

Application of Mixed Precision Training in Human Pose Estimation Model Training


Abstract
1. Introduction
2. Background Knowledge
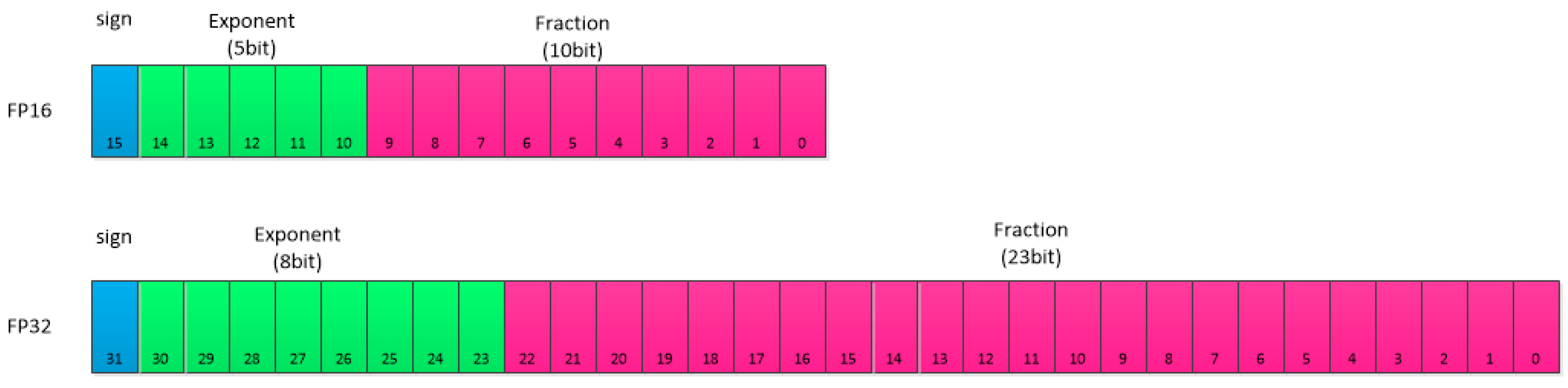
2.1. Floating-Point Data Type Parsing
2.2. Effective Range of FP16 and FP32
3. Hybrid Accuracy Training Working Mechanisms
3.1. Forward Propagation
3.2. Back Propagation
3.3. Loss Scaling
3.4. Parameter Update
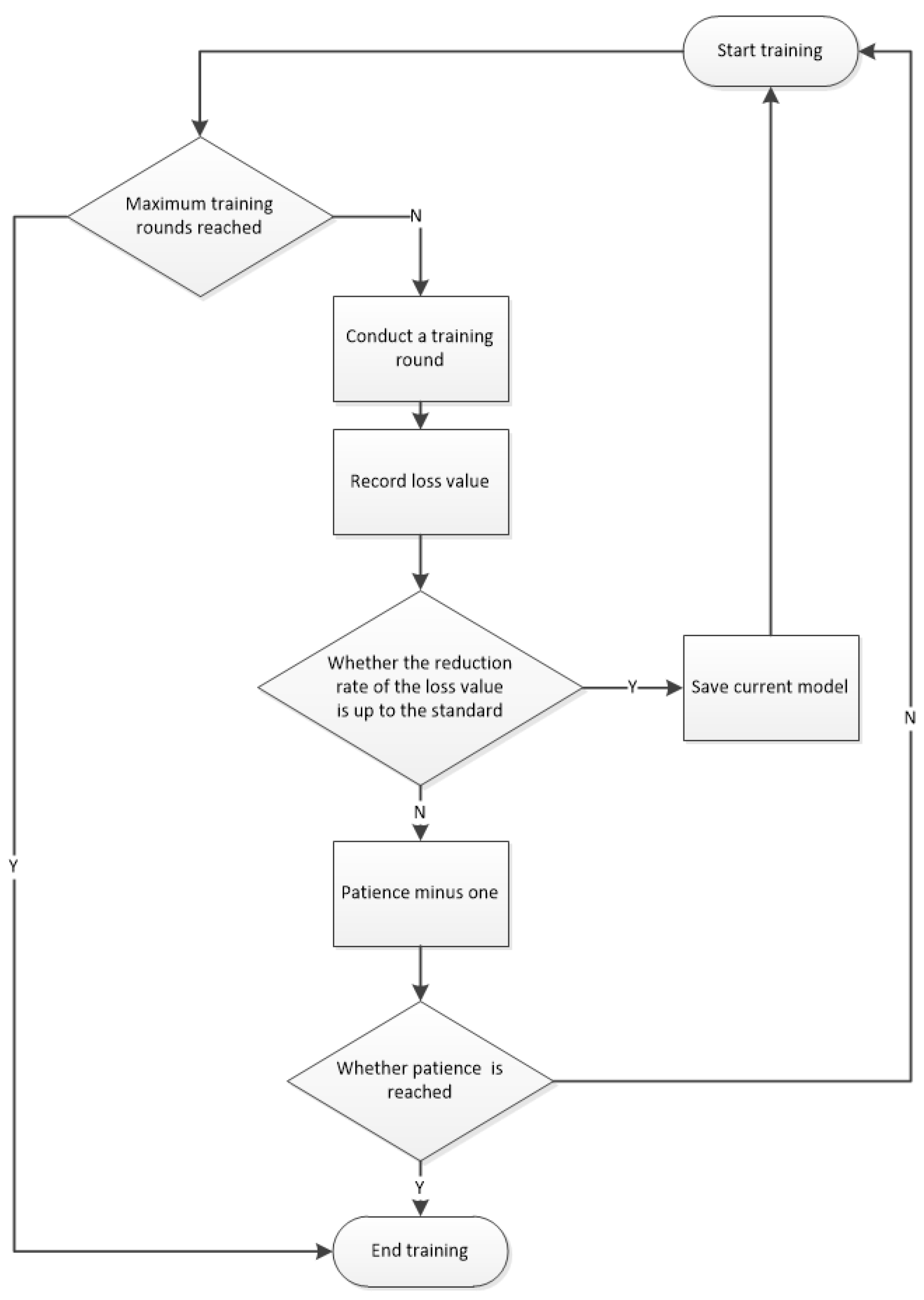
4. Early Stopping
4.1. Fundamentals
4.2. Implementation
5. Experimentation and Analysis
5.1. Models and Datasets
5.2. Co-Optimization of Hybrid Accuracy and Hardware Acceleration
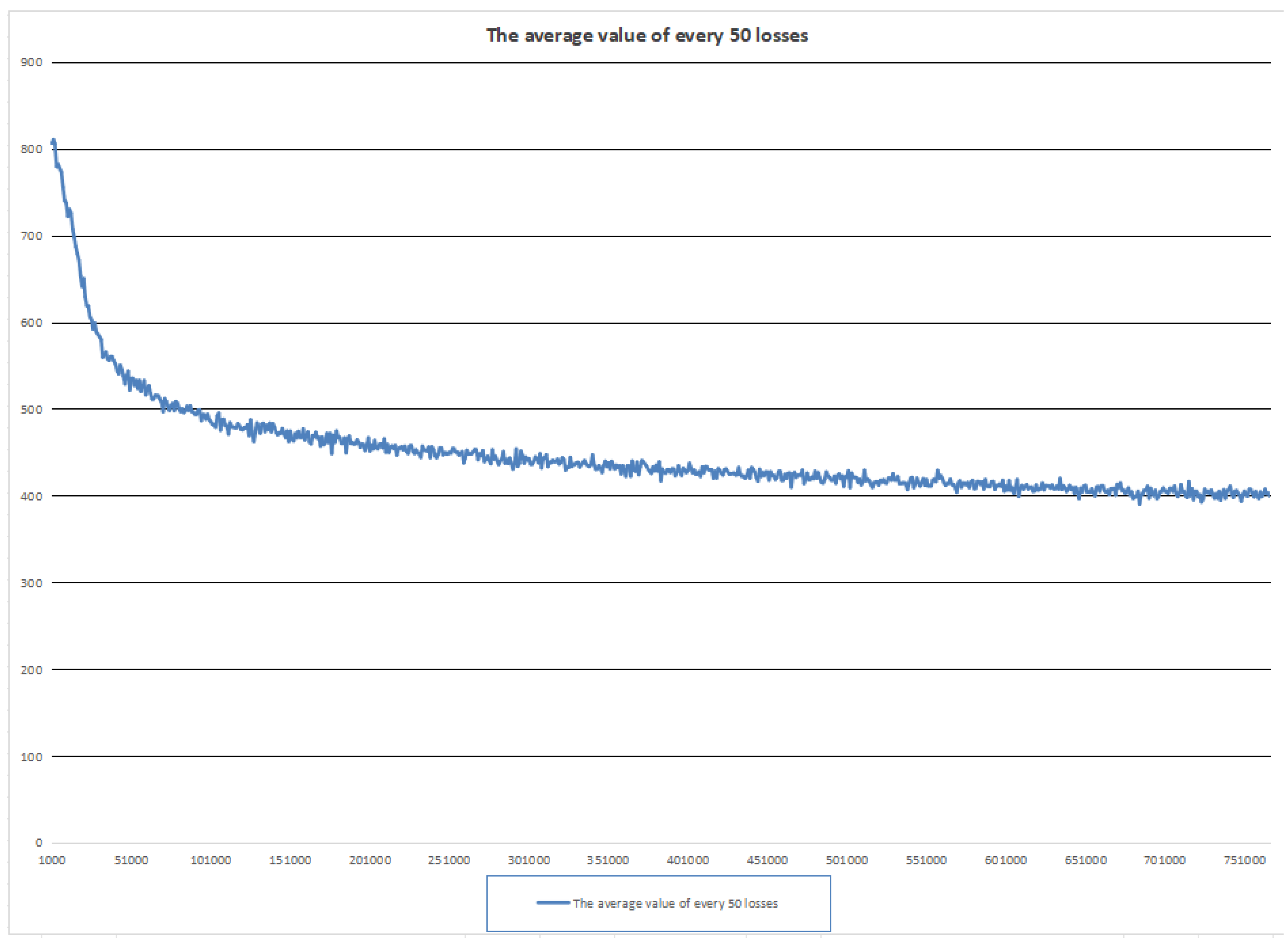
5.3. Dynamic Adjustment Mechanisms for Loss Scaling
5.4. Timing of the Intervention of the Early Stopping Method
5.5. Comparative Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7300. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1653–1660. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D Human Pose Estimation in Video with Temporal Convolutions and Semi-Supervised Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7334–7343. [Google Scholar]
- Fang, H.S.; Li, J.F.; Tang, H.Y.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.L.; Lu, C. AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2022, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Clever, H.M.; Erickson, Z.; Kapusta, A.; Turk, G.; Liu, C.K.; Kemp, C.C. Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6215–6224. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 11656–11665. [Google Scholar]
- Mehraban, S.; Taatit, B.; Adeli, V. MotionAgformer: Enhancing 3D Human Pose Estimation with a Transformer-GCN Formernetwork. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024. [Google Scholar]
- Pinheiro, G.S.; Jin, X.; Da Costa, V.T.; Lames, M. Body pose estimation integrated with notational analysis: A new approach to analyze penalty kicks strategy in elite football. Front. Sports Act. Living 2022, 4, 818556. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.X.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Yuan, Y.H.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Transformer for Dense Prediction. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021. [Google Scholar]
- Rajbhandari, S.; Rasley, J.; Ruwase, O.; He, Y. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC20), Online, 9–19 November 2020; pp. 379–388. [Google Scholar]
- Xu, J.; Zhou, W.; Fu, Z.; Zhou, H.; Li, L. A Survey on Green Deep Learning. arXiv 2021, arXiv:2111.05193. [Google Scholar]
- Liu, Y.; Hua, J. L-HRNet: A Lightweight High-Resolution Network for Human Pose Estimation. In Proceedings of the 2023 8th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 23–25 November 2023. [Google Scholar]
- Hou, B.; Chen, Q.; Wang, J.; Yin, G.; Wang, C.; Du, N.; Pang, R.; Chang, S.; Lei, T. Instruction-Following Pruning for Large Language Models. arXiv 2025, arXiv:2501.02086. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- IEEE 754-2008; IEEE Standard for Floating-Point Arithmetic. IEEE: Piscataway, NJ, USA, 2008.
- Ríos, J.O.; Armejach, A.; Petit, E.; Henry, G.; Casas, M. Dynamically Adapting Floating-Point Precision to Accelerate Deep Neural Network Training. In Proceedings of the 2021 IEEE International Conference on Machine Learning and Applications (ICMLA), Virtual, 13–16 December 2021. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.X.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning Delicate Local Representations for Multi-Person Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Prechelt, L. Early Stopping—But When? Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- NVIDIA Corporation. Turing Architecture Whitepaper(R). 2018. Available online: https://www.nvidia.cn/geforce/news/geforce-rtx-20-series-turing-architecture-whitepaper (accessed on 11 June 2025).

{kind=link}
{kind=link}
{kind=link}
| Computational Operations | FP32 Calculation Time (ms) | FP16 Calculation Time (ms) | Acceleration Ratio | Tensor Core Utilization |
|---|---|---|---|---|
| Convolutional layer forward computation | 18.6 | 6.2 | 92% | |
| Batch normalization | 2.8 | 1.1 | 35% | |
| Gradient updates | 10.3 | 4.5 | 78% |
| Training Methods | AP | AP.5 | AP.75 | AP(M) | AP(L) | AR | Time Taken |
|---|---|---|---|---|---|---|---|
| Single precision | |||||||
| Mixed precision | |||||||
| Early stopping | |||||||
| Mixed precision and early stopping |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Xu, J.; Feng, L.; Zhang, H. Application of Mixed Precision Training in Human Pose Estimation Model Training. Processes 2025, 13, 1894. https://doi.org/10.3390/pr13061894
Zhu J, Xu J, Feng L, Zhang H. Application of Mixed Precision Training in Human Pose Estimation Model Training. Processes. 2025; 13(6):1894. https://doi.org/10.3390/pr13061894
Chicago/Turabian StyleZhu, Jun, Jiwei Xu, Lei Feng, and Hao Zhang. 2025. "Application of Mixed Precision Training in Human Pose Estimation Model Training" Processes 13, no. 6: 1894. https://doi.org/10.3390/pr13061894
APA StyleZhu, J., Xu, J., Feng, L., & Zhang, H. (2025). Application of Mixed Precision Training in Human Pose Estimation Model Training. Processes, 13(6), 1894. https://doi.org/10.3390/pr13061894