High-Resolution Image Processing of Probe-Based Confocal Laser Endomicroscopy Based on Multistage Neural Networks and Cross-Channel Attention Module


Abstract
1. Introduction
2. Method
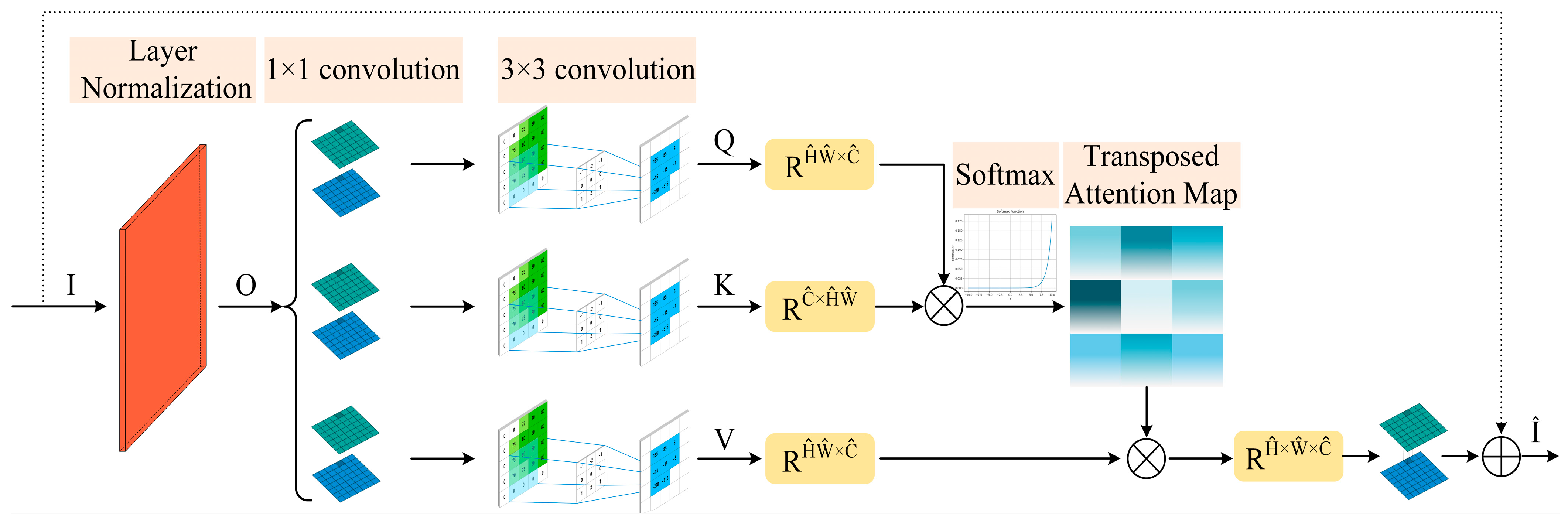
2.1. Cross-Channel Attention Module
2.2. Multistage Feature Processing and Fusion
2.3. Core Network Architecture
3. Experiment
3.1. Dataset
3.2. Implementation Details
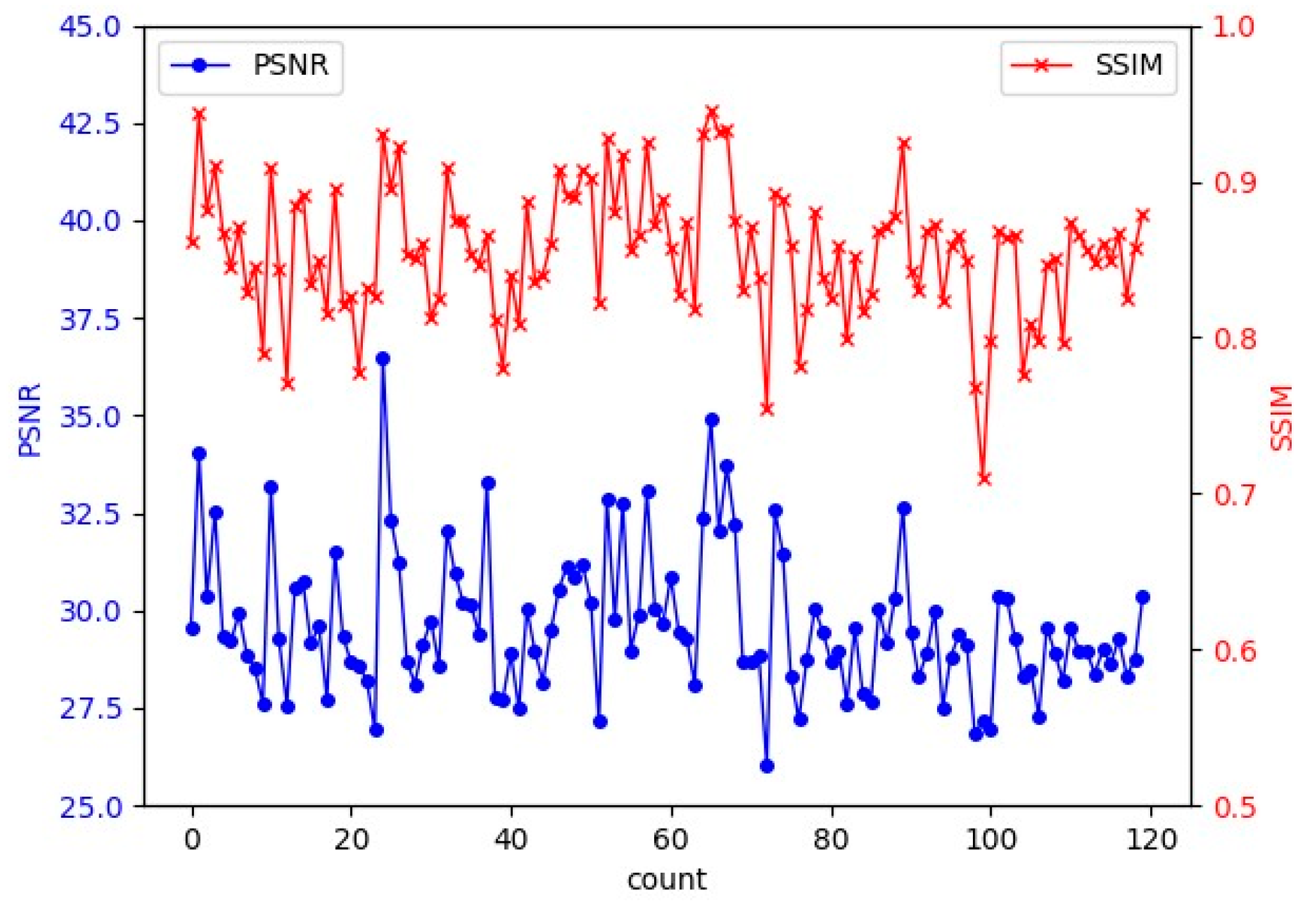
3.3. Evaluation on the Image Deblurring Network
3.4. Evaluate the Deblurring Effect on Real pCLE Images
3.5. Comparisons to Other Deep Learning Deblurring Methods
3.6. Ablation Studies
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shao, J.; Zhang, J.; Liang, R.; Barnard, K. Fiber bundle imaging resolution enhancement using deep learning. Opt. Express 2019, 27, 15880–15890. [Google Scholar] [CrossRef] [PubMed]
- Hughes, M.; Yang, G.Z. Line-scanning fiber bundle endomicroscopy with a virtual detector slit. Biomed. Opt. Express 2016, 7, 2257–2268. [Google Scholar] [CrossRef] [PubMed]
- Thrapp, A.D.; Hughes, M.R. Automatic Motion Compensation for Structured Illumination Endomicroscopy Using a Flexible Fiber Bundle. J. Biomed. Opt. 2020, 25, 026501. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Chen, M.; Zhu, D.; Liu, K.; Zhao, H.; Liao, J. Multi-Scale Cyclic Image Deblurring Based on PVC-Resnet. Photonics 2023, 10, 862. [Google Scholar] [CrossRef]
- Perperidis, A.; Dhaliwal, K.; McLaughlin, S. Image computing for fibre-bundle endomicroscopy: A review. Med. Image Anal. 2020, 62, 101620. [Google Scholar] [CrossRef]
- Hughes, M.; Yang, G.-Z. High speed, line-scanning, fiber bundle fluorescence confocal endomicroscopy for improved mosaicking. Biomed. Opt. Express 2015, 6, 1241–1252. [Google Scholar] [CrossRef]
- Weigert, M.; Schmidt, U.; Boothe, T. Content-aware image restoration: Pushing the limits of fluorescence microscopy. Nat. Methods 2018, 15, 1090–1097. [Google Scholar] [CrossRef]
- Ma, H.; Zhang, W.; Ning, X.; Liu, H.; Zhang, P.; Zhang, J. Turbulence Aberration Restoration Based on Light Intensity Image Using GoogLeNet. Photonics 2023, 10, 265. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tao, X.; Zhou, H.; Chen, Y. Image Restoration Based on End-to-End Unrolled Network. Photonics 2021, 8, 376. [Google Scholar] [CrossRef]
- Guo, Y.; Wu, X.; Qing, C.; Su, C.; Yang, Q.; Wang, Z. Blind Restoration of Images Distorted by Atmospheric Turbulence Based on Deep Transfer Learning. Photonics 2022, 9, 582. [Google Scholar] [CrossRef]
- Pan, J.S.; Dong, J.X.; Liu, Y.; Zhang, J.W.; Ren, J.M.; Tang, J.H.; Tai, Y.W.; Yang, M.H. Physics-Based Generative Adversarial Models for Image Restoration and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2449–2462. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.J.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Liu, M.; Su, X.; Yao, X.; Hao, W.; Zhu, W. Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture. Photonics 2023, 10, 1274. [Google Scholar] [CrossRef]
- Cheng, J.; Zhu, W.; Li, J.; Xu, G.; Chen, X.; Yao, C. Restoration of Atmospheric Turbulence-Degraded Short-Exposure Image Based on Convolution Neural Network. Photonics 2023, 10, 666. [Google Scholar] [CrossRef]
- Asim, M.; Shamshad, F.; Ahmed, A. Blind Image Deconvolution Using Deep Generative Priors. IEEE Trans. Comput. Imaging 2020, 6, 1493–1506. [Google Scholar] [CrossRef]
- Xue, J.; Liang, J.; He, J.; Zhang, Y.; Hu, Y. MMPDNet: Multi-Stage & Multi-Attention Progressive Image Denoising. In Proceedings of the 2021 20th International Conference on Ubiquitous Computing and Communications (IUCC/CIT/DSCI/SmartCNS), London, UK, 20–22 December 2021. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Thrapp, A.D.; Hughes, M.R. Reduced motion artifacts and speed improvements in enhanced line-scanning fiber bundle endomicroscopy. J. Biomed. Opt. 2021, 26, 056501. [Google Scholar] [CrossRef] [PubMed]
- Anwar, S.; Khan, S.; Barnes, N. A deep journey into super-resolution: A survey. ACM Comput. Surv. 2019, 53, 1–34. [Google Scholar] [CrossRef]
- Aubreville, M.; Stoeve, M.; Oetter, N.; Goncalves, M.; Knipfer, C.; Neumann, H.; Bohr, C.; Stelzle, F.; Maier, A. Deep learning-based detection of motion artifacts in probe-based confocal laser endomicroscopy images. Int. J. CARS 2019, 14, 31–42. [Google Scholar] [CrossRef]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Self-supervised learning for medical image analysis using image context restoration. Med. Image Anal. 2019, 58, 101539. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Y.; Zhu, Y.; Nichols, E.; Wang, Q.; Zhang, S.; Smith, C.; Howard, S. A Poisson-Gaussian Denoising Dataset with Real Fluorescence Microscopy Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, R.; El Helou, M.; Sage, D.; Laroche, T.; Seitz, A.; Süsstrunk, S. W2S: Microscopy Data with Joint Denoising and Super-Resolution for Widefield to SIM Mapping. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Chan, T.; Esedoglu, S.; Park, F.; Yip, A. Total variation image restoration: Overview and recent developments. In Handbook of Mathematical Models in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 17–31. [Google Scholar]
- Mou, C.; Wang, Q.; Zhang, J. Deep Generalized Unfolding Networks for Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking Coarse-to-Fine Approach in Single Image Deblurring 2021. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liehr, S.; Borchardt, C.; Münzenberger, S. Long-Distance Fiber Optic Vibration Sensing Using Convolutional Neural Networks as Real-Time Denoisers. Opt. Express 2020, 28, 39311. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Shan, Q.; Jia, J.; Agarwala, A. High-quality motion deblurring from a single image. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar]
- Yarotsky, D. Error Bounds for Approximations with Deep ReLU Networks. Neural Netw. 2017, 94, 103–114. [Google Scholar] [CrossRef] [PubMed]
- Adams, J.K.; Boominathan, V.; Avants, B.W.; Vercosa, D.G.; Ye, F.; Baraniuk, R.G.; Robinson, J.T.; Veeraraghavan, A. Single-frame 3D fluorescence microscopy with ultraminiature lensless FlatScope. Sci. Adv. 2017, 3, e1701548. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | MSE | PSNR/dB | SSIM |
|---|---|---|---|
| Previous work | 93.845 | 27.979 | 0.817 |
| Deblur-GAN | 860.423 | 28.359 | 0.828 |
| DGUNet | 83.300 | 28.463 | 0.828 |
| MIMO-Unet | 82.140 | 28.530 | 0.832 |
| Ours | 59.713 | 29.643 | 0.855 |
| Dataset | CAM | AM Filter | PSNR/SSIM |
|---|---|---|---|
| GoPro | √ | × | 28.393/0.859 |
| GoPro | × | √ | 27.992/0.851 |
| GoPro | √ | √ | 28.712/0.868 |
| Dataset | CAM | AM Filter | PSNR/SSIM |
|---|---|---|---|
| W2S | √ | × | 28.579/0.833 |
| W2S | × | √ | 28.363/0.826 |
| W2S | √ | √ | 29.643/0.855 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Zhang, H.; Yang, K.; Zhai, T.; Lu, Y.; Cao, Z.; Zhang, Z. High-Resolution Image Processing of Probe-Based Confocal Laser Endomicroscopy Based on Multistage Neural Networks and Cross-Channel Attention Module. Photonics 2024, 11, 106. https://doi.org/10.3390/photonics11020106
Qiu Y, Zhang H, Yang K, Zhai T, Lu Y, Cao Z, Zhang Z. High-Resolution Image Processing of Probe-Based Confocal Laser Endomicroscopy Based on Multistage Neural Networks and Cross-Channel Attention Module. Photonics. 2024; 11(2):106. https://doi.org/10.3390/photonics11020106
Chicago/Turabian StyleQiu, Yufei, Haojie Zhang, Kun Yang, Tong Zhai, Yipeng Lu, Zhongwei Cao, and Zhiguo Zhang. 2024. "High-Resolution Image Processing of Probe-Based Confocal Laser Endomicroscopy Based on Multistage Neural Networks and Cross-Channel Attention Module" Photonics 11, no. 2: 106. https://doi.org/10.3390/photonics11020106
APA StyleQiu, Y., Zhang, H., Yang, K., Zhai, T., Lu, Y., Cao, Z., & Zhang, Z. (2024). High-Resolution Image Processing of Probe-Based Confocal Laser Endomicroscopy Based on Multistage Neural Networks and Cross-Channel Attention Module. Photonics, 11(2), 106. https://doi.org/10.3390/photonics11020106