1. Introduction
Visible light communication (VLC) [
1] has recently been widely researched by academia and industry, due to its advantage of simultaneous lighting [
2] and communication. For low complexity and cost, intensity modulation using light emitting diodes (LED) and direct detection with a photodetector (PD) is commonly employed in the VLC system. However, there are some challenges that create an obstacle to the development of VLC. First, the nonlinearity characteristic of LEDs is significant. Thus, the transmitted signal usually satisfies the peak intensity constraint. Second, due to the limited bandwidth of LED, efficient constellation modulation [
3] is applied for a higher data rate. Third, the reflected signal leads to the inter-symbol-interference (ISI), which should be compensated by extra equalization [
4] or error correction code.
Machine learning, especially deep learning [
5], is now penetrating every facet of wireless communication [
6]. The general method of deep learning is comprised of two types: in one respect, the individual parts of communication systems, such as pilot design [
7], channel estimation and detection [
8], are replaced by a learned efficient neural network (NN); in the other respect, the end-to-end learning of the whole communication system creates a new paradigm for joint optimization of transceivers [
9]. Due to the similarity of autoencoder (AE) and communication systems, several works have been completed on transceiver design using AE to further promote the performance of transceivers. The early works of NN-based transceivers focus on the additive white Gaussian noise (AWGN) channel model, which deserves more practical consideration for application. In [
10], the authors focus on the continuous data transmission and synchronization issue in the receiver. However, the ISI is neglected, and a stacked fully connected neural network is inefficient. In [
11], the pilot and data are trained together in the AE; however, the fading channel is the only single path and the sequence length is limited due to the fully connected structure. In [
12], Zhu et al. provide the convolution neural network (CNN) structure, which is adequate for sequence training. Still, the simulated ISI channel is static and not practical for varying models.
During the next several years, similar approaches are migrated to enhance the performance of transceivers in the VLC domain, where typical characteristics, such as unipolarity of signal [
13], illumination requirements [
14,
15] and nonlinearity of channel [
16], should be sufficiently considered. In [
17], for higher bandwidth efficiency, the VLC orthogonal frequency division multiplexing (OFDM) system with the stochastic ISI model is optimized with the AE approach. However, the ISI is mainly eliminated by the cyclic prefix, which can be further modified through the deep learning method. Meanwhile, in [
18], to explicitly integrate the channel side information (CSI) into AE VLC system, the classic model-based method is required to estimate CSI in the receiver, which adds extra complexity to the whole system. Similarly, for more real-life application constraints, Ref. [
19] proposed VLCnet, which takes into account illumination level, flicker influence and channel impulse response. However, an additional minimum mean square error (MMSE) equalizer with real CSI is still required in practical implementation.
In this letter, we propose an NN-based transceiver for the VLC system over the ISI channel with the modified AE model, which extends the work [
20] focusing on the single path channel and CSI obtained by the traditional method. The contribution of this paper can be summarized as follows:
(1) To handle the sequence input issue, we propose the AE framework with a 1-D convolution (Conv1D) layer structure. Meanwhile, the residual network structure is utilized at the receiver to improve training performance. The whole architecture is flexible for processing continuous transmission signals, which is prevalent in current communication systems.
(2) To the best of the author’s knowledge, it is the initial work to integrate the pilot sequence and data sequence into the transceiver design with NN in the VLC domain. This joint structure enables the optimization of transmitter and receiver with implicit channel estimation in the whole system. Thus, the additional channel estimation part using the traditional method can be eliminated. The pilot-assisted transceiver enables the receiver to recover the data sequence directly without explicit CSI.
The simulation results demonstrate that the symbol error rate (SER) performance of the proposed transceiver can outperform the individually designed transceiver scheme and approach the ideal perfect CSI (PCSI) case with a few pilot symbols for above 2 level modulation or even no pilot for a 2 level case.
2. VLC System Model with ISI
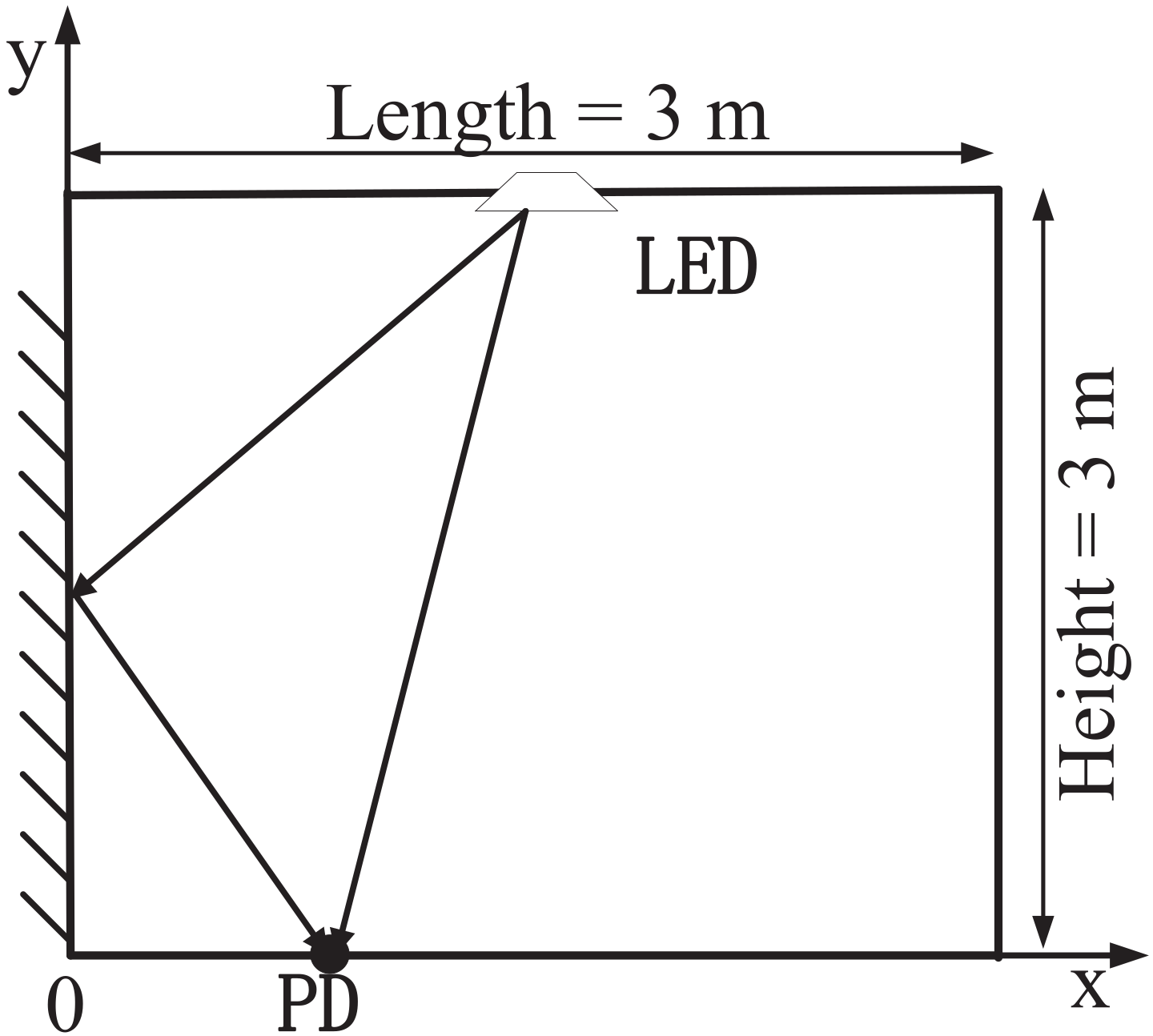
The common ISI VLC model can be given as in
Figure 1, where the light-of-sight (LOS) path is the dominant one and the reflected path by the wall causes the multipath distortion. The validation of the model has been experimentally illustrated in [
21] under the off-the-shelf devices and standard indoor environments. Due to the slowly changing property (compared to the baud rate), the ISI VLC model is usually regarded as a linear time-invariant system during multiple symbols duration. For the validity of channel estimation, data and pilot sequence experience the same channel condition. Referring to [
22], the received signal containing data and pilot can be written as:
where
and
are the impulse response for the LOS path and the reflected path, respectively,
is the transmitted signal,
is the transmission delay for the second path,
is the AWGN.
Assuming a matched filter with the impulse response of the LOS path, then we can obtain the discrete time model as [
18]:
where
is the received signal,
is the transmitted signal,
is the AWGN with mean 0 and variance
.
is a Toeplitz matrix containing the shifted two path channel coefficients and
-th element
is expressed as:
where
is the normalized delay,
d is the LOS path transmission distance,
is the reflected path transmission distance,
c is the speed of light and
T is the symbol time interval. In the indoor VLC model, the channel DC gain ratio
can be calculated as:
where
is the walls reflectivity factor. The channel DC gain
h of an optical link can be obtained as:
The order of Lambertian emission is
,
is the angle of irradiance,
is the angle of incidence and other parameters are introduced in
Table 1.
3. Autoencoder Model
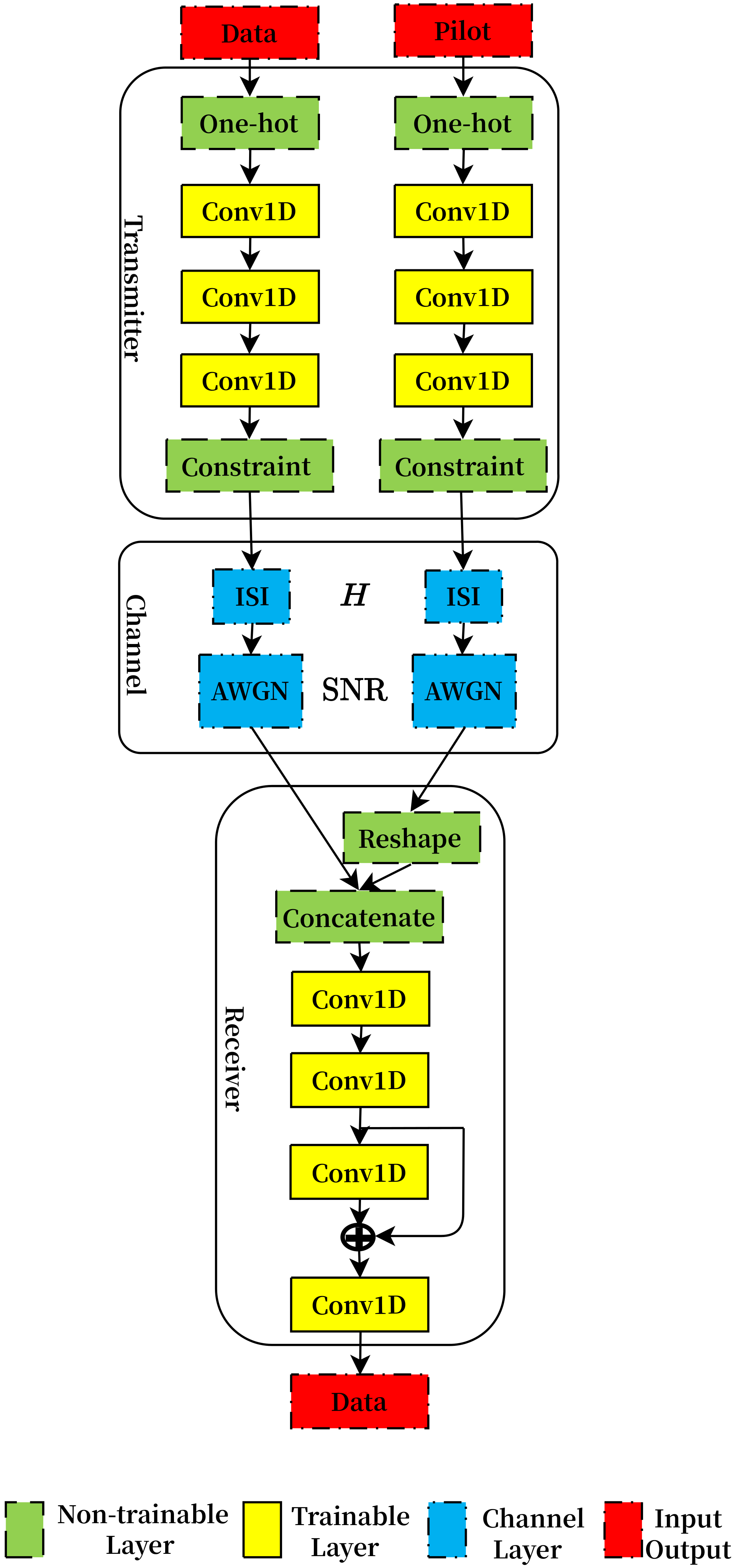
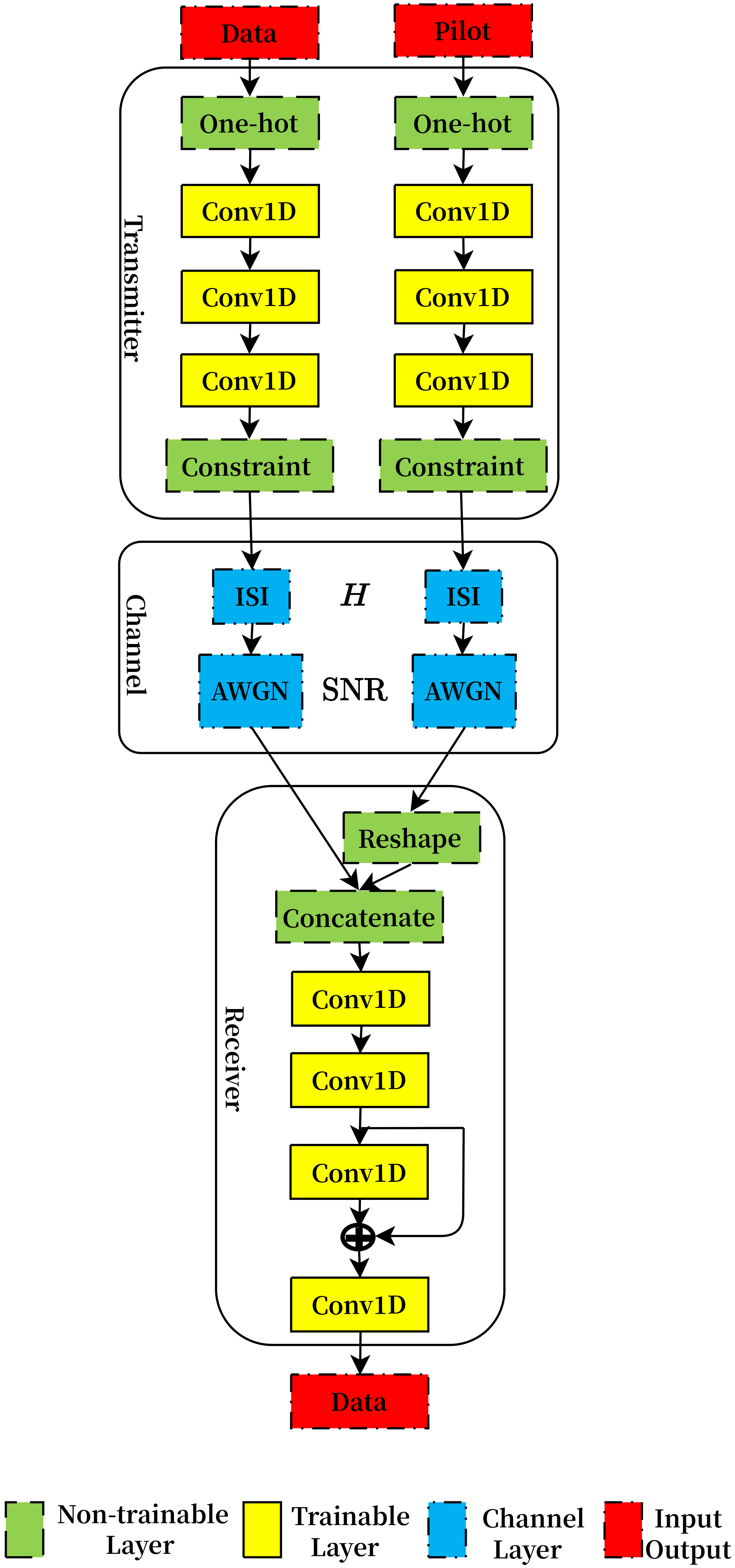
Here, we propose the NN framework in
Figure 2 to solve the transceiver design issues in the above section. For the flexibility of the processing sequence, we leverage Conv1D layers in the AE model. To compensate for the varying ISI, the pilot sequence is creatively incorporated into the NN-based transceiver.
In the transmitter part, data and pilot, which represent random and fixed value sequences, respectively, are input into the corresponding transmitter NNs. All the data sequences
and pilot sequences
are mapped into one-hot vectors, whose index value is 1 and other values are all 0. The Conv1D layer enables the input vectors to be convolved and added by trainable convolution kernels and biases, respectively, which offer efficient mutual operation between the kernel-size-dependent nearby independent symbols instead of redundant distant symbols in a fully connected structure. Detailed parameters of all Conv1D layers, including filters number, kernel size and activation function, are provided in
Table 2. The last Conv1D layers in the pilot transmitter, data transmitter and receiver employ a ‘valid’ padding scheme, while other Conv1D layers utilize the ‘same’ scheme. The strides are configured as 1. The rectified linear unit (ReLU) activation function used in majority layers produces nonlinearity and superior convergence performance, while the linear function employed in the layers before constraint layers guarantees that the signal space will not be adjusted. For satisfying the non-negative and peak power constraint of the sent light signal, that is,
, a weighted sigmoid activation function is utilized in the constraint layer, that is,
, where
A is the peak power constraint.
In the channel layer, both data and pilot sequences are firstly multiplied by an ISI Toeplitz matrix, whose row vectors are the shifted multipath channel vectors. Then, the noise generated from a standard normal distribution with a fixed variance , where SNR is the signal-to-noise ratio, is added into the distorted sequences.
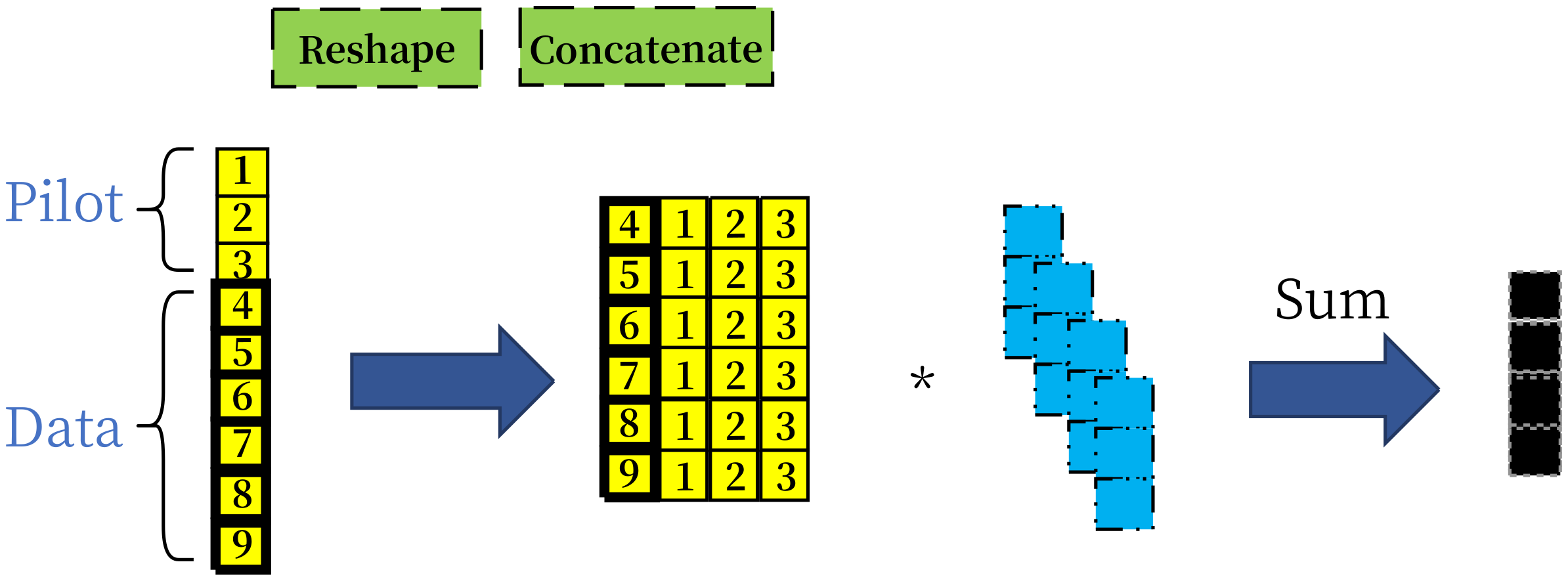
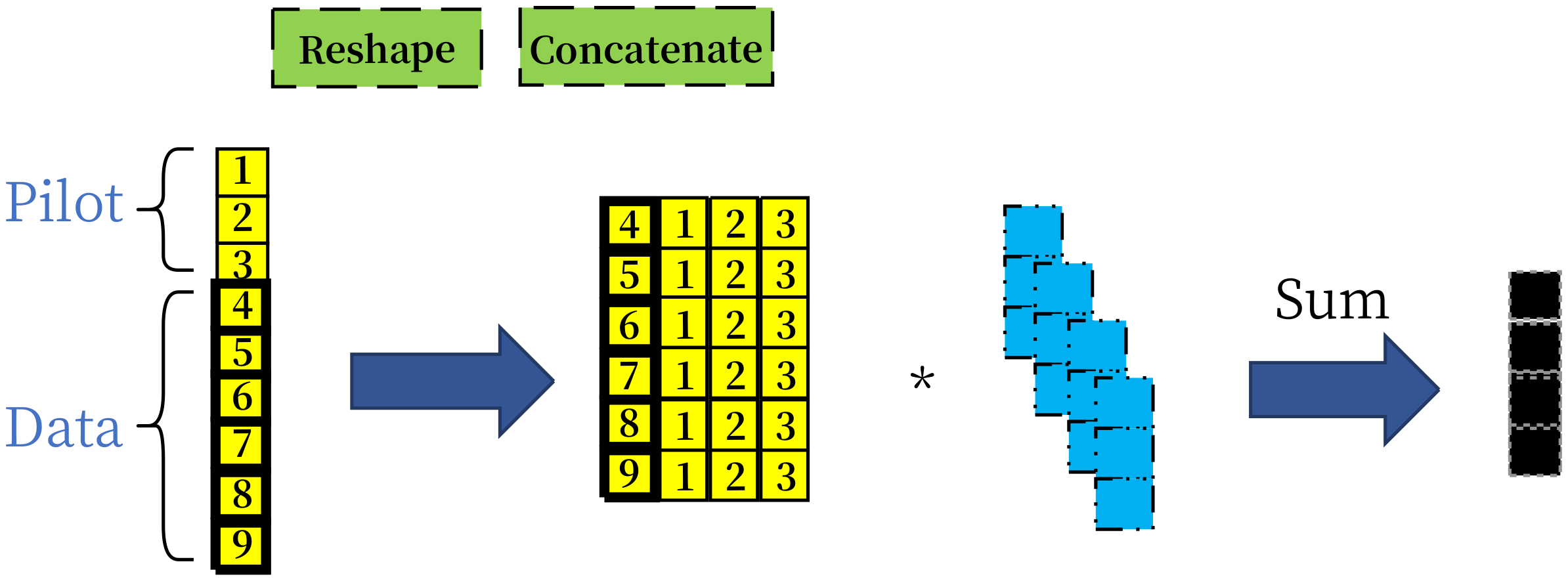
At the receiver part, if the noisy pilot sequence is only concatenated with the data sequence, it is notoriously hard for the receiver NN to treat pilot and data distinctively based on the provided modest NN scale. Therefore, for the sake of addressing the influence of the pilot, the noisy pilot sequence
is reshaped into pilot matrix
, and then data sequence
is concatenated together into the matrix
. An intuitive explanation of these operations is illustrated in
Figure 3. In the leftmost part of
Figure 3, the three boxes represent the pilot sequence while the next six bold boxes represent the data sequence. With the proposed concatenation method, in the following convolution operations, all the pilot symbols can influence the detection of the data symbol by implicit joint channel estimation and equalization. The concrete performances depend on the eventually learnable NN parameters. To enhance the capability of the NN receiver and accelerate its convergence, we leverage the residual network structure, which means the inputs and outputs of specific layers are added together. We use the softmax activation function in the last layer to transform the input values into a probability vector over all possible messages. The loss function of the training process is the categorical cross-entropy of a data sequence, which is given as:
where
represents the
mth index value of one-hot vector
and
is the corresponding estimated value.
The NN structure and parameters are conceived empirically. Extensive hyper-parameters searching, which might enhance the eventual performance, is not under consideration for brevity. The NN is trained using the back-propagation algorithm. The data and corresponding label are the same randomly generated signal sequence in the AE unsupervised learning strategy. Once the training process of NN is completed, the transmitter part can send the data and pilot sequence using the NN or simplified lookup table. Based on the perfectly synchronized pilot and data, the receiver can recover the data sequence straightforwardly without estimating the CSI explicitly.
4. Simulation Results
Based on the channel model in
Figure 1, we simulate two typical PD positions (around the corner/in the middle of the room) and the average performance to verify the effectiveness of our proposed method. The basic parameter configuration for the VLC system is given in
Table 1. The PD’s positions and corresponding parameters are presented in
Table 3.
We set the sequence length of data and pilot as and , respectively. The tested constellation set cardinality . The SNR is defined as here and peak power as . The multipath channel coefficients are generated randomly considering the PD uniformly appears in the x axis, that is, the PD’s coordinate satisfies , .
In our baseline method, we use
M-PAM for data and pilot sequences with length
and pilot value
at the transmitter. As for the receiver, minimum mean square error (MMSE) channel estimation result or PCSI is provided, and then maximum likelihood sequence estimation (MLSE), using the Viterbi algorithm [
23], is utilized.
In our simulation, we use TensorFlow 2.0 and Python 3.6. During the training process, samples are employed for 50 epochs. For every 10 epochs, the progressively increasing batch size from set is employed. The Adam optimizer is used and the learning rate decreases with the ‘loss’ monitor factor , the patience 2, the initial learning rate and the minimum learning rate . For training effectiveness, the early-stopping strategy is applied with the ‘loss’ monitor and the patience 5.
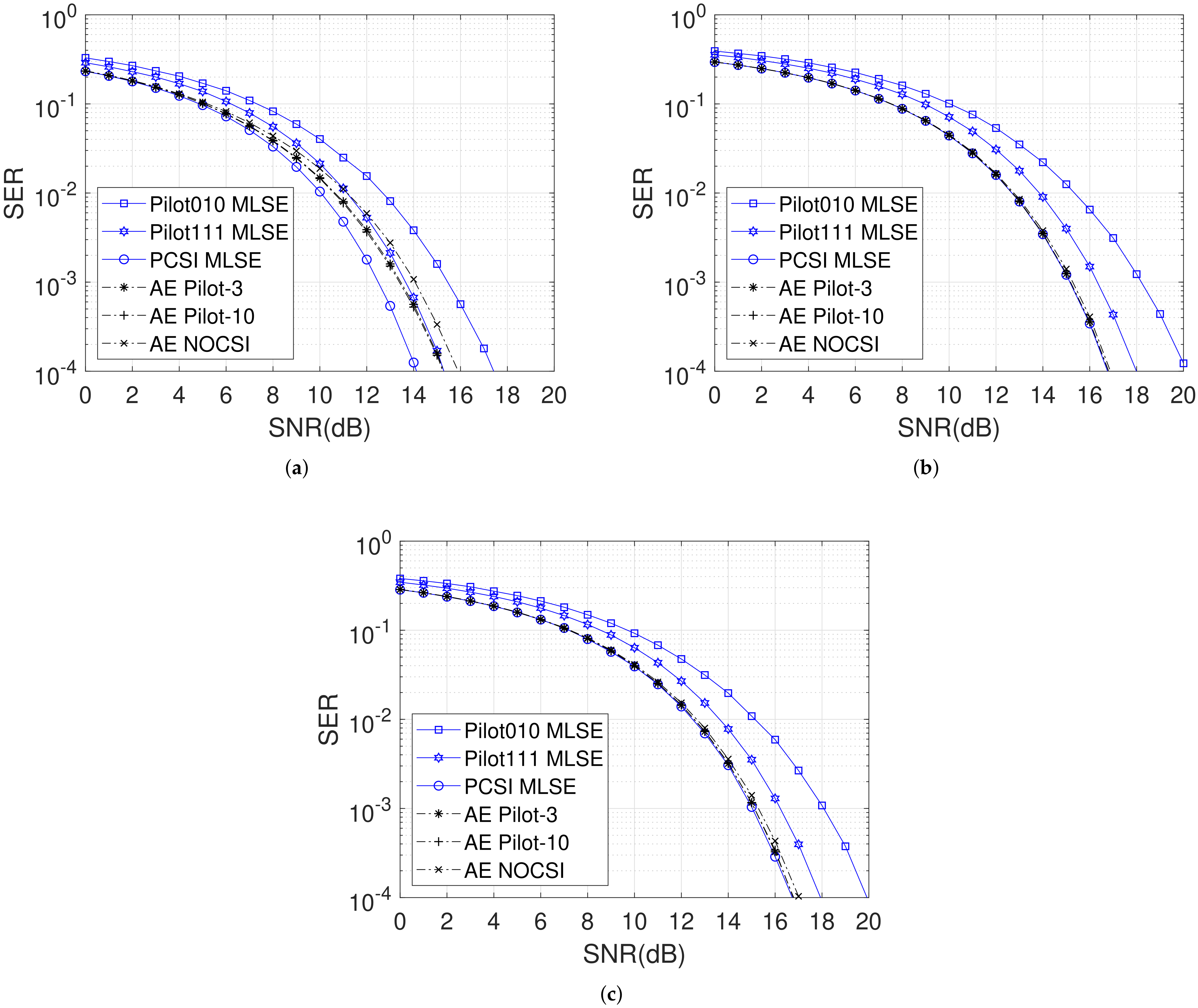
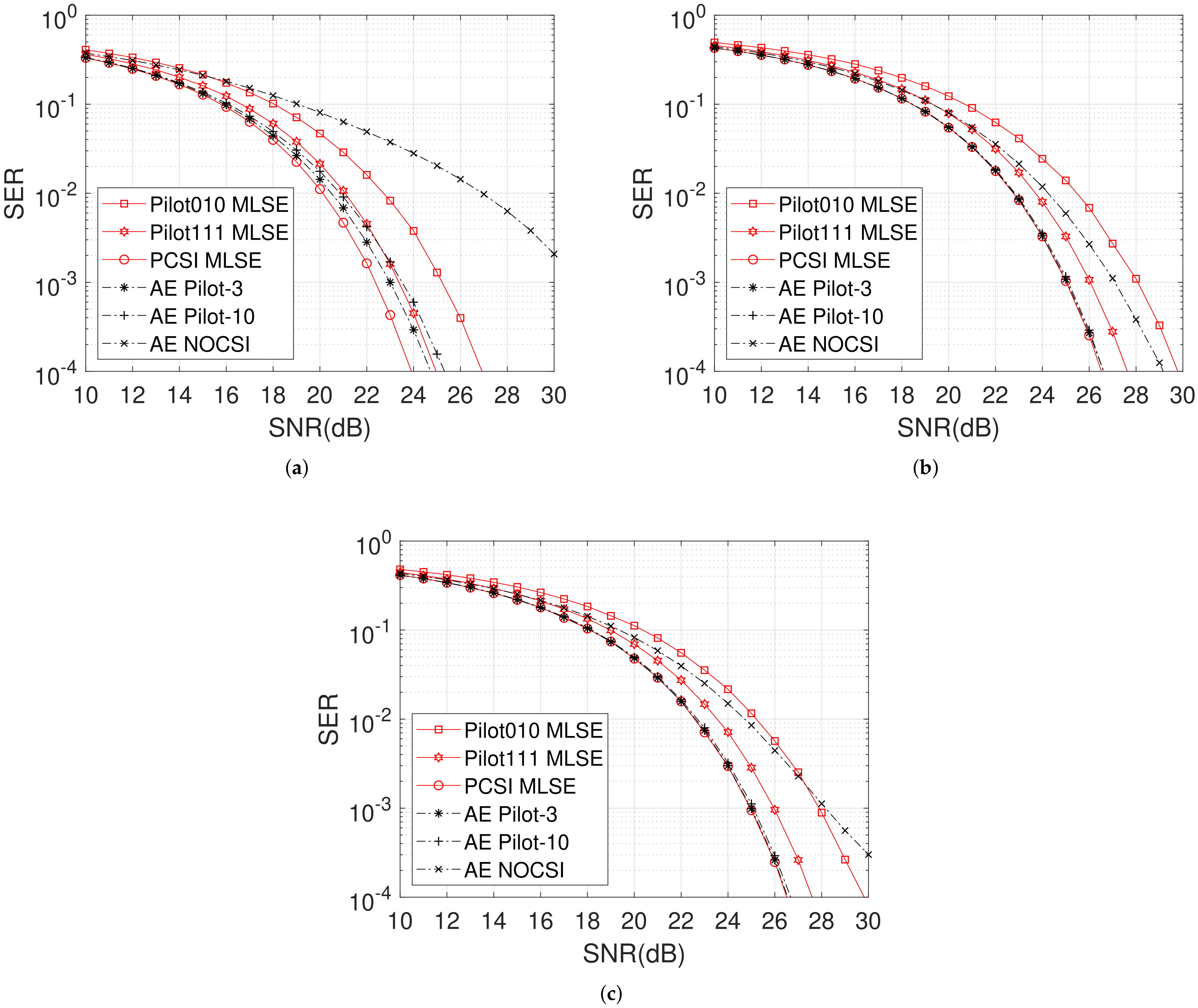
In
Figure 4, we consider the case
. ‘AE NOCSI’ means that no pilot or CSI is input into the receiver NN. The training SNR is given in the caption of
Figure 4 (In the ‘NOCSI’ case, if the training SNR is too low or the same as using the pilot case, the final SER performance will converge to a constant value in the high SNR domain; therefore, we configure the training SNR slightly higher than using the pilot case). Once the NN converges steadily, the learned data constellation
, the same as the 2-PAM scheme, for all the symbols in the sequence and the pilot sequence is
. It can be seen from
Figure 4a that when the PD locates around the corner of the room, the SER performance of AE schemes using pilot or not is inferior to MLSE schemes with excellent CSI conditions. However,
Figure 4b demonstrates that AE schemes with a few pilot symbols can approach the optimal MLSE with PCSI. The average SER performance in
Figure 4c further clarifies that in the majority positions in a room, AE can learn efficient transceiver and baseline methods, and even without CSI, the receiver can still compensate for the detrimental effect of ISI and can finally recover the sequence despite the limited decline in the high SNR domain.
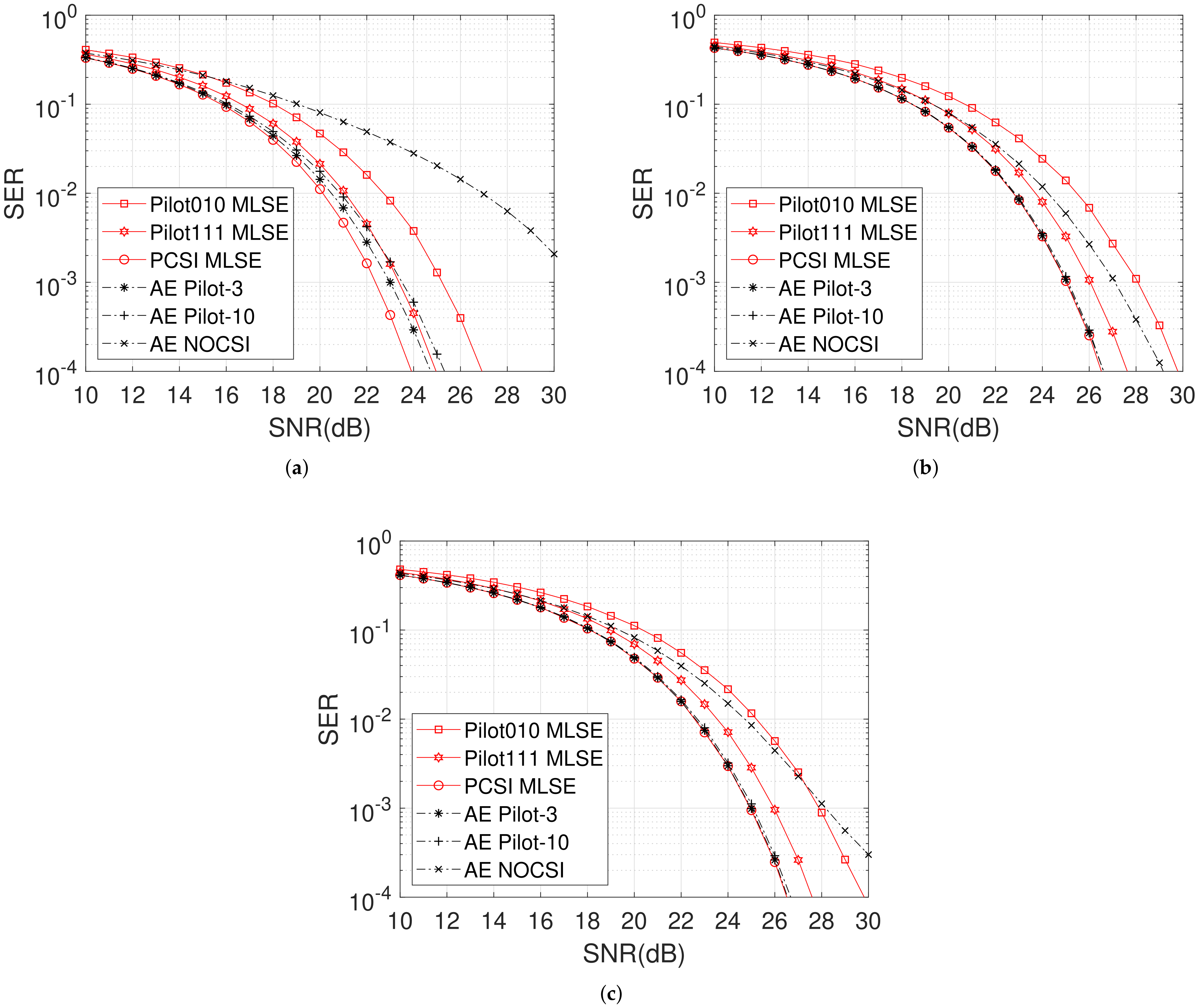
The AE results are slightly distinctive when
. Similar to the
case, the learned pilot sequence is
. Nonetheless, the learned data constellation sets illustrated in
Table 4 indicate that the constellation sets of schemes (Almost all the learned symbols in the sequence are mapped into the same constellation set. Only the last two or three symbols are mapped into different sets, but the values are still similar. Here, we only focus on the majority cases) using pilot converge to the equal-interval 4-PAM but the interval is irregular without CSI, which agrees with the PCSI and noisy CSI case in [
20]. It can be seen from
Figure 5 that the SER performance of ‘AE NOCSI’ significantly degrades compared with AE using pilot. Thus, the importance of CSI is obvious for above 2 level modulation. With the aid of the pilot sequence, the SER curve can approach the results of MLSE with PCSI in
Figure 5b,c, which shows that the joint design of the transceiver using AE can reduce the power consumption with fewer pilot symbols to meet the desired SER performance. However, the performance is unfavorable in
Figure 5a, similar to in
Figure 4a, especially in the high SNR case, where the ISI occupies a more important position than noise. To handle these issues, one feasible strategy is to enlarge the pilot symbol number and leverage a deeper NN structure, which deserves a delicate experimental validation in our future work.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}