Abstract
Background/Objectives: Large Language Models (LLMs) are artificial intelligence (AI) systems with the capacity to process vast amounts of text and generate human-like language, offering the potential for improved information retrieval in healthcare. This study aimed to assess and compare the evidence-based potential of answers provided by four LLMs to common clinical questions concerning the management and treatment of periodontal furcation defects. Methods: Four LLMs—ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft Copilot—were used to answer ten clinical questions related to periodontal furcation defects. The LLM-generated responses were compared against a “gold standard” derived from the European Federation of Periodontology (EFP) S3 guidelines and recent systematic reviews. Two board-certified periodontists independently evaluated the answers for comprehensiveness, scientific accuracy, clarity, and relevance using a predefined rubric and a scoring system of 0–10. Results: The study found variability in LLM performance across the evaluation criteria. Google Gemini Advanced generally achieved the highest average scores, particularly in comprehensiveness and clarity, while Google Gemini and Microsoft Copilot tended to score lower, especially in relevance. However, the Kruskal–Wallis test revealed no statistically significant differences in the overall average scores among the LLMs. Evaluator agreement and intra-evaluator reliability were high. Conclusions: While LLMs demonstrate the potential to answer clinical questions related to furcation defect management, their performance varies. LLMs showed different comprehensiveness, scientific accuracy, clarity, and relevance degrees. Dental professionals should be aware of LLMs’ capabilities and limitations when seeking clinical information.
1. Introduction
The rise in artificial intelligence (AI) has captured significant attention across numerous fields in recent years. A notable development within AI is Large Language Models (LLMs), which are designed to process vast quantities of text and generate coherent, human-like language [1]. These models offer the potential for faster and more accessible information retrieval compared to traditional methods. LLMs present significant opportunities to revolutionize healthcare. They can enhance efficiency and accuracy by automating tasks such as extracting data from electronic health records, summarizing and structuring medical information, clarifying complex medical texts, and optimizing administrative workflows in clinical settings [2,3,4]. Furthermore, LLMs can contribute to advancements in medical research, quality assurance, and educational initiatives [2,3,4]. Emerging evidence also suggests their potential in diagnostic support and prognostic modeling [5]. Deep learning algorithms, a subset of AI, demonstrate remarkable capabilities in analyzing medical images for disease detection and personalizing treatment plans, often achieving greater accuracy and efficiency than human capabilities [6]. Furthermore, AI holds promise in identifying individuals at risk of specific diseases, enabling tailored preventative and treatment strategies [7].
In dentistry, AI is emerging as a valuable tool for dental professionals, aiding in diagnosis, treatment planning, image analysis, and the prediction of treatment outcomes, and streamlining record-keeping and workflow [8]. Deep learning models show potential in the early detection of dental issues like caries and periapical periodontitis, leading to improved treatment decisions and patient care while saving clinical time [9,10]. Beyond enhancing professional capabilities, these LLM applications foster better-informed decision-making and superior patient outcomes in dentistry. While healthcare providers increasingly use LLMs for quick access to information from diverse sources, concerns regarding the accuracy and reliability of their responses, potential biases, and ethical and legal implications have been raised [11,12]. Studies evaluating the performance of LLMs in answering medical questions have revealed varying levels of accuracy, possibly influenced by inconsistencies in study design and reporting [13].
The integration of LLMs into everyday clinical workflows faces significant challenges. A key issue is the lack of transparency and accessibility regarding the data underpinning LLM-generated answers. Studies also indicate a tendency for LLMs to “hallucinate” or produce misinformation when faced with knowledge gaps [14]. Moreover, the prevalence of digital barriers requiring users to pay a fee or subscribe to view the full content restricts the availability of scientific information needed for training models like ChatGPT [15]. Compounding this, LLMs often have fixed information cut-off dates (September 2021 for GPT-4), which limits their capacity to synthesize responses using the most current scientific literature [16].
Clinicians face significant challenges in successfully treating molars with Class II and III furcation defects, exhibiting a higher rate of tooth loss [17,18]. The complex topography of furcation defects hinders proper debridement, posing the main clinical challenge for their treatment [19,20,21]. Non-surgical treatment has shown limited success, and a systematic review indicated that surgical debridement only provides modest improvement in clinical parameters [22,23,24]. A recent meta-analysis aimed to compare the clinical effectiveness of regenerative periodontal surgery versus open flap debridement for treating furcation defects and to evaluate different regenerative approaches [25]. The analysis of 20 randomized controlled trials revealed that regenerative techniques significantly outperformed open flap debridement regarding furcation improvement, horizontal and vertical clinical attachment level gain, and probing pocket depth reduction. Specifically, treatments involving bone replacement grafts demonstrated the highest probability of achieving the best outcomes for horizontal bone level gain. In contrast, non-resorbable membranes combined with bone replacement grafts ranked highest for vertical attachment level gain and pocket depth reduction [25].
The ability of chatbots to accurately respond to clinically essential questions has been assessed across various dental specialties, including pediatric dentistry [26], operative dentistry [27], oral and maxillofacial radiology [28], orthodontics [29], public health dentistry [30], endodontics [31], prosthodontics [32], oral pathology [33], dental trauma [34], periodontology [35], and implant dentistry [36]. A preliminary study explored how AI-powered face enhancement, specifically using FaceApp, could assist orthodontists in treatment planning by modifying facial attractiveness, and the authors indicated that AI-enhanced images were consistently rated as more attractive by respondents, with significant changes observed in features like lip fullness, eye size, and lower face height, suggesting a potential for AI to guide soft-tissue-focused and personalized orthodontic treatments [37]. As LLMs increasingly become a resource for dental information, evaluating their performance in this field is crucial. Considering the diverse approaches to treating furcation defects and the clinical importance of managing teeth with furcation involvement, it is particularly important to determine if AI can provide accurate and reliable answers. This research aimed to assess and compare the ability of four LLMs to offer evidence-based answers to typical clinical inquiries concerning the management and treatment of periodontal furcation defects. The study’s null hypothesis proposed no significant differences in the comprehensiveness, scientific accuracy, clarity, and relevance of the LLMs’ responses compared to the accepted scientific evidence and guidelines for addressing furcation defects.
2. Materials and Methods
This study investigated the performance of four popular LLMs in providing evidence-based answers to clinical questions specifically related to the treatment and management of periodontal furcation defects. As part of a larger set of ten periodontal questions (Table 1) developed by the EFP’s S3 guidelines for periodontitis [38], these furcation-focused inquiries aimed to reflect common scenarios encountered by general dentists. The LLM-generated responses were rigorously compared against a “gold standard” derived from EFP guidelines [38] and relevant recent systematic reviews [39,40,41,42,43,44,45,46] on furcation defect management and treatment. The evaluated LLMs were ChatGPT (GPT 4.0), Google Gemini (Gemini 2.0 Flash Experimental), Google Gemini Advanced (powered by Gemini Ultra 1.0), and Microsoft Copilot (Free Version).

Table 1.
Open-ended questions answered using ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot.
Two American Board of Periodontology-certified periodontists (G.S.C. and V.P.K.) independently assessed the responses from each LLM to the furcation defect treatment questions. These blinded evaluations used a standardized rubric to score the answers (0–10) based on their comprehensiveness, scientific accuracy, clarity, and relevance [29] in relation to the established “gold standard.” Each LLM was queried once per furcation defect question on 13 December 2024, without any follow-up. The same evaluators re-scored the answers after a one-month interval to determine the consistency of their assessments.
Statistical Analysis
The statistical analysis included descriptive statistics, Pearson and Spearman’s rho correlations, Cronbach’s α, and ICC to analyze the scores specifically for the furcation defect treatment questions and to assess inter-evaluator reliability. Wilcoxon’s and Friedman’s tests were employed to identify any statistically significant differences (p < 0.05) in the scores assigned by the different LLMs for these targeted questions. A Kruskal–Wallis test was performed to test the differences in the scores between the LLMs. All significance tests were evaluated at the 0.05 error level with a statistical software program (SPSS v.29.0, IBM, Armonk, NY, USA).
3. Results
Four LLMs—ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft Copilot—provided answers to ten clinical inquiries concerning the management and treatment of periodontal furcation defects, with their responses and the guideline/evidence-based “gold standard” detailed in Supplementary Table S1. The resulting answers were evaluated for comprehensiveness, scientific accuracy, clarity, and relevance, each scored from 0 to 10 by two independent specialists across two separate assessments conducted a month apart. Table 2 presents the descriptive statistics for these scores. Notably, Google Gemini Advanced received the highest average scores from both evaluators, while Google Gemini and Microsoft CoPilot received the lowest.
Table 2.
Descriptive statistics for scores given by 2 evaluators to answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot at two different times.
Pearson and Spearman’s rho correlations, presented in Table 3, indicated strong and significant agreement between the two evaluators’ scores for each LLM across both scoring occasions, suggesting consistent evaluation [47,48]. Cronbach’s α and ICC tests further confirmed high inter-evaluator reliability (Table 4). Furthermore, statistical tests showed no significant differences in the scores the two evaluators gave, either in the initial or subsequent evaluation, or when the scores were combined (Table 5).
Table 3.
Correlation between scores given by 2 evaluators to answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot at two different times. Pearson and Spearman’s rho correlations indicated strong and significant agreement between the two evaluators’ scores for each LLM across both scoring occasions, suggesting consistent evaluation.
Table 4.
Cronbach α and Interclass Correlation Coefficient (ICC) for scores given by 2 evaluators to answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot at 2 different times and pooled scores of 2 different occasions. Cronbach’s α and ICC tests further confirmed high inter-evaluator reliability.
Table 5.
Wilcoxon test for scores given by 2 evaluators to answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot at 2 different times. Friedman test for pooled scores given by 2 evaluators. Statistical analysis indicated no significant differences in scores given by the two evaluators across initial, subsequent, and combined evaluations.
Consequently, an average score was calculated for each LLM’s response. As shown in Table 6, Google Gemini Advanced (6.80) achieved the highest average scores overall, while Google Gemini (5.70) and Microsoft CoPilot (5.68) exhibited the lowest scores. Figure 1 schematically illustrates the average scores for each LLM. Figure 2 demonstrates the average scores across the ten individual questions, with only responses to Questions 1 and 10 consistently scoring above seven for all LLMs. Based on the results presented in Table 7, the Kruskal–Wallis test showed no statistically significant differences in the average scores of answers provided by any of the LLM pairs (p > 0.05 for all comparisons). This indicates that for this specific analysis, the LLMs performed statistically similarly to each other in terms of their average scores.
Table 6.
Descriptive statistics for average scores of answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot.
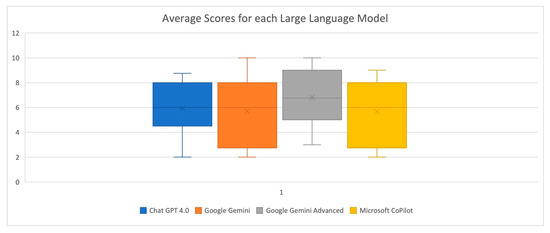
Figure 1.
Average scores for each Large Language Model.
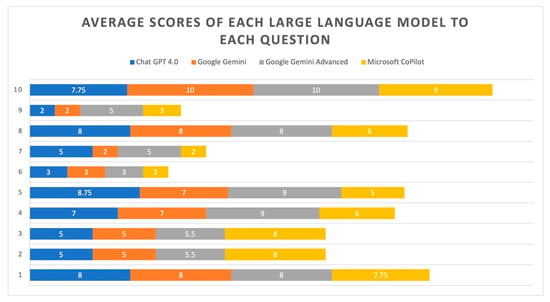
Figure 2.
Average scores across the ten individual questions.
Table 7.
Kruskal–Wallis test for average scores of answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft CoPilot.
Table 8 presents the descriptive statistics for the average scores assigned to answers from the four LLMs across four criteria: comprehensiveness, scientific accuracy, clarity, and relevance. The mean scores varied across LLMs and criteria, with Google Gemini Advanced generally achieving the highest mean scores for comprehensiveness and clarity. At the same time, Microsoft CoPilot tended to have slightly lower scores, particularly in relevance. The range of scores (minimum to maximum) indicates variability in the quality of answers within each LLM and across criteria. Overall, the LLMs demonstrated varying strengths and weaknesses across the assessed criteria, with no single LLM consistently outperforming the others in all categories; however, there is a trend for Google Gemini Advanced to score higher in comprehensiveness and clarity, and a trend for Microsoft CoPilot to score lower in relevance.
Table 8.
Descriptive statistics for the average scores to the answers provided by ChatGPT 4.0, Google Gemini, Google Gemini Advances, and Microsoft CoPilot based on the examined criteria including comprehensiveness (1), scientific accuracy (2), clarity (3), and relevance (4).
4. Discussion
The integration of AI in healthcare presents both opportunities and challenges. This study investigated the accuracy of four LLMs in answering common clinical inquiries concerning the management and treatment of periodontal furcation defects questions, comparing their responses to the “gold standard” of the EFP’s S3 Clinical Practice Guideline [38] and recent systematic reviews and meta-analyses [39,40,41,42,43,44,45,46]. The main findings of the present investigation were as follows:
- Google Gemini Advanced achieved the highest average scores, while Google Gemini and Microsoft Copilot received the lowest.
- The Kruskal–Wallis test showed no statistically significant differences in the average scores among the LLMs.
- Overall, the LLMs demonstrated varying strengths and weaknesses across the assessed criteria, with no single LLM consistently outperforming the others in all categories; however, there was a trend for Google Gemini Advanced to score higher in comprehensiveness and clarity, and a trend for Microsoft CoPilot to score lower in relevance.
In the present investigation, none of the pairwise comparisons between the LLMs showed a statistically significant difference in the average scores of their answers. All the adjusted p-values were very high (1.000), exceeding the typical significance level of 0.05. This indicates that based on this statistical test, the LLMs performed similarly regarding their average scores. Google Gemini Advanced tended to have the highest mean and median scores compared to the other LLMs, suggesting that on average, the evaluators rated its answers higher. Google Gemini and Microsoft CoPilot generally showed the lowest mean scores, indicating that their answers were rated somewhat lower on average. The standard deviations and variances indicate some variability in the scores for all the LLMs, showing that the quality of answers was not entirely uniform. Google Gemini exhibited the highest standard deviation (2.75) and variance (7.57), suggesting the greatest variability in its answers. Google Gemini Advanced displayed the lowest standard deviation (2.29) and variance (5.23), indicating the least variability. All the LLMs had a minimum score of 2.00, except for Google Gemini Advanced, which has a minimum of 3.00. The maximum scores ranged from 8.75 to 10.00.
The LLMs’ performance varied significantly across the ten questions. Some questions (Questions 1 and 10) generally received higher scores across all LLMs, while others (Questions 2, 6, and 7) tended to receive lower scores. This indicates that the quality of LLM-generated answers is affected by the inherent complexity or specific characteristics of the questions posed. Across most questions, Google Gemini Advanced demonstrated strong performance, often securing the highest or consistently high scores within each question group. This indicates a relatively consistent and strong performance. Microsoft CoPilot showed the most variability. While it performs reasonably well on some questions (Question 10), it tends to have lower scores on several others, suggesting less consistent performance. In addition, ChatGPT 4.0 showed a mixed performance, with some high scores and some moderate scores depending on the question. Google Gemini tended to have more moderate to lower scores than Google Gemini Advanced, indicating a difference in performance between the two Google LLMs. The varying scores across questions suggest that LLMs perform better on simpler inquiries (like Questions 1 and 10) and struggle with more complex or nuanced questions (such as Questions 2, 6, and 7).
Google Gemini Advanced demonstrated the strongest performance in comprehensiveness, suggesting that its answers were generally more thorough. Microsoft CoPilot tended to provide less comprehensive responses compared to the other LLMs. ChatGPT 4.0 and Google Gemini showed intermediate levels of comprehensiveness in their answers. Regarding scientific accuracy, Google Gemini Advanced exhibited relatively high scores, indicating a tendency to provide accurate information. Microsoft CoPilot’s responses showed the lowest average scores in this category, implying potential inaccuracies. The variability in standard deviations suggests inconsistencies in scientific accuracy across LLMs.
Furthermore, Google Gemini Advanced consistently performed well in terms of clarity, delivering answers that were generally well-articulated and easy to understand. While still reasonably clear, Microsoft CoPilot’s responses scored slightly lower on average than Google Gemini Advanced. Although some variability exists, all the LLMs showed a degree of consistency in clarity. Concerning relevance, Google Gemini Advanced maintained a relatively strong performance, indicating that its answers were generally pertinent to the questions. Microsoft CoPilot exhibited the lowest average scores for relevance, suggesting that its responses were sometimes less focused or off-topic. Google Gemini also showed the lowest mean in relevance.
A thorough examination of the existing literature indicated a scarcity of research evaluating and comparing the precision of LLMs in addressing typical clinical inquiries concerning the management and treatment of periodontal furcation defects, particularly when responses were measured against a “gold standard”. In a separate investigation, ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft Copilot were assessed for their effectiveness in responding to clinical questions pertinent to peri-implant disease [36]. This prior study involved presenting the LLMs with ten open-ended questions centered on the prevention and treatment of peri-implantitis and peri-implant mucositis. The outcomes showed that Google Gemini Advanced yielded the strongest performance, whereas Google Gemini exhibited the weakest. These findings align with the results observed in the current study. Furthermore, a distinct study focusing broadly on periodontology employed a comparable methodology, where clinical questions were posed to LLMs and periodontists then evaluated the responses based on comprehensiveness, scientific accuracy, clarity, and relevance; this research concluded that ChatGPT 4.0 generally demonstrated the best performance, while Google Gemini performed the least effectively [35].
Studies evaluating LLMs in dentistry show varied performance across specialties and models. In endodontics, ChatGPT demonstrated 57.3% accuracy and 85.4% consistency for dichotomous questions [31]. For oral and maxillofacial surgery, ChatGPT showed potential for patient-oriented responses (scoring 4.6 ± 0.8 on a 1–5 scale) but performed less effectively for technical answers (scoring 3.1 ± 1.5) [49]. When assessed on a board-style multiple-choice dental knowledge test, ChatGPT achieved a 76.9% correct answer rate, indicating competence in producing accurate dental content [50]. Similarly, ChatGPT 4.0 showed good accuracy for open-ended questions in head and neck surgery and provided accurate and current information regarding frequently asked questions about dental amalgam and its removal [51].
Comparisons between different LLMs within dentistry yield mixed results. One study found that ChatGPT-4 statistically outperformed ChatGPT-3.5, Bing Chat, and Bard [52]. In pediatric dentistry, ChatGPT achieved the highest accuracy among various LLMs, and the authors suggested that LLMs could be adjuncts in dental education and patient information distribution [53]. However, another study found no significant differences between ChatGPT and Google Bard when generating questions related to dental caries [9]. In oral and maxillofacial radiology examinations, ChatGPT, ChatGPT Plus, Bard, and Bing Chat generally performed unsatisfactorily, though ChatGPT Plus showed increased accuracy for basic knowledge [28]. Conversely, for clinically relevant orthodontic questions, Microsoft Bing Chat scored highest, outperforming ChatGPT 3.5 and Google Bard [29]. In endodontics, GPT-3.5 provided more credible information compared to Google Bard and Bing [37]. Overall, the diverse methodologies and dental specialties examined make direct comparisons of LLM performance challenging.
Several limitations within the study warrant consideration when interpreting its findings. Primarily, LLM performance can fluctuate based on question phrasing and the technical complexity of anticipated answers. This underscores the necessity for further research into how various question types impact LLMs’ capacity to produce accurate and pertinent information. To ensure a controlled comparison of LLM responses and mitigate potential biases stemming from uncontrolled elements like question quantity, wording, and specificity, follow-up questions were deliberately omitted. Although our methodology used a single input prompt per question to facilitate a controlled comparison and minimize biases from iterative prompting, it is recognized that this does not entirely mirror real-world user interactions, where follow-up questions are frequent and can affect the quality of LLM outputs. Open-ended questions can lead to inaccurate, irrelevant, or biased responses from LLMs because of the difficulty in evaluating and controlling the output. However, open-ended questions better mirror the type of inquiries clinicians typically use in practice, which are often not simple multiple-choice questions. They allow for a more natural interaction with the LLMs, similar to how a user might pose a question to a chatbot. In addition, the quality and scope of an LLM’s training data directly impacts its ability to analyze complex questions, potentially resulting in biased or incomplete conclusions. While we utilized a robust “gold standard” for evaluation, the inherent limitations of LLMs, such as their training data cutoffs and the unavailability of paywalled scientific information, are crucial considerations that may contribute to the observed variability in response quality and scientific accuracy.
The responses generated by the LLMs underwent independent evaluation on two separate occasions by two periodontists certified by the American Board of Periodontology. This assessment was conducted against a predefined criterion standard, and the process established high correlation and intra-evaluator reliability. This method minimizes the likelihood of individual bias influencing the scoring, given that the evaluations rely on the expert judgment of independent specialists. To comprehensively address various facets of furcation defect management and treatment, a set of 10 questions was chosen and presented to the LLMs. The study design incorporated a rigorous methodology, utilizing a predefined rubric to assess the LLM-generated answers for comprehensiveness, scientific accuracy, clarity, and relevance, enhancing the objectivity and reliability of the findings. This ensures that the assessment of the LLM-generated answers is structured and consistent. It reduces subjectivity, as the evaluators had clear benchmarks to follow instead of relying solely on their personal impressions. The open-ended questions allowed for a more in-depth evaluation of the LLM’s capabilities. It enabled us to assess not just the accuracy of a single fact, but also the comprehensiveness, clarity, and relevance of the information provided.
The clinical relevance of evaluating LLMs in dentistry is underscored by the challenging nature of managing periodontal furcation defects, a common issue where diverse treatment strategies exist and accurate information is crucial for optimal patient outcomes. This study provides a “snapshot” evaluation of current, widely accessible LLMs (ChatGPT 4.0, Google Gemini, Google Gemini Advanced, and Microsoft Copilot), acknowledging that while newer versions constantly emerge, this point-in-time assessment is vital for establishing benchmarks and understanding their evolving capabilities in healthcare. Despite the rapid advancements, this research offers forward-looking insights by identifying current strengths and weaknesses that can inform future LLM development, guide responsible clinical adoption, and highlight persistent challenges that necessitate ongoing human oversight in AI-assisted decision-making in dentistry.
To advance this field, subsequent investigations ought to explore diverse clinical scenarios, employing varied question formats. Further efforts could involve refining and validating these models to ensure more secure information accessibility and to facilitate the development of clinical recommendations, ultimately enhancing patient care. While Large Language Models possess significant potential to aid both patients and dental professionals, forthcoming studies should specifically investigate how this technology can contribute to better patient experiences and improved treatment outcomes.
5. Conclusions
The present investigation evaluated the performance of four LLMs in answering clinical questions related to the management and treatment of periodontal furcation defects. The findings indicate that while LLMs demonstrate potential in this area, their performance varies across different models and evaluation criteria. Google Gemini Advanced generally exhibited the strongest performance, particularly in comprehensiveness and clarity, whereas Google Gemini and Microsoft CoPilot tended to score lower. However, the overall statistical analysis revealed no significant differences in the average scores among the LLMs, suggesting a degree of similarity in their performance. Variability in LLM responses was observed across individual questions, highlighting the influence of question complexity and nature on answer quality.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/dj13060271/s1, Supplemental Table S1: The ten indicative questions relevant to common clinical issues concerning the management and treatment of periodontal furcation defects were asked to four different Large Language Models.
Author Contributions
Conceptualization, G.S.C. and E.G.K.; methodology, E.G.K.; software, G.S.C. and V.P.K.; validation, G.S.C. and V.P.K.; formal analysis, G.S.C.; investigation, G.S.C. and V.P.K.; resources, G.S.C., V.P.K., E.G.K. and L.T.; data curation, G.S.C.; writing—original draft preparation, G.S.C.; writing—review and editing, G.S.C., V.P.K., E.G.K. and L.T.; visualization, E.G.K. and L.T.; supervision, E.G.K. and L.T.; project administration, G.S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| LLM | Large Language Model |
References
- Orrù, G.; Piarulli, A.; Conversano, C.; Gemignani, A. Human-like problem-solving abilities in large language models using ChatGPT. Front. Artif. Intell. 2023, 6, 1199350. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A large language model for electronic health records. npj Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef]
- Tian, S.; Jin, Q.; Yeganova, L.; Lai, P.-T.; Zhu, Q.; Chen, X.; Yang, Y.; Chen, Q.; Kim, W.; Comeau, D.C.; et al. Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief. Bioinform. 2023, 25, bbad493. [Google Scholar] [CrossRef]
- Adams, L.C.; Truhn, D.; Busch, F.; Kader, A.; Niehues, S.M.; Makowski, M.R.; Bressem, K.K. Leveraging GPT-4 for Post Hoc Transformation of Free-text Radiology Reports into Structured Reporting: A Multilingual Feasibility Study. Radiology 2023, 307, e230725. [Google Scholar] [CrossRef]
- Jiang, L.Y.; Liu, X.C.; Pour Nejatian, N.; Nasir-Moin, M.; Wang, D.; Abidin, A.; Eaton, K.; Riina, H.A.; Laufer, I.; Punjabi, P.; et al. Health system-scale language models are all-purpose prediction engines. Nature 2023, 619, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.-Q.; Wu, X.-L.; Huang, S.-Y.; Wu, G.-G.; Ye, H.-R.; Wei, Q.; Bao, L.-Y.; Deng, Y.-B.; Li, X.-R.; Cui, X.-W.; et al. Lymph Node Metastasis Prediction from Primary Breast Cancer US Images Using Deep Learning. Radiology 2020, 294, 19–28. [Google Scholar] [CrossRef]
- Rim, T.H.; Lee, C.J.; Tham, Y.-C.; Cheung, N.; Yu, M.; Lee, G.; Kim, Y.; Ting, D.S.W.; Chong, C.C.Y.; Choi, Y.S.; et al. Deep-learning-based cardiovascular risk stratification using coronary artery calcium scores predicted from retinal photographs. Lancet Digit. Health 2021, 3, e306–e316. [Google Scholar] [CrossRef] [PubMed]
- Schwendicke, F.; Samek, W.; Krois, J. Artificial Intelligence in Dentistry: Chances and Challenges. J. Dent. Res. 2020, 99, 769–774. [Google Scholar] [CrossRef]
- Ahmed, W.M.; Azhari, A.A.; Fawaz, K.A.; Ahmed, H.M.; Alsadah, Z.M.; Majumdar, A.; Carvalho, R.M. Artificial intelligence in the detection and classification of dental caries. J. Prosthet. Dent. 2023, 133, 1326–1332. [Google Scholar] [CrossRef]
- Li, S.; Liu, J.; Zhou, Z.; Zhou, Z.; Wu, X.; Li, Y.; Wang, S.; Liao, W.; Ying, S.; Zhao, Z. Artificial intelligence for caries and periapical periodontitis detection. J. Dent. 2022, 122, 104107. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; Payne, P.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Khan, B.; Fatima, H.; Qureshi, A.; Kumar, S.; Hanan, A.; Hussain, J.; Abdullah, S. Drawbacks of Artificial Intelligence and Their Potential Solutions in the Healthcare Sector. Biomed. Mater. Devices 2023, 1, 731–738. [Google Scholar] [CrossRef] [PubMed]
- Wei, Q.; Yao, Z.; Cui, Y.; Wei, B.; Jin, Z.; Xu, X. Evaluation of ChatGPT-generated medical responses: A systematic review and meta-analysis. J. Biomed. Inform. 2024, 151, 104620. [Google Scholar] [CrossRef]
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and Other Large Language Models Are Double-edged Swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef] [PubMed]
- Piwowar, H.; Priem, J.; Larivière, V.; Alperin, J.P.; Matthias, L.; Norlander, B.; Farley, A.; West, J.; Haustein, S. The state of OA: A large-scale analysis of the prevalence and impact of Open Access articles. PeerJ 2018, 6, e4375. [Google Scholar] [CrossRef]
- McGrath, S.P.; Kozel, B.A.; Gracefo, S.; Sutherland, N.; Danford, C.J.; Walton, N. A comparative evaluation of ChatGPT 3.5 and ChatGPT 4 in responses to selected genetics questions. J. Am. Med. Inform. Assoc. 2024, 31, 2271–2283. [Google Scholar] [CrossRef]
- Nibali, L.; Zavattini, A.; Nagata, K.; Di Iorio, A.; Lin, G.H.; Needleman, I.; Donos, N. Tooth loss in molars with and without furcation involvement–a systematic review and meta-analysis. J. Clin. Periodontol. 2016, 43, 156–166. [Google Scholar] [CrossRef]
- Sanz, M.; Jepsen, K.; Eickholz, P.; Jepsen, S. Clinical concepts for regenerative therapy in furcations. Periodontology 2015, 68, 308–332. [Google Scholar] [CrossRef]
- Al-Shammari, K.F.; Kazor, C.E.; Wang, H.L. Molar root anatomy and management of furcation defects. J. Clin. Periodontol. 2001, 28, 730–740. [Google Scholar] [CrossRef]
- Jepsen, S.; Deschner, J.; Braun, A.; Schwarz, F.; Eberhard, J. Calculus removal and the prevention of its formation. Periodontology 2000 2011, 55, 167–188. [Google Scholar] [CrossRef]
- Svärdström, G.; Wennström, J.L. Furcation topography of the maxillary and mandibular first molars. J. Clin. Periodontol. 1988, 15, 271–275. [Google Scholar] [CrossRef] [PubMed]
- Loos, B.; Nylund, K.; Claffey, N.; Egelberg, J. Clinical effects of root debridement in molar and non-molar teeth. A 2-year follow-up. J. Clin. Periodontol. 1989, 16, 498–504. [Google Scholar] [CrossRef] [PubMed]
- Nordland, P.; Garrett, S.; Kiger, R.; Vanooteghem, R.; Hutchens, L.H.; Egelberg, J. The effect of plaque control and root debridement in molar teeth. J. Clin. Periodontol. 1987, 14, 231–236. [Google Scholar] [CrossRef] [PubMed]
- Graziani, F.; Gennai, S.; Karapetsa, D.; Rosini, S.; Filice, N.; Gabriele, M.; Tonetti, M. Clinical performance of access flap in the treatment of class II furcation defects. J. Clin. Periodontol. 2015, 42, 169–181. [Google Scholar] [CrossRef]
- Jepsen, S.; Gennai, S.; Hirschfeld, J.; Kalemaj, Z.; Buti, J.; Graziani, F. Regenerative surgical treatment of furcation defects: A systematic review and Bayesian network meta-analysis. J. Clin. Periodontol. 2020, 47, 352–374. [Google Scholar] [CrossRef]
- Dermata, A.; Arhakis, M.A.; Makrygiannakis, K.; Giannakopoulos, E.G.; Kaklamanos, E.G. Evaluating the evidence-based potential of six large language models in paediatric dentistry: A comparative study on generative artificial intelligence. Eur. Arch. Paediatr. Dent. 2025, 26, 527–535. [Google Scholar] [CrossRef]
- Ahmed, W.M.; Azhari, A.A.; Alfaraj, A.; Alhamadani, A.; Zhang, M.; Lu, C.T. The quality of AI-generated dental caries multiple choice questions: A comparative analysis of ChatGPT and Google Bard language models. Heliyon 2024, 10, e28198. [Google Scholar] [CrossRef]
- Jeong, H.; Han, S.S.; Yu, Y.; Kim, S.; Jeon, K.J. How well do large language model-based chatbots perform in oral and maxillofacial radiology? Dentomaxillofac. Radiol. 2024, 53, 390–395. [Google Scholar] [CrossRef]
- Makrygiannakis, M.A.; Giannakopoulos, K.; Kaklamanos, E.G. Evidence-based potential of generative artificial intelligence large language models in orthodontics: A comparative study of ChatGPT, Google Bard, and Microsoft Bing. Eur. J. Orthod. 2024, cjae017. [Google Scholar] [CrossRef]
- Tiwari, A.; Kumar, A.; Jain, S.; Dhull, K.S.; Sajjanar, A.; Puthenkandathil, R.; Paiwal, K.; Singh, R. Implications of ChatGPT in public health dentistry: A systematic review. Cureus 2023, 15, e40367. [Google Scholar] [CrossRef]
- Suárez, A.; Díaz-Flores García, V.; Algar, J.; Gómez Sánchez, M.; Llorente de Pedro, M.; Freire, Y. Unveiling the ChatGPT phenomenon: Evaluating the consistency and accuracy of endodontic question answers. Int. Endod. J. 2024, 57, 108–113. [Google Scholar] [CrossRef] [PubMed]
- Freire, Y.; Laorden, A.S.; Pérez, J.O.; Sánchez, M.G.; García, V.D.-F.; Suárez, A. ChatGPT performance in prosthodontics: Assessment of accuracy and repeatability in answer generation. J. Prosthet. Dent. 2024, 131, 659.e1–659.e6. [Google Scholar] [CrossRef] [PubMed]
- Albagieh, H.; Alzeer, Z.O.; Alasmari, O.N.; Alkadhi, A.A.; Naitah, A.N.; Almasaad, K.F.; Alshahrani, T.S.; Alshahrani, K.S.; Almahmoud, M.I. Comparing artificial intelligence and senior residents in oral lesion diagnosis: A comparative study. Cureus 2024, 16, e51584. [Google Scholar] [CrossRef] [PubMed]
- Ozden, I.; Gokyar, M.; Ozden, M.E.; SazakOvecoglu, H. Assessment of artificial intelligence applications in responding to dental trauma. Dent. Traumatol. 2024, 40, 722–729. [Google Scholar] [CrossRef]
- Chatzopoulos, G.S.; Koidou, V.P.; Tsalikis, L.; Kaklamanos, E.G. Large language models in periodontology: Assessing their performance in clinically relevant questions. J. Prosthet. Dent. 2024; in press. [Google Scholar] [CrossRef]
- Koidou, V.P.; Chatzopoulos, G.S.; Tsalikis, L.; Kaklamanos, E.G. Large language models in peri-implant disease: How well do they perform? J. Prosthet. Dent. 2025; in press. [Google Scholar] [CrossRef]
- Mohammad-Rahimi, H.; Ourang, S.A.; Pourhoseingholi, M.A.; Dianat, O.; Dummer, P.M.H.; Nosrat, A. Validity and reliability of artificial intelligence chatbots as public sources of information on endodontics. Int. Endod. J. 2023, 57, 305–314. [Google Scholar] [CrossRef]
- Sanz, M.; Herrera, D.; Kebschull, M.; Chapple, I.; Jepsen, S.; Beglundh, T.; Sculean, A.; Tonetti, M.S. Treatment of stage I–III periodontitis—The EFP S3 level clinical practice guideline. J. Clin. Periodontol. 2020, 47, 4–60. [Google Scholar] [CrossRef]
- Chatzopoulos, G.S.; Koidou, V.P.; Tsalikis, L. Local drug delivery in the treatment of furcation defects in periodontitis: A systematic review. Clin. Oral Investig. 2023, 27, 955–970. [Google Scholar] [CrossRef]
- Das, R.K.; Bharathwaj, V.V.; Sindhu, R.; Prabu, D.; Rajmohan, M.; Dhamodhar, D.; Sathiyapriya, S. Comparative analysis of various forms of local drug delivery systems on a class 2 furcation: A systematic review. J. Pharm. Bioallied Sci. 2023, 15, S742–S746. [Google Scholar] [CrossRef]
- Nibali, L.; Buti, J.; Barbato, L.; Cairo, F.; Graziani, F.; Jepsen, S. Adjunctive effect of systemic antibiotics in regenerative/reconstructive periodontal surgery: A systematic review with meta-analysis. Antibiotics 2021, 11, 8. [Google Scholar] [CrossRef]
- Chiou, L.L.; Herron, B.; Lim, G.; Hamada, Y. The effect of systemic antibiotics on periodontal regeneration: A systematic review and meta-analysis of randomized controlled trials. Quintessence Int. 2023, 54, 210–219. [Google Scholar] [CrossRef] [PubMed]
- Choi, I.G.G.; Cortes, A.R.G.; Arita, E.S.; Georgetti, M.A.P. Comparison of conventional imaging techniques and CBCT for periodontal evaluation: A systematic review. Imaging Sci. Dent. 2018, 48, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Walter, C.; Schmidt, J.C.; Rinne, C.A.; Mendes, S.; Dula, K.; Sculean, A. Cone beam computed tomography (CBCT) for diagnosis and treatment planning in periodontology: Systematic review update. Clin. Oral Investig. 2020, 24, 2943–2958. [Google Scholar] [CrossRef]
- Assiri, H.; Dawasaz, A.A.; Alahmari, A.; Asiri, Z. Cone beam computed tomography (CBCT) in periodontal diseases: A systematic review based on the efficacy model. BMC Oral Health 2020, 20, 191. [Google Scholar] [CrossRef] [PubMed]
- Jolivet, G.; Huck, O.; Petit, C. Evaluation of furcation involvement with diagnostic imaging methods: A systematic review. Dentomaxillofac. Radiol. 2022, 51, 20210529. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Hinkle, D.E.; Wiersma, W.; Jurs, S.G. Applied Statistics for the Behavioral Sciences, 5th ed.; Houghton Mifflin: Boston, MA, USA, 2003. [Google Scholar]
- Balel, Y. Can ChatGPT be used in oral and maxillofacial surgery? J. Stomatol. Oral Maxillofac. Surg. 2023, 124, 101471. [Google Scholar] [CrossRef]
- Danesh, A.; Pazouki, H.; Danesh, K.; Danesh, F.; Danesh, A. The performance of artificial intelligence language models in board-style dental knowledge assessment: A preliminary study on ChatGPT. J. Am. Dent. Assoc. 2023, 154, 970–974. [Google Scholar] [CrossRef]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Bolzoni, A.; Committeri, U.; Crimi, S.; et al. Accuracy of ChatGPT-Generated Information on Head and Neck and Oromaxillofacial Surgery: A Multicenter Collaborative Analysis. Otolaryngol. Head Neck Surg. 2024, 170, 1492–1503. [Google Scholar] [CrossRef]
- Giannakopoulos, K.; Kavadella, A.; Salim, A.A.; Stamatopoulos, V.; Kaklamanos, E.G. Evaluation of the Performance of Generative AI Large Language Models ChatGPT, Google Bard, and Microsoft Bing Chat in Supporting Evidence-Based Dentistry: Comparative Mixed Methods Study. J. Med. Internet Res. 2023, 25, e51580. [Google Scholar] [CrossRef]
- Rokhshad, R.; Zhang, P.; Mohammad-Rahimi, H.; Pitchika, V.; Entezari, N.; Schwendicke, F. Accuracy and consistency of chatbots versus clinicians for answering pediatric dentistry questions: A pilot study. J. Dent. 2024, 144, 104938. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).