

Advancing Real-Time Food Inspection: An Improved YOLOv10-Based Lightweight Algorithm for Detecting Tilapia Fillet Residues

Abstract
:1. Introduction
2. Materials and Methods
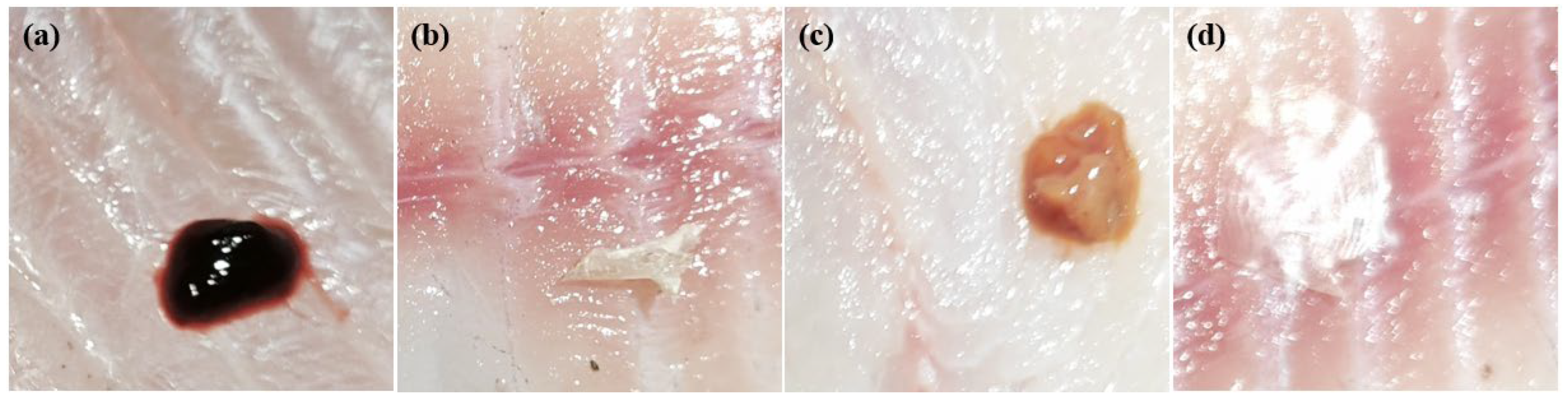
2.1. Dataset Acquisition and Construction
2.2. Training
2.3. Theoretical
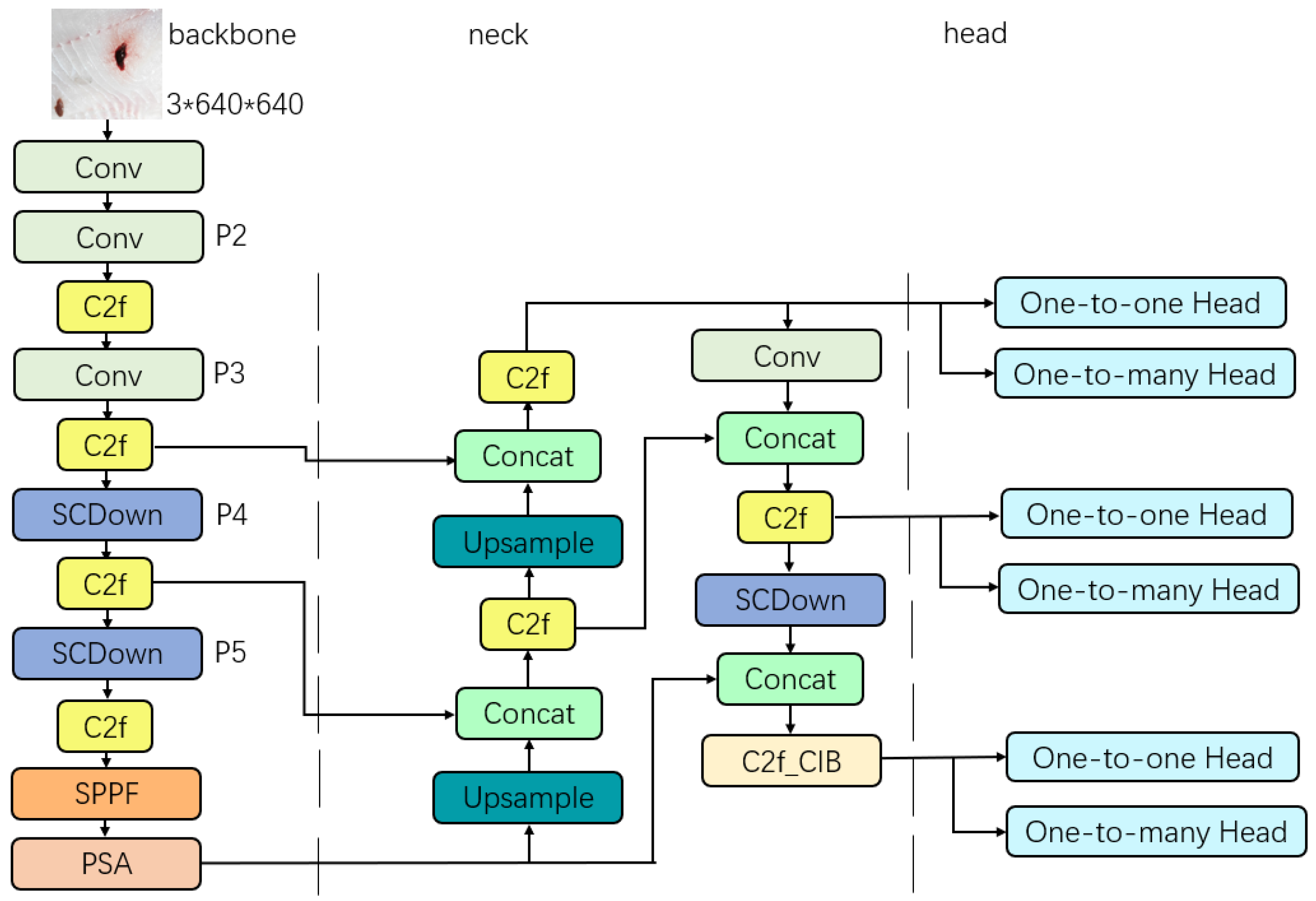
2.3.1. YOLOv10
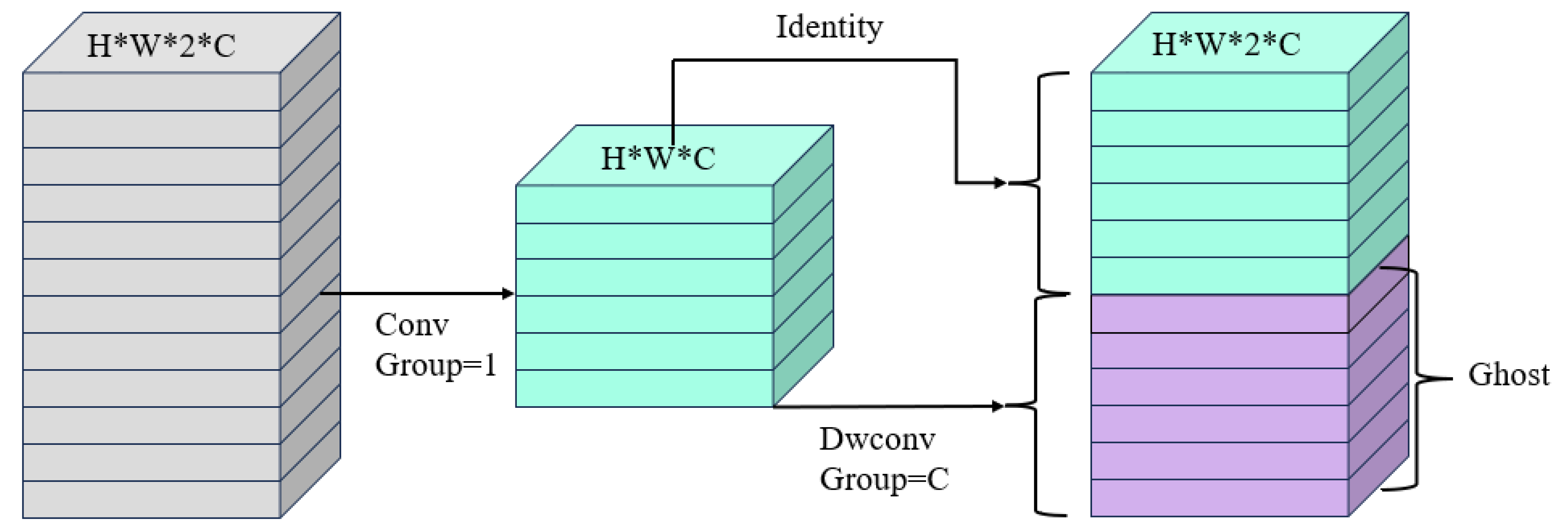
2.3.2. Ghost_Bottleneck Lightweight Module
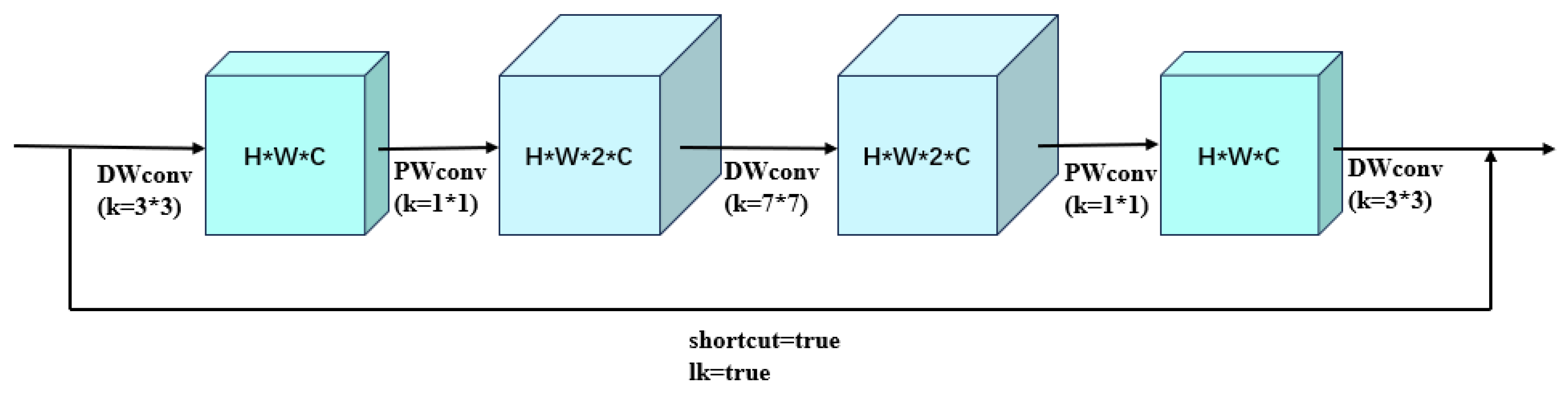
2.3.3. CIB Module
2.3.4. YOLO Detection Head
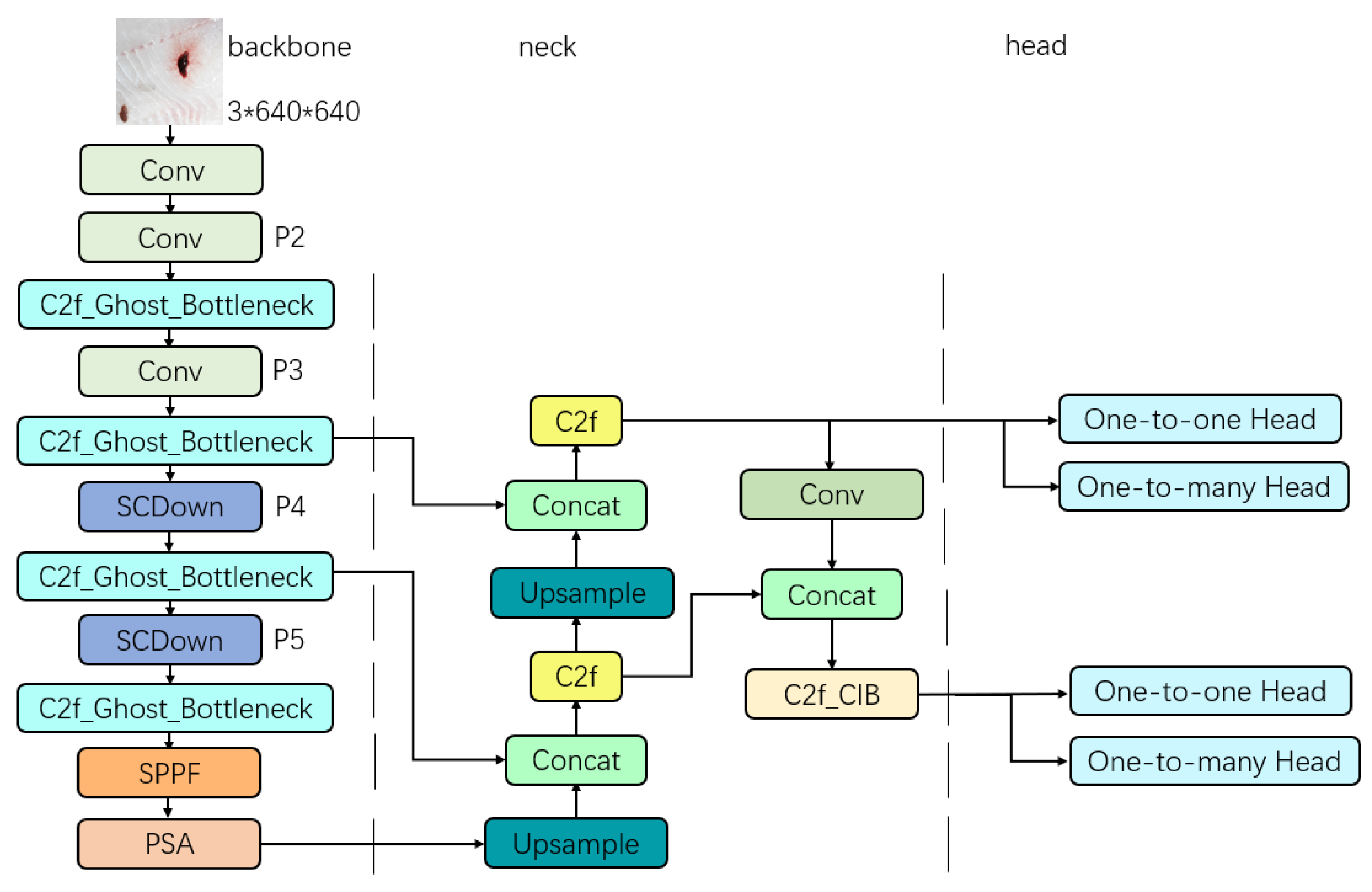
2.3.5. Double-Headed GC-YOLOv10n
2.4. Performance Evaluation Metrics
3. Results and Discussion
3.1. Experimental Results and Analysis of Ablation with Improved Algorithm
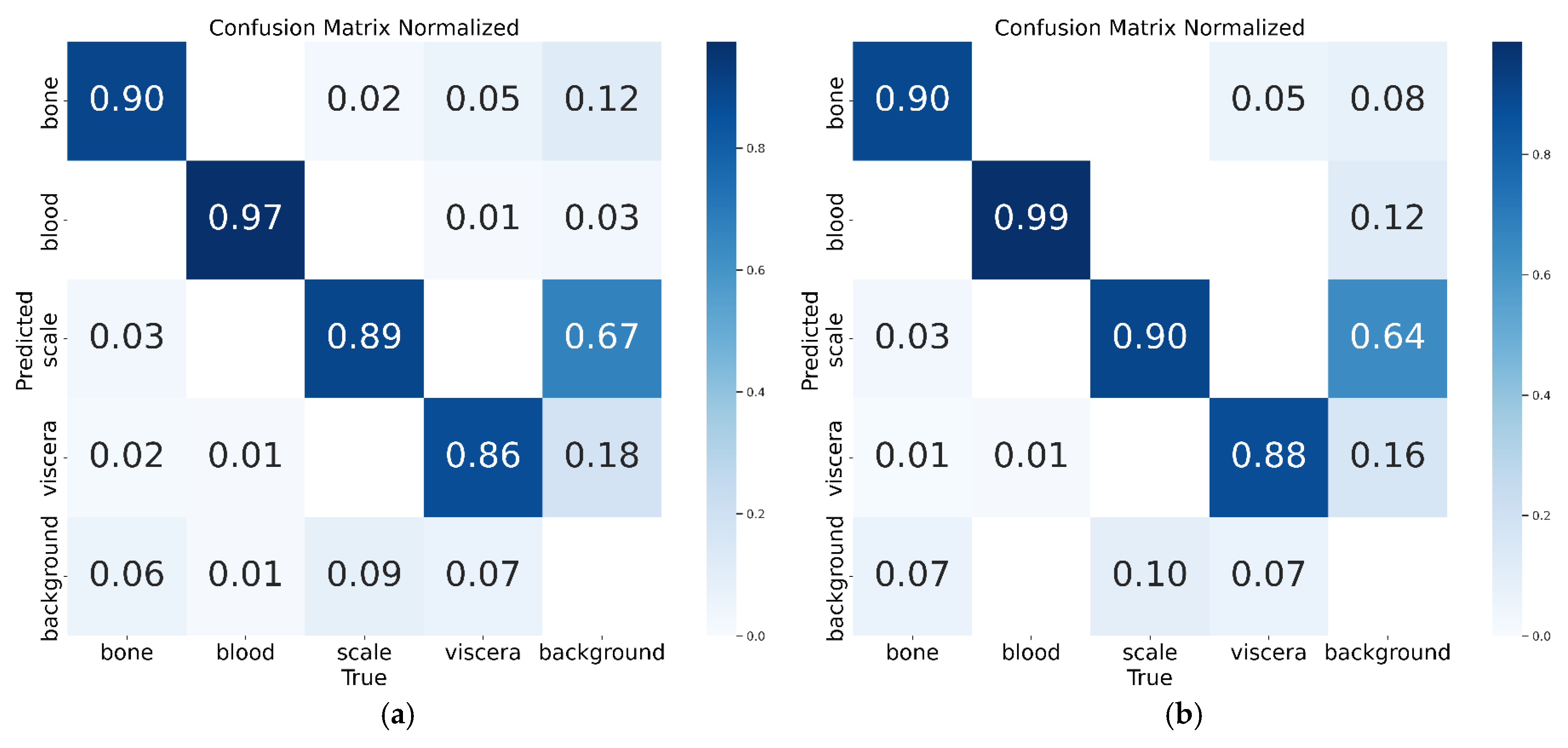
3.2. Validation Experiment on the Applicability of the Dual-Head GC Lightweighting Method
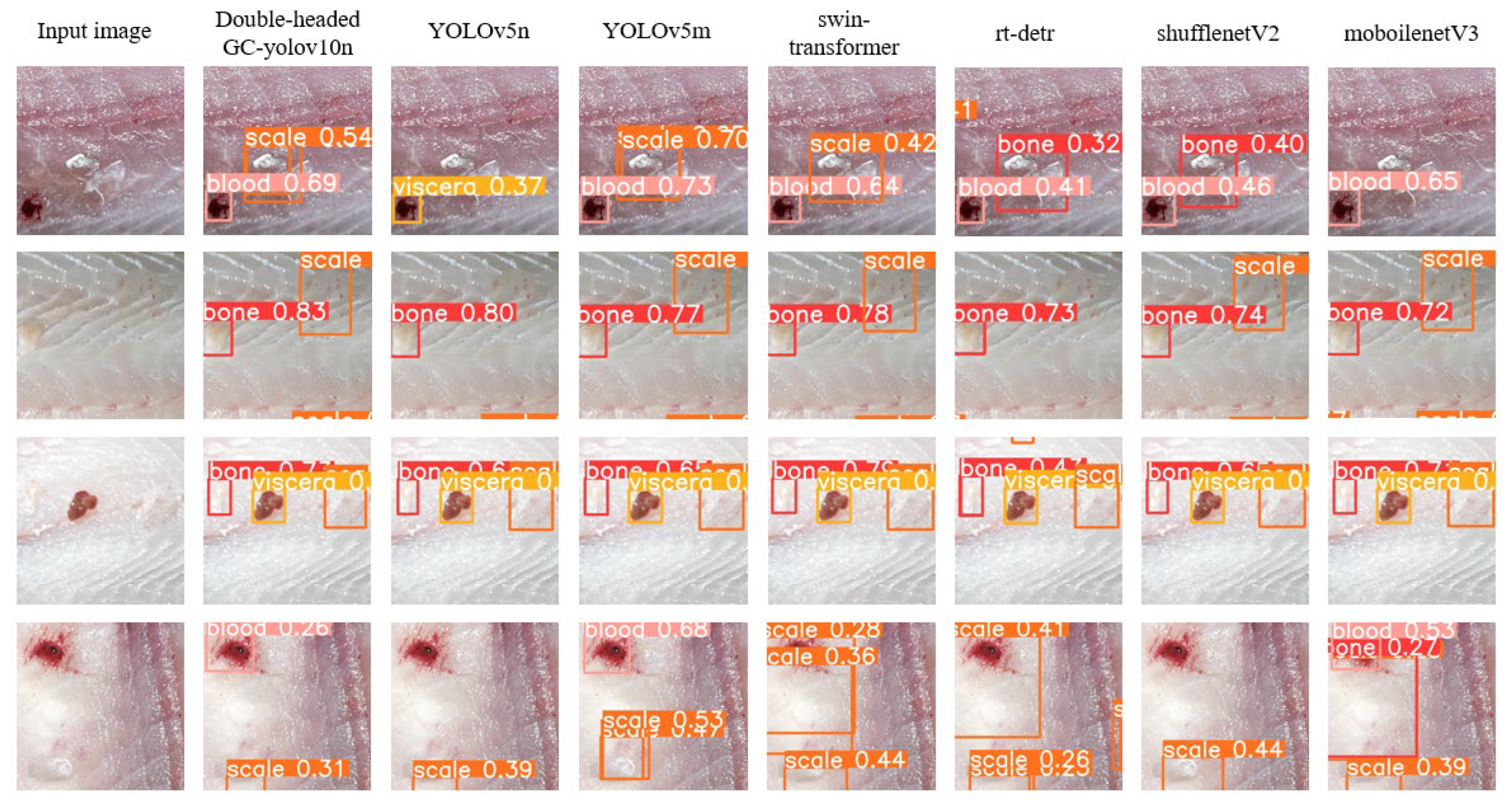
3.3. Experimental Results and Analysis of the Comparison Between Double-Headed GC-YOLOv10n and Mainstream Object Detection Algorithms
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jim, F.; Garamumhango, P.; Musara, C. Comparative Analysis of Nutritional Value of Oreochromis Niloticus (Linnaeus), Nile Tilapia, Meat from Three Different Ecosystems. J. Food Qual. 2017, 2017, 6714347. [Google Scholar] [CrossRef]
- El-Sayed, A.F.M.; Fitzsimmons, K. From Africa to the World—The Journey of Nile Tilapia. Rev. Aquac. 2023, 15, 6–21. [Google Scholar] [CrossRef]
- Zhu, J.; Zou, Z.; Li, D.; Xiao, W.; Yu, J.; Chen, B.; Yang, H. Comparative Transcriptomes Reveal Different Tolerance Mechanisms to Streptococcus Agalactiae in Hybrid Tilapia, Nile Tilapia, and Blue Tilapia. Fish Shellfish Immunol. 2023, 142, 109121. [Google Scholar] [CrossRef] [PubMed]
- Borderías, A.J.; Sánchez-alonso, I. First Processing Steps and the Quality of Wild and Farmed Fish. J. Food Sci. 2011, 76, R1–R5. [Google Scholar] [CrossRef] [PubMed]
- Erikson, U.; Misimi, E.; Fismen, B. Bleeding of Anaesthetized and Exhausted Atlantic Salmon: Body Cavity Inspection and Residual Blood in Pre-Rigor and Smoked Fillets as Determined by Various Analytical Methods. Aquac. Res. 2010, 41, 496–510. [Google Scholar] [CrossRef]
- Wang, H.; Wang, K.; Zhu, X.; Zhang, P.; Yang, J.; Tan, M. Integration of Partial Least Squares Regression and Hyperspectral Data Processing for the Nondestructive Detection of the Scaling Rate of Carp (Cyprinus carpio). Foods 2020, 9, 500. [Google Scholar] [CrossRef]
- Cheng, J.H.; Sun, D.W. Data Fusion and Hyperspectral Imaging in Tandem with Least Squares-Support Vector Machine for Prediction of Sensory Quality Index Scores of Fish Fillet. LWT 2015, 63, 892–898. [Google Scholar] [CrossRef]
- Song, S.; Liu, Z.; Huang, M.; Zhu, Q.; Qin, J.; Kim, M.S. Detection of Fish Bones in Fillets by Raman Hyperspectral Imaging Technology. J. Food Eng. 2020, 272, 109808. [Google Scholar] [CrossRef]
- Mery, D.; Lillo, I.; Loebel, H.; Riffo, V.; Soto, A.; Cipriano, A.; Aguilera, J.M. Automated Fish Bone Detection Using X-Ray Imaging. J. Food Eng. 2011, 105, 485–492. [Google Scholar] [CrossRef]
- Jidong, H.U.; Liu, Y.; Aihua, S.; Lin, H.; Xiaohua, G.; Rui, N.; Li, Y.; Limin, C. Application of X-Ray Technique to Detection of Fish Bones in Marine Fish Fillets. Food Sci. 2016, 37, 151–156. [Google Scholar] [CrossRef]
- Urazoe, K.; Kuroki, N.; Maenaka, A.; Tsutsumi, H.; Iwabuchi, M.; Fuchuya, K.; Hirose, T.; Numa, M. Automated Fish Bone Detection in X-Ray Images with Convolutional Neural Network and Synthetic Image Generation. IEEJ Trans. Electr. Electron. Eng. 2021, 16, 1510–1517. [Google Scholar] [CrossRef]
- Wang, S.; Nian, R.; Cao, L.; Sui, J.; Lin, H. Detection of Fish Bones in Cod Fillets by UV Illumination. J. Food Prot. 2015, 78, 1414–1419. [Google Scholar] [CrossRef]
- Xie, T.; Li, X.; Zhang, X.; Hu, J.; Fang, Y. Detection of Atlantic Salmon Bone Residues Using Machine Vision Technology. Food Control. 2021, 123, 107787. [Google Scholar] [CrossRef]
- Wang, Z.; Ling, Y.; Wang, X.; Meng, D.; Nie, L.; An, G.; Wang, X. An Improved Faster R-CNN Model for Multi-Object Tomato Maturity Detection in Complex Scenarios. Ecol. Inf. Inform. 2022, 72, 101886. [Google Scholar] [CrossRef]
- Yu, H.; Li, Z.; Li, W.; Guo, W.; Li, D.; Wang, L.; Wu, M.; Wang, Y. A Tiny Object Detection Approach for Maize Cleaning Operations. Foods 2023, 12, 2885. [Google Scholar] [CrossRef]
- Thangaraj Sundaramurthy, R.P.; Balasubramanian, Y.; Annamalai, M. Real-Time Detection of Fusarium Infection in Moving Corn Grains Using YOLOv5 Object Detection Algorithm. J. Food Process Eng. 2023, 46, e14401. [Google Scholar] [CrossRef]
- Feng, Y.; Li, X.; Zhang, Y.; Xie, T. Detection of Atlantic Salmon Residues Based on Computer Vision. J. Food Eng. 2023, 358, 111658. [Google Scholar] [CrossRef]
- Shu, Z.; Li, X.; Liu, Y. Detection of Chili Foreign Objects Using Hyperspectral Imaging Combined with Chemometric and Target Detection Algorithms. Foods 2023, 12, 2618. [Google Scholar] [CrossRef]
- Xie, Y.; Zhong, X.; Zhan, J.; Wang, C.; Liu, N.; Li, L.; Zhao, P.; Li, L.; Zhou, G. ECLPOD: An Extremely Compressed Lightweight Model for Pear Object Detection in Smart Agriculture. Agronomy 2023, 13, 1891. [Google Scholar] [CrossRef]
- Su, W.; Yang, Y.; Zhou, C.; Zhuang, Z.; Liu, Y. Multiple Defect Classification Method for Green Plum Surfaces Based on Vision Transformer. Forests 2023, 14, 1323. [Google Scholar] [CrossRef]
- Liu, H.; Wang, X.; Zhao, F.; Yu, F.; Lin, P.; Gan, Y.; Ren, X.; Chen, Y.; Tu, J. Upgrading Swin-B Transformer-Based Model for Accurately Identifying Ripe Strawberries by Coupling Task-Aligned One-Stage Object Detection Mechanism. Comput. Electron. Agric. 2024, 218, 108674. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: Karnataka, India, 2024; pp. 1–6. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. Springer Int. Publ. 2014, 8653, 740–755. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, L.; Huang, X.; Zheng, Z. Surface Defect Detection Method for Electronic Panels Based on Attention Mechanism and Dual Detection Heads. PLoS ONE 2023, 18, e0280363. [Google Scholar] [CrossRef] [PubMed]
- Mu, J.; Su, Q.; Wang, X.; Liang, W.; Xu, S.; Wan, K. A Small Object Detection Architecture with Concatenated Detection Heads and Multi-Head Mixed Self-Attention Mechanism. J. Real. Time Image Process 2024, 21, 184. [Google Scholar] [CrossRef]
- Zhang, S.; Che, S.; Liu, Z.; Zhang, X. A Real-Time and Lightweight Traffic Sign Detection Method Based on Ghost-YOLO. Multimed. Tools Appl. 2023, 82, 26063–26087. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, N.; Cai, S.; Jiang, C.; Li, X. A Lightweight Crack Detection Model Based on Multibranch Ghost Module in Complex Scenes. IEEE Sens. J. 2023, 23, 22754–22762. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. Ultralytics/Yolov5: V3.1—Bug Fixes and Performance Improvements. Zenodo 2020. Available online: https://zenodo.org/records/4154370 (accessed on 14 May 2025).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configure | Parameters |
|---|---|
| GPU | RTX 4090 |
| CPU | 16-core AMD EPYC 9354 |
| RAM | 24 GB |
| Python | v3.10.12 |
| Pytorch | v2.0.1 |
| A | B | C | Parameters | GFLOPs | Model_Size | FPS | mAP50 | mAP50-90 | R | P |
|---|---|---|---|---|---|---|---|---|---|---|
| 2,708,600 | 8.4 | 5.8 MB | 56 | 0.932 | 0.69 | 0.886 | 0.941 | |||
| √ | 1,981,424 | 7.8 | 4.3 MB | 67 | 0.937 | 0.692 | 0.891 | 0.947 | ||
| √ | 2,244,164 | 7.1 | 4.9 MB | 48 | 0.931 | 0.673 | 0.886 | 0.939 | ||
| √ | 2,654,200 | 7.9 | 5.7 MB | 52 | 0.94 | 0.682 | 0.883 | 0.94 | ||
| √ | √ | 1,516,988 | 6.4 | 3.4 MB | 71 | 0.935 | 0.686 | 0.895 | 0.948 | |
| √ | √ | 2,189,764 | 6.9 | 4.8 MB | 50 | 0.929 | 0.685 | 0.892 | 0.945 | |
| √ | √ | 1,933,552 | 7.6 | 4.2 MB | 64 | 0.937 | 0.695 | 0.913 | 0.955 | |
| √ | √ | √ | 1,469,116 | 6.3 | 3.3 MB | 77 | 0.942 | 0.682 | 0.898 | 0.953 |
| Model | Class | AP50 | AP50-90 | R | P |
|---|---|---|---|---|---|
| YOLOv10n | bone | 0.917 | 0.608 | 0.896 | 0.942 |
| blood | 0.994 | 0.764 | 0.981 | 0.987 | |
| scale | 0.927 | 0.634 | 0.859 | 0.889 | |
| viscera | 0.906 | 0.755 | 0.865 | 0.932 | |
| YOLOv10n + A | bone | 0.942 | 0.634 | 0.858 | 0.918 |
| blood | 0.993 | 0.75 | 0.954 | 1 | |
| scale | 0.914 | 0.619 | 0.854 | 0.948 | |
| viscera | 0.903 | 0.77 | 0.866 | 0.941 | |
| YOLOv10n + B | bone | 0.955 | 0.619 | 0.91 | 0.951 |
| blood | 0.993 | 0.756 | 0.961 | 1 | |
| scale | 0.899 | 0.606 | 0.786 | 0.906 | |
| viscera | 0.881 | 0.739 | 0.85 | 0.94 | |
| YOLOv10n + C | bone | 0.959 | 0.615 | 0.849 | 0.951 |
| blood | 0.995 | 0.748 | 1 | 0.968 | |
| scale | 0.921 | 0.623 | 0.845 | 0.888 | |
| viscera | 0.896 | 0.752 | 0.85 | 0.913 | |
| YOLOv10n + A + B | bone | 0.95 | 0.65 | 0.887 | 0.931 |
| blood | 0.993 | 0.773 | 1 | 0.982 | |
| scale | 0.924 | 0.599 | 0.874 | 0.895 | |
| viscera | 0.903 | 0.739 | 0.872 | 0.97 | |
| YOLOv10n + B + C | bone | 0.934 | 0.63 | 0.896 | 0.945 |
| blood | 0.991 | 0.755 | 0.964 | 1 | |
| scale | 0.924 | 0.629 | 0.885 | 0.938 | |
| viscera | 0.889 | 0.75 | 0.878 | 0.919 | |
| YOLOv10n + A + C | bone | 0.942 | 0.632 | 0.944 | 0.935 |
| blood | 0.993 | 0.77 | 0.987 | 0.999 | |
| scale | 0.941 | 0.628 | 0.903 | 0.94 | |
| viscera | 0.89 | 0.758 | 0.87 | 0.985 | |
| YOLOv10n + A + B + C | bone | 0.947 | 0.629 | 0.899 | 0.959 |
| blood | 0.995 | 0.761 | 0.981 | 1 | |
| scale | 0.928 | 0.625 | 0.893 | 0.916 | |
| viscera | 0.908 | 0.755 | 0.878 | 0.962 |
| Model | Parameters | GFLOPs | Model_Size | FPS | mAP50 | mAP50-90 | R | P |
|---|---|---|---|---|---|---|---|---|
| YOLOv10s | 8,069,448 | 24.8 | 16.6 MB | 43 | 0.937 | 0.697 | 0.91 | 0.956 |
| YOLOv10s + dual head GC | 4,858,200 | 17.6 | 10.1 MB | 53 | 0.943 | 0.706 | 0.918 | 0.959 |
| YOLOv10l | 31,205,864 | 144.6 | 63 MB | 21 | 0.944 | 0.707 | 0.911 | 0.949 |
| YOLOv10l + dual head GC | 15,644,592 | 77.3 | 31.9 MB | 32 | 0.944 | 0.709 | 0.911 | 0.953 |
| YOLOv8n | 3,011,628 | 8.2 | 6.3 MB | 62 | 0.93 | 0.671 | 0.875 | 0.936 |
| YOLOv8n + dual head GC | 1,484,980 | 5.9 | 3.3 MB | 74 | 0.933 | 0.678 | 0.885 | 0.938 |
| YOLOv8s | 11,137,148 | 28.7 | 22.6 MB | 40 | 0.937 | 0.695 | 0.902 | 0.949 |
| YOLOv8s + dual head GC | 5,423,056 | 19.6 | 11.2 MB | 50 | 0.94 | 0.692 | 0.914 | 0.949 |
| Model | Parameters | GFLOPs | Model_size | FPS | mAP50 | mAP50-90 | R | P |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 2,509,228 | 7.2 | 5.3 MB | 58 | 0.934 | 0.689 | 0.901 | 0.937 |
| YOLOv5m | 25,067,436 | 64.4 | 50.5 MB | 35 | 0.944 | 0.679 | 0.905 | 0.941 |
| Swin-Transformer | 51,323,782 | 132.2 | 103.2 MB | 24 | 0.933 | 0.684 | 0.899 | 0.942 |
| RT-DERT | 32,814,296 | 108 | 66.2 MB | 30 | 0.887 | 0.627 | 0.837 | 0.868 |
| ShuffleNetV2 | 1,373,596 | 4.8 | 3.0 MB | 81 | 0.924 | 0.642 | 0.886 | 0.927 |
| MobileNetV3 | 2,354,922 | 5.4 | 5.0 MB | 72 | 0.926 | 0.651 | 0.879 | 0.935 |
| ours | 1,469,116 | 6.3 | 3.3 MB | 77 | 0.942 | 0.682 | 0.898 | 0.953 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Z.; Tang, S.; Zhong, N. Advancing Real-Time Food Inspection: An Improved YOLOv10-Based Lightweight Algorithm for Detecting Tilapia Fillet Residues. Foods 2025, 14, 1772. https://doi.org/10.3390/foods14101772
Su Z, Tang S, Zhong N. Advancing Real-Time Food Inspection: An Improved YOLOv10-Based Lightweight Algorithm for Detecting Tilapia Fillet Residues. Foods. 2025; 14(10):1772. https://doi.org/10.3390/foods14101772
Chicago/Turabian StyleSu, Zihao, Shuqi Tang, and Nan Zhong. 2025. "Advancing Real-Time Food Inspection: An Improved YOLOv10-Based Lightweight Algorithm for Detecting Tilapia Fillet Residues" Foods 14, no. 10: 1772. https://doi.org/10.3390/foods14101772
APA StyleSu, Z., Tang, S., & Zhong, N. (2025). Advancing Real-Time Food Inspection: An Improved YOLOv10-Based Lightweight Algorithm for Detecting Tilapia Fillet Residues. Foods, 14(10), 1772. https://doi.org/10.3390/foods14101772