Fault Diagnosis Method for Hydraulic Directional Valves Integrating PCA and XGBoost



Abstract
1. Introduction
2. Principal Component Analysis-Based Data Dimensionality Reduction
2.1. Principle of PCA Dimensionality Reduction
2.2. Singular Value Decomposition
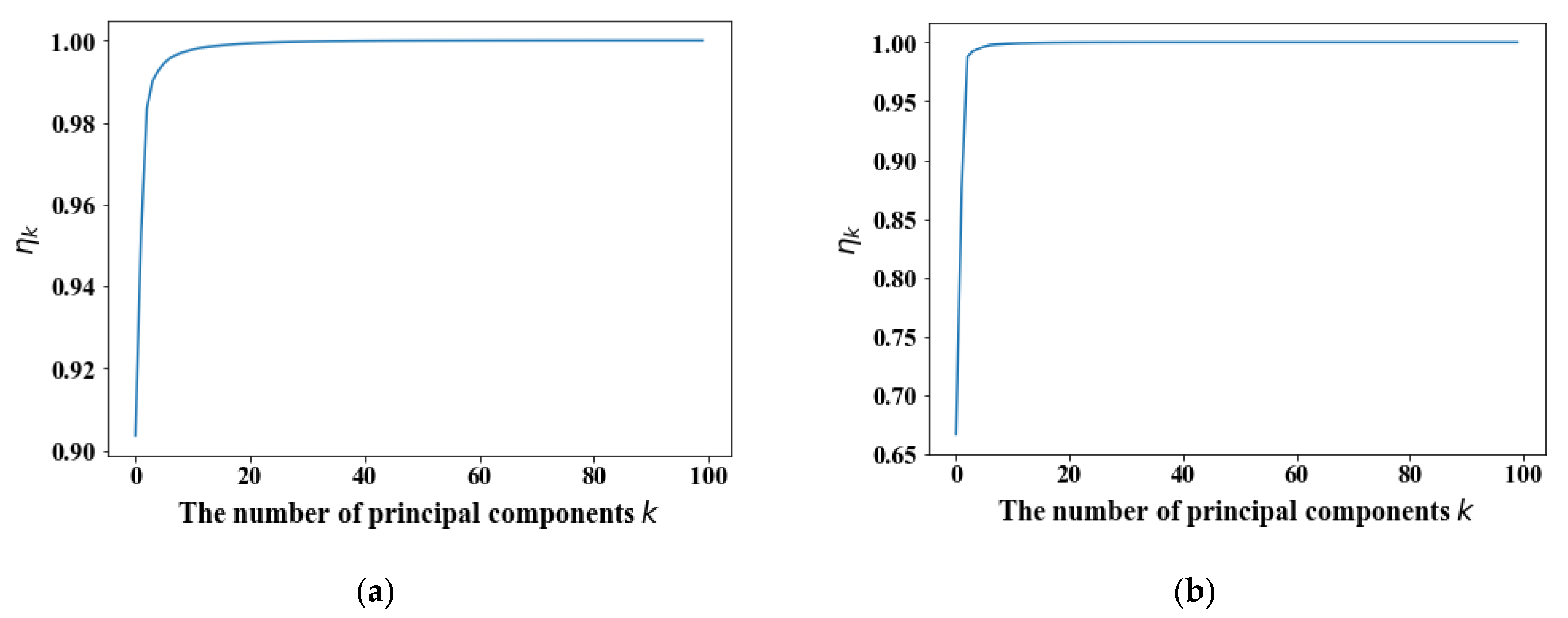
2.3. Determination of the Number of Principal Components
2.4. Main Steps of PCA
3. Principles of the XGBoost Algorithm
3.1. Objective Function of the Model
3.2. Solution of Loss Function in the Objective Function
3.3. Complexity Calculation in the Objective Function
3.4. Optimization of the Objective Function
4. Hydraulic Valve Failure Test
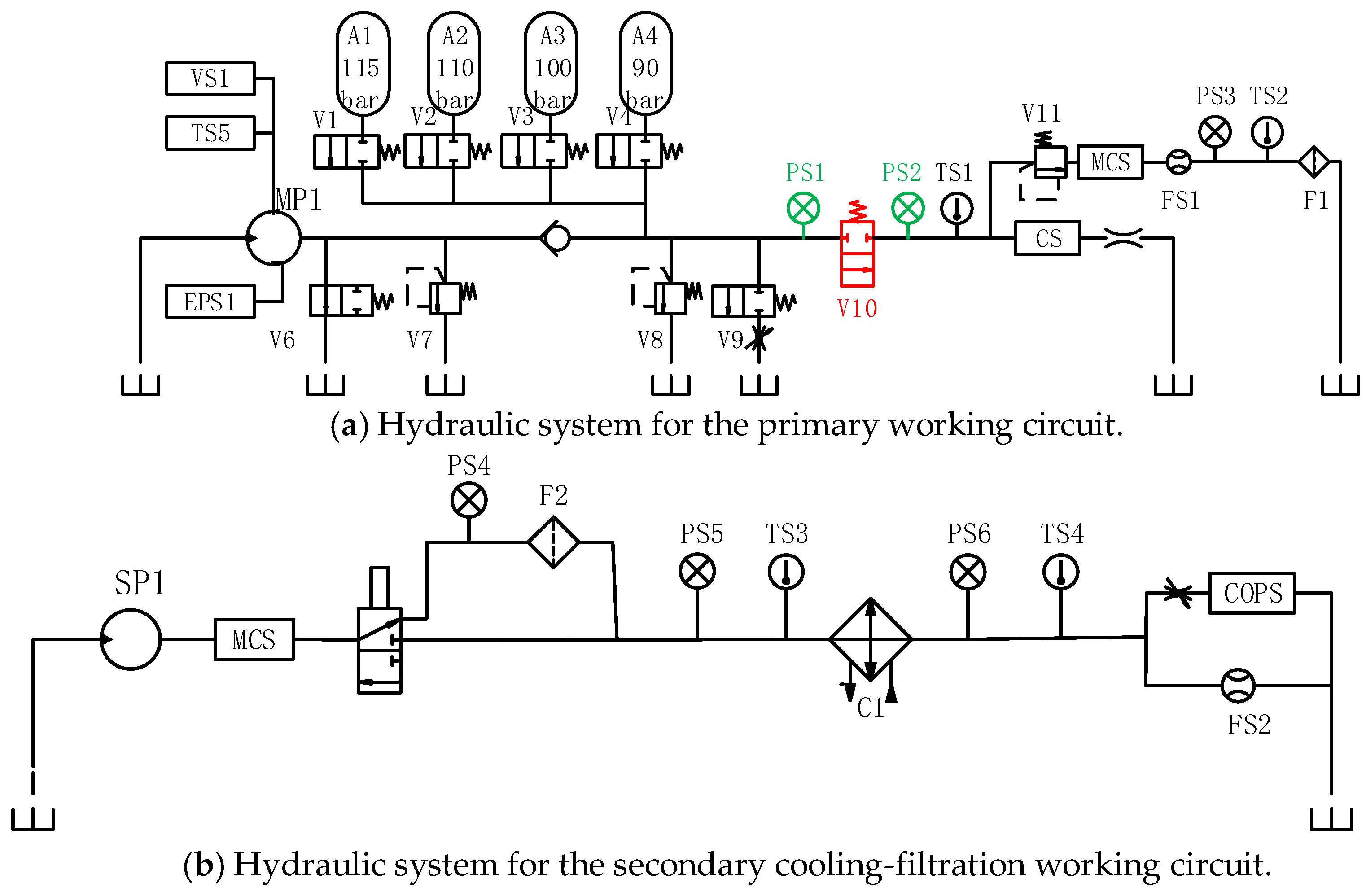
4.1. Introduction to the Experimental Platform
4.2. Data Acquisition System
4.3. Hydraulic Valve Fault Setting and Data Acquisition
5. Hydraulic Valve Fault Diagnosis Based on PCA and XGBoost
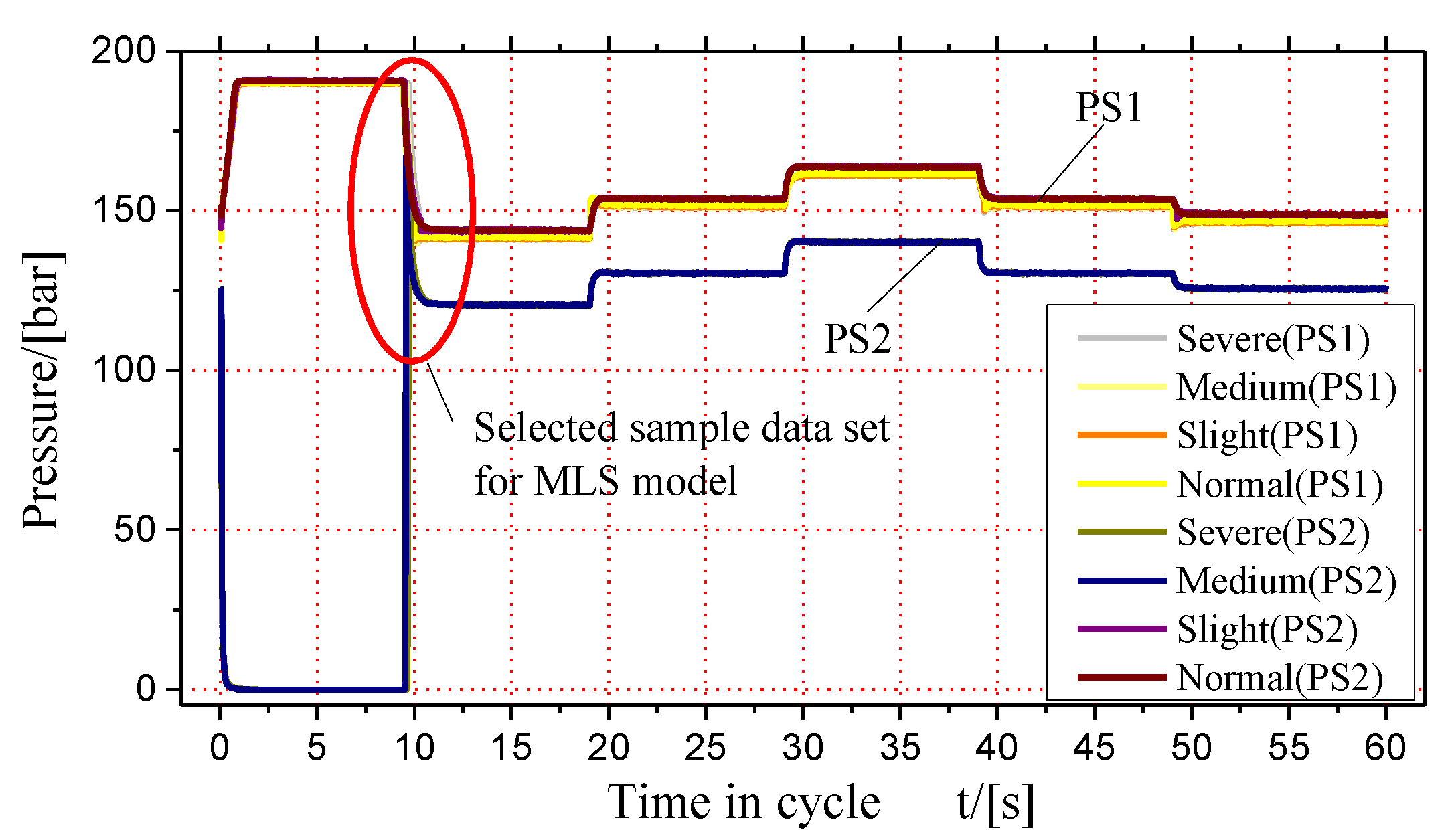
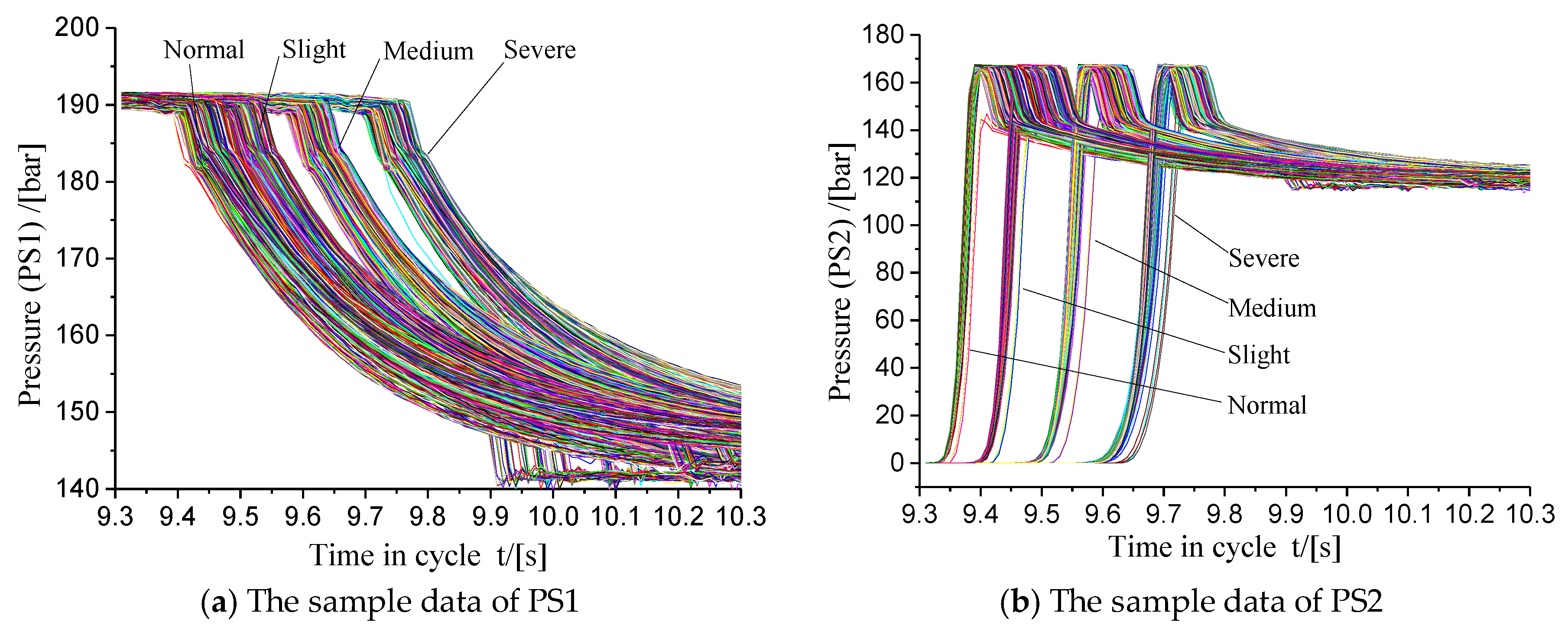
5.1. Acquisition of Sample Data for a Hydraulic Valve Fault Diagnosis
5.2. Dimensionality Reduction of a PCA-Based Training Set Sample
5.3. Model Establishment Based on the XGBoost Algorithm
5.4. Model Evaluation
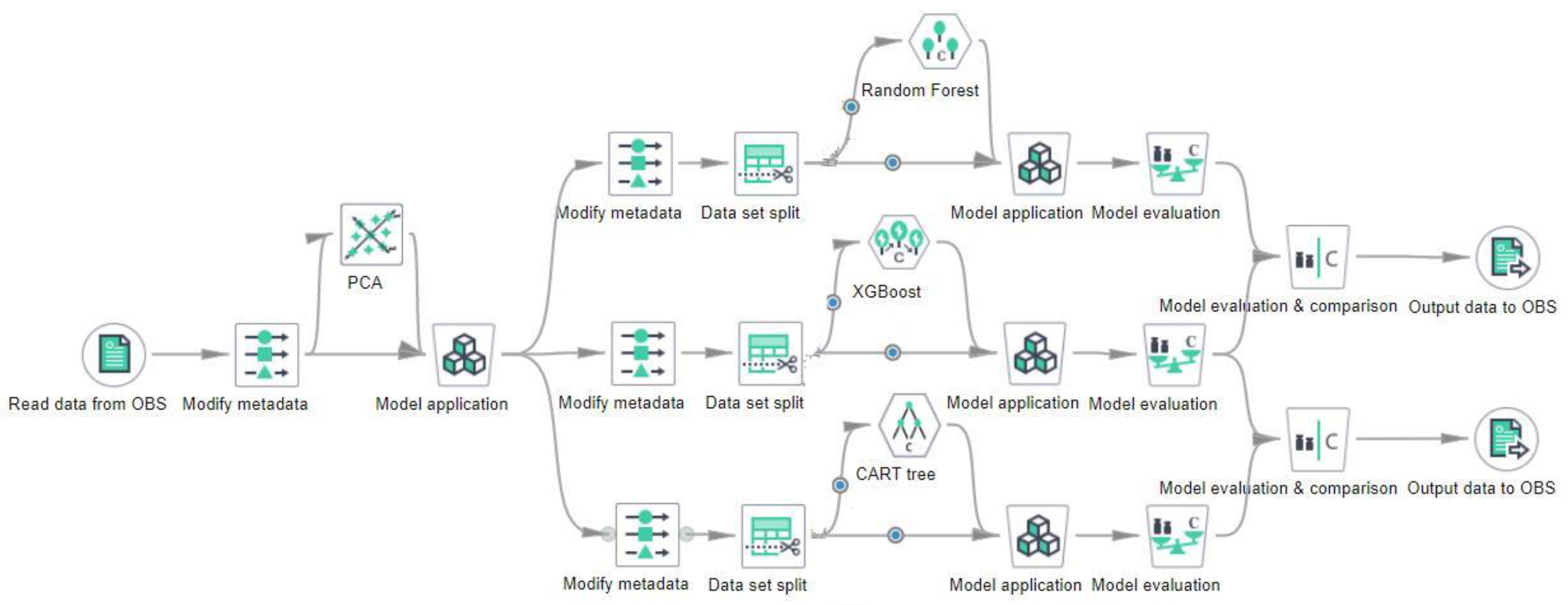
5.5. Comparison of Model Diagnosis Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Schneider, T.; Helwig, N.; Schütze, A. Automatic feature extraction and selection for classification of cyclical time series data. TM-Tech. Mess. 2017, 84, 198–206. [Google Scholar] [CrossRef]
- Goharrizi, A.Y.; Sepehri, N. Application of fast Fourier and wavelet transforms towards actuator leakage diagnosis: A comparative study. Int. J. Fluid Power 2013, 14, 39–51. [Google Scholar] [CrossRef]
- Watton, J. Modelling, Monitoring and Diagnostic Techniques for Fluid Power Systems; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Qian, J.Y.; Chen, M.R.; Liu, X.L.; Jin, Z.J. A numerical investigation of the flow of nanofluids through a micro Tesla valve. J. Zhejiang Univ. Sci. A 2019, 20, 50–60. [Google Scholar] [CrossRef]
- Qian, J.Y.; Gao, Z.X.; Liu, B.Z.; Jin, Z.J. Parametric study on fluid dynamics of pilot-control angle globe valve. ASME J. Fluids Eng. 2018, 140, 111103. [Google Scholar] [CrossRef]
- Zhang, J.; Xia, S.; Ye, S.; Xu, B.; Song, W.; Zhu, S.; Xiang, J. Experimental investigation on the noise reduction of an axial piston pump using free-layer damping material treatment. Appl. Acoust. 2018, 139, 1–7. [Google Scholar] [CrossRef]
- Ye, S.; Zhang, J.; Xu, B.; Zhu, S.; Xiang, J.; Tang, H. Theoretical investigation of the contributions of the excitation forces to the vibration of an axial piston pump. Mech. Syst. Signal Process. 2019, 129, 201–217. [Google Scholar] [CrossRef]
- Wang, C.; Hu, B.; Zhu, Y.; Wang, X.; Luo, C.; Cheng, L. Numerical study on the gas-water two-phase flow in the self-priming process of self-priming centrifugal pump. Processes 2019, 7, 330. [Google Scholar] [CrossRef]
- Wang, C.; Chen, X.; Qiu, N.; Zhu, Y.; Shi, W. Numerical and experimental study on the pressure fluctuation, vibration, and noise of multistage pump with radial diffuser. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 481. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Xu, W.; Wang, Y.; Zhu, W. Combining a HMM with a genetic algorithm for the fault diagnosis of photovoltaic inverters. J. Power Electron. 2017, 17, 1014–1026. [Google Scholar]
- Xu, X.; Wang, W.; Zou, N.; Chen, L.; Cui, X. A comparative study of sensor fault diagnosis methods based on observer for ECAS system. Mech. Syst. Signal Process. 2017, 87, 169–183. [Google Scholar] [CrossRef]
- Sun, H.; Yuan, S.; Luo, Y. Cyclic spectral analysis of vibration signals for centrifugal pump fault characterization. IEEE Sens. J. 2018, 18, 2925–2933. [Google Scholar] [CrossRef]
- Tang, S.; Gu, J.; Tang, K.; Zou, R.; Sun, X.; Uddin, S. A Fault-signal-based generalizing remaining useful life prognostics method for wheel hub bearings. Appl. Sci. 2019, 9, 1080. [Google Scholar] [CrossRef]
- Mao, Y.; Liu, G.; Zhao, W.; Ji, J. Vibration prediction in fault-tolerant flux-switching permanent-magnet machine under healthy and faulty conditions. IET Electr. Power Appl. 2017, 11, 19–28. [Google Scholar] [CrossRef]
- Chen, T.; Chen, L.; Xu, X.; Cai, Y.; Jiang, H.; Sun, X. Passive fault-tolerant path following control of autonomous distributed drive electric vehicle considering steering system fault. Mech. Syst. Signal Process. 2019, 123, 298–315. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, G.; Zhao, W.; Yu, X.; Gao, M. dynamic performance improvement of five-phase permanent-magnet motor with short-circuit fault. IEEE Trans. Ind. Electron. 2018, 65, 145–155. [Google Scholar] [CrossRef]
- Schneider, T.; Helwig, N.; Schütze, A. Industrial condition monitoring with smart sensors using automated feature extraction and selection. Meas. Sci. Technol. 2018, 29, 094002. [Google Scholar] [CrossRef]
- Zhu, Y.; Tang, S.; Quan, L.; Jiang, W.; Zhou, L. Extraction method for signal effective component based on extreme-point symmetric mode decomposition and Kullback-Leibler divergence. J. Braz. Soc. Mech. Sci. Eng. 2019, 41, 100. [Google Scholar] [CrossRef]
- Zhu, Y.; Qian, P.; Tang, S.; Jiang, W.; Li, W.; Zhao, J. Amplitude-frequency characteristics analysis for vertical vibration of hydraulic AGC system under nonlinear action. AIP Adv. 2019, 9, 035019. [Google Scholar] [CrossRef]
- Wu, W.; Yang, S.; Zhou, T. Application of complex three-order cumulants to fault diagnosis of hydraulic valve. J. Tianjin Univ. 2013, 46, 590–595. [Google Scholar]
- Gao, Y.; Huang, Y. Application of AR bi-spectrum in fault diagnosis of reducing valve. Mach. Des. Manuf. 2011, 11, 70–72. [Google Scholar]
- Li, T.; Fan, M.; Huang, Q.; Li, Z. Research on fault diagnosis method for auto pilot hydraulic valve based on fractal theory. China Meas. Test 2012, 38, 1–5. [Google Scholar]
- Raduenz, H.; Mendoza, Y.E.A.; Ferronatto, D.; Souza, F.J.; da Cunha Bastos, P.P.; Soares, J.M.C.; De Negri, V.J. Online fault detection system for proportional hydraulic valves. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 331. [Google Scholar] [CrossRef]
- Vianna, W.O.L.; de Souza Ribeiro, L.G.; Yoneyama, T. Electro hydraulic servovalve health monitoring using fading extended Kalman filter. In Proceedings of the 2015 IEEE Conference on Prognostics and Health Management (PHM), Austin, TX, USA, 2015, 22–25 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Folmer, J.; Schrüfer, C.; Fuchs, J.; Vermum, C.; Vogel-Heuser, B. Data-driven valve diagnosis to increase the overall equipment effectiveness in process industry. In Proceedings of the 2016 IEEE 14th International Conference on Industrial Informatics (INDIN), Poitiers, France, 18–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1082–1087. [Google Scholar]
- Lei, Y.; Jia, F.; Kong, D.; Lin, J.; Xing, S. Opportunities and challenges of machinery intelligent fault diagnosis in big data era. Chin. J. Mech. Eng. 2018, 54, 94–104. [Google Scholar] [CrossRef]
- Pei, H.; Hu, C.; Si, X.; Zhang, J.; Pang, Z.; Zhang, P. Review of machine learning based remaining useful life prediction methods for equipment. J. Mech. Eng. 2019, 55, 1–13. [Google Scholar]
- Zhu, Y.; Jiang, W.; Kong, X.; Quan, L.; Zhang, Y. A chaos wolf optimization algorithm with self-adaptive variable step-size. AIP Adv. 2017, 7, 105024. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. A 1901, 6, 559–572. [Google Scholar] [CrossRef]
- Fisher, R.A.; Mackenzie, W.A. Studies in crop variation. II. The manurial response of different potato varieties. J. Agric. Sci. 1923, 13, 311–320. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Mohanty, S.; Gupta, K.K.; Raju, K.S. Adaptive fault identification of bearing using empirical mode decomposition–principal component analysis-based average kurtosis technique. IET Sci. Meas. Technol. 2017, 11, 30–40. [Google Scholar] [CrossRef]
- Stief, A.; Ottewill, J.; Baranowski, J.; Orkisz, M. A PCA and two-stage bayesian sensor fusion approach for diagnosing electrical and mechanical faults in induction motors. IEEE Trans. Ind. Electron. 2019, 66, 9510–9520. [Google Scholar] [CrossRef]
- Caggiano, A. Tool wear prediction in Ti-6Al-4V machining through multiple sensor monitoring and PCA features pattern recognition. Sensors 2018, 18, 823. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ma, X.; Qian, P. Wind turbine fault detection and identification through PCA-based optimal variable selection. IEEE Trans. Sustain. Energy 2018, 9, 1627–1635. [Google Scholar] [CrossRef]
- Xiao, X.; Zhao, S.; Chen, K.; Zhang, M.; Liu, L. Application of principal component analysis in fault diagnosis of electro-hydrostatic actuators. Missiles Space Veh. 2019, 366, 98–104. [Google Scholar]
- Riba, J.R.; Canals, T.; Cantero, R. Recovered paperboard samples identification by means of mid-infrared sensors. IEEE Sensors J. 2013, 13, 2763–2770. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining ACM, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Nielsen, D. Tree Boosting with XGBoost-Why Does XGBoost Win “Every” Machine Learning Competition? Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Noreg, 2016. [Google Scholar]
- Zhang, D.; Qian, L.; Mao, B.; Huang, C.; Huang, B.; Si, Y. A data-driven design for fault detection of wind turbines using random forests and XGBoost. IEEE Access 2018, 6, 21020–21031. [Google Scholar] [CrossRef]
- Chakraborty, D.; Elzarka, H. Early detection of faults in HVAC systems using an XGBoost model with a dynamic threshold. Energy Build. 2019, 185, 326–344. [Google Scholar] [CrossRef]
- Zhang, R.; Li, B.; Jiao, B. Application of XGBoost Algorithm in Bearing Fault Diagnosis. IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 490, p. 072062. [Google Scholar]
- Nguyen, H.; Bui, X.N.; Bui, H.B.; Cuong, D.T. Developing an XGboost model to predict blast-induced peak particle velocity in an open-pit mine: A case study. Acta Geophys. 2019, 67, 477–490. [Google Scholar] [CrossRef]
- Pan, B. Application of XGBoost algorithm in hourly PM2. 5 concentration prediction. IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2018; Volume 113, p. 012127. [Google Scholar]
- Liu, Y.; Qiao, M. Heart disease prediction based on clustering and XGboost. Comput. Syst. Appl. 2019, 28, 228–232. [Google Scholar]
- Fitriah, N.; Wijaya, S.K.; Fanany, M.I.; Badri, C.; Rezal, M. EEG channels reduction using PCA to increase XGBoost’s accuracy for stroke detection. In Proceedings of the AIP Conference, 10–11 July 2017; AIP Publishing: Melville, NY, USA, 2017; Volume 1862, p. 030128. [Google Scholar]
- Zhao, W.; Dong, L. Machine Learning; Posts & Telecom Press: Beijing, China, 2018. [Google Scholar]
- Zhang, J. Multivariable Statistical Process Control; Chemical Industry Press: Beijing, China, 2000. [Google Scholar]
- Wang, G. Principal Component Analysis and Partial Least Square Method; Tsinghua University Press: Beijing, China, 2012. [Google Scholar]
- Wang, X. A Research on CTR Prediction Based on Ensemble of RF, XGBoost and FFM; Zhejiang University: Hangzhou, China, 2018. [Google Scholar]
- Available online: http://archive.ics.uci.edu/ml/datasets/Condition monit-oring of hydraulic systems (accessed on 26 April 2018).
- Helwig, N.; Pignanelli, E.; Schütze, A. Condition monitoring of a complex hydraulic system using multivariate statistics. In Proceedings of the 2015 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Pisa, Italy, 11–14 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 210–215. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Physical Quantity | Unit | Sampling Rate | Attribute Information |
|---|---|---|---|---|
| PS1-6 | Pressure | bar | 100 Hz | Actual sensor |
| EPS1 | Motor power | W | 100 Hz | Actual sensor |
| FS1-2 | Volume flow | L/min | 10 Hz | Actual sensor |
| TS1-4 | Temperature | °C | 1 Hz | Actual sensor |
| VS1 | Vibration | mm/s | 1 Hz | Actual sensor |
| CE | Cooling efficiency | % | 1 Hz | Virtual sensor |
| CP | Cooling power | kW | 1 Hz | Virtual sensor |
| SE | Efficiency factor | % | 1 Hz | Virtual sensor |
| Hydraulic Component | Fault Conditions | Control Parameters | Possible Range |
|---|---|---|---|
| Valve (V10) | Switching characteristic degradation | Control current of V10 | 0 … 100% of nom. current. |
| Pump (MP1) | Internal leakage | Switchable bypass orifices V9 | 3 × 0.2 mm, 3 × 0.25 mm |
| Accumulators (A1–A4) | Gas leakage | Accumulators A1–A4 with different pre-charge pressures | 90, 100, 110, 115 bar |
| Cooler (C1) | Cooling power decrease | Fan duty cycle of C1 | 0 … 100% (0.6 … 2.2 kW) |
| Number of Principal Component | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Unit | % | % | % | % | % | % | % | % | % |
| PS1 | 90.36 | 4.96 | 3.02 | 0.68 | 0.24 | 0.18 | 0.12 | 0.07 | 0.06 |
| PS2 | 66.72 | 20.90 | 11.19 | 0.46 | 0.21 | 0.17 | 0.12 | 0.05 | 0.03 |
| Number of Principal Component | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| Unit | % | % | % | % | % | % | % | % | % |
| PS1 | 0.04 | 0.04 | 0.03 | 0.02 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 |
| PS2 | 0.03 | 0.02 | 0.02 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Fault Conditions for the Hydraulic Valve | Normal | Slight | Medium | Severe | Total |
|---|---|---|---|---|---|
| The total number of samples | 369 | 360 | 360 | 360 | 1449 |
| Number of training samples | 257 | 252 | 238 | 264 | 1011 |
| Number of test samples | 112 | 108 | 122 | 96 | 438 |
| Confusion Matrix | Precision | Recall Rate | F1 Score | |||||
|---|---|---|---|---|---|---|---|---|
| Predicted | Normal | Slight | Medium | Severe | ||||
| Practical | ||||||||
| Normal | 101 | 11 | 0 | 0 | 0.990 | 0.902 | 0.944 | |
| Slight | 0 | 108 | 0 | 0 | 0.885 | 1.000 | 0.939 | |
| Medium | 0 | 3 | 119 | 0 | 1.000 | 0.975 | 0.988 | |
| Severe | 1 | 0 | 0 | 95 | 1.000 | 0.990 | 0.995 | |
| Model Algorithm | Fault Conditions for the Hydraulic Valve | Model Evaluation Index | ||
|---|---|---|---|---|
| Precision | Recall Rate | F1 Score | ||
| PCA-CART | Normal | 0.878 | 0.902 | 0.890 |
| Slight | 0.914 | 0.889 | 0.901 | |
| Medium | 0.907 | 0.959 | 0.932 | |
| Severe | 0.966 | 0.896 | 0.930 | |
| Average value | 0.916 | 0.911 | 0.913 | |
| PCA-RFs | Normal | 0.916 | 0.875 | 0.895 |
| Slight | 0.909 | 0.926 | 0.917 | |
| Medium | 0.929 | 0.959 | 0.944 | |
| Severe | 0.958 | 0.948 | 0.953 | |
| Average value | 0.928 | 0.927 | 0.927 | |
| PCA-XGBoost | Normal | 0.990 | 0.902 | 0.944 |
| Slight | 0.885 | 1.000 | 0.939 | |
| Medium | 1.000 | 0.975 | 0.988 | |
| Severe | 1.000 | 0.990 | 0.995 | |
| Average value | 0.969 | 0.967 | 0.966 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Y.; Jiang, W.; Jiang, A.; Zhu, Y.; Niu, H.; Zhang, S. Fault Diagnosis Method for Hydraulic Directional Valves Integrating PCA and XGBoost. Processes 2019, 7, 589. https://doi.org/10.3390/pr7090589
Lei Y, Jiang W, Jiang A, Zhu Y, Niu H, Zhang S. Fault Diagnosis Method for Hydraulic Directional Valves Integrating PCA and XGBoost. Processes. 2019; 7(9):589. https://doi.org/10.3390/pr7090589
Chicago/Turabian StyleLei, Yafei, Wanlu Jiang, Anqi Jiang, Yong Zhu, Hongjie Niu, and Sheng Zhang. 2019. "Fault Diagnosis Method for Hydraulic Directional Valves Integrating PCA and XGBoost" Processes 7, no. 9: 589. https://doi.org/10.3390/pr7090589
APA StyleLei, Y., Jiang, W., Jiang, A., Zhu, Y., Niu, H., & Zhang, S. (2019). Fault Diagnosis Method for Hydraulic Directional Valves Integrating PCA and XGBoost. Processes, 7(9), 589. https://doi.org/10.3390/pr7090589