
Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network




Abstract
1. Introduction
2. Neural Networks
2.1. Neural Networks in General
2.2. Recurrent Neural Networks
2.3. Long Short-Term Memory
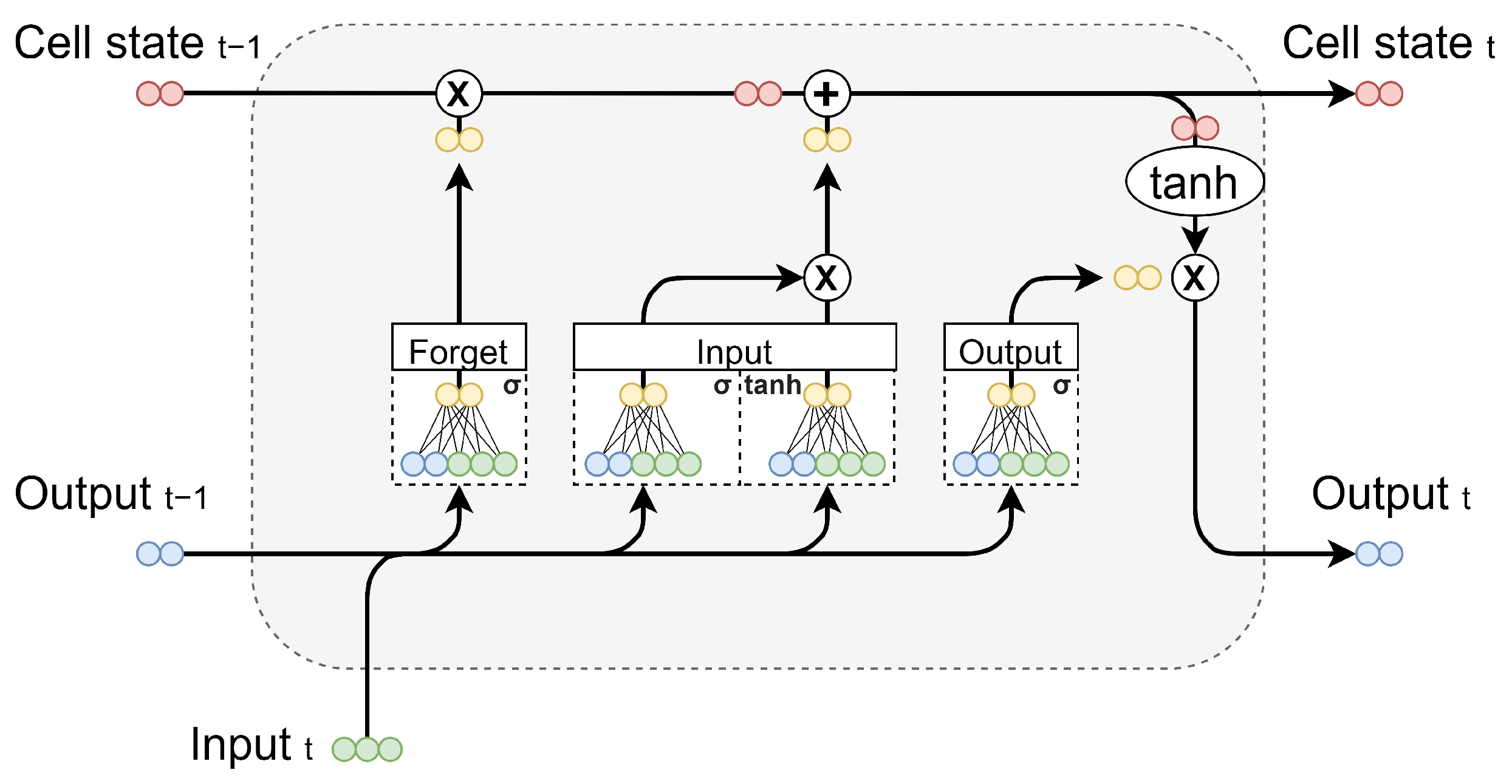
3. Case Study
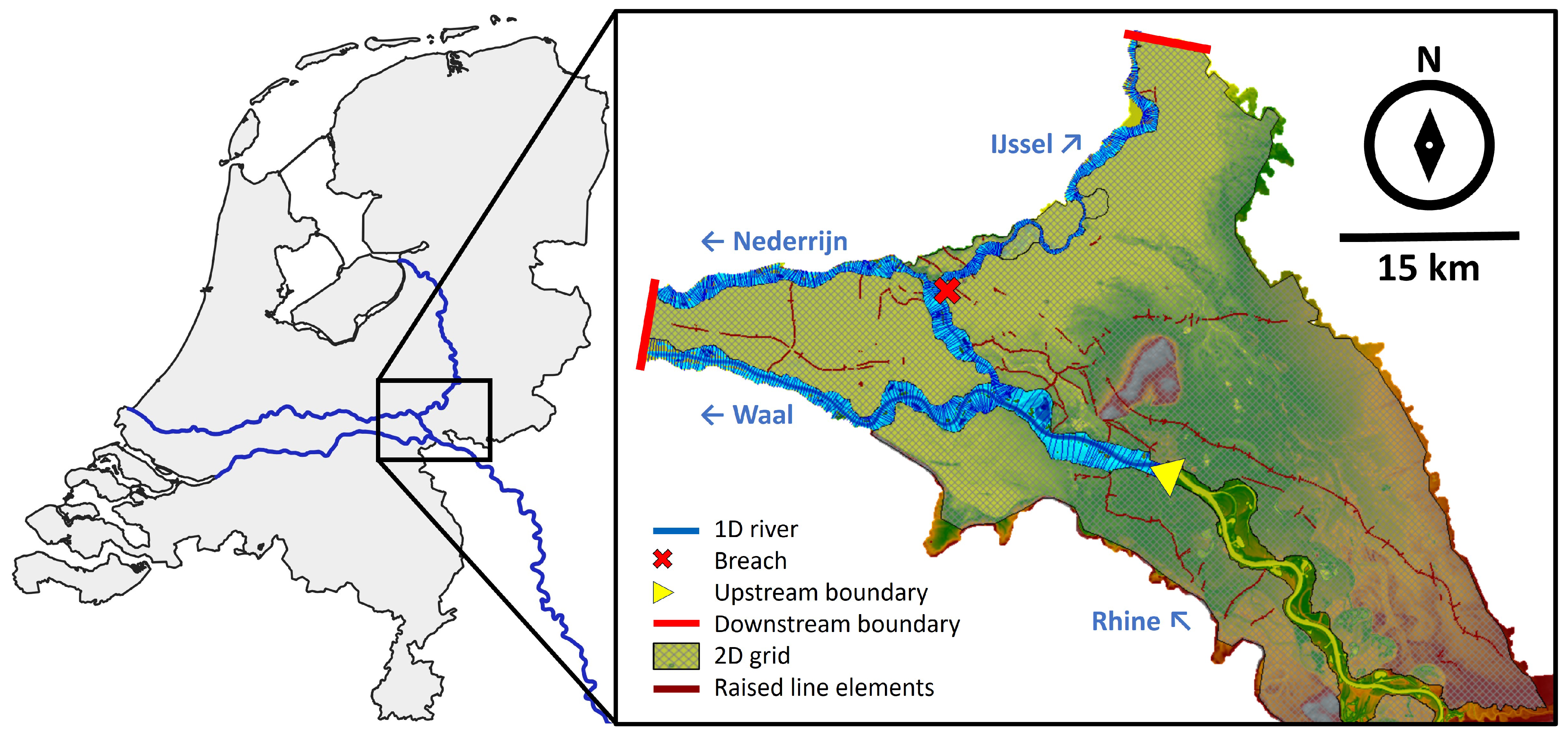
3.1. Hydrodynamic Model
3.1.1. River and Hinterland
3.1.2. Dikes and Breaches
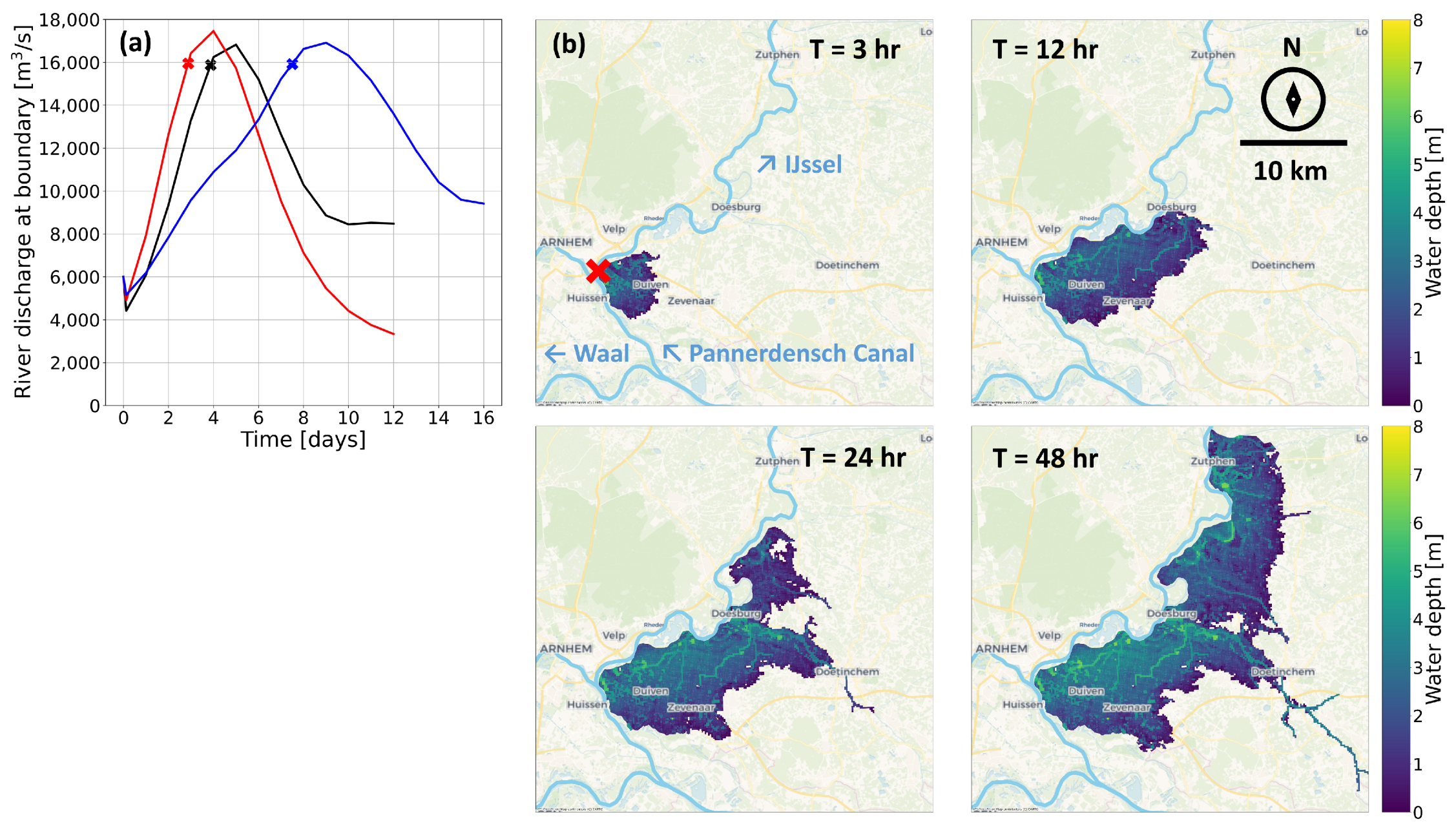
3.2. Available Data
3.3. Data Variability
4. Methods
4.1. LSTM Model Setup
4.1.1. Choice of Architecture
4.1.2. Parameter Optimization
4.1.3. Data Preparation
Performance Evaluation
4.1.4. Performance Indicators
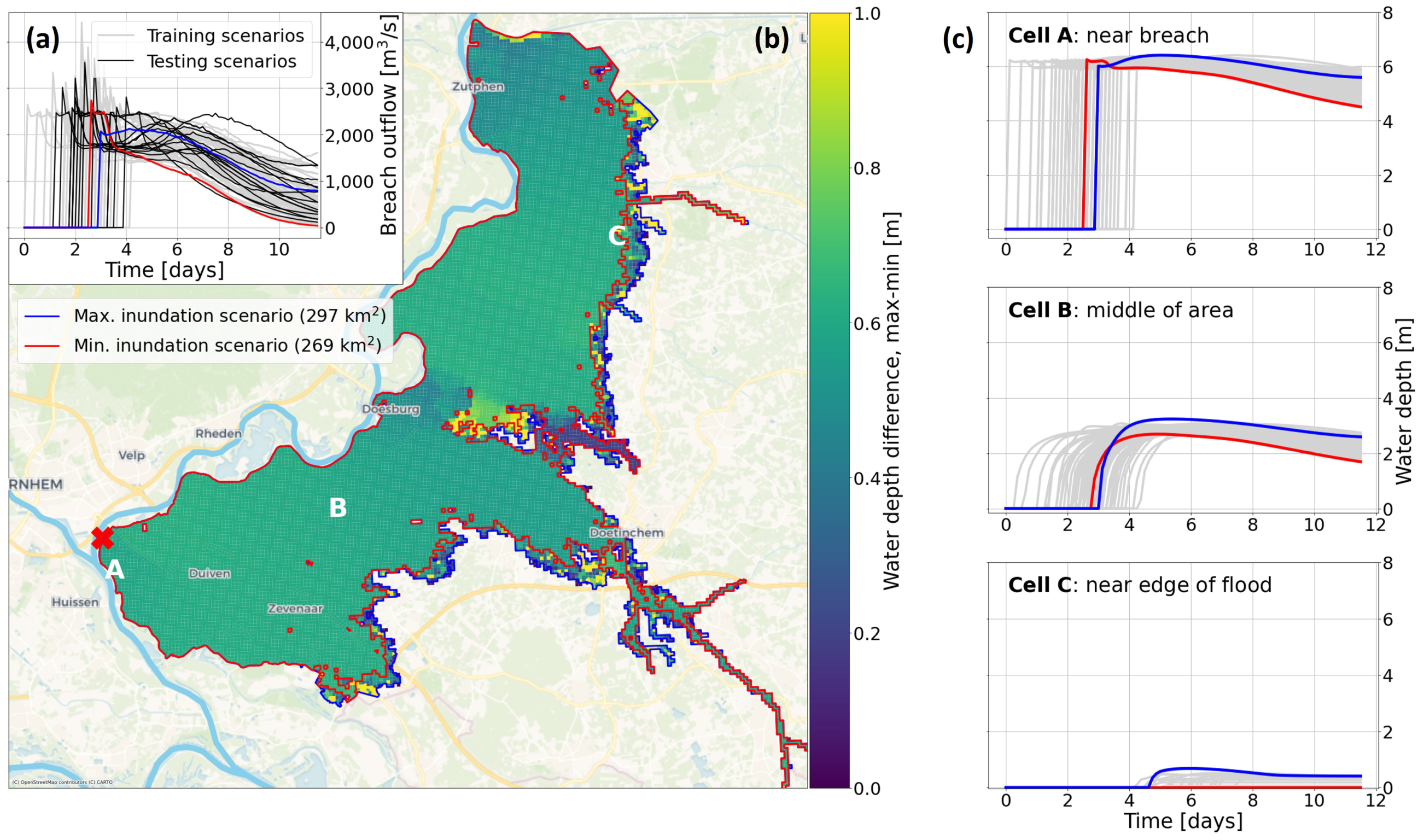
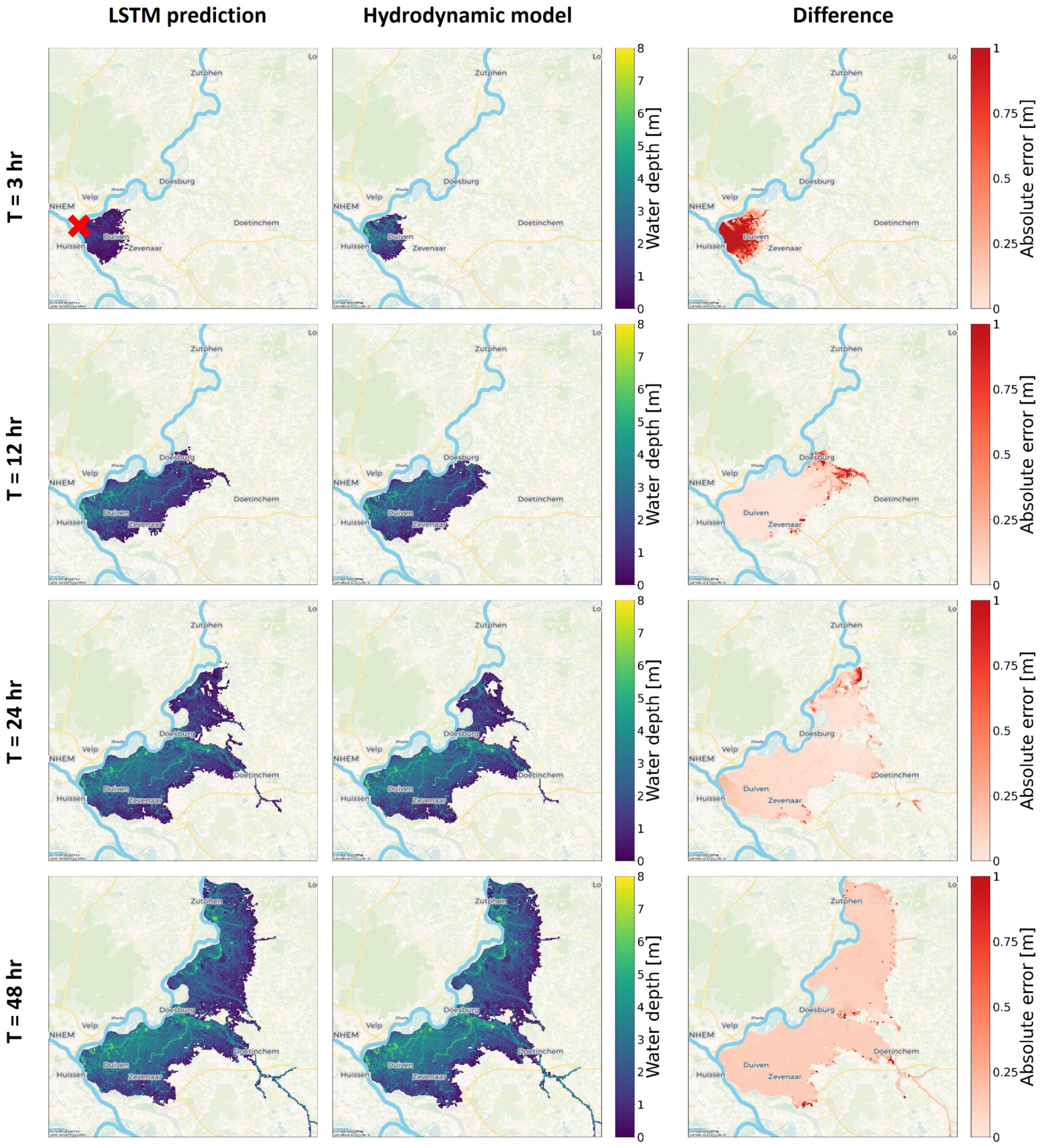
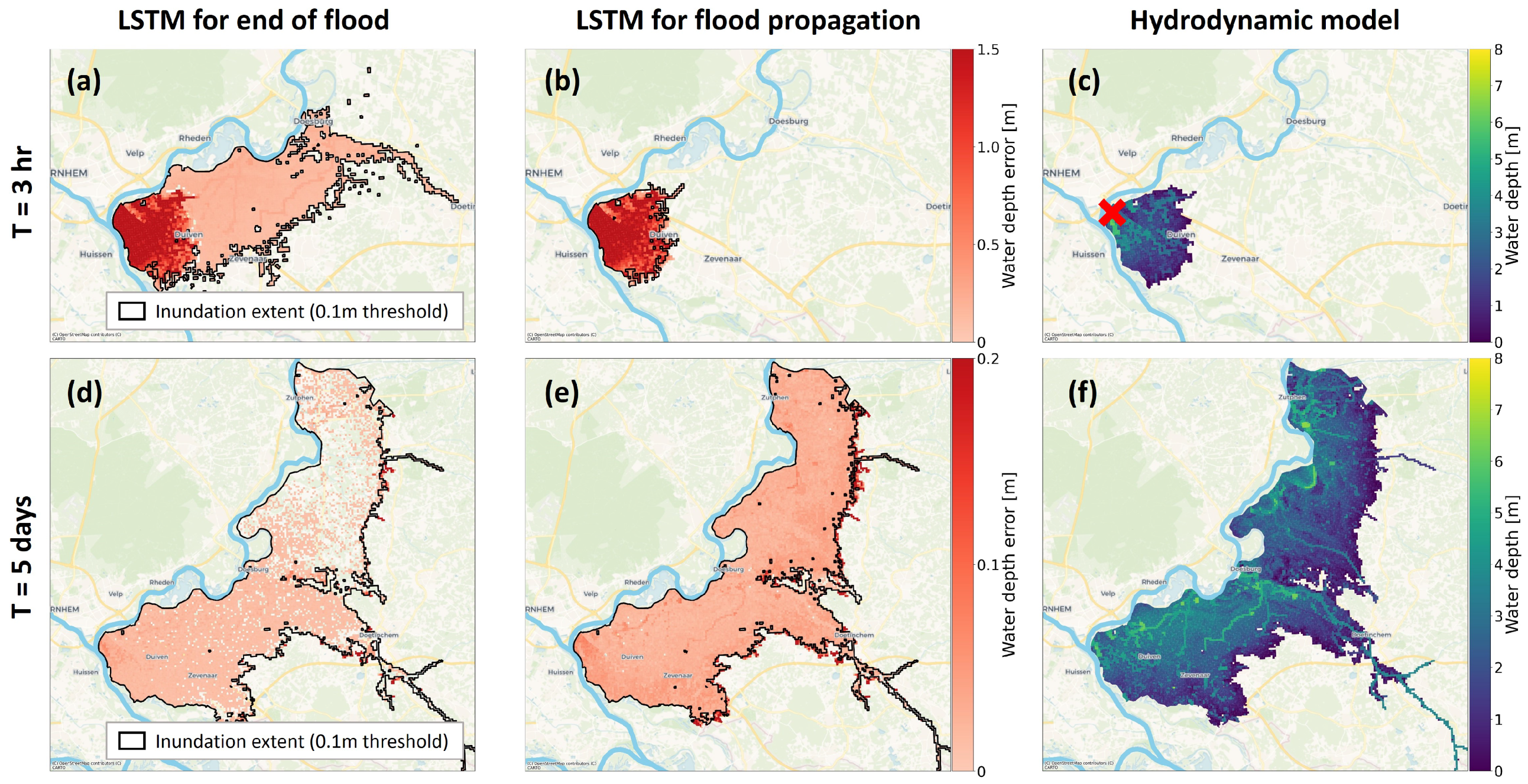
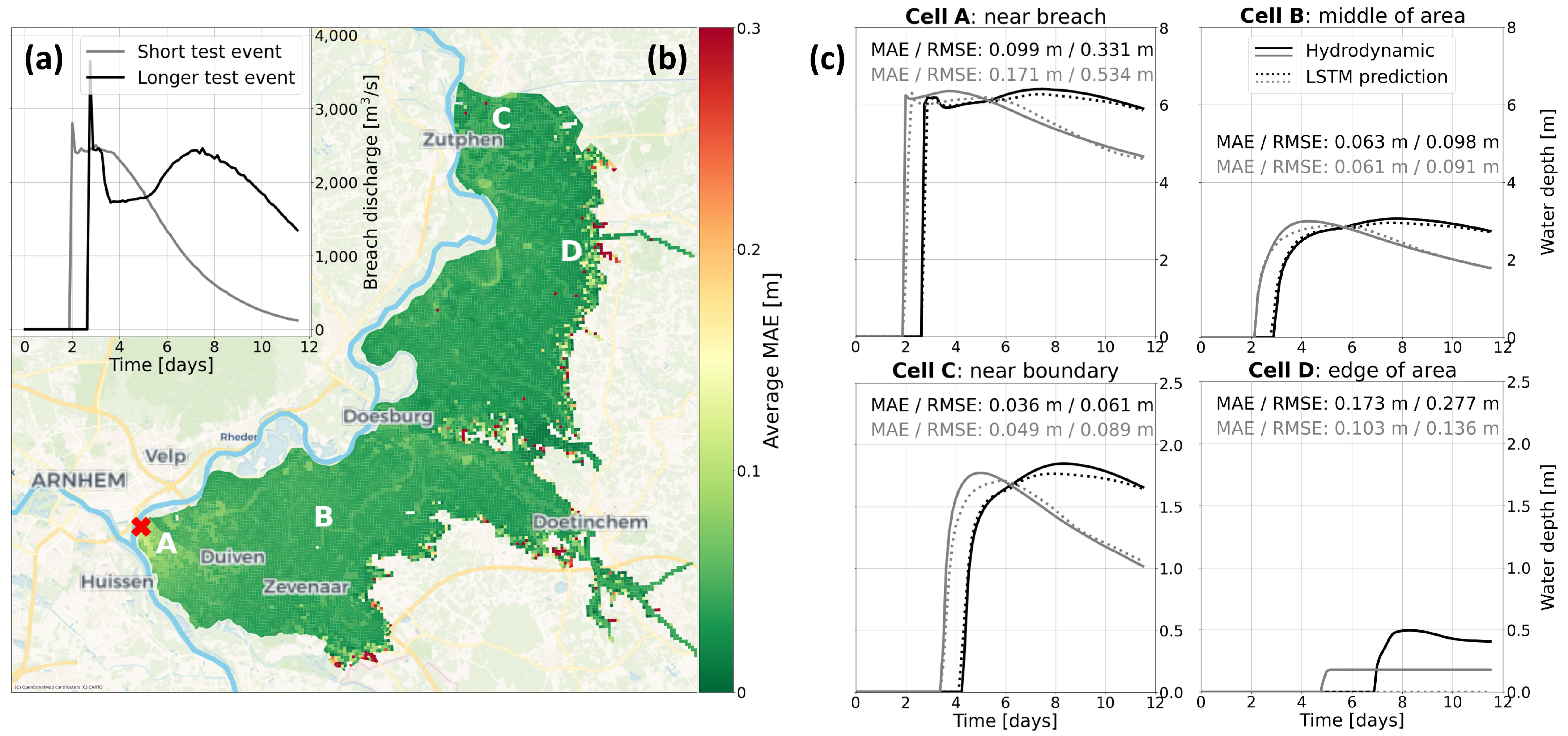
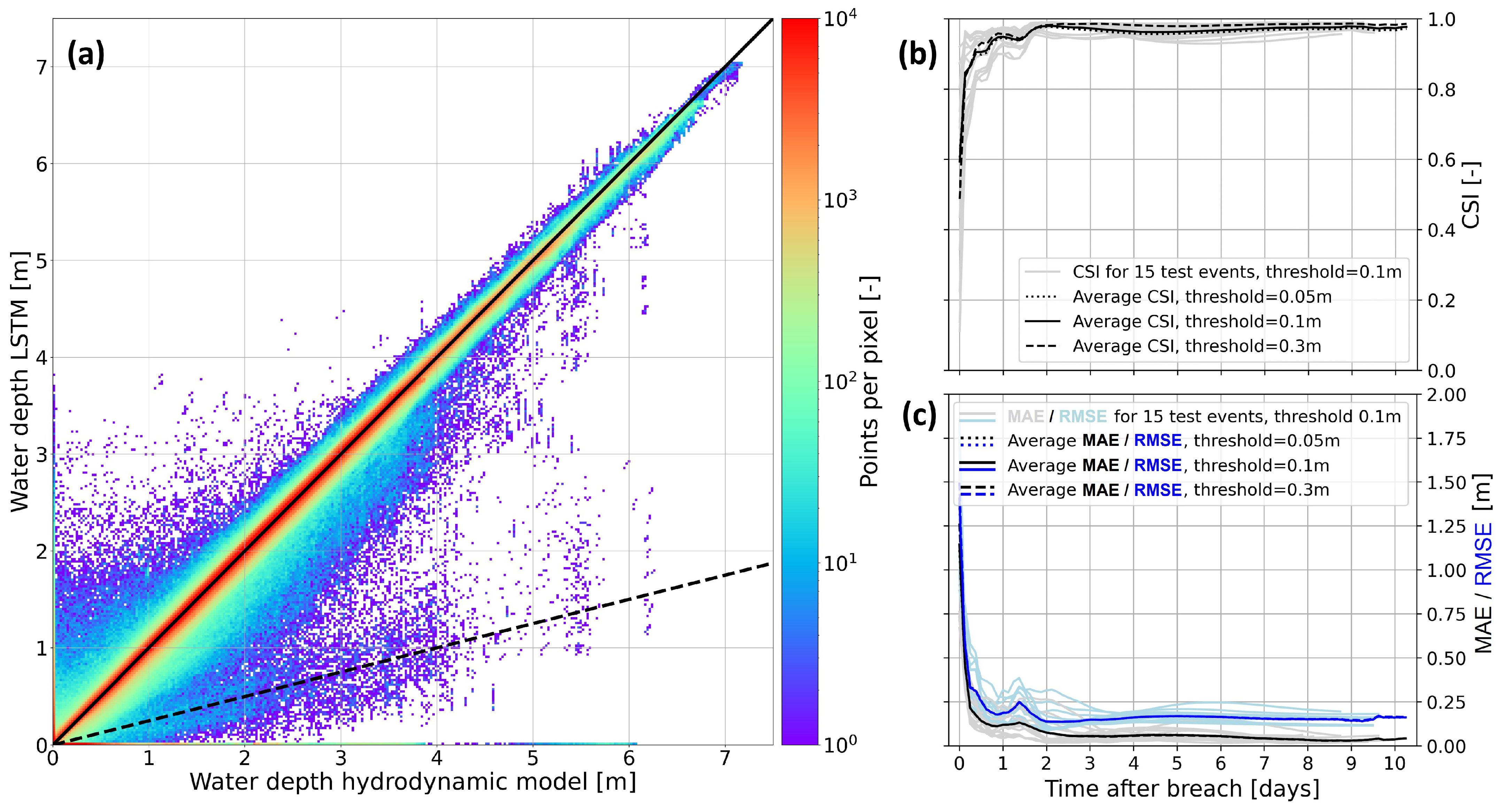
5. Results
5.1. Hyperparameter Optimization
5.2. LSTM Predictions
6. Discussion
6.1. Limitations and Improvements
6.2. Application
6.3. Future Research Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schröter, K.; Barendrecht, M.; Bertola, M.; Ciullo, A.; da Costa, R.T.; Cumiskey, L.; Curran, A.; Diederen, D.; Farrag, M.; Holz, F.; et al. Large-scale flood risk assessment and management: Prospects of a systems approach. Water Secur. 2021, 14, 100109. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.W. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Alkema, D.; Middelkoop, H. The influence of floodplain compartmentalization on flood risk within the Rhine-Meuse delta. Nat. Hazards 2005, 36, 125–145. [Google Scholar] [CrossRef]
- Vorogushyn, S.; Merz, B.; Lindenschmidt, K.E.; Apel, H. A new methodology for flood hazard assessment considering dike breaches. Water Resour. Res. 2010, 46, 8541. [Google Scholar] [CrossRef]
- Chu, H.; Wu, W.; Wang, Q.J.; Nathan, R.; Wei, J. An ANN-based emulation modelling framework for flood inundation modelling: Application, challenges and future directions. Environ. Model. Softw. 2020, 124, 104587. [Google Scholar] [CrossRef]
- Leskens, J.G.; Brugnach, M.; Hoekstra, A.Y.; Schuurmans, W. Why are decisions in flood disaster management so poorly supported by information from flood models? Environ. Model. Softw. 2014, 53, 53–61. [Google Scholar] [CrossRef]
- Apel, H.; Thieken, A.H.; Merz, B.; Blöschl, G. Flood risk assessment and associated uncertainty. Nat. Hazards Earth Syst. Sci. 2004, 4, 295–308. [Google Scholar] [CrossRef]
- Bomers, A.; Schielen, R.M.J.; Hulscher, S.J.M.H. Consequences of dike breaches and dike overflow in a bifurcating river system. Nat. Hazards 2019, 97, 309–334. [Google Scholar] [CrossRef]
- D’Oria, M.; Maranzoni, A.; Mazzoleni, M. Probabilistic Assessment of Flood Hazard due to Levee Breaches Using Fragility Functions. Water Resour. Res. 2019, 55, 8740–8764. [Google Scholar] [CrossRef]
- Teng, J.; Jakeman, A.J.; Vaze, J.; Croke, B.F.W.; Dutta, D.; Kim, S. Flood inundation modelling: A review of methods, recent advances and uncertainty analysis. Environ. Model. Softw. 2017, 90, 201–216. [Google Scholar] [CrossRef]
- Bhola, P.K.; Leandro, J.; Disse, M. Framework for Offline Flood Inundation Forecasts for Two-Dimensional Hydrodynamic Models. Geosciences 2018, 8, 346. [Google Scholar] [CrossRef]
- Ferrari, A.; Dazzi, S.; Vacondio, R.; Mignosa, P. Enhancing the resilience to flooding induced by levee breaches in lowland areas: A methodology based on numerical modelling. Nat. Hazards Earth Syst. Sci. 2020, 20, 59–72. [Google Scholar] [CrossRef]
- Slomp, R.; Kolen, B.; Westera, H.; Verweij, J.; Riedstra, D. Interpreting the impact of flood forecasts by combining policy analysis studies and flood defence. E3S Web Conf. 2016, 7, 03006. [Google Scholar] [CrossRef]
- Dazzi, S.; Vacondio, R.; Mignosa, P.; Aureli, F. Assessment of pre-simulated scenarios as a non-structural measure for flood management in case of levee-breach inundations. Int. J. Disaster Risk Reduct. 2022, 74, 102926. [Google Scholar] [CrossRef]
- Vacondio, R.; Palù, A.D.; Mignosa, P. GPU-enhanced Finite Volume Shallow Water solver for fast flood simulations. Environ. Model. Softw. 2014, 57, 60–75. [Google Scholar] [CrossRef]
- Morales-Hernández, M.; Sharif, M.B.; Kalyanapu, A.; Ghafoor, S.K.; Dullo, T.T.; Gangrade, S.; Kao, S.C.; Norman, M.R.; Evans, K.J. TRITON: A Multi-GPU open source 2D hydrodynamic flood model. Environ. Model. Softw. 2021, 141, 105034. [Google Scholar] [CrossRef]
- Razavi, S.; Tolson, B.A.; Burn, D.H. Review of surrogate modeling in water resources. Water Resour. Res. 2012, 48, W07401. [Google Scholar] [CrossRef]
- McGrath, H.; Bourgon, J.F.; Proulx-Bourque, J.S.; Nastev, M.; Abo El Ezz, A. A comparison of simplified conceptual models for rapid web-based flood inundation mapping. Nat. Hazards 2018, 93, 905–920. [Google Scholar] [CrossRef]
- Campolo, M.; Andreussi, P.; Soldati, A. River flood forecasting with a neural network model. Water Resour. Res. 1999, 35, 1191–1197. [Google Scholar] [CrossRef]
- Minns, A.W.; Hall, M.J. Artificial neural networks as rainfall-runoff models. Hydrol. Sci. J. 1996, 41, 399–417. [Google Scholar] [CrossRef]
- Liu, Y.; Pender, G. A flood inundation modelling using v-support vector machine regression model. Eng. Appl. Artif. Intell. 2015, 46, 223–231. [Google Scholar] [CrossRef]
- Xie, S.; Wu, W.; Mooser, S.; Wang, Q.J.; Nathan, R.; Huang, Y. Artificial neural network based hybrid modeling approach for flood inundation modeling. J. Hydrol. 2021, 592, 125605. [Google Scholar] [CrossRef]
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Deep Learning Methods for Flood Mapping: A Review of Existing Applications and Future Research Directions. Hydrol. Earth Syst. Sci. Discuss. 2022, 26, 4345–4378. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. [Google Scholar] [CrossRef]
- Kabir, S.; Patidar, S.; Xia, X.; Liang, Q.; Neal, J.; Pender, G. A deep convolutional neural network model for rapid prediction of fluvial flood inundation. J. Hydrol. 2020, 590, 125481. [Google Scholar] [CrossRef]
- Hosseiny, H. A deep learning model for predicting river flood depth and extent. Environ. Model. Softw. 2021, 145, 105186. [Google Scholar] [CrossRef]
- Bomers, A. Predicting Outflow Hydrographs of Potential Dike Breaches in a Bifurcating River System Using NARX Neural Networks. Hydrology 2021, 8, 87. [Google Scholar] [CrossRef]
- Le, X.H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Kao, I.F.; Liou, J.Y.; Lee, M.H.; Chang, F.J. Fusing stacked autoencoder and long short-term memory for regional multistep-ahead flood inundation forecasts. J. Hydrol. 2021, 598, 126371. [Google Scholar] [CrossRef]
- Kilsdonk, R.A.H.; Bomers, A.; Wijnberg, K.M. Predicting Urban Flooding Due to Extreme Precipitation Using a Long Short-Term Memory Neural Network. Hydrology 2022, 9, 105. [Google Scholar] [CrossRef]
- Karim, R. Animated RNN, LSTM and GRU: Recurrent Neural Network Cells in GIFs. 2018. Available online: https://towardsdatascience.com/animated-rnn-lstm-and-gru-ef124d06cf45 (accessed on 31 August 2024).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 31 August 2024).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 31 August 2024).
- Pascanu, R.; Gulcehre, C.; Cho, K.; Bengio, Y. How to Construct Deep Recurrent Neural Networks. arXiv 2014, arXiv:1312.6026. [Google Scholar] [CrossRef]
- Rajaee, T.; Ebrahimi, H.; Nourani, V. A review of the artificial intelligence methods in groundwater level modeling. J. Hydrol. 2019, 572, 336–351. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. The MNIST Database of Handwritten Digits. 1998. Available online: https://yann.lecun.com/exdb/mnist/ (accessed on 31 August 2024).
- Neelz, S.; Pender, G. Benchmarking the Latest Generation of 2D Hydraulic Modelling Packages; Technical Report; UK Environment Agency: Rotherham, UK, 2013.
- Wijaya, O.T.; Yang, T.H. A Novel Hybrid Approach Based on Cellular Automata and a Digital Elevation Model for Rapid Flood Assessment. Water 2021, 13, 1311. [Google Scholar] [CrossRef]
- Karim, F.; Armin, M.A.; Ahmedt-Aristizabal, D.; Tychsen-Smith, L.; Petersson, L. A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling. Water 2023, 15, 566. [Google Scholar] [CrossRef]
- Pianforini, M.; Dazzi, S.; Pilzer, A.; Vacondio, R. Real-time flood maps forecasting for dam-break scenarios with a transformer-based deep learning model. J. Hydrol. 2024, 635, 131169. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Pfaff, T.; Fortunato, M.; Sanchez-Gonzalez, A.; Battaglia, P.W. Learning Mesh-Based Simulation with Graph Networks. arXiv 2020, arXiv:2010.03409. [Google Scholar] [CrossRef]
- Sanchez-Gonzalez, A.; Godwin, J.; Pfaff, T.; Ying, R.; Leskovec, J.; Battaglia, P.W. Learning to Simulate Complex Physics with Graph Networks. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Virtual, 13–18 July 2020; PartF168147-11. pp. 8428–8437. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, W.; Jia, X.; Ma, F.; Gao, Y. Fluid Simulation System Based on Graph Neural Network. arXiv 2022, arXiv:2202.12619. [Google Scholar] [CrossRef]
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Rapid spatio-temporal flood modelling via hydraulics-based graph neural networks. Hydrol. Earth Syst. Sci 2023, 27, 4227–4246. [Google Scholar] [CrossRef]
- Besseling, L.; Bomers, A.; Hulscher, S. Data Accompanying the Publication: Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network. 4TU.ResearchData. 2024. Available online: https://doi.org/10.4121/6fd289d8-ec0e-4dd9-94fd-4566783e9c3d (accessed on 31 August 2024).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAE [m] | RMSE [m] | CSI [-] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time after Breach [days]: | 2 | 4 | 6 | All | 2 | 4 | 6 | All | 2 | 4 | 6 | All |
| LSTM for end of flood | 0.14 | 0.078 | 0.057 | 0.038 | 0.27 | 0.18 | 0.14 | 0.092 | 0.81 | 0.89 | 0.92 | 0.94 |
| LSTM for flood propagation | 0.082 | 0.071 | 0.067 | 0.045 | 0.19 | 0.17 | 0.17 | 0.13 | 0.91 | 0.94 | 0.95 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Besseling, L.S.; Bomers, A.; Hulscher, S.J.M.H. Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network. Hydrology 2024, 11, 152. https://doi.org/10.3390/hydrology11090152
Besseling LS, Bomers A, Hulscher SJMH. Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network. Hydrology. 2024; 11(9):152. https://doi.org/10.3390/hydrology11090152
Chicago/Turabian StyleBesseling, Leon S., Anouk Bomers, and Suzanne J. M. H. Hulscher. 2024. "Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network" Hydrology 11, no. 9: 152. https://doi.org/10.3390/hydrology11090152
APA StyleBesseling, L. S., Bomers, A., & Hulscher, S. J. M. H. (2024). Predicting Flood Inundation after a Dike Breach Using a Long Short-Term Memory (LSTM) Neural Network. Hydrology, 11(9), 152. https://doi.org/10.3390/hydrology11090152