1. Introduction
Salient object detection (SOD) emulates biological visual perception mechanisms to localize and segment the most visually conspicuous regions within images. As a critical component in computer vision systems, SOD enables diverse downstream applications including object tracking [
1,
2], medical image analysis [
3,
4], action recognition [
5,
6], and semantic segmentation [
7,
8]. Early-stage SOD methodologies mainly relied on hand-crafted feature extraction [
9], which incurred excessive temporal and human resource costs. The advent of deep learning architectures has revolutionized this field, with FCN [
10] and UNet [
11] emerging as fundamental frameworks due to their hierarchical feature learning capabilities, achieving significant performance breakthroughs. Nevertheless, these deep learning-based methods remain constrained to scattering-free RGB imagery, while continuing to struggle in turbid underwater environments where light–particle interactions induce scattering and absorption effects that substantially degrade detection accuracy. This challenge is further compounded in multi-target scenarios, where the superposition of inter-target scattering interference and the differences in target materials notably increase the complexity of SOD, thereby imposing stricter requirements on SOD performance. While the surface plasmon effects of 2D materials have been exploited for micro-scale detection in optical biosensing [
12], there is growing interest in leveraging polarization-dependent optical properties for adaptive SOD in complex scattering scenes such as turbid underwater scenes.
Recent advancements in polarization-based dehazing technology have achieved notable progress in turbid underwater environments, as polarimetric imaging provides more information to mitigate the scattering and absorption effects caused by suspended particles [
13,
14]. Additionally, polarization imaging delivers richer target surface information to improve the detection capacity of material identification through different polarization component evolutions [
15,
16]. Wang et al. integrated polarization characteristic dispersion with neural networks to enhance target detection in turbid environments [
17]. Gao et al. introduced a de-scattering neural network, MTM-Net [
18], to improve the performance of underwater imaging based on the physical Mueller matrix dehazing model. Hu et al. proposed a 3D-CNN framework [
19] utilizing polarization information to improve the image quality in high turbidity. These investigations demonstrate that the utilization of polarization characteristics can significantly suppress the particulate scattering interference in turbid underwater environments, achieving high-quality de-scattering imaging and object observation in a scattering underwater environment. In a recent study, Yang et al. [
20] proposed a lightweight MobileNetV2 backbone integrated with a Structural Feature Learning Module (StFLM) and Semantic Feature Learning Module (SeFLM), Their approach demonstrates promising performance in turbidity conditions by utilizing dual inputs of DoLP and S0. The architecture efficiently balances model efficiency and detection speed through spatial attention mechanisms and channel-wise feature recalibration, showing potential for underwater applications. However, further exploration is needed to incorporate additional polarization information, such as the AoP (angle of polarization), and to develop more targeted network designs, especially to address the challenges of multi-material and multi-target tasks in high-turbidity environments where scattering interference is intensified, inter-target interactions become more complex, and the distinct polarization characteristics of different materials are critical for accurate discrimination.
In this work, we propose a deep learning-based multi-modal polarimetric SOD method that integrates the polarimetric de-scattering mechanisms with the powerful feature learning capabilities of neural networks to achieve adaptive de-scattering multi-target SOD. The proposed polarization enhanced SOD network (PESODNet) innovatively integrates a material-aware channel attention (MACA) module to enhance feature discrimination of multi-material targets, along with a dynamic scattering suppression unit (DSSU) to adaptively mitigate scattering-induced noise. The experimental results demonstrate the excellent performance of the proposed PESODNet across multiple evaluation indicators for multi-target underwater SOD tasks, particularly in highly turbid underwater environments.
2. Physical Basis and Architecture of the Polarization-Enhanced De-Scattering Multi-Target SOD Network
The physical properties and surface structural characteristics of a target are critical determinants for its accurate detection and recognition. The polarized reflectance characteristics of target surfaces are fundamentally characterized by the polarized bidirectional reflectance distribution function model [
21]. The relationship between incident and reflected light can be modeled by the Jones matrix [
22]:
where the superscripts
r and
i of E correspond to reflected and incident light, respectively. The subscripts
s and
p indicate s and
p waves with polarization perpendicular and parallel to the incidence plane, respectively. The angle
φi is defined as the dihedral angle between the incident plane (spanned by the incident light direction and the macro-scale normal vector of the target surface) and the micro-scale incident plane (spanned by the incident light direction and the micro-scale normal vector of the microsurface), whereas the angle
φr analogously denotes the dihedral angle between the reflected plane (formed by the reflected light direction and the macro-scale normal) and the micro-scale reflected plane (formed by the reflected light direction and the micro-scale normal). The Fresnel reflection coefficients
rss and
rpp, which characterize the polarization-dependent reflectance at the material interface, are expressed as follows [
23]:
where
θi is the incident polar angle, and
n = n2/
n1,
n1 and
n2 are the refractive indices of the object and medium, respectively. According to the polarimetric reflectance characteristics of the target surface, the angle of polarization (AoP) and degree of linear polarization (DoLP) are mathematically formulated as follows [
24,
25,
26]:
where
S0 = I0 +
I90,
S1 = I0 −
I90, and
S2 = 2
I45 − (
I0+ I90) are the Stokes parameters, denoting the intensity (
S0), the horizontally and vertically linear polarization components (
S1), and the linear polarization components of 45° and 135° (
S2).
As recognized from Equations (2)–(5), the AoP is determined by the difference between the target surface and microsurface
φr, and the DoLP variation depends on the ratio of the refractive indices between the object and medium
n and the incident angle parameters
θi. Since n can be regarded as a key criterion for the detection and identification of multiple targets of different materials, the physical properties of detection targets can be characterized by the polarization information parameters, AoP and DoLP, in polarization imaging data. In particular, in a scattering turbid underwater environment, the utilization of polarization characteristics has demonstrated a significant achievement in de-scattering imaging, whereas optical intensity imaging severely degrades with the obscured detailed information of the target [
27].
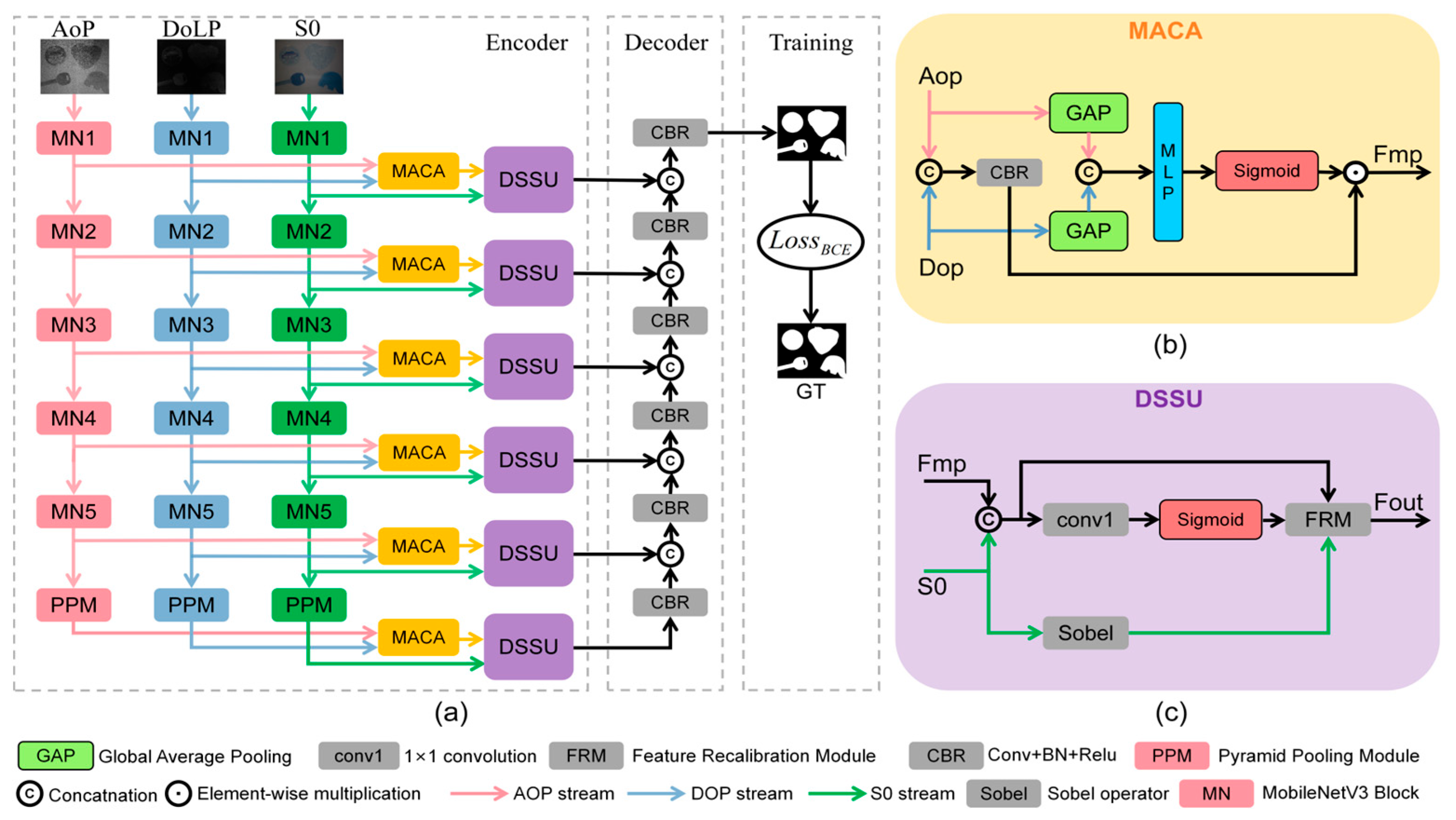
Herein, a polarization-enhanced SOD network (PESODNet) is constructed with an encoder–decoder structure, as shown in
Figure 1a. The encoder leverages MobileNetV3 (MN) [
28] as the backbone to extract multi-modal optical features. The polarization images AoP, DoLP, and the RGB image S0 are adopted as the inputs to the network. The RGB stream captures the color and brightness features, and the polarization streams extract the complementary polarization features. MobileNetV3 (MN) extracts features at five distinct levels for each stream. The Pyramid Pooling Module (PPM) [
29] is added at the end of each stream, allowing the network to capture both local and global context information. The MACA module fuses features from the AoP and DoLP streams at multiple levels. By leveraging the differences of polarization characteristics reflected by various materials, the MACA module generates material encoding to enhance the network’s feature responsiveness for the identification of materials such as metals, plastics, and wood. Subsequently, the DSSU dynamically suppresses scattering noise by integrating the polarization de-scattering function and S0-guided Sobel gradient operators [
30]. The final saliency map is obtained through the decoder with cascaded CBR modules.
By leveraging the differences in polarization properties reflected by different materials, the MACA module generates material encodings to enhance the network’s feature response to various materials. The MACA module involves input feature preprocessing, material encoding generation, and material-aware response enhancement, as shown in
Figure 1b. Specifically, the MACA module receives feature inputs from the AoP and DoLP streams and employs global average pooling operations to extract global statistical information,
AoPavg and
DoLPavg. After concatenation, the
AoPavg and
DoLPavg are fed into a lightweight multi-layer perceptron to generate the material encoding vector. Material-aware channel attention weights are obtained by applying the sigmoid function to the material encoding vector:
The CBR (Convolution + BatchNorm + Relu) module projects DoLP and AoP into higher-dimensional feature spaces, which then undergo channel-wise multiplication with the weights derived from Equation (6), thereby generating feature representations
Fmp with reinforced material perception sensitivity.
The DSSU module adaptively suppresses scattering noise by recalibrating material-aware response features
Fmp through S0-guided local gradient information, as shown in
Figure 1c. Specifically,
Fmp and S0 are fused along the channel dimension to constitute the feature
Fraw pending recalibration. The spatial scattering levels are subsequently estimated via a lightweight CNN architecture:
where the
Conv1×1 reduces channel depth to 1, with its output constrained to the [0, 1] interval via sigmoid activation.
Simultaneously, the Sobel threshold in the DSSU is treated as a hyperparameter and selected through extensive experiments across different turbidity levels (0–72 NTU), with the optimal setting of 0.2 validated to maintain consistent performance. The gradient feature
GS0 obtained from Sobel gradient operators is subsequently subjected to normalization and non-linear transformation to compute the gradient compensation coefficient:
where
α∈[0, 1] approaches 1 in high-gradient regions (object edges) and converges to 0 in low-gradient regions (scattering background areas).
The DSSU ultimately modulates feature weights via a dynamic suppression mechanism that synergistically combines spatial scattering intensity estimates S0 and gradient compensation coefficients
α, as formalized by the following:
The MACA module fuses polarization features (AoP/DoLP), generating material encoding through an MLP, and applying channel attention weights to reinforce material-aware features by the physical relationship between the DoLP and material feature (see Equations (2)–(5)). The DSSU integrates these fused features with S0-guided Sobel gradients to estimate scattering levels, dynamically suppressing noise while preserving edges through a gradient compensation coefficient. Through the collaborative fusion mechanism of the MACA and DSSU modules, polarization characteristics enhance RGB features by boosting the model’s material recognition capability and anti-scattering ability. The decoder receives the multi-scale features from the DSSU module via skip connections and employs multiple layers of CBR blocks for upsampling, enabling effective cross-layer feature fusion. This process effectively preserves high-level semantic information while integrating the structural details of lower layers, thereby enhancing the integrity and richness of the features. Through this stepwise refinement process, the decoder reconstructs high-quality outputs from abstract features to final predictions, ensuring precise alignment with ground truth labels and optimizing end-to-end task performance.
The framework outputs the final saliency map
y′. The standard binary cross-entropy loss
Lbce [
31] is utilized for optimization:
where
Lbce provides efficient optimization and effective binary classification. It automatically balances class weights when saliency/non-saliency regions are imbalanced. The GT (Ground Truth) refers to a precisely annotated binary mask where each spatial position within the image coordinate system is numerically encoded as 1 for pixels belonging to salient foreground objects and 0 for background regions.
3. Experiment Results and Discussion
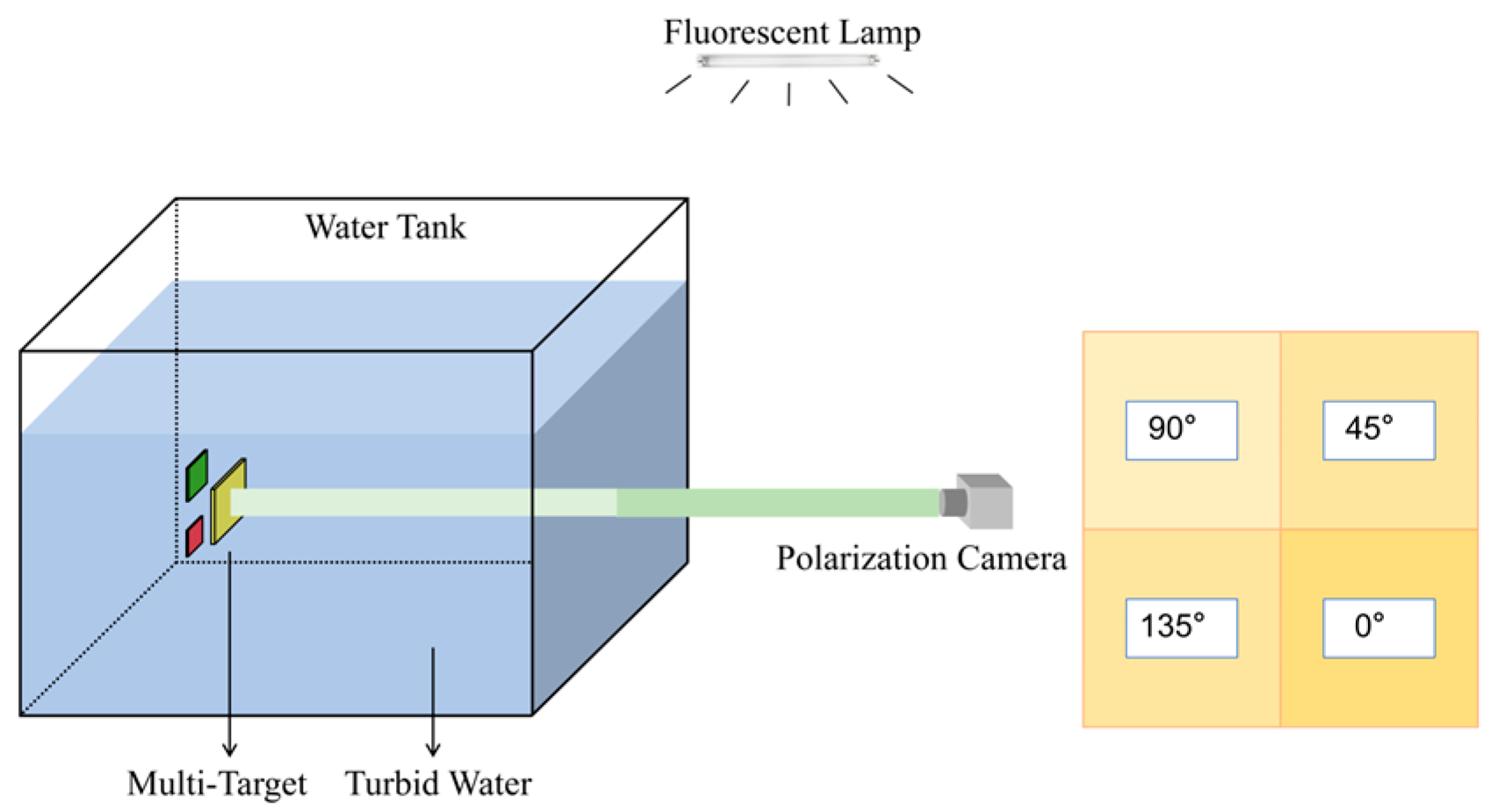
The underwater imaging experiments were conducted for the multi-target SOD, as illustrated in
Figure 2. A random number of targets were positioned within a transparent container (Acrylic tank, 65 × 30 × 40 cm
3) filled with water. The scattering environment under varying levels of turbidity was generated by adding different amounts of skim milk to the experimental container. Nephelometric Turbidity Units (NTU) were employed as the metric for quantifying the degree of scattering in turbid underwater environments [
32]. The reflected light from the target object is captured by a commercial focal-plane division polarization camera (LUCID, PHX050S-QC, Lucid Vision Labs Inc., Richmond, BC, Canada). The polarization camera has a pixel number of 2048 × 2448, and its pixel array consists of macroblocks with four different polarization components (90°, 45°, 135°, and 0° linear polarization components). This configuration, common in polarization imaging systems, is essential for computing the Stokes parameters and deriving key polarization metrics (AoP and DoLP) via Equations (3)–(5), thereby enabling the comprehensive extraction of polarization information required for material discrimination and scattering suppression in underwater environments [
17,
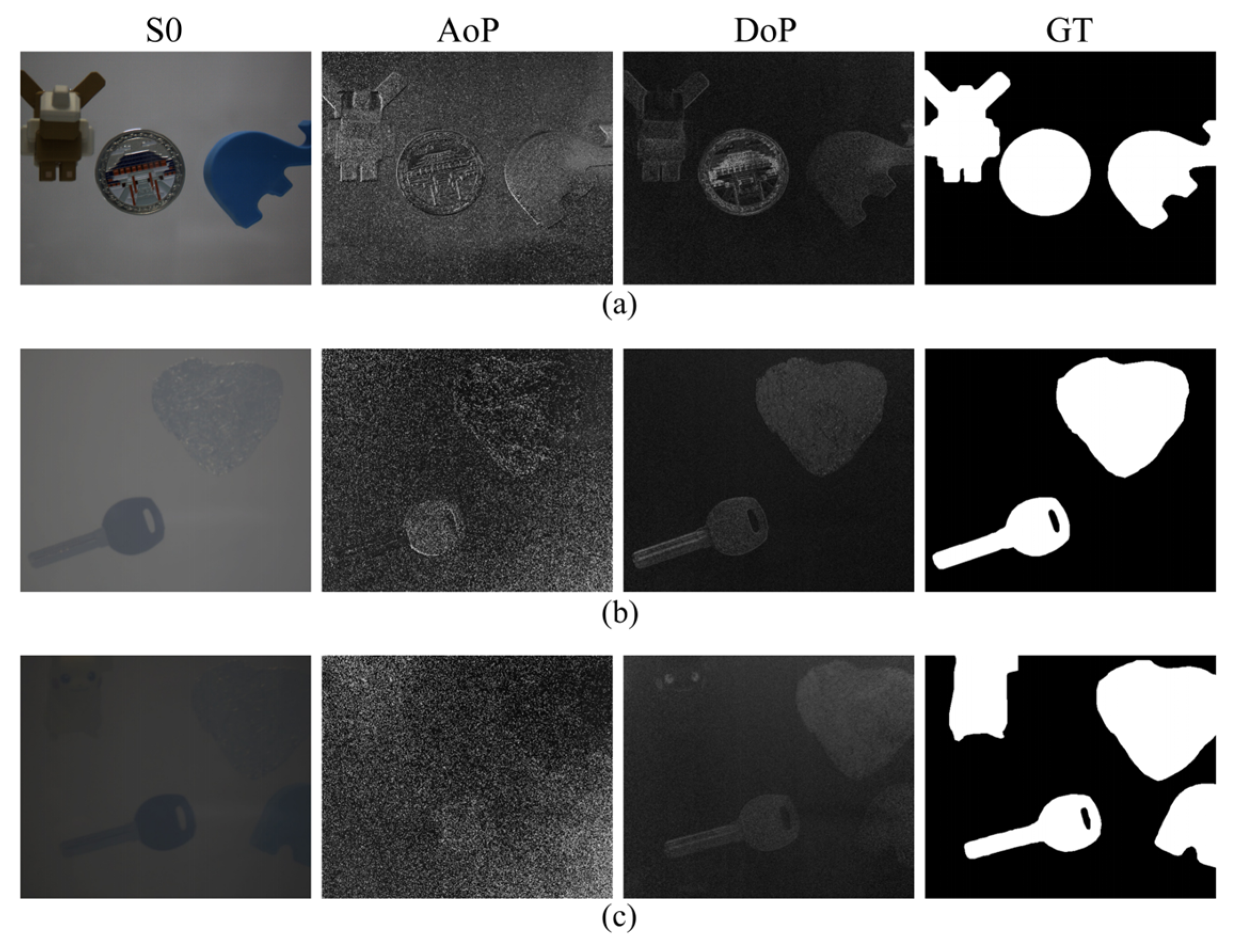
18]. Since the linear polarization components along four angles (0°, 45°, 90°, and 135°) can be directly detected by the polarization-sensitive pixel array of the commercial focal-plane division polarization camera used in our experiments, the four linear polarization components were adopted to calculate the AoP and DoLP. A total of 1000 groups of polarization images with various turbidity were collected as the original dataset, and each group included an intensity image S0, an AoP/DoLP image computed via Equations (2)–(5), and a ground truth (GT) image with manual annotations, as shown in
Figure 3. The dataset was augmented through a combination of geometric transformations (random cropping, rotation, and horizontal/vertical flipping), intensity adjustments (brightness and contrast variations), and noise injection (Gaussian blur and Poisson noise), and subsequently partitioned into training and validation subsets at an 8:2 ratio. Finally, the training dataset of 200,000 images with 448 × 448 pixel resolution was obtained. Training was conducted using an AdamW optimizer with an initial learning rate of 1 × 10
−4, scheduled via a polynomial decay strategy (‘poly’ LR scheduler) over 600 epochs with a batch size of 16, conducted on NVIDIA RTX 3090 Ti GPUs.
The comparison and ablation experiments were conducted to verify the validity of the proposed PESODNet, as shown in
Figure 4 with distinct turbidity environments (0 NTU, 36 NTU, and 72 NTU). In comparison experiments, the proposed method was compared with classical networks (UNet and FCN) trained exclusively on S0. In the ablation experiments, four PESODNet variants were compared without relevant modules: (1) Baseline (S0 stream only), (2) PES-M (without MACA), and (3) PES-D (without DSSU), to systematically evaluate the contributions of the core modules and multi-stream architecture.
In the comparison study, the PESODNet demonstrates superior segmentation accuracy compared to that of intensity-based methods (FCN and UNet) across varying turbidity conditions (0 NTU, 36 NTU, and 72 NTU), as shown in
Figure 4. In clear water (0 NTU), while FCN and UNet show generally acceptable object detection, the intensity-based methods (FCN and UNet) exhibit subtle edge inaccuracies. At this turbidity level, minimal scattering interference in clear water reduces reliance on the PESODNet’s polarization-based mechanisms (i.e., the dynamic scattering suppression unit (DSSU) and material-aware channel attention (MACA) modules), thus the visual discrepancy among the methods remains minimal. However, the PESODNet still demonstrates advantages with respect to fine-grained detail, such as sharper target boundaries and fewer segmentation voids, as shown in
Figure 4a. In moderate turbidity (36 NTU), the incomplete segmentation of multiple objects, such as the appearance of black holes (unsegmented regions), appears with the FCN method, and a large area of segmentation failure at the edge of the image occurs with UNet. Under extreme scattering (72 NTU), both FCN and UNet exhibit unacceptable segmentation results with severely incomplete edges and failed segmentation boundaries for all objects.
The ablation study evaluated three variants of the PESODNet: the baseline, PES-M, and PES-D. In clear water (0 NTU), all variants maintain relatively clear segmentation edges, and the PESODNet achieves higher edge precision. In moderate turbidity (36 NTU), the PES-M and PES-D exhibit edge blurring and minor internal voids, while the baseline shows more severe degradation. In extreme 72 NTU turbidity, the PES-M and PES-D produce serrated edges and structural separations, whereas the baseline suffers from large-area segmentation failures, as shown in
Figure 4.
In contrast, the PESODNet maintains structural integrity in its segmentation results across varying turbidity conditions, with higher edge consistency and better overlap with ground-truth boundaries, as shown in
Figure 4. These results validate the PESODNet’s superiority in multi-target SOD under turbid underwater environments. The polarization feature fusion and scattering suppression mechanisms of the PESODNet enable stable segmentation performance and strong robustness even under highly scattering interference.
To quantify the performance of these methods, Mean Absolute Error [
33] (MAE), S-measure [
34] (S), maximum F-measure [
35] (F), and maximum E-measure [
36] (E) were adopted as quantitative performance evaluation metrics. The MAE was used to evaluate the pixel-wise average error between the predicted image P and the GT:
, with lower values indicating superior model performance. The S-measure was used to calculate the structural similarity between the predicted image P and the GT:
, where
Sr is the region-based structural similarity,
So is the object-based structural similarity, and
α is empirically set to 0.5. The F-measure is the weighted harmonic mean of precision and recall, which was used to comprehensively evaluate the model’s performance:
, where the value of
β is empirically set to 0.3. The E-measure is an evaluation metric based on the enhanced alignment mapping between the predicted and true maps:
,where
φFM is the enhanced alignment matrix [
36]. Higher values of S, E, and F measure indicate better model performance. The corresponding evaluation metrics for various SOD methods are shown in
Table 1.
The experimental results demonstrate the consistent performance superiority of the PESODNet architecture across all tested turbidity conditions. The ablation study reveals a performance hierarchy among the different network variants. The removal of either key module (MACA or DSSU) leads to measurable performance degradation, as shown in
Table 1. Notably, the PES-M and PES-D variants still maintain a competitive advantage over traditional networks, particularly in high-turbidity scenarios. To investigate the interplay between the MACA and DSSU modules, we introduce the variant PES-MD, which excludes both modules. The PES-MD performs worse than the PESODNet, PES-M, and PES-D, yet outperforms traditional baselines such as FCN and UNet. This confirms the synergistic effect of the MACA and DSSU modules: MACA enhances material-related features while mitigating the impact of scattering-induced noise, thereby reducing the burden on the DSSU and in turn, the DSSU’s noise suppression reinforces the MACA module’s feature responses. Through the dual mechanisms of feature enhancement and noise suppression, the PESODNet achieves superior performance and robustness. Comparative experiments show that the PESODNet architecture exhibits remarkable robustness with increasing water turbidity, while other methods show progressive degradation, as shown in
Table 1. The performance gap between the PESODNet and conventional networks (UNet and FCN) widens substantially under challenging conditions, demonstrating the effectiveness of specialized design for the polarization feature fusion and scattering suppression mechanisms of the PESODNet. These results collectively validate the synergistic operation of the PESODNet’s core components and its superior capability in handling SOD in turbid underwater environments compared to existing approaches. This validates that polarization features provide a critical foundation for robust detection in turbid environments by mitigating the scattering-induced noise that undermines traditional RGB-based approaches. Our approach innovatively integrates the physics model of polarization parameter-dependent material recognition with deep learning technology to address underwater multi-target salient object detection, utilizing specialized modules to suppress scattering effects.
The inference time, the number of model parameters, and floating-point operations (FLOPs) were adopted as the key metrics for evaluating the efficiency of deep neural networks. The MobileNetV3 backbone serves as a lightweight foundation, with the MACA module adding approximately 0.2 M parameters and 0.05 GFLOPs via global pooling, a compact MLP, and channel attention, while the DSSU contributes ~0.15 M parameters and 0.03 GFLOPs through 1 × 1 convolutions and gradient operations. On an NVIDIA RTX 3090, the PESODNet achieves around 28 FPS for 448 × 448 images, outperforming UNet.
At the current stage, we focus on validating the feasibility of the polarization-based anti-scattering enhanced SOD mechanism in a controlled lab environment. Complex factors like dynamic lighting and organic particles in natural underwater scenes remain to be addressed in future work. Dynamic lighting, such as sunlight attenuation, may lead to less accurate scattering noise suppression in the DSSU due to intensity fluctuations in the S0 channel. However, the polarization parameters (AoP and DoLP) employed in the PESODNet are less sensitive to such brightness variations, as they characterize material properties rather than intensity. Organic particles in natural waters exhibit more complex scattering properties than the milk particles in our controlled setup. However, the multi-polarization parameter guidance in the PESODNet, specifically the adaptive feature fusion of the AoP and DoLP in the MACA module, mitigates such impacts. Since the MACA module encodes material differences based on polarization characteristics, it can capture the distinct polarization signatures of multi-material targets even under complex scattering. Additionally, the dynamic suppression mechanism in the DSSU adapts to varying scattering levels through S0-guided gradients, partially compensating for model mismatches caused by organic particle complexity and maintaining discriminability for multi-material targets. Depth-dependent color shifts affect the color consistency of the S0 channel, however, the polarization parameters AoP and DoLP help the model maintain stable detection accuracy. Their material-encoding properties are independent of spectral variations. Future research will further address the complexities of real-world underwater environments, such as dynamic lighting, organic particulate scattering, and depth-related color shifts, to enhance the model’s stability in practical underwater scenarios.





{kind=link}
{kind=link}
{kind=link}
{kind=link}