On-Chip Photonic Convolutional Processing Lights Up Fourier Neural Operator


Abstract
1. Introduction
2. Methods
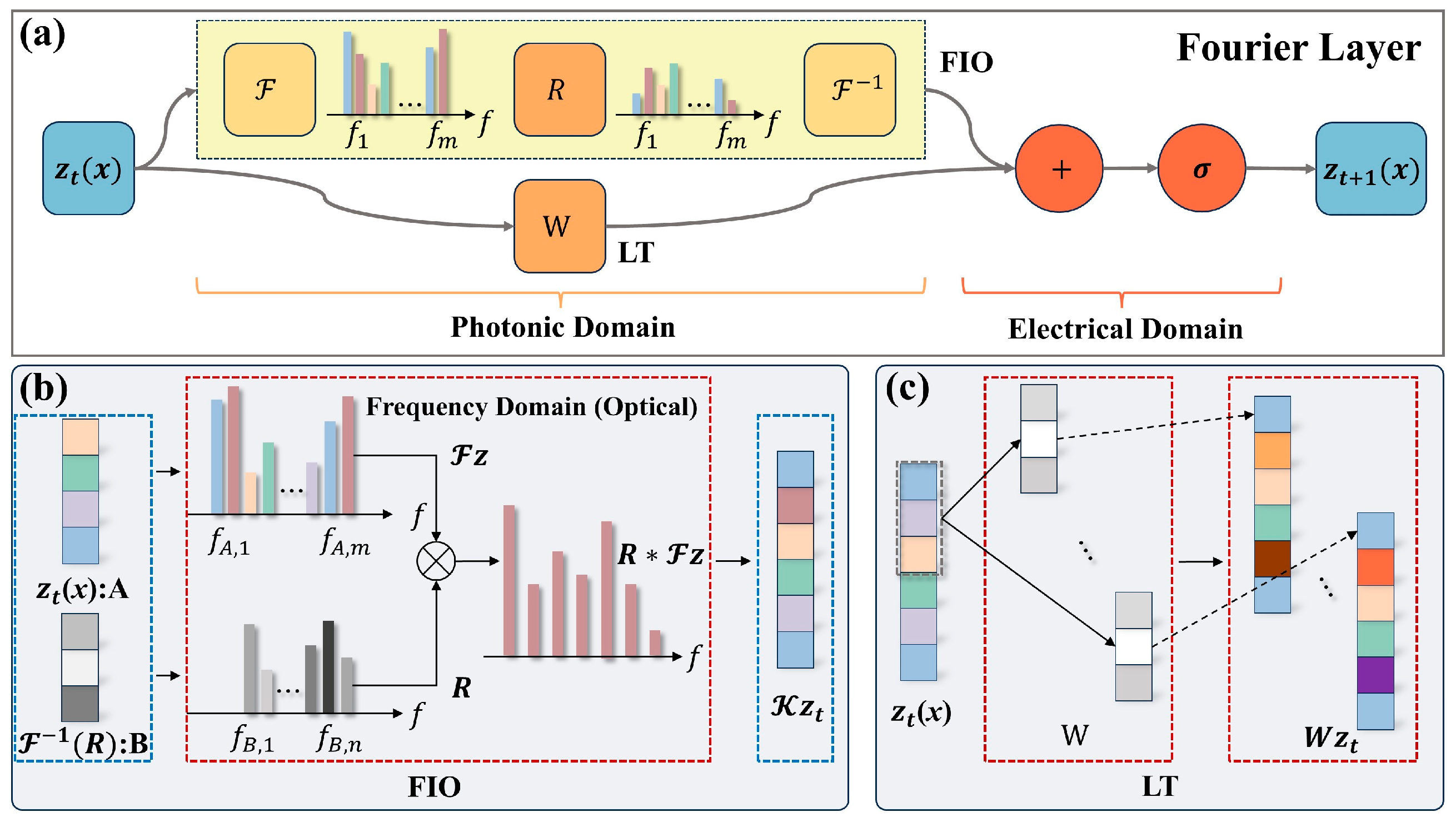
2.1. Principles of Implementing Fourier Layer with Photonic Computing Hardware
2.2. Principles of Photonic Computing Chips
3. Results
3.1. Experimental Evaluation of FIO Quantization Precision
3.2. Experimental Evaluation of LT Quantization Precision
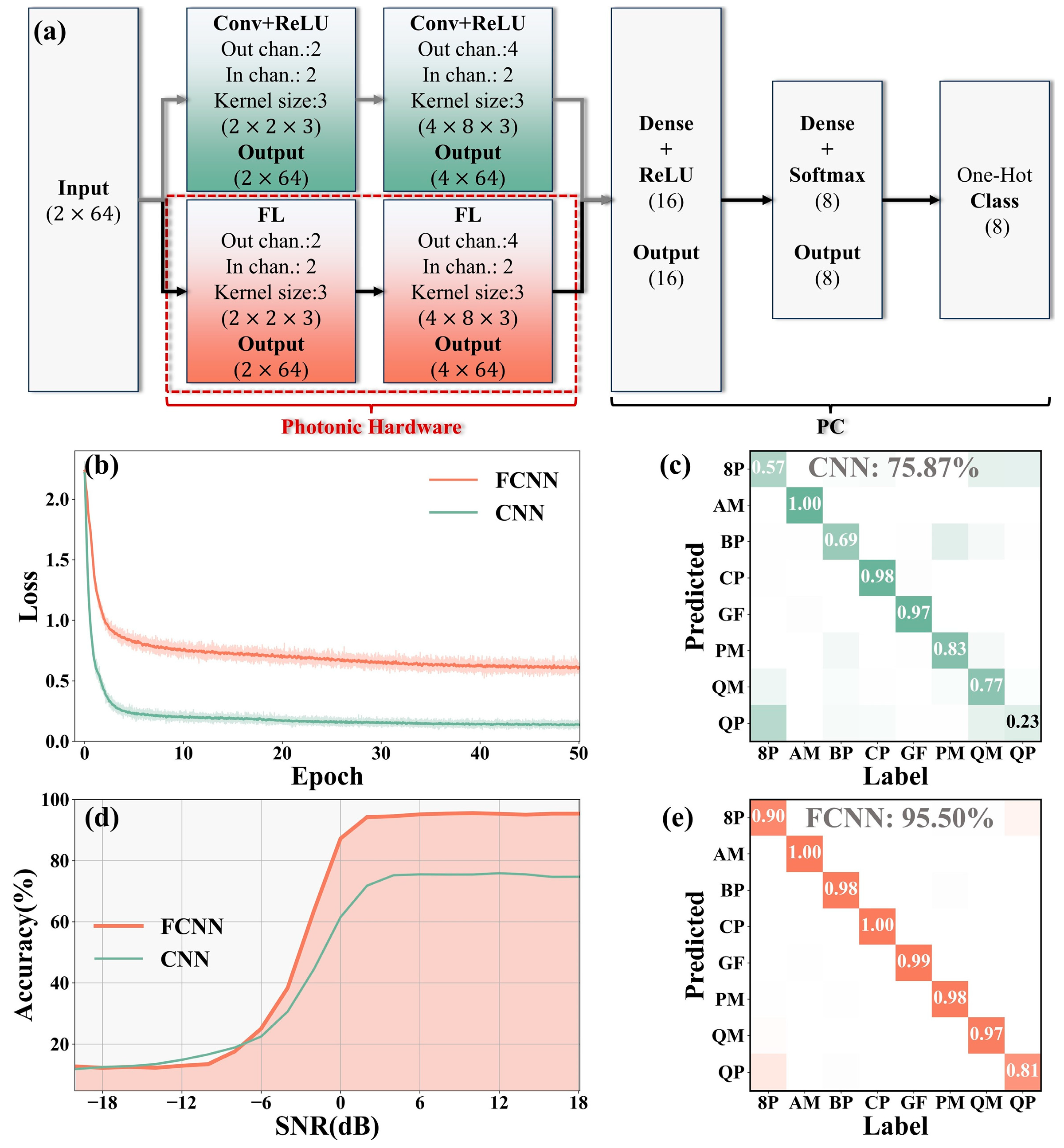
3.3. Fourier Convolutional Neural Network for Classification Tasks
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; Anandkumar, A. Fourier Neural Operator for Parametric Partial Differential Equations. arXiv 2020, arXiv:2010.08895. [Google Scholar]
- Cheng, Y.; Tang, B.; Hub, Z.; Liu, J. Fourier Neural Operator Network for the Signal Generation and Prediction. In Proceedings of the 2024 International Conference on Microwave and Millimeter Wave Technology (ICMMT), Bejing, China, 16 May 2024; pp. 1–3. [Google Scholar]
- Johnny, W.; Brigido, H.; Ladeira, M.; Souza, J.C.F. Fourier Neural Operator for Image Classification. In Proceedings of the 2022 17th Iberian Conference on Information Systems and Technologies (CISTI), Madrid, Spain, 22 June 2022; pp. 1–6. [Google Scholar]
- Huang, L.-J.; Wang, Y.-M. Fourier Series Neural Networks for Classification. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Chiba, Japan, 13–17 April 2018; pp. 881–884. [Google Scholar]
- Hojabr, R.; Sedaghati, A.; Sharifian, A.; Khonsari, A.; Shriraman, A. SPAGHETTI: Streaming Accelerators for Highly Sparse GEMM on FPGAs. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Repubic of Korea, 27 February–3 March 2021; pp. 84–96. [Google Scholar]
- Zhou, H.; Dong, J.; Cheng, J.; Dong, W.; Huang, C.; Shen, Y.; Zhang, Q.; Gu, M.; Qian, C.; Chen, H.; et al. Photonic Matrix Multiplication Lights up Photonic Accelerator and Beyond. Light Sci. Appl. 2022, 11, 30. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Harris, N.C.; Skirlo, S.; Prabhu, M.; Baehr-Jones, T.; Hochberg, M.; Sun, X.; Zhao, S.; Larochelle, H.; Englund, D.; et al. Deep Learning with Coherent Nanophotonic Circuits. Nat. Photon. 2017, 11, 441–446. [Google Scholar] [CrossRef]
- Bai, B.; Yang, Q.; Shu, H.; Chang, L.; Yang, F.; Shen, B.; Tao, Z.; Wang, J.; Xu, S.; Xie, W.; et al. Microcomb-Based Integrated Photonic Processing Unit. Nat. Commun. 2023, 14, 66. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Tan, M.; Corcoran, B.; Wu, J.; Boes, A.; Nguyen, T.G.; Chu, S.T.; Little, B.E.; Hicks, D.G.; Morandotti, R. 11 TOPS Photonic Convolutional Accelerator for Optical Neural Networks. Nature 2021, 589, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Zhou, T.; Ma, M.; Deng, C.; Dai, Q.; Fang, L. Large-Scale Photonic Chiplet Taichi Empowers 160-TOPS/W Artificial General Intelligence. Science 2024, 384, 202–209. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Huang, C.; Zhang, J.; Wu, B.; Zhang, W.; Liu, X.; Zhang, J.; Tang, Y.; Zhou, H.; Zhang, Q.; et al. Multimodal Deep Learning Using On-Chip Diffractive Optics with in Situ Training Capability. Nat. Commun. 2024, 15, 6189. [Google Scholar] [CrossRef] [PubMed]
- Ashtiani, F.; Geers, A.J.; Aflatouni, F. An On-Chip Photonic Deep Neural Network for Image Classification. Nature 2022, 606, 501–506. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Al-Hadeethi, Y.; Bakry, A.; Dalir, H.; Sorger, V.J. Integrated Photonic FFT for Photonic Tensor Operations towards Efficient and High-Speed Neural Networks. Nanophotonics 2020, 9, 4097–4108. [Google Scholar] [CrossRef]
- Ong, J.R.; Ooi, C.C.; Ang, T.Y.L.; Lim, S.T.; Png, C.E. Photonic Convolutional Neural Networks Using Integrated Diffractive Optics. IEEE J. Select. Top. Quantum Electron. 2020, 26, 1–8. [Google Scholar] [CrossRef]
- Li, J.; Fu, S.; Xie, X.; Xiang, M.; Dai, Y.; Yin, F.; Qin, Y. Low-Latency Short-Time Fourier Transform of Microwave Photonics Processing. J. Light. Technol. 2023, 41, 6149–6156. [Google Scholar] [CrossRef]
- Di Toma, A.; Brunetti, G.; Armenise, M.N.; Ciminelli, C. LiNbO3-Based Photonic FFT Processor: An Enabling Technology for SAR On-Board Processing. J. Light. Technol. 2025, 43, 912–921. [Google Scholar] [CrossRef]
- Zhu, H.H.; Zou, J.; Zhang, H.; Shi, Y.Z.; Luo, S.B.; Wang, N.; Cai, H.; Wan, L.X.; Wang, B.; Jiang, X.D.; et al. Space-Efficient Optical Computing with an Integrated Chip Diffractive Neural Network. Nat. Commun. 2022, 13, 1044. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, T.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. Proc. GNU Radio Conf. 2016, 1, 1. [Google Scholar]
- Zhang, J.; Tao, Z.; Yan, Q.; Du, S.; Tang, Y.; Liu, H.; Wei, K.; Zhou, T.; Jiang, T. Dual Optical Frequency Comb Neuron: Co-Developing Hardware and Algorithm. Adv. Intell. Syst. 2023, 5, 2200417. [Google Scholar] [CrossRef]
- Tao, Z.; You, J.; Ouyang, H.; Yan, Q.; Du, S.; Zhang, J.; Jiang, T. Silicon Photonic Convolution Operator Exploiting On-Chip Nonlinear Activation Function. Opt. Lett. 2025, 50, 582. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, Z.; Ouyang, H.; Yan, Q.; Du, S.; Hao, H.; Zhang, J.; You, J. On-Chip Photonic Convolutional Processing Lights Up Fourier Neural Operator. Photonics 2025, 12, 253. https://doi.org/10.3390/photonics12030253
Tao Z, Ouyang H, Yan Q, Du S, Hao H, Zhang J, You J. On-Chip Photonic Convolutional Processing Lights Up Fourier Neural Operator. Photonics. 2025; 12(3):253. https://doi.org/10.3390/photonics12030253
Chicago/Turabian StyleTao, Zilong, Hao Ouyang, Qiuquan Yan, Shiyin Du, Hao Hao, Jun Zhang, and Jie You. 2025. "On-Chip Photonic Convolutional Processing Lights Up Fourier Neural Operator" Photonics 12, no. 3: 253. https://doi.org/10.3390/photonics12030253
APA StyleTao, Z., Ouyang, H., Yan, Q., Du, S., Hao, H., Zhang, J., & You, J. (2025). On-Chip Photonic Convolutional Processing Lights Up Fourier Neural Operator. Photonics, 12(3), 253. https://doi.org/10.3390/photonics12030253