ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network


Abstract
:1. Introduction
2. Methods
2.1. Total Variation (TV) Method
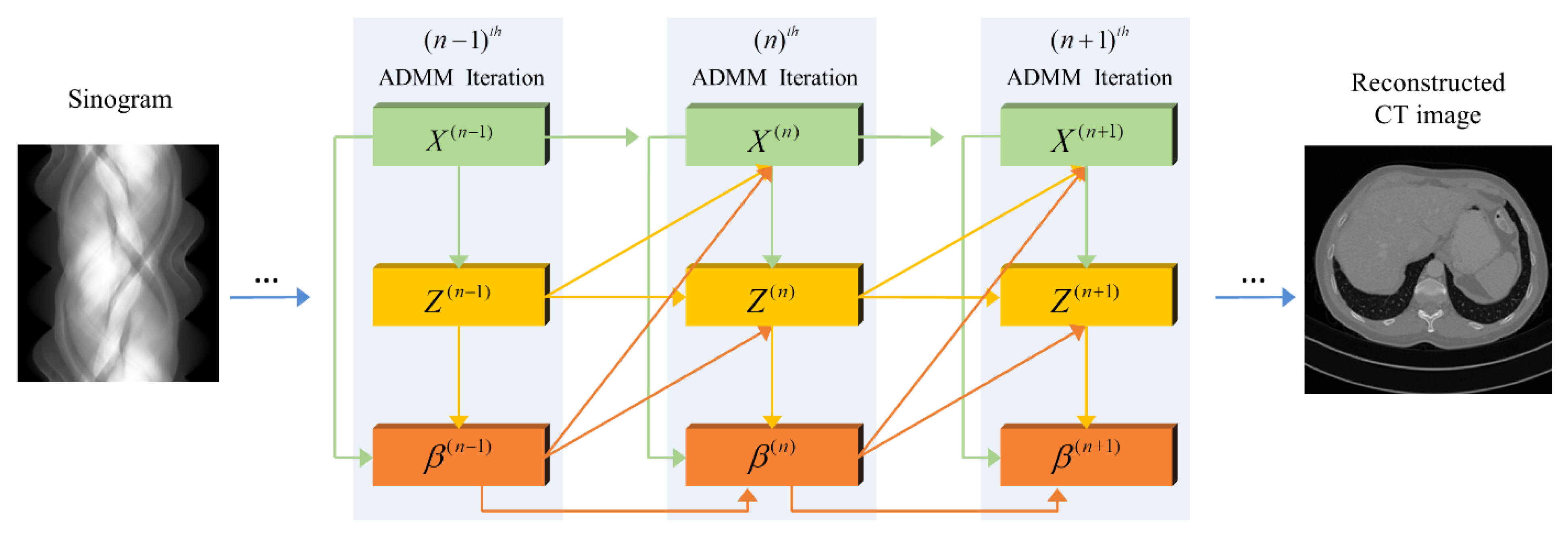
2.2. ADMM Algorithm for an Optimized Model
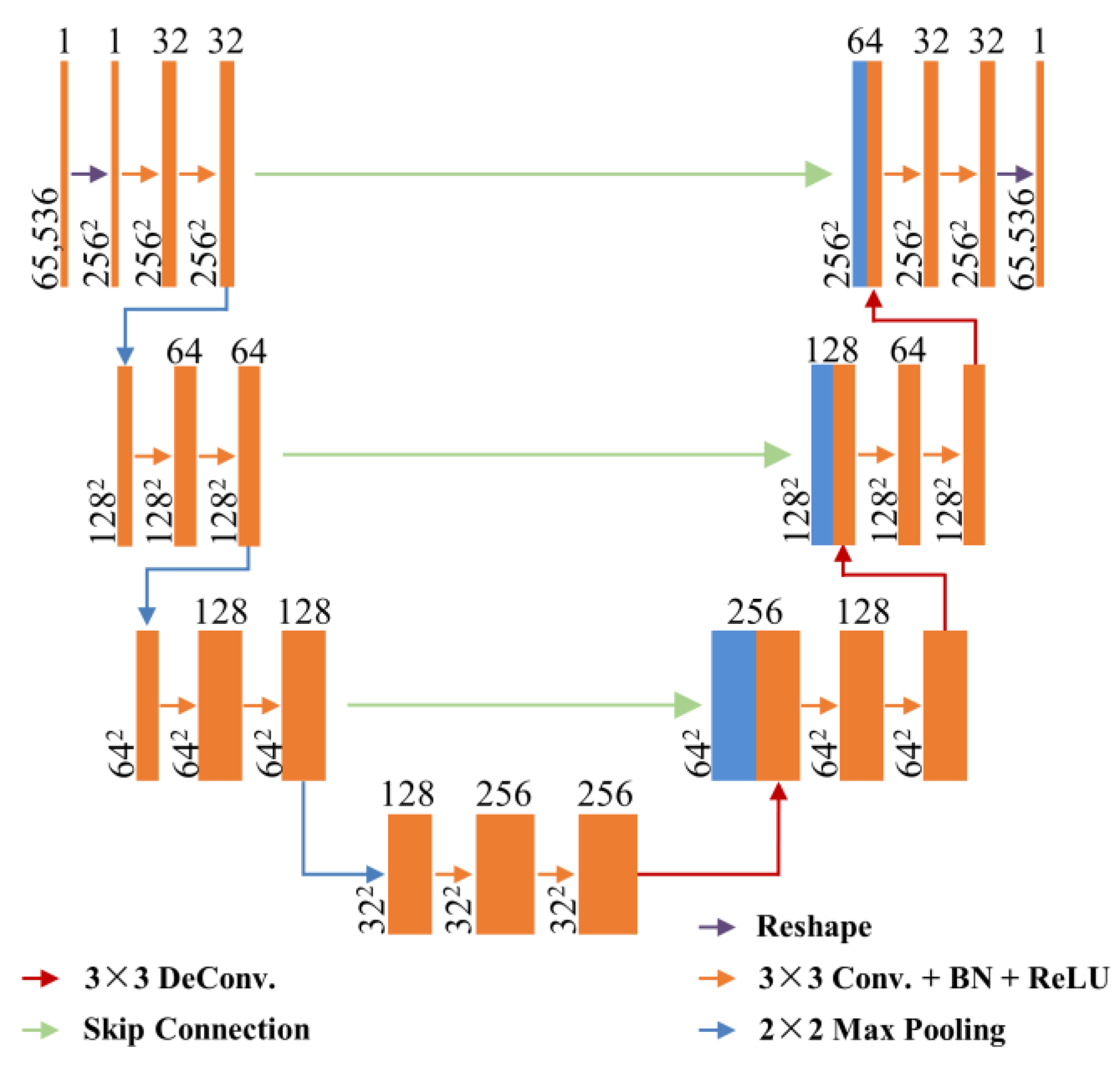
2.3. Proposed ADMM-Based Network
3. Experimental Steps
3.1. Training Details
3.2. Dataset
3.3. Comparison Methods
3.4. Robustness Validation
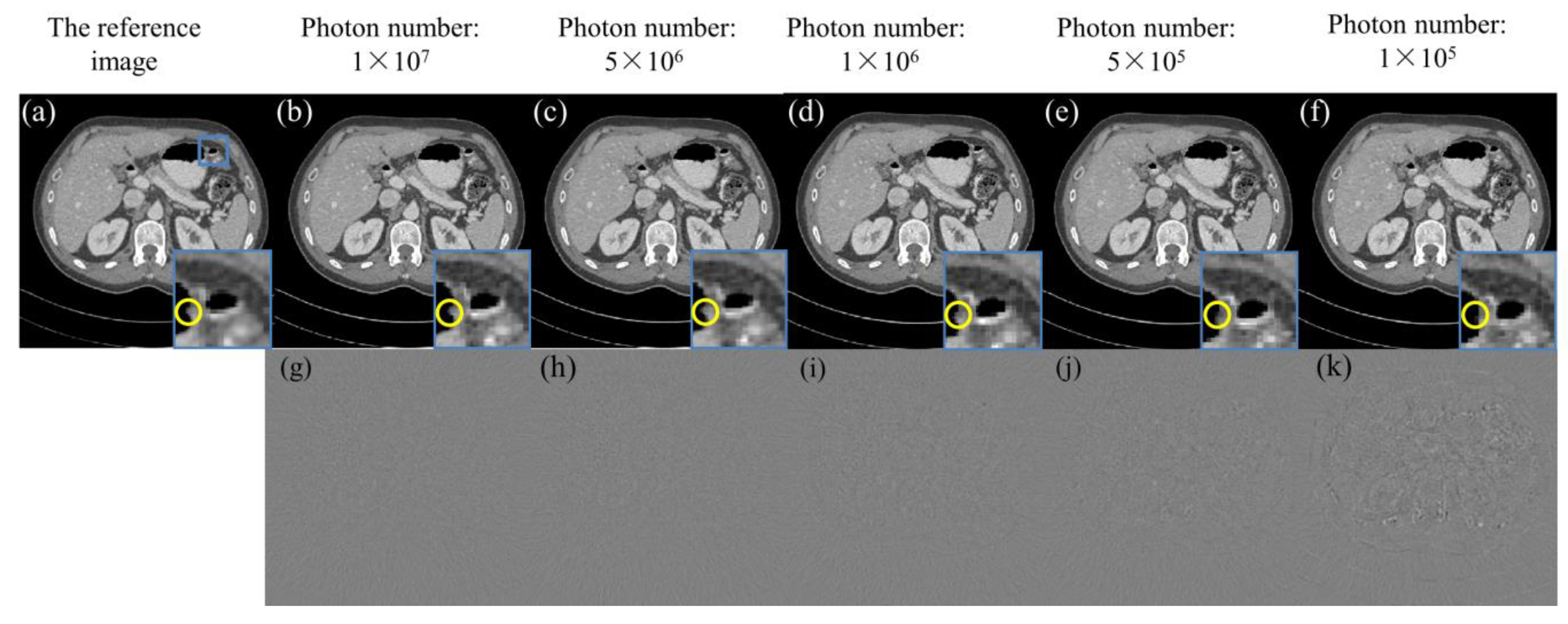
3.5. Low-Dose Reconstruction
4. Results
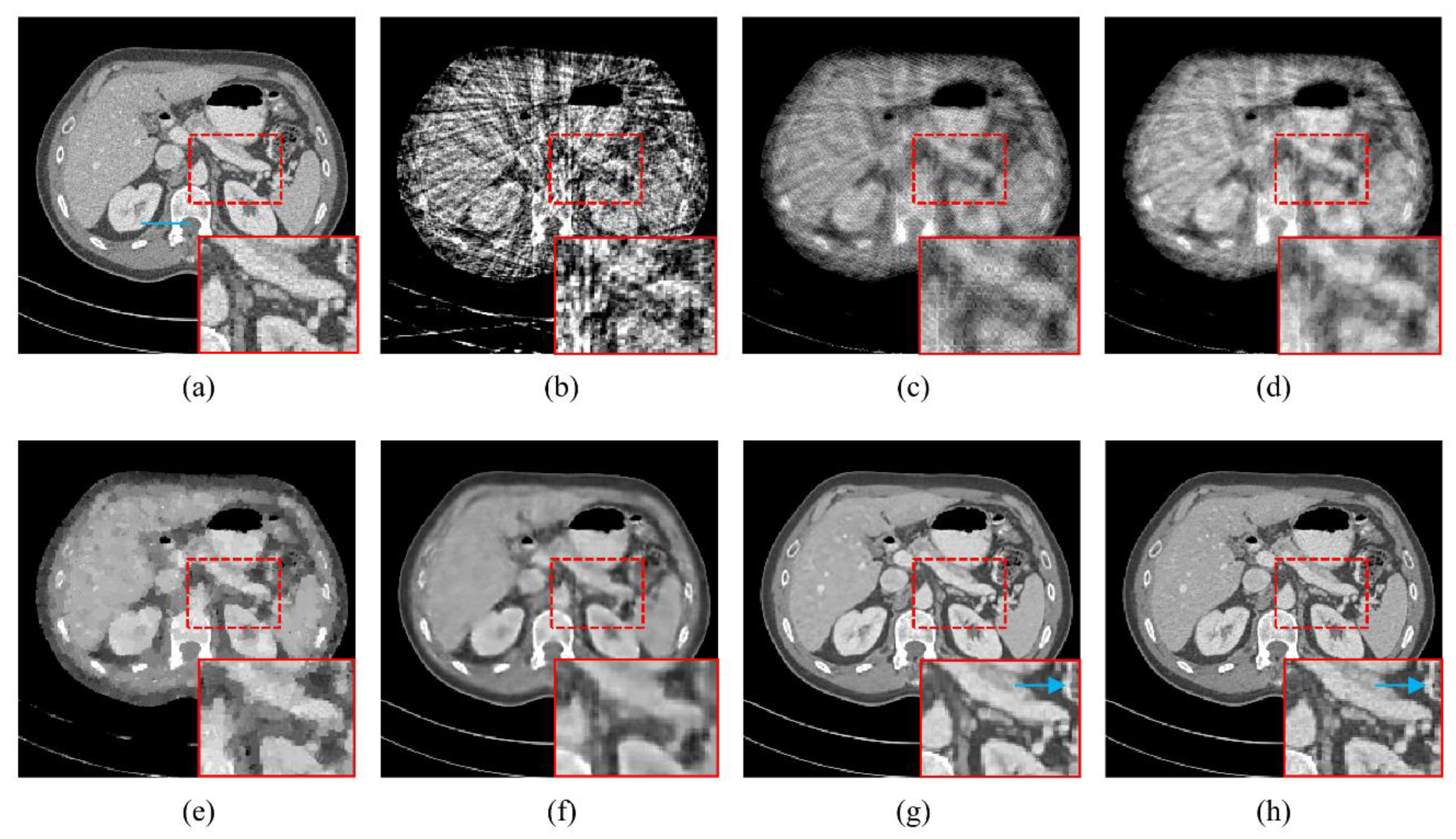
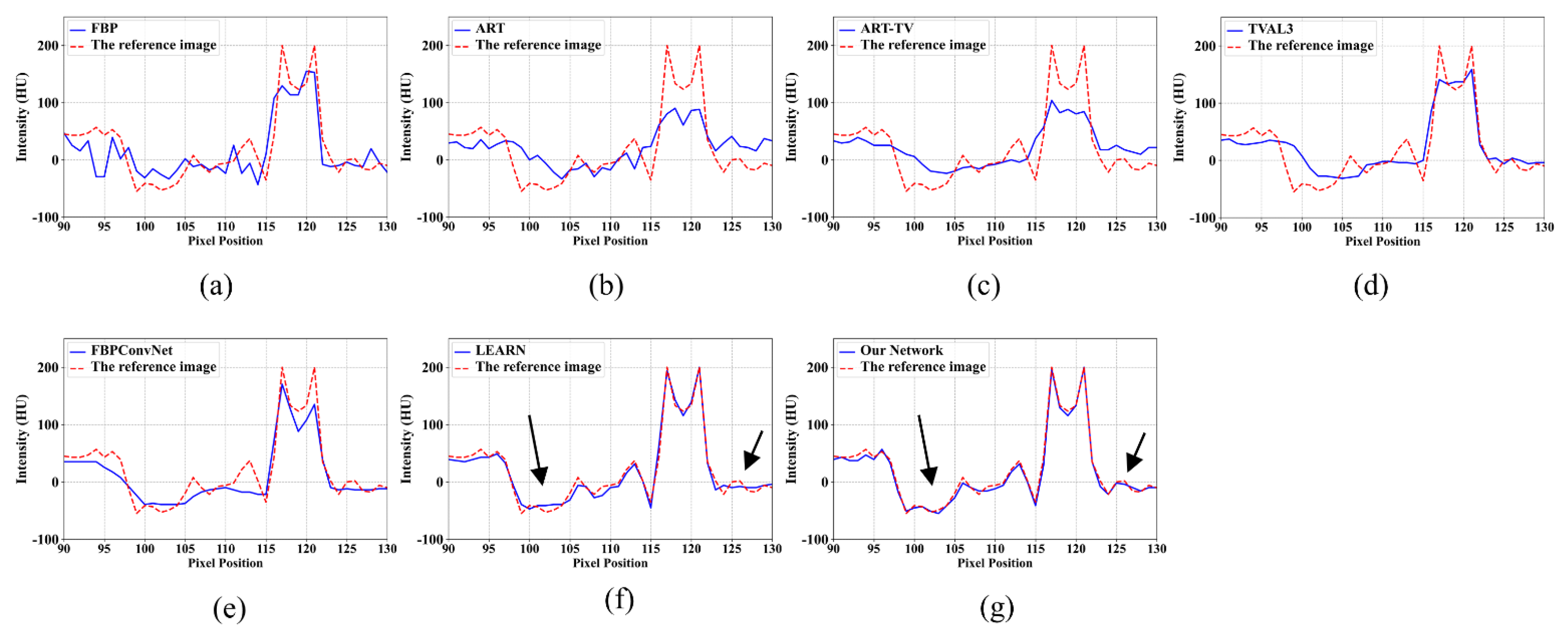
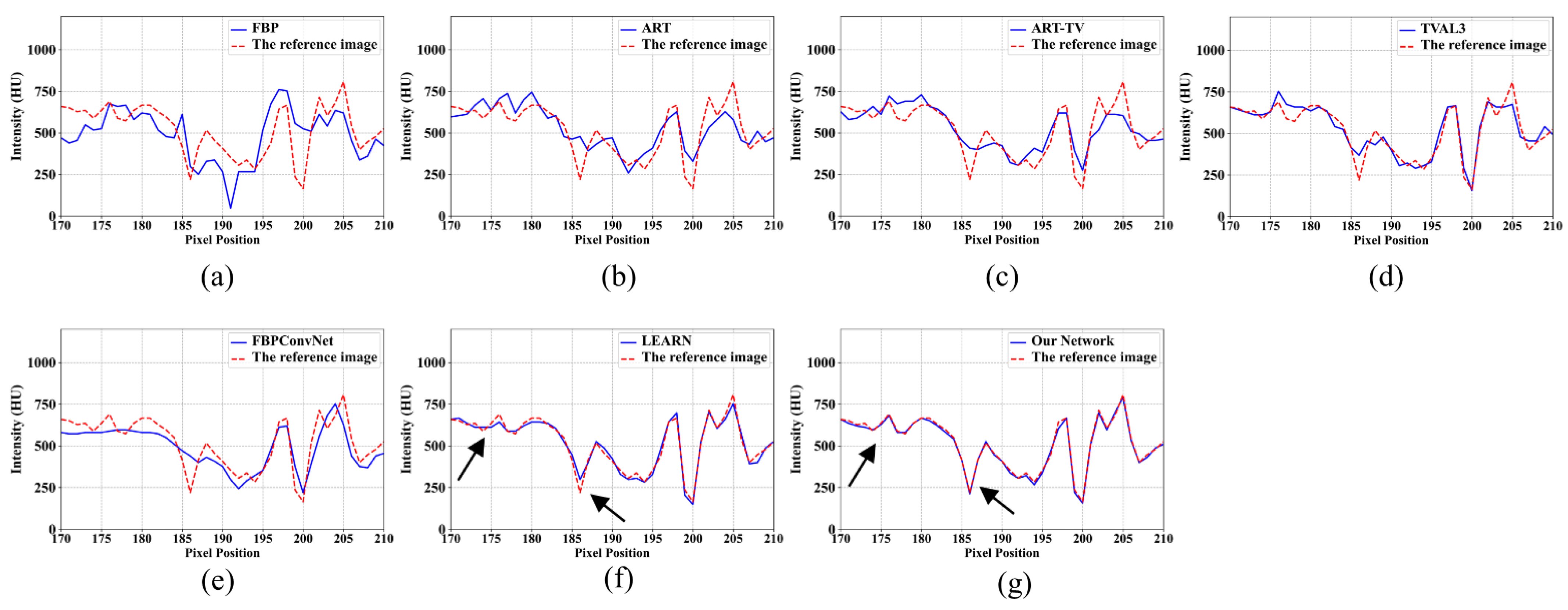
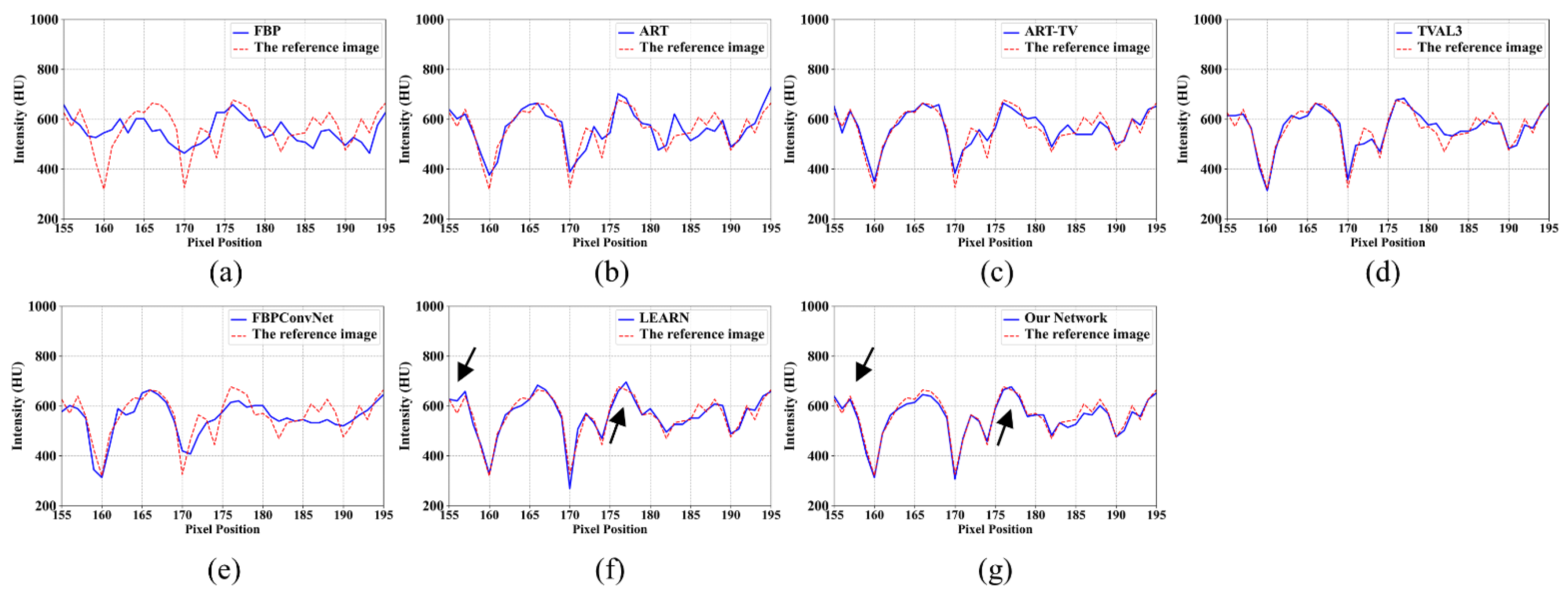
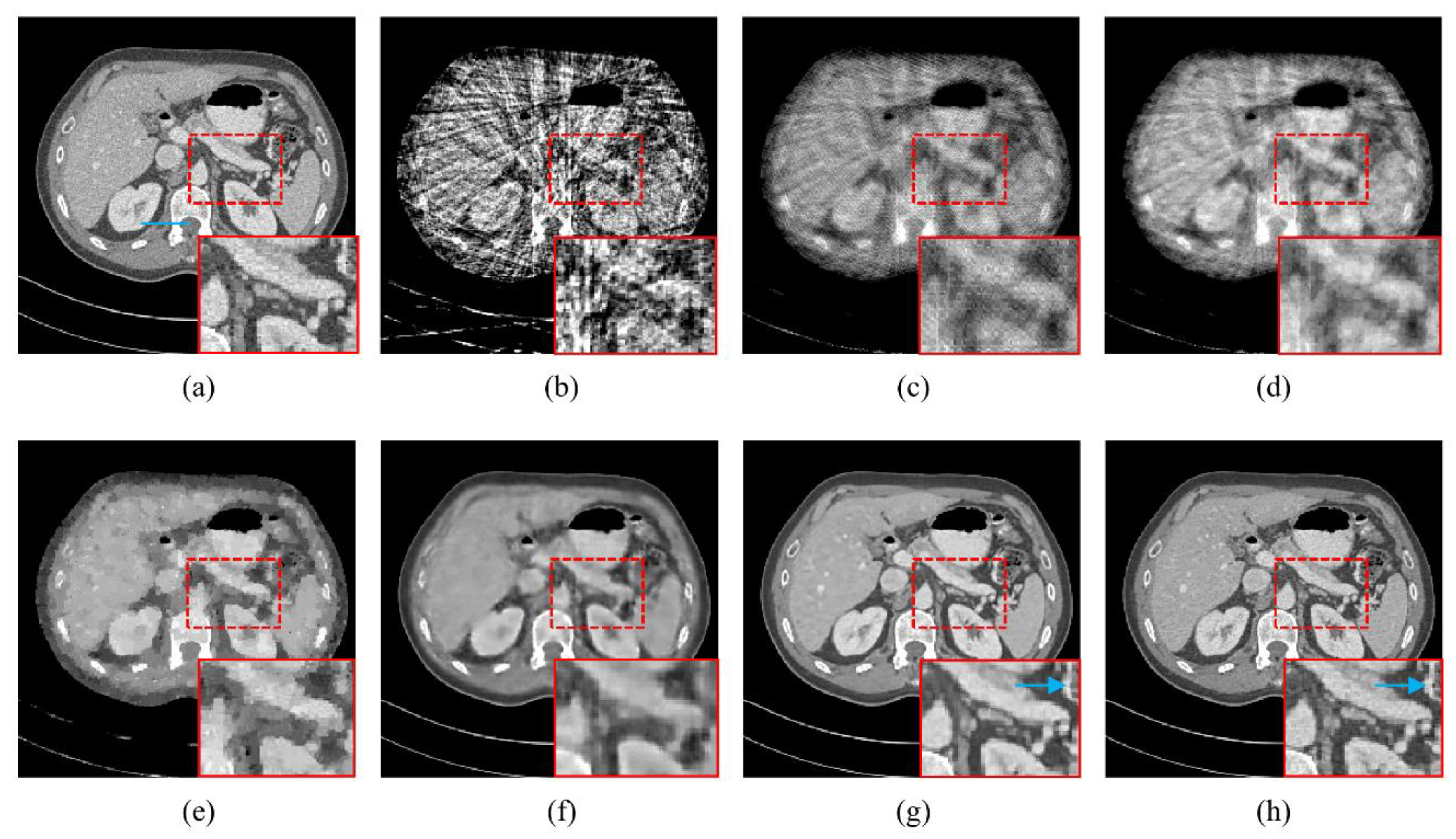
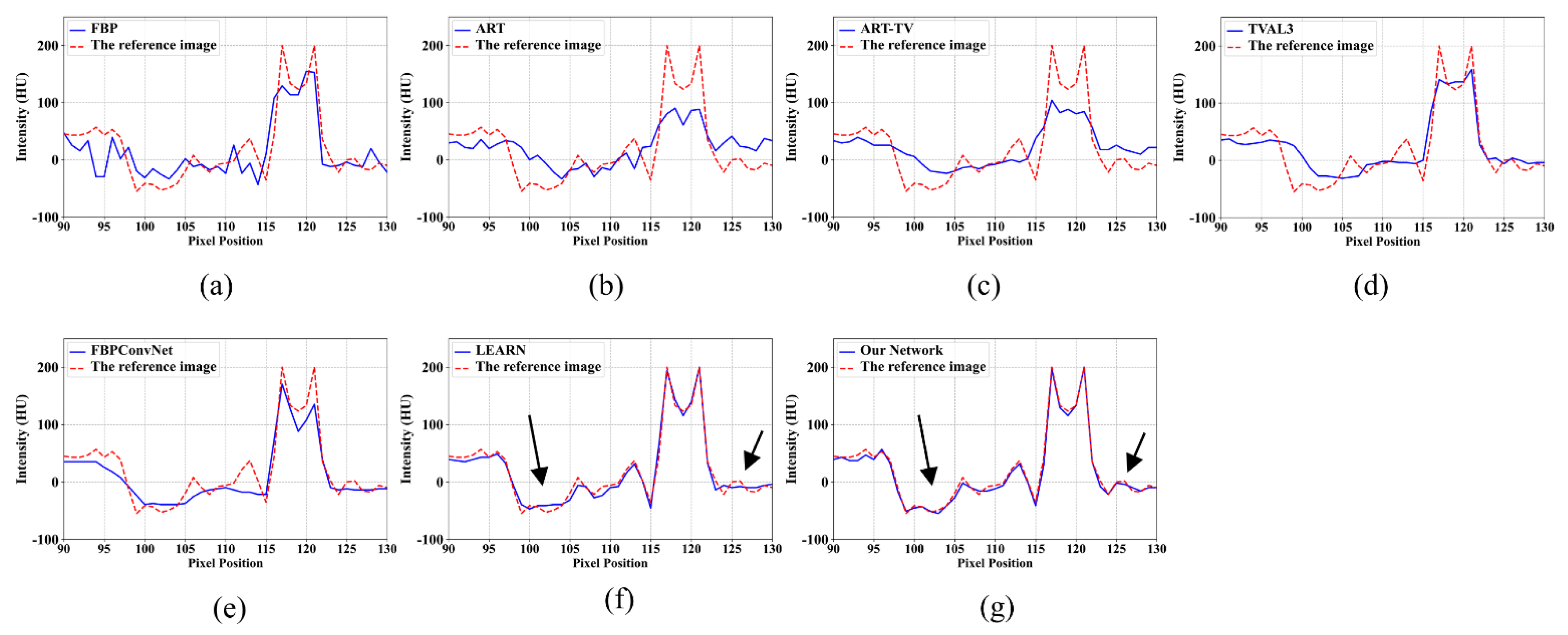
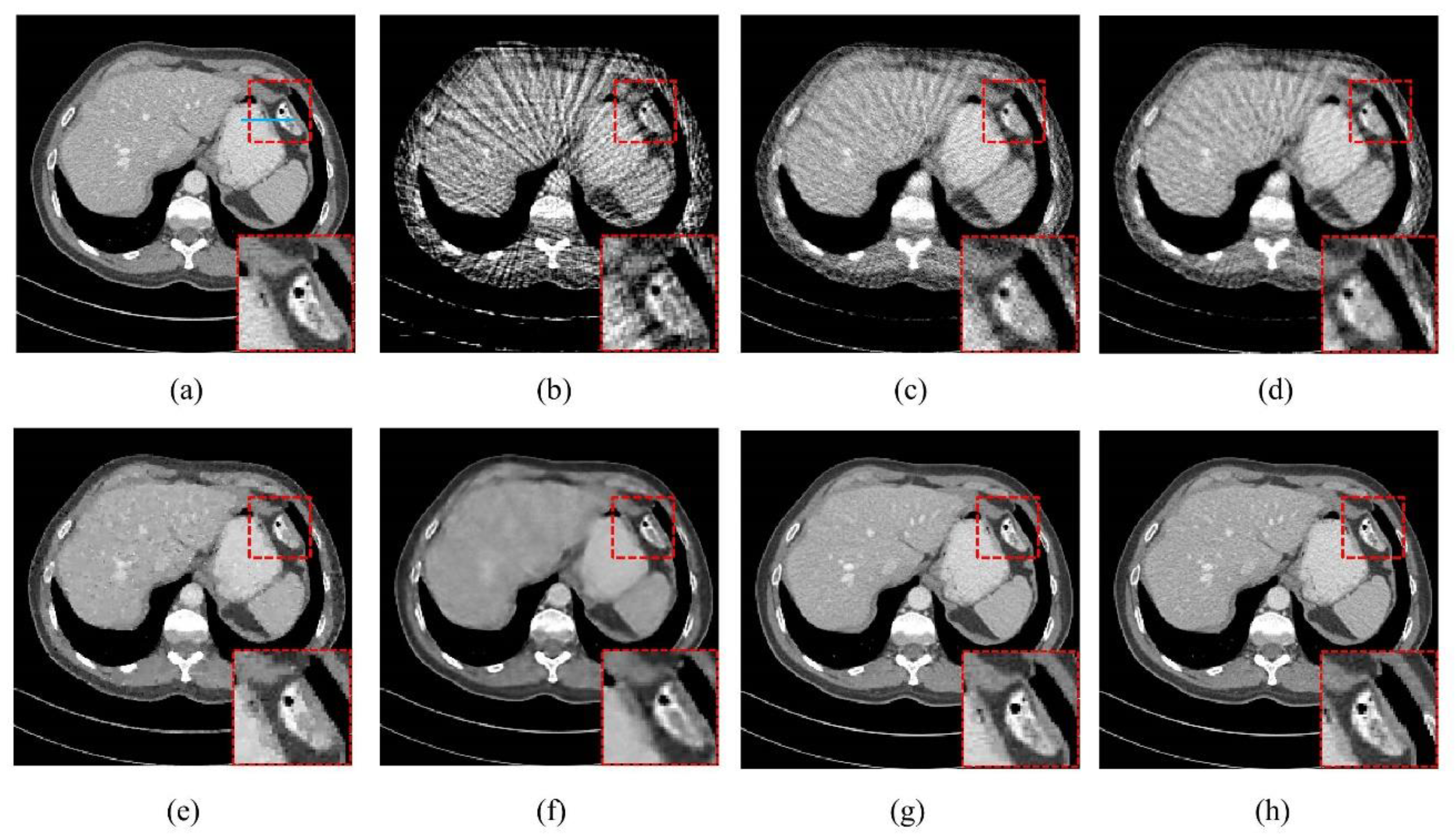
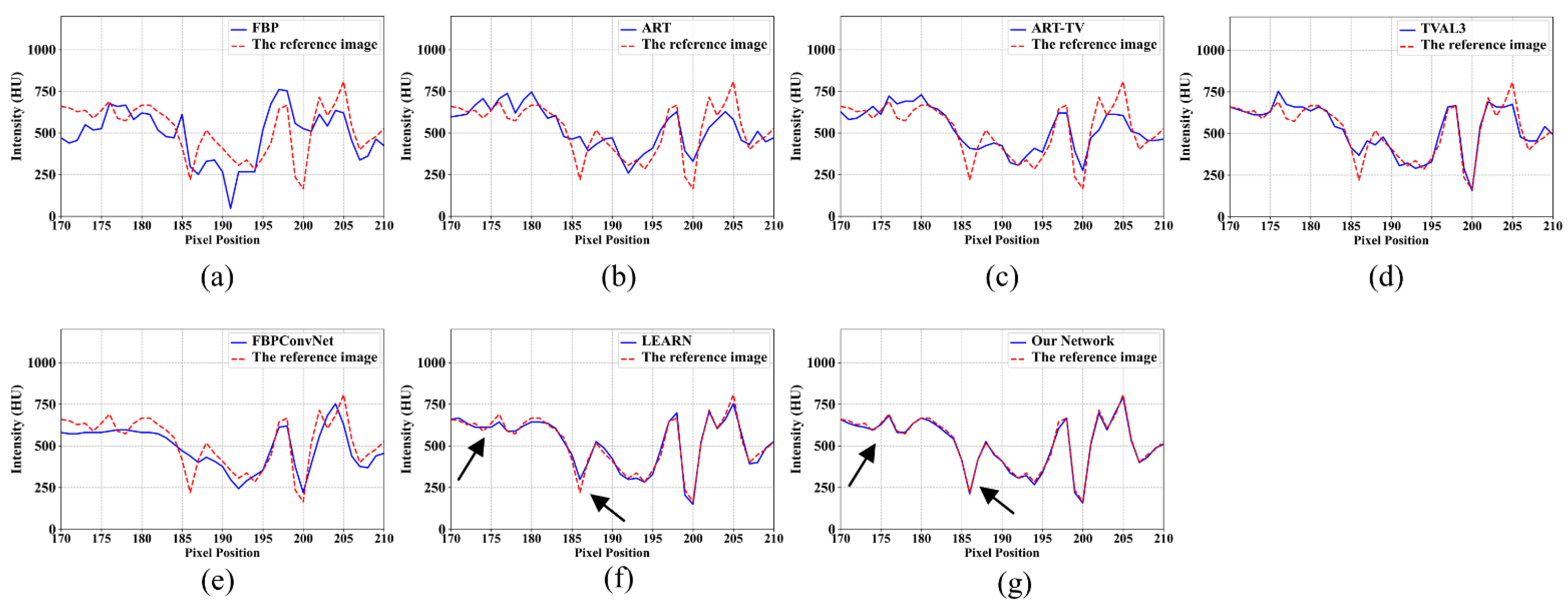
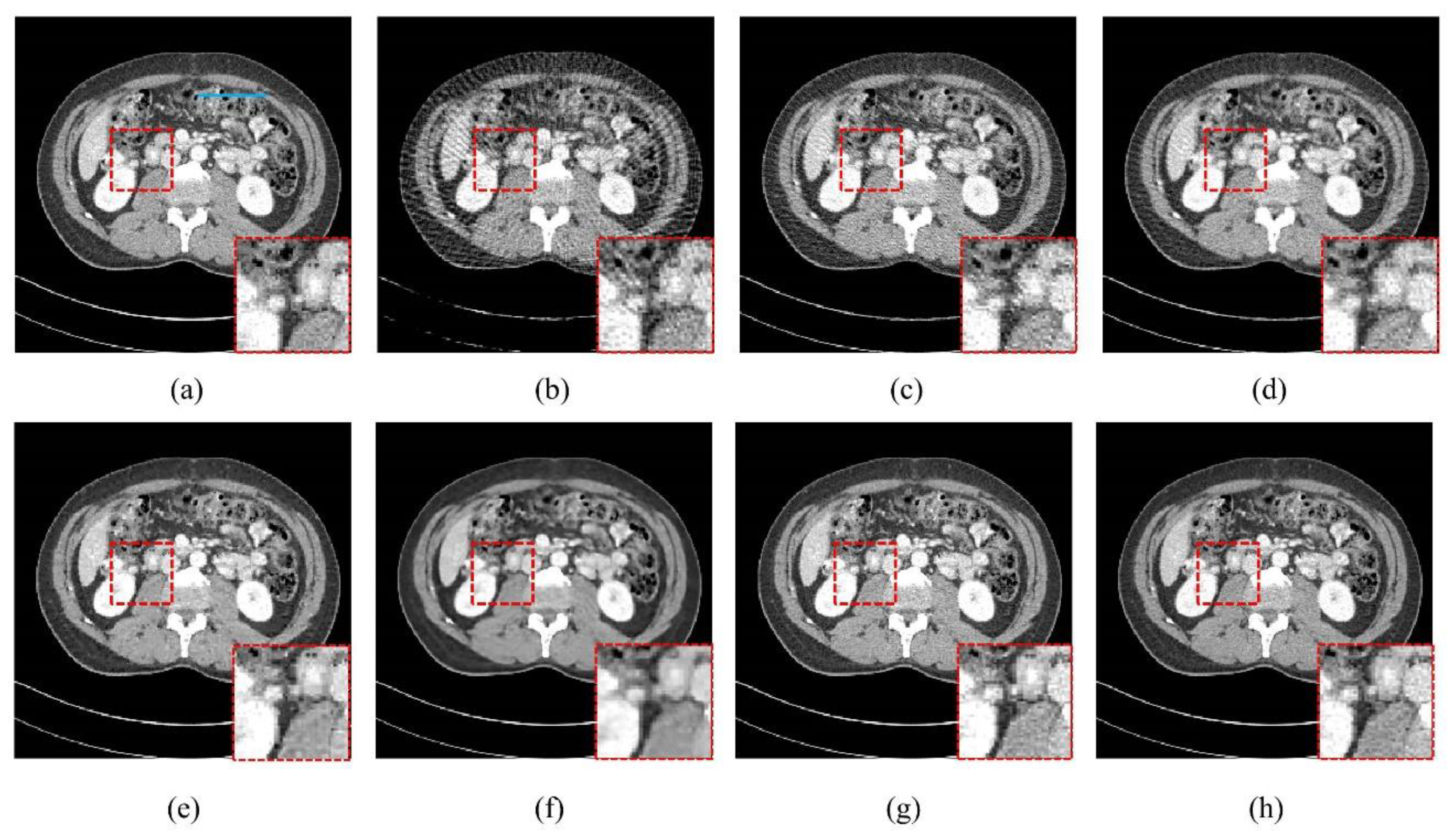
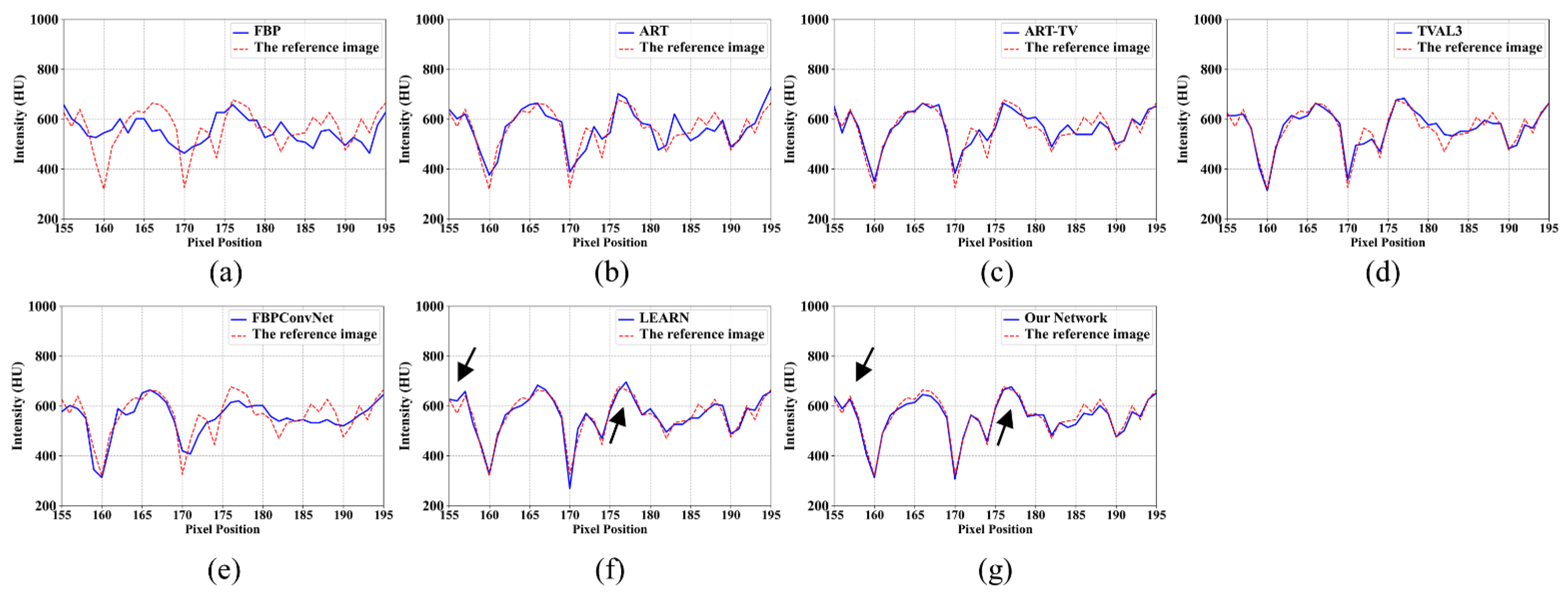
4.1. Visualization-Based Evaluation
4.2. Quantitative and Qualitative Evaluation
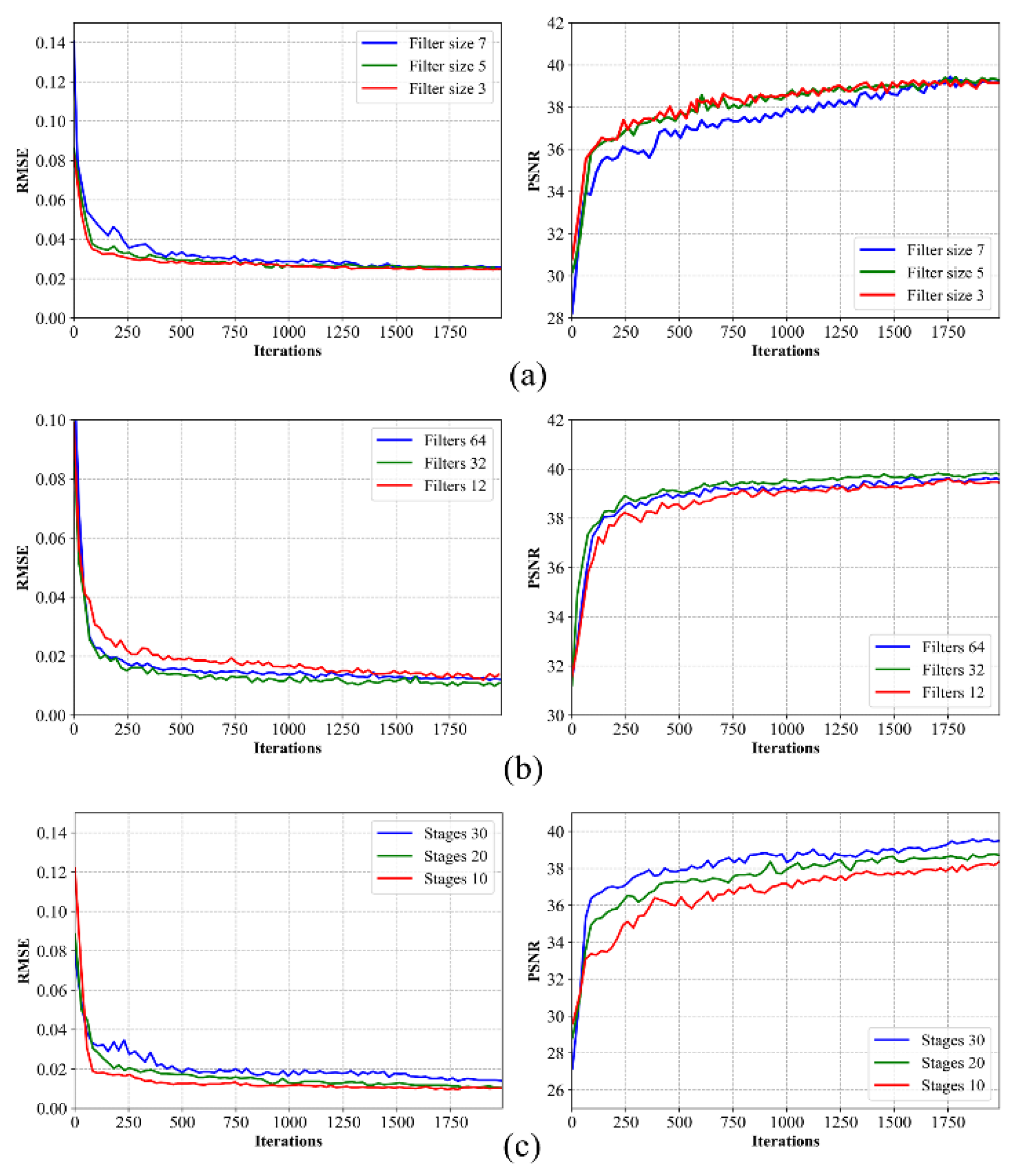
4.3. Model Structure Selection
- (1)
- Impact of the Filter Size
- (2)
- Number of Filters
- (3)
- Number of Stages
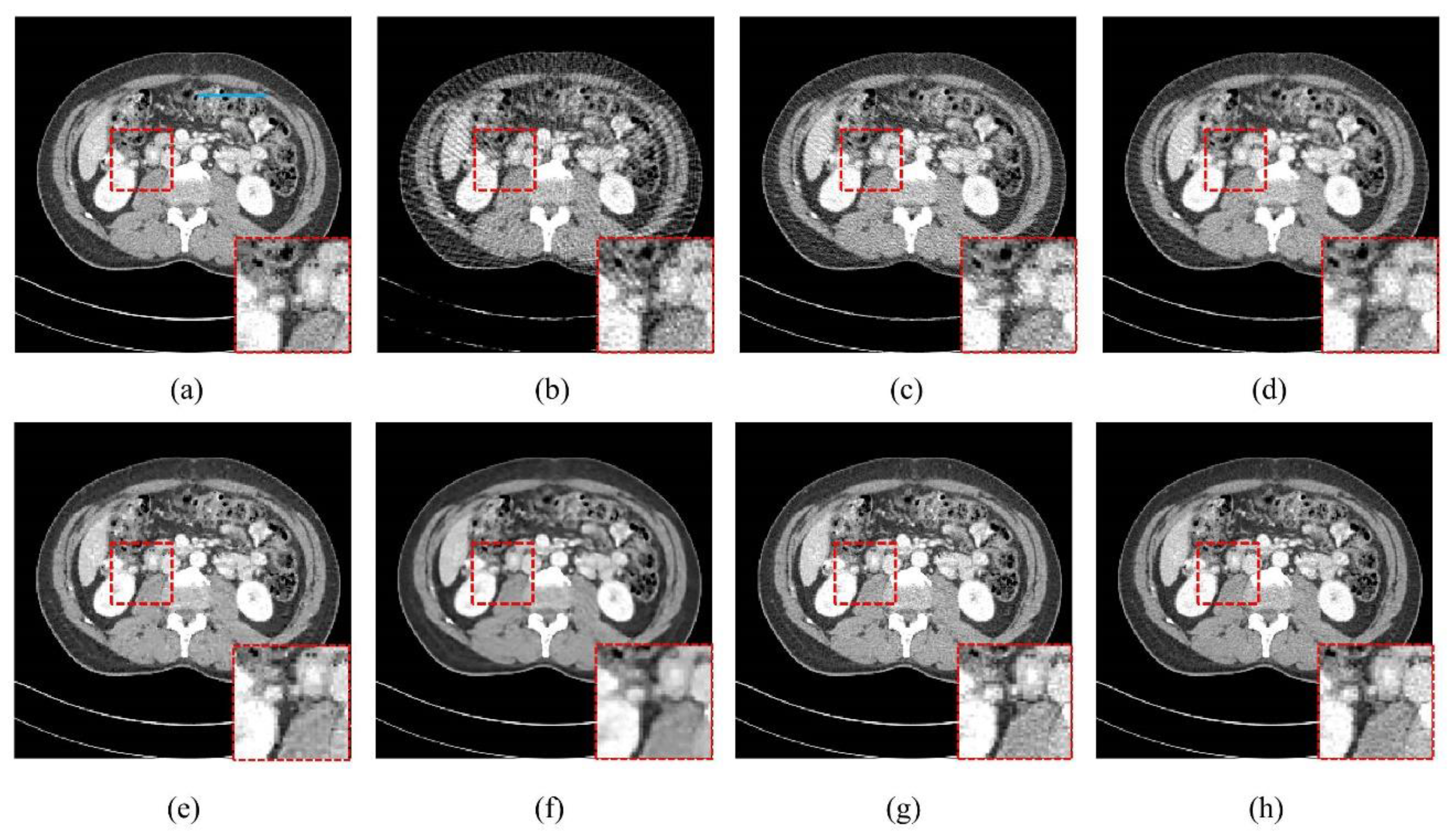
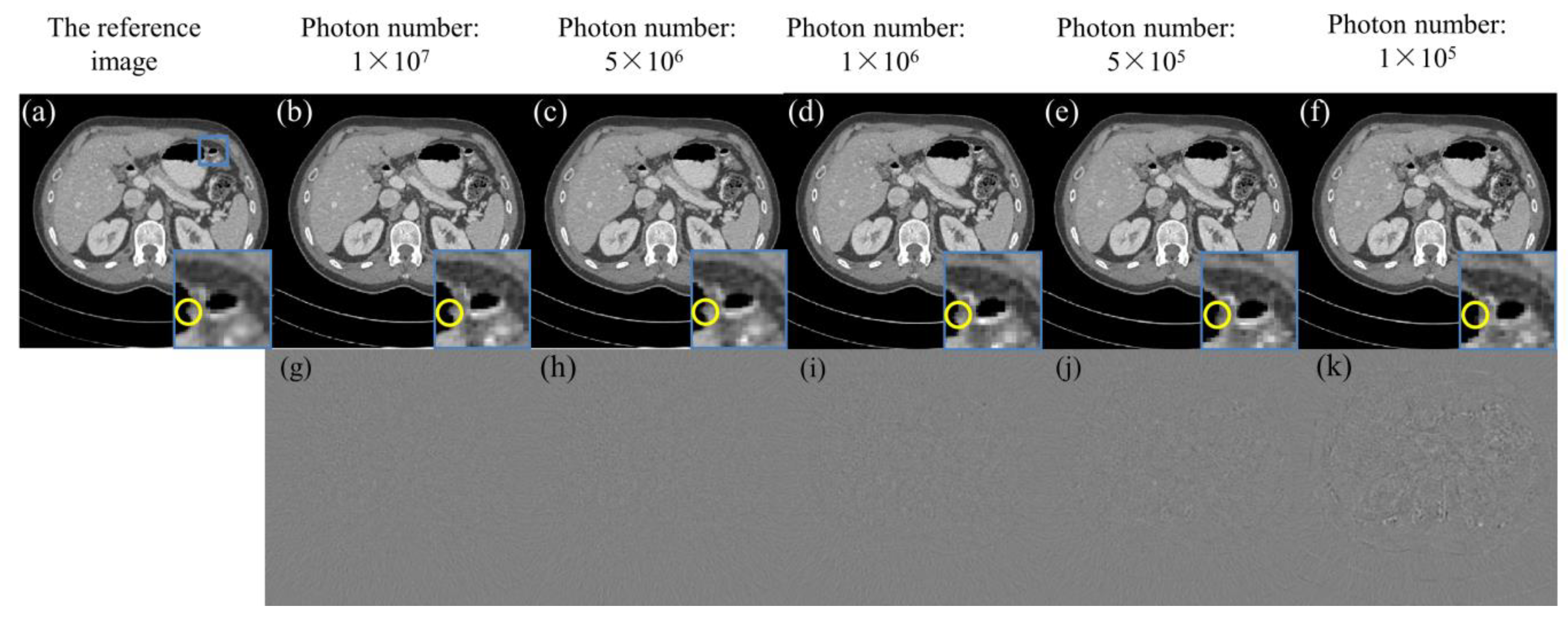
4.4. Robustness Results
4.5. Low-Dose Reconstruction Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hounsfield, G.N. Computerized transverse axial scanning (tomography): Part 1. Description of system. Br. J. Radiol. 1973, 46, 1016–1022. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Yu, H.; De Man, B. An outlook on x-ray CT research and development. Med. Phys. 2008, 35, 1051–1064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Slovis, T.L. The ALARA concept in pediatric CT: Myth or reality? Radiology 2002, 223, 5–6. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, L.; Feng, Q.; Yang, J.; Shu, H.; Luo, L.; Coatrieux, J.; Chen, W. Artifact Suppressed Dictionary Learning for Low-Dose CT Image Processing. IEEE Trans. Med. Imaging 2014, 33, 2271–2292. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.-H.; Tang, J.; Leng, S. Prior image constrained compressed sensing (PICCS): A method to accurately reconstruct dynamic CT images from highly undersampled projection data sets. Med. Phys. 2008, 35, 660–663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H.; Li, J.; Lin, X.; Qian, X. A Model-Driven Stack-Based Fully Convolutional Network for Pancreas Segmentation. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing, CCISP 2020, Chengdu, China, 13–15 November 2020. [Google Scholar]
- Chetih, N.; Messali, Z. Tomographic image reconstruction using filtered back projection (FBP) and algebraic reconstruction technique (ART). In Proceedings of the 3rd International Conference on Control, Engineering and Information Technology, CEIT 2015, Tlemcen, Algeria, 25–27 May 2015. [Google Scholar]
- Gordon, R.; Bender, R.; Herman, G.T. Algebraic Reconstruction Techniques (ART) for three-dimensional electron microscopy and X-ray photography. J. Theor. Biol. 1970, 29, 471–481. [Google Scholar] [CrossRef]
- Andersen, A.H.; Kak, A.C. Simultaneous Algebraic Reconstruction Technique (SART): A superior implementation of the ART algorithm. Ultrason. Imaging 1984, 6, 81–94. [Google Scholar] [CrossRef] [PubMed]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Chakradar, M.; Aggarwal, A.; Cheng, X.; Rani, A.; Kumar, M.; Shankar, A. A Non-invasive Approach to Identify Insulin Resistance with Triglycerides and HDL-c Ratio Using Machine learning. Neural Process. Lett. 2021, 2, 1–21. [Google Scholar] [CrossRef]
- Goyal, V.; Singh, G.; Tiwari, O.M.; Punia, S.K.; Kumar, M. Intelligent skin cancer detection mobile application using convolution neural network. J. Adv. Res. Dyn. Control Syst. 2019, 11, 253–259. [Google Scholar]
- Boublil, D.; Elad, M.; Shtok, J.; Zibulevsky, M. Spatially-Adaptive Reconstruction in Computed Tomography Using Neural Networks. IEEE Trans. Med. Imaging 2015, 34, 1474–1485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. Generative adversarial networks for noise reduction in low-dose CT. IEEE Trans. Med. Imaging 2017, 36, 2536–2545. [Google Scholar] [CrossRef] [PubMed]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-Dose CT With a Residual Encoder-Decoder Convolutional Neural Network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef]
- Zhang, Z.; Liang, X.; Dong, X.; Xie, Y.; Cao, G. A Sparse-View CT Reconstruction Method Based on Combination of DenseNet and Deconvolution. IEEE Trans. Med. Imaging 2018, 37, 1407–1417. [Google Scholar] [CrossRef]
- Kang, E.; Min, J.; Ye, J.C. A deep convolutional neural network using directional wavelets for low-dose X-ray CT reconstruction. Med. Phys. 2017, 44, 330–375. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Yan, P.; Zhang, Y.; Yu, H.; Shi, Y.; Mou, X.; Kalra, M.K.; Zhang, Y.; Sun, L.; Wang, G. Low-Dose CT Image Denoising Using a Generative Adversarial Network With Wasserstein Distance and Perceptual Loss. IEEE Trans. Med. Imaging 2018, 37, 1348–1357. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, B.; Yu, H.; Dong, B. MetaInv-Net: Meta Inversion Network for Sparse View CT Image Reconstruction. IEEE Trans. Med. Imaging 2021, 40, 621–634. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- LaRoque, S.J.; Sidky, E.Y.; Pan, X. Accurate image reconstruction from few-view and limited-angle data in diffraction tomography. J. Opt. Soc. Am. A. Opt. Image Sci. Vis. 2008, 25, 1772–1782. [Google Scholar] [CrossRef] [Green Version]
- Sidky, E.Y.; Pan, X. Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys. Med. Biol. 2008, 53, 4777–4807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rauhut, H.; Schnass, K.; Vandergheynst, P. Compressed Sensing and Redundant Dictionaries. IEEE Trans. Inf. Theory 2008, 54, 2210–2219. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Ye, X.; Huang, F. A novel method and fast algorithm for MR image reconstruction with significantly under-sampled data. Inverse Probl. Imaging 2010, 4, 223–240. [Google Scholar] [CrossRef]
- Xu, Q.; Yu, H.; Mou, X.; Zhang, L.; Hsieh, J.; Wang, G. Low-Dose X-ray CT Reconstruction via Dictionary Learning. IEEE Trans. Med. Imaging 2012, 31, 1682–1697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Würfl, T.; Hoffmann, M.; Christlein, V.; Breininger, K.; Huang, Y.; Unberath, M.; Maier, A.K. Deep Learning Computed Tomography: Learning Projection-Domain Weights From Image Domain in Limited Angle Problems. IEEE Trans. Med. Imaging 2018, 37, 1454–1463. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Lee, J.; Kim, H.; Cho, B.; Cho, S. Deep-Neural-Network-Based Sinogram Synthesis for Sparse-View CT Image Reconstruction. IEEE Trans. Radiat. Plasma Med. Sci. 2019, 3, 109–119. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Zhou, S.K.; Duncan, J.S.; Liu, C. Limited View Tomographic Reconstruction using a Cascaded Residual Dense Spatial-Channel Attention Network with Projection Data Fidelity Layer. IEEE Trans. Med. Imaging 2021, 40, 1792–1804. [Google Scholar] [CrossRef] [PubMed]
- Gupta, H.; Jin, K.H.; Nguyen, H.Q.; McCann, M.T.; Unser, M. CNN-Based Projected Gradient Descent for Consistent CT Image Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1440–1453. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Zhang, Y.; Chen, Y.; Zhang, J.; Zhang, W.; Sun, H.; Lv, Y.; Liao, P.; Zhou, J.; Wang, G. LEARN: Learned Experts’ Assessment-Based Reconstruction Network for Sparse-Data CT. IEEE Trans. Med. Imaging 2018, 37, 1333–1347. [Google Scholar] [CrossRef] [PubMed]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhu, H.; Wu, S.-Y. Primal and dual alternating direction algorithms for ℓ1-ℓ1-norm minimization problems in compressive sensing. Comput. Optim. Appl. 2013, 54, 441–459. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for compressive sensing MRI. Adv. Neural Inf. Process. Syst. 2016, 29, 10–18. [Google Scholar]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A Deep Learning Approach for Image Compressive Sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 521–538. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Cheng, X.; Gui, G. Co-Robust-ADMM-Net: Joint ADMM Framework and DNN for Robust Sparse Composite Regularization. IEEE Access 2018, 6, 47943–47952. [Google Scholar] [CrossRef]
- He, J.; Yang, Y.; Wang, Y.; Zeng, D.; Bian, Z.; Zhang, H.; Sun, J.; Xu, Z.; Ma, J. Optimizing a Parameterized Plug-and-Play ADMM for Iterative Low-Dose CT Reconstruction. IEEE Trans. Med. Imaging 2019, 38, 371–382. [Google Scholar] [CrossRef]
- Zhang, H.; Dong, B.; Liu, B. JSR-Net: A Deep Network for Joint Spatial-radon Domain CT Reconstruction from Incomplete Data. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3657–3661. [Google Scholar]
- Wang, J.; Zeng, L.; Wang, C.; Guo, Y. ADMM-based deep reconstruction for limited-angle CT. Phys. Med. Biol. 2019, 64, 115011. [Google Scholar] [CrossRef]
- Wang, G.; Ye, Y.; Yu, H. Approximate and Exact Cone-Beam Reconstruction with Standard and Non-Standard Spiral Scanning. Phys. Med. Biol. 2007, 52, 1–13. [Google Scholar] [CrossRef]
- Li, S.; Cao, Q.; Chen, Y.; Hu, Y.; Luo, L.; Toumoulin, C. Dictionary learning based sinogram inpainting for CT sparse reconstruction. Optik 2014, 125, 2862–2867. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.; Kim, H.; Kim, H.J. Sparse-view CT reconstruction based on multi-level wavelet convolution neural network. Phys. Medica 2020, 80, 352–362. [Google Scholar] [CrossRef]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- The 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge. Available online: http://www.aapm.org/GrandChallenge/LowDoseCT/ (accessed on 25 January 2022).
- Kak, A.C.; Slaney, M. Principles of Computerized Tomographic Imaging; Classics in Applied Mathematics; SIAM: Philadelphia, PA, USA, 2001; Volume 33, ISBN 978-0-89871-494-4. [Google Scholar]
- Chengbo, L.; Yin, W.; Zhang, Y. TVAL3: TV Minimization by Augmented Lagrangian and Alternating Direction Algorithms. Available online: https://www.caam.rice.edu/~optimization/L1/TVAL3/ (accessed on 25 January 2022).
- Li, T.; Li, X.; Wang, J.; Wen, J.; Lu, H.; Hsieh, J.; Liang, Z. Nonlinear sinogram smoothing for low-dose X-ray CT. IEEE Trans. Nucl. Sci. 2004, 51, 2505–2513. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value | |
|---|---|---|
| 1 | Distance from the X-ray source to the detector arrays | 1320.5 mm |
| 2 | Distance from the X-ray source to the center of rotation | 1050.5 mm |
| 3 | Number of detectors | 512 |
| 4 | Detector pixel size | 0.127 mm |
| 5 | Reconstruction size | 256 × 256 |
| 6 | Pixel size | 1 mm2 |
| Views | Index | FBP | ART | ART-TV | TVAL3 | FBPConvNet | LEARN | Our Network |
|---|---|---|---|---|---|---|---|---|
| 32 | RMSE | 0.11 5 | 0.04 9 | 0.046 | 0.033 | 0.03 4 | 0.01 8 | 0.009 |
| PSNR | 19.013 | 26.267 | 26.685 | 29.547 | 29.479 | 39.209 | 40.839 | |
| SSIM | 0.57 8 | 0.789 | 0.817 | 0.90 8 | 0.90 3 | 0.91 2 | 0.96 7 | |
| 64 | RMSE | 0.07 5 | 0.034 | 0.03 2 | 0.01 6 | 0.020 | 0.0 10 | 0.00 8 |
| PSNR | 22.553 | 29.323 | 30.032 | 36.141 | 33.891 | 42.170 | 44.521 | |
| SSIM | 0.630 | 0.87 5 | 0.89 8 | 0.959 | 0.935 | 0.9 70 | 0.98 8 | |
| 128 | RMSE | 0.049 | 0.01 7 | 0.01 4 | 0.008 | 0.010 | 0.00 7 | 0.006 |
| PSNR | 26.141 | 35.675 | 37.098 | 41.670 | 39.824 | 45.131 | 46.085 | |
| SSIM | 0.826 | 0.955 | 0.96 9 | 0.970 | 0.951 | 0.977 | 0.99 5 |
| Photon Number | 1 × 105 | 5 × 105 | 1 × 106 | 5 × 106 | 1 × 107 |
|---|---|---|---|---|---|
| RMSE | 0.0111 | 0.0089 | 0.0085 | 0.0083 | 0.0081 |
| PSNR | 39.0873 | 41.0521 | 41.4174 | 41.6286 | 41.7647 |
| SSIM | 0.9787 | 0.9850 | 0.9860 | 0.9867 | 0.9869 |
| Methods | NMSE | PSNR | FSIM |
|---|---|---|---|
| 3pADMM(40) | 0.018 | 39.242 | 0.948 |
| Our Network | 0.017 | 40.139 | 0.949 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, X.; Chen, P. ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network. Photonics 2022, 9, 186. https://doi.org/10.3390/photonics9030186
Wang S, Li X, Chen P. ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network. Photonics. 2022; 9(3):186. https://doi.org/10.3390/photonics9030186
Chicago/Turabian StyleWang, Sukai, Xuan Li, and Ping Chen. 2022. "ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network" Photonics 9, no. 3: 186. https://doi.org/10.3390/photonics9030186
APA StyleWang, S., Li, X., & Chen, P. (2022). ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network. Photonics, 9(3), 186. https://doi.org/10.3390/photonics9030186