
Geographic Origin Discrimination of Millet Using Vis-NIR Spectroscopy Combined with Machine Learning Techniques




Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Spectral Measurement
2.3. Data Analysis
2.4. Chemometrics Study
2.4.1. K-Nearest Neighbor (K-NN)
2.4.2. Linear Discriminant Analysis (LDA)
2.4.3. Logistic Regression (LR)
2.4.4. Random Forest (RF)
2.4.5. Support Vector Machine (SVM)
3. Results
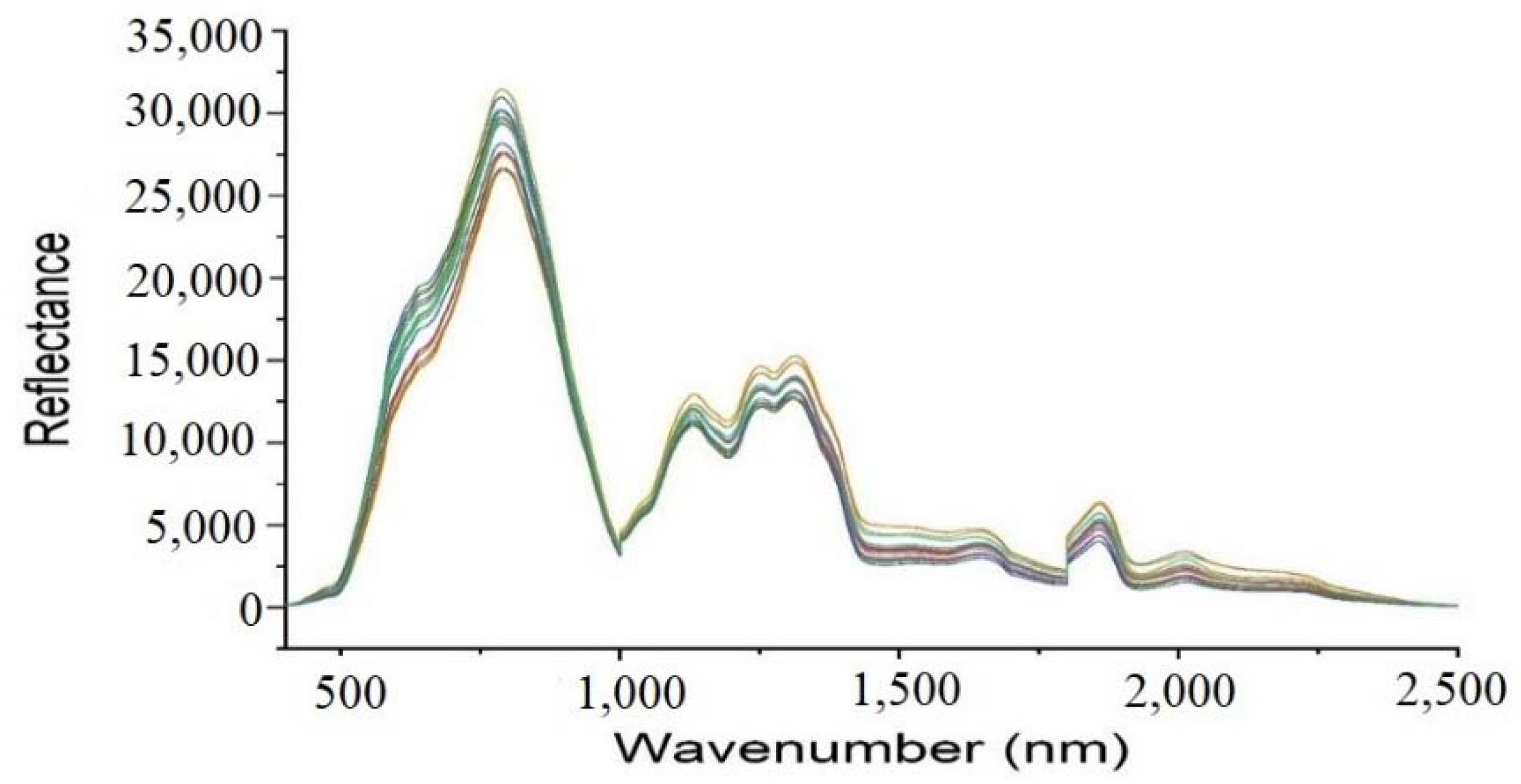
3.1. Spectra Analysis
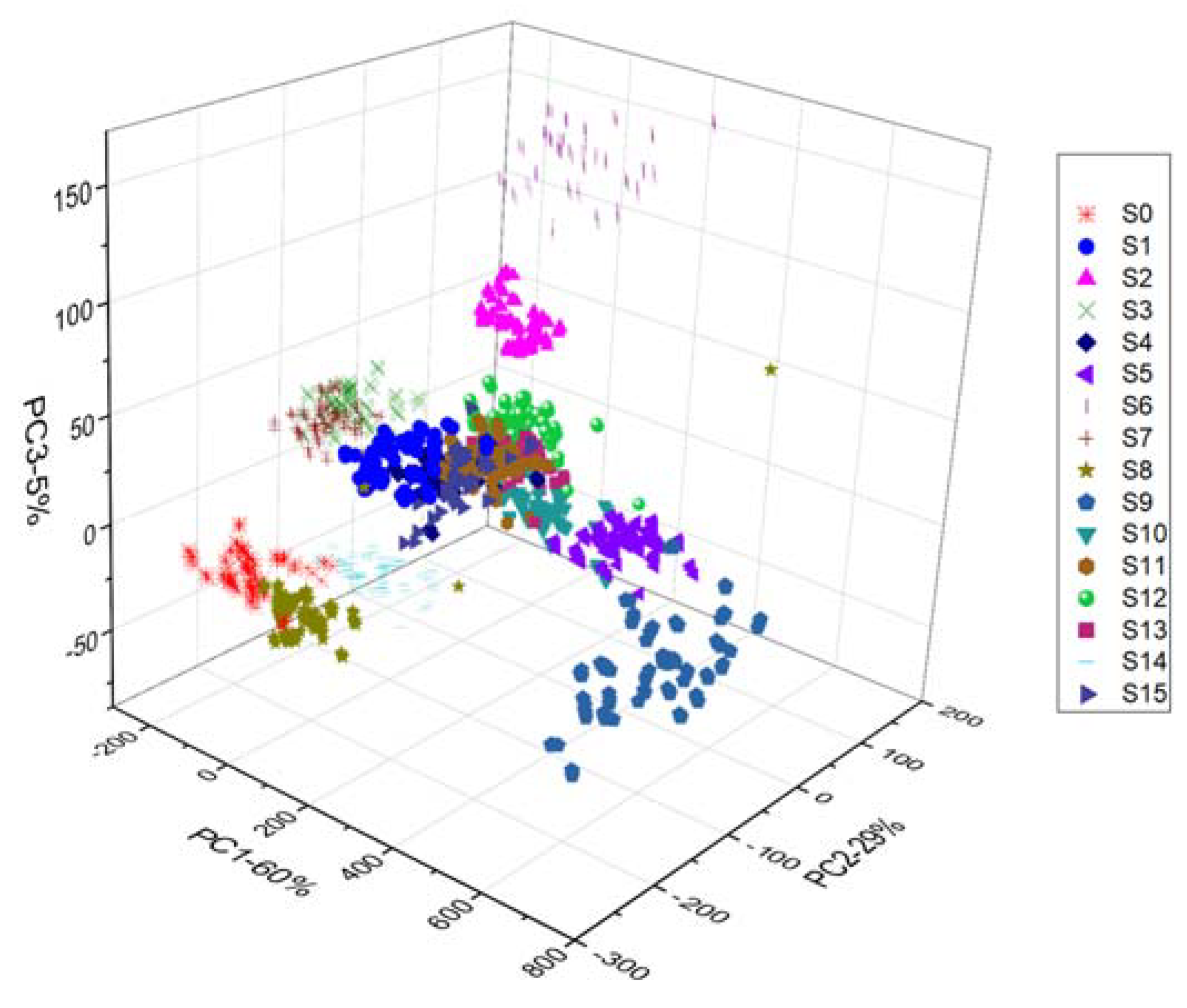
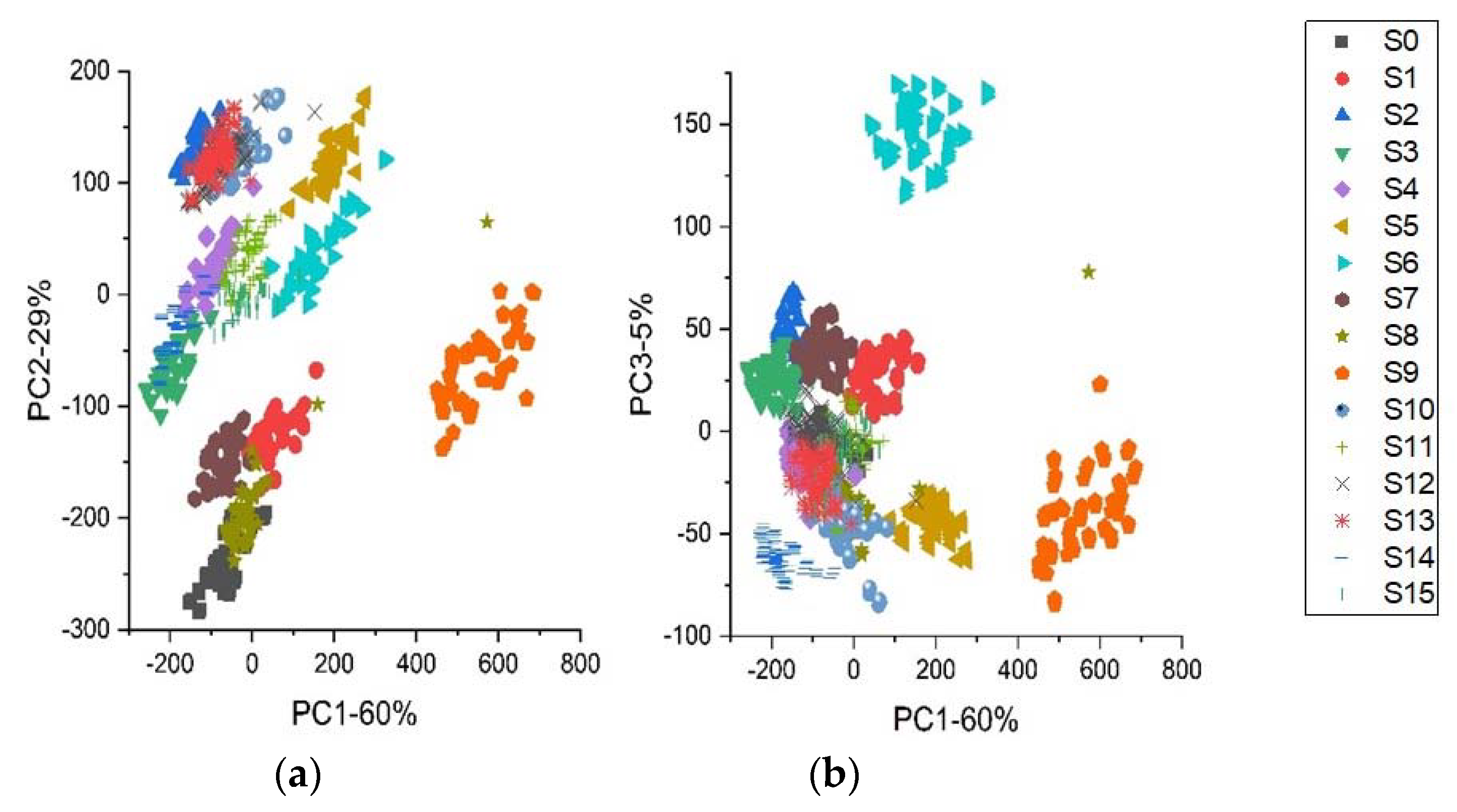
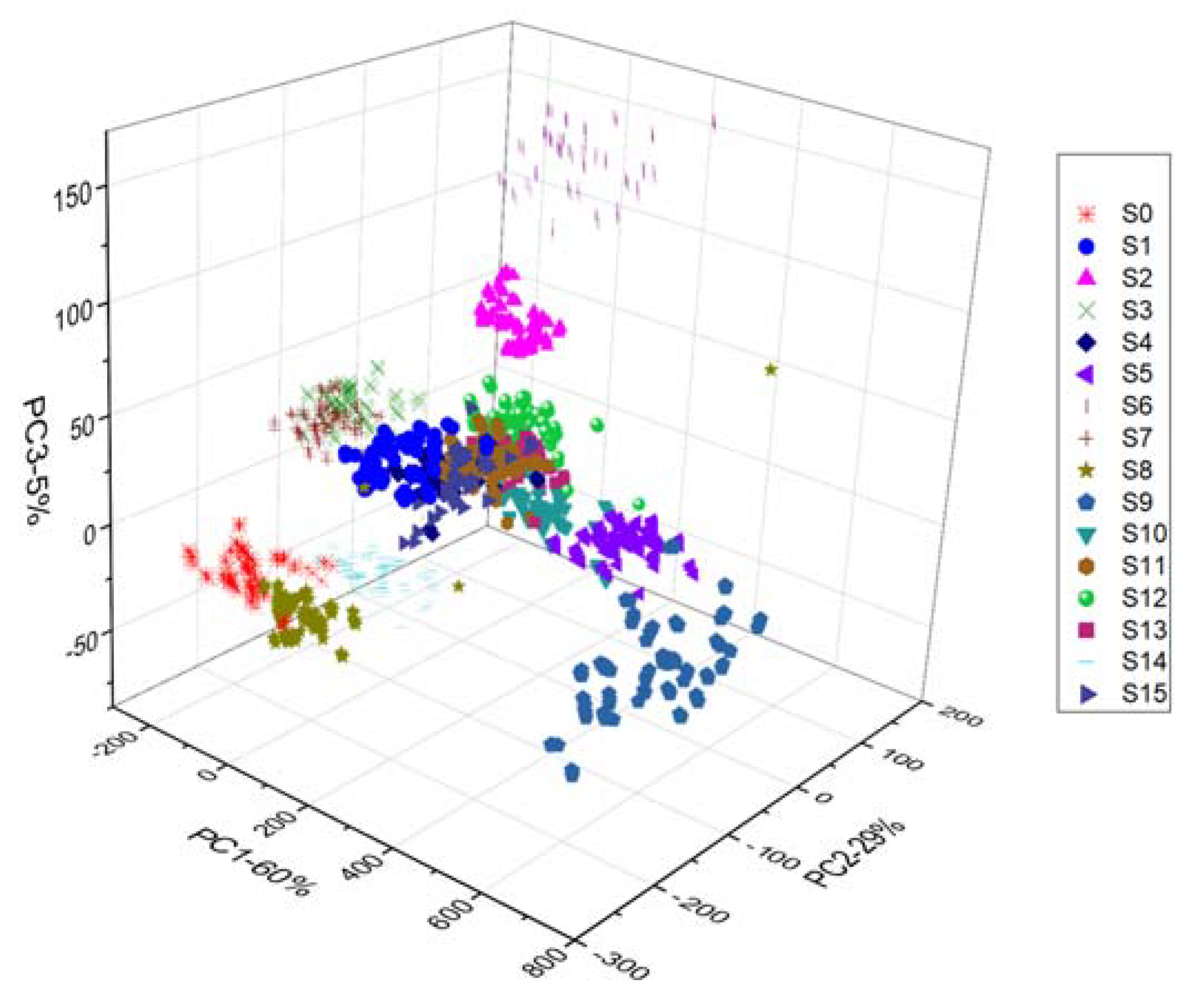
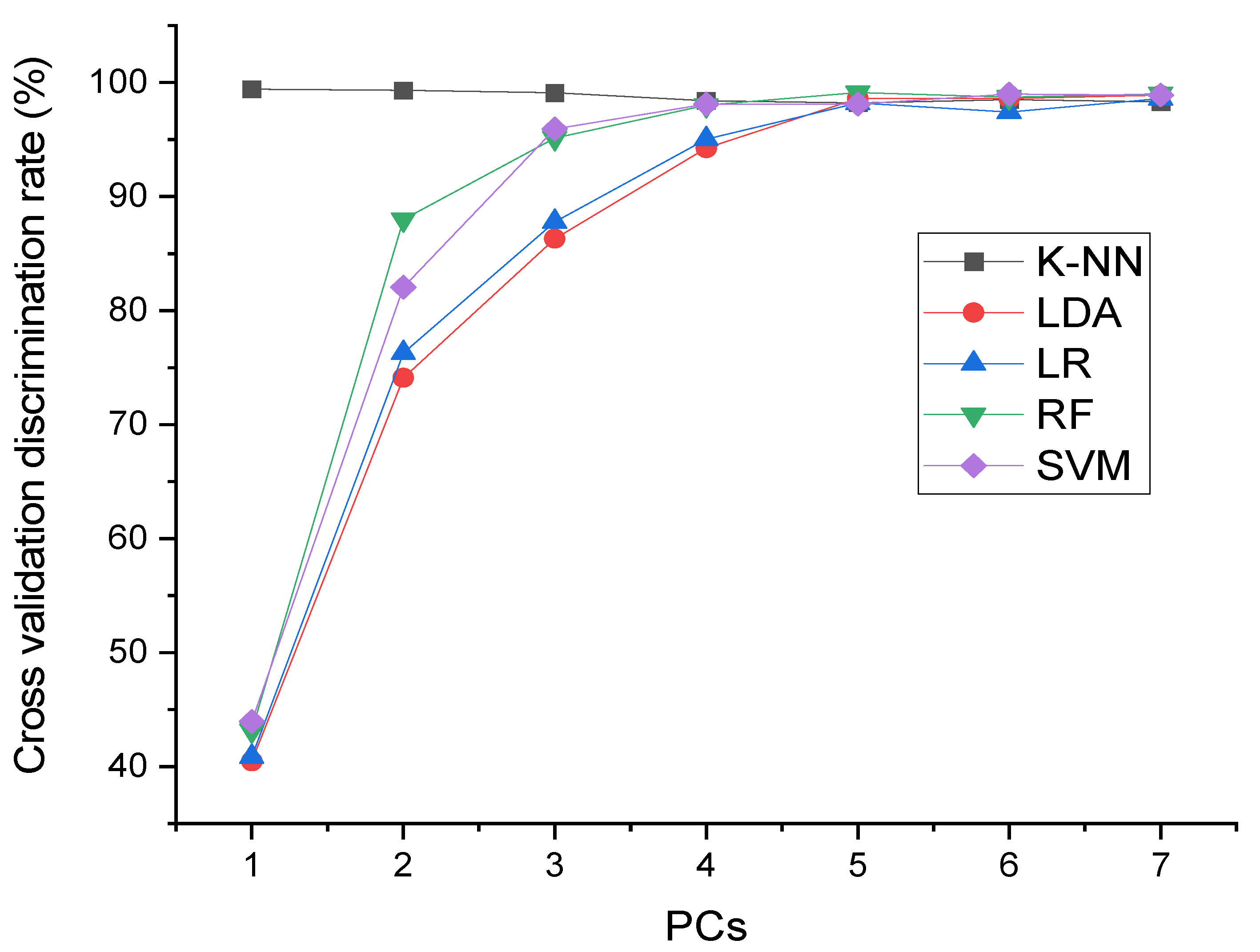
3.2. Principal Component Analysis
3.3. Models Optimization
3.3.1. Discrimination Results from the Different Models
3.3.2. Evaluation of the Accuracy of the Discrimination Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, H.; Zhang, J.; Liu, K.-B.; Wu, N.; Li, Y.; Zhou, K.; Ye, M.; Zhang, T.; Zhang, H.; Yang, X.; et al. Earliest domestication of common millet (Panicum miliaceum) in East Asia extended to 10,000 years ago. Proc. Natl. Acad. Sci. USA 2009, 106, 7367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, E.; Sarita, A. Nutraceutical and food processing properties of millets: A review. Austin J. Nutr. Food Sci. 2016, 4, 1–6. [Google Scholar]
- Fahad, S.; Bajwa, A.A.; Nazir, U.; Anjum, S.A.; Farooq, A.; Zohaib, A.; Sadia, S.; Nasim, W.; Adkins, S.; Saud, S. Crop production under drought and heat stress: Plant responses and management options. Front. Plant Sci. 2017, 8, 1147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taylor, J.R. Millets: Their unique nutritional and health-promoting attributes. In Gluten-Free Ancient Grains; Elsevier: Amsterdam, The Netherlands, 2017; pp. 55–103. [Google Scholar]
- De Girolamo, A.; Cervellieri, S.; Mancini, E.; Pascale, M.; Logrieco, A.F.; Lippolis, V. Rapid authentication of 100% italian durum wheat pasta by FT-NIR spectroscopy combined with chemometric tools. Foods 2020, 9, 1551. [Google Scholar] [CrossRef]
- Xie, D.; Guo, W. Measurement and calculation methods on absorption and scattering properties of turbid food in Vis/NIR range. Food Bioprocess Technol. 2020, 13, 229–244. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Plewka, N.; Huck, C.W. Insect protein content analysis in handcrafted fitness bars by NIR Spectroscopy. Gaussian process regression and data fusion for performance enhancement of miniaturized cost-effective consumer-grade sensors. Molecules 2021, 26, 6390. [Google Scholar] [CrossRef]
- Guindo, M.L.; Kabir, M.H.; Chen, R.; Liu, F. Particle swarm optimization and multiple stacked generalizations to detect nitrogen and organic-matter in organic-fertilizer using Vis-NIR. Sensors 2021, 21, 4882. [Google Scholar] [CrossRef]
- Zaukuu, J.Z.; Aouadi, B.; Lukács, M.; Bodor, Z.; Vitális, F.; Gillay, B.; Gillay, Z.; Friedrich, L.; Kovacs, Z. Detecting low concentrations of nitrogen-based adulterants in whey protein powder using benchtop and handheld NIR spectrometers and the feasibility of scanning through plastic bag. Molecules 2020, 25, 2522. [Google Scholar] [CrossRef]
- Wijewardane, N.K.; Ge, Y.; Sihota, N.; Hoelen, T.; Miao, T.; Weindorf, D.C. Predicting total petroleum hydrocarbons in field soils with VisNIR models developed on laboratory-constructed samples. J. Environ. Qual. 2020. [Google Scholar] [CrossRef]
- Wang, X.; Mao, D.-Z.; Yang, Y.-J. Calibration transfer between modelled and commercial pharmaceutical tablet for API quantification using backscattering NIR, Raman and transmission Raman spectroscopy (TRS). J. Pharm. Biomed. Anal. 2021, 194, 113766. [Google Scholar] [CrossRef]
- Fard, R.S.; Matinfar, H.R. Capability of vis-NIR spectroscopy and Landsat 8 spectral data to predict soil heavy metals in polluted agricultural land (Iran). Arab. J. Geosci. 2016, 9, 745. [Google Scholar] [CrossRef]
- Li, X.; Tsuta, M.; Hayakawa, F.; Nakano, Y.; Kazami, Y.; Ikehata, A. Estimating the sensory qualities of tomatoes using visible and near-infrared spectroscopy and interpretation based on gas chromatography—Mass spectrometry metabolomics. Food Chem. 2021, 343, 128470. [Google Scholar] [CrossRef]
- Pu, Y.; Pérez-Marín, D.; O’Shea, N.; Garrido-Varo, A. Recent advances in portable and handheld NIR spectrometers and applications in milk, cheese and dairy powders. Foods 2021, 10, 2377. [Google Scholar] [CrossRef]
- Beć, K.B.; Huck, C.W. Breakthrough Potential in Near-Infrared Spectroscopy: Spectra Simulation. A review of recent developments. Front. Chem. 2019, 7, 48. [Google Scholar] [CrossRef] [Green Version]
- Zeng, J.; Guo, Y.; Han, Y.; Li, Z.; Yang, Z.; Chai, Q.; Wang, W.; Zhang, Y.; Fu, C. A Review of the discriminant analysis methods for food quality based on near-infrared spectroscopy and pattern recognition. Molecules 2021, 26, 749. [Google Scholar] [CrossRef]
- Katerinopoulou, K.; Kontogeorgos, A.; Salmas, C.E.; Patakas, A.; Ladavos, A. Geographical origin authentication of agri-food products: A review. Foods 2020, 9, 489. [Google Scholar] [CrossRef] [PubMed]
- Agelet, L.E.; Hurburgh, C.R., Jr. A tutorial on near infrared spectroscopy and its calibration. Crit. Rev. Anal. Chem. 2010, 40, 246–260. [Google Scholar] [CrossRef]
- Achten, E.; Schütz, D.; Fischer, M.; Fauhl-Hassek, C.; Riedl, J.; Horn, B. Classification of Grain Maize (Zea mays L.) from Different Geographical Origins with FTIR Spectroscopy—A Suitable Analytical Tool for Feed Authentication? Food Anal. Methods 2019, 12, 2172–2184. [Google Scholar] [CrossRef]
- Nogales-Bueno, J.; Feliz, L.; Baca-Bocanegra, B.; Hernández-Hierro, J.M.; Heredia, F.J.; Barroso, J.M.; Rato, A.E. Comparative study on the use of three different near infrared spectroscopy recording methodologies for varietal discrimination of walnuts. Talanta 2020, 206, 120189. [Google Scholar] [CrossRef]
- De Girolamo, A.; Cortese, M.; Cervellieri, S.; Lippolis, V.; Pascale, M.; Logrieco, A.F.; Suman, M. Tracing the geographical origin of durum wheat by FT-NIR spectroscopy. Foods 2019, 8, 450. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Zhou, R.; Zhang, W.; Tang, S.; Hao, Z.; Li, X.; Lu, Y.; Zeng, X. Laser-induced breakdown spectroscopy assisted chemometric methods for rice geographic origin classification. Appl. Opt. 2018, 57, 8297–8302. [Google Scholar] [CrossRef]
- Fazeli Burestan, N.; Afkari Sayyah, A.H.; Taghinezhad, E. Prediction of some quality properties of rice and its flour by near-infrared spectroscopy (NIRS) analysis. Food Sci. Nutr. 2020, 9, 1099–1105. [Google Scholar] [CrossRef] [PubMed]
- Teye, E.; Amuah, C.L.Y.; McGrath, T.; Elliott, C. Innovative and rapid analysis for rice authenticity using hand-held NIR spectrometry and chemometrics. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 217, 147–154. [Google Scholar] [CrossRef]
- Jia, S.; Sun, Y.; Li, L.; Wang, R.; Xiang, Y.; Li, S.; Zhang, Y.; Jiang, H.; Du, Z. Discrimination of turmeric from different origins in China by MRM-based curcuminoid profiling and multivariate analysis. Food Chem. 2020, 338, 127794. [Google Scholar] [CrossRef]
- Liu, F.; Wang, W.; Shen, T.; Peng, J.; Kong, W. Rapid identification of Kudzu powder of different origins using laser-induced breakdown spectroscopy. Sensors 2019, 19, 1453. [Google Scholar] [CrossRef] [Green Version]
- Borraz-Martínez, S.; Simó, J.; Gras, A.; Mestre, M.; Boqué, R. Multivariate classification of prunus dulcis varieties using leaves of nursery plants and near infrared spectroscopy. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, L.; Sun, W.; Wu, C.; Ma, Y.; Chao, Z. Discrimination of trichosanthis fructus from different geographical origins using near infrared spectroscopy coupled with chemometric techniques. Molecules 2019, 24, 1550. [Google Scholar] [CrossRef] [Green Version]
- Luo, R.; Jiang, T.; Chen, X.; Zheng, C.; Liu, H.; Yang, J. Determination of geographic origin of Chinese mitten crab (Eriocheir sinensis) using integrated stable isotope and multi-element analyses. Food Chem. 2019, 274, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yao, L.; Xia, Z.; Gao, Y.; Gong, Z. Geographical discrimination and adulteration analysis for edible oils using two-dimensional correlation spectroscopy and convolutional neural networks (CNNs). Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 246, 118973. [Google Scholar] [CrossRef]
- Yuan, T.; Zhao, Y.; Zhang, J.; Wang, Y. Application of variable selection in the origin discrimination of Wolfiporia cocos (FA Wolf) Ryvarden & Gilb. based on near infrared spectroscopy. Sci. Rep. 2018, 8, 1–10. [Google Scholar]
- Gaiad, J.E.; Hidalgo, M.J.; Villafañe, R.N.; Marchevsky, E.J.; Pellerano, R.G. Tracing the geographical origin of Argentinean lemon juices based on trace element profiles using advanced chemometric techniques. Microchem. J. 2016, 129, 243–248. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Xie, W.; Jiang, J.; Zhao, Z.; Zhou, F.; Liu, F. Fast Quantification of honey adulteration with laser-induced breakdown spectroscopy and chemometric methods. Foods 2020, 9, 341. [Google Scholar] [CrossRef] [Green Version]
- Gok, S.; Severcan, M.; Goormaghtigh, E.; Kandemir, I.; Severcan, F. Differentiation of Anatolian honey samples from different botanical origins by ATR-FTIR spectroscopy using multivariate analysis. Food Chem. 2015, 170, 234–240. [Google Scholar] [CrossRef] [PubMed]
- Cui-qing, W.; Li-juan, K.; Sheng, W.; Yu-ming, G. Near infrared spectroscopy (NIRS) technology applied in millet feature extraction and variety identification. Afr. J. Agric. Res. 2017, 12, 2223–2231. [Google Scholar]
- Richter, B.; Rurik, M.; Gurk, S.; Kohlbacher, O.; Fischer, M. Food monitoring: Screening of the geographical origin of white asparagus using FT-NIR and machine learning. Food Control 2019, 104, 318–325. [Google Scholar] [CrossRef]
- Teye, E.; Huang, X.; Dai, H.; Chen, Q. Rapid differentiation of Ghana cocoa beans by FT-NIR spectroscopy coupled with multivariate classification. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2013, 114, 183–189. [Google Scholar] [CrossRef] [PubMed]
- Ruiz, J.R.; Canals, T.; Gomez, R.C. Comparative Study of Multivariate Methods to Identify Paper Finishes Using Infrared Spectroscopy. IEEE Trans. Instrum. Meas. 2012, 61, 1029–1036. [Google Scholar] [CrossRef] [Green Version]
- Moncayo, S.; Manzoor, S.; Navarro-Villoslada, F.; Caceres, J. Evaluation of supervised chemometric methods for sample classification by Laser Induced Breakdown Spectroscopy. Chemom. Intell. Lab. Syst. 2015, 146, 354–364. [Google Scholar] [CrossRef]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef]
- Strobl, C.; Malley, J.; Tutz, G. An introduction to recursive partitioning: Rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychol. Methods 2009, 14, 323. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Wu, Q.; Huang, J.Z.; Ng, M.K.; Li, X. Stratified sampling for feature subspace selection in random forests for high dimensional data. Pattern Recognit. 2013, 46, 769–787. [Google Scholar] [CrossRef]
- Liu, C.; Wang, W.; Wang, M.; Lv, F.; Konan, M. An efficient instance selection algorithm to reconstruct training set for support vector machine. Knowl.-Based Syst. 2017, 116, 58–73. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Zhu, Y.; Yang, X.; Li, J.; Tang, S.; Hao, Z.; Guo, L.; Li, X.; Zeng, X.; Lu, Y. Evaluation of sample preparation methods for rice geographic origin classification using laser-induced breakdown spectroscopy. J. Cereal Sci. 2018, 80, 111–118. [Google Scholar] [CrossRef]
- Yang, P.; Zhu, Y.; Tang, S.; Hao, Z.; Guo, L.; Li, X.; Lu, Y.; Zeng, X. Analytical-performance improvement of laser-induced breakdown spectroscopy for the processing degree of wheat flour using a continuous wavelet transform. Appl. Opt. 2018, 57, 3730–3737. [Google Scholar] [CrossRef]
- Luna, A.S.; da Silva, A.P.; Pinho, J.S.A.; Ferré, J.; Boqué, R. Rapid characterization of transgenic and non-transgenic soybean oils by chemometric methods using NIR spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2013, 100, 115–119. [Google Scholar] [CrossRef] [PubMed]
- Qi, J.; Li, Y.; Zhang, C.; Wang, C.; Wang, J.; Guo, W.; Wang, S. Geographic origin discrimination of pork from different Chinese regions using mineral elements analysis assisted by machine learning techniques. Food Chem. 2021, 337, 127779. [Google Scholar] [CrossRef]
- Visentini, I.; Snidaro, L.; Foresti, G.L. Diversity-aware classifier ensemble selection via f-score. Inf. Fusion 2016, 28, 24–43. [Google Scholar] [CrossRef]
- Kim, S.-W.; Gil, J.-M. Research paper classification systems based on TF-IDF and LDA schemes. Hum.-Cent. Comput. Inf. Sci. 2019, 9, 30. [Google Scholar] [CrossRef]
- Barbosa, R.M.; de Paula, E.S.; Paulelli, A.C.; Moore, A.F.; Souza, J.M.O.; Batista, B.L.; Campiglia, A.D.; Barbosa, F. Recognition of organic rice samples based on trace elements and support vector machines. J. Food Compos. Anal. 2016, 45, 95–100. [Google Scholar] [CrossRef]
- Szymczycha-Madeja, A.; Welna, M.; Jedryczko, D.; Pohl, P. Developments and strategies in the spectrochemical elemental analysis of fruit juices. TrAC Trends Anal. Chem. 2014, 55, 68–80. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variety ID. | Variety Name | Producing Area | Number of Samples |
|---|---|---|---|
| S0 | Qinxian yellow millet | Shanxi Province | 30 |
| S1 | Mizhi oil millet | Shaanxi Province | 30 |
| S2 | Huangjinmiao millet | Inner Mongolia | 30 |
| S3 | Taohua yellow millet | Hebei Province | 30 |
| S4 | Nandaobeimai millet | Liaoning Province | 30 |
| S5 | Xirui yellow millet | Jilin Province | 30 |
| S6 | Lucun millet | Shanxi Province | 30 |
| S7 | Longshan millet | Shandong Province | 30 |
| S8 | Qinzhou yellow millet | Shanxi Province | 30 |
| S9 | Jinxiang Millet | Shandong Province | 30 |
| S10 | Inner Mongolia yellow millet | Inner Mongolia | 30 |
| S11 | Weizhou yellow millet | Hebei Province | 30 |
| S12 | Fine yellow millet | Liaoning Province | 30 |
| S13 | Organic red millet | Liaoning Province | 30 |
| S14 | Black earth town organic millet | Heilongjiang Province | 30 |
| S15 | Tian-di-Liang-ren organic yellow millet | Liaoning Province | 30 |
| Discrimination Rate (%) | Preprocessing | MSC | Detrend | MC | SNV | 1st Der | 2nd Der |
|---|---|---|---|---|---|---|---|
| K-NN | Calibration | 100 | 99.80 | 99.90 | 100 | 100 | 100 |
| Testing | 98.84 | 98.61 | 99.30 | 99.07 | 98.84 | 90.50 | |
| LDA | Calibration | 99.30 | 99.53 | 99.53 | 99.76 | 99.53 | 89.68 |
| Testing | 98.80 | 99.00 | 98.90 | 98.61 | 99.00 | 88.65 | |
| LR | Calibration | 98.61 | 98.71 | 98.84 | 98.41 | 98.90 | 90.67 |
| Testing | 98.37 | 98.61 | 98.80 | 98.37 | 98.84 | 88.88 | |
| RF | Calibration | 100 | 100 | 100 | 100 | 100 | 100 |
| Testing | 99.07 | 99.30 | 99.30 | 99.30 | 99.53 | 91.20 | |
| SVM | Calibration | 99.30 | 99.30 | 99.53 | 99.20 | 99.53 | 95.53 |
| Testing | 99.07 | 99.07 | 99.40 | 98.84 | 99.20 | 91.89 |
| Models | Total Millet Samples | Discrimination Rate (%) | ||
|---|---|---|---|---|
| Calibration Set | Prediction Set | Calibration Set | Prediction Set | |
| K-NN | 1008 | 432 | 99.90 | 99.30 |
| LDA | 1008 | 432 | 99.53 | 99.00 |
| LR | 1008 | 432 | 98.90 | 98.84 |
| RF | 1008 | 432 | 100 | 99.53 |
| SVM | 1008 | 432 | 99.53 | 99.40 |
| Models | Precision | Recall | F-Score |
|---|---|---|---|
| K-NN | 0.992 | 0.990 | 0.991 |
| LDA | 0.995 | 0.995 | 0.995 |
| LR | 0.988 | 0.988 | 0.988 |
| RF | 0.995 | 0.995 | 0.995 |
| SVM | 0.995 | 0.995 | 0.995 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabir, M.H.; Guindo, M.L.; Chen, R.; Liu, F. Geographic Origin Discrimination of Millet Using Vis-NIR Spectroscopy Combined with Machine Learning Techniques. Foods 2021, 10, 2767. https://doi.org/10.3390/foods10112767
Kabir MH, Guindo ML, Chen R, Liu F. Geographic Origin Discrimination of Millet Using Vis-NIR Spectroscopy Combined with Machine Learning Techniques. Foods. 2021; 10(11):2767. https://doi.org/10.3390/foods10112767
Chicago/Turabian StyleKabir, Muhammad Hilal, Mahamed Lamine Guindo, Rongqin Chen, and Fei Liu. 2021. "Geographic Origin Discrimination of Millet Using Vis-NIR Spectroscopy Combined with Machine Learning Techniques" Foods 10, no. 11: 2767. https://doi.org/10.3390/foods10112767
APA StyleKabir, M. H., Guindo, M. L., Chen, R., & Liu, F. (2021). Geographic Origin Discrimination of Millet Using Vis-NIR Spectroscopy Combined with Machine Learning Techniques. Foods, 10(11), 2767. https://doi.org/10.3390/foods10112767