

Identification of Dendrobium Using Laser-Induced Breakdown Spectroscopy in Combination with a Multivariate Algorithm Model

 ,
,  , ,
, ,
Abstract

1. Introduction
2. Experimental Setup and Methods
2.1. Preparation of Experimental Samples
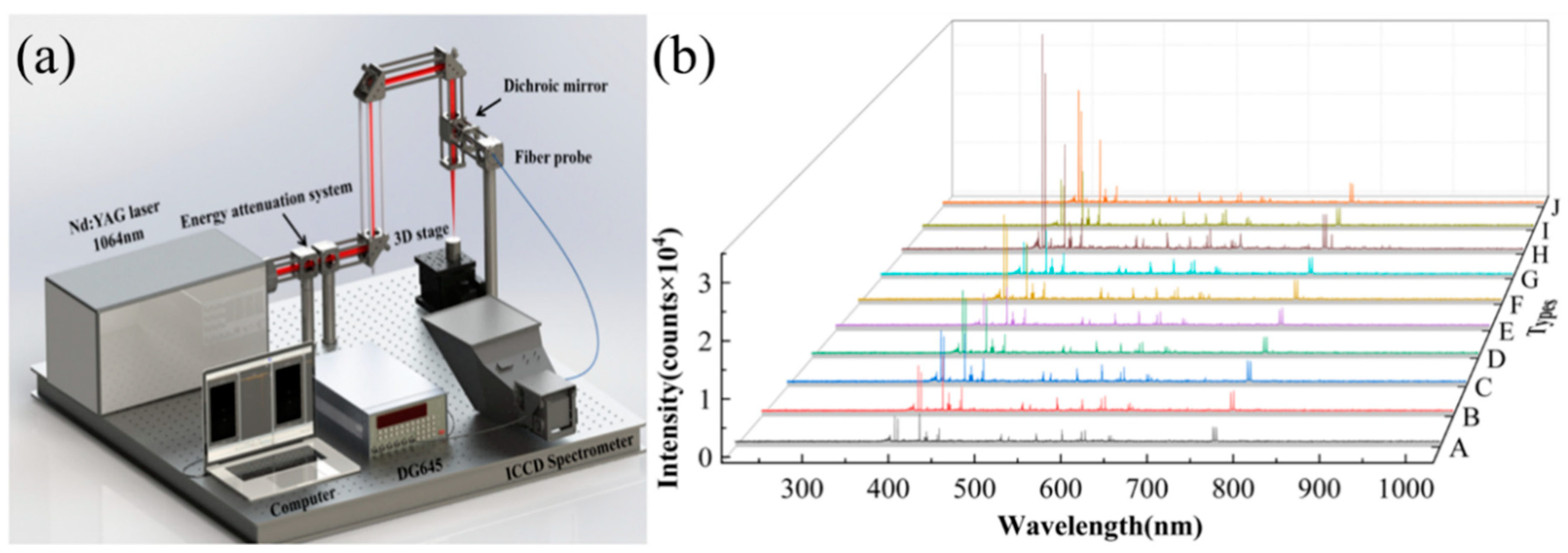
2.2. Experimental Setup and Spectral Acquisition
2.3. Algorithm Description
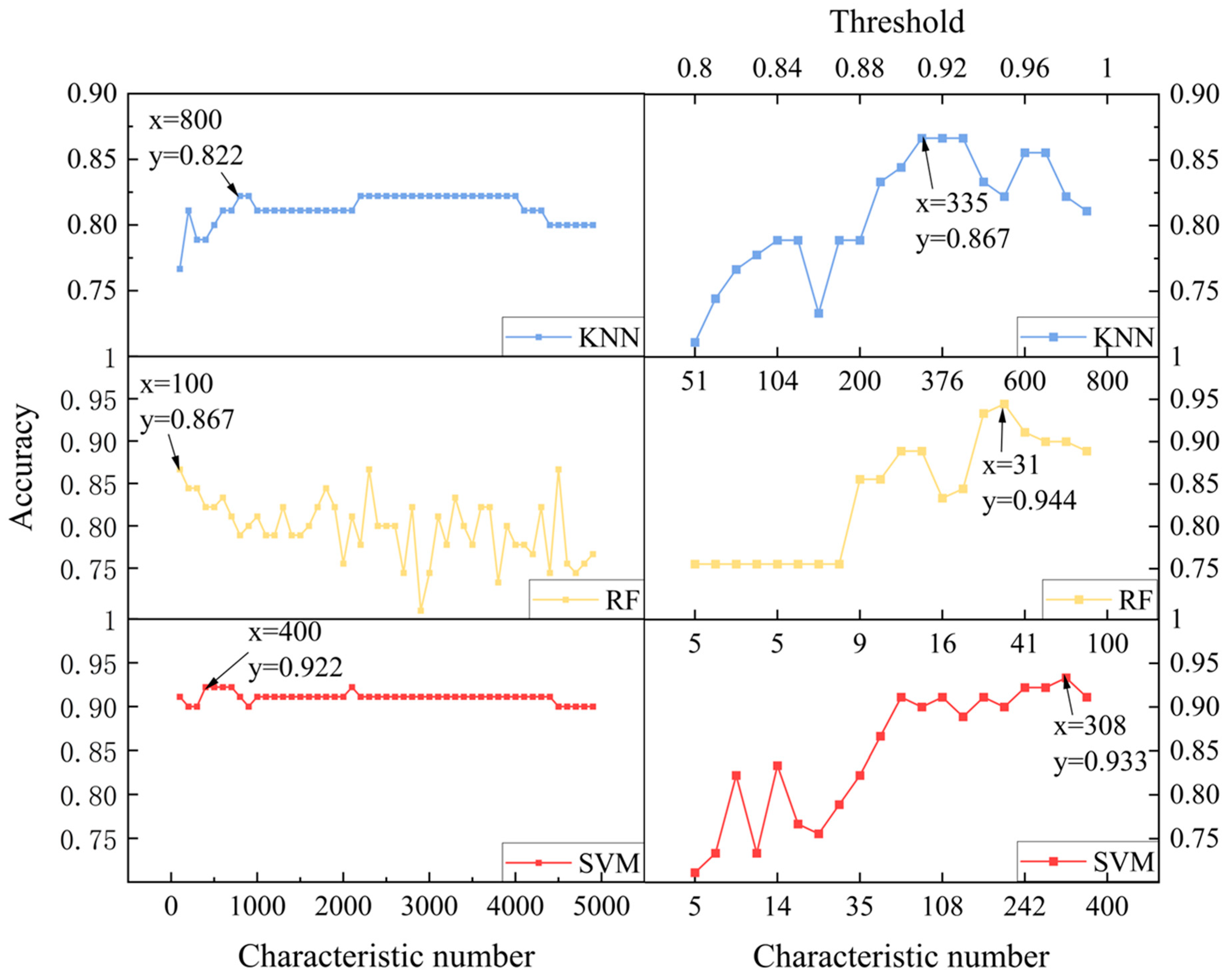
2.3.1. Gaussian Filtering and Feature Selection
2.3.2. Fusion Classification Model
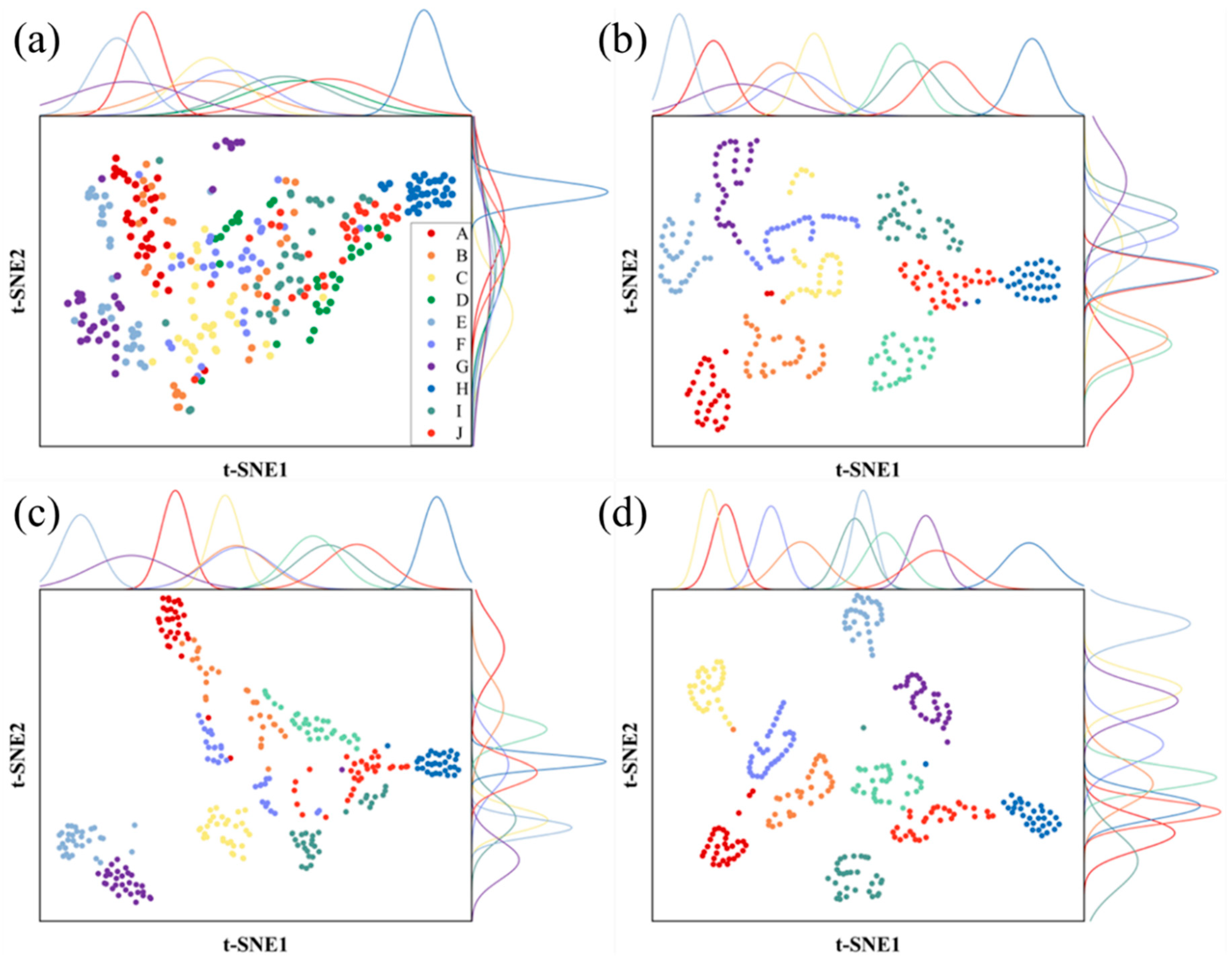
2.3.3. T-SNE Dimensionality Reduction Visualization
3. Results and Discussion
3.1. Control Group Analysis
3.2. Data Preprocessing
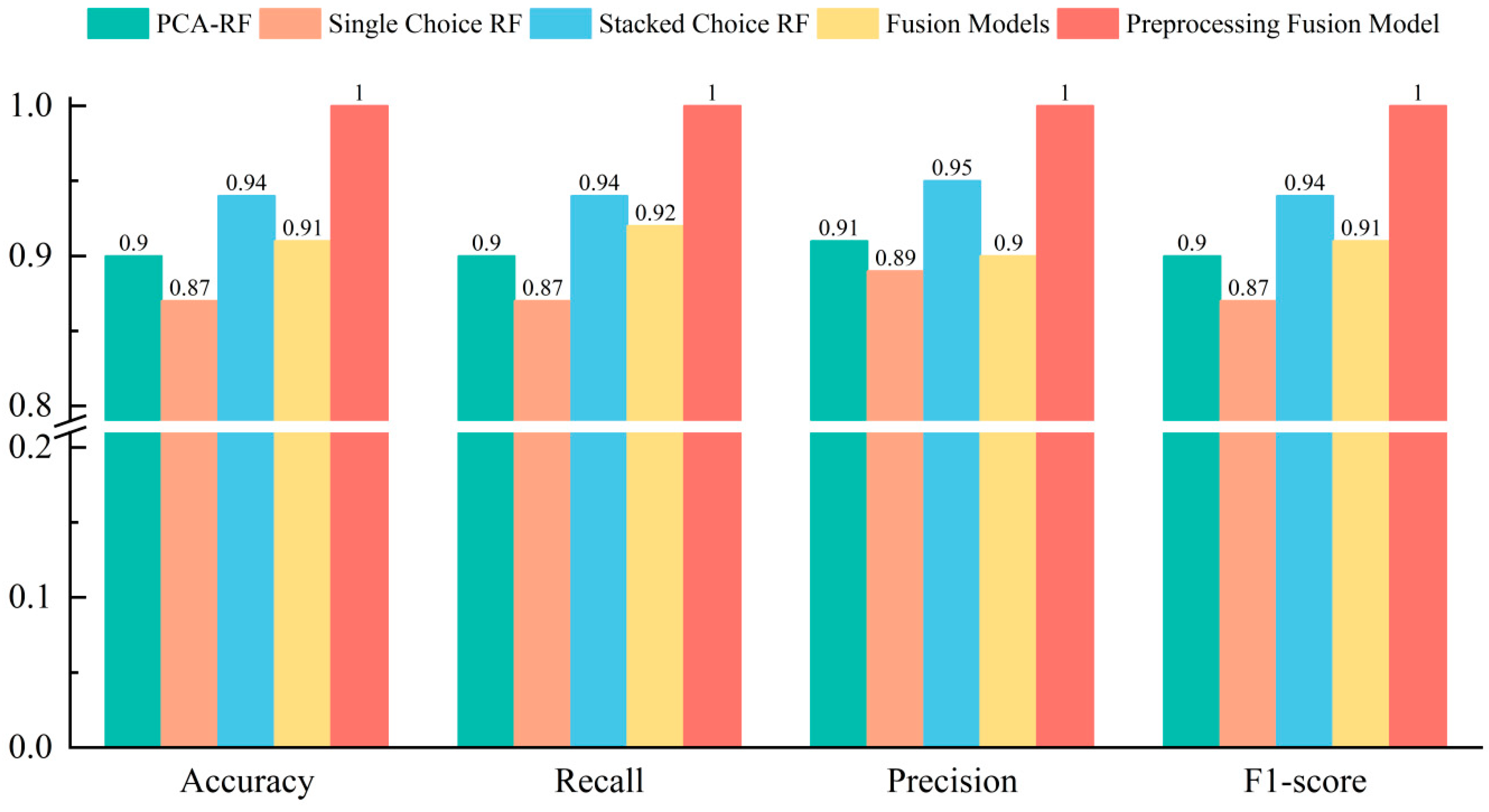
3.3. Fusion Model Construction and Data Analysis
3.4. Visual Analysis of the Experimental Process
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, P.; Wu, Q.; Feng, J.; Yan, L.; Sun, Y.; Liu, S.; Xiang, Y.; Zhang, M.; Pan, T.; Chen, X.; et al. Erianin, a Novel Dibenzyl Compound in Dendrobium Extract, Inhibits Lung Cancer Cell Growth and Migration via Calcium/Calmodulin-Dependent Ferroptosis. Signal Transduct. Target. Ther. 2020, 5, 51. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Zi, C.; Chen, D.; Li, J.; He, R.; Hu, J.-M. Target Acquisition of Anti-Aging Manno-Oligosaccharide That Triggers ECM Process via TGF-β/Smads-SIRT1 Signalling Pathway. Carbohydr. Polym. 2023, 302, 120380. [Google Scholar] [CrossRef] [PubMed]
- Liang, J.; Li, H.; Chen, J.; He, L.; Du, X.; Zhou, L.; Xiong, Q.; Lai, X.; Yang, Y.; Huang, S.; et al. Dendrobium Officinale Polysaccharides Alleviate Colon Tumorigenesis via Restoring Intestinal Barrier Function and Enhancing Anti-Tumor Immune Response. Pharmacol. Res. 2019, 148, 104417. [Google Scholar] [CrossRef]
- Kuang, M.-T.; Li, J.-Y.; Yang, X.-B.; Yang, L.; Xu, J.-Y.; Yan, S.; Lv, Y.-F.; Ren, F.-C.; Hu, J.-M.; Zhou, J. Structural Characterization and Hypoglycemic Effect via Stimulating Glucagon-like Peptide-1 Secretion of Two Polysaccharides from Dendrobium Officinale. Carbohydr. Polym. 2020, 241, 116326. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Diao, J.; Wang, Z.; Zhan, X.; Zhang, B.; Li, N.; Li, G. An Optimized Deep Convolutional Neural Network for Dendrobium Classification Based on Electronic Nose. Sens. Actuators A Phys. 2020, 307, 111874. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Z.; Diao, J.; Sun, X.; Luo, Z.; Li, G. Discrimination of Different Species of Dendrobium with an Electronic Nose Using Aggregated Conformal Predictor. Sensors 2019, 19, 964. [Google Scholar] [CrossRef]
- Yang, Y.; She, X.; Cao, X.; Yang, L.; Huang, J.; Zhang, X.; Su, L.; Wu, M.; Tong, H.; Ji, X. Comprehensive Evaluation of Dendrobium Officinale from Different Geographical Origins Using Near-Infrared Spectroscopy and Chemometrics. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2022, 277, 121249. [Google Scholar] [CrossRef]
- Wang, Y.; Zuo, Z.T.; Shen, T.; Huang, H.Y.; Wang, Y.Z. Authentication of Dendrobium Species Using Near-Infrared and Ultraviolet–Visible Spectroscopy with Chemometrics and Data Fusion. Anal. Lett. 2018, 51, 2790–2819. [Google Scholar] [CrossRef]
- Gu, X.; Zhu, S.; Du, H.; Bai, C.; Duan, X.; Li, Y.; Hu, K. Comprehensive Multi-Component Analysis for Authentication and Differentiation of 6 Dendrobium Species by 2D NMR-Based Metabolomic Profiling. Microchem. J. 2022, 176, 107225. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, H.Y.; Wang, Y.Z. Authentication of Dendrobium Officinale from Similar Species with Infrared and Ultraviolet-Visible Spectroscopies with Data Visualization and Mining. Anal. Lett. 2020, 53, 1774–1793. [Google Scholar] [CrossRef]
- Markiewicz-Keszycka, M.; Cama-Moncunill, X.; Casado-Gavalda, M.P.; Dixit, Y.; Cama-Moncunill, R.; Cullen, P.J.; Sullivan, C. Laser-Induced Breakdown Spectroscopy (LIBS) for Food Analysis: A Review. Trends Food Sci. Technol. 2017, 65, 80–93. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, Y.; Hou, Z.; Wang, Z. Stability and accuracy improvement of element analysis in steel alloys using polarization-resolved laser-induced breakdown spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2023, 203, 106666. [Google Scholar] [CrossRef]
- Ma, Q.; Liu, Z.; Zhang, T.; Zhao, S.; Gao, X.; Sun, T.; Dai, Y. Multielement Simultaneous Quantitative Analysis of Trace Elements in Stainless Steel via Full Spectrum Laser-Induced Breakdown Spectroscopy. Talanta 2024, 272, 125745. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Song, C.; Gao, X.; Chen, A.; Hao, Z.; Lin, J. Quantitative Determination of Al–Cu–Mg–Fe–Ni Aluminum Alloy Using Laser-Induced Breakdown Spectroscopy Combined with LASSO–LSSVM Regression. J. Anal. At. Spectrom. 2021, 36, 1634–1642. [Google Scholar] [CrossRef]
- Melessanaki, K.; Mateo, M.; Ferrence, S.C.; Betancourt, P.P.; Anglos, D. The Application of LIBS for the Analysis of Archaeological Ceramic and Metal Artifacts. Appl. Surf. Sci. 2002, 197–198, 156–163. [Google Scholar] [CrossRef]
- Wu, M.; Wang, X.; Niu, G.; Zhao, Z.; Zheng, R.; Liu, Z.; Zhao, Z.; Duan, Y. Ultrasensitive and Simultaneous Detection of Multielements in Aqueous Samples Based on Biomimetic Array Combined with Laser-Induced Breakdown Spectroscopy. Anal. Chem. 2021, 93, 10196–10203. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Song, C.; Gao, X.; Lin, J. Quantitative Analysis of Pb in Soil by Femtosecond-Nanosecond Double-Pulse Laser-Induced Breakdown Spectroscopy. Results Phys. 2019, 15, 102736. [Google Scholar] [CrossRef]
- Busser, B.; Moncayo, S.; Coll, J.-L.; Sancey, L.; Motto-Ros, V. Elemental Imaging Using Laser-Induced Breakdown Spectroscopy: A New and Promising Approach for Biological and Medical Applications. Coord. Chem. Rev. 2018, 358, 70–79. [Google Scholar] [CrossRef]
- Peng, J.; Liu, F.; Zhou, F.; Song, K.; Zhang, C.; Ye, L.; He, Y. Challenging Applications for Multi-Element Analysis by Laser-Induced Breakdown Spectroscopy in Agriculture: A Review. TrAC–Trends Anal. Chem. 2016, 85, 260–272. [Google Scholar] [CrossRef]
- Konieczynski, P.; Arceusz, A.; Wesolowski, M. Essential Elements and Their Relations to Phenolic Compounds in Infusions of Medicinal Plants Acquired from Different European Regions. Biol. Trace Elem. Res. 2016, 170, 466–475. [Google Scholar] [CrossRef]
- Liu, X.; Che, X.; Li, K.; Wang, X.; Lin, Z.; Wu, Z.; Zheng, Q. Geographical Authenticity Evaluation of Mentha Haplocalyx by LIBS Coupled with Multivariate Analyzes. Plasma Sci. Technol. 2020, 22, 44–50. [Google Scholar] [CrossRef]
- Kabir, M.H.; Guindo, M.L.; Chen, R.; Sanaeifar, A.; Liu, F. Application of Laser-Induced Breakdown Spectroscopy and Chemometrics for the Quality Evaluation of Foods with Medicinal Properties: A Review. Foods 2022, 11, 2051. [Google Scholar] [CrossRef]
- Peng, J.; Xie, W.; Jiang, J.; Zhao, Z.; Zhou, F.; Liu, F. Fast Quantification of Honey Adulteration with Laser-Induced Breakdown Spectroscopy and Chemometric Methods. Foods 2020, 9, 341. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Zhao, Y.; Zhang, C.; Li, Y.; Bao, Y.; Liu, F. Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods. Foods 2020, 9, 199. [Google Scholar] [CrossRef] [PubMed]
- Fang, L.; Ma, M.; Yin, G.; Chen, X.; Chen, F.; Zhao, N. Study on Microdamage Quantitative Analysis of Cd and Pb in Leaves by Laser Induced Breakdown Spectroscopy. Chemosensors 2022, 10, 242. [Google Scholar] [CrossRef]
- Zhu, C.; Lv, J.; Liu, K.; Li, Q.; Tang, Z.; Zhou, R.; Zhang, W.; Chen, J.; Liu, K.; Li, X.; et al. Fast Detection of Harmful Trace Elements in Glycyrrhiza Using Standard Addition and Internal Standard Method—Laser-Induced Breakdown Spectroscopy (SAIS-LIBS). Microchem. J. 2021, 168, 106408. [Google Scholar] [CrossRef]
- Brunnbauer, L.; Gajarska, Z.; Lohninger, H.; Limbeck, A. A Critical Review of Recent Trends in Sample Classification Using Laser-Induced Breakdown Spectroscopy (LIBS). TrAC—Trends Anal. Chem. 2023, 159, 116859. [Google Scholar] [CrossRef]
- Liang, J.; Li, M.; Du, Y.; Yan, C.; Zhang, Y.; Zhang, T.; Zheng, X.; Li, H. Data Fusion of Laser Induced Breakdown Spectroscopy (LIBS) and Infrared Spectroscopy (IR) Coupled with Random Forest (RF) for the Classification and Discrimination of Compound Salvia Miltiorrhiza. Chemom. Intell. Lab. Syst. 2020, 207, 104179. [Google Scholar] [CrossRef]
- Peng, J.; Ye, L.; Xie, W.; Liu, Y.; Lin, M.; Kong, W.; Zhao, Z.; Liu, F.; Huang, J.; Zhou, F. In-Situ and Fast Classification of Origins of Baishao (Radix Paeoniae Alba) Slices Based on Auto-Focus Laser-Induced Breakdown Spectroscopy. Opt. Lett. 2023, 48, 3567–3570. [Google Scholar] [CrossRef]
- Zhang, D.; Ding, J.; Feng, Z.; Yang, R.; Yang, Y.; Yu, S.; Xie, B.; Zhu, J. Origin Identification of Ginkgo Biloba Leaves Based on Laser-Induced Breakdown Spectroscopy (LIBS). Spectrochim. Acta Part B At. Spectrosc. 2021, 180, 106192. [Google Scholar] [CrossRef]
- Wang, Z.; Afgan, M.S.; Gu, W.; Song, Y.; Wang, Y.; Hou, Z.; Song, W.; Li, Z. Recent Advances in Laser-Induced Breakdown Spectroscopy Quantification: From Fundamental Understanding to Data Processing. TrAC Trends Anal. Chem. 2021, 143, 116385. [Google Scholar] [CrossRef]
- Fu, Y.; Hou, Z.; Li, T.; Li, Z.; Wang, Z. Investigation of Intrinsic Origins of the Signal Uncertainty for Laser-Induced Breakdown Spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2019, 155, 67–78. [Google Scholar] [CrossRef]
- Altman, N.; Krzywinski, M. The Curse(s) of Dimensionality. Nat. Methods 2018, 15, 399–400. [Google Scholar] [CrossRef] [PubMed]
- Bellman, R. Dynamic Programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef] [PubMed]
- Collaris, D.; van Wijk, J.J. StrategyAtlas: Strategy Analysis for Machine Learning Interpretability. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2996–3008. [Google Scholar] [CrossRef] [PubMed]
- Kundu, S. AI in Medicine Must Be Explainable. Nat. Med. 2021, 27, 1328. [Google Scholar] [CrossRef] [PubMed]
- Linderman, G.C.; Rachh, M.; Hoskins, J.G.; Steinerberger, S.; Kluger, Y. Fast Interpolation-Based t-SNE for Improved Visualization of Single-Cell RNA-Seq Data. Nat. Methods 2019, 16, 243–245. [Google Scholar] [CrossRef] [PubMed]
- Kobak, D.; Linderman, G.C. Initialization Is Critical for Preserving Global Data Structure in Both T-SNE and UMAP. Nat. Biotechnol. 2021, 39, 156–157. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.K. Major Development under Gaussian Filtering since Unscented Kalman Filter. IEEE/CAA J. Autom. Sin. 2020, 7, 1308–1325. [Google Scholar] [CrossRef]
- Xu, H.; Xu, F.; Jin, Y.-Q. Variable-Resolution SAR Imaging Mode With the Principle of Maximum Mutual Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Kumar, A.; Abirami, S. Aspect-Based Opinion Ranking Framework for Product Reviews Using a Spearman’s Rank Correlation Coefficient Method. Inf. Sci. 2018, 460–461, 23–41. [Google Scholar] [CrossRef]
- Valkenborg, D.; Rousseau, A.-J.; Geubbelmans, M.; Burzykowski, T. Support Vector Machines. Am. J. Orthod. Dentofac. Orthop. 2023, 164, 754–757. [Google Scholar] [CrossRef] [PubMed]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A Comparison of Random Forest Variable Selection Methods for Classification Prediction Modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A Brief Review of Nearest Neighbor Algorithm for Learning and Classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar] [CrossRef]
- Pérez-Rodríguez, M.; Mendoza, A.; González, L.T.; Lima Vieira, A.; Pellerano, R.G.; Gomes Neto, J.A.; Ferreira, E.C. Rice Labeling According to Grain Quality Features Using Laser-Induced Breakdown Spectroscopy. Foods 2023, 12, 365. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Hao, X.; Yang, Y. Laser-Induced Breakdown Spectroscopy Combined with Principal Component Analysis-Based Support Vector Machine for Rapid Classification of Coal from Different Mining Areas. Optik 2023, 286, 170990. [Google Scholar] [CrossRef]
- Zhou, J.; Ren, X.; Li, M.; Xu, Y.; Zhang, T.; Tang, H.; Li, H. Rapid Quantitative Analysis of Multiple Rare Earth Elements In Ndfeb Alloys Based on Laser-Induced Breakdown Spectroscopy (Libs) And Random Forest (Rf). Available online: https://ssrn.com/abstract=4688329 (accessed on 9 January 2024).
- Fan, Y.; Liu, J.; Tang, J.; Liu, P.; Lin, Y.; Du, Y. Learning Correlation Information for Multi-Label Feature Selection. Pattern Recognit. 2024, 145, 109899. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KNN | RF | SVM | PCA-KNN | PCA-RF | PCA-SVM | |
|---|---|---|---|---|---|---|
| Accuracy | 0.80 | 0.80 | 0.86 | 0.83 | 0.90 | 0.90 |
| Recall | 0.80 | 0.82 | 0.86 | 0.83 | 0.90 | 0.90 |
| Precision | 0.82 | 0.77 | 0.87 | 0.86 | 0.91 | 0.91 |
| F1 | 0.80 | 0.79 | 0.86 | 0.83 | 0.90 | 0.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Liu, Z.; Ma, Q.; Hu, D.; Dai, Y.; Zhang, X.; Zhou, Z. Identification of Dendrobium Using Laser-Induced Breakdown Spectroscopy in Combination with a Multivariate Algorithm Model. Foods 2024, 13, 1676. https://doi.org/10.3390/foods13111676
Zhang T, Liu Z, Ma Q, Hu D, Dai Y, Zhang X, Zhou Z. Identification of Dendrobium Using Laser-Induced Breakdown Spectroscopy in Combination with a Multivariate Algorithm Model. Foods. 2024; 13(11):1676. https://doi.org/10.3390/foods13111676
Chicago/Turabian StyleZhang, Tingsong, Ziyuan Liu, Qing Ma, Dong Hu, Yujia Dai, Xinfeng Zhang, and Zhu Zhou. 2024. "Identification of Dendrobium Using Laser-Induced Breakdown Spectroscopy in Combination with a Multivariate Algorithm Model" Foods 13, no. 11: 1676. https://doi.org/10.3390/foods13111676
APA StyleZhang, T., Liu, Z., Ma, Q., Hu, D., Dai, Y., Zhang, X., & Zhou, Z. (2024). Identification of Dendrobium Using Laser-Induced Breakdown Spectroscopy in Combination with a Multivariate Algorithm Model. Foods, 13(11), 1676. https://doi.org/10.3390/foods13111676