An Energy-Efficient High-Throughput Mesh-Based Photonic On-Chip Interconnect for Many-Core Systems

Abstract
:
1. Introduction
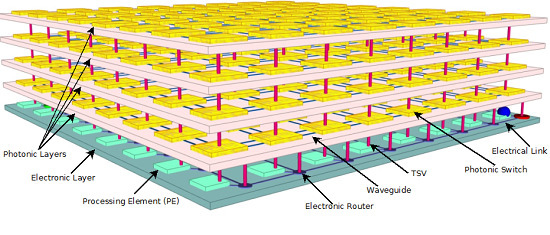
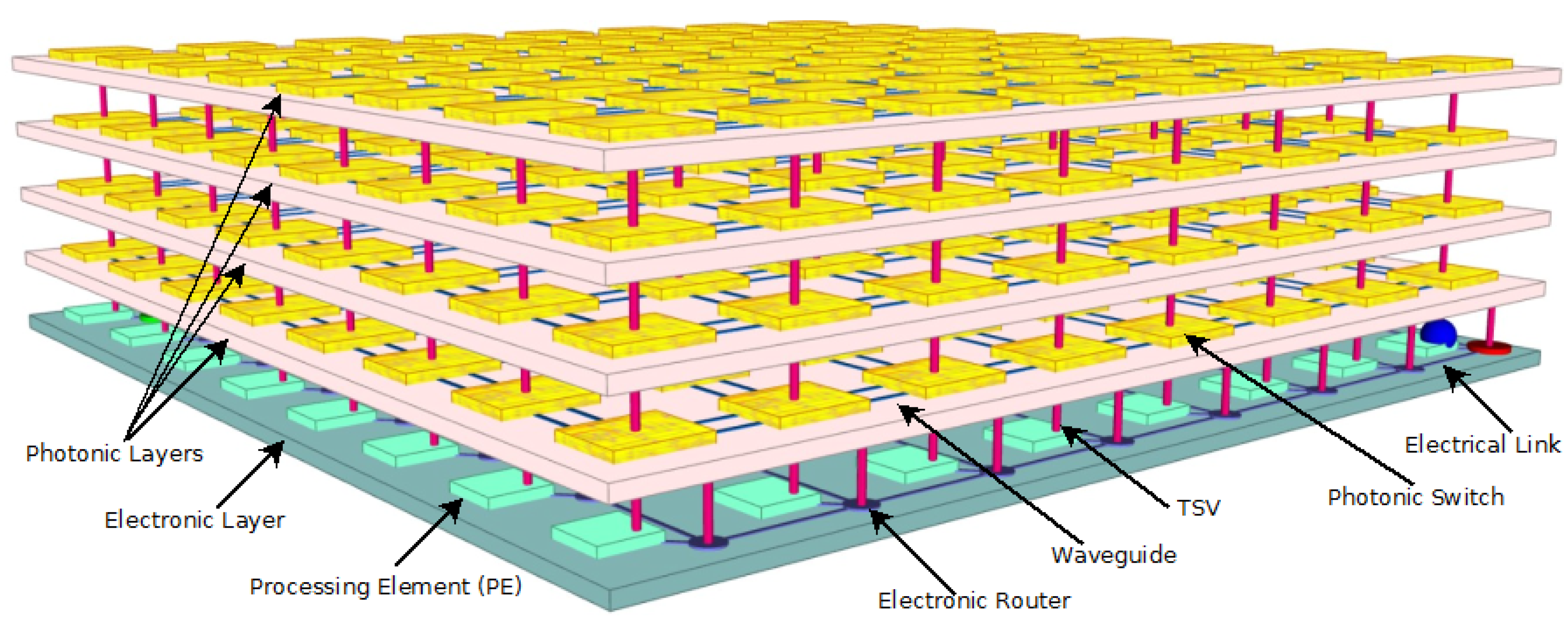
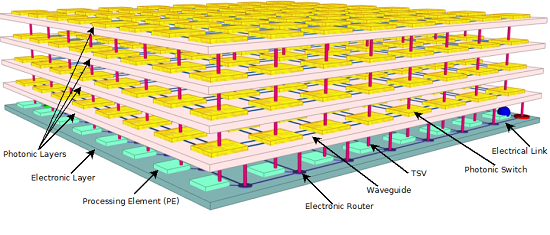
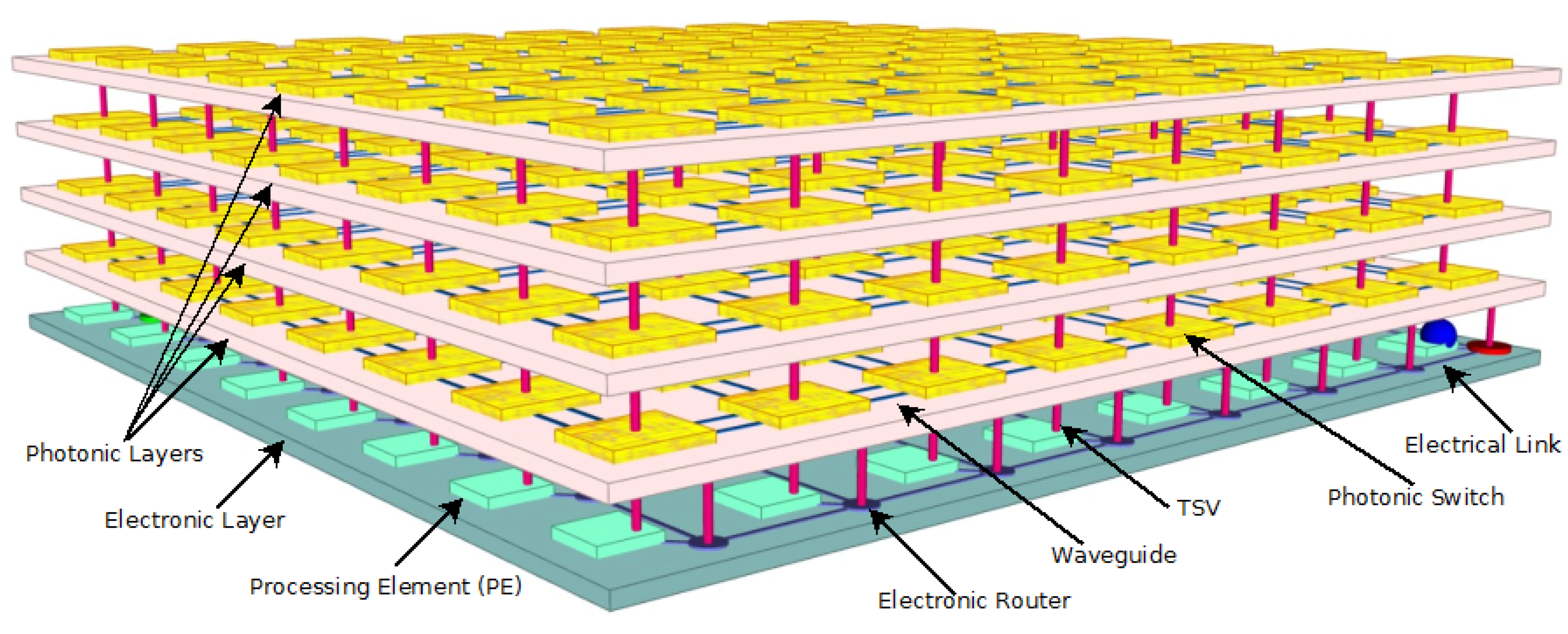
2. System Architecture
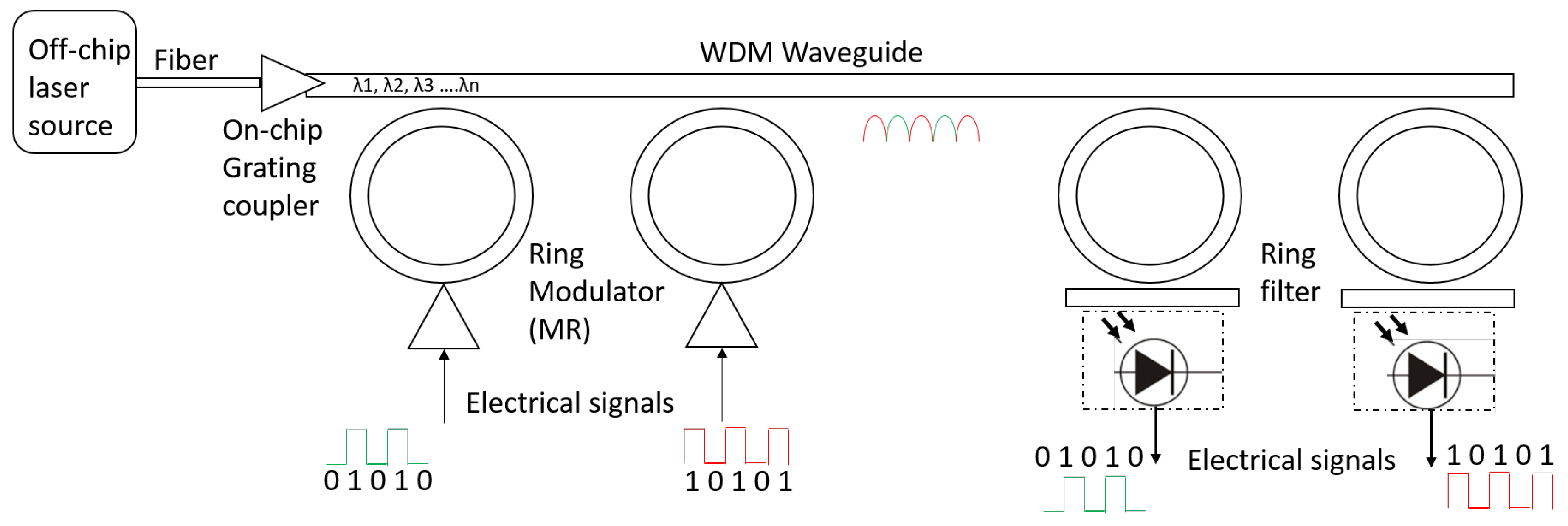
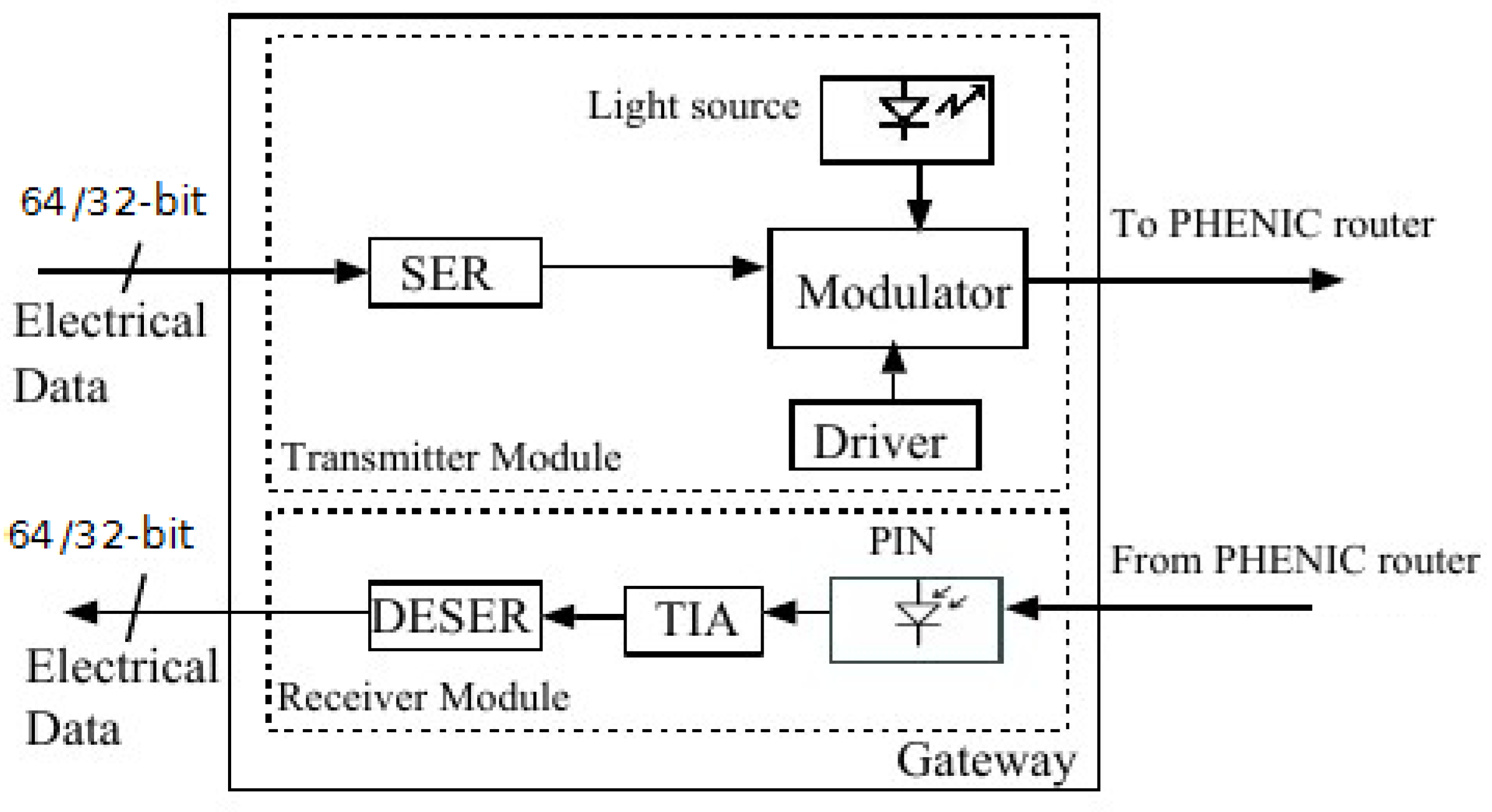
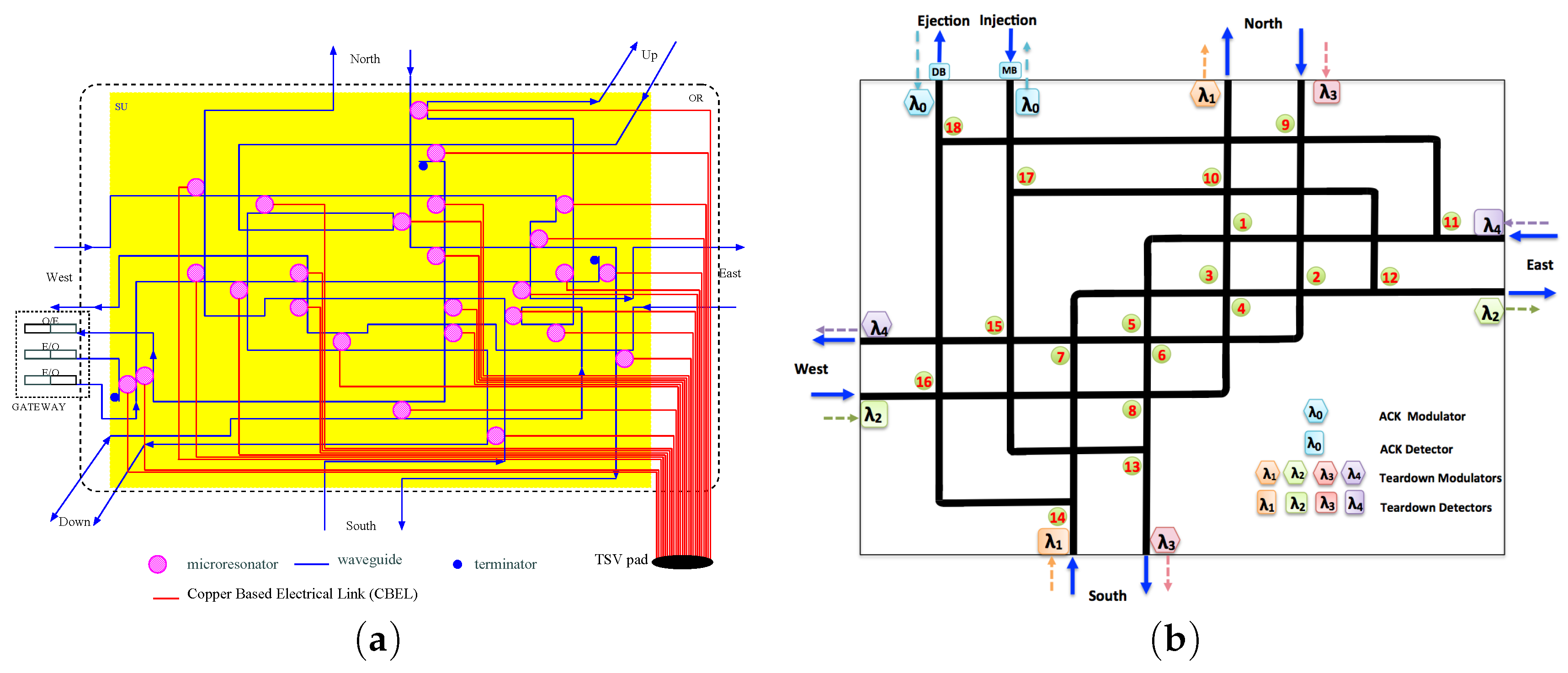
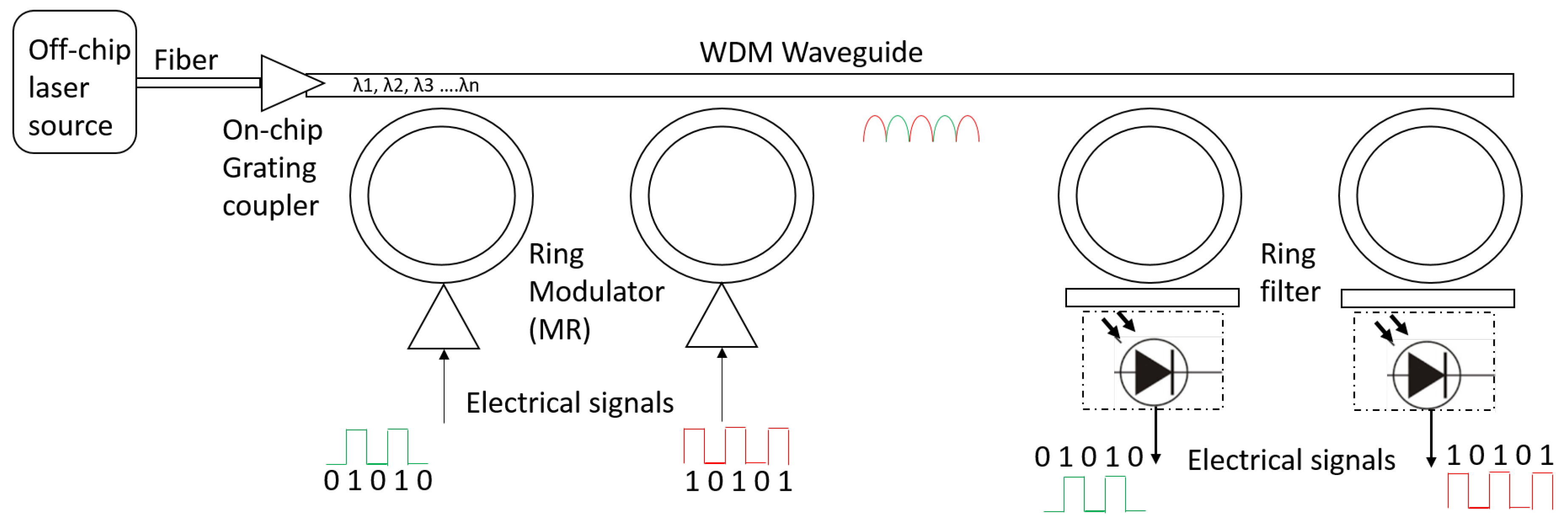
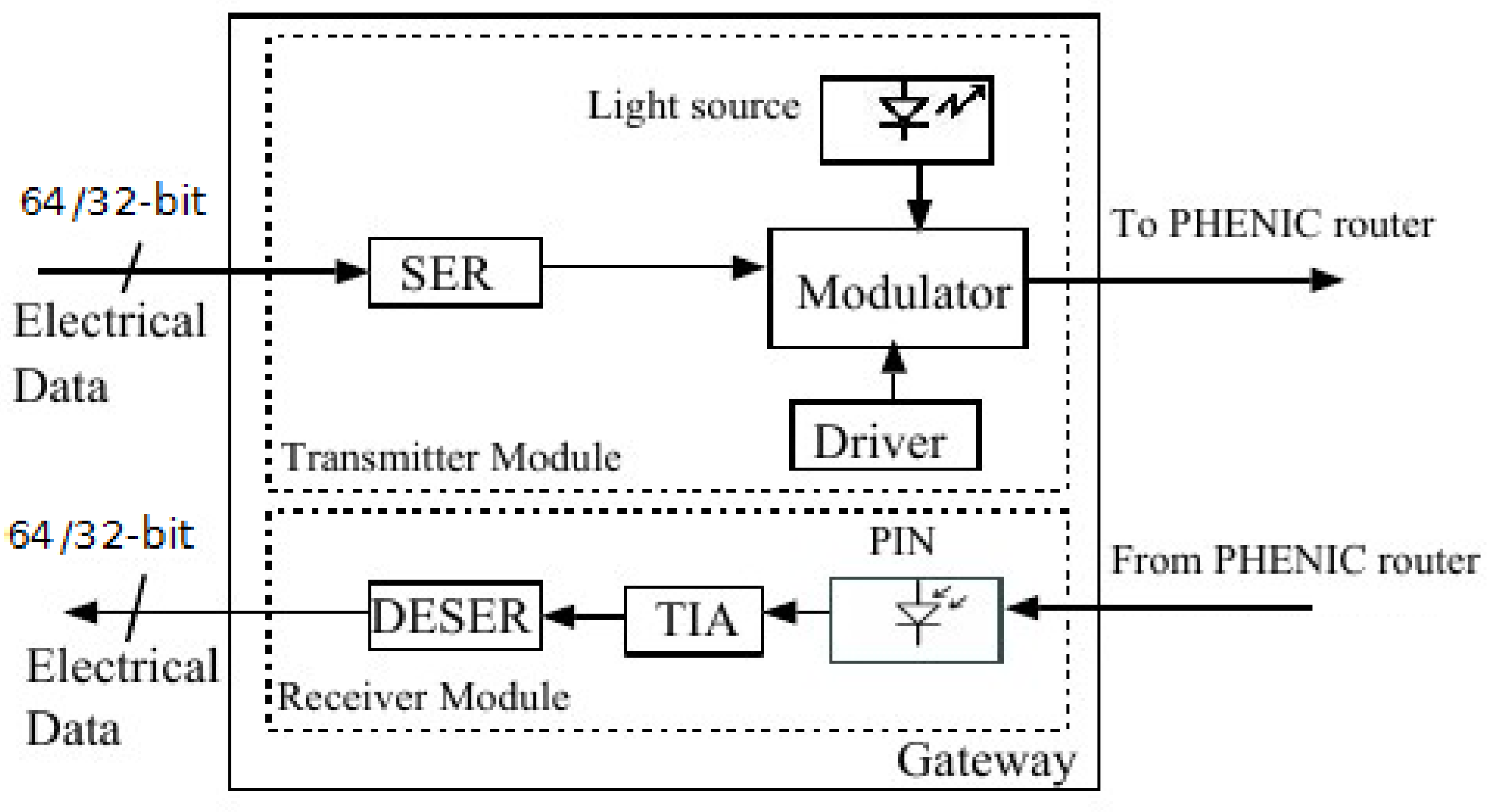
2.1. Photonic Building Blocks
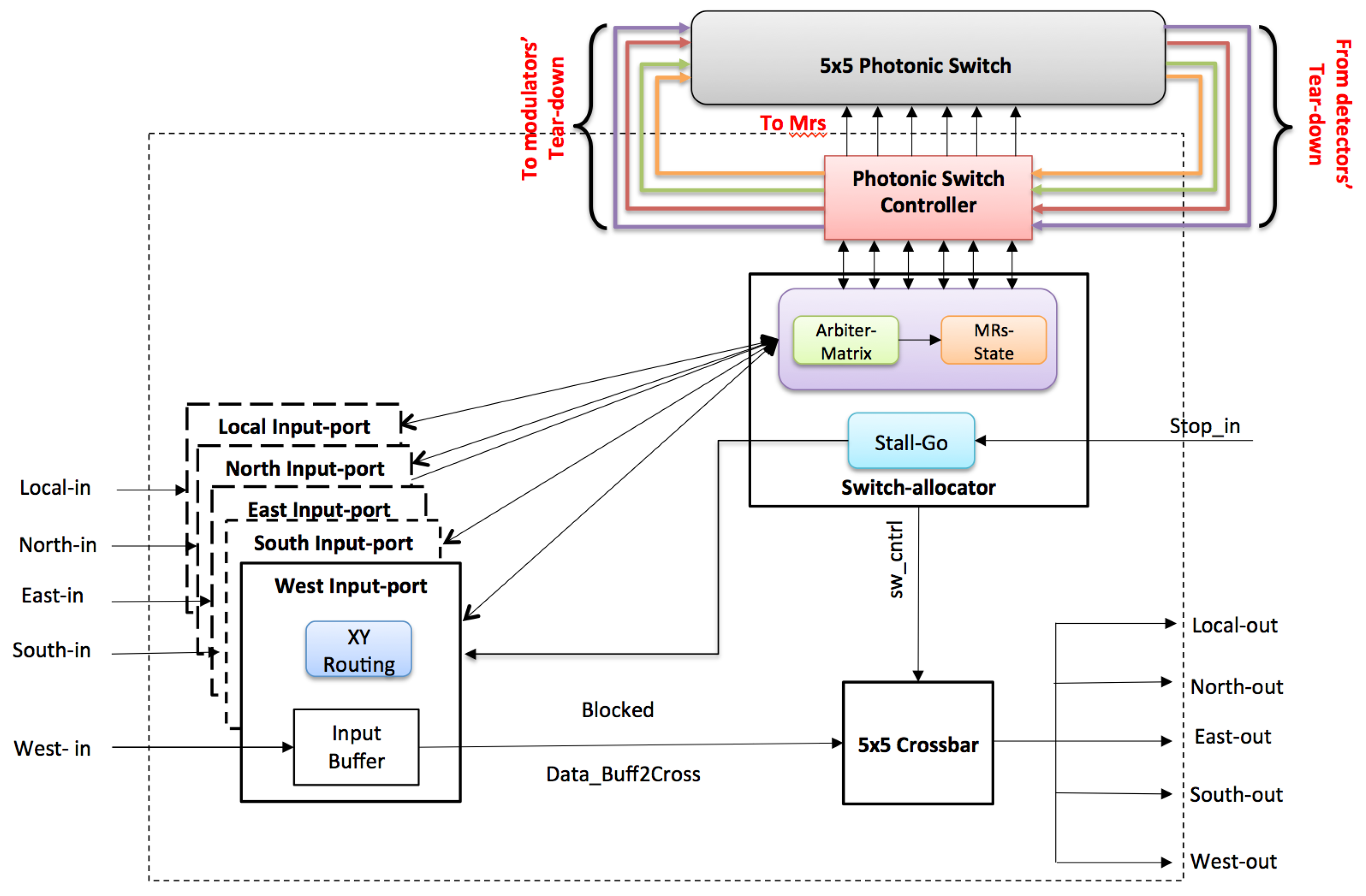
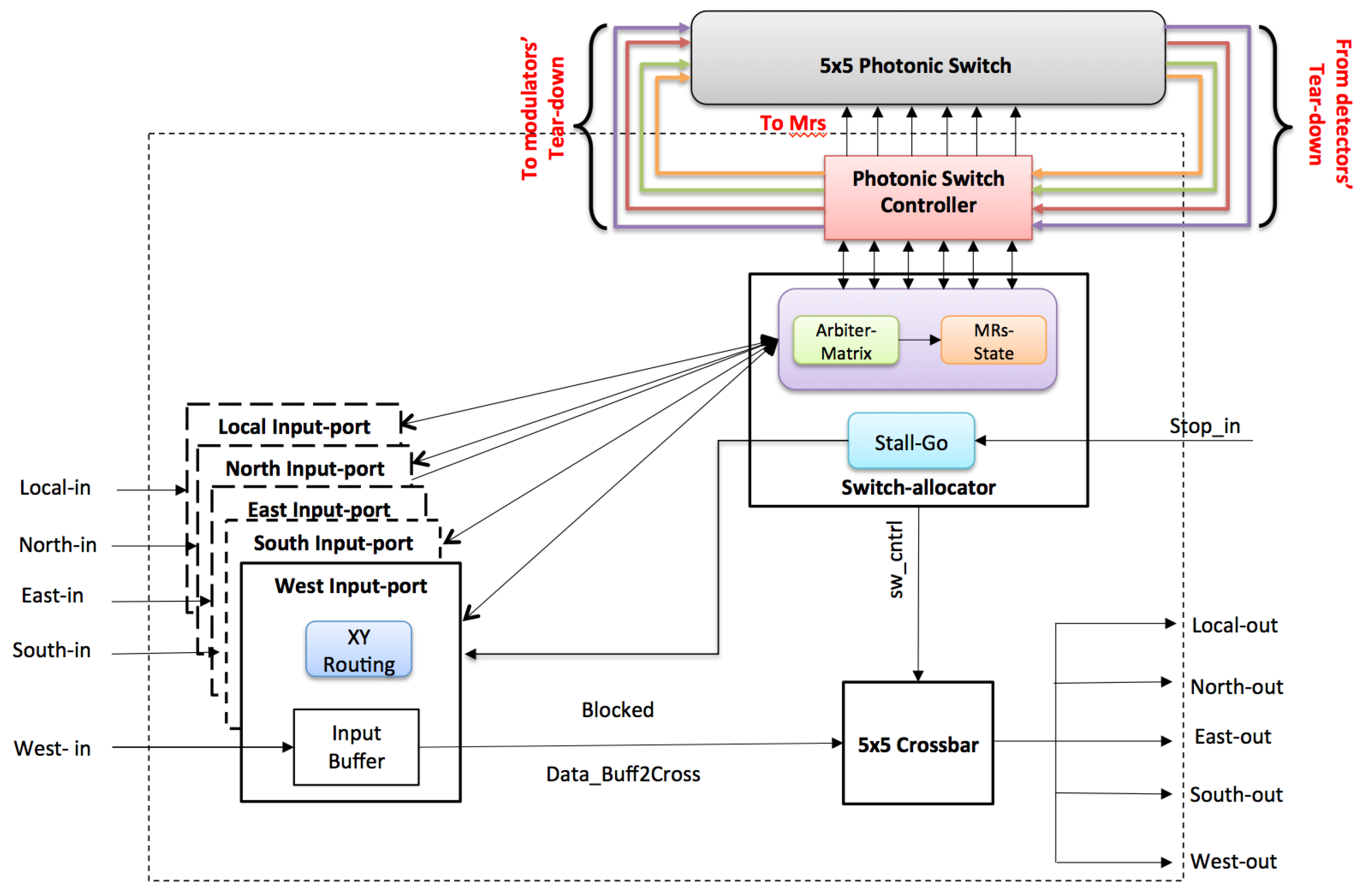
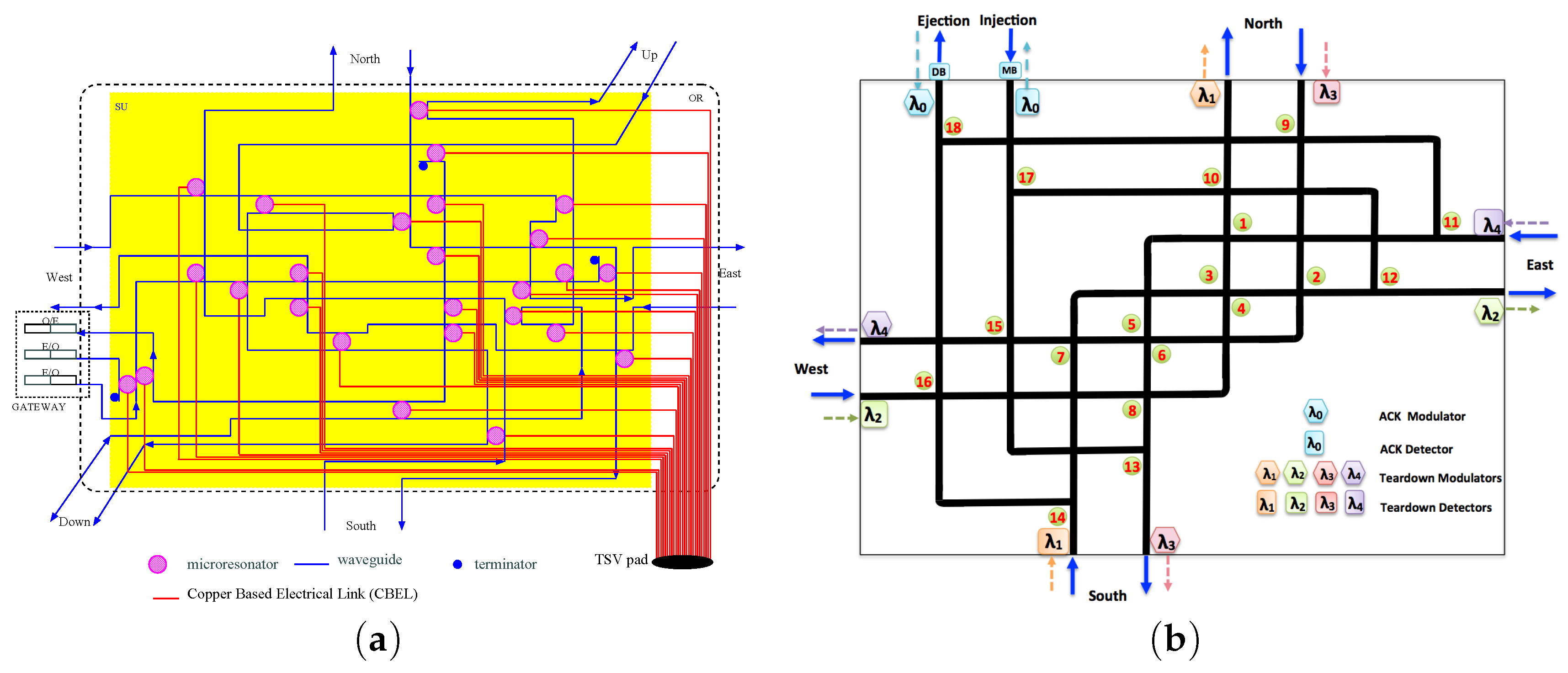
2.2. Photonic Router
2D Non-Blocking Photonic Switch
2.3. Contention-Aware Path Configuration Algorithm

3. Evaluation
3.1. Evaluation Methodology
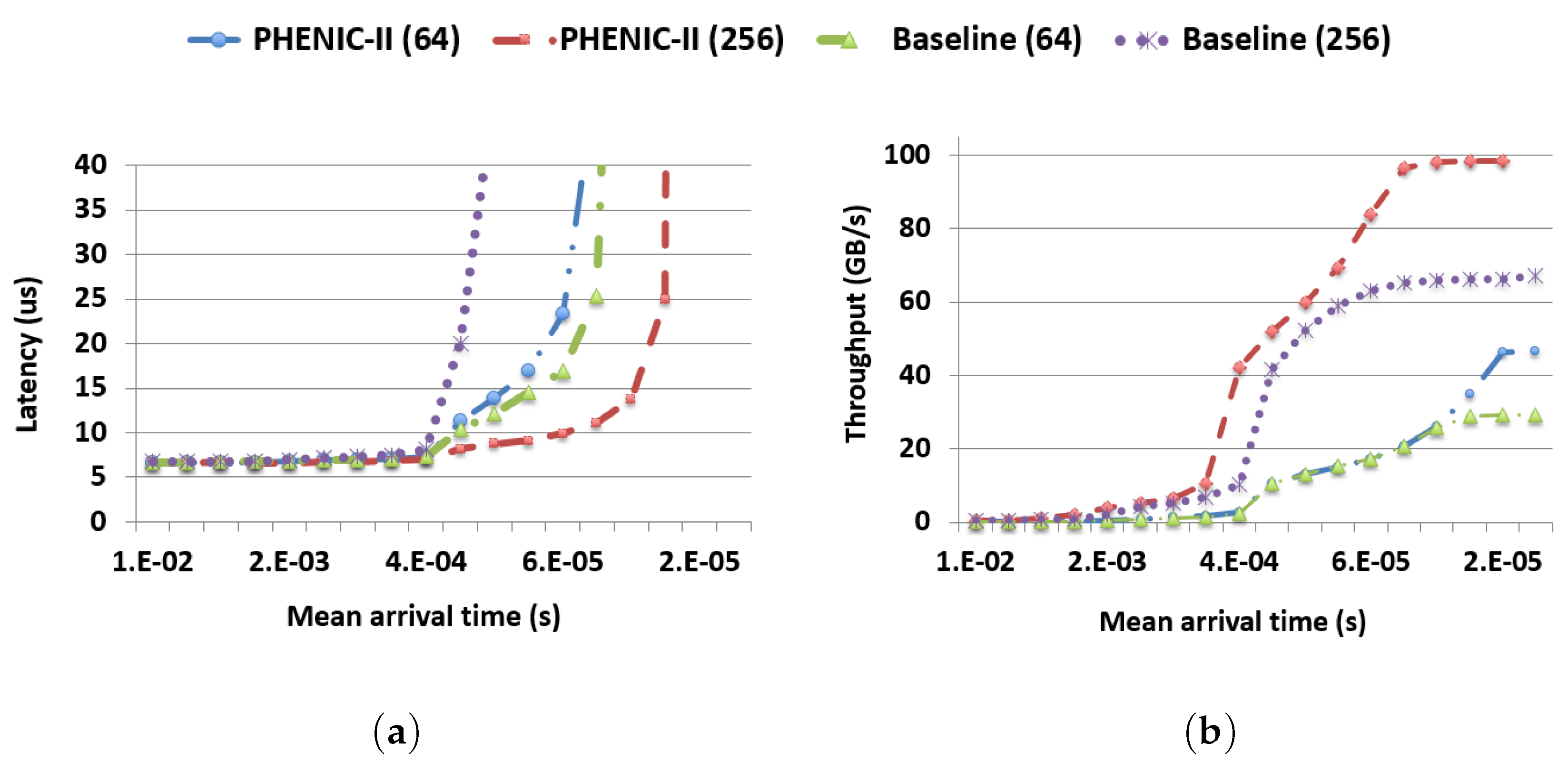
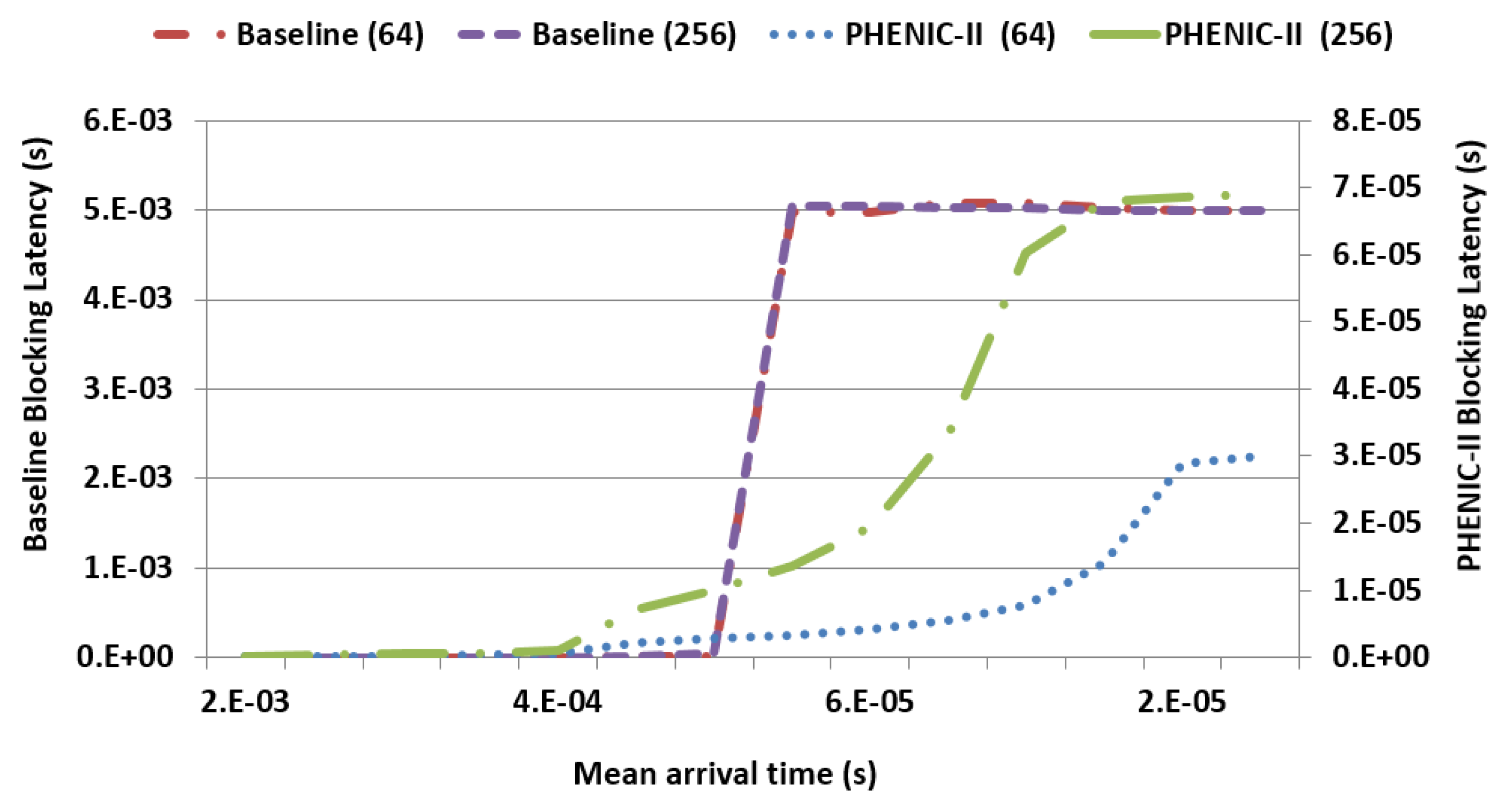
3.2. Evaluation under Synthetic Workloads
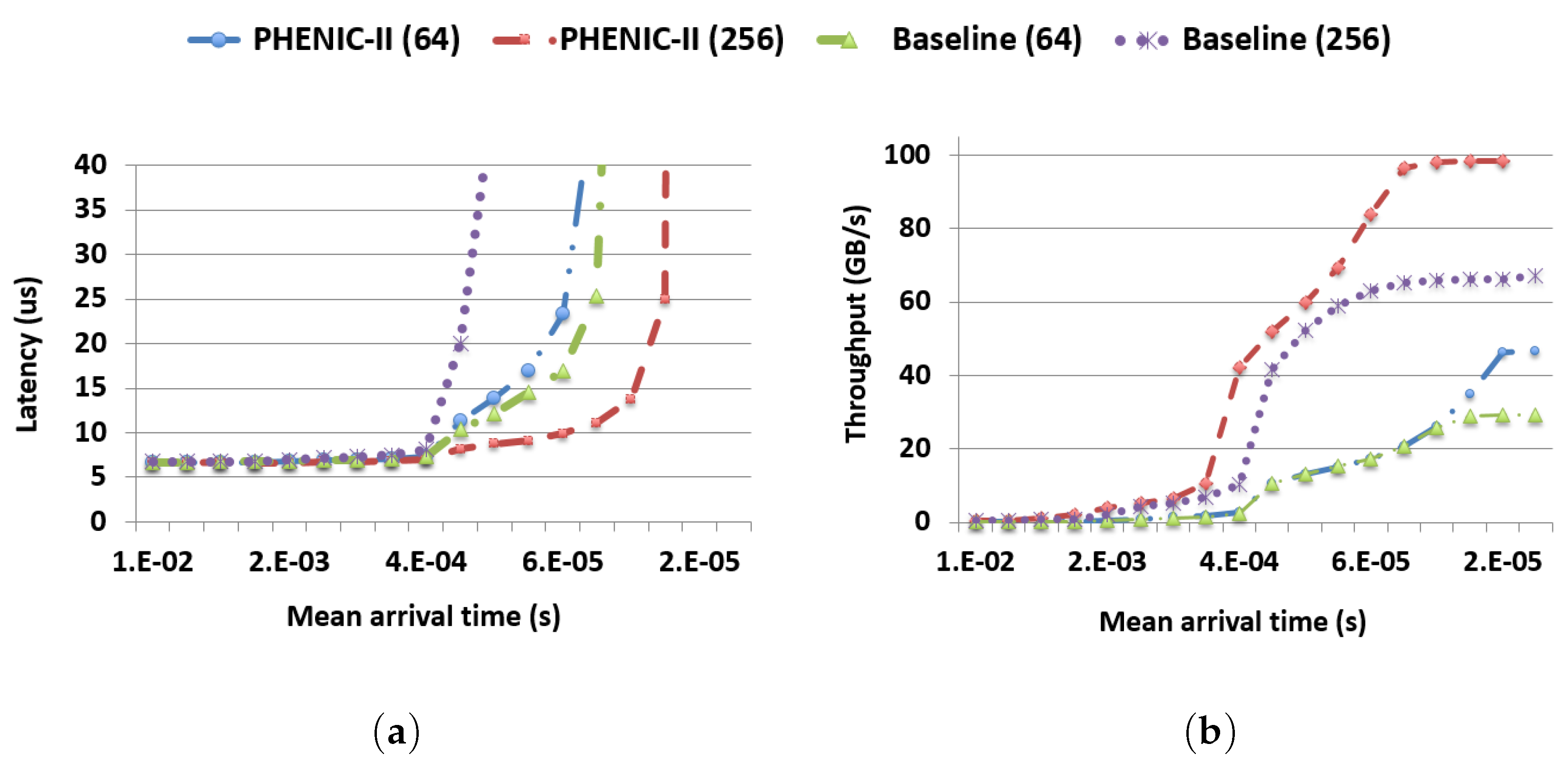
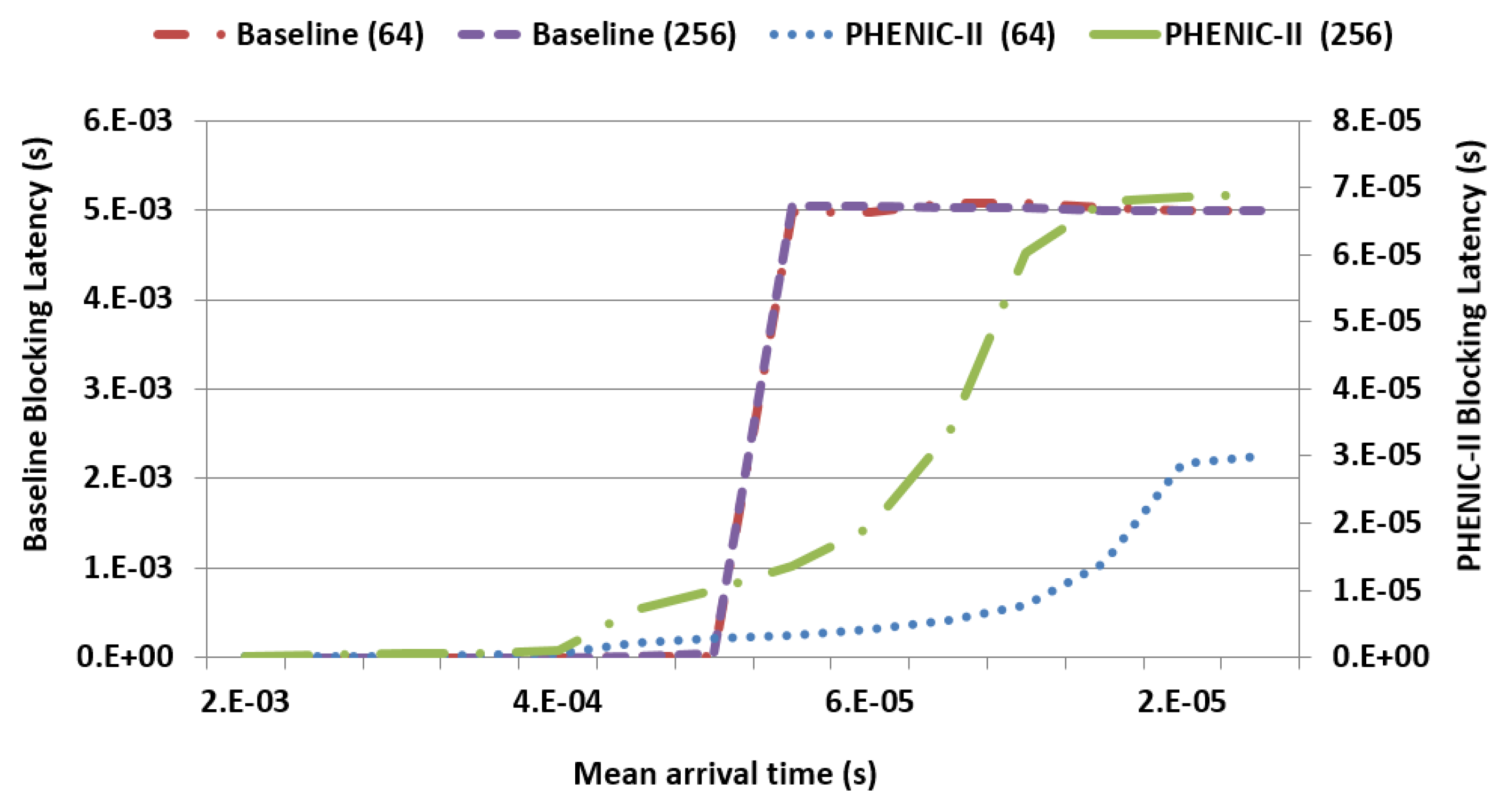
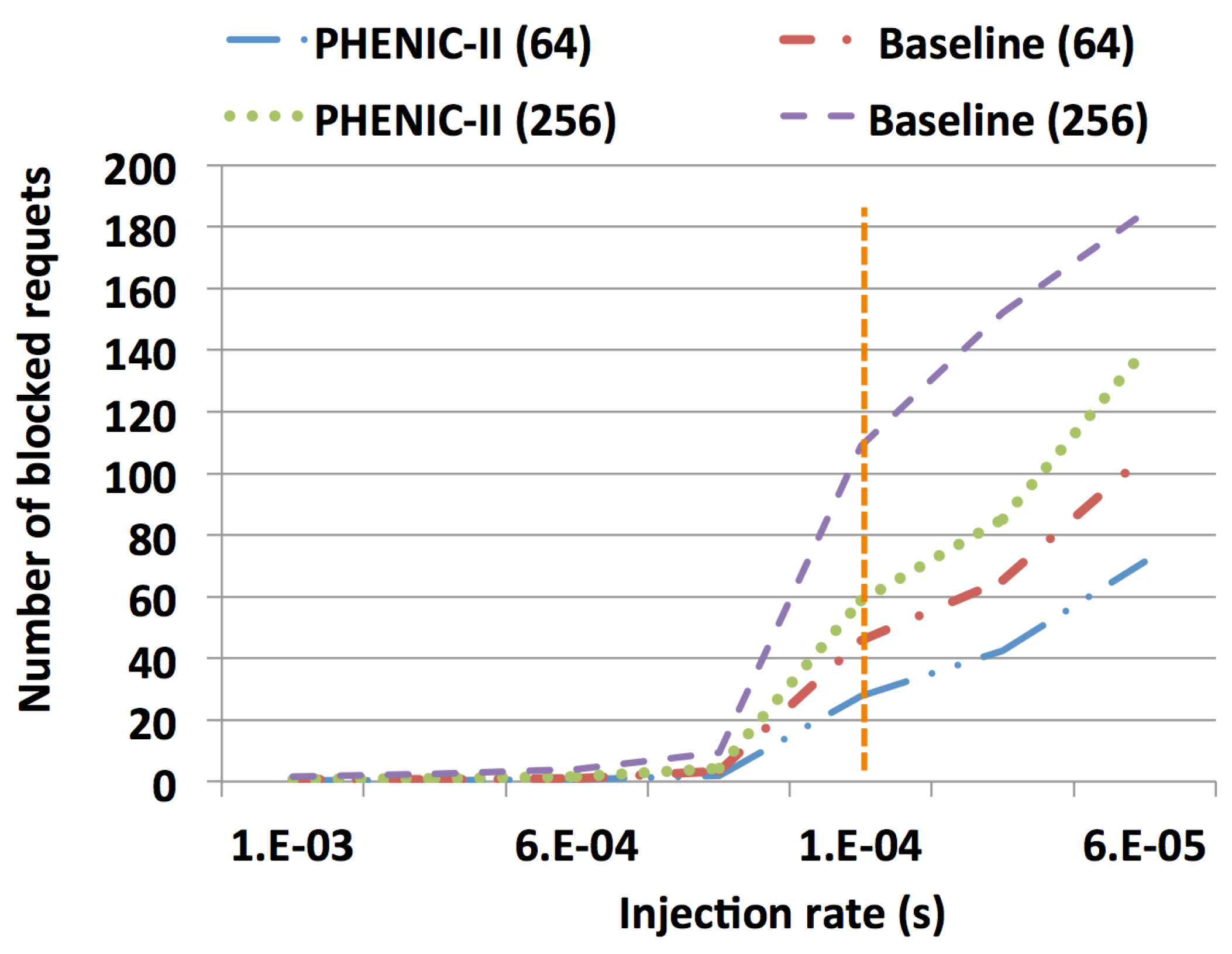
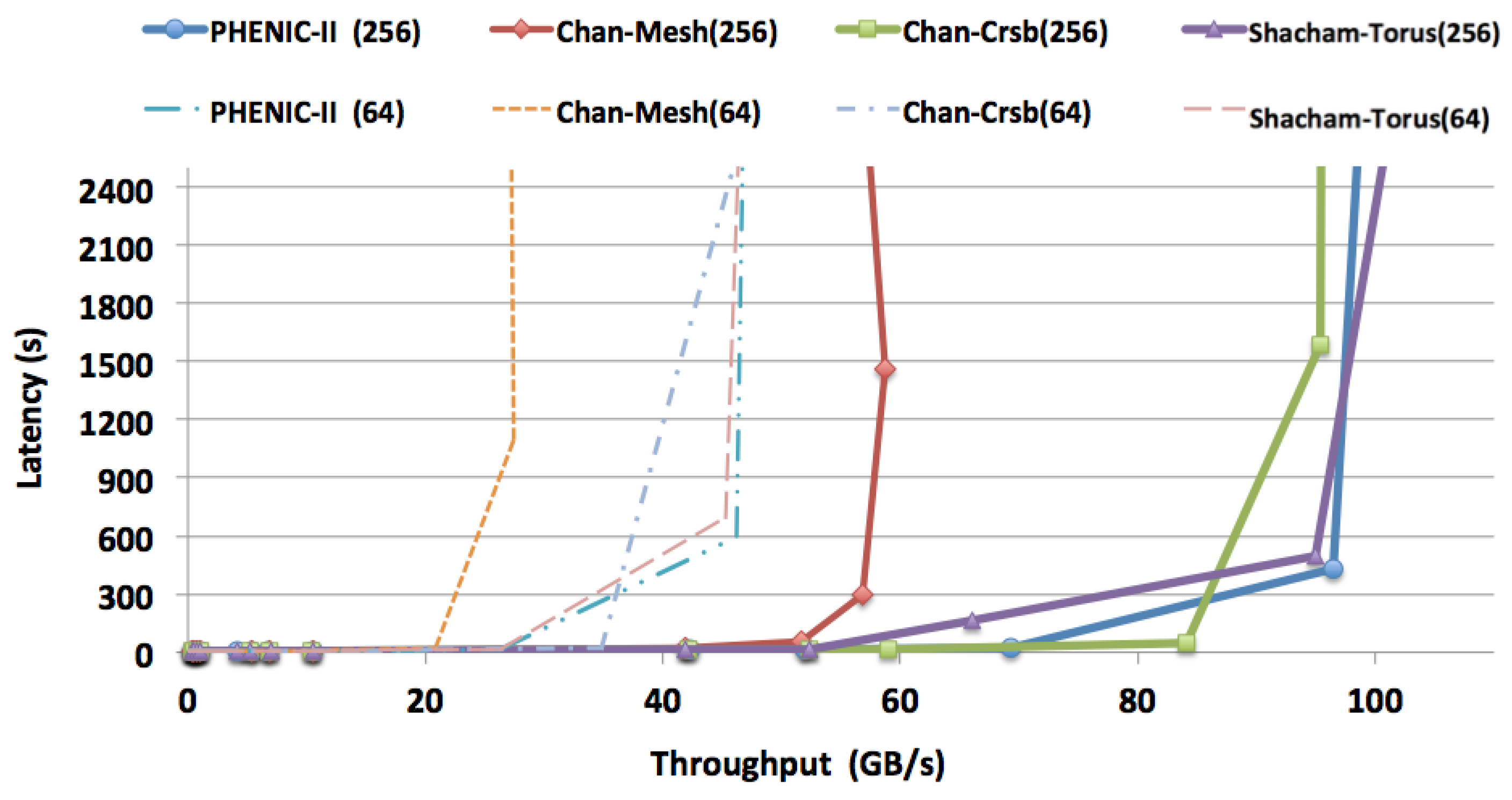
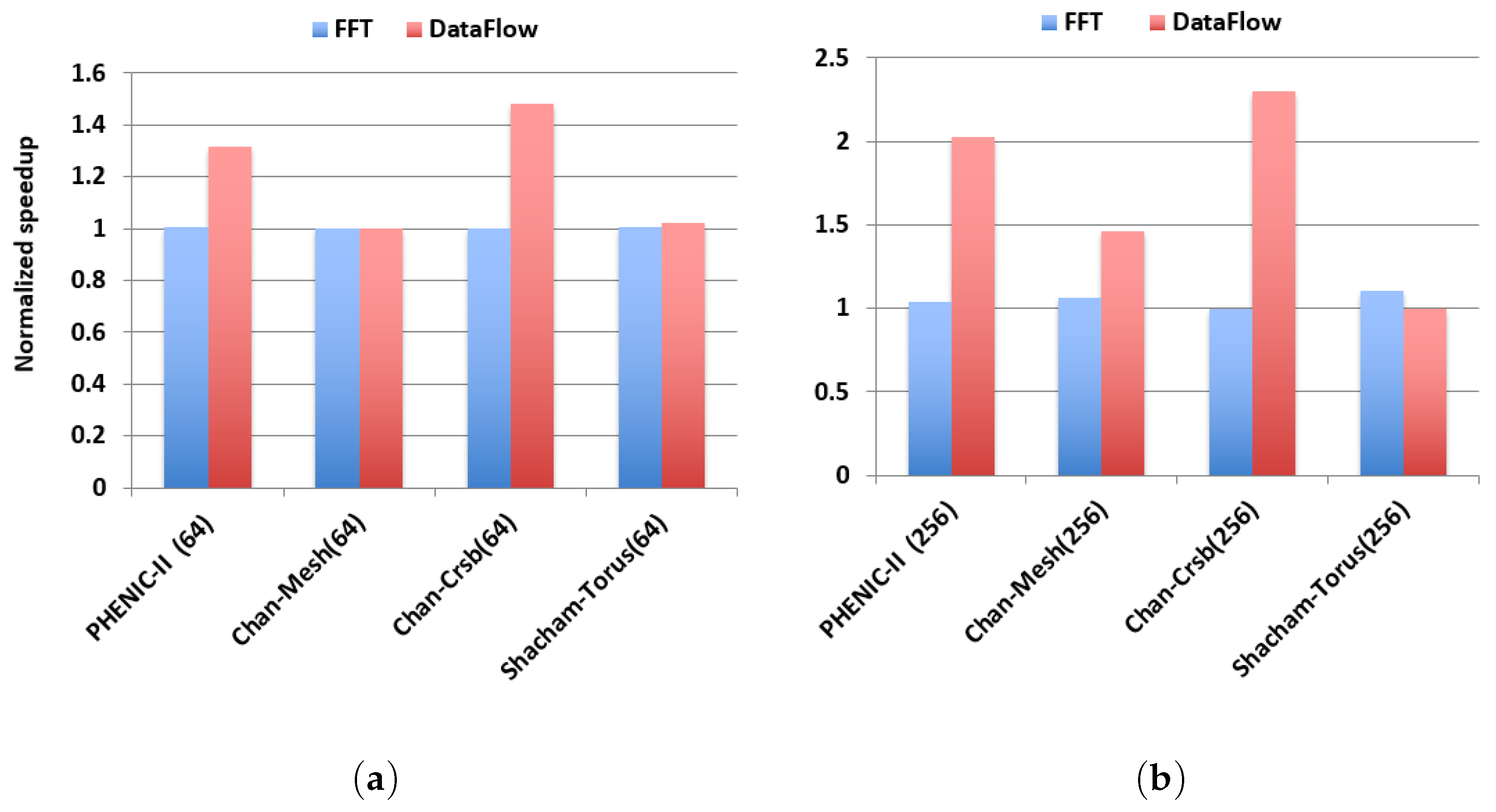
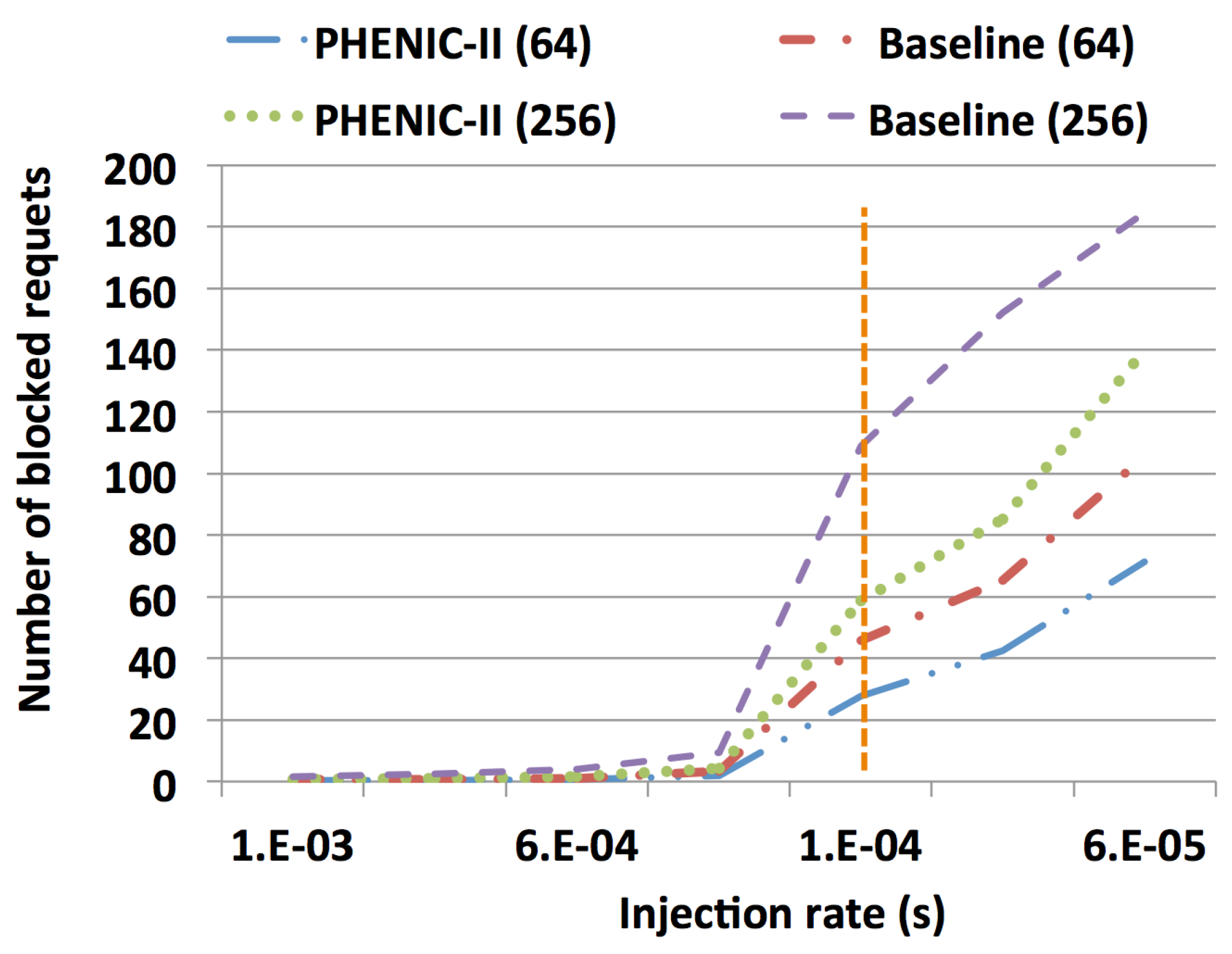
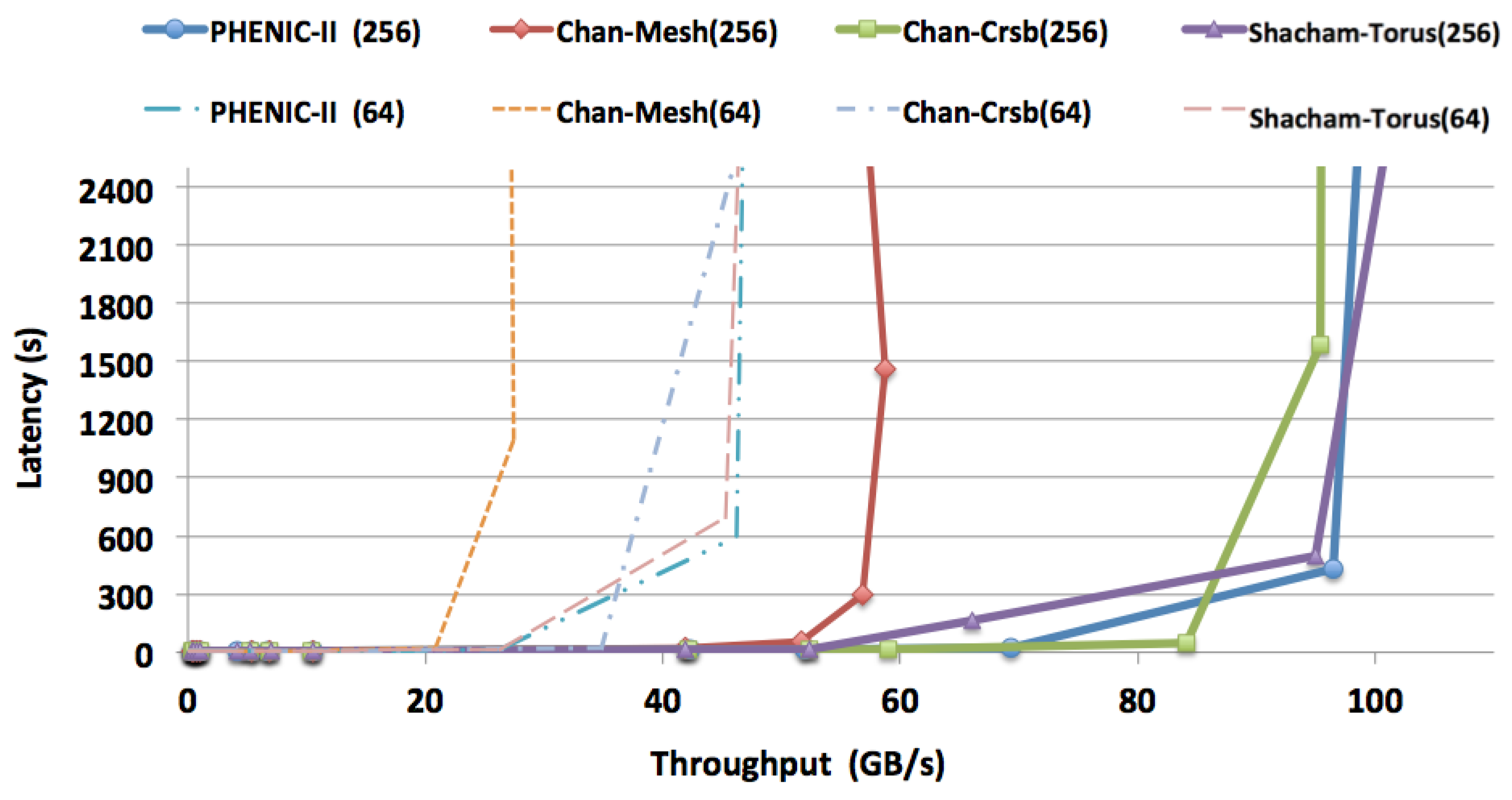
3.2.1. Latency and Throughput Evaluation
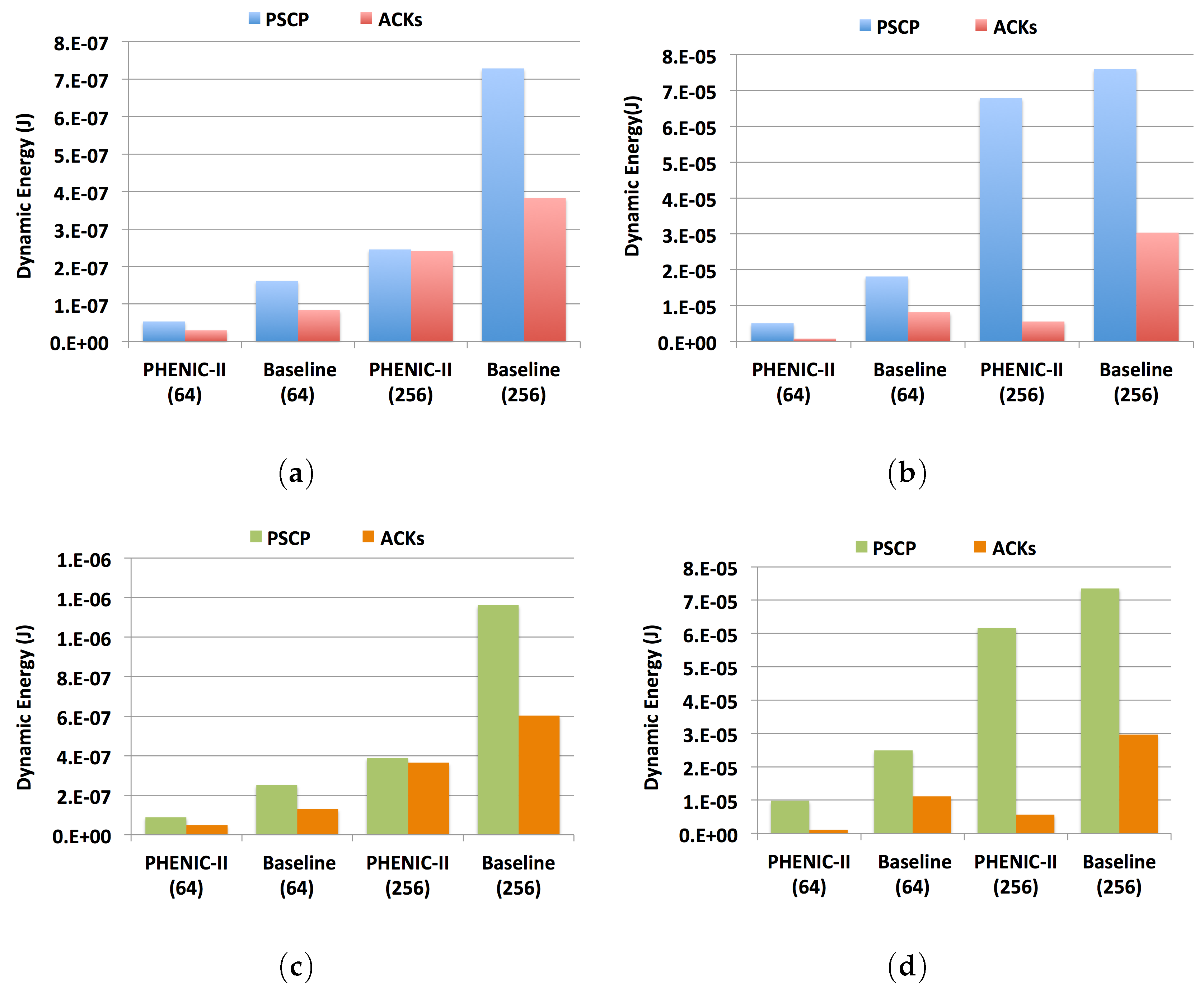
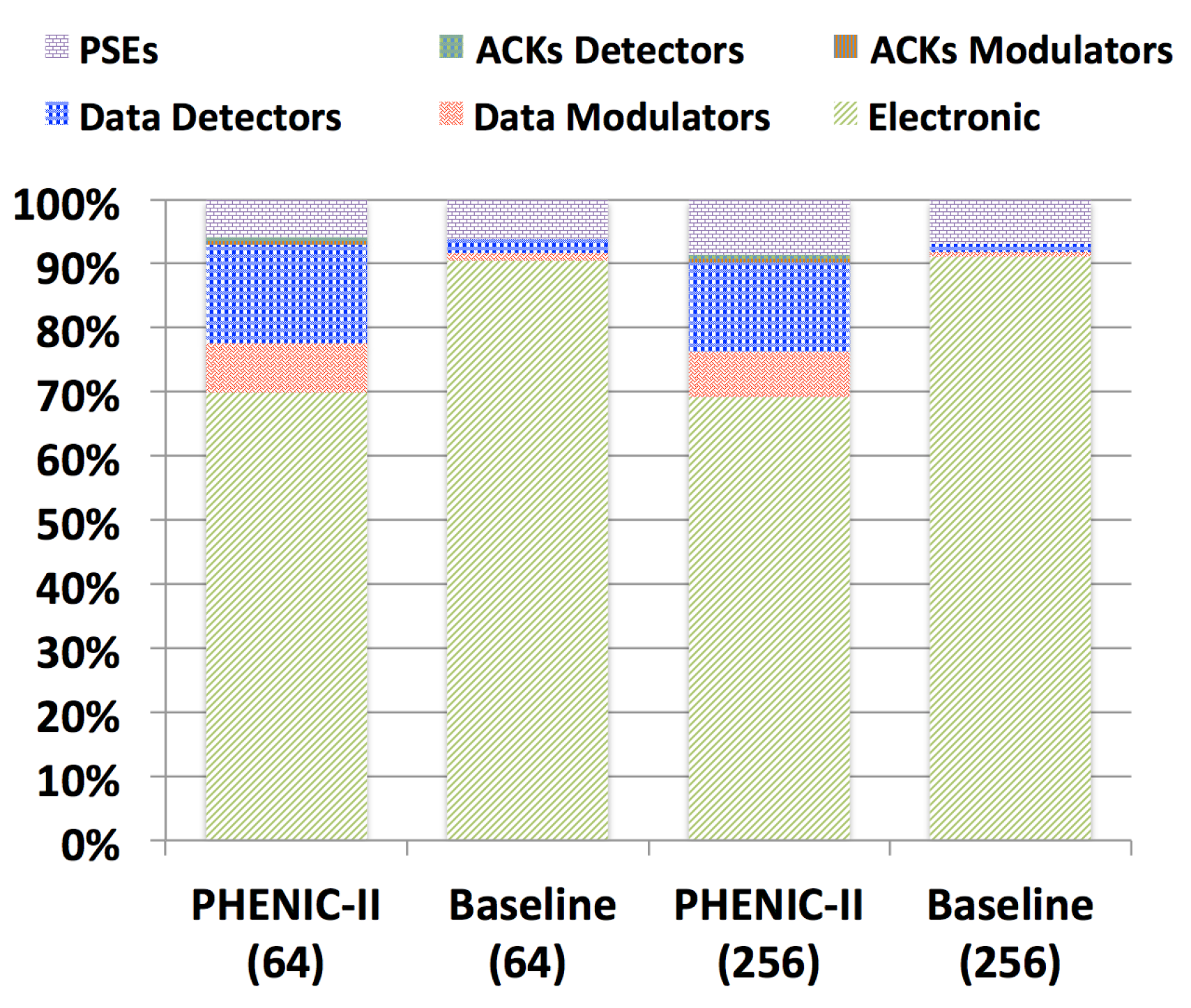
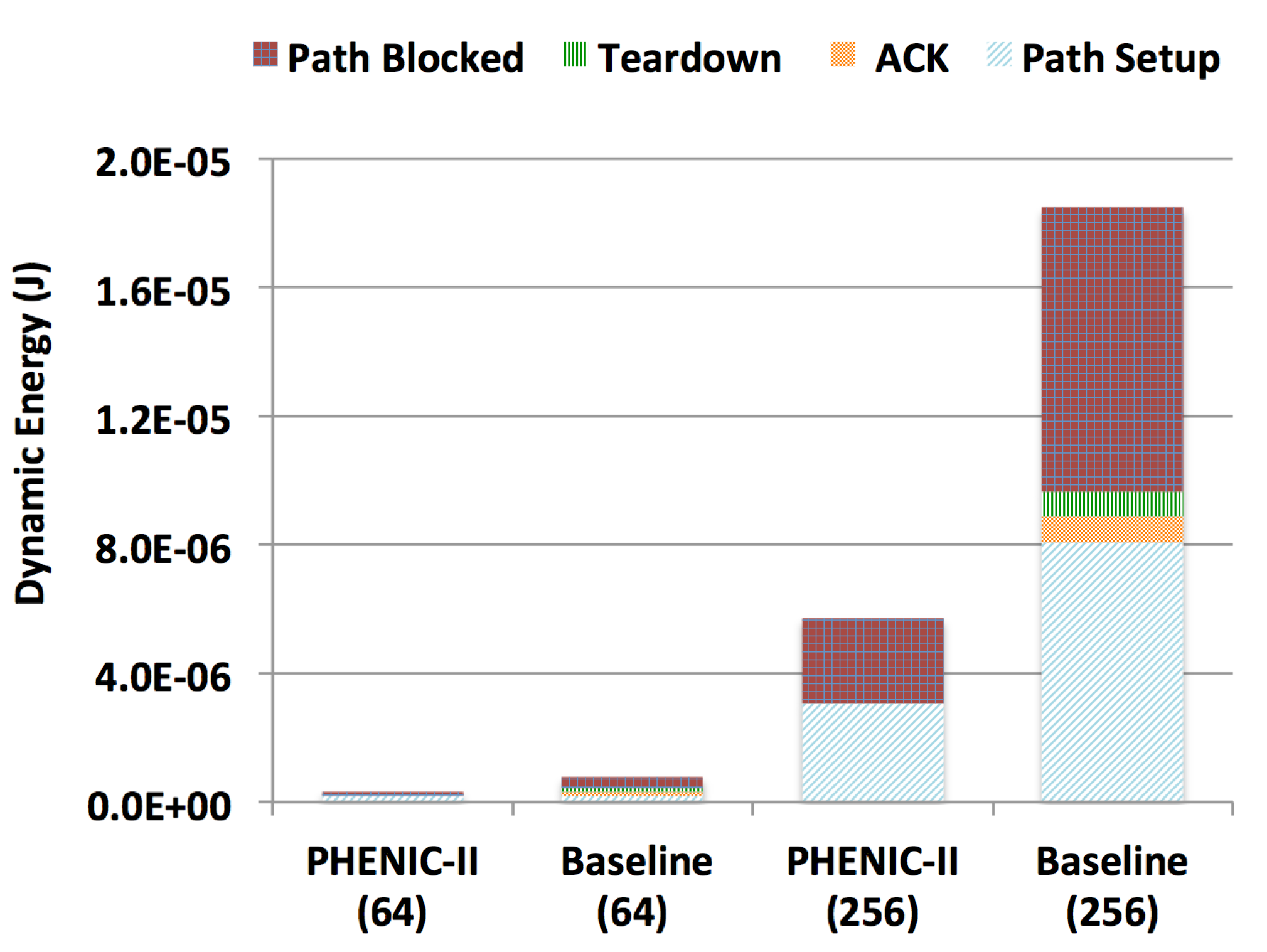
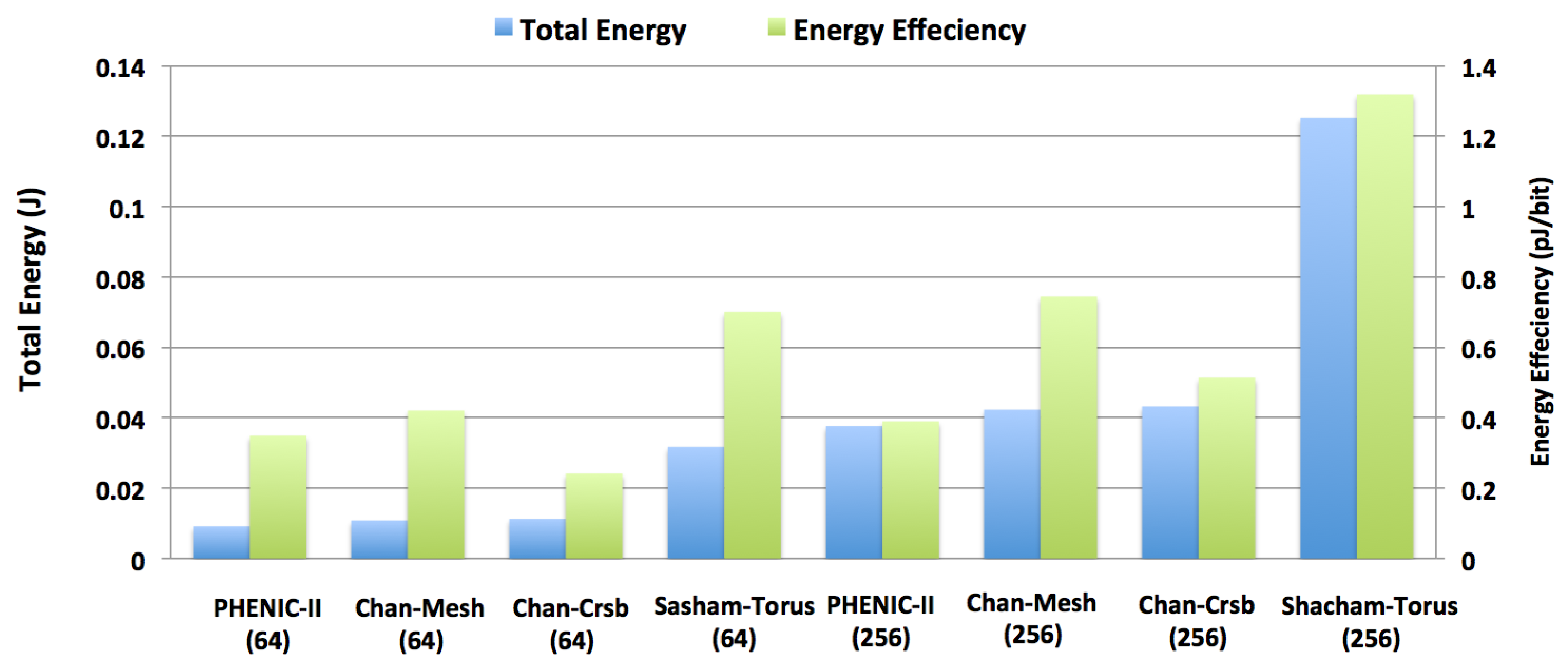
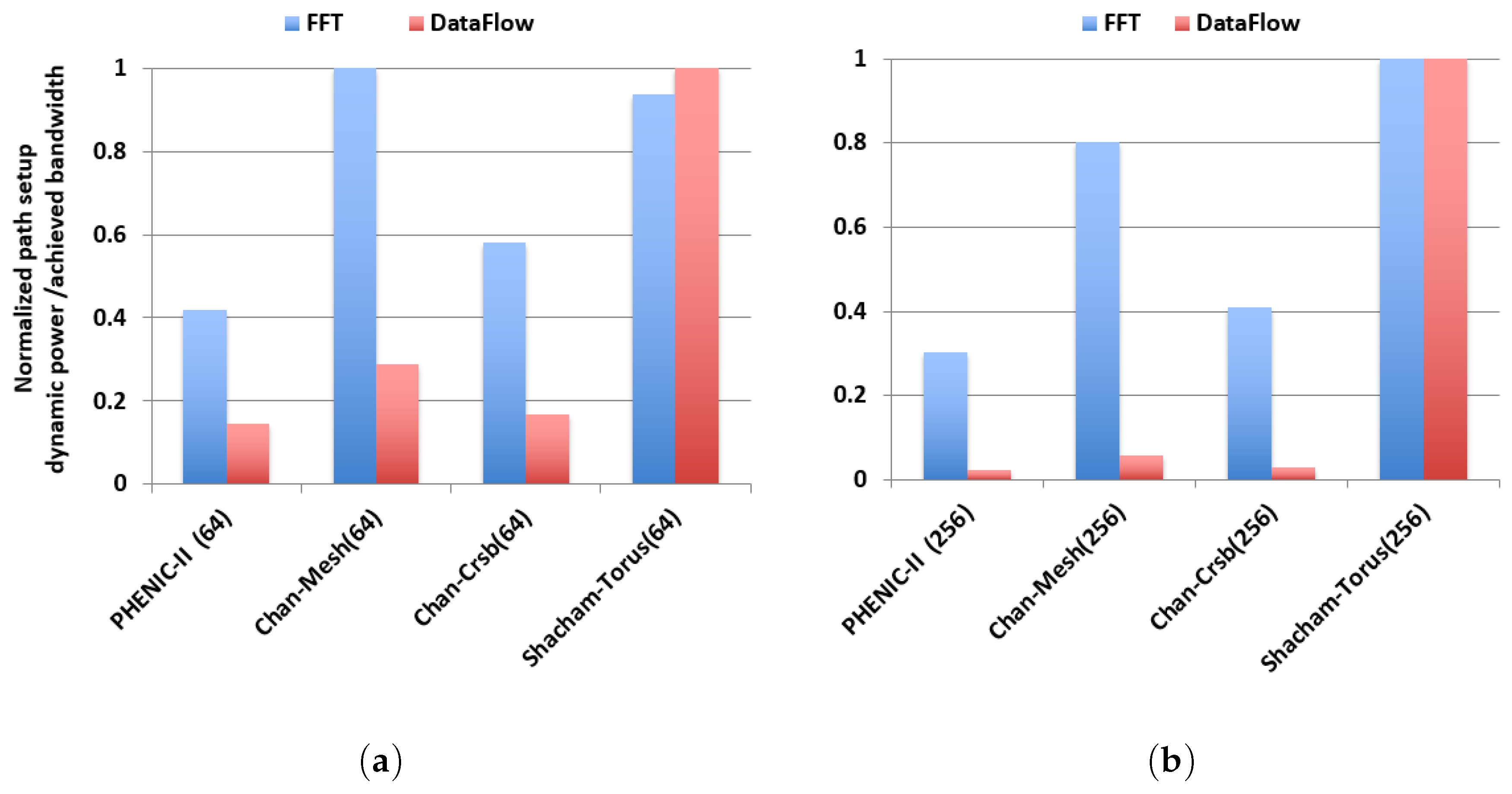
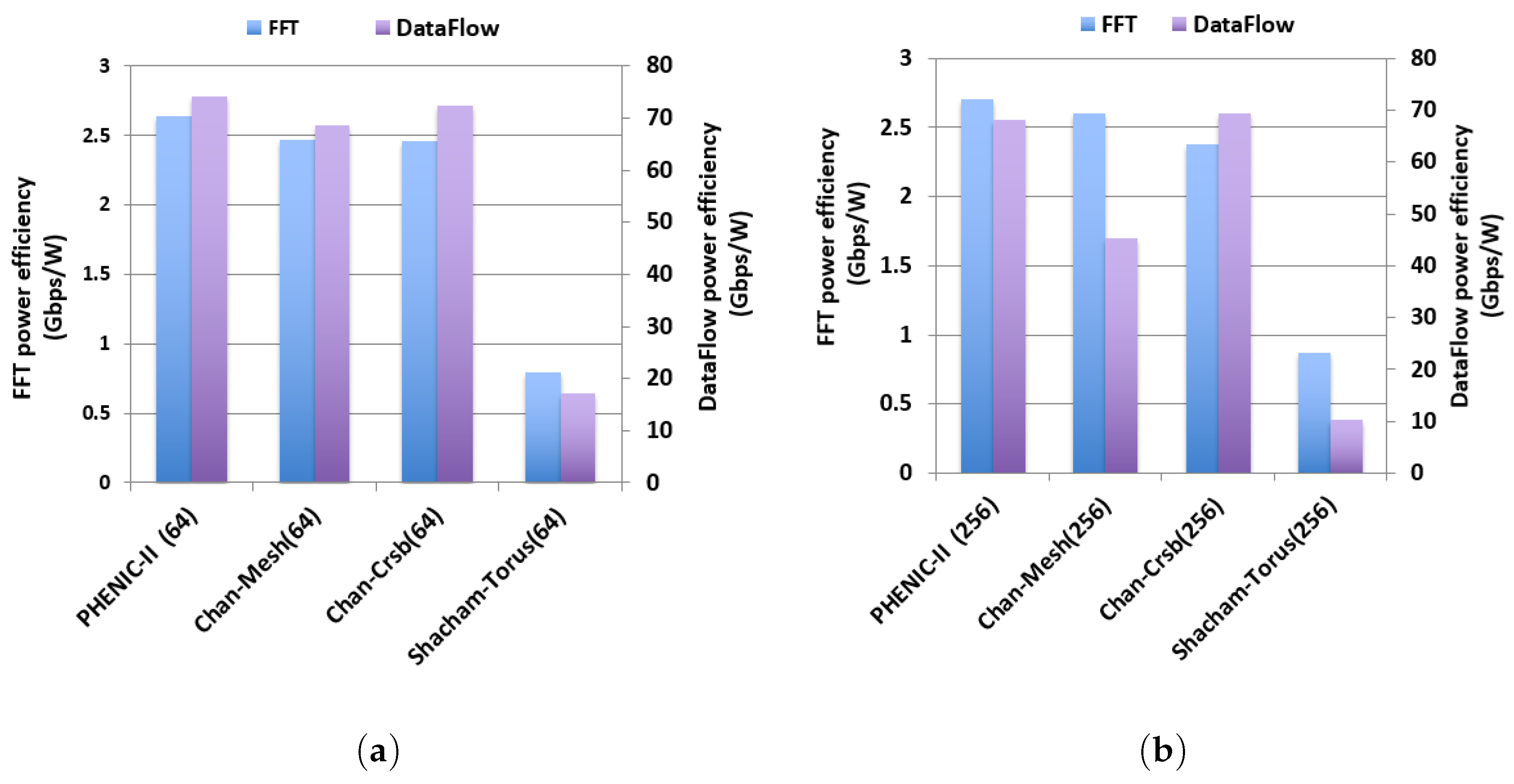
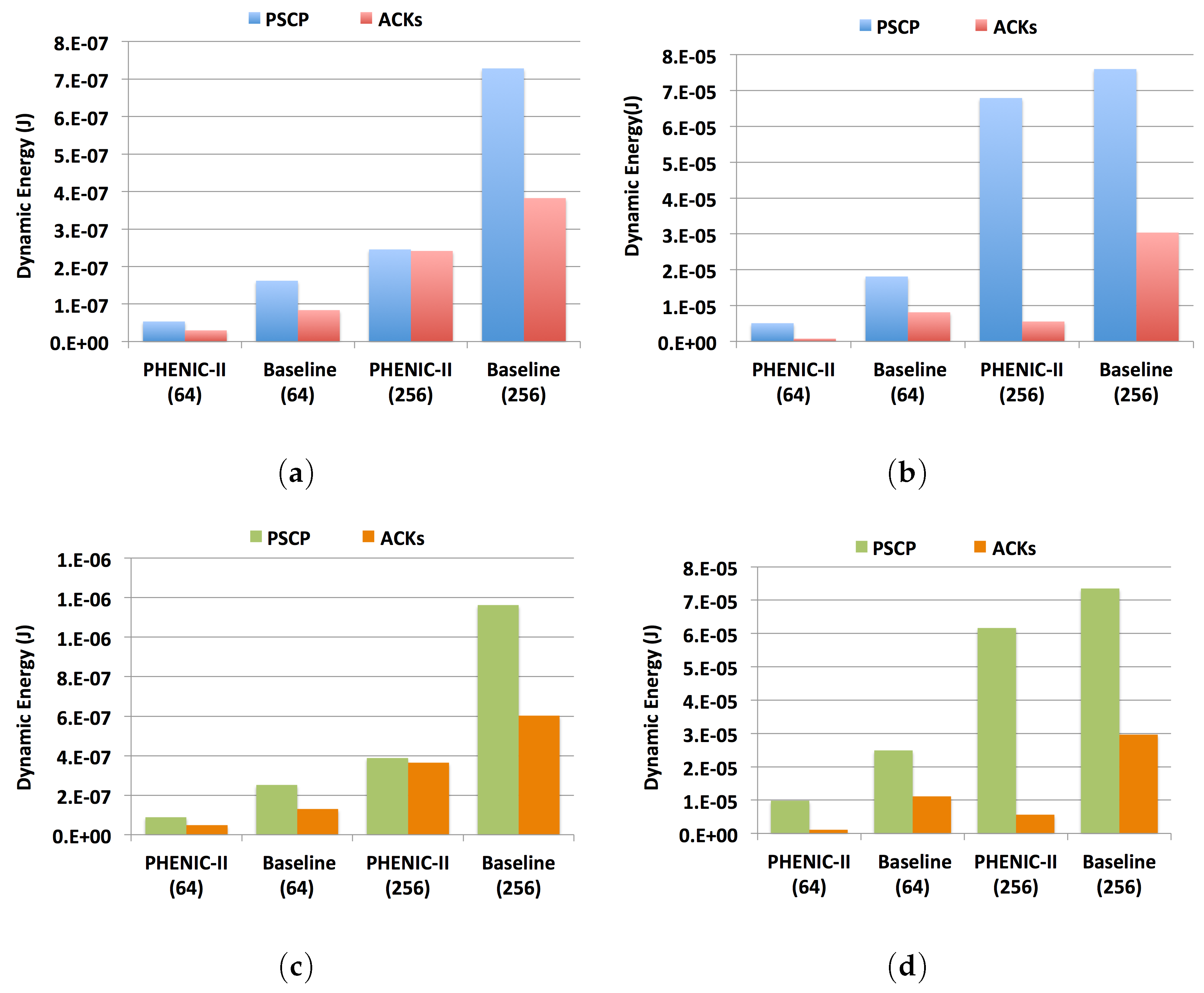
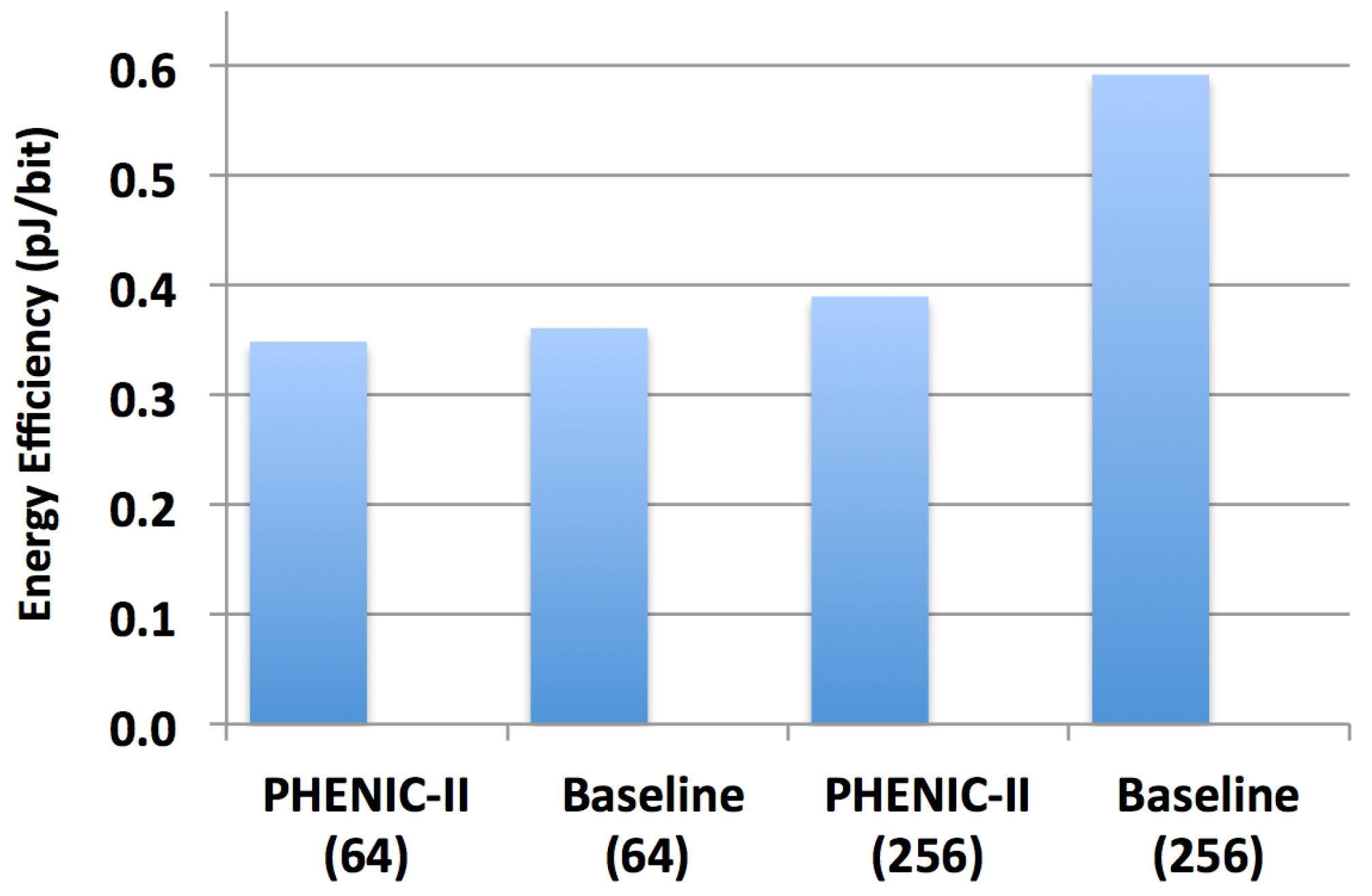
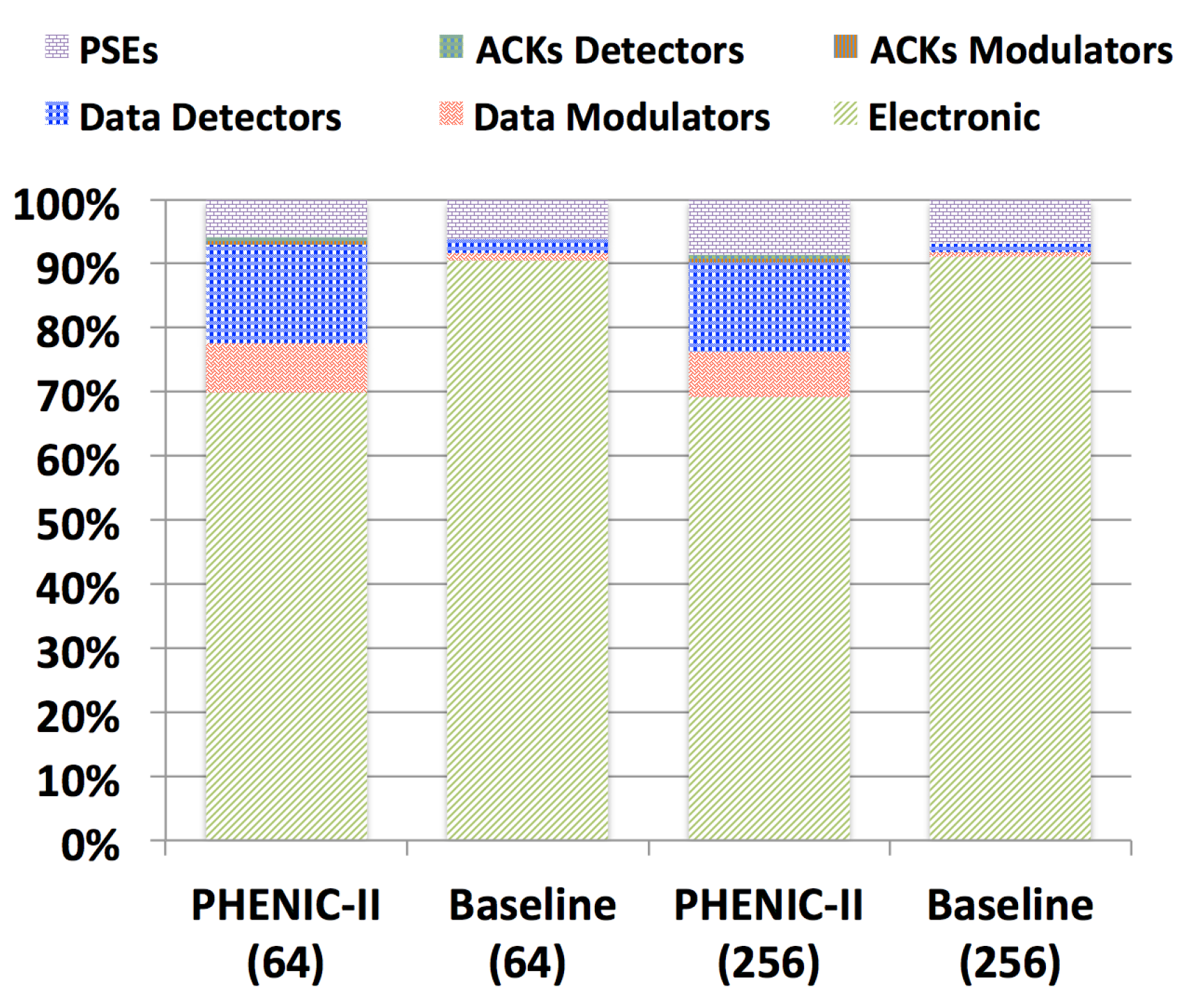
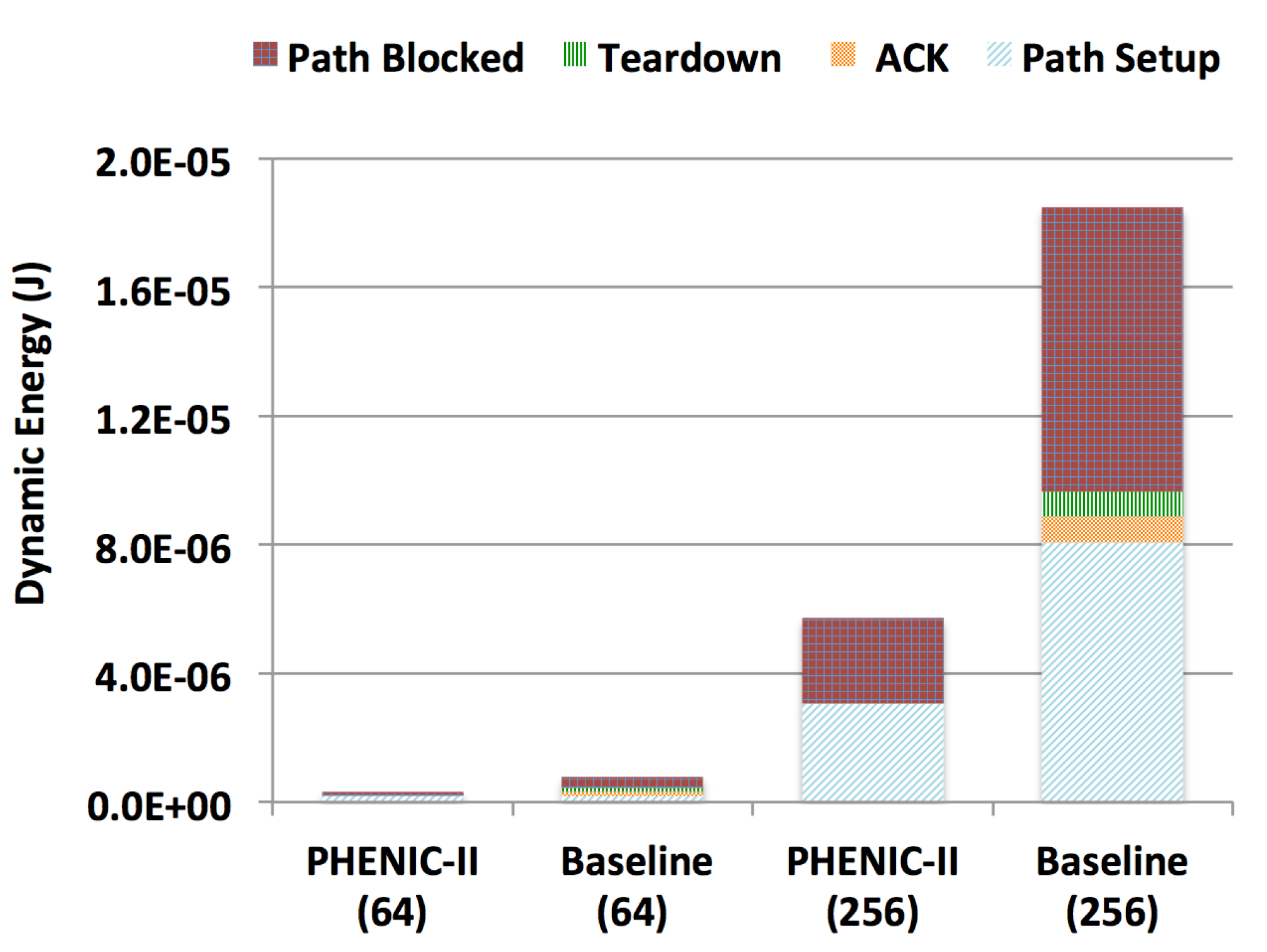
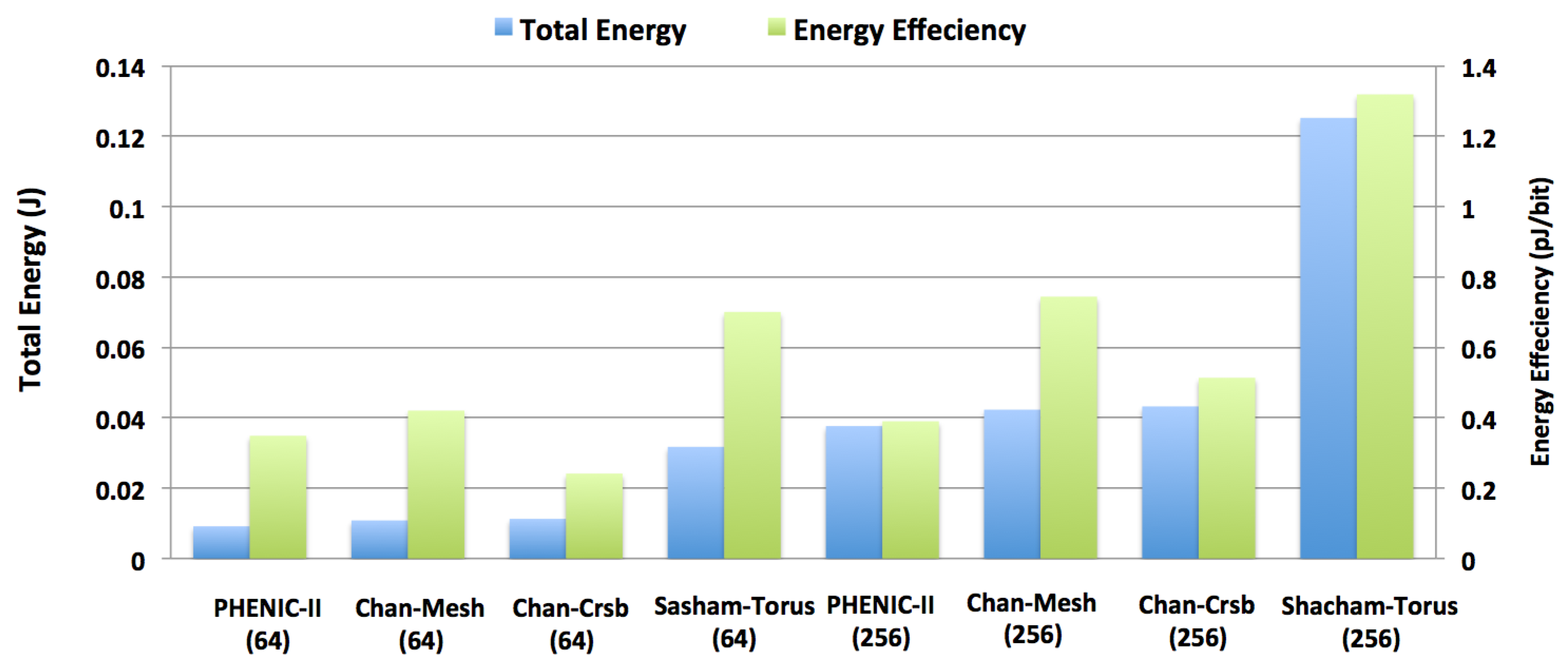
3.2.2. Energy Evaluation
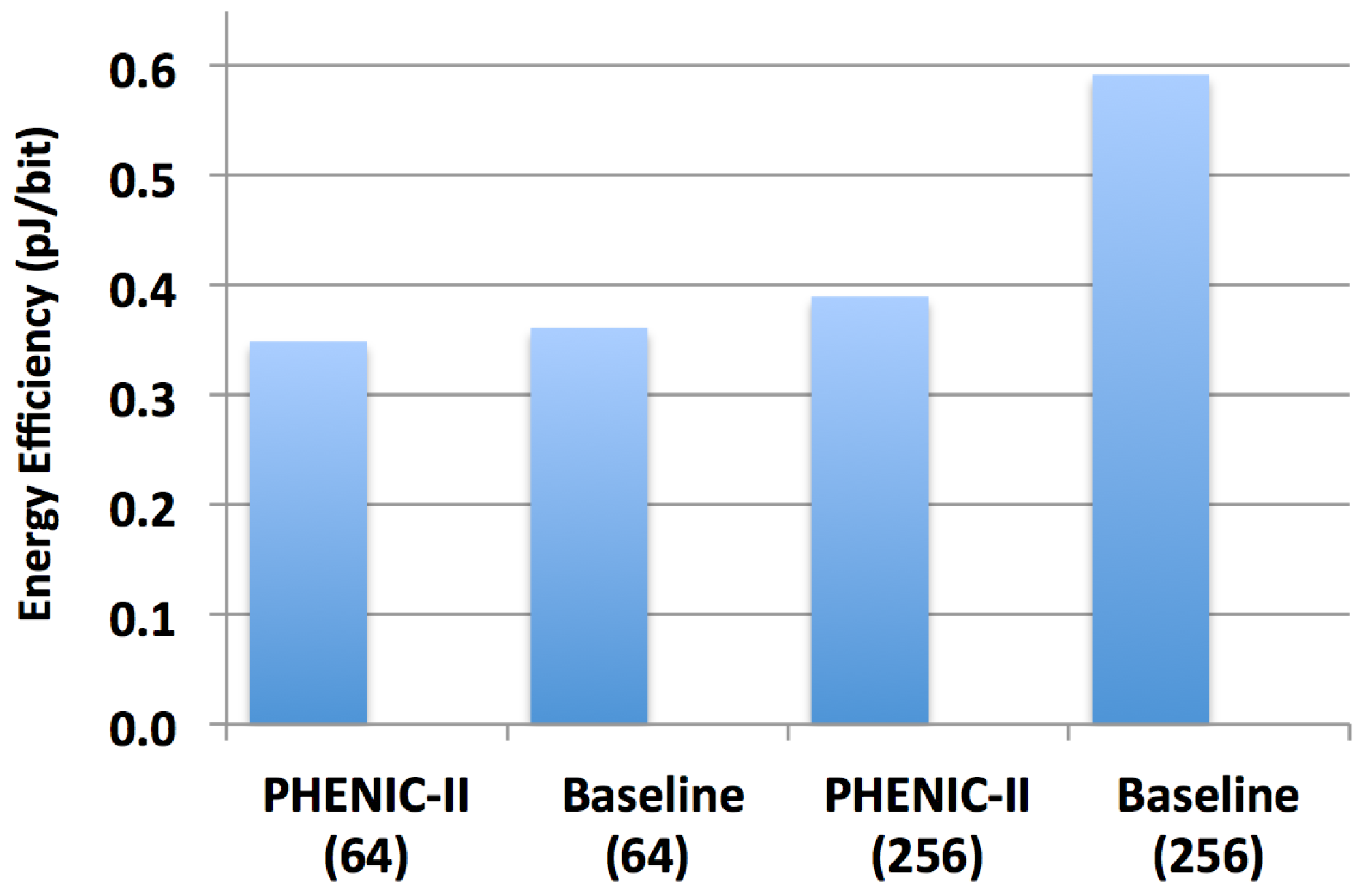
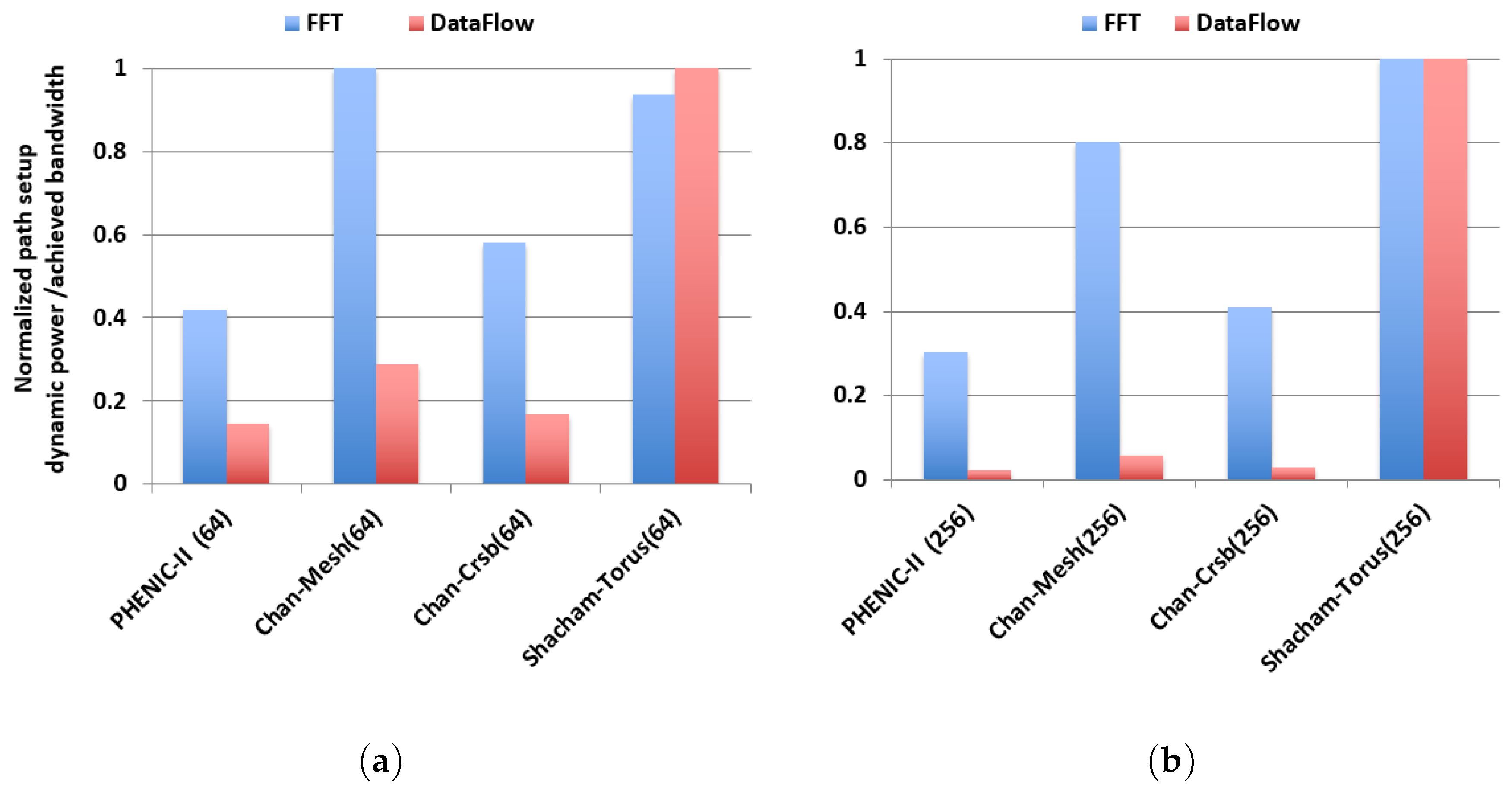
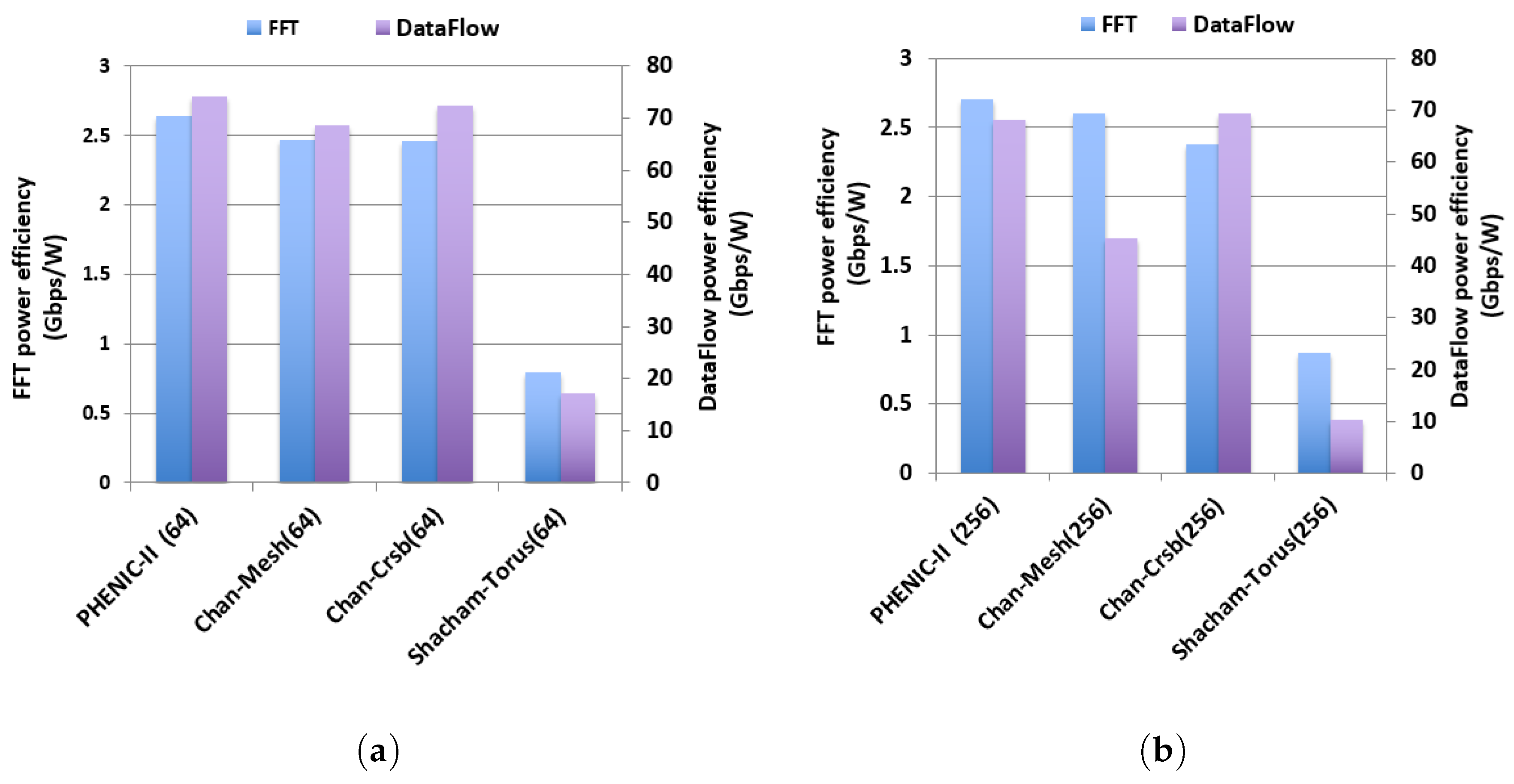
3.2.3. Performance and Energy Efficiency Comparison Results
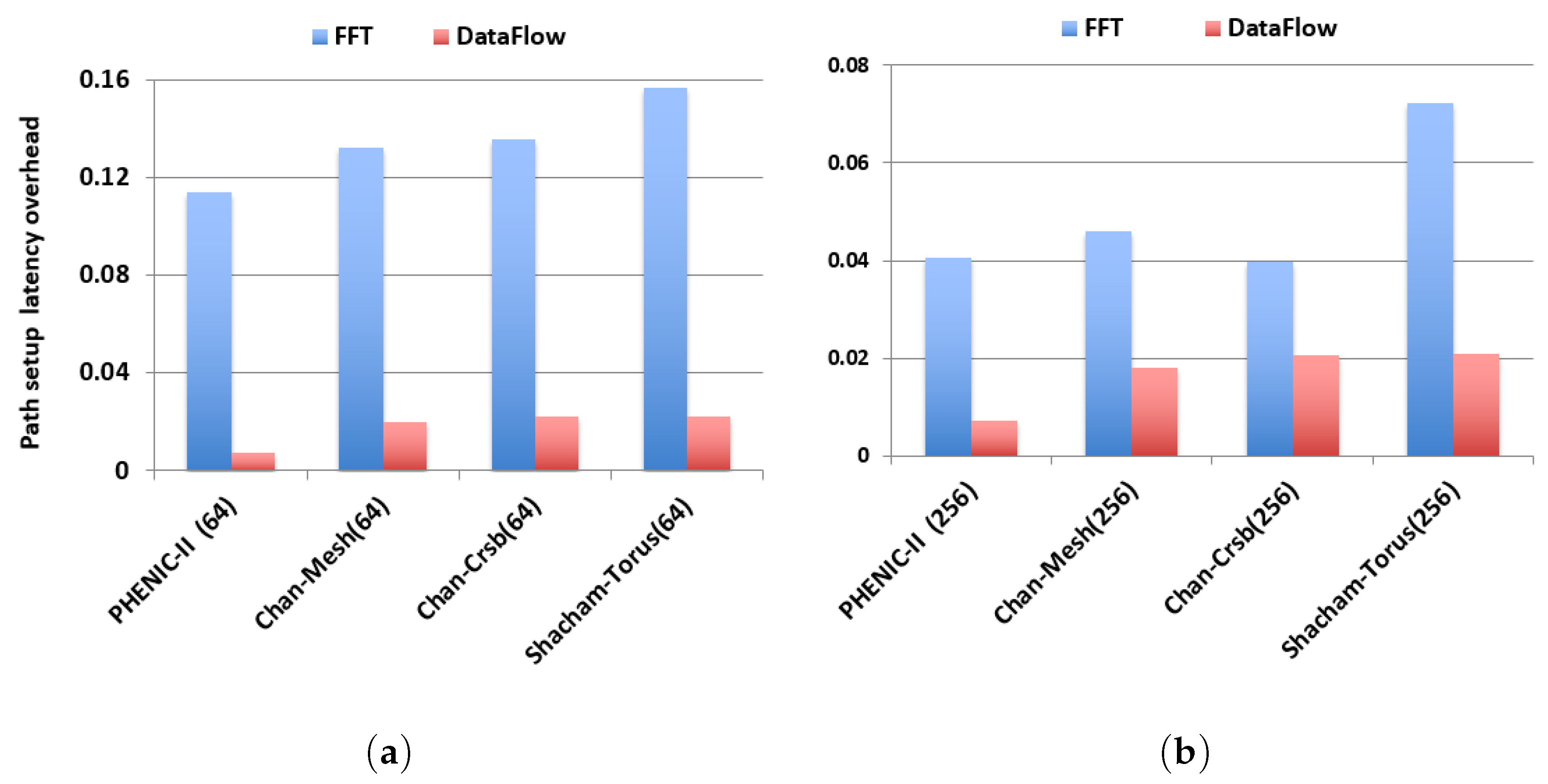
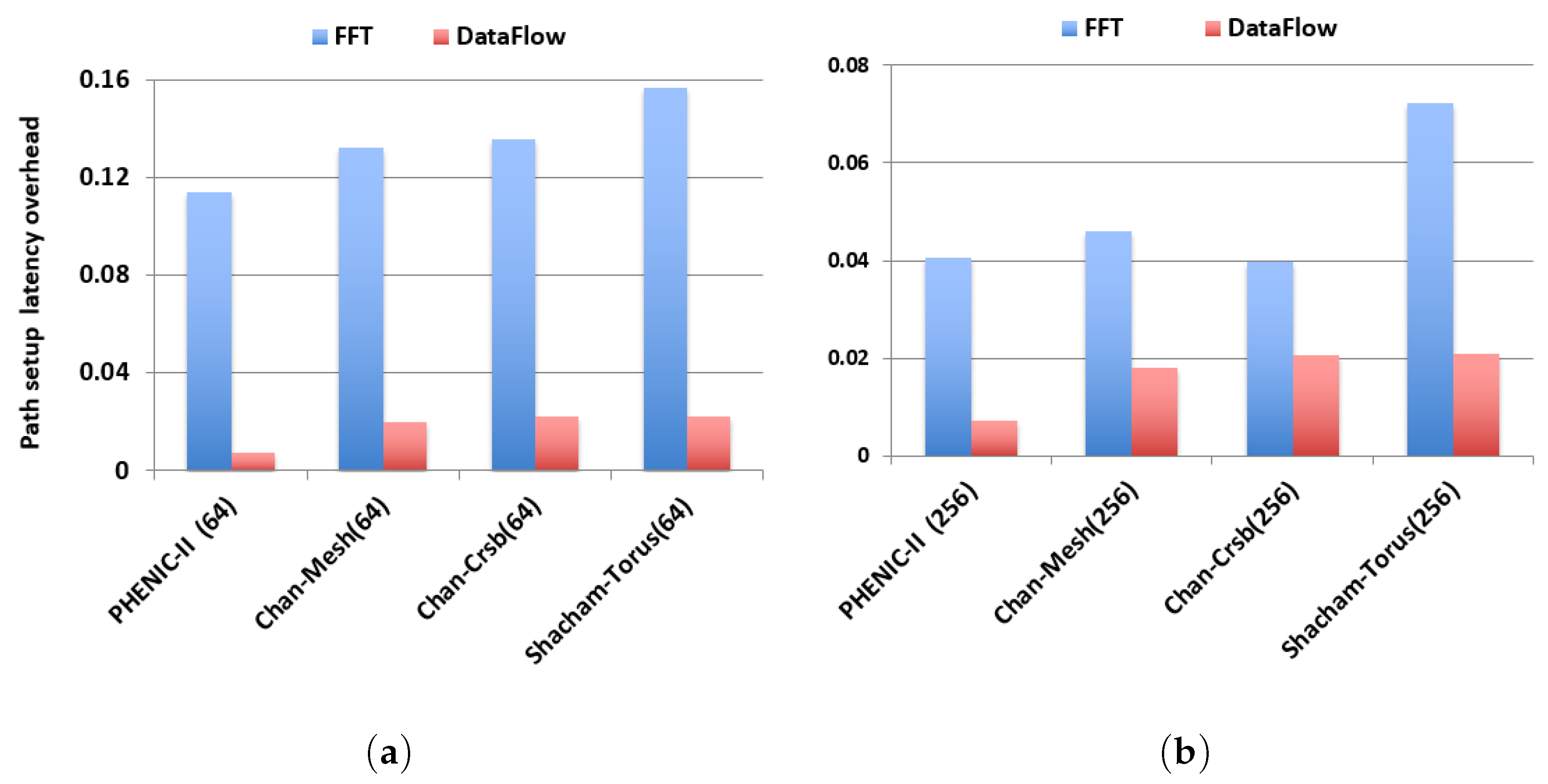
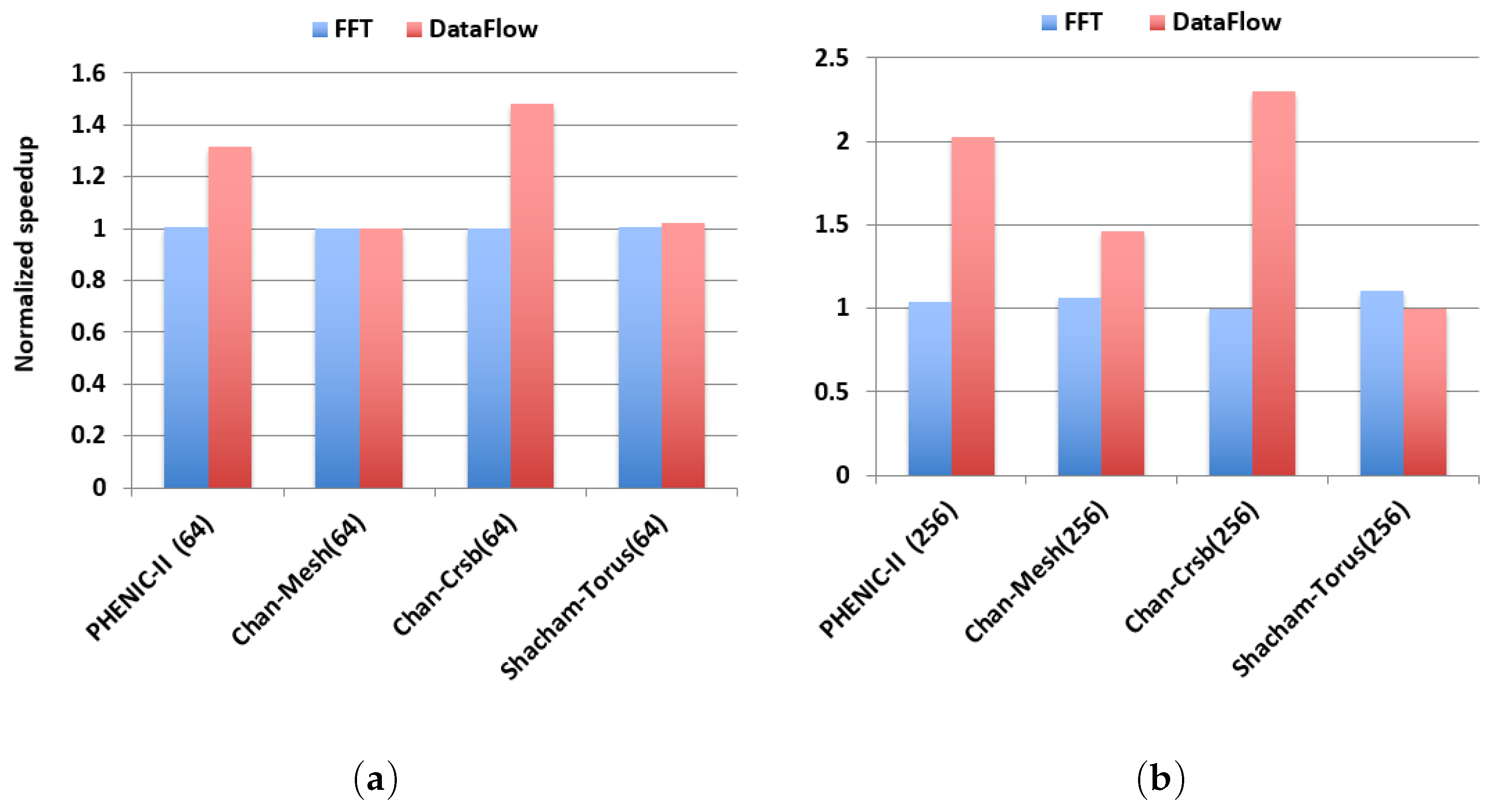
3.3. Evaluation under Realistic Workloads
4. Related Work
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ahmed, A.B.; Abdallah, A.B. PHENIC: Towards Photonic 3D-Network-on-Chip Architecture for High-throughput Many-core Systems-on-Chip. In Proceedings of the 14th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering, Sousse, Tunisia, 20–22 December 2013; pp. 1–9.
- Ahmed, A.B.; Meyer, M.; Okuyama, Y.; Abdallah, A.B. Efficient Router Architecture, Design and Performance Exploration for Many-core Hybrid Photonic Network-on-Chip (2D-PHENIC). In Proceedings of the Information Science and Control Engineering (ICISCE), Shanghai, China, 24–26 April 2015; pp. 202–206.
- Ye, Y.; Xu, J.; Huang, B.; Wu, X.; Zhang, W.; Wang, X.; Nikdast, M.; Wang, Z.; Liu, W.; Wang, Z. 3-D Mesh-Based Optical Network-on-Chip for Multiprocessor System-on-Chip. IEEE Trans. Comput. Aided Design Integr. Circuits Syst. 2013, 32, 584–596. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, X.; Yang, M.; Jiang, J.; Liu, P.; Yang, J. Circuit-switched on-chip photonic interconnection network. In Proceedings of the IEEE Photonics Society 9th International Conference on Group IV Photonics, San Diego, CA, USA, 29–31 August 2012; pp. 282–284.
- Adi, C.A.D.; Matsutani, H.; Koibuchi, M.; Irie, H.; Miyoshi, T.; Yoshinaga, T. An Efficient Path Setup for a Photonic Network-on-Chip. In Proceedings of the First International Conference on Networking and Computing, Higashi-Hiroshima, Japan, 17–19 November 2010; pp. 156–161.
- Ahmed, A.B.; Okuyama, Y.; Abdallah, A.B. Free Routing For Hybrid Photonic Mesh-based Network-On-Chip Systems. In Proceedings of the IEEE 9th International Symposium on Embedded Multicore/Manycore SoCs (MCSoC), Turin, Italy, 23–25 September 2015; pp. 235–242.
- Ahmed, A.B.; Meyer, M.; Okuyama, Y.; Abdallah, A.B. Photonic NoC Based On Non-blocking Photonic Switch and Light-weight Electronic Router. In Proceedings of the IEEE 2015 International Conference on Systems, Man and Cybernetics (SMC), Hong Kong, China, 9–12 October 2015; pp. 56–61.
- Benini, L.; de Micheli, G. Networks on Chips: Technology and Tools; Morgan Kauffmann: San Mateo, CA, USA, 2006. [Google Scholar]
- Mori, K.; Esch, A.; Abdallah, A.B.; Kuroda, K. Advanced design issues for OASIS network-on-chip architecture. In Proceedings of the IEEE 5th International Conference on Broadband, Wireless Computing, Communication and Applications, Fukuoka, Japan, 4–6 November 2010; pp. 74–79.
- Abdallah, A.B.; Sowa, M. Basic Network-on-Chip Interconnection for Future Gigascale MCSoCs Applications. In Proceedings of the Symposium on Science, Society, and Technology, Sousse, Tunisia, 4–6 December 2006.
- Ahmed, A.B.; Abdallah, A.B. LA-XYZ: Low Latency, High Throughput Look-Ahead Routing Algorithm for 3D Network-on-Chip (3D-NoC) Architecture. In Proceedings of the IEEE 6th International Symposium on Embedded Multicore SoCs (MCSoC-12), Aizu-Wakamatsu, Japan, 20–22 September 2012; pp. 167–174.
- Ahmed, A.B.; Abdallah, A.B. Low-overhead Routing Algorithm for 3D Network-on-Chip. In Proceedings of the Third International Conference on Networking and Computing (ICNC’12), Okinawa, Japan, 5–7 December 2012; pp. 23–32.
- Ahmed, A.B.; Ouchi, T.; Miura, S.; Abdallah, A.B. Run-Time Monitoring Mechanism for Efficient Design of Application-specific NoC Architectures in Multi/Manycore Era. In Proceedings of the 6th International Workshop on Engineering Parallel and Multicore Systems (ePaMuS2013’), Taichung, Taiwan, 3–5 July 2013.
- Ahmed, A.B.; Abdallah, A.B. Deadlock-Recovery Support for Fault-tolerant Routing Algorithms in 3D-NoC Architectures. In Proceedings of the 7th International Symposium on Embedded Multicore/Many-Core SoCs (MCSoC-13), Tokyo, Japan, 26–28 September 2013.
- Ahmed, A.B.; Abdallah, A.B. Graceful Deadlock-Free Fault-Tolerant Routing Algorithm for 3D Network-on-Chip Architectures. J. Parall. Distrib. Comput. 2014, 74, 2229–2240. [Google Scholar] [CrossRef]
- Ahmed, A.B. High-performance, Scalable Photonics On-chip Network for Many-core Systems-on-Chip. Ph.D. Thesis, Graduate School of Computer Science and Engineering, University of Aizu, Aizu, Japan, 2016. [Google Scholar]
- Chan, J.; Hendry, G.; Bergman, K.; Carloni, L.P. Physical-layer modeling and system-level design of chip-scale photonic interconnection networks. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2011, 30, 1507–1520. [Google Scholar] [CrossRef]
- Shacham, A.; Bergman, K.; Carloni, L.P. Photonic Networks-on-Chip for Future Generations of Chip Multiprocessors. IEEE Trans. Comput. 2008, 57, 1246–1260. [Google Scholar] [CrossRef]
- Petracca, M.; Lee, B.; Bergman, K.; Carloni, L. Design exploration of optical interconnection networks for chip multiprocessors. In Proceedings of the 16th IEEE Symposium High Performance Interconnects, Stanford, CA, USA, 26–28 August 2008; pp. 31–40.
- Wang, J.; Han, G.; Li, B.; Lu, J.; Dou, W. CPNoC: An Energy-Efficient Photonic Network-on-Chip. In Proceedings of the 27th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Barcelona, Spain, 25–28 March 2013; pp. 1571–1576.
- Shacham, A.; Bergman, K.; Carloni, L.P. On the design of a photonic network-on-chip. In Proceedings of the 1st International Symposium Networks-on-Chip, Princeton, NJ, USA, 7–9 May 2007; pp. 53–64.
- Parsricha, S.; Dutt, N. Trends in Emerging On-Chip Interconnect Technologies. IPSJ Trans. Syst. LSI Design Methodol. 2008, 1, 2–17. [Google Scholar] [CrossRef]
- Almeida, V.R.; Barrios, C.A.; Panepucci, R.R.; Lipson, M. All-optical switching on a silicon chip. Opt. Lett. 2004, 29, 2867–2869. [Google Scholar] [CrossRef] [PubMed]
- Briere, M.; Drouard, E.; Mieyeville, F.; Navarro, D.; O’Connor, I.; Gaffiot, F. Heterogeneous modelling of an optical network-on-chip with SystemC. In Proceedings of the 16th IEEE International Workshop on Rapid System Prototyping, Montreal, QC, Canada, 8–10 June 2005; pp. 10–16.
- Chan, J.; Hendry, G.; Biberman, A.; Bergman, K.; Carloni, L.P. PhoenixSim: A Simulator for Physical-Layer Analysis of Chip-Scale Photonic Interconnection Networks. In Proceedings of the Design, Automation and Test in Europe (DATE), Dresden, Germany, 8–12 March 2010.
- Abdallah, A.B.; Yoshinaga, T.; Sowa, M. Mathematical Model for Multiobjective Synthesis of NoC Architectures. In Proceedings of the 36th International Conference on Parallel Processing, Xi’an, China, 10–14 September 2007.
- Mori, K.; Abdallah, A.B.; Kuroda, K. Design and Evaluation of a Complexity Effective Network-on-Chip Architecture on FPGA. In Proceedings of the 19th Intelligent System Symposium (FAN 2009), Aizu-wakamatsu, Japan, 17–18 September 2009; pp. 318–321.
- Miura, S.; Abdallah, A.B.; Kuroda, K. PNoC: Design and Preliminary Evaluation of a Parameterizable NoC for MCSoC Generation and Design Space Exploration. In Proceedings of the 19th Intelligent System Symposium (FAN 2009), Aizu-wakamatsu, Japan, 17–18 September 2009; pp. 314–317.
- Ahmed, A.B.; Abdallah, A.B.; Kuroda, K. Architecture and Design of Efficient 3D Network-on-Chip (3D NoC) for Custom Multicore SoC. In Proceedings of the 5th International Conference on Broadband, Wireless Computing, Communication and Applications (BWCCA-2010), Fukuoka, Japan, 4–6 November 2010; pp. 67–73.
- Ahmed, A.B.; Abdallah, A.B. ONoC-SPL Customized Network-on-Chip (NoC) Architecture and Prototyping for Data-intensive Computation Applications. In Proceedings of the 4th International Conference on Awareness Science and Technology, Seoul, Korea, 21–24 August 2012; pp. 257–262.
- Ahmed, A.B.; Abdallah, A.B. Architecture and Design of High-throughput, Low-latency, and Fault-Tolerant Routing Algorithm for 3D-Network-on-Chip (3D-NoC). J. Supercomput. 2013, 66, 1507–1532. [Google Scholar] [CrossRef]
- Abdallah, A.B. Multicore Systems-on-Chip: Practical Hardware/Software Design, 2nd ed.; Atlantis Press: Paris, France, 2013. [Google Scholar]
- Wang, H.; Lee, B.G.; Shacham, A.; Bergman, K. On the Design of a 4 × 4 Nonblocking Nanophotonic Switch for Photonic Networks on Chip. In Proceedings of the Frontiers in Nanophotonics and Plasmonics, Guaruja, Brazil, 9–14 November 2007.
- Preston, K.; Sherwood-Droz, N.; Levy, J.S.; Lipson, M. Performance guidelines for WDM interconnects based on silicon microring resonators. In Proceedings of the Conference on Lasers and Electro-Optics (CLEO), Baltimore, MD, USA, 1–6 May 2011; pp. 1–2.
- Wang, H.S.; Zhu, X.; Peh, L.; Malik, S. Orion: A power-performance simulator for interconnection networks. In Proceedings of the 35th Annual IEEE/ACM International Symposium on Microarchitecture, Istanbul, Turkey, 18–22 November 2002; pp. 294–305.
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Hendry, G.; Robinson, E.; Gleyzer, V.; Chan, J.; Carloni, L.; Bliss, N.; Bergman, K. Circuit-switched memory access in photonic interconnection networks for high-performance embedded computing. In Proceedings of the 2010 International Conference for High Performance Computing, Networking, Storage and Analysis (SC), New Orleans, LA, USA, 13–19 November 2010; pp. 1–12.
- Frigo, M.; Johnson, S.G. BenchFFT. Available online: http://www.fftw.org/benchfft/ffts.html (accessed on 1 August 2015).
- Vantrease, D.; Schreiber, R.; Monchiero, M.; McLaren, M.; Jouppi, N.P.; Fiorentino, M.; Davis, A.; Binkert, N.; Beausoleil, R.G.; Ahn, J.H. Corona System Implications of Emerging Nanophotonic Technology. In Proceedings of the 35th International Symposium on Computer Architecture, Beijing, China, 21–25 June 2008; pp. 153–164.
- Vantrease, D.; Binkert, N.L.; Schreiber, R.; Lipasti, M.H. Light speed arbitration and flow control for nanophotonic interconnects. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, NY, USA, 12–16 December 2009; pp. 304–315.
- Gu, H.; Xu, J.; Zhang, W. A low-power fat tree-based optical network on-chip for multiprocessor system-on-chip. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Nice, UK, 20–24 April 2009; pp. 3–8.
- Batten, A.J.C.; Kwon, Y.J.; Beamer, S.; Shamim, I.; Asanovic, K.; Stojanovic, V. Silicon-photonic Clos networks for global on-chip communication. In Proceedings of the 3rd ACM/IEEE NoCS, San Diego, CA, USA, 10–13 May 2009; pp. 124–133.
- Li., C; Browning, M.; Gratz, P.V.; Palermo, S. LumiNOC: A Power-Efficient, High-Performance, Photonic Network-on-Chip. IEEE Trans. Comput. Aided Design Integr. Circuits Syst. 2014, 33, 826–838. [Google Scholar] [CrossRef]
- Kao, Y.; Chao, J.J. BLOCON: A bufferless photonic clos network-on-chip architecture. In Proceedings of the Fifth IEEE/ACM International Symposium on Networks on Chip (NoCS), Pittsburgh, PA, USA, 1–4 May 2011; pp. 81–88.
- Pasricha, S.; Dutt, N. ORB: An on-chip optical ring bus communication architecture for multi-processor systems-on-chip. In Proceedings of the Asia South Pacific Conference Design Automation, Seoul, Karea, 21–24 March 2008; pp. 789–794.
- Beausoleil, R.; Ahn, J.; Binkert, N.; Davis, A.; Fattal, D.; Fiorentino, M.; Jouppi, N.P.; McLaren, M.; Santori, C.M.; Schreiber, R.S. A nanophotonic interconnect for high-performance many-core computation. In Proceedings of the 16th IEEE Symposium in High Performance Interconnects, Stanford, CA, USA, 26–28 August 2008; pp. 182–189.
- Zhang, X.; Louri, A. A Multilayer Nanophotonic Interconnection Network for On-Chip Many-Core Communications. In Proceedings of the ACM/IEEE 47th Design and Automation Conference (DAC), Anaheim, CA, USA, 13–18 June 2010; pp. 156–161.
- Morris, R.W.; Kodi, A.K.; Louri, A.; Whaley, R.D. Three-Dimensional Stacked Nanophotonic Network-on-Chip Architecture with Minimal Reconfiguration. IEEE Trans. Comput. 2014, 63, 243–255. [Google Scholar] [CrossRef]
- Kirman, K.; Martinez, J. A Power-efficient All-optical On-chip Interconnect Using Wavelength-based Oblivious Routing. In Proceedings of the Fifteenth Edition of ASPLOS on Architectural Support for Programming Languages and Operating Systems, Pittsburgh, PA, USA, 13–17 March 2010; pp. 15–28.
- Aggarwal, A.; Bar-Noy, A.; Coppersmith, D.; Ramaswami, R.; Schieber, B.; Sudan, M. Efficient routing in optical networks. J. ACM 1994, 43, 973–1001. [Google Scholar] [CrossRef]
- Chen, Z.; Gu, H.; Chen, Y.; Zhang, H. Wavelength assignment in Optical Network-on-Chip: Design and performance. In Proceedings of the 2013 IEEE Region 10 Conference, Xi’an, China, 22–25 October 2013; pp. 1–4.
- Pan, Y.; Kim, J.; Memik, G. Flexishare: Channel sharing for an energy-efficient nanophotonic crossbar. In Proceedings of the International Symposium High-Performance Computer Architecture (HPCA), Bangalore, India, 9–14 January 2010; pp. 1–12.
- Hendry, G.; Robinson, E.; Gleyzer, V.; Chan, J.; Carloni, L.; Bliss, N.; Bergman, K. Circuit-Switched Memory Access in Photonic Interconnection Networks for High-Performance Embedded Computing. In Proceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 13–19 November 2010; pp. 1–12.
- Chan, J.; Bergman, K. Photonic interconnection network architectures using wavelength-selective spatial routing for chip-scale communications. Opt. Commun. Netw. 2012, 4, 189–201. [Google Scholar] [CrossRef]
- Matsutani, H.; Koibuchi, M.; Amano, H.; Yoshinaga, T. Prediction Router: Yet Another Low Latency On-Chip Router Architecture. In Proceedings of the 15th IEEE International Symposium on High-Performance Computer Architecture (HPCA 2009), Raleigh, NC, USA, 14–18 February 2009; pp. 367–378.
- Hendrya, G.; Robinsonb, E.; Gleyzerb, V.; Chana, J.; Carlonic, L.P.; Blissb, N.; Bergmana, K. Time-Division-Multiplexed Arbitration in Silicon Nanophotonic Networks-On-Chip for High- Performance Chip Multiprocessors. J. Parall. Distrib. Comput. 2011, 71, 641–650. [Google Scholar] [CrossRef]
- Hendry, G.; Chan, J.; Kamil, S.; Oliker, L.; Shalf, J.; Carloni, L.P.; Bergman, K. Silicon nanophotonic network-on-chip using TDM arbitration. In Proceedings of the IEEE Symposium on High-Performance Interconnects, Mountain View, CA, USA, 18–20 August 2010; pp. 88–95.
- Pan, Y.; Kumar, P.; Kim, J.; Memik, G.; Zhang, Y.; Choudhary, A. Firefly: Illuminating future network-on-chip with nanophotonics. In Proceedings of the 36th International Symposium on Computer Architecture (ISCA 2009), Austin, TX, USA, 20–24 June 2009; pp. 429–440.
- Tan, X.; Yang, M.; Zhang, L.; Wang, X.; Jiang, Y. A Hybrid Optoelectronic Networks-on-Chip Architecture. J. Lightw. Technol. 2014, 32, 991–998. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output/Input | Local | North | East | South | West |
|---|---|---|---|---|---|
| Local | - | 9,18 | 11,18 | 14 | 16 |
| North | 17,10 | - | 1 | 3 | None |
| East | 17,12 | 2 | - | None | 4 |
| South | 13 | 6 | None | - | 8 |
| West | 15 | None | 5 | 7 | - |
| Network Configuration | Value |
|---|---|
| Process technology | 32 nm |
| Number of tiles | 64/256 |
| Chip area (equally-divided among tiles) | 400 mm |
| Core frequency | 2.5 GHz |
| Electronic control frequency | 1.5 GHz |
| Power model | Orion 2.0 |
| Buffer depth | 2 |
| Physical channel width | 32 |
| Forwarding | Wormhole switching like |
| Scheduling | Round-robin |
| Control flow | Stall-go |
| Routing | DOR-XY |
| Message size | 2 kilobytes |
| Simulation time | 10 ms (25 × cycles) |
| Network Configuration | Value |
|---|---|
| Data rate (per wavelength) | 2.5 GB/s |
| MRs’ dynamic energy | 375 fJ/bit |
| MRs’ static energy | 400 μW |
| Modulators dynamic energy | 85 fJ/bit |
| Modulators static energy | 30 μW |
| Photodetector energy | 50 fJ/bit |
| MRs’ thermal tuning | 100 μW/ring |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben Ahmed, A.; Ben Abdallah, A. An Energy-Efficient High-Throughput Mesh-Based Photonic On-Chip Interconnect for Many-Core Systems. Photonics 2016, 3, 15. https://doi.org/10.3390/photonics3020015
Ben Ahmed A, Ben Abdallah A. An Energy-Efficient High-Throughput Mesh-Based Photonic On-Chip Interconnect for Many-Core Systems. Photonics. 2016; 3(2):15. https://doi.org/10.3390/photonics3020015
Chicago/Turabian StyleBen Ahmed, Achraf, and Abderazek Ben Abdallah. 2016. "An Energy-Efficient High-Throughput Mesh-Based Photonic On-Chip Interconnect for Many-Core Systems" Photonics 3, no. 2: 15. https://doi.org/10.3390/photonics3020015
APA StyleBen Ahmed, A., & Ben Abdallah, A. (2016). An Energy-Efficient High-Throughput Mesh-Based Photonic On-Chip Interconnect for Many-Core Systems. Photonics, 3(2), 15. https://doi.org/10.3390/photonics3020015