1. Introduction
Cell fate decisions and phenotypes are determined by the intracellular molecular events in signaling and gene transcription [
1,
2,
3]. The collective behavior and evolution of cells are linked to these intracellular events. Nevertheless, most of the cell population models are decoupled from signaling and gene transcription. A key challenge to modeling multicellular systems considering signaling and gene transcription is the multiscale nature of the problem [
4]. Cell death, division, and evolution take place at a longer time scale compared to intracellular biochemical transformations in signaling and gene transcription. Bridging these multiscale phenomena in a model is imperative to mechanistically study cellular development and evolution [
5].
In this work, we present a new framework for multiscale modeling and simulation of multicellular systems. It provides a unique capability to systematically expand a single-cell biochemical network model into a cell population model. Using a message passing interface (MPI) [
6] parallel algorithm, the models can bridge cellular processes to the temporal molecular events in signaling and gene transcription.
In an unconventional approach, the framework launches parallel simulations on a single-cell biochemical network model and then treats each stand-alone parallel process as a cell object. Under the MPI scheme, each parallel process behaves like an agent or software object of an agent-based model [
7], and, together, all parallel processes represent the cell population. Cellular heterogeneities can be introduced in the population by creating the parallel processes with distinct parameter values or initial conditions. The cell objects (parallel processes) are communicated, synchronized, and controlled remotely using MPI communications. The cell objects evolve through death and division based on the state variables representing intracellular network species. The death of a cell object is simulated by terminating the process. The division of a cell is simulated by creating a new process (daughter cell) from an existing process (mother cell). Cellular attributes and memory can be passed from one process to another (mother to daughter) during the cell division process.
To implement the above scheme, we break down a model into two separate computer programs. One program describes the cellular processes (cell death, division, or changes in the phenotypes) and their dependencies on the intracellular network species. In the other program, we define a complete biochemical network model describing the intracellular events. We then communicate these two programs in a server-client fashion to connect the cellular processes and the intracellular network.
The separation of the cellular and intracellular molecular-scale processes into two programs provides modularity and versatility in model development. It permits a signaling pathway or gene transcription network model to be defined separately and then readily expanded into a population model. This distributed framework can enable scalable model development considering computationally expensive mechanistic details at the single-cell level.
We first use two simple example models to demonstrate the capabilities of the framework. In one model, we treat cells as independent objects. In the other model, we consider cellular dependency by incorporating cell-to-cell communications. Using the former model, we analyze computational performance of the MPI formulation. This model is also used to demonstrate how MPI could be used to model a temporally-changing growth environment and link it to a multicellular system of evolving cell populations. We utilize the latter model to show how MPI could be used to model cellular interdependencies arising from the cell-to-cell communication in an evolving cell population. Finally, we demonstrate the framework by creating a full-scale model of bacterial quorum sensing. We first create a single-cell biochemical network model by incorporating the intracellular protein-protein interactions, as described in Boada et al. [
8], and systematically expand this single-cell model into a population model using the MPI framework. We present an analysis on the computational performance and accuracy of the population model by validating against an accurate model based on direct implementation of the Gillespie method [
9]. Although in this work we have provided a specific example of modeling bacterial quorum sensing, the approach is general and applicable to modeling yeast or mammalian cell systems.
2. Results
2.1. The Population Modeling Framework
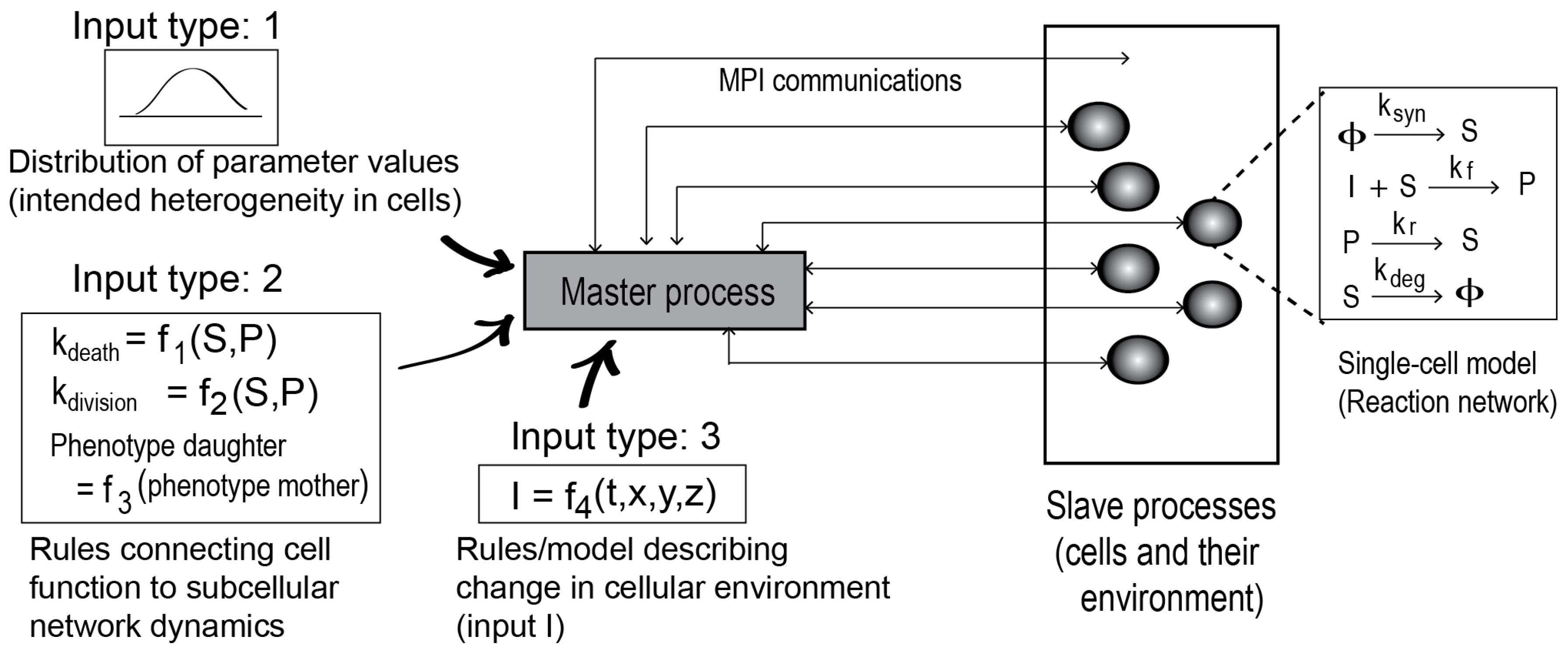
The framework is illustrated in
Figure 1. To create a cell population model, the framework requires a single-cell biochemical network model implementing a stochastic method, such as the Gillespie algorithm [
9].
The biochemical network model could be a signaling pathway or gene transcription network model describing the intracellular protein-protein interaction and their biochemical transformations. The framework also requires three additional inputs, as shown. The Type 1 inputs are cellular distributions of the model parameter values and protein copy numbers. Distribution functions can be defined for the parameters and initial concentrations to incorporate cell-to-cell variability in the population model. The Type 2 inputs are model-specific rules that link the temporal intracellular events (time evolution of a network species, for example) to cellular functions (death, division, or phenotypes). The Type 3 inputs define the cell environment (growth condition).
Given the inputs, the framework launches parallel simulations on the single cell biochemical network model. Each of the simulation processes is then treated as a cell object, as in an agent-based model. Based on the parameter distribution functions, each cell object may acquire properties that are distinct from the other cell objects in the population.
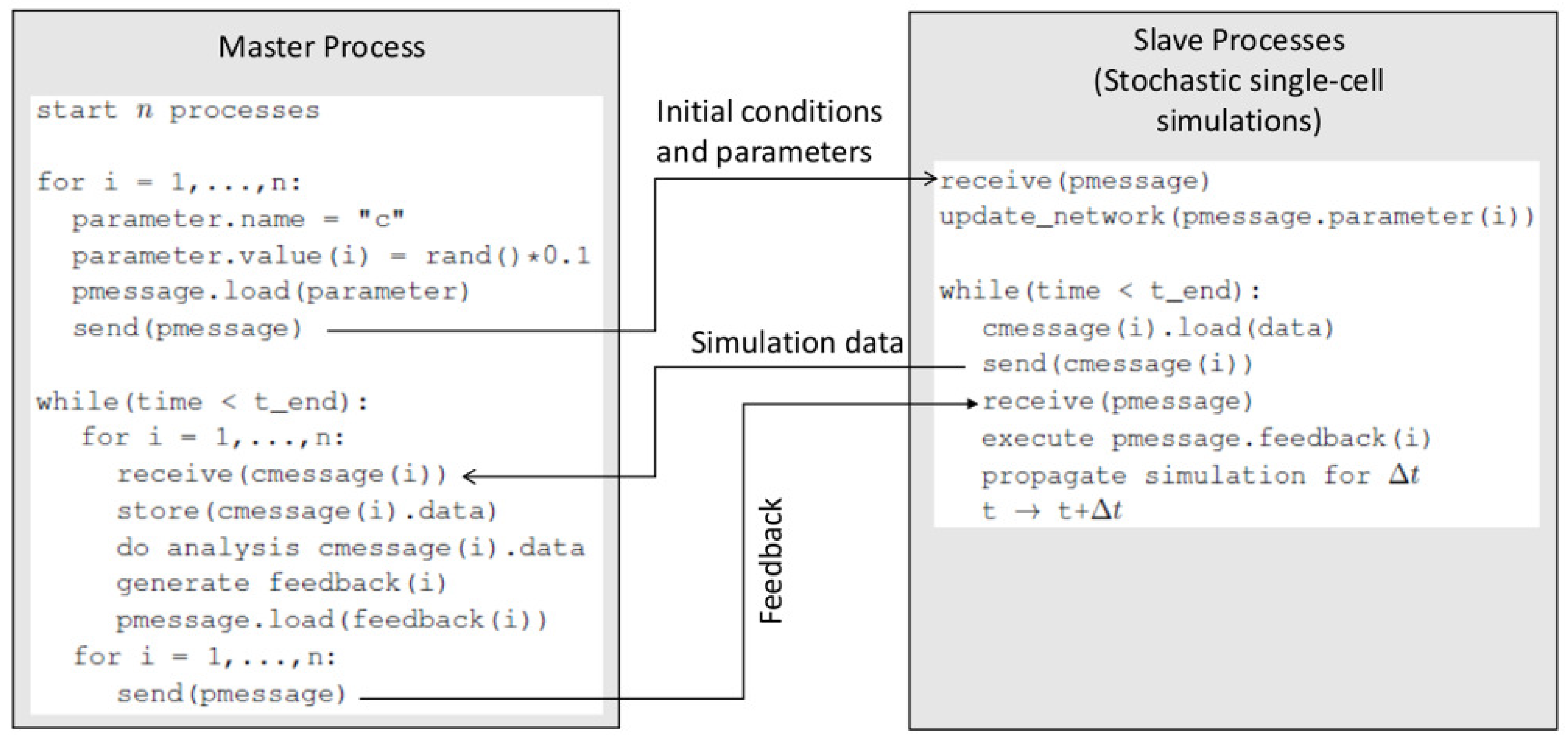
The framework works as a server (a master process), while each of the parallel simulations on the biochemical network model serves as a client (a slave process). MPI is used to mediate the server-client communications. A detailed algorithm of this server-client scheme is provided in
Supplementary Materials (S1_File.pdf). This sever-client scheme is illustrated in
Figure 2. Each cell object (slave process) is allowed to propagate simulation (Gillespie algorithm on the intracellular network) for a prescribed time interval
. At the end of each
, the master process and the slave processes communicate. The master process collects simulation data from each slave process (cell object) and analyzes the data against the rules (Type 2 and Type 3 inputs). Based on the analysis, it sends cell-specific instructions to each slave process using MPI. In addition, it takes actions to execute death, division, or other functions for a cell object if corresponding conditions specified in the rules are met.
If the internal state of any cell object meets the conditions for cell death (specified in the Type 2 rules), the master process terminates the parallel process. Similarly, if the internal state of a cell object meets the conditions for cell division, the master launches a new parallel process to create a daughter cell object. It then sends an MPI message to the newly created process to specify its initial condition, as defined in the rules (Type 2 inputs). Following cell division, the framework partitions the contents (network species) of the mother cell between the mother and the daughter based on binomial distribution [
10].
Based on the Type 3 inputs, the master process evaluates the extracellular environment in each . It sends MPI messages to the cell objects about the updated environment variables. Such variables may include the concentration of an extracellular signal (the concentration of a drug, ligand, or other biomolecules, for example) that may affect the intracellular reactions. Based on the updated environment, the cell objects propagate simulation for another , and the process can be repeated.
It should be noted that the algorithm above is based on an approximation, rather than the accurate implementation of the Gillespie method. The approximation involves discretizing time in small intervals () within which the cells are assumed independent (simulated in parallel). An accurate implementation of the Gillespie algorithm over a multicellular system could be impractical if the detailed molecular interactions are considered at the single-cell level.
We discretize the simulation time with s. The assumption here is that the change in the extracellular environment in this period is small. In addition, this period is also small compared to the time scale of the cellular processes (death and division), which typically take several minutes to hours. This approximation may potentially improve computation, as we demonstrate in the result section. In our algorithm, the time step can be chosen arbitrarily small. However, a smaller could increase the frequency and overhead of the MPI communication.
2.2. Simple Models
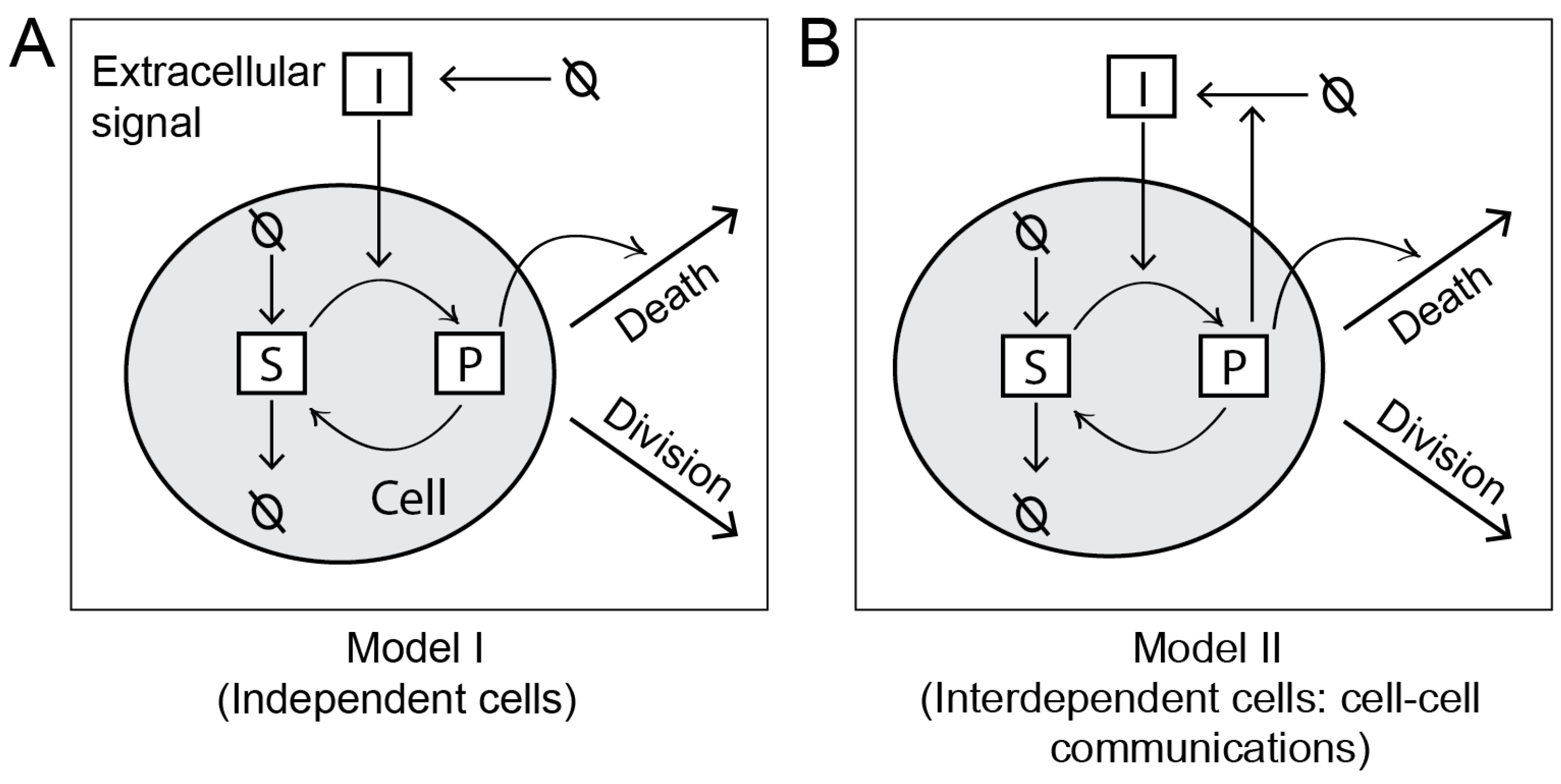
Considering two simple intracellular networks, we demonstrate how the MPI framework builds population models by expanding a single-cell biochemical network model. These simple models are illustrated in
Figure 3.
2.2.1. Model I
In this model, we consider cells as independent objects. Therefore, the death, division, or intracellular reactions of any cell is not affected by other cells in the population.
In a C++ program, we define a biochemical network model describing the intracellular events at the molecule scale. As illustrated in
Figure 3A, we consider four elementary reactions in the network. These reactions and corresponding rate constants are listed in
Table 1. The reactions describe a signaling pathway, which is activated in response to an extracellular signal
I. A receptor protein
S is synthesized and degraded in a zeroth and first-order reaction, respectively. In the presence of extracellular
I,
S is activated to produce
P and deactivated in a reverse reaction. In the model,
P serves as a pro-death signal for a cell. Intracellular accumulation of
P elicits cell death by inducing the mean rate of cell death
.
In a separate C++ program, we introduce the cellular processes and associated parameters (
Table 2). We ignore cellular heterogeneity (Type 1 input). A rule (Type 2 input) is included to define the dependency of cell death on intracellular
P. This rule simply states a linear relationship:
(
Table 2). Here,
is the mean rate of cell death in the absence of
P or extracellular
I. The proportionality constant
(
Table 2) measures the sensitivity of a cell to intracellular
P. A second rule is included to binomially distribute the contents (network species) of a cell when it is divided to create a new cell. We assume that the extracellular environment (
I) remains unchanged throughout the simulation.
As explained earlier, we have two programs: one program (acting as slave) defining the biochemical network model, and the other program (acting as master) defining the cellular processes. These two programs contain complementary MPI calls to communicate in a server-client fashion. The master program launches a number of parallel simulations on the slave program to create the initial population of cell objects. For an interval,
s, all the simulation processes (cell objects) propagate simulations (Gillespie algorithm) on the biochemical network system. At the end of
, the master process collects simulation data from the cell objects. Based on the analysis of the simulation data against the rules, the master process performs few checks and takes actions accordingly. First, it evaluates each cell object for death or division. A cell is selected for death if
, where
is a uniform random number between 0 and 1. Similarly, a cell is selected for division if
. Cell death is executed by terminating the corresponding parallel process, while cell division is executed by creating a new process (daughter cell) from the existing process (mother cell). The master process then analyzes the level of pro-death signal
P in each (living) cell and updates the cell’s
according to the rule. Note that cell death could be linked to a variety of pro-death (apoptotic) signals, such as an external cue [
11,
12,
13] or intracellular expression of a death-inducing protein [
14,
15]. In this example model,
P represents such an intracellular signal. The framework allows arbitrary functions (rules) linking such signals to cell death. The function, which is a modeler’s choice, could be defined based on an educated guess and existing knowledge.
While the master process performs the checks mentioned above, the slave processes (cell objects) remain in a blocking mode. This blocking mode is released upon receiving a message from the master program. The slave processes then propagate simulation for another , and the process is repeated until the simulation end time is reached.
2.2.2. Model II
This model is shown in
Figure 3B. The model has the same set of intracellular reactions as Model I. However, in this model, cells are interdependent due to cell-to-cell communication. We consider a reaction whereby cells can secrete
I in proportion to their intracellular
P. Thus, each cell contributes to the global pool of
I in the environment, which is shared by all cells. An increase in
I in the environment further stimulates the intracellular production
P in the cells, thus inducing cell death.
The slave program of Model II defining the biochemical network model remains essentially the same as in Model I, with the exception of the master program, where an additional rule (Type 3 input) is included. According to this rule, a cell
i secretes
amount of
I in time
:
, where
is a constant (
Table 2) and
is the intracellular
P at time
t. The total change of the environment is computed by summing up the contributions from all cells:
, where
is the number of cells at time
t.
As in Model I, the master process communicates with the slave processes after each interval, s, and evaluates cell death, division, and for each of the cell objects. In addition, it also evaluates the change in I in the environment. It then updates the slave processes (cell objects) about the change in the environment by sending MPI messages. Upon receiving the MPI message, the cell object replaces the old I with a new I. Each cell object then propagates simulation for based on the new extracellular environment. The process is repeated until the simulation end time is reached.
2.2.3. Scalability and Performance Analysis
We first test our Model I for its computational performance. The test is performed against an equivalent model (referred to as sequential model), which is developed based on the traditional (non-parallel) formulation. In this sequential model, the intracellular reactions in all cells are gathered into a single reaction list. In addition, this list also contains the division and death of individual cells as reactions. The reactions in this list is then probabilistically sampled and executed by the exact Gillespie method.
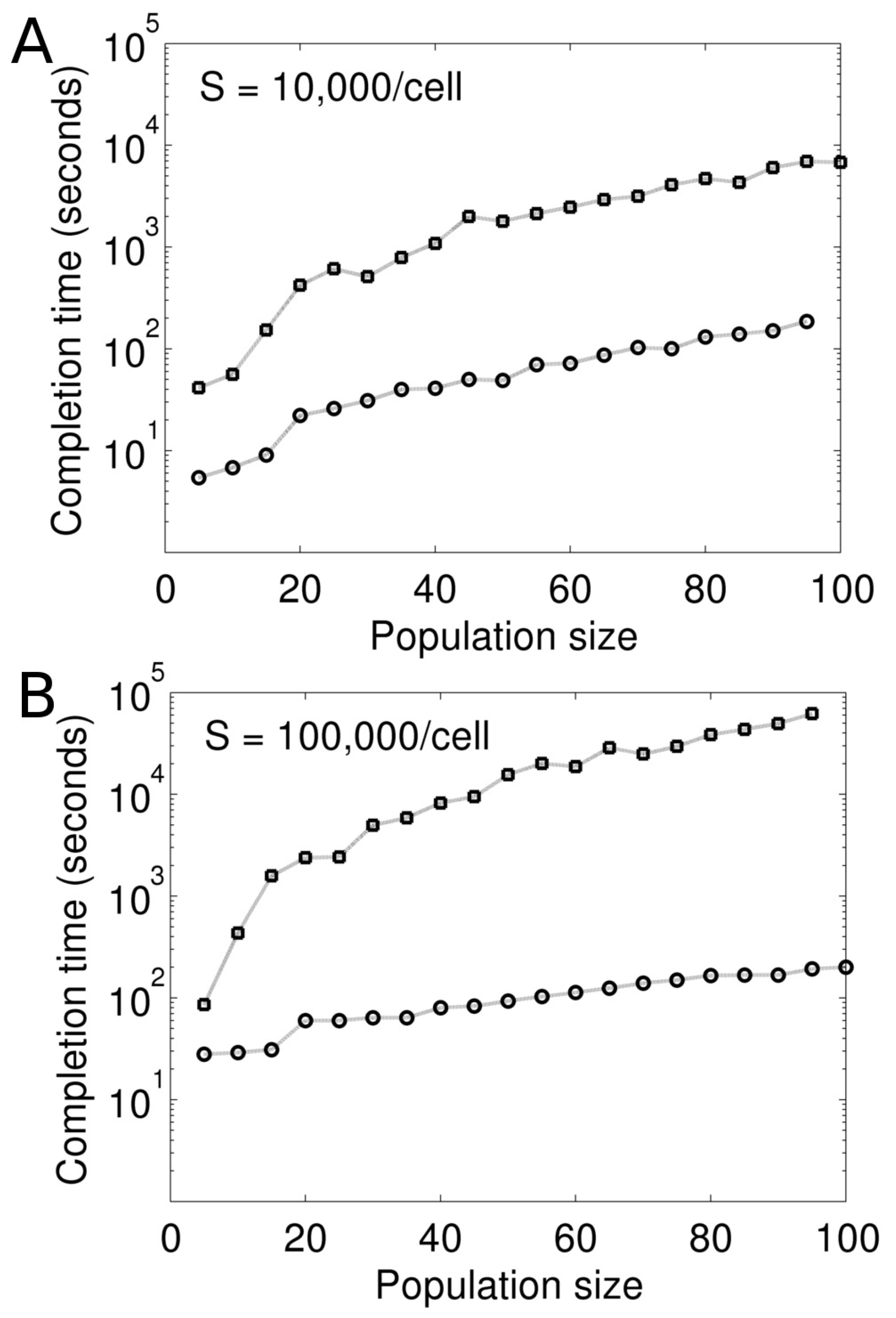
Figure 4 compares these two models in terms of their scalability and speed of computation. We vary the scale of the model by changing the cell population size. For consistency, all simulations are performed in the absence of stimulation (
). This is to ensure that the mean cell population size remains constant during the simulations. For each population size, we simulate the two models for 1000 s and note the simulation completion time (wall clock seconds) (
Figure 4). The simulations are carried out on a dedicated 20-core machine.
As seen in
Figure 4, computation is orders of magnitude faster in the parallel formulation compared to its sequential counterpart. The difference becomes more significant when the models are made more computationally expensive by increasing the concentration of molecule
S (
Figure 4).
Figure 4B represents a 10-fold higher
S in the models compared to
Figure 4A. Simulation using the Gillespie method at the cellular level becomes more expensive when
S is increased. This makes computation prohibitively slow in the sequential model.
The faster computation in the parallel formulation is due to the MPI parallelism as well as the numerical approximation in the algorithm. As explained in the method section, we discretize the simulation time in s. In each , the cell objects are simulated independently and in parallel. At the end of each , the cell objects are synchronized and updated. On the contrary, in the sequential model, the Gillespie algorithm is accurately implemented over a single reaction list that represents the entire multicellular system. The sequential model is not scalable as the number of reactions in the list is determined by the number of cells in the system. In the parallel formulation, the time discretization ( s) is small because the mean waiting time for cell death and division is much longer ( s). We expect some loss of accuracy from this approximation, which, however, significantly improves computation.
Note that the concentrations
and
in the example above are arbitrarily chosen for the demonstration purpose. These numbers represent a typical expression level of many cellular signal transduction proteins [
16]. However, the framework permits a model to incorporate a much larger protein copy number in the range of a few hundred thousands [
17]. Its computation for a multicellular system remains feasible as long as the Gillespie algorithm at the single-cell remains tractable.
2.2.4. MPI to Link Intracellular Dynamics to Population Response
The rate of cell death in Model I is linked to the intracellular concentration of
P (activated
S) by a linear function, as discussed in the Method section.
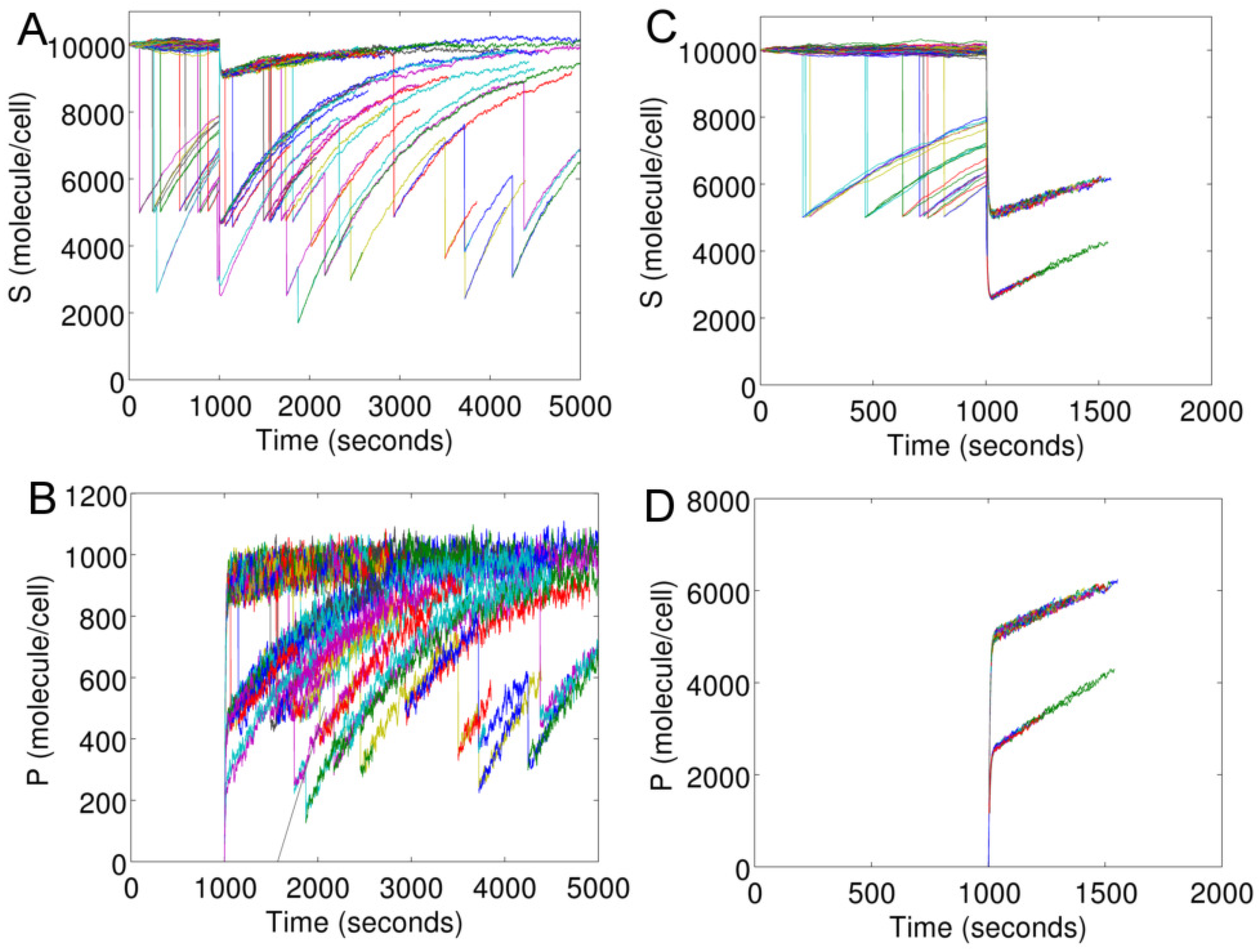
Figure 5 shows intracellular
S and
P of individual cells in an evolving cell population. We launch an initial population of 100 cells (parallel processes) at time zero. At
s, the population is stimulated with
s
(
Figure 5A,B) and
s
(
Figure 5C,D).
In
Figure 5, each curve for
S or
P represents an individual cell. The start and end of a curve correspond to the birth and death time of a cell, respectively. The sharp fall of any curve marks a cell division. The fall is due to the decrease in the cellular content of a mother cell because of its division. When a cell divides, the contents (network species) are divided between the two cells based on binomial distribution.
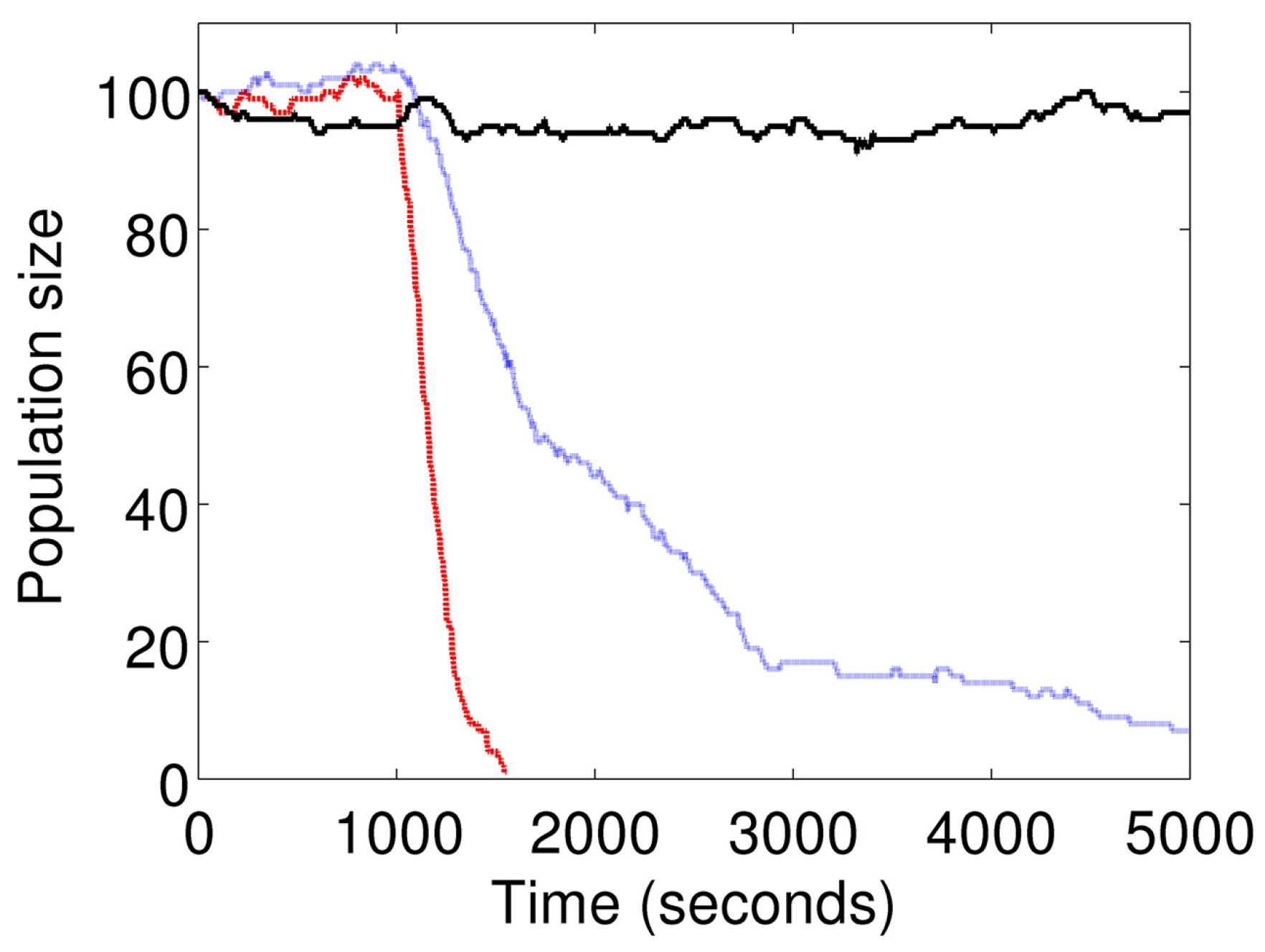
Figure 6 shows the cell population size at different doses of
I. The curve showing a constant mean population size represents the basal condition (
). The intermediate curve indicates a slow decline in the population size represents stimulation at
s
. The curve indicating a sharp decline represents stimulation at
s
.
2.2.5. MPI to Link the Intracellular Reactions and Cell Environment
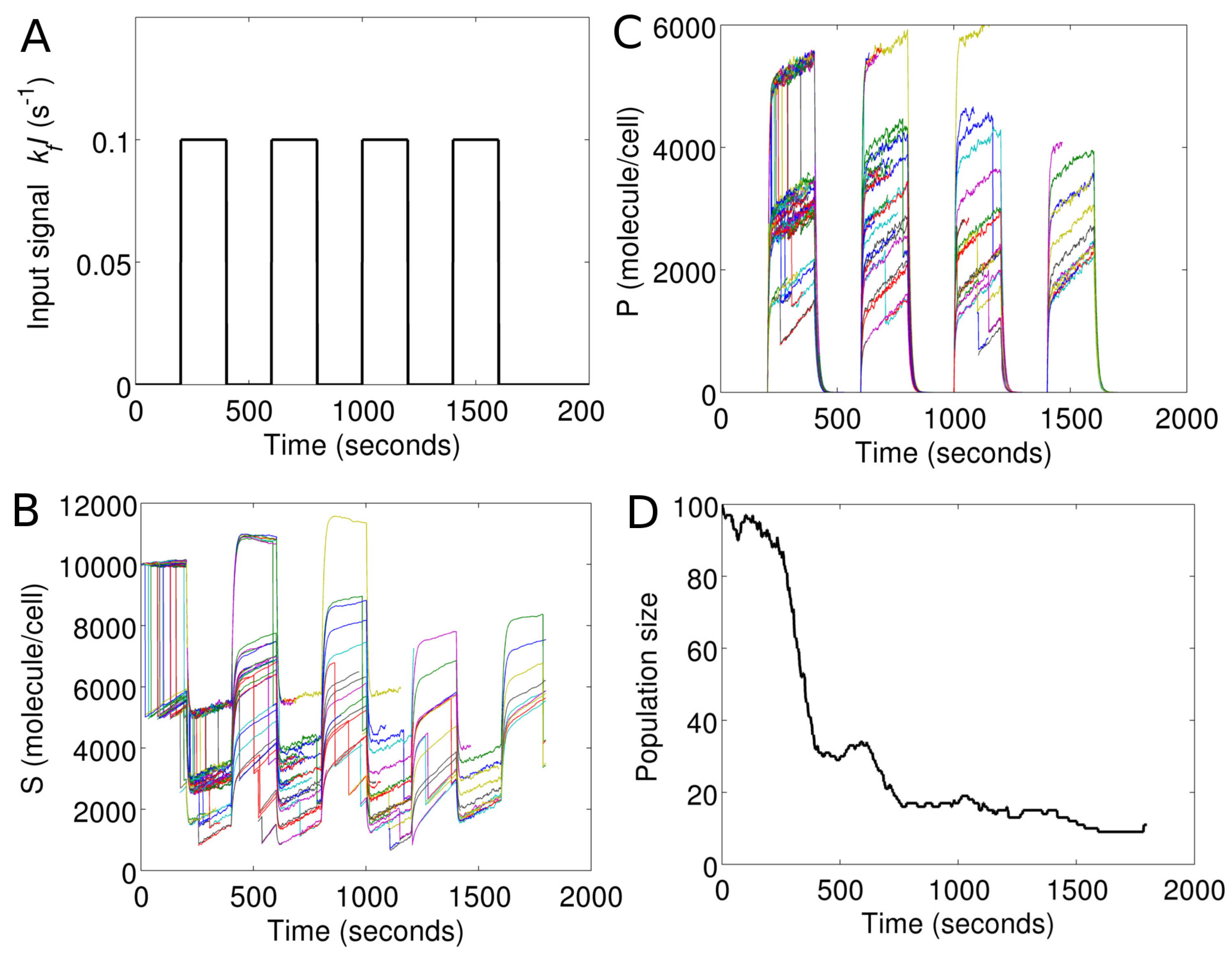
Figure 7 demonstrates cell population response in Model I under a temporally-evolving extracellular environment. To model the cell environment, we simply include an additional rule (Type 3 input) in the master program of Model I. This rule introduces a periodic pulse in
I, as shown in
Figure 7A.
At the end of each
, the master program sends a message to each cell object. The message contains a new value of
I for the global environment, which is shared by all cells. Upon receiving the message, the new value of
I replaces the old one, in each cell object. The cell objects then propagate the reactions (Gillespie algorithm) based on this new value of
I.
Figure 7B,C show the intracellular
S and
P in each cell in the changing environment.
Figure 7D shows corresponding changes in the cell population size as a function of time.
2.2.6. MPI to Model Cellular Communications
Our Model II is inspired by multicellular systems where cell-to-cell communications determine the collective behavior of cells [
18]. In many physiologically-relevant systems, cells respond in an interdependent manner. Such dependencies may arise from the direct or indirect communications among the cells. Cells may directly communicate via physical interactions [
19]. On the other hand, indirect communications may arise when cells modify a shared growth environment. Cells can release proteins or metabolites into the environment, which may affect other cells. An example of such indirect communication is called quorum sensing [
20].
Recent studies have identified a family of quorum-sensing peptides, called Extracellular Death Factors (EDFs), that induces programmed cell death in
E. coli [
21] and several other bacteria [
22]. Reportedly, secretion of these peptides by bacteria may elicit collective cell death in a population. In Model II, we consider a similar scenario where cells can produce and secrete
I in proportion to their intracellular
P. We implement this by simply adding a rule (a Type 3 input) in the master program of Model I. In each
s, the master program evaluates the intracellular
P in each cell object and the secretion of
I by the cell object. The global environment is changed based on the contributions from all cells in the population. The change in the environment is implemented by sending MPI messages, as explained in the previous section.
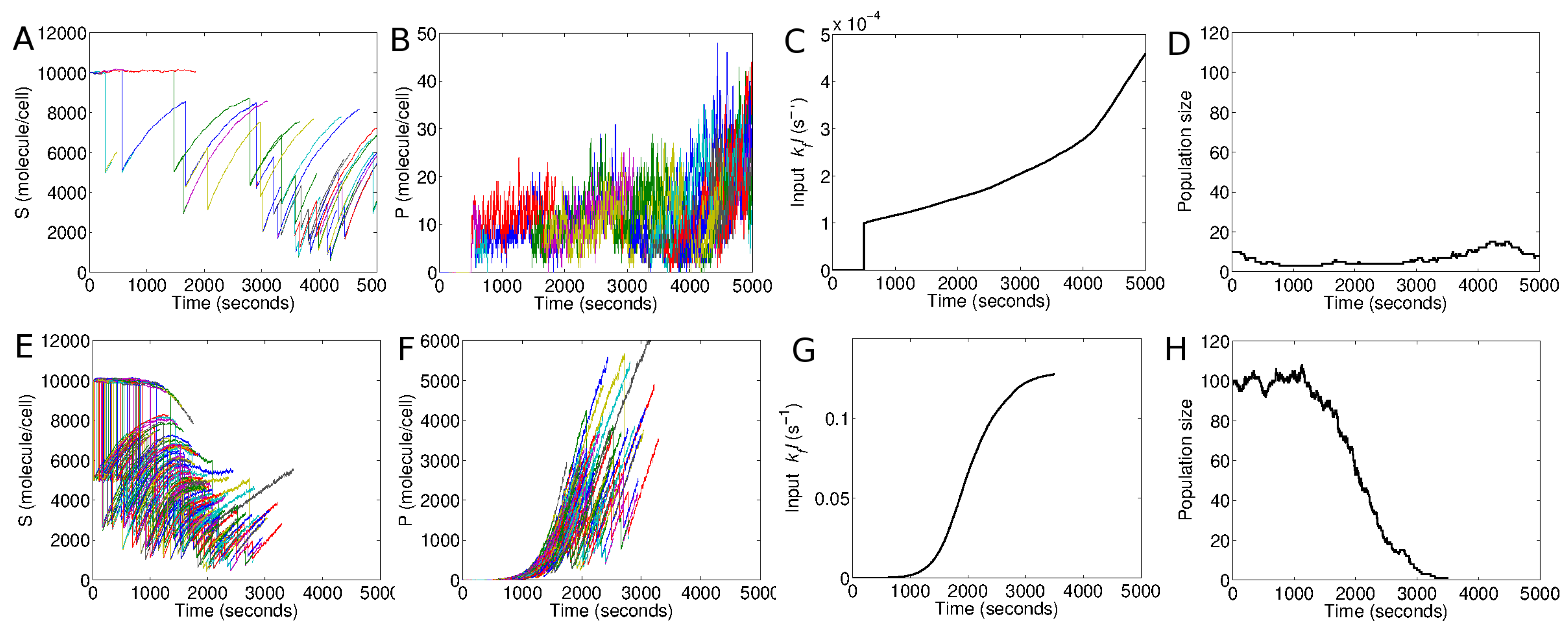
Figure 8 shows the population response in Model II. In the top panels (
Figure 8A–D), an initial population of 10 cells are launched at time zero, and stimulated at
s with a small dose of the extracellular signal,
s
. The population remains non-responsive to this signal. The average population size is not affected, as seen in
Figure 8D. In the bottom panels (
Figure 8E–H), an initial population of 100 cells are launched and subjected to the same level of stimulation,
s
, at
s. Except for the population size, all other conditions are identical to those in the top panels. Nevertheless, contrary to the smaller population, this larger population displays a dramatic response (
Figure 8E,F). The quorum-sensing positive feedback is triggered because of the collective contribution of the population. This leads to a rapid buildup of intracellular
P (
Figure 8F) and extracellular
I (
Figure 8G). As a result, the population shows a rapid post-stimulation decay (
Figure 8H).
It should be noted that the selection of the population sizes in this example (100 or 10 cells) is completely arbitrary. In reality, millions of cells may participate in such a process. Nevertheless, the same qualitative differences could be reproduced at different relative scales of the model. An increase in the model scale (population size) would simply require an adjustment in the parameter
(
Table 2), which denotes the rate of secretion of
I by each cell per molecule of its intracellular
P.
3. A Full-Scale Model: Bacterial Quorum Sensing
Our previous examples involved two mock models with very simple sets of intracellular reactions. Here, we consider a full-scale model of bacterial quorum sensing with a more complex intracellular biochemical network. The model is based on an earlier model by Boada et al. [
8]. The intracellular biochemical network reactions associated of this model are illustrated in
Figure 9. The MPI expansion of this reaction network system into a population model is also illustrated in
Figure 9.
In the master-slave scheme of our framework (
Figure 9), the biochemical reactions in each cell is independently simulated using the Gillespie algorithm for a short interval
. Each cell object simulates the Gillespie algorithm based on the reactions shown in
Figure 9. The updated intracellular species concentrations from each cell object (slave process) are sent back to the master process using MPI. The master process then updates the common (well-mixed) extracellular environment based on the rules specified as an input to the master process (
Figure 9). Here, the master takes two types of inputs. Type 1 input describes the distribution of parameters to incorporate cellular heterogeneity and type 2 input is the relationship between cell and environment defined as the net change between external autoinducer concentration (
) and internal autoinducer concentration (
AHL) over each time interval
. The parameters values associated with this model are taken from [
8].
In the model, cell division is simulated by splitting the molecular concentration of the mother cell based on binomial distribution into two daughter cells. The cell population size is kept constant by killing (removing) a randomly selected cell (parallel thread) every time a cell division occurs.
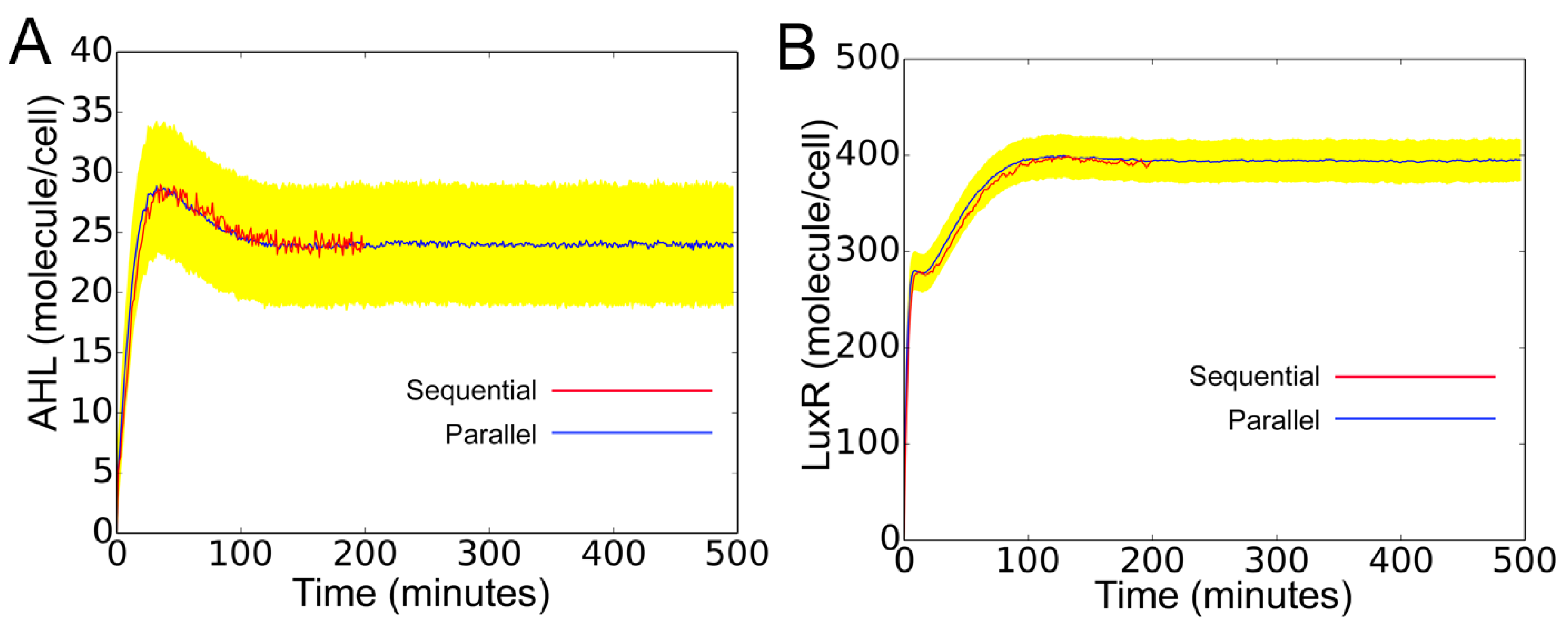
In
Figure 10, we validate the above model against a corresponding accurate (sequential) model. In the sequential model, the intracellular reactions, cell death, and divisions associated with all cells in the population are grouped into one single list. The reactions from this list are sampled and executed following the Gillespie algorithm. As seen in the figure, despite the independent simulation of cells for discrete interval
, the parallel model is in perfect agreement with the sequential model. The yellow region is the standard deviation, representing cell-to-cell variability arising from distribution of rate constant parameters. The change of molecular concentration under cellular birth and death are shown in
Supplementary Materials (S2_File.pdf).
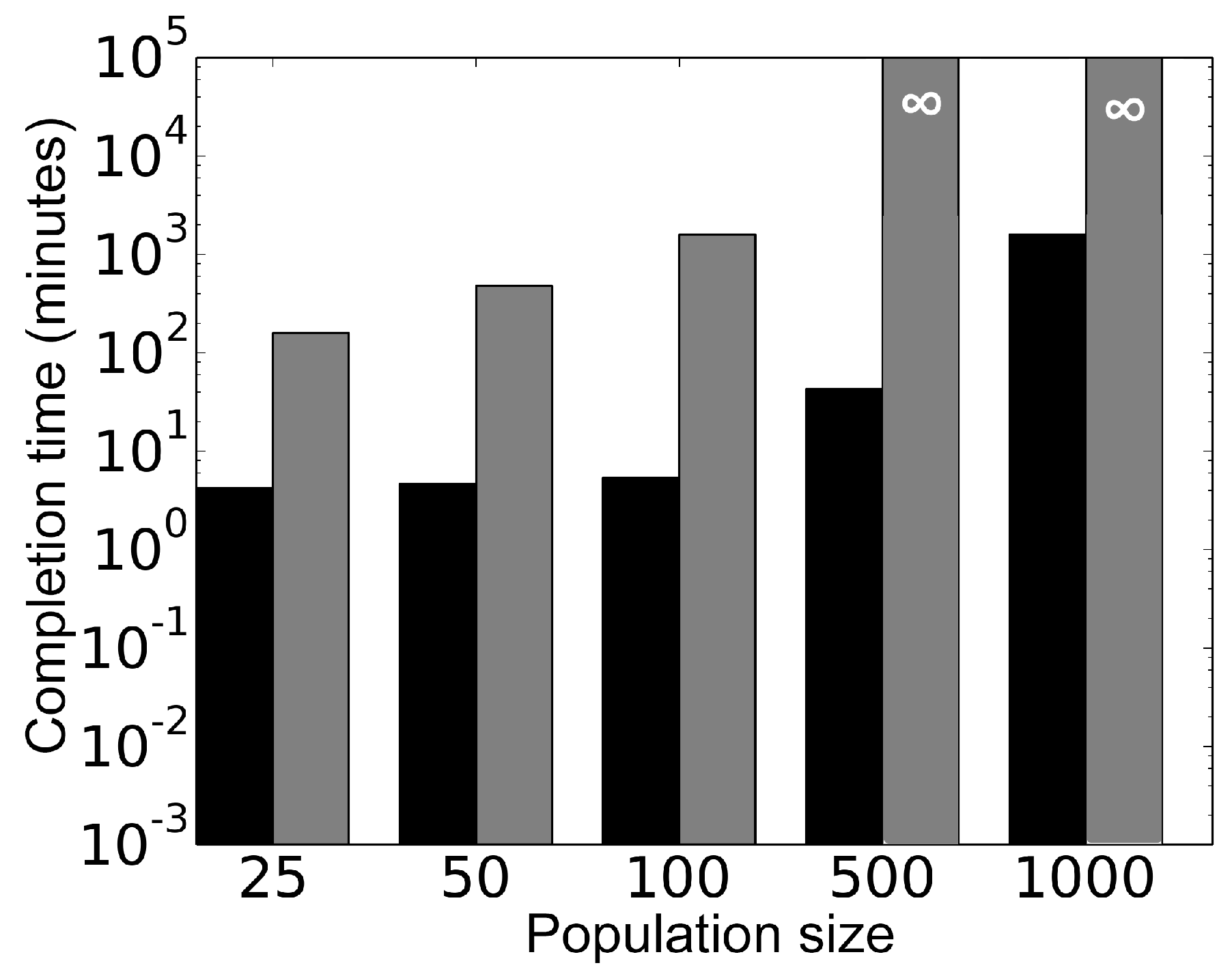
Figure 11 shows comparison of the computational performance between the parallel model and the sequential model, carried out on dedicated 50 cores of a high performance computing cluster. Using the two models, different cell population sizes were simulated for 100 min and corresponding simulation completion times (clock time) were recorded for each model. The result indicates the parallel algorithm is at least two orders of magnitude faster than the corresponding sequential algorithm for a population of 25 cells. Moreover, this gap between the parallel and the sequential algorithms widens with the increase in population size. Note that existing literature on quorum sensing [
23,
24] shows modeling of up to 240 cells using sequential approaches.
Figure 11 shows that simulation of 500 and 1000 cells using the sequential approach remain unfinished after 168 h and are denoted by
∞. On the contrary, the proposed parallel framework exhibits scalability by simulating up to 1000 cells in less than 18 h.
4. Discussion
The goal of this work is to introduce a systematic method for developing mechanistic but computationally efficient cell population models. The question that we raise here is whether it is possible to systematically expand a biochemical network model into a cell population model. The commonly employed techniques to model multicellular systems include the continuum (equation-based) approach, cellular potts modeling (CPM) [
25], and discrete agent-based modeling [
26]. The equation-based approach and CPM are useful for modeling long-time behavior and evolution of cells. However, these methods have limited ability to capture the intracellular protein-protein interactions in a population model.
Arguably, agent-based modeling (ABM) is the most versatile framework for mechanistic modeling of multicellular systems [
27,
28,
29,
30]. In an agent-based model, individual cell agents could be assigned with cellular attributes at various time and spatial scales. However, mechanistic agent-based models could be computationally expensive and demand significant programming efforts.
Unlike the agent-based approach, we represent cells by stand-alone parallel simulation processes on a biochemical network model. We have shown that MPI-based remote communications can be used to treat such parallel processes as software objects like an agent-based model. In an agent-based approach, parallelism could also address the scalability issues and speed up computation. However, such implementation could be model-specific and require expertise in parallel logic implementation. We aim at providing a modular framework that would require minimal programming efforts. We separate a model into two different programs. We show that cellular-scale processes described in one program can be linked to the molecular-scale processes described in another program remotely to create a unified model. This allows a cellular and a biochemical network model to be defined separately and then combined to create a mechanistic population model.
Our framework is currently developed in an ad hoc approach that can only support biochemical network models written in C++ in a prescribed format. Nevertheless, the framework can be extended to make it compatible with other modeling languages and software platforms. It can be extended to create cell population models from the biochemical network models developed using other tools.
For demonstration purposes, the cellular protein-protein interactions in our example model is defined by a network of four elementary reactions. However, the network could be made as detailed as intended. Many advanced tools can develop highly mechanistic biochemical network models. For example, the rule-based modeling tools [
31,
32,
33] can model biochemical network systems where cellular protein molecules can be defined with their site-specific details, such as binding domains and phosphorylation motifs [
34,
35,
36]. Our framework can be integrated with such tools. This can be easily accomplished by embedding necessary MPI calls between a master program and the program running the simulation on a rule-based model. Such integration may provide the ability to study cellular evolution arising from the site-specific (point) mutations in the cellular protein domains and motifs.
This framework can only extend biochemical network models formulated in a stochastic approach, such as the Gillespie method [
9]. In a stochastic model, it is possible to introduce a run-time change in the model parameter values and simulation conditions. In a deterministic model, such changes would lead to discontinuities. Therefore, it is not extensible for the deterministic models.
An important limitation of our approach is that it must synchronize the parallel simulation processes (cell objects) at discrete intervals. The synchronization limits the computation speed by the slowest process in a population. In a large number of parallel processes implementing stochastic simulations, the cost of computation could be considerably different from the processes. This issue could be partially addressed by developing a dynamic load-balancing and resource allocation scheme.
A second limitation is an overhead associated with MPI communications. For a large number of cells in a model, such communication overhead could be significant. Overhead can be the limiting factor if the simulation of the biochemical network is not computation intensive. This issue could be partly addressed through serialization of the MPI messages. In the current framework, the messages are passed as C data structures without serialization. The cost of overhead could also be addressed by developing a more distributed system having multiple servers and clients. Our current framework is based on a centralized system, where communications occur between a single server and multiple clients.
We have applied our framework to model quorum sensing in bacteria, where we consider a homogeneous distribution of environment across all cells and their interaction with the environment through diffusion. As part of future work, we shall extend it to accommodate spatial position of cells and the environmental molecules as discussed in [
37,
38] to incorporate the cellular heterogeneity. There would be a minor variation in our framework once the spatial model is incorporated. At present, our framework constitutes a master module which controls the activities of the cells in the system. In the spatial model, our master node will re-determine the coordinates of the cells and environmental molecules after fixed intervals of time.
This framework can be extended to model other bacteria, yeast [
39], fungus and higher organisms (eukaryotic cells) [
40,
41]. For example, different proteins that copy number of yeast and Hela cells are listed in Kulak et al. [
16]. These modelings will follow a similar approach as quorum sensing, where bacteria synchronize themselves based on feedback response from their environment.
Our framework presents a general approach to connect the molecular scale to the cell population scale. It is noteworthy that cancer cells have similar multi scale features in low scale (production of molecules from genes), intermediate scale (interaction of gene with its cellular environment) and high scale (collective behavior of cells) [
42,
43,
44,
45]. Our framework can incorporate these hallmarks to study the nature and phenotype of cancer cells. Furthermore, we intuit that our proposed framework can also be applied to any drug delivery system, where the concentration of optimum drug dosage can be quantitatively estimated [
11,
12,
13,
46]. The different dosages (e.g., constant dose, periodic dose) of drugs can be modeled as environmental variables as described in
Figure 6 and
Figure 7.
Finally, our approach could also find applications in modeling biological systems that are of scientific, pathological, and clinical interests. Examples include the evolutionary mechanisms of stem cells [
47], clonal expansion of B and T lymphocytes [
48,
49], autocrine, paracrine, and endocrine signaling [
50,
51], and chemotactic cell migration [
52].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}