
Deep Learning-Based Near-Infrared Hyperspectral Imaging for Food Nutrition Estimation

 , ,
, ,  ,
, 
Abstract
:1. Introduction
2. Material and Methods
2.1. Sample Preparation
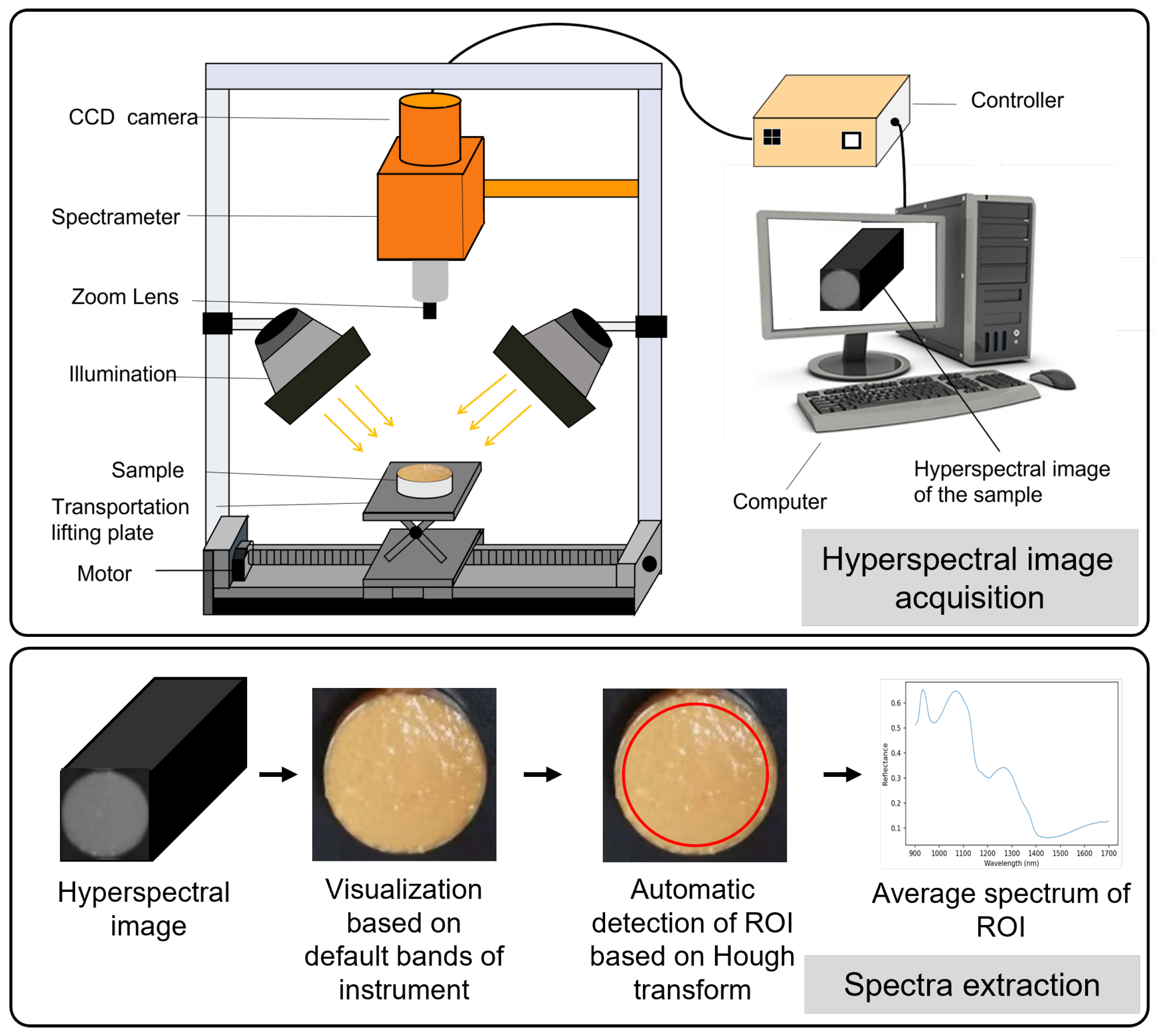
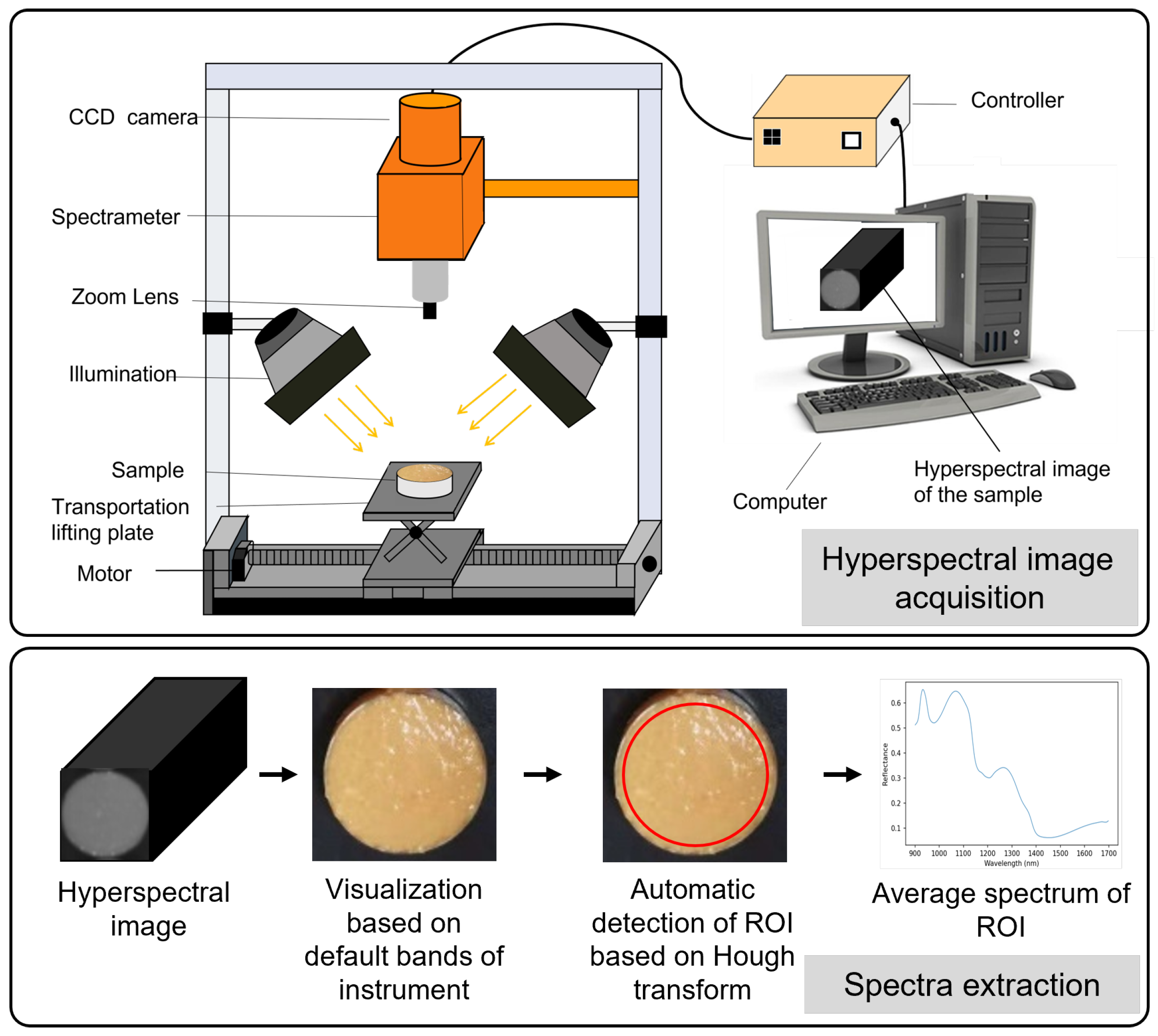
2.2. Hyperspectral Image Acquisition and Spectra Extraction
2.2.1. Hyperspectral Imaging System
2.2.2. Hyperspectral Image Correction
2.2.3. Spectra Extraction
2.3. Reference Measurement of Protein Content
2.4. A Deep Learning Framework for Wavelength Selection and Regression Simultaneously
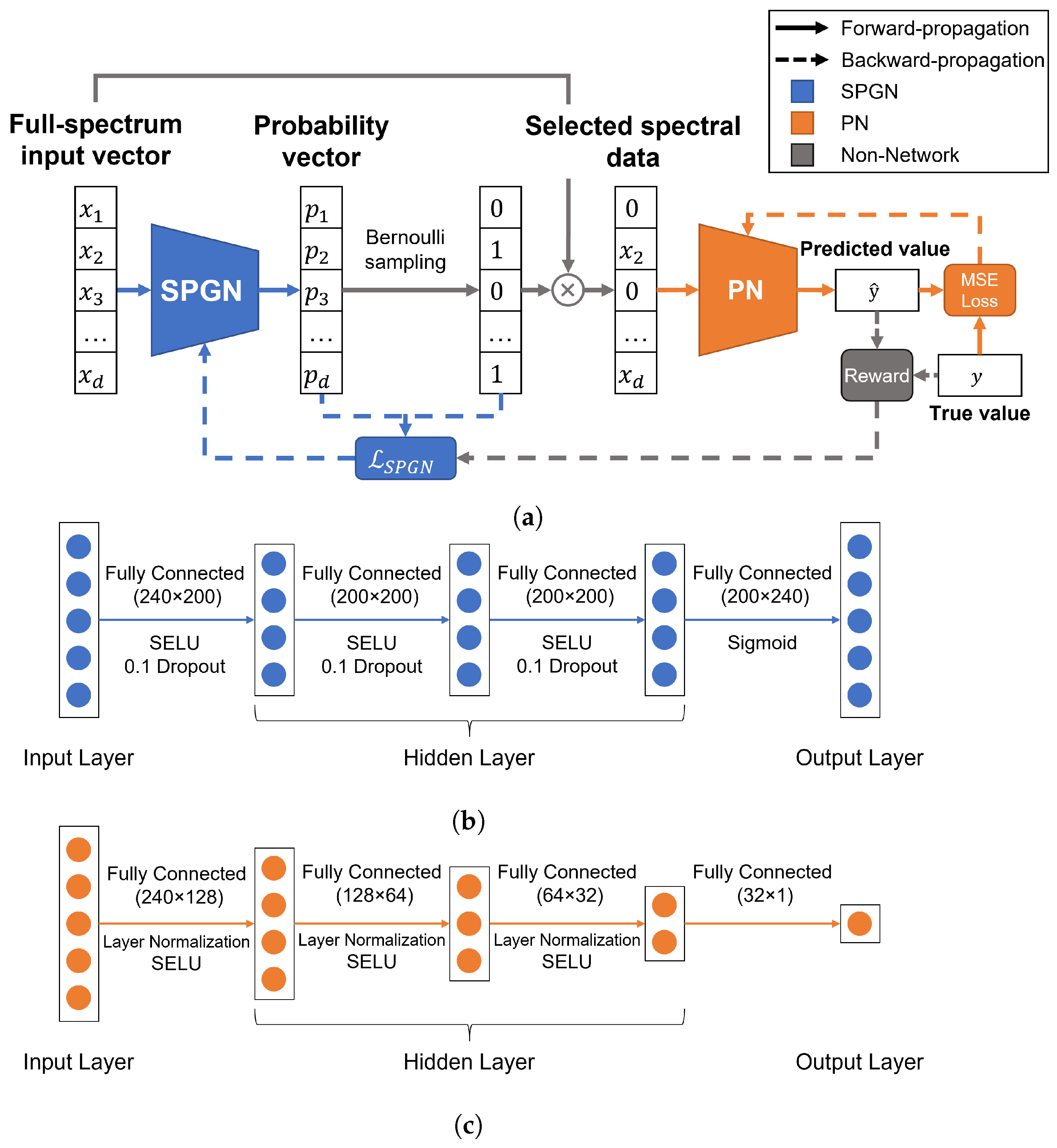
2.4.1. Overall Network Architecture
2.4.2. Joint Training Strategy
2.4.3. Loss Functions
2.5. Conventional Approaches
2.5.1. Common Regression Models
2.5.2. Effective Wavelength Selection
2.6. Model Evaluation
3. Results
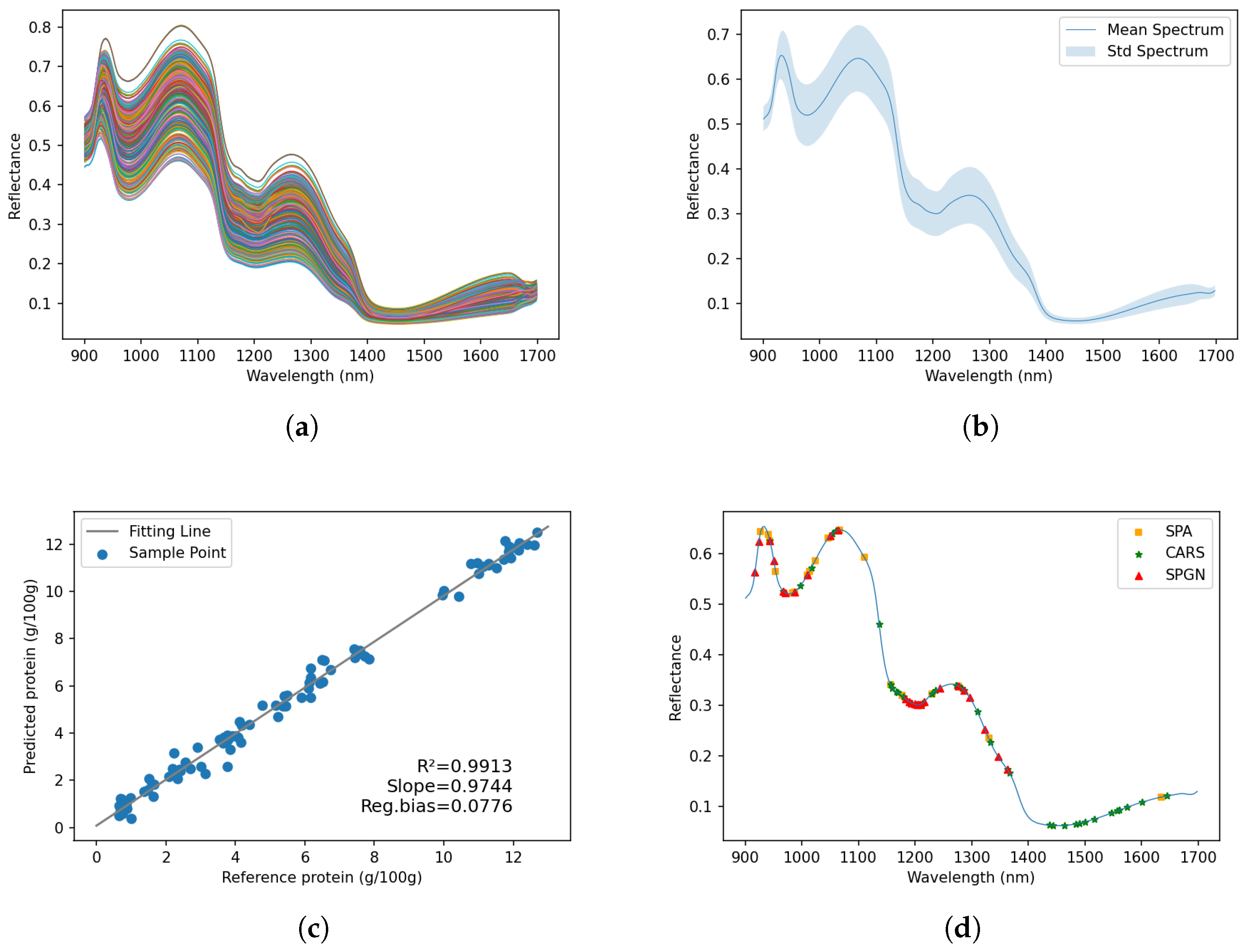
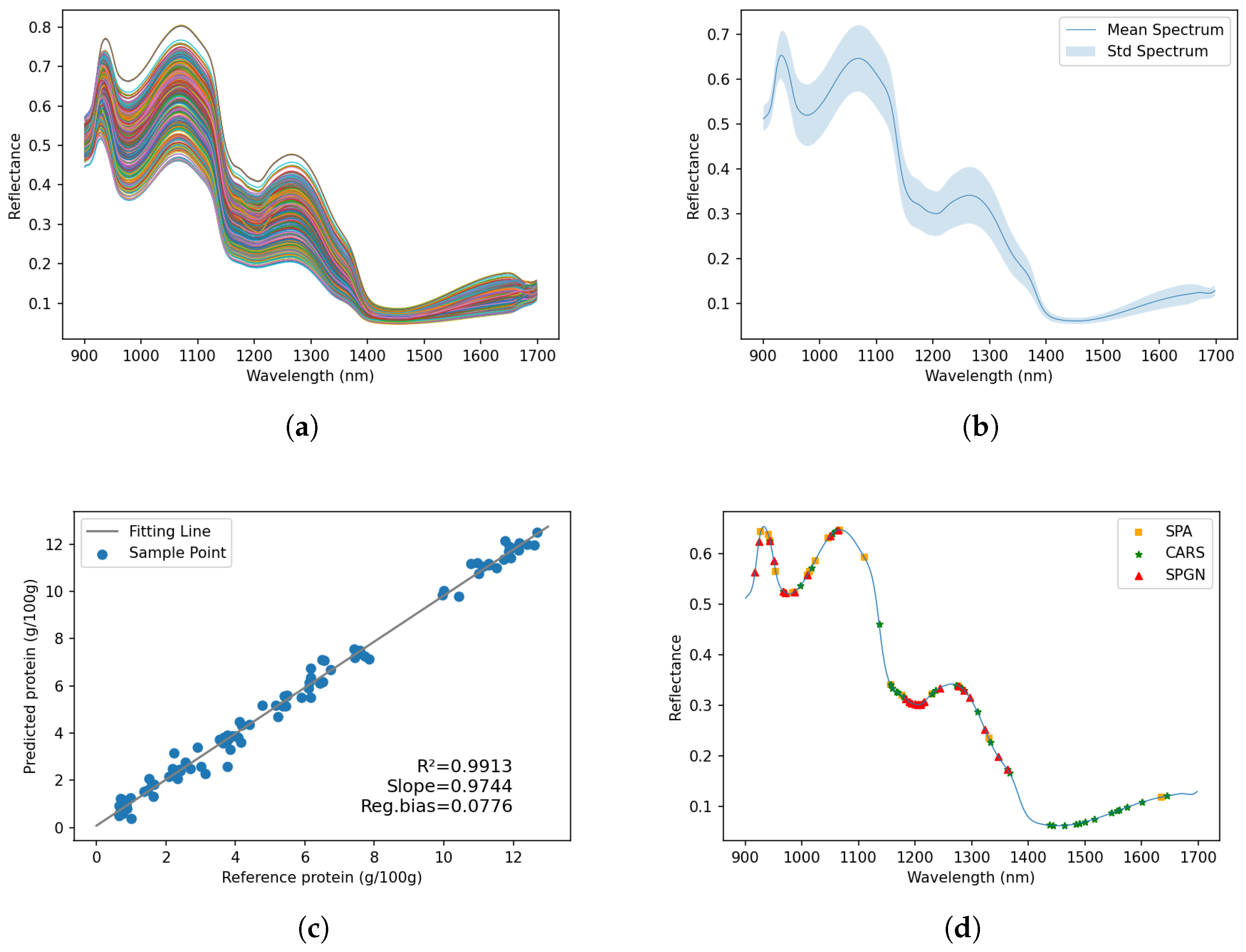
3.1. Spectral Profiles
3.2. Sample Set Split
3.3. Experimental Setup
3.3.1. Deep Learning Approaches
3.3.2. Conventional Approaches
3.4. Result Analysis
3.5. Ablation Study on Deep Learning Approaches
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
- The following abbreviations are used in this manuscript:
| NIR-HSI | Near-infrared hyperspectral imaging |
| RMSE | Root mean square error |
| NIR | Near infrared |
| ROI | Region of interest |
| SPGN | Selection probability generation network |
| PN | Prediction network |
| MLP | Multilayer perceptron |
| SELU | Scaled exponential linear unit |
| LN | Layer normalization |
| MSE | Mean squared error |
| PLS | Partial least squares |
| SVR | Support vector regression |
| SPA | Successive projections algorithm |
| CARS | Competitive adaptive reweighted sampling |
| RPD | Predictive residual deviation |
References
- Miller, V.; Webb, P.; Cudhea, F.; Shi, P.; Zhang, J.; Reedy, J.; Erndt-Marino, J.; Coates, J.; Mozaffarian, D. Global dietary quality in 185 countries from 1990 to 2018 show wide differences by nation, age, education, and urbanicity. Nat. Food 2022, 3, 694–702. [Google Scholar] [CrossRef] [PubMed]
- O’Hearn, M.; Erndt-Marino, J.; Gerber, S.; Lauren, B.N.; Economos, C.; Wong, J.B.; Blumberg, J.B.; Mozaffarian, D. Validation of Food Compass with a healthy diet, cardiometabolic health, and mortality among US adults, 1999–2018. Nat. Commun. 2022, 13, 7066. [Google Scholar]
- Min, W.; Jiang, S.; Liu, L.; Rui, Y.; Jain, R. A survey on food computing. ACM Comput. Surv. CSUR 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Wang, W.; Min, W.; Li, T.; Dong, X.; Li, H.; Jiang, S. A review on vision-based analysis for automatic dietary assessment. Trends Food Sci. Technol. 2022, 122, 223–237. [Google Scholar] [CrossRef]
- Mirtchouk, M.; Merck, C.; Kleinberg, S. Automated estimation of food type and amount consumed from body-worn audio and motion sensors. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 451–462. [Google Scholar]
- Ma, P.; Lau, C.P.; Yu, N.; Li, A.; Liu, P.; Wang, Q.; Sheng, J. Image-based nutrient estimation for Chinese dishes using deep learning. Food Res. Int. 2021, 147, 110437. [Google Scholar] [CrossRef]
- Shao, W.; Hou, S.; Jia, W.; Zheng, Y. Rapid Non-Destructive Analysis of Food Nutrient Content Using Swin-Nutrition. Foods 2022, 11, 3429. [Google Scholar] [CrossRef]
- Shao, W.; Min, W.; Hou, S.; Luo, M.; Li, T.; Zheng, Y.; Jiang, S. Vision-based food nutrition estimation via RGB-D fusion network. Food Chem. 2023, 424, 136309. [Google Scholar] [CrossRef]
- Ma, P.; Zhang, Z.; Li, Y.; Yu, N.; Sheng, J.; McGinty, H.K.; Wang, Q.; Ahuja, J.K. Deep learning accurately predicts food categories and nutrients based on ingredient statements. Food Chem. 2022, 391, 133243. [Google Scholar] [CrossRef]
- Lau, E.; Goh, H.J.; Quek, R.; Lim, S.W.; Henry, J. Rapid estimation of the energy content of composite foods: The application of the Calorie Answer. Asia Pac. J. Clin. Nutr. 2016, 25, 18–25. [Google Scholar]
- Ahn, D.; Choi, J.Y.; Kim, H.C.; Cho, J.S.; Moon, K.D.; Park, T. Estimating the composition of food nutrients from hyperspectral signals based on deep neural networks. Sensors 2019, 19, 1560. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, Q.; Chen, Y. NIRSCAM: A Mobile Near-Infrared Sensing System for Food Calorie Estimation. IEEE Int. Things J. 2022, 9, 18934–18945. [Google Scholar] [CrossRef]
- Wu, G. Amino acids: Metabolism, functions, and nutrition. Amino Acids 2009, 37, 1–17. [Google Scholar] [CrossRef]
- Li, H.; Sun, H.; Li, M. Detection of vitamin C content in head cabbage based on visible/near-infrared spectroscopy. Trans. Chin. Soc. Agric. Eng. 2018, 34, 269–275. [Google Scholar]
- Yoon, J.; Jordon, J.; van der Schaar, M. INVASE: Instance-wise variable selection using neural networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- ElMasry, G.; Sun, D.W.; Allen, P. Non-destructive determination of water-holding capacity in fresh beef by using NIR hyperspectral imaging. Food Res. Int. 2011, 44, 2624–2633. [Google Scholar] [CrossRef]
- Wu, D.; Sun, D.W. Potential of time series-hyperspectral imaging (TS-HSI) for non-invasive determination of microbial spoilage of salmon flesh. Talanta 2013, 111, 39–46. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, W.; Zhou, L.; Cheng, H.; Ye, X.; He, Y. Developing deep learning based regression approaches for determination of chemical compositions in dry black goji berries (Lycium ruthenicum Murr.) using near-infrared hyperspectral imaging. Food Chem. 2020, 319, 126536. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Proceedings of the Advances in Neural Information Processing Systems 28 (2015), Montreal, QC, Canada, 7–12 December 2015; pp. 2962–2970. [Google Scholar]
- Workman, J., Jr.; Weyer, L. Practical Guide and Spectral Atlas for Interpretive Near-Infrared Spectroscopy; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Daszykowski, M.; Wrobel, M.; Czarnik-Matusewicz, H.; Walczak, B. Near-infrared reflectance spectroscopy and multivariate calibration techniques applied to modelling the crude protein, fibre and fat content in rapeseed meal. Analyst 2008, 133, 1523–1531. [Google Scholar] [CrossRef]
- Hayati, R.; Zulfahrizal, Z.; Munawar, A.A. Robust prediction performance of inner quality attributes in intact cocoa beans using near infrared spectroscopy and multivariate analysis. Heliyon 2021, 7, e06286. [Google Scholar] [CrossRef] [PubMed]
- Workman, J., Jr.; Springsteen, A. Applied Spectroscopy: A Compact Reference for Practitioners; Academic Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Weinstock, B.A.; Janni, J.; Hagen, L.; Wright, S. Prediction of oil and oleic acid concentrations in individual corn (Zea mays L.) kernels using near-infrared reflectance hyperspectral imaging and multivariate analysis. Appl. Spectrosc. 2006, 60, 9–16. [Google Scholar] [CrossRef] [PubMed]
- Balbino, S.; Vincek, D.; Trtanj, I.; Egređija, D.; Gajdoš-Kljusurić, J.; Kraljić, K.; Obranović, M.; Škevin, D. Assessment of pumpkin seed oil adulteration supported by multivariate analysis: Comparison of GC-MS, colourimetry and NIR spectroscopy data. Foods 2022, 11, 835. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xiong, F.; Zhang, Y.; Wang, S.; Yuan, Y.; Lu, C.; Nie, J.; Nan, T.; Yang, B.; Huang, L.; et al. Application of hyperspectral imaging assisted with integrated deep learning approaches in identifying geographical origins and predicting nutrient contents of Coix seeds. Food Chem. 2023, 404, 134503. [Google Scholar] [CrossRef]
- Manley, M. Near-infrared spectroscopy and hyperspectral imaging: Non-destructive analysis of biological materials. Chem. Soc. Rev. 2014, 43, 8200–8214. [Google Scholar] [CrossRef] [PubMed]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large scale visual food recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9932–9949. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Liu, W.; Wang, L.; Sun, J. HSIFoodIngr-64: A Dataset for Hyperspectral Food-Related Studies and a Benchmark Method on Food Ingredient Retrieval. IEEE Access 2023, 11, 13152–13162. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Data Split | Minimum (g/100 g) | Maximum (g/100 g) | Mean (g/100 g) | Standard Deviation (g/100 g) |
|---|---|---|---|---|
| Training set | 0.6258 | 12.9541 | 5.4654 | 3.7056 |
| Validation set | 0.6016 | 13.1858 | 5.5092 | 3.6868 |
| Test set | 0.6505 | 12.6843 | 5.3266 | 3.8062 |
| Models | Data Type | N.V. * | Training Set | Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | RPD | R2 | RMSE | RPD | |||
| PLS | Full | 240 | 0.9624 | 0.7187 | 0.9689 | 0.6497 | 5.6742 | 0.9487 | 0.8620 | 4.4154 |
| CARS | 37 | 0.9673 | 0.6697 | 0.9745 | 0.5887 | 6.2628 | 0.9558 | 0.8004 | 4.7553 | |
| SPA | 19 | 0.9535 | 0.7990 | 0.9638 | 0.7015 | 5.2556 | 0.9507 | 0.8449 | 4.5051 | |
| SPGN | 25 | 0.9569 | 0.7691 | 0.9645 | 0.6943 | 5.3104 | 0.9504 | 0.8478 | 4.4897 | |
| SVR | Full | 240 | 0.9872 | 0.4189 | 0.9833 | 0.4767 | 7.7335 | 0.9772 | 0.5748 | 6.6219 |
| CARS | 37 | 0.9799 | 0.5247 | 0.9781 | 0.5453 | 6.7605 | 0.9649 | 0.7131 | 5.3372 | |
| SPA | 19 | 0.9835 | 0.4762 | 0.9807 | 0.5116 | 7.2059 | 0.9773 | 0.5740 | 6.6314 | |
| SPGN | 25 | 0.9722 | 0.6182 | 0.9749 | 0.5845 | 6.3075 | 0.9653 | 0.7090 | 5.3684 | |
| PN | Full | 240 | 0.9922 | 0.3267 | 0.9834 | 0.4748 | 7.7644 | 0.9876 | 0.4238 | 8.9802 |
| CARS | 37 | 0.9926 | 0.3191 | 0.9814 | 0.5027 | 7.3334 | 0.9822 | 0.5073 | 7.5021 | |
| SPA | 19 | 0.9814 | 0.5061 | 0.9720 | 0.6167 | 5.9779 | 0.9754 | 0.5971 | 6.3740 | |
| SPGN | 25 | 0.9945 | 0.2761 | 0.9840 | 0.4666 | 7.9021 | 0.9852 | 0.4633 | 8.2159 | |
| OptmWave | 25 | 0.9938 | 0.2920 | 0.9796 | 0.5263 | 7.0045 | 0.9913 | 0.3548 | 10.7278 | |
| Method | Training Set | Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | RPD | R2 | RMSE | RPD | |
| PN | 0.9922 | 0.3267 | 0.9834 | 0.4748 | 7.7644 | 0.9876 | 0.4238 | 8.9802 |
| SELU | 0.9902 | 0.3667 | 0.9811 | 0.5075 | 7.2643 | 0.9773 | 0.5731 | 6.6409 |
| LN | 0.9566 | 0.7717 | 0.9564 | 0.7694 | 4.7917 | 0.9574 | 0.7859 | 4.8428 |
| LN and SELU | 0.9475 | 0.8488 | 0.9599 | 0.7379 | 4.9965 | 0.9460 | 0.8845 | 4.3032 |
| OptmWave | 0.9938 | 0.2920 | 0.9796 | 0.5263 | 7.0045 | 0.9913 | 0.3548 | 10.7278 |
| joint training strategy | 0.9945 | 0.2761 | 0.9840 | 0.4666 | 7.9021 | 0.9852 | 0.4633 | 8.2159 |
| 0.9363 | 0.9349 | 0.8011 | 1.6444 | 2.2420 | 0.8248 | 1.5929 | 2.3894 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wei, W.; Xing, S.; Min, W.; Zhang, C.; Jiang, S. Deep Learning-Based Near-Infrared Hyperspectral Imaging for Food Nutrition Estimation. Foods 2023, 12, 3145. https://doi.org/10.3390/foods12173145
Li T, Wei W, Xing S, Min W, Zhang C, Jiang S. Deep Learning-Based Near-Infrared Hyperspectral Imaging for Food Nutrition Estimation. Foods. 2023; 12(17):3145. https://doi.org/10.3390/foods12173145
Chicago/Turabian StyleLi, Tianhao, Wensong Wei, Shujuan Xing, Weiqing Min, Chunjiang Zhang, and Shuqiang Jiang. 2023. "Deep Learning-Based Near-Infrared Hyperspectral Imaging for Food Nutrition Estimation" Foods 12, no. 17: 3145. https://doi.org/10.3390/foods12173145
APA StyleLi, T., Wei, W., Xing, S., Min, W., Zhang, C., & Jiang, S. (2023). Deep Learning-Based Near-Infrared Hyperspectral Imaging for Food Nutrition Estimation. Foods, 12(17), 3145. https://doi.org/10.3390/foods12173145