
A Machine Learning Pipeline for Predicting Pinot Noir Wine Quality from Viticulture Data: Development and Implementation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction and Background
1.1. Pinot Noir Wines
1.2. Wine Quality
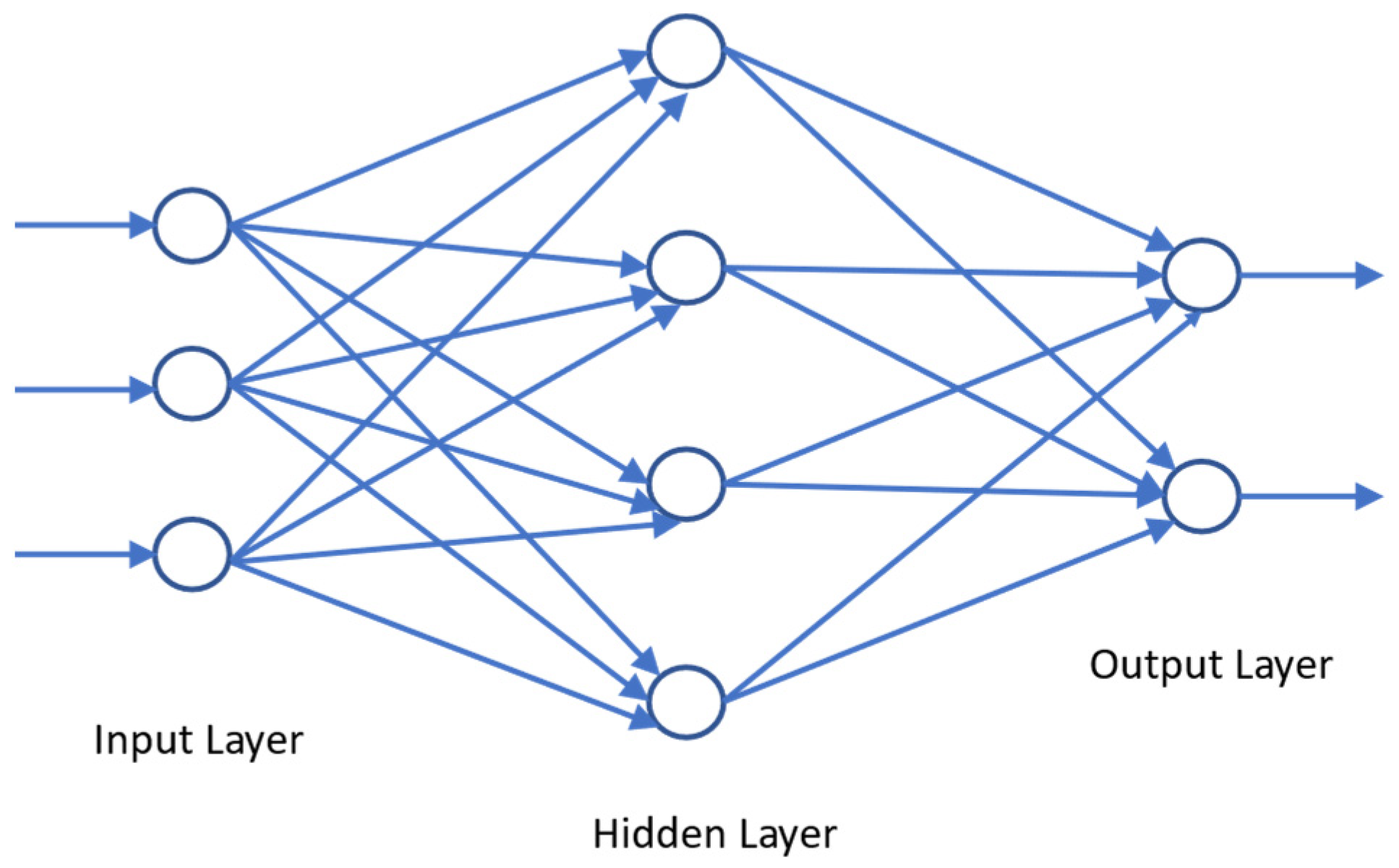
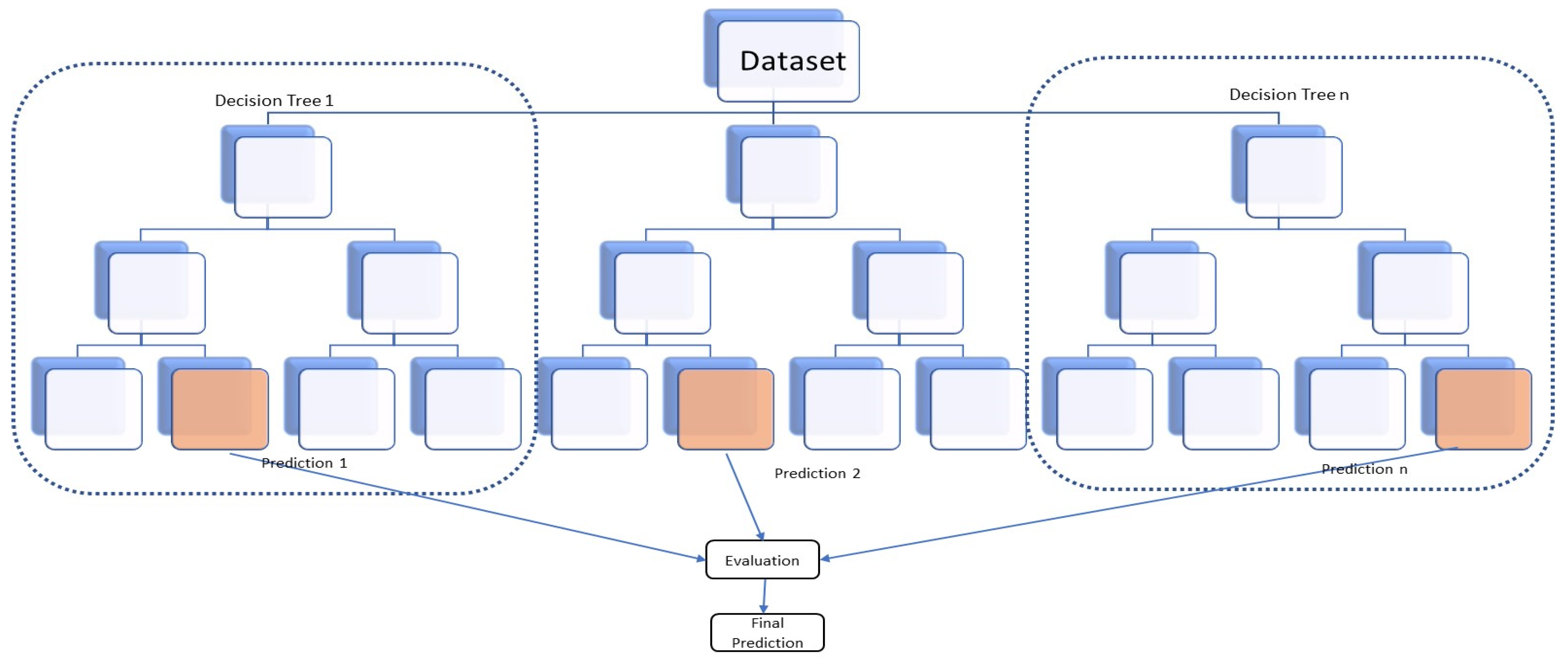
1.3. Machine Learning in Viticulture
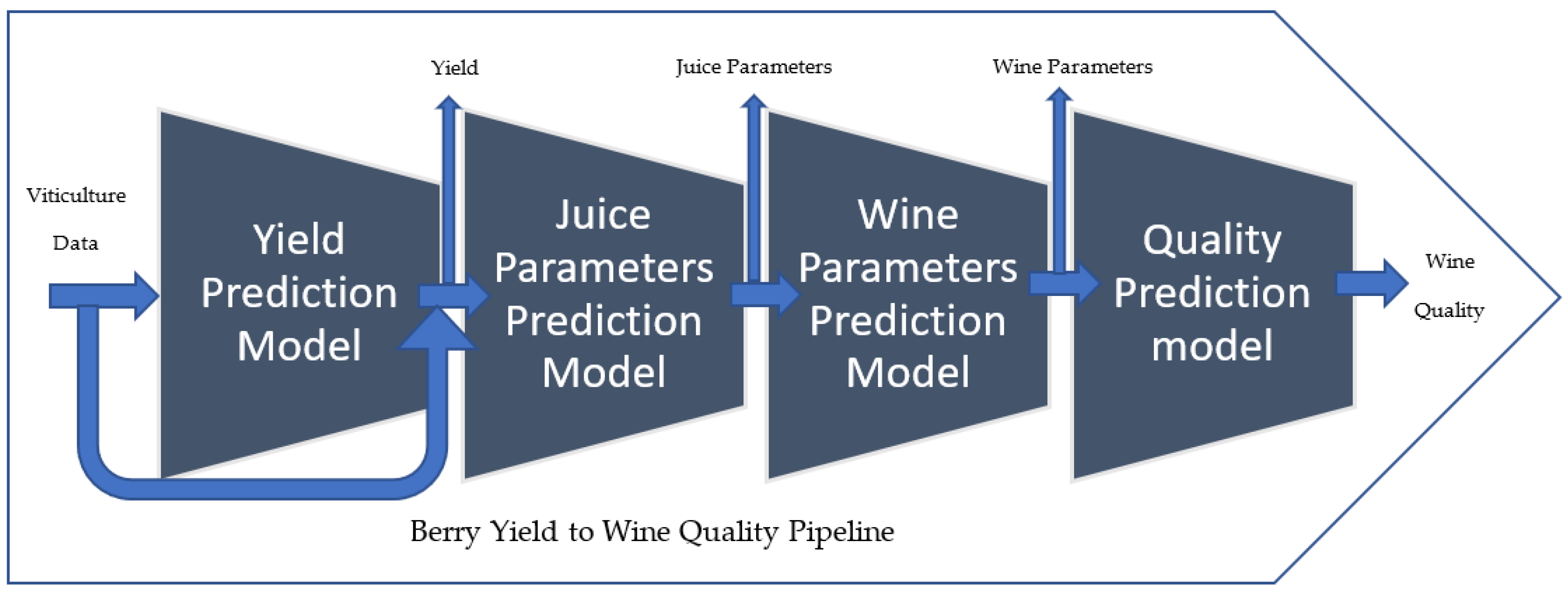
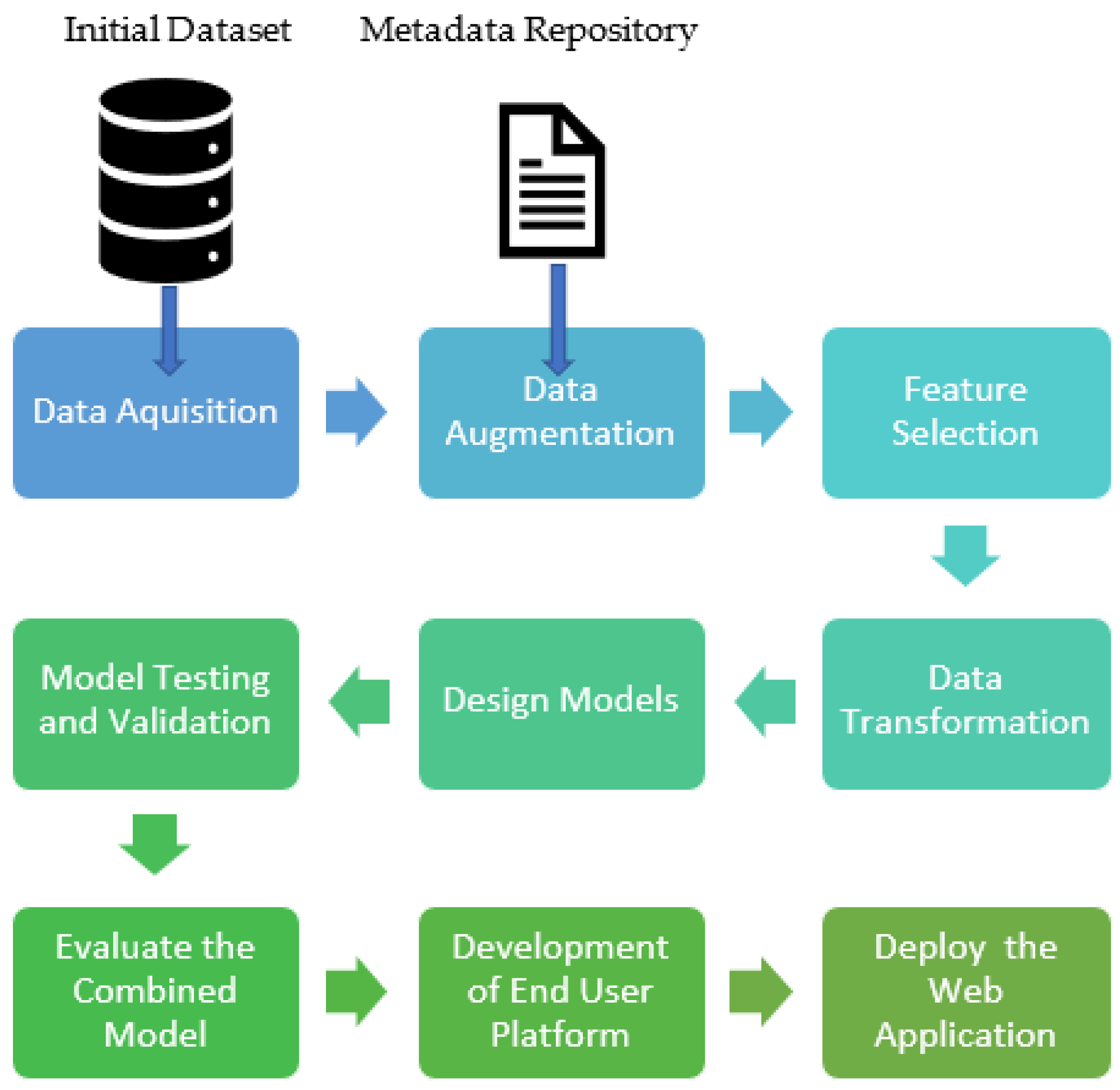
2. A Vine-to-Wine Quality Pipeline
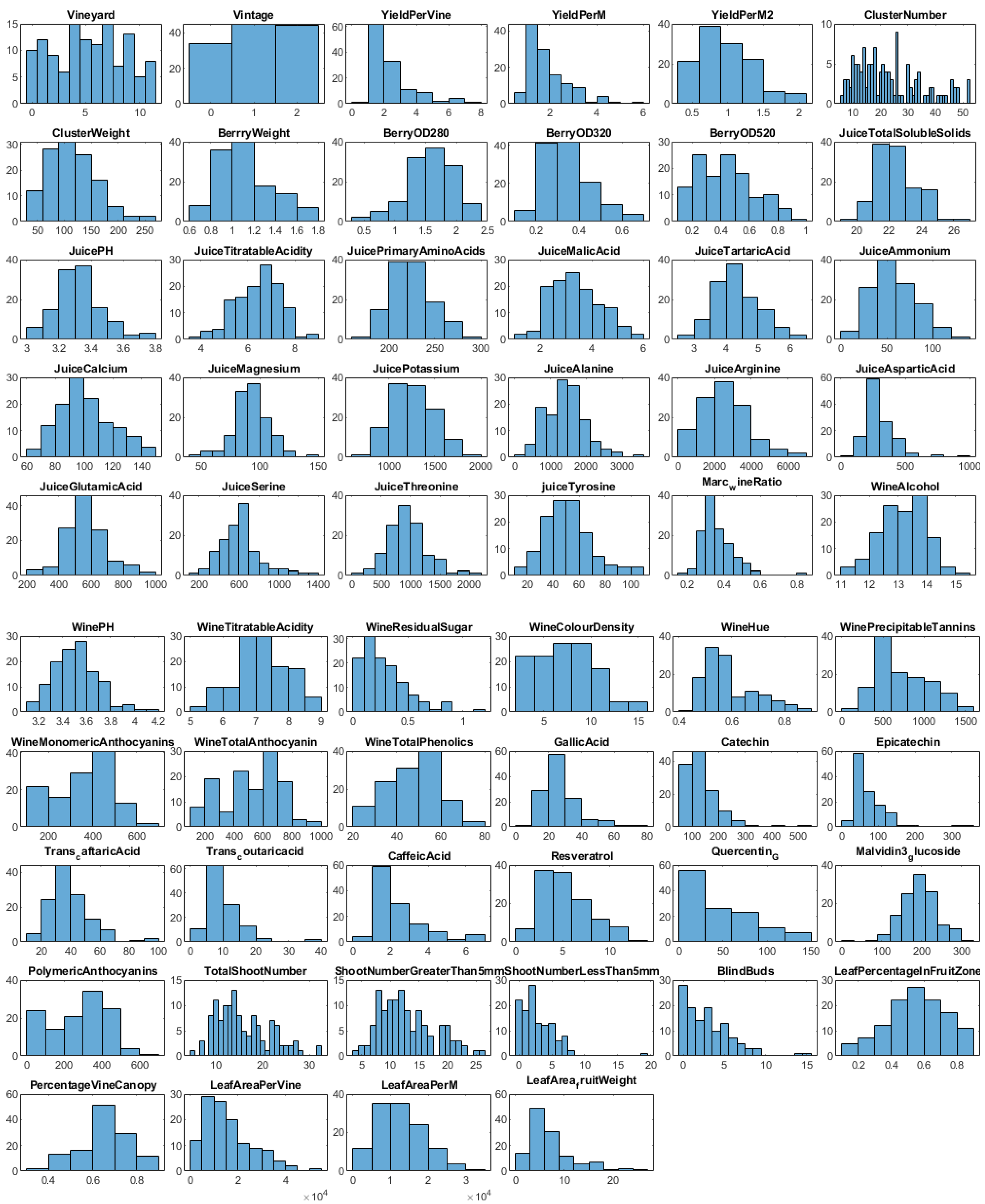
2.1. Data Acquisition
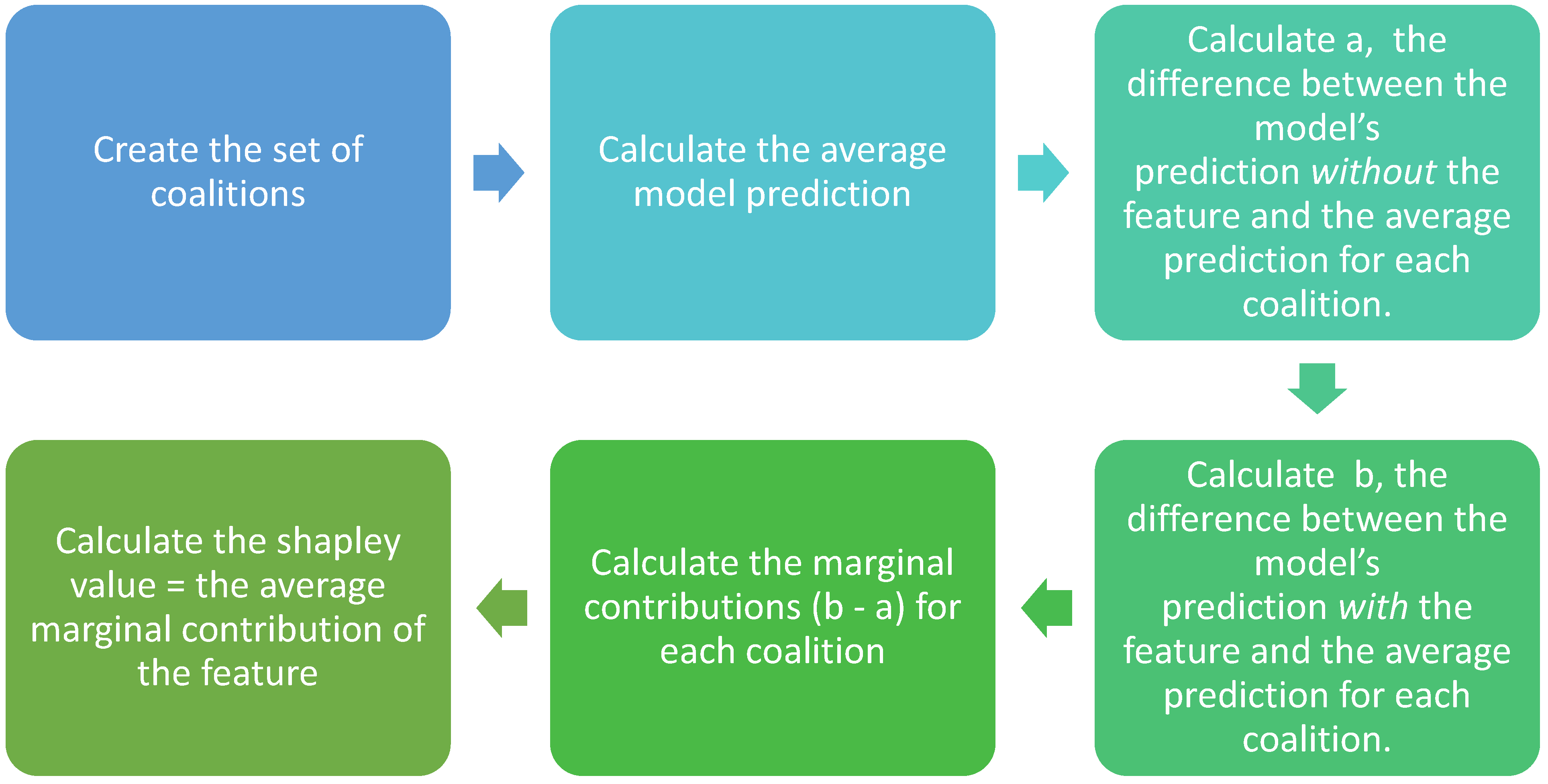
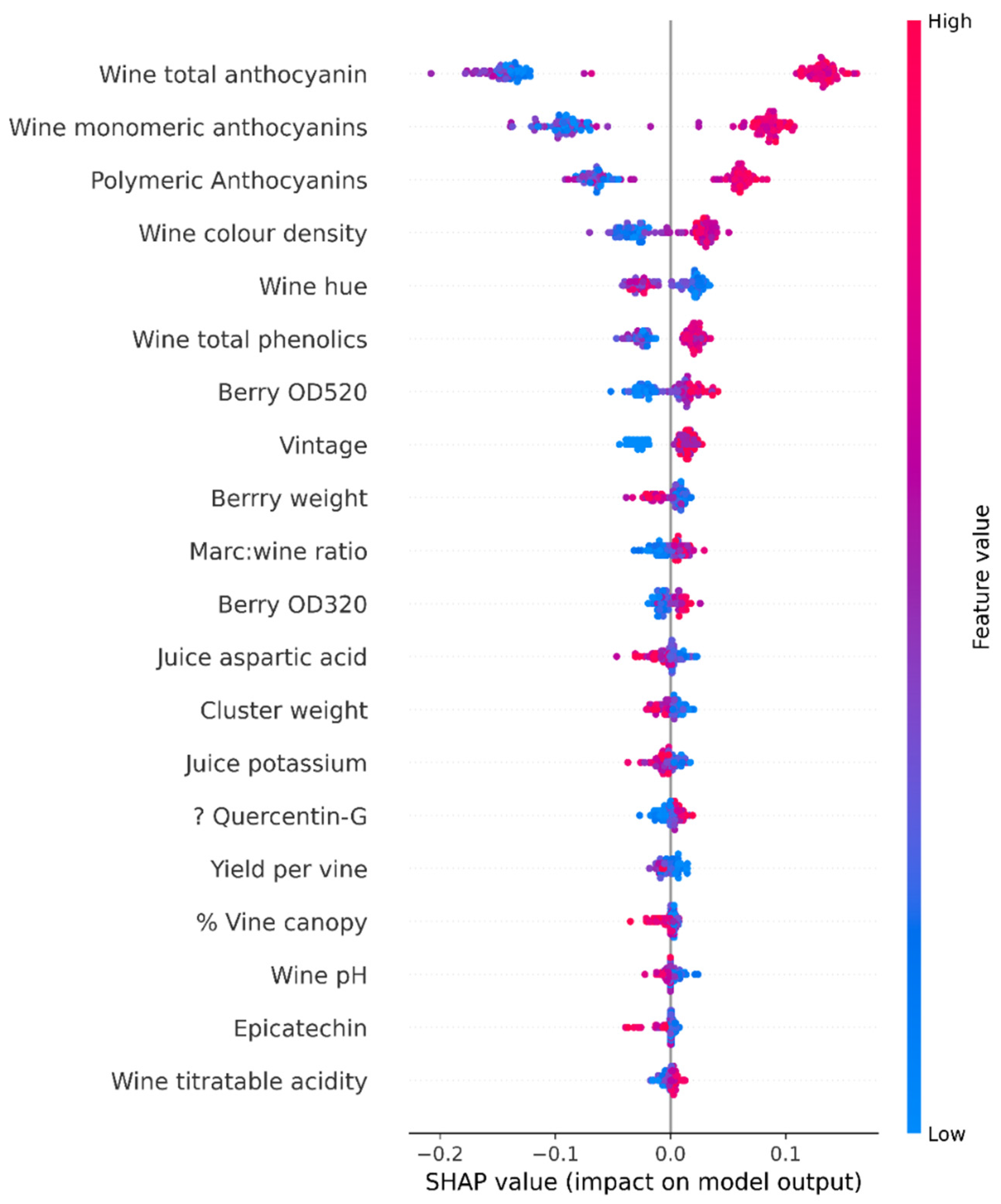
2.2. SHAP Value Analysis
2.3. R2 Scores in Linear Regression
2.4. Feature Extraction
2.4.1. Feature Selection for the Models
2.4.2. Data Augmentation
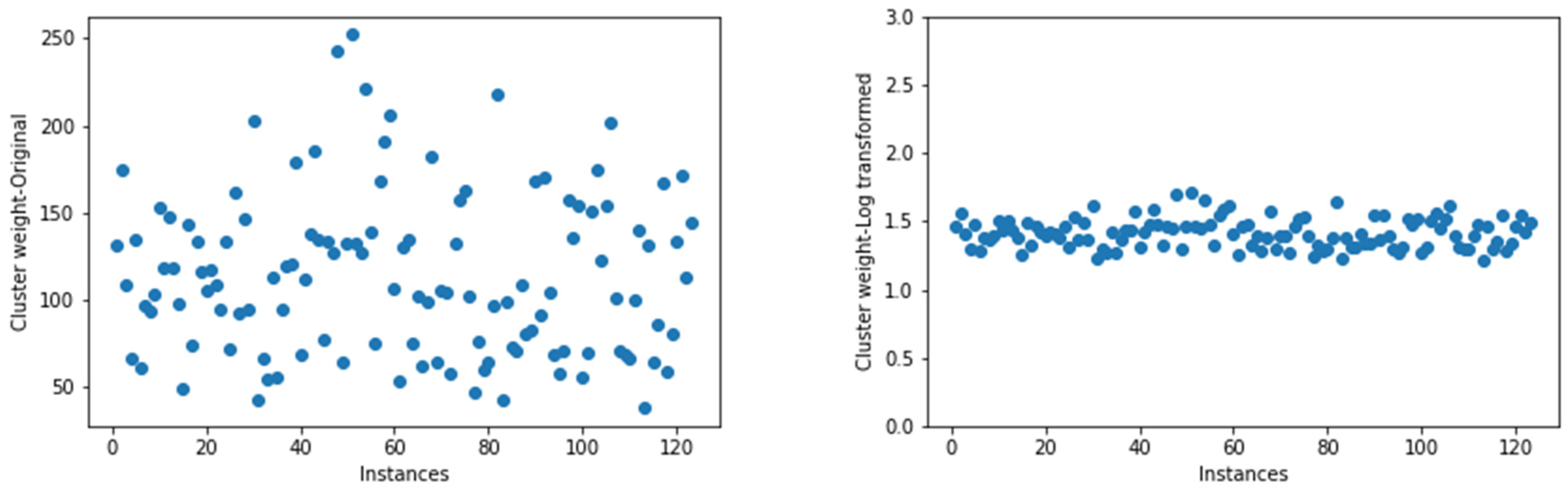
2.5. Data Transformation
3. Development of Sub-Models
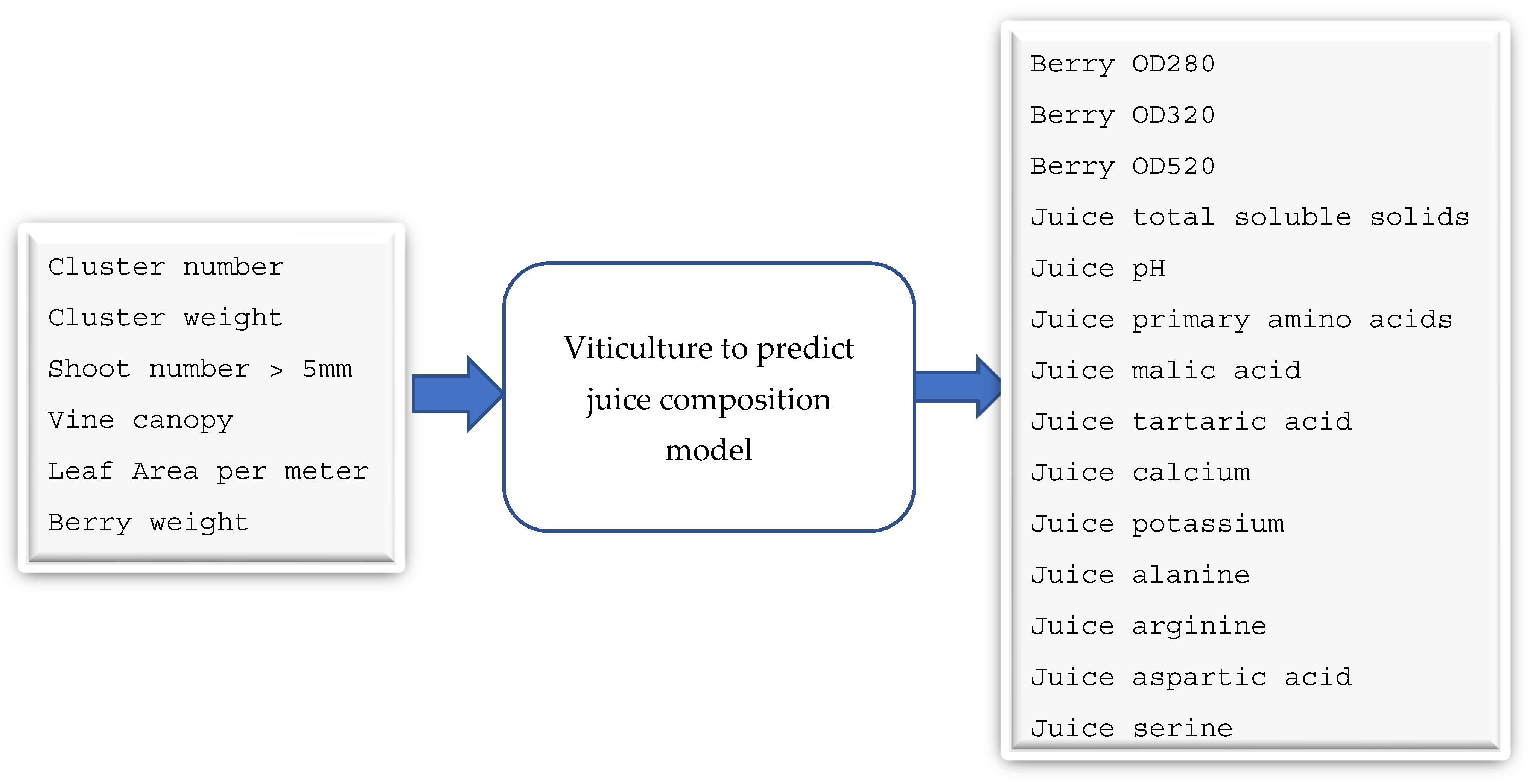
3.1. Viticulture to Predict Yield Model
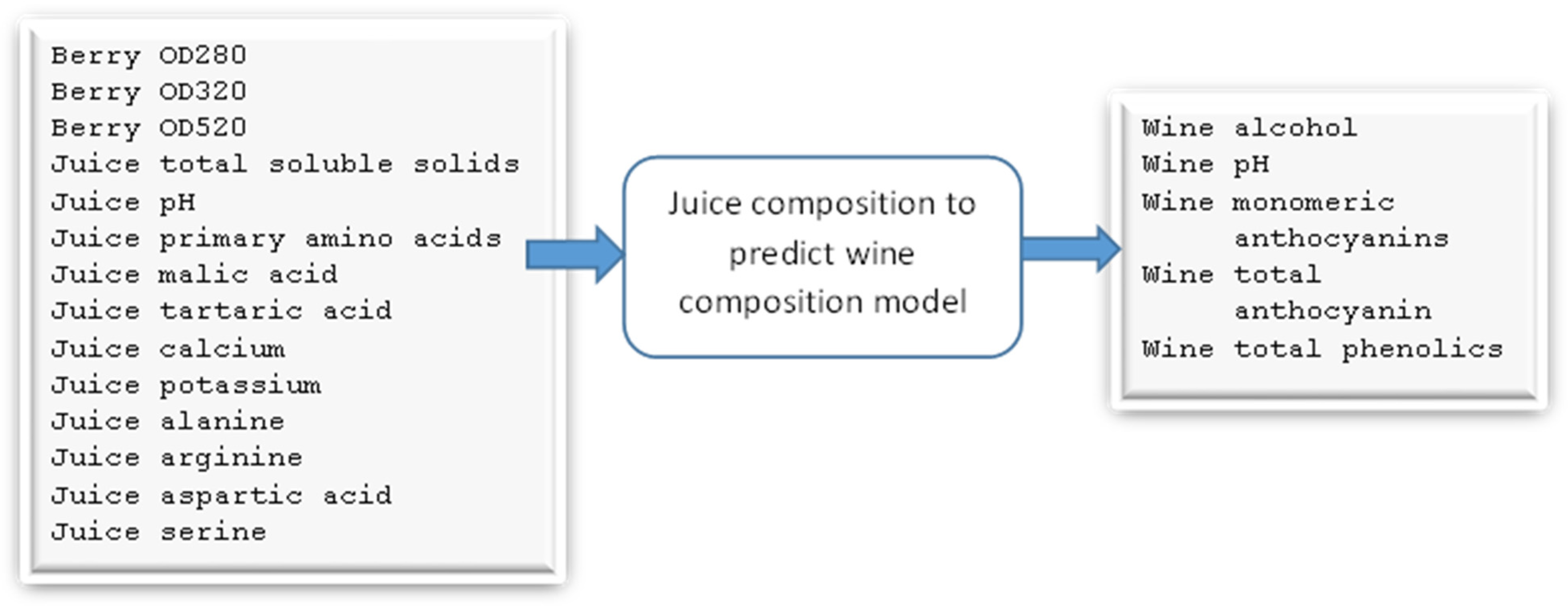
3.2. Juice-Parameters-to-Wine-Parameters Model
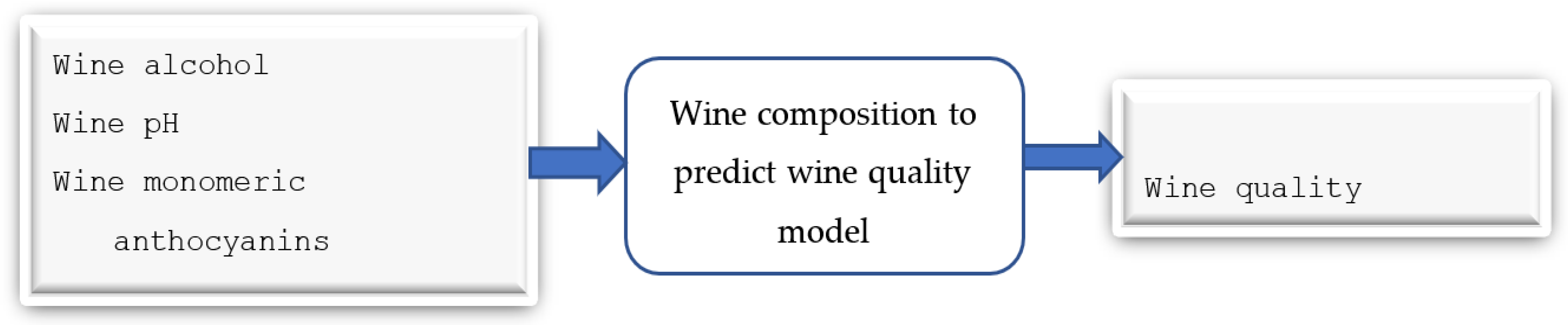
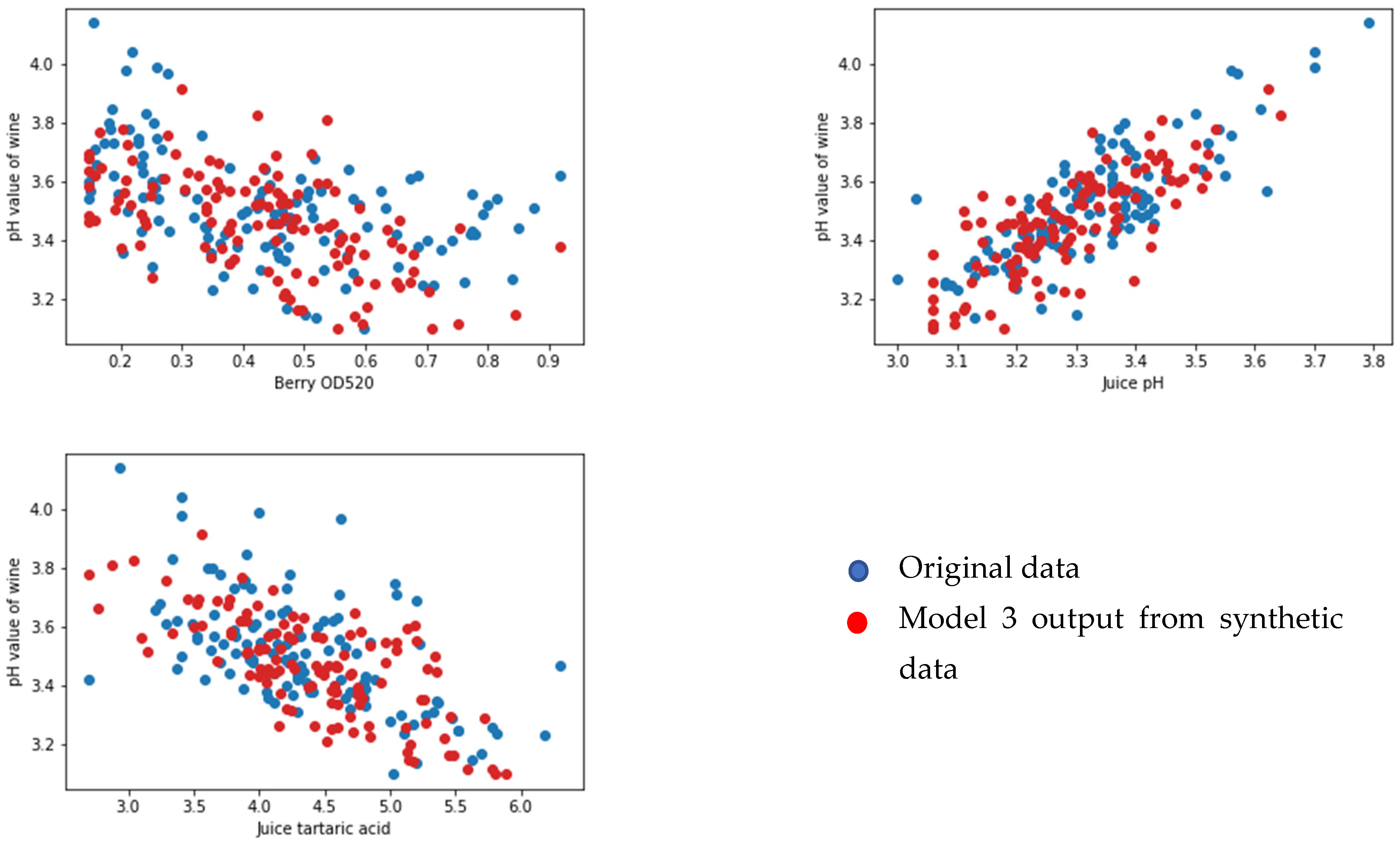
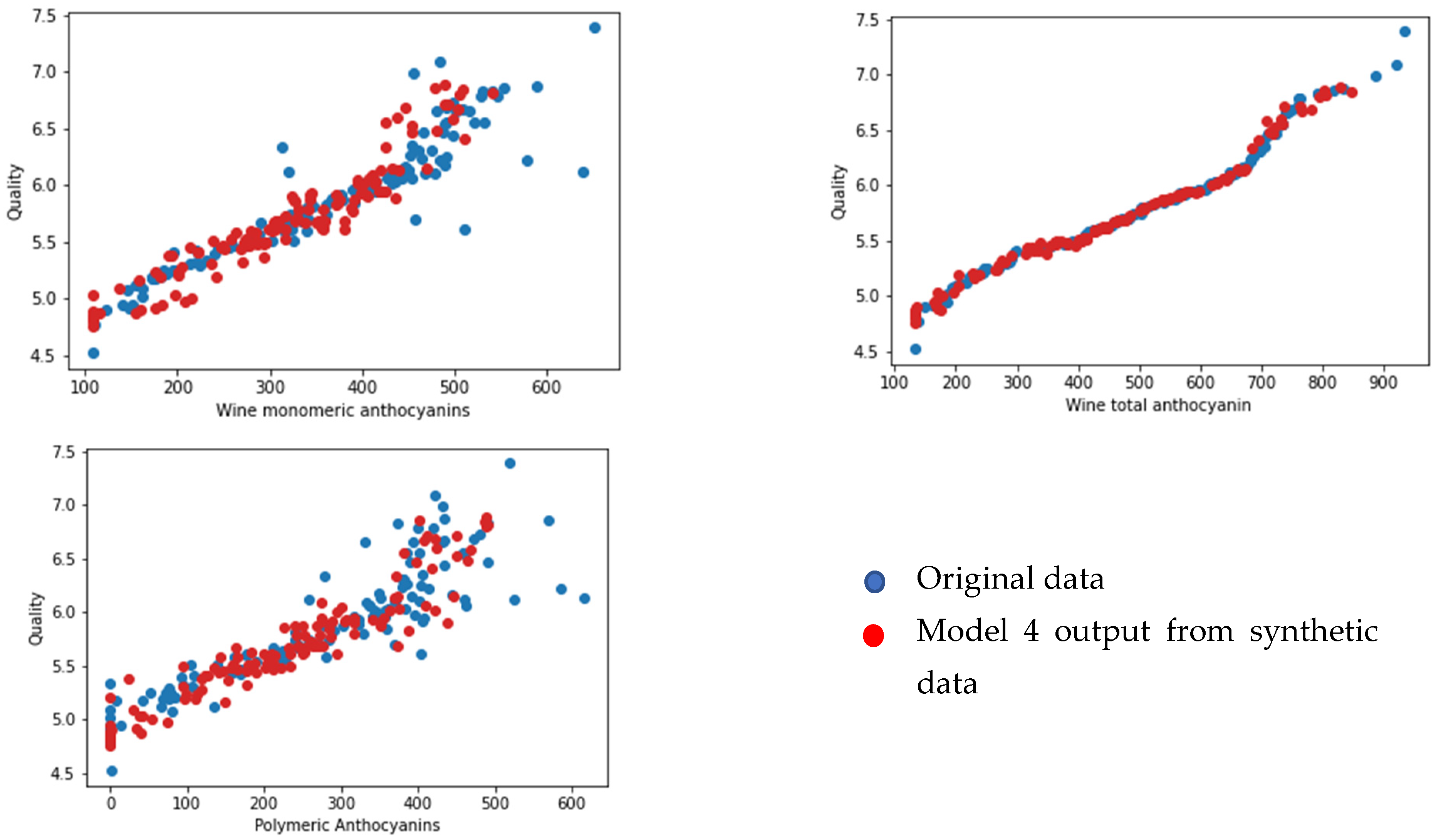
3.3. Wine Parameters for Predicting the Quality of the Wine Product Model
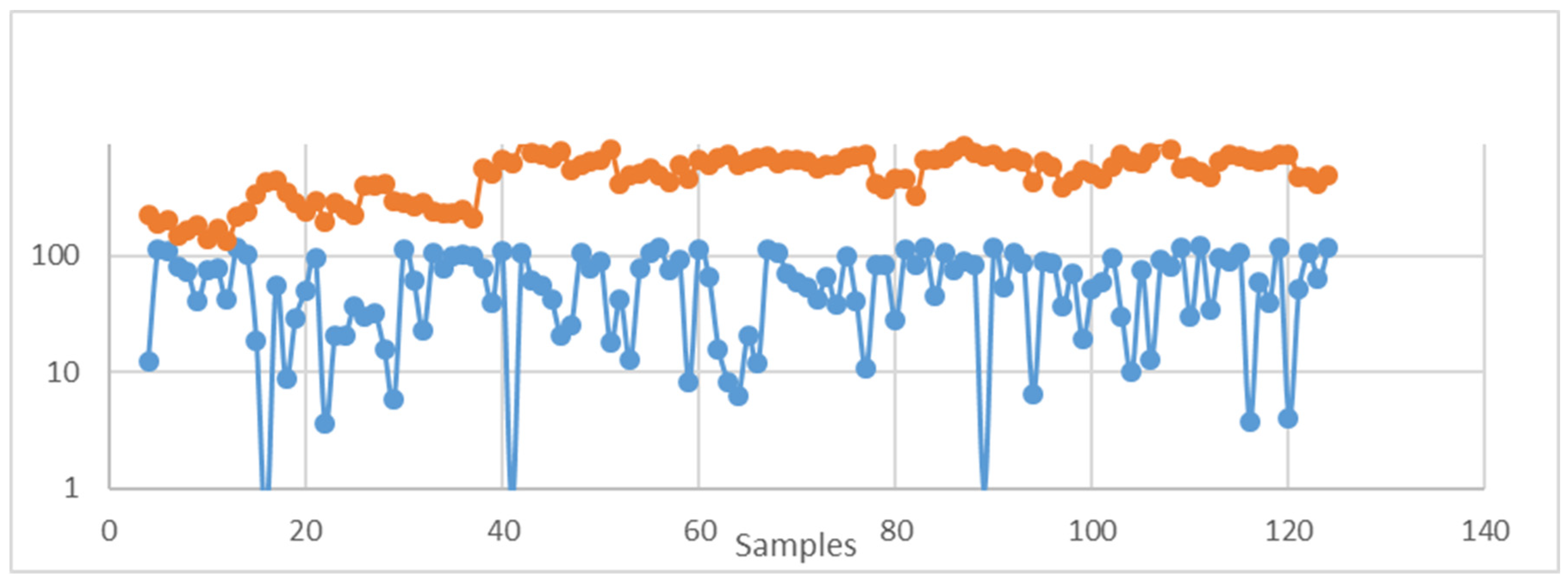
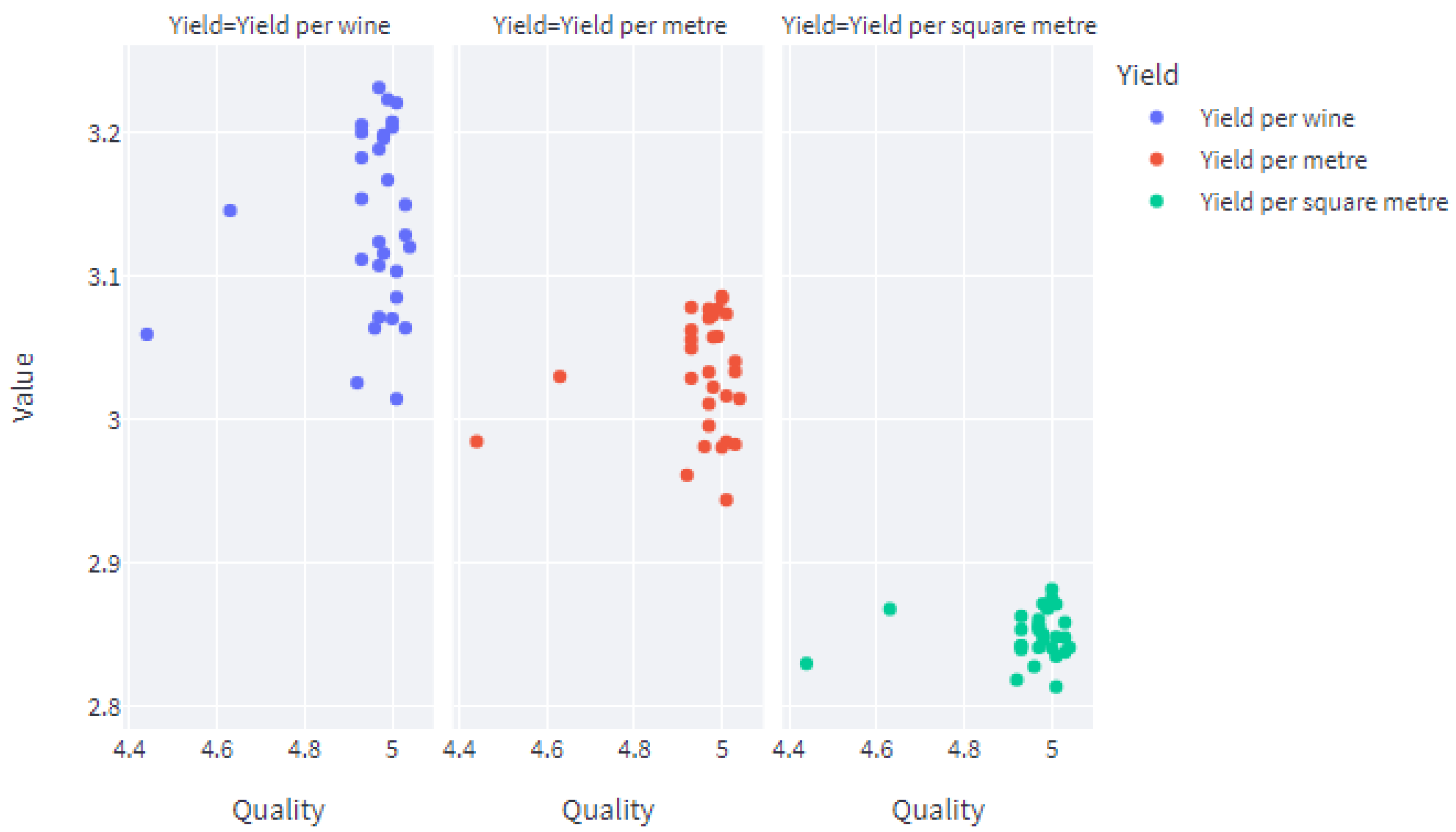
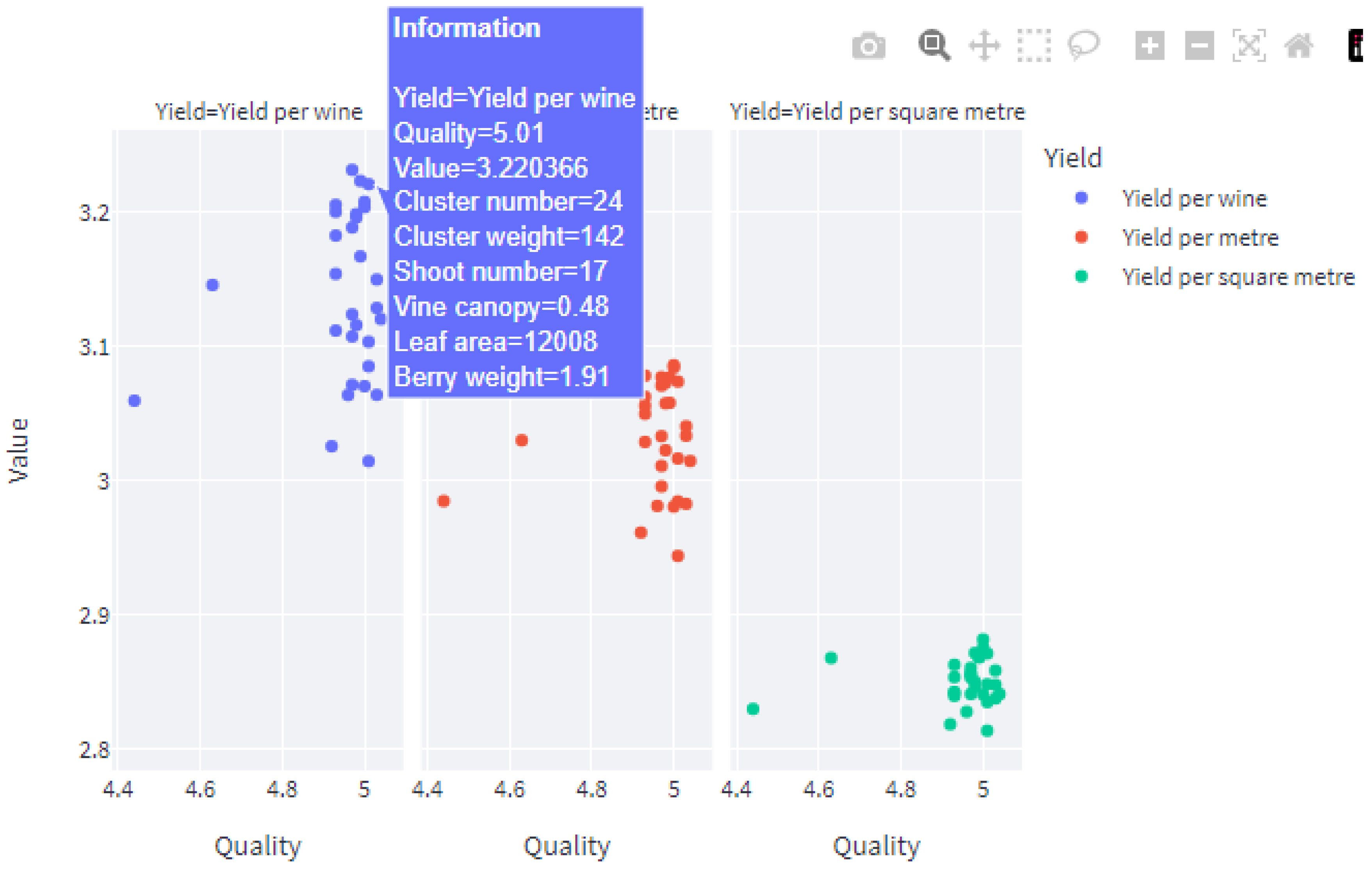
4. Discussion of the Results
Face Validation of the Models
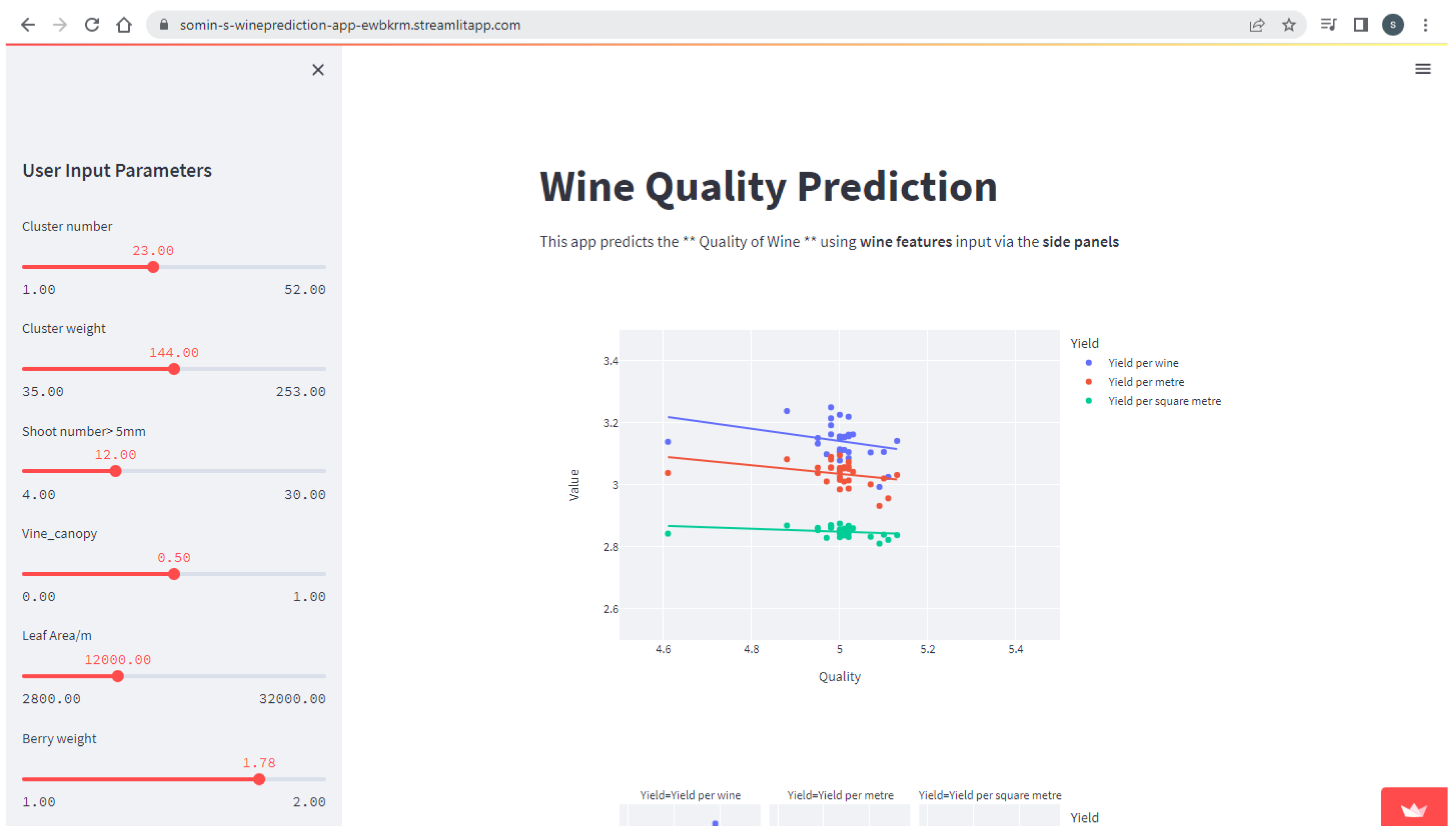
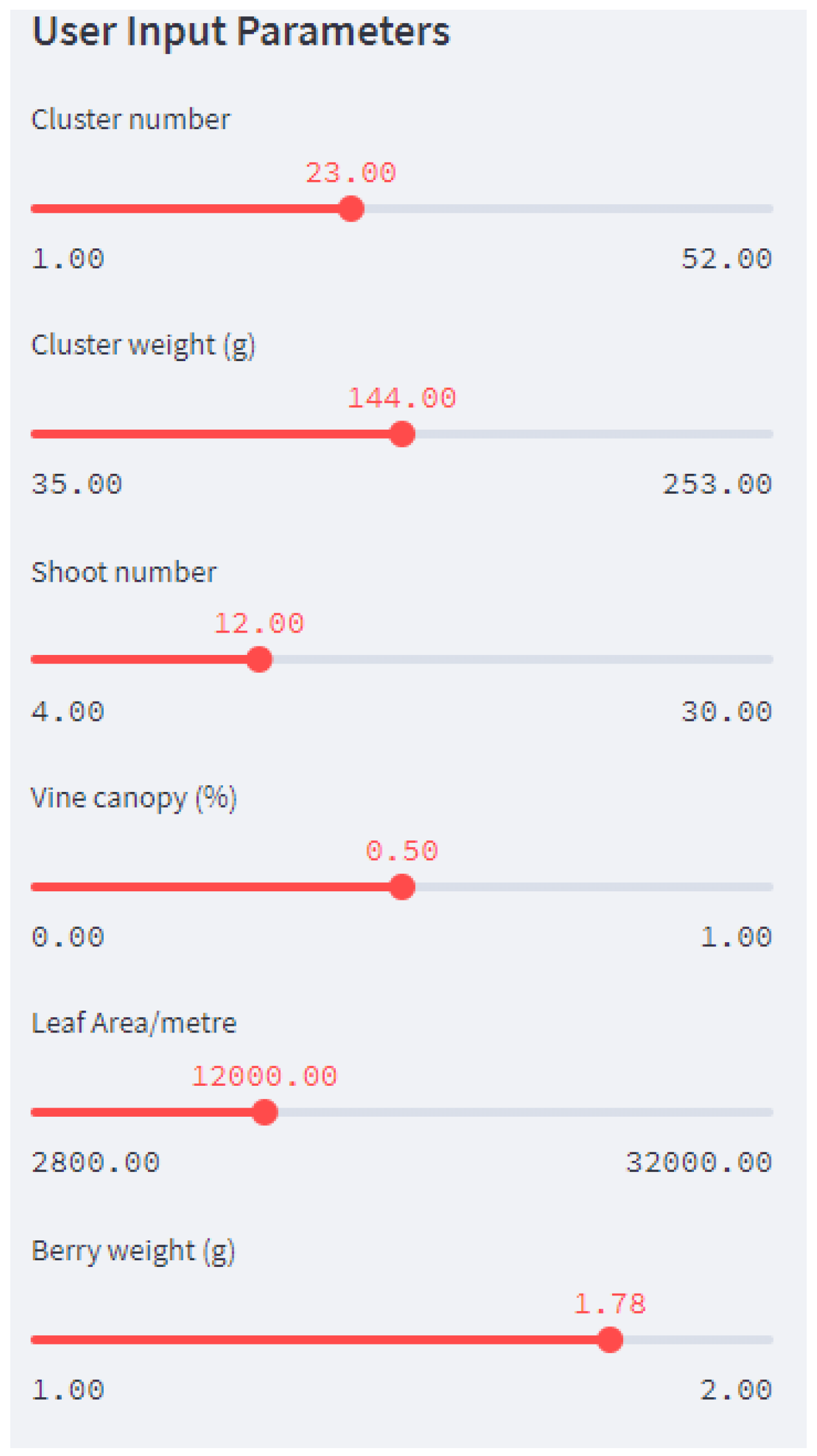
5. Development of a Web Application for the End User
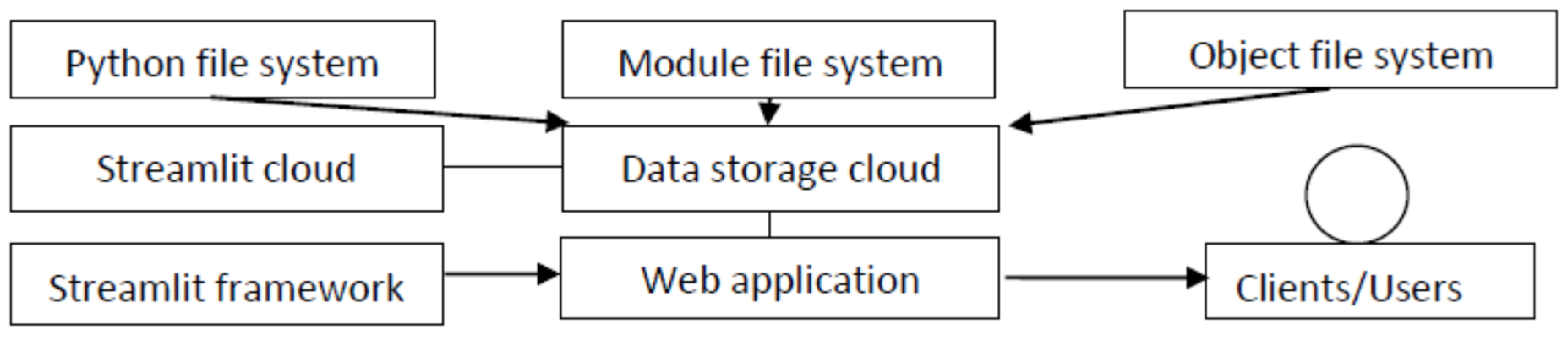
5.1. Cloud Service Technology
5.2. The Streamlit Framework
6. Conclusions and Future Directions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barr, A. Pinot Noire; Penguin Books Limited: London, UK, 1992. [Google Scholar]
- Sousa, E.C.; Uchôa-Thomaz, A.M.A.; Carioca, J.O.B.; de Morais, S.M.; de Lima, A.; Martins, C.G.; Alexandr, C.D.; Ferreira, P.A.T.; Rodrigues, A.L.M.; Rodrigues, S.P.; et al. Chemical composition and bioactive compounds of grape pomace (Vitis vinifera L.), Benitaka variety, grown in the semiarid region of Northeast Brazil. Food Sci. Technol. 2014, 34, 135–142. [Google Scholar] [CrossRef]
- Waterhouse, A.L.; Sacks, G.L.; Jeffery, D.W. Chapter 31. Grape genetics, chemistry, and breeding. In Understanding Wine Chemistry; John Wiley & Sons: Hoboken, NJ, USA, 2016; pp. 400–403. [Google Scholar]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Modeling wine preferences by data mining from physicochemical properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef]
- Rauhut, D.; Kiene, F. Aromatic Compounds in Red Varieties. In Red Wine Technology; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Schamel, G.; Anderson, K. Wine quality and varietal, regional and winery reputations: Hedonic prices for Australia and New Zealand. Econ. Rec. 2003, 79, 357–369. [Google Scholar] [CrossRef]
- Gambetta, J.M.; Cozzolino, D.; Bastian, S.E.P.; Jeffery, D.W. Towards the Creation of a Wine Quality Prediction Index: Correlation of Chardonnay Juice and Wine Compositions from Different Regions and Quality Levels. Food Anal. Methods 2016, 9, 2842–2855. [Google Scholar] [CrossRef]
- Charters, S.; Pettigrew, S. The dimensions of wine quality. Food Qual. Prefer. 2007, 18, 997–1007. [Google Scholar] [CrossRef]
- Thach, L. How American Consumers Select Wine. Wine Bus. Mon. 2008, 15, 66–71. [Google Scholar]
- Bhardwaj, P.; Tiwari, P.; Olejar, K.; Parr, W.; Kulasiri, D. A machine learning application in wine quality prediction. Mach. Learn. Appl. 2022, 8, 100261. [Google Scholar] [CrossRef]
- Ickes, C.M.; Cadwallader, K.R. Effects of Ethanol on Flavor Perception in Alcoholic Beverages. Chemosens. Percept. 2017, 10, 119–134. [Google Scholar] [CrossRef]
- Dambergs, R.G.; Kambouris, A.; Schumacher, N.; Francis, I.L.; Esler, M.B.; Gishen, M. Wine quality grading by near infrared spectroscopy. In Proceedings of the 10th International Conference, Kyonguji, Korea, 10–15 June 2001; NIR Publications: Chichester, UK, 2002; pp. 187–189. [Google Scholar]
- Somers, C.T.; Evans, M.E. Spectral evaluation of young red wines: Anthocyanin equilibria, total phenolics, free and molecular SO2 Chemical Age. J. Sci. Food Agric. 1977, 28, 279–287. [Google Scholar] [CrossRef]
- Aquino, A.; Diago, M.P.; Millán, B.; Tardáguila, J. A new methodology for estimating the grapevine-berry number per cluster using image analysis. Biosyst. Eng. 2017, 156, 80–95. [Google Scholar] [CrossRef]
- Casser, V. Using Feedforward Neural Networks for Color Based Grape Detection in Field Images. In Proceedings of the Computer Science Conference for University of Bonn Students, Bonn, Germany, 10–15 June 2016. [Google Scholar]
- Chamelat, R.; Rosso, E.; Choksuriwong, A.; Rosenberger, C.; Laurent, H.; Bro, P. Grape Detection By Image Processing. In Proceedings of the IECON 2006—32nd Annual Conference on IEEE Industrial Electronics, Paris, France, 6–10 November 2006. [Google Scholar]
- Dunn, G.M.; Martin, S.R. Yield prediction from digital image analysis: A technique with potential for vineyard assessments before harvest. Aust. J. Grape Wine Res. 2008, 10, 196–198. [Google Scholar] [CrossRef]
- Liu, S.; Whitty, M. Automatic grape bunch detection in vineyards with an SVM classifier. J. Appl. Log. 2015, 13, 643–653. [Google Scholar] [CrossRef]
- Liu, S.; Marden, S.; Whitty, M. Towards Automated Yield Estimation in Viticulture. In Proceedings of the Australasian Conference on Robotics and Automation, ACRA, Sydney, Australia, 2–4 December 2013. [Google Scholar]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 2352–2358. [Google Scholar]
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Narasimhan, S.; Singh, S. Automated Visual Yield Estimation in Vineyards. J. Field Robot. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Pérez, D.S.; Facundo, B.; Carlos, A.D. Image classification for detection of winter grapevine buds in natural conditions using scale-invariant features transform, a bag of features and support vector machines. Comput. Electron. Agric. 2017, 135, 81–95. [Google Scholar] [CrossRef]
- Palacios, F.; Diago, M.P.; Moreda, E.; Tardaguila, J. Innovative assessment of cluster compactness in wine grapes from auto-mated on-the-go proximal sensing application. In Proceedings of the 14th International Conference on Precision Agriculture, Montreal, QC, Canada, 24–27 June 2018. [Google Scholar]
- Avila, F.; Mora, M.; Fredes, C. A method to estimate Grape Phenolic Maturity based on seed images. Comput. Electron. Agric. 2014, 101, 76–83. [Google Scholar] [CrossRef]
- Iatrou, G.; Mourelatos, S.; Gewehr, S.; Kalaitzopo, S.; Iatrou, M.; Zartaloudis, Z. Using multispectral imaging to improve berry harvest for winemaking grapes. Ciência E Técnica Vitivinícola 2017, 32, 33–41. [Google Scholar] [CrossRef]
- Dahal, K.R.; Dahal, J.N.; Banjade, H.; Gaire, S. Prediction of Wine Quality Using Machine Learning Algorithms. Open J. Stat. 2021, 11, 278–289. [Google Scholar] [CrossRef]
- Kumar, S.; Agrawal, K.; Mandan, N. Red wine quality prediction using machine learning techniques. In Proceedings of the 2020 International Conference on Computer Communication and Informatics, ICCCI, Coimbatore, India, 22–24 January 2020. [Google Scholar]
- Shaw, B.; Suman, A.K.; Chakraborty, B. Wine quality analysis using machine learning. In Emerging Technology in Modelling and Graphics. Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 937, pp. 239–247. [Google Scholar]
- Trivedi, A.; Sehrawat, R. Wine quality detection through machine learning algorithms. In Proceedings of the 2018 International Conference on Recent Innovations in Electrical, Electronics and Communication Engineering, ICRIEECE, Bhubaneswar, India, 27–28 July 2018; pp. 1756–1760. [Google Scholar]
- Lee, S.; Park, J.; Kang, K. Assessing wine quality using a decision tree. In Proceedings of the 1st IEEE International Symposium on Systems Engineering, ISSE, Rome, Italy, 28–30 September 2015; pp. 176–178. [Google Scholar]
- Gupta, M.U.; Patidar, Y.; Agarwal, A.; Singh, K.P. Wine quality analysis using machine learning algorithms. In Micro-Electronics and Telecommunication Engineering; Lecture Notes in Networks and Systems; Springer: Singapore, 2020; Volume 106, pp. 11–18. [Google Scholar]
- Fuentes, S.; Damir, D.T.; Tongston, E.; Viejo, C.G. Machine Learning Modeling of Wine Sensory Profiles and Color of Vertical Vintages of Pinot Noir Based on Chemical Fingerprinting, Weather and Management Data. Sensors 2020, 20, 3618. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, S.; Tongson, E.; Torrico, D.; Viejo, C.G. Modeling Pinot Noir Aroma Profiles Based on Weather and Water Man-agement Information Using Machine Learning Algorithms: A Vertical Vintage Analysis Using Artificial Intelligence. Foods 2020, 9, 33. [Google Scholar] [CrossRef]
- New Zealand Winegrowers. Vineyard Register 2019–2022. 2022. Available online: https://www.nzwine.com/media/15542/vineyard-register-report-20192022.pdf (accessed on 15 July 2022).
- Shaw, T.B. A climatic analysis of wine regions growing Pinot noir. J. Wine Res. 2012, 23, 203–228. [Google Scholar] [CrossRef]
- Tiwari, P.; Bhardwaj, P.; Somin, S.; Parr, W.V.; Harrison, R.; Kulasiri, D. Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way? Foods 2022, 11, 3072. [Google Scholar] [CrossRef]
- Martin, D.; Grab, F.; Grose, C.; Stuart, L.; Scofield, C.; McLachlan, A.; Rutan, T. Vintage by vine interactions most strongly influence Pinot noir grape composition in New Zealand: This article is published in cooperation with the XIIIth International Terroir Congress November 17–18 2020, Adelaide, Australia. Guest editors: Cassandra Collins and Roberta De Bei. OENO One 2020, 54, 881–902. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed.; Independently Published. 2020. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 9 September 2022).
- Rozemberczki, B.; Watson, L.; Bayer, P.; Yang, H.-T.; Kiss, O.; Nilsson, S.; Sarkar, R. The Shapley Value in Machine Learning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-2022), Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Dalson, F.; Silva, J.; Enivaldo, R. What is R2 all about? Leviathan-Cad. De Pesqui. Polútica 2011, 3, 60–68. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Patki, N.; Wedge, R.; Veeramachaneni, K. The Synthetic Data Vault. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 399–410. [Google Scholar]
- Tabular Preset—SDV 0.16.0 Documentation. MIT Data to AI Lab. 2018. Available online: https://sdv.dev/SDV/user_guides/single_table/tabular_preset.html#what-is-the-fast-ml-preset (accessed on 9 September 2022).
- SMOTE—Version 0.9.1. The Imbalanced-Learn Developers. 2014. Available online: https://imbalanced-learn.org/stable/references/generated/imblearn.over_sampling.SMOTE.html (accessed on 9 September 2022).
- Feng, C.; Wang, H.; Lu, N.; Tu, X.M. Log transformation: Application and interpretation in biomedical research. Stat. Med. 2012, 32, 230–239. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Wang, H.; Lu, N.; Chen, T.; He, H.; Lu, Y.; Tu, X.M. Log-transformation and its implications for data analysis. Shanghai Arch. Psychiatry 2014, 26, 105–109. [Google Scholar] [CrossRef] [PubMed]
- Popescu, M.C.; Balas, V.E.; Popescu, L.P.; Mastorakis, N. Multilayer Perceptron and Neural Networks. WSEAS Trans. Circuits Syst. 2009, 7, 579–588. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Int. J. Eng. Appl. Sci. Technol. 2020, 4, 310–316. [Google Scholar] [CrossRef]
- Derya, S. A Comparison of Optimization Algorithms for Deep Learning. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2052013. [Google Scholar]
- Nowakowski, G.; Dorogyy, Y.; Doroga-Ivaniuk, O. Neural Network Structure Optimization Algorithm. J. Autom. Mob. Robot. Intell. Syst. 2018, 12, 5–13. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests (PDF). In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995. [Google Scholar]
- Cutler, A.; Cutler, D.; Stevens, J. Random Forests. In Ensemble Machine Learning: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 157–176. [Google Scholar]
- Hegelich, S. Decision Trees and Random Forests: Machine Learning Techniques to Classify Rare Events. Eur. Policy Anal. 2016, 2, 98–120. [Google Scholar] [CrossRef]
- Law, A. Simulation Modeling and Analysis, 5th ed.; McGraw Hill: New York, NY, USA, 2014. [Google Scholar]
- Streamlit—The Fastest Way to Build and Share Data Apps. Streamlit Inc. 2022. Available online: https://streamlit.io/ (accessed on 13 September 2022).
- McCafferty, D. Cloudy Skies: Public versus Private Option Still up in the Air. Baseline 2010, 103, 28–33. [Google Scholar]
- Booth, G.; Soknacki, A. Cloud Security: Attacks and Current Defenses. In Proceedings of the 8th Annual Symposium on Information and Assurance, Albany, NY, USA, 4–5 June 2013. [Google Scholar]
- Castagna, R.; Lelii, S. Cloud Storage. 9 June 2021. Available online: https://www.techtarget.com/searchstorage/definition/cloud-storage (accessed on 9 September 2021).
- He, F.; Liang, N.-N.; Mu, L.; Pan, Q.-H.; Wang, J.; Reeves, M.J.; Duan, C.-Q. Anthocyanins and Their Variation in Red Wines I. Monomeric Anthocyanins and Their Color Expression. Molecules 2012, 17, 1571–1601. [Google Scholar] [CrossRef] [PubMed]

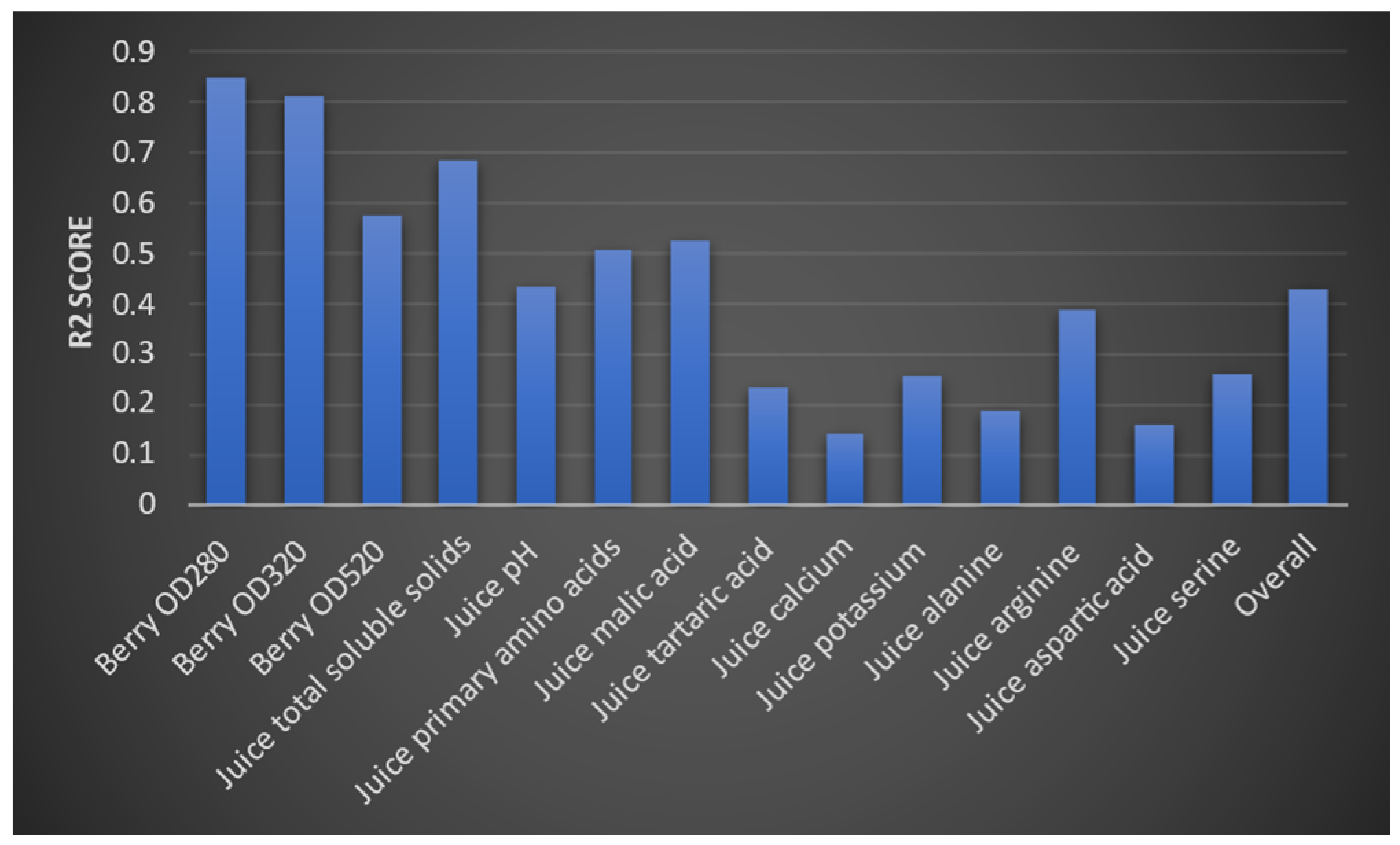
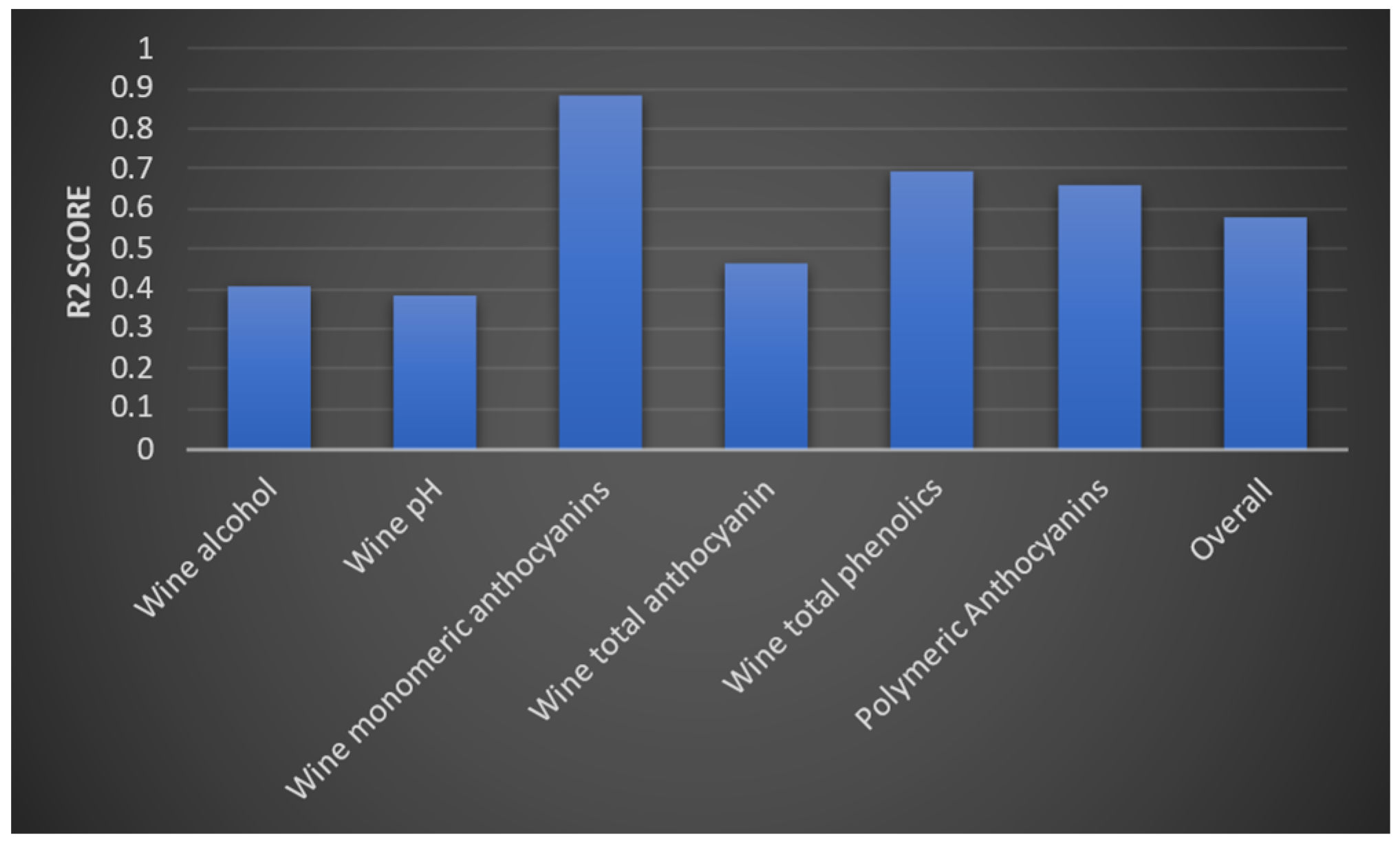
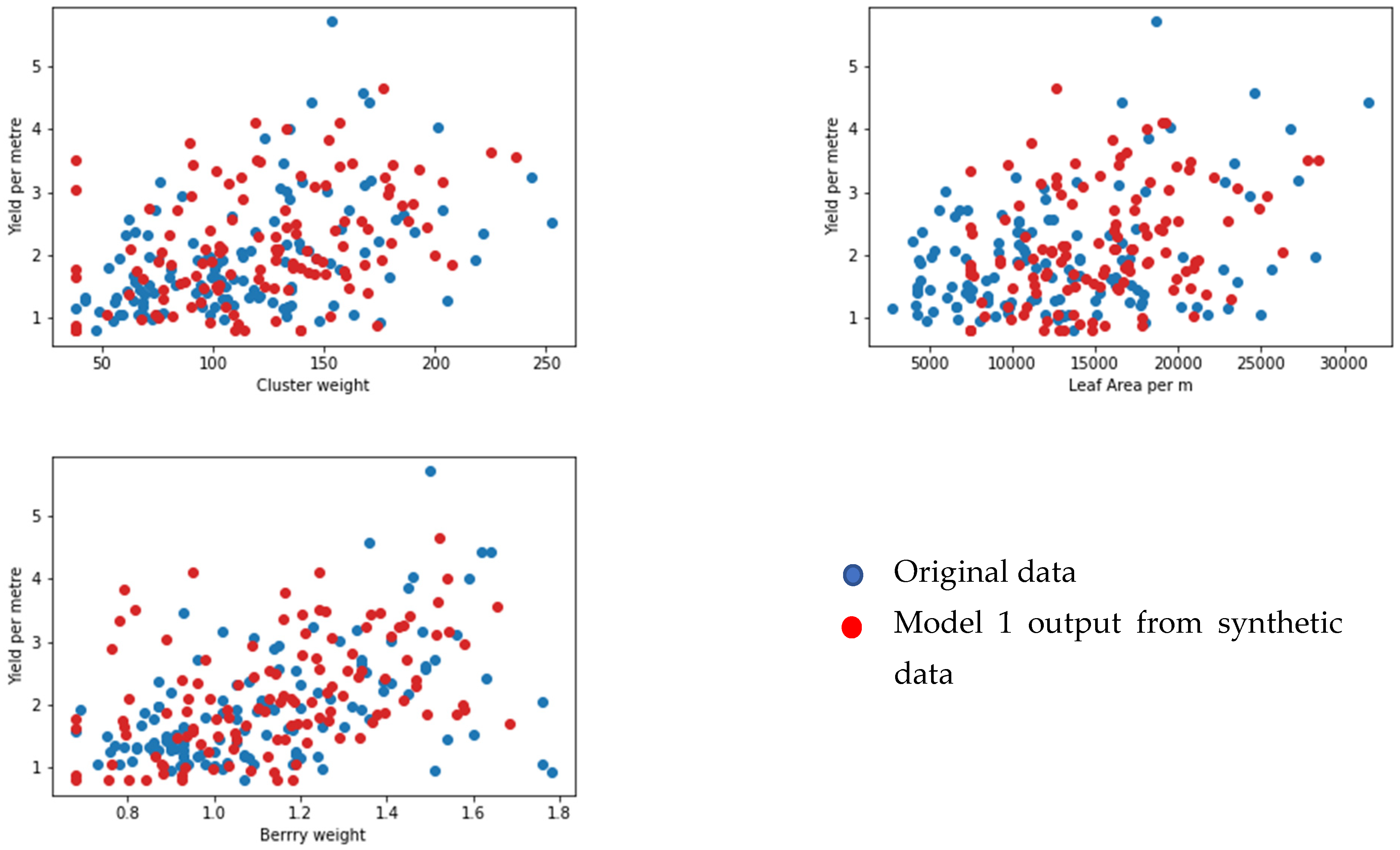
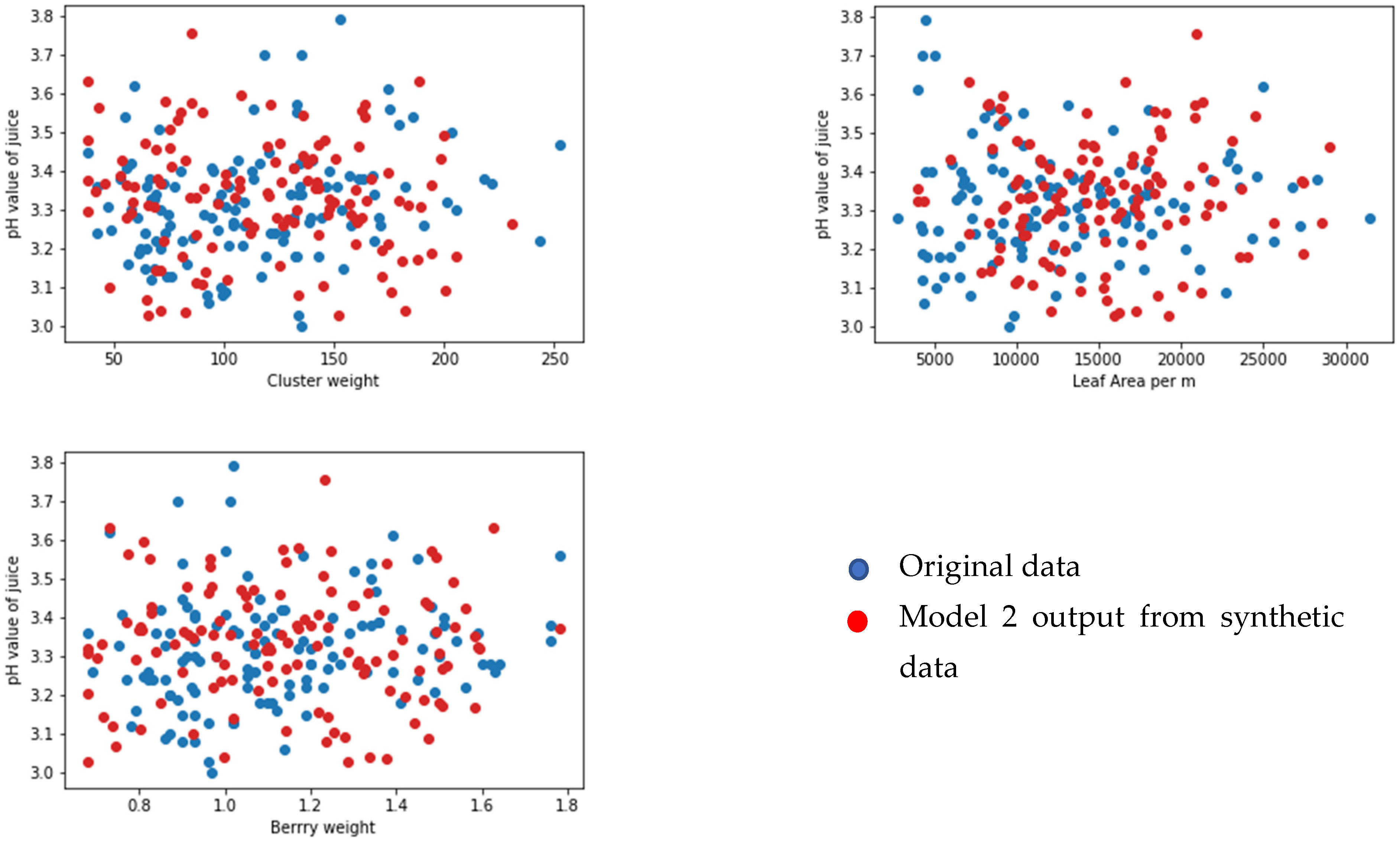
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kulasiri, D.; Somin, S.; Kumara Pathirannahalage, S. A Machine Learning Pipeline for Predicting Pinot Noir Wine Quality from Viticulture Data: Development and Implementation. Foods 2024, 13, 3091. https://doi.org/10.3390/foods13193091
Kulasiri D, Somin S, Kumara Pathirannahalage S. A Machine Learning Pipeline for Predicting Pinot Noir Wine Quality from Viticulture Data: Development and Implementation. Foods. 2024; 13(19):3091. https://doi.org/10.3390/foods13193091
Chicago/Turabian StyleKulasiri, Don, Sarawoot Somin, and Samantha Kumara Pathirannahalage. 2024. "A Machine Learning Pipeline for Predicting Pinot Noir Wine Quality from Viticulture Data: Development and Implementation" Foods 13, no. 19: 3091. https://doi.org/10.3390/foods13193091
APA StyleKulasiri, D., Somin, S., & Kumara Pathirannahalage, S. (2024). A Machine Learning Pipeline for Predicting Pinot Noir Wine Quality from Viticulture Data: Development and Implementation. Foods, 13(19), 3091. https://doi.org/10.3390/foods13193091