
CV-YOLOv10-AR-M: Foreign Object Detection in Pu-Erh Tea Based on Five-Fold Cross-Validation


 ,
,
Abstract

1. Introduction
2. Materials and Methods
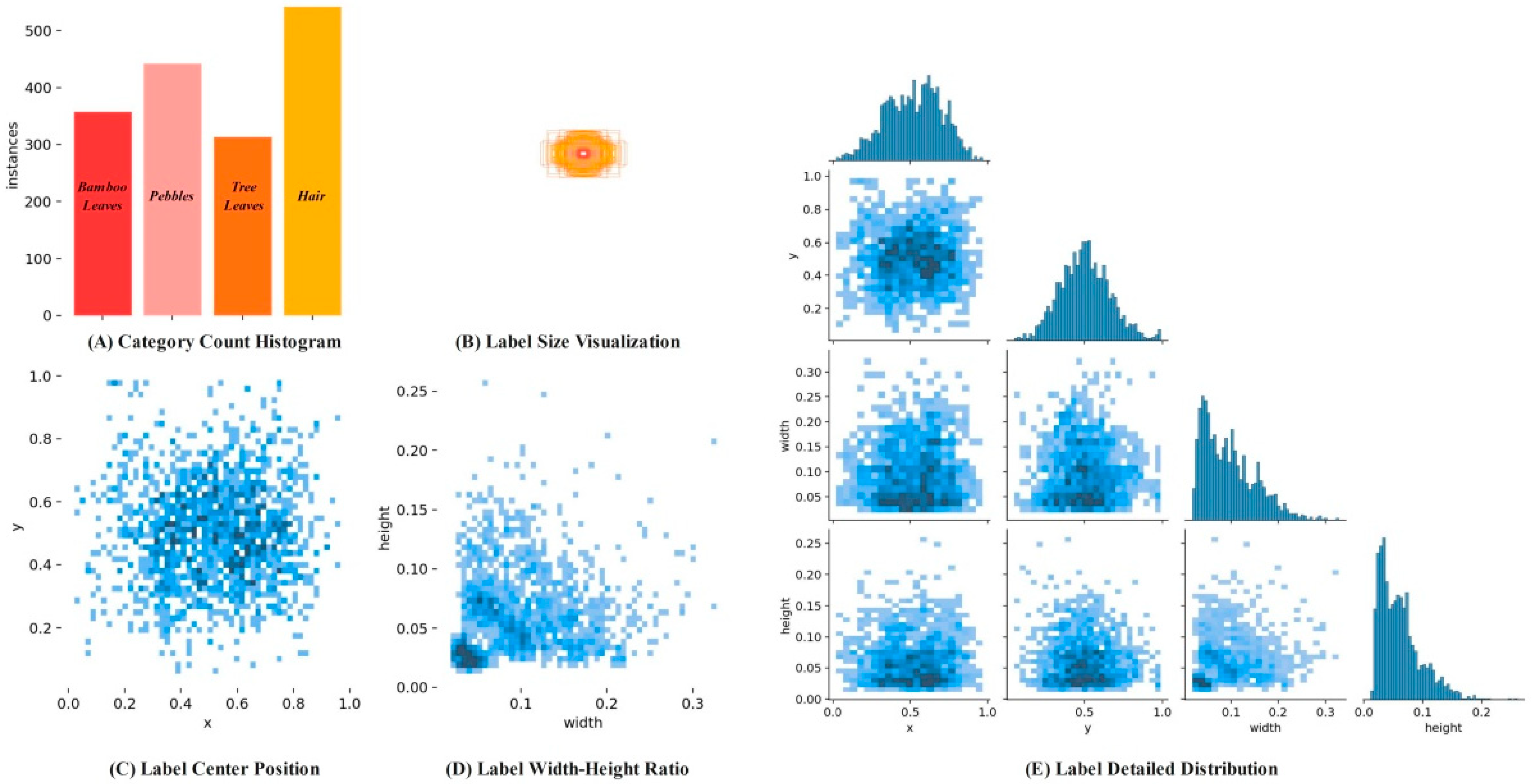
2.1. Image Acquisition and Dataset Construction
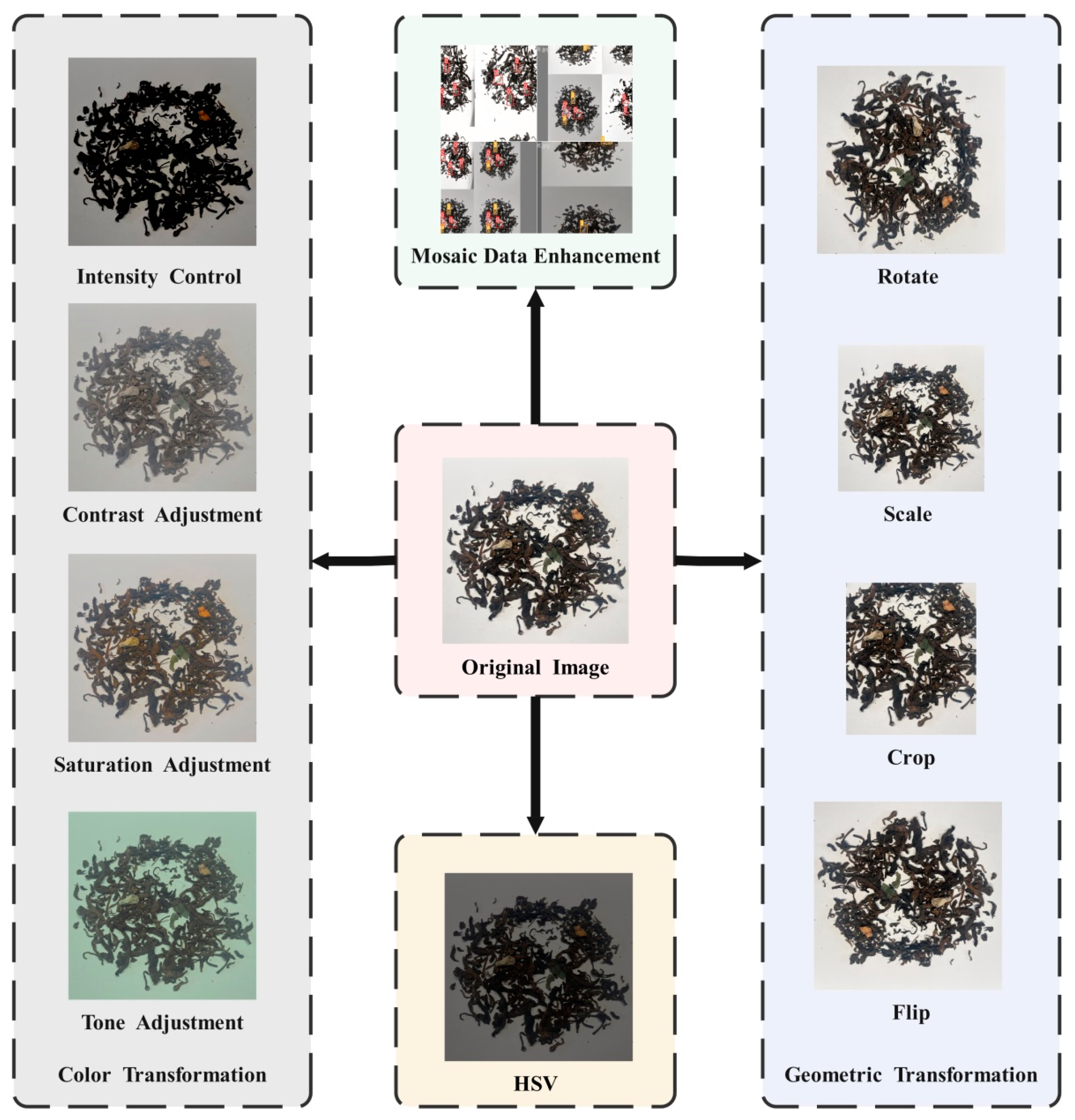
2.2. Data Augmentation
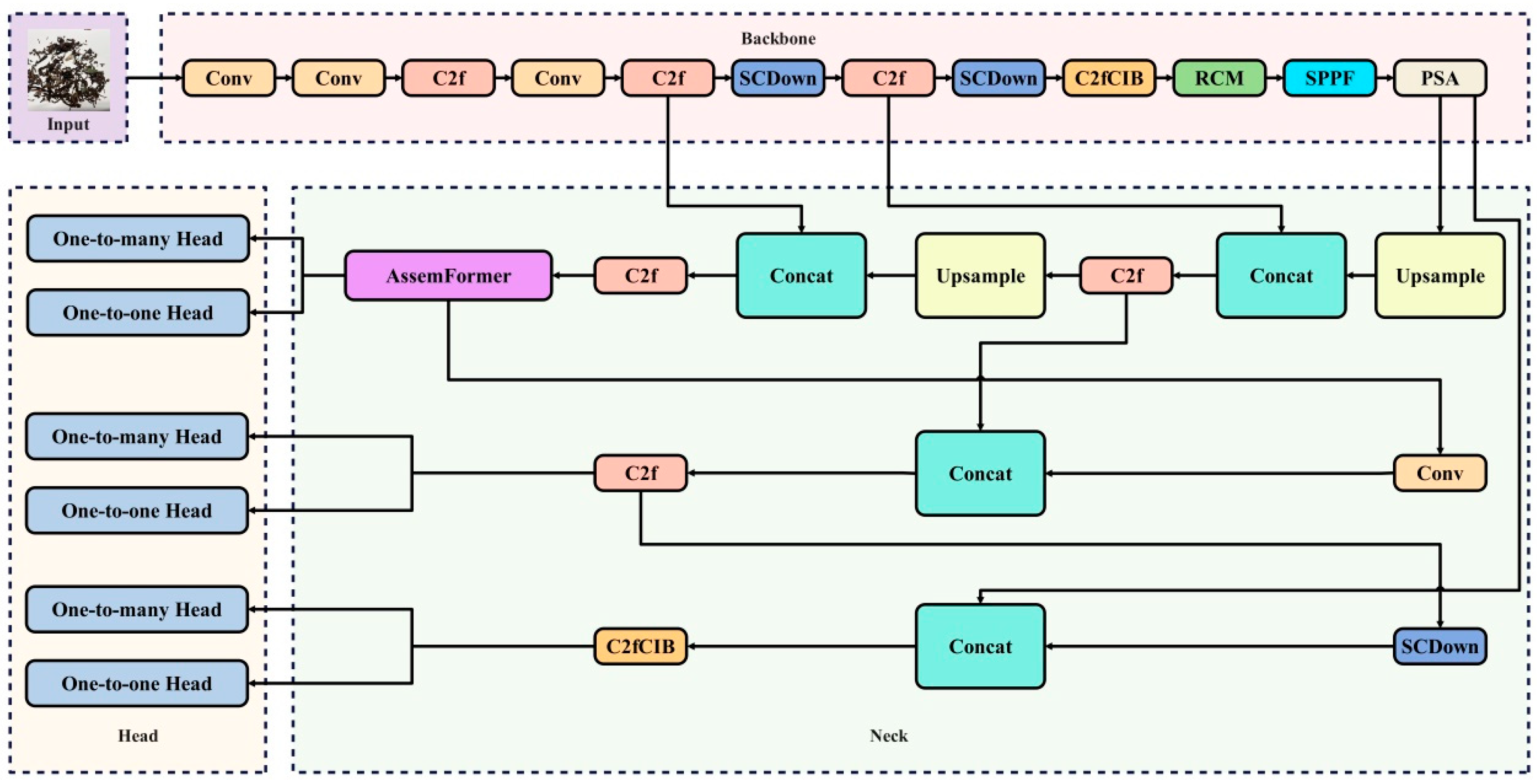
2.3. YOLOv10 Network Improvements
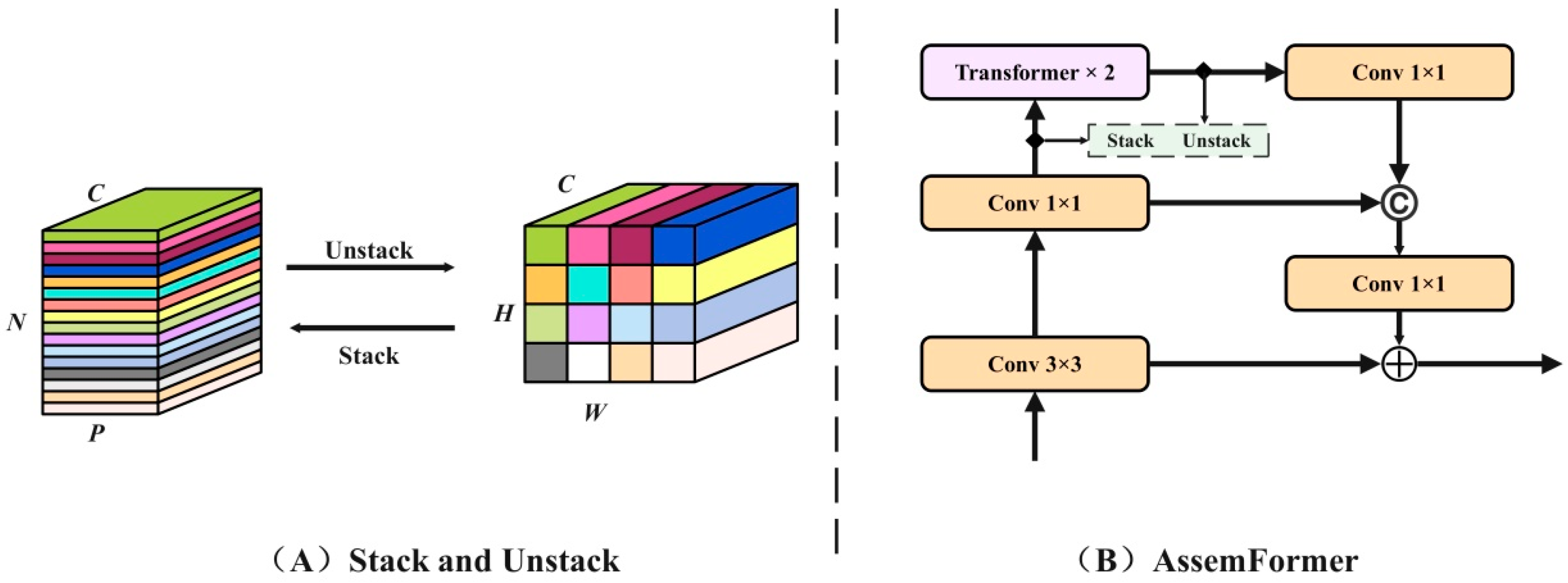
2.3.1. AssemFormer Optimization
2.3.2. Rectangular Self-Calibrated Module Optimization
2.3.3. Loss Function Optimization
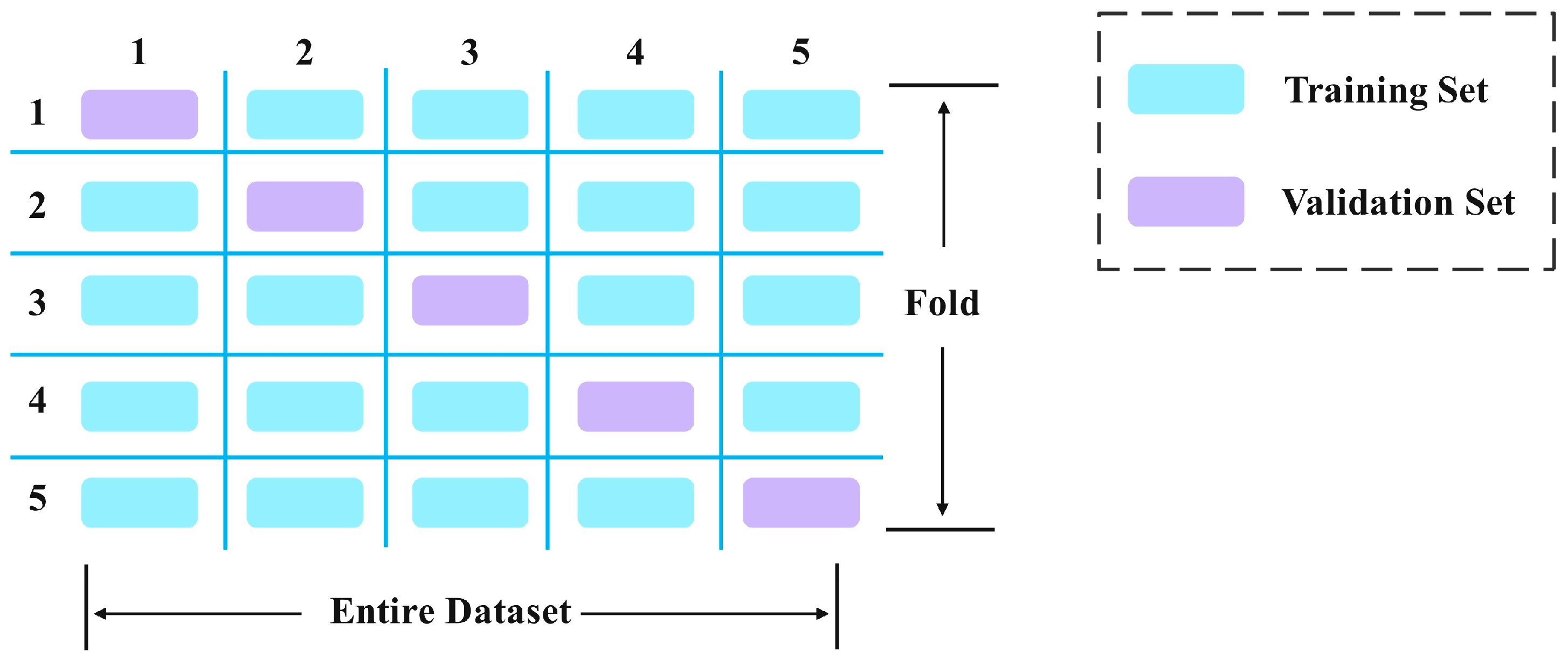
2.4. Five-Fold Cross-Validation
2.5. Evaluation Metrics
3. Results
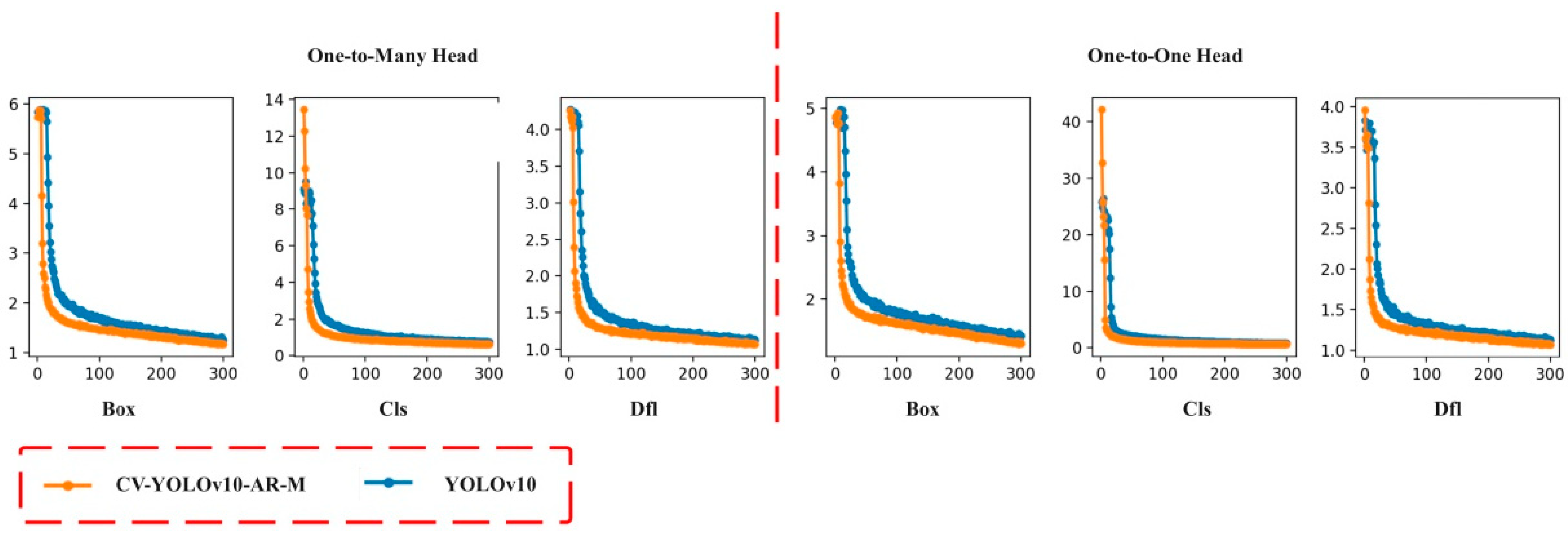
3.1. Model Performance Analysis
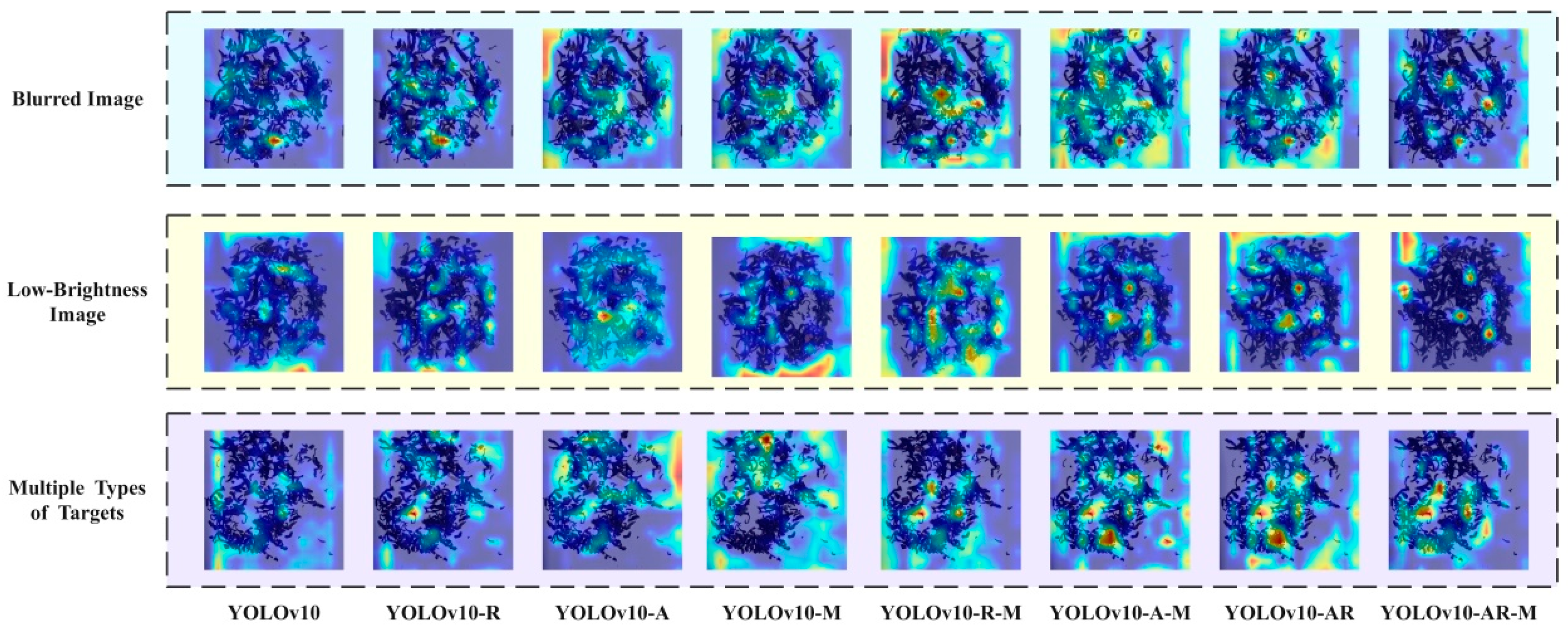
3.2. Ablation Study
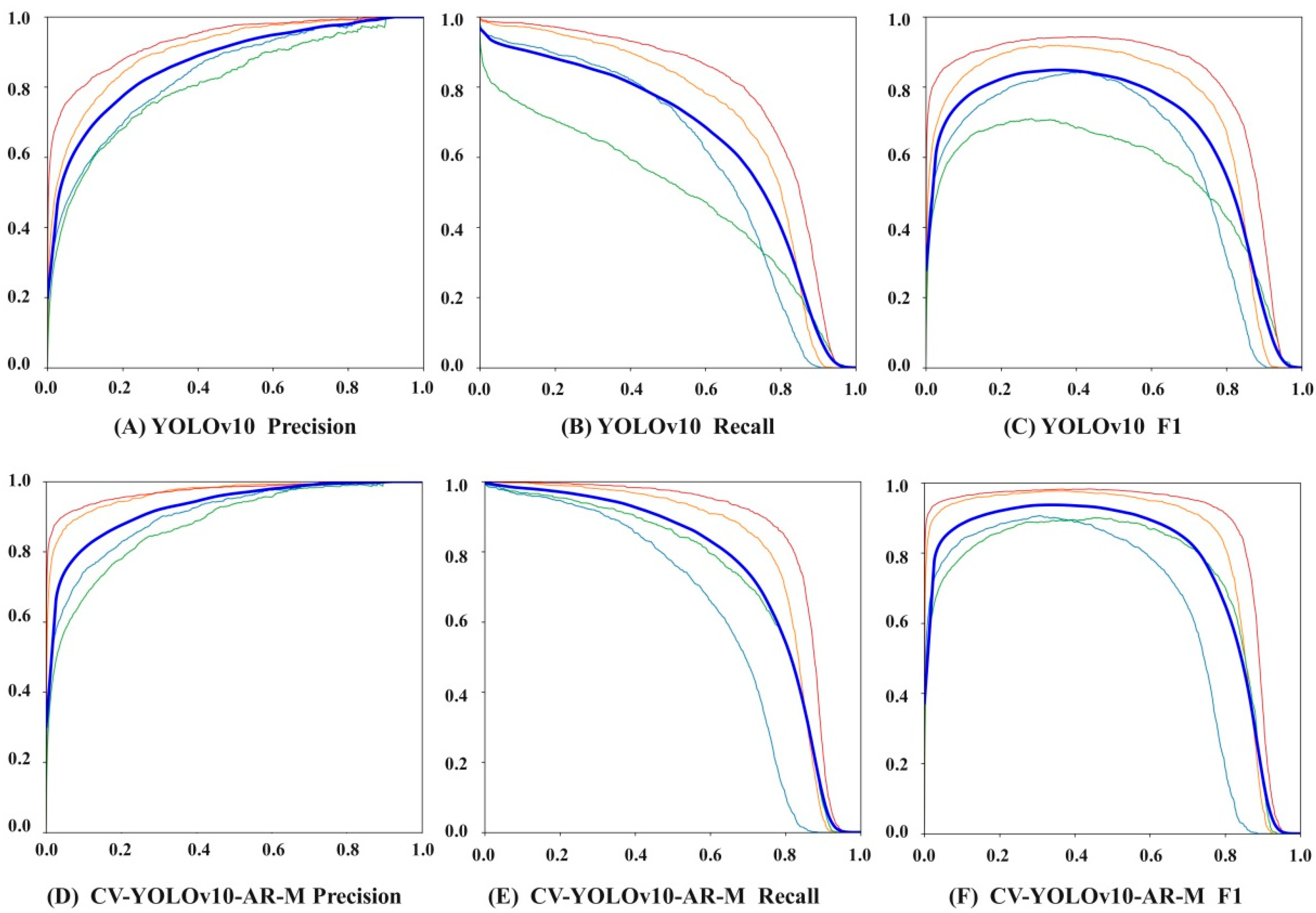
3.3. Comparative Model Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, P.; Li, J.; Yao, T.; Gan, Z.T. Fungal community composition and function in different Chinese post-fermented teas. Sci. Rep. 2025, 15, 8514. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Bo, N.G.; Guan, Y.Q.; Yang, D.H.; Chen, Q.Y.; Guan, Y.H.; Liu, S.Z.; Wang, Z.H.; Duan, H.X.; Ma, Y.; et al. An integrated flavoromics and chemometric analysis of the characteristic flavor, chemical basis and flavor wheel of ancient plant ripened puerh tea. Food Chem. X 2025, 26, 102278. [Google Scholar] [CrossRef]
- Wen, D.; Li, X.; Zhou, Y.; Shi, Y.; Wu, S.; Jiang, C. Integrated sensing-communication-computation for edge artificial intelligence. IEEE Internet Things Mag. 2024, 7, 14–20. [Google Scholar] [CrossRef]
- Li, H.; Yuan, W.; Xia, Y.; Wang, Z.; He, J.; Wang, Q.; Zhang, S.; Li, L.; Yang, F.; Wang, B. YOLOv8n-WSE-Pest: A Lightweight Deep Learning Model Based on YOLOv8n for Pest Identification in Tea Gardens. Appl. Sci. 2024, 14, 8748. [Google Scholar] [CrossRef]
- Sun, X.D.; Cui, D.D.; Shen, Y.; Li, W.P.; Wang, J.H. Non-destructive Detection for Foreign Bodies of Tea Stalks in Finished Tea Products Using Terahertz Spectroscopy and Imaging. Infrared Phys. Technol. 2022, 121, 104018. [Google Scholar] [CrossRef]
- Shu, Z.; Li, X.; Liu, Y.D. Detection of Chili Foreign Objects Using Hyperspectral Imaging Combined with Chemometric and Target Detection Algorithms. Foods 2023, 12, 2618. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Mehdi, K.; Reza, G.M.; Marziye, M.; Ahmad, K.H. Detection of foreign materials in cocoa beans by hyperspectral imaging technology. Food Control 2021, 129, 108242. [Google Scholar]
- Chen, L.S.; Meng, K.; Zhang, H.Y.; Zhou, J.Q.; Lou, P.H. SR-FABNet: Super-Resolution branch guided Fourier attention detection network for efficient optical inspection of nanoscale wafer defects. Adv. Eng. Inform. 2025, 65, 103200. [Google Scholar] [CrossRef]
- Sun, K.; Tang, M.D.; Li, S.; Tong, S.Y. Mildew detection in rice grains based on computer vision and the YOLO convolutional neural network. Food Sci. Nutr. 2024, 12, 860. [Google Scholar] [CrossRef]
- Zhang, C.J.; Yun, L.J.; Yang, C.G.; Chen, Z.Q.; Cheng, F.Y. LRNTRM-YOLO: Research on Real-Time Recognition of Non-Tobacco-Related Materials. Agronomy 2025, 15, 489. [Google Scholar] [CrossRef]
- Peng, J.Y.; Zhang, Y.N.; Xian, J.Y.; Wang, X.C.; Shi, Y.Y. YOLO Recognition Method for Tea Shoots Based on Polariser Filtering and LFAnet. Agronomy 2024, 14, 1800. [Google Scholar] [CrossRef]
- Xing, Y.; Han, X.; Pan, X.D.; An, D.; Liu, W.D.; Ba, Y.S. EMG-YOLO: Road crack detection algorithm for edge computing devices. Front. Neurorobot. 2024, 18, 1423738. [Google Scholar] [CrossRef]
- Cui, Z.S.; Yao, Y.B.; Li, S.L.; Zhao, Y.C.; Xin, M. A lightweight hash-directed global perception and self-calibrated multiscale fusion network for image super-resolution. Image Vis. Comput. 2024, 151, 105255. [Google Scholar] [CrossRef]
- Sagar, N.; Suresh, K.P.; Sridhara, S.; Patil, B.; Archana, C.A.; Sekar, Y.S.; Naveesh, Y.B.; Nandan, A.S.; Sushma, R. Precision detection of grapevine downy and powdery mildew diseased leaves and fruits using enhanced ResNet50 with batch normalization. Comput. Electron. Agric. 2025, 232, 110144. [Google Scholar] [CrossRef]
- Reit, M.; Lu, X.; Zarges, J.C.; Heim, H.P. Use of machine learning methods for modelling mechanical parameters of PLA and PLA/native potato starch compound using aging data. Int. Polym. Process. 2025, 40, 94–109. [Google Scholar] [CrossRef]
- Zhu, H.Y.; Qu, Z.G.; Guo, Z.L.; Zhang, J.F. Transfer learning-based prediction and evaluation for ionic osmotic energy conversion under concentration and temperature gradients. Appl. Energy 2025, 386, 125574. [Google Scholar] [CrossRef]
- Xu, J.C.; Yang, Y.H.; Chu, M.X. MPGA-YOLOv8: A Leaf Disease Detection Network Combining Multi-Scale Progressive Feature Network and Global Attention. IAENG Int. J. Comput. Sci. 2025, 52, 436–446. [Google Scholar]
- Li, Q.; Zhao, F.; Zhao, L.L.; Liu, M.K.; Wang, Y.B.; Zhang, S.; Guo, Y.Y.; Wang, S.L.; Wang, W.G. A System of Multimodal Image-Text Retrieval Based on Pre-Trained Models Fusion. Concurr. Comput. Pract. Exp. 2024, 37, e8345. [Google Scholar] [CrossRef]
- Cano, P.; Musulen, E.; Gil, D. Diagnosing Helicobacter pylori using autoencoders and limited annotations through anomalous staining patterns in IHC whole slide images. Int. J. Comput. Assist. Radiol. Surg. 2025, 20, 765–773. [Google Scholar] [CrossRef]
- Chen, Z.M.; Chen, B.F.; Huang, Y.; Zhou, Z.S. GE-YOLO for Weed Detection in Rice Paddy Fields. Appl. Sci. 2025, 15, 2823. [Google Scholar] [CrossRef]
- Hai, T.; Shao, Y.X.; Zhang, X.Y.; Yuan, G.Q.; Jia, R.H.; Fu, Z.J.; Wu, X.H.; Ge, X.J.; Song, Y.H.; Dong, M.; et al. An Efficient Model for Leafy Vegetable Disease Detection and Segmentation Based on Few-Shot Learning Framework and Prototype Attention Mechanism. Plants 2025, 14, 760. [Google Scholar] [CrossRef] [PubMed]
- Fu, S.J.; Pan, H.; Huang, J.Z.; Zhang, X.Y.; Jing, Z.L. AGD-YOLO: A forward-looking sonar target detection method with attention-guided denoising convolutional neural network. Aerosp. Syst. 2025, 1–16. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, Z.; Zhang, Y.; Yang, Z. MDFN: A Multi-level Dynamic Fusion Network with self-calibrated edge enhancement for lung nodule segmentation. Biomed. Signal Process. Control 2024, 87, 105507. [Google Scholar] [CrossRef]
- Mohammadi, A.; Tsang, J.; Huang, X.; Kearsey, R. Convolutional neural network based methodology for flexible phase prediction of high entropy alloys. Can. Metall. Q. 2025, 64, 431–443. [Google Scholar] [CrossRef]
- Kaur, M.; Valderrama, C.E.; Liu, Q. Hybrid vision transformer framework for efficient and explainable SEM image-based nanomaterial classification. Mach. Learn. Sci. Technol. 2025, 6, 015066. [Google Scholar] [CrossRef]
- Ma, X.Y.; Sun, H.T.; Yuan, G.; Tang, Y.F.; Liu, J.; Chen, S.Q.; Zheng, J. Cross-Attention Adaptive Feature Pyramid Network with Uncertainty Boundary Modeling for Mass Detection in Digital Breast Tomosynthesis. Bioengineering 2025, 12, 196. [Google Scholar] [CrossRef]
- Tanaka, S.; Garuda, F. CMA-ES-based topology optimization accelerated by spectral level-set-boundary modeling. Comput. Methods Appl. Mech. Eng. 2024, 432, 117331. [Google Scholar] [CrossRef]
- Wang, C.H.; Yi, H.A. DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery. Appl. Sci. 2025, 15, 2789. [Google Scholar] [CrossRef]
- Byun, Y.H.; Son, J.; Yun, J.; Choo, H.; Won, J. Machine learning-based pattern recognition of Bender element signals for predicting sand particle-size. Sci. Rep. 2025, 15, 6949. [Google Scholar] [CrossRef]
- Liu, J.D.; Zhang, B.; Xu, H.Z.; Zhang, L.C.; Zhang, X.L. Method for Recognizing Disordered Sugarcane Stacking Based on Improved YOLOv8n. Appl. Sci. 2024, 14, 11765. [Google Scholar] [CrossRef]
- Guo, F.X.; Li, J.; Liu, X.C.; Chen, S.N.; Zhang, H.Z.; Cao, Y.L.; Wei, S.H. Improved YOLOv7-Tiny for the Detection of Common Rice Leaf Diseases in Smart Agriculture. Agronomy 2024, 14, 2796. [Google Scholar] [CrossRef]
- Kang, R.R.; Kim, Y.G.; Hong, M.; Ahn, Y.M.; Lee, K.Y. AI-based personalized real-time risk prediction for behavioral management in psychiatric wards using multimodal data. Int. J. Med. Inform. 2025, 198, 105870. [Google Scholar] [CrossRef]
- An, D.D.; Yang, Y.; Gao, X.; Qi, H.D.; Yang, Y.; Ye, X.; Li, M.Z.; Zhao, Q. Reinforcement learning-based secure training for adversarial defense in graph neural networks. Neurocomputing 2025, 630, 129704. [Google Scholar] [CrossRef]
- Syed, N.T.; Zhou, J.; Marinello, F.; Lakhiar, N.I.; Chandio, A.F.; Rottok, T.L.; Zheng, Y.F.; Gamechu, T.T. Definition of a reference standard for performance evaluation of autonomous vehicles real-time obstacle detection and distance estimation in complex environments. Comput. Electron. Agric. 2025, 232, 110143. [Google Scholar] [CrossRef]
- Yu, M.; Li, Y.X.; Li, Z.L.; Yan, P.; Li, X.T.; Tian, Q.; Xie, B.L. Dense detection algorithm for ceramic tile defects based on improved YOLOv8. J. Intell. Manuf. 2024, 1–16. [Google Scholar] [CrossRef]
- Fu, G.Q.; Lin, K.L.; Lu, C.J.; Wang, X.; Wang, T. Spindle thermal error regression prediction modeling based on ConvNeXt and weighted integration using thermal images. Expert Syst. Appl. 2025, 274, 127038. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, X.T.; Luo, N.; Chen, F.; Yu, H.L.; Sun, C.H. A novel method for Pu-erh tea face traceability identification based on improved MobileNetV3 and triplet loss. Sci. Rep. 2023, 13, 6986. [Google Scholar] [CrossRef]
- Plessen, M. Accelerated sub-image search for variable-size patches identification based on virtual time series transformation and segmentation. Smart Agric. Technol. 2025, 10, 100736. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | From | Module | Arguments |
|---|---|---|---|
| 0 | −1 | Conv | [3, 16, 3, 2] |
| 1 | −1 | Conv | [16, 32, 3, 1] |
| 2 | −1 | C2f | [32, 32, 1, True] |
| 3 | −1 | Conv | [32, 64, 3, 2] |
| 4 | −1 | C2f | [64, 64, 2, True] |
| 5 | −1 | SCDown | [64, 128, 3, 2] |
| 6 | −1 | C2f | [128, 128, 2, True] |
| 7 | −1 | SCDown | [128, 256, 3, 2] |
| 8 | −1 | C2fCIB | [256, 256, 1, True, True] |
| 9 | −1 | RCM | [256] |
| 10 | −1 | SPPF | [256, 256, 5] |
| 11 | −1 | PSA | [256, 256] |
| 12 | −1 | Upsample | [None, 2, ‘nearest’] |
| 13 | [−1, 6] | Concat | [1] |
| 14 | −1 | C2f | [384, 128, 1] |
| 15 | −1 | Upsample | [None, 2, ‘nearest’] |
| 16 | [−1, 4] | Concat | [1] |
| 17 | −1 | C2f | [192, 64, 1] |
| 18 | −1 | AssemFormer | [64] |
| 19 | −1 | Conv | [64, 64, 3, 2] |
| 20 | [−1, 14] | Concat | [1] |
| 21 | −1 | C2f | [192, 128, 1] |
| 22 | −1 | SCDown | [128, 128, 3, 2] |
| 23 | [−1, 11] | Concat | [1] |
| 24 | −1 | C2fCIB | [384, 256, 1, True, True] |
| 25 | [18, 21, 24] | v10Detect | [4, 64, 128, 256] |
| Model | Precision (%) | Recall (%) | mAP (%) | Layers | Parameters | Gradients |
|---|---|---|---|---|---|---|
| YOLOv10 | 88.26 | 82.99 | 89.15 | 402 | 2,496,998 | 2,496,982 |
| YOLOv10-R | 88.91 | 88.25 | 92.32 | 421 | 2,769,894 | 2,769,878 |
| YOLOv10-A | 88.56 | 86.52 | 91.51 | 464 | 2,555,368 | 2,555,352 |
| YOLOv10-M | 86.87 | 87.38 | 91.13 | 402 | 2,496,998 | 2,496,982 |
| YOLOv10-R-M | 90.33 | 91.12 | 94.77 | 421 | 2,769,894 | 2,769,878 |
| YOLOv10-A-M | 90.20 | 90.62 | 94.42 | 464 | 2,555,368 | 2,555,352 |
| YOLOv10-AR | 92.07 | 92.36 | 95.91 | 483 | 2,828,264 | 2,828,248 |
| YOLOv10-AR-M | 93.61 | 94.71 | 97.47 | 483 | 2,828,264 | 2,828,248 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP (%) |
|---|---|---|---|---|
| CV-YOLOv10-AR-M | 93.61 | 94.71 | 94.16 | 97.47 |
| YOLOv10 | 88.26 | 82.99 | 85.54 | 89.15 |
| YOLOv12 | 85.16 | 82.9 | 84.01 | 88.98 |
| CornerNet | 78.41 | 74.12 | 76.2 | 81.44 |
| RT-DETR | 85.14 | 79.02 | 81.97 | 86.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, W.; Yang, C.; Wang, X.; Wang, Q.; Chen, L.; Zou, M.; Fan, Z.; Zhou, M.; Wang, B. CV-YOLOv10-AR-M: Foreign Object Detection in Pu-Erh Tea Based on Five-Fold Cross-Validation. Foods 2025, 14, 1680. https://doi.org/10.3390/foods14101680
Yuan W, Yang C, Wang X, Wang Q, Chen L, Zou M, Fan Z, Zhou M, Wang B. CV-YOLOv10-AR-M: Foreign Object Detection in Pu-Erh Tea Based on Five-Fold Cross-Validation. Foods. 2025; 14(10):1680. https://doi.org/10.3390/foods14101680
Chicago/Turabian StyleYuan, Wenxia, Chunhua Yang, Xinghua Wang, Qiaomei Wang, Lijiao Chen, Man Zou, Zongpei Fan, Miao Zhou, and Baijuan Wang. 2025. "CV-YOLOv10-AR-M: Foreign Object Detection in Pu-Erh Tea Based on Five-Fold Cross-Validation" Foods 14, no. 10: 1680. https://doi.org/10.3390/foods14101680
APA StyleYuan, W., Yang, C., Wang, X., Wang, Q., Chen, L., Zou, M., Fan, Z., Zhou, M., & Wang, B. (2025). CV-YOLOv10-AR-M: Foreign Object Detection in Pu-Erh Tea Based on Five-Fold Cross-Validation. Foods, 14(10), 1680. https://doi.org/10.3390/foods14101680