Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network



Abstract
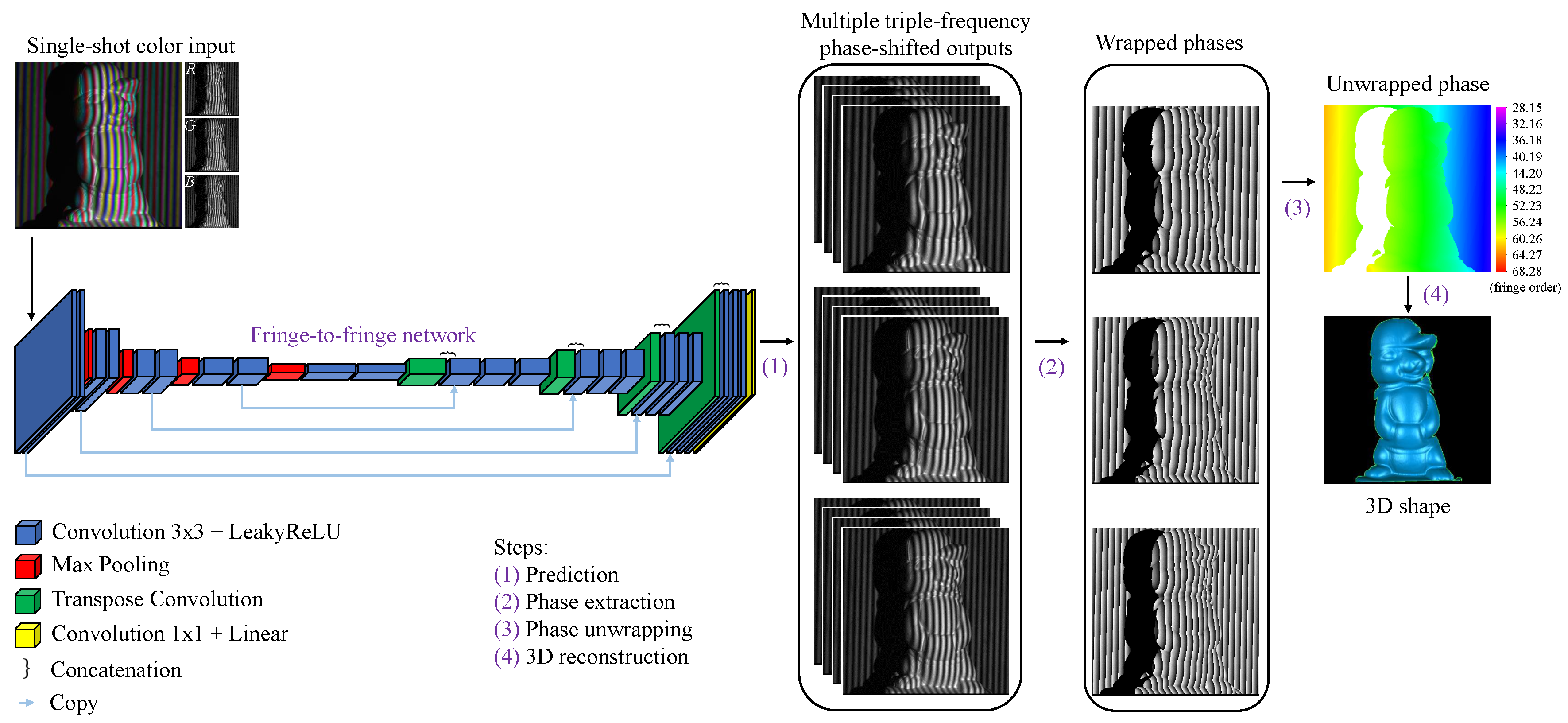
1. Introduction
2. Materials and Methods
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of Kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, S. Status, challenges, and future perspectives of fringe projection profilometry. Opt. Lasers Eng. 2020, 135, 106193. [Google Scholar] [CrossRef]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel(R) RealSense(TM) Stereoscopic Depth Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1267–1276. [Google Scholar] [CrossRef]
- Nguyen, H.; Wang, Z.; Jones, P.; Zhao, B. 3D shape, deformation, and vibration measurements using infrared Kinect sensors and digital image correlation. Appl. Opt. 2017, 56, 9030–9037. [Google Scholar] [CrossRef]
- ATOS Core: Precise Industrial 3D Metrology. Available online: https://www.atos-core.com/ (accessed on 4 October 2021).
- ZEISS colin3D-Optical 3D Capture and 3D Analysis. Available online: https://www.zeiss.com/metrology/products/software/colin3d.html (accessed on 4 October 2021).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2016, 521, 436–444. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018. [Google Scholar] [CrossRef]
- Pathak, A.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Proced. Comp. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Bianco, V.; Mazzeo, P.; Paturzo, M.; Distante, C.; Ferraro, P. Deep learning assisted portable IR active imaging sensor spots and identifies live humans through fire. Opt. Lasers Eng. 2020, 124, 105818. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Han, X.F.; Laga, H.; Bennamoun, M. Image-Based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. IEEE Trans. Patt. Anal. Mach. Intell. 2021, 43, 1578–1604. [Google Scholar] [CrossRef]
- Chen, J.; Kira, Z.; Cho, Y. Deep Learning Approach to Point Cloud Scene Understanding for Automated Scan to 3D Reconstruction. J. Comp. Civ. Eng. 2019, 33, 105818. [Google Scholar] [CrossRef]
- Fanello, S.; Rhemann, C.; Tankovich, V.; Kowdle, A.; Escolano, S.; Kim, D.; Izadi, S. Hyperdepth: Learning depth from structured light without matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5441–5450. [Google Scholar] [CrossRef]
- Wang, H.; Yang, J.; Liang, W.; Tong, X. Deep single-view 3d object reconstruction with visual hull embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8941–8948. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, X.; Bai, S.; Yao, C.; Bai, X. Deep Learning Representation using Autoencoder for 3D Shape Retrieval. Neurocomputing 2016, 204, 41–50. [Google Scholar] [CrossRef]
- Lin, B.; Fu, S.; Zhang, C.; Wang, F.; Li, Y. Optical fringe patterns filtering based on multi-stage convolution neural network. Opt. Lasers Eng. 2020, 126, 105853. [Google Scholar] [CrossRef]
- Yan, K.; Yu, Y.; Huang, C.; Sui, L.; Qian, K.; Asundi, A. Fringe pattern denoising based on deep learning. Opt. Comm. 2019, 437, 148–152. [Google Scholar] [CrossRef]
- Yuan, S.; Hu, Y.; Hao, Q.; Zhang, S. High-accuracy phase demodulation method compatible to closed fringes in a single-frame interferogram based on deep learning. Opt. Express 2021, 29, 2538–2554. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Li, Y.; Kemao, Q.; Di, J.; Zhao, J. One-step robust deep learning phase unwrapping. Opt. Express 2019, 27, 15100–15115. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, X.; Shao, J.; Luo, H.; Liang, R. Phase unwrapping in optical metrology via denoised and convolutional segmentation networks. Opt. Express 2019, 27, 14903–14912. [Google Scholar] [CrossRef] [PubMed]
- Qiao, G.; Huang, Y.; Song, Y.; Yue, H.; Liu, Y. A single-shot phase retrieval method for phase measuring deflectometry based on deep learning. Opt. Comm. 2020, 476, 126303. [Google Scholar] [CrossRef]
- Li, Y.; Shen, J.; Wu, Z.; Zhang, Q. Passive binary defocusing for large depth 3D measurement based on deep learning. Appl. Opt. 2021, 60, 7243–7253. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Dunne, N.; Li, H.; Wang, Y.; Wang, Z. Real-time 3D shape measurement using 3LCD projection and deep machine learning. Appl. Opt 2019, 58, 7100–7109. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, J.; Shao, J.; Song, B.; Yao, B.; Liang, R. Deep Convolutional Neural Network Phase Unwrapping for Fringe Projection 3D Imaging. Sensors 2020, 20, 3691. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, Z.; Li, H.; Li, X.; Zhou, X. Single-shot phase extraction for fringe projection profilometry using deep convolutional generative adversarial network. Meas. Sci. Tech. 2020, 32, 015007. [Google Scholar] [CrossRef]
- Fan, S.; Liu, S.; Zhang, X.; Huang, H.; Liu, W.; Jin, P. Unsupervised deep learning for 3D reconstruction with dual-frequency fringe projection profilometry. Opt. Express 2021, 29, 32547–32567. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wang, C.; Guan, Q. Single-shot fringe projection profilometry based on deep learning and computer graphics. Opt. Express 2021, 29, 8024–8040. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Wang, Y.; Wang, Z. Single-Shot 3D Shape Reconstruction Using Structured Light and Deep Convolutional Neural Networks. Sensors 2020, 20, 3718. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Ly, K.L.; Tran, T.; Wang, Y.; Wang, Z. hNet: Single-shot 3D shape reconstruction using structured light and h-shaped global guidance network. Results Opt. 2021, 4, 100104. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar] [CrossRef] [PubMed]
- Qian, J.; Feng, S.; Tao, T.; Han, J.; Chen, Q.; Zuo, C. Single-shot absolute 3D shape measurement with deep-learning-based color fringe projection profilometry. Opt. Lett. 2020, 45, 1842–1845. [Google Scholar] [CrossRef]
- Shi, J.; Zhu, X.; Wang, H.; Song, L.; Guo, Q. Label enhanced and patch based deep learning for phase retrieval from single frame fringe pattern in fringe projection 3D measurement. Opt. Express 2019, 27, 28929–28943. [Google Scholar] [CrossRef]
- Yao, P.; Gai, S.; Chen, Y.; Chen, W.; Da, F. A multi-code 3D measurement technique based on deep learning. Opt. Lasers Eng. 2021, 143, 106623. [Google Scholar] [CrossRef]
- Spoorthi, G.; Gorthi, R.; Gorthi, S. PhaseNet 2.0: Phase Unwrapping of Noisy Data Based on Deep Learning Approach. IEEE Trans. Image Process. 2020, 29, 4862–4872. [Google Scholar] [CrossRef]
- Qian, J.; Feng, S.; Tao, T.; Hu, Y.; Li, Y.; Chen, Q.; Zuo, C. Deep-learning-enabled geometric constraints and phase unwrapping for single-shot absolute 3D shape measurement. APL Photonics 2020, 5, 046105. [Google Scholar] [CrossRef]
- Zhang, Z.; Towers, D.; Towers, C. Snapshot color fringe projection for absolute three-dimensional metrology of video sequences. Appl. Opt. 2010, 49, 5947–5953. [Google Scholar] [CrossRef]
- Yu, H.; Chen, X.; Zhang, Z.; Zuo, C.; Zhang, Y.; Zheng, D.; Han, J. Dynamic 3-D measurement based on fringe-to-fringe transformation using deep learning. Opt. Express 2020, 28, 9405–9418. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Hou, Q.; Li, Y.; Cai, Z.; Liu, X.; Xi, J.; Peng, X. Phase error compensation based on Tree-Net using deep learning. Opt. Lasers Eng. 2021, 143, 106628. [Google Scholar] [CrossRef]
- Vo, M.; Wang, Z.; Pan, B.; Pan, T. Hyper-accurate flexible calibration technique for fringe-projection-based three-dimensional imaging. Opt. Express 2012, 20, 16926–16941. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, D.; Wang, Z.; Kieu, H.; Le, M. Real-time, high-accuracy 3D imaging and shape measurement. Appl. Opt. 2015, 54, A9–A17. [Google Scholar] [CrossRef]
- Nguyen, H.; Liang, J.; Wang, Y.; Wang, Z. Accuracy assessment of fringe projection profilometry and digital image correlation techniques for three-dimensional shape measurements. J. Phys. Photonics 2021, 3, 014004. [Google Scholar] [CrossRef]
- Feng, S.; Zuo, C.; Yin, W.; Gu, G.; Chen, Q. Micro deep learning profilometry for high-speed 3D surface imaging. Opt. Laser Eng. 2019, 121, 416–427. [Google Scholar] [CrossRef]
- Mass, A.; Hannun, A.; Ng, A. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; Volume 28, p. 1. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; p. 13. [Google Scholar]
- Jeught, S.; Dirckx, J. Deep neural networks for single shot structured light profilometry. Opt. Express 2019, 27, 17091–17101. [Google Scholar] [CrossRef]
- Nguyen, H.; Tran, T.; Wang, Y.; Wang, Z. Three-dimensional Shape Reconstruction from Single-shot Speckle Image Using Deep Convolutional Neural Networks. Opt. Laser Eng. 2021, 143, 106639. [Google Scholar] [CrossRef]
- Yao, P.; Gai, S.; Da, F. Coding-Net: A multi-purpose neural network for Fringe Projection Profilometry. Opt. Comm. 2021, 489, 126887. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filters | Kernel Size/ Pool Size | Stride | Output Size | Params |
|---|---|---|---|---|---|
| input | - | - | - | 352 × 640 × 3 | 0 |
| conv1a + LeakyReLU conv1b + LeakyReLU max pool | 32 32 - | 3 × 3 3 × 3 2 × 2 | 1 1 2 | 352 × 640 × 32 352 × 640 × 32 176 × 320 × 32 | 896 9248 0 |
| conv2a + LeakyReLU conv2b + LeakyReLU max pool | 64 64 - | 3 × 3 3 × 3 2 × 2 | 1 1 2 | 176 × 320 × 64 176 × 320 × 64 88 × 160 × 64 | 18,496 36,928 0 |
| conv3a + LeakyReLU conv3b + LeakyReLU max pool | 128 128 - | 3 × 3 3 × 3 2 × 2 | 1 1 2 | 88 × 160 × 128 88 × 160 × 128 44 × 80 × 128 | 73,856 147,584 0 |
| conv4a + LeakyReLU conv4b + LeakyReLU max pool | 256 256 - | 3 × 3 3 × 3 2 × 2 | 1 1 2 | 44 × 80 × 256 44 × 80 × 256 22 × 40 × 256 | 295,168 590,080 0 |
| conv5a + LeakyReLU conv5b + LeakyReLU dropout | 512 512 - | 3 × 3 3 × 3 - | 1 1 - | 22 × 40 × 512 22 × 40 × 512 22 × 40 × 512 | 1,180,160 2,359,808 0 |
| transpose conv concat conv6a + LeakyReLU conv6b + LeakyReLU | 256 - 256 256 | 3 × 3 - 3 × 3 3 × 3 | 2 - 1 1 | 44 × 80 × 256 44 × 80 × 512 44 × 80 × 256 44 × 80 × 256 | 1,179,904 0 1,179,904 590,080 |
| transpose conv concat conv7a + LeakyReLU conv7b + LeakyReLU | 128 - 128 128 | 3 × 3 - 3 × 3 3 × 3 | 2 - 1 1 | 88 × 160 × 128 88 × 160 × 256 88 × 160 × 128 88 × 160 × 128 | 295,040 0 295,040 147,584 |
| transpose conv concat conv8a + LeakyReLU conv8b + LeakyReLU | 64 - 64 64 | 3 × 3 - 3 × 3 3 × 3 | 2 - 1 1 | 176 × 320 × 64 176 × 320 × 128 176 × 320 × 64 176 × 320 × 64 | 73,792 0 73,792 36,928 |
| transpose conv concat conv9a + LeakyReLU conv9b + LeakyReLU | 32 - 32 32 | 3 × 3 - 3 × 3 3 × 3 | 2 - 1 1 | 352 × 640 × 32 352 × 640 × 64 352 × 640 × 32 352 × 640 × 32 | 18,464 0 18,464 9248 |
| conv10 + Linear | 12 | 1 × 1 | 1 | 352 × 640 × 12 | 396 |
| Total | 8,630,860 |
| Method | Fringe-to-Fringe | Fringe-to-Depth | Speckle-to-Depth | Fringe-to-ND | ||||
|---|---|---|---|---|---|---|---|---|
| Valiation | Test | Valiation | Test | Valiation | Test | Valiation | Test | |
| RMSE | 0.0650 | 0.0702 | 0.5673 | 0.6376 | 0.6801 | 0.7184 | 0.0667 | 0.0538 |
| Mean | 0.0091 | 0.0109 | 0.3363 | 0.3738 | 0.3167 | 0.3838 | 0.0216 | 0.0126 |
| Median | 0.0087 | 0.0105 | 0.3239 | 0.3511 | 0.3030 | 0.3729 | 0.0204 | 0.0105 |
| Trimean | 0.0088 | 0.0106 | 0.3310 | 0.3622 | 0.3042 | 0.3789 | 0.0207 | 0.0108 |
| Best 25% | 0.0053 | 0.0040 | 0.2790 | 0.2859 | 0.2150 | 0.2543 | 0.0153 | 0.0067 |
| Worse 25% | 0.0138 | 0.0181 | 0.4080 | 0.4891 | 0.4451 | 0.5289 | 0.0297 | 0.0225 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.; Wang, Z. Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network. Photonics 2021, 8, 459. https://doi.org/10.3390/photonics8110459
Nguyen H, Wang Z. Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network. Photonics. 2021; 8(11):459. https://doi.org/10.3390/photonics8110459
Chicago/Turabian StyleNguyen, Hieu, and Zhaoyang Wang. 2021. "Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network" Photonics 8, no. 11: 459. https://doi.org/10.3390/photonics8110459
APA StyleNguyen, H., & Wang, Z. (2021). Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network. Photonics, 8(11), 459. https://doi.org/10.3390/photonics8110459