2. Materials and Methods
The training of a neural network requires a training set of positive and negative examples—in this case, words that are descriptive of flavors as opposed to other words in product reviews that do not describe flavor. To minimize the burden of manual annotation, we developed an interactive visual tagging tool. Full-text reviews were preprocessed to provide a list of potentially descriptive word forms for human annotation as descriptive or non-descriptive, and then individual instances of these descriptive and non-descriptive words in context were used to train and test the proposed LSTM architecture.
2.1. Data Collection
The dataset we used to train our model contains a total of 8036 full-text English whisky reviews scraped from four websites: WhiskyAdvocate (WA; 4288 reviews), WhiskyCast (WC; 2309 reviews), The Whiskey Jug (WJ; 1095 reviews), and Breaking Bourbon (BB; 344 reviews). WA and WC reviews are from websites affiliated with a magazine and podcast, respectively, and written by professional reviewers scoring whiskies from around the world and providing tasting notes. BB and WJ are smaller “semi-professional” review websites more focused on American whiskey. BB and WA have multiple named reviewers writing the tasting notes for their websites, while WC and WJ each have a single named reviewer.
WC, WJ, and BB were scraped using beautifulsoup4 in Python v3.7, while WA was scraped using the rvest package v0.3.2 in the R Statistical Environment v3.5.3. A combination of GET-specific scrapers were used to collect the review-containing URLs from the various sites, and then the content was collected with site-specific scrapers. When possible, page formatting was used to collect metadata about the products being reviewed such as country of production or the proportion of alcohol by volume (ABV), as well as the review itself, but the metadata were not consistent across sites.
2.2. Data Preparation
After collection, each review was converted from full text (excluding the title and metadata elements such as the date of publication) into a list of potentially-descriptive word base forms called “lemmas” that occurred in each review using the workflow described in [
19]. Briefly, the reviews were first tokenized, or converted into an ordered list of individual words and punctuation. Each token was tagged with a part-of-speech (POS) label such as “adjective” or “punctuation”, and all tokens other than nouns, adjectives, and a small whitelist of verbs were removed. The remaining tokens were lemmatized, or converted into their base form (e.g., “drying“ to “dry”).
This was done using Spacy v2.1.8 in Python v3.7. The pretrained model en_core_web_sm v2.1.0 was used as the basis for calculating predictions and R package cleanNLP v3.0 was used in R v3.5.3 to convert the data to a tabular CSV format.
These lemmas were used as the list of potential descriptors for manual annotation with our interactive visual tagging tool (described in the next section). The frequency of occurrence (as an adjective or noun) for each lemma was used to prioritize more common lemmas for annotation.
2.3. Interactive Tagging Tool
To create examples of descriptive and non-descriptive words in context for this study, human annotators used a browser-based interactive tagger tool based on a word cloud visualization, seen in
Figure 1. The tool was built for this purpose in Javascript and HTML5 using jQuery v3.4.1. A CSV file of token frequencies is uploaded from the user’s local storage, the most common terms are rendered into a word cloud using jQCloud v2.0.3, and the user assigns words to the descriptor (1) or non-descriptor (0) classes using one of three interaction modes. The central wordcloud display (
Figure 1B) repopulates with progressively less common words as the user assigns words to classes, and the resulting corpus of labeled words is exported along with unlabeled words as a CSV file to the user’s local storage. Up to 50 words can be displayed in the central panel at a time, based on the rendering algorithm described in [
20]. Fancybox v3.5.7 is used to display tooltips.
With a low learning curve, the user is able to sift through the text in a timely manner and create a human-annotated list of positive and negative examples. The user is then able to save the corpus of labeled words to a comma separated value (CSV) file.
2.4. Gold Standard Annotations
We asked four annotators (A, B, C, and D) from Food Science to use the interactive tagger tool to create an annotated training set. The annotators were chosen based on their expertise in Sensory Science, a sub-field of Food Science. Annotators A and B were involved with annotating all the datasets, while C was a tiebreaker for datasets WA and WC and D was a tiebreaker for BB and WJ. A lemma was deemed a descriptor if it was tagged as such by two out of the three annotators; otherwise, the lemma was tagged as not being a descriptor. As such, the number of annotators was chosen so a best two out of three consensus could be achieved. This is important as it provides a more accurate set of labeled annotations and is a common practice in both corpus annotation in NLP [
21] and in the analysis of freeform comments in sensory science survey research [
22]. A total number of 1794 lemmas (499 descriptive, 1295 non-descriptive) were tagged and used to create a training and test set. There were a total of 2638 unique descriptive/non-descriptive tokens tagged based on these lemmas (e.g., the lemma “fruit” could appear in the text as “fruity” or “fruits”, i.e., a lemma could result in multiple tagged tokens). All individual occurrences of the tokens in context were used for training.
2.5. Word Embeddings
A word embedding is a representation of a word as a high-dimensional vector. The closer a pair of word vectors are in the high-dimensional space, the more the words are conceptually “similar” or “related”. An input sequence for each word (i.e., potential descriptor) was created from the context and potential descriptor (unigram). Each potential descriptor and context word is assigned a 300 dimensional GloVe [
23] word embedding. GloVe embeddings with 1.9 million tokens were used. A key note is that terms generally used in a domain specific language, such as those of whisky tasting notes, are not commonly used by the lay person, so this is a key consideration for domain-specific keyword extraction.
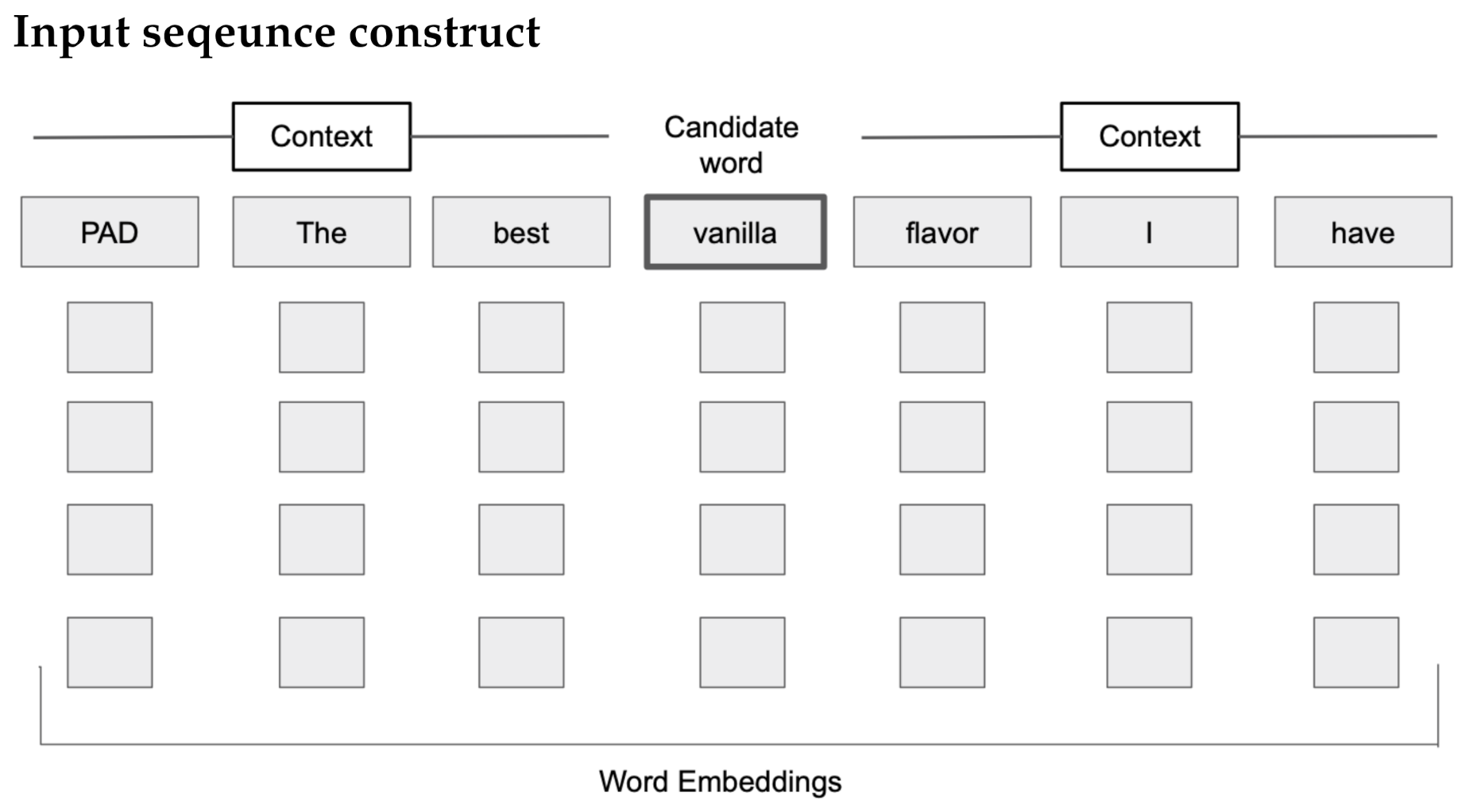
As illustrated in
Figure 2, three words before and after were used as context, n = 3. If the context was less than three words; e.g., if the word was the first word of a sentence, then a PAD, a filler value, was used to signal no available context. The PAD value is assigned the zero vector. It is these input sequences that were used to train the model described in the next section.
2.6. Descriptor Extractor
We chose a uni-directional Long Short-Term Memory (LSTM) deep neural network architecture since it works well with the context of language. An LSTM is a Recurrent Neural Network (RNN) designed for modeling sequence data. LSTMs have a memory segment that can “remember” up to a certain degree of events in time. Hence, it works well with remembering context in language and the relationships between words. The context that a descriptor is found is essential to identifying what is or is not a descriptor. How a word is used can be a deciding factor.
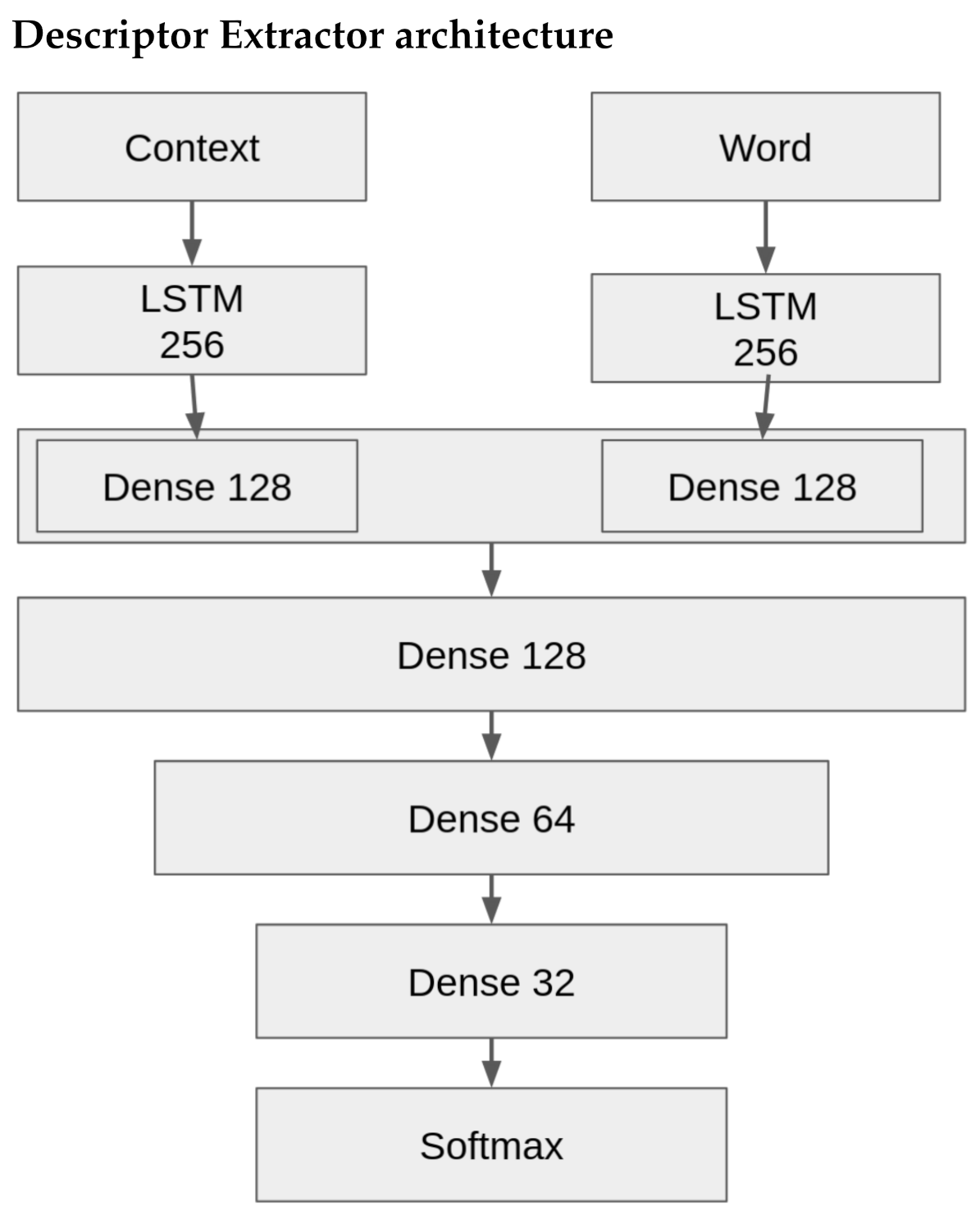
The architecture used was inspired by [
18] and can be seen in
Figure 3. There are two inputs, the context of a potential descriptor and the potential descriptor itself. Each is fed into a uni-directional LSTM of 256 units followed by a dense layer of size 128 units. These two dense layers are concatenated and fed forward to a series of decreasing dense layers ending with a binary softmax output layer that decides whether the input word is a descriptor or not. Defining the size of the context is flexible while we currently fix the descriptor (word) to a unigram as we observed most descriptors are single words. However, we chose a context of three words before and after a descriptor, n = 3.
We decided to use a traditional LSTM as a starting point for our keyword (descriptor) extractor. We wanted to see how well this model structure could perform before turning to more sophisticated model architectures in the future such as transformers [
24]. As we will discuss in our results, the model architecture performed well.
The Descriptor Extractor was written in Python v3.6.9 with the deep learning architecture built using Keras v2.3.1 and Tensorflow v1.14.0. Comet.ml [
25] was used to track different aspects of the model training, allowing us to provide detailed information presented in some of the figures in the Results section.
3. Results
Our experiments focused on testing our LSTM architecture as it was tailored to the problem space. For a comparison baseline, we chose parts-of-speech (POS) tagging since it closely reflects the characteristics of descriptors, which are generally adjectives and nouns. The POS approach is currently state-of-the-art for Sensory Science and therefore reflects a valid comparison [
10,
19].
Our first experiment combined the WA and WC datasets into one dataset for training and validation. We used an Adam optimizer with a learning rate of 0.0001, and our loss function was binary cross entropy with a batch size of 32. We had the BB and WJ datasets annotated in the same fashion as WA and WC so as to have a labeled test set. The results on the test set (accuracy/precision/recall/F1-score) can be seen in
Table 1. The scores were lower compared to those of the training set. This made us rethink why this could be happening. We realized that an important difference between WA/WC and BB/WJ was that WA/WC were professionally written reviews, whereas BB/WJ were hobbyist reviews. There are likely different writing styles between the two kinds of reviews driving this difference in performance.
We then combined all the datasets (WA, WC, BB, WJ) into one dataset and performed a train/test split of 80/20. We approached our methodology of splitting up the train and test sets differently. After combining WA, WC, BB, and WJ, we tokenized the reviews into words (tokens) and performed a train/test split on the tokens themselves instead of on a review basis. We also recorded the specific review it occurred in, the sentence within the review, and the position in the sentence. Therefore, instead of just performing a search for all locations of vanilla, for example, in all reviews for each training and test sets, we used the specifically tagged location for each instance of vanilla. From there, we were able to extract the context (n = 3 words before and after each token). Hence, we isolated where each instance of vanilla was for the respective training and test set. Combining the reviews to create a new train and test set allowed the model to be exposed to more variations in writing styles and hence become a more robust classifier.
Given the labeled descriptors/non-descriptors (2638 unique), we identified around 250K instances of the labeled words. As mentioned, we used a randomly chosen 80/20 split for training and testing. The total number of words used for training and validation were around 200K for training and around 50K for testing. For training, we removed punctuation but kept stop words as they are part of the context. Twenty percent of the training data were used for validation. Each training/test split contained a class ratio of 56% non-descriptors and 44% descriptors; hence, there was no class imbalance.
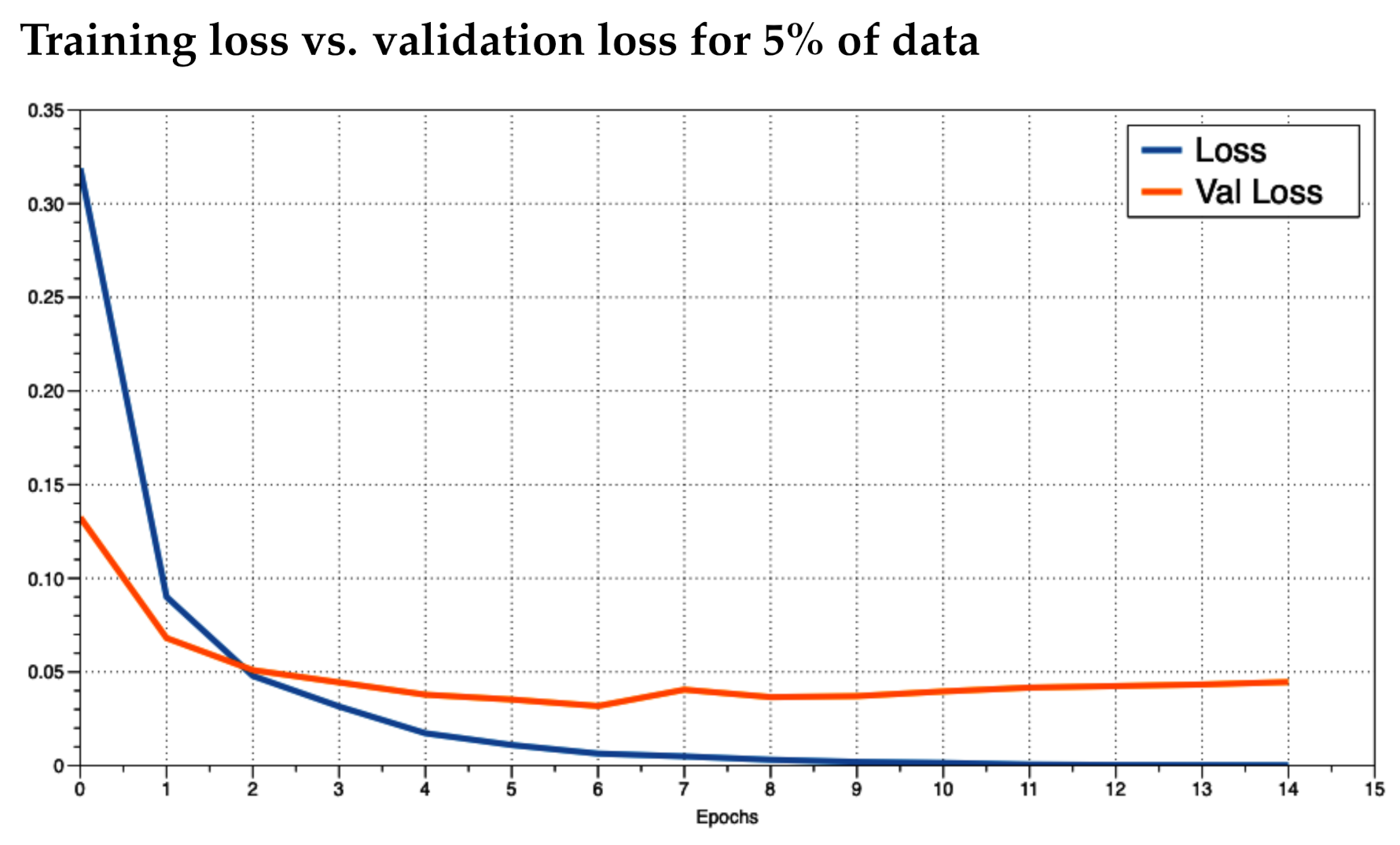
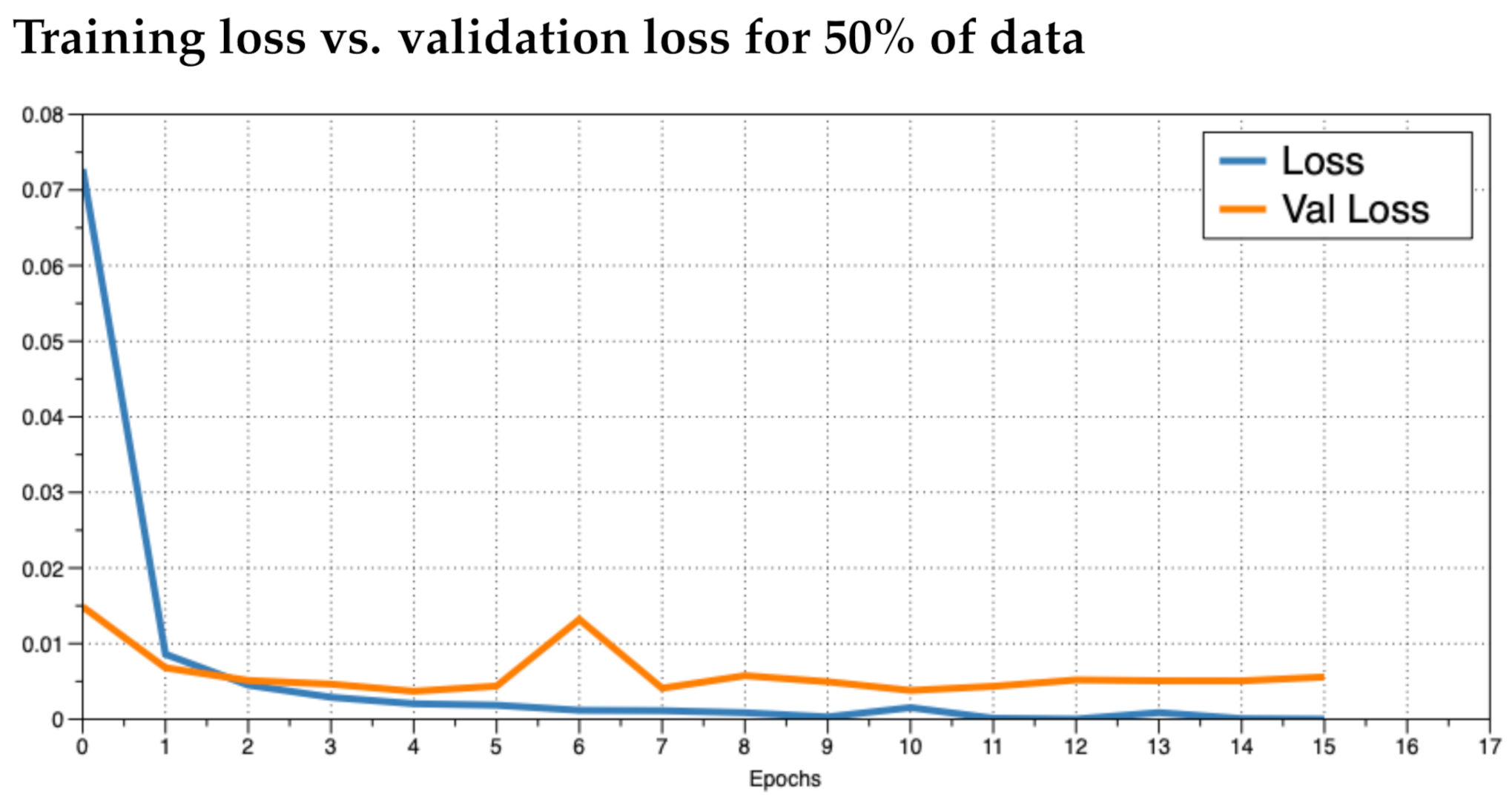
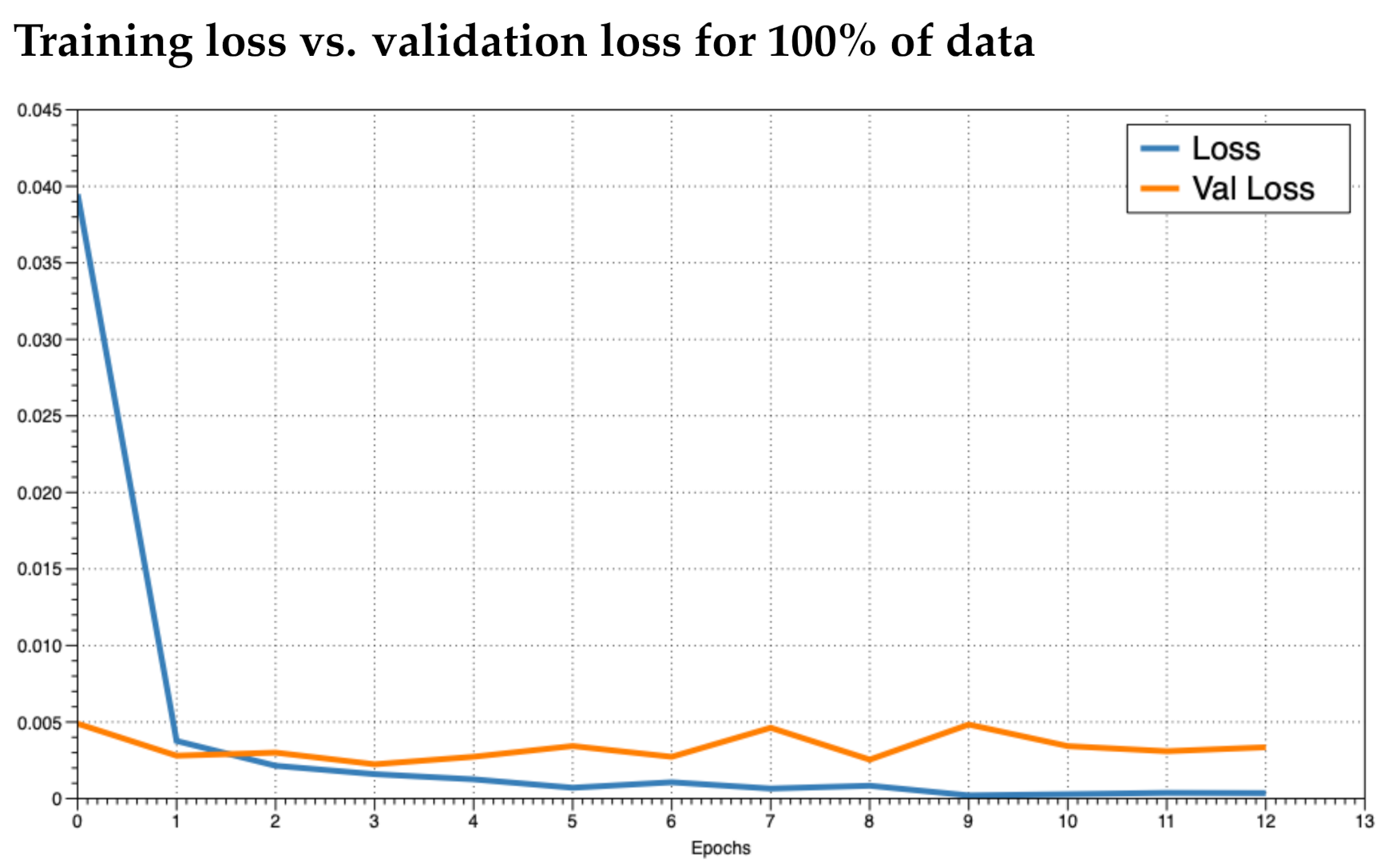
It was unclear as to how many epochs to train for. An epoch is the number of passes through the entire training dataset. We noticed that the accuracy converged to near 100% quickly (within the first two epochs). To prevent overfitting, we ran the training for as many epochs as necessary until the loss did not improve and then plotted the training loss versus the validation loss to see how the training was behaving. We trained the model in increments of 5% use of the data up to using 100%. This resulted in 20 training sessions. This was done to observe how the model behaved given different numbers of training data. In practice, if a model performs poorly, the inclusion of more training data may improve results. We investigated the plots for 5%, 50%, and 100% (
Figure 4,
Figure 5 and
Figure 6, respectively). We observed that the loss values consistently crossed roughly around three epochs an then diverged (overfitting). This is marked as “Epoch 2” in the figures as Epoch 1 is really Epoch 0 in the figures. Hence, we chose to train for three epochs.
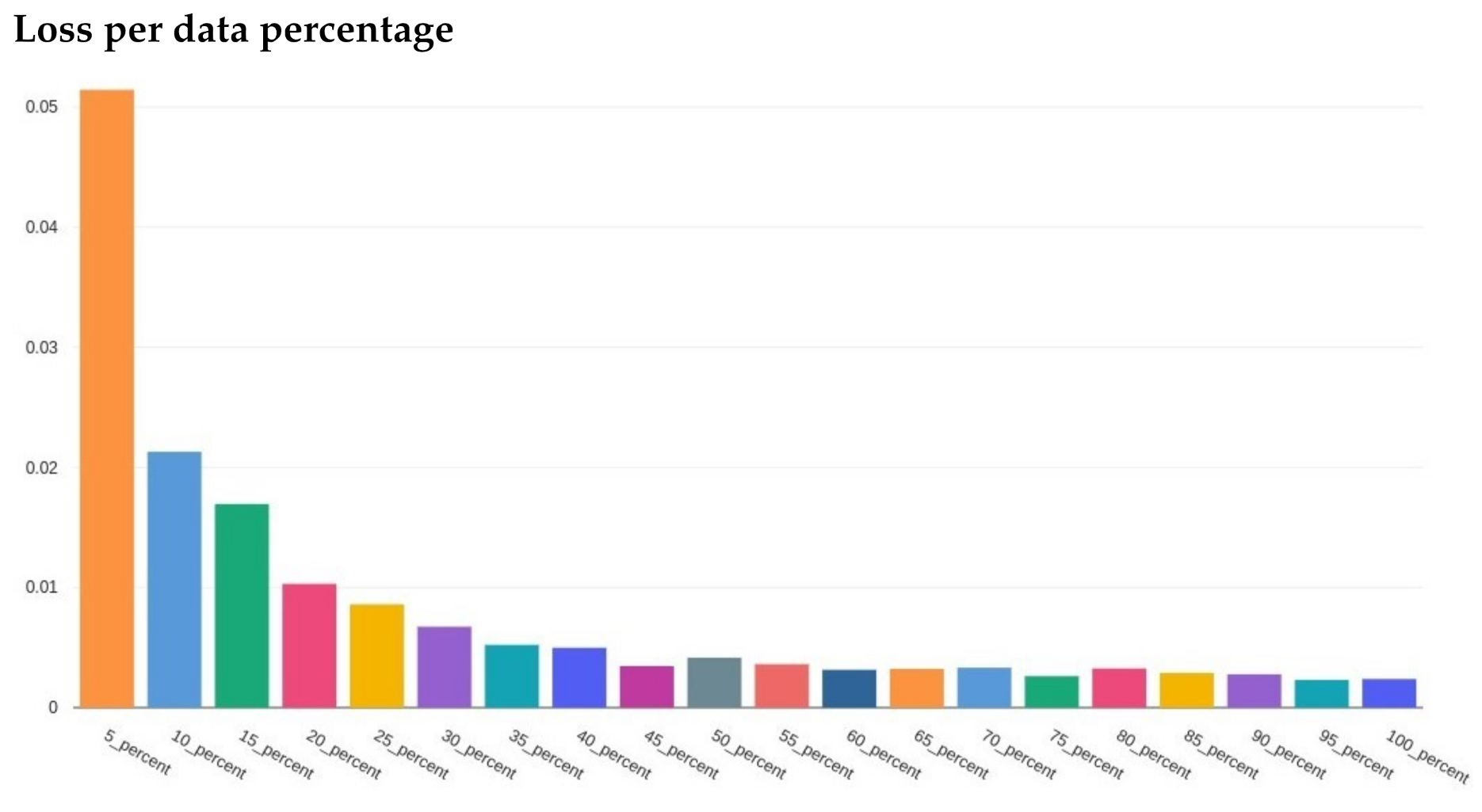
After reviewing the loss and accuracy for each incremental iteration, we decided to report on using 100% of the training data. The gain from using all the data was small, e.g., loss difference of 0.00231 loss for 95% of the data versus 00.00238 for 100%. The difference in accuracy was equally minimal. Since the training with 100% of the data did not take long (around 5 min for three epochs using a desktop CPU), the small increase was still worth the extra training time.
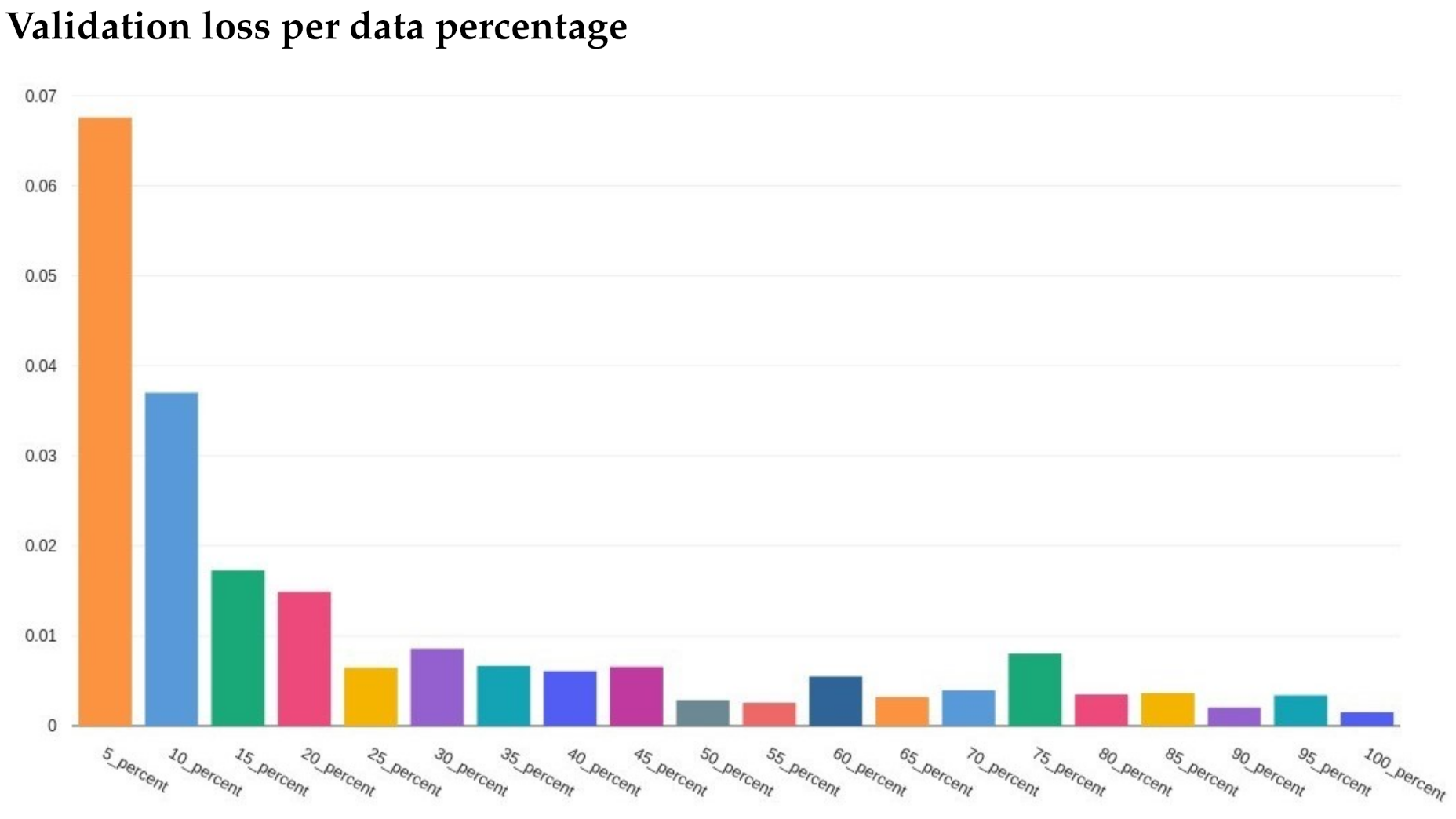
Figure 7 and
Figure 8 illustrate the training loss and validation loss, respectively, in which each loss (
y-axis) is plotted in comparison to the percent of the data used in training (
x-axis).
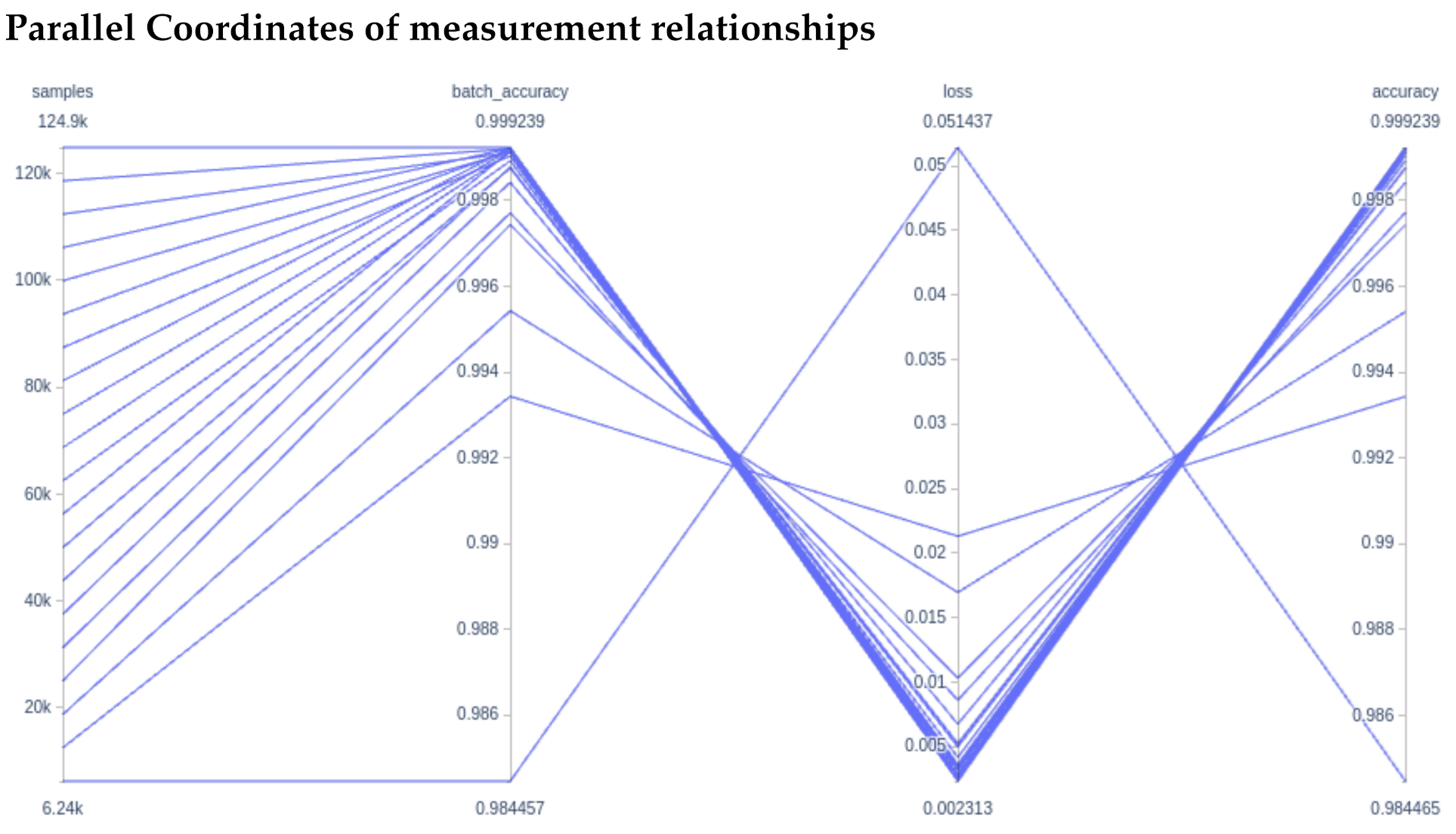
We then use a parallel coordinate system (
Figure 9) to illustrate how the use of more samples (higher percentage of data used) increases the batch accuracy, which corresponds to a lower loss and an overall higher accuracy. Note that the axis ranges for batch accuracy, loss, and accuracy are quite small.
The results from training can be seen in
Table 2. Here the loss and accuracy are reported for the cases where available. Our model’s training accuracy hovered at 99% with POS at 51.3%. The precision, recall, and F1-scores for the test set are presented in
Table 3. One thing to note is that the recall is very high for POS. POS classifying is essentially saying “all nouns and adjectives are descriptors”. In that case, there will be very few false negatives, because almost all descriptors ARE nouns and adjectives. Since recall = true positives/(true positives + true negatives), recall will be very high.
An illustration of a case where the LSTM model struggles can be seen in
Figure 10. The orange underlined words were identified by both a human annotator and the LSTM model. The blue ones were not identified by the LSTM model but were by the human annotator. The primary differences tend to be that the LSTM model only identifies the more descriptive word in bi-gram descriptor phrases (e.g., “banana chips“) and will classify uncommon words, especially proper nouns, as descriptive, albeit with a low probability (e.g., “Redbreast”, prediction of 71%). The challenge with bi-grams is a focus of future work discussed later, and the low probabilities can be addressed by using a filter threshold.
Figure 10 also demonstrates the difficulty in creating a tagged gold standard corpus, as words like “copper” and “heavy” that are not usually flavor words were annotated by the LSTM model as non-descriptors. In certain contexts, as in the idiosyncratic text of this review, these words are arguably capable of describing flavor. In the majority of reviews, however, “copper” instead describes the color (not flavor) of the spirit. The difficulty that these kinds of rarely descriptive words present for rapid annotation is also a focus of future work for the tagging scheme described in this paper.
We were also interested in viewing the relationships between words chosen as descriptors or non-descriptors. One approach to do this is to visualize the GloVe word embeddings using a t-SNE plot, an approach to visualize high-dimensional data in a two-dimensional space [
26]. What results is a scatter plot visualization where distance between each word represents “similarity” based on word embeddings. The closer they are, the more conceptually similar.
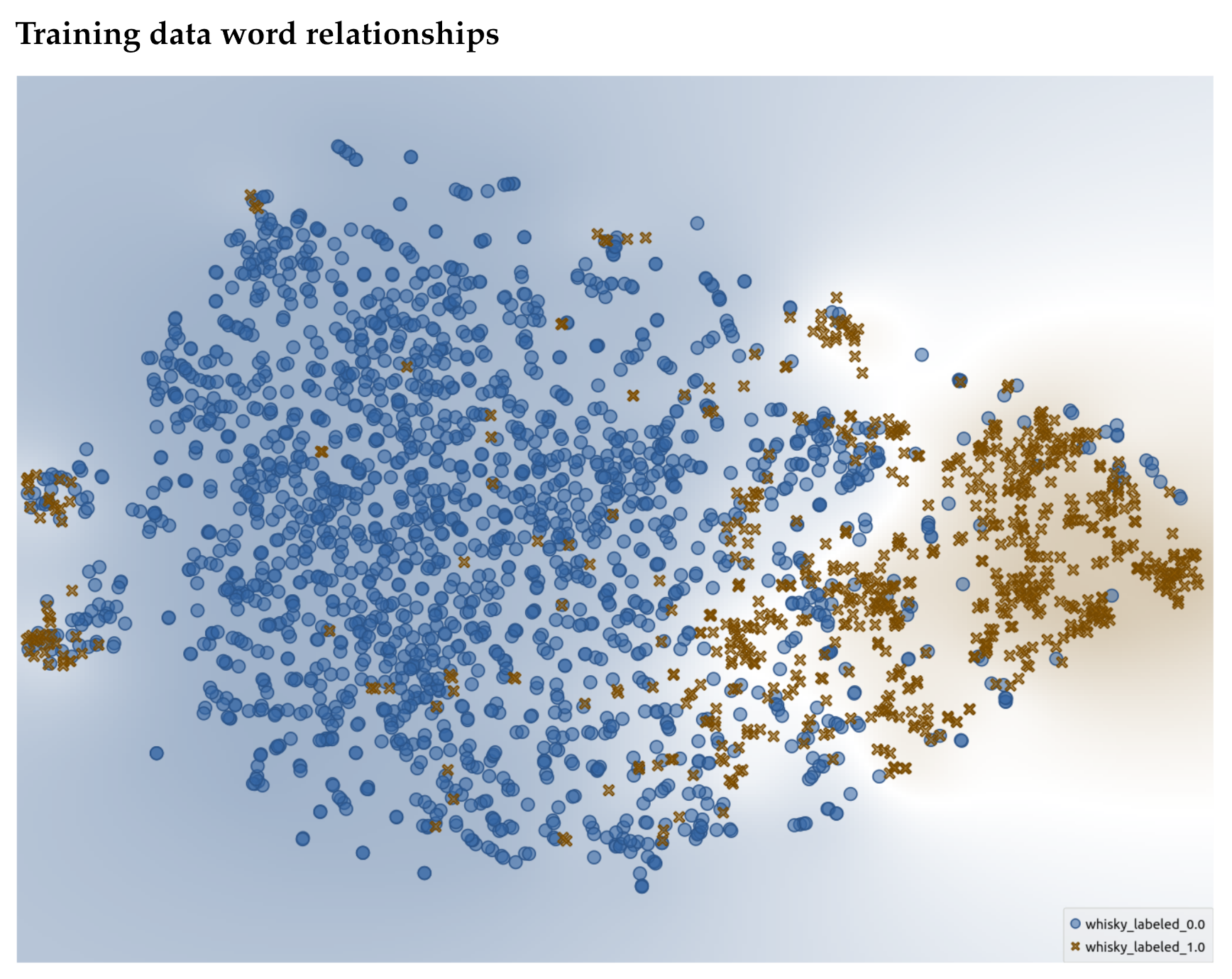
We first plot the t-SNE for the annotated words within the training set. This can be seen in
Figure 11 with a descriptor being a brown “X” and non-descriptor a blue dot. The words that were labeled in the training dataset create distinct clusters. This demonstrates that the human annotations created a well-defined cluster space, and hence, supports that the provided annotations were of good quality and the embeddings have enough understanding of flavor language to have captured it in the embedding space. The same can be said for the clusters for the test dataset (
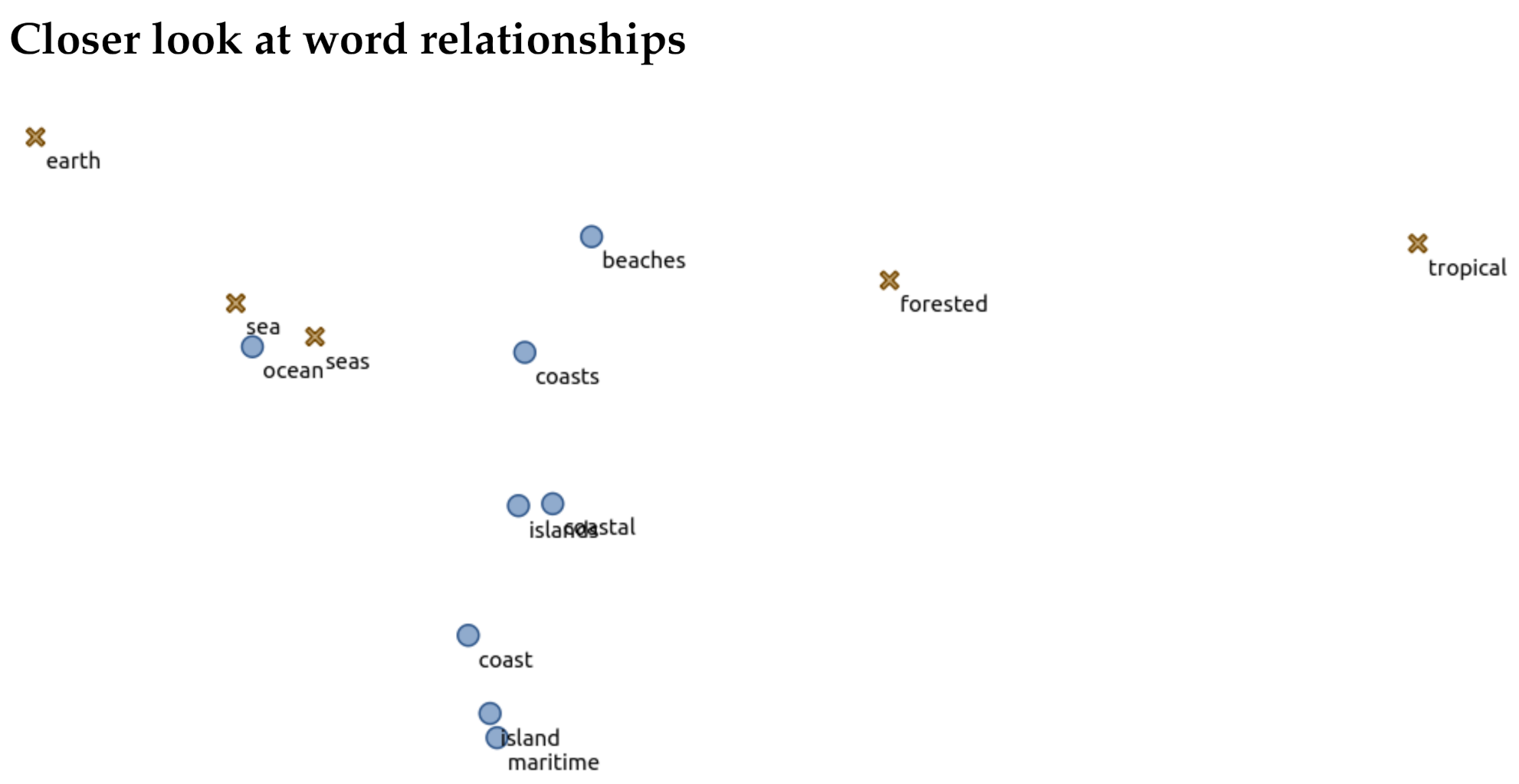
Figure 12). One may notice that there are some descriptor/non-descriptors “speckled” across the opposing cluster, i.e., words labeled as a descriptor are found within the non-descriptor cluster. This demonstrates that just because words are similar in an embedding space, their contextual meaning can vary. Zooming in to an example (
Figure 13) of this, we see various terms that describe different aspects of bodies of water or climates. These words hold some form of similarities but are not deemed “equal” in a descriptive sensory sense.
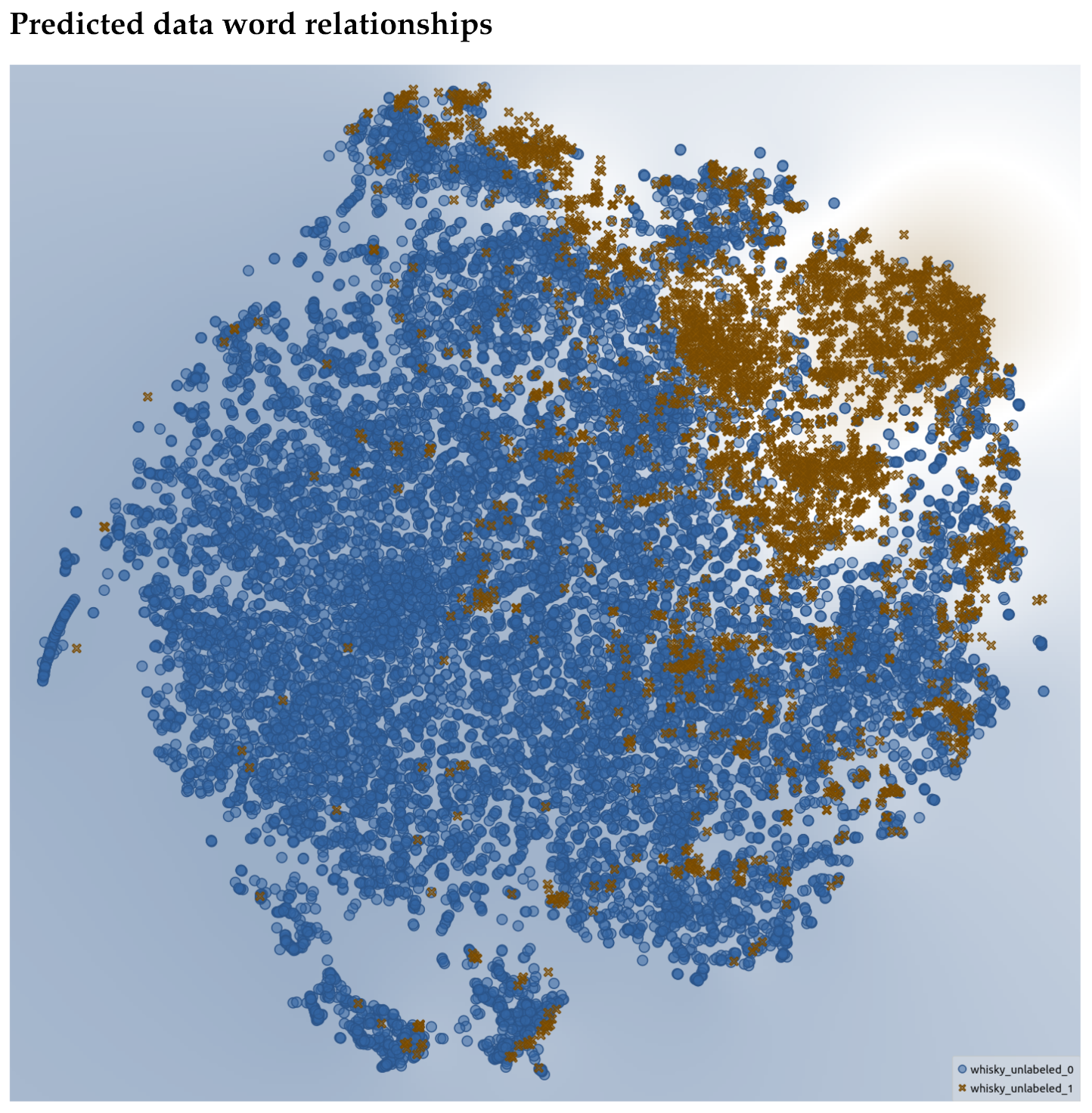
In
Figure 14, we see the embedding space for words that were predicted to be a descriptor (brown “X”) or not a descriptor (blue dot). As can be seen, neatly defined clusters also emerge along with some “speckles”. This provides support that the trained model is able to segment the space into descriptors and non-descriptors and hence carve out sensory terms. Another observation is that in all the t-SNE embedding plots, the non-descriptors outnumber the descriptors as was noted to be the case in the Related Works section by [
8]. The actual descriptors are the minority, which makes sense as we observed that in the reviews, most words are non-sensory.
4. Discussion
We were able to build a deep learning model architecture based on LSTMs to provide descriptor identification within free-form text whisky reviews. Our results were very promising with training, validation, and test accuracies around 99%. The precision, recall, and F1-Scores were equally high. This is substantially higher than the current state of the art for Sensory Science. We were concerned about overfitting with such high scores, so we tracked the training and validation loss over many epochs, a common approach to detect overfitting. The tracking showed overfitting after three epochs, so we stopped our training at three epochs.
We were successfully able to automatically separate flavor-descriptive terms from those with no sensory meaning in written descriptions of food experiences (reviews). Our LSTM architecture was able to capture the language constructs that dictate what is and is not a descriptor. We view this as one of our key contributions.
Another key contribution is the pipeline for data preparation, annotation, training, and testing not seen before in sensory science. This opens the door for researchers in Sensory Science and Food Science in general.
We also introduced a novel interactive word tagging tool for creating a set of human-labeled descriptor/non-descriptor words. With multiple annotators using the tool, the set of human-labeled words provided an excellent training set. This supports the possibility of performing the same annotation with other datasets in other domains in order to facilitate the creation of a labeled set of words, hence training a model for those domains.
Visualizing the results using t-SNE revealed some interesting results. First, the embedding space of human labeled words by the interactive word tagger was segmented fairly cleanly into two clusters: those words that are descriptors and those that are not. This supports that the annotations are of high quality. Similarly, the embedding space for predicted words from the test set (non-annotated words) reveals two fairly clean clusters for descriptors and non-descriptors. This provides support that the trained model is able to learn the language structure of sensory terms.
These contributions result in some interesting and novel implications. We trained a model that can identify descriptors in texts, leading to the ability to create a lexicon for a whisky. Lexicons allow a comparison between whiskies: a $50 bottle of whisky can have a similar lexicon to that of a $300 bottle. This allows the consumer to “experience” the $300 whisky by trying the $50 whisky. Lexicons of whiskies can also map distinct descriptors to that of different metadata of the whiskies, such as age, region of origin, ingredients, and price. This can provide a foundation to perform predictive analyses, such as Random Forests. By fitting a model to predict continuous variables (e.g., bottle price, quality score) or classify products (e.g., region of origin) based on the presence or absence of flavor terms in the bodies of reviews, we can identify which flavors or flavor terms drive the price and consumer liking of whiskies or differentiate between product categories.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}