Progressive System: A Deep-Learning Framework for Real-Time Data in Industrial Production

Abstract
1. Introduction
2. Related Work
2.1. Machine-Learning and the Processing of Small-Scale Data
2.2. CNN and TensorFlow Platform
2.2.1. CNN and Inception-V3
2.2.2. TensorFlow Framework Introduced
3. Framework Introduction and Implementation Plan
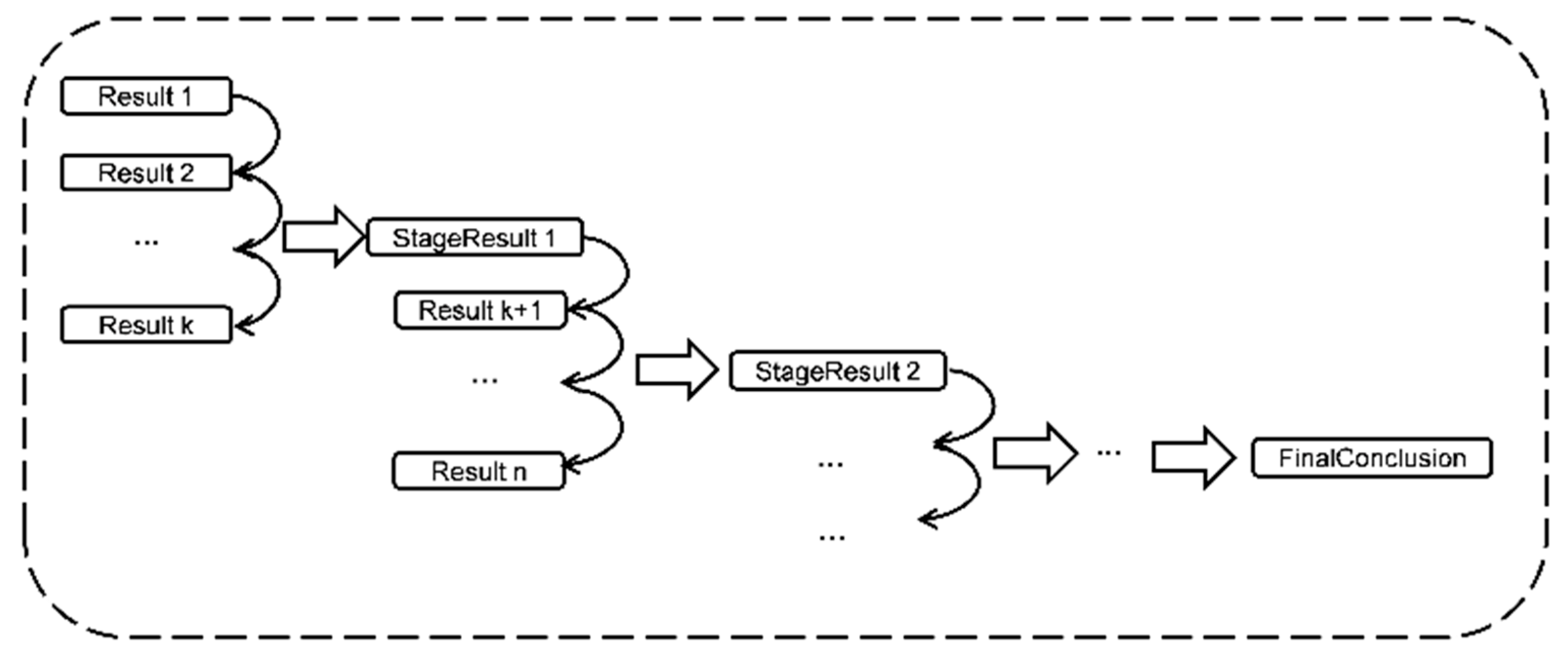
3.1. Framework Introduction
3.2. Data Collection
| Algorithm 1. Data preprocessing algorithm |
| Inputs: the training data that entered the framework, the amount of data Num, and the data label . Outputs: cleaned data set .
|
3.3. Results Statistics
3.4. Model Update Strategy
4. Experiment
4.1. Data Preparation
4.2. Training and Statistical Results
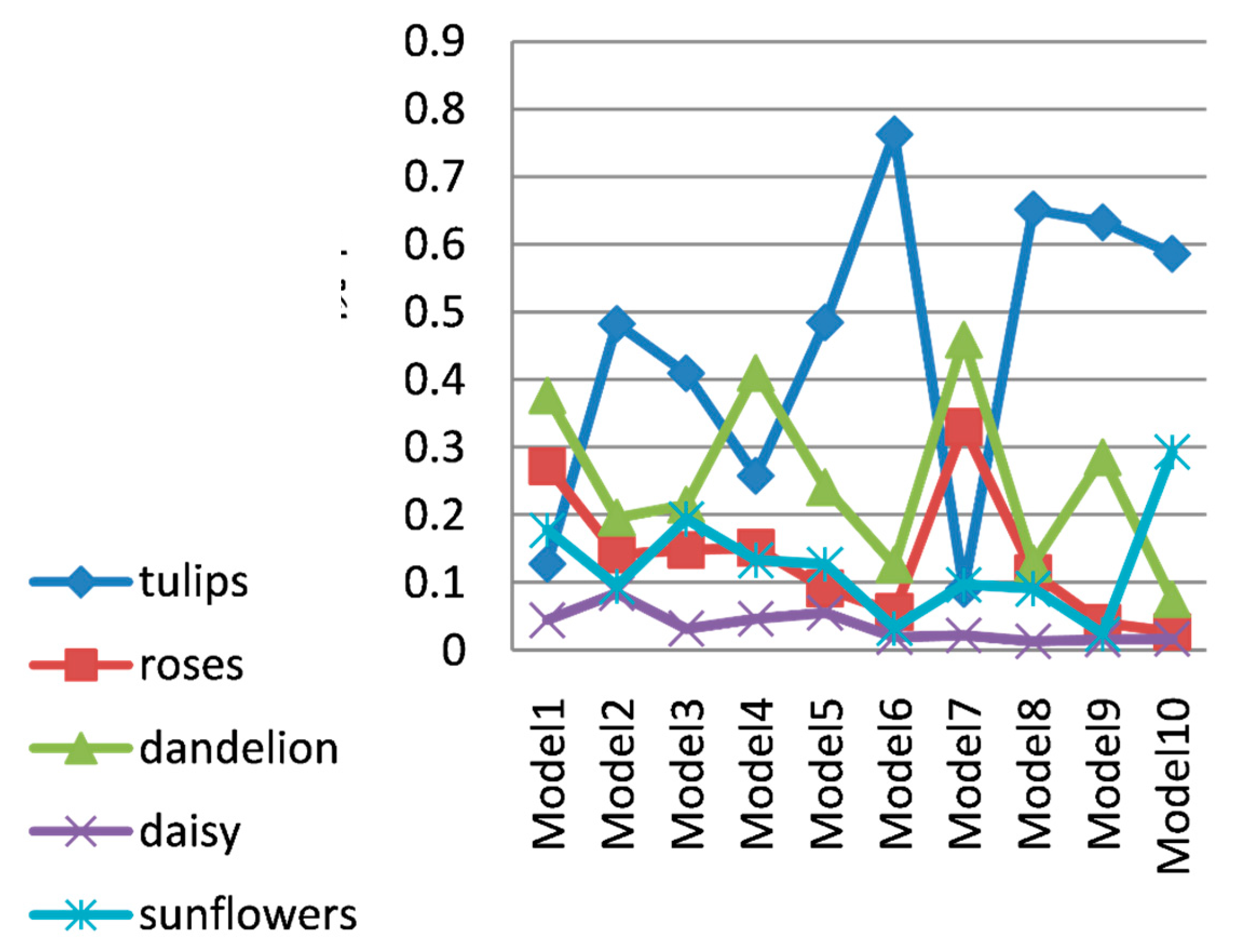
4.2.1. Flowers Dataset
4.2.2. Cars Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Proc. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. ICDAR 2003, 3, 958–962. [Google Scholar]
- Neumaier, A. Solving ill-conditioned and singular linear systems: A tutorial on regularization. SIAM Rev. 1998, 40, 636–666. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Guo, K.; Duan, G. 3D image retrieval based on differential geometry and co-occurrence matrix. Neural Comput. Appl. 2014, 24, 715–721. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Guo, K.; Xiao, Y.; Duan, G. A cost-efficient architecture for the campus information system based on transparent computing platform. Int. J. Ad Hoc Ubiquitous Comput. 2016, 21, 95–103. [Google Scholar] [CrossRef]
- Guo, K.; Liu, Y.; Duan, G. Differential and statistical approach to partial model matching. Math. Probl. Eng. 2013. [Google Scholar] [CrossRef]
- Zhu, Y.; Sun, D.; He, X.; Liu, M. Short-term wind speed prediction based on EMD-GRNN and probability statistics. Comput. Sci. 2014, 41, 72–75. [Google Scholar]
- Liu, D.; Li, S.; Cao, Z. A Review of deep learning and its application in image object classification and detection. Comput. Sci. 2016, 43, 13–23. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Tulips | Roses | Daisy | Dandelion | Sunflower |
|---|---|---|---|---|---|
| 1 | 4 | 3 | 1 | 2 | 5 |
| 2 | 1 | 3 | 5 | 2 | 4 |
| 3 | 1 | 4 | 5 | 2 | 3 |
| 4 | 2 | 3 | 5 | 1 | 4 |
| 5 | 1 | 4 | 5 | 2 | 3 |
| 6 | 1 | 3 | 5 | 2 | 4 |
| 7 | 4 | 2 | 5 | 1 | 3 |
| 8 | 1 | 3 | 5 | 2 | 4 |
| 9 | 1 | 3 | 4 | 2 | 5 |
| 10 | 1 | 4 | 5 | 3 | 2 |
| Model | Tulips | Roses | Daisy | Dandelion | Sunflower |
|---|---|---|---|---|---|
| Probability | 0.386 | 0.080 | 0.011 | 0.206 | 0.066 |
| Batch | Model | Probability | Rank | Whether to Eliminate (Y/N) |
|---|---|---|---|---|
| 1 | Model 1 | 0.128 | 4 | Y |
| 1 | Model 2 | 0.483 | 1 | N |
| 1 | Model 3 | 0.410 | 1 | N |
| 2 | Stage1 | 0.446 | 1 | N |
| 2 | Model 4 | 0.258 | 2 | Y |
| 2 | Model 5 | 0.485 | 1 | N |
| 3 | Stage2 | 0.457 | 1 | N |
| 3 | Model 6 | 0.763 | 1 | N |
| 3 | Model 7 | 0.091 | 4 | Y |
| 4 | Stage3 | 0.614 | 1 | N |
| 4 | Model 8 | 0.652 | 1 | N |
| 4 | Model 9 | 0.633 | 1 | N |
| 5 | Stage4 | 0.642 | 1 | N |
| 5 | Model 10 | 0.586 | 1 | Y |
| Type | Before | After |
|---|---|---|
| Tulip | 0.385992 | 0.643649 |
| Rose | 0.206354 | 0.142315 |
| Daisy | 0.065914 | 0.010431 |
| Dandelion | 0.010578 | 0.005371 |
| Sunflower | 0.079717 | 0.029415 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, W.; Du, W. Progressive System: A Deep-Learning Framework for Real-Time Data in Industrial Production. Processes 2020, 8, 649. https://doi.org/10.3390/pr8060649
Liu Y, Zhang W, Du W. Progressive System: A Deep-Learning Framework for Real-Time Data in Industrial Production. Processes. 2020; 8(6):649. https://doi.org/10.3390/pr8060649
Chicago/Turabian StyleLiu, Yifeng, Wei Zhang, and Wenhao Du. 2020. "Progressive System: A Deep-Learning Framework for Real-Time Data in Industrial Production" Processes 8, no. 6: 649. https://doi.org/10.3390/pr8060649
APA StyleLiu, Y., Zhang, W., & Du, W. (2020). Progressive System: A Deep-Learning Framework for Real-Time Data in Industrial Production. Processes, 8(6), 649. https://doi.org/10.3390/pr8060649