Enhancing Content Discovery of Open Repositories: An Analytics-Based Evaluation of Repository Optimizations


Abstract
Abstract
Data Set
1. Introduction
2. Repository Visibility and Discovery: Related Work
3. Methodology
3.1. Implemented Repository Changes
3.2. Data Collection
4. Results
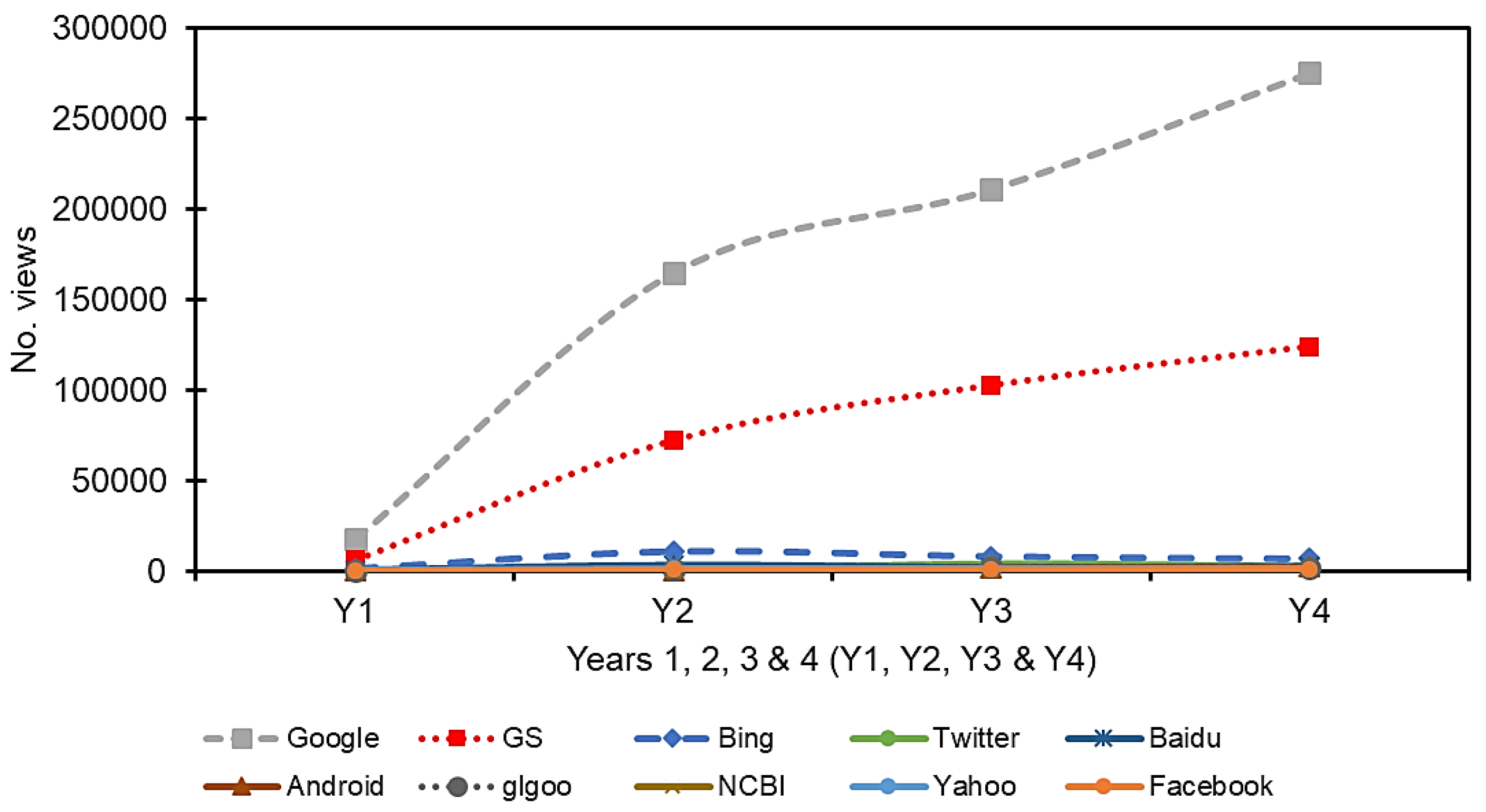
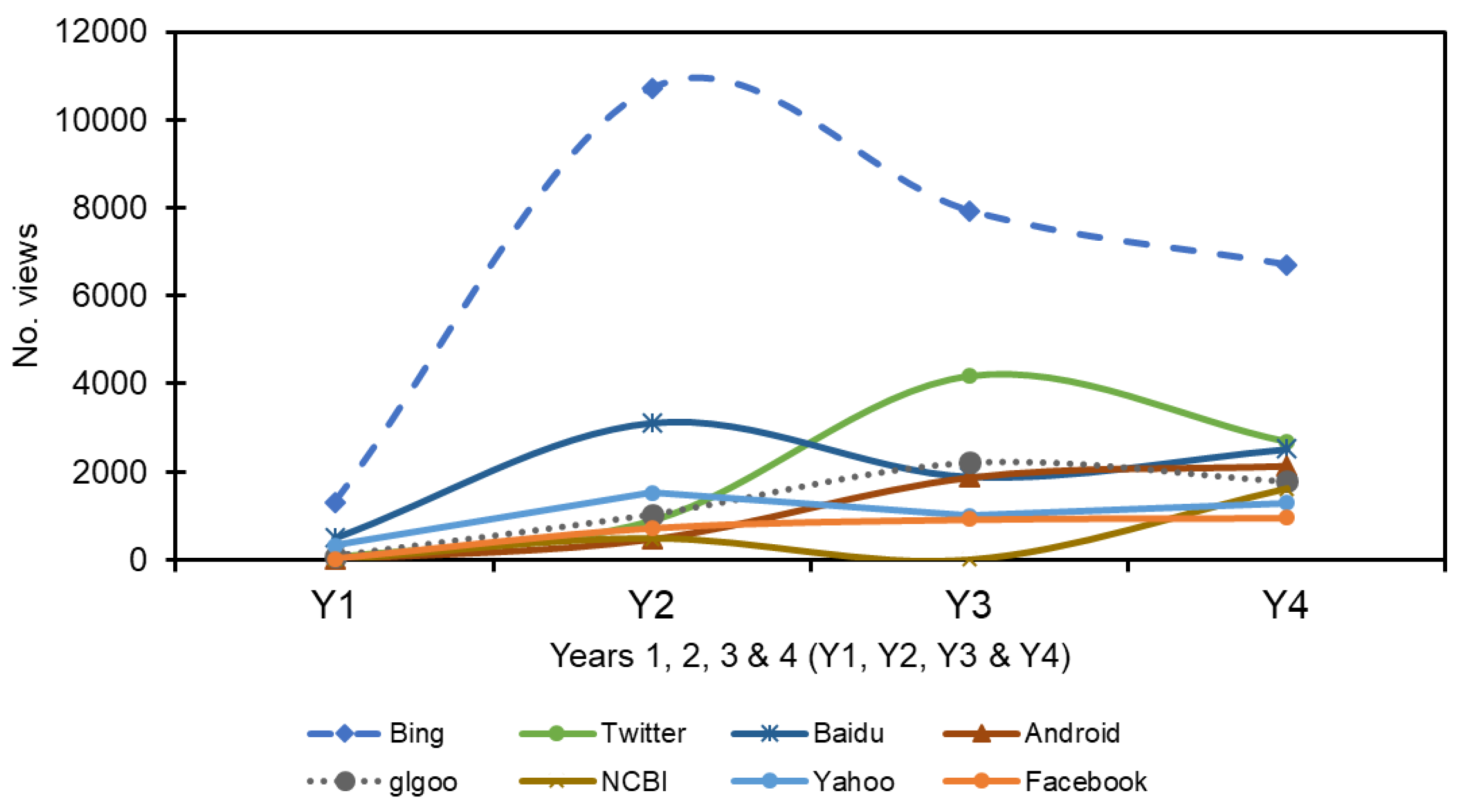
4.1. Analytics
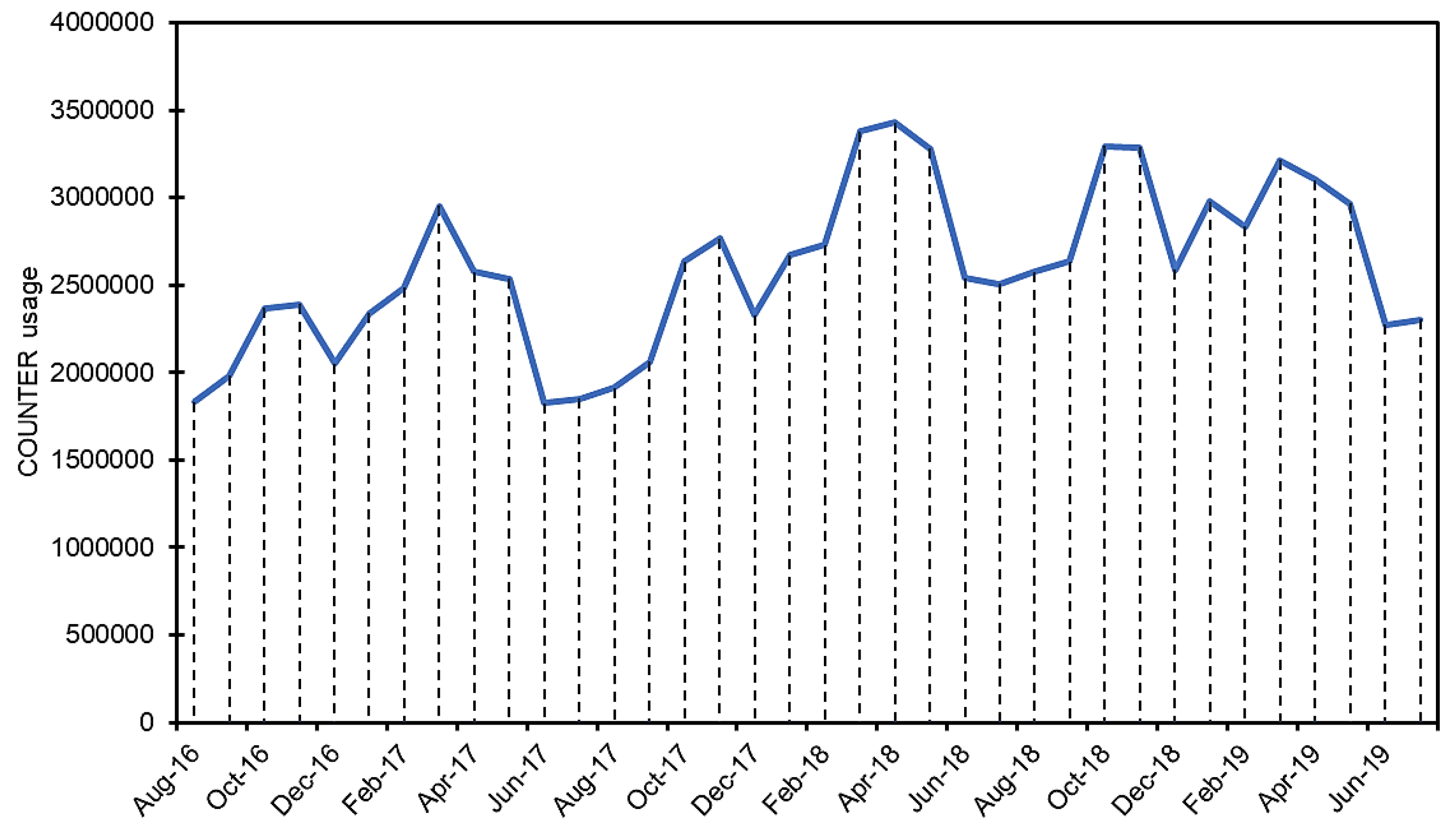
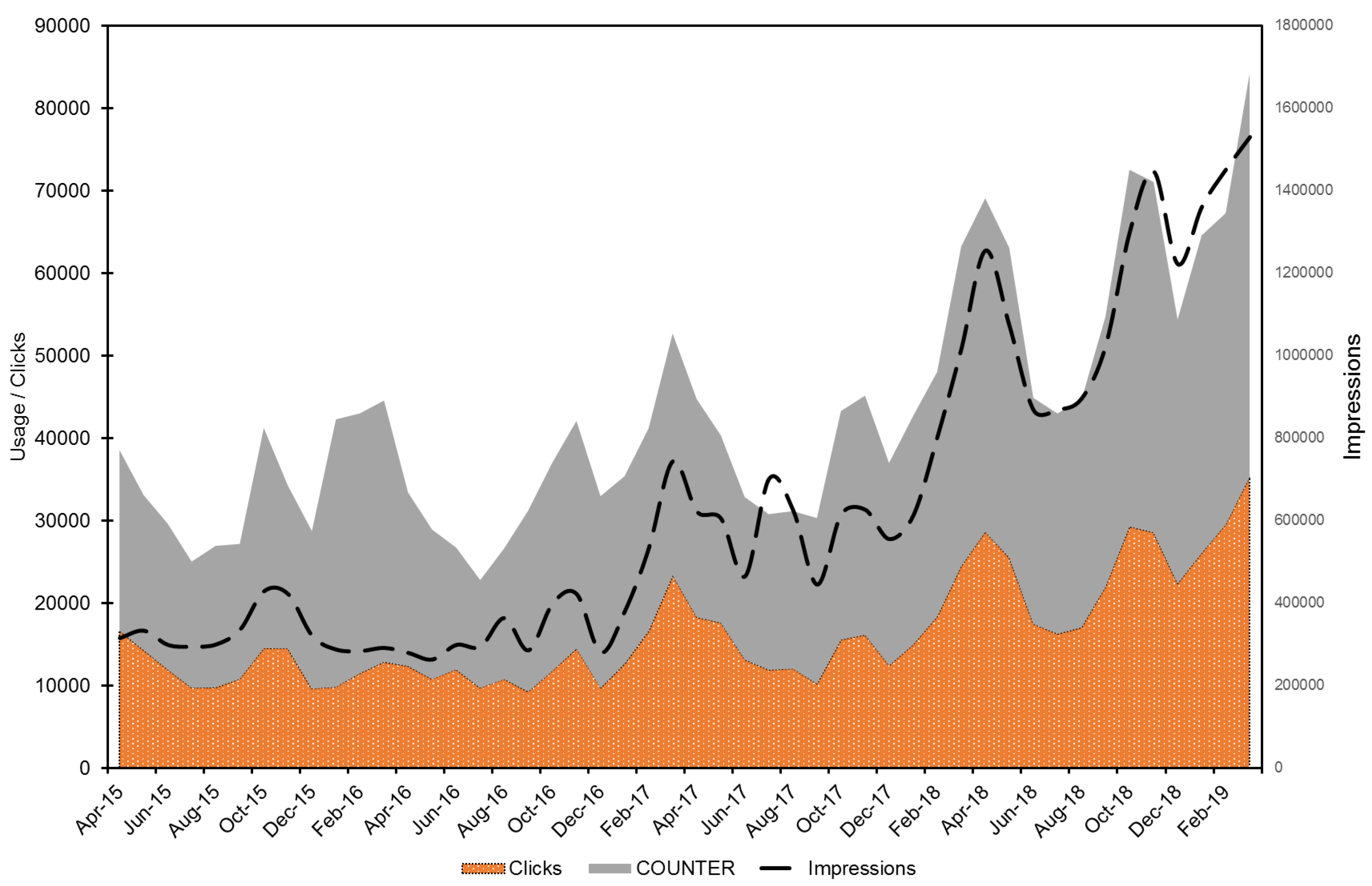
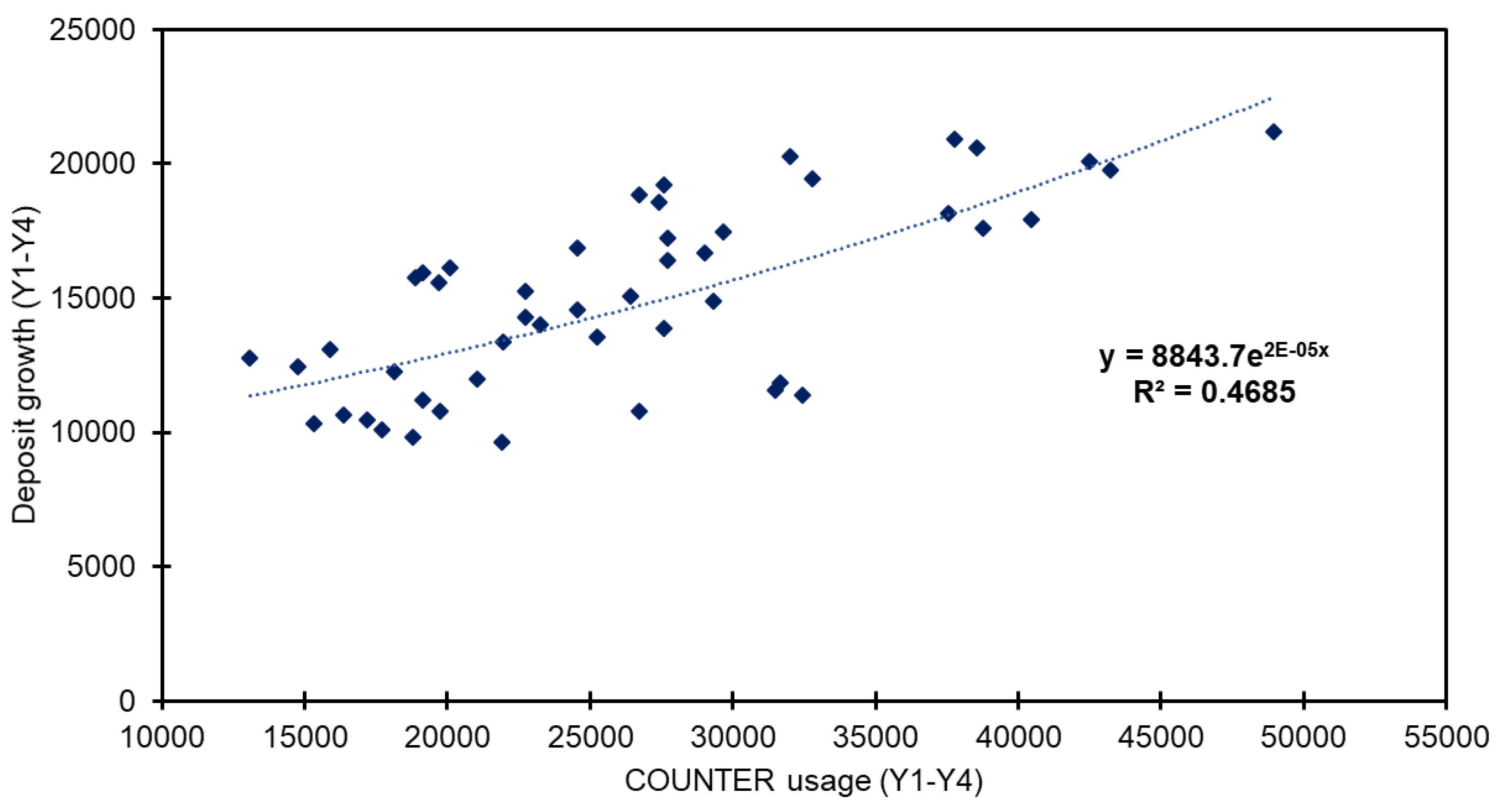
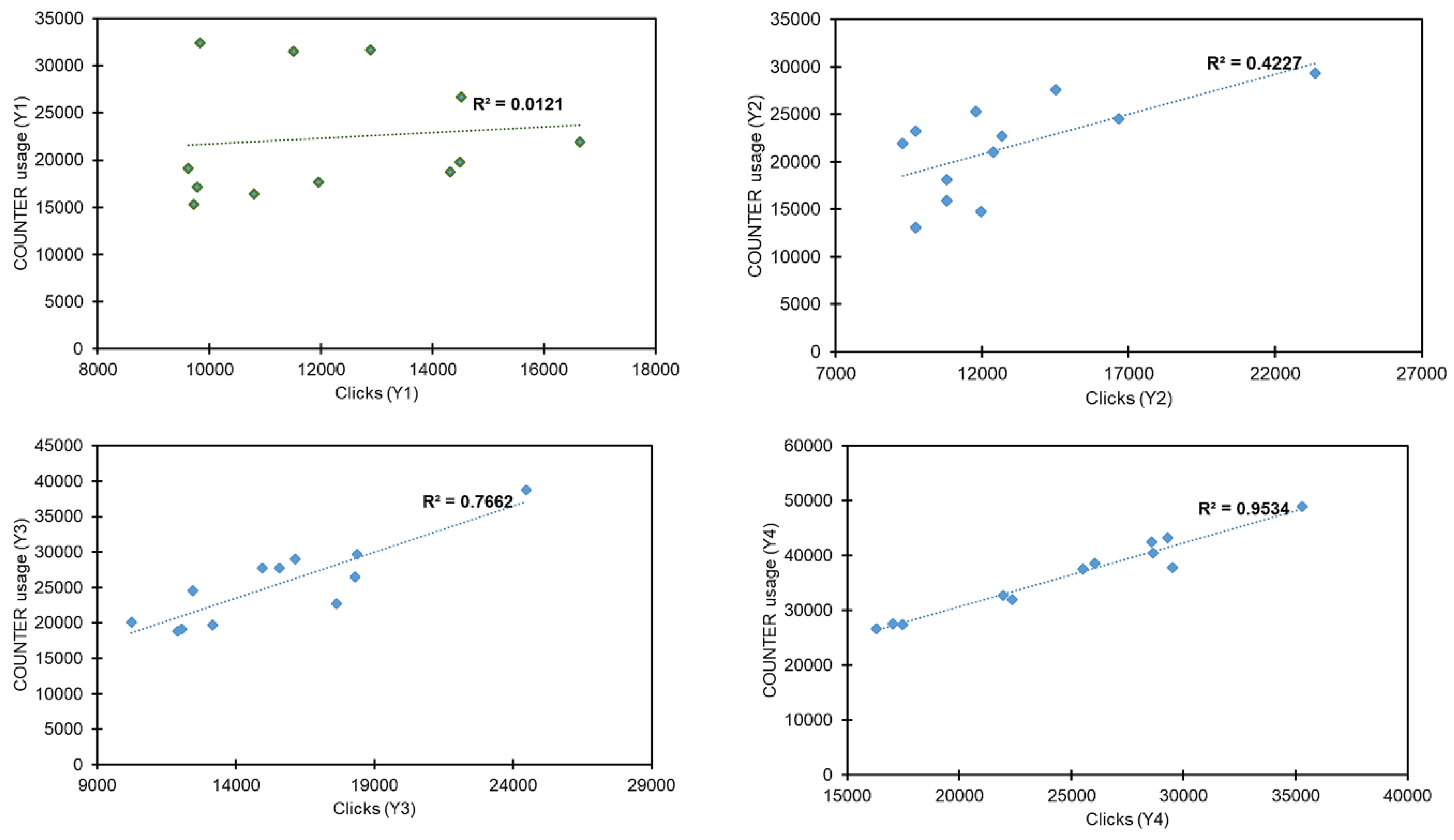
4.2. Repository Content Discovery and Usage
5. Discussion
Limitations
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Pinfield, S.; Salter, J.; Bath, P.A.; Hubbard, B.; Millington, P.; Anders, J.H.S.; Hussain, A. Open-access repositories worldwide, 2005–2012: Past growth, current characteristics, and future possibilities. J. Assoc. Inf. Sci. Technol. 2014, 65, 2404–2421. [Google Scholar] [CrossRef]
- Lynch, C.A. Institutional Repositories: Essential Infrastructure For Scholarship In The Digital Age. Portal: Libr. Acad. 2003, 3, 327–336. [Google Scholar] [CrossRef]
- McKiernan, E.C.; Bourne, P.E.; Brown, C.T.; Buck, S.; Kenall, A.; Lin, J.; McDougall, D.; Nosek, B.A.; Ram, K.; Soderberg, C.K.; et al. How open science helps researchers succeed. eLife 2016, 5, e16800. [Google Scholar] [CrossRef] [PubMed]
- De Castro, P. 7 Things You Should Know about Institutional Repositories, CRIS Systems, and Their Interoperability. 2017. Available online: https://perma.cc/69A4-TSL8 (accessed on 21 May 2019).
- Moore, S.; Gray, J.; Lämmerhirt, D.; Swan, A. PASTEUR4OA Briefing Paper: Infrastructures for Open Scholarly Communication; Technical Report; National Documentation Centre: Athens, Greece, 2016; Available online: http://pasteur4oa.eu/resources/229 (accessed on 20 December 2019).
- Macgregor, G. Repository and CRIS interoperability issues within a ’connector lite’ environment. In Proceedings of the 14th International Conference on Open Repositories (OR2019), Universität Hamburg, Hamburg, Germany, 10–13 June 2019; Available online: https://strathprints.strath.ac.uk/68240/ (accessed on 27 December 2019).
- COAR. Next Generation Repositories: Behaviours and Technical Recommendations of the COAR Next Generation Repositories Working Group; Technical Report; COAR: Göttingen, Germany, 2017; Available online: https://www.coar-repositories.org/files/NGR-Final-Formatted-Report-cc.pdf (accessed on 21 May 2019).
- Macgregor, G. Improving the discoverability and web impact of open repositories: Techniques and evaluation. Code4lib J. 2019. Available online: https://journal.code4lib.org/articles/14180 (accessed on 13 May 2019).
- Arlitsch, K.; OBrien, P. Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar. Libr. Tech. 2012, 30, 60–81. [Google Scholar] [CrossRef]
- Ferreras-Fernández, T.; Merlo-Vega, J.A.; García-Peñalvo, F.J. Impact of Scientific Content in Open Access Institutional Repositories: A Case Study of the Repository Gredos. In Proceedings of the First International Conference on Technological Ecosystem for Enhancing Multiculturality, TEEM ’13, Salamanca, Spain, 14–15 November 2013; ACM: New York, NY, USA, 2013; pp. 357–363. [Google Scholar] [CrossRef]
- Kelly, B.; Nixon, W. SEO Analysis of Institutional Repositories: What’s the Back Story? Open Repositories 2013. Available online: http://opus.bath.ac.uk/35871/ (accessed on 19 July 2019).
- Pekala, S. Microdata in the IR: A Low-Barrier Approach to Enhancing Discovery of Institutional Repository Materials in Google. Code4lib J. 2018. Available online: https://journal.code4lib.org/articles/13191 (accessed on 13 August 2018).
- Aguillo, I. Altmetrics of the Open Access Institutional Repositories: A Webometrics Approach. In Proceedings of the 23rd International Conference on Science and Technology Indicators (STI 2018), Leiden, The Netherlands, 12–14 September 2018; pp. 159–169. [Google Scholar]
- Aguillo, I.F. TRANSPARENT RANKING: Institutional Repositories by Google Scholar. 2019. Available online: http://repositories.webometrics.info/en/institutional (accessed on 26 December 2019).
- Müller, U.; Scholze, F.; Arning, U.; Bange, D.; Beucke, D.; Hartmann, T.; Korb, N.; Meinecke, I.; Pampel, H.; Schirrwagen, J.; et al. DINI Certificate for Open Access Repositories and Publication Services 2016; Humboldt-Universität zu Berlin: Berlin, Germany, 2017. [Google Scholar] [CrossRef]
- Arlitsch, K. Driving Traffic to Institutional Repositories: How Search Engine Optimization can Increase the Number of Downloads from IR. Zenodo 2017. [Google Scholar] [CrossRef]
- Askey, D.; Arlitsch, K. Heeding the Signals: Applying Web best Practices when Google recommends. J. Libr. Adm. 2015, 55, 49–59. [Google Scholar] [CrossRef]
- Arlitsch, K.; OBrien, P. Introducing the “Getting Found” Web Analytics Cookbook for Monitoring Search Engine Optimization of Digital Repositories. Qual. Quant. Methods Libr. (QQML) 2015, 4, 947–953. Available online: https://scholarworks.montana.edu/xmlui/handle/1/9668 (accessed on 22 May 2019).
- OBrien, P.; Arlitsch, K.; Mixter, J.; Wheeler, J.; Sterman, L.B. RAMP—The Repository Analytics and Metrics Portal. Libr. Tech. 2017, 35, 144–158. [Google Scholar] [CrossRef]
- Acharya, A. Indexing Repositories: Pitfalls and Best Practices; Indiana University: Bloomington, IN, USA, 2015; Available online: https://media.dlib.indiana.edu/media_objects/9z903008w (accessed on 5 September 2018).
- Tonkin, E.L.; Taylor, S.; Tourte, G.J.L. Cover sheets considered harmful. Inf. Serv. Use 2013, 33, 129–137. [Google Scholar] [CrossRef]
- Bull, S.; Beh, E. Release 5 of the COUNTER Code of Practice. Ser. Libr. 2018, 74, 179–186. [Google Scholar] [CrossRef]
- Wood-Doughty, A.; Bergstrom, T.; Steigerwald, D.G. Do Download Reports Reliably Measure Journal Usage? Trusting the Fox to Count Your Hens? Coll. Res. Libr. (C andRl) 2019, 80. [Google Scholar] [CrossRef]
- MacIntyre, R.; Needham, P.; Lambert, J.; Alcock, J. Measuring the Usage of Repositories via a National Standards-based Aggregation Service: IRUS-UK. In New Avenues for Electronic Publishing in the Age of Infinite Collections and Citizen Science: Scale, Openness and Trust: Proceedings of the 19th International Conference on Electronic Publishing; IOS Press: Amsterdam, The Netherlands, 2015; pp. 83–92. [Google Scholar] [CrossRef]
- Macgregor, G. Reviewing Repository Discoverability: Approaches to Improving Repository Visibility and Web Impact. 2017. Available online: https://strathprints.strath.ac.uk/61333/ (accessed on 3 August 2018).
- Wang, Z.; Phan, D. Using Page Speed in Mobile Search Ranking. 2018. Available online: https://perma.cc/8QKP-NE5S (accessed on 3 August 2018).
- Zhang, F. Rolling Out Mobile-First Indexing. 2018. Available online: https://docs.lib.purdue.edu/libf (accessed on 22 January 2020).
- Jayasankar, S. Our Approach to Mobile-Friendly Search. 2015. Available online: https://perma.cc/5EQQFCGC (accessed on 22 January 2020).
- Google. Google Search Console. 2019. Available online: https://www.google.com/webmasters/tools/home (accessed on 13 May 2019).
- Macgregor, G. Supporting dataset for: Repository optimisation and techniques to improve discoverability and web impact: An evaluation. Dataset 2018. [Google Scholar] [CrossRef]
- Rowlands, I.; Nicholas, D.; Williams, P.; Huntington, P.; Fieldhouse, M.; Gunter, B.; Withey, R.; Jamali, H.R.; Dobrowolski, T.; Tenopir, C. The Google generation: the information behaviour of the researcher of the future. Aslib Proc. 2008, 60, 290–310. [Google Scholar] [CrossRef]
- CSIC. Transparent Ranking: Institutional Repositories by Google Scholar (May 2019)|Ranking Web of Repositories. 2019. Available online: https://repositories.webometrics.info/en/institutional (accessed on 10 August 2018).
- OBrien, P.; Arlitsch, K.; Sterman, L.B.; Mixter, J.; Wheeler, J.; Borda, S. Undercounting File Downloads from Institutional Repositories. J. Libr. Adm. 2016, 56, 1–24. Available online: https://scholarworks.montana.edu/xmlui/handle/1/9943 (accessed on 13 August 2018). [CrossRef][Green Version]
- Cisco Systems, I. Cisco Visual Networking Index: Forecast and Trends, 2017–2022; White Paper; Cisco Systems, Inc.: San Jose, CA, USA, 2019; Available online: https://perma.cc/9D9X-Y7MZ (accessed on 26 December 2019).
| 1. | Strathprints: https//:strathprints.strath.ac.uk/ |
| 2. | Google Search Console: https://www.google.com/webmasters/tools/home |
| 3. | IRUS-UK: https://irus.jisc.ac.uk/ |
| 4. | Google Analytics: https://analytics.google.com/ |
| 5. | Interquartile range has been omitted owing to the small number of cases. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Key Technical ‘Adjustments’ |
| Modification of file-naming conventions |
| ‘Minification’ of all relevant repository source files |
| Rationalisation of all CSS and JavaScript (JS) files in order to remove unused rules and variables |
| Asynchronous loading of JS resources |
| Deployment of GZIP compression |
| Image optimization, e.g., compression, use of .webp, etc. |
| Migration to InnoDB as the MySQL storage engine |
| Deployment of Google Data Highlighter |
| Key Technical ‘Improvements’ |
| Repository user interface (UI) improvements |
| ‘Mobile first’, responsive re-engineering of repository to align with new weighting in PageRank, etc. |
| ‘White hat’ improvements, e.g., navigation, hyperlink labels, content improvements promoting user interaction |
| ‘Connector-lite’ ecosystem implemented within repository-CRIS interactions |
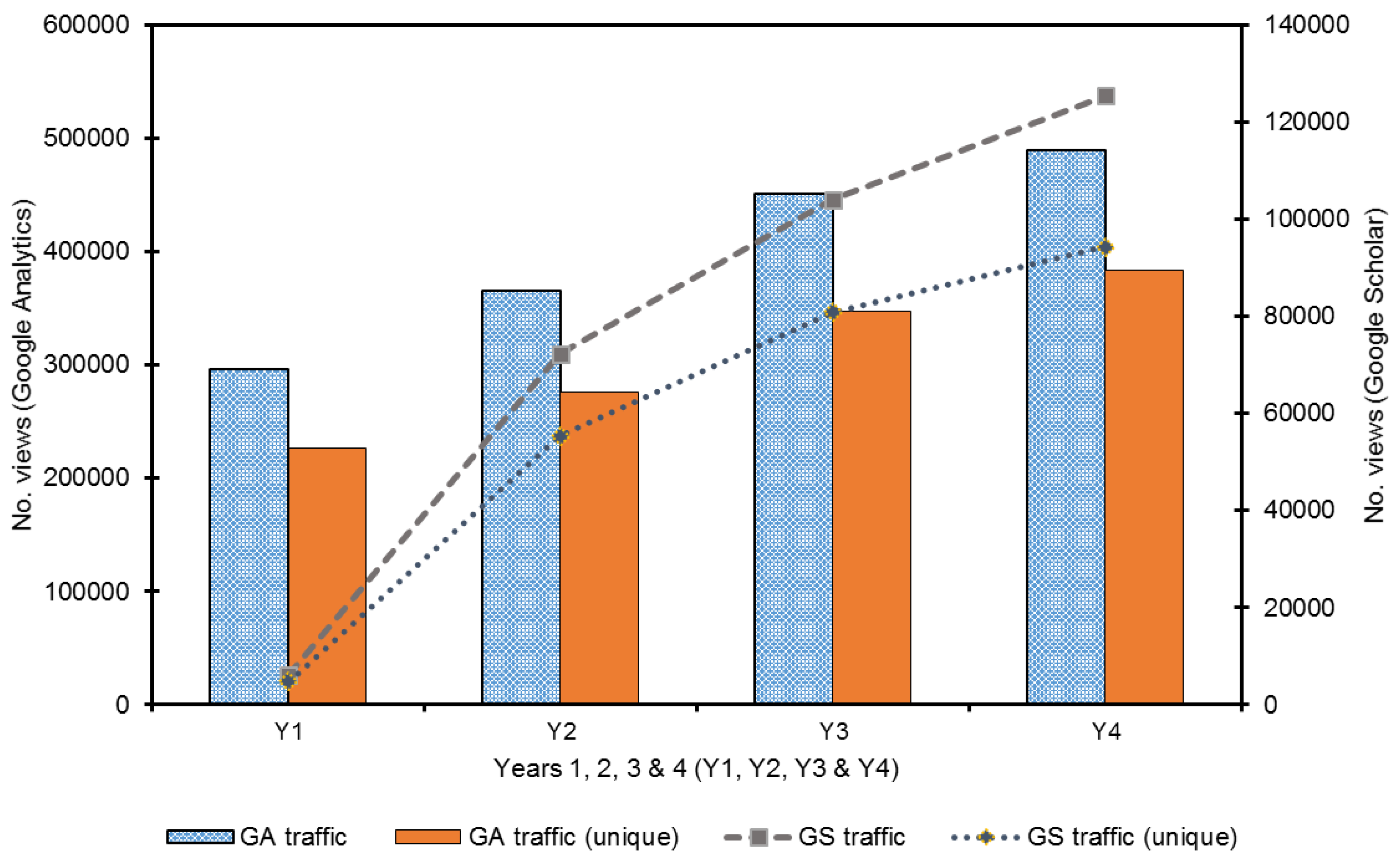
| Total | Unique | Unique Google | GS | Unique GS | ||
|---|---|---|---|---|---|---|
| Y1 | 296,200 | 226,791 | 17,436 | 13,274 | 6208 | 4827 |
| Y2 | 365,024 | 276,042 | 164,550 | 130,565 | 72,179 | 55,294 |
| Y3 | 450,520 | 346,851 | 230,953 | 182,227 | 104,051 | 80,786 |
| Y4 | 489,140 | 383,117 | 274,983 | 217,826 | 125,405 | 94,305 |
| Total Y1–Y4 | 1,600,884 | 1,232,801 | 687,922 | 543,892 | 307,843 | 235,212 |
| % growth (Y2) | 23.24 | 21.72 | 843.74 | 883.61 | 1062.68 | 1045.51 |
| % growth (Y3) | 23.42 | 25.65 | 40.35 | 39.57 | 44.16 | 46.1 |
| % growth (Y4) | 8.57 | 10.46 | 19.06 | 19.54 | 20.52 | 16.73 |
| % growth (Exc. Y1) | 34 | 38.79 | 73.74 | 70.55 | 67.11 | 66.83 |
| Total % growth (Y1–Y4) | 65.14 | 68.93 | 1477.1 | 1541 | 1920.05 | 1853.7 |
| Current Data—A | Total | Unique | GS | Unique GS | Unique Google | |
|---|---|---|---|---|---|---|
| Mean () | 400,221 | 308,200.3 | 76,960.75 | 58,803 | 171,980.5 | 135,973 |
| Standard deviation () | 86,594.41 | 70,161.76 | 51,992.13 | 39,451.94 | 112,585.5 | 89,300.31 |
| Prior Data—B | Total | Unique | GS | Unique GS | Unique Google | |
| Mean () | 386,908 | 296,311 | 83,569.33 | 63,691.33 | 196,783.67 | 154,834.67 |
| Standard deviation () | 95,203.59 | 73,250.7 | 27,735.22 | 22,046.71 | 50,429.38 | 38,672.46 |
| Current Data—A* | Total | Unique | GS | Unique GS | Unique Google | |
| Mean () | 434,894.67 | 335,336.67 | 100,545 | 76,795 | 223,495.33 | 176,872.67 |
| Standard deviation () | 63,516.21 | 54,458.23 | 26,785.65 | 19,809.36 | 55,592.94 | 43,876.21 |
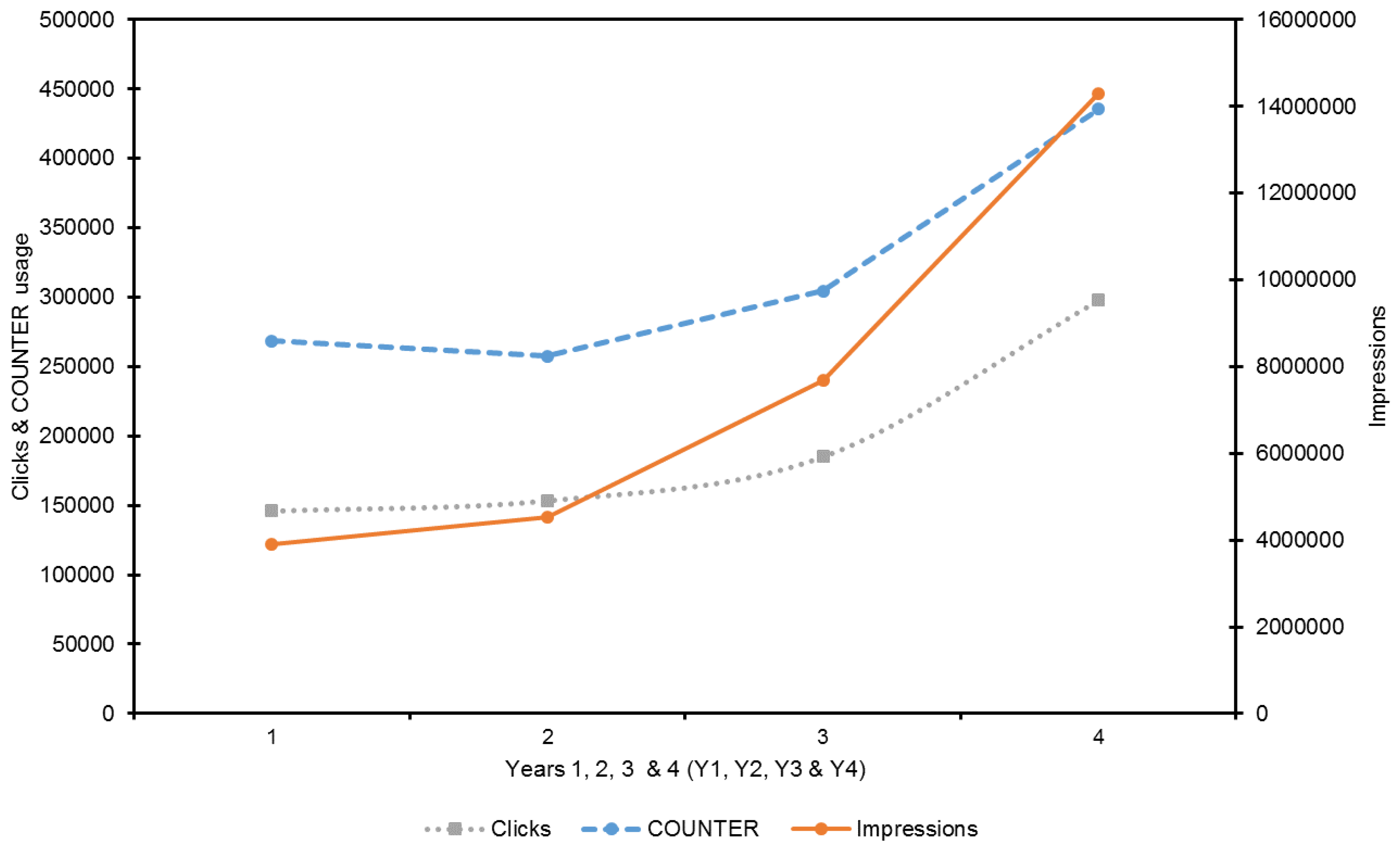
| Impressions | Clicks | Usage | Deposits (OA) | Deposits (OA and Emb.) | |
|---|---|---|---|---|---|
| Sub-total (Y1) | 3,903,830 | 146,064 | 268,453 | 2326 | 2346 |
| Sub-total (Y2) | 4,537,744 | 153,539 | 257,560 | 2978 | 3074 |
| Sub-total (Y3) | 7,687,550 | 185,232 | 304,327 | 2314 | 3010 |
| Sub-total (Y4) | 14,290,059 | 298,020 | 435,467 | 2861 | 3620 |
| Total (Y1–Y4) | 30,419,183 | 782,855 | 1,265,807 | 10,479 | 12,050 |
| % growth (Y2) | 16.24 | 5.12 | −4.06 | 28.03 | 31.03 |
| % growth (Y3) | 69.41 | 20.64 | 18.16 | −22.3 | −2.08 |
| % growth (Y4) | 85.89 | 60.89 | 43.09 | 23.64 | 20.27 |
| Total % (Y1–Y4) | 266.05 | 104.03 | 62.21 | 23 | 54.31 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macgregor, G. Enhancing Content Discovery of Open Repositories: An Analytics-Based Evaluation of Repository Optimizations. Publications 2020, 8, 8. https://doi.org/10.3390/publications8010008
Macgregor G. Enhancing Content Discovery of Open Repositories: An Analytics-Based Evaluation of Repository Optimizations. Publications. 2020; 8(1):8. https://doi.org/10.3390/publications8010008
Chicago/Turabian StyleMacgregor, George. 2020. "Enhancing Content Discovery of Open Repositories: An Analytics-Based Evaluation of Repository Optimizations" Publications 8, no. 1: 8. https://doi.org/10.3390/publications8010008
APA StyleMacgregor, G. (2020). Enhancing Content Discovery of Open Repositories: An Analytics-Based Evaluation of Repository Optimizations. Publications, 8(1), 8. https://doi.org/10.3390/publications8010008