown by
and
, respectively) are calculated:
Finally, the relative closeness to
and
is determined:
is equal to 0 or 1, if and only if the identified solution has the worst or the best conditions, respectively.
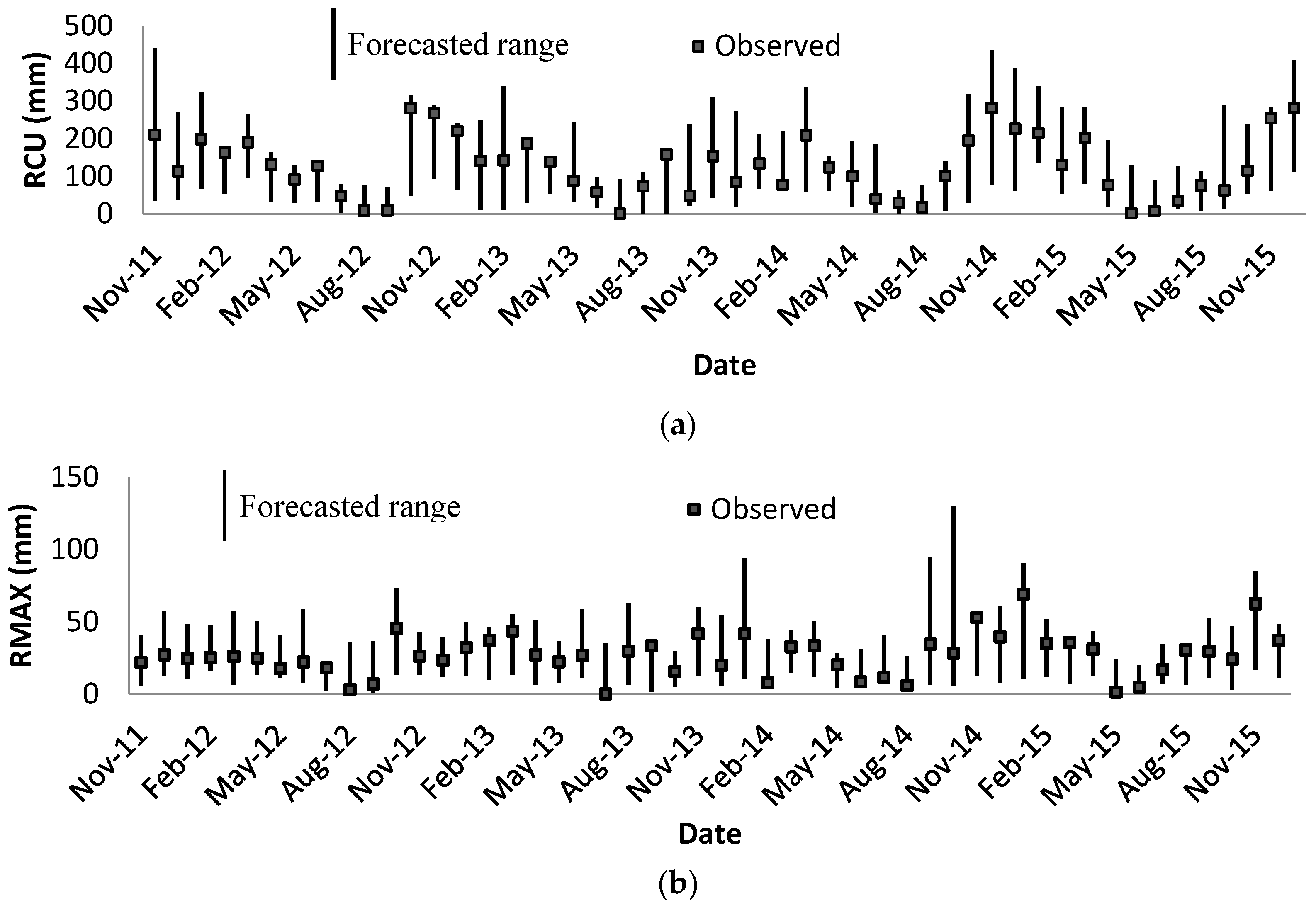
Among the observed events in the rainfall timeseries (i.e., m alternatives), the last 10% of the events are kept to check the performance of the forecasting models. The rest of observed data are used to build the models. In other words, for each of the last 10% of the events, the model will look into the rest of the events (i.e., m − 10% × m events) to find the worst and the best alternatives and then identify the alternative with the highest value of relative closeness based on Equation (15).
To improve the performance of the TOPSIS models for the rainfall forecasting, instead of identifying only one alternative as the solution, 10 rainfall events with the highest values of relative closeness are selected. For this purpose, a set of alternatives is ranked according to the descending order of
. Then, the ten alternatives with the highest values of
are selected and combined using their corresponding relative weights:
where
is the forecasted value of rainfall with one month lead time by TOPSIS,
are the rainfall events with the highest values of relative closeness, and
are the values of relative closeness corresponding to the identified rainfalls. This procedure is repeated for all of the rainfall events kept for checking the models’ performance, while models have different decision matrices. To identify the model with the ideal number of criteria (
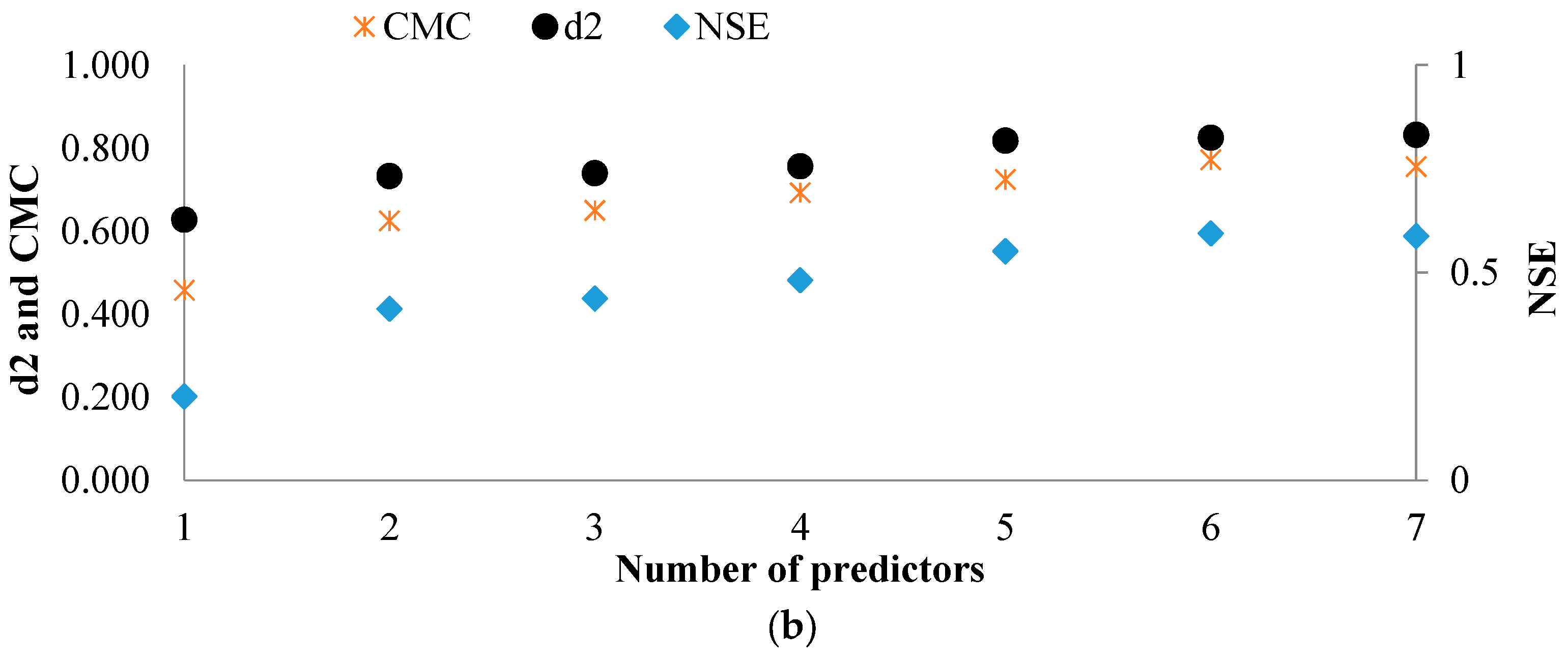
n), the models’ performance for rainfall forecasting should be compared.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}