Training of Artificial Neural Networks Using Information-Rich Data


Abstract
:1. Introduction
2. Methodology
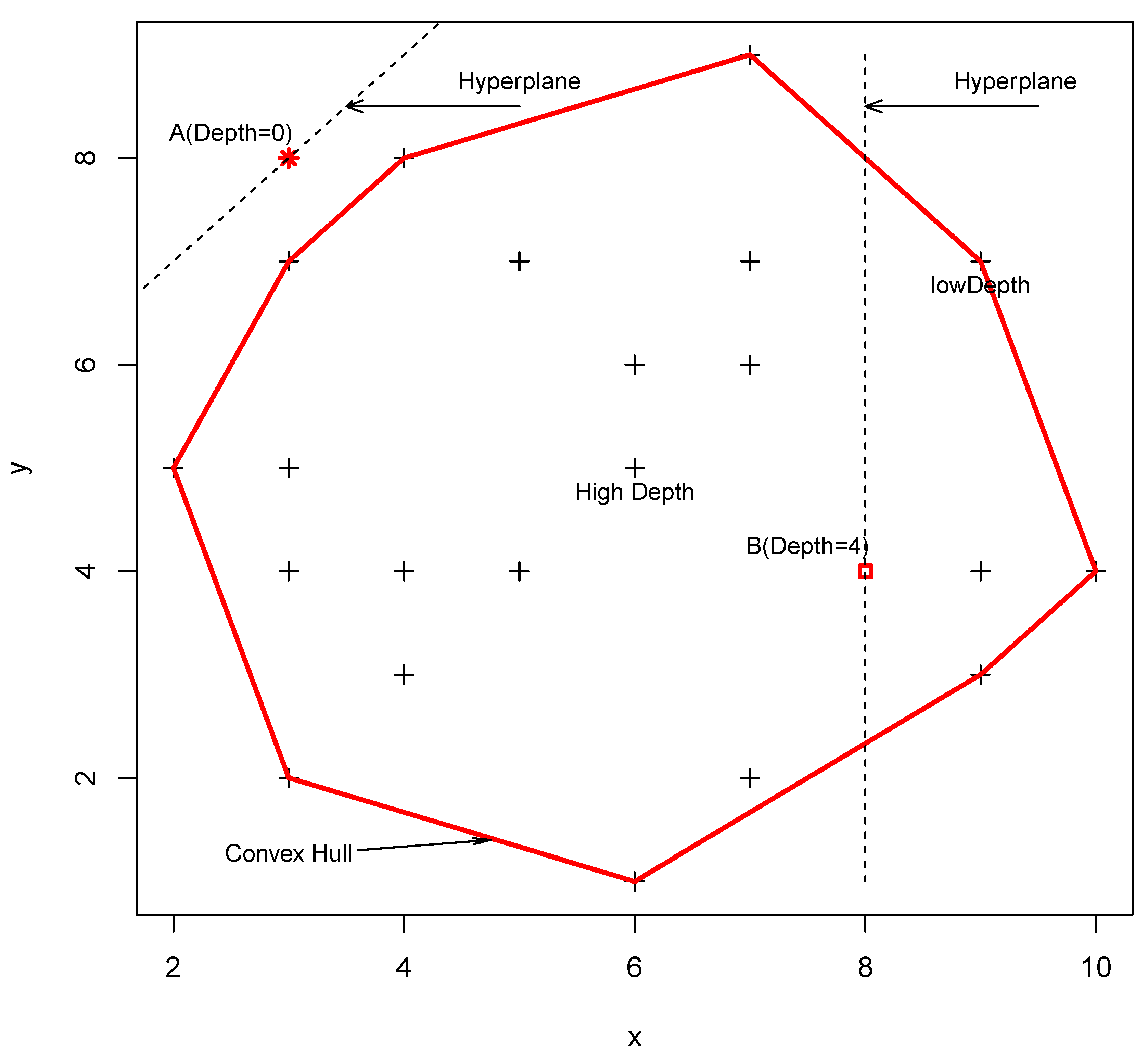
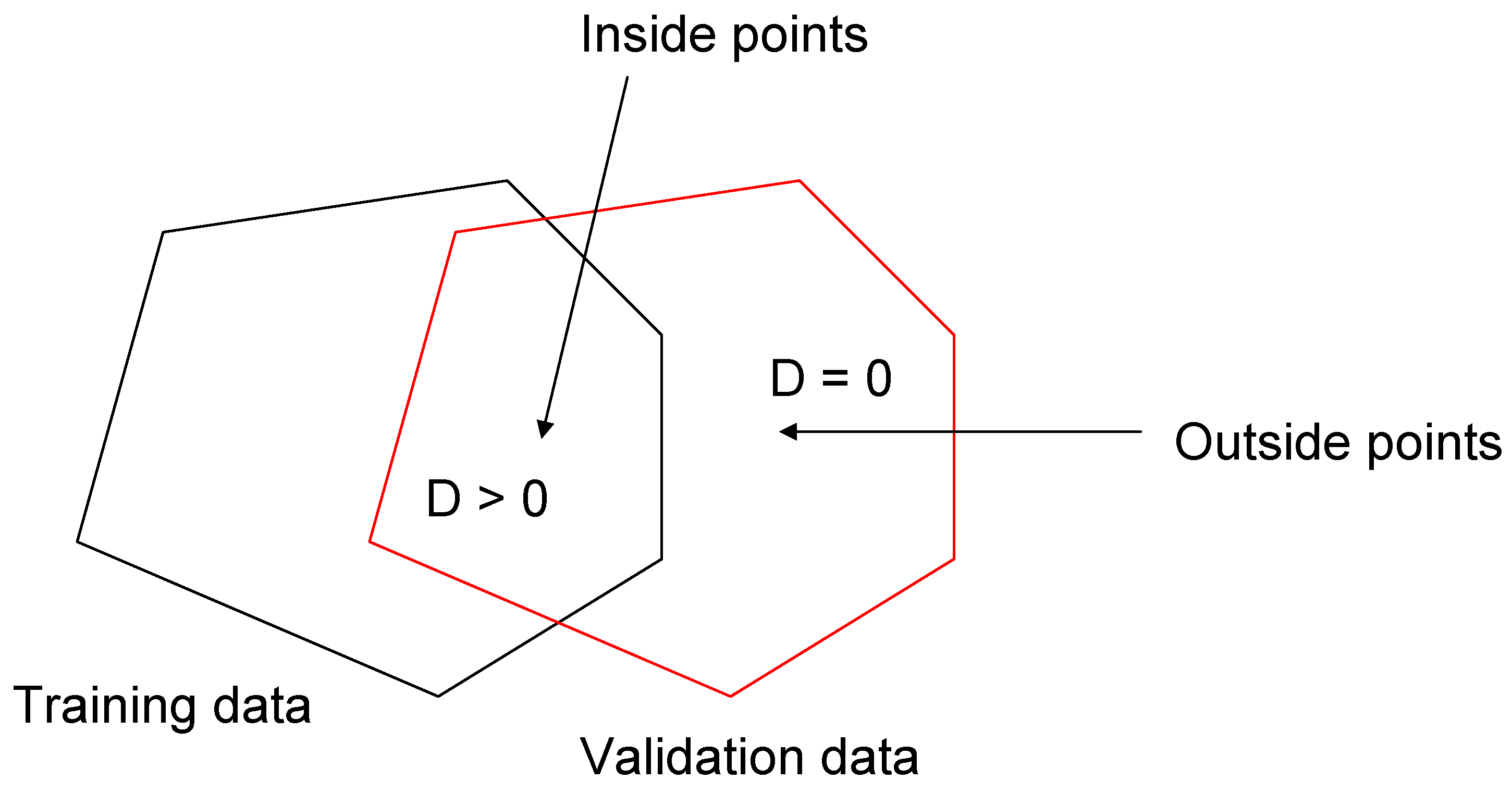
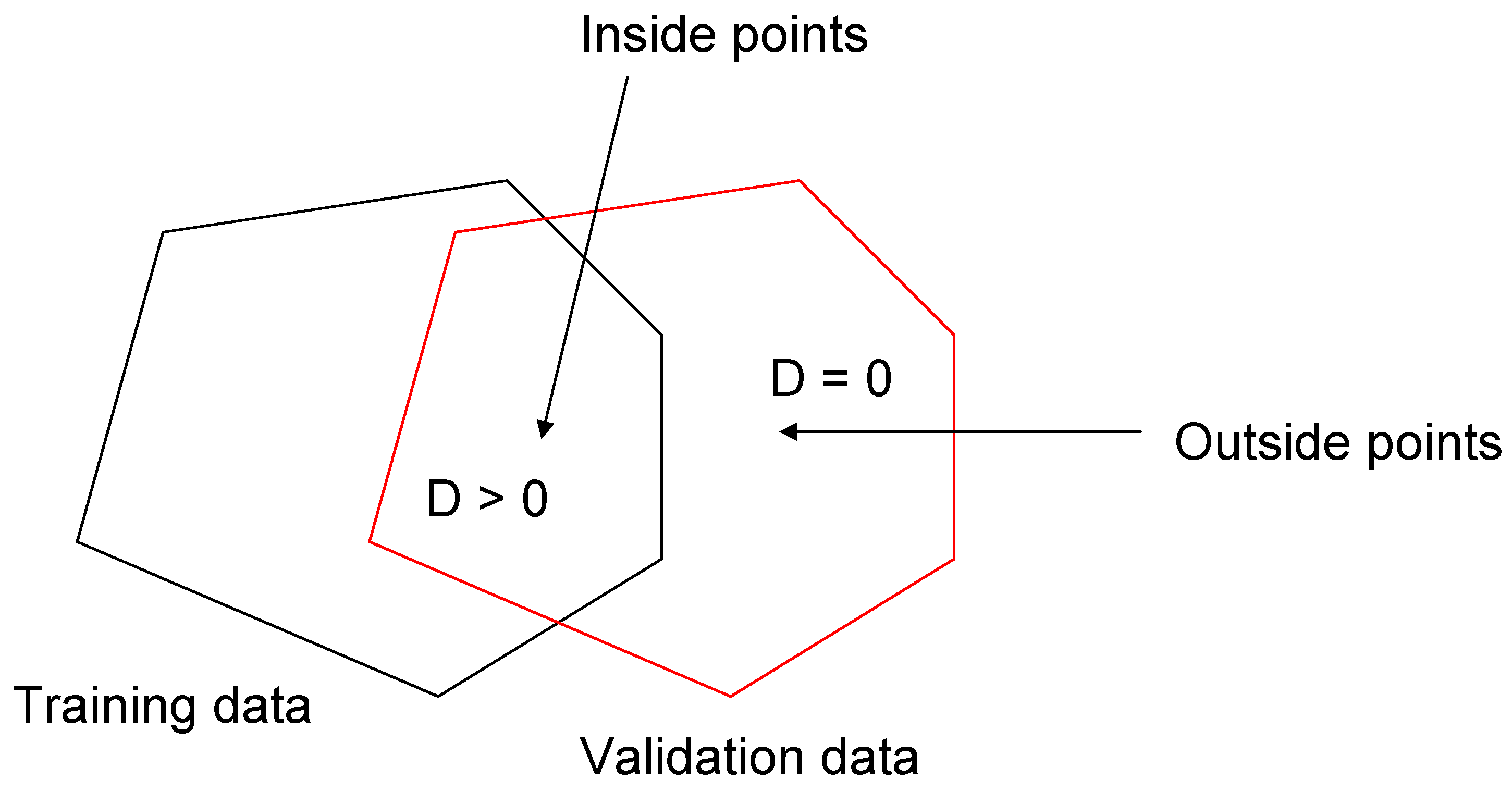
2.1. Data Depth Function
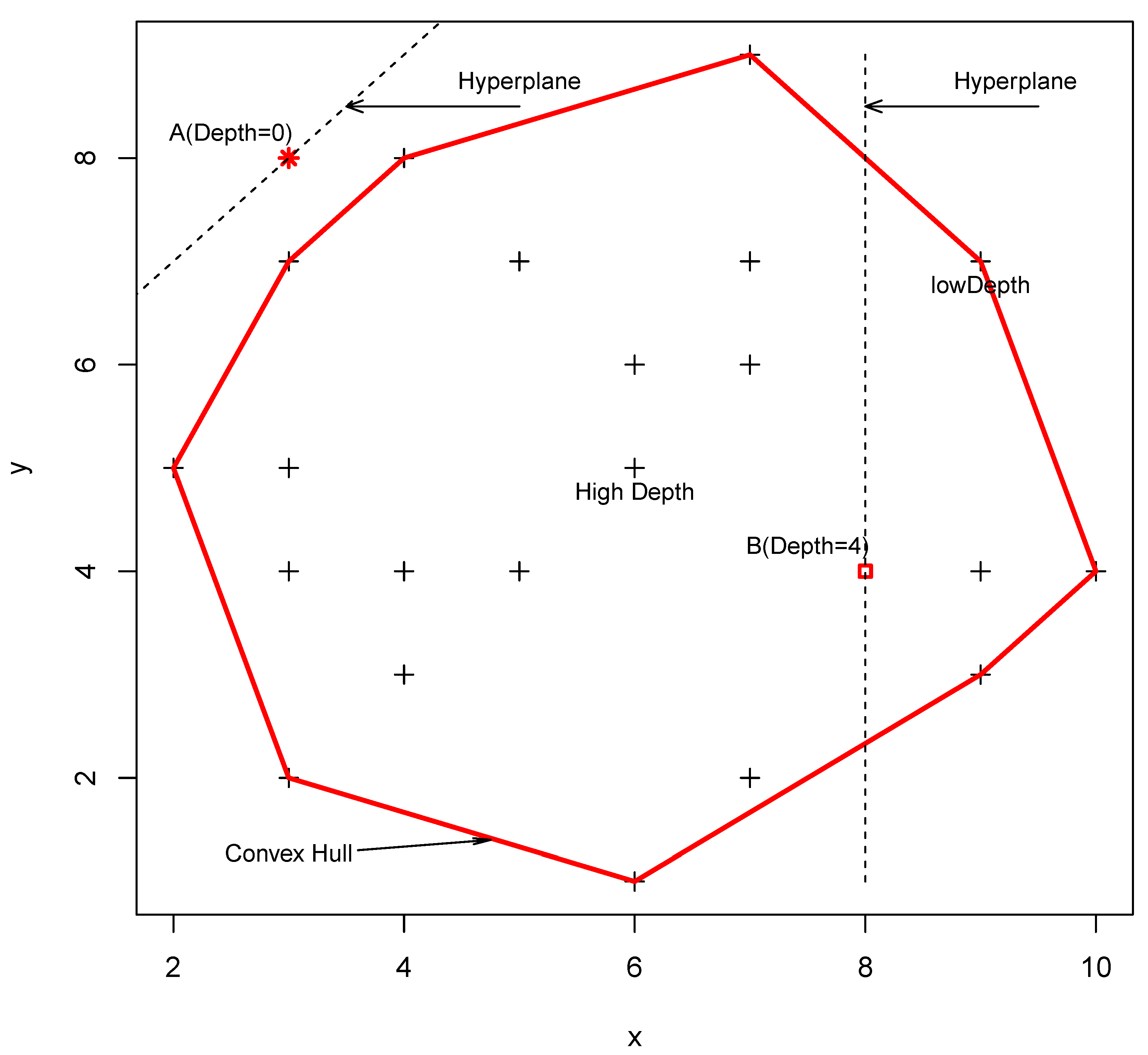
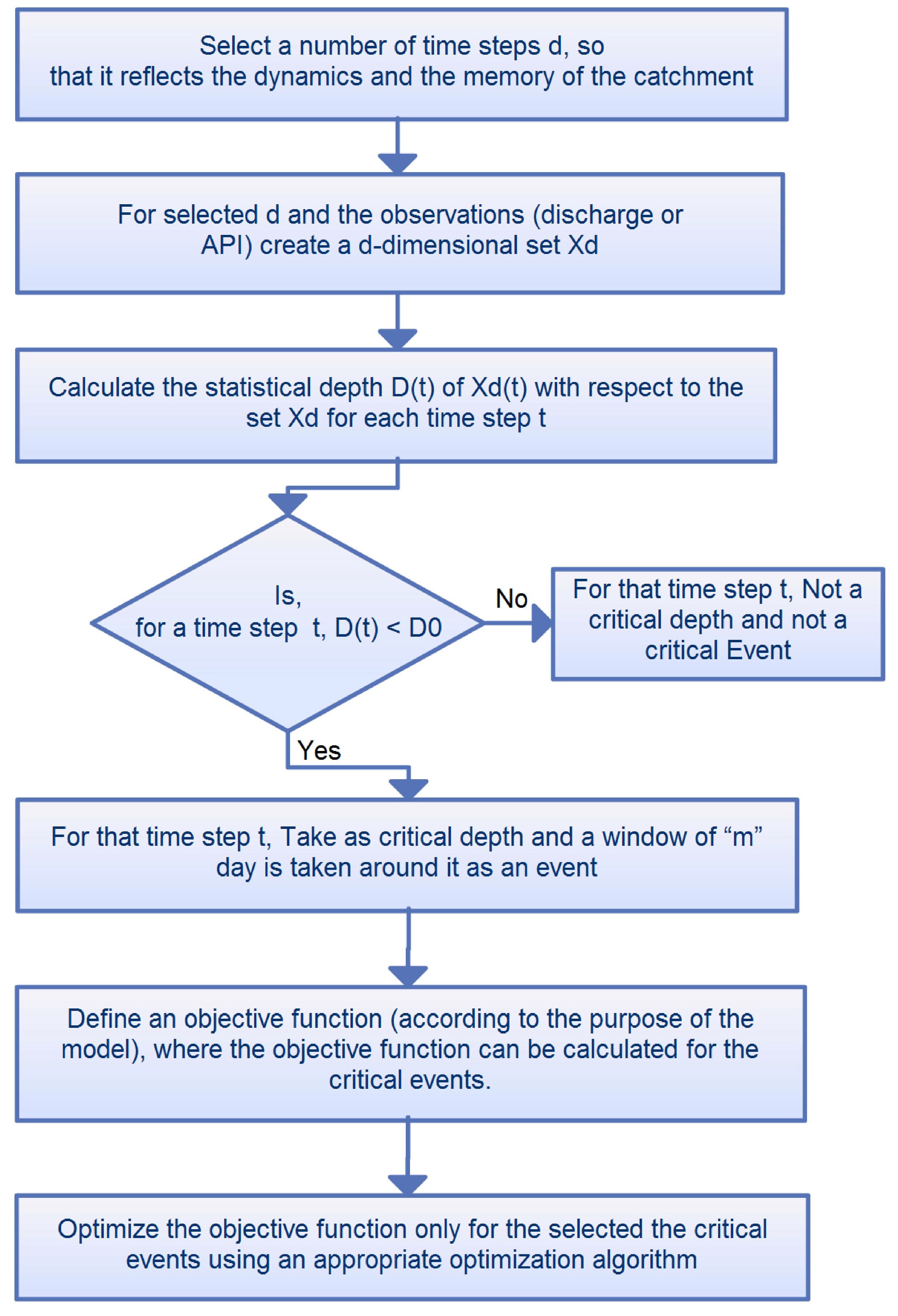
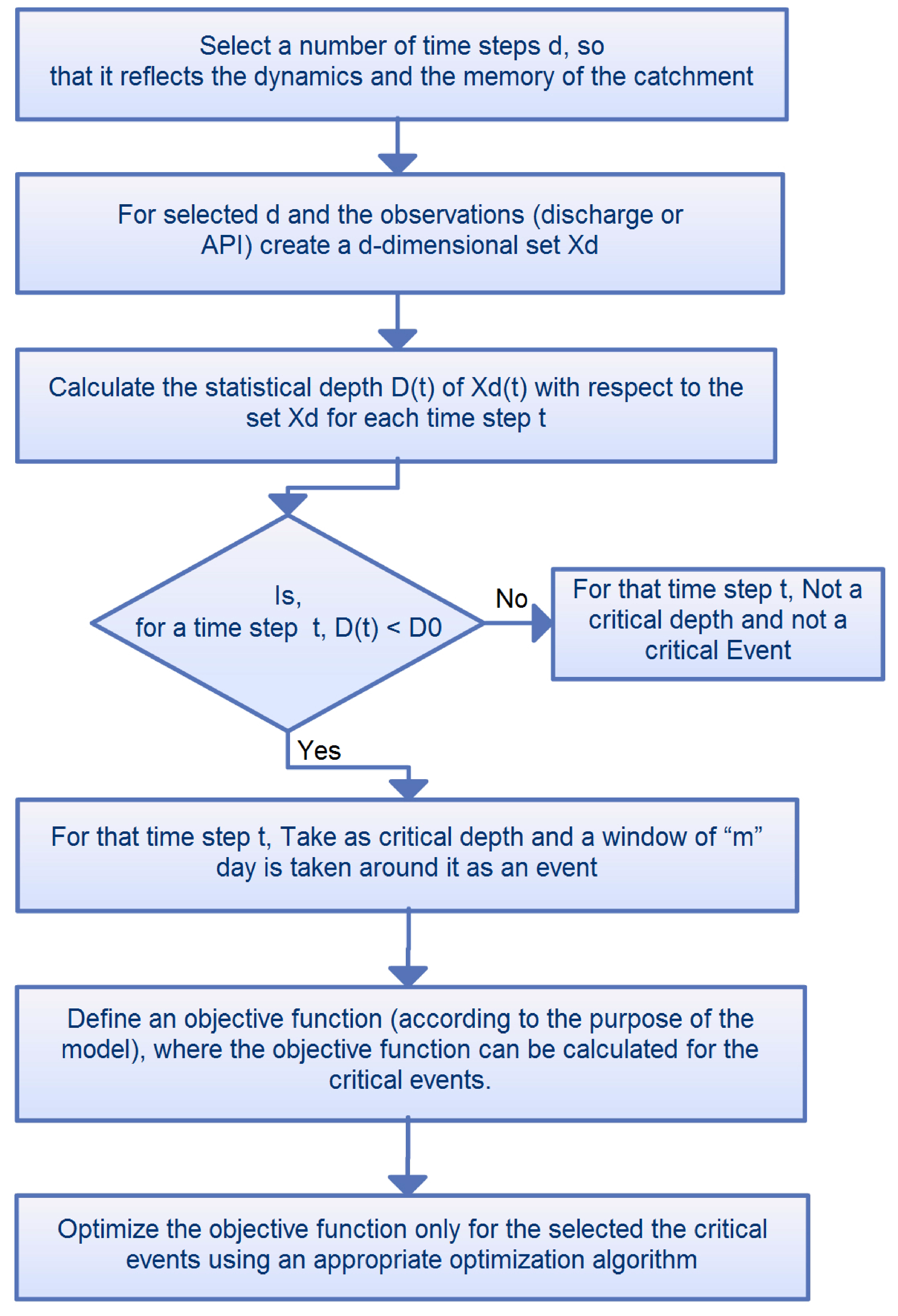
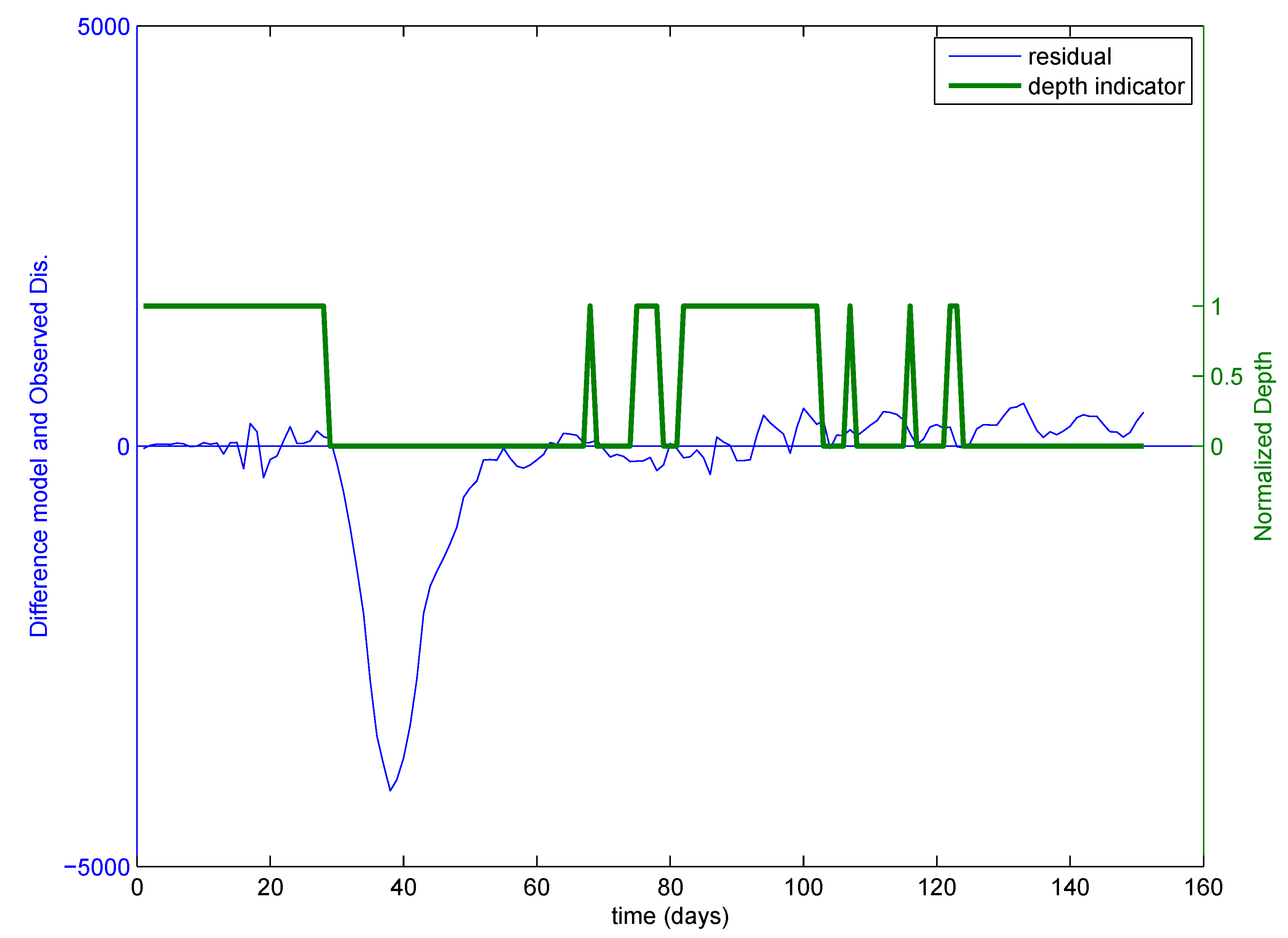
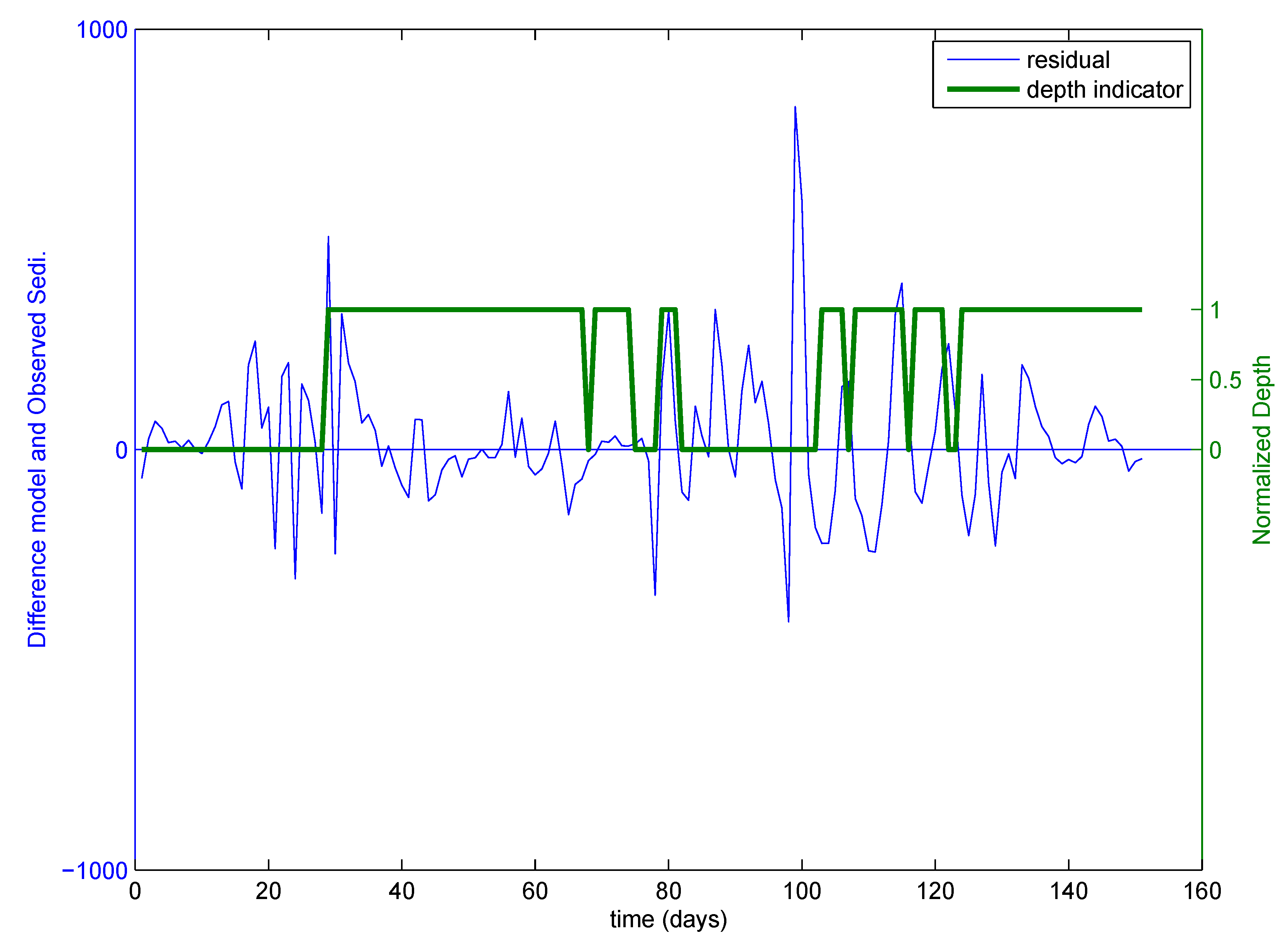
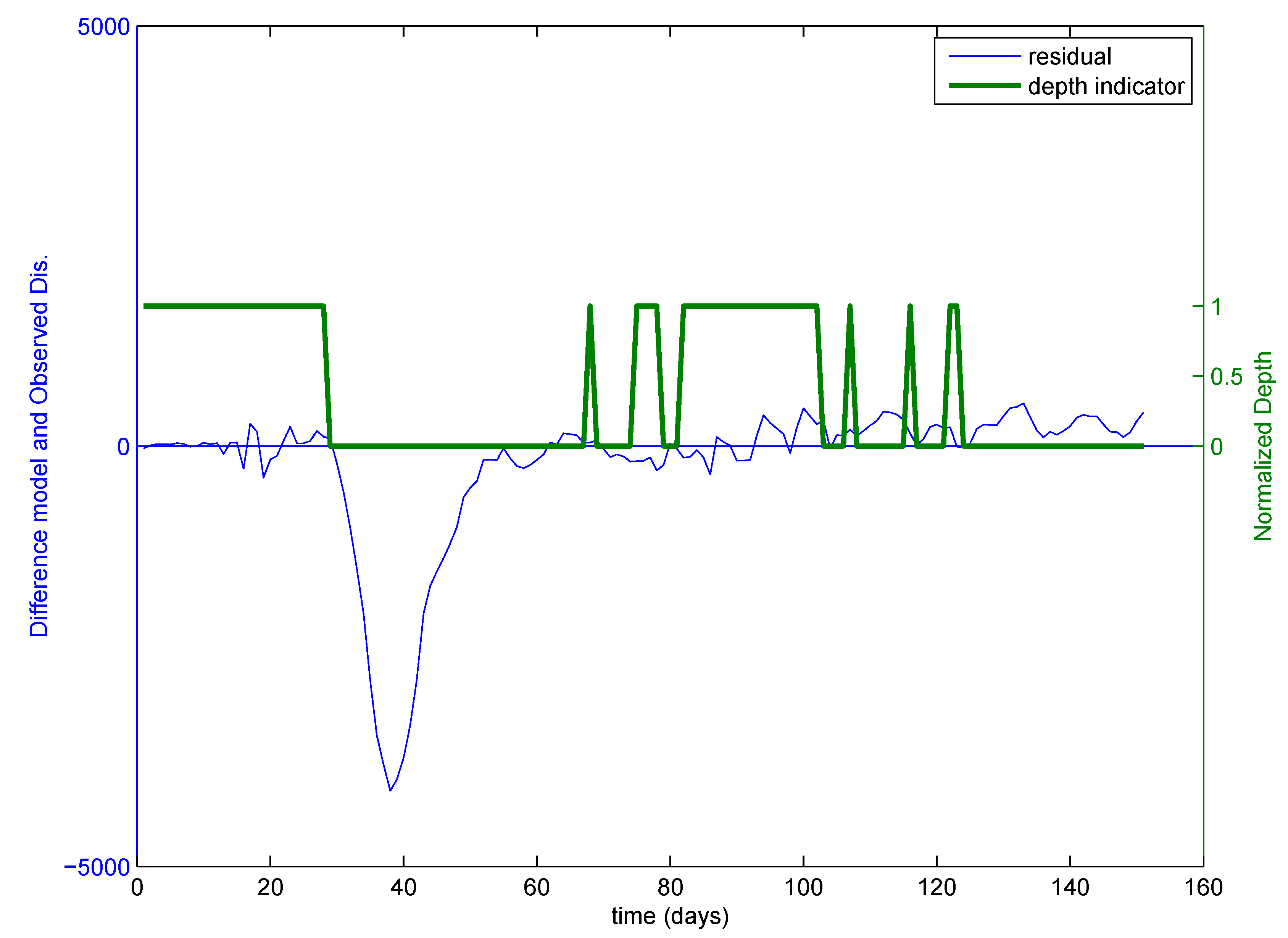
2.2. Identification of Critical Time Period Using the Data Depth Function
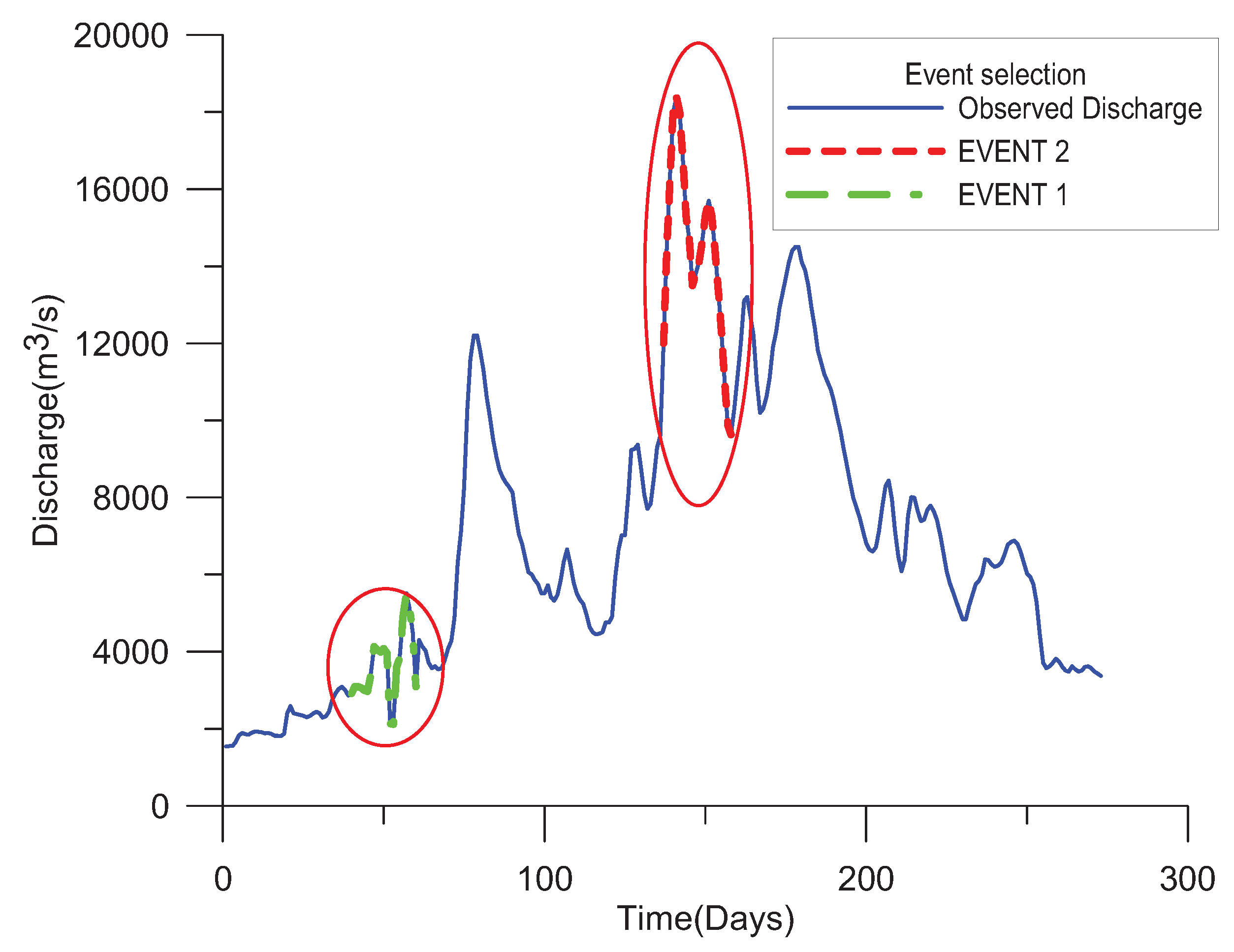
3. Case Study
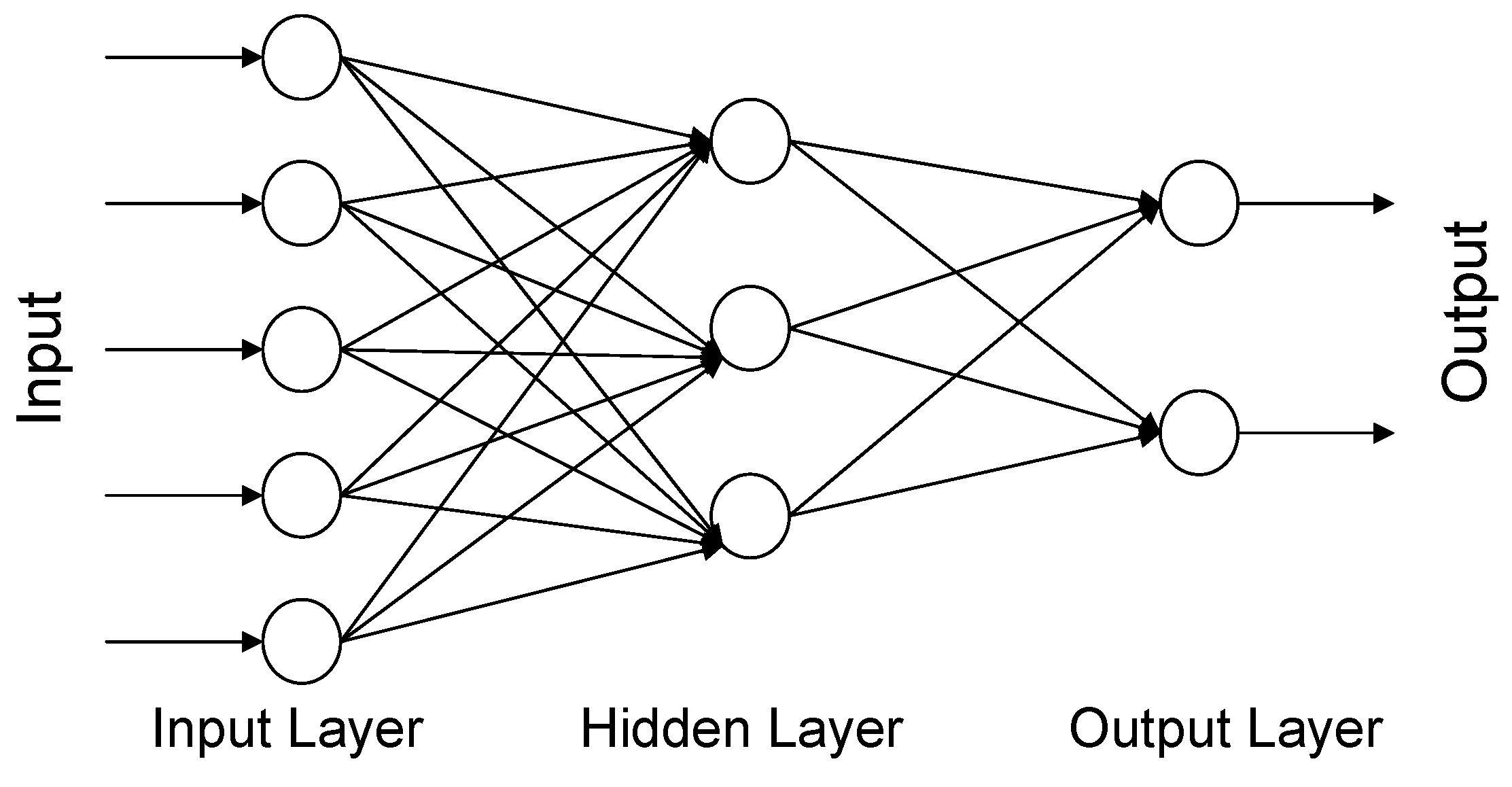
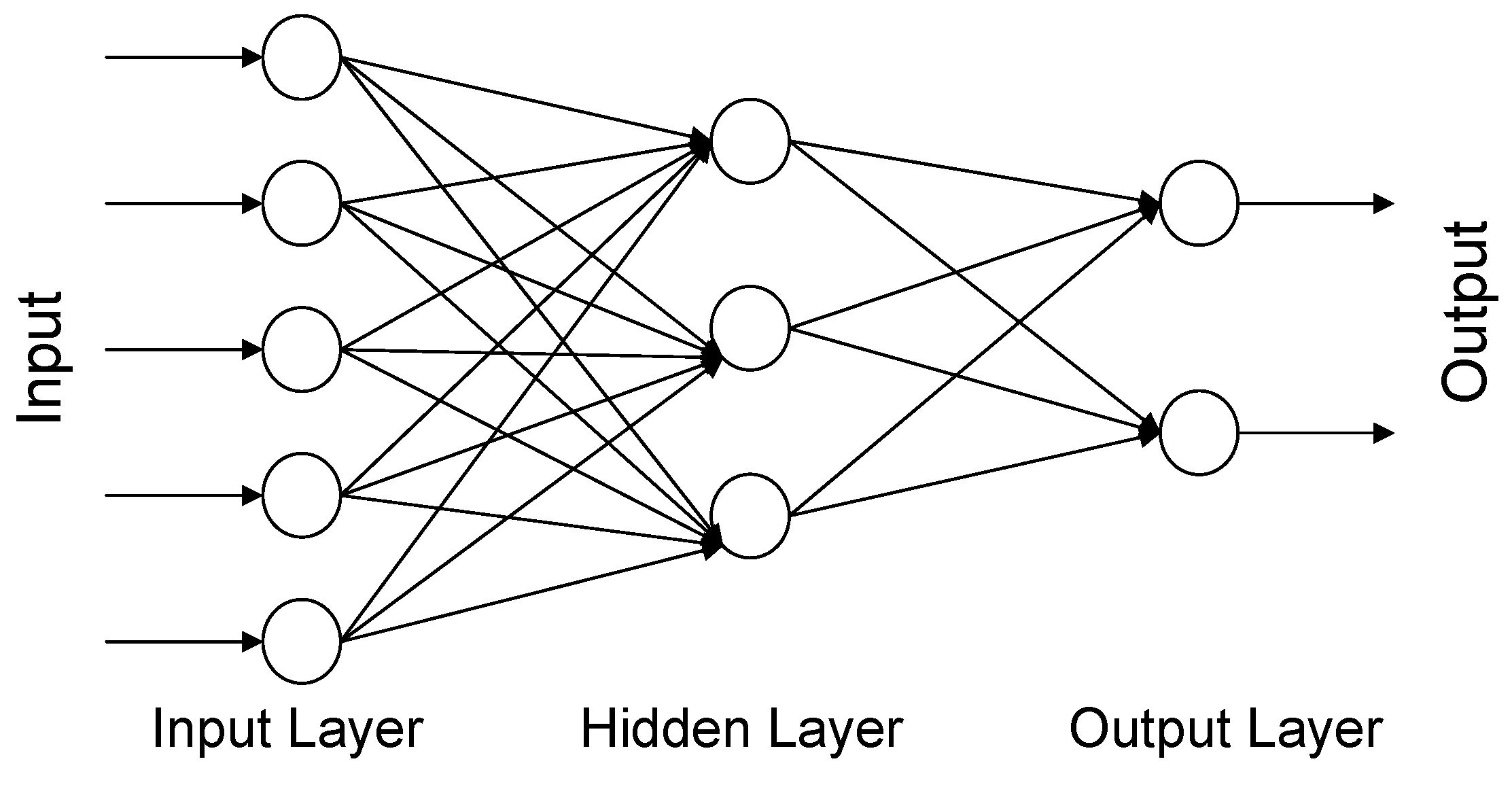
3.1. Artificial Neural Networks
3.2. Data Used in the Study
3.3. Rating Curves and Input to ANN
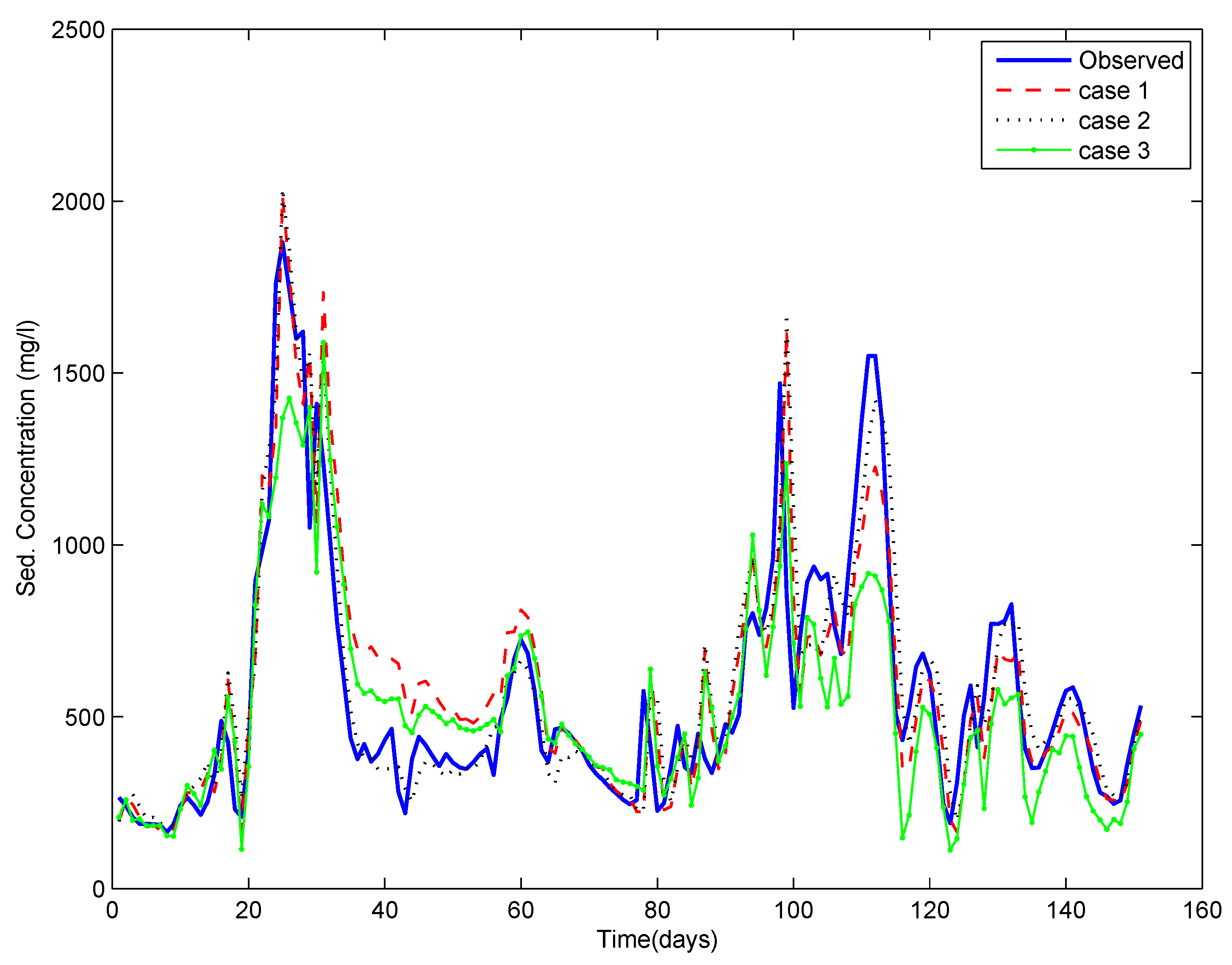
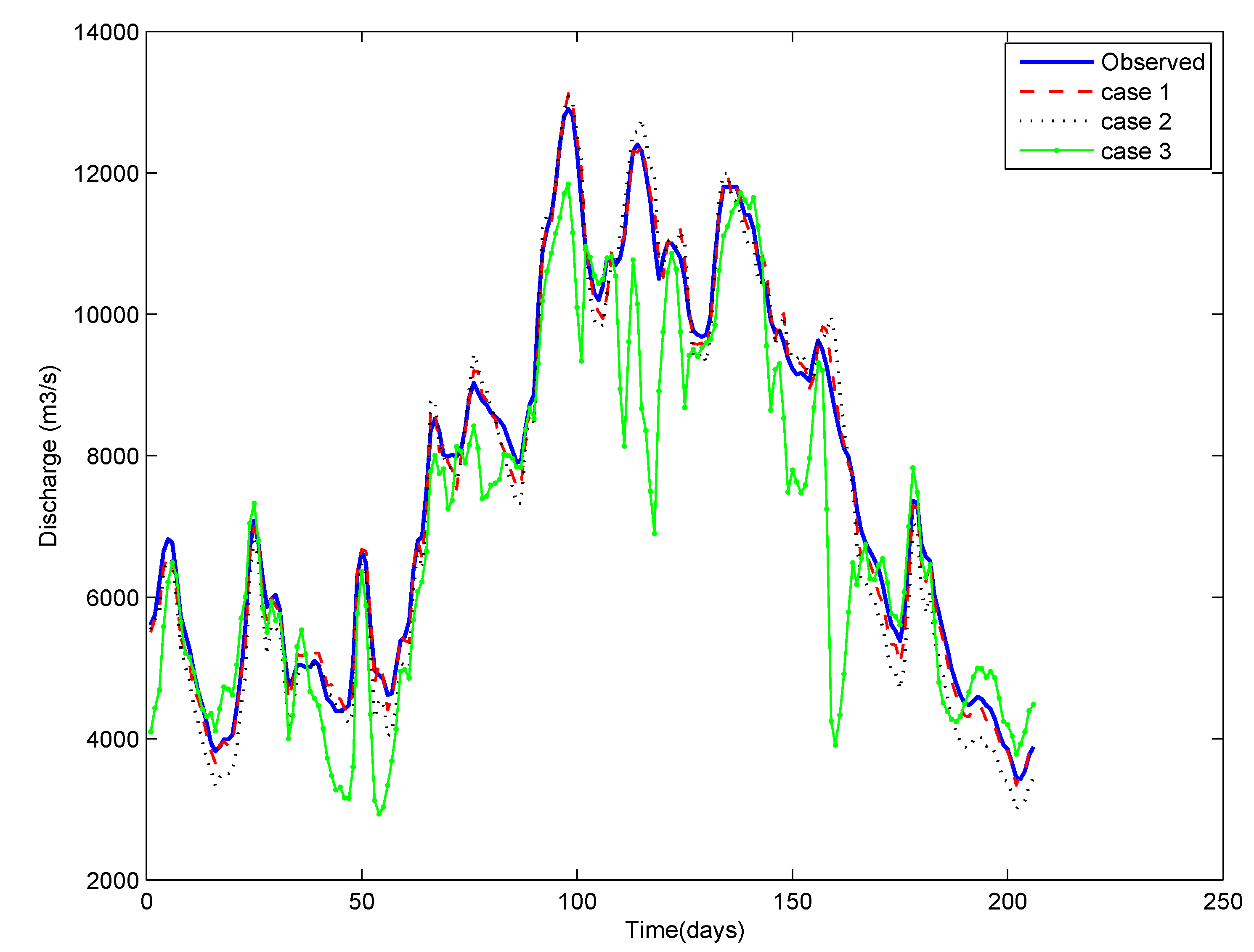
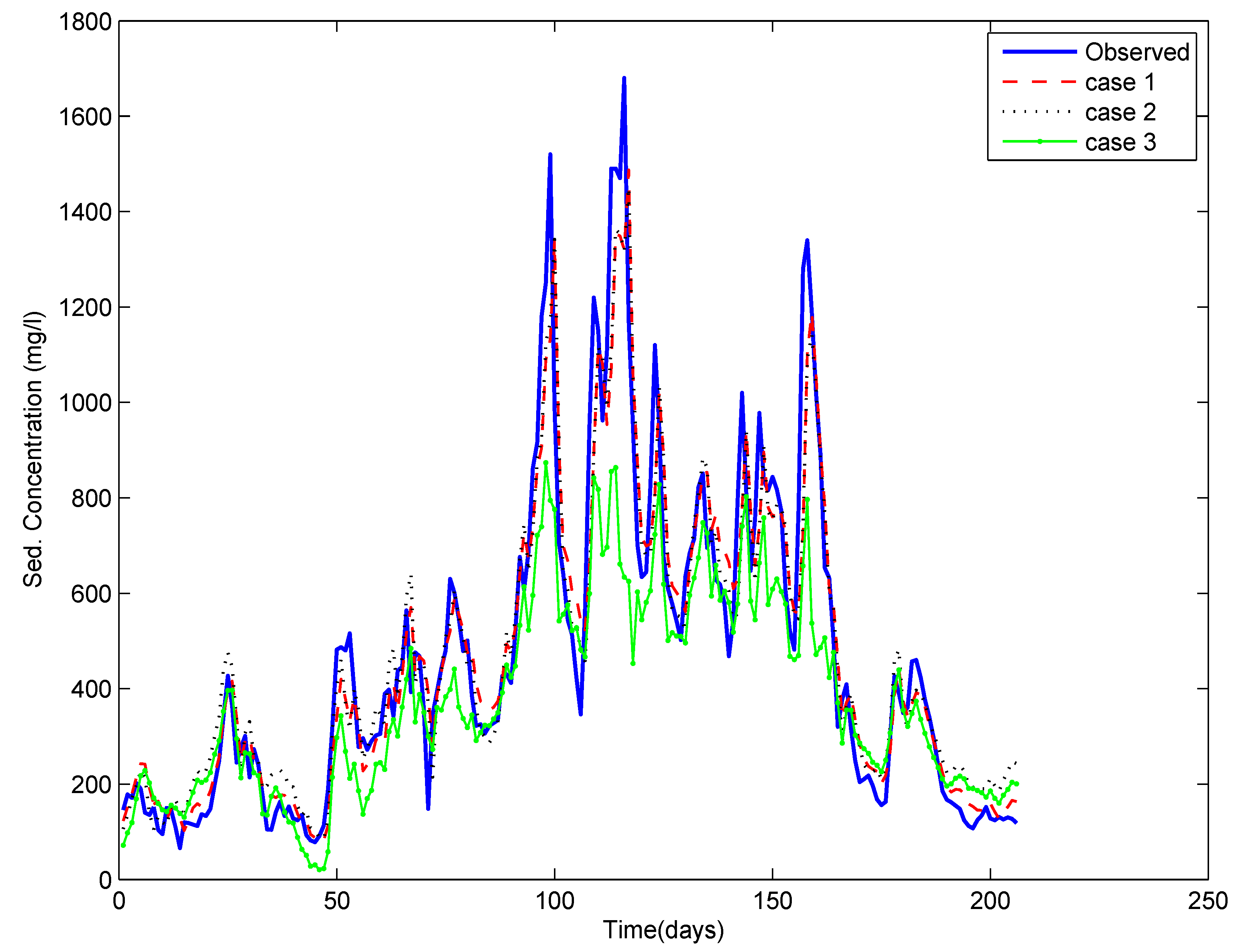
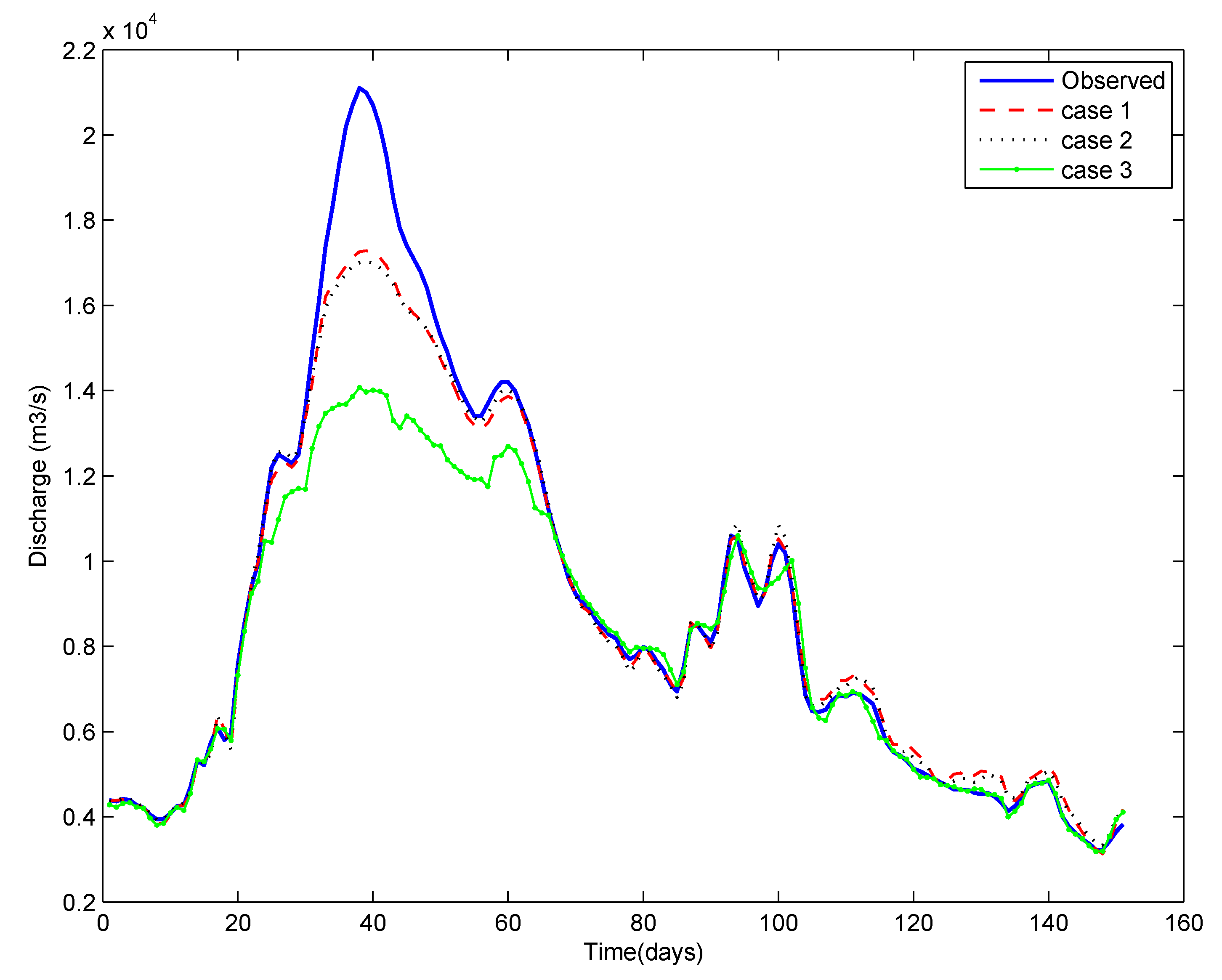
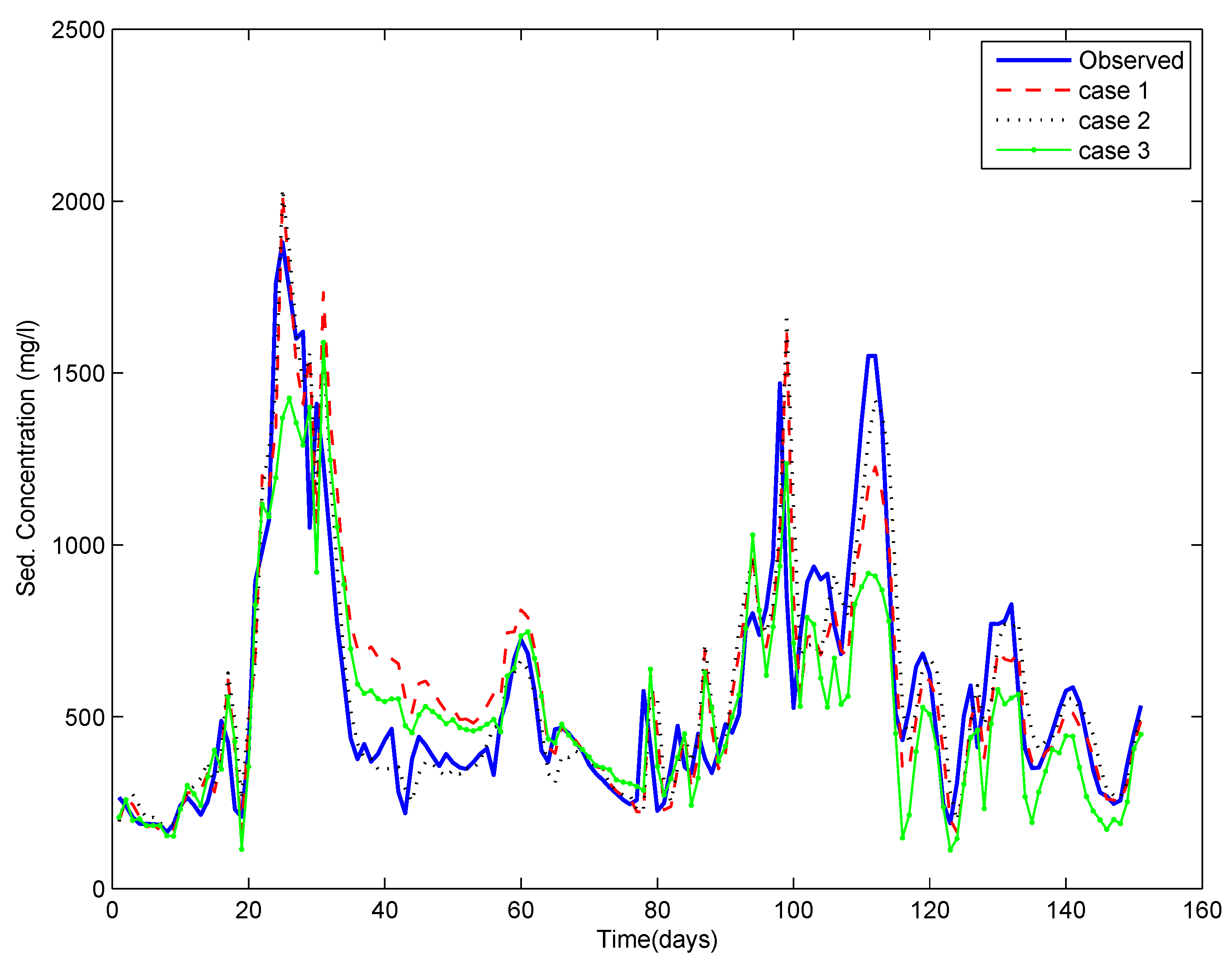
3.4. Different Cases for the Training of ANN
- Case 1: using the entire time series of data available,
- Case 2: using the data pertaining to critical events only (selected by the depth function (ICE algorithm)), and
- Case 3: using the data pertaining to randomly selected events (the same number of events as in Case 2). Here, a number of runs were taken by randomly selecting the events, and the results reflect the average of ten repetitions.
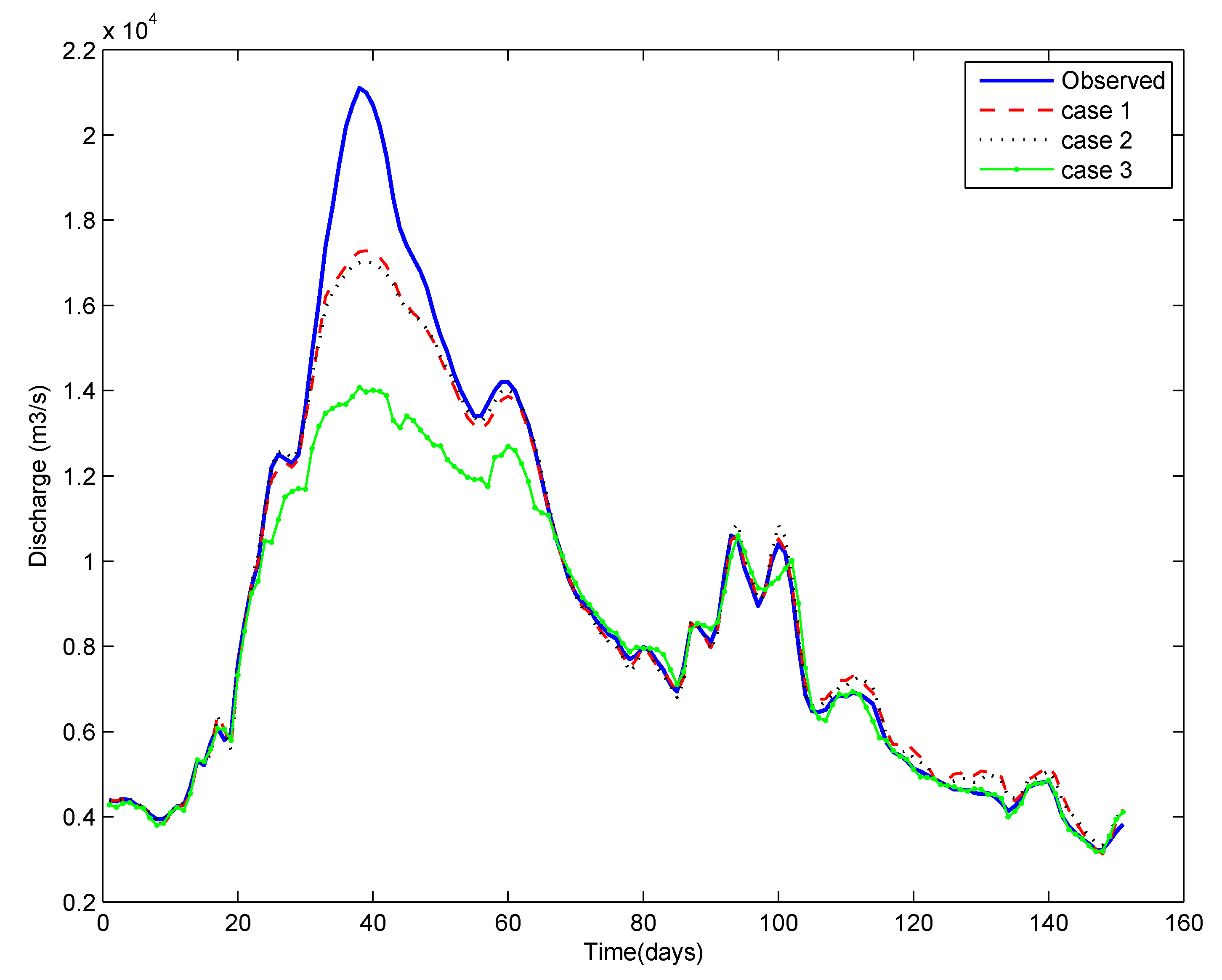
4. Results and Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Discharge | Sediments | % | ||
|---|---|---|---|---|---|
| Correlation | RMSE | Correlation | RMSE | Data Used | |
| Case 1 | 9.977×10 | 1.330×10 | 9.537×10 | 6.116×10 | 100 |
| Case 2 | 9.979×10 | 1.503×10 | 9.502×10 | 7.823×10 | 53 |
| Case 3 | 9.954×10 | 2.309×10 | 9.212×10 | 7.908×10 | 53 |
| Cases | Discharge | Sediments | ||
|---|---|---|---|---|
| Correlation | RMSE | Correlation | RMSE | |
| Case 1 | 9.928×10 | 6.557×10 | 8.695×10 | 7.874×10 |
| Case 2 | 9.904×10 | 6.914×10 | 9.049×10 | 6.859×10 |
| Case 3 | 9.670×10 | 2.129×10 | 8.444×10 | 1.225×10 |
| Cases | Discharge | Sediments | % | ||
|---|---|---|---|---|---|
| Correlation | RMSE | Correlation | RMSE | Data Used | |
| Case 1 | 9.946e-01 | 2.137e-02 | 9.045e-01 | 5.636e-02 | 100 |
| Case 2 | 9.929e-01 | 3.273e-02 | 8.296e-01 | 1.023e-01 | 29 |
| Case 3 | 9.723e-01 | 6.034e-02 | 7.425e-01 | 9.816e-02 | 29 |
| Cases | Discharge | Sediments | ||
|---|---|---|---|---|
| Correlation | RMSE | Correlation | RMSE | |
| Case 1 | 9.975e-01 | 1.085e-02 | 9.439e-01 | 3.987e-02 |
| Case 2 | 9.949e-01 | 2.226e-02 | 9.440e-01 | 4.049e-02 |
| Case 3 | 9.273e-01 | 1.017e-01 | 8.984e-01 | 1.510e-01 |
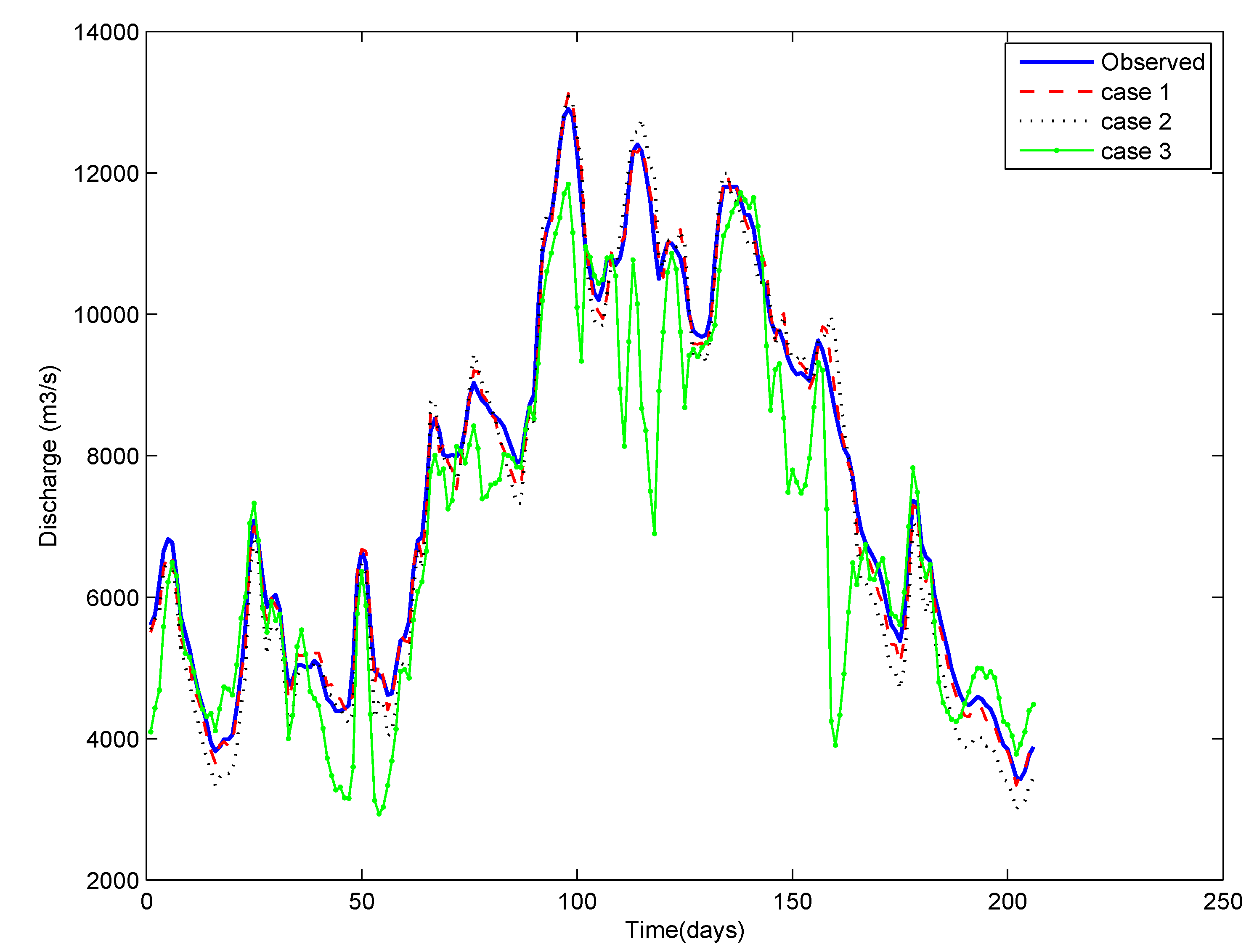
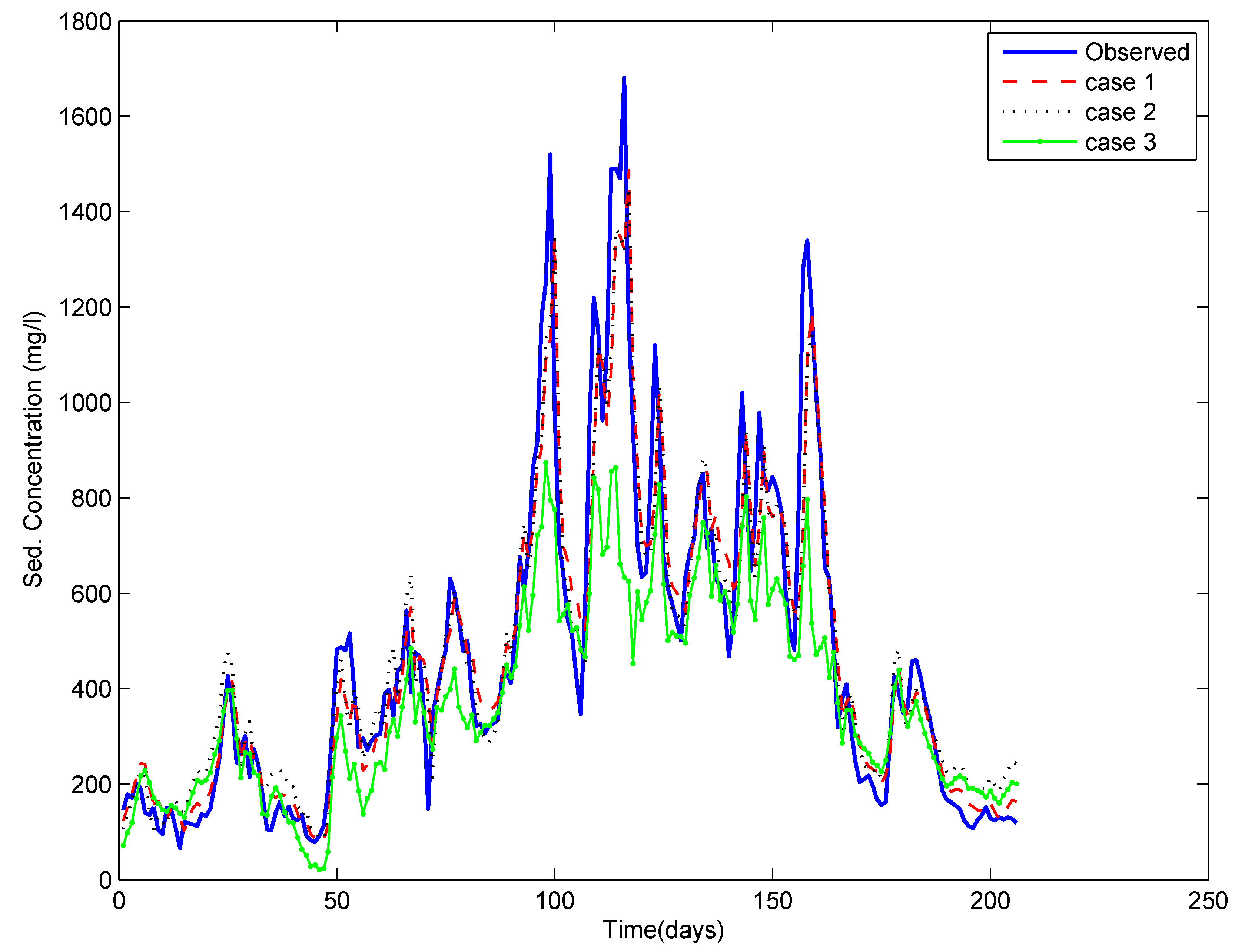

5. Summary and Conclusions
Author Contributions
Conflicts of Interest
References
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Bowden, G.J.; Maier, H.R.; Dandy, G.C. Optimal division of data for neural network models in water resources applications. Water Resour. Res. 2002, 38, 1010. [Google Scholar] [CrossRef]
- Anctil, F.; Perrin, C.; Andréassian, V. Impact of the length of observed records on the performance of ANN and of conceptual parsimonious rainfall-runoff forecasting models. Environm. Model. Softw. 2004, 19, 357–368. [Google Scholar] [CrossRef]
- Bowden, G.J.; Dandy, G.C.; Maier, H.R. Input determination for neural network models in water resources applications. Part 1—Background and methodology. J. Hydrol. 2005, 301, 75–92. [Google Scholar] [CrossRef]
- Leahy, P.; Kiely, G.; Corcoran, G. Structural optimisation and input selection of an artificial neural network for river level prediction. J. Hydrol. 2008, 355, 192–201. [Google Scholar] [CrossRef]
- Nawi, N.M.; Atomi, W.H.; Rehman, M. The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef]
- Marinković, Z.; Marković, V. Training data pre-processing for bias-dependent neural models of microwave transistor scattering parameters. Sci. Publ. State Univ. NOVI Pazar Ser. A Appl. Math. Inform. Mech. 2010, 2, 21–28. [Google Scholar]
- Gaweda, A.E.; Zurada, J.M.; Setiono, R. Input selection in data-driven fuzzy modeling. In Proceedings of the 10th IEEE International Conference of Fuzzy Systems (FUZZ-IEEE), Melbourne, VIC, Australia, 2–5 December 2001; Volume 1, pp. 2–5.
- May, R.J.; Maier, H.R.; Dandy, G.C.; Fernando, T.M.K. Non-linear variable selection for artificial neural networks using partial mutual information. Environ. Model. Softw. 2008, 23, 1312–1326. [Google Scholar] [CrossRef]
- Fernando, T.M.K.G.; Maier, H.R.; Dandy, G.C. Selection of input variables for data-driven models: An average shifted histogram partial mutual information estimator approach. J. Hydrol. 2009, 367, 165–176. [Google Scholar] [CrossRef]
- Jain, A.; Maier, H.R.; Dandy, G.C.; Sudheer, K.P. Rainfall-runoff modeling using neural network: State-of-art and future research needs. ISH J. Hydraul. Eng. 2009, 15, 52–74. [Google Scholar] [CrossRef]
- Abrahart, R.J.; Anctil, F.; Coulibaly, P.; Dawson, C.W.; Mount, N.J.; See, L.M.; Shamseldin, A.Y.; Solomatine, D.P.; Toth, E.; Wilby, R.L. Two decades of anarchy? Emerging themes and outstanding challenges for neural network river forecasting. Progr. Phys. Geogr. 2012, 36, 480–513. [Google Scholar] [CrossRef]
- Cigizoglu, H.; Kisi, O. Flow prediction by three back propagation techniques using k-fold partitioning of neural network training data. Nordic Hydrol. 2005, 36, 49–64. [Google Scholar]
- Wagener, T.; McIntyre, N.; Lees, M.J.; Wheater, H.S.; Gupta, H.V. Towards reduced uncertainty in conceptual rainfall-runoff modelling: Dynamic identifiability analysis. Hydrol. Process. 2003, 17, 455–476. [Google Scholar] [CrossRef]
- Chau, K.; Wu, C.; Li, Y. Comparison of several flood forecasting models in Yangtze River. J. Hydrol. Eng. 2005, 10, 485–491. [Google Scholar] [CrossRef]
- Chau, K.W.; Muttil, N. Data mining and multivariate statistical analysis for ecological system in coastal waters. J. Hydroinforma. 2007, 9, 305–317. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Li, Y.S. Methods to improve neural network performance in daily flows prediction. J. Hydrol. 2009, 372, 80–93. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Li, Y.S. Predicting monthly streamflow using data-driven models coupled with data-preprocessing techniques. Water Resour. Res. 2009, 45, W08432. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Fan, C. Prediction of rainfall time series using modular artificial neural networks coupled with data-preprocessing techniques. J. Hydrol. 2010, 389, 146–167. [Google Scholar] [CrossRef]
- Chen, W.; Chau, K. Intelligent manipulation and calibration of parameters for hydrological models. Int. J. Environ. Pollut. 2006, 28, 432–447. [Google Scholar] [CrossRef]
- Wu, C.; Chau, K.; Li, Y. River stage prediction based on a distributed support vector regression. J. Hydrol. 2008, 358, 96–111. [Google Scholar] [CrossRef]
- Wang, W.C.; Xu, D.M.; Chau, K.W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO-SVM model based on EEMD. J. Hydroinform. 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Kote, A.S. Improving the performance of data-driven techniques through data pre-processing for modelling daily reservoir inflow. Hydrol. Sci. J. 2011, 56, 168–186. [Google Scholar] [CrossRef]
- Moody, J.; Darken, C.J. Fast learning in networks of locally-tuned processing units. Neural Comput. 1989, 1, 281–294. [Google Scholar] [CrossRef]
- Famili, F.; Shen, W.M.; Weber, R.; Simoudis, E. Data pre-processing and intelligent data analysis. Int. J. Intell. Data Anal. 1997, 1, 3–23. [Google Scholar] [CrossRef]
- Singh, S.K.; Bárdossy, A. Identification of critical time periods for the efficient calibration of hydrological models. Geophys. Res. Abstr. 2009, 11, EGU2009-5748. [Google Scholar]
- Singh, S.K.; Bárdossy, A. Calibration of hydrological models on hydrologically unusual events. Adv. Water Resour. 2012, 38, 81–91. [Google Scholar] [CrossRef]
- Tukey, J. Mathematics and Picturing Data. In Proceedings of the 1974 International 17 Congress of Mathematics, Vancouver, BC, Canada, 21–29 August 1975; Volume 2, pp. 523–531.
- Singh, S.K.; Liang, J.; Bárdossy, A. Improving the calibration strategy of the physically-based model WaSiM-ETH using critical events. Hydrol. Sci. J. 2012, 57, 1487–1505. [Google Scholar] [CrossRef]
- Bárdossy, A.; Singh, S.K. Robust estimation of hydrological model parameters. Hydrol. Earth Syst. Sci. 2008, 12, 1273–1283. [Google Scholar] [CrossRef]
- Singh, S.K.; McMillan, H.; Bárdossy, A. Use of the data depth function to differentiate between case of interpolation and extrapolation in hydrological model prediction. J. Hydrol. 2013, 477, 213–228. [Google Scholar] [CrossRef]
- Gupta, V.K.; Sorooshian, S. The relationship between data and the precision of parameter estimates of hydrologic models. J. Hydrol. 1985, 81, 57–77. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Struyf, A. Computing location depth and regression depth in higher dimensions. Stat. Comput. 1998, 8, 193–203. [Google Scholar] [CrossRef]
- Liu, R.Y.; Parelius, J.M.; Singh, K. Multivariate analysis by data depth: Descriptive statistics, graphics and inference. Ann. Stat. 1999, 27, 783–858. [Google Scholar]
- Zuo, Y.; Serfling, R. General notions of statistical depth function. Ann. Stat. 2000, 28, 461–482. [Google Scholar] [CrossRef]
- Chebana, F.; Ouarda, T.B.M.J. Depth and homogeneity in regional flood frequency analysis. Water Resour. Res. 2008. [Google Scholar] [CrossRef]
- Dutta, S.; Ghosh, A.K.; Chaudhuri, P. Some intriguing properties of Tukey’s half-space depth. Bernoulli 2011, 17, 1420–1434. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial neural networks in hydrology, I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- Smith, J.; Eli, R.N. Neural network models of rainfall-runoff process. J. Water Resour. Plan. Manag. 1995, 121, 499–508. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial neural networks in hydrology, II: Hydrological applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- Maier, H.; Jain, A.; Dandy, G.; Sudheer, K.P. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Govindaraju, R.S.; Rao, A. Artificial Neural Networks in Hydrology; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Cigizoglu, H.K. Estimation, forecasting and extrapolation of river flows by artificial neural networks. Hydrol. Sci. J. 2003, 48, 349–361. [Google Scholar] [CrossRef]
- Wilby, R.L.; Abrahart, R.J.; Dawson, C.W. Detection of conceptual model rainfall-runoff processes inside an artificial neural network. Hydrol. Sci. J. 2003, 48, 163–181. [Google Scholar] [CrossRef]
- Lin, G.F.; Chen, L.H. A non-linear rainfall-runoff model using radial basis function network. J. Hydrol. 2004, 289, 1–8. [Google Scholar] [CrossRef]
- Imrie, C.E.; Durucan, S.; Korre, A. River flow prediction using artificial neural networks: Generalization beyond the calibration range. J. Hydrol. 2000, 233, 138–153. [Google Scholar] [CrossRef]
- Lekkas, D.F.; Imrie, C.E.; Lees, M.J. Improved non-linear transfer function and neural network methods of flow routing for real-time forecasting. J. Hydroinforma. 2001, 3, 153–164. [Google Scholar]
- Shrestha, R.R.; Theobald, S.; Nestmann, F. Simulation of flood flow in a river system using artificial neural networks. Hydrol. Earth Syst. Sci. 2005, 9, 313–321. [Google Scholar] [CrossRef]
- Campolo, M.; Soldati, A.; Andreussi, P. Artificial neural network approach to flood forecasting in the River Arno. Hydrol. Sci. J. 2003, 48, 381–398. [Google Scholar] [CrossRef]
- Jain, S.K.; Das, A.; Srivastava, D.K. Application of ANN for reservoir inflow prediction and operation. J. Water Resour. Plan. Manag. ASCE 1999, 125, 263–271. [Google Scholar] [CrossRef]
- Jain, S.K.; Singh, V.P.; van Genuchten, M. Application of ANN for reservoir inflow prediction and operation. J. Water Resour. Plan. Manag. ASCE 2004, 9, 415–420. [Google Scholar] [CrossRef]
- Bhattacharya, B.; Lobbrecht, A.H.; Solomatine, D.P. Neural networks and reinforcement learning in control of water systems. J. Water Resour. Plan. Manag. ASCE 2003, 129, 458–465. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.W.; Sethi, R. Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice Lagoon. Eng. Appl. Artif. Intell. 2012, 25, 1670–1676. [Google Scholar] [CrossRef]
- Cheng, C.; Chau, K.; Sun, Y.; Lin, J. Long-term prediction of discharges in Manwan reservoir using artificial neural network models. Lect. Notes Comput. Sci. 2005, 3498, 1040–1045. [Google Scholar]
- Zealand, C.M.; Burn, D.H.; Simonovic, S.P. Short term streamflow forecasting using artificial neural networks. J. Hydrol. 1999, 214, 32–48. [Google Scholar] [CrossRef]
- Tokar, A.S.; Johnson, P.A. Rainfall-runoff modelling using artificial neural networks. J. Hydrol. Eng. 1999, 4, 232–239. [Google Scholar] [CrossRef]
- Cigizoglu, H.K. Estimation and forecasting of daily suspended sediment data by multi layer perceptrons. Adv. Water Resour. 2004, 27, 185–195. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Jain, A. Explaining the internal behaviour of artificial neural network river flow models. Hydrol. Process. 2004, 18, 833–844. [Google Scholar] [CrossRef]
- Kumar, A.R.S.; Sudheer, K.P.; Jain, S.K. Rainfall-runoff modeling using artificial neural networks: Comparison of network types. Hydrol. Process. 2005, 19, 1277–1291. [Google Scholar] [CrossRef]
- Cigizoglu, H.K.; Kisi, O. Flow prediction by three back propagation techniques using k-fold partitioning of neural network training data. Nordic Hydrol. 2005, 361, 1–16. [Google Scholar]
- Cigizoglu, H.K.; Kisi, O. Methods to improve the neural network performance in suspended sediment estimation. J. Hydrol. 2006, 317, 221–238. [Google Scholar] [CrossRef]
- Cigizoglu, H.K.; Alp, M. Generalized regression neural network in modelling river sediment yield. Adv. Eng. Softw. 2006, 372, 63–68. [Google Scholar] [CrossRef]
- Lin, J.; Cheng, C.T.; Chau, K.W. Using support vector machines for long-term discharge prediction. Hydrol. Sci. J. 2006, 51, 599–612. [Google Scholar] [CrossRef]
- Alp, M.; Cigizoglu, H.K. Suspended sediment estimation by feed forward back propagation method using hydro meteorological data. Environ. Model. Softw. 2007, 22, 2–13. [Google Scholar] [CrossRef]
- Solomatine, D.; Ostfeld, A. Data-driven modelling: Some past experiences and new approaches. J. Hydroinform. 2008, 10, 3–22. [Google Scholar] [CrossRef]
- Shamseldin, A. Artificial neural network model for river flow forecasting in a developing country. J. Hydroinform. 2010, 12, 22–35. [Google Scholar] [CrossRef]
- Kumar, M.; Raghuwanshi, N.S.; Singh, R.; Wallender, W.W.; Pruitt, W.O. Estimating evapotranspiration using artificial neural network. J. Irrig. Drain. Eng. ASCE 2002, 128, 224–233. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Gosain, A.K.; Rangan, D.M.; Saheb, S.M. Modeling evaporation using artificial neural network algorithm. Hydrol. Process. 2002, 16, 3189–3202. [Google Scholar] [CrossRef]
- Keskin, M.E.; Terzi, O. Artificial Neural Network models of daily pan evaporation. J. Hydrol. Eng. 2006, 11, 65–70. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Jain, S.K. Radial basis function neural networks for modelling rating curves. J. Hydrol. Eng. 2003, 8, 161–164. [Google Scholar] [CrossRef]
- Trajkovic, S.; Todorovic, B.; Stankovic, M. Forecasting reference evapotranspiration by artificial neural networks. J. Irrig. Drain. Eng. 2003, 129, 454–457. [Google Scholar] [CrossRef]
- Kisi, O. Evapotranspiration modeling from climatic data using a neural computing technique. Hydrol. Process. 2007, 21, 1925–1934. [Google Scholar] [CrossRef]
- Kisi, O. Generalized regression neural networks for evapotranspiration modeling. J. Hydrol. Sci. 2006, 51, 1092–1105. [Google Scholar] [CrossRef]
- Kisi, O.; Öztürk, O. Adaptive neurofuzzy computing technique for evapotranspiration estimation. J. Irrig. Drain. Eng. 2007, 133, 368. [Google Scholar] [CrossRef]
- Jain, S.K.; Nayak, P.C.; Sudheer, K.P. Models for estimating evapotranspiration using artificial neural networks, and their physical interpretation. Hydrol. Process. 2008, 22, 2225–2234. [Google Scholar] [CrossRef]
- Muttil, N.; Chau, K.W. Neural network and genetic programming for modelling coastal algal blooms. Int. J. Environ. Pollut. 2006, 28, 223–238. [Google Scholar] [CrossRef]
- Zhang, Q.; Stanley, S.J. Forecasting raw-water quality parameters for the North Saskatchewan River by neural network modeling. Water Res. 1997, 31, 2340–2350. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.Y.; Tkalich, P. An ANN application for water quality forecasting. Marine Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef] [PubMed]
- Singh, K.P.; Basant, A.; Malik, A.; Jain, G. Artificial neural network modeling of the river water quality—A case study. Ecol. Model. 2009, 220, 888–895. [Google Scholar] [CrossRef]
- Jain, S.K. Development of integrated sediment rating curves using ANNS. J. Hydraul. Eng. 2001, 127, 30–37. [Google Scholar] [CrossRef]
- Porterfield, G. Computation of fluvial-sediment discharge. In Techniques of Water-Resources Investigations of the United States Geological Survey; US Government Printing Office: Washington, DC, USA, 1972; Chapter C3; pp. 1–66. [Google Scholar]
- USGS Sediment Data Portal. Available online: http://co.water.usgs.gov/sediment/introduction.html (accessed on 30 September 2009).
- Jain, S.K.; Chalisgaonkar, D. Setting up stage-discharge relations using ANN. J. Hydrol. Eng. 2000, 5, 428–433. [Google Scholar] [CrossRef]
- Bárdossy, A.; Singh, S.K. Regionalization of hydrological model parameters using data depth. Hydrol. Res. 2011, 42, 356–371. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Singh, S.K.; Jain, S.K.; Bárdossy, A. Training of Artificial Neural Networks Using Information-Rich Data. Hydrology 2014, 1, 40-62. https://doi.org/10.3390/hydrology1010040
Singh SK, Jain SK, Bárdossy A. Training of Artificial Neural Networks Using Information-Rich Data. Hydrology. 2014; 1(1):40-62. https://doi.org/10.3390/hydrology1010040
Chicago/Turabian StyleSingh, Shailesh Kumar, Sharad K. Jain, and András Bárdossy. 2014. "Training of Artificial Neural Networks Using Information-Rich Data" Hydrology 1, no. 1: 40-62. https://doi.org/10.3390/hydrology1010040
APA StyleSingh, S. K., Jain, S. K., & Bárdossy, A. (2014). Training of Artificial Neural Networks Using Information-Rich Data. Hydrology, 1(1), 40-62. https://doi.org/10.3390/hydrology1010040