1. Introduction
With the continuous complexity of the coal mine working environment and the improvement of safety requirements, the research on underground positioning technology in coal mines has become an important field for coal mine safety management and production efficiency improvement. During underground operations, inaccurate personnel positioning can lead to the mislocation or misjudgment of a miner’s position, thereby increasing the risk of accidents. For example, suppose the positioning system misjudges a miner’s location. In that case, it may cause the worker to mistakenly enter a hazardous area or approach dangerous equipment, increasing the likelihood of experiencing accidents and incidents. Moreover, accurate personnel localization is critical for the emergency rescue of a coal fire, landslides, or other accidents. Inaccurate positioning can impede rescuers from quickly and accurately locating trapped personnel, resulting in a delayed emergency response time and intensifying the difficulty and risk of rescue efforts. Accurate personnel location can help to monitor and manage miners’ working status and duration. Ensuring the precise positioning of underground coal mine personnel can improve the management of their entry and exit, thereby reducing the safety risk and management difficulty in coal mines. Therefore, realizing the accurate positioning of underground personnel in coal mines is essential to ensure the safe production and efficient operation of coal mines. Various positioning methods have been proposed to address the underground personnel positioning challenge, including Wi-Fi positioning, Bluetooth positioning, radio frequency identification (RFID), ultra-wideband (UWB) positioning, and others [
1,
2,
3,
4]. Wi-Fi positioning technology has disadvantages such as complex hotspot acquisition and high power consumption; Bluetooth positioning technology usually relies on Bluetooth hotspots deployed in space, which requires precise arrangement and adjustment and increases the complexity of system deployment and maintenance; RFID technology was first applied to personnel positioning under the mines, but it has disadvantages such as a small transmission range and low positioning accuracy; and UWB technology has a higher positioning accuracy, but due to the broadband characteristics of UWB, it may produce interference with other wireless signals, affecting the positioning accuracy and reliability. Moreover, realizing high-precision UWB positioning requires specialized hardware equipment, which increases the cost and deployment difficulties. Compared with these wireless technologies, visible light communication (VLC) utilizes the visible light spectrum for data transmission and communication and has advantages, including unrestricted operation within the wireless spectrum, a high bandwidth capacity, strong anti-interference capabilities, and enhanced security. Moreover, the prevalence of lighting devices within underground coal mine environments facilitates the deployment of visible light positioning (VLP). By leveraging existing lighting infrastructure, VLP presents a forward-looking solution to the challenge of locating personnel in underground coal mines.
According to the different receivers, VLP is usually divided into an imaging type [
5] and a non-imaging type [
6]. Imaging-based VLP employs a camera or image sensor to capture visible light signals, utilizing image processing and computer vision technology to determine the device’s position. The device’s location is determined by analyzing the captured image’s features, textures, or markers. However, this approach necessitates complex hardware, thus increasing the system’s overall complexity and cost. On the other hand, non-imaging VLP does not rely on image data directly but utilizes parameters that are extracted from the received visible light signal for localization. This method primarily relies on signal measurement and processing techniques, such as Time of Arrival (TOA), Time Difference of Arrival (TDOA), Angle of Arrival (AOA), and received signal strength (RSS) [
7,
8,
9,
10]. Among these techniques, the fingerprint localization method based on received signal strength has garnered extensive research attention due to its utilization of simple hardware equipment and its high localization accuracy.
Machine learning and deep learning technologies have been widely used in the mining industry, bringing many advantages to coal mine production and management. Jo et al. [
11] proposed an IoT technology prediction system for air quality pollutants in underground mines. The system collects real-time air quality data using various sensors deployed in underground mines and employs machine learning algorithms to analyze and predict the data. Wang et al. [
12] summarized the advantages and challenges of applying machine learning and deep learning to classify microseismic events in mines, which provides reliable technical support for mine safety and geologic disaster prevention. Li et al. [
13] proposed a hierarchical deep learning framework based on images used for coal and gangue detection. This framework employs deep learning algorithms and utilizes a hierarchical structure to solve the problem of coal and gangue differentiation in coal mines. These studies indicate that introducing machine learning and deep learning technology provides more intelligent and automated coal mine production and management solutions, thus effectively improving efficiency, safety, and sustainability. Therefore, combining deep learning and visible light positioning technology is feasible to accurately position people who are underground in coal mines. More and more researchers are also applying deep learning to visible light localization. By selecting suitable deep learning models and optimizing them for specific positioning tasks, researchers can improve the models’ learning and generalization abilities, thereby enhancing the positioning accuracy and opening up new possibilities.
Chen et al. [
14] proposed a long short-term memory fully connected network (LSTM-FCN)-based localization algorithm for implementing a VLP system with a single LED and multiple photodetectors (PDs). Lin et al. [
15] proposed a model replication technique utilizing a position cell model to generate additional position samples and augment the diversity of the training data. Wei et al. [
16] developed a method employing a metaheuristic algorithm to optimize the initial weights and thresholds of the extreme learning machine (ELM), thereby improving localization accuracy. However, the use of an optimization-seeking algorithm adds complexity to the model. Zhang et al. [
17] presented a 3D indoor visible light positioning system based on an artificial neural network with a hybrid phase difference of arrival (PDOA) and RSS approach, enhancing the system stability in light signal intensity variations and reducing the impact of modeling inaccuracies. However, the effect of reflection was not considered. Presently, most visible light positioning studies focus solely on 2D localization [
18,
19,
20]. However, a reliable 3D localization method is crucial for locating people underground in mines. This is because the heights of the miners vary according to the job’s requirements, and height fluctuations can impact the positioning accuracy. Conventional 3D positioning methods typically require at least three LEDs for positioning [
21,
22]. These LEDs emit signals and communicate with a receiver to determine the target’s location. However, this method has several limitations. First, multiple LEDs need to be installed, increasing the complexity and cost of the system. Second, since the signals emitted by the LEDs are reflected on surfaces such as the walls in the mine, the traditional method ignores the effect of such reflections on the localization results. This can lead to an increase in localization errors, especially in complex underground mine environments. In addition, the PD’s tilt and the PD height’s fluctuation can also impact the positioning accuracy, which are factors that are often not adequately considered in conventional methods. Some existing 3D visible light positioning systems employ hybrid algorithms [
23,
24,
25], increasing the system complexity. To address these challenges and enhance the accuracy and simplicity of underground mine localization, this paper proposes a convolutional neural network (CNN) 3D visible light positioning system based on the Inception-v2 module [
26] and efficient channel attention (ECA) module [
27]. In this study, two LEDs were utilized as emitters and four PDs were used as receivers, and the effects of the wall reflections and PDs’ tilts on localization were considered. Conventional convolutional neural networks often rely on stacking deeper convolutional layers to improve performance, which increases the model’s parameter count and the risk of overfitting. This paper employs the Inception module, enabling parallel operations of multiple convolutional and pooling layers with varying sizes. This approach yields multiple feature representations of the input and reduces the computational complexity. Additionally, the ECA module assigns weights to different channel features, extracting the most critical features and ultimately enhancing the localization accuracy.
Its simplicity and ease of implementation characterize the proposed algorithmic model in this paper. Simulation experiments have validated its efficacy in localizing personnel in underground mines. The rest of this paper is organized as follows:
Section 2 elucidates the components of the visible light positioning model.
Section 3 expounds the structure and principles of Inception-ECANet.
Section 4 explores the network parameters that influence localization.
Section 5 presents the simulation and experimental results. Lastly,
Section 6 provides a conclusion to the study.
6. Conclusions
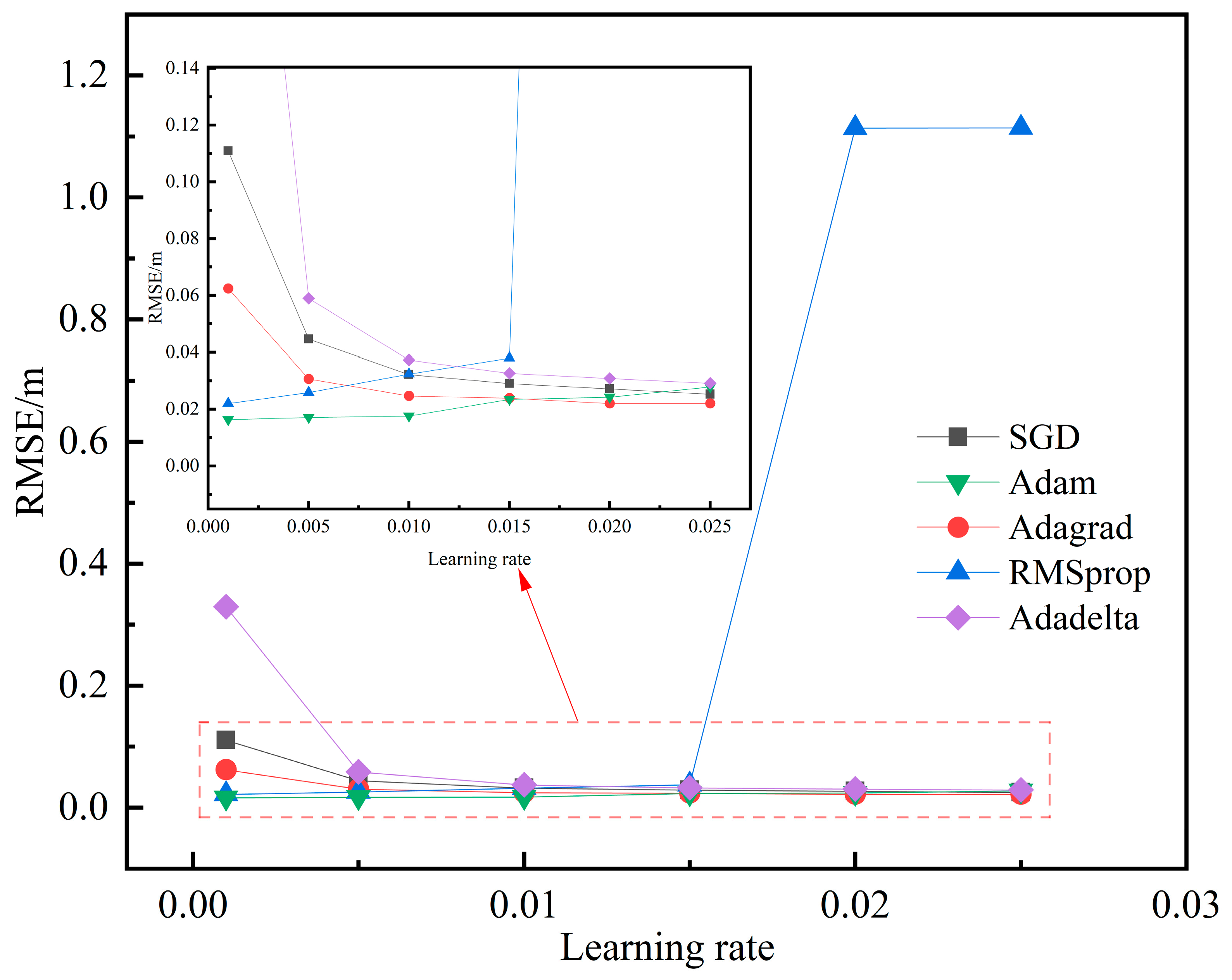
We proposed a convolutional neural network visible light 3D localization system for localizing underground coal mine personnel by combining the Inception-v2 and ECA modules. The system employed two LEDs as transmitting base stations and four PDs mounted on miners’ helmets as receivers. The optical power data acquired from the receivers are used to train the Inception-ECANet model, enabling a precise prediction of the position coordinates. The simulation results demonstrate that within a 6 m × 3 m × 3.6 m space, the Inception-ECANet localization method achieves an average error of 1.63cm and a maximum error of 14.71 cm, with 90% of the localization errors below 4.55 cm. An experimental validation further confirmed the effectiveness of the proposed method, achieving an average error of 11.12 cm and a maximum error of 59.54 cm within the same-sized localization space. It was worth noting that compared to four other positioning methods (BPNN, RNN, LSTM, and CNN), the proposed positioning method in this paper demonstrates outstanding performance. The research results show that when using this method, 90% of the positioning errors are within 28.75 cm, which is far superior to the other four positioning methods. Compared to the BPNN, the algorithm reduced the average positioning error by 33.35%. Similarly, compared to the RNN, the average positioning error was reduced by 48.19%. Compared to the LSTM, the average positioning error was reduced by 49.56%. Furthermore, the proposed algorithm reduced the average positioning error by 13.96% compared to the CNN. Through a comprehensive comparative analysis, it can be seen that the positioning method proposed in this paper exhibits lower positioning errors, which further validates the superiority and practicality of the proposed positioning algorithm in underground personnel positioning in coal mines.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}