1. Introduction
Recent developments and the growing accessibility of generative artificial intelligence (AI) tools have had a significant impact on the higher education sector, opening remarkable opportunities for the use of new technology, while also forcing the community to re-examine traditional approaches to issues such as academic integrity and transparent science [
1,
2]. Generative Pre-Trained Transformer (ChatGPT 3.5) is a statistical model for generating new data based on variable relationships in a dataset. It is a specific application of a large language model (LLM), which represents a neural network trained on a large dataset. Its natural language processing capabilities enable it to generate well-structured text, written in fluent language, and based on input prompts.
Essentially, ChatGPT is a chatbot capable of remarkable simulation of human conversation and work, utilising the vast amount of data on which it has been trained. The underlying algorithms enable it to provide coherent responses to questions by filling in data from predetermined datasets. This means that ChatGPT, as a form of generative AI, creates content by combining a variety of information to provide responses to user requests.
In the context of higher education, technology initially raised concerns primarily regarding traditional assessment methods, such as written assignments and standardised tests [
3]. At the formal level, recommendations have been developed for higher education institutions with basic guidelines on the use of ChatGPT in higher education and its application in teaching and learning, administration, and community involvement. Proposed solutions, in addition to providing clear guidance for students and instructors and reviewing and updating policies relating to academic integrity, also include updating higher education courses to include AI literacy and core AI competencies and skills. When choosing to use AI technology in higher education institutions, an important factor to consider is open-source access [
4]. In terms of potential opportunities for educators, higher education faculties are encouraged to adapt their instructional strategies, using ChatGPT in flipped learning and student-centred approaches. Innovative assessment tasks should focus on students’ creative and critical thinking abilities, rather than devising AI-proof solutions [
3]. Students should be provided with clear guidance and expectations for using chatbots responsibly, including proper attribution and ethical considerations [
5].
Considering the role of academic libraries in this rapidly changing information landscape, discussions have focused on understanding the future possibilities of AI text generators and the possible impact on library services. The limitations concerning training data, bias, and false information are emphasised as concepts crucial for information professionals [
6]. The natural language processing abilities of ChatGPT could be used to improve search and discovery, reference and information services, cataloguing, metadata generation, and content creation [
7]. Suggested applications of ChatGPT in academic libraries include the creation of virtual assistants, complementing reference services (such as a simulated reference librarian), improving user experience, the selective dissemination of information, optimising collection development, and copy cataloguing. ChatGPT technology offers possibilities for integration into library discovery tools and simplifying repetitive aspects of the research process. Academic librarians can use the content generation abilities of the tool in lesson planning and the creation of open educational resources (OER) [
8,
9].
A whole range of AI-powered commercial applications targeted at the higher education market appeared during the first half of 2023, ranging from literature review apps, research support tools, article summarisers, and content analysers to personalised reading assistants. The management of AI expectations is crucial for academic libraries in light of the overwhelming interest in these tools and products. Consequences faced by library professionals include reshaping their roles and becoming involved in quality assessment, algorithm literacy, the co-development of AI tools, and new search methods [
10]. The persistent problem of the reliability of sources retrieved by ChatGPT can be solved by developing frameworks such as CORE-GPT, which integrates LLMs with a large-scale corpus of open-access full-text scientific articles from Core to provide a reliable and fact-based platform to answer questions [
11].
In this context, it is important to note that mature AI products are costly and require large-scale training data. In addition, developers working in this field are highly trained professionals. Academic libraries, as traditionally underfunded institutions, face the problems of budget, data access, and human resources.
In summary, ChatGPT represents cutting-edge technology in natural language processing and artificial intelligence. By exploring its application in instructional design, this research expands the understanding of how emerging technologies can be integrated into educational contexts. Additionally, aligning with the principles of open educational resources, the research suggests innovative approaches to creating openly licenced resources for information literacy education.
The purpose of this paper is to investigate possible applications of ChatGPT in a small-scale environment and a specific field: instructional design for information literacy courses in academic libraries. The starting point for our research is to use openly licenced informational resources, i.e., ‘content infrastructure’, as facilitators in creating educational resources. It has already been widely recognised that LLMs, which use deep learning techniques to generate text based on prompts, contribute greatly to the speed of creating information resources that comprise the content infrastructure [
12].
Information literacy is a critical skill in the digital age, and academic libraries play a vital role in promoting it. This research addresses the challenge of effectively teaching information literacy by leveraging ChatGPT to create interactive and adaptive learning experiences tailored to individual student needs. Through practical implementation, this research can provide insights into the effectiveness of using ChatGPT in instructional design for information literacy courses. Additionally, research contributes to the establishment of best practices and guidelines for integrating AI technologies into educational settings.
Our study focused on developing a strategy to produce an information literacy syllabus and additional resources using ChatGPT. Using free-of-charge platforms, our objective was to investigate the possibilities of creating content that would represent OER under the common definition [
13]. In this study, we investigated the following questions:
The research questions were addressed in two phases. In the first phase of the study, the ChatGPT model was directed to produce a final text output according to predefined standards and a prompt script. In the second phase, we experimented with introducing a limited corpus of resource documents and designing a small model that could respond to queries.
The prompt script used to train the model, the output generated by this script, and the custom model instructions are all available as
Supplementary Materials accompanying this article.
2. Materials and Methods
2.1. Setting the Methodological Context
Academic libraries serve as central hubs for information dissemination, resource access, and scholarly support within educational institutions. Information literacy plays a central role in this context. Due to technological advancements, the traditional definition of information literacy has been supplemented by a new concept of AI literacy. AI literacy entails a basic understanding of how artificial intelligence and machine learning work: their underlying logic and their limitations [
14]. By studying ChatGPT’s role in instructional practices, this research aims to bridge theory and practice, paving the way for the informed adoption of AI tools.
For the purpose of this study, ChatGPT was chosen over other generative AI tools for several reasons. Firstly, OpenAI’s solution was unveiled in November 2022 and had reached a staggering number of users in the space of a few months. It should be noted that the preliminary phase of this research began in March 2023. Although the generative AI market has exploded since then, the statistics show that ChatGPT was still the most widely used text generation AI tool in the world in 2023, with an approximate 20% share of users [
15]. Secondly, the decision to use ChatGPT was based on the availability of support infrastructure and community knowledge. The growing community of users on the GitHub developer platform offered invaluable advice in the process of experimental setup.
In the first part of the investigation, we adapted the method used by Eager and Brunton [
16]. The method is focused on prompt engineering, i.e., writing effective text-based inputs to guide AI models in generating teaching and learning content. External reviewers, selected based on professional profiles and experience in higher education, are involved in evaluating the generated content. The method of collecting textual responses from reviewers was selected for the purpose of obtaining qualitative insights.
In the second part of the research, our approach was mainly based on testing available tools for the customisation of the chat model. The preparation stage involved the extensive research of available solutions for designing chatbots trained with user-defined content. The fundamental requirement was to find a low-code or no-code method of designing and developing custom applications. The low-code approach enables users to design and create applications using intuitive graphical tools, thus reducing the traditional coding requirements. Users with basic coding skills can use low-code tools to develop and integrate custom applications. In comparison, no-code approaches eliminate the need for programming knowledge, allowing nontechnical users to develop applications without writing any code. The proposed method allows a broader range of users to participate in building similar solutions.
In the experimental design of the custom chatbot model, we used a limited dataset with a focus on a specific topic. The main advantages of using a limited dataset are as follows:
Computational resources: smaller datasets require less computational power for training, which can be advantageous for resource-limited environments;
Storage and processing: limited datasets reduce storage and processing requirements.
2.2. Developing a Strategy to Produce an Information Literacy Syllabus Using ChatGPT
The model training strategy was developed for a specific task and with a specific goal in mind. The key concepts considered were the intended audience, purpose, and tone of the content generated by the model. The four steps of the strategy used in this study were as follows:
Assign the model the role of a subject-matter expert (SME);
Provide the model with context;
Instruct the model to use specific standards and input data;
Instruct the model to use a specific output format.
The task selected for this study was designing information literacy instruction material for a postgraduate course: ‘Academic/Scholarly Writing’, delivered at the University of Split Faculty of Economics, Business and Tourism, as part of the international postgraduate study programme in Economics and Management. The role, context, standards, and output format were developed following a detailed analysis of the course implementation plan.
Role assignment: The model was assigned a role by specifying a particular identity or perspective to ensure that the text generated by the model was relevant and appropriate for the intended audience and purpose. The prompt used for this purpose was ‘Act as an instructional designer’.
Context: Specifying the intended task provided additional context for the model. The prompt used for this purpose was as follows: ‘You are tasked with supporting an academic to design a syllabus for a 1st year PhD course in Academic/Scholarly Writing’.
Standards and input data: The parameters and conditions were introduced using input data from the course implementation plan (number of lecture and seminar hours, percentage of e-learning, course objectives, learning outcomes, course content, and assessment methods) and information literacy standards for higher education [
17].
Output format: The model was instructed to organise the content in a specific format (e.g., modules, short summary, table, etc.).
2.3. Model Training
Training the model was conducted using a prompt script (see the
Supplementary Materials, Document S1). The prompt script contained a linear series of structured prompts or queries of inputs. A systematic approach to communicating with the model is termed ‘prompt engineering’, and includes fine-tuning the questions in order to produce more relevant results and coherent output. The CLEAR framework for incorporating prompt engineering into information literacy instructions suggests the following method to improve AI-generated responses [
18]:
Concise: brevity and clarity in prompts;
Logical: structured and coherent prompts;
Explicit: clear output specifications;
Adaptive: flexibility and customisation in prompts;
Reflective: continuous evaluation and improvement of prompts.
The basic prompts for writing steps include defining specific outcomes and the format and type of content. After testing the initial prompt, the model output was reflected and evaluated. If the results failed to meet the expectations, the prompt was adjusted and the process was repeated. A well-written prompt includes the following components: verbal action, action outcome, task parameters, narrowed topic, alignment with goals, and any constraints or limitations, if applicable [
16]. The prompt script used to train the model contained prompt examples aligned with learning goals, assessment criteria, critical thinking, problem-solving skills, and student engagement and interaction.
2.4. Conducting the Review Process
The evaluation of the final output of the ChatGPT model was carried out by two external reviewers with the following profiles: Academic Library Information Literacy Programme Coordinator and Assistant Professor of English Language. The reviewers received the raw output, without any interventions in the text. The only additions to the ChatGPT output included formatting into paragraphs and tables, for the purpose of facilitating the review process. The reviewers were informed of the purpose of the final document and the use of ChatGPT in the process of its preparation. Reviewers were asked to provide general comments, answering the following questions:
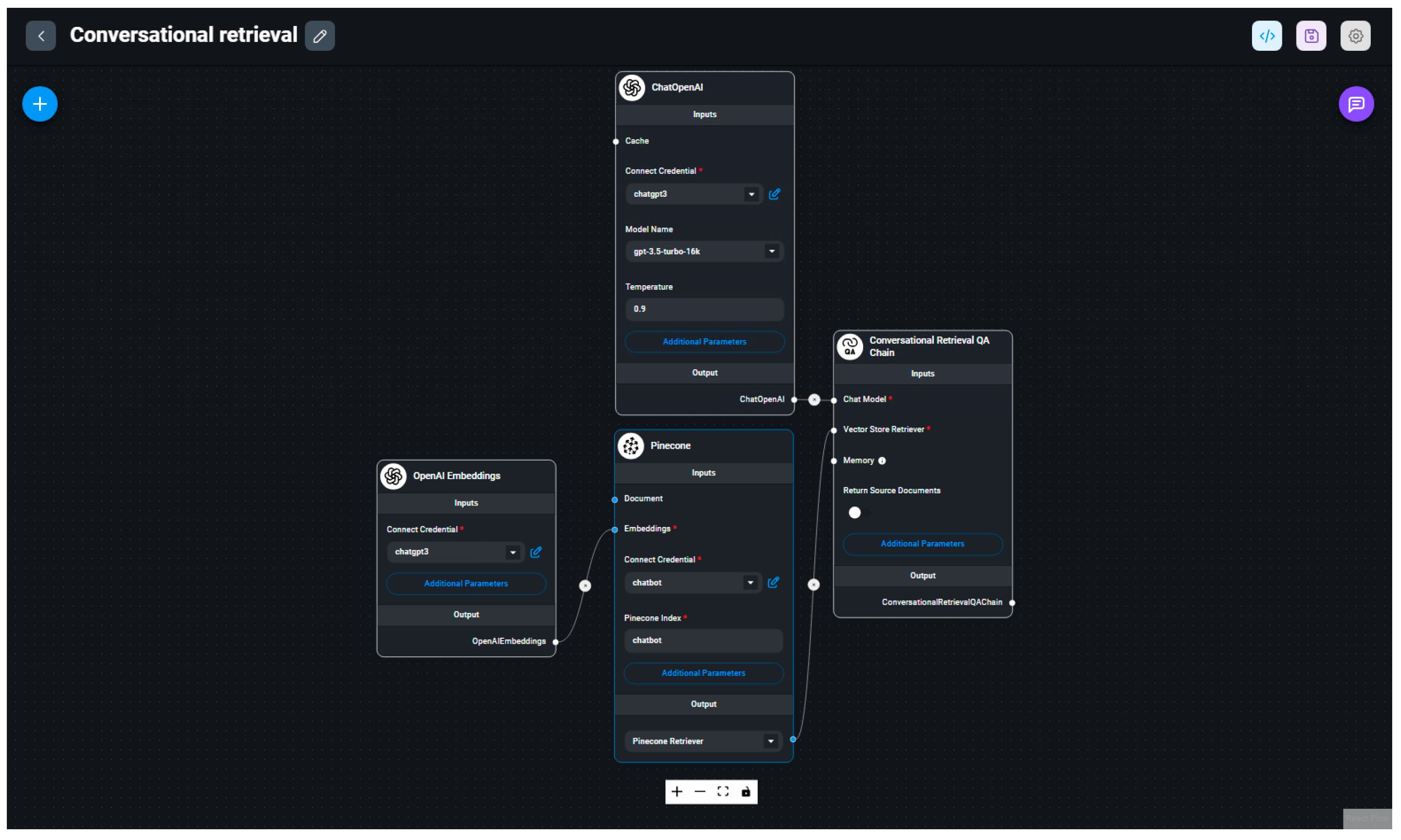
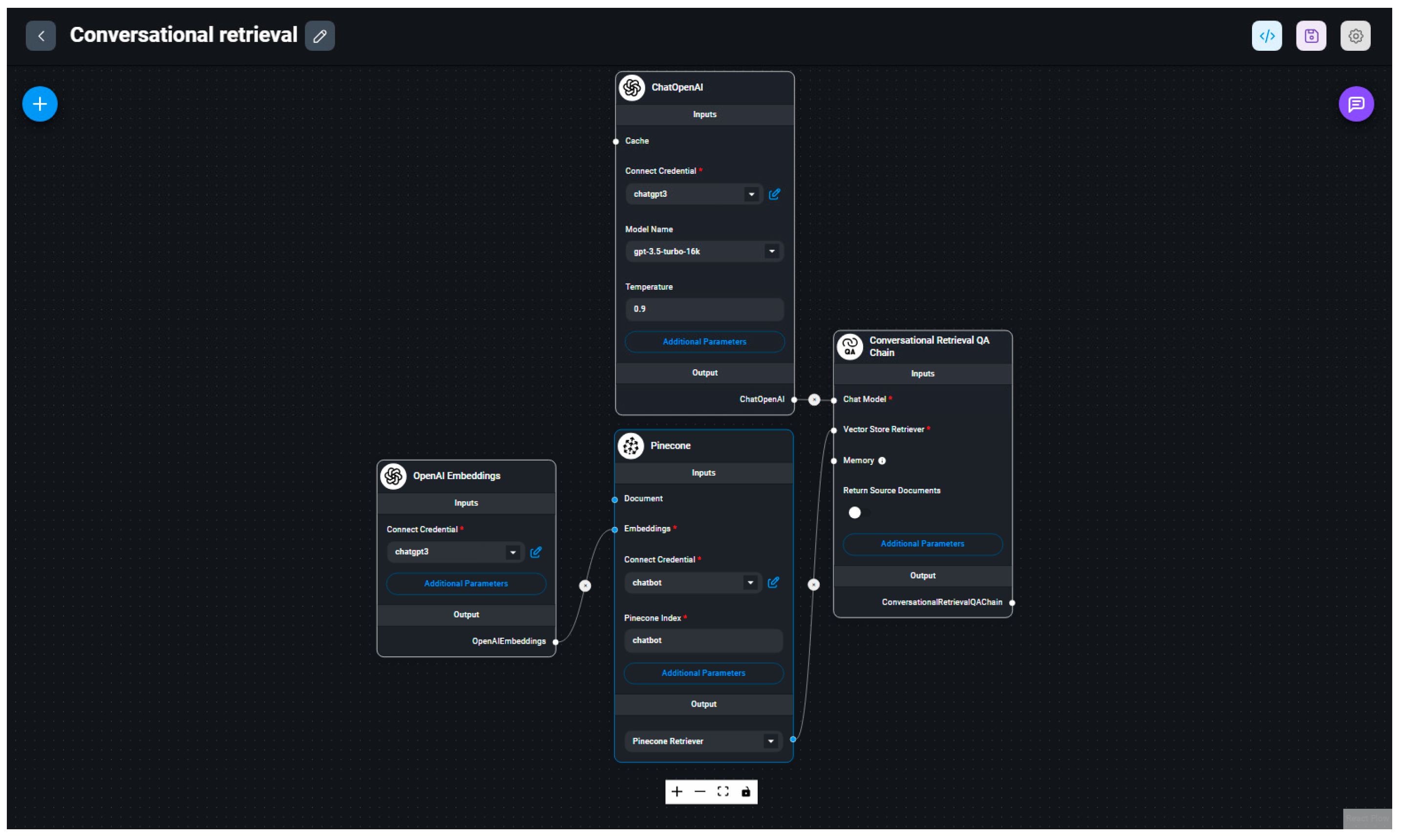
2.5. Developing a Custom Chat Model
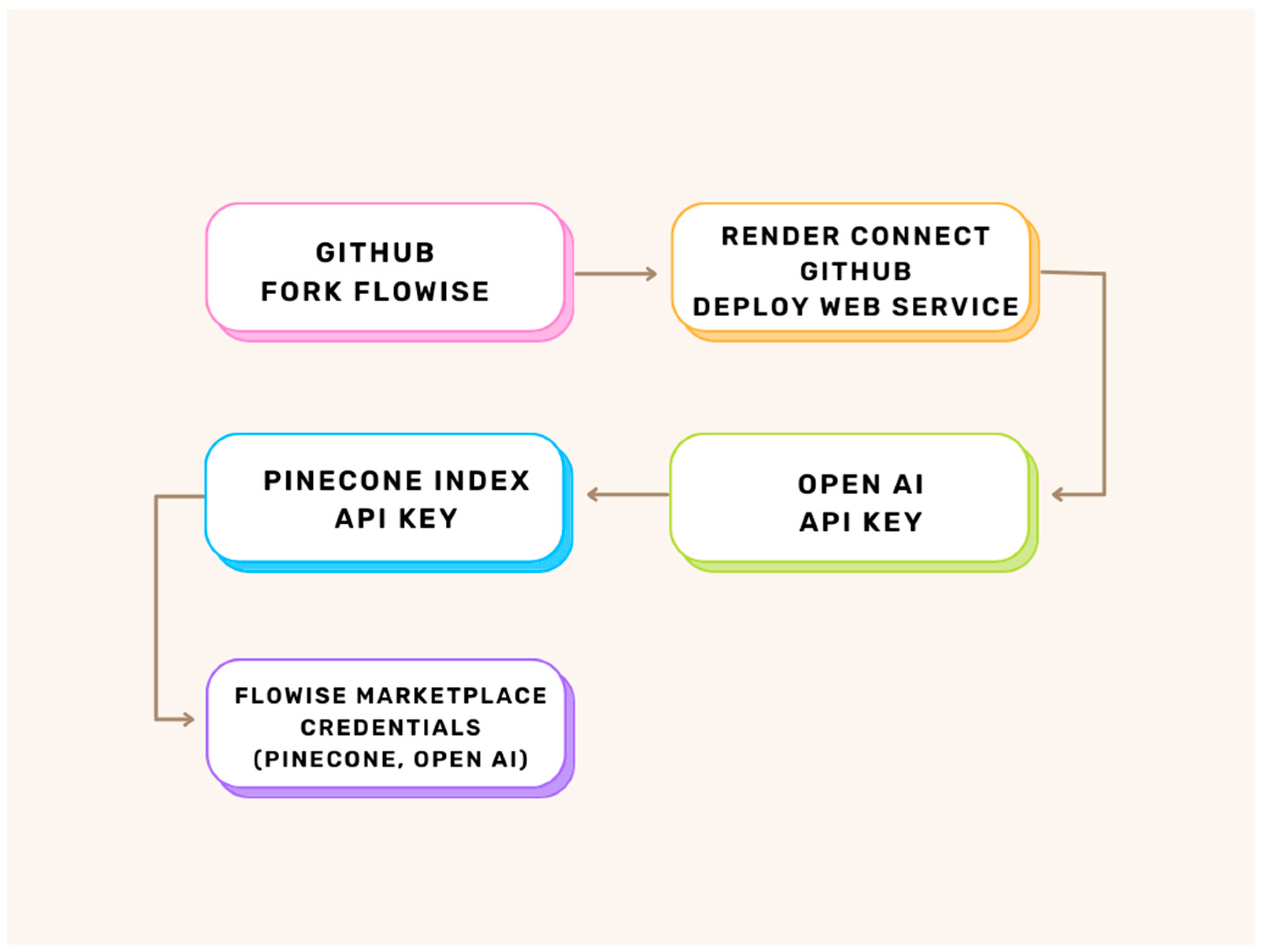
The proposed custom AI chatbot template combines the OpenAI architecture with a limited set of source documents. The selected set of documents is a list of required full textbooks and articles and additional course materials for the course ‘Academic/Scholarly Writing’, in the format of .pdf files. This part of the research was conducted using a GitHub account and applications and services available at no cost through the free plans offered by service providers. For the purpose of creating a custom AI chatbot, the following platforms were used:
Flowise AI: versatile low-code/no-code platform designed to simplify the creation of applications utilizing LLMs. It offers a user-friendly drag-and-drop interface, enabling users to visualize and construct LLM apps with ease (
https://flowiseai.com; accessed on 31 August 2023);
Render: a unified cloud to build and run all apps and websites with free TLS certificates, global CDN, private networks, and auto-deploys from Git (
https://render.com; accessed on 31 August 2023);
Pinecone: a vector-based database that offers high-performance search and similarity matching (
https://www.pinecone.io; accessed on 31 August 2023).
4. Discussion
4.1. ChatGPT as an Instructional Design Tool
In the first part of the study, we investigated how the output of ChatGPT could be used in instructional design. The specific subject of instruction is information literacy in academic libraries. The instructional material produced by ChatGPT was evaluated by experts in the field, as presented in
Section 3. Although earlier studies have explored the possible impacts of ChatGPT in academic libraries [
6,
7], they have not explicitly addressed the instructional potential of the tool.
The feedback from the reviewers highlights both strengths and areas for improvement in the proposed course content. The introduction and objectives are well defined, but some learning outcomes appear redundant. Additionally, clearer criteria for resource selection and improved lecture content are recommended. Overall, the reviewers concluded that the document required editing to match the required postgraduate level.
Our study suggests that instructors may benefit from using ChatGPT as assistive tool in preparing course materials. Compared to the results of the Eager and Brunton case study [
16], our results confirm that exploring features and experimenting with functionalities of ChatGPT is necessary to better understand their capabilities and limitations. In their case study, Eager and Brunton explored the transformative impact of AI-augmented teaching and learning in higher education, emphasizing the need for educators to develop prompt engineering skills to effectively utilize AI tools such as ChatGPT. The authors advocate for the strategic integration of AI and present a case study on AI-assisted assessment design to illustrate practical applications.
The results of the same case study demonstrated a significant time-saving potential of implementing AI-augmented processes in instructional design. However, this point could be argued in terms of the extensive preparation time required for drafting a prompt script that can elicit consistent and contextualised responses from ChatGPT.
In summary, the reviewers concluded that the final output generated by ChatGPT could only be used in the actual classroom environment after careful review and optimisation. Most of the positive comments of the reviewers refer to the structure of sections (course objectives, learning outcomes, workshop plan, and assessment). This was expected, since ChatGPT is trained on a large set of teaching materials and can easily generate lesson plans in an acceptable format. Instructional prompts written in a precise and unambiguous language and including fixed elements such as topic, learning goals, and type of content produced a satisfactory result. In-depth analysis of the text revealed issues concerning the vagueness of phrases generated by ChatGPT and the lack of clarity in defining certain concepts. Despite being instructed to operate as a subject-matter expert on both levels (general settings and role assignment), the model fails to retain the complexity level of the output. The described shortfalls could be resolved by training the model further and adjusting the context, instruction, or constraints.
The results can also be interpreted in the context of open educational resources. In our research, we focused on the integration of ChatGPT into teaching practices as a supportive tool for creating syllabi and lesson plans, which are listed as common open educational resources. We can compare our findings with some of the expectations voiced in the open education community regarding the use of generative AI tools in OER creation process. Lalonde [
19] suggests that educators may shift towards becoming editors who validate and revise AI-generated content, ensuring its accuracy and credibility.
Wiley [
12] anticipates that such tools will reduce the costs associated with drafting OERs, as they can produce reasonable first drafts much more quickly than humans. Although they can support the initial creation process, producing quality content would still require human expertise. Our results have confirmed these expectations. Reviewers’ comments can easily be translated into reflective prompts, guiding the model to produce content that is more appropriate for the context or task. Repeated testing of prompts and iterating the process can give more refined results.
Methods and strategies for prompt engineering presented in this study can be used to prepare personalized lesson plans, tailored specifically to students’ needs and interests. ChatGPT can be used in course design by suggesting optimal course structures, the sequencing of topics, and learning objectives. Instructors can use the presented strategies to create educational content such as quizzes, exercises, and study materials.
Overall, in the dynamic landscape of education, the integration of new technologies holds immense promise for instructional designers. Specifically, the adoption of AI tools introduces a twofold positive impact. First, it significantly enhances efficiency by automating routine tasks, allowing instructional designers to allocate more time to strategic planning and pedagogical considerations. ChatGPT can serve as a dynamic “sounding board”, enabling the rapid prototyping of ideas and immediate feedback. Second, content creation with the assistance of ChatGPT has implications for open educational resources (OERs). However, rigorous evaluation is essential. Designers must assess the accuracy, relevance, and alignment of ChatGPT-generated output with learning objectives. The “four-eyes principle”—collaborative review by multiple experts—ensures the integrity of instructional materials before publication. Looking ahead, empirical research should explore the impact of AI-powered instructional design on student satisfaction and academic self-efficacy. Understanding these links would inform future design practices and ensure that AI-enhanced learning experiences align with educational goals.
4.2. Custom Chatbot Model
Adetayo [
8] mentions several cases of the deployment of chatbots in a library setting, listing examples of virtual reference service chatbots from as early as 2013. These examples fall under the category of traditional chatbots, which are task-specific and rule-based, i.e., producing predefined responses and lacking the ability to handle complex queries or unclear user input. In comparison, ChatGPT offers a variety of unique benefits, including contextual understanding, natural language processing, flexibility, and adaptability.
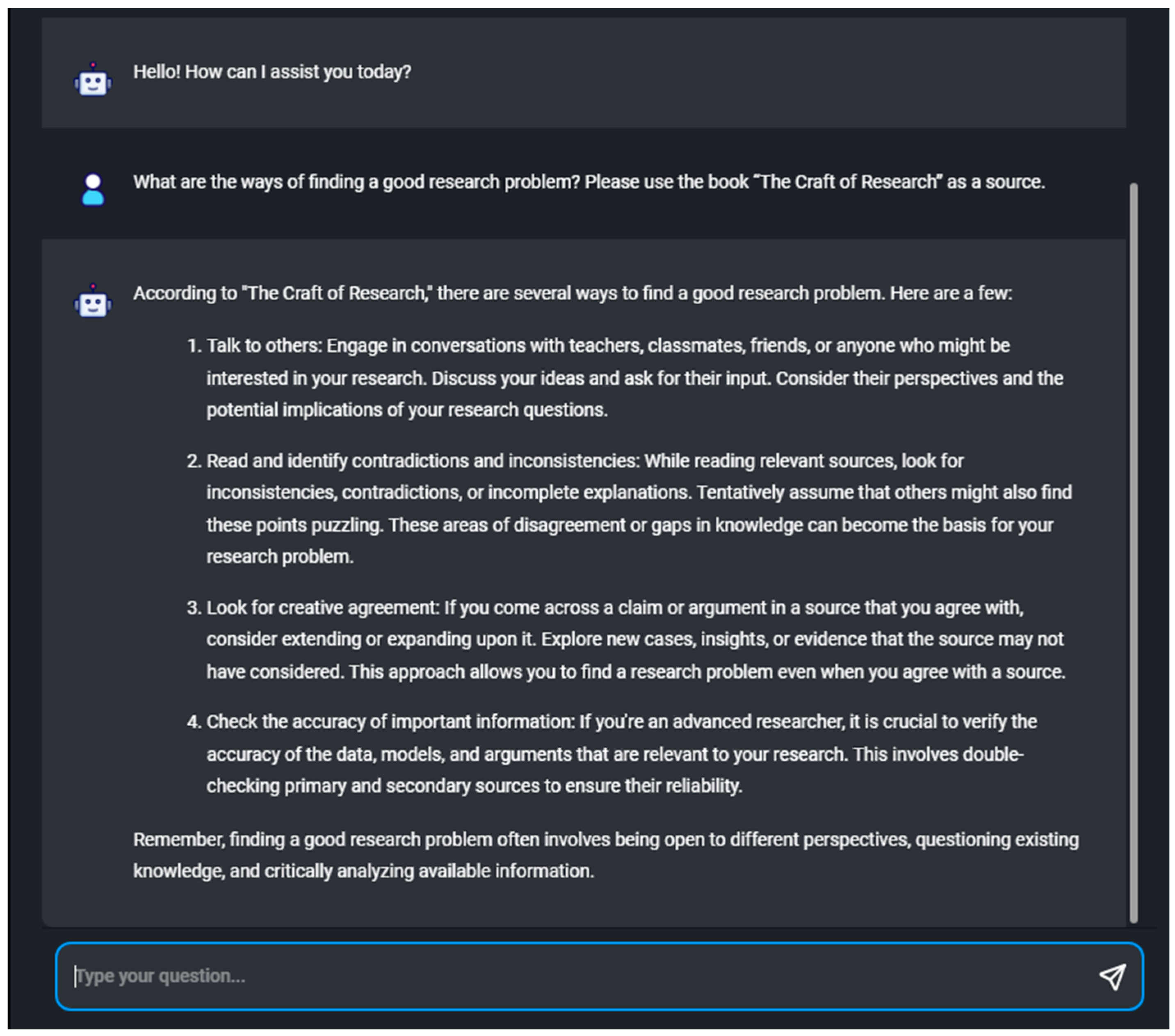
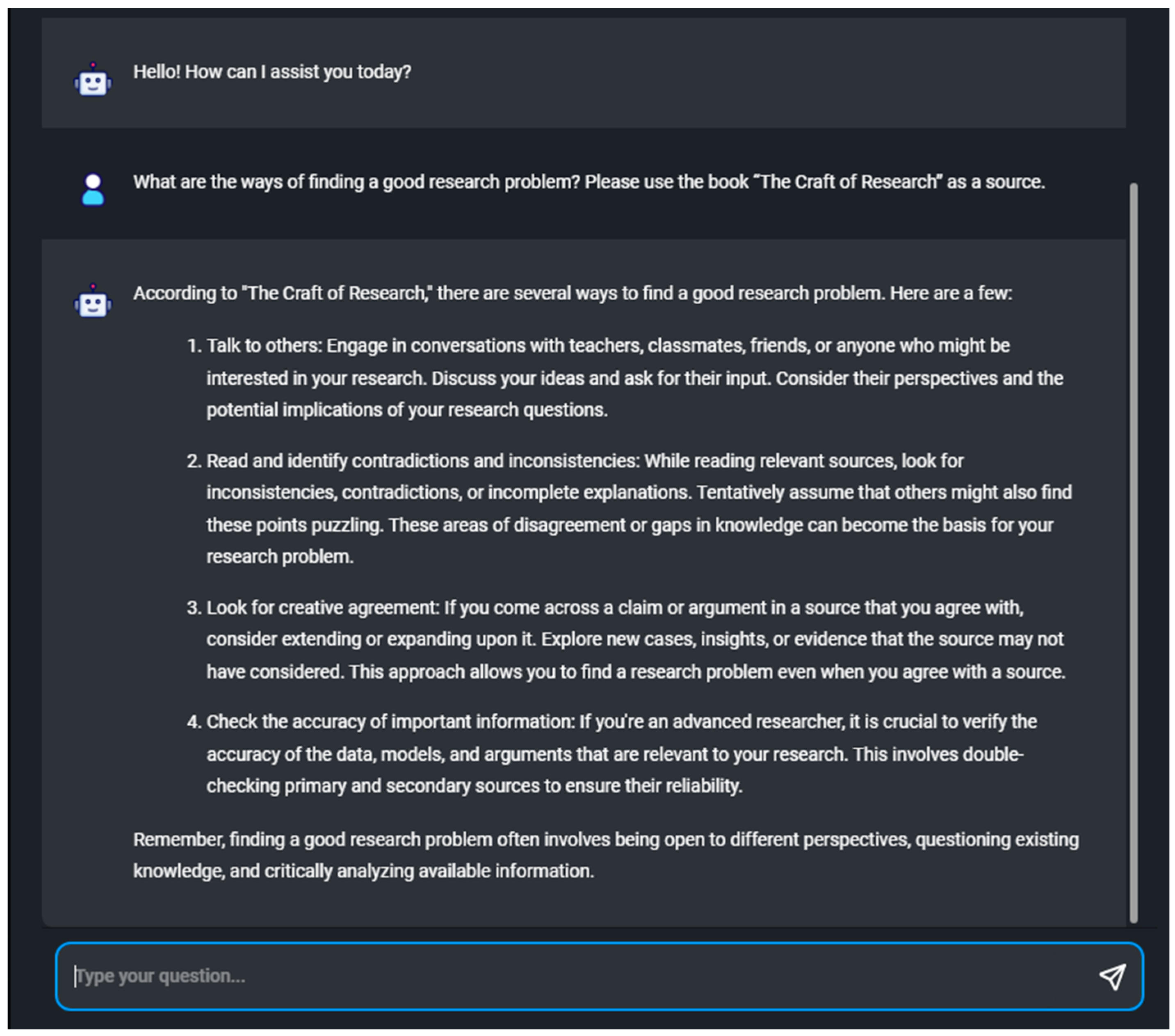
Testing of the custom chatbot model confirmed that ChatGPT can be adapted to retrieve answers from a pre-defined set of source documents. It was found that the chatbot is able to retrieve information from the corpus. Recently developed software development kits enable the embedding of tools for accessing pre-defined custom data. The process requires minimum coding knowledge and could be used as a cost-effective solution for building custom AI chatbots. The most important limitation is the fact that we only used free plans offered by software developers to build the custom chatbot, which have restrictions on storage volume, available tokens, etc. However, the results provide the foundation for the in-house development of applications. The initial idea could be developed even further, depending on the selected text corpus fed into the model, allowing the user ‘to have a conversation with the text’.
More research is needed to investigate how temperature settings and additional parameters influence the behaviour of the chatbot. There are several options available to tweak the configuration [
20]. Temperature is the most common and determines the predictability level of the words generated by the model. A temperature of 0 means that the model will always choose the words with the highest probability of being appropriate. This makes it more likely to produce the same response if the request is repeated, but will be less creative and may appear less natural. Increasing the temperature allows the LLM to consider progressively less probable subsequent words. At really high temperatures, the sampling distribution from which the model is pulling for each word is so large that it tends to produce erratic and even non-sensical results. At a temperature of 2, which is the current maximum for OpenAI’s models, the result becomes disordered and unusable. Generally, a temperature value should be selected on the basis of the desired trade-off between coherence and creativity for a specific application.
The top probability parameter (top_p) is associated with the top-p sampling technique, or nucleus sampling. GPT models generate the next word by assigning probabilities to all possible next words in its vocabulary. With top_p sampling, instead of considering the entire vocabulary, the next word will be sampled from a smaller set of words that collectively have a cumulative probability above the top_p value. The top_p ranges from 0 to 1 (default), and a lower top_p means that the model samples from a narrower selection of words, making the output less random and diverse. Given that top_p impacts output randomness, OpenAI recommends adjusting either top_p or temperature, but not both.
Additional parameters available for a custom-built model are the frequency penalty and the presence penalty. Both parameters address the problem of repetition in generated text and can be used to suppress or increase word frequency, thus impacting the diversity of language use.
4.3. Proper Attribution and the Responsible Use of Content Generated Using ChatGPT
The results of our study should be considered in the context of the proper attribution and responsible use of ChatGPT-generated content. Atlas [
5] discusses best practices for the attribution of ChatGPT in various contexts. The standard requirement for any content used in a higher education setting is to disclose the use of LLM in the acknowledgement section or equivalent. This requirement is also in line with the OpenAI sharing and publication policy, which stipulates that the role of AI must be clearly disclosed for any content co-authored with the OpenAI API. Furthermore, the content must comply with the OpenAI content policy or terms of use.
At the end of April 2023, UNESCO published a quick-start guide [
4] that addresses some of the main challenges and ethical implications of the use of generative artificial intelligence in higher education. The central theme of the document is academic integrity and the urgent need to adapt traditional assessment strategies, only marginally suggesting that teachers, researchers, and students need to be trained on how to improve the queries they pose to ChatGPT. In our study, our objective was to put a more positive spin on the dominant narrative and investigate how instructors can use the tool to improve teaching and learning practices.
In its 2023 position paper on artificial intelligence tools and their responsible use in higher education learning and teaching [
21], the European University Association (EUA) highlights the need to review and reform teaching and assessment practices and adapt them in a such a manner as to ensure that AI is used effectively and appropriately. While urging the academic community to consider the academic integrity, e.g., obligation to reference the use of AI in academic and student work, and recognising the many shortcomings associated with the use of AI, EUA also acknowledges numerous potential benefits for academic work, including improved efficiency, personalised learning, and new ways of working. Our findings support this position, as they provide practical insight into how the model can be applied.
Finally, an interesting example of the implementation of recommendations comes from an independent higher education institution [
22], in the form of guidance on the use of ChatGPT for teaching and learning. Since it is not accepted as a supported tool, if instructors choose to use ChatGPT for their teaching, they assume responsibility for reviewing and vetting concerns with accessibility, privacy, and security. The possibility of privacy and copyright violations is highlighted. The guidelines also include suggestions for teaching strategies, focusing on the limitations of the dataset, concerns about academic dishonesty, and economic and environmental implications. This rather conservative approach does not include any recommendations for instructors on how to explore the benefits offered by ChatGPT. However, this could be interpreted in terms of university policy and the fact that the university renegotiated a system-wide agreement with Microsoft to include Microsoft Azure OpenAI, as a solution offering higher data security and compliance with regulatory requirements.
4.4. AI in Education: Opportunities, Challenges, and Ethical Considerations
If we consider the long-term impact on student learning outcomes, possible benefits for the students may include enhanced user experiences, personalised learning, streamlined searching and study assistance.
According to a survey conducted among undergraduate students in summer 2023 in the United States [
23], 85% of undergraduate students confirmed that they would feel more comfortable using artificial intelligence (AI) tools if they were developed and vetted by trusted academic sources. Furthermore, 65% also agreed that AI will improve how students learn rather than have negative consequences on learning. In this broader context of AI in education, our results validate the need to explore the potential of developing trustworthy and verified content.
While students may embrace the timesaving potential of newly available tools, this could lead to students’ over-reliance on generative AI technology. It is certain that the old assessment schemes will have to be replaced, shifting focus to a student’s process and approach. Instructors will be expected to use more inventive and varied assessment methods. In this context, it should be noted that tools advertised as being able to detect AI writing in student essays have been found to be very unreliable, especially if the authors are non-native English speakers [
24].
The issue of academic integrity is closely associated with AI literacy. We believe that that the focus and the main concepts of information literacy remain unchanged—the reflective discovery of information, the understanding of how information is produced and valued, and the use of information in creating new knowledge and participating ethically in communities of learning [
14]. How to apply these concepts in the new reality, while boundaries related to the use of generative AI tools are continuously shifting, is a challenge to be faced by library professionals. As core institutions of universities, academic libraries are important stakeholders in the innovation activities related to the digital transition of European higher education [
25], focused on the common task of preparing students for the workforce of the future.
5. Conclusions
In this paper, we have presented results of two possible uses of ChatGPT in information literacy instruction in higher education. Firstly, we have outlined a method for producing written teaching material with the assistance of ChatGPT, demonstrating how the model can be used effectively. Secondly, we developed and tested a small-scale custom AI chatbot that can be used as a supplementary teaching tool.
Our research has highlighted the importance of adopting a strategic approach to interacting with LLMs such as ChatGPT, i.e., setting clear goals and defining purposes, context, and constraints of how the model interacts with the user. Prompt engineering remains an exploratory activity that requires a number of iterations. The proposed custom chatbot model provides a starting point, which can be modified for different topics or applications in instructional design.
Some limitations should be considered. Firstly, the current study was not specifically designed to test the user experience or measure student satisfaction with AI-generated instructional material. The custom chatbot model proposed in this study is designed to provide students with immediate and relevant answers to the questions related to the course materials stored in the model database. This form of learning support can motivate students to become more active in the learning process. However, the actual impact on student motivation and academic performance can only be measured by conducting in-class experiments.
Secondly, the custom chatbot model that we tested in our study is a basic configuration with a small workload. Such models can be tested using free plans; however, more serious deployment of any custom chatbot would require proprietary paid solutions. Small-scale models are appropriate for environments such as a single academic course or the testing of capabilities before considering purchasing an AI tool from a vendor. The effective evaluation of such tools requires some knowledge of how the tool was built and is necessary before any institution-wide decision is made.
The findings of this study can be helpful in understanding the collaborative potential of generative AI as a teaching assistant, tasked with planning activities, managing classroom time, and designing performance-based assessments. The method used to design a custom chatbot model can be applied in the instructional design of digital higher education courses and programmes. Considered in a more limited context, ChatGPT can allow academic libraries to bridge the financing gap caused by limited public funding, enabling the in-house development of applications adapted to the specific needs of a library.
Future studies could investigate whether the content produced in this way can meet the quality assurance standards for open educational resources (OERs). Copyright issues and the licencing of remixed content are additional areas that need to be explored further.
The integration of AI in education is approached with a healthy dose of scepticism, which can be summarised in one question: How can we trust the quality of information? The underlying concern is the transparency of data on which the models are trained. The models are vulnerable to biases in the source material or the selection process for training data, affecting the behaviour of models and causing misrepresentations or factual distortions. Additionally, learning and processing algorithms can be used to grant privilege to one group of users or reinforce stereotypes. Privacy and data security may be compromised during interaction with generative AI models, as personal data improve the quality of training models. All these concerns have been continuously voiced and addressed in the academic community since the launch of ChatGPT. As institutions traditionally focused on issues such as diversity, ethics, privacy and fair use, academic libraries occupy a crucial role in developing university frameworks on the use of generative AI tools and establishing policy guidelines. In this process, libraries can serve as meditators and collaborators, while information professionals need to educate their communities on how to navigate the new information landscape.
In conclusion, all stakeholders in the higher education process should be aware that the arrival of generative AI would bring about a paradigm shift comparable to the one we saw with the arrival of the World Wide Web. Therefore, there is a significant need to constructively integrate these tools into higher education instructional practices.






{kind=link}
{kind=link}
{kind=link}