1. Introduction
Recently, artificial neural networks (ANNs) have achieved significant developments rapidly and extensively. As the fastest developing computing method of artificial intelligence, deep learning has made remarkable achievements in machine vision [
1], image classification [
2], game theory [
3], speech recognition [
4], natural language processing [
5], and other aspects. The use of elementary particles for data transmission and processing can lead to smaller equipment, greater speed, and lower energy consumption. The electron is the most widely used particle to date, and has become the cornerstone of the information society in signal transmission (cable) and data processing (electronic computer). Artificial intelligence chips represented by graphics processing units (GPUs), application-specific integrated circuits (ASICs), and field programmable gate arrays (FPGAs) have enabled electronic neural networks (ENNs) to achieve high precision, high convergence regression, and predict task performance [
6]. When dealing with tasks with high complexity and high data volume, insurmountable shortcomings have emerged in ENNs, such as long time delay and low power efficiency caused by the interaction of many parameters in the network with the storage modules of electronic devices.
Fortunately, as a kind of boson, the photon has faster speed and lower energy consumption, resulting in it being significantly better than electrons in signal transmission and processing, and it has become a strong competitor for the elementary particles used in the next generation of information technology. Development of all-optical components, photonic chips, interconnects, and processors will bring the speed of light, photon coherence properties, field confinement and enhancement, information-carrying capacity, and the broad spectrum of light into the high-performance computing, the internet of things, and industries related to cloud, fog, and recently edge computing [
7]. Due to the parallel characteristics of light in propagation, light interference, diffraction, and dispersion, phenomena can easily simulate various matrix linear operations, which are similar to the layer algorithm of forward propagation in neural networks. To pursue faster operating speed and higher power efficiency in information processing, the optical neural network (ONN), which uses photons as the information carrier, came at the right moment. Various ONN architectures have been proposed, including the optical interference neural network [
8], the diffractive optical neural network [
9,
10,
11,
12], photonic reservoir computing [
13,
14], the photonic spiking neural network [
15], and the recurrent neural network [
16]. To process high-throughput and high-complexity data in real time, the algorithms in ONNs must have the characteristics of real-time information collection and rapid information measurement.
Photon time stretching (PTS), also known as dispersive Fourier transform technology (DFT), is a high-throughput real-time information collection technology that has emerged in recent years [
17]. PTS can overcome the limitations of electronic equipment bandwidth and sampling speed, thus being able to realize ultra-fast information measurement, and its imaging frame rate is mainly determined by the mode-locked laser, which can reach tens of MHz/s or even GHz/s. DFT is widely used in ultra-high-speed microscopic imaging, microwave information analysis, spectral analysis, and observation of transient physical processes such as dissipative soliton structure, relativistic electron clusters, and rough waves [
18]. It is worth emphasizing that this architecture plays an important role in the capture of rare events such as the early screening of cancer cells with large data volume characteristics. DFT broadens the pulse-carrying cell characteristics in the time domain and maps spectral information to the time domain; then, the information of the stretched light pulse is obtained through photo detection and a high-speed analog-to-digital converter, and finally the information is input into a computer or a special data signal processing chip for data processing. In 2009, researchers in the United States first proposed a method to achieve ultrafast imaging using PTS technology [
19]. They then combined ultra-fast imaging and deep learning technology to distinguish colon cancer cells in the blood in 2016 [
20]. In 2017, researchers from the University of Hong Kong reduced the monitoring of phytoplankton communities and used support vector machines to classify them, which can detect 100,000–1,000,000 cells per second [
21]. In biomedicine, the combination of DFT and optical fluidics technology can complete high-flux imaging of hundreds of thousands to millions of cells per second, including various conditions in human blood and algae cells. It has great significance in cell classification [
20], early cell screening [
22,
23,
24] and feature extraction [
25,
26,
27,
28,
29].
The high-throughput characteristics of PTS technology will inevitably produce a lot of data. Typically, the amount of data generated by a PTS system can reach 1 Tbit per second, which brings huge challenges to data storage and processing based on electronic devices and limits the application scope of this technology [
30]. The high-throughput data generation of the DFT and the high-throughput processing characteristics of the photon neural network are perfectly complementary. Based on this characteristic, we propose a new architecture combining time-lens with the optical neural network (TL-ONN). According to the optical space–time duality [
31] (that is, the spatial evolution characteristics of the light field caused by the diffraction effect and the time evolution characteristics of the optical pulse caused by the dispersion effect are equivalent), the imaging of the time signal can be realized by controlling the phase information of the timing signal, namely the time-lens. We establish a numerical model for simulation analysis to verify the feasibility of this architecture. By training 20,000 sets of speech data, we obtained a stable 98% recognition accuracy within one training cycle, which has obvious advantages of faster convergence and stable recognition accuracy compared with a deep neural network (DNN) with the same number of layers. This architecture implemented with all-optical components will offer outstanding improvements in biomedical science, cell dynamics, nonlinear optics, green energy, and other fields.
Here, we first introduce the architectural composition of the proposed TL-ONN, and then combine the time-lens principle with the neural network to drive the forward propagation and reverse optimization process. Finally, we use a speech dataset to train the proposed TL-ONN, and use numerical calculation to verify the classification function of this architecture.
2. Materials and Methods
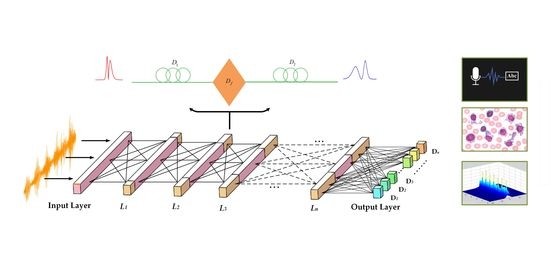
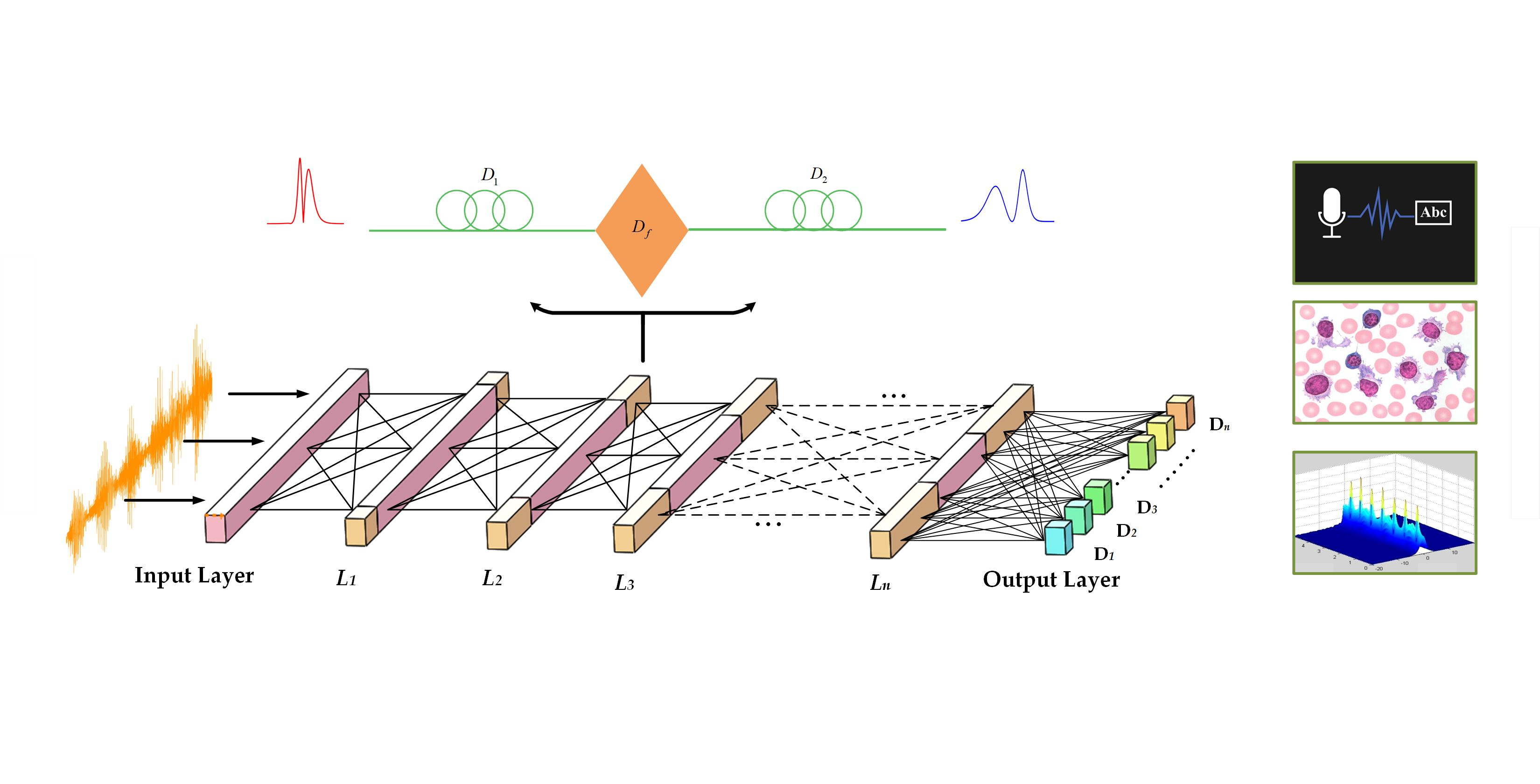
The proposed ONN combines the conventional neural network with time stretch, realizing the deep learning function based on optics. As shown in
Figure 1, two kinds of operations—time-lens transform and matrix multiplication—must be performed in each layer. The core optical structure which adapts the time-lens method is used to implement the first linear computation process. After that, the results are modulated by a weights matrix. Finally, the outputs serve as the input vector in the next layer. After calculation by the neural network composed of multiple time-lens layers, all input data are probed by a detector in the output layer. The prediction data and the target output are calculated by the cost function, and the gradient descent algorithm is carried out for each weights matrix (W
2) from backward propagation to achieve the optimal neural network structure. The input data of this network structure are generally one-dimensional time data. In the input layer, the physical information at each point in the time series is transferred to the neurons in each layer. Through the optical algorithm, each neuron between the layers is transmitted to realize the information processing behavior of the neural network.
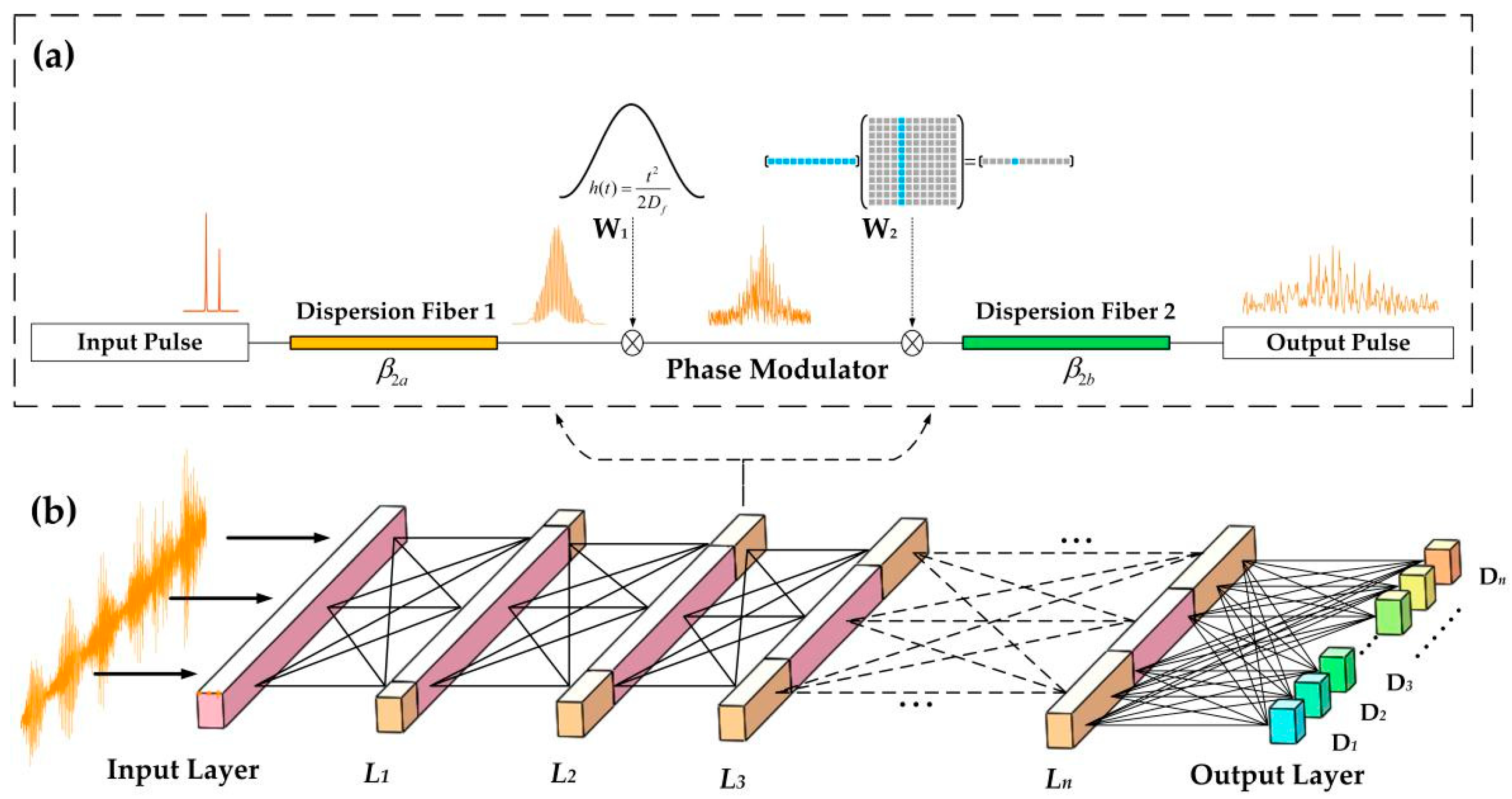
Like the diffraction of space light, the time-lens plays a role of dispersion in time. As a result, the time-lens [
32] can realize the imaging of the light pulse on the time scale. This is similar to the idea that the neurons in each layer of the neural network are derived from each neuron in the previous layer through a specific algorithm. The amplitude and phase of each point of the pulse after the time-lens is derived from the previous pulse calculated for each point. Based on this algorithm, an optical neural network based on the time lens is designed. Each neural network layer is formed by two segments of dispersive fiber and a second-order phase factor. The two layers are transmitted through intensity or a phase modulator. After backward propagation, each modulation factor is optimized by the gradient descent algorithm to obtain the best architecture.
2.1. Time-Lens Principle and Simulation Results
Analogous to the process by which a thin lens can image an object in space, a time-lens can image sequences in the time domain, such as laser pulses and sound sequences. In this section, we will introduce the principle of a time-lens starting from the propagation of narrow-band light pulses.
Assuming that the propagation area is infinite, the electric field envelop
of a narrow-band laser pulse with a center frequency of
propagation in space coordinates
and time
satisfies
where
is the electric field envelope of the input light pulse,
is the dispersion coefficient, and
represents the angular frequency. Expanding the dispersion coefficient
with Taylor series and retaining it to the second order, the frequency spectrum
after Fourier transformation can be described as
Then, we perform the inverse Fourier transform on (2) to obtain the time domain pulse envelope:
where
is the group velocity,
. If we establish a new coordinate whose frame moves at the speed of the group velocity of light, the corresponding transformation can be described as
where
and
are the time and the space initial points, respectively. Under this circumstance, (3) can be simplified as
Then, we can get the spectrum of the signal envelope by Fourier transform:
where
is the time variable in frequency domain,
is the imaginary number. It can be seen from the time domain envelope equation that the second order phase modulation of the independent variable T is carried out in the time-lens algorithm. Like the space lens, the space diffraction equation of a paraxial beam and the propagation equation of a narrow-band optical pulse in the dispersive medium both modulate the independent variable (x, y, and t) second order.
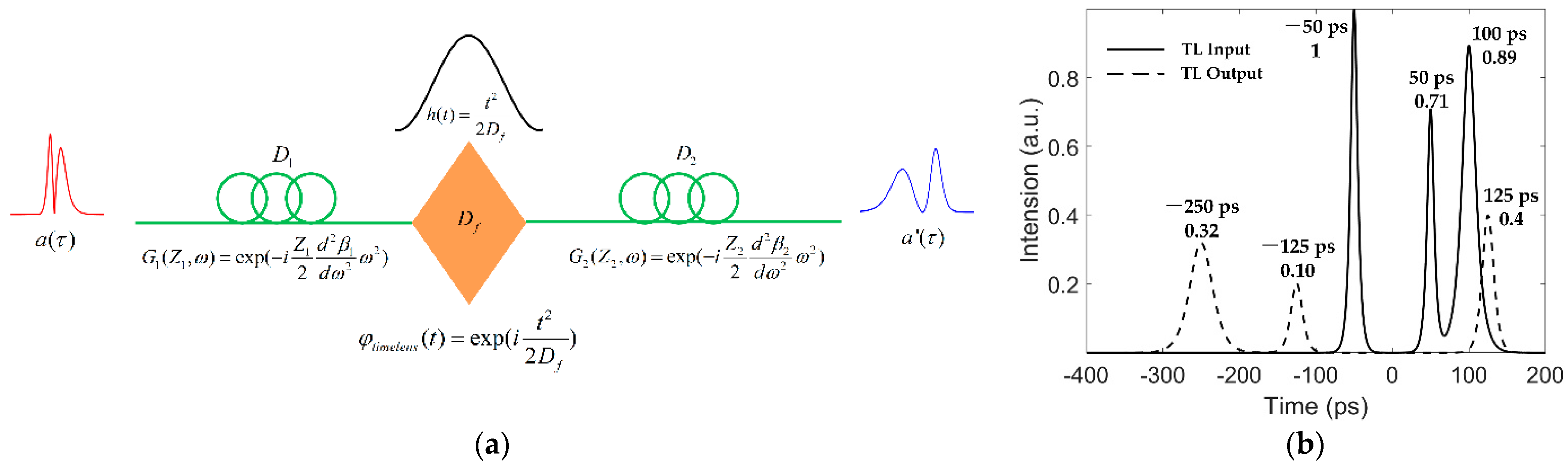
The time lens mainly comprises three parts—the second-order phase modulator and the dispersion medium before and after the modulator (
Figure 2a). In the dispersion medium part, the pulse passing through the long distance dispersion fiber is equivalent to the pulse being modulated in the frequency domain by a factor determined by the fiber length and the second-order dispersion coefficient, which can be expressed as
where
and
represent the length of fiber
i and the second-order dispersion coefficient, respectively. When passing through the time domain phase modulator, the phase factor satisfying the imaging condition of the time-lens is the quadratic function of time
by
, and
is the focal length of the time-lens satisfying the imaging conditions of the time-lens. With respect to analog space-lens imaging conditions, the time-lens imaging condition is
Its magnification can be expressed as
(see
Appendix A).
Figure 2b shows a comparison of the duration of a group of soliton pulses and their output of the time lens at M = 2.5; the peak position and normalized intensity of the pulse are marked to verify its magnification. In summary, after passing through the time-lens, the pulse is
times larger in amplitude and M times larger in duration, and a second order phase modulation is added in phases.
2.2. Mathematical Analysis of TL-ONN
In this section, we will analyze the transmission process of input data in two adjacent time-lens layers. Suppose that the input pulse can be expressed as
, that is, the initial intensity in time of the pulse into the first dispersion fiber of the time lens. The intensity of the input data at each time point will be mapped to all time points according to a specific algorithm after two segments of the dispersion fiber in the time lens and second-order phase modulation in the time domain. Equation (9) shows the algorithm results; its derivation can be found in
Appendix A. In the neural network based on this algorithm, each neuron in the
mth layer can be regarded as the result of mapping all neurons in the
(m −
1)th layer.
where
represents the magnification factor of the time-lens,
and
are the second-order dispersion coefficients of the two segments of the dispersion fiber,
and
are the lengths of the two segments of the dispersion fiber,
l represents the layer number,
represents all neurons that contribute to the neuron
in the
lth layer.
The intensity and phase of the neuron
in the L layer are determined by both the input pulse in the L − 1 layer and the modulation coefficient in the L layer. For the Lth layer of the network, the information on each neuron can be expressed by
where
is the input pulse to neuron
of layer
,
represents the contribution of the
k-th neuron of the layer
l − 1 to the neuron
of the layer
l.
is the modulation coefficient of the neuron
in layer
l; the modulation coefficient of a neuron comprises amplitude and phase items, i.e.,
.
The forward model of our TL-ONN architecture is illustrated in
Figure 1 and notated as follows:
where
refers to a neuron of the
lth layer, and
k refers to a neuron of the previous layer, connected to neuron
by optical dispersion. The input pulse
, which is located at layer 0 (i.e., the input plane), is in general a complex-valued quantity and can carry information in its phase and/or amplitude channels.
Assuming that the TL-ONN design is composed of N layers (excluding the input and output planes), the data transmitted through the architecture are finally detected by PD, and detectors are placed at the output plane to measure the intensity of the output data. If the bandwidth of the PD is much narrower than the output signal bandwidth, the PD will serve not only as an energy transforming device but also as a pulse energy accumulator. The final output of the architecture can be expressed as
where
represents the neuron
of the output layer (N), and
is the energy accumulation coefficient of PD on the time axis of the data.
To train a TL-ONN design, we used the error back-propagation algorithm along with the stochastic gradient descent optimization method. A loss function was defined to evaluate the performance of the network parameters to minimize the loss function. Without loss of generality, here we focus on our classified architecture and define the loss function (E) using the cross-entropy error between the output plane intensity
and the target
:
In the network based on a time-lens algorithm consisting of N time-lens layers, the data characteristics in the previous layer with neurons are extracted into neurons in the current layer with neurons, where and
represents the scaling multiples between the (L − 1)th layer and the Lth layer. The time-lens algorithm has a similar function of removing the redundant information and compressing the features as the pooling layer in a conventional ANN. The characteristics carried by the input data will emerge and be highlighted through each layer after being transmitted through this classification architecture, and finally evolve into the labels of the corresponding category.
3. Results
In order to verify the effectiveness of the system in the time-domain information classification, we used numerical methods to simulate the TL-ONN to realize the recognition of specific sound signals. We used a dataset containing 18,000 training data and 2000 test data picked from intelligent speech database [
33] to evaluate the performances of TL-ONN. The content in the speech dataset is the wake phrase “Hi, Miya!” in English and Chinese collected in the actual home environment using a microphone array and Hi-Fi microphone. The test subset provides paired target/non-target answers to evaluate verification results. In general, we used the dichotomy problem to test the classification performances of two kinds of systems including the TL-ONN and the conventional DNN.
We first constructed a TL-ONN composed of five time-lens layers to verify the classification feasibility of this architecture.
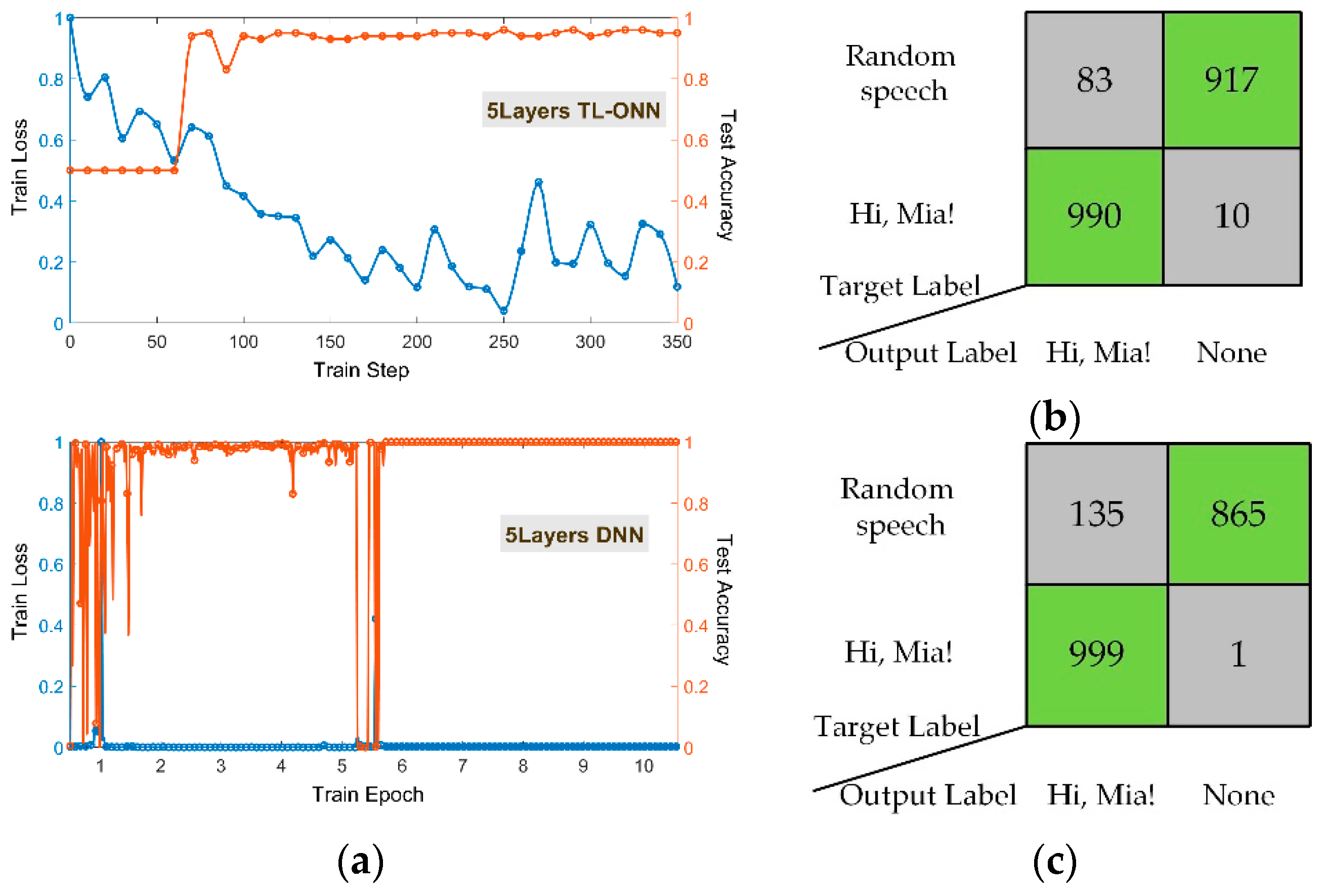
Figure 3a shows the training results of TL-ONN in the cases of
. The accuracy of the TL-ONN for a total of 2000 test samples is above 98% (
Figure 3a top), which is close to the accuracy for the DNN (
Figure 3a bottom). The horizontal axis represents the number of training steps in one training batch (batch size = 50). The accuracy of this test fluctuates greatly in the first few steps, and then reaches over 98% at about 17 steps and remains stable. In contrast, it was difficult for a five-layer DNN network under the same conditions to achieve stable accuracy and training loss in one epoch (
Figure 3a). When the training epoch was set to 10, it was found that the test accuracy and training loss still changed suddenly at the 10th training epoch, which might be due to gradient explosion, overfitting, or another reason. We define the accuracy as the proportion of the number of output labels that are the same as the target label to the total number of test sets. Using the same 2000 test set to test the two networks’ architecture, the accuracy rates reached 95.35% (
Figure 3b) and 93.2% (
Figure 3c). In general, TL-ONN has significant advantages over DNN in verifying classification performance.
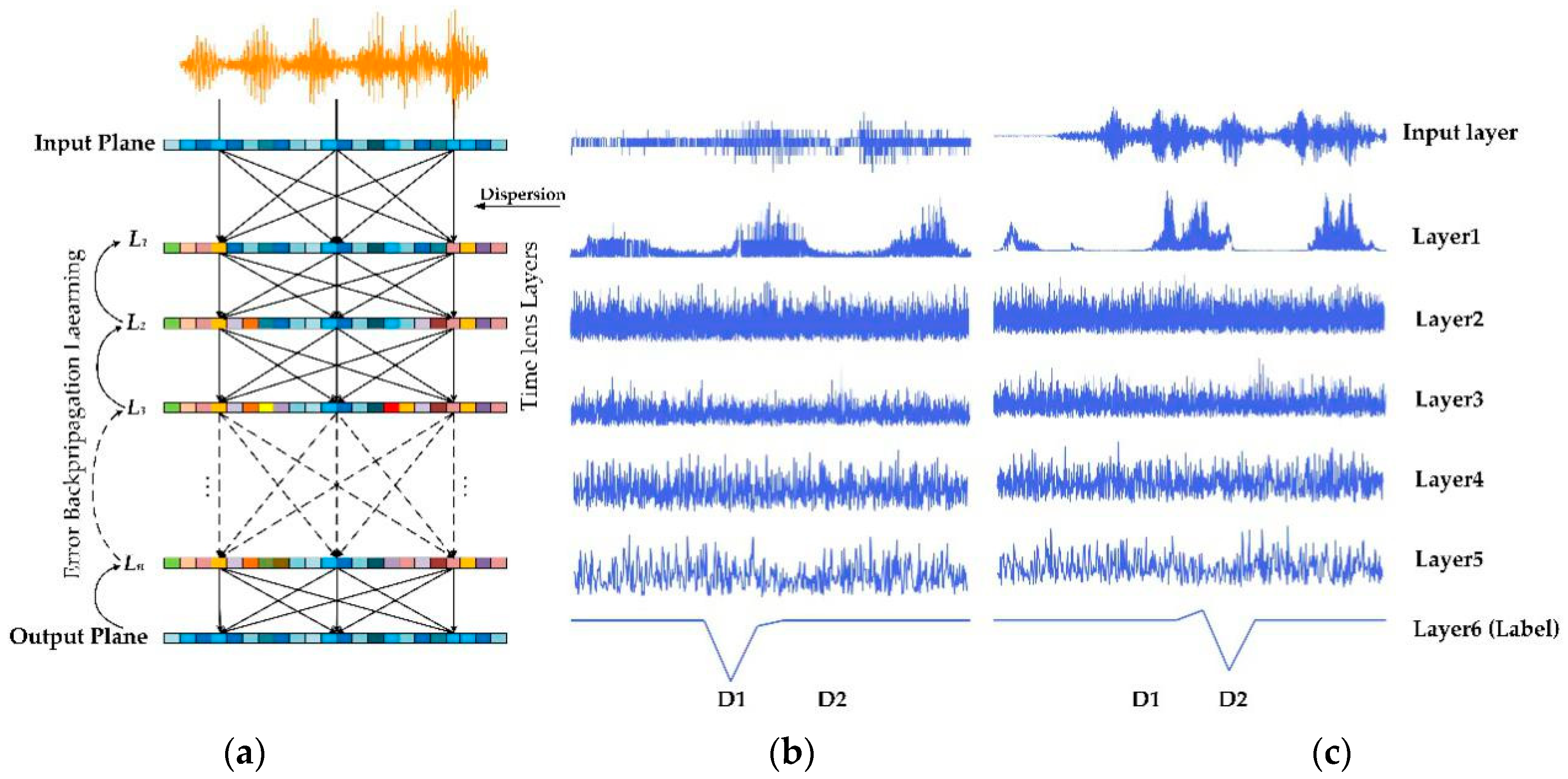
To easily see the changes of the two types of voice information in each layer of TL-ONN, we extracted two sets of input with typical characteristics for observation.
Figure 4a shows the layer structure of this network, which contains multiple time-lens layers, where each time point on a given layer acts as a neuron with a complex dispersion coefficient.
Figure 4b,c shows the data evolution of each layer when two types of speech are input to the network. From the input layer, we can distinguish the differences between the two types of input data from the shape of the waveform. The waveform containing “Hi, Miya!” has a higher continuity, while the waveform of random speech has quantized characteristics and always has a value on the time axis. On the second layer of the network, the “Hi, Miya!” input will change into several sets of pulses through the time-lens layer and another type of information will spread all over the time. After being transmitted by multiple time-lens layers, the two inputs will eventually change to the shape in Layer 6, and the two types of speech will eventually evolve into the shape of the impact function at different time points. As shown in
Figure 4b,c, D1 and D2 correspond to detectors of different input types. The random speech eventually responds at D1, while the input containing “Hi, Miya!” responds at D2.
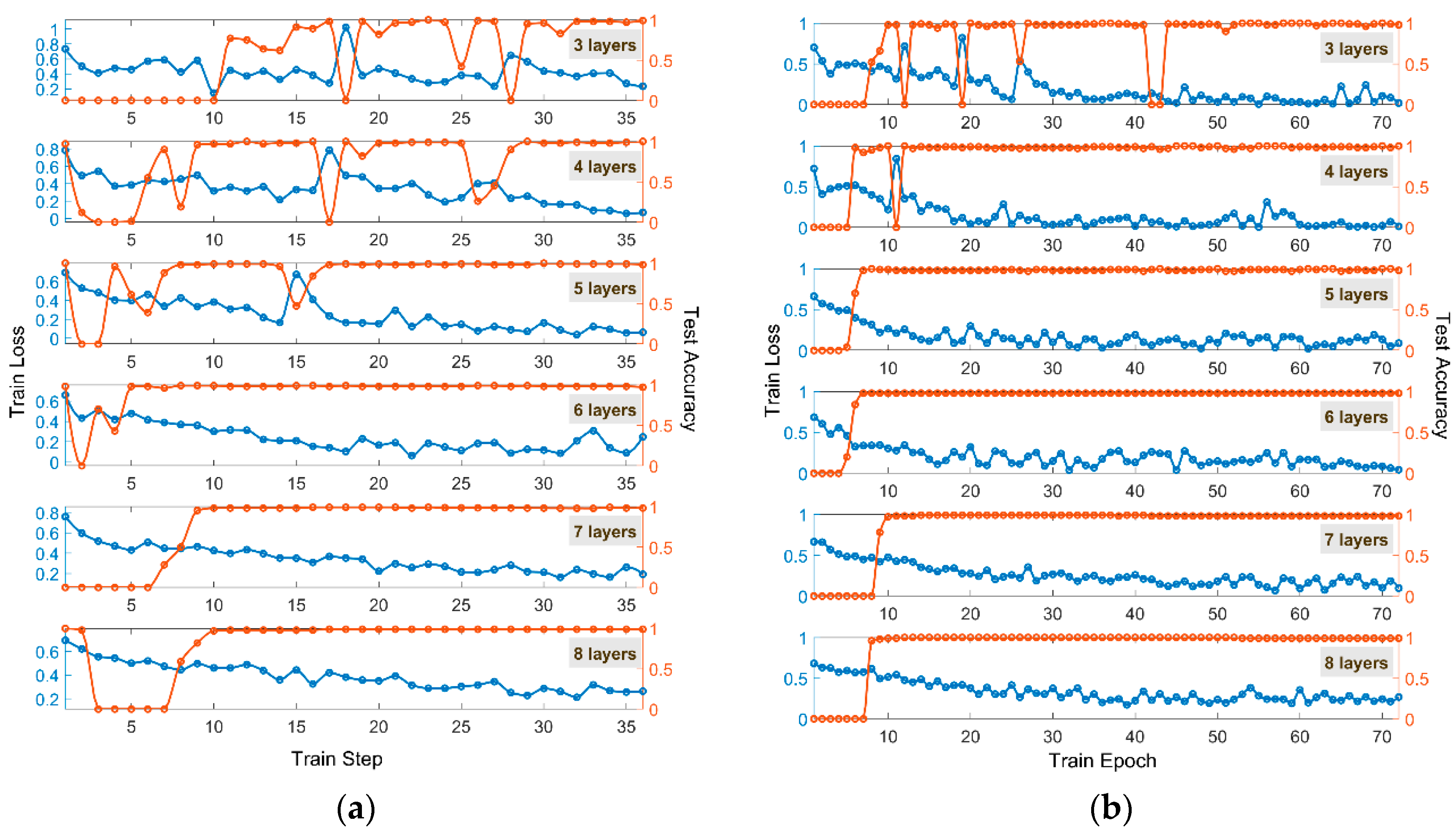
To eliminate the contingency of the experiment, we set up a series of networks consisting of 3–8 layers to test the influence of different numbers of time-lens layers on classification performance.
Figure 5 shows the test results of the TL-ONN architecture composed of different numbers of time-lens layers—33, 30, and17 steps are needed in the TL-ONN with three, four, and five layers, respectively, to reach an accuracy of 98% (
Figure 5a). When the number of time-lens layers is increased to six or more, the accuracy can be stabilized at 98–99% after about 10 training steps; however, an unlimited increase in the number of time-lens layers does not make the results of network training infinitely better. For example, we can see that compared with a network with six, seven, or eight layers, TL-ONN requires more steps to achieve stable accuracy. Overall, the network with six time-lens layers has the best classification performance. All the results discussed above occur in one training epoch. At least a few epochs were needed to achieve stable classification accuracy for conventional DNN with the same dataset. TL-ONN has obvious advantages of faster convergence speed and stable classification accuracy.
Similarly, we reverse the order of the phase modulator W
1 and W
2, and use the same training set for training.
Figure 5b shows the classification results under this architecture, and the time-scaling multiple between two layers is still 0.6. Under the same conditions, a series of networks consisting of three–eight layers were constructed to test the classification performance. To achieve an accuracy of 98%, 55 and 12 steps are needed in the TL-ONN with three and four layers, respectively. The accuracy can be stabilized at 98–99% after about 10 training steps when the number of time-lens layers is increased to five or more. As with the previous results, compared with a network with six, seven, or eight layers, TL-ONN requires more steps to achieve stable accuracy. Overall, the network structure with six time-lens layers has the best classification performance, and it is consistent with the results of the former architecture.
At the detector/output plane, we measured the intensity of the network output, and as a loss function to train the classification TL-ONN, we used its mean square error (MSE) against the target output. The classification of TL-ONN was trained using a modulator (W
2), where we aimed to maximize the normalized signal of each target’s corresponding detector region, while minimizing the total signal outside of all the detector regions. We used the stochastic gradient descent algorithm, Adam [
34], to back-propagate the errors and update the layers of the network to minimize the loss function. The classifier TL-ONN was trained with speech datasets [
33], and achieved the desired mapping functions between the input and output planes after five steps. The training batch size was set to be 50 for the speech classifier network. To verify the feasibility of the TL-ONN architecture, we used the python language to establish a simulation model for theoretical analysis. The networks were implemented using Python version 3.8.0. and PyTorch version 1.4.0. Using a desktop computer (GeForce GTX 1060 Graphical Processing Unit, GPU and Intel(R) Core (TM) i7-8700 CPU @3.20GHz and 64GB of RAM, running a Windows 10 operating system, Microsoft), the above-outlined PyTorch-based design of a TL-ONN architecture took approximately 26 h to train for the classifier networks.
Compared with conventional DNNs, TL-ONN is not only a physical and optical neural network but also has some unique architecture. First, the time-lens algorithm applied at each layer of the network can refine the features of the input data, similar to what is used as a pooling layer, remove redundant information, and compress features. The time-lens method can be regarded as the pooling element in the photon. Second, TL-ONN can handle complex values, such as complex nonlinear dynamics in passively mode-locked lasers. The phase modulators can respectively modulate different physical parameters, and as long as the modulator parameters are determined, a passive all-optical neural network can be basically realized. Third, the output of each neuron is coupled to the neurons in the next layer through a certain weight relationship through the dispersion effect of the optical fiber, thereby providing a unique interconnection from within the network.
4. Discussion
In this paper, we proposed a new optical neural network based on the time-lens method. The forward transmission of the neural network can be realized by the time lens to enlarge or reduce the data in the time dimension, and the characteristics of the signal extracted by the time-lens algorithm are modulated with the amplitude or phase modulator to realize the weight matrix optimization process in linear operation. After the time signal is compressed and modulated by the multilayer based on the time-lens method, it will eventually evolve into the corresponding target output, so as to realize the classification function of the optical neural network. To verify the feasibility of the network, we used the speech data set to train it and got a test accuracy of 95.35%. The accuracy is obviously more stable and has faster convergence compared with the same number of layers in a DNN.
Our optical architecture implements a feedforward neural network through a time-stretching method; thus, when completing high-throughput data processing and large-scale tasks, it basically proceeds at the speed of light in the optical fiber, and requires little additional power consumption. The system has a clear correspondence between the theoretical neural network and the actual optical component parameters; thus, once each parameter in the network can be optimized, it can basically be realized completely by optical devices, which provides the possibility of building an all-optical neural network test system composed of optical fibers, electro-optic modulators, etc.
Here, we verify the feasibility of the proposed TL-ONN by numerical simulation, and we will work to build a test system to realize all-optical TL-ONN in the future. It is often accompanied by noise and loss in experiments. We conservatively speculate that such noise may reduce the classification accuracy of the architecture. On the other hand, in order to solve the influence of loss on the experiment, an optical amplifier is generally added to improve the signal-to-noise ratio. The non-linear effects of the optical amplifier have similar functions to the activation function in the neural network, and it may play an important role in all-optical neural networks in the future.
The emergence of ONNs provides a solution for real-time online processing of high-throughput timing information. By fusing the ONN with the photon time stretching test system, not only can real-time data processing be achieved, but also the system’s dependence on broadband high-speed electronic systems can be significantly reduced. In addition, cost and power consumption can be reduced, and the system can be used in medicine and biology, green energy, physics, and optical communication information extraction, having more extensive applications. This architecture is expected to provide breakthroughs in the identification of rare events such as the initial screening of cancer cells and be widely used in high-throughput data processing such as early cell screening [
22], drug development [
23], cell dynamics [
21], and environmental improvement [
35,
36], as well as in other fields.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




