1. Introduction
With the rapid development of information and communication technologies and the increasing demand for wireless communication, traditional radio frequency spectrum resources are gradually becoming saturated. To address this challenge, researchers have begun exploring new communication spectra, among which Visible Light Communication (VLC) has gained widespread attention due to its abundant spectrum resources, lack of electromagnetic interference, and strong confidentiality. Orthogonal Frequency Division Multiplexing (OFDM), known for its strong inter-symbol interference resistance and ultra-high frequency band utilization, has been successfully applied in radio frequency systems and is also widely used in VLC systems. Unlike radio frequency systems, data in VLC are modulated onto the instantaneous light intensity emitted by Light Emitting Diodes (LEDs) through Intensity Modulation (IM) and directly detected by Photodiodes (PDs). Consequently, all signals in the VLC channel must be real, non-negative, and bounded. Direct Current-biased Optical OFDM (DCO-OFDM) adds a direct current bias and employs Hermitian symmetry to provide non-negative real-valued signals, combining the low-cost structure of Intensity Modulation and Direct Detection (IM/DD). This makes it widely applicable in high-capacity, high-speed VLC systems [
1,
2].
In traditional communication systems, data processing requires multiple signal processing modules within both the transmitter and receiver. Although there are mature technologies available for handling relevant signals in both radio frequency and optical communication systems, each module is designed and optimized independently for specific tasks under different assumptions. This approach often results in local optimization but makes achieving global system optimization difficult. Additionally, various communication channel models are typically represented as numerical analysis-based mathematical models. These models often involve significant computational complexity and high time complexity, and the assumptions may not accurately describe the transmission scenarios, thereby significantly reducing the system’s transmission performance. To address these issues, end-to-end systems have been introduced in wireless and fiber optic communication systems [
3,
4]. This approach transforms the entire communication system into an autoencoder (AE), jointly optimizing the transmitter, channel model, and receiver to achieve an optimized solution for the entire communication system. Meanwhile, deep learning techniques can achieve similar results to numerical analysis methods in many aspects, while significantly reducing the required time [
5].
The importance of OFDM for achieving high-capacity VLC systems is self-evident. Ganesh and colleagues used the Top Samples Detection and Appending (TSDA) technique to reduce the PAPR performance in DCO-OFDM-based VLC systems [
6]. Hong et al. studied the impact of modulation order and DC bias voltage on the signal-to-noise ratio (SNR) in DCO-OFDM-based VLC systems [
7]. Farzaneh and colleagues proposed a hybrid OFDM–pulse time modulation (PTM) scheme to enhance the bit error rate (BER) performance of DCO-OFDM systems [
8]. Several studies have explored communication systems based on end-to-end learning, where traditional transceivers are represented by deep neural networks (DNNs). As depicted in
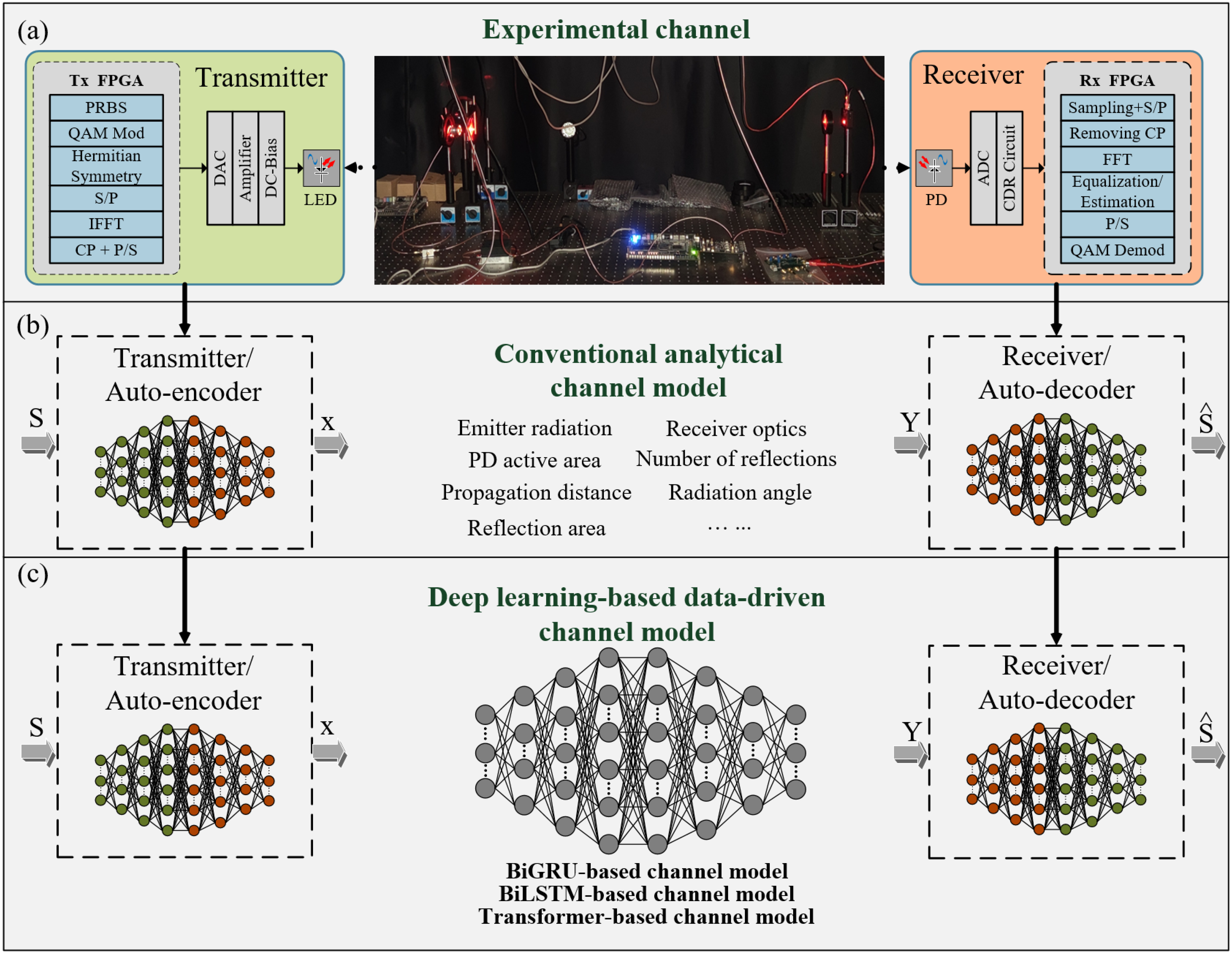
Figure 1b, the transmitter learns to encode the transmitted symbols into coded data X, which is then sent through the channel, while the receiver learns to recover the transmitted symbols from the received signal Y. From
Figure 1b, it can be seen that updating the DNN requires optimizing a loss function and updating the network parameters. Recently, data-driven methods based on learning have provided a new perspective for dealing with hypothetical channel models [
9]. Deep learning (DL) techniques have also been applied to improve traditional communication performance, such as channel estimation [
10,
11], channel equalization [
12], and signal decoding [
13]. Furthermore, DL technology can enhance system performance through the joint optimization of system modules, such as joint channel coding and source coding [
14]. Li et al. employed a deep learning scheme based on autoencoders (AE) to reduce low-frequency noise in PAM-based VLC systems [
15]. Additionally, some studies have used neural networks to predict and optimize link blockage in VLC/RF systems [
16]. Traditional analytical channel models are nondifferentiable, making it impossible to calculate gradients during the backpropagation process in neural networks, which prevents the updating of end-to-end systems. Consequently, conventional analytical channel models cannot be directly cascaded into end-to-end systems. Therefore, it is necessary to establish a differentiable channel model for Visible Light Communication to meet the requirements of end-to-end systems. Meanwhile, DCO-OFDM is crucial for providing high-capacity access services in future VLC systems, and the construction of end-to-end systems should not be limited to PAM systems.
This paper aims to investigate channel models suitable for end-to-end VLC systems. In existing studies, many channel models are based on theoretical analysis or simulation, which, while providing significant references for VLC system research, often fail to fully reflect the channel characteristics in real environments. To establish an accurate channel model, we comprehensively consider factors such as ambient light interference, multi-path effects, and scattering. We collect a large amount of channel response data and use various channel modeling algorithms to accurately model the channels of the DCO-OFDM VLC system. To validate the effectiveness of the model in end-to-end VLC systems, we conduct a comparative analysis of the bit error rate (BER) performance between traditional channel modeling schemes, existing DL-based channel estimation schemes, and the end-to-end channel model optimization scheme proposed in this paper.
2. Principle
Considering that VLC transmission systems typically transmit sequential data, this paper proposes the use of three algorithms—Transformer, Bidirectional Long Short-Term Memory (BiLSTM), and Bidirectional Gated Recurrent Unit (BiGRU)—to construct differentiable channel models for end-to-end systems. These algorithms are well suited for handling sequential data. However, existing algorithm structures cannot be directly applied to VLC channels, and there is currently no research on channel modeling for end-to-end VLC systems using OFDM. Therefore, we need to design specific neural network structures and parameters tailored to fit the DCO-OFDM VLC channel. By leveraging the strengths of these algorithms, which are adept at processing sequential data, we can develop channel models that are capable of being updated through backpropagation. This capability is crucial for integrating these models into end-to-end systems and achieving joint optimization of the entire communication process.
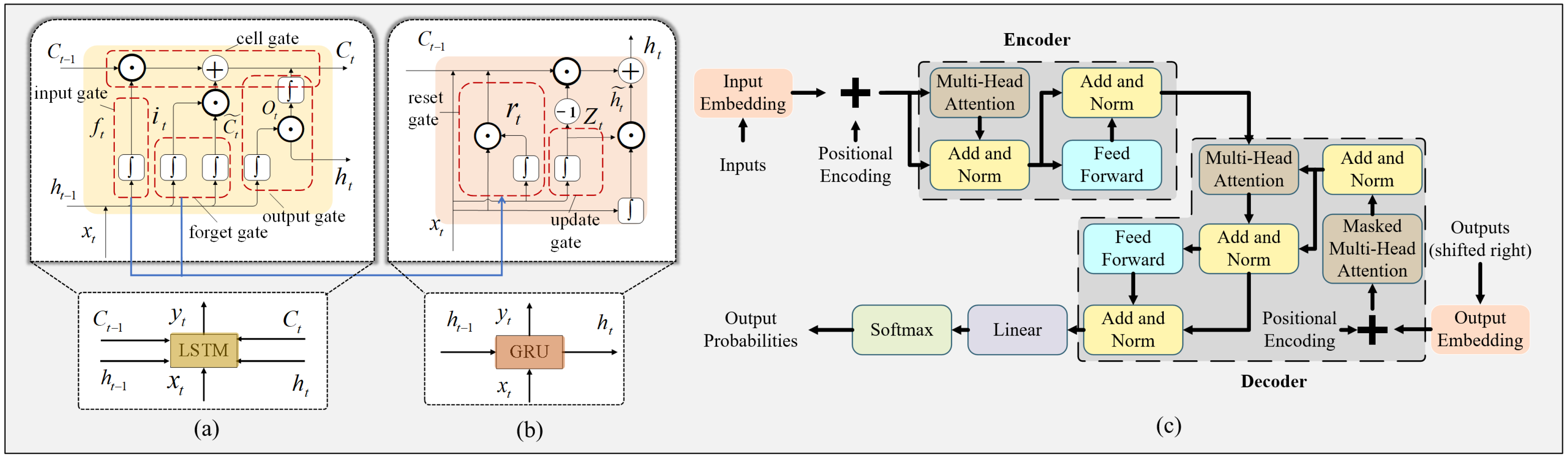
Figure 2 shows the structural principles of the three algorithms.
2.1. Principle of BiLSTM
BiLSTM networks are an extension of Long Short-Term Memory (LSTM) networks. LSTM networks address the vanishing gradient problem encountered in traditional Recurrent Neural Networks (RNNs) by introducing memory cells (cell state) and three gates, the input gate, the forget gate, and the output gate, allowing the network to retain long-term dependencies. BiLSTM consists of two LSTM networks: one processes the sequence from the beginning to the end (forward direction), while the other processes the sequence from the end to the beginning (backward direction). The outputs of both LSTMs are then concatenated, providing a complete context for each time step in the sequence.
The forget gate determines which information in the cell state should be discarded. It is a sigmoid layer that outputs a number between 0 and 1 for each number in the cell state
. A value of 1 means “completely keep this”, while a value of 0 means “completely get rid of this [
12]”:
The input gate decides which new information will be stored in the cell state. It is composed of a sigmoid layer and a tanh layer. The sigmoid layer decides which values to update, and the tanh layer creates a vector of new candidate values
that could be added to the cell state
The output gate decides which parts of the cell state will be output. The output is based on the cell state, but it is a filtered version. First, a sigmoid layer decides which parts of the cell state are output. Then, the cell state is put through the tanh function and multiplied by the output of the sigmoid gate:
By processing sequences in both forward and backward directions, BiLSTM networks can capture information from the entire sequence context, leading to a more comprehensive understanding of the data. This capability makes BiLSTM particularly effective for tasks requiring an understanding of temporal dependencies, such as VLC channel modeling for DCO-OFDM systems.
2.2. Principle of BiGRU
Bidirectional Gated Recurrent Unit (BiGRU) networks are an extension of Gated Recurrent Unit (GRU) networks. GRU simplifies the structure of Long Short-Term Memory (LSTM) networks by merging the input gate and forget gate into a single update gate and removing the separate cell state, using only two gates (reset gate and update gate) to control the flow of information.
BiGRU consists of two GRU networks: one processes the sequence from the beginning to the end (forward direction), while the other processes the sequence from the end to the beginning (backward direction). The outputs of both GRUs are then concatenated, providing a complete context for each time step in the sequence.
The reset gate determines how much of the previous hidden state
is used to compute the candidate hidden state
. It controls the contribution of the past information to the new candidate state:
The update gate determines how much of the previous hidden state
is retained and passed to the current hidden state
. It controls the balance between the old state and the new candidate state:
The candidate hidden state combines the new input
and the previous hidden state
, modified by the reset gate. The reset gate
controls the extent to which the previous hidden state is used:
The current hidden state ht is a linear interpolation between the previous hidden state
and the candidate hidden state
, controlled by the update gate
:
By processing sequences in both forward and backward directions, BiGRU networks can capture information from the entire sequence context, leading to a more comprehensive understanding of the data. This capability makes BiGRU particularly effective for tasks requiring an understanding of temporal dependencies, such as VLC channel modeling for DCO-OFDM systems.
2.3. Principle of Transformer
The Transformer model is a sequence-to-sequence model based on the attention mechanism, designed to address the inefficiencies of RNNs in handling long-distance dependencies. The Transformer achieves the mapping between input and output by stacking multiple layers of encoders and decoders. Input embedding converts the input sequence into fixed-dimension vectors. Positional encoding adds positional information to the input vectors to retain the order of the sequence since the Transformer model does not inherently capture positional relationships. The multi-head attention mechanism computes the similarity between different positions in the input sequence to capture global dependencies. Each attention head independently performs the attention operation, and their results are concatenated and linearly transformed. Feed-forward network applies an independent nonlinear transformation to each position’s vector. Residual connections and layer normalization mitigate the vanishing gradient problem and accelerate convergence. Each sub-layer is followed by a residual connection and layer normalization.
Each layer of the encoder and decoder consists of a multi-head attention mechanism and a feed-forward network. The decoder also includes a masked multi-head attention mechanism to ensure that future information is not visible when predicting the next word. By leveraging the attention mechanism, the Transformer model can effectively capture long-range dependencies and global context, making it highly suitable for sequential data tasks such as VLC channel modeling for DCO-OFDM systems.
The number of hidden layers for both BiGRU and BiLSTM is set to 2, and the learning rate is set to 0.0001 to fit the channel response more quickly and accurately. We use the Adam optimizer for optimization. We collect 262,144 sample data points and divide the OFDM signal into segments of 512 data points each to speed up the training process. The number of neurons and the number of layers in the neural network model are crucial for the model’s expressive power. An overly complex model can result in a slow training process, while too few neurons may lead to insufficient expressive power. The number of layers and neurons in the neural network directly affects the model’s expressive capability, learning ability, and training complexity. When designing a neural network, it is essential to select these two parameters wisely based on the specific task, data, and resources to achieve optimal model performance. The number of epochs during training is set to 6000. The neural network structure of the Transformer channel model is even more complex. We use three Transformer hidden layers, each with 4096 neurons. Due to the greater complexity of the OFDM signal, the number of attention heads is set to 64, and the input size for each training iteration is 1024. To prevent overfitting, the dropout rate is set to 0.1. The number of epochs during training is set to 6000.
3. Results and Discussion
A series of experiments were conducted to validate the performance of the proposed channel models for end-to-end VLC systems, and the results were analyzed. As shown in
Figure 1a, OFDM signals were generated in MATLAB and transmitted using an arbitrary waveform generator (AWG, Tektronix AWG5012). The setup consisted of a set of
with a length of 64, corresponding to an FFT length
of 2 × 64 + 2. The cyclic prefix
was set to 1/4 of the length of
, resulting in a complete OFDM symbol length of
. The signal data rate was 250 Mbps, with the LED (OSRAM LUW W5SM) biased at 6 V and the signal driving voltage set to 1 V. At the receiving end, a commercial PD (Thorlabs PDA10A-EC) was used to receive the optical signal and perform photoelectric conversion at a distance of 3 m from the LED. A real-time oscilloscope (LeCroy SDA760Zi) was then used to collect actual channel response data. We collected DCO-OFDM signal data from both ends of the channel to train the channel models.
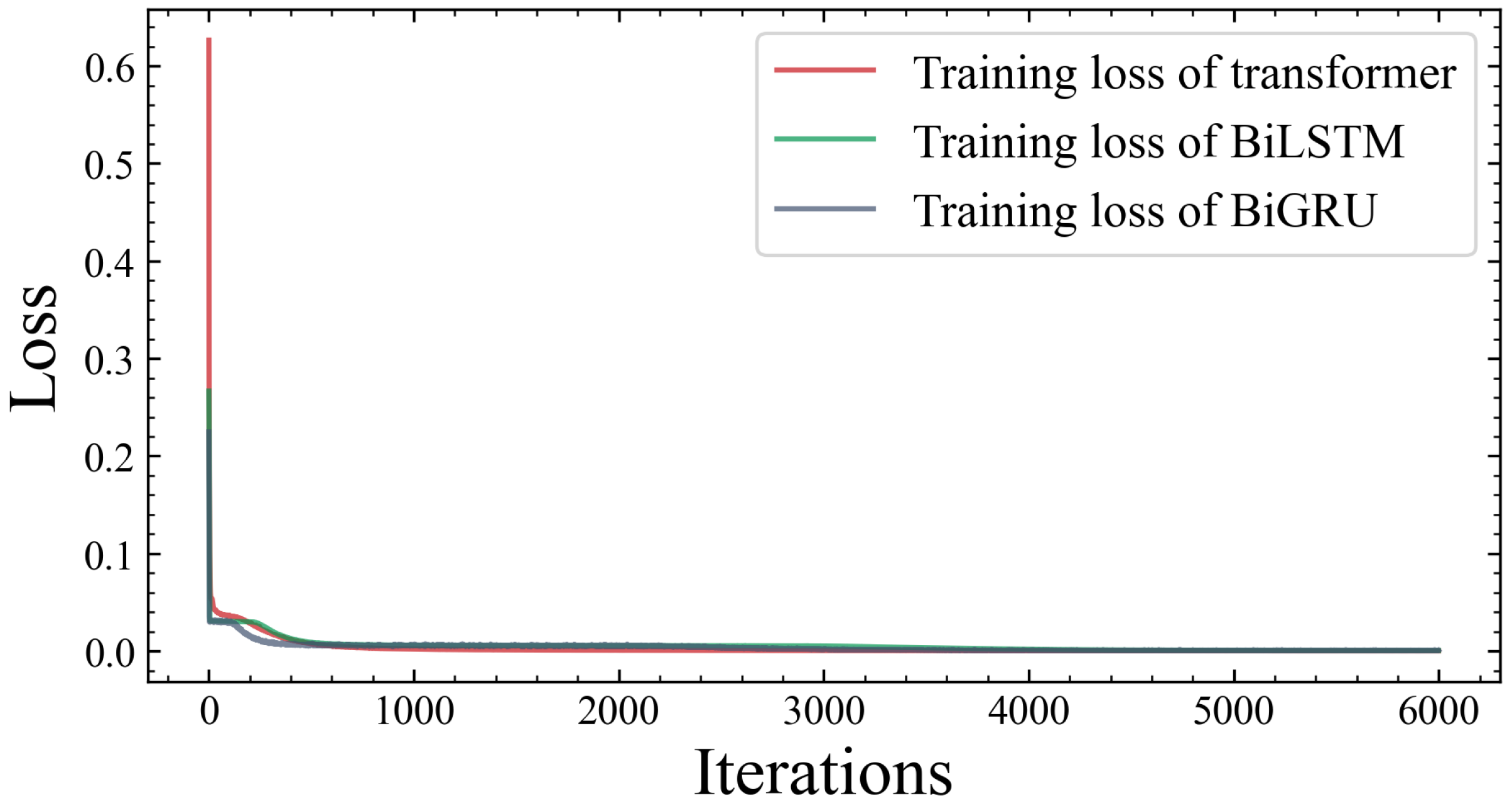
As shown in
Figure 3, the loss functions of the proposed three channel models converge under 6000 training iterations. All models achieve a relatively low training loss level, indicating effective training and fitting of the channel models.
Additionally, R-square was used to evaluate the fitting performance of the models [
17], and it is calculated using the following formula:
The formula used incorporates the following variables: n represents the length of the sequence, denotes the i-th data point of the target sequence, is the i-th output from the neural network, and is the mean of the target sequence. The R2 value ranges from 0 to 1, with values closer to 1 indicating better fitting performance.
Figure 4 illustrates the fitting performance of the three proposed channel models: BiLSTM, BiGRU, and Transformer. The diagrams show the comparison between the actual values and the predicted values by each model. BiLSTM Model: The fitting performance demonstrates a good match between the actual and predicted values, capturing the overall trend and patterns in the data. BiGRU Model: Similar to the BiLSTM model, the BiGRU model shows strong fitting performance, effectively modeling the sequential data with slight variations from the actual values. Transformer Model: The Transformer model exhibits the best fitting performance among the three, closely aligning with the actual values due to its ability to capture complex dependencies through the multi-head attention mechanism.
As shown in
Figure 4, the channel model structures of the three proposed algorithms all achieve good fitting performance. However, compared to the Transformer model with multi-head attention mechanism, the data fitting performance of the BiLSTM and BiGRU models is slightly inferior, though they still demonstrate quite impressive performance. The R-square values for the models indicate that while the Transformer model achieves the highest fitting performance, the BiLSTM and BiGRU models also provide substantial accuracy and effectiveness in modeling the VLC channel. The multi-head attention mechanism in the Transformer allows it to capture more complex dependencies and interactions within the data, giving it an edge in performance. However, the BiLSTM and BiGRU models still offer robust solutions for channel modeling, especially in scenarios where computational simplicity and efficiency are desired. These fitting performance plots visually confirm the R-square evaluations, highlighting the strengths and slight differences in effectiveness among the three models in fitting the VLC channel data.
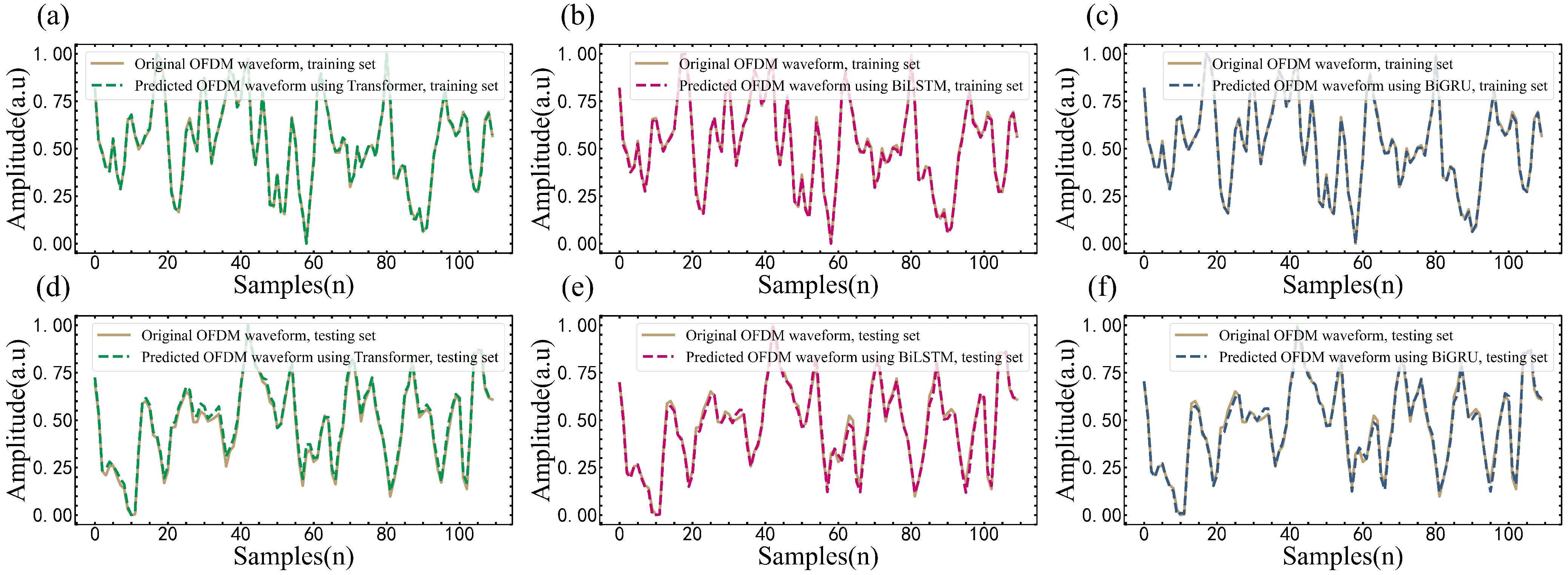
In the training and testing sets, the OFDM signal waveform intensities through the experimental channel and the channels based on different models are shown in
Figure 5. It can be seen that in both the training and testing sets, the waveform through the BiLSTM model channel can well fit the experimental waveform.
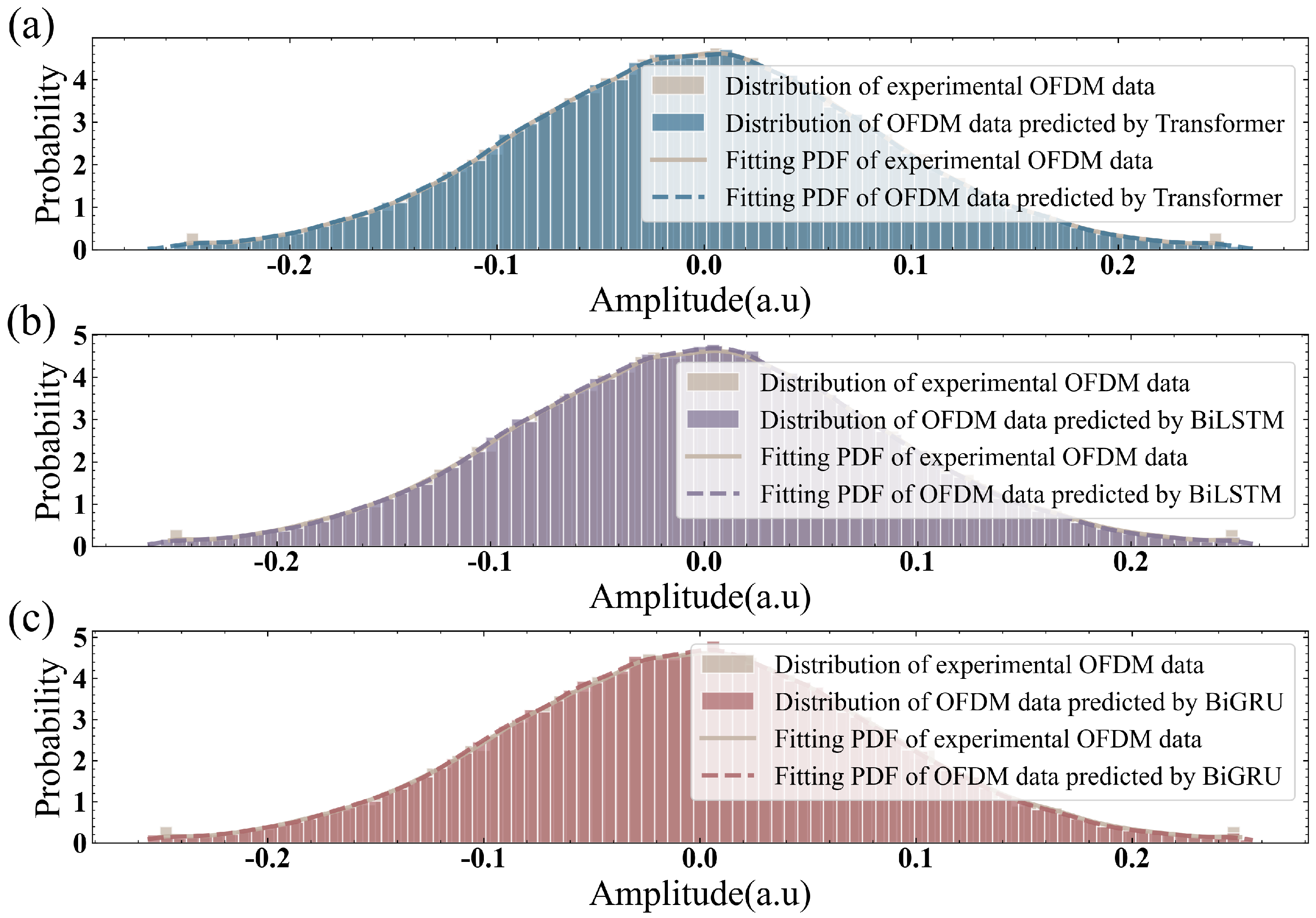
Figure 6 presents the data distribution and Probability Density Function (PDF) of the experimental OFDM data compared to the predicted data from the three different channel models. The figure illustrates that the predicted data distributions from all three proposed models closely match the original experimental OFDM data. This indicates that the proposed models accurately capture the statistical properties of the OFDM signals, providing a good fit to the experimental data.
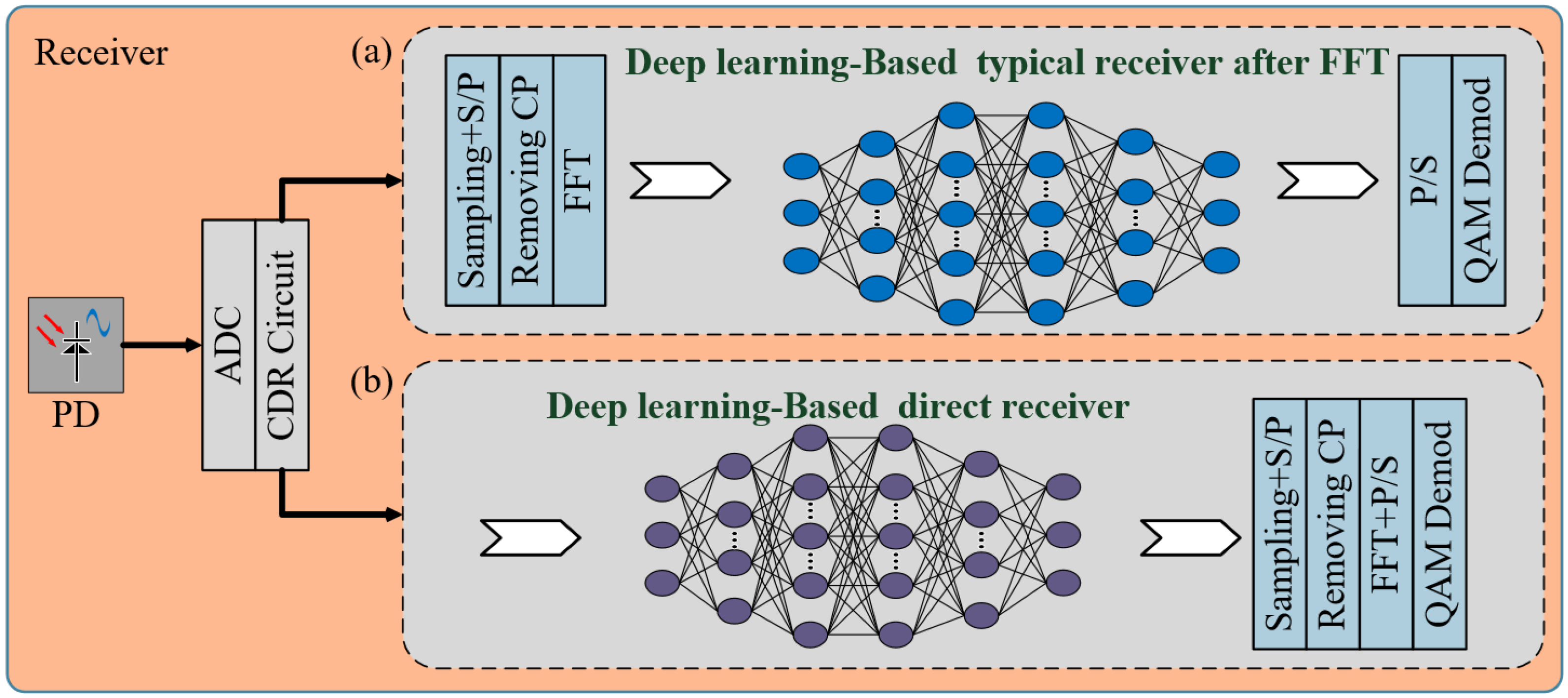
The establishment of end-to-end systems aims to optimize the structure of communication systems to achieve global system performance optimization and to help the receiver better receive signals. In traditional receivers, channel estimation usually employs methods like Least Squares (LS) and Minimum Mean Square Error (MMSE). However, LS performs poorly due to noise amplification, and MMSE is proven to be impractical due to its high complexity [
18]. Recently, some typical schemes have used deep learning (DL) methods to replace the channel estimation part of traditional schemes, as shown in
Figure 7a. In this paper, the established channel models are used to directly process the signals received by the receiver to evaluate the performance of the models as illustrated in
Figure 7b. Unlike the approach in
Figure 7a, which requires traditional DSP processing first, then uses the DL model, and finally performs traditional DSP processing again, the proposed method can directly equalize the waveform and perform simple DSP processing at the end.
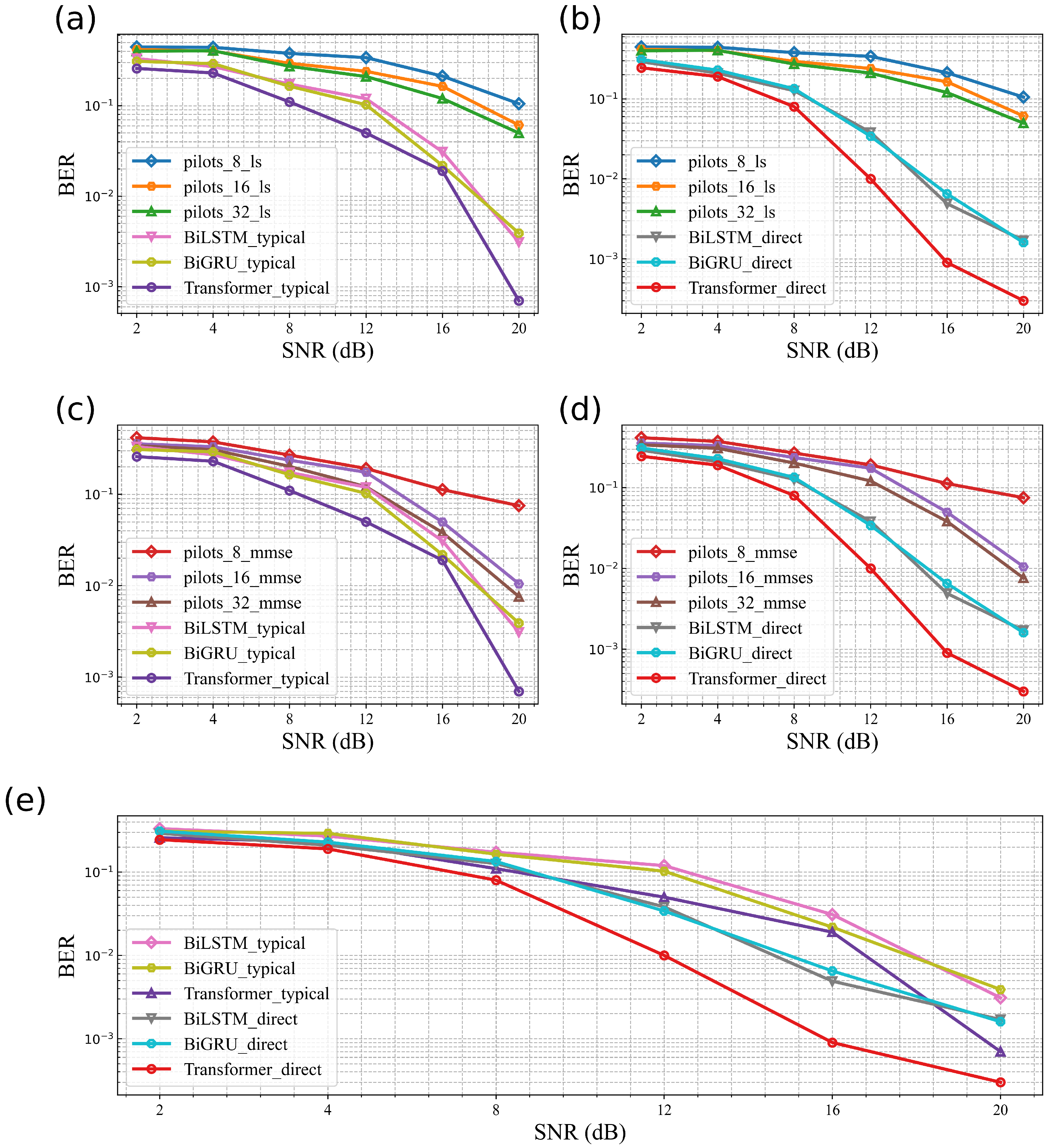
To validate the performance of the proposed end-to-end VLC system channel model, we evaluated the BER performance using traditional channel estimation methods, existing typical DL-based methods, and the proposed direct DL method. We collected 262,144 sample data points under different signal-to-noise ratio (SNR) conditions. These data include the transmission characteristics of VLC signals under various SNR conditions, and they are used to validate the performance and accuracy of the proposed model and method. In the experimental setup, the power at the transmitter is determined by the power of the LED. The LED power at the transmitter starts at 10 mW and gradually increases to vary the system’s SNR. As shown in
Figure 8, the direct reception scheme proposed in this paper effectively reduces the system BER, outperforming both traditional channel estimation schemes and existing DL-based schemes. Among the three proposed model structures, the Transformer model demonstrates significantly better BER performance in direct equalization compared to all other schemes.
The bit error rate (BER) performance results show that the DL-based scheme achieves better BER performance without occupying additional spectrum resources, whereas traditional pilot-based schemes exhibit several orders of magnitude of disadvantage. Although existing typical deep learning-based schemes do not require extra spectra compared to traditional pilot schemes, they are slightly inferior to the direct reception scheme proposed in this paper. Moreover, their signal processing process is more complex, making them less suitable for application in end-to-end VLC systems.
To further verify the accuracy of the proposed algorithm structure for end-to-end DCO-OFDM VLC, we calculate the cumulative distribution function (CDF) of the data error predicted by three different algorithm structures, allowing us to observe the error distribution across all data points as shown in
Figure 9. All three algorithm structures achieve good error performance, with eighty percent of the data points having an error within 0.05, indicating that all three channel models can effectively fit the experimental channel of the DCO-OFDM VLC system. The details in the figure show that the Transformer outperforms BiLSTM and BiGRU in error performance for most data points, owing to its multi-head attention mechanism that accurately captures various channel effects.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}