
Visualization of Moisture Distribution in Stacked Tea Leaves on Process Flow Line Using Hyperspectral Imaging

 ,
,  , ,
, ,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
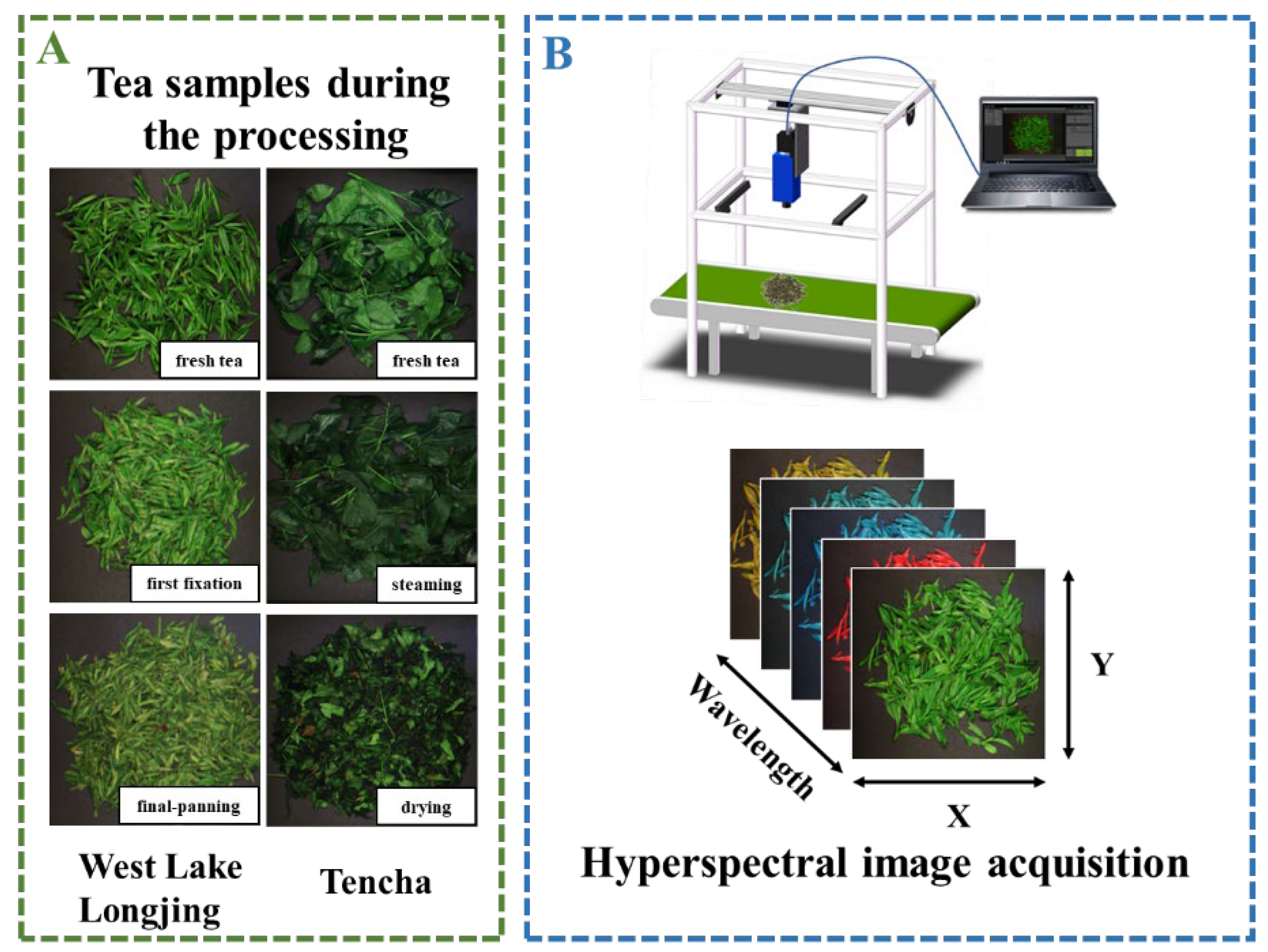
2.1. Samples Collections and Preparations
2.2. Hyperspectral Image Acquisition
2.3. Determination of Moisture Content of Tea
2.4. Data Processing
2.4.1. Spectral Pre-Processing
2.4.2. Feature Band Extraction
2.4.3. Classification Models and Model Evaluation
2.4.4. Regression Model and Model Evaluation
2.4.5. Generalization Capability of the Model
2.4.6. Visualization of Moisture Content
3. Results and Discussion
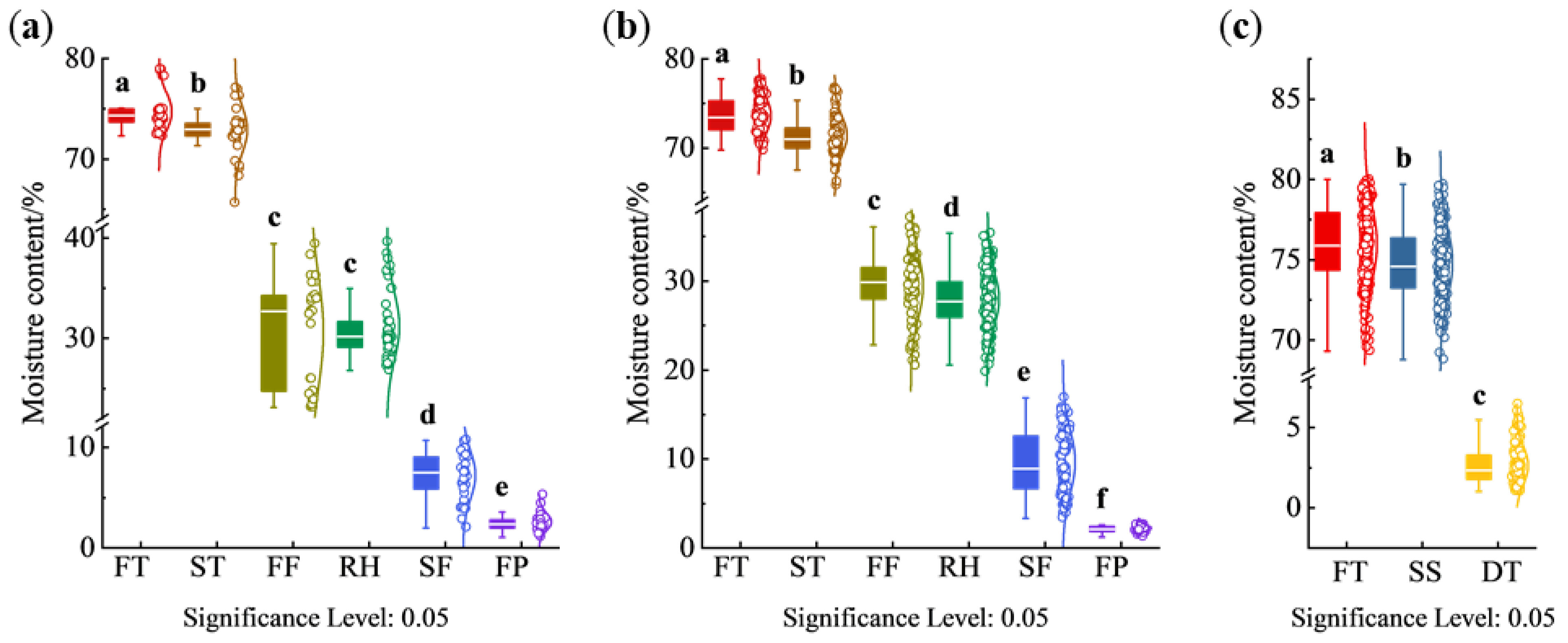
3.1. Moisture Content Analysis of Different Processes
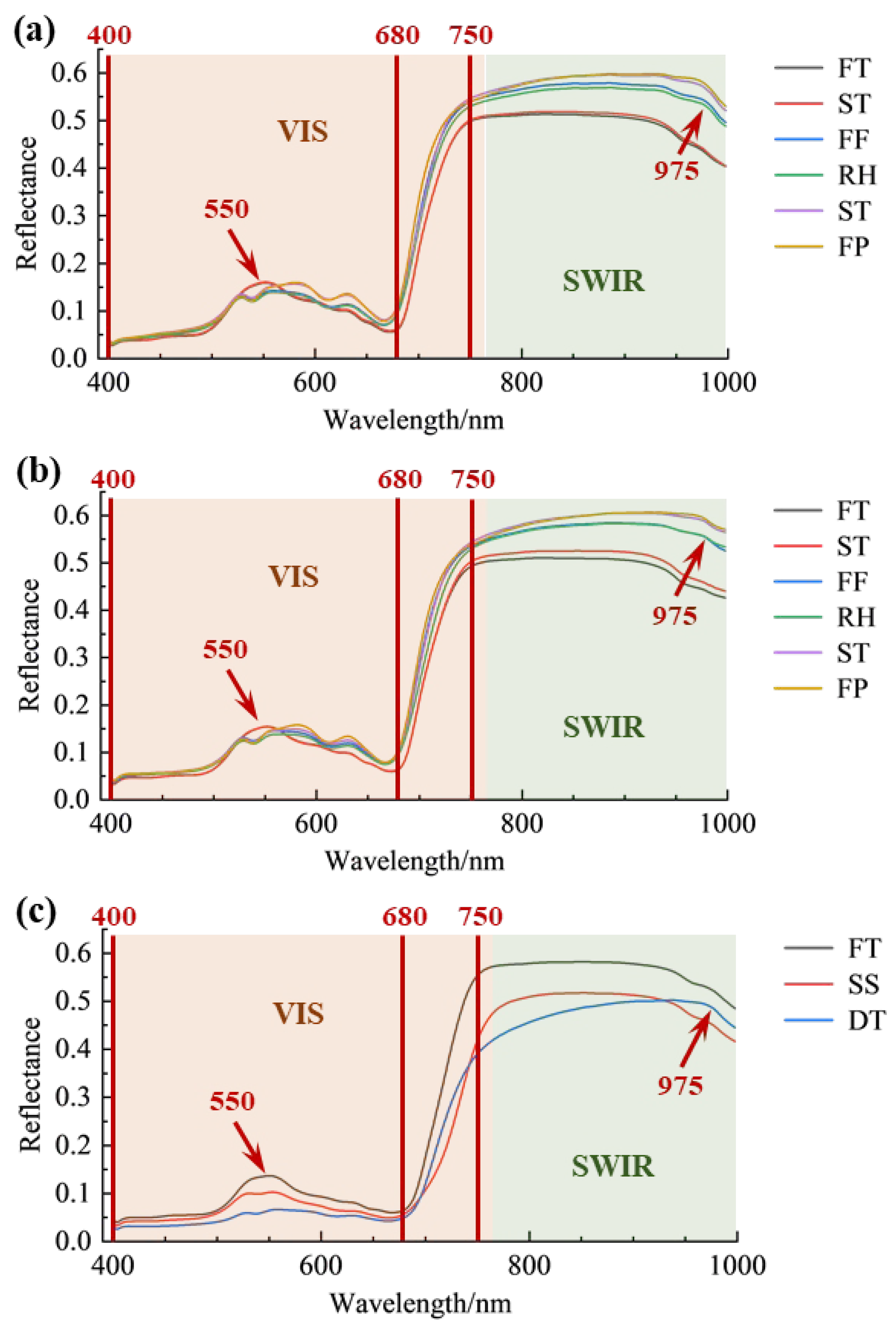
3.2. Spectral Analysis
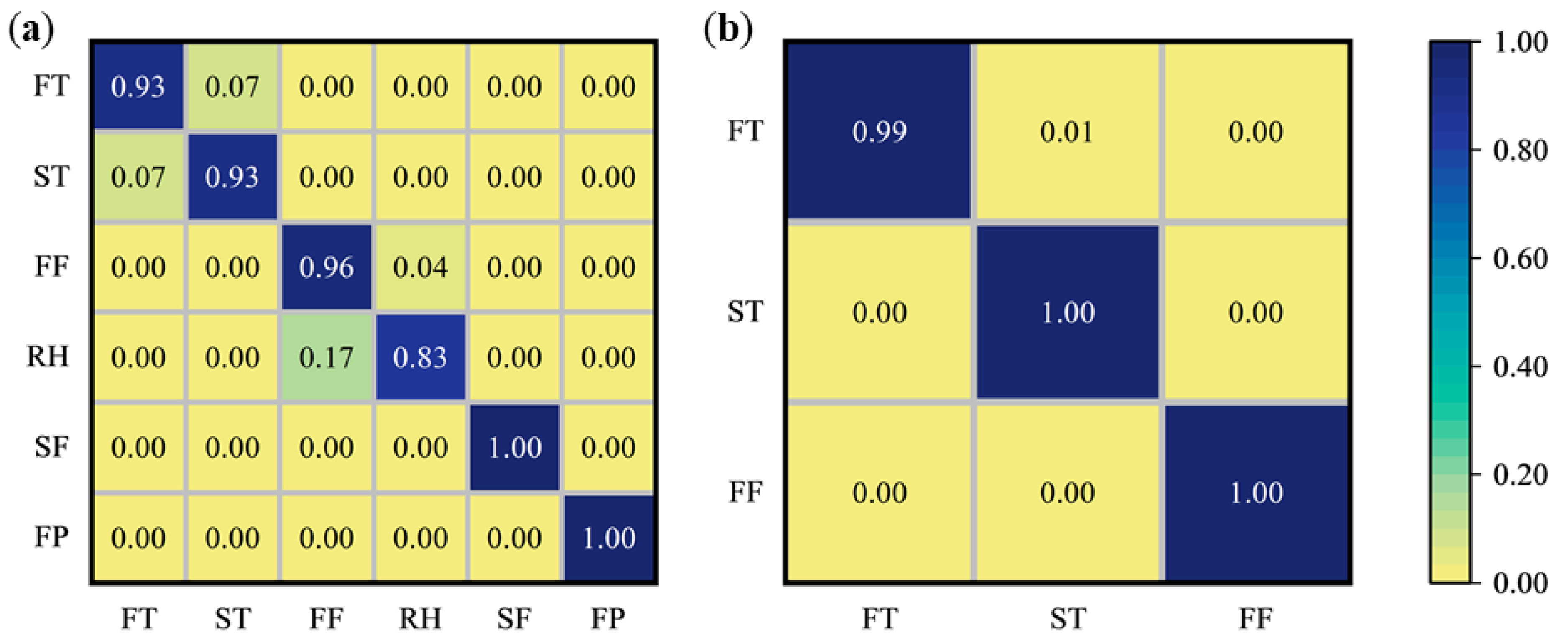
3.3. Classification of Different Processing Procedures
3.4. Quantitative Determination of Tea Moisture Content
3.5. Generalization Capability of Spectral Determination Model of Moisture
3.6. Visualization of the Moisture Distribution
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qu, F.; Zeng, W.; Tong, X.; Feng, W.; Chen, Y.; Ni, D. The new insight into the influence of fermentation temperature on quality and bioactivities of black tea. LWT 2020, 117, 108646. [Google Scholar] [CrossRef]
- Fu, J.Y.; Jiang, C.X.; Wu, M.Y.; Mei, R.Y.; Yang, A.F.; Tao, H.P.; Chen, X.J.; Zhang, J.; Huang, L.; Zhao, X.F. Theabrownin Induces Cell Apoptosis and Cell Cycle Arrest of Oligodendroglioma and Astrocytoma in Different Pathways. Front. Pharmacol. 2021, 12, 664003. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Fu, L.; Kojima, R.; Yamamoto, A.; Ueno, T.; Matsui, T. Theaflavins prevent the onset of diabetes through ameliorating glucose tolerance mediated by promoted incretin secretion in spontaneous diabetic Torii rats. J. Funct. Foods 2021, 86, 104702. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, Z.; Li, M.; Lu, C.; Deng, W.-W.; Zhang, Z.; Ning, J. From lab to factory: A calibration transfer strategy from HSI to online NIR optimized for quality control of green tea fixation. J. Food Eng. 2023, 339, 111284. [Google Scholar] [CrossRef]
- Kumar, L. High-spectral resolution data for determining leaf water content in Eucalyptus species: Leaf level experiments. Geocarto Int. 2007, 22, 3–16. [Google Scholar] [CrossRef]
- Wei, Y.; Li, X.; He, Y. Generalisation of tea moisture content models based on VNIR spectra subjected to fractional differential treatment. Biosyst. Eng. 2021, 205, 174–186. [Google Scholar] [CrossRef]
- An, T.; Yu, S.; Huang, W.; Li, G.; Tian, X.; Fan, S.; Dong, C.; Zhao, C. Robustness and accuracy evaluation of moisture prediction model for black tea withering process using hyperspectral imaging. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 269, 120791. [Google Scholar] [CrossRef]
- Deb, S.; Jolvis Pou, K.R. A Review of Withering in the Processing of Black Tea. J. Biosyst. Eng. 2016, 41, 365–372. [Google Scholar] [CrossRef]
- Li, J.; Yu, X.-N.; Ge, W.-Z.; An, D. Qualitative Analysis of Maize Haploid Kernels Based on Calibration Transfer by Near-Infrared Spectroscopy. Anal. Lett. 2019, 52, 249–267. [Google Scholar] [CrossRef]
- Wang, F.; Xie, B.; Lü, E.; Zeng, Z.; Mei, S.; Ma, C.; Guo, J. Design of a Moisture Content Detection System for Yinghong No. 9 Tea Leaves Based on Machine Vision. Appl. Sci. 2023, 13, 1806. [Google Scholar] [CrossRef]
- Lin, X.; Sun, D. Recent developments in vibrational spectroscopic techniques for tea quality and safety analyses. Trends Food Sci. Technol. 2020, 104, 163–176. [Google Scholar] [CrossRef]
- Reeves, J.B. Near- versus mid-infrared diffuse reflectance spectroscopy for soil analysis emphasizing carbon and laboratory versus on-site analysis: Where are we and what needs to be done? Geoderma 2010, 158, 3–14. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, S.; Lee, H.; Cho, B.-K. A review of vibrational spectroscopic techniques for the detection of food authenticity and adulteration. Trends Food Sci. Technol. 2015, 46, 85–98. [Google Scholar] [CrossRef]
- Zang, Z.; Wang, J.; Cui, H.-L.; Yan, S. Terahertz spectral imaging based quantitative determination of spatial distribution of plant leaf constituents. Plant Methods 2019, 15, 106. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yang, C.; Yuan, C.; Li, Y.; An, T.; Dong, C. Moisture content monitoring in withering leaves during black tea processing based on electronic eye and near infrared spectroscopy. Sci. Rep. 2022, 12, 20721. [Google Scholar] [CrossRef]
- Shen, S.; Hua, J.; Zhu, H.; Yang, Y.; Deng, Y.; Li, J.; Yuan, H.; Wang, J.; Zhu, J.; Jiang, Y. Rapid and real-time detection of moisture in black tea during withering using micro-near-infrared spectroscopy. LWT 2022, 155, 112970. [Google Scholar] [CrossRef]
- Su, W.; He, H.; Sun, D. Non-Destructive and rapid evaluation of staple foods quality by using spectroscopic techniques: A review. Crit. Rev. Food Sci. Nutr. 2017, 57, 1039–1051. [Google Scholar] [CrossRef]
- Ekinzog, E.; Schlerf, M.; Kraft, M.; Werner, F.; Riedel, A.; Rock, G.; Mallick, K. Revisiting crop water stress index based on potato field experiments in Northern Germany. Agric. Water Manag. 2022, 269, 107664. [Google Scholar] [CrossRef]
- Huang, Z.; Sanaeifar, A.; Tian, Y.; Liu, L.; Zhang, D.; Wang, H.; Ye, D.; Li, X. Improved generalization of spectral models associated with Vis-NIR spectroscopy for determining the moisture content of different tea leaves. J. Food Eng. 2021, 293, 110374. [Google Scholar] [CrossRef]
- Ma, J.; Sun, D. Prediction of monounsaturated and polyunsaturated fatty acids of various processed pork meats using improved hyperspectral imaging technique. Food Chem. 2020, 321, 126695. [Google Scholar] [CrossRef]
- Wang, D.; Li, R.; Liu, T.; Liu, S.; Sun, C.; Guo, W. Combining vegetation, color, and texture indices with hyperspectral parameters using machine-learning methods to estimate nitrogen concentration in rice stems and leaves. Field Crops Res. 2023, 304, 109175. [Google Scholar] [CrossRef]
- Gowen, A.; O’Donnell, C.; Cullen, P.; Downey, G.; Frias, J.M. Hyperspectral imaging—An emerging process analytical tool for food quality and safety control. Trends Food Sci. Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Matese, A.; Prince Czarnecki, J.M.; Samiappan, S.; Moorhead, R. Are unmanned aerial vehicle-based hyperspectral imaging and machine learning advancing crop science? Trends Plant Sci. 2023, 29, 196–209. [Google Scholar] [CrossRef]
- Turner, D.; Cimoli, E.; Lucieer, A.; Haynes, R.S.; Randall, K.; Waterman, M.J.; Lucieer, V.; Robinson, S.A. Mapping water content in drying Antarctic moss communities using UAS-borne SWIR imaging spectroscopy. Remote Sens. Ecol. Conserv. 2024, 10, 296–311. [Google Scholar] [CrossRef]
- Luo, X.; Sun, C.; He, Y.; Zhu, F.; Li, X. Cross-cultivar prediction of quality indicators of tea based on VIS-NIR hyperspectral imaging. Ind. Crops Prod. 2023, 202, 117009. [Google Scholar] [CrossRef]
- Wei, Y.; Wu, F.; Xu, J.; Sha, J.; Zhao, Z.; He, Y.; Li, X. Visual detection of the moisture content of tea leaves with hyperspectral imaging technology. J. Food Eng. 2019, 248, 89–96. [Google Scholar] [CrossRef]
- Wang, S.; Sun, J.; Fu, L.; Xu, M.; Tang, N.; Cao, Y.; Yao, K.; Jing, J. Identification of red jujube varieties based on hyperspectral imaging technology combined with CARS-IRIV and SSA-SVM. J. Food Process Eng. 2022, 45, e14137. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, F.; Kung, H.; Johnson, V.C. New methods for improving the remote sensing estimation of soil organic matter content (SOMC) in the Ebinur Lake Wetland National Nature Reserve (ELWNNR) in northwest China. Remote Sens. Environ. 2018, 218, 104–118. [Google Scholar] [CrossRef]
- Yin, Y.; Li, J.; Ling, C.; Zhang, S.; Liu, C.; Sun, X.; Wu, J. Fusing spectral and image information for characterization of black tea grade based on hyperspectral technology. LWT 2023, 185, 115150. [Google Scholar] [CrossRef]
- Krakowska, B.; Custers, D.; Deconinck, E.; Daszykowski, M. The Monte Carlo validation framework for the discriminant partial least squares model extended with variable selection methods applied to authenticity studies of Viagra (R) based on chromatographic impurity profiles. Analyst 2016, 141, 1060–1070. [Google Scholar] [CrossRef]
- Li, S.; Song, Q.; Liu, Y.; Zeng, T.; Liu, S.; Jie, D.; Wei, X. Hyperspectral imaging-based detection of soluble solids content of loquat from a small sample. Postharvest Biol. Technol. 2023, 204, 112454. [Google Scholar] [CrossRef]
- Meiyan, S.; Jinyu, Z.; Xiaohong, Y.; Xiaohe, G.; Baoguo, L.; Yuntao, M. A spectral decomposition method for estimating the leaf nitrogen status of maize by UAV-based hyperspectral imaging. Comput. Electron. Agric. 2023, 212, 108100. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, W.; Li, J.; Liu, S.; Fan, S. Assessment of protein content and insect infestation of maize seeds based on on-line near-infrared spectroscopy and machine learning. Comput. Electron. Agric. 2023, 211, 107969. [Google Scholar] [CrossRef]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hategan, A.; David, M.; Berghian-Grosan, C.; Magdas, D. Geographical and varietal origin differentiation of alcoholic beverages through the association between FT-Raman spectroscopy and advanced data processing strategies. Food Chem. X 2023, 20, 100902. [Google Scholar] [CrossRef]
- He, H.; Wu, D.; Sun, D. Rapid and non-destructive determination of drip loss and pH distribution in farmed Atlantic salmon (Salmo salar) fillets using visible and near-infrared (Vis-NIR) hyperspectral imaging. Food Chem. 2014, 156, 394–401. [Google Scholar] [CrossRef]
- Kamruzzaman, M.; Makino, Y.; Oshita, S. Rapid and non-destructive detection of chicken adulteration in minced beef using visible near-infrared hyperspectral imaging and machine learning. J. Food Eng. 2016, 170, 8–15. [Google Scholar] [CrossRef]
- Ahmed, T.; Wijewardane, N.K.; Lu, Y.; Jones, D.S.; Kudenov, M.; Williams, C.; Villordon, A.; Kamruzzaman, M. Advancing sweetpotato quality assessment with hyperspectral imaging and explainable artificial intelligence. Comput. Electron. Agric. 2024, 220, 108855. [Google Scholar] [CrossRef]
- Jiang, M.; You, S.; Sha, H.; Bai, B.; Zhang, L.; Tu, K.; Peng, J.; Song, L.; Lan, W.; Pan, L. Detection of Alternaria alternata infection in winter jujubes based on optical properties and their correlation with internal quality parameters during storage. Food Chem. 2023, 409, 135298. [Google Scholar] [CrossRef]
- Wu, C.; Qian, J.; Zhang, J.; Wang, J.; Li, B.; Wei, Z. Moisture measurement of tea leaves during withering using multifrequency microwave signals optimized by ant colony optimization. J. Food Eng. 2022, 335, 111174. [Google Scholar] [CrossRef]
- Zhai, Y.; Cui, L.; Zhou, X.; Gao, Y.; Fei, T.; Gao, W. Estimation of nitrogen, phosphorus, and potassium contents in the leaves of different plants using laboratory-based visible and near-infrared reflectance spectroscopy: Comparison of partial least-square regression and support vector machine regression methods. Int. J. Remote Sens. 2013, 34, 2502–2518. [Google Scholar] [CrossRef]
- Jiao, Y.; Song, Y.; Yan, Z.; Wu, Z.; Yu, Z.; Zhang, D.; Ni, D.; Chen, Y. The New Insight into the Effects of Different Fixing Technology on Flavor and Bioactivities of Orange Dark Tea. Molecules 2023, 28, 1079. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, H.; Liu, Y.; Wang, Y.; Lu, C.; Li, T.; Wei, Y.; Ning, J. Monitoring green tea fixation quality by intelligent sensors: Comparison of image and spectral information. J. Sci. Food Agric. 2023, 103, 3093–3101. [Google Scholar] [CrossRef] [PubMed]
- Zong, X.; Sheng, X.; Li, L.; Zan, J.; Jiang, Y.; Zou, H.; Shen, S.; Yuan, H. Rapid Detection of Moisture Content in the Processing of Longjing Tea by Micro-Near-Infrared Spectroscopy and a Portable Colorimeter Based on a Data Fusion Strategy. Horticulturae 2022, 8, 1007. [Google Scholar] [CrossRef]
- Huang, M.; Wang, Q.; Zhang, M.; Zhu, Q. Prediction of color and moisture content for vegetable soybean during drying using hyperspectral imaging technology. J. Food Eng. 2014, 128, 24–30. [Google Scholar] [CrossRef]
- Cho, J.; Choi, J.; Moon, K.D. Hyperspectral imaging technology for monitoring of moisture contents of dried persimmons during drying process. Food Sci. Biotechnol. 2020, 29, 1407–1412. [Google Scholar] [CrossRef]
- Jiang, Y.; Zareef, M.; Liu, L.; Ouyang, Q. Monitoring of carotenoids changes during the matcha drying process using a portable developed spectral analytical system. J. Food Compos. Anal. 2024, 125, 105849. [Google Scholar] [CrossRef]
- Netto, J.M.S.; Honorato, F.A.; Azoubel, P.M.; Kurozawa, L.E.; Barbin, D.F. Evaluation of melon drying using hyperspectral imaging technique in the near infrared region. LWT 2021, 143, 111092. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, C.; Wang, H.; Chen, S.; Liu, W.; Li, Y.; Li, J. Machine learning technique combined with data fusion strategies: A tea grade discrimination platform. Ind. Crops Prod. 2023, 203, 117127. [Google Scholar] [CrossRef]
- You, J.; Li, D.; Wang, Z.; Chen, Q.; Ouyang, Q. Prediction and visualization of moisture content in Tencha drying processes by computer vision and deep learning. J. Sci. Food Agric. 2024, 104, 5486–5494. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhang, R.; Yang, C.; Hu, B.; Luo, X.; Li, Y.; Dong, C. Research on moisture content detection method during green tea processing based on machine vision and near-infrared spectroscopy technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 271, 120921. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yang, C.; Luo, X.; Hu, B.; Dong, C. Research on the online rapid sensing method of moisture content in famous green tea spreading. J. Food Process Eng. 2021, 44, e13853. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, Z.; Zhou, C.; Chen, H.; Ding, Z. Research on hyperspectral timely monitoring model of green tea processing quality based on PSO-LSSVR. J. Food Compos. Anal. 2024, 134, 106490. [Google Scholar] [CrossRef]
- Sun, J.; Zhou, X.; Hu, Y.; Wu, X.; Zhang, X.; Wang, P. Visualizing distribution of moisture content in tea leaves using optimization algorithms and NIR hyperspectral imaging. Comput. Electron. Agric. 2019, 160, 153–159. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
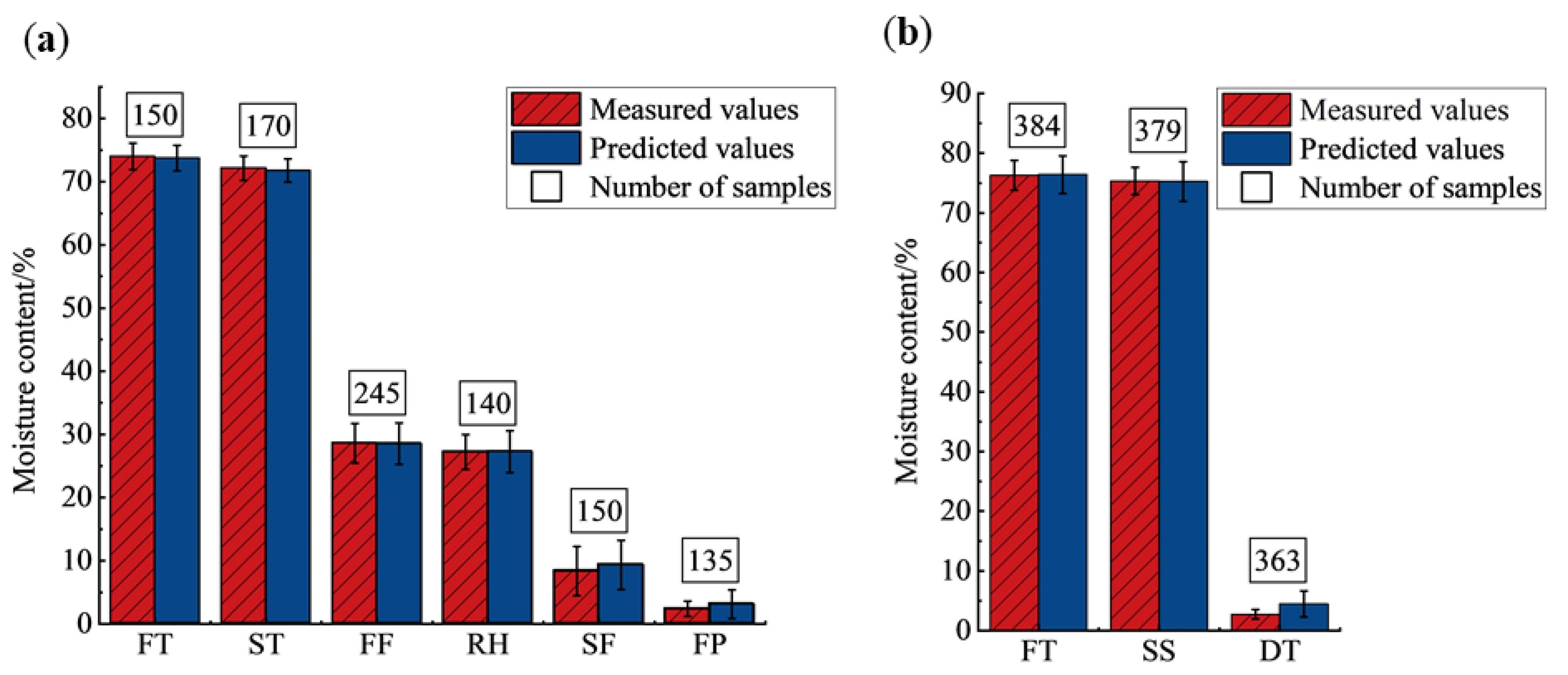
| Types | Varieties | Fresh Tea | Spreading | First Fixation/Steaming | Rehydration | Second Fixation | Final Panning/ Drying | Total |
|---|---|---|---|---|---|---|---|---|
| West Lake Longjing | Longjing 43 | 35 | 50 | 50 | 30 | 40 | 30 | 235 |
| Quntizhong | 115 | 120 | 165 | 100 | 110 | 105 | 715 | |
| Tencha | Jiukeng | 384 | 0 | 379 | 0 | 0 | 363 | 1126 |
| Varieties | Models | Pretreatment | Accuracy | |
|---|---|---|---|---|
| Train/% | Test/% | |||
| West Lake Longjing | PLS-DA | None | 100.00 | 92.75 |
| MSC | 100.00 | 91.47 | ||
| SG | 99.60 | 94.59 | ||
| NOR | 100.00 | 89.08 | ||
| RF | None | 100.00 | 81.93 | |
| MSC | 100.00 | 88.62 | ||
| SG | 99.60 | 82.57 | ||
| NOR | 100.00 | 90.37 | ||
| Tencha | PLS-DA | None | 99.92 | 99.54 |
| MSC | 99.94 | 99.64 | ||
| SG | 99.87 | 99.64 | ||
| NOR | 99.92 | 99.74 | ||
| RF | None | 99.95 | 99.50 | |
| MSC | 99.95 | 99.74 | ||
| SG | 99.95 | 99.29 | ||
| NOR | 99.95 | 99.80 | ||
| Types | Models | Modeling Results | ||||
|---|---|---|---|---|---|---|
| RMSECV | RMSEP | RPD | ||||
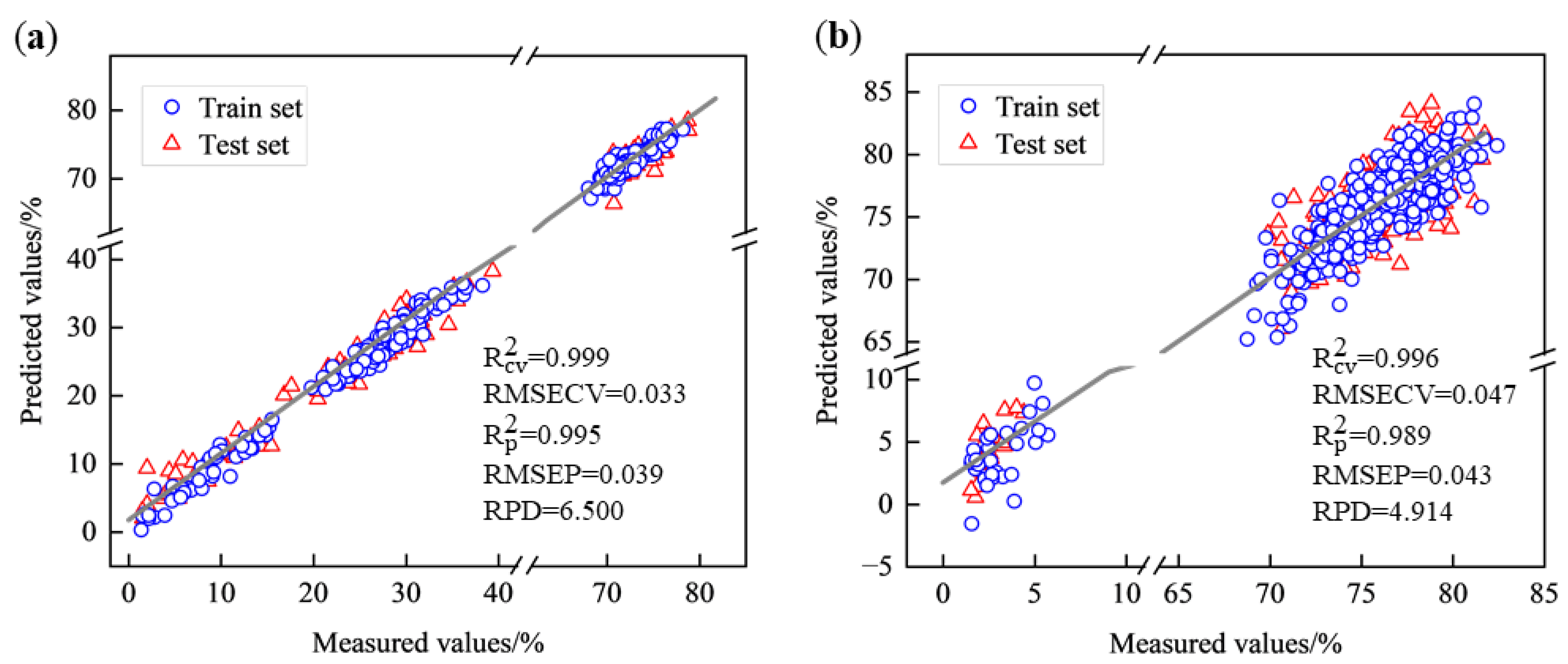
| West Lake Longjing | PLSR | 0.999 | 0.033 | 0.995 | 0.039 | 6.500 |
| SVR | 0.960 | 0.051 | 0.946 | 0.059 | 4.323 | |
| Tencha | PLSR | 0.996 | 0.047 | 0.989 | 0.043 | 4.914 |
| SVR | 0.956 | 0.047 | 0.945 | 0.049 | 4.301 | |
| All | PLSR | 0.996 | 0.054 | 0.992 | 0.054 | 4.659 |
| SVR | 0.974 | 0.045 | 0.972 | 0.042 | 5.925 | |
| Train Set/Test Set | Pretreatment | Modeling Results | ||||
|---|---|---|---|---|---|---|
| RMSECV | RMSEP | RPD | ||||
| West Lake Longjing /Tencha | None | 0.999 | 0.033 | 0.455 | 0.161 | 1.355 |
| MSC | 0.999 | 0.037 | 0.364 | 0.174 | 1.254 | |
| SG | 0.997 | 0.033 | 0.606 | 0.137 | 1.592 | |
| NOR | 0.998 | 0.036 | 0.778 | 0.103 | 2.121 | |
| MSC-NOR | 0.998 | 0.036 | 0.778 | 0.103 | 2.121 | |
| SG-NOR | 0.997 | 0.037 | 0.736 | 0.112 | 1.947 | |
| Tencha /West Lake Longjing | None | 0.996 | 0.042 | 0.838 | 0.101 | 2.484 |
| MSC | 0.997 | 0.033 | 0.500 | 0.347 | 0.724 | |
| SG | 0.993 | 0.042 | 0.912 | 0.074 | 3.378 | |
| NOR | 0.996 | 0.037 | 0.599 | 0.159 | 1.578 | |
| MSC-NOR | 0.996 | 0.037 | 0.599 | 0.159 | 1.578 | |
| SG-NOR | 0.994 | 0.037 | 0.761 | 0.123 | 2.046 | |
| Train Set/Test Set | Pretreatment | CVD * | Modeling Results | ||||
|---|---|---|---|---|---|---|---|
| RMSECV | RMSEP | RPD | |||||
| West Lake Longjing/Tencha | None | 86 | 0.999 | 0.029 | 0.455 | 0.161 | 1.355 |
| MSC | 77 | 0.999 | 0.028 | 0.364 | 0.174 | 1.254 | |
| SG | 69 | 0.998 | 0.029 | 0.606 | 0.137 | 1.592 | |
| NOR | 75 | 0.999 | 0.036 | 0.894 | 0.071 | 3.069 | |
| MSC-NOR | 88 | 0.999 | 0.036 | 0.894 | 0.071 | 3.069 | |
| SG-NOR | 95 | 0.998 | 0.030 | 0.736 | 0.112 | 1.947 | |
| Tencha/ West Lake Longjing | None | 67 | 0.994 | 0.040 | 0.855 | 0.096 | 2.630 |
| MSC | 59 | 0.995 | 0.035 | 0.302 | 0.189 | 1.103 | |
| SG | 103 | 0.993 | 0.040 | 0.868 | 0.092 | 2.748 | |
| NOR | 97 | 0.994 | 0.037 | 0.941 | 0.061 | 4.117 | |
| MSC-NOR | 53 | 0.994 | 0.037 | 0.873 | 0.090 | 2.811 | |
| SG-NOR | 81 | 0.993 | 0.034 | 0.922 | 0.070 | 3.585 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liao, B.; Gouda, M.; Luo, X.; Song, X.; Guo, Y.; Qi, Y.; Zeng, H.; Zhou, C.; Wang, Y.; et al. Visualization of Moisture Distribution in Stacked Tea Leaves on Process Flow Line Using Hyperspectral Imaging. Foods 2025, 14, 1551. https://doi.org/10.3390/foods14091551
Zhang Y, Liao B, Gouda M, Luo X, Song X, Guo Y, Qi Y, Zeng H, Zhou C, Wang Y, et al. Visualization of Moisture Distribution in Stacked Tea Leaves on Process Flow Line Using Hyperspectral Imaging. Foods. 2025; 14(9):1551. https://doi.org/10.3390/foods14091551
Chicago/Turabian StyleZhang, Yuying, Binhui Liao, Mostafa Gouda, Xuelun Luo, Xinbei Song, Yihang Guo, Yingjie Qi, Hui Zeng, Chuangchuang Zhou, Yujie Wang, and et al. 2025. "Visualization of Moisture Distribution in Stacked Tea Leaves on Process Flow Line Using Hyperspectral Imaging" Foods 14, no. 9: 1551. https://doi.org/10.3390/foods14091551
APA StyleZhang, Y., Liao, B., Gouda, M., Luo, X., Song, X., Guo, Y., Qi, Y., Zeng, H., Zhou, C., Wang, Y., Zhang, J., & Li, X. (2025). Visualization of Moisture Distribution in Stacked Tea Leaves on Process Flow Line Using Hyperspectral Imaging. Foods, 14(9), 1551. https://doi.org/10.3390/foods14091551