Depth Estimation Using Feature Pyramid U-Net and Polarized Self-Attention for Road Scenes


Abstract
:1. Introduction
- (1)
- PSA is used in the monocular self-supervised depth estimation model. It can guide the model to learn pixel-level semantic information, so it can get the depth map with more accurate boundaries.
- (2)
- We design a new decoder splicing method by combining the skip connection of U-net and FPN. This approach can get better results without significantly increasing the amount of calculation.
2. Related Work
2.1. Self-Supervised Monocular Depth Estimation
2.2. The Network Combining FPN and U-Net
2.3. Self-Attention Mechanism
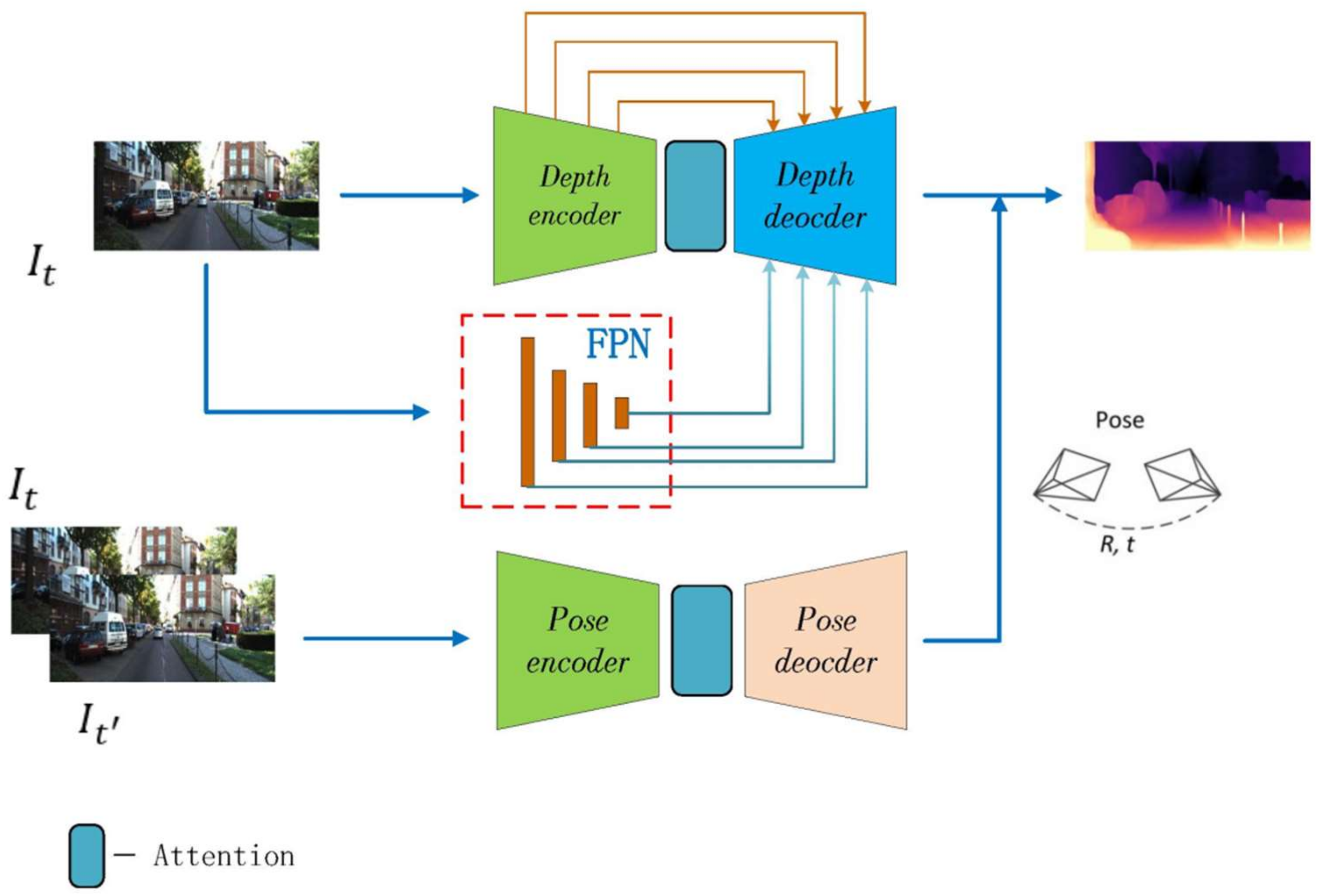
3. Methods
3.1. Network Architecture
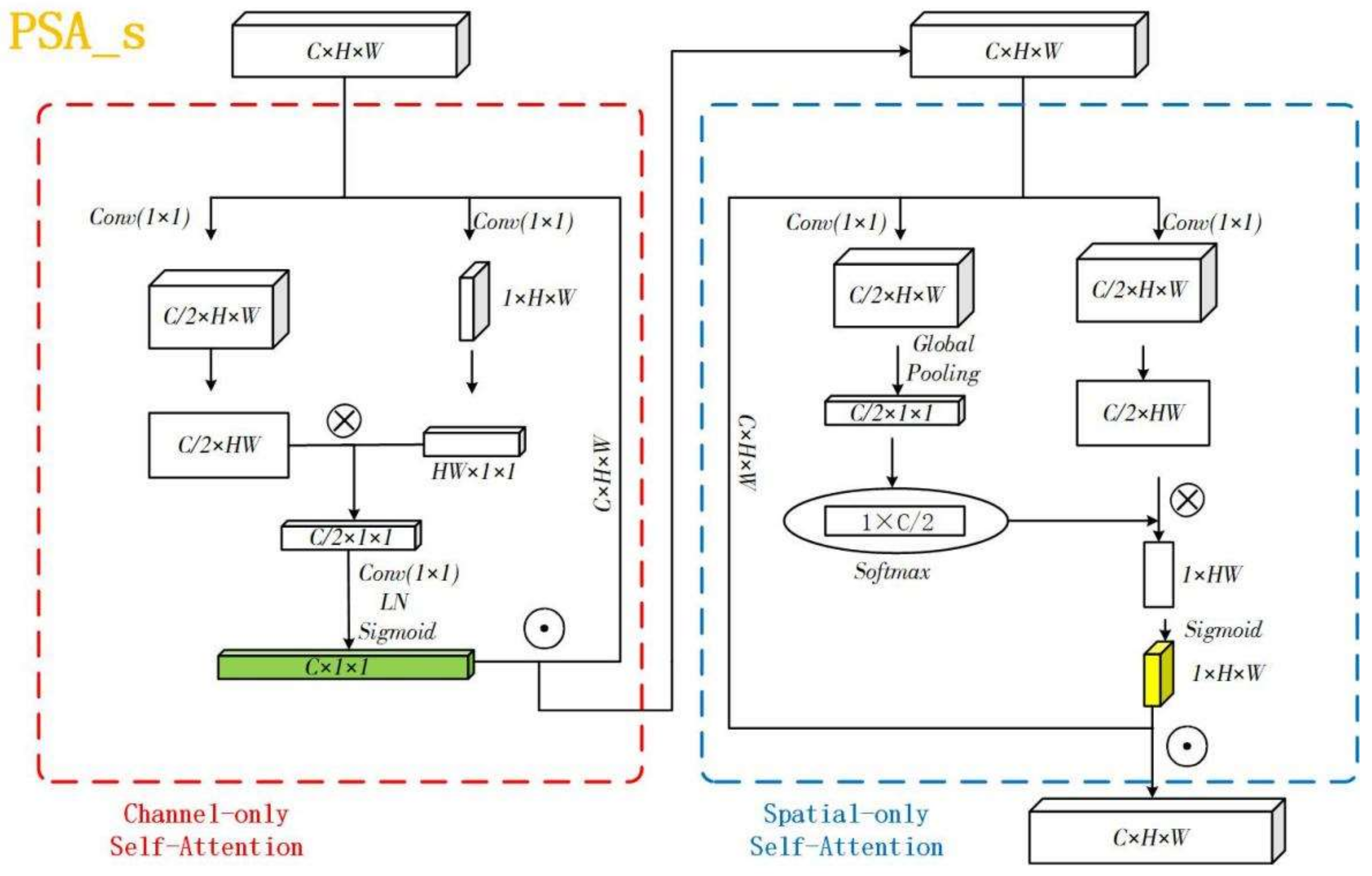
3.1.1. Channel-Only Branch
3.1.2. Spatial-Only Branch
3.2. Loss Function
4. Results and Discussion
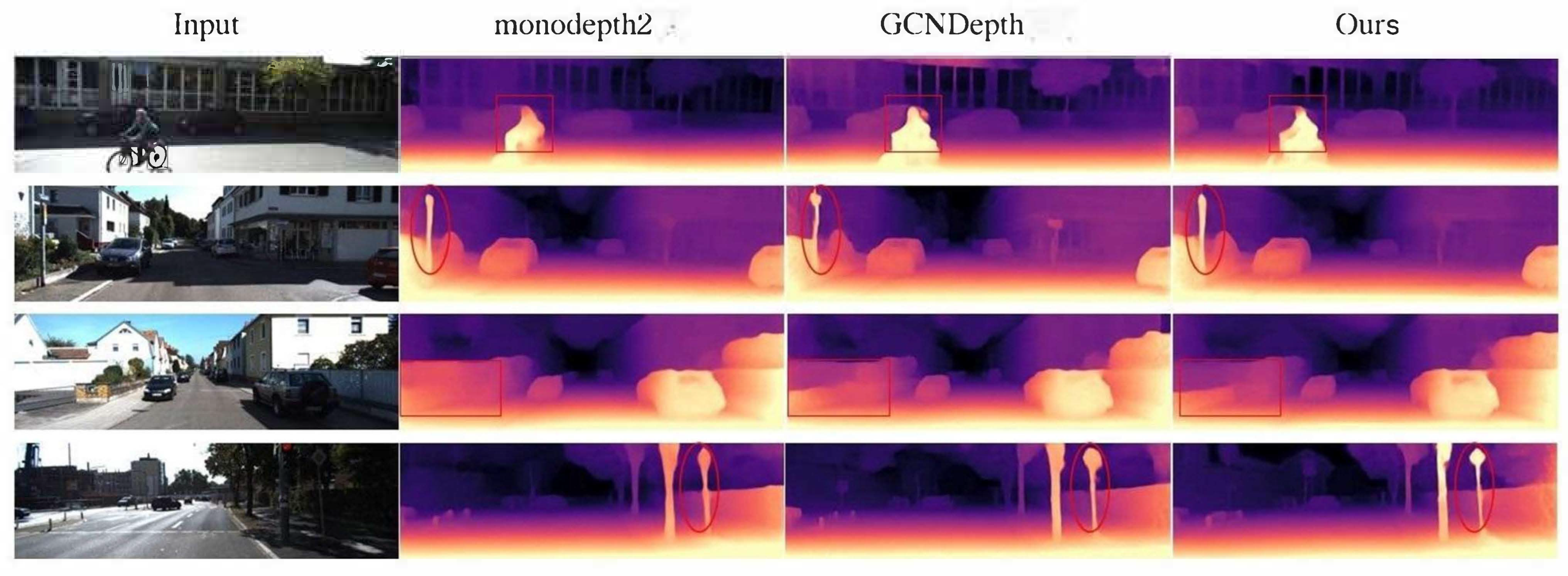
4.1. KITTI Results
4.2. Make3D Results
4.3. Generalizing to Other Datasets
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pagliari, D.; Pinto, L. Calibration of Kinect for Xbox One and Comparison between the Two Generations of Microsoft Sensors. Sensors 2015, 15, 27569–27589. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, X.; Wu, W.; Zhang, L.; Yan, Q.; Fu, G.; Chen, Z.; Long, C.; Xiao, C. Shading-aware shadow detection and removal from a single image. Vis. Comput. 2020, 36, 2175–2188. [Google Scholar] [CrossRef]
- Fu, Y.; Yan, Q.; Liao, J.; Chow, A.L.H.; Xiao, C. Real-time dense 3D reconstruction and camera tracking via embedded planes representation. Vis. Comput. 2020, 36, 2215–2226. [Google Scholar] [CrossRef]
- Fu, Y.; Yan, Q.; Liao, J.; Xiao, C. Joint Texture and Geometry Optimization for RGB-D Reconstruction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5949–5958. [Google Scholar] [CrossRef]
- Hao, Z.; Li, Y.; You, S.; Lu, F. Detail Preserving Depth Estimation from a Single Image Using Attention Guided Networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 304–313. [Google Scholar] [CrossRef] [Green Version]
- Klodt, M.; Vedaldi, A. Supervising the New with the Old: Learning SFM from SFM. In Proceedings of the Computer Vision—ECCV 2018. ECCV 2018, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11214. [Google Scholar]
- Yang, N.; Wang, R.; Stückler, J.; Cremers, D. Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry. In Proceedings of the Computer Vision—ECCV 2018. ECCV 2018, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11212. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into Self-Supervised Monocular Depth Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3827–3837. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.; Fan, X.; Zhang, M.; Xu, R.; Zhong, W. Unsupervised Monocular Depth Estimation via Recursive Stereo Distillation. IEEE Trans. Image Processing 2021, 30, 4492–4504. [Google Scholar] [CrossRef]
- Klingner, M.; Termöhlen, J.A.; Mikolajczyk, J.; Fingscheidt, T. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance. In Proceedings of the ECCV, 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 2619–2627. [Google Scholar]
- Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R. LEGO: Learning Edge with Geometry all at Once by Watching Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 225–234. [Google Scholar] [CrossRef] [Green Version]
- Jiang, D.; Li, G.; Sun, Y.; Hu, J.; Yun, J.; Liu, Y. Manipulator grabbing position detection with information fusion of color image and depth image using deep learning. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10809–10822. [Google Scholar] [CrossRef]
- Tao, B.; Liu, Y.; Huang, L.; Chen, G.; Chen, B. 3D reconstruction based on photoelastic fringes. Concurr. Comput. Pract. Exp. 2022, 34, e6481. [Google Scholar] [CrossRef]
- Tao, B.; Wang, Y.; Qian, X.; Tong, X.; He, F.; Yao, W.; Chen, B.; Chen, B. Photoelastic Stress Field Recovery Using Deep Convolutional Neural Network. Front. Bioeng. Biotechnol. 2022, 10, 818112. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised learning of geometry from videos with edge-aware depth-normal consistency. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA; 2018; pp. 7493–7500. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Wang, C.; Miguel Buenaposada, J.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.B. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 38–55. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12232–12241. [Google Scholar]
- Luo, C.; Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R.; Yuille, A. Every pixel counts ++: Joint learning of geometry and motion with 3d holistic understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2624–2641. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks. In Proceedings of the Computer Vision—ECCV 2016. ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908. [Google Scholar]
- Chen, P.-Y.; Liu, A.H.; Liu, Y.-C.; Wang, Y.-C.F. Towards Scene Understanding: Unsupervised Monocular Depth Estimation with Semantic-Aware Representation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2619–2627. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xing, X.; Cai, Y.; Wang, Y.; Lu, T.; Yang, Y.; Wen, D. Dynamic Guided Network for Monocular Depth Estimation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5459–5465. [Google Scholar] [CrossRef]
- Phan, M.H.; Phung, S.L.; Bouzerdoum, A. Ordinal Depth Classification Using Region-based Self-attention. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3620–3627. [Google Scholar] [CrossRef]
- Zhang, Y.; Han, J.H.; Kwon, Y.W.; Moon, Y.S. A New Architecture of Feature Pyramid Network for Object Detection. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1224–1228. [Google Scholar] [CrossRef]
- Song, M.; Lim, S.; Kim, W. Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4381–4393. [Google Scholar] [CrossRef]
- Lai, Z.; Tian, R.; Wu, Z.; Ding, N.; Sun, L.; Wang, Y. DCPNet: A Densely Connected Pyramid Network for Monocular Depth Estimation. Sensors 2021, 21, 6780. [Google Scholar] [CrossRef] [PubMed]
- Ng, M.Y.; Chng, C.B.; Koh, W.K.; Chui, C.K.; Chua, M.C.H. An enhanced self-attention and A2J approach for 3D hand pose estimation. Multimed. Tools Appl. 2021, 9, 124847–124860. [Google Scholar] [CrossRef]
- Yang, J.; Yang, J. Aspect Based Sentiment Analysis with Self-Attention and Gated Convolutional Networks. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; pp. 146–149. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, G.; Yu, M.; Xu, T.; Luo, T. Attention-Based Dense Decoding Network for Monocular Depth Estimation. IEEE Access 2020, 8, 85802–85812. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, G.; Huang, M.; Wang, H.; Wen, S. Generative Adversarial Networks for Abnormal Event Detection in Videos Based on Self-Attention Mechanism. IEEE Access 2021, 9, 124847–124860. [Google Scholar] [CrossRef]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Weakly-Supervised Sound Event Detection with Self-Attention. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 66–70. [Google Scholar] [CrossRef]
- Johnston, A.; Carneiro, G. Self-Supervised Monocular Trained Depth Estimation Using Self-Attention and Discrete Disparity Volume. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4755–4764. [Google Scholar] [CrossRef]
- Wang, C.; Deng, C. On the Global Self-attention Mechanism for Graph Convolutional Networks. 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8531–8538. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521v1. [Google Scholar]
- Huang, Y.-K.; Wu, T.-H.; Liu, Y.-C.; Hsu, W.H. Indoor Depth Completion with Boundary Consistency and Self-Attention. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1070–1078. [Google Scholar] [CrossRef] [Green Version]
- Mathew, A.; Patra, A.P.; Mathew, J. Self-Attention Dense Depth Estimation Network for Unrectified Video Sequences. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Virtual Conference, 25–28 October 2020; pp. 2810–2814. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized Self-Attention: Towards High-quality Pixel-wise Regression. arXiv 2021, arXiv:2107.00782. Available online: https://arxiv.org/abs/2107.00782 (accessed on 14 May 2022).
- Aziz, S.; Bilal, M.; Khan, M.; Amjad, F. Deep Learning-based Automatic Morphological Classification of Leukocytes using Blood Smears. 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Pixel-Wise Crowd Understanding via Synthetic Data. Int. J. Comput. Vis. 2021, 129, 225–245. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Sang, X.; Chen, D.; Wang, P. Self-Supervised Learning of Monocular Depth Estimation Based on Progressive Strategy. in IEEE Transactions on Computational Imaging 2021, 7, 375–383. [Google Scholar] [CrossRef]
- Zhou, S.; Wu, J.; Zhang, F.; Sehdev, P. Depth occlusion perception feature analysis for person re-identification. Pattern Recognit. Lett. 2020, 138, 617–623. [Google Scholar] [CrossRef]
- Pillai, S.; Ambrus, R.; Gaidon, A. SuperDepth: Self-Supervised, Super-Resolved Monocular Depth Estimation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9250–9256. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2041–2050. [Google Scholar] [CrossRef] [Green Version]
- Goldman, M.; Hassner, T.; Avidan, S. Learn Stereo, Infer Mono: Siamese Networks for Self-Supervised, Monocular, Depth Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 15–20 June 2019; pp. 2886–2895. [Google Scholar] [CrossRef] [Green Version]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 27 January–1 February 2019; pp. 8001–8008. [Google Scholar]
- Garg, R.; VijayKumar, B.G.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the ECCV, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the CVPR, 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Mehta, I.; Sakurikar, P.; Narayanan, P.J. Structured adversarial training for unsupervised monocular depth estimation. In Proceedings of the 3DV, 2018 International Conference on 3d Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 314–323. [Google Scholar]
- Poggi, M.; Tosi, F.; Mattoccia, S. Learning monocular depth estimation with unsupervised trinocular assumptions. In Proceedings of the 3DV, 2018 International Conference on 3d Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 324–333. [Google Scholar]
- Watson, J.; Firman, M.; Brostow, G.; Turmukhambetov, D. Self-Supervised Monocular Depth Hints. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2162–2171. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Wang, S.; Long, Z.; Gu, D. Undeepvo: Monocular visual odometry through unsupervised deep learning. In Proceedings of the ICRA, 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar]
- Masoumian, A.; Rashwan, H.; Abdulwahab, S.; Cristiano, J. GCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network. arXiv 2021, arXiv:2112.06782. [Google Scholar]
- Godet, P.; Boulch, A.; Plyer, A.; Le Besnerais, G. STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2462–2469. [Google Scholar] [CrossRef]
- Tao, B.; Huang, L.; Zhao, H.; Li, G.; Tong, X. A time sequence images matching method based on the siamese network. Sensors 2021, 21, 5900. [Google Scholar] [CrossRef] [PubMed]
- Vasiljevic, I.; Kolkin, N.; Zhang, S.; Luo, R.; Wang, H.; Dai, F.Z.; Daniele, A.F.; Mostajabi, M.; Basart, S.; Walter, M.R.; et al. DIODE: A Dense Indoor and Outdoor Depth Dataset. arXiv 2019, arXiv:1908.00463. [Google Scholar]
- Varma, G.; Subramanian, A.; Namboodiri, A.; Chandraker, M.; Jawahar, C. IDD: A Dataset for Exploring Problems of Autonomous Navigation in Unconstrained Environments. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1743–1751. [Google Scholar] [CrossRef] [Green Version]
- Hao, Z.; Wang, Z.; Bai, D.; Tao, B.; Tong, X.; Chen, B. Intelligent detection of steel defects based on improved split attention networks. Front. Bioeng. Biotechnol. 2022, 9, 810876. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Train | Abs Rel | Sq Rel | RMSE | RMSE log | δ < 1.25 | ||
|---|---|---|---|---|---|---|---|---|
| Zhou, et al. [26] | M(K) | 0.183 | 1.595 | 6.709 | 0.270 | 0.734 | 0.902 | 0.959 |
| Yang, et al. [17] | M(K) | 0.182 | 1.481 | 6.501 | 0.267 | 0.725 | 0.906 | 0.963 |
| Mahjourian, et al. [18] | M(K) | 0.163 | 1.240 | 6.220 | 0.250 | 0.762 | 0.916 | 0.968 |
| GeoNet [19] | M(K) | 0.149 | 1.060 | 5.567 | 0.226 | 0.796 | 0.935 | 0.975 |
| DDVO [20] | M(K) | 0.151 | 1.257 | 5.583 | 0.228 | 0.810 | 0.936 | 0.974 |
| DF-Net [21] | M(K) | 0.150 | 1.124 | 5.507 | 0.223 | 0.806 | 0.933 | 0.973 |
| Ranjan, et al. [22] | M(K) | 0.148 | 1.149 | 5.464 | 0.226 | 0.815 | 0.935 | 0.973 |
| EPC++ [23] | M(K) | 0.141 | 1.026 | 5.291 | 0.215 | 0.816 | 0.945 | 0.979 |
| Struct2depth [51] | M(K) | 0.141 | 1.026 | 5.291 | 0.215 | 0.816 | 0.945 | 0.979 |
| Monodepth2 [9] | M(K) | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.980 |
| Klingner, et al. [11] | M(K) | 0.113 | 0.870 | 4.720 | 0.187 | 0.876 | 0.958 | 0.978 |
| Johnston, et al. [37] | M(K) | 0.110 | 0.872 | 4.714 | 0.189 | 0.878 | 0.958 | 0.980 |
| Current study | M(K) | 0.110 | 0.838 | 4.706 | 0.180 | 0.878 | 0.960 | 0.982 |
| Garg, et al. [52] | S(K) | 0.152 | 1.226 | 5.489 | 0.246 | 0.784 | 0.921 | 0.967 |
| Monodepth R50 [53] | S(K) | 0.133 | 1.142 | 5.533 | 0.230 | 0.830 | 0.936 | 0.970 |
| StrAT [54] | S(K) | 0.128 | 1.019 | 5.403 | 0.227 | 0.827 | 0.935 | 0.971 |
| 3Net(R50) [55] | S(K) | 0.129 | 0.996 | 5.281 | 0.223 | 0.831 | 0.939 | 0.974 |
| 3Net(R18) [55] | S(K) | 0.112 | 0.953 | 5.007 | 0.207 | 0.862 | 0.949 | 0.976 |
| Monodepth2 [9] | S(K) | 0.109 | 0.873 | 4.960 | 0.209 | 0.864 | 0.948 | 0.975 |
| Hint-Monodepth [56] | S(K) | 0.111 | 0.912 | 4.977 | 0.205 | 0.862 | 0.950 | 0.977 |
| Current study | S(K) | 0.111 | 0.870 | 4.917 | 0.205 | 0.866 | 0.952 | 0.977 |
| UnDeepVO [57] | MS(K) | 0.183 | 1.730 | 6.571 | 0.268 | − | − | − |
| EPC++ [23] | MS(K) | 0.128 | 0.936 | 5.011 | 0.209 | 0.831 | 0.945 | 0.979 |
| Monodepth2 [9] | MS(K) | 0.107 | 0.819 | 4.751 | 0.198 | 0.873 | 0.955 | 0.977 |
| Current study | MS(K) | 0.110 | 0.857 | 4.741 | 0.190 | 0.882 | 0.960 | 0.981 |
| Method | Train | Abs Rel | Sq Rel | RMSE | RMSE log |
|---|---|---|---|---|---|
| Zhou, et al. [26] | M(K) | 0.386 | 5.328 | 10.472 | 0.478 |
| monodepth2 [9] | M(K) | 0.324 | 3.586 | 7.415 | 0.164 |
| Johnston, et al. [37] | M(K) | 0.306 | 3.100 | 7.126 | 0.160 |
| Current study | M(K) | 0.284 | 2.903 | 7.011 | 0.149 |
| Train | PSA_p | PSA_s | Abs Rel | Sq Rel | RMSE | RMSE log | |||
|---|---|---|---|---|---|---|---|---|---|
| M(K) | √ | × | 0.116 | 0.865 | 4.816 | 0.194 | 0.874 | 0.958 | 0.980 |
| × | √ | 0.117 | 0.908 | 4.878 | 0.192 | 0.870 | 0.959 | 0.982 | |
| √ | √ | 0.110 | 0.838 | 4.706 | 0.180 | 0.878 | 0.960 | 0.982 | |
| × | × | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.980 | |
| S(K) | √ | × | 0.110 | 0.919 | 5.000 | 0.207 | 0.865 | 0.950 | 0.976 |
| × | √ | 0.110 | 0.893 | 4.958 | 0.206 | 0.886 | 0.950 | 0.977 | |
| √ | √ | 0.111 | 0.870 | 4.917 | 0.205 | 0.866 | 0.952 | 0.977 | |
| × | × | 0.109 | 0.873 | 4.960 | 0.209 | 0.864 | 0.948 | 0.975 | |
| MS(K) | √ | × | 0.110 | 0.857 | 4.741 | 0.190 | 0.882 | 0.960 | 0.981 |
| × | √ | 0.117 | 0.857 | 4.877 | 0.191 | 0.863 | 0.956 | 0.982 | |
| √ | √ | 0.111 | 0.862 | 4.742 | 0.190 | 0.883 | 0.960 | 0.981 | |
| × | × | 0.107 | 0.819 | 4.751 | 0.198 | 0.873 | 0.955 | 0.977 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, B.; Shen, Y.; Tong, X.; Jiang, D.; Chen, B. Depth Estimation Using Feature Pyramid U-Net and Polarized Self-Attention for Road Scenes. Photonics 2022, 9, 468. https://doi.org/10.3390/photonics9070468
Tao B, Shen Y, Tong X, Jiang D, Chen B. Depth Estimation Using Feature Pyramid U-Net and Polarized Self-Attention for Road Scenes. Photonics. 2022; 9(7):468. https://doi.org/10.3390/photonics9070468
Chicago/Turabian StyleTao, Bo, Yunfei Shen, Xiliang Tong, Du Jiang, and Baojia Chen. 2022. "Depth Estimation Using Feature Pyramid U-Net and Polarized Self-Attention for Road Scenes" Photonics 9, no. 7: 468. https://doi.org/10.3390/photonics9070468
APA StyleTao, B., Shen, Y., Tong, X., Jiang, D., & Chen, B. (2022). Depth Estimation Using Feature Pyramid U-Net and Polarized Self-Attention for Road Scenes. Photonics, 9(7), 468. https://doi.org/10.3390/photonics9070468