Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing

Abstract
:1. Introduction
2. Background
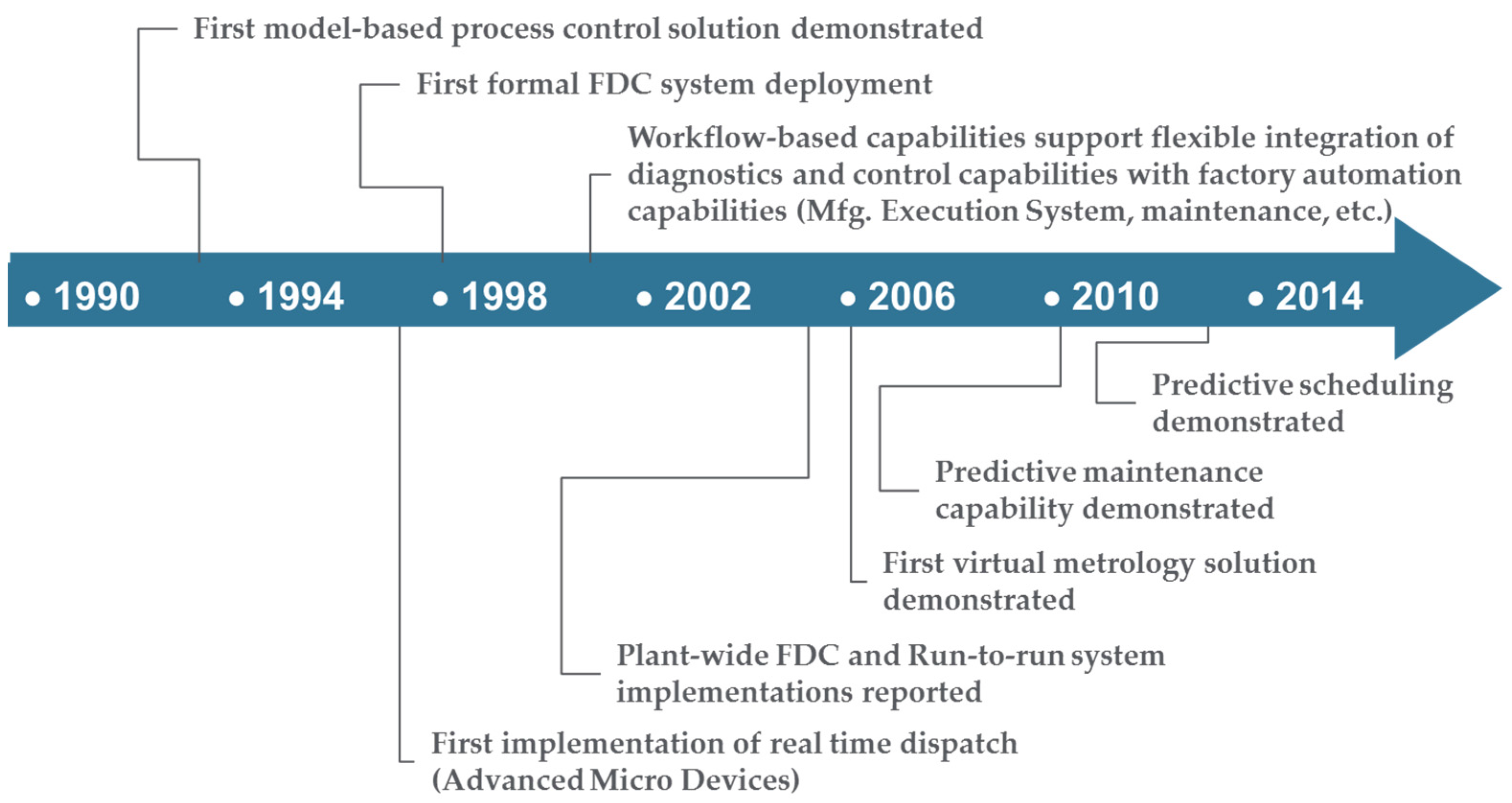
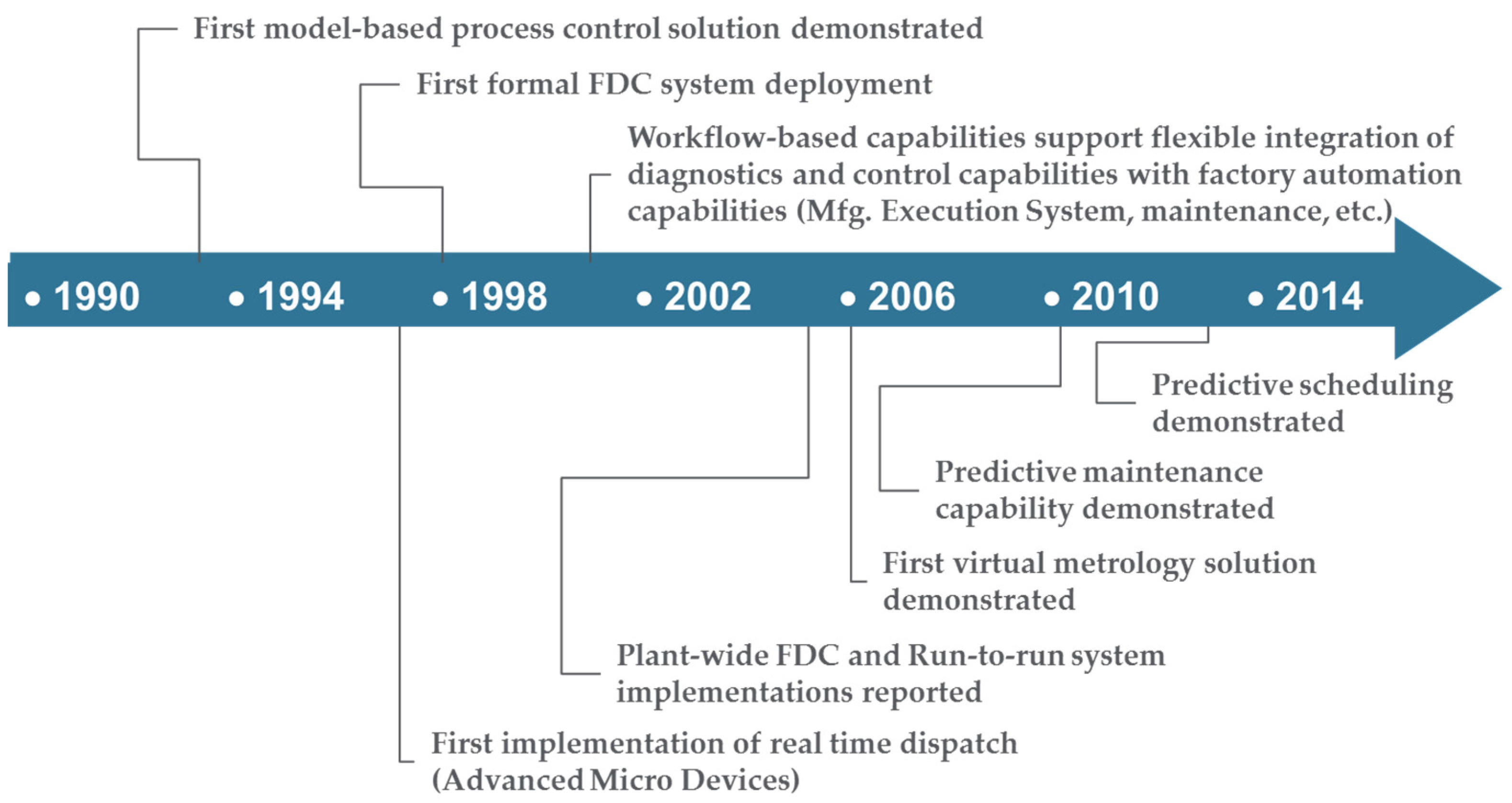
2.1. Semiconductor Manufacturing and the Emergence of On-Line Analytics
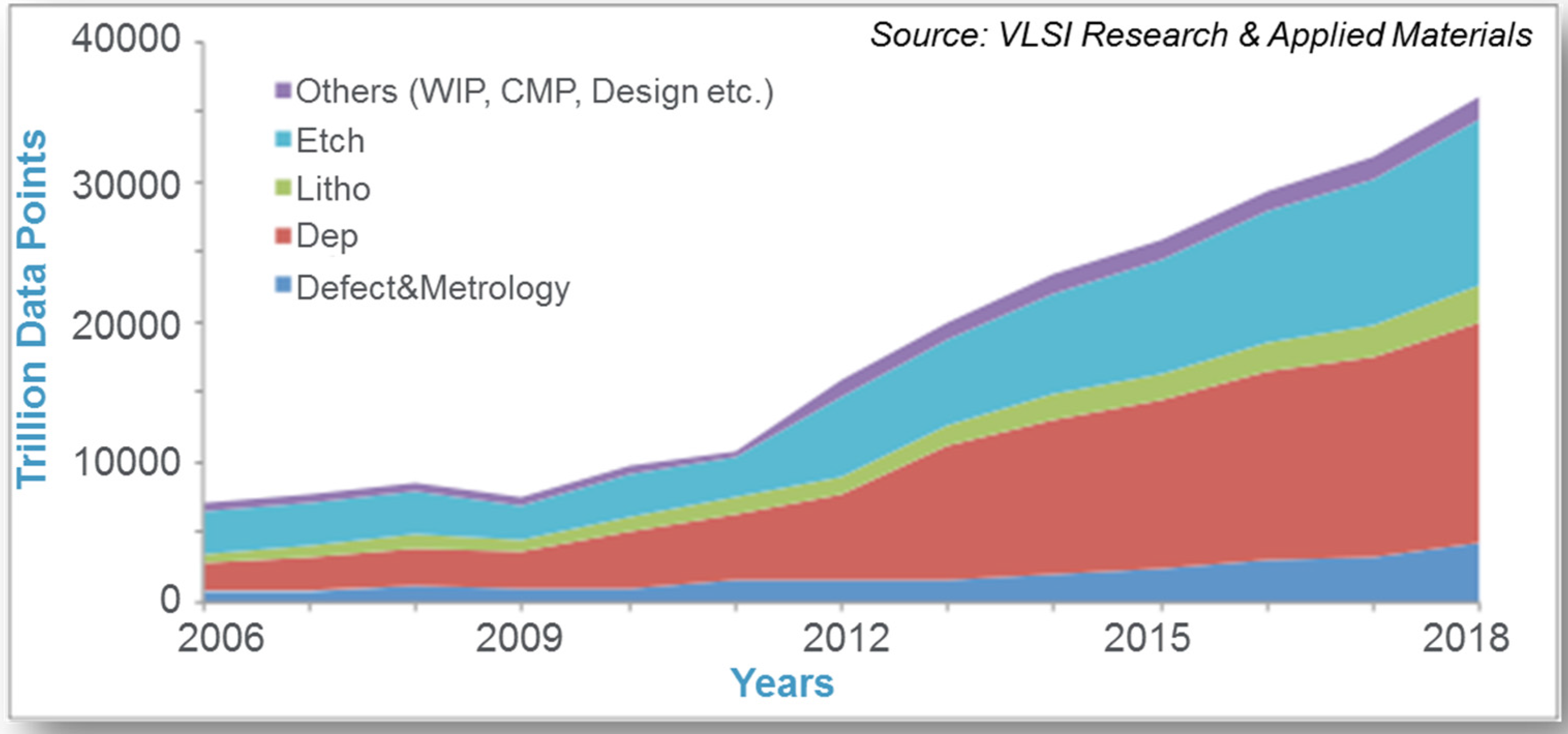
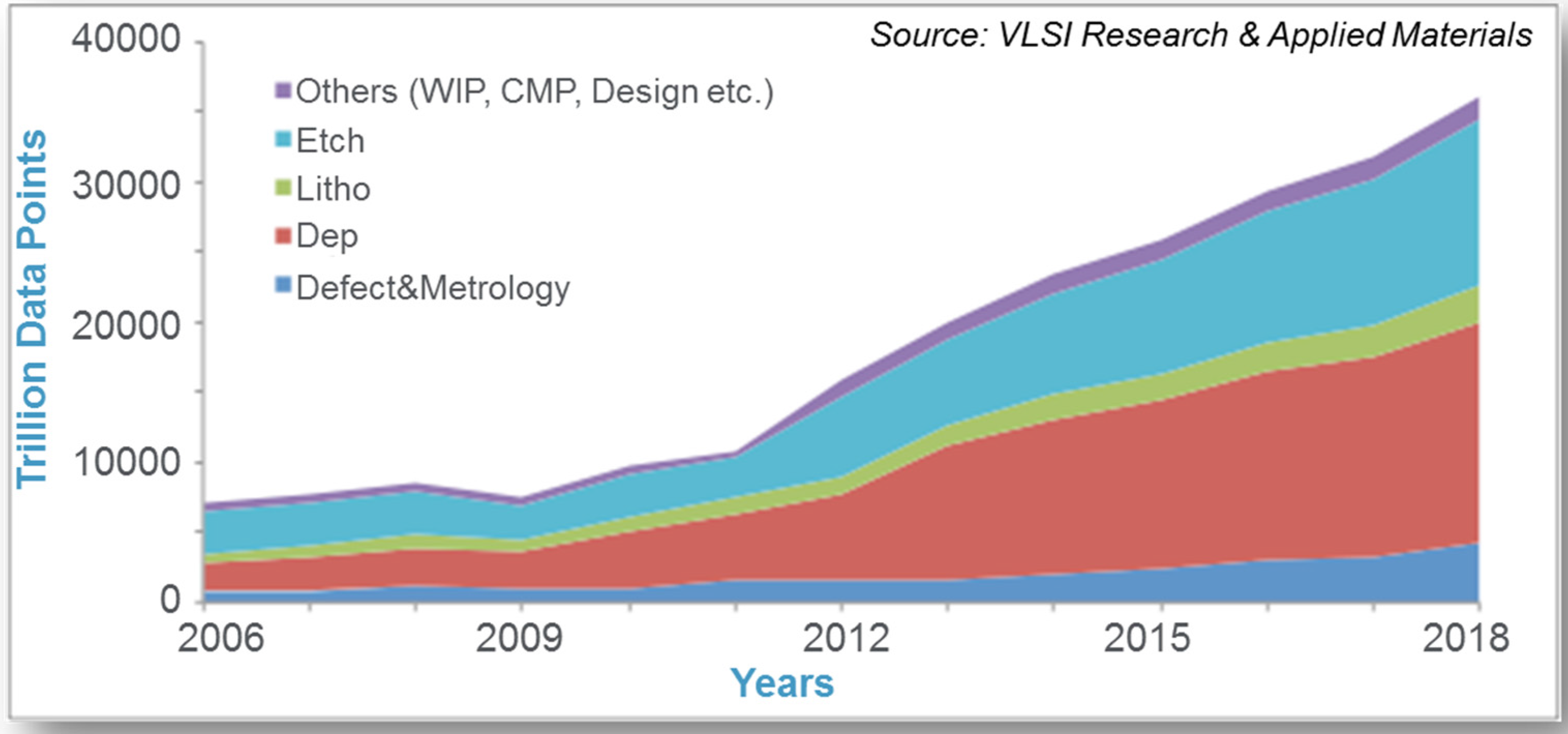
2.2. The Big Data Revolution and Associated Challenges
2.3. Big Data Enabled APC Capabilities
2.4. Leveraging Lessons-Learned to Other Industries
3. Analytics Approaches in Semiconductor Manufacturing
3.1. Semiconductor Industry Specific Challenges Impacting Analytics
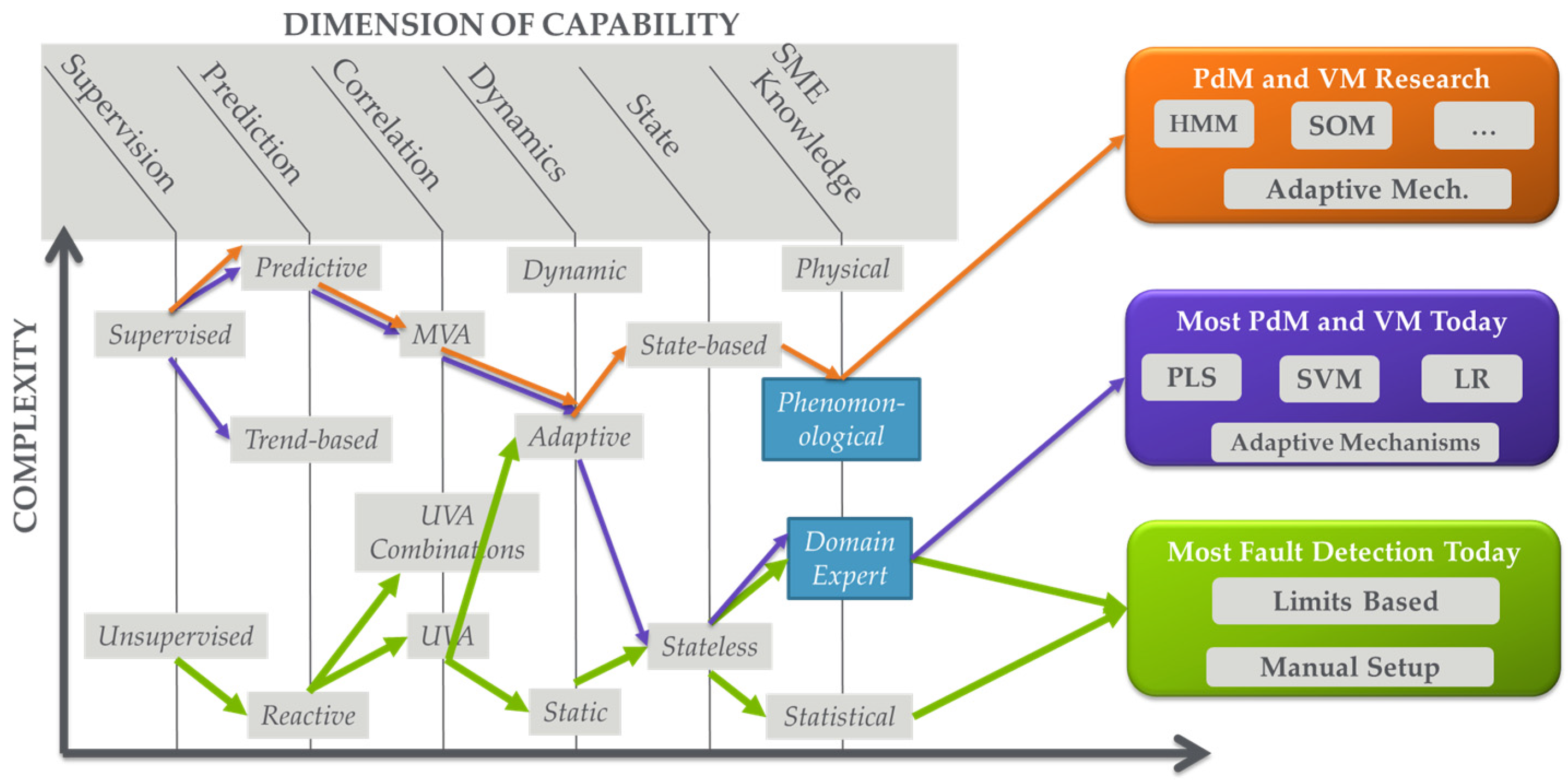
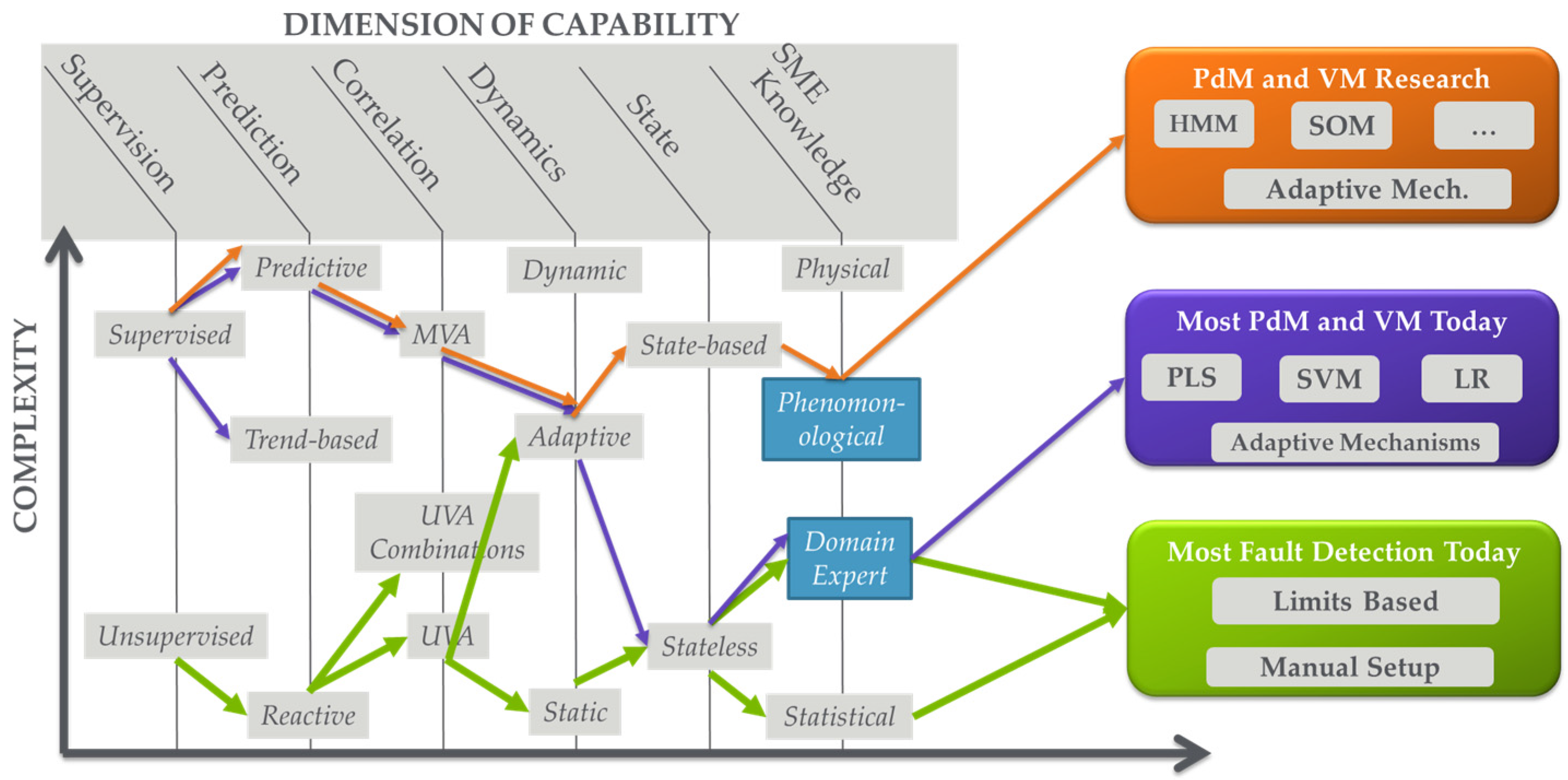
3.2. Dimensions of Analytics Capabilities
- Level of Supervision: This dimension can be thought of as the level of input-output data correlation that the analytic seeks to provide between datasets. In purely unsupervised scenarios, analytics generally operate on a single dataset with no direct objective of correlation to other data sets. A good example is traditional FD, which is actually anomaly detection. Equipment data is analyzed to determine if there is an anomaly in which parameters are anomalous (e.g., out of range). Some EHM applications are also unsupervised. At the other extreme, analytics can focus on determining correlations between “input” and “output” datasets [26,27]. As an example, PdM and VM determine relationships between equipment data (trace or processed, e.g., through FD) and maintenance and metrology measurement data, respectively. Between the two of these are a variety of semi-supervised scenarios in which supervised data may be used strictly for model training, or the input data set is associated with labels such as “good” or “bad” providing a level of supervision.
- Level of Prediction: This dimension identifies the ability of the analytic to forecast or predict outputs. At one end, analytics can be purely reactive, detecting an event after it has happened. Good examples are traditional fault detection and data mining, in which the analytic provides information based on the understanding that the event has already occurred. At the other end of the spectrum are purely predictive analytics such as PdM where an event is forecasted before it occurs. Note that predictions are usually accompanied by some indication of prediction horizon or time-to-failure and an indication of quality or range of prediction; this is explored further in Section 4.2. Between purely reactive and purely predictive are a number of somewhat predictive capabilities. A good example is trend-based analysis where a generally reactive monitoring capability is analyzed with respect to trends that are extrapolated to anticipate a future event.
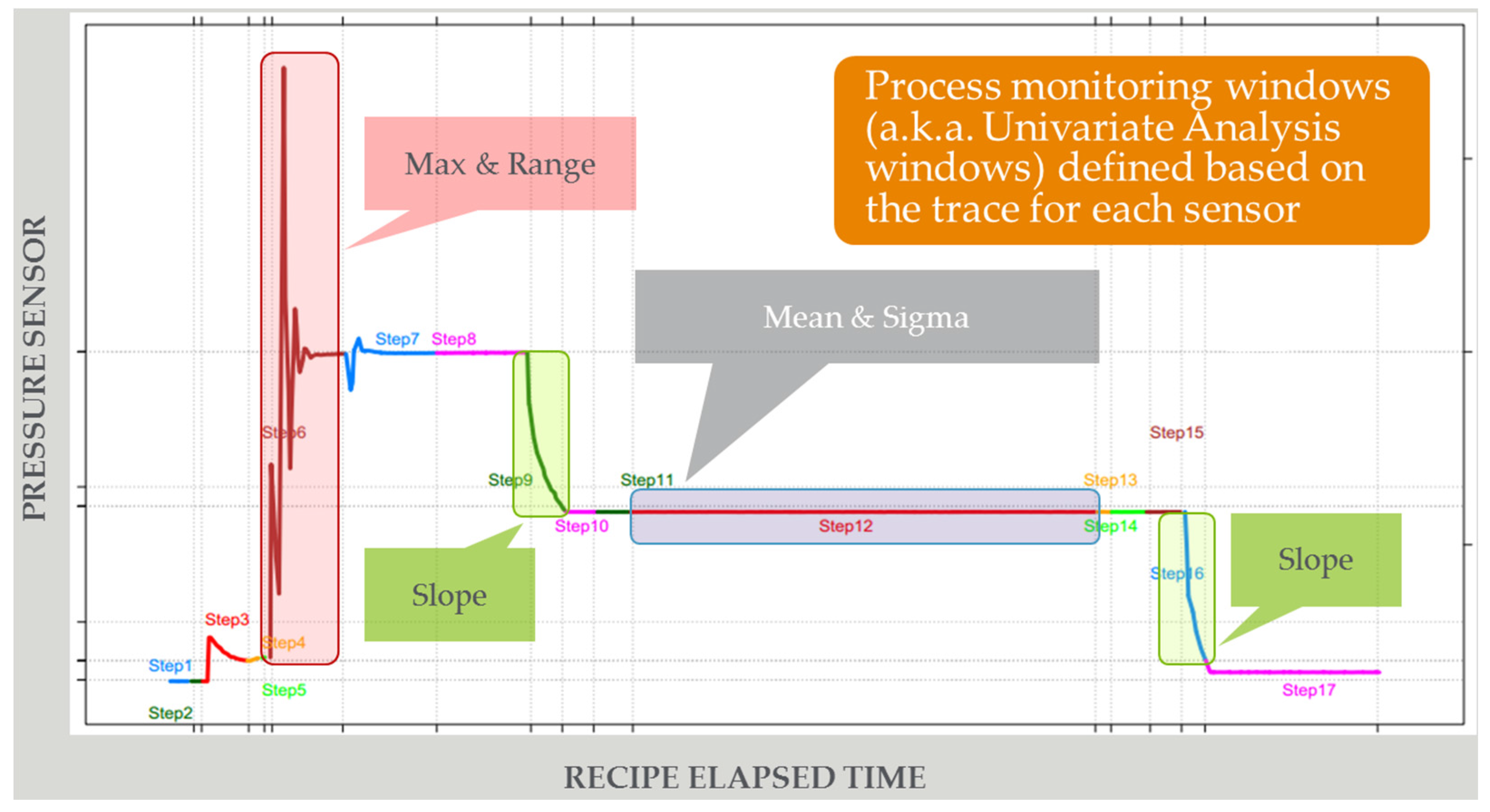
- Level of Correlation Among Parameters Analyzed: This dimension defines how the variables are analyzed with respect to each other in a dataset. At one end we have purely univariate (UVA) analysis in which each parameter is analyzed individually. A large number of FD solutions leverage UVA analysis. Note that this does not mean that parameters are not correlated; it just means that the analysis technique does not explore this correlation. At the other end of the spectrum are multivariate analysis techniques that fully explore parameter correlations. In between are a number of techniques to provide some level of correlation analysis. Good examples are UVA analysis techniques in which variables can be combined in equations or as Boolean variables; these techniques are often available in traditional FD solutions.
- Level of Incorporation of Dynamics: This dimension characterizes how completely the analytic can track or profile the changes in relationships between parameters over time, e.g., capturing and accommodating drift and shift in a process. At one end are purely static analytics that cannot incorporate dynamics or do not even include a concept of dynamics or time in analysis. At the other end are dynamics that fully address the evolution of relationships over time, e.g., with an evolving model. In between these extremes are a variety of techniques that track or incorporate dynamics to some level. Good examples are adaptive models such as those found in R2R control, in which the model form may not be adjusted over time, but the model (zeroth order term) offset is re-evaluated to track and capture dynamics [13].
- Level of Incorporation of State: This dimension identifies how well the analytic incorporates the logical progression of system state in the analysis. In other words, it identifies how well the analytic incorporates an understanding of how a system logically operates into the analysis. Note that this is differentiated from the previous dimension where dynamics may be tracked, but logical progression of system state may or may not be understood. At one extreme of this state dimension, the analytic has no concept of state. These analytics are often called “snapshot” because they provide an analysis at an instance of time. At the other end of the spectrum, state-based analytics incorporate state evolution into the analysis.
- Level of Incorporation of SME: This dimension identifies the level to which SME is incorporated into the analytic. At one end of the spectrum are purely statistical or data-driven analytics where no SME is involved. Some “one-size-fits-all” multivariate (MVA) FD or EHM techniques fall into this category where a dataset is analyzed statistically and an index is reported. At the other end of the spectrum are purely non-statistical physical techniques that rely on complete knowledge of the system with no data-driven component. Between these two extremes are a large number of analytics where SME is incorporated to some extent. The incorporation may be as simple as parameter down selection prior to data-driven analysis, or more complicated as in development of model forms that define the physics of an operation (i.e., phenomenological models) that are tuned using data-driven approaches. Note that, with this dimension, the level, type, method, and formalism by which SME is incorporated can all vary.
3.3. Typical APC Applications and Analytics Approaches in Today’s Semiconductor Manufacturing Facilities
3.4. Emerging APC Analytics Applications and Analytics Trends in Semiconductor Manufacturing Facilities
4. Case Studies of Big Data Analytics Approaches in Semiconductor Manufacturing
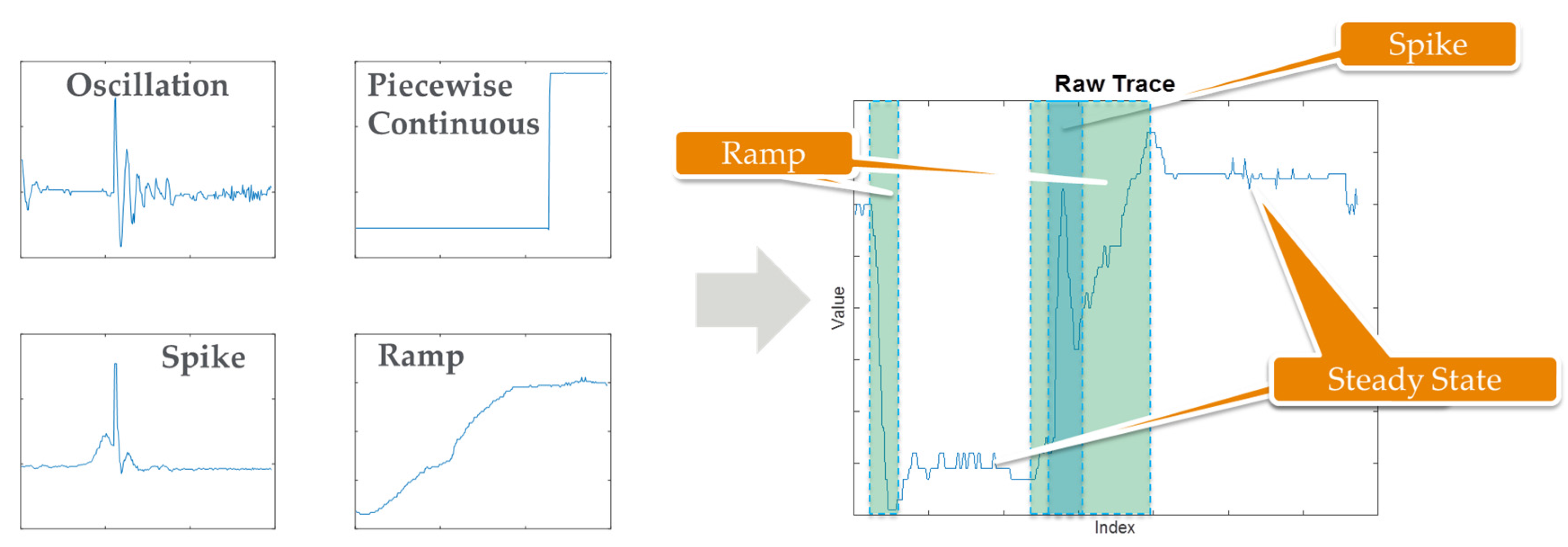
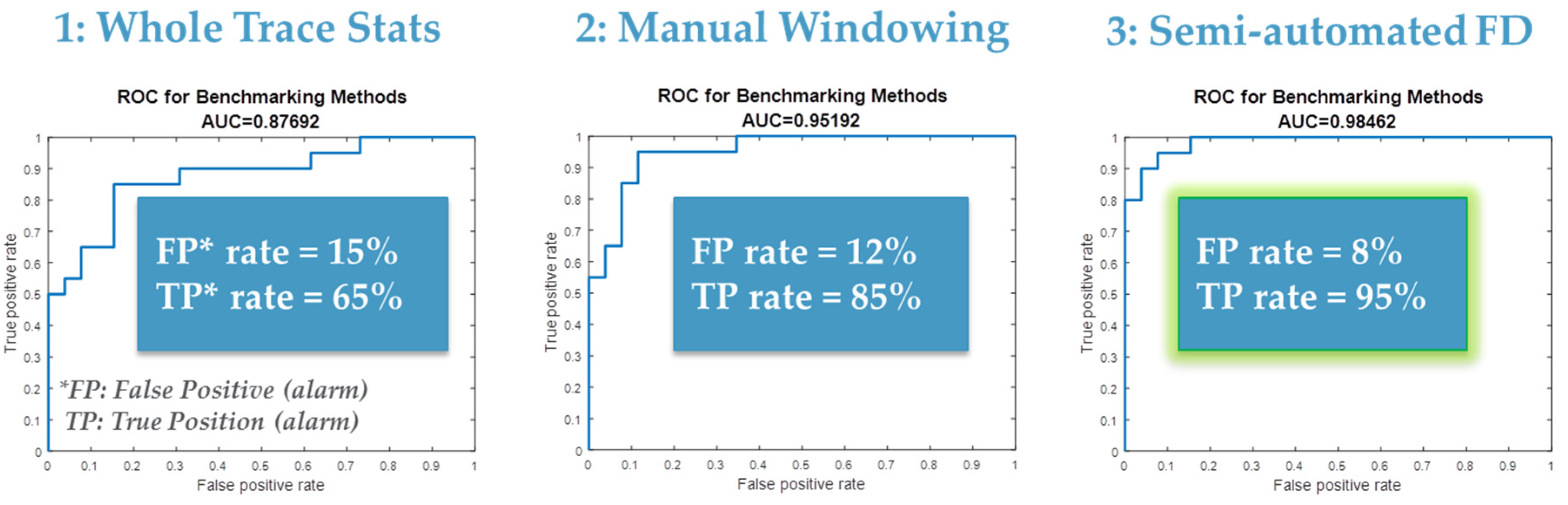
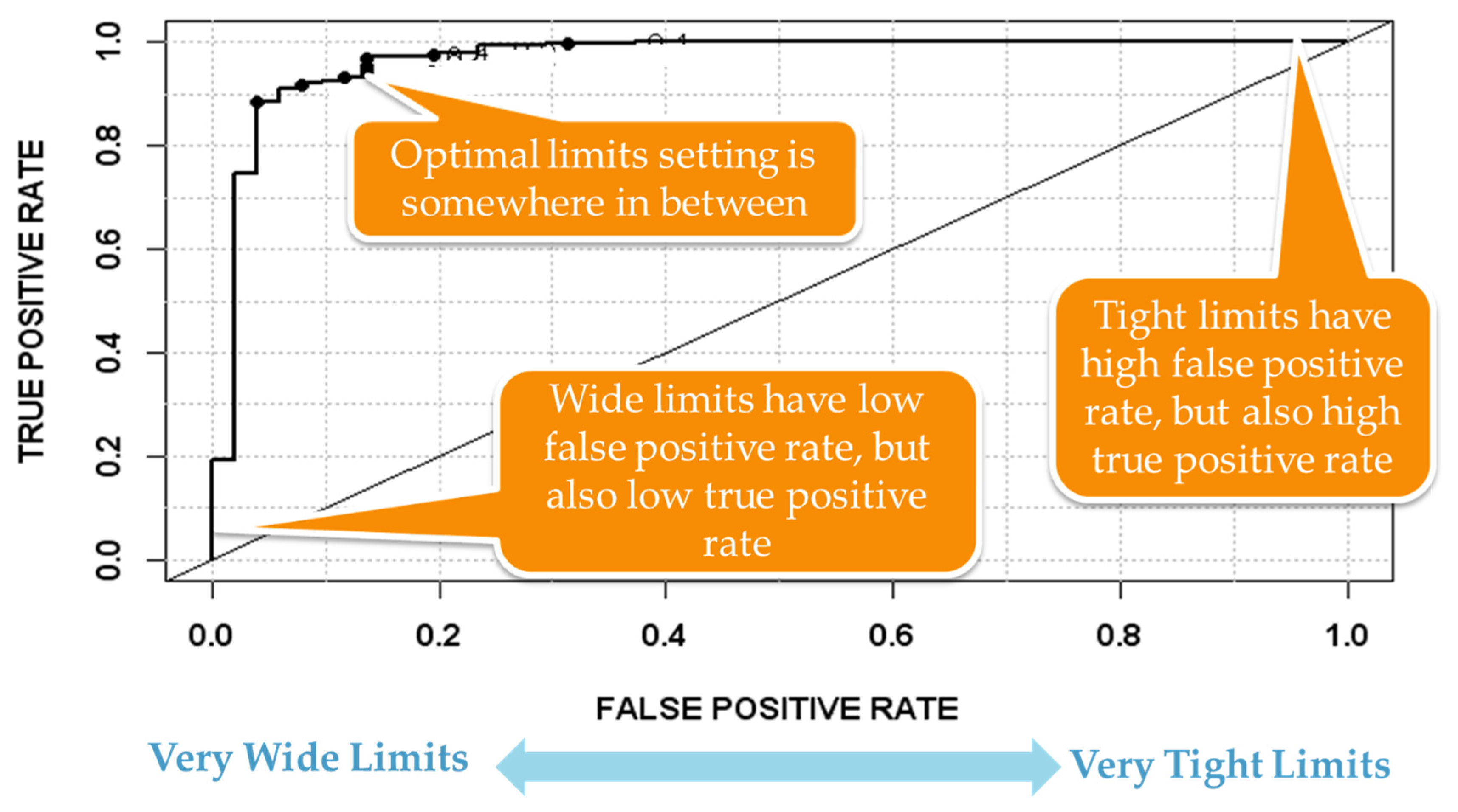
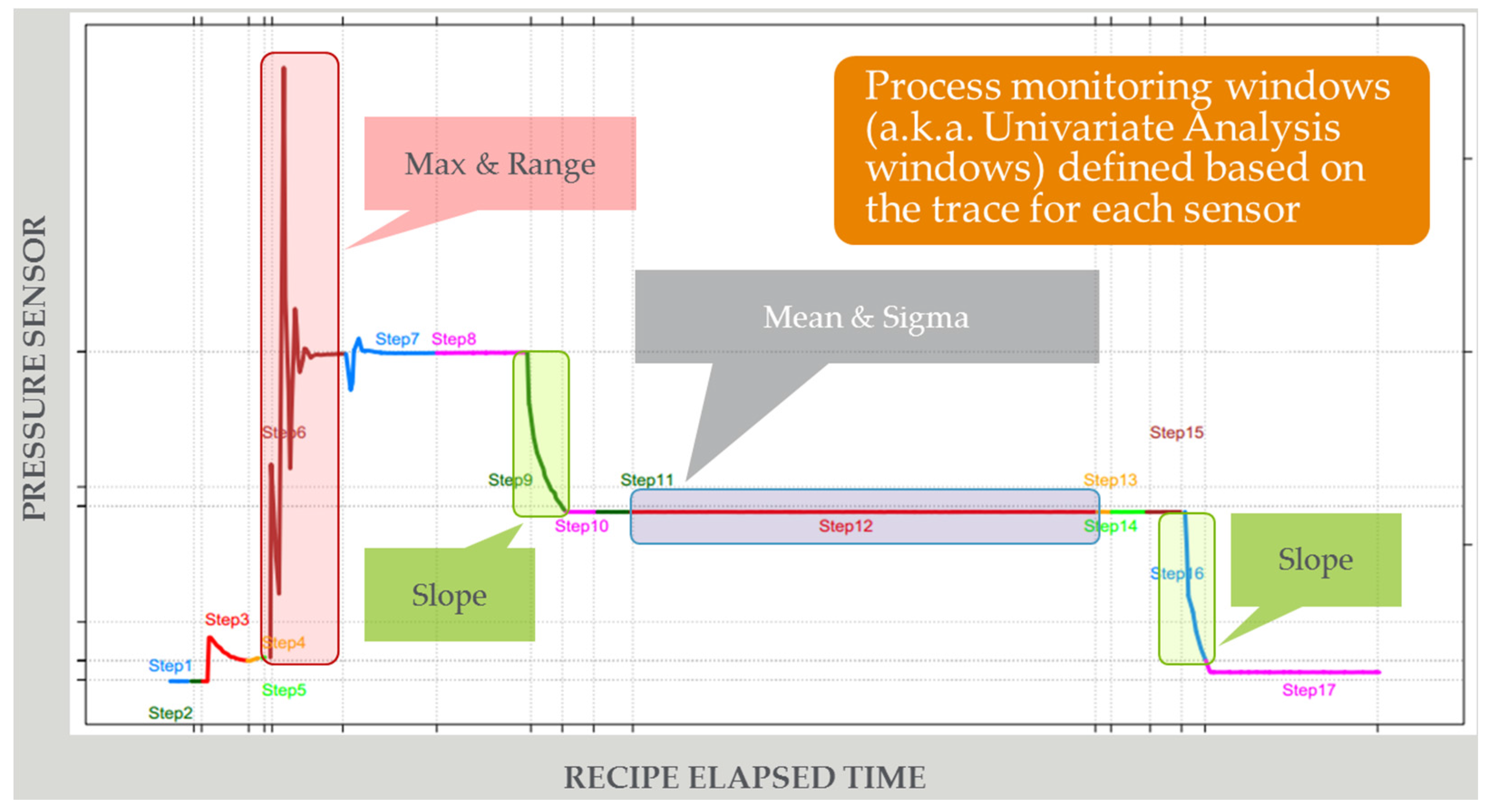
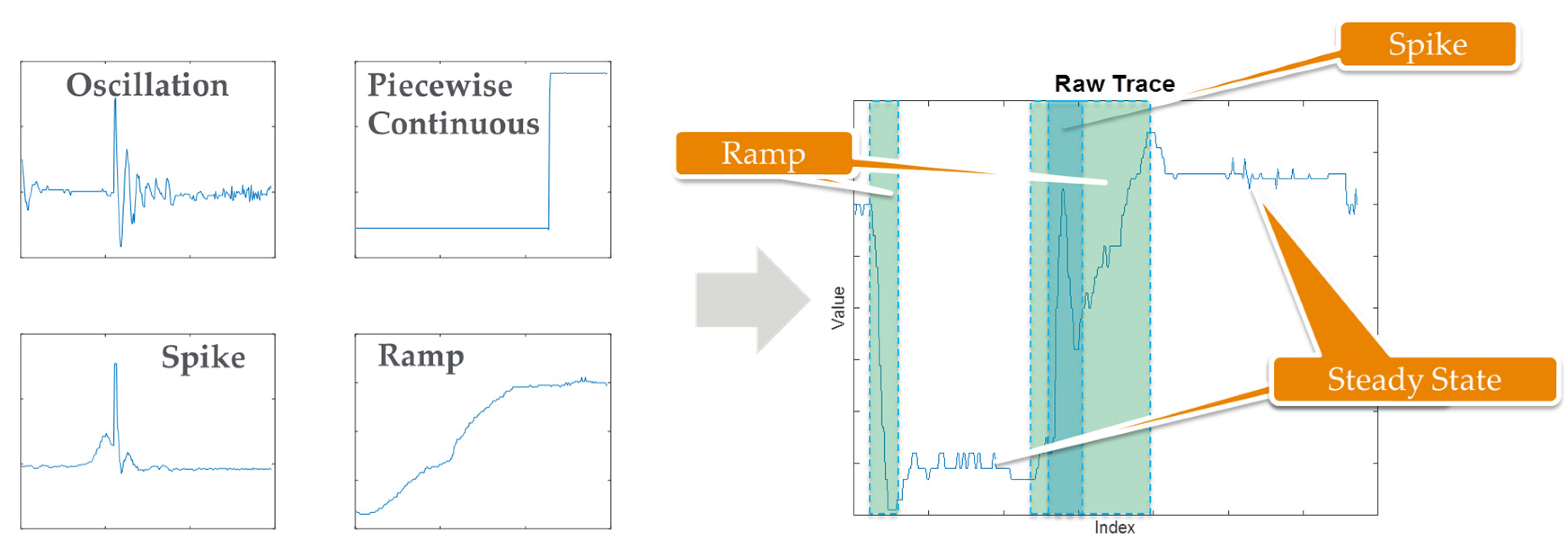
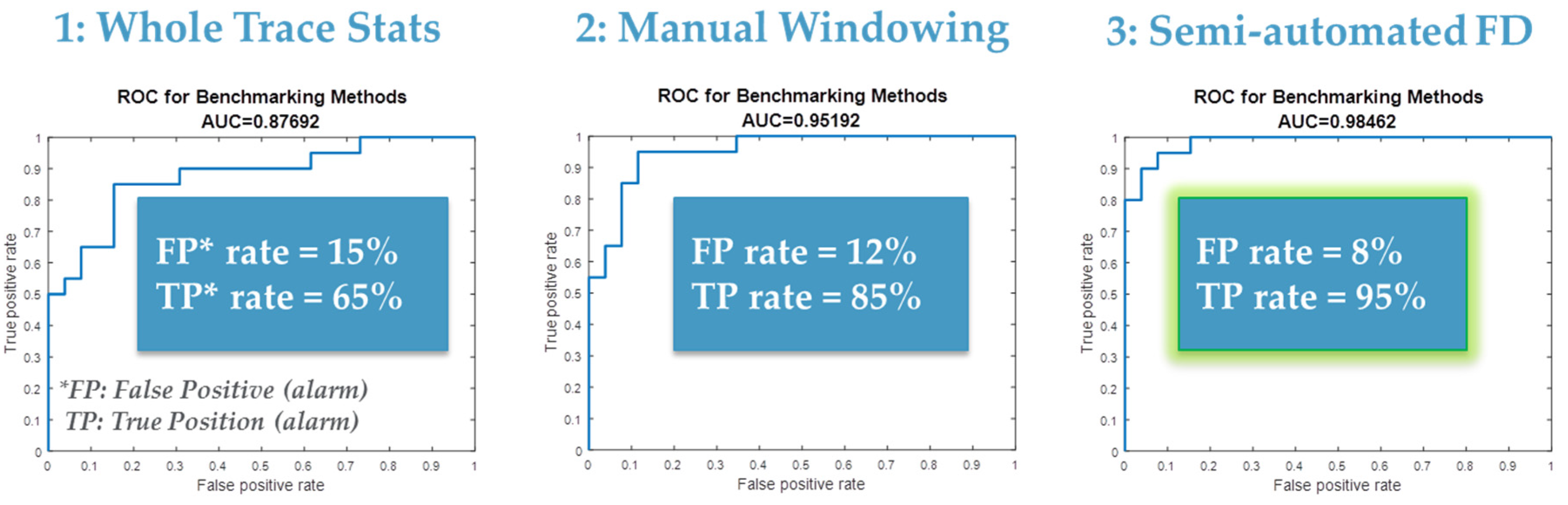
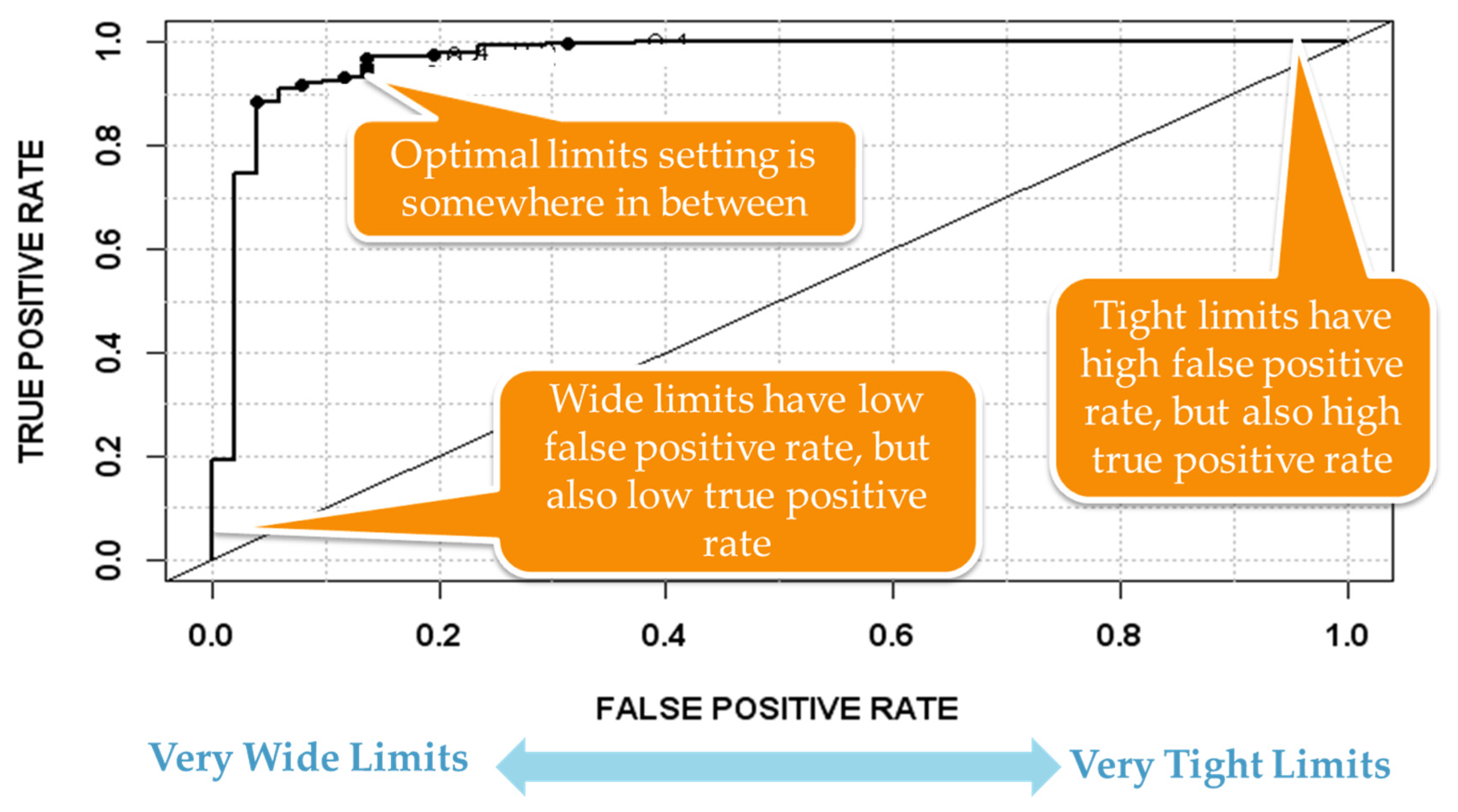
4.1. Next Generation Fault Detection and Classification (NG-FDC)
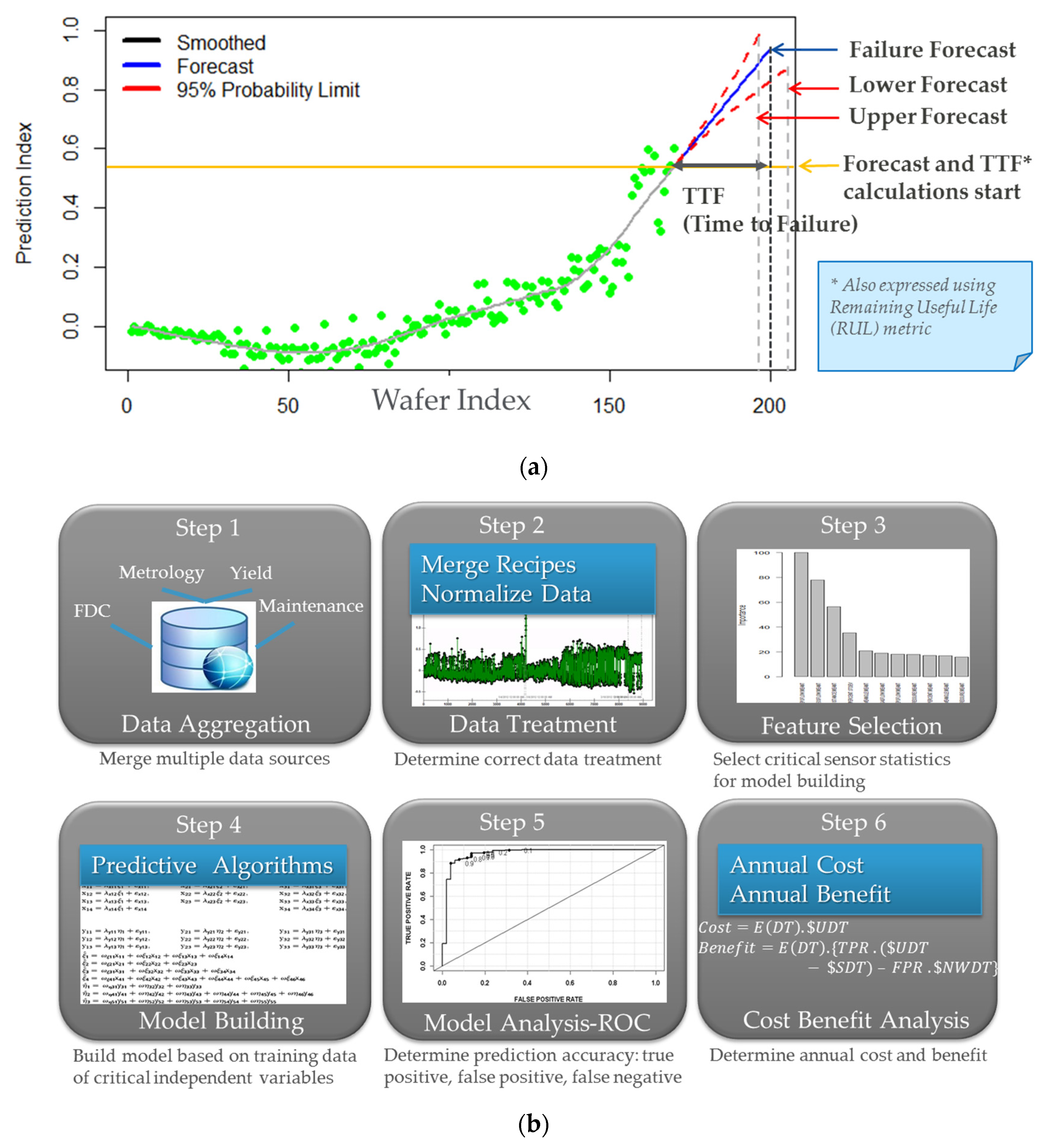
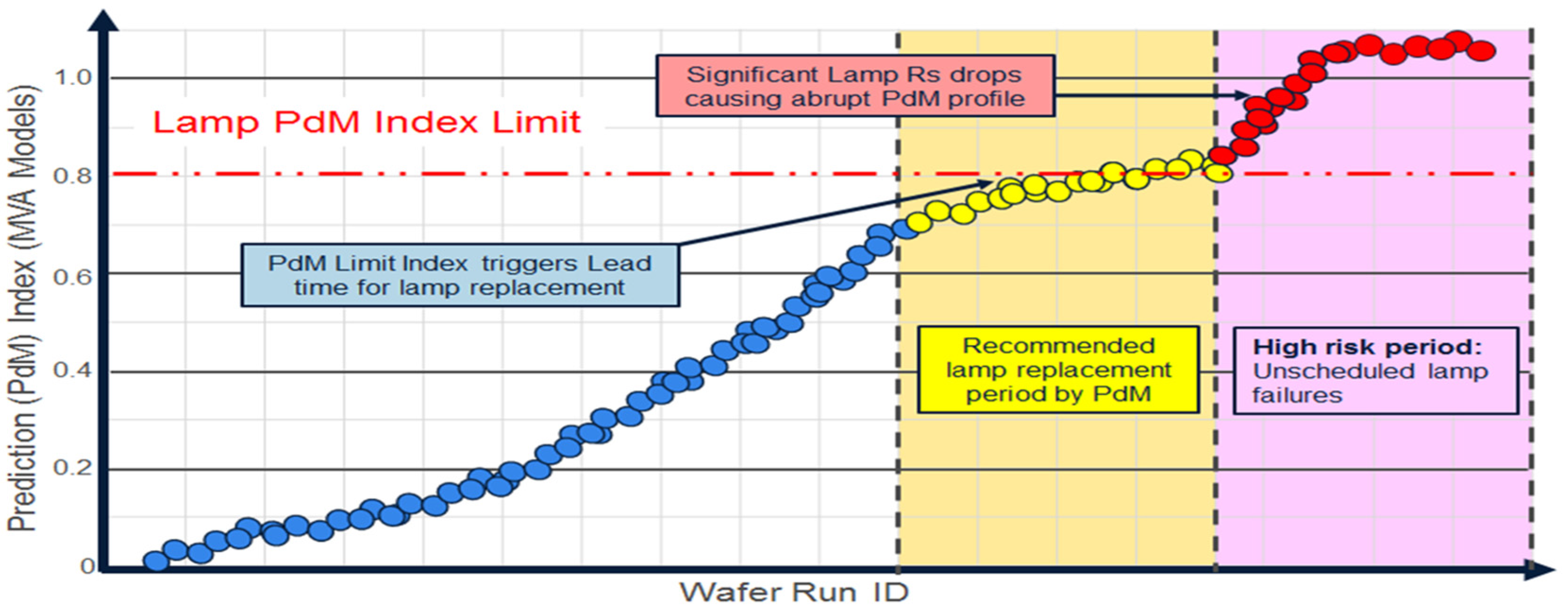
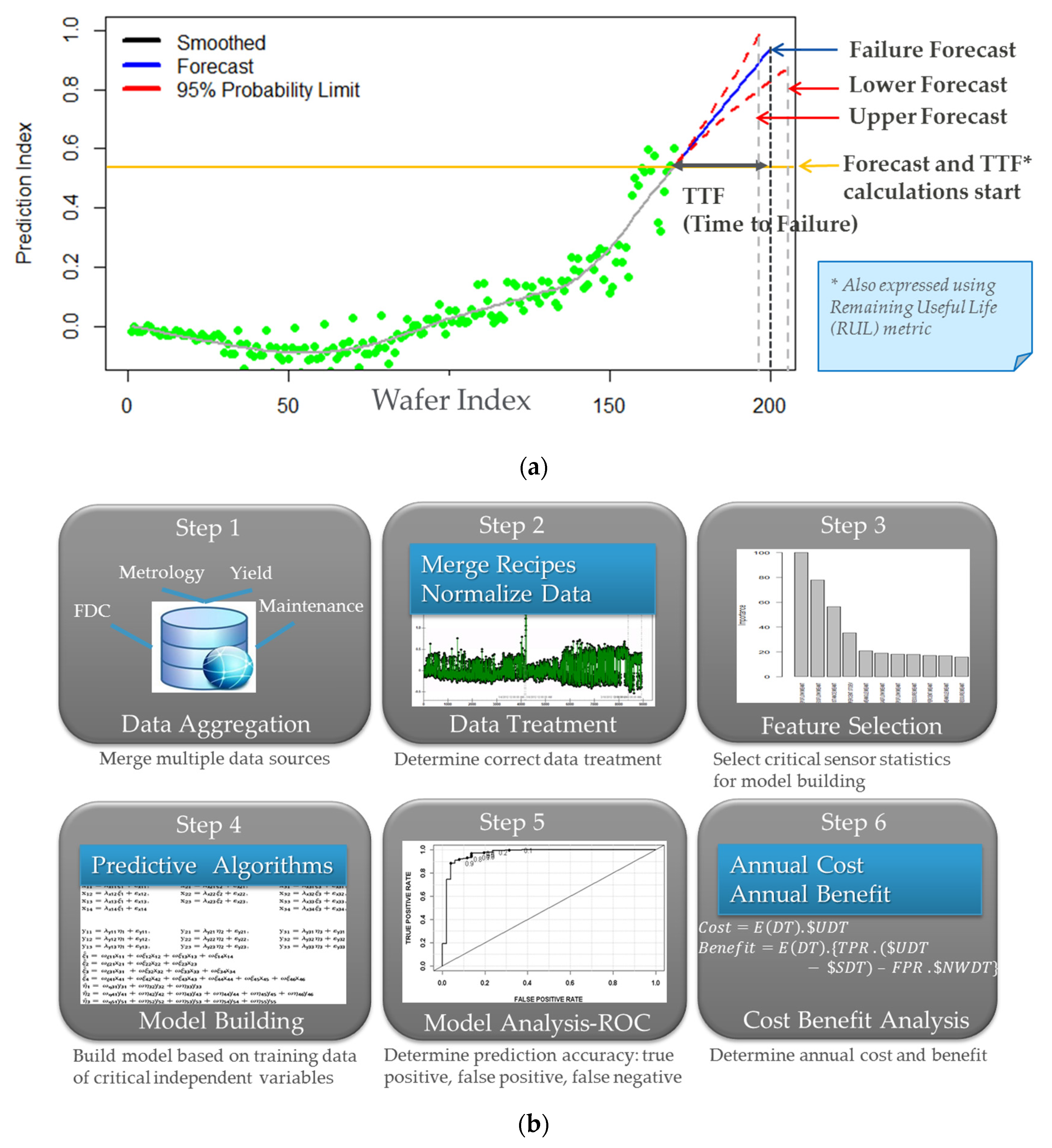
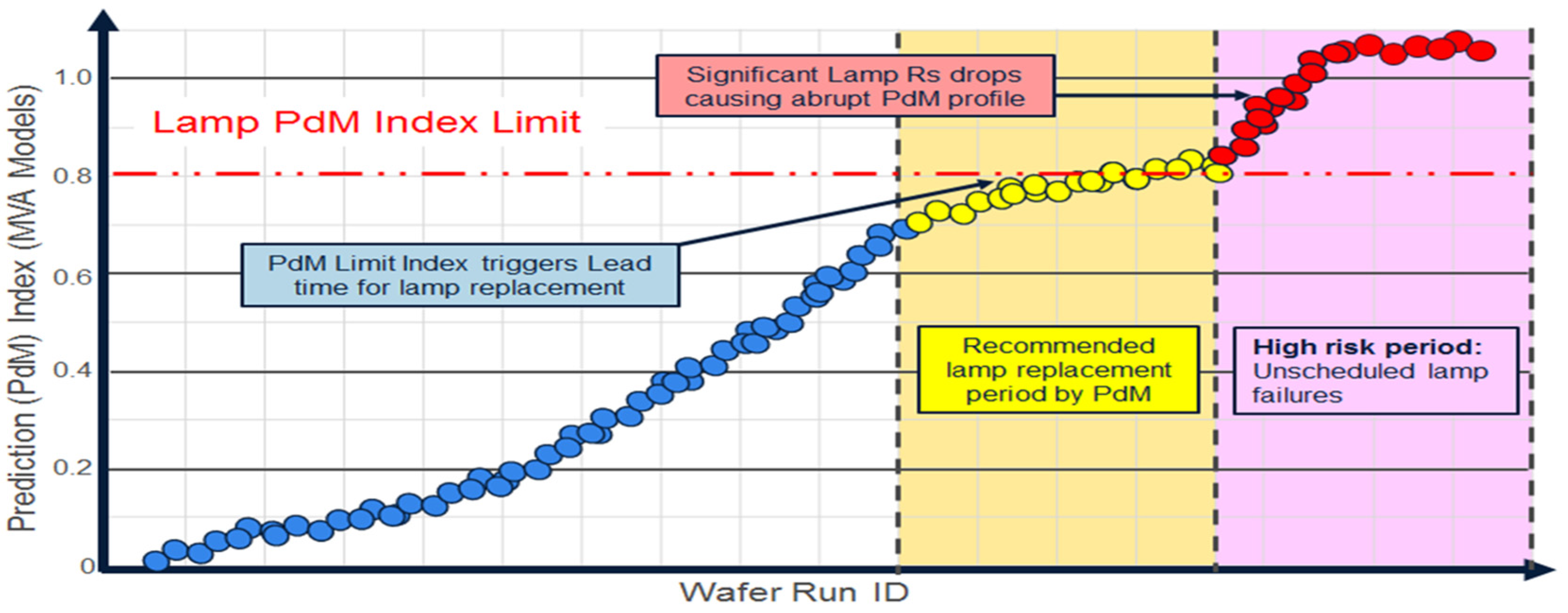
4.2. Predictive Maintenance (PdM)
5. Discussion: The Evolving Big Data Landscape and Analytics
5.1. Big Data Architectures
5.2. Emergence of Artificial Intelligence and Other Big Data-Friendly Analytics
5.3. Realizing the Complete Smart Manufacturing Vision
- Integration with the supply chain network: The smart factory will become an integral part of the supply chain with factory optimization part of overall supply chain optimization. The tighter connectivity will allow for leaner operation, higher flexibility of operation, improved response to demand, and better traceability for analytics such as warranty recall investigation. It will also represent an integration of the SM vision up and down the supply chain.
- Improved use of cyber-physical systems (CPS): CPS refers to the “tight conjoining of and coordination between computational and physical resources” [58]. While systems that generally integrate computational and physical resources have been in existence for some time, future systems will continue to improve in terms of “adaptability, autonomy, efficiency, functionality, reliability, safety, and usability.” Big data analytics will play an important role in the advancement of these CPSs.
- Incorporating the simulation space and the concepts of virtual factory and digital twin: the prediction vision for semiconductor manufacturing is identified as “a state of fab operations where (1) yield and throughput prediction is an integral part of factory operation optimization, and (2) real-time simulation of all fab operations occurs as an extension of existing system with dynamic updating of simulation models.” [19,20]. The latter concept, which is a component of the CPS vision, is often referred to as “digital twin.” Many of the predictive applications being developed in the industry today will likely continue to evolve to more directly support this vision.
- Leveraging big data architectures infrastructures: These infrastructures include the data management, but also the analytics and applications that leverage the infrastructure to improve SM operation.
- Leveraging advanced analytics: As noted throughput this paper, the benefits of the big data evolution will be provided primarily by applying analytics that take advantage of big data to improve existing capabilities such as FDC or realize new capabilities such as prediction.
- Reliance on a knowledge network: The overall consensus of the SM vision in semiconductor manufacturing is that SME knowledge will continue to be leveraged as an integral part of analytical solutions, with cooperation required between users, solution suppliers, and equipment and components manufacturers to support a service-based approach for delivering and maintain solutions [19,20]. Issues such as data sharing and partitioning, intellectual property security, and managing solutions in the cloud have all come to the forefront as part of the move to enhance support for the cooperative knowledge network [19,20,25,46].
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AAKR | Auto-Associative Kernel Regression |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| APC | Advanced Process Control |
| BD | Big Data |
| CPS | Cyber-Physical System |
| EHM | Equipment Health Monitoring |
| ERP | Enterprise Resource Planning |
| EWMA | Exponentially Weighted Moving Average |
| FC | Fault Classification |
| FD | Fault Detection |
| FDC | Fault Detection and Classification |
| GTM | Generative Topographic Mapping |
| HMM | Hidden Markov Model |
| IoT | Internet of Things |
| k-NN | k-Nearest Neighbors |
| LR | Linear Regression |
| MES | Manufacturing Execution System |
| MVA | Multivariate Analysis |
| NG-FDC | Next Generation Fault Detection and Classification |
| PCA | Principal Component Analysis |
| PdM | Predictive Maintenance |
| PLS | Partial Least Squares or Project on Latent Structures |
| R2R | Run-to-Run (control) |
| ROC | Receiver Operating Characteristic |
| RUL | Remaining Useful Life |
| SM | Smart Manufacturing |
| SME | Subject Matter Expertise |
| SOM | Self-Organizing Map |
| SPC | Statistical Process Control |
| SVM | Support Vector Machines |
| TTF | Time To Failure |
| UVA | Univariate Analysis |
| VM | Virtual Metrology |
References
- Wikipedia: Smart Manufacturing. Available online: https://en.wikipedia.org/wiki/Smart_manufacturing (accessed on 1 June 2017).
- Davis, J.; Edgar, T.; Porter, J.; Bernaden, J.; Sarli, M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance. Comput. Chem. Eng. 2012, 47, 145–156. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.A.; Yang, S. Service Innovation and smart analytics for industry 4.0 and big data environment. Proced. Cirp 2014, 16, 3–8. [Google Scholar] [CrossRef]
- Thoben, K.-D.; Wiesner, S.; Wuest, T. “Industrie 4.0” and smart manufacturing—A review of research issues and application examples. Int. J. Autom. Technol. 2017, 11, 4–16. [Google Scholar] [CrossRef]
- Kagermann, H.; Wahlster, W. Industrie 4.0: Smart Manufacturing for the Future; Germany Trade and Invest: Berlin, Germany, 2016. [Google Scholar]
- Moyne, J.; Iskandar, J.; Armacost, M. Big Data Analytics Applied to Semiconductor Manufacturing. In Proceedings of the AIChE 3rd Annual Big Data Analytics Conference, San Antonio, TX, USA, 28 March 2017. [Google Scholar]
- Romero-Torres, S.; Moyne, J.; Kidambi, M. Towards Pharma 4.0; Leveraging Lessons and Innovation from Silicon Valley. American Pharmaceutical Review. 5 February 2017. Available online: http://www.americanpharmaceuticalreview.com/Featured-Articles/333897-Towards-Pharma-4-0-Leveraging-Lessons-and-Innovation-from-Silicon-Valley/ (accessed on 1 June 2017).
- Evans, P. Initiatives for Applying Smart Manufacturing to the Continuous Processing Industries. Available online: https://www.aiche.org/sites/default/files/community/291721/aiche-community-site-page/315581/initiativesforapplyingsmartmanufacturingtothecontinuous-rev1.pdf (accessed on 1 June 2017).
- Handy, J. What’s It Like in a Semiconductor Fab. Forbes 2011. Available online: https://www.forbes.com/sites/jimhandy/2011/12/19/whats-it-like-in-a-semiconductor-fab/#2ecf8c9745ef (accessed on 1 June 2017).
- May, G.S.; Spanos, C.J. Fundamentals of Semiconductor Manufacturing and Process Control; IEEE, Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Sarfaty, M.; Shanmugasundram, A.; Schwarm, A. Advance Process Control solutions for Semiconductor Manufacturing. In Proceedings of the IEEE Advanced Semiconductor Manufacturing Conference, Boston, MA, USA, 30 April 2002. [Google Scholar]
- Moyne, J. Introduction to and Practical Application of APC: A Tutorial. In Proceedings of the Advanced Process Control Conference XXVII, Phoenix, AZ, USA, 17–20 October 2016. [Google Scholar]
- Moyne, J.; Del Castillo, E.; Hurwitz, A. Run-to-Run Control in Semiconductor Manufacturing; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Dimond, K.; Nowalk, T.; Yelverton, M. Implementing and Assessing the Value of Factory-Wide Fault Detection Deployment at a High Volume Foundry. In Proceedings of the Advanced Process Control Symposium XV, XXX, Colorado Springs, CO, USA, 9–12 September 2003. [Google Scholar]
- Moyne, J. A Blueprint for Enterprise-Wide Deployment of APC. In Proceedings of the Advanced Process Control Symposium XXI, XXX, Ann Arbor, MI, USA, 27–30 September 2009. [Google Scholar]
- Hu, C. 3D FinFET and other sub-22nm transistors. In Proceedings of the 19th IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA), Marina Bay Sands, Singapore, 2–6 July 2012. [Google Scholar]
- Hasserjian, K. Emerging Trends in IC Manufacturing Analytics and Decision Making. Keynote. In Proceedings of the Advanced Process Control Conference XXVII, Phoenix, AZ, USA, 17–20 October 2016. [Google Scholar]
- International Roadmap for Devices and Systems (IRDS): Beyond CMOS (Emerging Research Device) White Paper, 2016 Edition. Available online: http://irds.ieee.org/images/files/pdf/2016_BC.pdf (accessed on 1 June 2017).
- International Technology Roadmap for Semiconductors (ITRS): Factory Integration Chapter, 2016 Edition. Available online: www.itrs2.net (accessed on 1 June 2017).
- International Roadmap for Devices and Systems (IRDS): Factory Integration White Paper, 2016 Edition. Available online: http://irds.ieee.org/images/files/pdf/2016_FI.pdf (accessed on 1 June 2017).
- Moyne, J. International Technology Roadmap for Semiconductors (ITRS) Factory Integration, 2015: Summary of Updates and Deep Dive Into Big Data Enhancements. In Proceedings of the APC Conference XXVII, Austin, TX, USA, 12–14 October 2015. [Google Scholar]
- Rebooting the IT Revolution: A Call to Action; Semiconductor Industry Association and Semiconductor Research Corporation: Washington, DC, USA, 4 January 2016. Available online: https://www.src.org/newsroom/press-release/2016/758/ (accessed on 1 June 2017).
- Big Data Standards. Available online: http://bigdata.ieee.org/standards (accessed on 1 June 2017).
- SEMI E133-1014: Specification for Automated Process Control Systems Interface. Semiconductor Equipment and Materials International, 2014. Available online: http://www.semi.org/en/Standards/StandardsPublications (accessed on 1 June 2017).
- Lopez, F.; Saez, M.; Shao, Y.; Balta, E.C.; Moyne, J.; Mao, Z.M.; Barton, K.; Tilbury, D. Categorization of anomalies in smart manufacturing systems to support the selection of detection mechanisms. IEEE Robot. Autom. Lett. 2017, 2, 1885–1892. [Google Scholar] [CrossRef]
- Wuest, T. Identifying Product and Process state Drivers in Manufacturing Systems Using Supervised Machine Learning; Springer: New York, NY, USA, 2015. [Google Scholar]
- Wuest, T.; Irgens, C.; Thoben, K.-D. An approach to quality monitoring in manufacturing using supervised machine learning on product state data. J. Intell. Manuf. 2014, 25, 1167–1180. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Pearson Education International: London, UK, 2002. [Google Scholar]
- Moyne, J.; Schulze, B.; Iskandar, J.; Armacost, M. Next Generation Advanced Process Control: Leveraging Big Data and Prediction. In Proceedings of the 27th Annual Advanced Semiconductor Manufacturing Conference (ASMC 2016), Saratoga Springs, NY, USA, 16–19 May 2016. [Google Scholar]
- Iskandar, J.; Moyne, J.; Subrahmanyam, K.; Hawkins, P.; Armacost, M. Predictive Maintenance in Semiconductor Manufacturing: Moving to Fab-Wide Solutions. In Proceedings of the 26th Annual Advanced Semiconductor Manufacturing Conference (ASMC 2015), Saratoga Springs, NY, USA, 3–6 May 2015. [Google Scholar]
- Ma, J.; Perkins, S. Time-Series Novelty Detection Using One-Class Support Vector Machines. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003. [Google Scholar]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier Detection Using k-Nearest Neighbour Graph. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 430–433. [Google Scholar]
- Markou, M.; Singh, S. Novelty detection: A review—Part 2: Neural network based approaches. Signal Process. 2003, 83, 2499–2521. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Wang, J.; He, Q.P.; Edgar, T.F. State estimation in high-mix semiconductor manufacturing. J. Process Control 2009, 19, 443–456. [Google Scholar] [CrossRef]
- Khan, A.; Moyne, J.; Tilbury, D. Fab-wide control utilizing virtual metrology. IEEE Trans. Semicond. Manuf. Spec. Issue Adv. Process Control 2007, 20, 364–375. [Google Scholar] [CrossRef]
- Cheng, F.-T.; Kao, C.-A.; Chen, C.-F.; Tsai, W.-H. Tutorial on applying the VM technology for TFT-LCD manufacturing. IEEE Trans. Semicond. Manuf. 2015, 28, 55–69. [Google Scholar]
- Kidambi, M.; Krishnaswamy, S.; Marteney, S.; Moyne, J.; Norman, D.; Webb, J. Improving Lithography Throughput and Minimizing Waste Using Predictive Multi-area Scheduling. In Proceedings of the SPIE Metrology Inspection, and Process Control for Microlithography XXV Conference, San Jose, CA, USA, 29 March 2012. [Google Scholar]
- Moyne, J.; Schulze, B. Yield management enhanced advanced process control system (YMeAPC): Part I, description and case study of feedback for optimized multi-process control. IEEE Trans. Semicond. Manuf. Spec. Issue Adv. Process Control 2010, 23, 221–235. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines, advances in neural information processing systems 9. 1997, 9, 155–161. [Google Scholar]
- Kohonen, T. The self-organizing map. Neurocomputing 1998, 21, 1–6. [Google Scholar] [CrossRef]
- Bishop, C.; Svensén, M.; Williams, C.K.I. GTM: The generative topographic mapping. Neural Comput. 1998, 10, 215–234. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B. An Introduction to hidden markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Integrated Measurement Association (IMA) APC Council Meeting Minutes: October 2015 Meeting. Available online: http://info.cimetrix.com/blog/default-blog/blog/2015_advanced_process_control_conference (accessed on 1 June 2017).
- Chao, J.; Di, Y.; Moyne, J.; Iskandar, J.; Hao, H.; Schulze, B.; Armacost, M.; Lee, J. Extensible framework for pattern recognition-augmented feature extraction (PRAFE) in robust prognostics and health monitoring. In Preparation for Submission to IEEE Trans. Semicond. Manuf.
- Ho, T.; Wang, W.; Villareal, G.; Hall, C.; McCormick, E. Dynamic Full Trace FDC. In Proceedings of the Advanced Process Control Conference XXVII, Phoenix, AZ, USA, 17–20 October 2016. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (roc) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Moyne, J. Method and Apparatus for Optimizing Profit in Predictive Systems. U.S. Patent 20,150,105,895, 5 February 2015. [Google Scholar]
- Iskandar, J.; Moyne, J. Maintenance of Virtual Metrology Models. In Proceedings of the 27th Annual Advanced Semiconductor Manufacturing Conference (ASMC 2016), Saratoga Springs, NY, USA, 16–19 May 2016. [Google Scholar]
- Wikipedia: Apache_Hadoop. Available online: http://en.wikipedia.org/wiki/Apache_Hadoop (accessed on 1 June 2017).
- Moyne, J.; Samantaray, J.; Armacost, M. Big data capabilities applied to semiconductor manufacturing advanced process control. IEEE Trans. Semicond. Manuf. 2016, 29, 283–291. [Google Scholar] [CrossRef]
- Wikipedia: Artificial Intelligence. Available online: https://en.wikipedia.org/wiki/Artificial_intelligence (accessed on 1 June 2017).
- Najafabadi, M.N.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Lammers, D. Big data and neural networks: New drivers for the semiconductor industry. Nanochip Fab Solut. 2017, 12. submitted for publication. [Google Scholar]
- Vogel-Walcutt, J.J.; Gebrim, J.B.; Bowers, C.; Carper, T.M.; Nicholson, D. Cognitive load theory vs. constructivist approaches: Which best leads to efficient, deep learning? J. Comput. Assist. Learn. 2011, 27, 133–145. [Google Scholar] [CrossRef]
- Cyber-Physical Systems (CPS) Program Solicitation NSF 10-515. Available online: https://www.nsf.gov/pubs/2010/nsf10515/nsf10515.htm (accessed on 1 June 2017).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Definition |
|---|---|
| Advanced Process Control (APC) | The manufacturing discipline for applying control strategies and/or employing analysis and computation mechanisms to recommend optimized machine settings and detect faults and determine their cause. |
| APC Base Technologies as Defined in [24] | |
| Fault Detection (FD) | The technique of monitoring and analyzing variations in tool and/or process data to detect anomalies. FD includes both univariate (UVA) and multivariate (MVA) statistical analysis techniques. |
| Fault Classification (FC) | The technique of determining the cause of a fault once it has been detected. |
| Fault Detection and Classification (FDC) | A combination of FD and FC. |
| Fault Prediction (or prognosis) (FP) | The technique of monitoring and analyzing variations in process data to predict anomalies. |
| Run-to-Run (R2R) Control | The technique of modifying recipe parameters or the selection of control parameters between runs to improve processing performance. A “run” can be a batch, lot, or an individual wafer. |
| Statistical Process Control (SPC) | The technique of using statistical methods to analyze process or product metrics to take appropriate actions to achieve and maintain a state of statistical control and continuously improve the process capability. |
| APC Extended Technologies as Defined in [19,20] | |
| Equipment Health Monitoring (EHM) | The technology of monitoring tool parameters to assess the tool health as a function of deviation from normal behavior. EHM is not necessarily predictive in nature, but is often a component of predictive systems. |
| Predictive Maintenance (PdM) | The technology of utilizing process and equipment state information to predict when a tool or a particular component in a tool might need maintenance, and then utilizing this prediction as information to improve maintenance procedures. This could mean predicting and avoiding unplanned downtimes and/or relaxing un-planned downtime schedules by replacing schedules with predictions. PdM solutions as defined herein address the entire maintenance cycle, from predicting maintenance through addressing recovery from maintenance events towards returning to production. |
| Predictive Scheduling | The technology of utilizing current and projected future information on tool and factory state, capabilities, WIP, schedule, dispatch and orders to predict and improve scheduling of a system (tool, group of tools, fab, etc.). |
| Virtual Metrology (VM) | The technology of prediction of post process metrology variables (either measurable or not measurable) using process and wafer state information that could include upstream metrology and/or sensor data. Terms such as virtual sensing and sensor fusion have also been used to represent this capability. |
| Yield Prediction | The technology of monitoring information across the fab (e.g., tool and metrology) to predict process or end of line yield. |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moyne, J.; Iskandar, J. Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing. Processes 2017, 5, 39. https://doi.org/10.3390/pr5030039
Moyne J, Iskandar J. Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing. Processes. 2017; 5(3):39. https://doi.org/10.3390/pr5030039
Chicago/Turabian StyleMoyne, James, and Jimmy Iskandar. 2017. "Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing" Processes 5, no. 3: 39. https://doi.org/10.3390/pr5030039
APA StyleMoyne, J., & Iskandar, J. (2017). Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing. Processes, 5(3), 39. https://doi.org/10.3390/pr5030039