1. Introduction
Seasonal time series forecasting with computers had early success with seasonal adjusted methods as proposed in 1978 [
1] or with the the X-11 method [
2]. Over the years, improved versions, such as the X-13 [
3], various variants of such models and new techniques in the area of statistical models, were developed [
4], and a new field emerged in computational intelligence dealing with seasonal time series forecasting arose [
5]. Recently, a method based on Fourier analysis was introduced [
6]. Fourier analysis can be used for estimating seasonal components in a time series. The frequency content of a time series over its complete range can be approximated with Fourier analysis. Varying seasonality imposes a problem for forecasting methods that assume a non-varying seasonality, because Fourier analysis gives only a representation of the frequency content of a time series and does not give a relation of frequency patterns to specific time intervals [
7]. For example, the relationship of high frequency peaks at a specific time interval cannot be captured by Fourier analysis [
7]. Different frequencies can be captured with Fourier analysis as part of the whole time series without a specific relation to time intervals. The recognition of high frequencies is constrained by the sample rate (Nyquist–Shannon sampling theorem [
8]), whereas for low frequencies, it is constrained by the total length of the time series itself.
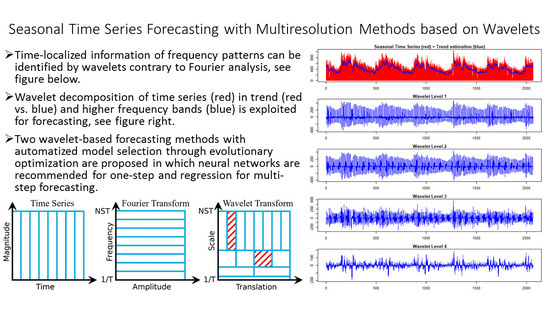
In contrast, the wavelet analysis uses short time intervals for capturing high frequencies in order to relate them to specific time intervals (localization in time) more precisely than Fourier analysis. Low frequencies are treated with longer time intervals (compared to the high frequencies), since the recognition of low frequencies depends on the maximal length of the time interval used for analysis. Large high frequency bands are captured with small time intervals, whereas the small low frequency bands are captured with large time intervals. Therefore, it is interesting to apply wavelet analysis for seasonal time series forecasting in order to investigate the potential of such a model to adapt to complex seasonal structures. In this work, two time series forecasting methods using the redundant Haar wavelet decomposition were implemented and compared to several state-of-the-art forecasting methods, including a Fourier method [
6] and other multiresolution methods [
9,
10]. The rough sketch of the wavelet algorithm is based on [
11,
12,
13,
14,
15], but no software was referenced there. Moreover, no method for efficiently computing the best coefficient selection from their prediction scheme existed.
Thus, we propose the use of a differential evolutionary optimization strategy to solve the complex model selection problem in the wavelet forecasting concept introduced by [
16]. This strategy does not require the user to set any parameters since such a task can be performed automatically by computational intelligence. The two algorithms are open-source and provided in Python and R [
17,
18] without the necessity to manually set parameters.
Currently, the following methods in Python or R for computing the wavelet decomposition for different task and with different approaches are accessible: signal processing with the continuous wavelet transform [
19], signal and image processing with various wavelet transforms [
20,
21], wavelet analysis with scalogram tools [
22], univariate and bivariate wavelet analysis [
23], wavelet analysis (Angi, R.; Harald, S., 2018), signal processing [
24], signal processing for one to three dimensions [
25], wavelet statistics [
26] and testing white noise with wavelets [
27]. There are three packages in R dealing with time series forecasting with the wavelet decomposition, but all three packages require the user to set parameters. The first uses a redundant Haar wavelet decomposition in combination with an ARIMA framework [
28,
29]. The second one uses a redundant Haar wavelet decomposition combined with an artificial neural network [
30,
31]. The last one uses GARCH and is of no interest here [
32].
There has been a plethora of developments in time series forecasting over the last four decades [
4]. The main direction is to evaluate forecasting techniques on out-of-sample forecasts [
33], perform model selection with a cross validation [
34] and to compare results with relative or scaled errors [
35]. Much effort was put in empirical studies [
36,
37,
38,
39], comparing many techniques across multiple datasets, which was recommended for classification tasks by [
40]. The naïve method forecasts the time series by continuing the last value. Adapted to seasonality patterns, the last value of the last season of the forecast is taken. In this work, such a method will be defined as seasonal naïve. The assumption is that any forecasting method should at least outperform the seasonal naïve method [
36,
37,
38,
39].
The main contribution of this work is as follows:
An open-source and application-oriented wavelet framework combined with an automatic model selection through differential evolutionary optimization with standardized access in Python and R.
Contrary to prior works, a systematic comparison of state-of-the-art methods and open-source accessible seasonal univariate forecasting methods to our framework.
Wavelet forecasting performs equally well on short-term and long-term forecasting.
This work is structured as follows.
Section 2 explains the forecasting setting and presents the multiresolution forecasting method for which the software is available on pypi and CRAN [
17,
18]. The cross validation designed for time series forecasting is outlined, datasets are introduced, the quality measures are defined and justified, and an estimation and visualization technique for the distribution is presented.
Section 3 shows the results with a scaled quality measure used for benchmarking. The results with a relative error are in
Appendix B.
Section 4 discusses the results and
Section 5 closes with a conclusion.
2. Materials and Methods
The first
Section 2.1 outlines the selection of open-source available time series forecasting algorithms.
Section 2.2 explains an adaptation of cross validation for out-of-sample forecasts, which is used for the computations and whose results are presented in
Section 3.
Section 2.3 illustrates the datasets which are used for evaluation and outlines their industrial application.
Section 2.4 and
Section 2.5 define the quality measures used here to evaluate the forecast errors computed with
Section 2.2.
Section 2.6 presents an estimation and visualization technique for probability density functions, which is used to analyze the samples obtained with the two quality measures from
Section 2.4 and
Section 2.5. The last
Section 2.7 presents the multiresolution method.
2.1. Related Work
The focus of this work is the forecasting of seasonal univariate time series. Therefore, open access forecasting methods are selected that are specially designed for dealing with seasonality (periodic patterns) independently of the classification into short- and long-term methods. Although in the general case different forecast horizons require different methods [
41], Fourier decomposition of time series allows to use methods, such as Prophet, in both cases [
6]. Moreover, short- and long-term forecasting strategies usually depend strongly on the resolution of the time series [
42,
43], whereas periodic patterns do not necessarily depend on the resolution. Hence, the performance of all methods over all 14 horizons are computed and grouped by horizon one versus horizon above one (multi-step). Implicitly, the performance of the one-step forecasts represents a short-term evaluation, and the multi-step forecasts represent a long-term evaluation. In both cases, the distribution is estimated visualized separately with the MD plot [
44]. The performance of the method is evaluated with rolling forecasting origins [
34] on multiple datasets competing against 10 other forecasting techniques. To the knowledge of the authors, no systematic benchmarking using wavelet forecasting was performed so far. The 12 forecasting techniques were selected, according to their potential of dealing with seasonal time series and their open-source accessibility.
As it is a common issue in data science that published techniques are not implemented (e.g., swarm-based techniques [
45]), this work focuses on methods for which open-source implementations are provided through either the Comprehensive R Archive Network (CRAN) or the Python Package Index (pypi). The current state-of-the-art method, according to accessible open-sources for time series forecasting in Python and R, contain the following techniques: ARIMA, Cubic Spline extrapolation, decomposition models, exponential smoothing, Croston, MAPA, naive/random walks, neural networks, Prophet and the theta method. Two automatized forecasting methods are used to represent the current state of the art for ARIMA models: the first one is RJDemetra, which is an ARIMA model with seasonal adjustment, according to the “ESS Guidelines on Seasonal Adjustment” [
46] available from the National Bank of Belgium, using two leading concepts TRAMO-SEATS+ and X-12ARIMA/X-13ARIMA-SEATS [
3] and referred to as “SARIMA” (or short “SA”) [
47] and an automatized ARIMA referred to as “AutoARIMA” (or short “AA”) [
48,
49]. Modeling ARIMA for time series forecasting follows an objective and thus can be completely automatized by optimizing an information criterion for which AutoARIMA and SARIMA are two different approaches [
48]. Cubic spline extrapolation is a special case of the ARIMA (0,2,2) model [
50], and is represented by the ARIMA models. Croston is not used since it does only provide one-step forecasts [
51]. The Multi Aggregation Prediction Algorithm (“MAPA”) uses exponential smoothing as a forecasting technique on multiple resolution levels, which are recombined into one forecast on one specified resolution level [
9,
10,
52]. Since the combination of forecasts tends to yield better results [
53], MAPA represents the exponential smoothing methodology. The naïve method or random walk is incorporated in the quality measure used in the results section. In order to represent neural networks, a feed-forward neural network (“NN”), a multilayer perceptron (“MLP”) and a long short-term memory (“LSTM”) with one hidden layer is used since neural networks were recommended as robust forecasting techniques if they have at least one hidden layer [
54]. “Prophet” is a decomposition model, using Fourier theory, specially designed for seasonal time series forecasting [
6,
55]. Therefore, no other decomposition model is used besides Prophet. Forecasts with the Theta method “are equivalent to simple exponential smoothing with drift” [
56] and are here represented with MAPA. Furthermore, XGBoost (“XGB”) [
57] is included since it was recommended as a robust algorithm for general machine learning tasks [
58].
There are two related forecasting frameworks using wavelets: [
28,
30], proposed independently of each other and so far not compared to each other. Both methods are based on the redundant Haar wavelet decomposition. In both methods, the wavelets and the last smooth approximation levels are forecasted on each level, separately. Ref. [
30] incorporates artificial neural networks for that purpose, whereas [
28] incorporates an ARIMA framework in contrast to our method, which uses regression optimized with least squares [
59]. In these two comparable methods, the final forecasts are obtained by exploiting the additive nature of the reconstruction of the redundant Haar wavelet decomposition. Thus, a forecast is created by forecasting each level of this decomposition separately and by reconstructing the time series value (forecast) from it. Their methodology is opposed to the approach we take in this work. However, both methods do not provide a framework for model selection. Instead, the parameters, such as the wavelet levels, have to be specified by the user. Hence, in this study, their parameters remain in the default setting specified by the documentation of the packages, i.e., require parameters indicating the number of decomposition levels (“Waveletlevels”), a boundary condition (“boundary”), the maximum non-seasonal order (“nonseaslag”), and the maximum seasonal order (“seaslag”). Such parameters are not necessary in our proposed multiresolution framework. In the following sections, the wavelet method using an artificial neural network is denoted as “MRANN”, whereas the method using ARIMA is denoted as “MRA”. The abbreviation “MR” stands for “multiresolution”.
2.2. Rolling Forecast
A specific cross-validation approach to compute out-of-sample forecasts is explained here as follows. The data are repeatedly split into training and evaluation sets. The training data are used for fitting a model, and the evaluation set is used for model evaluation. A cross validation is performed by dividing the data multiple times. However, time series data cannot be split arbitrarily because the training set always consists of observations occurring in time prior to the evaluation set. Fitting a forecasting method to the data yields a forecasting model. Suppose k values are required for creating a forecasting model. A cross validation for time series forecasting known as “rolling forecasting origin” with a forecast horizon h is obtained as follows:
Split time series into training and test set:
Training: 1, …, k + i − 1.
Evaluation: k + h + i − 1.
Fit the forecasting method on the training dataset and compute the error of the resulting forecasting model for k + h + i − 1 on the evaluation dataset.
Repeat the above steps for i = 1, …, k + h + i − 1, with t being the total length of the time series.
Compute a quality measure based on the errors obtained from the previous steps.
This procedure is applied for the general case of multi-step forecasts. For one-step forecasts, h = 1 is applied. The model is trained and evaluated multiple times in order to determine its ability for generalization. The large set of out-of-sample forecasts ensure a more accurate total error measurement and sufficient samples for statistical analysis. The forecasts in
Section 3 are computed with a rolling forecasting origin for a forecast horizon from h = 1 to h = 14 for the last 365 days. Hence, this work assumes that on the investigated datasets, the longest seasonality is not longer than a year.
The rolling forecast uses a training set to adapt the parameters of a specific forecasting method to create a model and an evaluation set to estimate the models forecasting performance. In order to obtain a supposedly best model, the choice of the parameters can be estimated with criteria based on the training data. One possibility is to split the training dataset a second time as explained above for the rolling forecast and to determine the model with the best out-of-sample forecast on the test dataset, which can be called model selection. The model selection could be either done once in order to determine one global model for the complete rolling forecast on the evaluation dataset, or it could be done in each iteration step of the rolling forecast in order to obtain a dynamic model selection approach. Let the two model selections be named fixed and dynamic parameter selections, respectively. The dynamic parameter selection is used in the automatized forecast techniques AARIMA [
48] and SARIMA [
47]. The fixed parameter selection is used for the four methods multiresolution method with the regression (MRR) and neural network (MRNN), MAPA and Prophet. The neural networks MLP and LSTM, and the gradient boosting machine XGBoost (each with input size 3) are fitted on training data and tested on the test set without any selection since they are recommended as robust methods.
2.3. Datasets
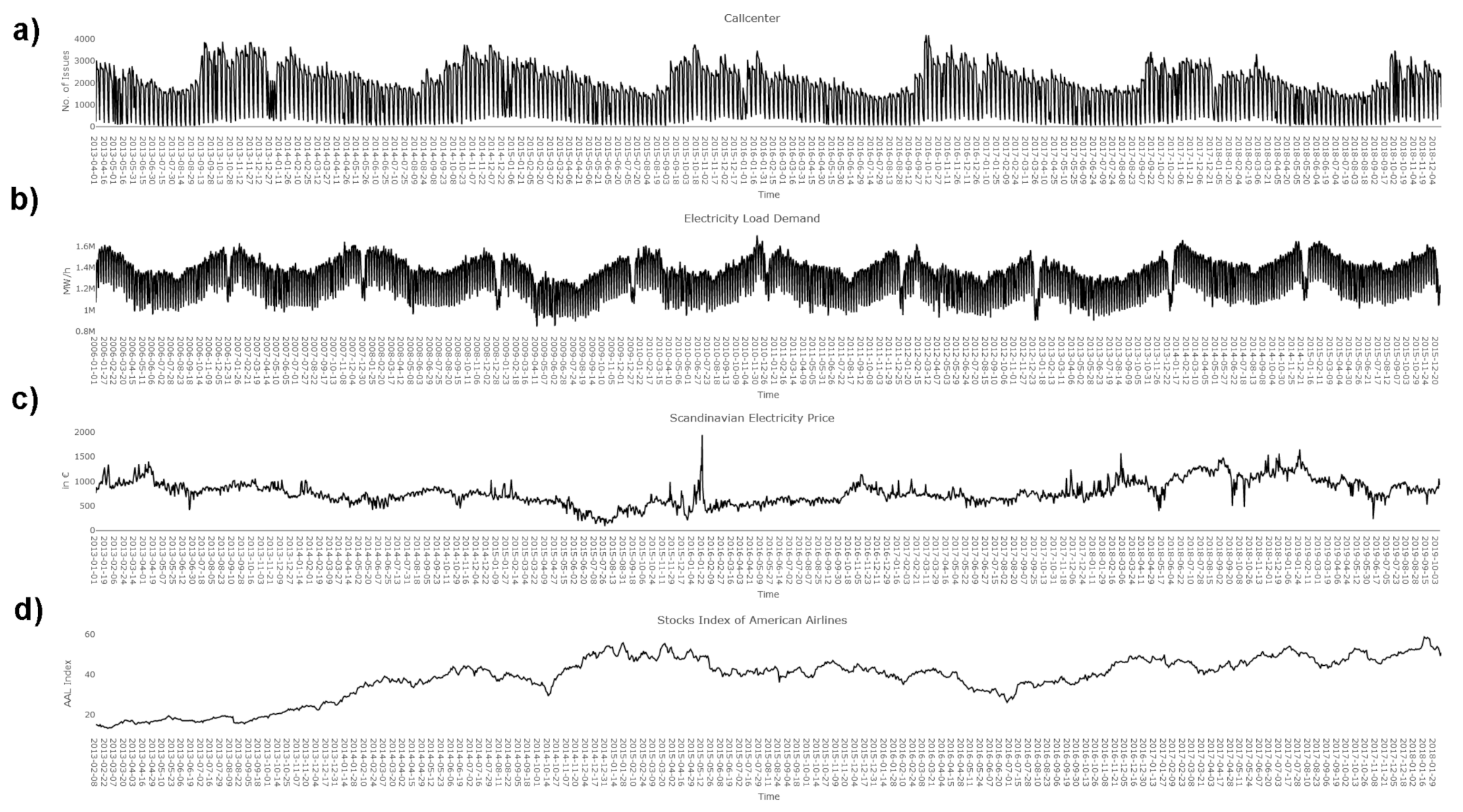
There are four datasets used in this work. All are common-use cases for time series forecasting in recent literature [
12,
60,
61,
62]. The datasets treat electric load demand, stocks, prices and calls arriving in a call center. The European Network of Transmission System Operators for Electricity time series data describes the daily load values in Germany covering a time range from 2006 to 2015. The time series is in an hourly format per country and was aggregated to a daily basis. It contains 3652 data points. This time series has very strong seasonal components; therefore, a Fourier-based approach is expected to yield positive results. The Stocks time series contains stock values for the corporation key American Airlines from Standard and Poor’s (SAP 500). It ranges from the start of 2013 to June 2017, containing 1259 data points. The Scandinavian Electricity Price time series data provides hourly prices per Scandinavian country. The system price is chosen here. The data range from the start of 2013 to the start of 2016, containing 2473 data points. The call center data provide the number of issues in a call center per day. The observations reach from 1 April 2013 to the 15 December 2018, containing 2082 data points. This time series has very strong seasonal components, comparably to the dataset of Electricity. Therefore, a Fourier-based approach is expected to yield positive results. The time series are called in the appearing order “Electricity”, “Stocks”, “Prices”, and “Callcenter”. The Electricity and Callcenter datasets are seasonal time series. The Price dataset has varying seasonal components. External influences on electricity prices cause varying “seasonality at the daily, weekly and annual levels and abrupt, short-lived and generally unanticipated price spikes” [
43]. The Stocks dataset is based on a stock time series, and it can be assumed that future stock prices depend largely on external information not included in the data. Moreover, according to the Random Walk Theory, stocks time series result from a purely stochastic process [
63]. The time series all have a daily resolution, and there are no missing values. The datasets were taken from the web with the exception of the callcenter data, which were provided by Tino Gehlert. Electricity can be found on [
64]. The Stocks dataset is part of the SAP500 and can be found on [
65]. Prices (Scandinavian Electricity Prices) can be found on [
66].
2.4. Mean Average Scaled Error
The Mean Average Scaled Error (MASE) was proposed by [
35]. An absolute scaled error is defined by the following:
Each forecast error is scaled by the Mean Absolute Error (MAE) of the in-sample forecasts created with the naïve method.In the case of seasonal data, the seasonal naïve method is used, and the formula changes from to , where p denotes the strongest period of the time series. The strongest period is evaluated by computing the MAE for all periods and selecting the argument of the minimum.
In this work, the naïve method was used to scale the MASE on datasets Prices and Stocks, and the seasonal naïve method was used in the case of datasets Electricity and Callcenter. Positive and negative forecast errors are penalized equally. Values greater than one indicate worse out-of-sample one-step forecasts, compared to the average one-step naïve forecast computed in-sample, whereas values smaller than one indicate better forecasts. Hence, MASE divides in outperforming and underperforming methods. The computation of the MASE results in a quality measure independent from the data scale, and thus enables a forecast error comparison between different methods and across different time series. The only case in which the computation of MASE is critical, meaning infinite or undefined values, is when all time points in the data are identical. For multi-step forecasts, the absolute scaled error from Equation (
1) is defined as
with
instead of
. The Mean Absolute Scaled Error is the mean of the preceding scaled error definition (
1):
In this work, the MASE is used to provide a quality measure to compare different methods across different datasets. The scaling is the main reason for the choice of this measure. Furthermore, the scaling with the naïve method provides a benchmark with a simple method.
MASE scales the forecast errors so that the performance of each method can be compared with all other performances of methods across different datasets.
2.5. Symmetric Mean Absolute Percentage Error
Ref. [
67] proposed the Symmetric Mean Absolute Percentage Error (
SMAPE). Armstrongs original definition is without absolute values in the dominator:
The difference to the MAE is the division by and the multiplication with . Forecasts higher than the actual time series value are penalized less than forecasts, which lie below the actual time series value. SMAPE scales the forecast errors so that the error value is relative to the actual data value.
2.6. MD Plot
A large sample of forecasts are obtained with the rolling forecasting origin. The forecasts are analyzed with an appropriate quality measure and yield a new view on the forecast performance. Especially, the resulting distribution is of interest. The distribution defined by the empirical probability density function (pdf) can be visualized with a special density estimation tool called mirrored density plot (MD plot), which was proposed by [
44]. This empirical distribution provides important information about the underlying process. Conventional methods, such as classic histograms, violin or bean plots with their default parameter settings, showed to have difficulties visualizing distributions correctly [
44]. In the same work, it is shown that MD plots can outperform them if there is no parameter adjustment. For the MD plot, the probability density function is estimated to be parameter-free with the Pareto density estimation [
68]. With some simplification, the visualization of the MD plot is obtained by mirroring the pdf.
2.7. Multiresolution Method
The multiresolution method of a time series
with
N observations is realized with wavelet theory, following the work of [
11,
12,
13,
14,
15,
16]. Wavelets are a standard tool for multiresolution analysis and widely used in data mining [
69]. The wavelet decomposition yields smooth approximations, which are different resolution levels of the time series and wavelet scales, which capture the frequency bands of the time series. Usually, a non-redundant discrete wavelet transform is used for computation, but some points need to be considered when adapting wavelets to the task of time series forecasting. First, a redundant scheme is necessary since at each time point, the information of every wavelet scale must be available [
14]. Second, the wavelet decomposition should not be invariant since a shift in the time series would yield different time series forecasting models [
14]. Third, asymmetric wavelets need to be used in order to allow only information of the past or present to be processed for creating estimations of the future [
14]. Haar wavelets are used for edge detection in data mining [
69]. Furthermore, Haar wavelets yield an orthogonal wavelet decomposition [
14]. This implies a reconstruction formula (
4), which uses only wavelet coefficients from scale
to
J and the coefficient of the last smooth scale (
J) at time point
t in order to recover the value of the original time series at time
t [
69].
denotes the wavelet coefficient at scale
j,
is the value of the original time series, and
is the last smooth approximation coefficient each at time translation
t. The resolution level or smooth approximations of the redundant Haar wavelet decomposition are computed with a filter
; see (
5), [
14]. The first approximation level at
with coefficients
is obtained by filtering the original time series
. In general, the following formula is applicable:
The computation of the wavelet coefficients follow from (
4) and (
5) and are the differences between the original time series and the smooth approximations, respectively. This, again, starts with the original time series
and the successive approximation levels from
to
J:
The maximum attainable number of levels for the redundant Haar wavelet decomposition is constrained by two mechanisms. First, an offset is created at the start of the decomposition, which grows with the power of two as in dependence of the scale j. In other words, the length of the required support for constructing the wavelet and resolution levels can, at maximum, adopt the largest power of two smaller than the length of the time series: , with being the maximum attainable level size. Second, the last smooth approximation is a filter, which has growing support with increasing scale. The filter with growing support creates a more and more constant resolution level. Eventually, it must become constant at the latest when the maximum possible carrier is chosen. This effect can occur before the maximum level is attained. Then, the last smooth approximation level, which can be regarded as a trend estimation, does not carry any information any more.
The coefficients from all obtained wavelet scales and from the last smooth approximation need to be chosen in order to compute a one-step forecast. The coefficients can be processed with linear and nonlinear methods. Here, a regression optimized with least squares [
59] and a multilayer perceptron with one hidden layer (neural network) [
70] are chosen, denoted as MRR and MRNN respectively. The challenge of model selection can be decided with a criterion, such as AIC [
71], but is computationally complex; he work of [
14] proposed a more straightforward solution. Since the redundant Haar wavelet decomposition is an orthogonal projection, the coefficients can be chosen in a way to form an orthogonal basis [
14]: Selecting an orthogonal basis follows a lagged scheme, where the step size for selecting coefficients is
for scale
j (lagged coefficient selection) [
14]. The selection of coefficients can be reduced to subsets of the basis with a total of
coefficients per scale
j. So, the wavelet coefficients for forecasting time point
are
for
and the smooth coefficients are
for
. The choice of each number
is part of the model selection. From this scheme, a constrained selection of coefficients can be made, which can be again decided with a criterion, such as AIC. The Markov property states that the optimal prediction can be obtained only from finite past values [
72]. If the Markov property applies, then the lagged coefficient selection is able to return the optimal prediction [
14].
The lagged coefficient selection described above has a complexity of
, where
denotes the maximum possible number of coefficients at scale
j. Here, finding the best wavelet model means to find the best combination of number of decomposition levels and, at the same time, finding the best number of coefficients per each level, which fits historical data with the goal to forecast future time points [
73]. There is a potentially large set of possible input parameters, which define the model of our framework, and the output for each input is obtained by a potentially complex computation (e.g., rolling forecasting origin [
73]). This can be viewed as a search problem. A simple but complex solution would be the search through all possible inputs, which we found to be not practical for such complexity. Therefore, a more sophisticated approach is required.
The approach used in this work is a “differential evolutionary optimization”. In this work, multiple coefficients of a prediction scheme with varying decomposition depth are optimized, using EA. In the following, a rough outline of the evolutionary optimization is given. A population is randomly initialized, which stands in competition, forcing a selected reproduction based on a fitness function (survival of the fittest) [
73]. The starting set of candidates can be randomly initialized [
73]. The fitness is based on a quality measure (e.g., for measuring the forecast performance). The best candidates are chosen (survival of the fittest) [
73]. Those candidates (parents) are used to generate the next generation [
73]. The two operations for building the next generation are recombination and mutation [
73]. The new set of candidates is called children [
73]. The new selection is based on a fitness function based on the quality measure and the age of the candidates. This procedure is iterated until a stopping condition is reached. This can be, for example, a sufficient quality level or a maximum number of steps.
In our framework, we evaluate each possible decomposition with
levels, separately. The vector
carries the number of coefficients associated with the respective wavelet level
J or the last smooth approximation level. The difference between classical evolutionary optimization and differential optimization is that the candidate solutions are vectors
, and the new mutant
is produced by adding a perturbation vector
to an existing one:
where
p is a scaled vector difference of two already existing, randomly chosen candidates, which are rounded to yield the following integer vectors:
and
is a real number, which controls the evolution rate.
Here, two to five decomposition levels in the model selection procedure for the framework are used which allows one to fifteen coefficients per level for the regression method, and one to eight coefficients per level for the neural network. The multiresolution forecasting framework with a neural network is denoted as “MRNN” and with a regression as “MRR”. The difference for the multiresolution method in [
28,
30] is the lagged coefficient selection and the computation of the forecast based on a prediction scheme, using the wavelet decomposition as one unit without the reconstruction scheme. Furthermore, the proposed multiresolution framework does not require the user to set any parameters since this will be completely undertaken by the model selection based on the differential evolutionary optimization.
Typically, variations of evolutionary algorithms (EA) are used in time series forecasting in order to adapt complex models to the training data. For example, [
74] employ EA to optimize the time delay and architectural factors of an (adaptive) time-delayed neural network (GA-ATNN and GA-TDNN). EA is used to optimize artificial neural networks’ architectural factors for time series forecasting [
75]. Ref. [
76] utilize EA to optimize the parameters of support vector regressions for time series forecasting. Alternatively, a prediction scheme with a matrix system of equations is constructed that incorporates the time-series sequence piecewise by exploiting algebraic techniques, using various control and penalty coefficients, which are optimized, using EA [
77]. Further, an improvement of this approach is proposed in [
78].
3. Results
The forecasting performance of 12 different forecasting methods are compared with each other across four different datasets. Different forecast horizons require different methods [
41]. Nevertheless, the performance of all methods over all horizons is computed; the selected horizons and two summarized periods are presented in
Table 1,
Table 2,
Table A3, and
Table A4. Moreover, the performance of the one-step forecasts and the multi-step forecasts are separately processed and visualized with the mirrored density plot (MD plot). For the out-of-sample forecast the errors are computed as described in
Section 2.2,
Section 2.4, and
Section 2.5 for the Mean Absolute Scaled Error (MASE) and the Mean Absolute Percentage Error (SMAPE).
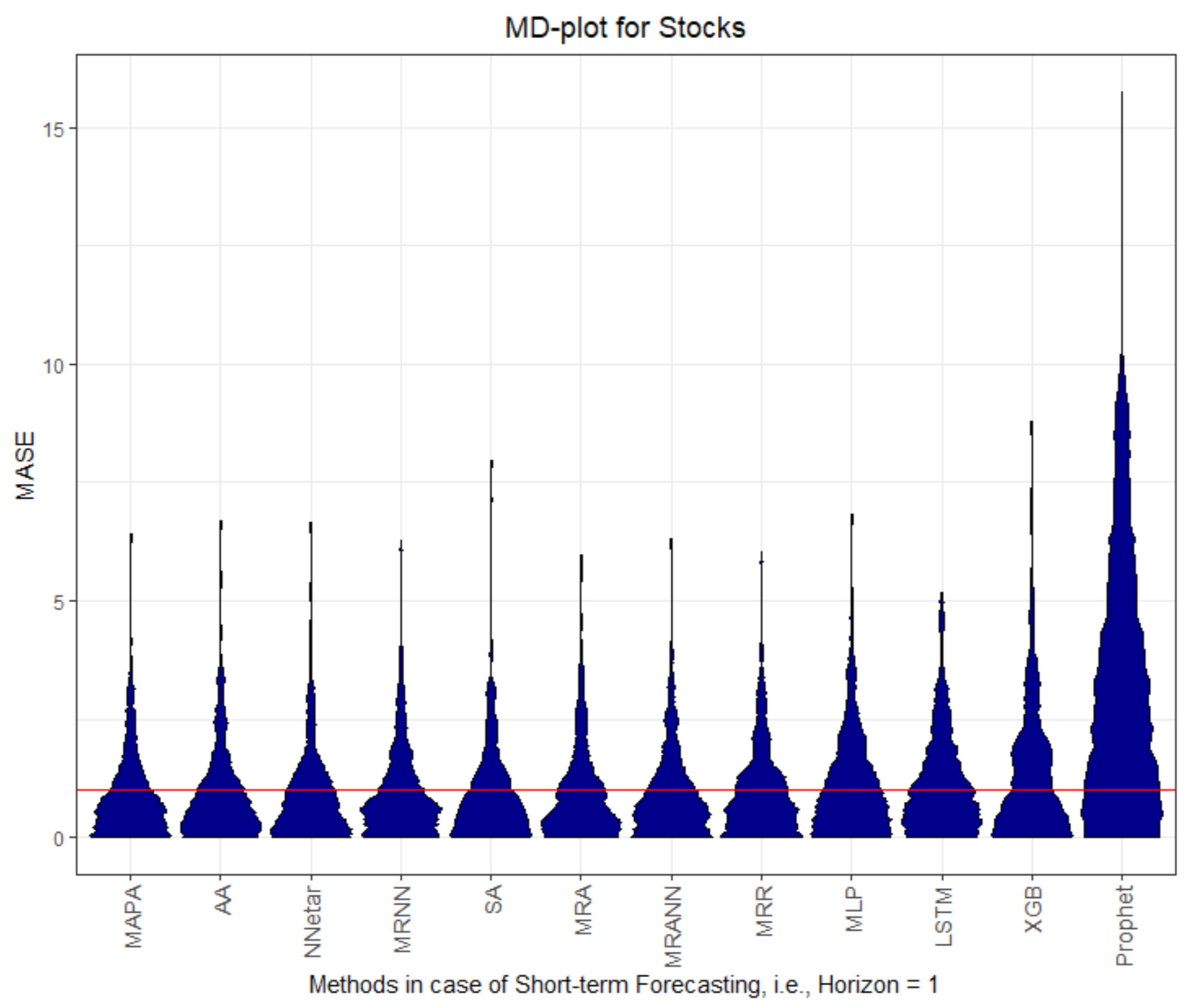
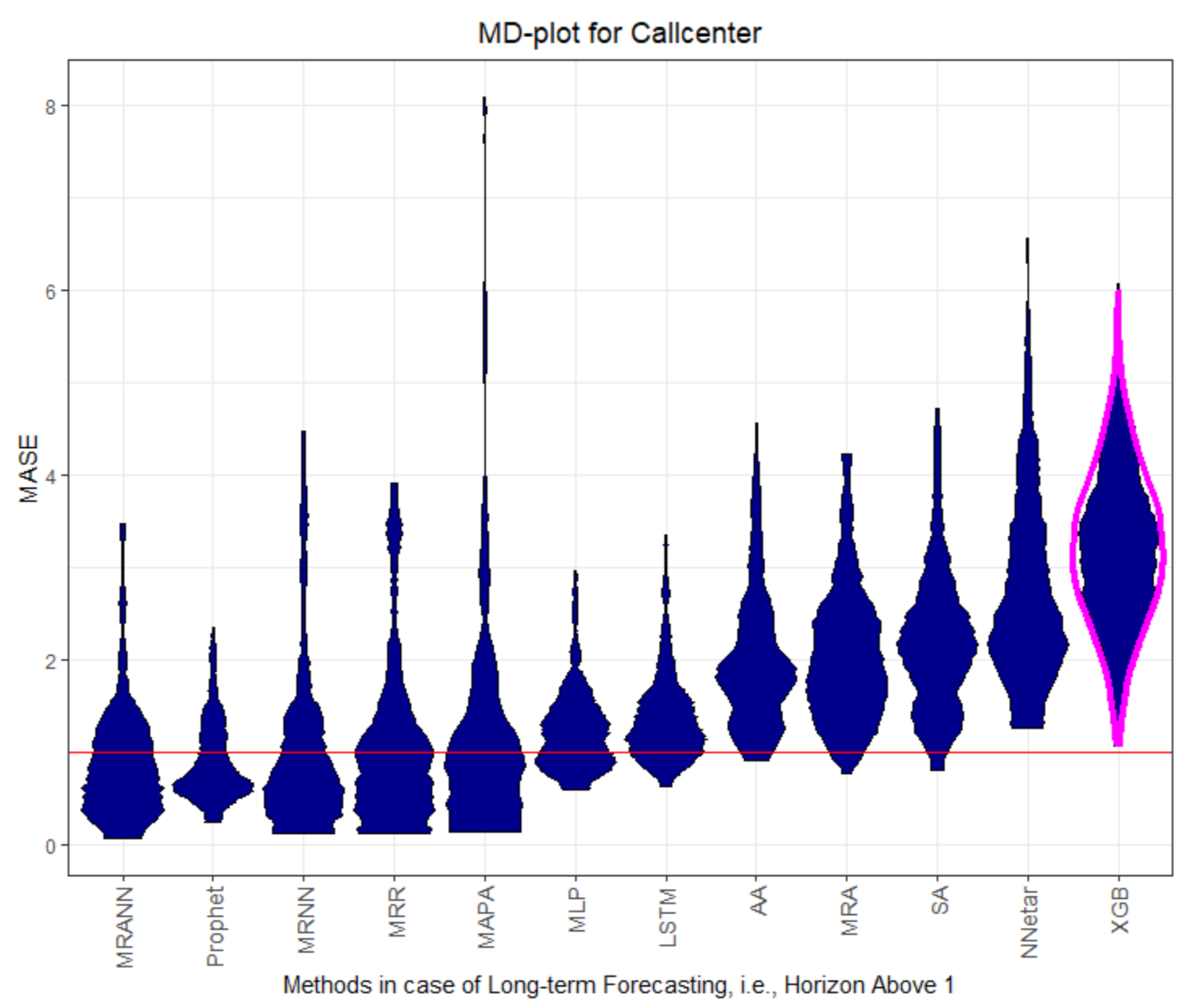
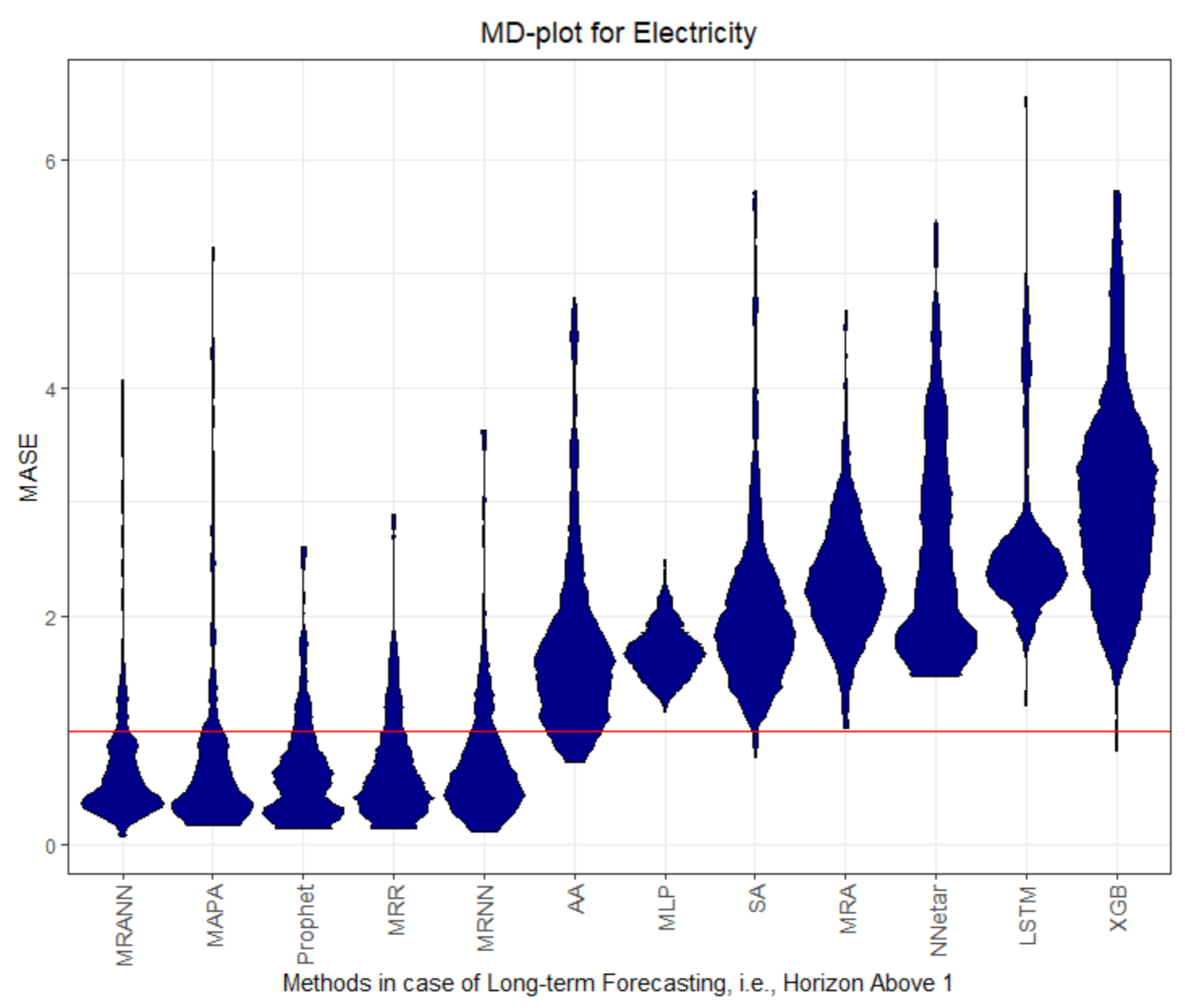
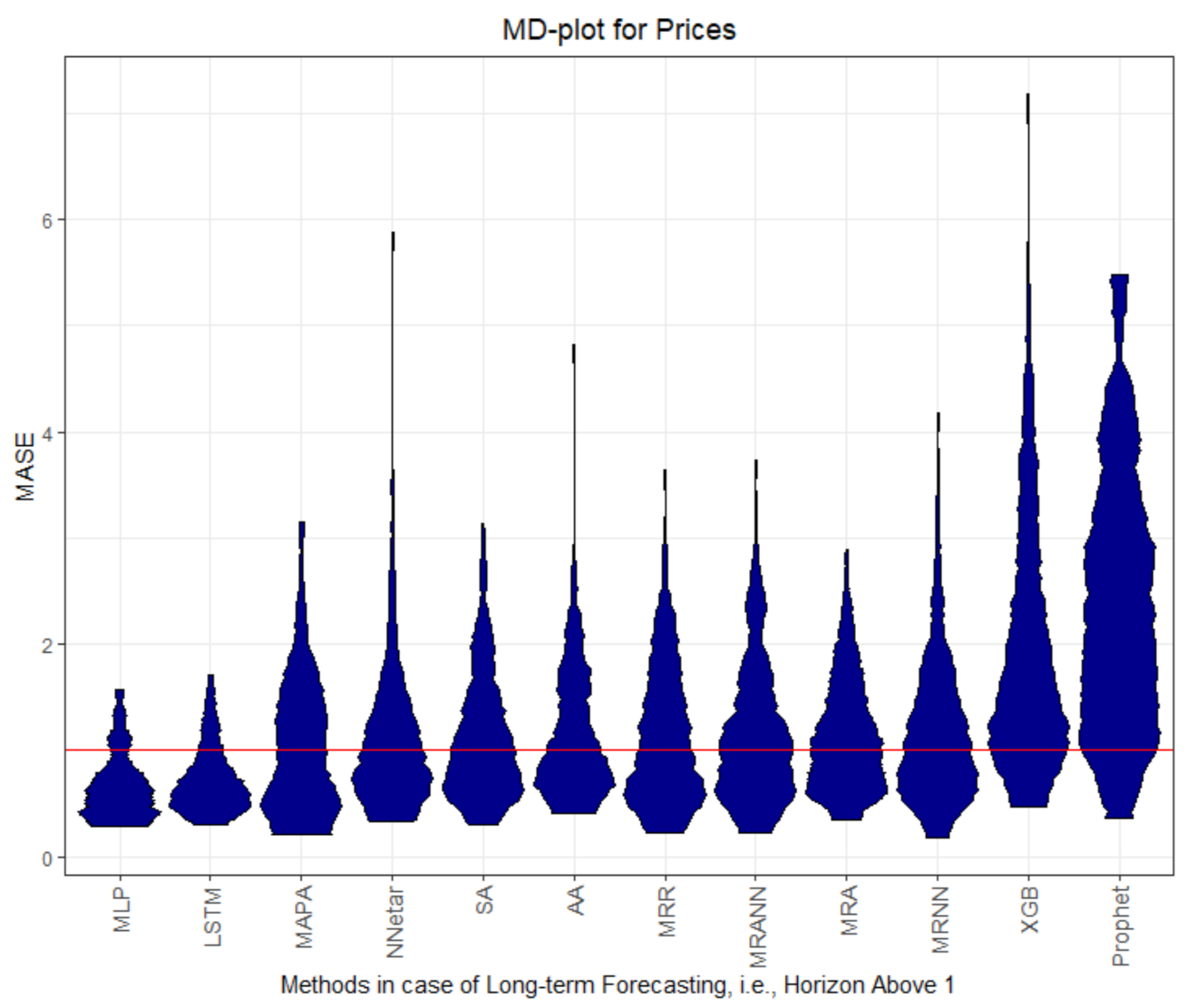
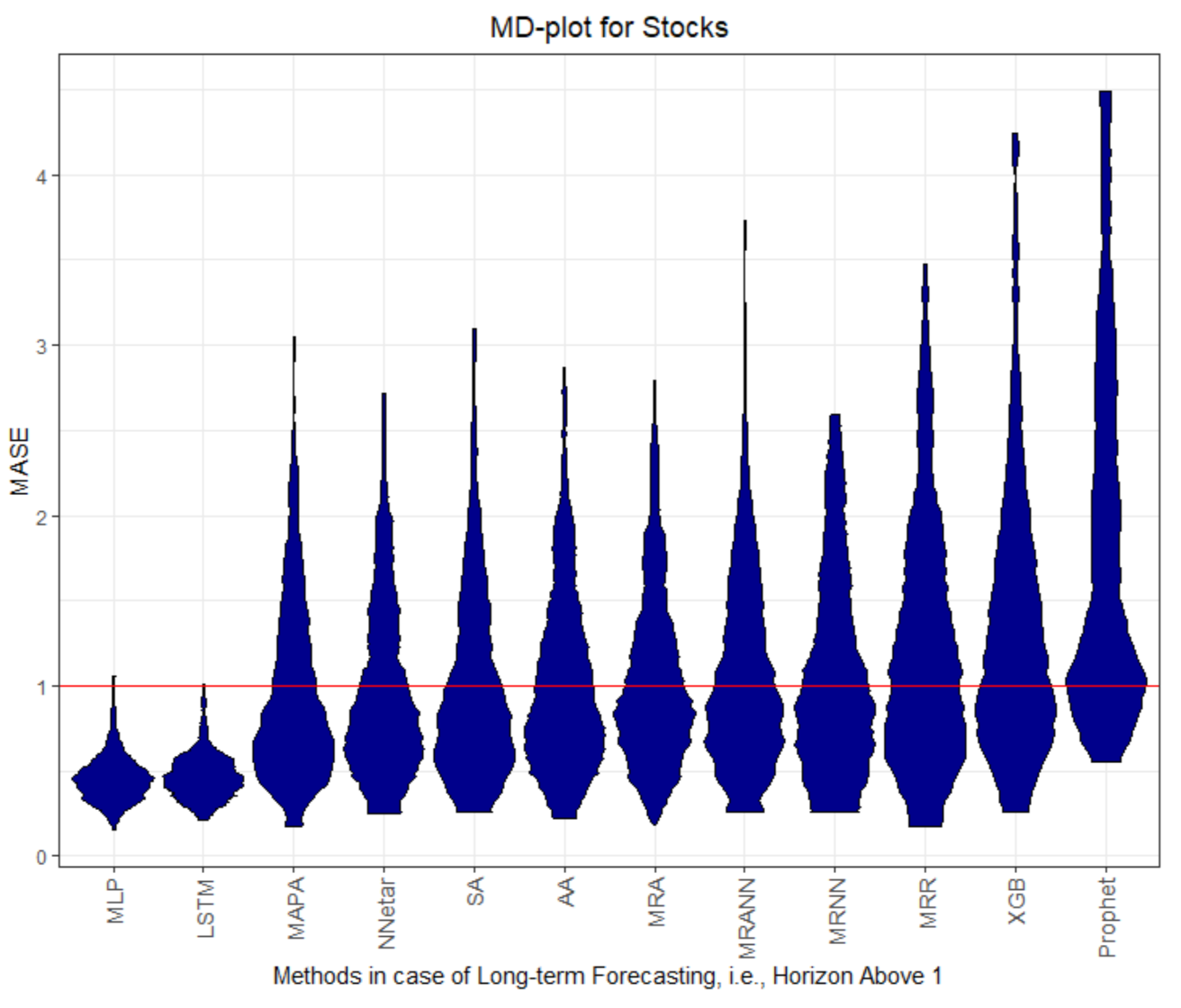
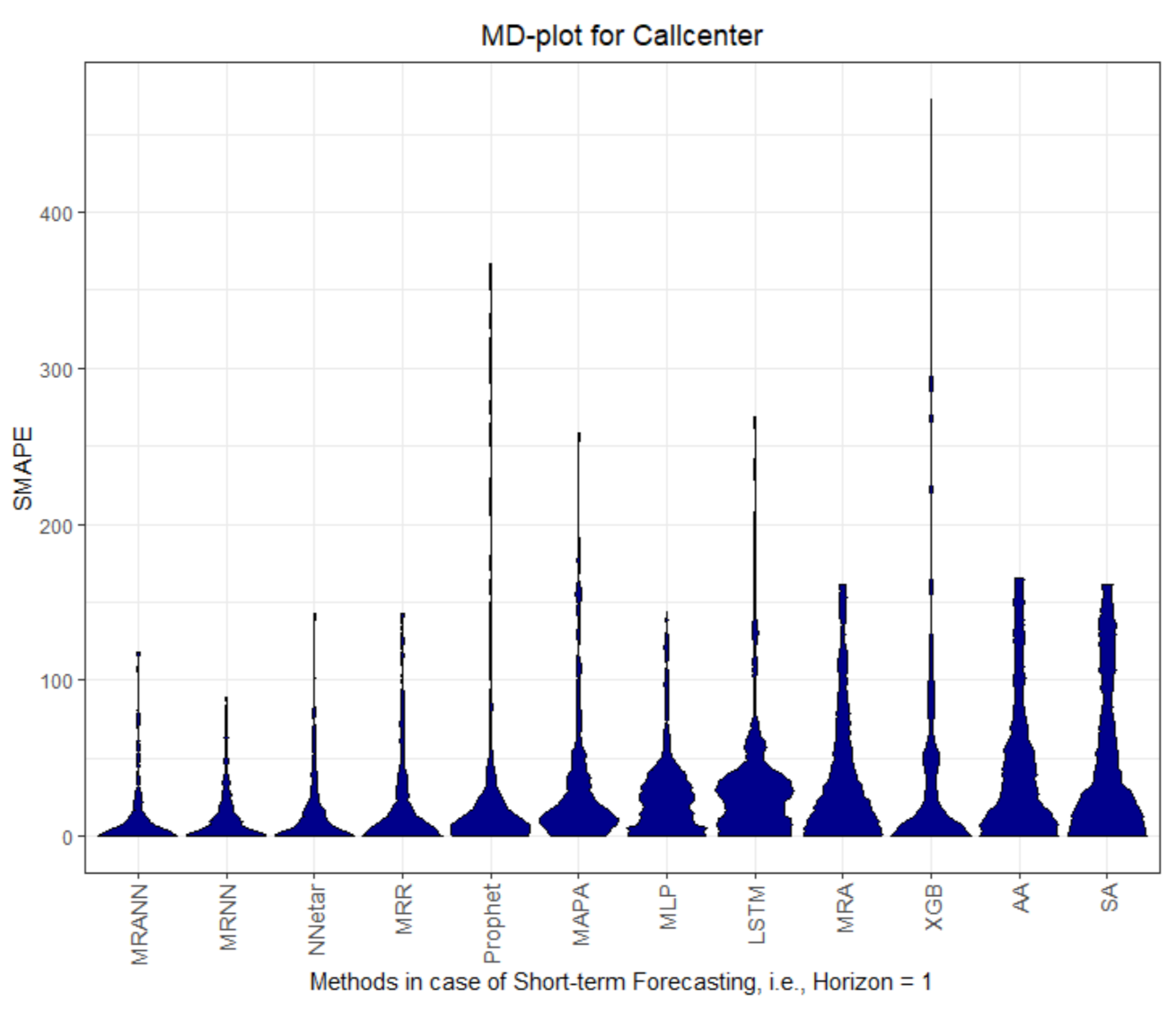
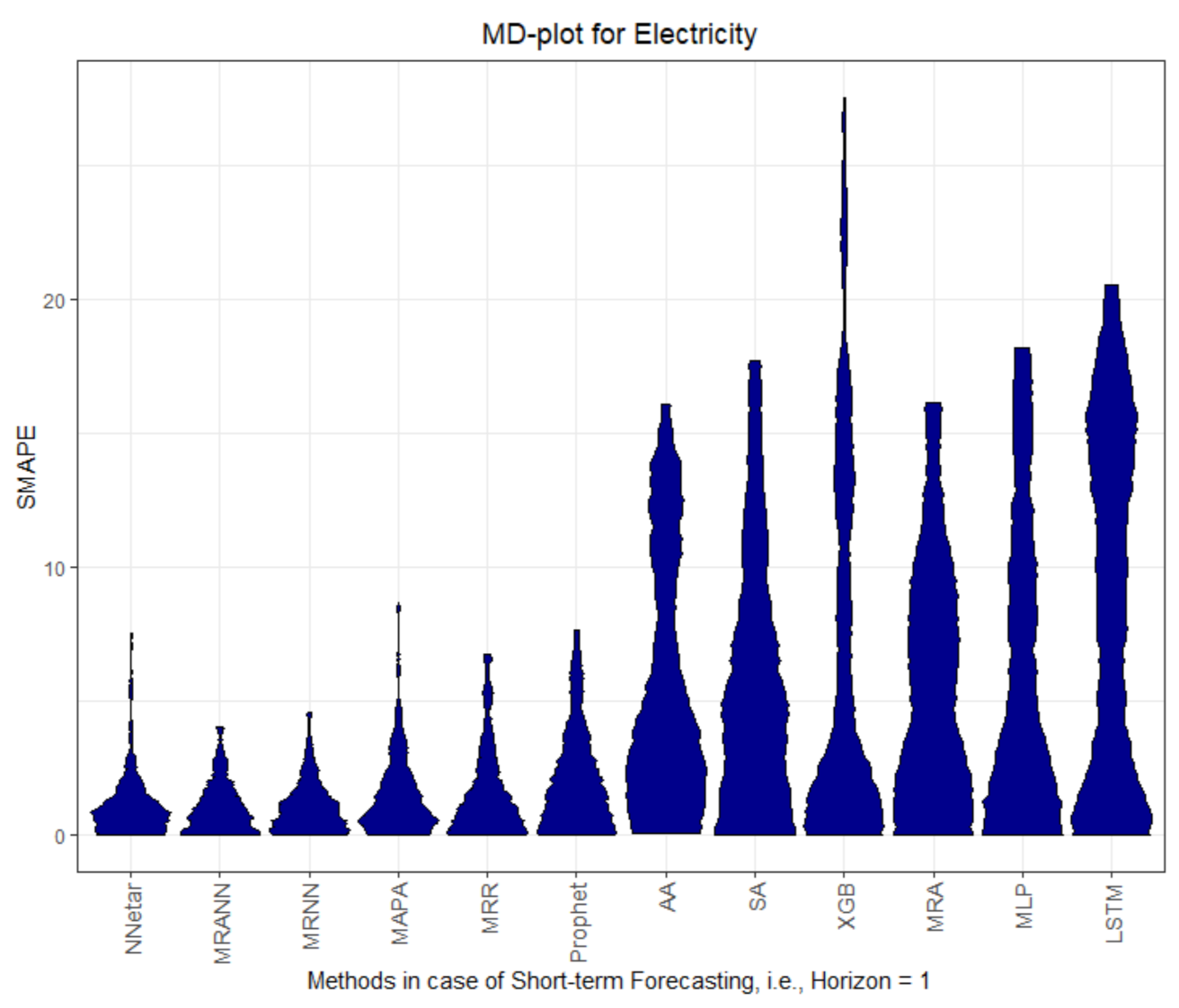
Figure 1,
Figure 2,
Figure 3,
Figure 4,
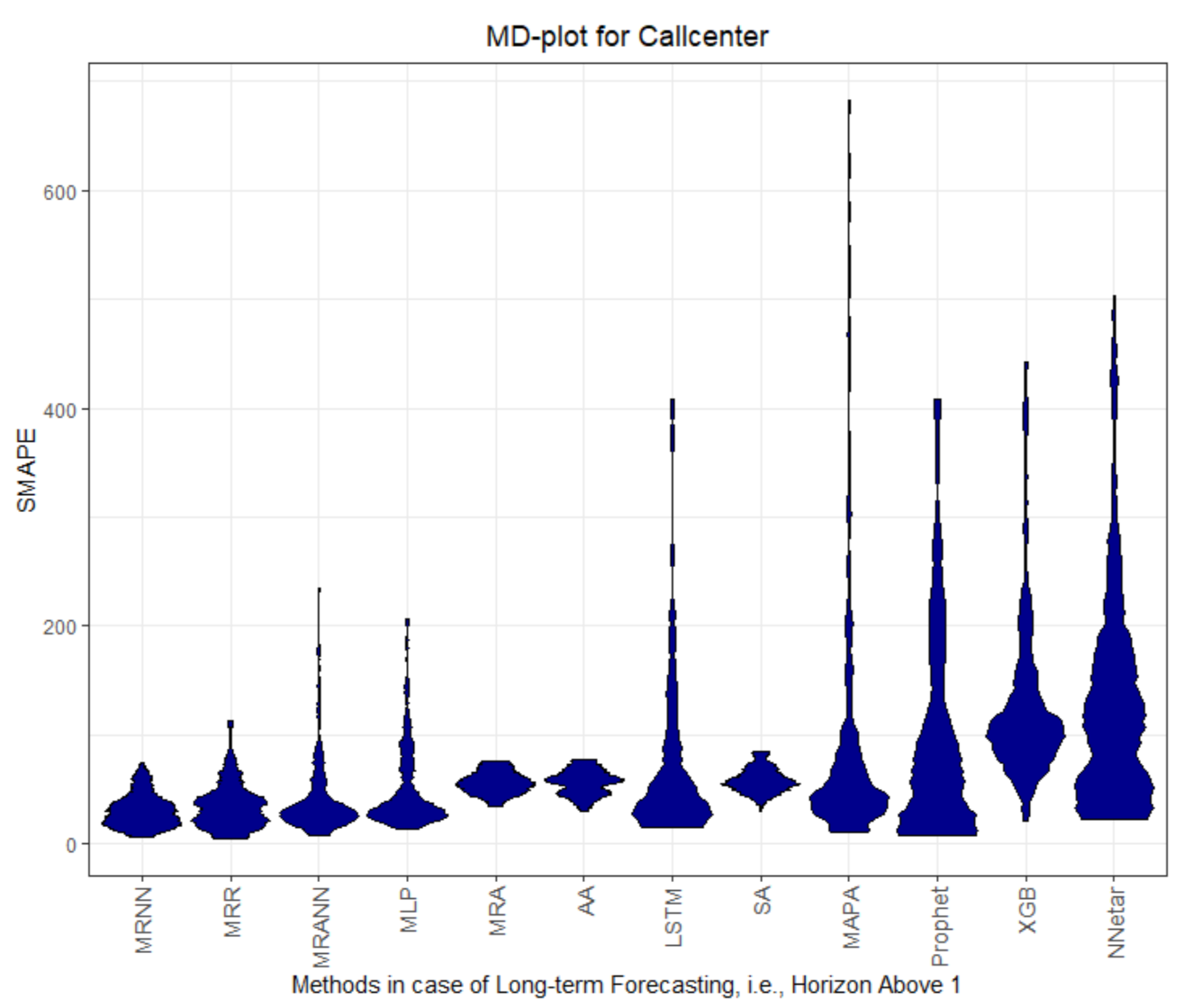
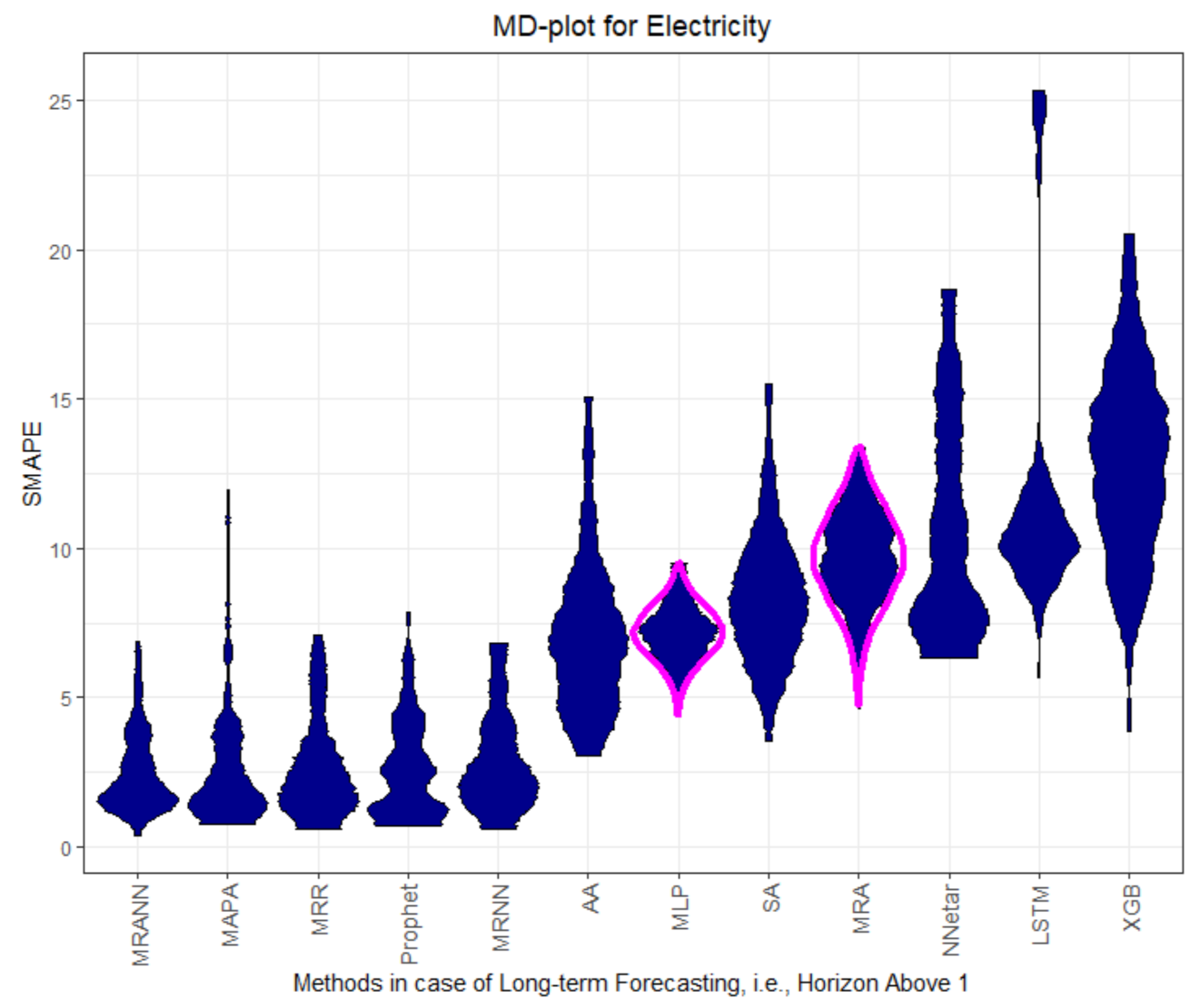
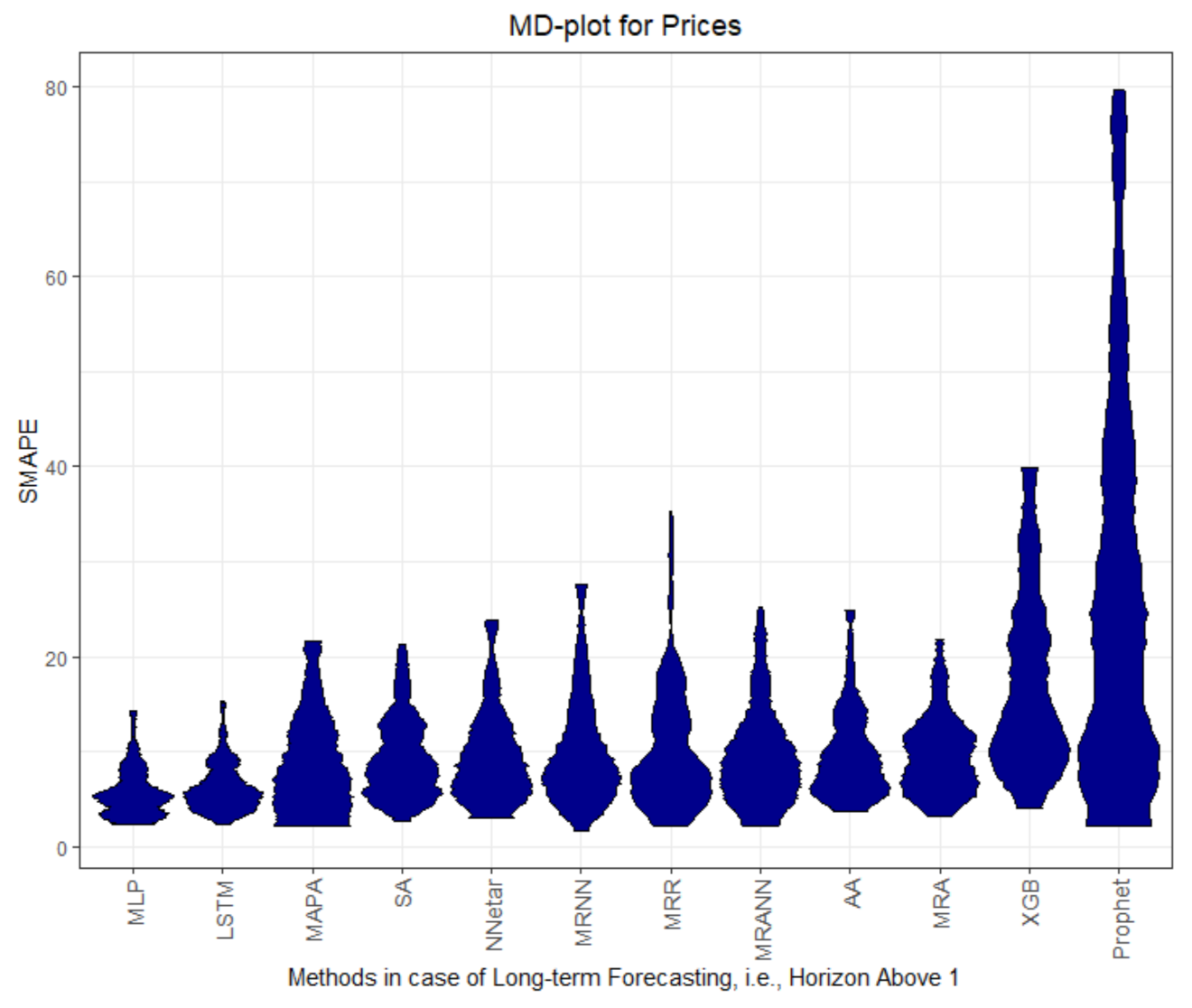
Figure 5,
Figure 6,
Figure 7 and
Figure 8 visualize the MASE distribution with the MD plot.
Figure A2,
Figure A3,
Figure A4,
Figure A5,
Figure A6,
Figure A7,
Figure A8 and
Figure A9 show the SMAPE distribution in the appendix. The results show both the distribution of the forecast error processed with MASE and SMAPE for all datasets and methods are divided in two parts. First, the forecast errors for horizon 1 are visualized in
Figure 1,
Figure 2,
Figure 3 and
Figure 4 and
Figure A2,
Figure A3,
Figure A4 and
Figure A5. Second, all forecast errors of horizons from 2 to 14 are summarized and then visualized in
Figure 5,
Figure 6,
Figure 7 and
Figure 8 and
Figure A6,
Figure A7 and
Figure A8.
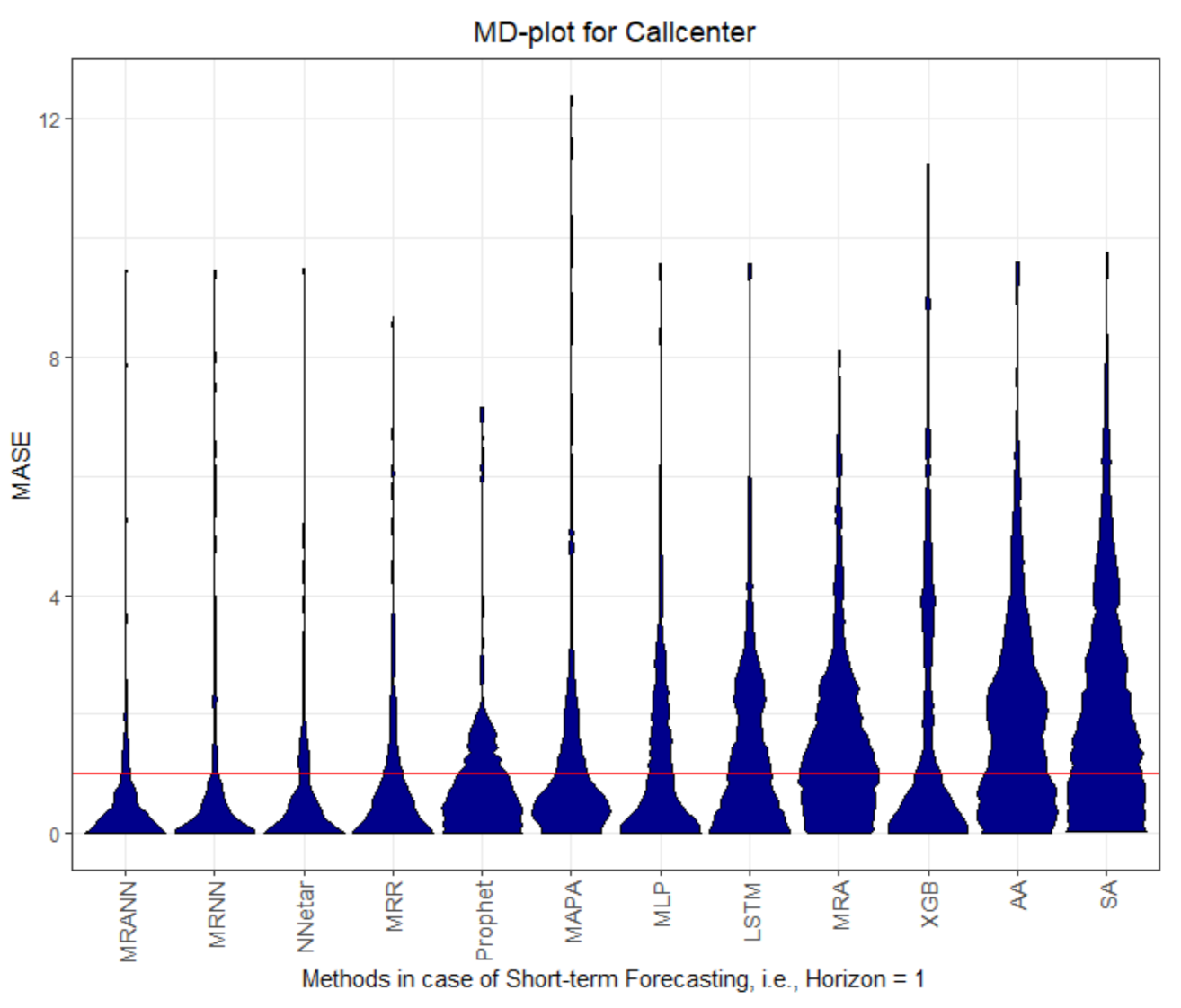
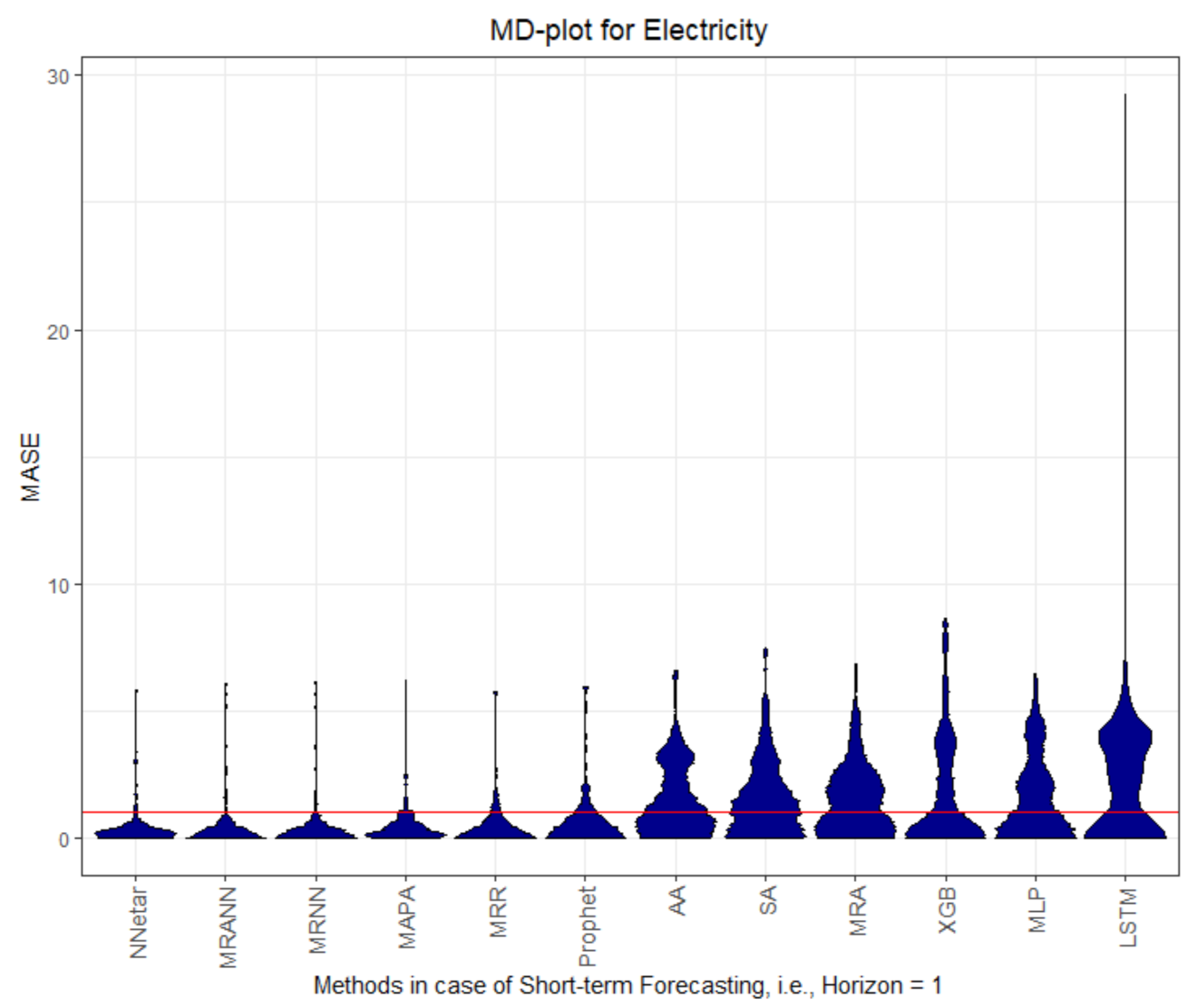
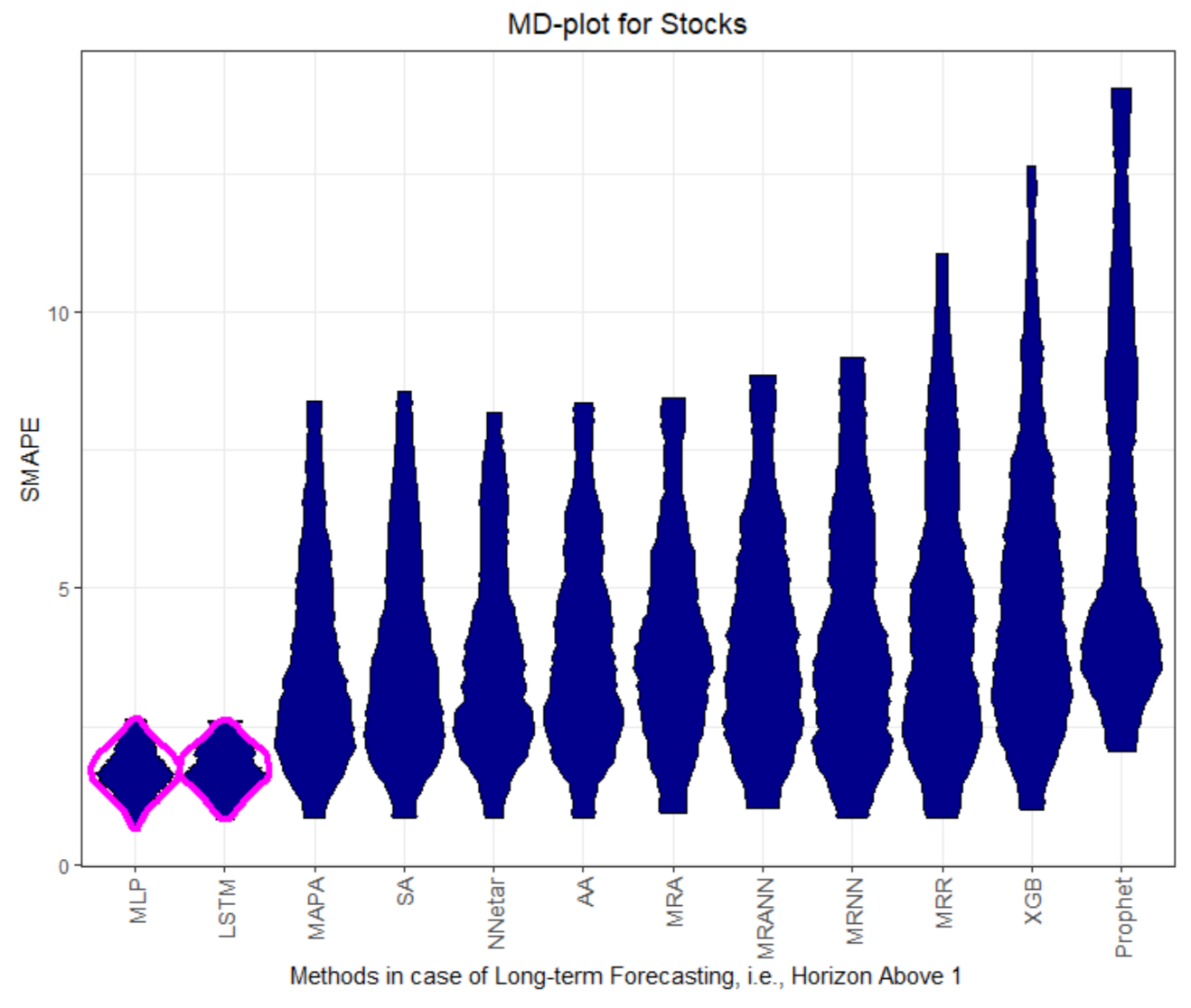
The MD plots show various properties of the quality measures at once. The distribution of the quality measure is visualized, which, in most cases, is a unimodal distribution, except for AA, MLP, and LSTM in
Figure 2, AA and SA in
Figure 5, Prophet in
Figure 6, LSTMM in
Figure A2, AA and LSTM in
Figure A3, MRR in
Figure A4, and Prophet in
Figure A7. The fat or thin long tails give a measure of uncertainty. The outliers show the worst possible performance. A high variance of the distribution indicates underfitting.
The Kolmogorov–Smirnov tests indicate a F distribution of the MASE for almost all cases, shown in
Table A1 and
Table A2 with the exception of LSTM, MRA, NNetar and XGBoost on dataset Electricity for horizon 1, LSTM and NNetar on dataset Electricity for overall horizons, XGBoost on dataset Callcenter for horizon 1, and SARIMA and AARIMA on dataset Stocks on horizon 1. All other 87 cases had a significant value for the Kolmogorov–Smirnov test, testing for an F distribution. Assuming an F distribution, the central tendency can be computed and is used to compare the overall performance of the methods.
Table 1 and
Table 2 show the MASE for all methods on all four datasets for various horizons and for the mean over horizons from 1 to 7 and 1 to 14. This could not be done for SMAPE since there were no distributions, fitting most of the samples significantly. In the case of SMAPE and unimodal distributions, the median was used instead of the mean.
Table 1 and
Table 2 provide insight about the forecast performance for each method across various horizons. The progress of the performance can be tracked along the horizon. The overall measurement summarizes the quality measure over all horizons from 1 to 7 (one week) and from 1 to 14 (two weeks) as the mean over all samples.
Table A3 and
Table A4 show the same computation but for SMAPE and with the median.
The MASEs of Prophet, MAPA, MRANN, MRNN and MRR on dataset Electricity are the only ones below or equal to 1, and therefore, is better than the seasonal naïve method; see
Table 1. In the case of dataset Electricity, the four multiresolution methods outperform the seasonal naive method.
On dataset Callcenter, the two multiresolution methods with neural networks (MRNN) and with an artificial neural network (MRANN) outperform every other method. The only other method performing better than the seasonal naive method for horizons larger than 1 is Prophet, which can be seen by the explicit value of the central tendency of the MASE distribution that serves as a comparison (see the overview for MASE in
Table 1).
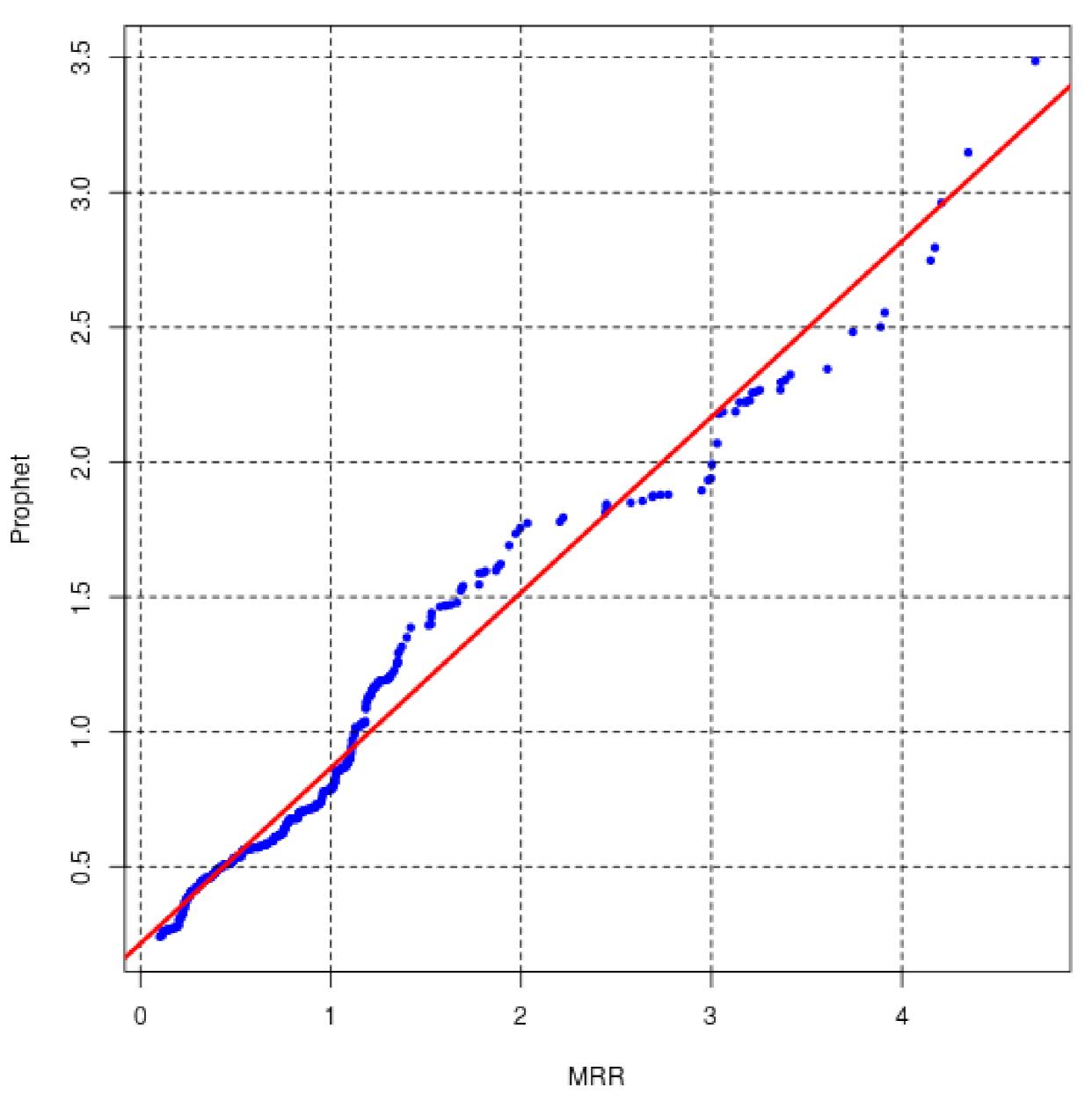
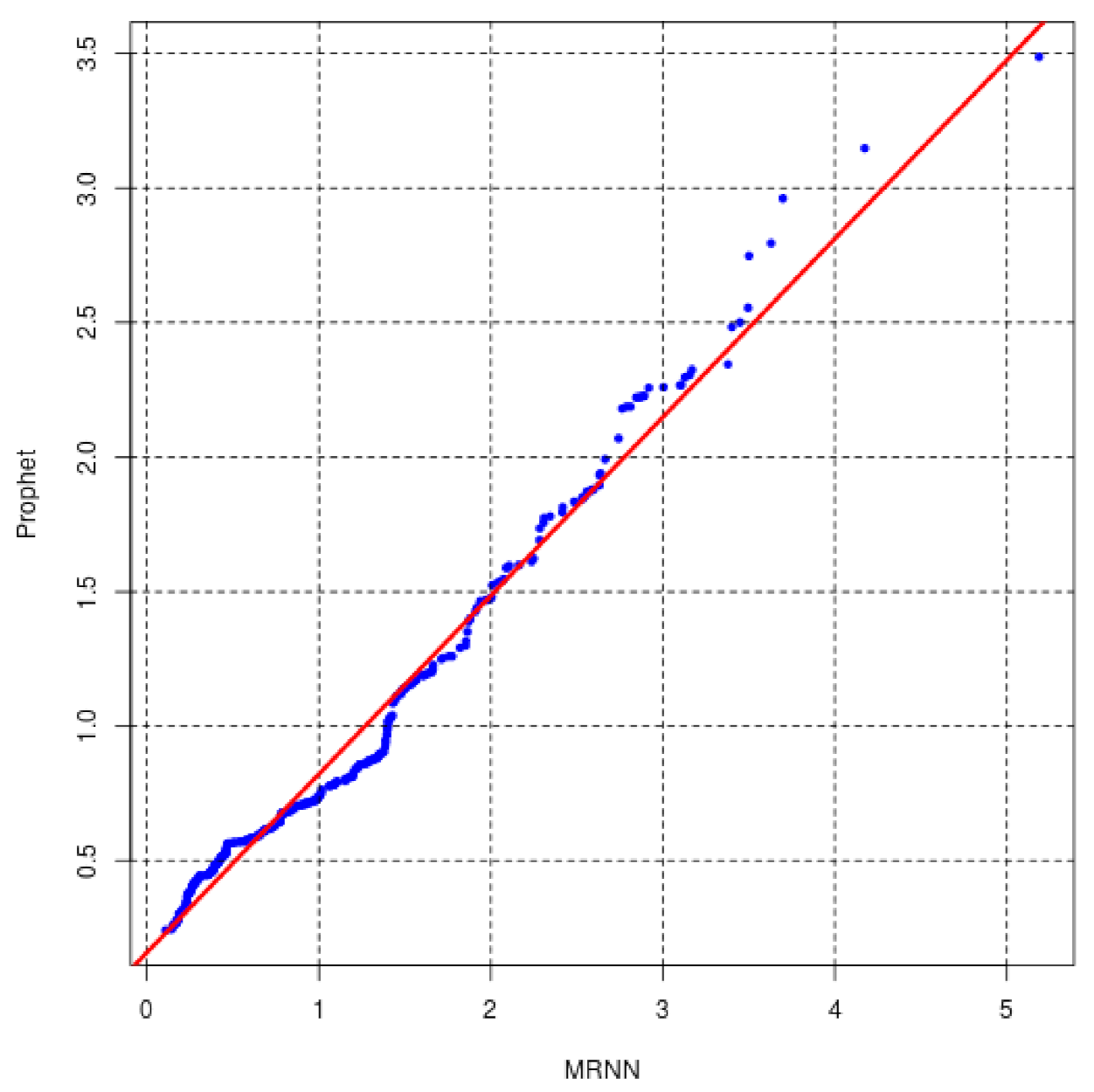
However, the QQ plot in
Figure A11 shows that the full MASE distribution of errors of Prophet and MRNN are equal, which indicates similar performance. For the first horizon on dataset Prices and Stocks, no method outperforms the naïve method. Only the LSTM and the MLP have better performance than the naïve method, with multi-step forecasts on dataset Prices and Stocks.
4. Discussion
This work follows the argumentation in [
33,
79]: “There are two cultures in the use of statistical modeling to reach conclusions from data. One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown” [
79]. “Forecasters generally agree that forecasting methods should be assessed for accuracy using out-of-sample tests rather than goodness of fit to past data (in-sample tests)” [
33]. Here, the quality of the predictive models for practical purposes is evaluated for 365 time steps. With such a sample size, the MD plot is able to discover fine details of the underlying distribution (Thrun et al., 2020) under the assumption that the largest seasonality lies within a year [
44]. It should be noted that restricting evaluation to specific datasets makes it challenging to provide evidential results that can be generalized, which, in our opinion, remains a great challenge in forecasting. In general, the learnability of machine learning methods for data cannot be proven [
80]. Hence, we follow the typical approach of supervised methods by dividing the data and estimating the learnability on test data as described in
Section 2.1. The quality indicators are evaluated on a large enough sample (here, 365 steps) for the distribution analysis [
44].
The visualization of the forecasting error distribution with the MD plot can give insights about the statistics of the errors. The long and fat tails of the distributions indicate high uncertainty when estimating forecasts. Thin tails on the other hand indicate more outliers. Outliers may happen if external variables influence the time series values on specific time points. Specific errors can be related to time and potential causes and context. For example, Electricity Prices may be influenced on extreme weather situations that require higher usage of cooling or heating devices. In practice, outliers can be removed from the overall measurement when judgmental reasoning is applicable [
34].
In our evaluation of the test data with MASE, lower than one implicates a better Mean Average Error than the naïve method. Thus, our results indicate that the multiresolution method and Prophet are able to forecast the seasonal datasets more successfully than naïve forecast and other methods. The performance for one-step forecast is different to that of multi-step forecasts for recursive multi-step forecasting methods. The error of preceding computations propagates with increasing horizon. This is not the case for Prophet, which uses curve fitting. The multi-step forecasts of Prophet increase in performance in comparison to the one-step forecast for datasets Electricity and Callcenter.
SMAPE has almost only multimodal distributions, according to the Hartigans’ dip test for which the Bonferroni correction for multiple testing was applied. Therefore, it is critical to investigate the distribution of SMAPE errors instead of providing only table of averages. However, in many time series forecasting evaluations, SMAPE is applied regardless of an evaluation of the SMAPE distribution and therefore the averages are also discussed here [
37,
38]. The median is statistically more robust than the mean and is therefore applied here.
For datasets Electricity and Callcenter, the multiresolution method and Prophet outperform the other methods in regard to MASE and SMAPE; see
Table 1,
Table 2,
Table A3 and
Table A4. On dataset Callcenter, Prophet has equal performance to the seasonal naïve method. The multiresolution method has the best one-step forecasts. Prophet does perform slightly worse than the multiresolution method for multi-step forecasts on Callcenter and Electricity. However, the performance of the multiresolution method and Prophet is equally good for multi-step forecasts, which is shown by the approximately straight lines in QQplots of the MASE distributions of Prophet versus the multiresolution method in
Figure A10,
Figure A11,
Figure A12 and
Figure A13. Straight lines mean that the error distributions are approximately equal. The MASE lower than one implicates a better Mean Average Error than the naïve method and thus infers that only the multiresolution method and Prophet are able to forecast the seasonal datasets more successfully than the naïve forecast. The multiresolution method outperforms every other methods on the given datasets on one-step forecasts, with the exception of the Stocks dataset. This exception is not surprising since Stock values follow the Random Walk theory and are stochastic in nature. The resulting progress should not be predictable. The best performance of MLP and LSTM on Stocks is doubtful. Neural network forecasting methods are prone to overfitting and at least on Stocks, it is questionable whether the performance would be stable with a longer evaluation period. The small SMAPE values do not indicate good performance on the Stocks dataset since the changes within the Stocks time series are marginal in nature. MASE values lower than one do not necessarily indicate good performance for dataset Stocks either since MASE relies on the benchmark method, which is the naïve method for the Stocks time series. The naïve method uses the last value, which is neither a good indicator for changes in the Stocks dataset, nor a stable prediction for multi-step forecasts in that case. Hence, seemingly good performance can be obtained in this case, which does not apply in the real world.
The MRR as well as MRNN (proposed multiresolution framework), and the MRANN [
30] method perform similarly across horizons and for the overall measurements (see
Table 1,
Table 2,
Table A3 and
Table A4). For the datasets investigated, the multiresolution method with neural networks (MRNN and MRANN) tends to have larger outliers than the MRR. The MRNN has better one-step forecast performance than the MRR, whereas it is the opposite for multi-step forecasts. Computing the mean average of the MASE, it could be deduced that MRANN performs better than MRR or MRNN in
Table 1 and
Table 2. However, the estimated probability density functions in the MD plot are highly similar. Moreover, according to the Kruskal–Wallis test, the null hypothesis that the location parameters of the distribution of x are the same, cannot be rejected (
p-value > 0.05) in the case of the one-step forecasts of MRANN vs. MRNN and the multi-step forecasts in the case of MRANN vs. MRR. The difference between the overall measurements is comparably small on the seasonal datasets Electricity and Callcenter (Callcenter: MRANN: mean(MASE, h = [1,7]) = 0.9 and mean(MASE, h = [1,14]) = 0.9; MRNN: mean(MASE, h = [1,7]) = 1.0, mean(MASE, h = [1,14]) = 1.1; MRR: mean(MASE, h = [1,7]) = 1.1, mean(MASE, h = [1,14]) = 1.1. Electricity: MRANN: mean(MASE, h=[1,7]) = 0.6, mean(MASE, h = [1,14]) = 0.7; MRNN: mean(MASE, h = [1,7]) = 0.7, mean(MASE, h = [1,14]) = 0.7; MRR: mean(MASE, h = [1,7]) = 0.7, mean(MASE, h = [1,14]) = 0.7, see overall measurements in the last two columns of
Table 1 and
Table 2).
The performance of the forecasting method combining the concepts of multiresolution and ARIMA [
28] does not perform comparably well to the investigated methods here, although [
28] based their work on [
13], similar to our proposed work. However, they used ARIMA as the underlying forecasting method and achieved worse results (for both seasonal datasets, MASE for MRA is above 2). In contrast, MRANN [
30] forecasted each level (wavelet and the last smooth approximation level) separately with an ANN, and then reconstructing the forecast by applying the reconstruction formula on the forecasted wavelet decomposition. Note, that their proposition overlaps with [
28] by using the Haar wavelet decomposition [
30] that is also used here. Yet in their work, no comparison with a method comparable to the approach proposed by [
13,
14] is made.
The overall measurements are always quite close on the seasonal datasets Electricity and Callcenter (see
Table 1 and
Table 2). The performance of the forecasting method combining the concepts of multiresolution and ARIMA [
28] does not yield any positive results and thus, does not require any further discussions.
XGBoost was recommended as a robust method for general machine learning tasks [
58], and neural networks with at least one hidden layer were recommended for time series forecasting [
54]. The computed results were unable to verify this claim. The performance on seasonal time series was worse than the seasonal naïve in the datasets Electricity Demand and Callcenter. However, the results of the neural network, using wavelet coefficients, showed relatively good performance on the seasonal time series, indicating the potential use of neural networks in time series forecasting. It could be argued that preprocessing is necessary prior to the use of neural networks, which is supported by the results of [
81]. However, there was no elaborate testing of different parameter settings for the multilayer perceptron and long short-term memory, such as the input size. This could apply for XGBoost as well but was not investigated in this study.
The benchmarking performed in this work indicates that statistical approaches, such as seasonal adapted ARIMA, performed quite poorly in comparison to the Fourier and multiresolution-based methods. The machine learning algorithms also performed better than the ARIMA frameworks used here in at least two cases (comparing the results from the best performing method from each field: Callcenter: MLP = 1.3 vs. ARIMA = 2.0; Electricity: MLP = 1.7 vs. ARIMA = 1.8; Prices: MLP = 0.7 vs. SARIMA = 1.1; Stocks: MLP = 0.5 vs. SARIMA = 1.0).
In sum, the results showed that reportedly suitable methods, such as the seasonal adapted ARIMA methods as well as machine learning methods, performed insufficiently on the investigated seasonal time series. It serves as an indication for a more careful selection in practice and an adaptation of the algorithm to the task.
The performance evaluation uses a test set covering a whole year. Therefore, models are selected, which performed best over the whole year, under the assumption that the largest seasonality is not longer than a year. This forces the model to have an overall best performance without considering temporal differences in performance within the year. Allowing repeated model fitting throughout the evaluation would enable a dynamic approach to incorporate changes in the data and could increase performance. Hence, better models could be obtained by allowing regular updates of the model itself and its parameter settings. The multiresolution method could benefit from this effect, especially regarding the dataset Prices, which has varying seasonal components. Furthermore, the automated forecast methods used here, such as ARIMA or SARIMA, perform model fitting at each forecasting origin, meaning a continuous adaptation to the data and disabling the possibility of a nested cross validation (only simple cross validation is possible). Prophet does partially adapt to the time series by updating some parameters automatically, such as the seasonal component, due to potential break point changes. This may be the reason that Prophet performs similarly to multiresolution methods MRR and MRNN on the datasets Electricity Demand and Callcenter because for these methods, the adaption was only performed once. Further work is required to improve this disadvantage. Since time series can potentially change their behavior at any time, a dynamic approach to forecasting time series is recommended, despite the possibility of overfitting. Adaptive model fitting could be used for allowing a dynamic adaptation to temporal high frequent changes.This could especially improve the performance of the wavelet method.
Further improvements in the future could be made by integrating multivariate data into the wavelet framework by including the multivariate data to the linear equation system.
As an alternative, Coarse grain time series analysis techniques could be used to model time series [
82] and create short-term predictions [
83]. Here, the evaluation is restricted to a linear and nonlinear strategy in order to investigate the potential of wavelets for time series forecasting, although the wavelets used could be processed in many other methods as well [
14].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}