1. Introduction
The focus of this article is to design and test a filter algorithm that uses risk ratios (RR), otherwise known as relative risk, to rank the importance of predictor variables in data mining classification problems, with special attention to healthcare data. Variable importance ranking is the process that assigns numeric values, or some other form of quantifiers, to individual predictors in a dataset, indicating the level of their importance in predicting the outcome. After such a ranking has been established, variables that rank low can be expunged from a predictive model without compromising goodness of fit or predictive accuracy. Variable selection is necessary in the era of big data where voluminous data is generated from healthcare activities, including diagnosis, epidemiology analysis, and patient medical history. These data often consist of many attributes, some of which are not needed in data mining classification, and thus the need to select only the relevant ones is imperative.
Consider a dataset
consisting of
observations, where
are predictor variables having dimension
and
where
is a class label. In data mining, classification is defined as a mapping of the form
where
is a classifier [
1]. One of the ways of measuring the performance of a classifier is by evaluating its classification accuracy. That is, how accurately it can predict the classes of a set of vectors whose classes are unknown. The predictive accuracy of classification models is enhanced by the choice of variables used for model construction.
In [
2], classification accuracy evaluation methods have been divided into two categories: scalar metrics and graphical methods. Scalar metrics compute accuracy by taking the ratio of correctly classified observations versus total number of observations in the validation set. For binary classification problems, scalar values representing accuracy are obtained from a confusion matrix, which is a tabulation of wrong and correct classification for each class [
2,
3]. In graphical methods, such as a receiver operating characteristics curve, accuracy is plotted on a
-axis to represent the tradeoffs between the cost of correct or wrong classification into class 0 or 1 [
3].
The RR, just like odds ratios (OR), is a statistical measure of the association between binary variables across two different groups, where one group is referred to as the independent group while the other as the dependent group [
4,
5]. While odds ratios are known to overestimate the strength of association, the RR technique does not exhibit this demerit [
6]. Additionally, odds ratios have the property of reciprocity, which allows for the direction of an association to be changed by taking the inverse of the OR estimate [
6]. It turns out that RR does not exhibit this property. For the purposes of variable importance ranking, the direction of association is usually from independent variable to dependent variable and not vice versa; therefore, the lack of reciprocity in RR is a good property. Cashing in on the usefulness of the RR measure, this study will construct an algorithm that first binarizes data values of predictors in a dataset with a dichotomous response. Next, the algorithm evaluates the RR of each predictor with the response, and then outputs a value that signifies the relative importance of that predictor in determining the response. Computed values of RR will indicate the strength of the association, with larger values meaning strong association and, thus, high importance.
Literature evidence indicates that risk ratios have been deployed previously for different purposes within the healthcare domain. For example, [
7] used RR to evaluate the extent to which red blood cells transfusion strategies are associated with the risk of infection among patients. The study, conducted on 7456 patient records, concluded that irrespective of the strategy used, blood transfusion was not associated with reduced risk of infection, generally. However, transfusion strategies were found to be associated with a minimized risk of specifically dangerous infections. In a related study, [
8] used RR to investigate the relationship between caregiving and risk of hypertension incidence among American older adults. The research, conducted on 5708 Americans aged 50 years and above, held that caregiving for a spouse is associated with the possibility of becoming hypertensive by the caregiver in the long run. The association between diabetes and the possibility of prostate cancer incidence was investigated by [
9] using RR. The research reported risk ratios representing the extent of this association as 5.83, 2.09, and 1.35 for ages 40–64, 65–70, and 75 years and above, respectively, on a sample of 1 million Taiwanese patients.
The aforementioned applications of RR in the healthcare domain give evidence that this technique holds good prospects for further deployment in this area. To our knowledge, risk ratios have so far been applied only in cohort and specific studies, with results limited in scope and generalization potentials. Against this backdrop, this research will explore the possibility of using the RR as the basis for developing a generic variable importance ranking algorithm. The algorithm will facilitate reduction of the dimension space of any healthcare dataset in order to enhance predictive accuracy and efficiency.
There are basically three categories of variable selection methods: filter, embedded, and wrapper [
10]. The filter methods do not depend on any machine learning algorithm [
11]. Filters are executed on raw datasets as a form of preprocessing in order to determine the appropriate predictor subset that will produce the most accurate classification results. On their own, filter algorithms cannot tell how effective a selected subset can be for model construction, unless a particular learning algorithm is deployed. Embedded methods are dependent on particular machine learning models. They incorporate variable selection mechanisms into the model construction algorithms such that learning and variable selection work hand-in-hand [
10]. Wrapper methods scan through the variable space, evaluating different subsets using the machine learning algorithm itself to determine the subset that produced the best-performing model [
12]. Three commonly used techniques of wrapper methods are forward selection, backward elimination, and recursive elimination.
3. Methodology
3.1. Experimental Datasets
A number of datasets, mostly from the healthcare domain, were deployed to demonstrate the effectiveness of the proposed algorithm in feature selection. Since the proposed algorithm places emphasis on a dichotomous response, each experimental dataset considered in this experiment has a binary outcome. The considered datasets are listed below:
Psychological Capital (PsyCap). This dataset carries psychological capital (PsyCap) information of some workers in the hospitality industry. Psychological capital measures the capabilities of an individual that enable them to excel in the work environment [
31]. Each worker’s PsyCap was assessed on the four components of psychological capital (hope, efficacy, resilience, and optimism), using the questionnaire presented in [
32]. The workers willingly completed the questionnaires and returned the same, and there were no requirements for prior ethics approval. The dataset has a binary class variable, where 0 and 1 represent low and high PsyCap, respectively.
Diabetes in Pima Indian Women (Diabetes). The dataset consists of 332 observations about diabetes test results of Indian women of Pima indigene. The population sample was those from 21 years and above, residing in Arizona. This dataset, accessible through the R language “MASS” package, reported in [
33], is named Pimat.te within the package, and was originally sourced from [
34]. The dataset has a binary response variable named “type”, where 0 and 1 signify non-diabetic and diabetic, respectively.
Survival from Malignant Melanoma (Melanoma). This dataset, available in the R package “boot”, records information on the survival of patients from malignant melanoma [
35]. The patients had surgery at the Department of Plastic Surgery of the University Hospital, Odense, Denmark, between 1962 and 1977. Several measurements were taken and reported as predictor variables, with a binary class “ulcer”, where 1 indicates an ulcerated tumor and 0, non-ulcerated.
Spam E-mail Data (Spam). The dataset consists of e-mail items with measurements relating to total length of words written in capital letters, numbers of times the “
$” and “!” symbols occur within the e-mail, etc.; and a binary class variable, “yes”, with 1 classifying an e-mail as spam and 0 otherwise. The dataset, titled spam7, can be accessed in the R package “DAAG” [
36].
Biopsy Data of Breast Cancer Patients (Cancer). Named biopsy in the R package, “MASS” in [
33], the dataset measures the biopsies of breast tumors on a number of patients. The dataset was obtained from the University of Wisconsin Hospital, Madison, with known binary outcome named “class”, where 0 = benign and 1 = malignant.
Some characteristics of the experimental datasets are presented in
Table 2.
3.2. Design of Proposed Algorithm
In this section, we will consider
,
as a set of predictors in a high dimensional space
. In most cases, especially with big data, some of these predictors are irrelevant, duplicative, and, thus, not needed in machine learning tasks [
37]. Usually, the objective is to reduce the number of predictors to
where
, such that
consists of the most relevant explanatory variables needed in classification. This is the objective the proposed algorithm seeks to achieve.
Let RawData denote a dataset consisting observations, predictors, and the outcome variable . Let RawDat denote a data point at row , column where and .
Preprocessing. This algorithm will require a normalized dataset on the interval [0,1], also referred to as min-max normalization [
38,
39]. The proposed algorithm, presented in
Appendix A, will take the following steps:
The first step of the proposed algorithm, as presented in Listing 1, is to binarize the dataset. It is a requirement that both independent and dependent variables carry only binary values for the risk ratio measure to be deployed. On purpose, we did not design the algorithm to print the output of the binary dataset. This is to guard against users inadvertently using the binary dataset for model construction. The binary data is only useful for RR computation, after which classification models are fit on the original dataset.
In the second step, listed in Listing 2, the algorithm counts, for each predictor and the class , all occurrences where Just as in step 1, these computations are kept behind the scene, without printing any output visible to the user.
The third step, listed in Listing 3, applies the risk ratio formula of Equation (4) on the values computed in Listing 2 to produce the variable importance rankings. This algorithm outputs the importance rankings of the variables in the order the predictors appear in the dataset. For a better view of the results, the user may decide to arrange the output in ascending or descending order. It is upon the judgment of the modeler to determine the cutoff point of those variables to include in a model.
The statement on line 44 of the algorithm, in
Appendix A, will output the names of predictor variables and their RR values, separated by a tab, each on a separate line. Each RR value constitutes the importance rank of the corresponding predictor, signifying the extent to which it is associated with the class.
The processes involved in feature ranking by the proposed algorithm are shown in the pseudo code below:
| Algorithm 1. Pseudo code |
START Convert dataset to binary, that is, round all values < 0.5 to 0 and > = 0.5 to 1 FOR each input/output, DO the following: IF INPUT is 1 AND OUTPUT is 1 THEN Count that is ELSE Count , that is END IF IF INPUT is 0 AND OUTPUT is 1 THEN Count that is ELSE Count , that is END IF NEXT input/output IF All input/output are exhausted, compute the following: FOR each variable to lowerSum upperSum
= - 21.
PRINT and space, and - 22.
NEXT variable - 23.
STOP
|
A higher value of
VIM for a predictor signifies strong association with the class, and consequently indicates its importance in classification. This algorithm is summarized in Equation (7).
where
is the importance ranking of the
jth predictor,
,
is the total number of observations with
input = 1 and
output = 1,
is the total number of observations with
input = 1 and
output = 0,
is the total number of observations with
input = 0 and
output = 1, and
is the total number of observations with
input = 0 and
output = 0.
3.3. Experiment and Results
Execution of the Proposed Algorithm on the Datasets. The proposed algorithm was executed on all the datasets in order to rank the variables according to importance. The existing varImp function and the regsubsets methods (nvmax, forward, backward) were also deployed to rank the variables. Equally, the Fisher score and Pearson’s correlation were deployed. This was done in order to compare the effectiveness of the proposed algorithm against existing methods of variable selection.
Two machine learning algorithms, namely Logistic Regression and Random Forest, were used in the experiment for model construction, evaluation of goodness of fit, and predictive accuracy. Samples of variable ranking results on the Diabetes and Melanoma datasets are shown in
Table 3.
Performance evaluation of the proposed algorithm in comparison with existing algorithms was done in two steps. First, the goodness of fit of models developed using variables selected by the new algorithm and existing ones was examined, and secondly, the predictive accuracy evaluation was carried out.
Goodness of Fit Evaluation. The goodness of fit test was assessed on two metrics: deviance and Mean Squared Error (MSE). In Logistic regression models, two deviance types are reported: null deviance and residual deviance [
40]. The residual deviance is calculated cumulatively as predictors are added to the model. The difference between the final residual deviance and the null deviance explains the goodness of fit of a model. When comparing two models, the model with the smallest deviance is said to have better fit. The MSE is a parameter-free measure that gives information on the difference between actual and predicted values [
41]. Lower values of MSE for a model indicate better fit. A sample result of the goodness of fit test of the various models is presented in
Table 4.
The goodness of fit results presented in
Table 4 show that the subsets selected by the proposed algorithm competed favorably with those selected by the existing varImp algorithm.
Predictive Accuracy Evaluation. The results of the predictive accuracy test of models constructed with subsets selected by the proposed algorithm compared with those constructed with variables selected by existing algorithms were examined. Before fitting the models, each dataset was split into 80% and 20% train and test sets, respectively. The train sets were used for model construction, while the test sets were used to evaluate the predictive power of the models. Typically, the predictive accuracy is computed using Equation (5). However, Equation (5) assumes that classes of the dataset are balanced. This is usually not the case in real life as could be seen in
Table 2, where the number of observations in class 0 is not same as that in class 1 across all experimental datasets. For imbalanced datasets, the balanced classification accuracy (BCA) defined in Equation (6) is applied to calculate predictive accuracy.
In this article, the BCA was used throughout the experiments for predictive accuracy computations. The proposed algorithm was executed on all the datasets to obtain importance rankings of predictor variables. After generating the rankings, the best subsets were selected for modeling using Random Forest and Logistic regression classification. Two criteria were adopted in arriving at best subsets. The first option was to sequentially select all variables with ranking values close to each other until there is an unusual decline with subsequent variables down the group. The second option was to keep adding variables with reasonably high ranking values until further additions do not improve model performance. Existing ranking algorithms, namely regsubstes (nvmax, forward, and backward), varImp, Fisher score, and Pearson’s, were equally executed on the datasets. The best subsets generated by these algorithms were selected for modeling.
The balanced classification accuracy of each model was computed on the test sets of the datasets, yielding the results presented in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9. The
Table 5 indicates the predictive accuracy comparison of various ranking algorithms on the PsyCap dataset, while
Table 6 reports results of predictive accuracies on the Diabetes dataset. Relatedly,
Table 7 reports various predictive accuracies generated by each ranking algorithm on the Melanoma dataset, while
Table 8 presents accuracy results on the Spam dataset. In
Table 9, the predictive accuracies on the Cancer dataset for the various ranking algorithms are reported.
As could be observed in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, the variable subsets selected by the proposed algorithm performed competitively with the selection by existing algorithms.
4. Discussion
A predictive accuracy test was conducted in order to determine how well the variables selected by both existing algorithms and the proposed algorithm can predict the outcome variable on the validation set. Output was determined as probabilities of the form where is the data value for each predictor, . The boundary used in making a decision was . What the program typically did was that, if then otherwise . When this test was run on the different models generated by the various ranking algorithms, their respective predictive accuracies were obtained using Equation (6).
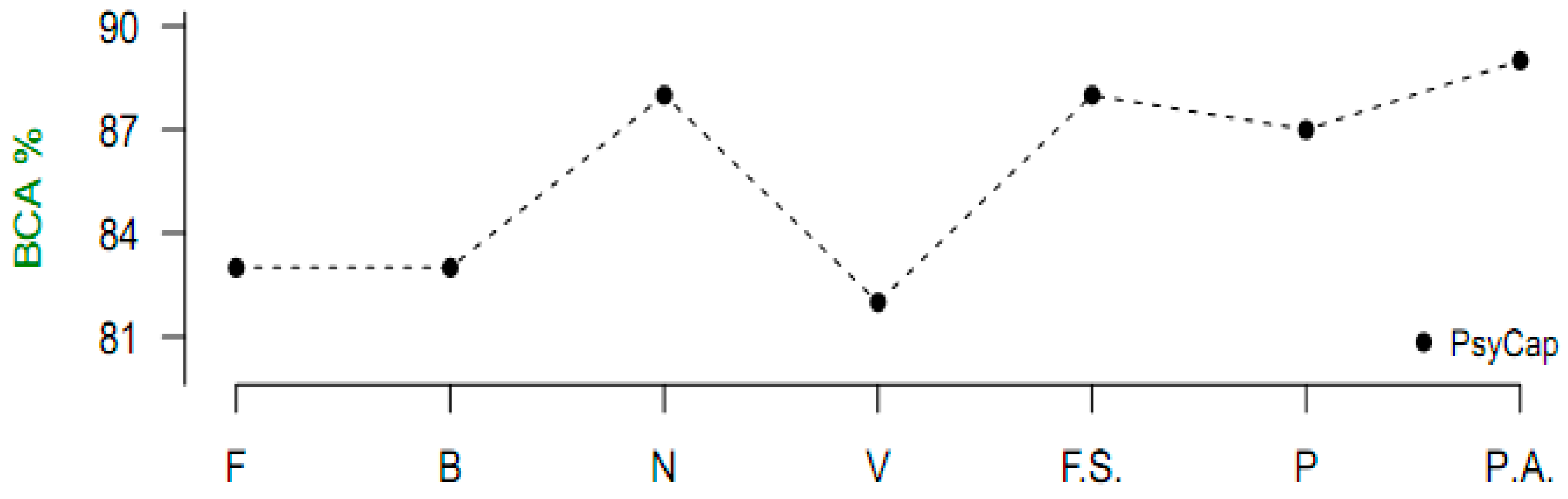
Figure 1 and
Figure 2 represent graphically that variables selected by the proposed algorithm in all datasets produced higher predictive accuracies, except in one instance, compared with the selections by the existing algorithms. Therefore, the new algorithm can be said to be a good choice of filter variable ranking in machine learning classification.
Apart from selecting variable subsets that resulted in good model performance, another plus for the proposed algorithm over the existing algorithms is the way ranking values are presented to the user. As could be observed in
Table 3, one of the ranking values in the diabetes dataset is a negative number. For quick insights into how much one predictor is more or less important than another, it would be better for all values to carry the same sign across the board. The Pearson’s is a correlation-based method, which means all ranking values produced will fall within the interval [−1,1]. In big data, where some datasets consist of a high number of features, say 100 and above, ranking the entire feature space within this interval may not give quick visual insights. The RR deployed in the proposed algorithm produces values within the range of 0 to infinity. This range seems more appropriate for representing ranking values when the feature space is large.
5. Conclusions
In the era of big data, where voluminous, high-dimensional data are constantly being generated from healthcare delivery activities, it is necessary to pay more attention to the problem of variable selection. The majority of the attributes that come with historical or daily data are usually not necessary in modeling. When such unimportant attributes are not eliminated before model construction, many metrics of model diagnostics, such as variance, deviance, degrees of freedom, and predictive accuracy, are negatively affected. Furthermore, machine learning algorithms train slower, and constructed models are over-fitted and more complex to interpret if irrelevant predictors are included. The ranking algorithm developed in this research, which performs competitively with some existing algorithms, will be a useful tool for dimensionality reduction in healthcare data to guard against these unwanted results in classification.
As could be observed in
Figure 1 and
Figure 2, this algorithm demonstrates that it is more appropriate for healthcare datasets than other domains. Better performance was recorded in the cancer, PsyCap, diabetes, and melanoma datasets compared with the spam e-mail dataset. The algorithm achieves a variable importance ranking by employing the statistical measure of risk ratio to evaluate the association between a predictor and the response. Predictors exhibiting a strong association with the class will be selected for classification, while those with a weak association will be excluded. The algorithm does not include a means of determining a threshold of which variables to include in a model. It is left to the discretion of the modeler to apply trial and error in adding or removing variables based on the ranking and performance of previous models. In future research, the algorithm should be extended to be able to determine a cut-off point of important variables algorithmically. Also, the possibility of implementing this algorithm in a way that makes it compatible with open-source languages, such as R, should be explored. As a candidate filter method, the algorithm is independent of any machine learning tool. It is meant to effect variable selection as a preprocessing activity, after which any modeling tool can be applied for model fitting proper. The algorithm is generic; thus, it can execute on any healthcare dataset, provided it is numeric with a dichotomous response.




{kind=link}
{kind=link}