2. Materials and Methods
2.1. Segmentation
Segmentation is a process in image processing that identifies objects and determines their classification, defining what is displayed in an image and where specific objects are located. There exist numerous types of segmentation, including semantic and instance segmentation. In semantic segmentation, each pixel is assigned a specific class, and once each pixel is classified, adjacent pixels are grouped to form objects of a particular classification. The key distinction between semantic and instance segmentation is that instance segmentation differentiates between individual objects within the same class. Moreover, in instances of segmentation, the necessity of individual pixel classification is not universally applicable, as objects can be segmented as whole entities, contingent upon the type of neural network employed for instance classification [
10].
Segmentation enables the identification of objects in an image, thereby allowing for subsequent decision-making based on the extracted information. In manufacturing processes where multiple objects appear in a single image, instance segmentation is predominantly utilized. This approach allows for the detection and individual processing of multiple objects of the same classification within a single frame. Due to this capability, instance segmentation was chosen for the development of the sorting system. Consequently, the camera’s field of view could capture multiple potatoes simultaneously, thereby accelerating the sorting process and increasing the number of potatoes sorted per hour.
2.2. Mask R-CNN
Mask R-CNN, developed by the Facebook AI Research (FAIR) team (Meta Platforms, Menlo Park, CA, USA), is one of the various R-CNN neural network methods by which instance segmentation is carried out. Instance segmentation performed with neural network architecture R-CNN and its derivatives (i.e., Fast R-CNN and Faster R-CNN) identifies object instances within an image and returns their bounding boxes and labels [
10]. The key distinction between these methods and Mask R-CNN, a method built upon the Faster R-CNN architecture, is its capacity to not only generate bounding boxes and labels, but also to produce a segmentation mask for each object, enabling Mask R-CNN to provide precise pixel-level information regarding object regions, a functionality not attainable with other R-CNN methods (
Figure 1) [
10].
For this key reason, Mask R-CNN was chosen for the segmentation process. This enabled the forwarding of cropped images of each potato instance to a secondary neural network dedicated to classification. The pixel values corresponding to the potato instance were preserved, while all other pixels were set to 0, thereby simplifying classification by eliminating irrelevant background information.
2.3. Hardware and Software Utilized
Images of potatoes for training and evaluation were taken with Basler acA2500-14gc (Basler AG, Ahrensburg, Germany). The entire training and evaluation process was conducted on an Asus ROG Flow X16 (2022) GV601RM laptop (ASUSTeK Computer Inc., Taipei, Taiwan) equipped with an NVIDIA GeForce RTX 3060 laptop GPU with a TDP of 125W (NVIDIA Corporation, Santa Clara, CA, USA). The process was executed using MATLAB 23.2 (MathWorks, Natick, MA, USA) and the Python programming language, version 3.10.14 (Python Software Foundation, Beaverton, OR, USA). Python was implemented within the Anaconda environment (Anaconda, Inc., Austin, TX, USA), which included the following essential libraries: OpenCV 4.7.0 (OpenCV.org, Kizhevsk, Russia), pip 23.3.1 (Python Software Foundation, Beaverton, OR, USA), and PyTorch 2.2.2+cu118 (Meta Platforms, Inc., Menlo Park, CA, USA). Additionally, the NVIDIA CUDA 11.8 architecture (NVIDIA Corporation, Santa Clara, CA, USA) was utilized to optimize GPU-based computations.
2.4. Research Process
The research commenced with the acquisition of a dataset of images of potatoes for training, followed by the preprocessing and organization of images and data. Subsequently, a training dataset was prepared through manual annotation of potato instances. Following the processing of all data, the neural network training phase was initiated. The final step involved the evaluation of all trained neural networks and a comparative analysis of the obtained results.
2.5. Image Preparation
A series of images were captured using a camera while the potatoes were positioned on the rollers of the sorting machine. The potatoes could have been placed on any surface; however, it was determined that placement on rollers would be optimal for the sorting system. This setup was expected to enhance both the neural network’s performance and segmentation accuracy. By rotating the rollers, the potatoes were turned, allowing images to be taken from multiple angles. In a practical application, rotation of the potatoes would also be necessary, as decay might be present only on one side.
Potential improvements in the classification of potato decay were explored by capturing infrared-spectrum images using a thermal camera. Decayed sections of the potatoes appeared colder than the healthy areas.
The images containing multiple potatoes were categorized into three distinct groups: rotten potatoes, feed potatoes, and high-quality potatoes. Rotten potatoes exhibited clear signs of decay, feed potatoes were either bruised or green (unsuitable for retail sale), and high-quality potatoes met the standards for commercial distribution. The potatoes were categorized by an expert that evaluated the quality of each potato.
A total of 696 images were collected, with 105 images of rotten potatoes, 375 images of feed potatoes, and 216 images of high-quality potatoes (
Figure 2). The distribution of images utilized for training and evaluation of the neural networks is presented in
Table 1. Of the total, 521 images were selected for training, comprising all potato categories, with a predominant focus on feed potatoes (70.5%) and rotten potatoes (19.7%). This emphasis was necessary because, in some cases, the difference between mud-covered rollers and the potatoes was minimal, potentially affecting classification accuracy.
The selected images were imported into the MATLAB programming environment, where they were processed and prepared for neural network training using the built-in Image Labeler application (Computer Vision Toolbox 23.2). During the preparation process, a class of polynomial annotations named “Potato” was created. Each potato in the images was outlined with a polygonal annotation, ensuring that the number of labeled objects corresponded to the number of potatoes in the image. The annotations were made as precisely as possible; however, due to the polygonal nature of the labels, perfect accuracy was not attainable. The total number of labeled objects created across all images was 2028, with the number of potatoes per image ranging from three to six, and an average of nearly four potatoes per image.
Following the completion of the manual segmentation of the selected images, the annotation files in MATLAB were saved as “labelingProject.prj”, which contained the progress of the annotations, and “gTruth.mat”, which stored a dictionary named “Ground Truth”. This dictionary included all data regarding the location of the processed images, the number of object classes present in each image, and the coordinates of the polygons outlining these objects.
2.6. Preparation of the Neural Network in MATLAB
Using the gTruth.mat file, data on the manually labeled images, including information on the polygons of actual objects in the images, were imported into the neural network training program. Based on these polygons, the boundary coordinates of the bounding box for each object were calculated. In addition to calculating the bounding box for each polygon, logical images were created for each polygon, with the same size as the images containing the potatoes. The logical image was structured such that every pixel within the polygon was marked with a value of 1, while pixels outside the polygon were marked with a value of 0.
Once all the necessary data were obtained using various functions in MATLAB, the parameterization of the Mask R-CNN neural network training settings began. During the training of different neural networks, only the number of epochs, over which the network was trained, was modified. Therefore, the training settings common to all models in MATLAB are presented in
Table 2.
In the future, all neural networks will be numbered sequentially and labeled as NNn (Neural Network n), where “n” represents the neural network number in order.
Neural Network 1 (NN1) was trained on 10 epochs of images with dimensions 1080 × 1920. One epoch represents one complete cycle over the entire dataset intended for training. In this case, the dataset consisted of all images designated for neural network training. Consequently, if NN1 underwent 10 epochs of training, it completed 10 cycles over the entirety of the dataset [
19]. Neural Network 2 (NN2) was trained on 500 epochs of images with dimensions 480 × 270. The third neural network (NN3) was trained on 500 epochs of images with dimensions 1280 × 720. The fourth neural network (NN4) was trained on 1000 epochs of images with dimensions 480 × 270.
The dimensions of the images were modified during the training of the neural networks for several reasons. The objective was to attain equal or superior segmentation quality at the minimum possible image size, as this affects numerous segmentation parameters. By reducing the image size, the aim was to shorten the training time of the neural network, as large neural networks can make the training process very time consuming. The required image size for segmentation also impacts the selection and acquisition of the camera integrated into the sorter, as the larger the required image size, the more expensive the camera. The image size also influences the storage space occupied by each image, which, in addition to occupying space, affects the speed of image transfer and processing during segmentation. All these parameters ultimately influence the costs and speed of sorter operation.
After setting up the neural networks, the Mask R-CNN neural network architecture was imported, and training commenced based on the dictionary created specifically for training. The dictionary contained polygons, polygon masks, bounding boxes, and image locations.
2.7. Preparation of the Neural Network in Python
The neural network was implemented also in Python, as this programming language facilitates more seamless integration with other languages and exhibits superior speed compared to MATLAB. Given that the images had previously been processed and labeled with regions containing potatoes in the MATLAB environment, the decision to process the data in Python was more straightforward. However, it should be noted that Python does not natively support reading .mat files. To address this limitation, the gTruth.mat file was converted into a gTruth.json file using the MATLAB function exportGroundTruthToJSON. A salient benefit of this format is its capacity to ensure the legibility of JSON files by humans [
20].
The PyTorch library was utilized to construct the neural network, a process that necessitated the adaptation of the data format. Logical mask images were generated from polygon information with pre-prepared functions, and the images were stored in a dictionary, facilitating the efficient processing of individual images.
Prior to training the neural network, the images underwent random transformations, including posterization, grayscale conversion, contrast adjustment, brightness modification, and horizontal flipping. Each transformation was applied with a probability ranging from 10% to 50%. These transformations were implemented to ensure the neural network’s functionality under diverse lighting conditions within the sorting system, given that the original images were captured under uniform lighting conditions, since a study comparing YOLOv8 and Mask R-CNN proved that Mask R-CNN detected objects worse under different lightning conditions [
21].
Once the images were collected and properly processed with transformations, the training of the neural network (NN5) followed, using a dataset of images with dimensions 512 × 512 for 40 epochs.
The different learning parameters of the trained neural networks are shown in
Table 3.
2.8. Preparation of Images for the Evaluation of Neural Networks
A total of 164 images of potatoes on rollers were included in the evaluation set, none of which had been used for training the neural network, thereby ensuring the most realistic results for assessing the network’s performance. This was due to the fact that the network was exposed to new images that it might encounter in practical applications. To optimize the evaluation process, the images were cropped to a dimension of 1920 × 580, as the rollers were located only within this section of the full image, originally sized 1920 × 1080, captured by the sorting system’s camera. Cropping the images also had practical value in the sorting program, as only the areas where potatoes could appear were analyzed, reducing the likelihood of errors.
The images designated for evaluation were processed manually to ensure that all objects belonging to the potato class were labeled. These images were then transferred into a ground-truth file, which contained both the images and the corresponding object data. The file format was identical to the one used for training the neural network, except that it contained different images and objects. The images were subsequently prepared for evaluation in Python, as well as in MATLAB, using the methods presented in the following section.
2.9. Methods for Evaluating Instance Segmentation
The performance of neural networks can be evaluated in several ways. In all methods, a comparison is made between the actual polygon areas of objects from the ground-truth file and the polygon areas of objects obtained from the neural network. Actual objects refer to the instances of objects that appear in each image (e.g., four potato objects), while segmented objects represent those detected by the neural network. The number of actual objects and segmented objects in an image may differ.
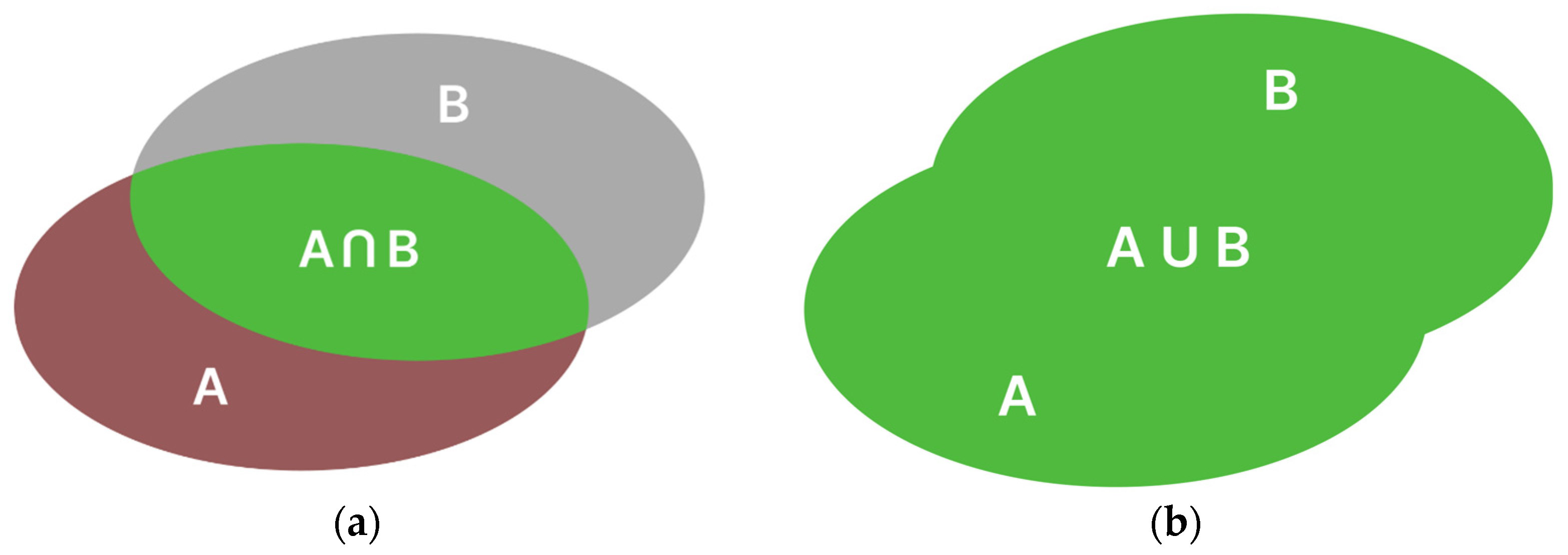
The first metric for evaluating the performance of a neural network is IoU (Intersection over Union). IoU represents the ratio of the intersection area of the actual object polygon and the segmented object polygon to the area of the union of these polygons (Equation (1)) (
Figure 3). The IoU parameter is a dimensionless value ranging from 0 to 1, where 1 indicates perfect overlap between the masks, while 0 indicates no overlap between the masks [
22,
23,
24].
This method is highly advantageous for comparing masks of individual objects; nevertheless, it is not optimal for assessing the overall suitability of the neural network. It is possible for too few objects to be detected, yet these objects may possess a high IoU value. Consequently, the average IoU value is calculated, despite the fact that not all objects were accurately identified.
To address this challenge, the mAP parameter is frequently employed. This parameter is founded on three concepts: precision (P), recall (R), and average precision (AP). Prior to delving into the properties of these parameters, it is essential to elucidate the methodologies employed to assess the segmentation of individual objects.
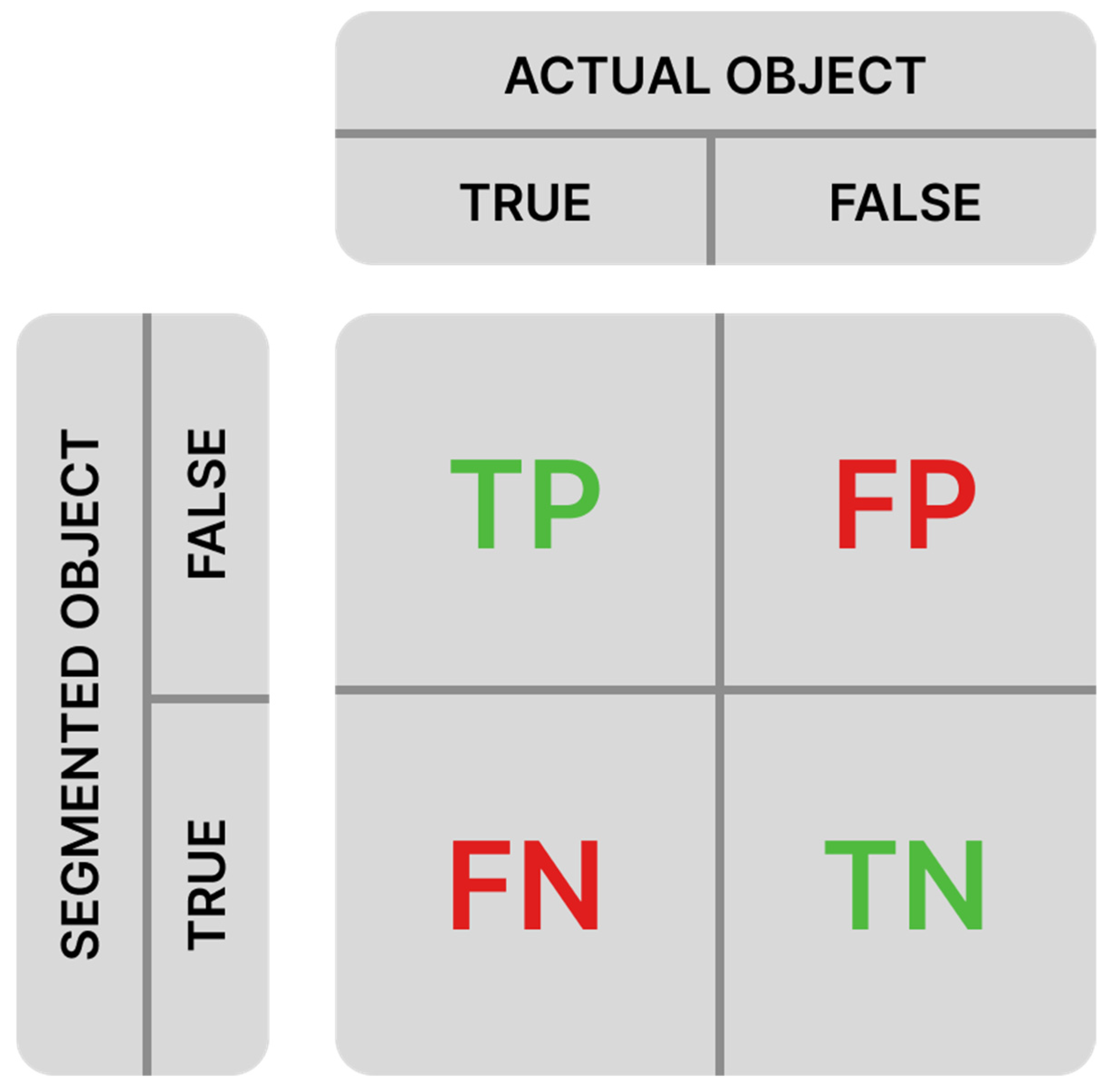
Each segmented object is classified into three categories determined by the comparison of its IoU value and the established overlap threshold [
10]: TP (true positive), FP (false positive), and FN (false negative). TN (true negative), which represents background that was not segmented as an object, is also known. A confusion matrix (
Figure 4) is used for the classification of the segmented object, which graphically illustrates into which category the segmented object falls.
Precision (P) is defined as the ratio of the number of TP classifications to the total number of segmented objects (Equation (2)). Recall (R) is calculated as the ratio of the number of TP classifications to the total number of actual objects (Equation (3)) [
25].
The evaluation of neural networks is based on a comparison of precision and recall, which results in a graph of the precision–recall relationship. Since recall frequently does not range between the limits of 0 and 1, including the boundary values, n recall values were defined, evenly distributed between 0 and 1. In this way, precision values were interpolated based on recall, which allowed for the creation of a graph with n connected points. This produced a continuous function that illustrates the previously mentioned relationship. To quantify this relationship, the average precision (AP) parameter was calculated, representing the area under the continuous precision–recall curve, enabling a facile evaluation of the neural network’s performance based on the AP value. AP can range between 0 and 1, where 1 indicates perfect neural network performance at a given overlap threshold. The AP value is calculated as the average of the maximum interpolated precision values based on n evenly distributed recall values from 0 to 1 [
22,
24].
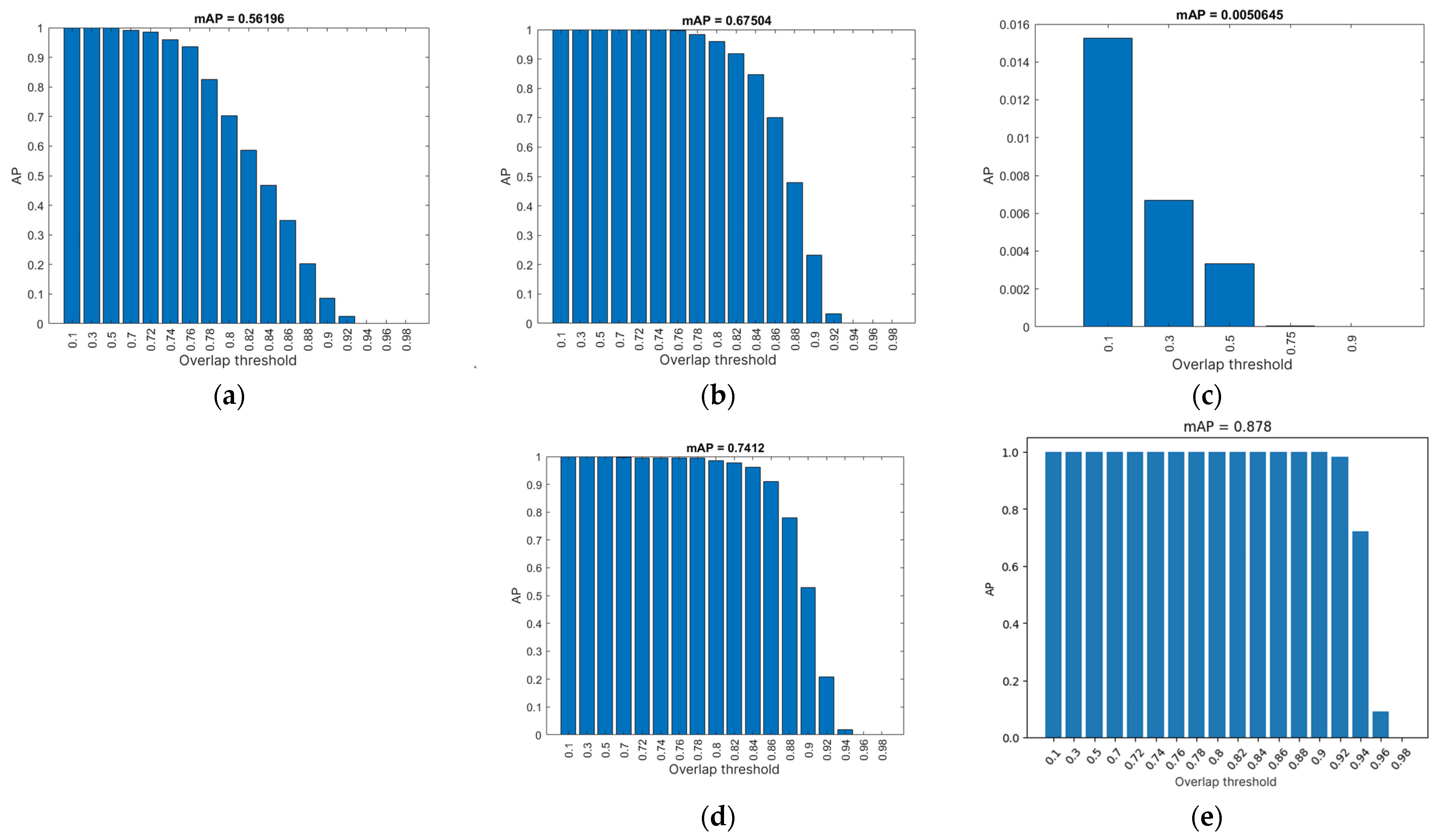
To obtain the mean average precision (mAP) for all specified precision thresholds, the average of all AP values is easily calculated. In the equation used to calculate mAP, the variable N represents the number of calculated AP parameters, which is equal to the number of overlap thresholds used (Equation (5)) [
22,
24].
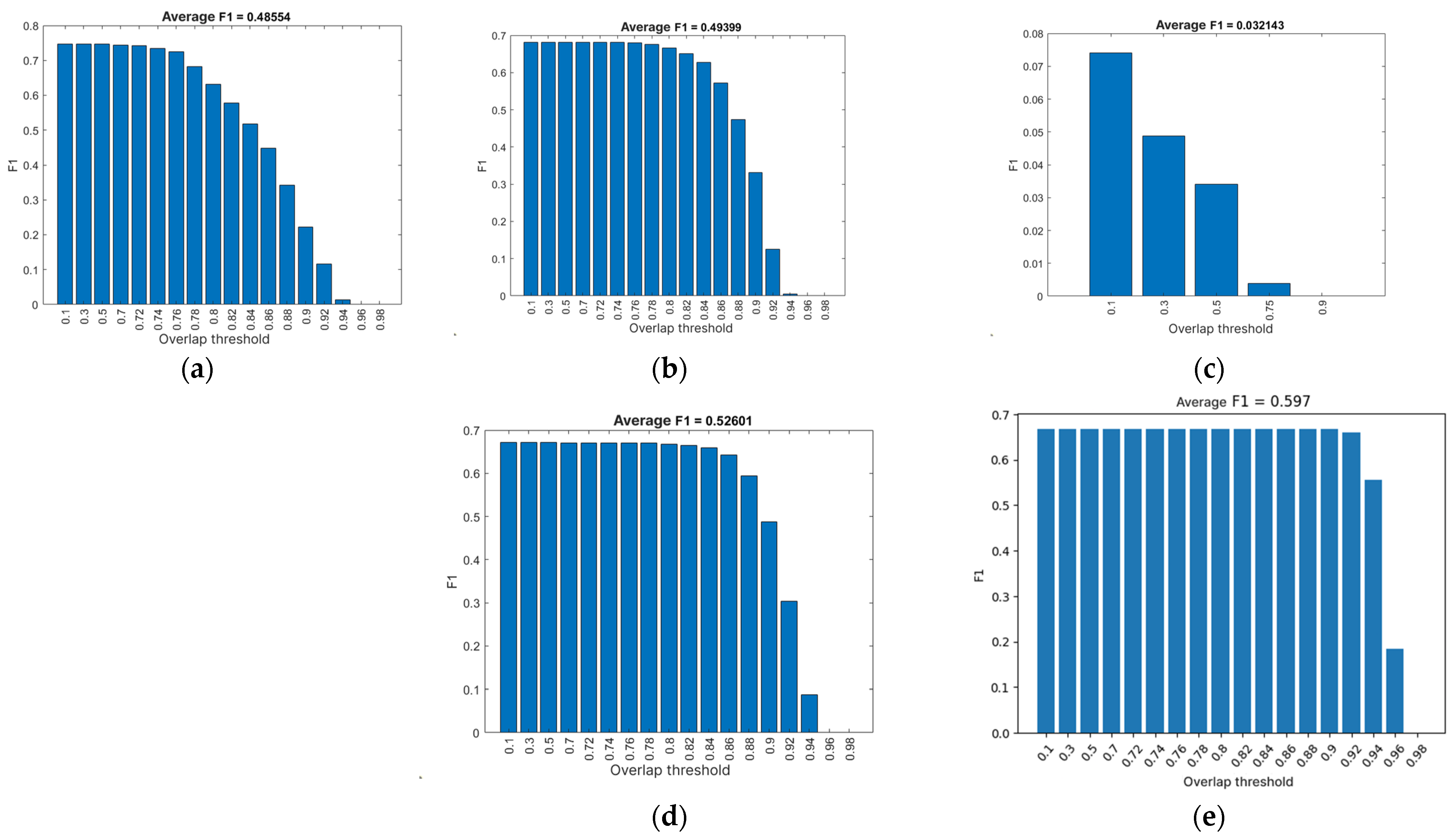
The subsequent parameter that facilitates the evaluation of the neural network using recall and accuracy is the
F1 score, which provides a straightforward perspective on the relationship between recall and accuracy of the neural network, akin to the AP value. The closer the
F1 score value is to 1, the superior the performance. The method selected for calculating the
F1 score necessitates the average value of all recalls and accuracies [
25,
26].
Given that the equation is performed by multiplying the average values of recall and accuracy, it is impossible for the F1 score to reach a value of 1, as the recall values are distributed between 0 and 1.
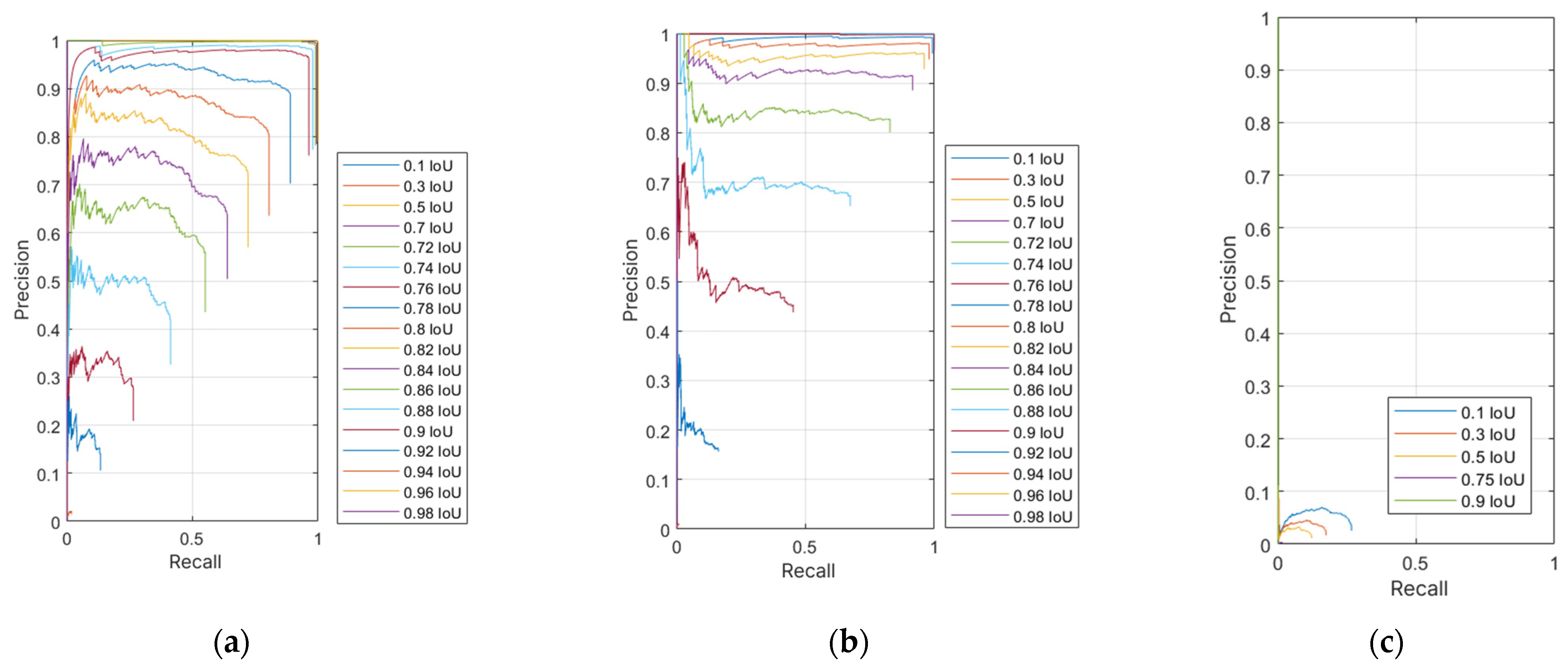
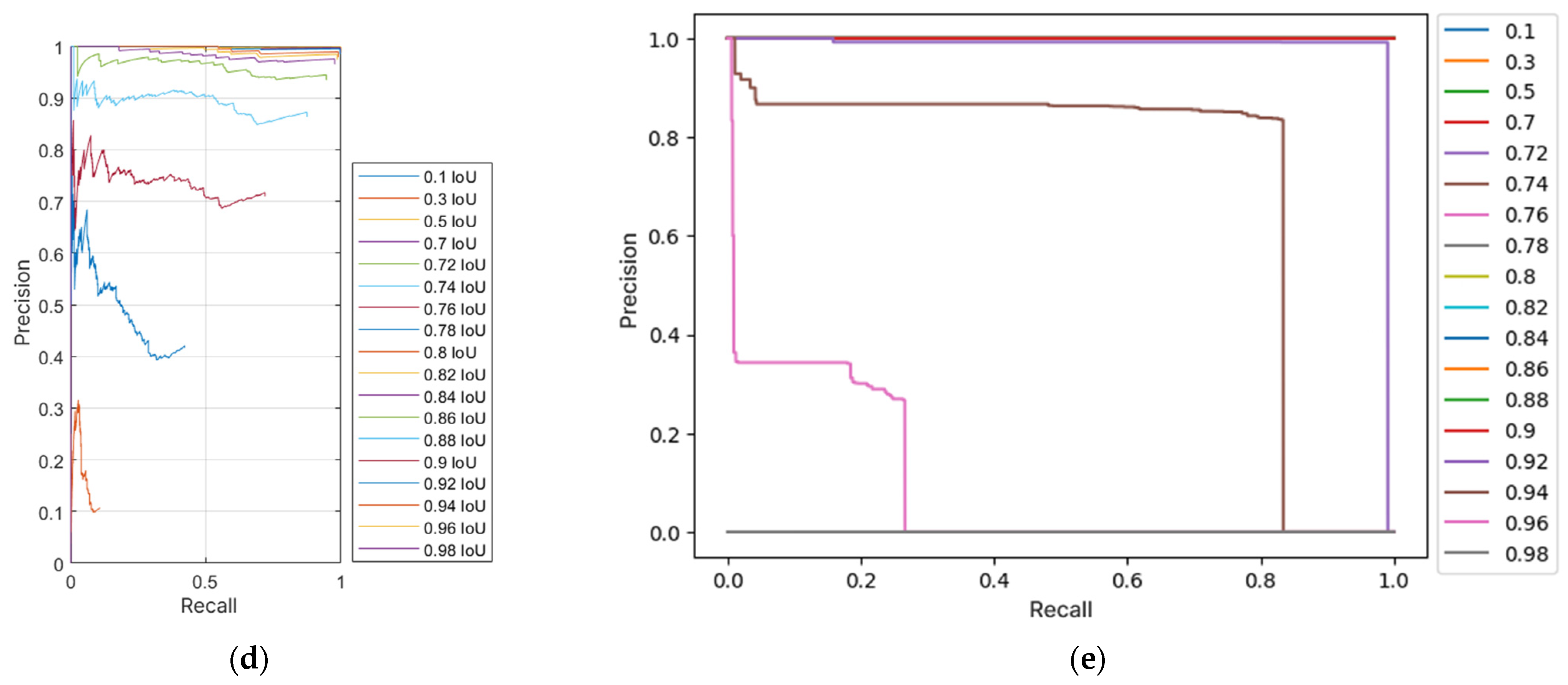
In order to compare the performance of the neural network, the values of AP and F1 were compared at different overlap threshold values. Therefore, it was necessary to create multiple graphs of the relationship between accuracy and recall based on different overlap threshold values.
4. Discussion
This study focused on training and applying a Mask R-CNN neural network to work in a potato sorter designed for industrial agriculture application. Within the study, the NN5 model demonstrated the most optimal outcomes, both visually and through computational evaluation. This outcome was influenced by several parameters, including the implementation of random alterations to training images and changing the number of epochs. The alternative software used with NN5 affected the segmentation speed of the model, thereby enhancing its usability in the production process, since the effectiveness of a neural network is determined not only by its accuracy but also by the speed of data generation. A notable characteristic of this neural network is its superior evaluation performance with a lower number of epochs, indicating that optimizing the learning parameters can improve the network’s overall performance. It was also observed that unpredictable errors might occur during the training of a neural network, potentially leading to malfunction and rendering the model unusable in a production environment. Therefore, the possibility of errors must be considered during training, which extends the learning process, as an additional model must be trained to ensure proper functionality. All of the wrong segmentation results in other models would be the result of training on too few epochs, since the segmentation results increased with the increase in the number of epochs.
The processing speed of a neural network directly impacts the efficiency of a sorting system. In this study, the trained models demonstrated a processing rate of 6.46 FPS. When utilized in conjunction with a wide-lens configuration, the sorting machine should exhibit the capacity to process multiple potatoes per second, with the precise number adjustable based on the available computational power. The utilization of advanced graphic cards is expected to yield enhanced performance, though it should be noted that this approach is accompanied by a higher cost for the sorting system. Testing on images that had not been previously encountered confirmed the efficacy of a region-based convolutional neural network in accurately segmenting potatoes within a realistic production environment. The subsequent stage involves integrating the neural network into an actual production process and evaluating the performance of the entire sorting system. While the focus would be integrating Mask R-CNN into a production environment, numerous industrial food-sorting systems rely on the use of classical computer-vision techniques (e.g., threshold-based segmentation and SVM-based classification). The good quality of such techniques is their ability to exhibit low computational demands, allowing for a higher quantity of produce being processed in equal amount of time. However, research has demonstrated that classical computer-vision techniques encounter challenges in complex segmentation tasks, particularly in scenarios involving occlusion, overlapping, and variable lighting conditions [
28,
29]. Conversely, deep learning models, such as Mask R-CNN, exhibit a marked advantage in addressing these issues by learning spatial relationships within the image and generating precise segmentation masks for each instance, albeit at the expense of a longer processing time. Leading industry entities such as TOMRA (TOMRA Systems ASA, Asker, Norway) and Key Technology (Key Technology, Walla Walla, USA) employ a suite of vision-based sorting techniques, including hyperspectral imaging and classical computer-vision algorithms, to automate food sorting at an industrial scale. While these systems are optimized for speed and efficiency, the focus of this work is on integrating deep learning-based segmentation methods, such as Mask R-CNN, which have the potential to enhance defect detection, produce classification, and object appearance handling.
It would be particularly interesting to observe how the neural network performs within a production sorter, where various parameters (e.g., changes in lighting conditions) may fluctuate. Such fluctuations could potentially lead to improper segmentation, which could result in a broken segmentation system. Following the observation, a subsequent evaluation of segmentation should be conducted, using images of potatoes on a working sorting system where the fluctuations would be clearly visible. Given that the sorting system utilizes a closed light box for the purpose of segmenting potatoes, the only variable that is expected to undergo change is the sharpness of the image. Upon implementing the sorting system, a cost calculation comparing the cost of manual labor to the cost of an automated sorting system would also be valuable. This should include factors such as the cost of electricity and the potential cost of a supervising worker. Another system enhancement could involve enabling the segmentation of different potato varieties, which could be achieved by expanding the dataset used for training the neural network. Future work should focus on optimizing inference speed, integrating real-time monitoring, and testing alternative deep learning architectures (e.g., YOLOv8, Swin Transformer) to further enhance segmentation efficiency based on speed and precision. The testing of the architectures could also include an analysis of the segmentation failures, encompassing false positives, false negatives, and occlusions. It would be interesting seeing where different models experience errors. The study could also continue with a focus on synthetic data augmentation to increase the training image dataset and evaluate the results of a neural network trained on such dataset.
5. Conclusions
This study explored the application of Mask R-CNN for segmenting potatoes in an industrial potato-sorting process, comparing different implementations and training variables to determine the most effective approach. The results highlight that while deep learning-based segmentation significantly outperforms traditional methods, the performance is highly dependent on software environment, training parameters, and data augmentation techniques. Among the tested models, the neural network (NN5) achieved the highest mean average precision (mAP = 0.878) and F1 score (0.597), demonstrating superior segmentation accuracy. The findings indicate that strategic selection of training variables and model optimization can yield substantial improvements in both accuracy and processing speed. Notably, increasing the number of training epochs does not always lead to better performance, emphasizing the importance of efficient model tuning and proper dataset preparation. Despite these promising results, several challenges remain for real-world deployment. Factors such as varying lighting conditions, potato shape irregularities, and high-speed conveyor operation must be addressed to ensure robustness in industrial applications.
Ultimately, this research confirms that Mask R-CNN is a viable solution for automated potato sorting, with potential scalability to broader agricultural applications. Implementing this approach in production environments could significantly improve sorting accuracy, reduce manual labor costs, and enhance overall efficiency in food processing industries.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}