3. Results
Two distinct ML architectures were experimented. One uses Gradient Boosted Trees regressors to obtain the exact value of each personality trait (Architecture I) while the other uses Gradient Boosted Trees classifiers to obtain the bin of each personality trait (Architecture II). Different experiments were conducted with two distinct datasets. One with 250 observations (No DA) and another with 5230 observations (With DA). Both architectures receive, as input, the one-hot encoded selection of adjectives.
Nested cross-validation was performed to tune the hyperparameters and to have a stronger validation of the obtained results. Inner cross-validation was performed using , with random search being used to find the best set of hyperparameters. In the inner loop, 700 fits were performed (4 folds × 175 combinations). The outer cross-validation loop used , totalling 2100 fits (3 folds × 700 fits). Two independent training trials were performed, with a grand total of 4200 fits (2 trials × 2100 fits) per architecture per dataset.
3.1. Architecture I—Big Five Regressors
All candidate models were evaluated in regard to RMSE and MAE error metrics.
Table 5 depicts the best hyperparameter configuration for Architecture I, for both datasets. What immediately stands out is the better performance of the candidate models when using the larger dataset. In fact, RMSE decreases about 30% when using the dataset
With DA. This was already expected since the dataset with
No DA was made of only 250 observations.
Overall, for Architecture I with
No DA the error is of approximately 8 units of measure. Since RMSE outputs an error in the same unit of the features that are being predicted by the model, it means that this Architecture is able to obtain the value of each personality trait with an error of 8 units. On the other hand, for Architecture I
With DA, RMSE is of approximately 5.6 units of measure. It is also possible to discern that RMSE tends to be more stable when using the
With DA dataset when compared to the
No DA dataset which shows higher error variance. In
Table 5, the
Evaluation column presents the error value of the best candidate model in the outer test fold. These values provide a second and stronger validation of the ability to classify of the best model per split.
The hyperparameter tuning process is significantly faster for Architecture I with No DA, taking around 3.7 min to perform 700 fits and around 22 min to perform the full run. On the other hand, Architecture I With DA takes more than 1 hour to perform the same amount of fits, requiring more than 6.5 hours to complete. Overall, the models that behaved the best used 300 gradient boosted trees. Interestingly, when using the dataset with No DA, all models required 20% of the entire feature set when constructing each tree (colsample by tree) and used a maximum depth of 4 levels, building shallower trees which helps controlling overfitting in the smaller dataset. On the other hand, when using the dataset With DA, the best models not only required 30% of the feature set but also required deeper trees, which indicate the need for more complex trees to find relations in the larger dataset. To strengthen this assertion, the learning rate is also smaller in Architecture I With DA allowing models to move slower through the gradient.
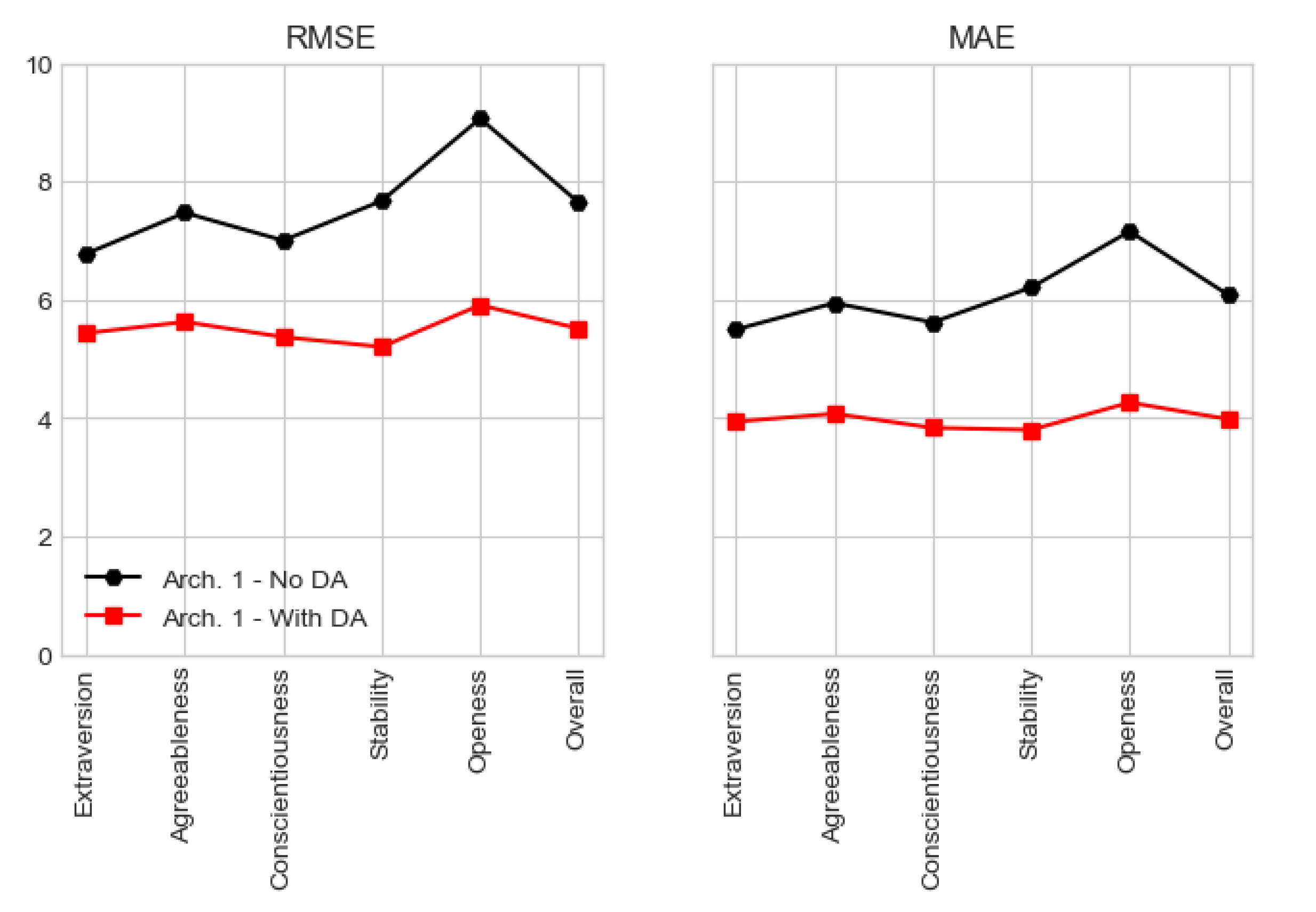
Focusing the results obtained from testing in the test fold of the outer-split, Architecture I
With DA presents a global RMSE of 5.512 and MAE of 3.979. On the other hand, Architecture I with
No DA presents higher error values, with a global RMSE and MAE of 7.644 and 6.082, respectively. The fact that RMSE and MAE have relatively close values implies that not many outliers, or distant classifications, were provided by the models. It is also interesting to note that, independently of the dataset,
Openness is the most difficult trait to classify. All these data is given by
Table 6, where the MSE is also displayed, being used to compute the RMSE.
Figure 7 provides a graphical view of RMSE and MAE for Architecture I for both datasets, being possible to discern that both metrics present a lower error value when conceiving models over the augmented dataset.
3.2. Architecture II—Big Five Bin Classifiers
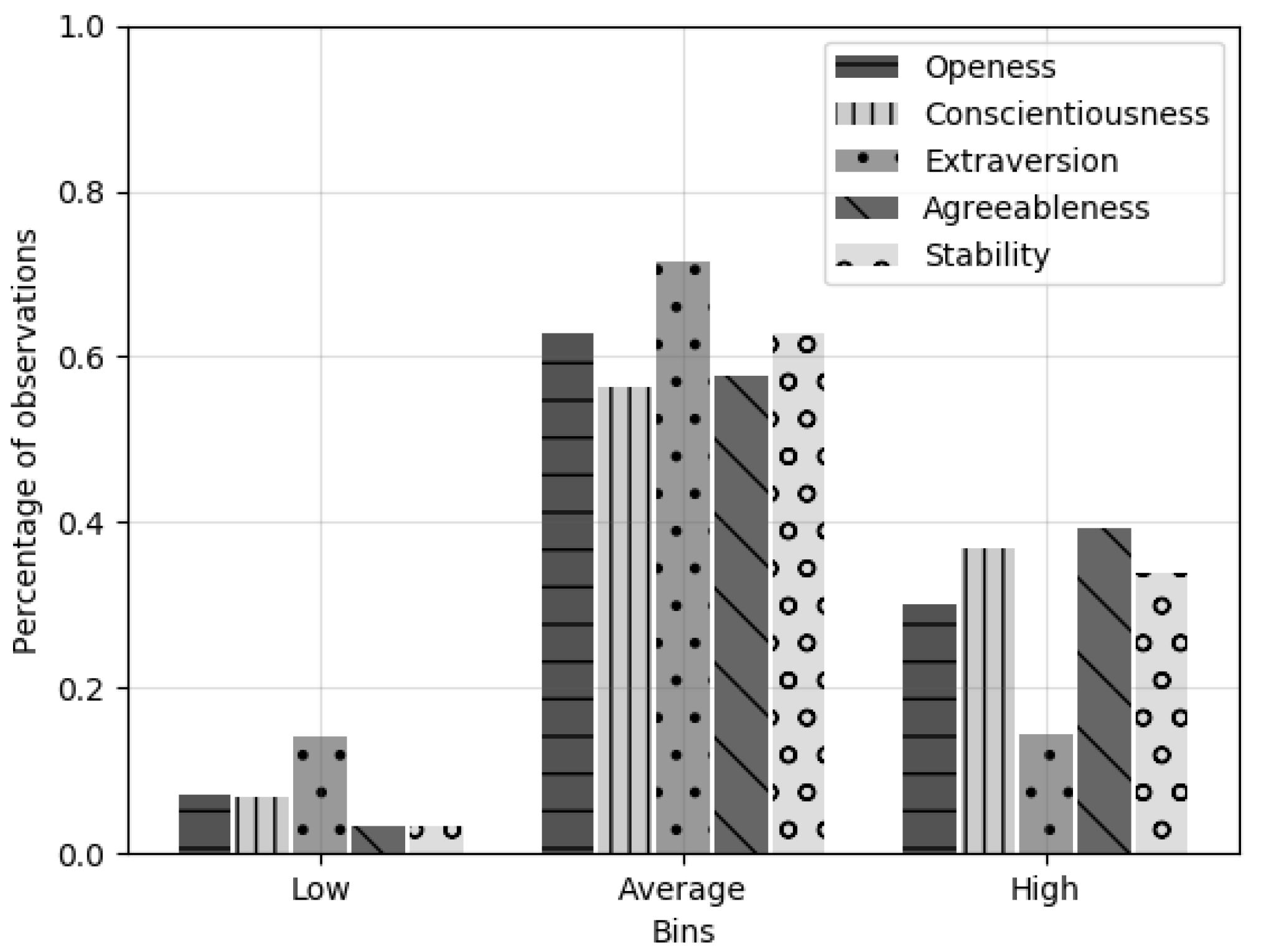
Architecture II candidate models, which classify personality traits in three bins (low, average and high), were evaluated using several classification metrics.
Table 7 depicts the best hyperparameter configuration for Architecture II, for the two datasets, using accuracy as metric. Again, models conceived over the dataset
With DA outperform those conceived over the dataset with
No DA, more than doubling the accuracy value. In addition, their evaluation values also tend to be more stable and less prone to variations. However, one may argue that the accuracy values attained by the candidate models and presented in
Table 7 are low. Hence, it is of the utmost importance to assert that such accuracy values correspond to samples that had all five traits correctly classified. I.e., if one trait of a sample was wrongly classified, than that sample would be considered as badly-classified even if the remaining four traits were correctly classified. To provide a stronger validation metric,
Table 8 provides metrics based on traits’ accuracy instead of samples’ accuracy, presenting significantly higher values.
Still regarding
Table 7, it becomes clear that the tuning process is significantly faster for Architecture II with
No DA, taking around 50 min to complete the process. On the other hand, when using the larger dataset, the process takes more than 12 hours to complete. Overall, models tend to use 300 gradient boosted trees and require 30% of the entire feature set per tree. The best classifiers also require deeper trees, with 12 or 18 levels. It is also worth mentioning that all the best models conceived over the dataset
With DA required a minimum child weight of 4. This hyperparameter defines the minimum sum of weights of all observations required in a child node, being used to control overfitting and prevent under-fitting, which may happen if high values are used when setting this hyperparameter.
As stated previously, all metrics provided in
Table 8 are based on traits’ accuracy. Using class accuracy instead of sample accuracy, the mean error of Architecture II candidate models using the dataset
With DA is of 0.165, which corresponds to an accuracy higher than 83%. On the other hand, the mean error with
No DA increases to 0.338. Overall, all models show better results when using the dataset
With DA.
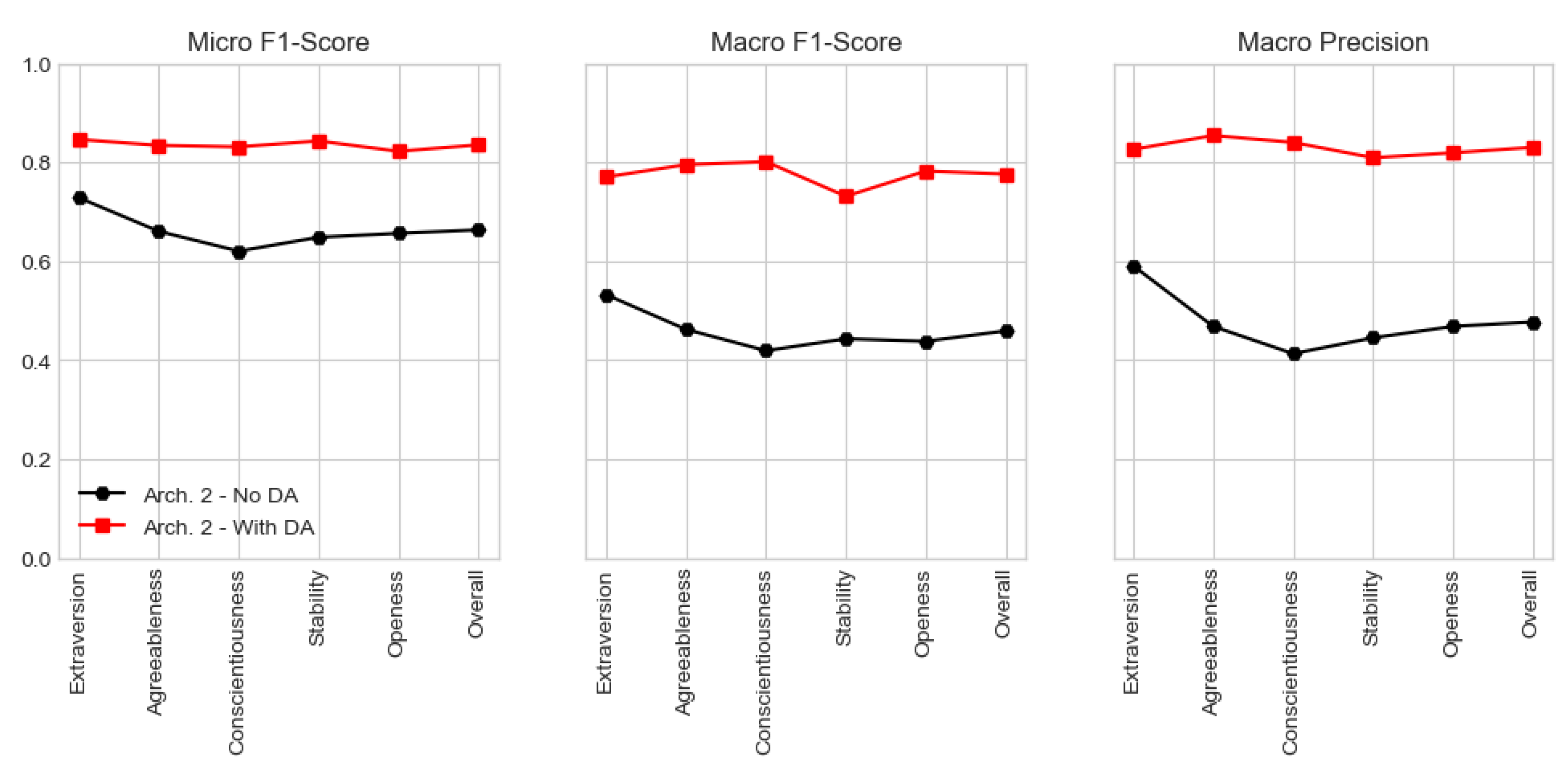
In this study, both micro and macro-averaged metrics were evaluated. However, since we are interested in maximising the number of correct predictions each classifier makes, special importance is given to micro-averaging. In fact, micro f1-score of the classifiers conceived over the dataset
With DA display an interesting overall value of 0.835, with the
Openness trait being, again, the one showing the lower value. It is worth mentioning that micro-averaging in a multi-class setting with all labels included, produces the same exact value for the f1-score, precision and recall metrics, being this the reason why
Table 8 only displays micro f1-score. On the other hand, macro-averaging computes each error metric independently for each class and then averages the metrics, treating all classes equally. Hence, since models depict a lower macro f1-score when compared to the micro one, this could mean that there may be some classes that are less used when classifying, such as
low or
high. Nonetheless, macro f1-score still present a very interesting global value of 0.776. Macro-averaged precision also depicts a high value, strengthening the ability of models to correctly classify true positives and avoid false positives. Finally, models’ global macro-averaged recall is of 0.742, still a significant value that tells us that the best candidate models are able, in some extent, to avoid false negatives.
Figure 8 provides a graphical view of micro and macro-averaged f1-score and precision for Architecture II for both datasets, being again possible to recognise a better performance when using the dataset
With DA.
3.3. Feature Importance
Gradient Boosted Trees allow the possibility of estimating feature importance, i.e., a score that measures how useful each feature was when building the boosted trees. This importance was estimated using gain as importance type, which corresponds to the improvement in accuracy brought by a feature to the branches it is on. A higher value for a feature when compared to another, implies it is more important for classifying the label.
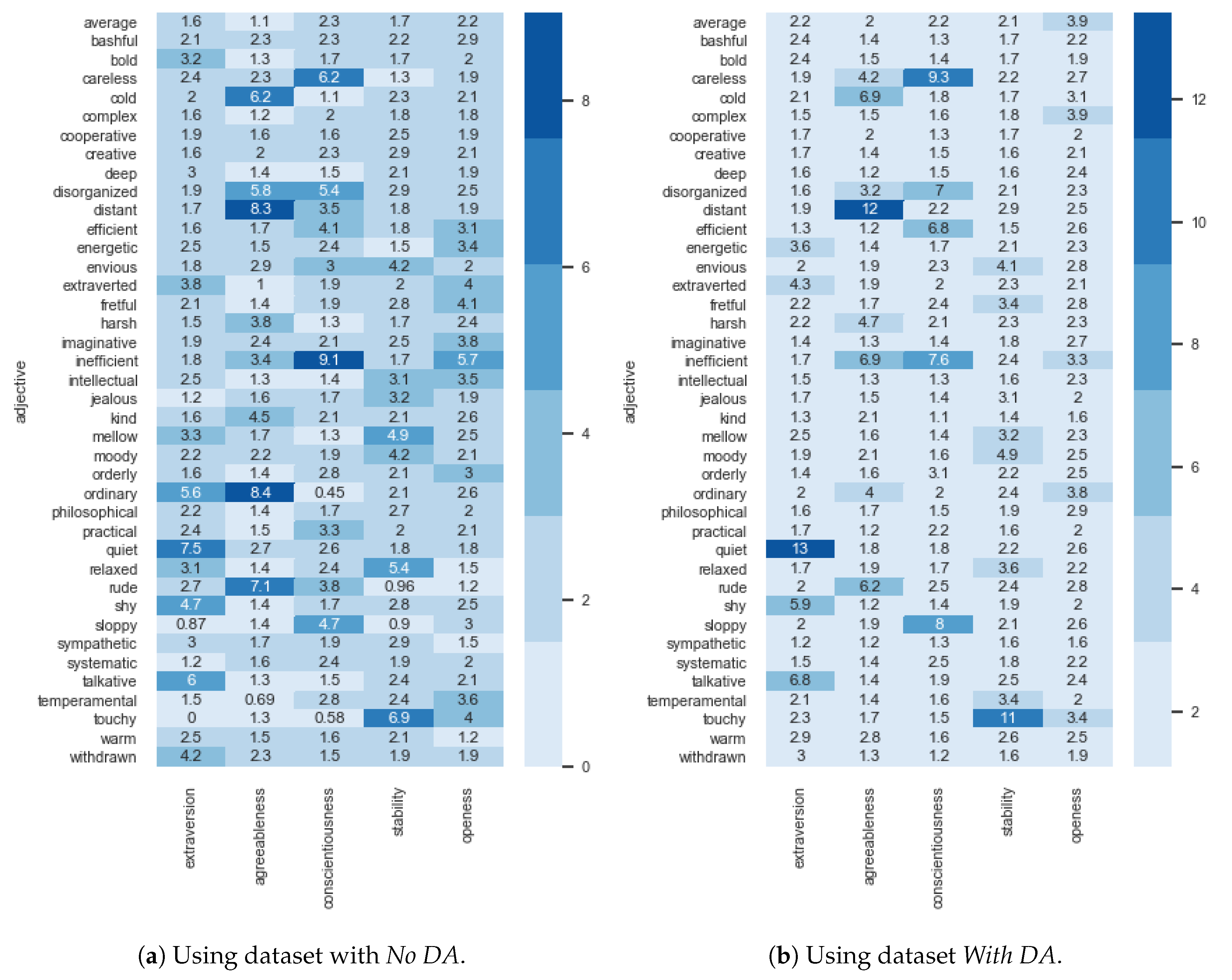
Figure 9 presents the estimated feature importance of Architecture I using an heat-map view. Interestingly, models conceived using the dataset with
No DA (
Figure 9a) give an higher importance to the selection of the adjective
inefficient when classifying the
Conscientiousness trait.
Sloppy,
disorganized and
careless are other adjectives that assume special relevance when classifying the same personality trait. Regarding the
Extraversion trait,
talkative,
quiet and
withdrawn are the most important adjectives, being only then followed by the
extroverted and
energetic ones. The
Agreeableness trait gives higher importance to
distant,
harsh,
cold and
rude. On the other hand, feature importance is more uniform in the
Stability and
Openness personality traits, with the most important adjectives assuming a relative importance of about 7%. Another interesting fact that arises from these results, is that some adjectives have lower importance for all five traits. Examples include
bashful,
bold,
intellectual and
jealous.
As for the models conceived using the dataset
With DA (
Figure 9b), results are similar to the smaller dataset. In these models there are less important features, but the ones considered as important have a stronger importance. An example is the case of the adjective
talkative for the
Extraversion trait, which increases its importance from 16% to 22%, and quiet, which increases from 11% to 17%.
Withdrawn and
quiet have a reduced importance. Interestingly, for the
Agreeableness trait, the adjective
kind becomes the most important one, increasing from 3.2% to 15%. The
Openness trait still assumes a more uniform importance for all features, being this one of the reasons why it was the trait showing worst performance using Architecture I models.
Regarding Architecture II,
Figure 10 presents the estimated feature importance for both datasets. What immediately draws one attention is the fact that importance values are much more balanced when compared to Architecture I. Indeed, the highest importance value is of 9.1% with
No DA and 13%
With DA when compared to 20% and 22% of Architecture I, respectively. Nonetheless, except for a few exceptions, adjectives assuming higher importance in Architecture I also assume higher importance in Architecture II. The main difference is that values are closer together, having a lower amplitude.
4. Discussion and Conclusions
The proposed ASAP method aims to use ML-based models to reinstate the process of rating adjectives or answering questions by an adjective selection process. To achieve this goal, two different ML architectures were proposed, experimented and evaluated. The first architecture uses Gradient Boosted Trees regressors to quantify the Big Five personality traits. Overall, this architecture is able to quantify such traits with an error of approximately 5.5 units of measure, providing an accurate output given the limited amount of available records. On the other hand, Architecture II uses Gradient Boosted Trees classifiers to qualify the bin in which the subject stands, for each trait. Bins are based on Saucier’s original study where trait scores between are considered Low, between are considered Average, and between are considered High. This architecture was able to quantify the personality traits with a micro-averaged f1-score of more than 83%. A better performance of both architectures in the augmented dataset was also expected since the original dataset had a limited amount of records. The implemented data augmentation techniques aimed to increase the dataset size following well-defined rationales but also included several randomised decisions based on a probabilistic approach in order to reduce bias and create a more generalised version of the dataset. For this, data exploration and pattern mining, in the form of Association Rules Learning, assumed an increased importance, allowing us to understand relations between selected adjectives. Results for records with very few adjectives selected may be biased to the dataset used to train the models since the ability to quantify traits based on the selection of just one or two adjectives is of an extreme difficulty. Hence, for the ASAP method to behave properly, subjects should be encouraged to select four, or more, adjectives.
A further validation was carried out by means of a significance analysis between the correlation differences of predicted and actual scores. The best overall candidate model of Architecture I was trained using, as input data, 90% of the original dataset, with the remaining being used to obtain predictions. Predictions were compared with the actual scores of the five traits. As expected, the p-value returned an high value (0.968), with a z-score of 0.039. Such values tell, with a high degree of confidence, that the null hypothesis should be retained and that both correlation coefficients are not significantly different from each other. This is in line with expectations since the conceived models are optimizing a differentiable loss function, using a gradient descent procedure that reduces the model’s loss to increase the correlation between predictions and actual scores.
Architecture II took significantly more time to fit than Architecture I. However, it provides more accurate results, which are less prone to error. It should be noted that Architecture II only provides an approximation to the Big Five of the subject, i.e., it does not numerically quantify each trait, instead it tells in which bin the subject finds himself. This can be useful in cases where the general qualification of each trait is more important than the specific score of the trait. On the other hand, Architecture I will provide an exact score for each personality trait based on a selection of adjectives. Indeed, the working hypothesis has been confirmed, i.e., it is possible to achieve promising performances using ML-based models where the subject, instead of rating forty adjectives or answering long questions, selects the adjectives he relates the most with. This allows one to obtain the Big Five using a method with a reduced complexity and that takes a small amount of time to complete. Obviously, the obtained results are just estimates, with an underlying error. The conducted experiments shown the ability of ML-based models to compute estimates of personality traits, and should not be seen as a definitive psychological assessment of one’s personality traits. For a full personality assessment, tests such as the one proposed by Saucier, Goldberg or the NEO-personality-inventory should be used.
The use of augmented sets of data may bring an intrinsic bias to the candidate models. In all cases, preference should always be given to the collection and use of real data. However, in scenarios where data is extremely costly, an approximation may allow ML models to be analyzed with augmented data. In such scenarios, data augmentation processes should make use of several randomized decisions based on probabilistic approaches to create a generalized version of the smaller dataset. Experiments should be carefully conducted, implementing two, or more, independent trials, cross-validation and even nested cross-validation. Models, when deployed, should monitor their performance and, in situations with a clear performance degradation, should be re-trained with new collected data.
In Saucier’s test, each personality trait is computed using the rating of eight unipolar adjectives, i.e, no adjective is used for more than one personality trait. Indeed, it is known, beforehand, which adjectives are used by each trait. For example, the Extroversion trait is computed based on four positively weighted adjectives (extroverted, talkative, energetic and bold) and four negative ones (shy, quiet, withdrawn and bashful). However, in the proposed ML architectures that make the ASAP method, all 40 adjectives are used to compute all traits, allowing the ML models to use adjectives selection/non-selection to compute several traits, thus harnessing inter-trait relationships. For instance, bold, one of the adjectives used by Saucier to compute Extroversion, shows a small importance in the conceived architectures when quantifying Extroversion. The same happens for bashful in Extroversion, creative in Openness, and practical in Conscientiousness, just to point a few. This could lead us to hypothesise that, one, the list of forty adjectives could be further reduced to a smaller set of adjectives by removing those that are shown to have a smaller importance and that, two, there are adjectives that can be used to quantify distinct personality traits, such as the case of disorganised, which can be used for the Conscientiousness and the Agreeableness traits. It is also interesting to note the lack of features assuming high importance when quantifying Openness. In fact, one of its adjectives, ordinary, seems to assume higher importance in the Agreeableness trait. Overall, Saucier’s adjective-trait relations are being found and used by the conceived models.
Since the conceived ML architectures proved to be both performant and efficient using a selection of adjectives, future research points towards a reduction to the minimum required set of adjectives that does not harm the method’s accuracy, further reducing complexity and the time it takes to be performed by the subject.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}