
Geographical Origin Identification of Chinese Red Jujube Using Near-Infrared Spectroscopy and Adaboost-CLDA



Abstract
1. Introduction
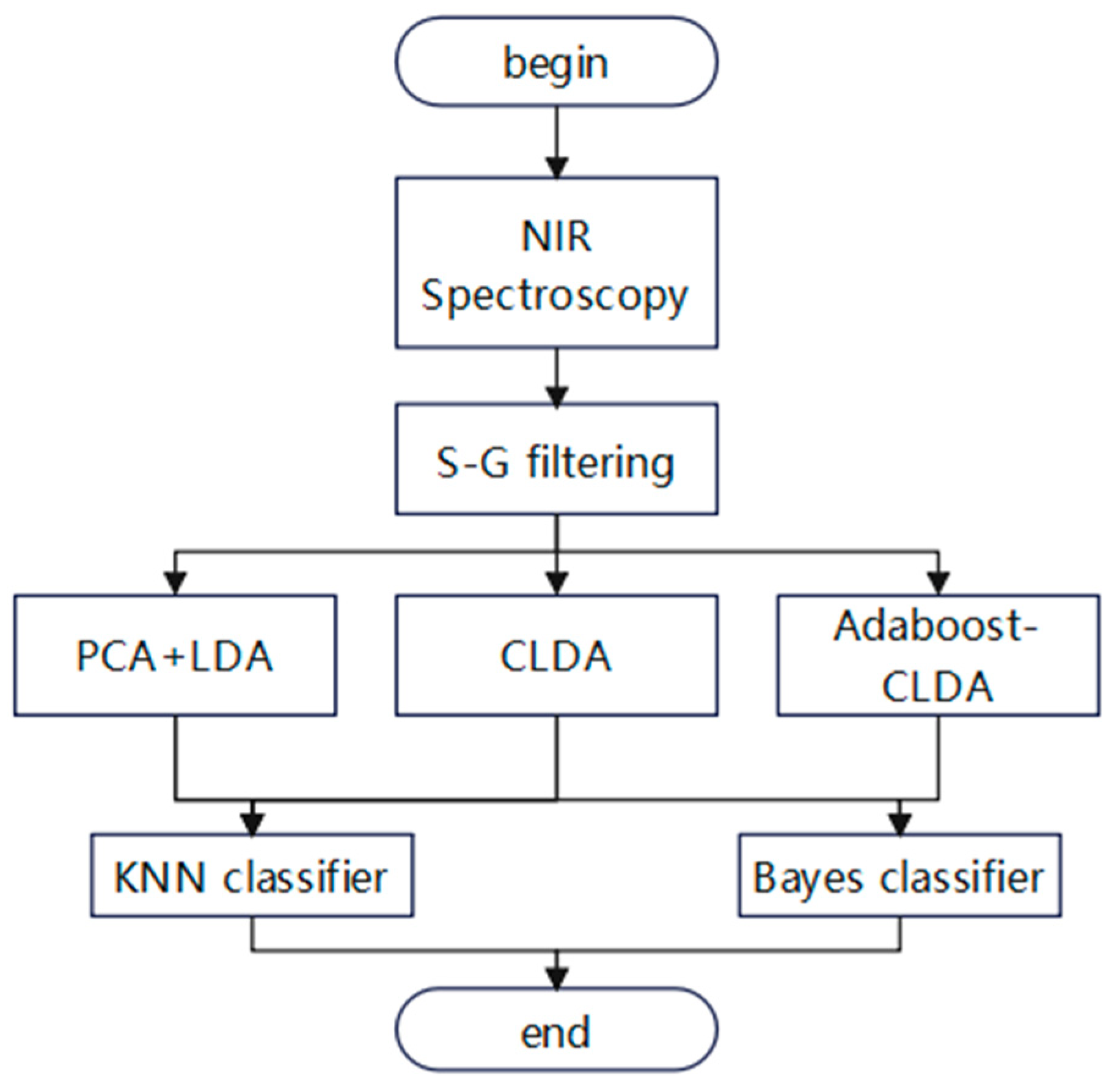
2. Materials and Methods
2.1. Jujube Sample Preparation
2.2. NIR Acquisition
2.3. Spectral Data Preprocessing
2.4. CLDA
2.5. Adaboost
2.6. Adaboost-CLDA
- (1)
- Normalize the weights:
- (2)
- CLDA is executed to derive (where is the number of classes) optimal feature vectors. These feature vectors serve as the projection space for training data, resulting in the creation of a new training set denoted as ( dimensional data set). , .
- (3)
- Utilize the nearest-neighbor classifier (NNC) as the weak classifier, supplying NNC with the distribution . Obtain a hypothesis in return.
- (4)
- Compute the error of . If or , then set and terminate the loop.
- (5)
- Set
- (6)
- Update the weights:
- (7)
- Generate the final hypothesis:
2.7. KNN Classifier
2.8. Bayes Classifier
2.9. Software
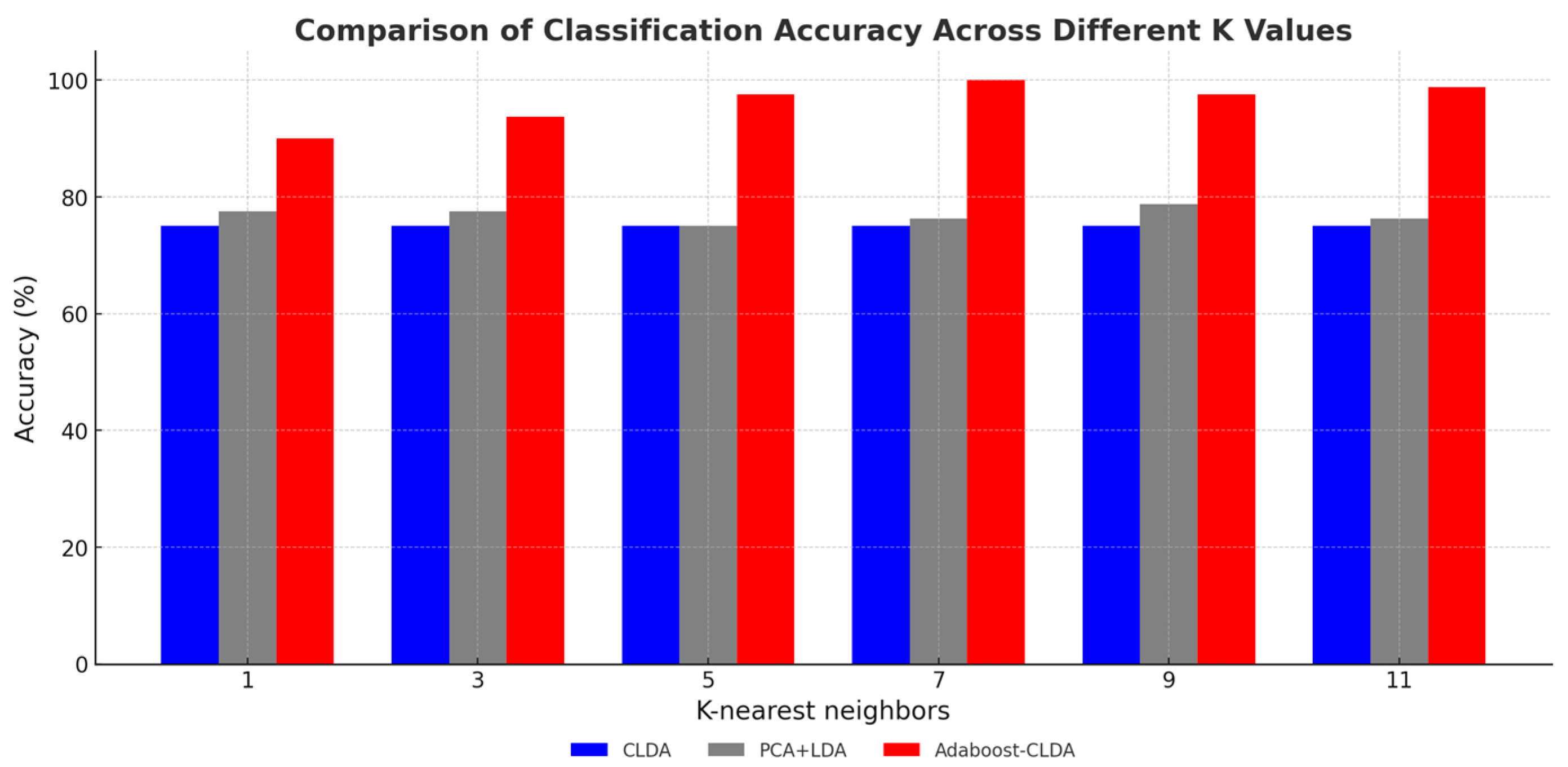
3. Results
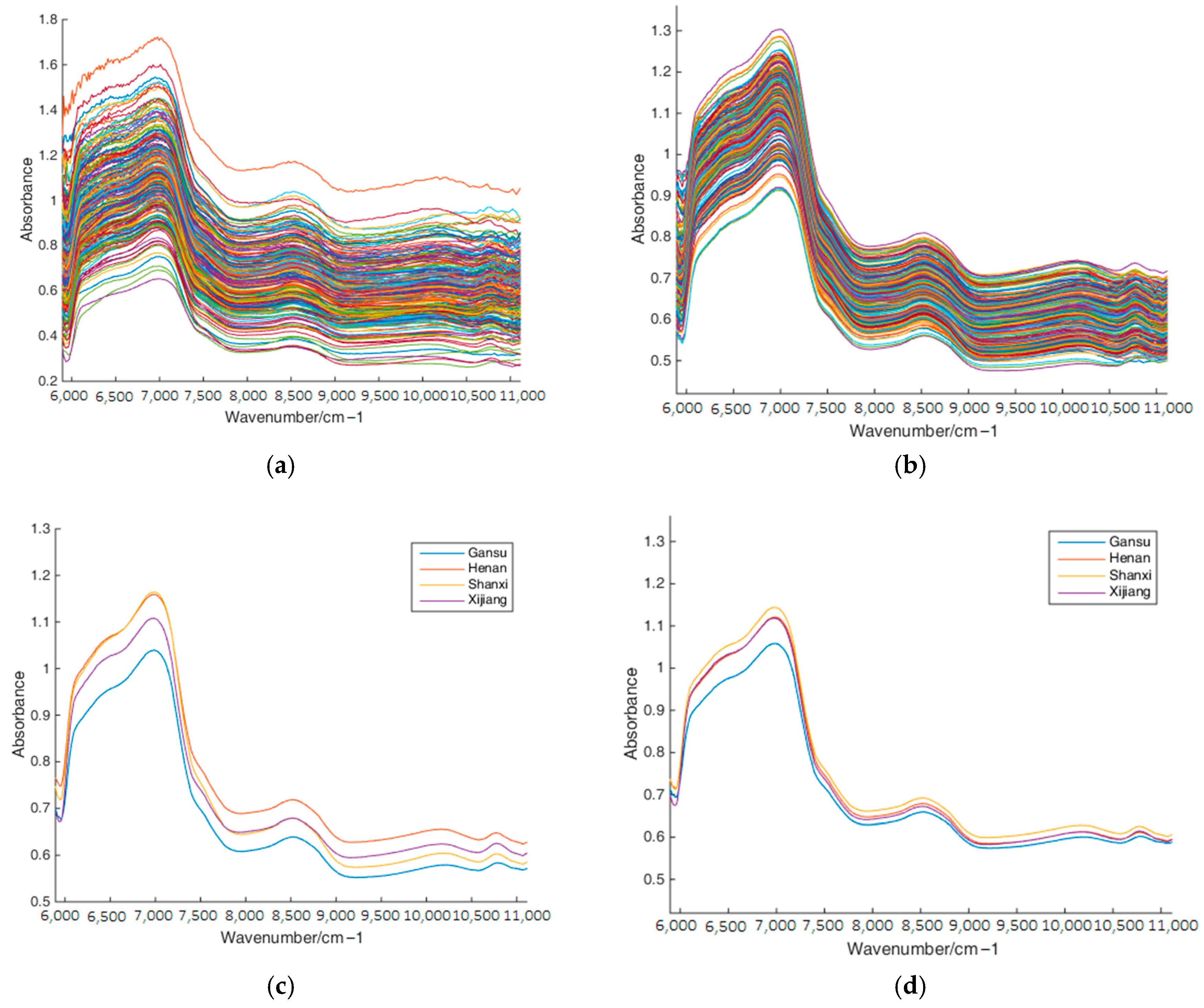
3.1. Spectral Analysis
3.2. Spectral Preprocessing
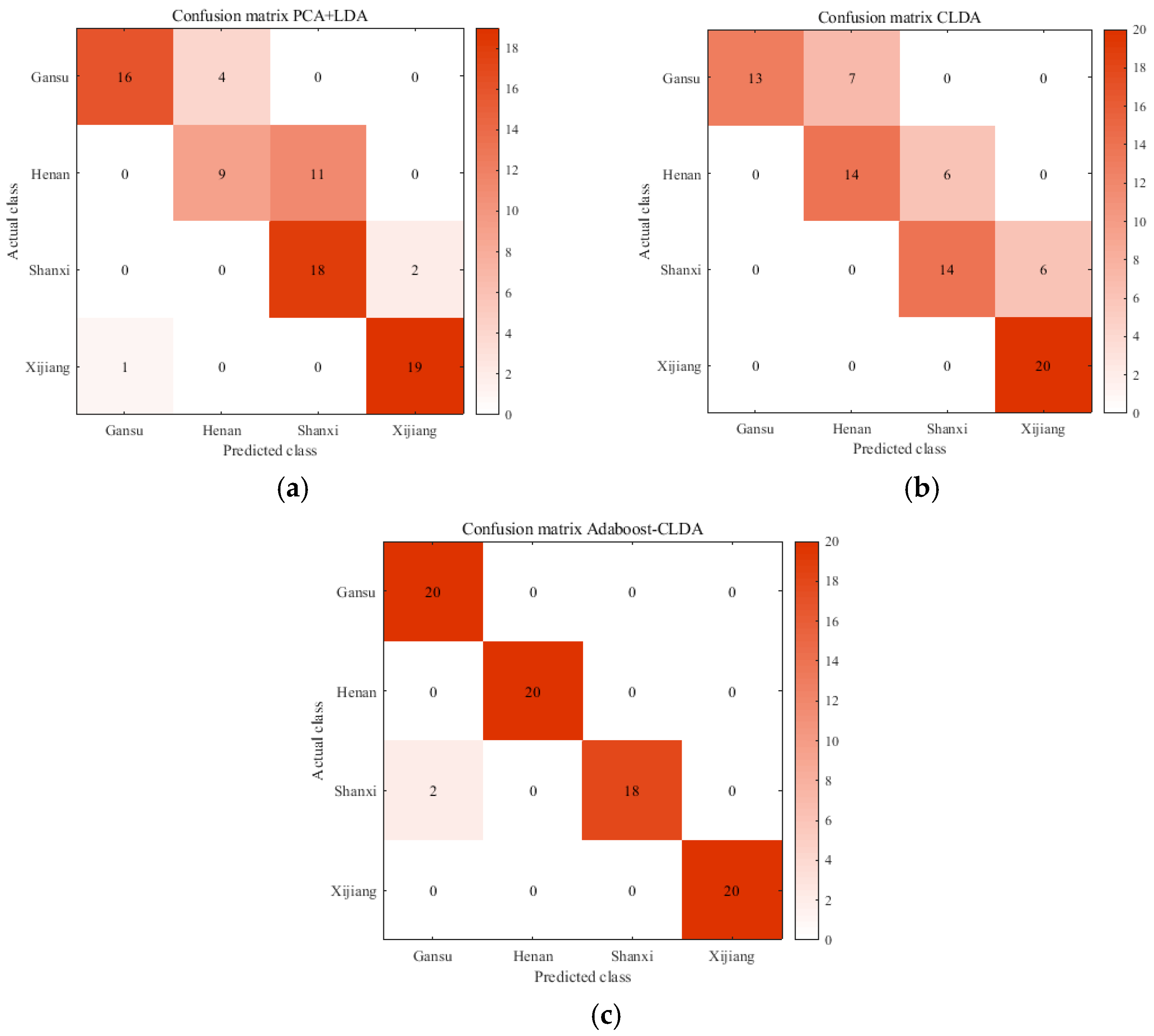
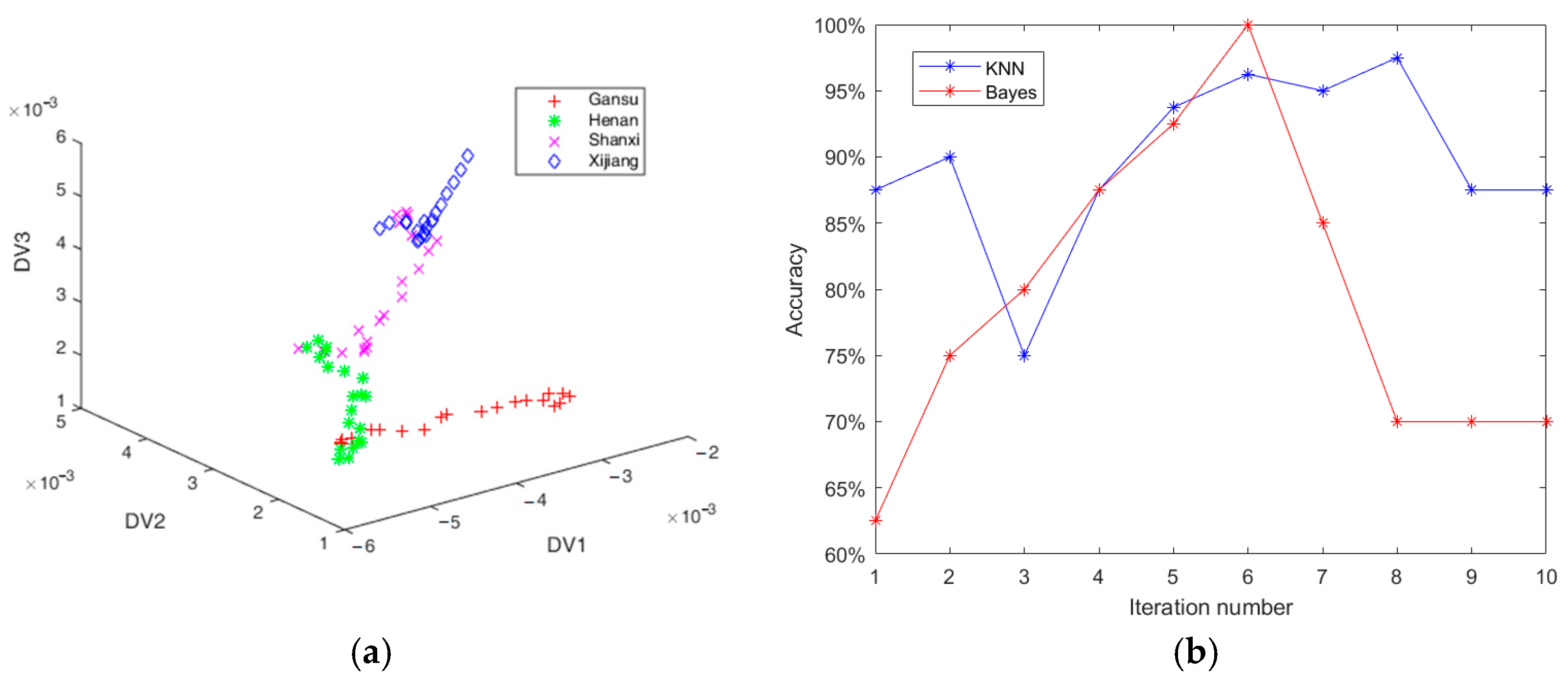
3.3. Classification with CLDA
3.4. Classification with Adaboost-CLDA
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Sun, J.; Fu, L.; Xu, M.; Tang, N.; Cao, Y.; Yao, K.; Jing, J. Identification of red jujube varieties based on hyperspectral imaging technology combined with CARS-IRIV and SSA-SVM. J. Food Process Eng. 2022, 45, e14137. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Wu, F.; Gu, D.; Tao, H.; Zhang, R. Organic acid and aromatic compounds create distinctive flavor in the blackening process of jujube. Food Chem. 2024, 439, 138199. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Sun, J.; Zhou, X.; Nirere, A.; Wu, X.; Dai, R. Classification detection of saccharin jujube based on hyperspectral imaging technology. J. Food Process. Pres. 2020, 44, e14591. [Google Scholar] [CrossRef]
- Hu, C.; Xu, H.; Fu, Z.; Zhang, R.; Zhi, C. Non-destructive identification of the geographical origin of red jujube by near-infrared spectroscopy and fuzzy clustering methods. Int. J. Food Prop. 2023, 26, 3275–3290. [Google Scholar] [CrossRef]
- Arslan, M.; Zareef, M.; Tahir, H.E.; Ali, S.; Huang, X.W.; Rakha, A.; Shi, J.; Zou, X. Comparative analyses of phenolic compounds and antioxidant properties of Chinese jujube as affected by geographical region and drying methods (Puff-drying and convective hot air-drying systems). J. Food Meas. 2021, 15, 933–943. [Google Scholar] [CrossRef]
- Li, Z.; Li, W.; Wang, J.; Zhang, J.; Wang, Z. Drip irrigation shapes the soil bacterial communities and enhances jujube yield by regulating the soil moisture content and nutrient levels. Agr. Water Manag. 2023, 289, 108563. [Google Scholar] [CrossRef]
- Öztürk, M.; Yalçın, O.; Tekgündüz, C.; Tekgündüz, E. Origin of the effects of optical spectrum and flow behaviour in determining the quality of dry fig, jujube, pomegranate, date palm and concentrated grape vinegars. Spectrochim. Acta A 2022, 270, 120792. [Google Scholar] [CrossRef] [PubMed]
- Ruan, J.; Li, H.; Lu, M.; Hao, M.; Sun, F.; Yu, H.; Zhang, Y.; Wang, T. Bioactive triterpenes of jujube in the prevention of colorectal cancer and their molecular mechanism research. Phytomedicine 2023, 110, 154639. [Google Scholar] [CrossRef]
- Si, Q.; Su, L.; Wang, D.; De, B.J.; Na, R.; He, N.; Byambaa, T.; Dalkh, T.; Bao, X.; Yi, L. An evaluation of the qualitative superiority of the Mongolian medicinal herb hurdan-tsagaan (Platycodi Radix) from five different geographic origins based on anti-inflammatory effects. J. Ethnopharmacol. 2023, 310, 116331. [Google Scholar] [CrossRef]
- Wu, L.; Li, L.; Zhang, G.; Jiang, N.; Ouyang, X.; Wang, M. Geographical and varietal traceability of Chinese jujubes based on physical and nutritional characteristics. Foods 2021, 10, 2270. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Y.; Wang, W.; Zheng, F.; Chen, F. Comparison of volatile compositions of 15 different varieties of Chinese jujube (Ziziphus jujuba Mill.). J. Food Sci. Technol. 2019, 56, 1631–1640. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Paliwal, J. Near-infrared spectroscopy and imaging in food quality and safety. Sens. Instrum. Food Qual. Saf. 2007, 1, 193–207. [Google Scholar] [CrossRef]
- Cortés, V.; Blasco, J.; Aleixos, N.; Cubero, S.; Talens, P. Monitoring strategies for quality control of agricultural products using visible and near-infrared spectroscopy: A review. Trends Food Sci. Technol. 2019, 85, 138–148. [Google Scholar] [CrossRef]
- Kademi; Ibrahim, H.; Ulusoy, B.H.; Hecer, C. Applications of miniaturized and portable near-infrared spectroscopy (NIRS) for inspection and control of meat and meat products. Food Rev. Int. 2019, 35, 201–220. [Google Scholar] [CrossRef]
- Tahir, H.E.; Mariod, A.A.; Hashim, S.B.H.; Arslan, M.; Mahunu, G.K.; Huang, X.; Li, Z.; Abdalla, I.I.H.; Zou, X. Classification of Black Mahlab seeds (Monechma ciliatum) using GC–MS and FT-NIR and simultaneous prediction of their major volatile compounds using chemometrics. Food Chem. 2023, 408, 134948. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Nakano, K.; Ohashi, S. Nondestructive detection of internal insect infestation in jujubes using visible and near-infrared spectroscopy. Postharvest Biol. Technol. 2011, 59, 272–279. [Google Scholar] [CrossRef]
- Luo, H.; Lu, Q.; Ding, H.; Gao, H.; Guo, L. Study on online detection modeling parameters of jujube internal quality of southern Xinjiang with near infrared spectrometric techniques. Spectrosc. Spectr. Anal. 2012, 32, 1225–1229. [Google Scholar]
- Guo, Y.; Ni, Y.; Kokot, S. Evaluation of chemical components and properties of the jujube fruit using near infrared spectroscopy and chemometrics. Spectrochim. Acta A 2016, 153, 79–86. [Google Scholar] [CrossRef] [PubMed]
- McGrath, T.F.; Haughey, S.A.; Islam, M.; Elliott, C.T. The potential of handheld near infrared spectroscopy to detect food adulteration: Results of a global, multi-instrument inter-laboratory study. Food Chem. 2021, 353, 128718. [Google Scholar] [CrossRef]
- Qi, Z.; Wu, X.; Yang, Y.; Wu, B.; Fu, H. Discrimination of the red jujube varieties using a portable NIR spectrometer and fuzzy improved linear discriminant analysis. Foods 2022, 11, 763. [Google Scholar] [CrossRef]
- Wu, X.; Fu, H.; Tian, X.; Wu, B.; Sun, J. Prediction of pork storage time using Fourier transform near infrared spectroscopy and Adaboost-ULDA. J. Food Process Eng. 2017, 40, e12566. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, X.; Wu, B.; Dai, C.; Fu, H. Rapid authentication of the geographical origin of milk using portable near-infrared spectrometer and fuzzy uncorrelated discriminant transformation. J. Food Process Eng. 2022, 45, e14040. [Google Scholar] [CrossRef]
- Qin, H.; Wang, H.; Li, W.; Jin, X. Application of DPLS-based LDA in corn qualitative near infrared spectroscopy analysis. Spectrosc. Spectr. Anal. 2011, 31, 1777–1781. [Google Scholar]
- Diniz, P.H.G.D.; Gomes, A.A.; Pistonesi, M.F.; Band, B.S.F.; de Araújo, M.C.U. Simultaneous classification of teas according to their varieties and geographical origins by using NIR spectroscopy and SPA-LDA. Food Anal. Methods 2014, 7, 1712–1718. [Google Scholar] [CrossRef]
- Cevikalp, H.; Neamtu, M.; Wilkes, M.; Barkana, A. Discriminative common vectors for face recognition. IEEE Trans. Pattern Anal. 2005, 27, 4–13. [Google Scholar] [CrossRef] [PubMed]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Pan, W.; Liu, W.; Huang, X. Rapid identification of the geographical origin of Baimudan tea using a Multi-AdaBoost model integrated with Raman Spectroscopy. Curr. Res. Food Sci. 2024, 8, 100654. [Google Scholar] [CrossRef] [PubMed]
- Ranganathan, S.; Gribskov, M.; Nakai, K.; Schönbach, C. Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Murphy, K.P. Naive Bayes Classifiers. Univ. B. C. 2006, 18, 1–8. [Google Scholar]
- Wu, L.; He, J.; Liu, G.; Wang, S.; He, X. Detection of common defects on jujube using Vis-NIR and NIR hyperspectral imaging. Postharvest Biol. Technol. 2016, 112, 134–142. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Method | MSC | SNV | SG | MSC + SG | SNV + SG | MSC + SNV |
|---|---|---|---|---|---|---|
| PCA + LDA | 53.75 | 62.5 | 77.5 | 78.75 | 88.75 | 53.75 |
| CLDA | 52.5 | 47.5 | 75 | 67.5 | 68.75 | 53.75 |
| Adaboost-CLDA | 100 | 98.75 | 97.5 | 98.75 | 97.5 | 98.75 |
| Feature Extraction Method | MSC | SNV | SG | MSC + SG | SNV + SG | MSC + SNV |
|---|---|---|---|---|---|---|
| PCA + LDA | 71.25 | 67.5 | 81.25 | 78.75 | 92.5 | 71.25 |
| CLDA | 40 | 42.5 | 77.5 | 50 | 47.5 | 40 |
| Adaboost-CLDA | 92.5 | 87.5 | 100 | 96.25 | 91.25 | 88.75 |
| num_training | num_test | PCA + LDA (%) | CLDA (%) | Adaboost-CLDA (%) |
|---|---|---|---|---|
| 120 | 120 | 75 | 54.17 | 93.34 |
| 140 | 100 | 82 | 70 | 94 |
| 144 | 96 | 82.29 | 71.88 | 96.88 |
| 160 | 80 | 77.5 | 75 | 97.5 |
| 180 | 60 | 76.67 | 68.33 | 90 |
| 192 | 48 | 72.92 | 68.75 | 91.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Yang, Z.; Yang, Y.; Wu, B.; Sun, J. Geographical Origin Identification of Chinese Red Jujube Using Near-Infrared Spectroscopy and Adaboost-CLDA. Foods 2025, 14, 803. https://doi.org/10.3390/foods14050803
Wu X, Yang Z, Yang Y, Wu B, Sun J. Geographical Origin Identification of Chinese Red Jujube Using Near-Infrared Spectroscopy and Adaboost-CLDA. Foods. 2025; 14(5):803. https://doi.org/10.3390/foods14050803
Chicago/Turabian StyleWu, Xiaohong, Ziteng Yang, Yonglan Yang, Bin Wu, and Jun Sun. 2025. "Geographical Origin Identification of Chinese Red Jujube Using Near-Infrared Spectroscopy and Adaboost-CLDA" Foods 14, no. 5: 803. https://doi.org/10.3390/foods14050803
APA StyleWu, X., Yang, Z., Yang, Y., Wu, B., & Sun, J. (2025). Geographical Origin Identification of Chinese Red Jujube Using Near-Infrared Spectroscopy and Adaboost-CLDA. Foods, 14(5), 803. https://doi.org/10.3390/foods14050803