
Solving the Problem of Class Imbalance in the Prediction of Hotel Cancelations: A Hybridized Machine Learning Approach

 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Works
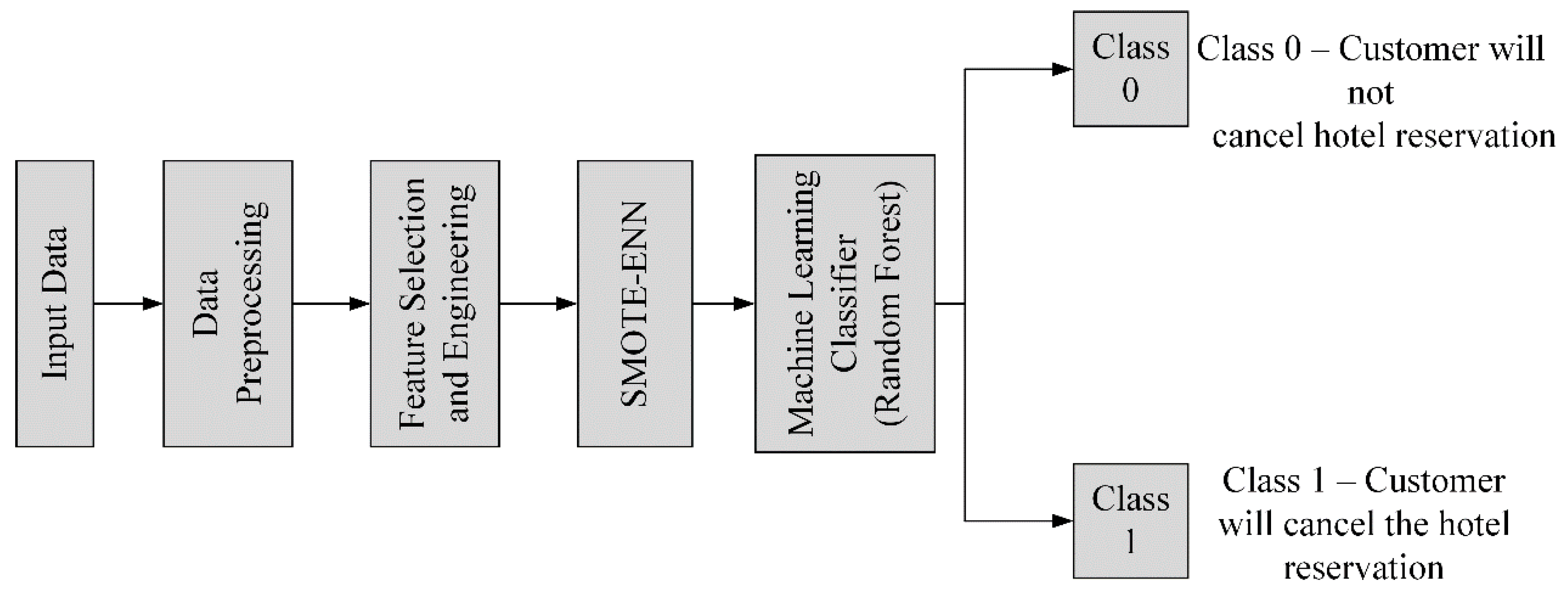
3. Methods
3.1. Dataset Description and Understanding
3.2. Feature Selection and Engineering
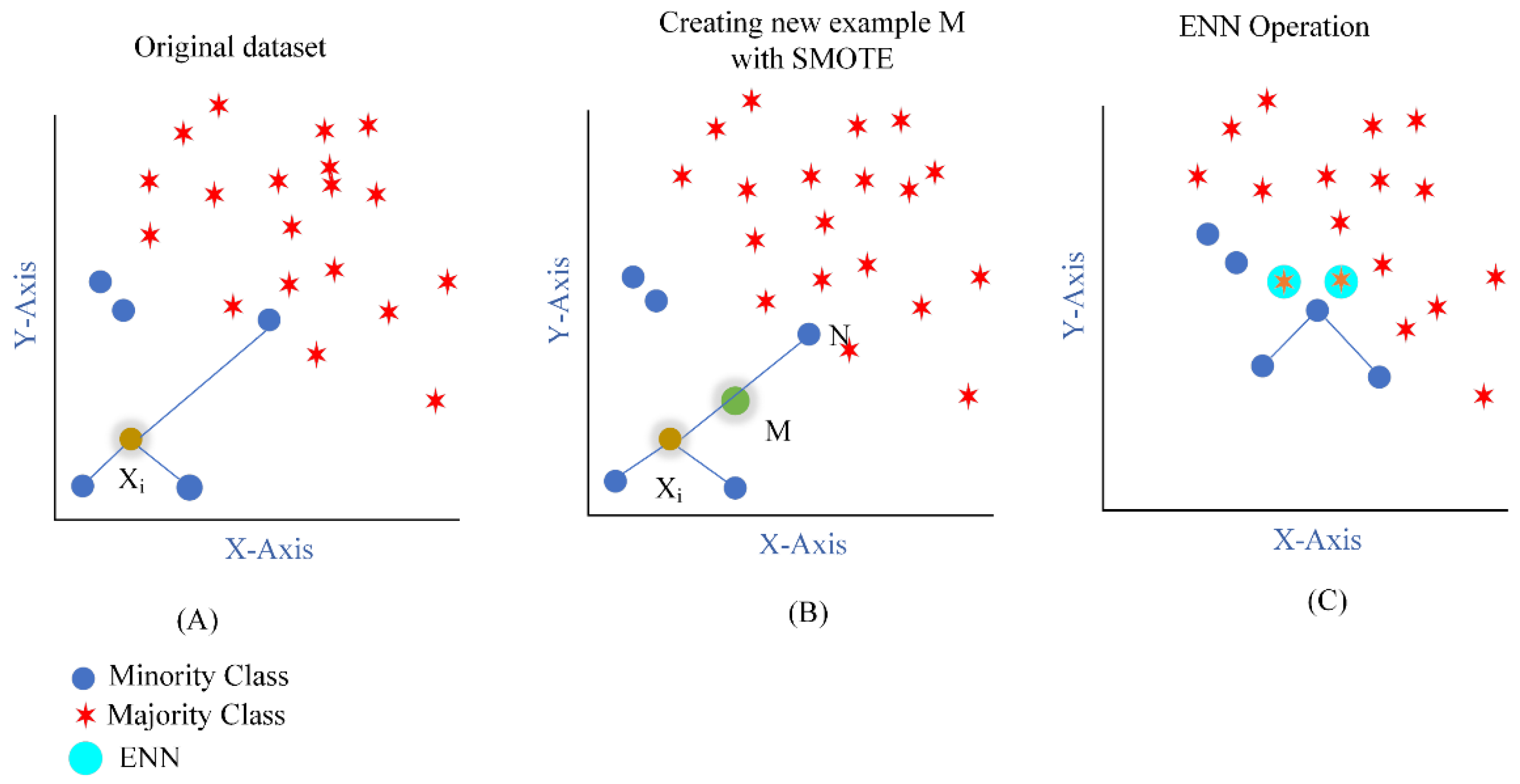
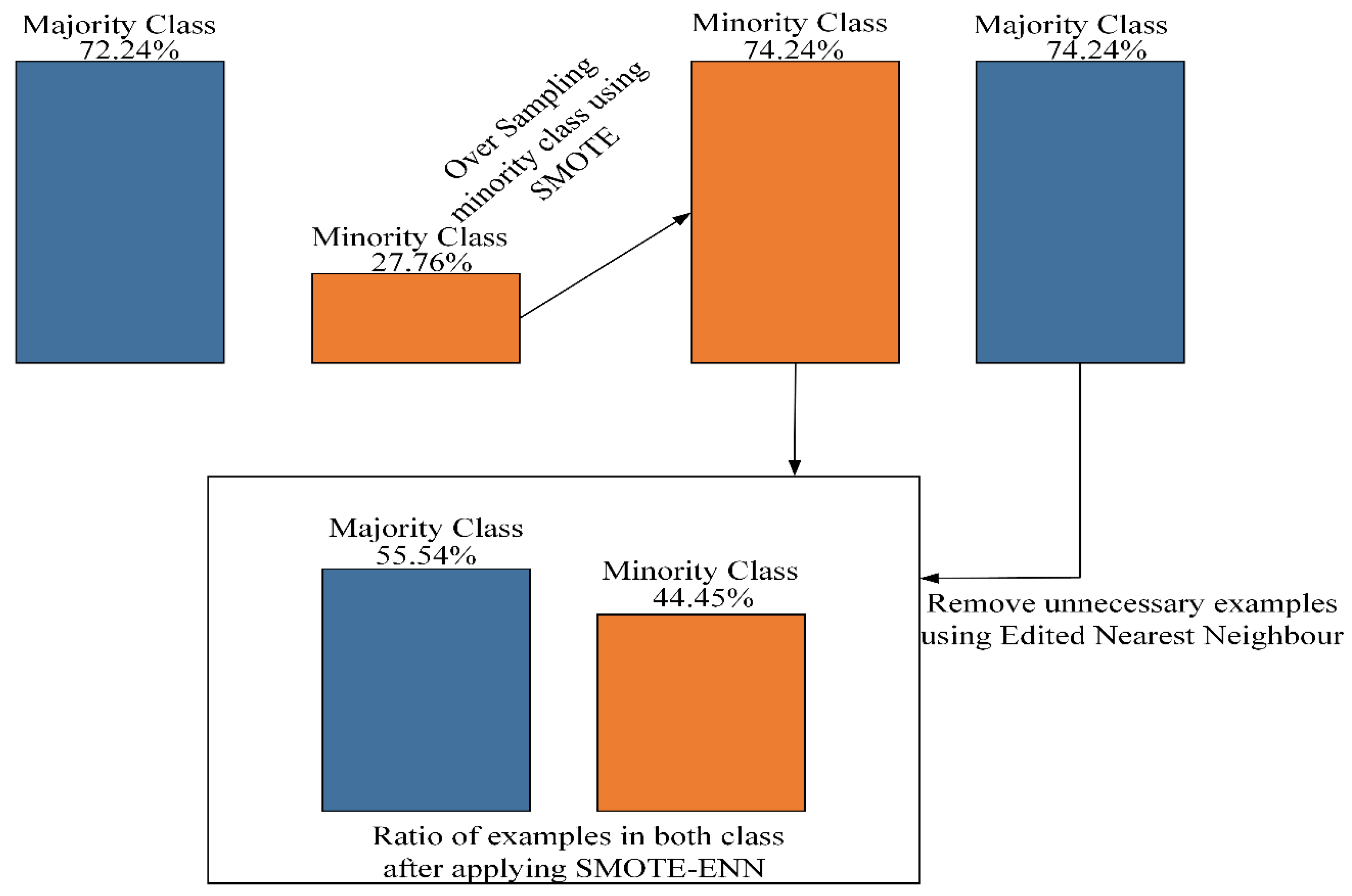
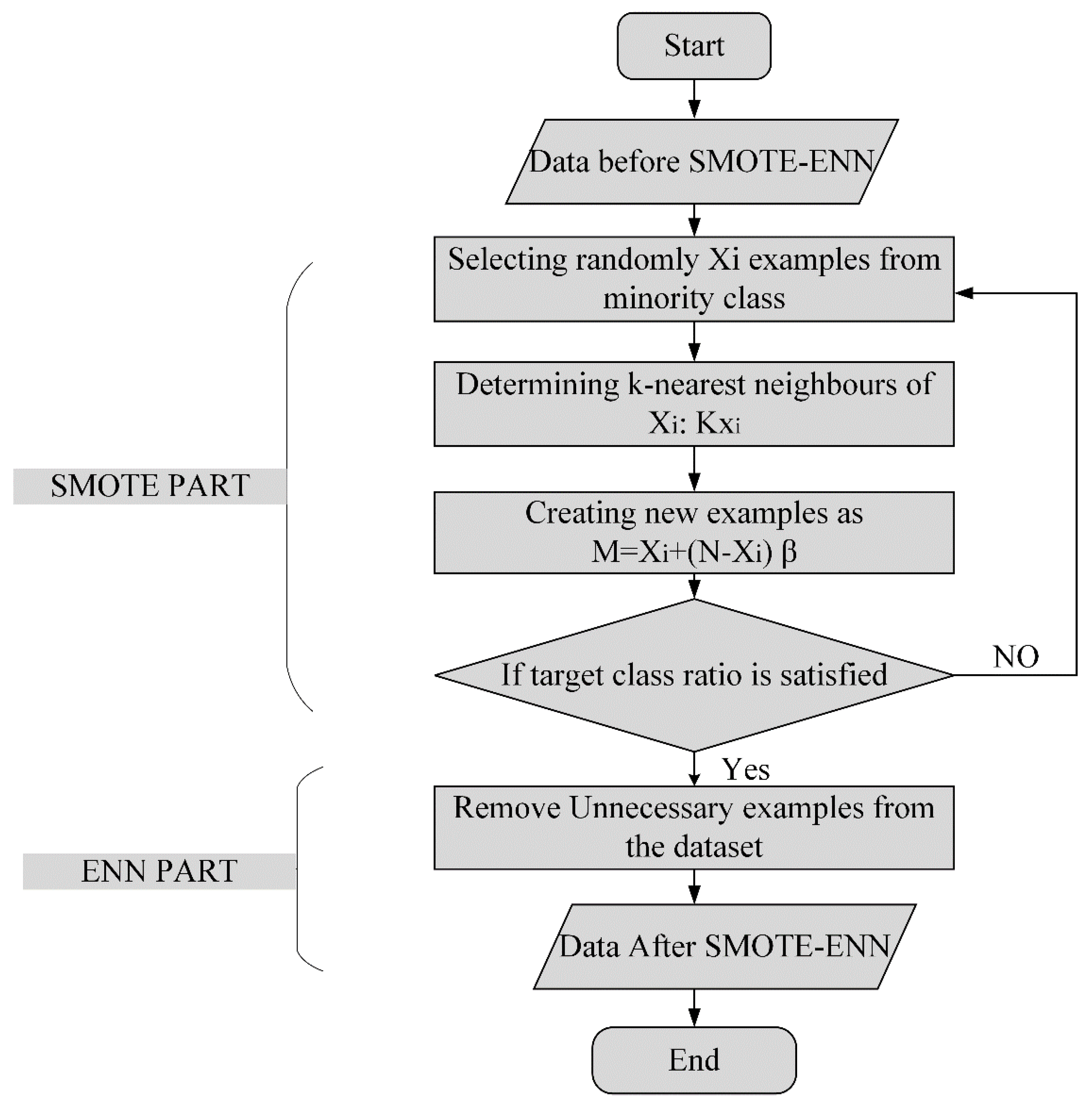
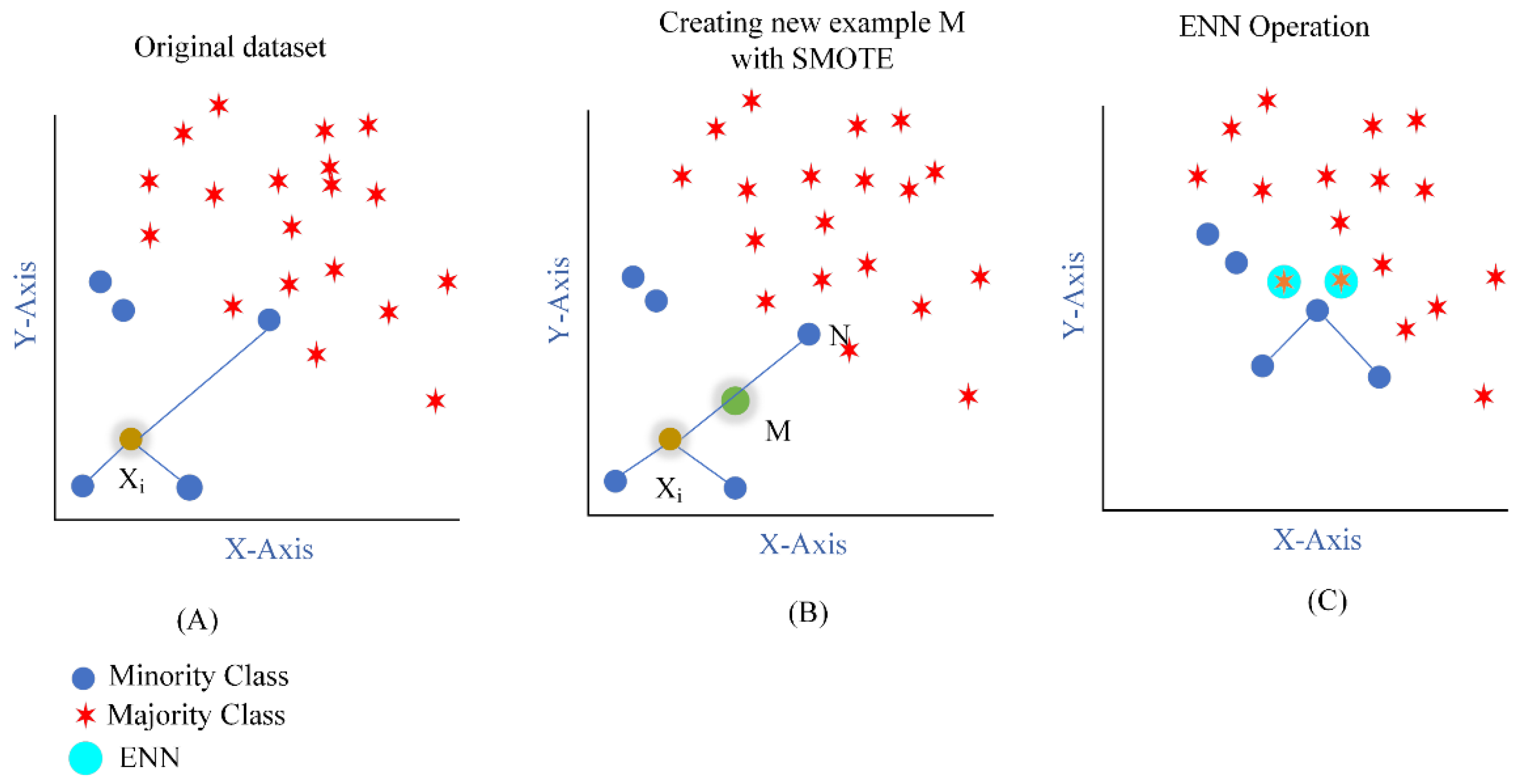
3.3. SMOTE-ENN
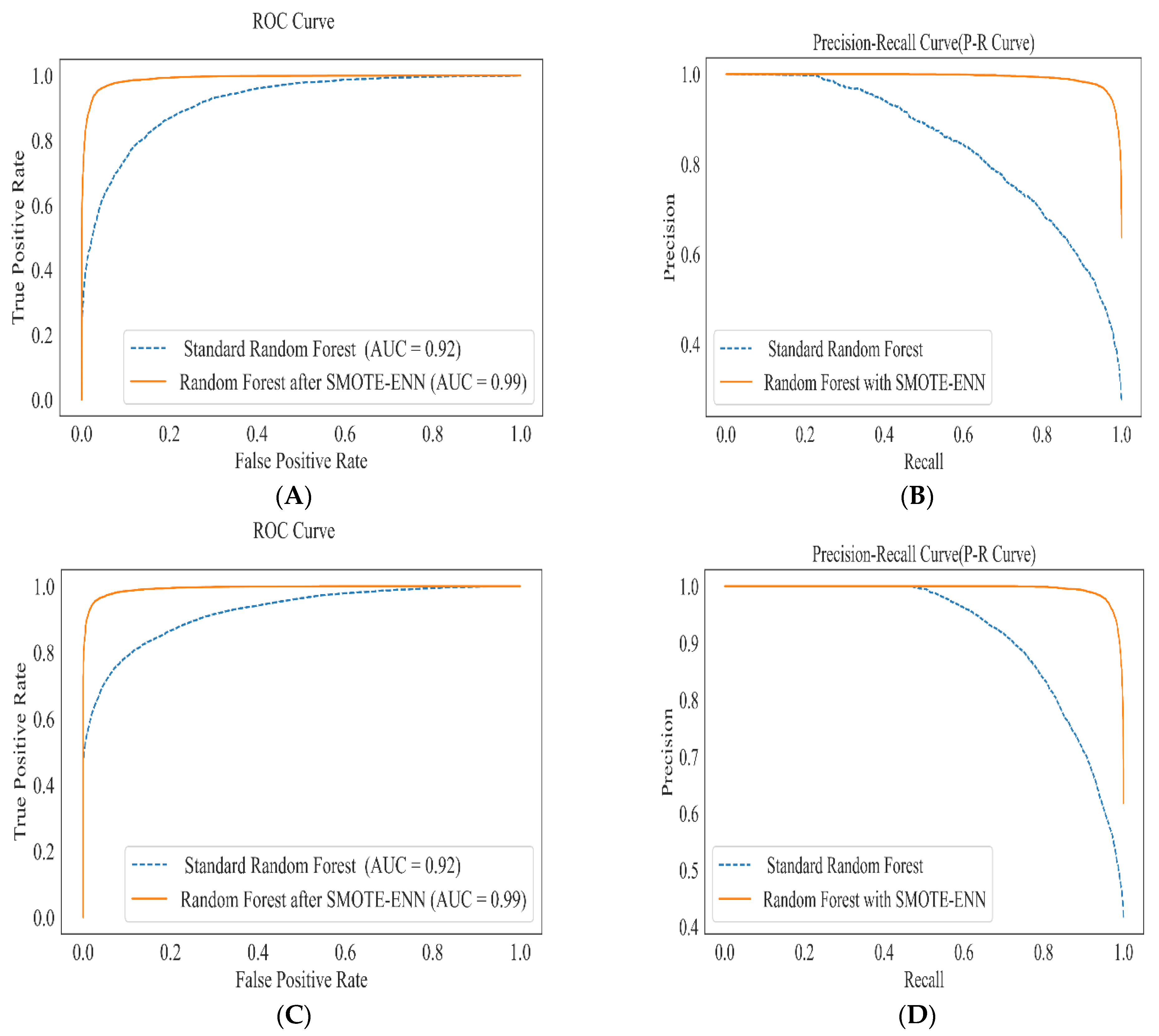
4. Modelling and Performance Evaluation
5. Conclusions
6. Implications
7. Limitations and Directions for Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kimes, S.E.; Wirtz, J. Has revenue management become acceptable? Findings from an International study on the perceived fairness of rate fences. J. Serv. Res. 2003, 6, 125–135. [Google Scholar] [CrossRef]
- Chiang, W.C.; Chen, J.C.H.; Xu, X. An overview of research on revenue management: Current issues and future research. Int. J. Revenue Manag. 2007, 1, 97. [Google Scholar] [CrossRef]
- Mehrotra, R.; Ruttley, J. Revenue Management, 2nd ed.; American Hotel & Lodging Association (AHLA): Washington, DC, USA, 2006. [Google Scholar]
- Talluri, K.T.; Van Ryzin, G.J. The Theory and Practice of Revenue Management; Kluwer Academic Publishers: Boston, MA, USA, 2004. [Google Scholar]
- Smith, S.J.; Parsa, H.; Bujisic, M.; Van Der Rest, J.-P. Hotel Cancelation Policies, Distributive and Procedural Fairness, and Consumer Patronage: A Study of the Lodging Industry. J. Travel Tour. Mark. 2015, 32, 886–906. [Google Scholar] [CrossRef]
- Chen, C.-C.; Schwartz, Z.; Vargas, P. The search for the best deal: How hotel cancellation policies affect the search and booking decisions of deal-seeking customers. Int. J. Hosp. Manag. 2011, 30, 129–135. [Google Scholar] [CrossRef]
- Chen, C.-C.; Xie, K.L. Differentiation of cancellation policies in the U.S. hotel industry. Int. J. Hosp. Manag. 2013, 34, 66–72. [Google Scholar] [CrossRef]
- Morales, D.R.; Wang, J. Forecasting cancellation rates for services booking revenue management using data mining. Eur. J. Oper. Res. 2010, 202, 554–562. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.H. Hotel demand/cancelation analysis and estimation of unconstrained demand using statistical methods. In Revenue Management and Pricing: Case Studies and Applications; Yeoman, I., McMahon-Beattie, U., Eds.; Cengage Learning EMEA: Bedford Row, London, UK, 2004; pp. 91–108. [Google Scholar]
- Alpaydm, E. Combined 5× 2 cv F Test for Comparing Supervised Classification Learning Algorithms. Neural Comput. 1999, 11, 1885–1892. [Google Scholar] [CrossRef]
- Noone, B.M.; Lee, C.H. Hotel overbooking: The effect of overcompensation on customers’ reactions to denied service. J. Hosp. Tour. Res. 2010, 35, 334–357. [Google Scholar] [CrossRef]
- Stanislav, I. Hotel Revenue Management: From Theory to Practice; Zangador: Varna, Bulgaria, 2014; Available online: https://ssrn.com/abstract=2447337 (accessed on 13 March 2021).
- Hayes, D.K.; Miller, A.A. Revenue Management for the Hospitality Industry; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Freisleben, B.; Gleichmann, G. Controlling airline seat allocations with neural networks. In Proceedings of the Twenty-Sixth Hawaii International Conference on System Sciences, Wailea, HI, USA, 8 January 1993. [Google Scholar]
- Garrow, L.; Ferguson, M. Revenue management and the analytics explosion: Perspectives from industry experts. J. Revenue Pricing Manag. 2008, 7, 219–229. [Google Scholar] [CrossRef]
- Hueglin, C.; Vannotti, F. Data mining techniques to improve forecast accuracy in airline business. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001. [Google Scholar] [CrossRef]
- Lemke, C. Combinations of Time Series Forecasts: When and Why Are They Beneficial? Bournemouth University, 2010. Available online: http://dec.bournemouth.ac.uk/staff/bgabrys/publications/C_Lemke_PhD_thesis.pdf (accessed on 19 March 2021).
- Subramanian, J.; Stidham, S., Jr.; Lautenbacher, C.J. Airline Yield Management with Overbooking, Cancellations, and No-Shows. Transp. Sci. 1999, 33, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Gil Yoon, M.; Lee, H.Y.; Song, Y.S. Linear approximation approach for a stochastic seat allocation problem with cancellation & refund policy in airlines. J. Air Transp. Manag. 2012, 23, 41–46. [Google Scholar] [CrossRef]
- Schwartz, Z.; Uysal, M.; Webb, T.; Altin, M. Hotel daily occupancy forecasting with competitive sets: A recursive algorithm. Int. J. Contemp. Hosp. Manag. 2016, 28, 267–285. [Google Scholar] [CrossRef]
- Caicedo-Torres, W.; Payares, F. A machine learning model for occupancy rates and demand forecasting in the hospitality industry. Presented at the Ibero-American Conference on Artificial Intelligence, San José, Costa Rica, 23–25 November 2016; Springer: Cham, Switzerland, 2016; pp. 201–211. [Google Scholar]
- Antonio, N.; de Almeida, A.; Nunes, L. Using data science to predict hotel booking cancelations. In Handbook of Research on Holistic Optimization Techniques in the Hospitality, Tourism, and Travel Industry; Vasant, P., Kalaivanthan, M., Eds.; Business Science Reference: Hershey, PA, USA, 2017; pp. 141–167. [Google Scholar]
- Huang, H.-C.; Chang, A.Y.; Ho, C.-C. Using artificial neural networks to establish a customer-cancelation prediction model. Prz. Elektrotech. 2013, 89, 178–180. [Google Scholar]
- Antonio, N.; De Almeida, A.; Nunes, L. Predicting hotel booking cancellations to decrease uncertainty and increase revenue. Tour. Manag. Stud. 2017, 13, 25–39. [Google Scholar] [CrossRef] [Green Version]
- Antonio, N.; De Almeida, A.; Nunes, L. An Automated Machine Learning Based Decision Support System to Predict Hotel Booking Cancellations. Data Sci. J. 2019, 18, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Antonio, N. Predictive models for hotel booking cancellation: A semi-automated analysis of the literature. Tour. Manag. Stud. 2019, 15, 7–21. [Google Scholar] [CrossRef]
- Leevy, J.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behaviour of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Le, T.; Vo, M.T.; Vo, B.; Lee, M.Y.; Baik, S.W. A Hybrid Approach Using Oversampling Technique and Cost-Sensitive Learning for Bankruptcy Prediction. Complexity 2019, 2019, 8460934. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 2019, 5, 1–36. [Google Scholar] [CrossRef]
- Dimiduk, D.M.; Holm, E.A.; Niezgoda, S.R. Perspectives on the Impact of Machine Learning, Deep Learning, and Artificial Intelligence on Materials, Processes, and Structures Engineering. Integrating Mater. Manuf. Innov. 2018, 7, 157–172. [Google Scholar] [CrossRef] [Green Version]
- Attaran, M.; Deb, P. Machine learning: The new ‘big thing’ for competitive advantage. Int. J. Knowl. Eng. Data Min. 2018, 5, 277–305. [Google Scholar] [CrossRef]
- Patel, H.; Purvi, P. Study and Analysis of Decision Tree Based Classification Algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78. [Google Scholar] [CrossRef]
- Gil Yoon, M.; Lee, H.Y.; Song, Y.S. Dynamic pricing & capacity assignment problem with cancellation and mark-up policies in airlines. Asia Pac. Manag. Rev. 2017, 22, 97–103. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.-Z.; Lahcen, A.A.; Belfkih, S. Big Data technologies: A survey. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Feng, F.; Li, K.-C.; Shen, J.; Zhou, Q.; Yang, X. Using Cost-Sensitive Learning and Feature Selection Algorithms to Improve the Performance of Imbalanced Classification. IEEE Access 2020, 8, 69979–69996. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Flath, C.M.; Stein, N. Towards a data science toolbox for industrial analytics applications. Comput. Ind. 2018, 94, 16–25. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wilson, D.L. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Trans. Syst. Man Cybern. 1972, SMC-2, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Antonio, N.; de Almeida, A.M.; Nunes, L. Big Data in Hotel Revenue Management: Exploring Cancellation Drivers to Gain Insights into Booking Cancellation Behavior. Cornell Hosp. Q. 2019, 60, 298–319. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Natarajan, N.; Koyejo, O.; Ravikumar, P.; Dhillon, I. Consistent Binary Classification with Generalized Performance Metrics. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2744–2752. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [Green Version]
- Beger, A. Precision-Recall Curves. 2016. Available online: https://ssrn.com/abstract=2765419 (accessed on 13 March 2021).
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Original/Modified | Description |
|---|---|---|
| Is_canceled | Categorical | Outcome feature: showing whether the booking was canceled (0: no; 1: yes) |
| Lead_time | numeric | Number of days before appearance that the booking was set in the hotel |
| Stays_in_weekend_nights | Numeric | From the entire evening, how many were in ends of the week (Saturday and Sunday) |
| Stays_in_week_nights | Numeric | From the entire evening, how many were during workdays (Monday to Friday) |
| Is_repeated_guest | categorical | Binary value indicating whether a customer was a repeated guest at the time of booking (0: No, 1: Yes), created by comparing the time of booking with the guest history creation record |
| Previous_cancelations | Numeric | Total of previous bookings that were canceled by the client |
| Previous_bookings_not_canceed | Total of previous bookings that were not canceled by the client | |
| Booking_changes | Numeric | Heuristic made by adding the count of booking changes (corrections) earlier to the entry that may show cancelation behavior (arrival or departure dates, number of people, type of meal, ADR, or reserved room type) |
| Days_in_waiting_list | Numeric | Count of booked days was shown in list before it was affirmed |
| Adr | Numeric | Average daily rate |
| Required_car_parking_space | Numeric | Total car parking spaces a visitor required |
| Total_of_special_requests | Numeric | Total extraordinary demands made by a client |
| Stay_nights (Derived) | Numeric | Total number of nights stays in hotel |
| Bill (Derived) | Numeric | Multiplication of stays night and average daily rate |
| Is_family (Derived) | Categorial | Based on the logical operation whether visiting customer was whole family, a couple, or single |
| Total_customer (Derived) | Numeric | Sum of the adults, children, and babies |
| Deposit_given (Modified) | Categorical | Modified from deposit type column |
| Meal | Categorical | ID of meal guest |
| Market_segment | categorical | Group of segments to which the booking was assigned |
| Distribution channel | Categorical | Name of the medium used to make booking |
| Room assignment (Modified) | Categorical | Room type assigned to a customer |
| Customer type | sort of client (group, contract, transitory, or temporary party who required more than one room) |
| Optimal Parameter | Hotel H1 | Hotel H2 |
|---|---|---|
| Criterion | Entropy | Gini |
| Max_features | Log2 | Auto |
| Min_samples_leaf | 1 | 1 |
| Min_samples_split | 4 | 4 |
| N_estimators | 100 | 200 |
| Method | TNR | FPR | FNR | Accuracy | Precision | Recall | F1 Score | AUC | PR-AUC | G-Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| LR | 75.82 | 24.17 | 15.71 | 82.60 | 93.44 | 84.26 | 88.61 | 73.77 | 75.44 | 71.10 |
| LR + SMOTE | 81.51 | 15.64 | 17.01 | 83.66 | 84.39 | 82.98 | 83.68 | 83.76 | 93.79 | 83.53 |
| LR + SMOTE-ENN | 86.34 | 13.65 | 15.80 | 86.30 | 84.67 | 84.76 | 84.72 | 86.15 | 96.27 | 85.95 |
| DT | 52.90 | 47.09 | 12.01 | 81.88 | 86.90 | 87.94 | 87.42 | 77.89 | 71.64 | 77.18 |
| DT + SMOTE | 88.99 | 14.01 | 12.71 | 86.61 | 85.48 | 87.28 | 86.37 | 86.60 | 89.88 | 86.45 |
| DT + SMOTE-ENN | 93.19 | 6.43 | 6.70 | 93.41 | 91.99 | 93.21 | 92.61 | 93.28 | 95.56 | 93.04 |
| AB | 76.97 | 23.02 | 15.47 | 83.04 | 93.76 | 84.52 | 88.90 | 74.29 | 77.67 | 71.70 |
| AB + SMOTE | 81.85 | 18.14 | 15.30 | 83.96 | 80.29 | 86.42 | 83.24 | 83.93 | 93.18 | 84.40 |
| AB + SMOTE-ENN | 86.32 | 13.67 | 11.77 | 87.76 | 82.17 | 89.66 | 85.74 | 87.23 | 96.31 | 87.12 |
| GB | 79.68 | 20.31 | 15.34 | 83.71 | 94.68 | 84.65 | 89.39 | 74.77 | 79.61 | 72.20 |
| GB + SMOTE | 83.49 | 16.50 | 11.48 | 85.37 | 82.22 | 87.51 | 84.80 | 85.34 | 90.00 | 85.35 |
| GB + SMOTE-ENN | 89.21 | 10.78 | 9.69 | 89.68 | 96.24 | 90.30 | 88.22 | 89.35 | 96.96 | 89.46 |
| RF | 78.69 | 21.30 | 11.67 | 85.97 | 92.78 | 88.43 | 90.55 | 80.42 | 83.78 | 79.40 |
| RF + SMOTE | 90.78 | 9.21 | 10.34 | 90.21 | 90.76 | 89.65 | 90.20 | 90.21 | 97.00 | 90.28 |
| RF + SMOTE-ENN | 94.95 | 4.54 | 4.49 | 95.39 | 94.20 | 95.43 | 94.82 | 95.28 | 99.17 | 95.08 |
| Method | TNR | FPR | FNR | Accuracy | Precision | Recall | F1 Score | AUC | PR-AUC | G-Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| LR | 85.75 | 14.24 | 20.42 | 81.58 | 92.07 | 79.57 | 85.37 | 79.47 | 86.16 | 78.48 |
| LR + SMOTE | 86.10 | 13.89 | 21.02 | 82.08 | 87.95 | 78.95 | 83.21 | 82.02 | 91.12 | 81.92 |
| LR + SMOTE-ENN | 91.93 | 8.06 | 17.51 | 87.30 | 90.73 | 82.48 | 84.72 | 86.41 | 95.59 | 88.13 |
| DT | 77.92 | 22.07 | 15.42 | 81.77 | 84.14 | 84.49 | 84.23 | 81.19 | 82.40 | 81.21 |
| DT + SMOTE | 83.03 | 16.96 | 15.45 | 83.78 | 83.06 | 84.54 | 83.80 | 83.79 | 87.58 | 83.80 |
| DT + SMOTE-ENN | 95.07 | 4.92 | 5.56 | 94.79 | 93.81 | 94.43 | 94.12 | 94.69 | 96.50 | 94.57 |
| AB | 85.53 | 14.76 | 20.07 | 81.70 | 91.68 | 79.92 | 85.40 | 79.90 | 87.51 | 78.80 |
| AB + SMOTE | 86.11 | 13.88 | 22.12 | 81.40 | 88.23 | 77.87 | 82.73 | 81.33 | 90.88 | 81.06 |
| AB + SMOTE-ENN | 92.60 | 7.39 | 17.56 | 87.58 | 91.59 | 82.43 | 86.77 | 87.98 | 96.65 | 88.16 |
| GB | 86.40 | 13.59 | 20.08 | 82.02 | 92.42 | 79.91 | 85.71 | 79.93 | 88.53 | 79.00 |
| GB + SMOTE | 88.33 | 11.66 | 21.68 | 82.49 | 90.35 | 78.31 | 83.90 | 82.42 | 91.93 | 81.98 |
| GB + SMOTE-ENN | 93.46 | 6.53 | 17.77 | 89.04 | 92.46 | 84.40 | 88.24 | 89.38 | 97.25 | 89.73 |
| RF | 85.57 | 14.20 | 14.85 | 85.39 | 90.81 | 85.14 | 87.88 | 84.32 | 91.72 | 84.15 |
| RF + SMOTE | 88.93 | 11.06 | 15.31 | 87.24 | 89.65 | 85.73 | 87.64 | 87.22 | 95.21 | 87.30 |
| RF + SMOTE-ENN | 96.98 | 3.01 | 4.87 | 96.14 | 96.27 | 95.12 | 95.69 | 96.16 | 99.50 | 96.33 |
| Methods | p-Value | F-Statistic |
|---|---|---|
| RF vs. LR | 9.064 × 10−9 | 134.339 |
| RF vs. CLF | 1.295 × 10−5 | 158.175 |
| RF vs. AB | 2.400 × 10−5 | 123.369 |
| RF vs. GB | 2.624 × 10−5 | 119.012 |
| RF + SMOTE vs. LR + SMOTE | 1.364 × 10−7 | 983.107 |
| RF + SMOTE vs. CLF + SMOTE | 1.024 × 10−7 | 1102.694 |
| RF + SMOTE vs. AB + SMOTE | 4.543. × 10−7 | 607.249 |
| RF + SMOTE vs. GB + SMOTE | 1.052 × 10−7 | 1091.102 |
| RF + SMOTE-ENN vs. RF + SMOTE-ENN | 3.518 × 10−7 | 672.790 |
| RF + SMOTE-ENN vs. CLF + SMOTE-ENN | 3.495 × 10−5 | 106.001 |
| RF + SMOTE-ENN vs. AB + SMOTE-ENN | 1.576 × 10−9 | 368.736 |
| RF + SMOTE-ENN vs. GB + SMOTE-ENN | 9.064 × 10−9 | 2910.776 |
| Methods | p-Value | F-Statistic |
|---|---|---|
| RF vs. LR | 6.128 × 10−6 | 213.791 |
| RF vs. CLF | 8.897 × 10−7 | 463.883 |
| RF vs. AB | 6.031 × 10−6 | 215.159 |
| RF vs. GB | 6.372 × 10−6 | 210.458 |
| RF + SMOTE vs. LR + SMOTE | 1.759 × 10−7 | 888.049 |
| RF + SMOTE vs. CLF + SMOTE | 5.199 × 10−6 | 228.393 |
| RF + SMOTE vs. AB + SMOTE | 4.823 × 10−6 | 235.392 |
| RF + SMOTE vs. GB + SMOTE | 6.970 × 10−6 | 203.003 |
| RF + SMOTE-ENN vs. RF + SMOTE-ENN | 1.573 × 10−7 | 928.726 |
| RF + SMOTE-ENN vs. CLF + SMOTE-ENN | 1.26 × 10−4 | 62.714 |
| RF + SMOTE-ENN vs. AB + SMOTE-ENN | 2.052 × 10−7 | 834.984 |
| RF + SMOTE-ENN vs. GB + SMOTE-ENN | 1.249 × 10−6 | 404.781 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adil, M.; Ansari, M.F.; Alahmadi, A.; Wu, J.-Z.; Chakrabortty, R.K. Solving the Problem of Class Imbalance in the Prediction of Hotel Cancelations: A Hybridized Machine Learning Approach. Processes 2021, 9, 1713. https://doi.org/10.3390/pr9101713
Adil M, Ansari MF, Alahmadi A, Wu J-Z, Chakrabortty RK. Solving the Problem of Class Imbalance in the Prediction of Hotel Cancelations: A Hybridized Machine Learning Approach. Processes. 2021; 9(10):1713. https://doi.org/10.3390/pr9101713
Chicago/Turabian StyleAdil, Mohd, Mohd Faizan Ansari, Ahmad Alahmadi, Jei-Zheng Wu, and Ripon K. Chakrabortty. 2021. "Solving the Problem of Class Imbalance in the Prediction of Hotel Cancelations: A Hybridized Machine Learning Approach" Processes 9, no. 10: 1713. https://doi.org/10.3390/pr9101713
APA StyleAdil, M., Ansari, M. F., Alahmadi, A., Wu, J.-Z., & Chakrabortty, R. K. (2021). Solving the Problem of Class Imbalance in the Prediction of Hotel Cancelations: A Hybridized Machine Learning Approach. Processes, 9(10), 1713. https://doi.org/10.3390/pr9101713