2. Materials and Methods
A dominant aspect in the motivation and foundation of the developed research methodology lies in designing, developing and validating a new forecasting method for the month-ahead hourly electricity consumption in the case of medium industrial consumers, a method that is able to offer a forecasting accuracy suitable for the contractor’s real needs, so that he can use it in his business activities and rely on the accurate provided predictions. In a previous work [
26], along with members of my research group, a series of artificial neural networks in view of forecasting the hourly electricity consumption of a large hypermarket chain using the non-linear autoregressive (NAR) and NARX models have been successfully developed, using as exogenous variables in the case of the NARX developed artificial neural networks a time stamps constructed dataset, along with the outdoor temperature.
Although there were significant differences with regard to the consumption profiles of the two consumers, the first logical approach was to investigate how well the previous forecasting methods developed in [
26] would perform in this case, and whether they could meet the medium industrial consumer requirements regarding the accurate hourly forecast for the month-ahead. After having applied the previously developed methods from [
26], in the case of the NAR model the results have been unsatisfactory, while in the NARX case the contractor was not willing to purchase daily meteorological forecasts for the area within which the factory was located, taking into account that these forecasts would have cost more in contrast to the ones needed by the hypermarket-chain situated in Bucharest. After having experimented with artificial neural networks developed based on the NARX model and using only timestamp datasets as exogenous variables, the results were only of average quality when trying to forecast the hourly consumption, not being accurate enough to be used by the industrial consumer for an hourly month-ahead forecast.
Afterwards, the hourly values were aggregated as to obtain daily electricity consumptions, in order to be able to experiment further with the artificial neural networks developed based on the NARX model. In this case, when forecasting the daily aggregated electricity consumption for a month-ahead using the previously daily aggregated electricity consumption data with associated timestamps, it was observed that the results were very good in terms of daily forecasting accuracy at the level of the medium industrial consumer.
In order to surpass the encountered deficiencies and achieve an accurate hourly forecast, while benefiting from the fact that a daily forecast was possible, all that remained was to be able to disaggregate it appropriately as to attain the desired accurate hourly forecast. In order for the forecasting method to be able to learn and manage long-term dependencies between the data, aspects that were of paramount importance in the absence of obtaining other possible exogenous variables like the temperature, LSTM artificial neural networks have been developed as to support exogenous variables like the timestamps corresponding to the hourly consumption along with the daily aggregated consumption forecasted by the NARX artificial neural networks.
The new developed forecasting method for the hourly electricity consumption of a medium industrial consumer has been developed using the following hardware and software configurations: “the ASUS Rampage V Extreme motherboard, the Intel i7-5960x from the Haswell family central processing unit (CPU), with the standard clock frequency of 3.0 GHz, having the turbo boost feature enabled, 32 GB double data rate fourth-generation (DDR4) quad channel synchronous dynamic random-access memory (SDRAM), 2144 MHz operating frequency; the NVIDIA GeForce GTX 1080 TI graphics processing unit (GPU) based on the Pascal architecture, the GPU having support for the compute unified device architecture (CUDA) and 11 GB of double data rate type five synchronous graphics random-access memory (GDDR5X) having a 352-bit bandwidth, driver version 419.17; the Windows 10 operating system, version 1803, OS build 17134.523; the MATLAB R2018b development environment.”
The technical maturity and evolution that the compute-unified device architecture has undergone during the last years [
27], along with the fact that professional development environments, like MATLAB, offer state-of-the-art artificial intelligence development tools that can harness the huge parallel processing capability of the CUDA architecture, led to the decision of developing and making use within the same forecasting method, throughout different processing stages, of the excellent forecasting capabilities of both NARX artificial neural networks and LSTM artificial neural networks with exogenous variables support, overcoming what would have been not long ago a huge computational cost affecting the necessary time to train the ANNs.
Another aspect worth mentioning rests in the fact that the whole process of designing, developing, validating and implementing is conveniently achievable from the cost–benefit perspective, considering the fact that the contractor (namely the medium industrial consumer) was not compelled to acquire computational oriented professional Tesla or Quadro graphics card in order to benefit from the exponential speedup achieved regarding the training time, a home consumer oriented graphics card being sufficient even in the case of a medium industrial electricity consumer that necessitates frequent updates or retraining processes of the method. The contractor also did not have to invest in purchasing a MATLAB license, as the whole developed forecasting method was delivered compiled, so all that the contractor needed was a free-license MATLAB Runtime in order to use the forecasting method.
In addition to the above-mentioned advantages of the choices that have been made when developing the hourly forecasting method for the month-ahead, the contractor needed to implement the compiled method initially as a module under the form of a Java package in the decision support information system developed by my research group over the course of the scientific research project [
28]. After one year had passed since its implementation, when the testing phase had finished, the contractor had the possibility to implement the hourly forecasting method for the month-ahead in a licensed MATLAB Production Server, benefitting from custom analytics and exclusive distributed servers at the whole enterprise level.
In the following, the main concepts used in developing the forecasting approach are presented, starting with theoretical elements regarding the NARX models and afterwards, the LSTM artificial neural networks.
2.1. The Non-Linear Autoregressive with Exogenous Inputs (NARX) Model
In a wide variety of problems involving time series, when developing forecasting models, one uses ANNs that can be trained to predict a time series future values starting from the previous values of the series, therefore obtaining non-linear autoregressive (NAR) models. In many cases, in order to improve the forecasting accuracy, the forecasting models are trained as to relate both the previous values of the time series and the past values of another external time series, correlated to the first one and influencing it, namely the exogenous time series, obtaining thus NARX models. As mathematical formalism, the NARX model is represented through the equation [
26,
29]:
Equation (1) describes the way in which the actual value of the time series denoted by is forecasted based on of the previous values of the same time series and on the same number of values of the exogenous time series denoted by , where is the delay parameter. The purpose of the forecasting is to obtain an as accurate as possible nonlinear function , based on methods that are specific to the ANNs approach, while , the last term from Equation (1), is the approximation error of the actual value of the time series.
The optimization of the approximation of the nonlinear function is achievable by testing and assessing different settings of the networks, for example the number of neurons per layer, the total number of layers, the weights and biases of the ANNs. In this way, one can identify the ANN providing the best accuracy in terms of forecasting. A very important aspect that must be taken into consideration when using the above-mentioned approach is the fact that the number of neurons per layer must be managed carefully, as a too lower value has the potential to reduce the neural network’s computational power and to restrict the ability of the method to be effective across a wide range of inputs and applications, therefore reducing its generalization capability. Meanwhile, increasing the number of neurons too much causes a raise in the system’s complexity and can cause an overfitting of the network with regard to the training set, and therefore the ANN will learn very well the training data, but it will not be able to generalize to new data.
In order to train the forecasting ANNs one could use various training algorithms. For example, the MATLAB R2018b development environment [
30] offers a wide range of training algorithms (like Levenberg–Marquardt, BFGS quasi-Newton, resilient backpropagation, Bayesian regularization, scaled conjugate gradient, conjugate gradient with Powell/Beale restarts, Fletcher–Powell conjugate gradient, Polak–Ribiére conjugate gradient, one step secant, variable learning rate backpropagation). Identifying the most suitable training algorithm for a certain problem could represent a difficult task, as the answer depends on a multitude of factors such as the problem’s complexity, the dimension of the training set, the amount of weights and biases of the ANN, the purpose of the neural network (whether it is used for pattern recognition, or in regression purposes). In this study, three of the most representative training algorithms, namely the Levenberg–Marquardt (LM), the Bayesian regularization (BR) and the scaled conjugate gradient (SCG), have been used in developing the NARX ANNs.
The LM training algorithm is based on an iterative approach, being a curve fitting method that aims to construct a curve as to pass through a set of given points, represented by a function that approximates these points. Therefore, the method considered a parametrized form of this function, computes its associated errors and the sum of their squares and targets to obtain the minimum of this sum. The LM training algorithm represents a merger of two optimization techniques: the gradient descent and the Gauss–Newton methods, taking advantages of both these two component parts. Thus, when the obtained forecasting accuracy is low, the algorithm behaves like the gradient descent method in order to obtain the final convergence, while in the case when the forecasted results are close to the experimental ones, the algorithm performs like the Gauss–Newton method [
31,
32,
33,
34]. In this way, the LM training algorithm provides a suite of irrefutable advantages to the scientists and therefore it has been chosen to be implemented in this research, in view of developing the NARX ANN forecasting solution for the month-ahead daily consumed electricity, using the timestamps dataset as exogenous variables.
The BR training algorithm combines the Levenberg–Marquardt and the backward propagation algorithms in order to minimize an objective function constructed as a linear combination of the squared errors (like in the case of the LM training algorithm) and of the squares of the network weights (considered as a “penalty” term). By adjusting this function, the BR training algorithm improves the network’s generalization features based on the Bayesian inference technique. A specific feature and an important advantage of the Bayesian regularization training algorithm consists in the fact that, unlike other training algorithms, it does not necessitate to reserve data for processing validation steps and therefore, the processing costs are reduced. Throughout the years, the BR training algorithm has shown its effectiveness in developing artificial neural networks in contrast to a wide range of other training algorithms and therefore it has been considered an interesting and advantageous choice that was worth to be assessed when developing the NARX ANN forecasting solution for the daily consumed electricity, for the month-ahead, using as the timestamps dataset [
31,
35,
36] as exogenous variables.
During the years, the SCG training algorithm has proven its usefulness in developing forecasting ANNs. As a matter of fact, the SCG training algorithm is a supervised learning algorithm, wholly automated, not depending on parameters provided by the programmers. The main advantage of the SCG training algorithm consists in the fact that it circumvents the necessity to determine the step size at each iteration. In order to obtain a local minimum, other training algorithms need to perform a line search, thus increasing the processing costs due to the necessity of computing at each search the response of the ANN. The SCG training algorithm avoids this search by merging two approaches, namely the trust region of the Levenberg–Marquardt’s model and the conjugate gradient one, relying on conjugate directions. Through this combined approach, the SCG training algorithm offers a reduced processing time. Based on its incontestable advantages, the SCG training algorithm has been chosen to be studied in order to decide if it is suitable for developing the NARX ANN forecasting solution for the month-ahead daily consumed electricity using as exogenous variables the timestamps dataset [
31,
37].
2.2. The Long Short-Term Memory (LSTM) Neural Networks
One of the most frequently met problems in science is related to timeseries forecasting. During the years, scientists have developed various approaches in order to address these problems and, among them, one of the most effective is represented by the LSTM artificial neural networks, a specific type of recurrent neural networks (RNNs). When compared to “classical” feed-forward ANNs, one can easily remark that the main specific components of a LSTM ANN’s architecture consist in the sequence input layer whose purpose is to input the sequences or the time series into the network and a specific LSTM layer designed to learn and remember patterns for long durations of time. A specific feature of this type of RNNs is represented by the fact that they incorporate specific loops that facilitate the persistence of information, which is transmitted within the network from one step to the subsequent one. LSTMs have been first introduced in 1997 [
38], after that being popularized, used and refined by many other researchers [
39,
40,
41,
42,
43].
Due to their improved performance, the LSTM ANNs are employed in a wide variety of time series problems, for example in forecasting, processing, or classifying data, in applications within various domains like handwriting recognition [
44], artificial intelligence, natural language processing [
45,
46], being also frequently used by many prominent companies like Google, Amazon, Apple, Microsoft, and Facebook.
Along with the specific cell designed to remember the values and pass them within the network from a certain step to the subsequent one, a LSTM ANN also comprises three gates, whose role is to manage the flow of information through the above-mentioned cell: a first input gate, a second output gate and a third forget gate. Each of these components of the long short-term memory artificial neural networks’ cell architecture realizes specific tasks, managing and performing certain activities. Thus, the input gate controls and manages the process of filling the cell with new values, the output gate being responsible for the process within which the values from a cell are utilized in obtaining the output, and the forget gate manages the process in which a certain value is stored in the cell. The three gates are connected among them and a part of the connections are also recurrent.
The cell takes the input data and afterwards, stores it for a certain period of time, a process that can be expressed using the mathematical formalism through the identical function, which is applied to an input
x, generating as output the same
x:
The issue regarding the vanishing gradient is frequently encountered in the case of RNN ANNs developed based on gradient-based learning methods, and it occurs when the activation function (the one that transforms the activation level of a neuron into an output signal) is lower than a certain threshold. In the case when this process takes place, due to the fact that many derivatives having low-values are multiplied when computing the chain rule, the gradient vanishes to 0. In the case of the LSTM ANNs, the derivative of the identical function from Equation (2) is the constant function 1 and this fact represents a certain advantage in the case when the LSTM is trained based on the backpropagation, because in this case the gradient is not vanishing [
47].
The vanishing gradient occurrence represented a major issue as, in this case, the devised gradient-based method faced difficulties in learning and adjusting the parameters that were passed from the network’s previous layers and this issue worsens along with the increase in the network’s number of layers. Actually, the vanishing gradient issue was encountered when small changes in the values of a certain parameter affected the output only to a small extent, or even in an imperceptible way, a case in which the network faced serious problems when trying to learn this parameter, while the network’s output gradients regarding such type of parameters decreased significantly. In these cases, although the values of the parameters that were passed from the network’s previous layers were considerably modified, the impact on their corresponding outputs was practically neglectable.
The aim of the LSTM ANN is to learn the weights corresponding to the connections between the gates when the training process finishes, because these weights influence the way in which the gates operate. The LSTM ANN’s training error can be minimized by adjusting the weights on the base of an iterative gradient descend technique. In the general case of the RNNs trained based on this technique, the vanishing gradient issue can occur, but in the specific case of the LSTM units, the errors are kept in their memory in the moment when they are generated and propagated back, to the gates, based on the output, through a back-propagation process that continues until the gates learn to end the process, therefore interrupting it. As a consequence, the main disadvantage of the vanishing gradient, frequently encountered in the case when using the back-propagation technique for the RNN ANNs, is avoided in the case of LSTMs and therefore this technique becomes effective in their case, facilitating them to learn and remember patterns for long durations of time.
In the scientific literature, the gradient descendent (GD) algorithm is considered as one of the most popular methods that can be used for training and optimizing artificial neural networks, being implemented in a wide variety of specific deep-learning libraries. Taking into consideration the volumes of data implied in computing the objective function’s gradient, the GD algorithm has three versions: the mini-batch, the stochastic and the batch gradient descent. For each of these three cases, the data size influences the process of parameters’ update from the accuracy and the required updating time points of view. The principle on which GD is based is the following: its target is to obtain the minimum of an objective function by updating the model’s parameters, along with an opposite direction towards one of the objective function’s gradients, computed relative to the parameters under discussion.
The GD algorithm can be optimized based on specific training algorithms, and a few examples of such training algorithms that are the most widely known and frequently utilized by the researchers, are: Adadelta, Adagrad, AdaMax, AMSGrad, Momentum, Nadam, Nesterov accelerated gradient. In this study, three of the most representative GD training algorithms, namely the stochastic gradient descent with momentum (SGDM), the root mean square propagation (RMSPROP), and the adaptive moment estimation (ADAM), have been used in developing LSTM ANNs with exogenous variables support.
Using a similar approach as in the case of the SGD, the SGDM training algorithm target is to obtain the minimum of the objective function by modifying the weights and biases of the network, along with an opposite direction towards one of the objective function’s gradients. In the case of the stochastic gradient descent algorithm, at an arbitrary training step, each parameter is updated according to a rule that evaluates the difference between the parameter’s value in the previous step and the product between the learning rate and the gradient of the objective function, computed using the entire training dataset. This training algorithm exposes a series of disadvantages, caused by the fact that when computing the local minimum, it might oscillate along the searching direction [
48]. Therefore, in order to overcome these oscillations, the SGDM training algorithm improves SGD by adding to the updating rule a new term (entitled the “momentum term”), computed as a product between a parameter and the difference between the values of the parameter under discussion in the previous two iteration steps. In this way, SGD is subjected to an acceleration process along the relevant direction and in the same time the oscillations are reduced, due to the contribution of the “momentum term”.
Another approach in improving the GD training algorithm tackles issues regarding the way in which the minimization of the objective function is achieved. In the case of the GD training algorithm, all the network’s parameters (weights and biases) are updated using identical learning rates. The RMSPROP algorithm and many other optimization algorithms approach this aspect in an opposite manner, considering various learning rates for different network’s parameters. One can observe that the RMSPROP training algorithm is similar to the SGDM one from the perspective of the oscillation’s approach, because it also reduces them but by addressing only the vertical ones. In this way, the learning rate is improved, and the algorithm advances the searching in the horizontal direction, in which the convergence is faster. In order to obtain the parameters’ updating rule, the RMSPROP algorithm computes first the moving average through an iterative process, as a linear combination between the moving average in the previous step and the square of the gradient of the objective function, computed for the parameter under discussion [
49]. An interesting aspect that is worth mentioning is the multiplying parameter of the moving average in the previous step, entitled the decay rate of the moving average, whose usual values are 0.9, 0.99 or 0.999. After computing the moving average, RMSPROP normalizes the parameters’ updates, using a different relation for each of them. Therefore, at each step, the updated value of the parameter under discussion is computed as a difference between the parameter’s value from the previous step and a fraction whose nominator is a multiple between the learning rate and the gradient of the objective function, computed for the parameter under discussion, while the denominator contains the sum between the square root of the moving average in the previous step and a certain small positive parameter (whose role is to circumvent the division by zero). The RMSPROP algorithm’s main characteristic is the fact that it lowers the learning rates corresponding to the parameters having large gradients, while increasing the learning rates of the parameters with small gradients [
49].
The ADAM training algorithm computes tailored adaptive learning rates for each of the model’s parameters, evaluating first the average of the second moments of the gradient and the squared gradient. The past gradient is computed through an iterative process, as a linear combination of the previous value of the past gradient (multiplied with the gradient decay rate) and the gradient of the objective function, computed for the parameter under discussion. The past squared gradient is also computed using an iterative approach, as a linear combination of the previous value of the past gradient (multiplied with the decay rate of the moving average) and the squared gradient of the objective function, computed for the parameter under discussion. Afterwards, the ADAM training algorithm computes the update rule for the parameter under discussion based on the average of the second moments of the gradient and the squared gradient. The update rule is computed as a difference between the parameter’s value from the previous step and a fraction whose nominator is a multiple between the learning rate and the gradient of the objective function, computed for the parameter under discussion, while the denominator contains the sum between the square root of the squared gradient of the objective function in the previous step and a certain small positive parameter (whose role is to circumvent the division by zero) [
49]. Concluding, the main difference between the classical SGD algorithm and the ADAM training algorithm consists in the fact that SGD is based on a unique learning rate for updating the network’s parameters and for all the training steps, while ADAM employs different learning rates for the different parameters of the network, adapting them during the learning process.
In the following, details regarding the stages and steps comprised by the developed forecasting method are presented.
2.3. Stage I: Data Acquisition and Preprocessing
During the first stage of the devised forecasting method that comprises three steps, in the first step we acquired the dataset, provided by the medium industrial electricity consumer who retrieved them from the smart metering device. The dataset consisted of 8760 records representing the hourly electricity consumption dataset corresponding to the year 2018, measured in MW h.
Afterwards, in the second step of this stage, taking into account the fact that sometimes one might encounter abnormal or missing values in the dataset (caused due to smart metering device’s recording errors or malfunctioning), we searched these values in order to reconstruct the historical hourly consumed electricity dataset. In the specific case of the analyzed medium industrial consumer, for the period to which the recorded data correspond, these kinds of values were not encountered, but due to the fact that the forecasting method targeted a wider range of medium industrial consumers posing similar characteristics, in order to be able to generalize the proposed approach, this step has been designed to manage the situations in which such values could appear. In this purpose, during this stage, we applied a gap-filling method based on the linear interpolation that provided reliable results when it has been developed and applied in previous studies that have been conducted along with my research team [
25,
26,
32].
An important issue that has to be taken into account when one applies the filling method consists of identifying a particular threshold concerning the number of missing values (particularly the ones that are consecutive) which, when surpassed, can affect the training processes of the ANNs in terms of forecasting accuracy. In order to test the efficiency of the gap filling technique and to identify the above-mentioned threshold, we deleted on purpose several consecutive values from the electricity consumption dataset and, after applying the filling technique and using the developed forecasting method, it was remarked that the accuracy of the devised forecasting method was affected for a threshold consisting 16 or more consecutive missing values, especially when the missing values overlapped two consecutive days. In the case when the number of consecutive missing values would have surpassed the above-mentioned threshold, the efficiency of the filling method was lowered and therefore one should have to discard the missing or abnormal data altogether in the training process, if it had not been possible to acquire a new dataset from the contractor. In this case, as the dataset retrieved from the smart metering device had no missing or abnormal values and the medium industrial electricity consumer encountered no power outages within the considered period of one year, it was possible to use the whole hourly electricity consumption dataset, measured in MW h, consisting of 24 records per day, namely 8760 records corresponding to the year 2018.
In the third step of the first stage of the forecasting method, the reconstructed historical hourly consumed electricity dataset was divided into two data subsets, namely a training subset (representing the January–November period of the year 2018, consisting of 8016 samples) and a validation subset (representing the month of December of the year 2018, consisting of 744 samples). The first subset was used in developing, training, and validating the forecasting method, while the second one was put aside in order to obtain a final validation of the forecasting method through a comparison between the predicted hourly electricity consumption values for the month of December and the real, registered ones.
The contractor was a medium industrial electricity consumer from Romania that holds a bakery factory endowed with a flour mill, that produces pastries (such as bread, sweet bread, croissants, cornflakes, pretzels, pasta, biscuits, cakes, cookies), and has contracts with major retail stores, supermarket chains, and catering companies. Therefore, analyzing their specific activities, the quarterly sales reports, the local purchasing patterns and traditions, it was observed that, even in the national public holidays or winter holidays, the bakery factory’s work schedule was carried out in three work shifts.
Moreover, analyzing the Romanian eating habits, one can remark that bread is the most common consumed aliment and it is generally preferred at each meal, regardless of the category of population, if considering the age, gender, occupation, educational level and family type classification criteria. The report [
50] states that in Romania the amount of bread consumption surpasses 95 kg per person per year, while in the rest of Europe the average yearly consumption is of about 60 kg per capita. Moreover, the same report remarks that the domestic bakery market in Romania (namely 1.1 billion Euro) represents more than 60% from the total Romanian bakery market (namely 1.8 billion Euro). Therefore, one can easily remark that the contractor’s activity is conducted continuously, working around the clock, in three shifts, regardless of the seasons, holidays, as its products are sold and bought daily by the Romanian customers.
A challenge that had to be overcome consisted of the fact that in Romania, in the year 2019, the smart metering devices’ implementation was still in an incipient phase and regardless of numerous legislative proposals [
51], their adoption was made at a slow pace. Therefore, the dataset that has been registered and provided by the contractor contained the overall consumption at the bakery factory level, without having individual electricity consumption of different equipment used in the different stages of the production process available. Of particular interest for this research and also for the medium industrial electricity consumer was to obtain a method that can provide as accurate a forecast as possible of the hourly electricity consumption for the month-ahead.
2.4. Stage II: Developing the NARX ANN Forecasting Solution for the Daily Consumed Electricity, Based on the LM, BR and SCG Training Algorithms, Using as Exogenous Variables the Timestamps Dataset
The second stage of the forecasting method comprises seven steps. In the first step of this stage, we constructed a daily aggregated electricity consumption dataset using the hourly training subset, therefore obtaining a subset of 334 samples, representing the daily electricity consumption for the January-November period of the year 2018.
Subsequently, in the second step of this stage, a daily timestamp dataset corresponding to the daily aggregated electricity consumption dataset was constructed, comprising of, for each of the above-mentioned 334 samples, the day of the week (denoted from 1 to 7, where 1 corresponds to the first day of the week, Monday), the day of the month (denoted from 1 to the number of days of the respective month, which can be 28, 30 or 31) and the month (denoted from 1 to 11, where 1 corresponds to the month of January and 11 to the month of November).
In the next step of the second stage, the third one, there are concatenated the daily aggregated dataset for the January–November period of the year 2018 and its associated timestamps dataset.
During the steps 4, 5 and 6 of the second stage we developed a series of ANNs forecasting solutions based on the NARX model, testing different settings and configurations regarding the employed training algorithm (Levenberg–Marquardt, Bayesian regularization, scaled conjugate gradient), the number of neurons from the hidden layer (n) and the value of the delay parameter (d). In the case of the NARX ANNs one employs not only the previous time series values but also additional, external values of another time series, the exogenous variables, that exert an influence upon the initial time series. In this case, the datasets from step 3 have been used as input parameters, namely the daily aggregated dataset for the January–November period of the year 2018 is used as time series, while its associated timestamps dataset is used as exogenous variables.
For each of the three above-mentioned training algorithms (LM, BR and SCG), 16 ANNs have been developed in order to forecast the month-ahead daily consumed electricity, having various architectures, namely, four neurons for the input data (one neuron for the daily electricity consumption dataset, three neurons for the timestamps exogenous data), a hidden layer’s size of n neurons, where , the delay parameter taking the values , the output layer containing one neuron and also one neuron for the output data (measured in MW h).
In all the cases, for all the pairs, in developing the forecasting NARX ANNs, for the LM and SCG training algorithms and the above-mentioned situations, the input dataset (comprising both the time series and the exogenous variables), containing 334 samples, has been divided according to the 70%—15%—15% approach, corresponding to the training, testing and validation processes, while in the case of the BR training algorithm the last 15% of the input dataset has not been allocated, because in this case the validation process does not take place. The decision to maintain unallocated this percentage is justified by the fact that in this way the dimension of the datasets used in the training and testing processes is the same, for all the three training algorithms, this fact assuring the relevance when comparing the obtained forecasting results.
Taking into consideration the fact that the input data has various ranges, in the purpose of minimizing the influence of these ranges on the obtained forecasted results, the normalization performance parameter has been set to the standard value, in this way ensuring the fact that the development environment considers the output elements as ranging in the interval
and computes the errors in accordance [
52].
For each case we computed 30 training iterations, within which the samples corresponding to the above-mentioned percentages have been randomly allocated, the weights and biases of the NARX ANNs being re-initialized each time when the data from the percentages were re-allocated. When developing forecasting artificial neural networks, one should train them as to learn and perform certain tasks, based on specific training algorithms. In order to identify the most advantageous training algorithm, one should take into account both the forecasting accuracy and the training time criteria, the best training algorithm being characteristic to each specific case and problem, depending on many factors (the complexity of the analyzed problem, the network’s complexity and its specific architecture, the training set’s dimension, the weights and biases of the network, the desired level of accuracy, the previously specified level of accepted error, the training error’s purpose).
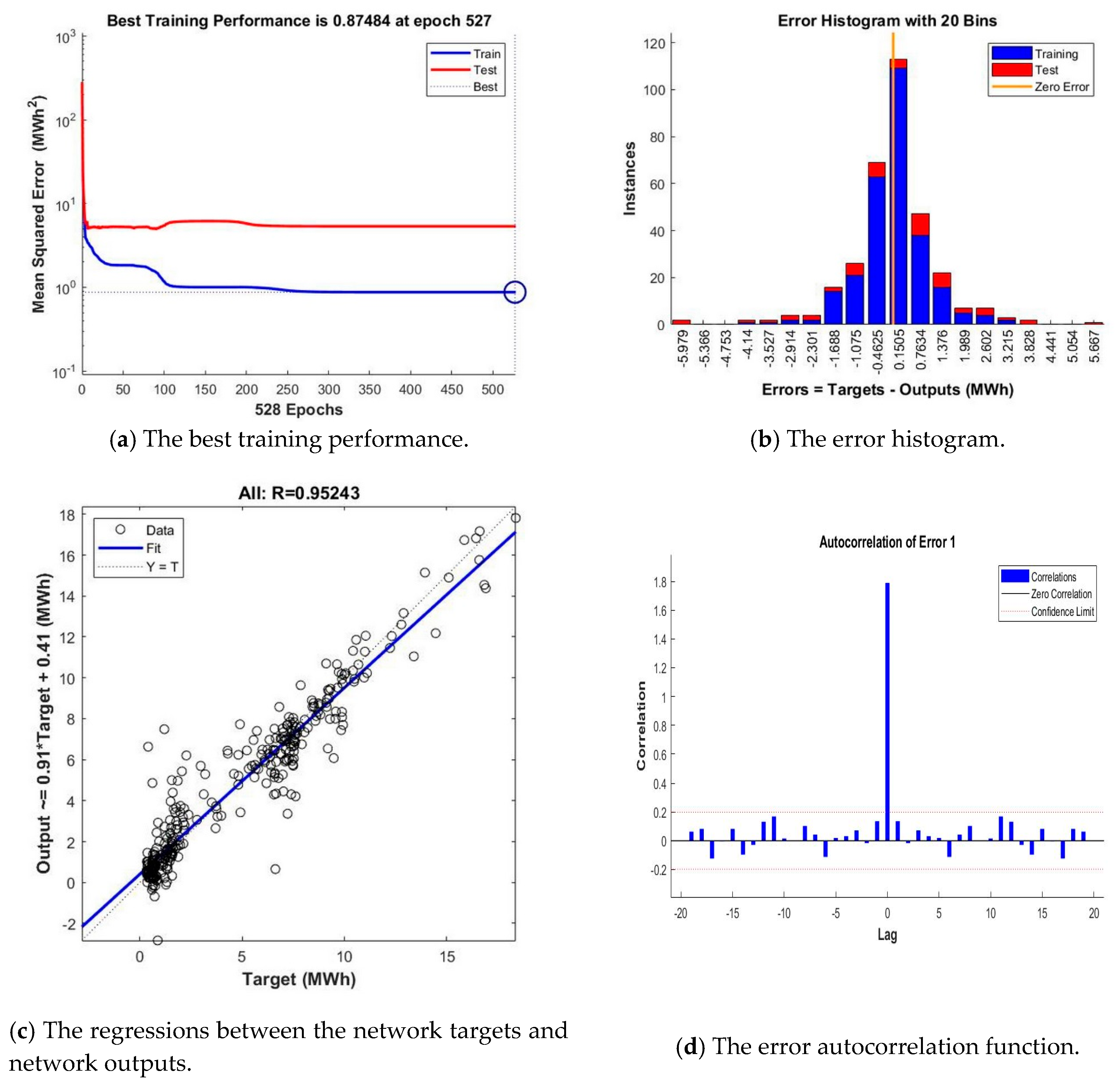
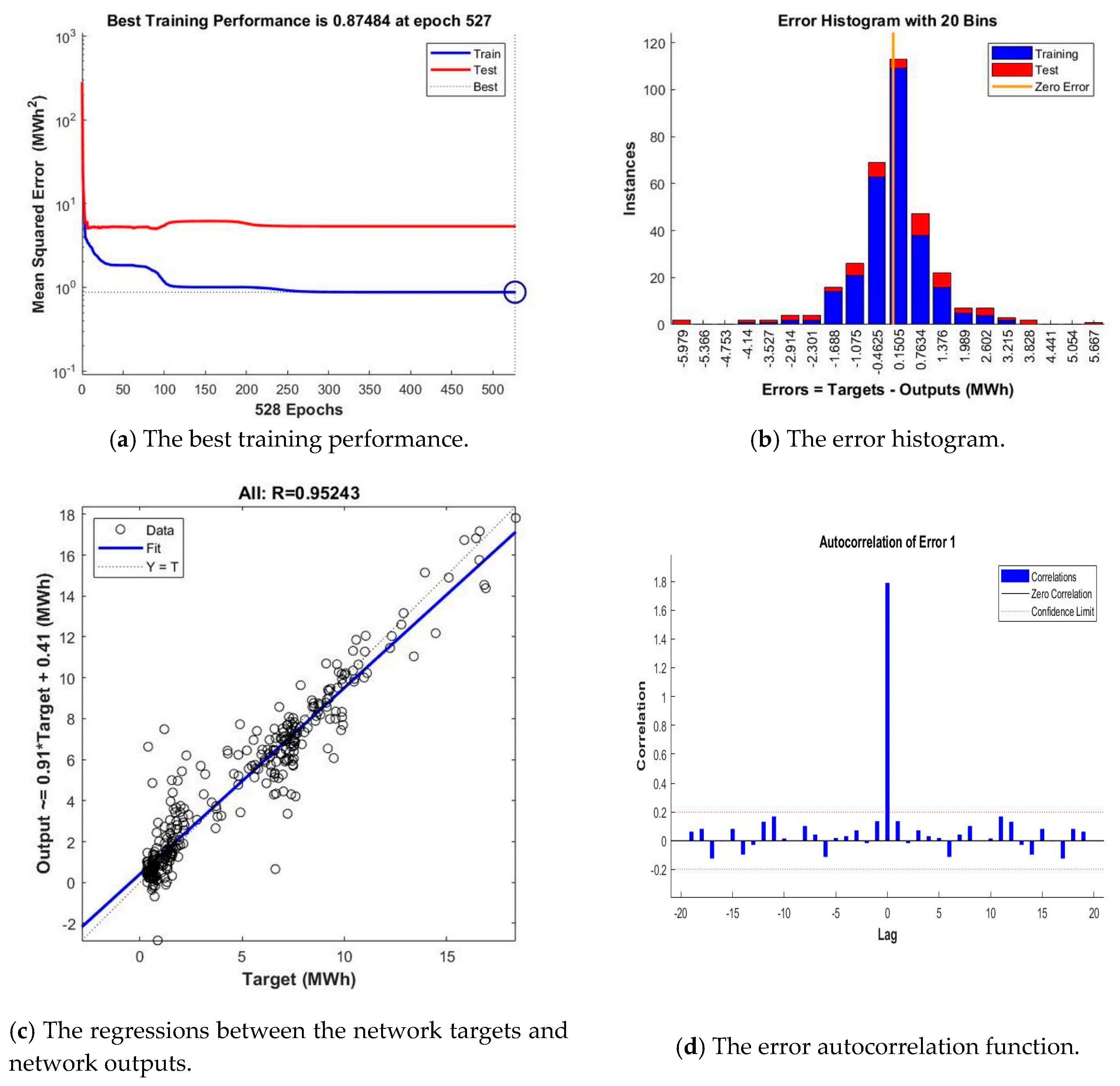
The training time represents a particularly important aspect that should be considered in evaluating the performance of the developed ANN-based forecasting solution, because when this solution is put into operation, the neural networks necessitate subsequent re-training procedures due to the fact that over the course of time, new datasets that contain timestamps are registered and provided as new inputs for the developed ANNs. Therefore, in assessing the networks’ performance, along with the performance metrics, the registered training times have also been taken into consideration. Regarding the 30 training iterations, there were recorded different results in terms of forecasting accuracy highlighted by the training times and the performance metrics, namely the MSE, R, the error histogram, the error autocorrelation, based on which the best NARX ANN has been identified and saved, while discarding the others. In this way, we identified and saved 16 NARX ANNs for each of the three training algorithms, therefore a total number of 48 neural networks. Afterwards, for each training algorithm was identified the best NARX ANN forecasting solution by comparing the registered training times and the values of the above-mentioned performance metrics, while the remaining networks, providing lower accuracies, have been discarded.
In the final step of the second stage, the seventh, the forecasting accuracies of the three NARX ANNs identified in the previous three steps, developed based on the three training algorithms (LM, BR and SCG), were assessed by comparing the registered training times and the above-mentioned performance metrics. Consequently, the best NARX ANN forecasting solution for the daily aggregated consumption dataset for the month-ahead has been identified, while the other two networks were discarded.
2.5. Stage III: Developing the LSTM ANN with Exogenous Variables Support Electricity Consumption Forecasting Solution Based on the ADAM, SGDM and RMSPROP Training Algorithms
The third stage of the devised hourly forecasting method for the month-ahead takes place over the course of seven steps. In the first step of this stage, we retrieved the training subset constructed in the last step of the first stage, representing the hourly consumed electricity dataset for the January–November period of the year 2018, consisting in 8016 samples.
Afterwards, in the second step of the third stage, we constructed an hourly timestamp dataset that matches the moments of time when the values of the above-mentioned dataset have been registered, comprising for each of the 8016 samples, the following elements: the hour of the day (denoted from 1 to 24), the day of the week (denoted from 1 to 7, where 1 corresponds to the first day of the week, Monday), the day of the month (denoted from 1 to the number of days of the respective month, which can be 28, 30 or 31) and the month (denoted from 1 to 11, where 1 corresponds to the month of January and 11 to the month of November). During the same step, we constructed an hourly electricity consumption dataset by filling in, for each of the hours, the daily aggregated consumption for the January-November period of the year 2018.
In the next step, the third one of the third stage, there are concatenated the hourly electricity consumption dataset containing for each of the hours, the daily aggregated electricity consumption for the January-November period of the year 2018, and its associated timestamps dataset.
According to the official development environment (MATLAB) documentation recommendations, in order to attain a better fitting and avoid the risk of a divergence during the training process, in the fourth step of this stage, the hourly time series dataset and its associated timestamps dataset have been normalized, processing the data as to have a variance of 1 and a 0 mean [
53].
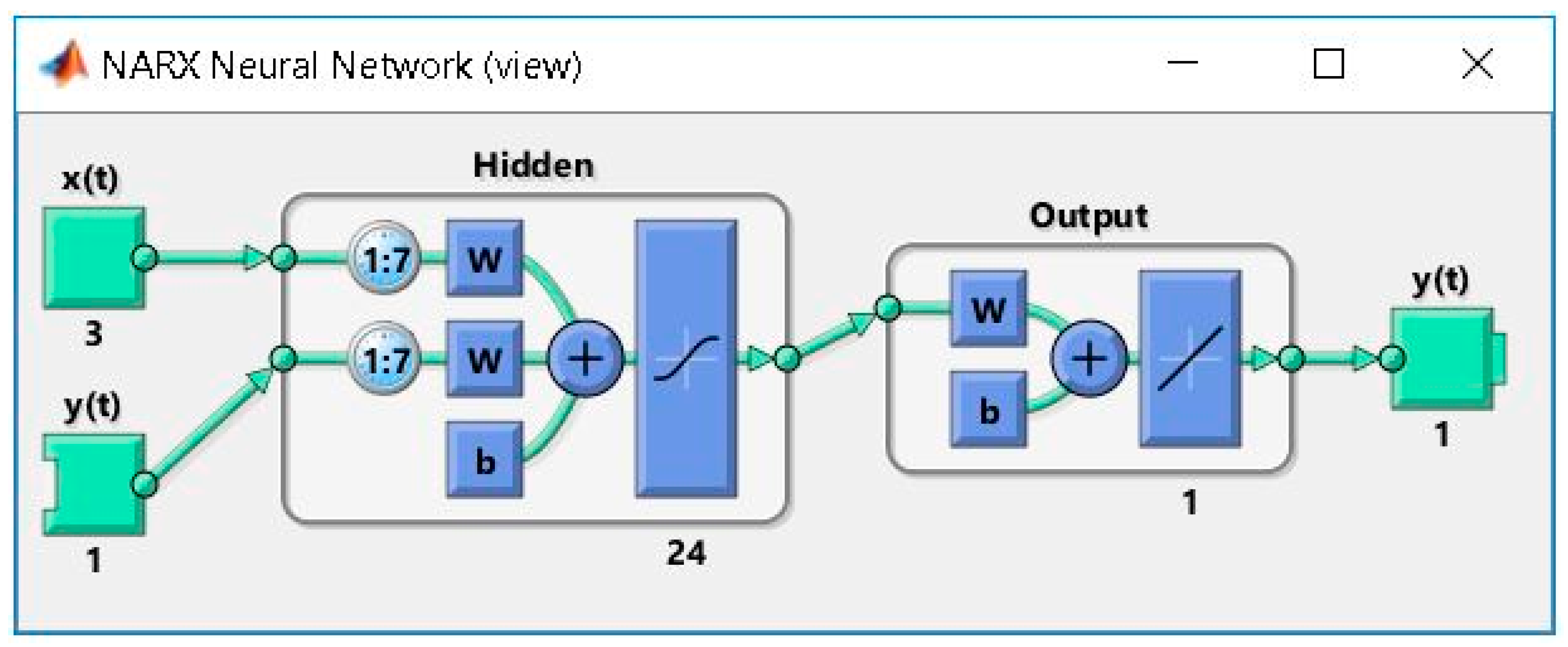
During the steps 5, 6 and 7 of the third stage, we developed a series of LSTM ANNs with exogenous variables support hourly electricity consumption forecasting solutions based on the ADAM, SGDM and RMSPROP training algorithms, using the datasets from step 4 as input parameters. Therefore, for each training algorithm, we developed 19 LSTM ANNs with exogenous variables support, in order to obtain in the subsequent stage the most accurate forecast of the hourly electricity consumption for the month-ahead, the networks having various architectures, namely 6 neurons for the sequence input layer (one neuron for the hourly electricity consumption dataset, 4 neurons for the timestamps exogenous data, one neuron for the aggregated electricity consumption dataset), a variable number of hidden units, , one neuron for the fully connected layer and a regression layer.
2.6. Stage IV: Obtaining and Validating the Forecasting Method by Obtaining the Hourly Forecasted Consumed Electricity for the Month Ahead Using the Best NARX ANN’s Daily Aggregated Electricity Consumption Forecast along with the Associated Timestamps Dataset and the Best LSTM ANN
During the first step of the fourth stage of the devised forecasting method that comprises five steps, we constructed a daily timestamp dataset for the month of December, containing 31 samples that comprise the day of the week (denoted from 1 to 7, where 1 corresponds to the first day of the week, Monday), the day of the month (ranging from 1 to 31) and the month (denoted with 12, corresponding to the month of December).
In the second step of this stage, using the closed loop form of the best NARX ANN forecasting solution identified and saved at the last step of Stage II and the daily timestamp dataset for the month of December, identified in the previous step of this stage, the daily aggregated consumption dataset for the month of December has been forecasted.
Afterwards, in the third step of the fourth stage, we constructed an hourly timestamp dataset for the month of December, comprising 744 samples that contain the hour of the day (denoted from 1 to 24), the day of the week (denoted from 1 to 7, where 1 corresponds to the first day of the week, Monday), the day of the month (ranging from 1 to 31) and the month (denoted with 12, corresponding to the month December).
In the fourth step of this stage, using the LSTM with exogenous variables support hourly electricity consumption forecasting ANNs developed based on the ADAM, SGDM and RMSPROP training algorithms, that have been previously developed in the last step of Stage III, along with the daily aggregated consumption dataset for the month of December that has been forecasted in the second step of the fourth stage and with the hourly timestamp dataset for the month of December constructed in the third step, in each case the hourly consumption dataset for the month of December has been forecasted, comprising of 744 samples.
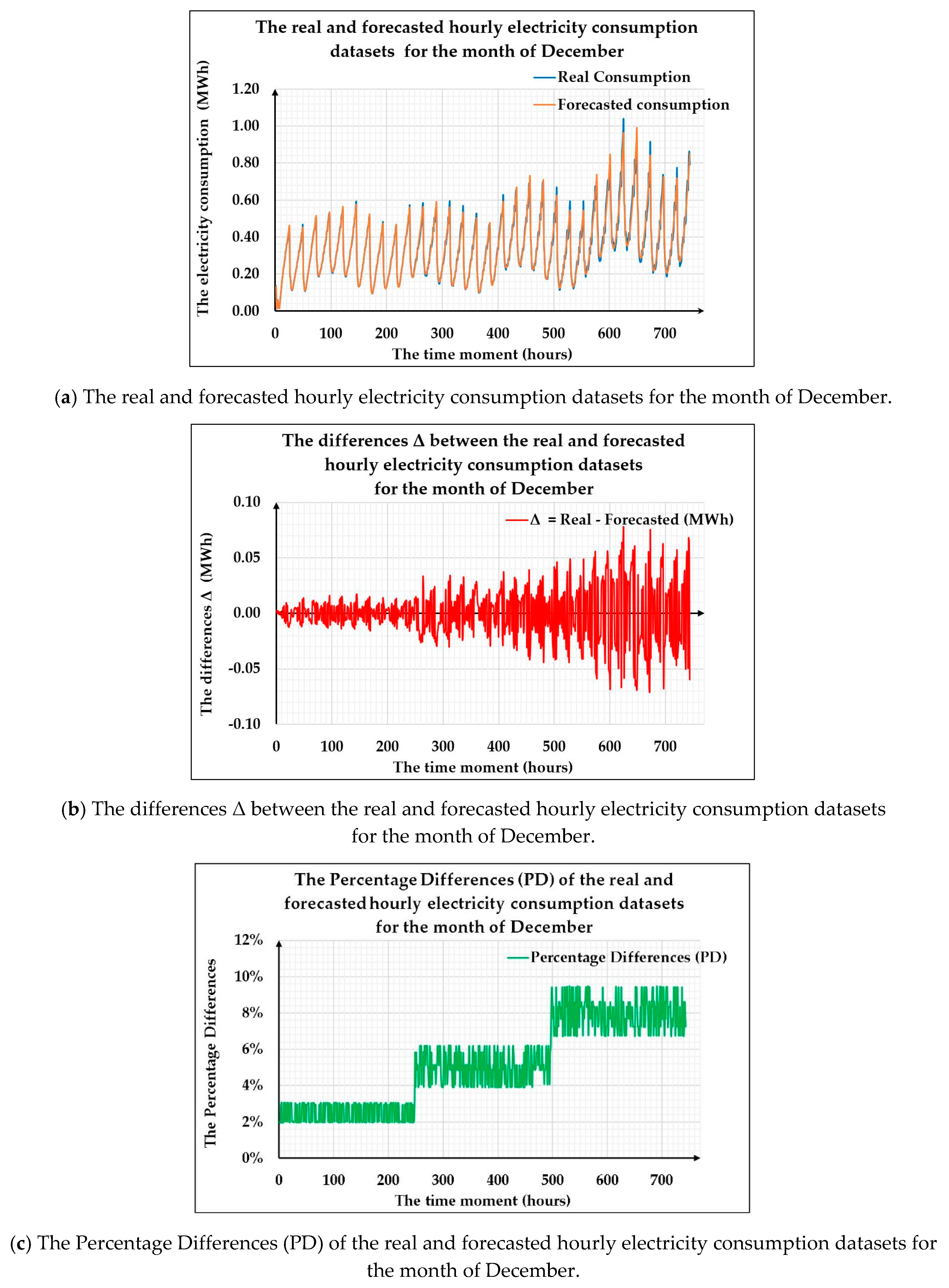
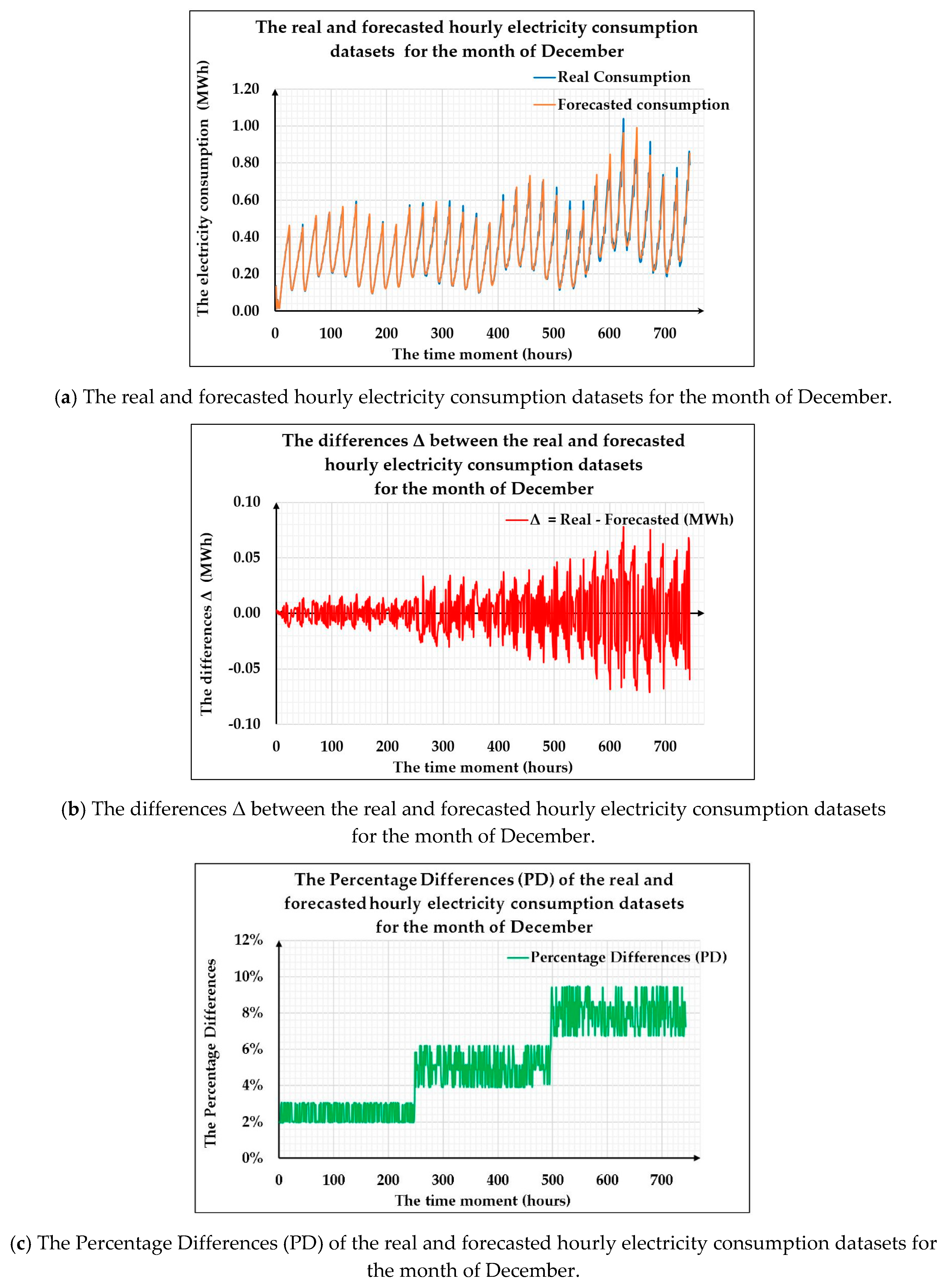
In the last step of this stage, the fifth, we obtained and validated the developed forecasting method by comparing the obtained hourly electricity consumption forecasts for the month-ahead with the real consumption values from the validation subset. In order to obtain a relevant comparison, during this stage, the differences between the real, registered values (stored in the validation dataset) and the forecasted ones corresponding to the hourly consumption dataset for the month of December, have been computed and evaluated.
According to the same methodology as in the case of the NARX ANNs, for each training algorithm and each number of hidden units, we computed 30 training iterations and, by comparing the registered training times and the values of the RMSE performance metric computed using the predicted values and the real ones, the best LSTM ANNs with exogenous variables support have been identified and saved for each training algorithm and value of n, while discarding the others. Each time when the networks have been retrained, during the 30 iterations, the training set has been divided in a random manner and therefore we minimized the influence that one could have obtained if the minibatches corresponding to the large dimension training dataset had been allocated incorrectly.
In this way, we saved 19 LSTM ANNs with exogenous variables support for each of the three training algorithms, therefore a total number of 57 neural networks. Afterwards, for each training algorithm, we identified and saved the best LSTM ANN forecasting solution by comparing the registered training times and the values of the above-mentioned performance metric, while the remaining networks, providing lower accuracies, have been discarded.
Afterwards, the forecasting accuracies of the three LSTM ANNs with exogenous variables support previously identified, developed based on the three training algorithms have been assessed, by comparing the above-mentioned performance metrics. Consequently, the best LSTM ANN hourly electricity forecasting solution for the month-ahead has been identified, while the other two networks have been discarded.
The designed, developed and validated forecasting method, presented in the above
Section 2.3,
Section 2.4,
Section 2.5 and
Section 2.6 for the month-ahead hourly electricity consumption in the case of medium industrial consumers, which benefits from both the advantages of NARX model and LSTM neural networks, is synthesized in the following flowchart (
Figure 1).
The next section depicts the results registered during the experimental tests and their significance.
4. Discussion
The decision to devise the above-described forecasting method has as main starting points the recent technical evolution and development of the CUDA architecture along with the fact that a wide range of state-of-the-art artificial intelligence development tools offered by professional development environments allow the harnessing of the huge parallel processing capability of the CUDA architecture. Therefore, based on these arguments, the forecasting method has been developed for the month-ahead hourly electricity consumption in the case of medium industrial consumers, by making use in different processing stages of the method, of the excellent forecasting capabilities of both NARX and LSTM ANNs with exogenous variables support, overcoming what would have been not long ago a huge computational cost affecting the necessary time to train and retrain the ANNs.
As stated and proved within the validation stage, the devised forecasting method offers an excellent forecasting accuracy. However, a mandatory comparison that should be made in order to justify the devised approach consists in evaluating the performance of the NARX and LSTM artificial neural networks, considering each of them as separate individual forecasting methods for the month-ahead hourly electricity consumption in the case of medium industrial consumers, based on the same case study, namely the one of the bakery factory.
For this purpose, firstly we developed an approach based only on the NARX ANNs (entitled NARX_ONLY), using the same hourly dataset, the same division into training and validation subsets, the same hourly timestamps dataset as exogenous variables, the same training algorithms (LM, BR and SCG) and the same number of training iterations like in the developed forecasting method’s case. In all the cases, the registered forecasting results were considerably lower than the ones of the developed approach, for example in the case of the best NARX ANN developed using the BR training algorithm, comprising 24 hidden neurons and having a delay parameter of 7, the registered value of the RMSE is 0.2513. As mentioned previously, in the developed forecasting method, in the best identified case, we registered a RMSE value of 0.0244, which is more than 10 times lower than in the case of the method developed based solely on the NARX ANN.
Secondly, an approach has been developed based solely on the LSTM ANNs (entitled LSTM_ONLY), using the same hourly dataset, the same hourly timestamps dataset as exogenous variables, the same training algorithms (ADAM, SGDM and RMSPROP) and the same number of training iterations like in the case of the developed forecasting method. In all the situations, the registered forecasting results were considerably lower than the ones provided by the developed approach, for example in the case of the best LSTM ANN developed using the ADAM training algorithm, comprising 400 hidden units, the registered value of the RMSE is 0.4103. As mentioned previously, in the developed forecasting method, in the best identified case we registered the value of 0.0244 for the RMSE performance metric, which is more than 16 times lower than in the case of the method developed based solely on the LSTM ANN.
For the two mentioned examples, the two cases analyzed above along with the comparison to the developed forecasting method are synthetized in
Table 3.
Based on these remarks, one can state that the devised forecasting method that benefits in different processing stages from the forecasting capabilities of both NARX and LSTM ANNs with exogenous variables support, outperforms each of the NARX and LSTM artificial neural networks, considering them as separate approaches for the month-ahead hourly electricity consumption in the case of medium industrial consumers.
After developing the method from this paper, the NARX_ONLY and the LSTM_ONLY approaches, three more approaches for predicting the month-ahead hourly electricity consumption in the case of medium industrial consumers have been developed, in order to compare them with the approach developed within the current paper.
When compared to the study developed in [
26] along with members of my research group, a scientific article within which forecasting solutions regarding electricity consumption in the case of commercial center type consumers have been developed, in the current paper another type of customer is approached, having a different electricity consumption profile. As the forecasting methods from the previous paper (based on NAR and NARX models) did not offer satisfactory results in the case of a medium industrial consumer, the forecasting method developed in the current study has been developed based on a different approach, employing in its different stages NARX along with LSTM artificial neural networks. Moreover, even if in both papers the purpose was to obtain a month-ahead accurate hourly consumption, in the case of the commercial center type consumer research, the exogenous data that have been used in developing the NARX ANNs consisted in both a timestamps dataset and a meteorological dataset (containing the outdoor temperature), while in the case of the current study we used as exogenous variables only a timestamps dataset, for both the LSTM and NARX ANNs. The increased obtained forecasting accuracy of the developed method represents an advantage for the industrial contractor, as in using the devised approach he will not have to purchase daily meteorological forecasts for the geographic area within which the bakery factory is located.
A wide range of papers from the scientific literature analyze issues regarding the industrial electricity consumption, developing various approaches, targeting the specific of the consumer and the desired type of forecasting. In this purpose, the researchers used different approaches and optimizations techniques, like: the grey model [
6,
14], SVM models [
7,
15], linear regression techniques [
7], Markov chains [
8,
11], AdaBoost, ESN, FOA techniques [
10], bottom-up approach combined with the linear hierarchical models [
11], GA, PSO and BPNN [
12], Granger causality and partial Grainger causality networks [
13], LSSVM enriched using a MCC [
15], while the current paper develops an approach based on the NARX along with LSTM artificial neural networks. Analyzing the forecast time horizon of the developed approaches from the literature, one can remark that the prediction horizon in the case of the industrial consumer varies in accordance to the necessities and requests of the industrial operator, ranging from short-term [
7,
12] up to medium [
17] and long-term [
11], in this last category being also comprised the developed forecasting method from the current paper. With respect to the obtained results, obviously each approach is tailored for its specific problem and therefore a relevant comparison between the approaches cannot be devised without taking into consideration the fact that these studies use different datasets and target different final purposes. However, one can state that all the approaches provide very good results in terms of forecasting accuracy, fulfilling the purposes for which they were developed and bringing real benefits to the beneficiaries.
Even if the obtained forecasting results highlighted by the performance metrics, the performance plots, the comparison between the real consumption and the forecasted one, allow one to consider the devised forecasting method as an accurate, useful tool for obtaining the hourly electricity consumption forecast for the month-ahead, the developed approach still has its limitations, and the most prominent one is the fact that it requires historical data for at least 11 months in order to obtain an hourly forecast for the month-ahead, otherwise the forecasting results are not consistent and reliable.
Considering the increased reluctance of the industrial operators to provide and share with one another data regarding their activity, including the electricity consumption, future work consists in prospecting the possibility of applying an encryption technique, namely the multilayered structural data sectors switching algorithm [
54] in view of convincing the industrial operators to share their data and take advantage of a larger data pool, from several industrial operators, while maintaining their own sensible information private and secure.
As a result of performing an in-depth study of the scientific literature, one can remark that there are numerous scientists who have devoted their work on forecasting accurately the electricity consumption of industrial consumers and of the industrial sector as a whole, aiming to devise an extensive diversity of prediction methods targeted at certain case studies. Devising an exhaustive comparison with regard to the significant aspects of the various methods is a hard to attain task, all the more so an unattainable one, considering the wide variety of case studies, datasets and objectives that all of this research involves. Nevertheless, when particular targeted problems pose certain characteristics in common, it becomes conceivable for a method to be adjusted fittingly from one particular case to another, during the course of a generalizing process. The bakery factory on which the developed forecasting method has been applied to, is a non-limitative case of putting into practice the developed forecasting method, considering the fact that the industrial consumer is a representative case for other operating industrial consumers that are categorized from the electricity consumption point of view by the European Regulations in the same Band-IC category [
55].
In view of this perspective, the forecasting method for the month-ahead hourly electricity consumption in the case of medium industrial consumers, devised, developed and validated according to the presented methodology from
Section 2, can be applied successfully, and to that end, generalized to further case studies posing similar characteristics to the analyzed one. In addition, the proposed prediction method has been developed and compiled in a state-of-art development environment, being able to be implemented in a wide range of forecasting applications, assuring its install-ability, modularity, adaptability, reusability and changeability characteristics from the software quality point of view, particular features that substantiate the generalization capability also from the software implementation perspective, consequently highlighting the efficiency of the proposed approach.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}