



Evaluation of Chatbot Responses to Text-Based Multiple-Choice Questions in Prosthodontic and Restorative Dentistry

 ,
,  ,
,  ,
,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Question Selection
2.2. Chatbot Selection and Configuration
2.3. Evaluation of the Accuracy of AI-Generated Multiple-Choice Answers
2.4. Evaluation of the Quality of Rationale Accompanying the Multiple-Choice Answers
- Accuracy: Whether the rationale is correct.
- Relevance and comprehensiveness: Whether the rationale directly relates to the question and fully addresses all necessary elements to support the answer.
- Correct Answer, Correct Rationale: The AI chatbot answered accurately and considered all factors correctly, making its response both relevant and comprehensive.
- Correct Answer, Partly Correct/Wrong Rationale: The AI chatbot answered accurately but did not consider all factors correctly, making its rationale either partly or completely irrelevant and/or incomplete.
- Wrong Answer, Correct Rationale: The AI chatbot answered incorrectly but considered all factors correctly, making its rationale relevant and comprehensive.
- Wrong Answer, Partly Correct/Wrong Rationale: The AI chatbot answered incorrectly and did not consider all factors correctly, making its rationale either partly or completely irrelevant and/or incomplete.
2.5. Statistical Analysis
3. Results
3.1. Accuracy of AI-Generated Multiple-Choice Answers
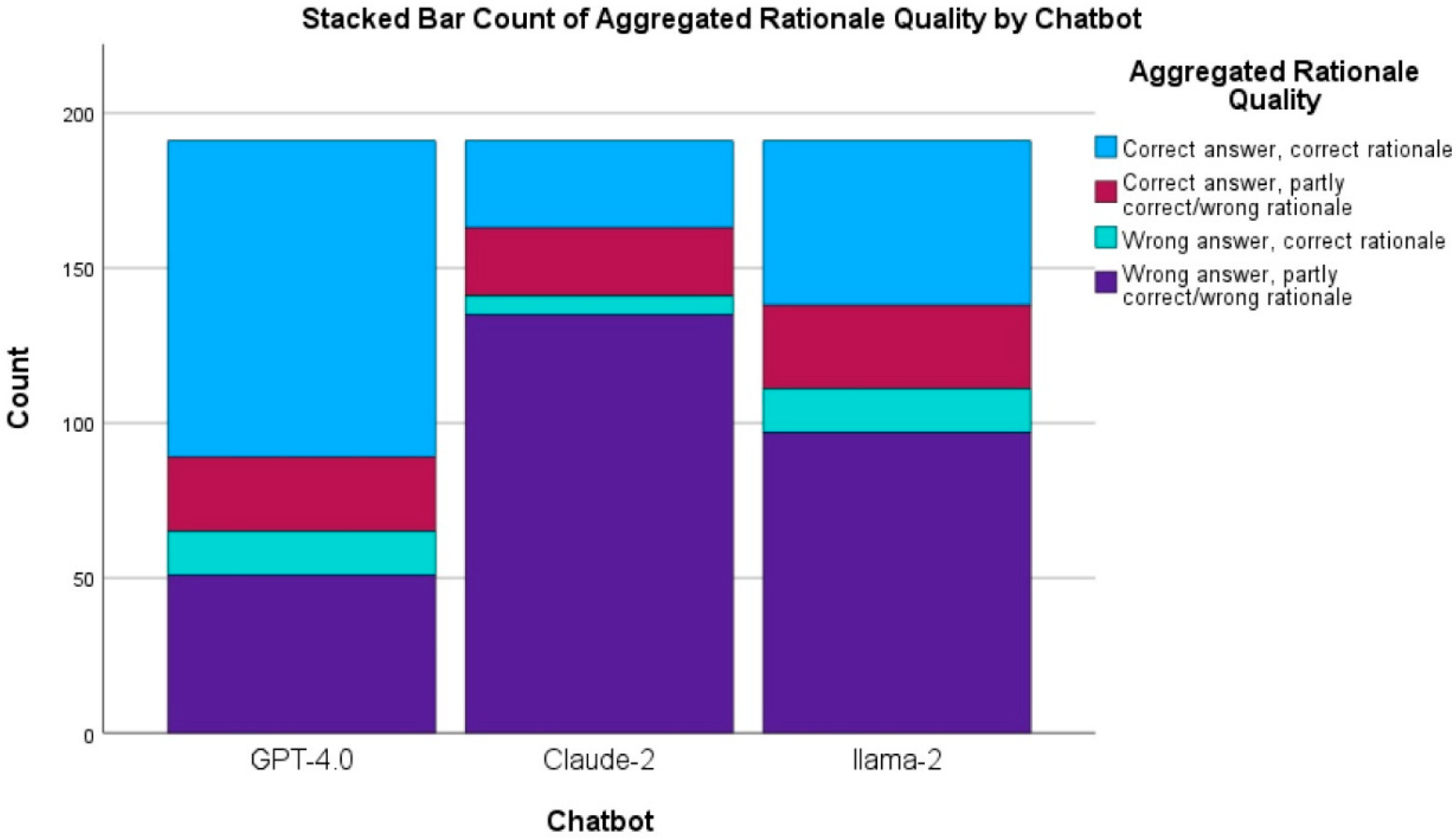
3.2. Quality of Rationale Accompanying the Multiple-Choice Answers
3.3. Inter-Rater Reliability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NBDE | United States National Board Dental Examination |
| ORE | Overseas Registration Examination |
| AI | Artificial Intelligence |
| US | United States |
| UK | United Kingdom |
| QS | Quacquarelli Symonds |
| OHI | Oral Health Instructions |
References
- Saraswat, D.; Bhattacharya, P.; Verma, A.; Prasad, V.K.; Tanwar, S.; Sharma, G.; Bokoro, P.N.; Sharma, R. Explainable AI for healthcare 5.0: Opportunities and challenges. IEEE Access 2022, 10, 84486–84517. [Google Scholar] [CrossRef]
- Zhang, K.; Aslan, A.B. AI technologies for education: Recent research & future directions. Comput. Educ. Artif. Intell. 2021, 2, 100025. [Google Scholar]
- Biswas, S.S. Role of Chat GPT in public health. Ann. Biomed. Eng. 2023, 51, 868–869. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.R.; Dobbs, T.D.; Hutchings, H.A.; Whitaker, I.S. Using ChatGPT to write patient clinic letters. Lancet Digit. Health 2023, 5, e179–e181. [Google Scholar] [CrossRef]
- Harris, E. Large Language Models Answer Medical Questions Accurately, but Can’t Match Clinicians’ Knowledge. JAMA 2023, 330, 792–794. [Google Scholar] [CrossRef] [PubMed]
- Dashti, M.; Londono, J.; Ghasemi, S.; Moghaddasi, N. How much can we rely on artificial intelligence chatbots such as the ChatGPT software program to assist with scientific writing? J. Prosthet. Dent. 2023, 133, 1082–1088. [Google Scholar] [CrossRef]
- The Lancet Regional Health–Europe. Embracing Generative AI in Health Care; Elsevier: Amsterdam, The Netherlands, 2023; Volume 30, p. 100677. [Google Scholar] [CrossRef]
- INBDE® History and Purpose. Available online: https://jcnde.ada.org/inbde/inbde-history (accessed on 20 April 2023).
- General Dental Council. Overseas Registration Examination Part 1 Results for August 2022; General Dental Council: London, UK, 2022.
- McHarg, J.; Kay, E. Designing a dental curriculum for the twenty-first century. Br. Dent. J. 2009, 207, 493–497. [Google Scholar] [CrossRef]
- Klineberg, I.; Eckert, S. Functional Occlusion in Restorative Dentistry and Prosthodontics; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Khanagar, S.B.; Al-Ehaideb, A.; Vishwanathaiah, S.; Maganur, P.C.; Patil, S.; Naik, S.; Baeshen, H.A.; Sarode, S.S. Scope and performance of artificial intelligence technology in orthodontic diagnosis, treatment planning, and clinical decision-making-a systematic review. J. Dent. Sci. 2021, 16, 482–492. [Google Scholar] [CrossRef]
- Thurzo, A.; Strunga, M.; Urban, R.; Surovková, J.; Afrashtehfar, K.I. Impact of artificial intelligence on dental education: A review and guide for curriculum update. Educ. Sci. 2023, 13, 150. [Google Scholar] [CrossRef]
- Chau, R.C.W.; Thu, K.M.; Yu, O.Y.; Hsung, R.T.-C.; Lo, E.C.M.; Lam, W.Y.H. Performance of Generative Artificial Intelligence in Dental Licensing Examinations. Int. Dent. J. 2024, 74, 616–621. [Google Scholar] [CrossRef]
- Künzle, P.; Paris, S. Performance of large language artificial intelligence models on solving restorative dentistry and endodontics student assessments. Clin. Oral Investig. 2024, 28, 575. [Google Scholar] [CrossRef] [PubMed]
- Suárez, A.; Díaz-Flores García, V.; Algar, J.; Gómez Sánchez, M.; Llorente de Pedro, M.; Freire, Y. Unveiling the ChatGPT phenomenon: Evaluating the consistency and accuracy of endodontic question answers. Int. Endod. J. 2024, 57, 108–113. [Google Scholar] [CrossRef]
- Rokhshad, R.; Zhang, P.; Mohammad-Rahimi, H.; Pitchika, V.; Entezari, N.; Schwendicke, F. Accuracy and consistency of chatbots versus clinicians for answering pediatric dentistry questions: A pilot study. J. Dent. 2024, 144, 104938. [Google Scholar] [CrossRef] [PubMed]
- Tomášik, J.; Zsoldos, M.; Oravcová, Ľ.; Lifková, M.; Pavleová, G.; Strunga, M.; Thurzo, A. AI and Face-Driven Orthodontics: A Scoping Review of Digital Advances in Diagnosis and Treatment Planning. AI 2024, 5, 158–176. [Google Scholar] [CrossRef]
- QS World University Rankings by Subject 2023: Dentistry. Available online: https://www.topuniversities.com/university-rankings/university-subject-rankings/2023/dentistry (accessed on 20 April 2023).
- Dowd, F.J. Mosby’s Review for the NBDE Part Two; Mosby Elsevier: St. Louis, MO, USA, 2007. [Google Scholar]
- Amazon.com: US NBDE Book. Available online: https://www.amazon.com/s?k=US+nbde+books&crid=254FFUWU4IBTB&sprefix=usnbde+books%2Caps%2C456&ref=nb_sb_noss (accessed on 20 April 2023).
- Hammond, D. Best of Fives for Dentistry, 3rd ed.; PasTest Ltd.: Knutsford, UK, 2014; 320p. [Google Scholar]
- Fan, K.F.M.; Jones, J.; Quinn, B.F.A. MCQs for Dentistry, 3rd ed.; PasTest Ltd.: Knutsford, UK, 2014; 320p. [Google Scholar]
- Books by Pastest. Available online: https://www.bookdepository.com/publishers/Pastest (accessed on 20 April 2023).
- Pilny, A.; Kelly, M.; Amanda, S.; Moore, K. From manual to machine: Assessing the efficacy of large language models in content analysis. Commun. Res. Rep. 2024, 41, 61–70. [Google Scholar] [CrossRef]
- Büttner, M.; Leser, U.; Schneider, L.; Schwendicke, F. Natural Language Processing: Chances and Challenges in Dentistry. J. Dent. 2024, 141, 104796. [Google Scholar] [CrossRef]
- Quora. About Poe. Available online: https://poe.com/about (accessed on 8 May 2025).
- Lin, P.-Y.; Tsai, Y.-H.; Chen, T.-C.; Hsieh, C.-Y.; Ou, S.-F.; Yang, C.-W.; Liu, C.-H.; Lin, T.-F.; Wang, C.-Y. The virtual assessment in dental education: A narrative review. J. Dent. Sci. 2024, 19, S102–S115. [Google Scholar] [CrossRef]
- Giannakopoulos, K.; Kavadella, A.; Aaqel Salim, A.; Stamatopoulos, V.; Kaklamanos, E.G. Evaluation of the performance of generative AI large language models ChatGPT, Google Bard, and Microsoft Bing Chat in supporting evidence-based dentistry: Comparative mixed methods study. J. Med. Internet Res. 2023, 25, e51580. [Google Scholar] [CrossRef]
- Viera, A.J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar]
- Kishimoto, T.; Goto, T.; Matsuda, T.; Iwawaki, Y.; Ichikawa, T. Application of artificial intelligence in the dental field: A literature review. J. Prosthodont. Res. 2022, 66, 19–28. [Google Scholar] [CrossRef]
- Chau, R.C.W.; Cheng, A.C.C.; Mao, K.; Thu, K.M.; Ling, Z.; Tew, I.M.; Chang, T.H.; Tan, H.J.; McGrath, C.; Lo, W.-L. External Validation of an AI mHealth Tool for Gingivitis Detection among Older Adults at Daycare Centers: A Pilot Study. Int. Dent. J. 2025, 75, 1970–1978. [Google Scholar] [CrossRef] [PubMed]
- Shan, T.; Tay, F.; Gu, L. Application of artificial intelligence in dentistry. J. Dent. Res. 2021, 100, 232–244. [Google Scholar] [CrossRef] [PubMed]
- Gheisarifar, M.; Shembesh, M.; Koseoglu, M.; Fang, Q.; Afshari, F.S.; Yuan, J.C.-C.; Sukotjo, C. Evaluating the validity and consistency of artificial intelligence chatbots in responding to patients’ frequently asked questions in prosthodontics. J. Prosthet. Dent. 2025. [Google Scholar] [CrossRef] [PubMed]
- Ozdemir, Z.M.; Yapici, E. Evaluating the Accuracy, Reliability, Consistency, and Readability of Different Large Language Models in Restorative Dentistry. J. Esthet. Restor. Dent. 2025, 37, 1740–1752. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.-S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable artificial intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Danesh, A.; Pazouki, H.; Danesh, F.; Danesh, A.; Vardar-Sengul, S. Artificial intelligence in dental education: ChatGPT’s performance on the periodontic in-service examination. J. Periodontol. 2024, 95, 682–687. [Google Scholar] [CrossRef]
- Liu, J.; Liang, X.; Fang, D.; Zheng, J.; Yin, C.; Xie, H.; Li, Y.; Sun, X.; Tong, Y.; Che, H.; et al. The Diagnostic Ability of GPT-3.5 and GPT-4.0 in Surgery: Comparative Analysis. J. Med. Internet Res. 2024, 26, e54985. [Google Scholar] [CrossRef]
- Kipp, M. From GPT-3.5 to GPT-4.o: A Leap in AI’s Medical Exam Performance. Information 2024, 15, 543. [Google Scholar] [CrossRef]
- Chau, R.C.-W.; Thu, K.M.; Hsung, R.T.-C.; McGrath, C.; Lam, W.Y.-H. Self-monitoring of Oral Health Using Smartphone Selfie Powered by Artificial Intelligence: Implications for Preventive Dentistry. Oral Health Prev. Dent. 2024, 22, 327–340. [Google Scholar]
- Schwendicke, F.a.; Samek, W.; Krois, J. Artificial intelligence in dentistry: Chances and challenges. J. Dent. Res. 2020, 99, 769–774. [Google Scholar] [CrossRef]

{kind=link}
| CHATBOT | CORRECT ANSWER | WRONG ANSWER |
|---|---|---|
| GPT-4.0 | 125/191 (65.4%) a | 66/191 (34.6%) a |
| CLAUDE-2 | 80/191 (41.9%) b | 111/191 (58.1%) b |
| LLAMA-2 | 50/191 (26.2%) c | 141/191 (73.8%) c |
| CHATBOT | CORRECT ANSWER | WRONG ANSWER | ||
|---|---|---|---|---|
| Correct Rationale | Partly Correct/Wrong Rationale | Correct Rationale | Partly Correct/Wrong Rationale | |
| GPT-4.0 | 111/191 (58.1%) a | 14/191 (7.3%) a | 22/191 (11.5%) a | 44/191 (23.0%) a |
| CLAUDE-2 | 71/191 (37.2%) b | 10/191 (5.2%) a,b | 29/191 (15.2%) a | 81/191 (42.4%) b |
| LLAMA-2 | 46/191 (24.1%) c | 4/191 (2.1%) b | 20/191 (10.5%) a | 121/191 (63.4%) c |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chau, R.C.W.; Thu, K.M.; Yu, O.Y.; Hsung, R.T.-C.; Wang, D.C.P.; Man, M.W.H.; Wang, J.J.; Lam, W.Y.H. Evaluation of Chatbot Responses to Text-Based Multiple-Choice Questions in Prosthodontic and Restorative Dentistry. Dent. J. 2025, 13, 279. https://doi.org/10.3390/dj13070279
Chau RCW, Thu KM, Yu OY, Hsung RT-C, Wang DCP, Man MWH, Wang JJ, Lam WYH. Evaluation of Chatbot Responses to Text-Based Multiple-Choice Questions in Prosthodontic and Restorative Dentistry. Dentistry Journal. 2025; 13(7):279. https://doi.org/10.3390/dj13070279
Chicago/Turabian StyleChau, Reinhard Chun Wang, Khaing Myat Thu, Ollie Yiru Yu, Richard Tai-Chiu Hsung, Denny Chon Pei Wang, Manuel Wing Ho Man, John Junwen Wang, and Walter Yu Hang Lam. 2025. "Evaluation of Chatbot Responses to Text-Based Multiple-Choice Questions in Prosthodontic and Restorative Dentistry" Dentistry Journal 13, no. 7: 279. https://doi.org/10.3390/dj13070279
APA StyleChau, R. C. W., Thu, K. M., Yu, O. Y., Hsung, R. T.-C., Wang, D. C. P., Man, M. W. H., Wang, J. J., & Lam, W. Y. H. (2025). Evaluation of Chatbot Responses to Text-Based Multiple-Choice Questions in Prosthodontic and Restorative Dentistry. Dentistry Journal, 13(7), 279. https://doi.org/10.3390/dj13070279