
Recent Advances in Reinforcement Learning for Chemical Process Control



Abstract
1. Introduction
2. Reinforcement Learning Basics
2.1. Markov Decision Processes and Useful Definitions
2.2. State-of-the-Art RL Algorithms
- Deep Q-Learning
- Deterministic Policy Gradient
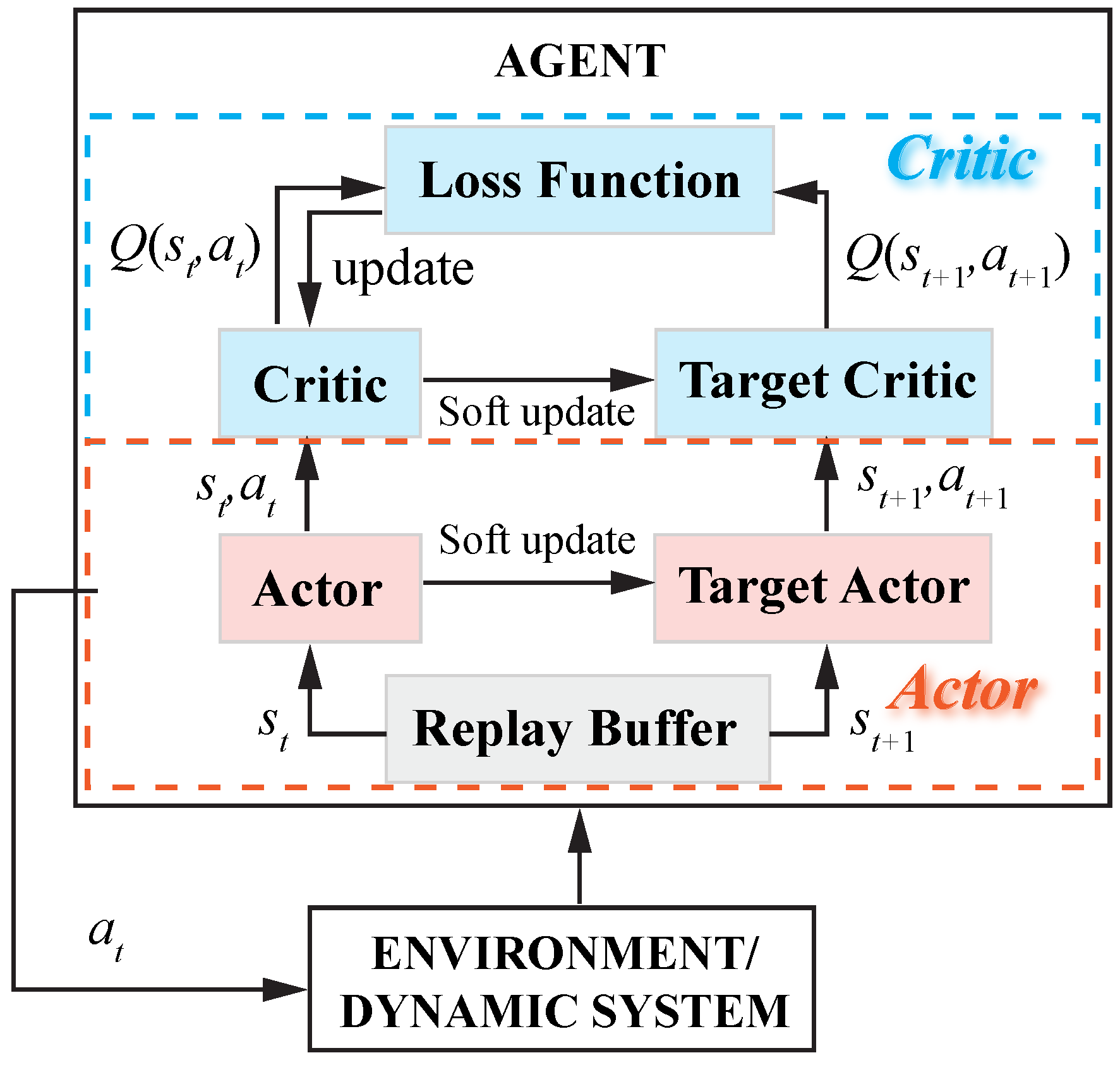
- Deep Deterministic Policy Gradient
- Trust Region Policy Optimization
- Proximal Policy Optimization
- Twin Delayed Deep Deterministic Policy Gradient
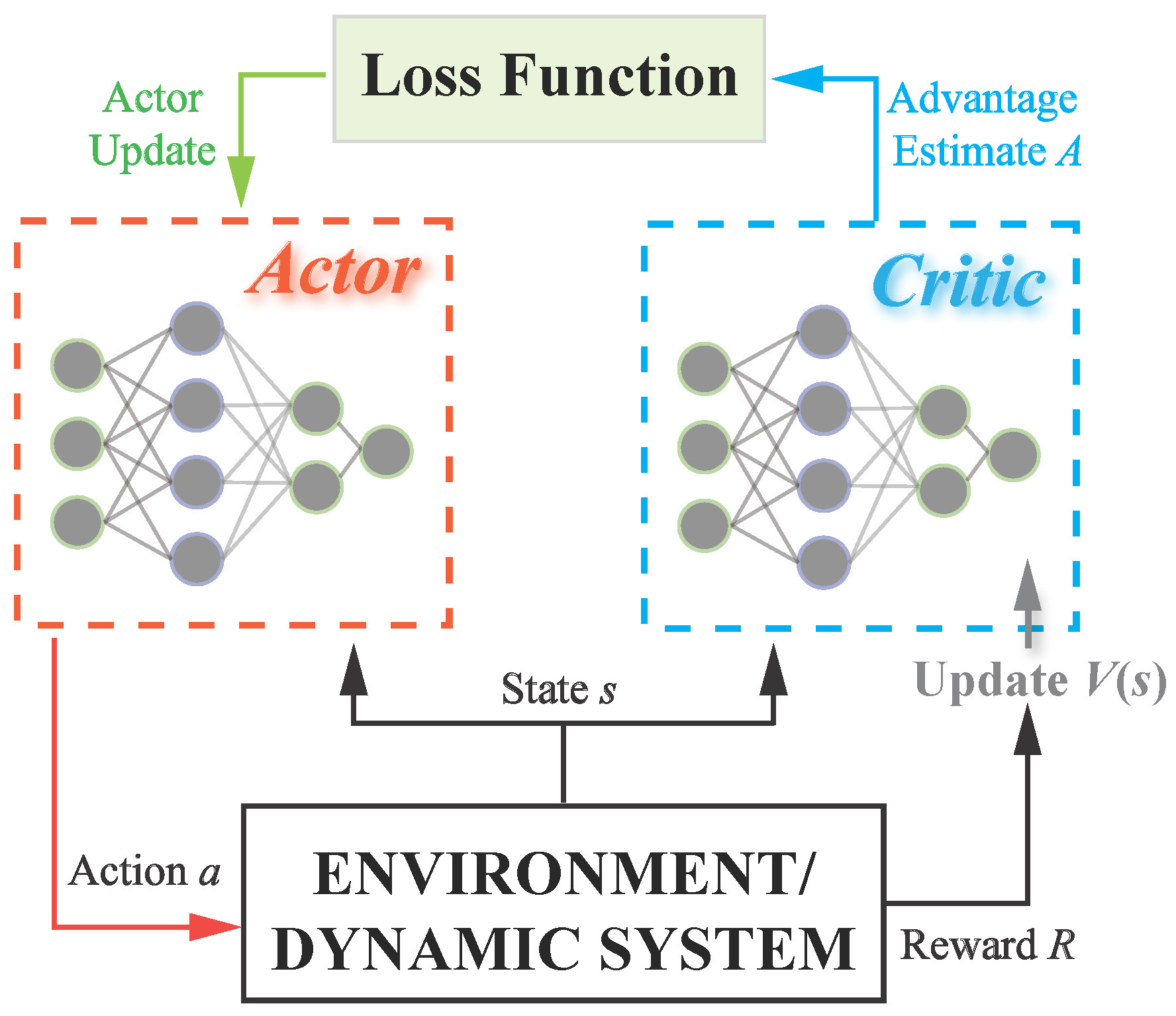
- Soft Actor–Critic
- Random Network Distillation
- Conservative Q-Learning
- Distributional SAC
- Diffusion Q-Learning
- Offline-to-Online RL
- Parallelized Q-network
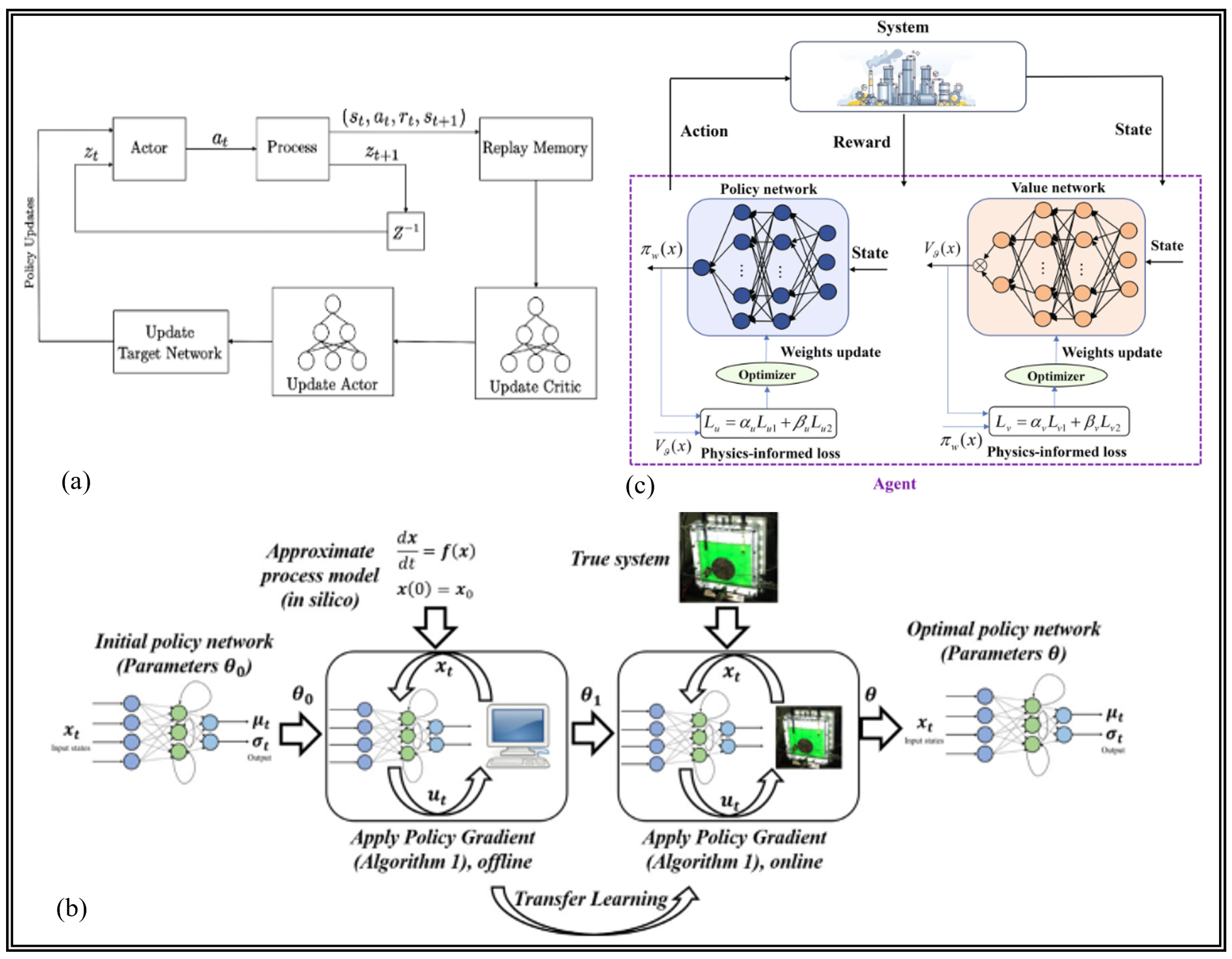
3. Implementations for Process Control
3.1. RL-Based PID Tuning
3.2. Application of RL on Other Controllers
3.3. RL for Control Policy Learning
4. Safe Reinforcement Learning
4.1. General Basics
- Safety Policy: How to find an optimal policy that is also compliant with the safety constraints (i.e., to avoid adversary attacks, undesirable situations, reduce risks).
- Safety Applications: What are the latest advances for the applications?
- Safety Benchmarks: What benchmarks can be used to examine safe RL performance in a fair and holistic manner?
- Safety Challenges: What are the challenges for the research of safe RL?
4.2. Safe RL Approaches in Chemical Process Control
- Constraint Tightening with Backoffs
- Control Barrier Functions
- Control Invariant Sets
5. Limitations, Emerging and Future Explorations
5.1. Environments for RL Design and Benchmark
5.2. Data Efficiency
5.3. Uncertainty-Aware RL Algorithms
5.4. State Observability
5.5. RL Enhanced by Large Language Models
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bequette, B.W. Process Control: Modeling, Design, and Simulation; Prentice Hall Professional: Hoboken, NJ, USA, 2003. [Google Scholar]
- Kravaris, C.; Kookos, I.K. Understanding Process Dynamics and Control; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Borase, R.P.; Maghade, D.; Sondkar, S.; Pawar, S. A review of PID control, tuning methods and applications. Int. J. Dyn. Control 2021, 9, 818–827. [Google Scholar] [CrossRef]
- Lee, J.H. Model predictive control: Review of the three decades of development. Int. J. Control Autom. Syst. 2011, 9, 415–424. [Google Scholar] [CrossRef]
- Schwenzer, M.; Ay, M.; Bergs, T.; Abel, D. Review on model predictive control: An engineering perspective. Int. J. Adv. Manuf. Technol. 2021, 117, 1327–1349. [Google Scholar] [CrossRef]
- Daoutidis, P.; Megan, L.; Tang, W. The future of control of process systems. Comput. Chem. Eng. 2023, 178, 108365. [Google Scholar] [CrossRef]
- Biegler, L.T. A perspective on nonlinear model predictive control. Korean J. Chem. Eng. 2021, 38, 1317–1332. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Petsagkourakis, P.; Sandoval, I.; Bradford, E.; Zhang, D.; Del Rio-Chanona, E. Reinforcement learning for batch bioprocess optimization. Comput. Chem. Eng. 2020, 133, 106649. [Google Scholar] [CrossRef]
- Shin, J.; Badgwell, T.A.; Liu, K.H.; Lee, J.H. Reinforcement Learning—Overview of recent progress and implications for process control. Comput. Chem. Eng. 2019, 127, 282–294. [Google Scholar] [CrossRef]
- Nian, R.; Liu, J.; Huang, B. A review On reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Faria, R.D.R.; Capron, B.D.O.; Secchi, A.R.; De Souza, M.B. Where Reinforcement Learning Meets Process Control: Review and Guidelines. Processes 2022, 10, 2311. [Google Scholar] [CrossRef]
- Dogru, O.; Xie, J.; Prakash, O.; Chiplunkar, R.; Soesanto, J.; Chen, H.; Velswamy, K.; Ibrahim, F.; Huang, B. Reinforcement Learning in Process Industries: Review and Perspective. IEEE/CAA J. Autom. Sin. 2024, 11, 283–300. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, X.; Wu, Z. A tutorial review of policy iteration methods in reinforcement learning for nonlinear optimal control. Digit. Chem. Eng. 2025, 15, 100231. [Google Scholar] [CrossRef]
- Nievas, N.; Pagès-Bernaus, A.; Bonada, F.; Echeverria, L.; Domingo, X. Reinforcement Learning for Autonomous Process Control in Industry 4.0: Advantages and Challenges. Appl. Artif. Intell. 2024, 38, 2383101. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian Decision Process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Vlassis, N.; Ghavamzadeh, M.; Mannor, S.; Poupart, P. Bayesian Reinforcement Learning. In Reinforcement Learning; Wiering, M., Van Otterlo, M., Eds.; Adaptation, Learning, and Optimization; Springer: Berlin/Heidelberg, Germany, 2012; Volume 12, pp. 359–386. [Google Scholar] [CrossRef]
- Chenna, S.K.; Jain, Y.K.; Kapoor, H.; Bapi, R.S.; Yadaiah, N.; Negi, A.; Rao, V.S.; Deekshatulu, B.L. State Estimation and Tracking Problems: A Comparison Between Kalman Filter and Recurrent Neural Networks. In Neural Information Processing; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3316, pp. 275–281. [Google Scholar] [CrossRef]
- Meng, L.; Gorbet, R.; Kulić, D. Memory-based Deep Reinforcement Learning for POMDPs. arXiv 2021. [Google Scholar] [CrossRef]
- Chadès, I.; Pascal, L.V.; Nicol, S.; Fletcher, C.S.; Ferrer-Mestres, J. A primer on partially observable Markov decision processes (POMDPs). Methods Ecol. Evol. 2021, 12, 2058–2072. [Google Scholar] [CrossRef]
- Xiang, X.; Foo, S. Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems: Part 1—Fundamentals and Applications in Games, Robotics and Natural Language Processing. Mach. Learn. Knowl. Extr. 2021, 3, 554–581. [Google Scholar] [CrossRef]
- AlMahamid, F.; Grolinger, K. Reinforcement Learning Algorithms: An Overview and Classification. In Proceedings of the 2021 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Virtual Conference, 12–17 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Padakandla, S. A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments. Acm Comput. Surv. 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Han, D.; Mulyana, B.; Stankovic, V.; Cheng, S. A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation. Sensors 2023, 23, 3762. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Rolf, B.; Jackson, I.; Müller, M.; Lang, S.; Reggelin, T.; Ivanov, D. A review on reinforcement learning algorithms and applications in supply chain management. Int. J. Prod. Res. 2023, 61, 7151–7179. [Google Scholar] [CrossRef]
- Hu, K.; Li, M.; Song, Z.; Xu, K.; Xia, Q.; Sun, N.; Zhou, P.; Xia, M. A review of research on reinforcement learning algorithms for multi-agents. Neurocomputing 2024, 599, 128068. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015. Version Number: 6. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018. Version Number: 3. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018. Version Number: 2. [Google Scholar] [CrossRef]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by Random Network Distillation. arXiv 2018, arXiv:1810.12894. [Google Scholar]
- Kumar, A.; Zhou, A.; Tucker, G.; Levine, S. Conservative Q-Learning for Offline Reinforcement Learning. arXiv 2020, arXiv:2006.04779. [Google Scholar]
- Duan, J.; Guan, Y.; Li, S.E.; Ren, Y.; Cheng, B. Distributional Soft Actor-Critic: Off-Policy Reinforcement Learning for Addressing Value Estimation Errors. arXiv 2020, arXiv:2001.02811. [Google Scholar] [CrossRef]
- Ma, X.; Xia, L.; Zhou, Z.; Yang, J.; Zhao, Q. DSAC: Distributional Soft Actor Critic for Risk-Sensitive Reinforcement Learning. arXiv 2020, arXiv:2004.14547. [Google Scholar]
- Wang, Z.; Hunt, J.J.; Zhou, M. Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning. arXiv 2023, arXiv:2208.06193. [Google Scholar]
- Zheng, H.; Luo, X.; Wei, P.; Song, X.; Li, D.; Jiang, J. Adaptive Policy Learning for Offline-to-Online Reinforcement Learning. arXiv 2023, arXiv:2303.07693. [Google Scholar] [CrossRef]
- Gallici, M.; Fellows, M.; Ellis, B.; Pou, B.; Masmitja, I.; Foerster, J.N.; Martin, M. Simplifying Deep Temporal Difference Learning. arXiv 2025, arXiv:2407.04811. [Google Scholar]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5064–5078. [Google Scholar] [CrossRef]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the Brownian motion. Phys. Rev. 1930, 36, 823. [Google Scholar] [CrossRef]
- Osband, I.; Aslanides, J.; Cassirer, A. Randomized prior functions for deep reinforcement learning. arXiv 2018, arXiv:1806.03335. [Google Scholar]
- Daley, B.; Amato, C. Reconciling λ -Returns with Experience Replay. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Seborg, D.E.; Mellichamp, D.A.; Edgar, T.F. Process Dynamics and Control, 3rd ed.; Wylie Series in Chemical Engineering; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Wang, H.; Ricardez-Sandoval, L.A. A Deep Reinforcement Learning-Based PID Tuning Strategy for Nonlinear MIMO Systems with Time-varying Uncertainty. IFAC-PapersOnLine 2024, 58, 887–892. [Google Scholar] [CrossRef]
- Howell, M.; Best, M. On-line PID tuning for engine idle-speed control using continuous action reinforcement learning automata. Control Eng. Pract. 2000, 8, 147–154. [Google Scholar] [CrossRef]
- Dogru, O.; Velswamy, K.; Ibrahim, F.; Wu, Y.; Sundaramoorthy, A.S.; Huang, B.; Xu, S.; Nixon, M.; Bell, N. Reinforcement learning approach to autonomous PID tuning. Comput. Chem. Eng. 2022, 161, 107760. [Google Scholar] [CrossRef]
- Lakhani, A.I.; Chowdhury, M.A.; Lu, Q. Stability-Preserving Automatic Tuning of PID Control with Reinforcement Learning. arXiv 2022, arXiv:2112.15187. [Google Scholar] [CrossRef]
- Fujii, F.; Kaneishi, A.; Nii, T.; Maenishi, R.; Tanaka, S. Self-Tuning Two Degree-of-Freedom Proportional–Integral Control System Based on Reinforcement Learning for a Multiple-Input Multiple-Output Industrial Process That Suffers from Spatial Input Coupling. Processes 2021, 9, 487. [Google Scholar] [CrossRef]
- Mate, S.; Pal, P.; Jaiswal, A.; Bhartiya, S. Simultaneous tuning of multiple PID controllers for multivariable systems using deep reinforcement learning. Digit. Chem. Eng. 2023, 9, 100131. [Google Scholar] [CrossRef]
- Li, J.; Yu, T. A novel data-driven controller for solid oxide fuel cell via deep reinforcement learning. J. Clean. Prod. 2021, 321, 128929. [Google Scholar] [CrossRef]
- Li, J.; Yu, T. Optimal adaptive control for solid oxide fuel cell with operating constraints via large-scale deep reinforcement learning. Control Eng. Pract. 2021, 117, 104951. [Google Scholar] [CrossRef]
- Lawrence, N.P.; Forbes, M.G.; Loewen, P.D.; McClement, D.G.; Backström, J.U.; Gopaluni, R.B. Deep reinforcement learning with shallow controllers: An experimental application to PID tuning. Control Eng. Pract. 2022, 121, 105046. [Google Scholar] [CrossRef]
- Chowdhury, M.A.; Al-Wahaibi, S.S.; Lu, Q. Entropy-maximizing TD3-based reinforcement learning for adaptive PID control of dynamical systems. Comput. Chem. Eng. 2023, 178, 108393. [Google Scholar] [CrossRef]
- Veerasamy, G.; Balaji, S.; Kadirvelu, T.; Ramasamy, V. Reinforcement Learning Based Adaptive PID Controller for a Continuous Stirred Tank Heater Process. Iran. J. Chem. Chem. Eng. 2025, 44, 265–282. [Google Scholar] [CrossRef]
- Shuprajhaa, T.; Sujit, S.K.; Srinivasan, K. Reinforcement learning based adaptive PID controller design for control of linear/nonlinear unstable processes. Appl. Soft Comput. 2022, 128, 109450. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep reinforcement learning in parameterized action space. arXiv 2015, arXiv:1511.04143. [Google Scholar]
- Kumar, K.P.; Detroja, K.P. Gain Scheduled PI controller design using Multi-Objective Reinforcement Learning. IFAC-PapersOnLine 2024, 58, 132–137. [Google Scholar] [CrossRef]
- Makumi, W.; Greene, M.L.; Bell, Z.; Bialy, B.; Kamalapurkar, R.; Dixon, W. Hierarchical Reinforcement Learning and Gain Scheduling-based Control of a Hypersonic Vehicle. In Proceedings of the Aiaa Scitech 2023 Forum, National Harbor, MD, USA & Online, 23–27 January 2023. [Google Scholar] [CrossRef]
- Timmerman, M.; Patel, A.; Reinhart, T. Adaptive Gain Scheduling using Reinforcement Learning for Quadcopter Control. arXiv 2024, arXiv:2403.07216. [Google Scholar]
- Rizvi, S.A.A.; Lin, Z. Reinforcement Learning-Based Linear Quadratic Regulation of Continuous-Time Systems Using Dynamic Output Feedback. IEEE Trans. Cybern. 2020, 50, 4670–4679. [Google Scholar] [CrossRef] [PubMed]
- Bradtke, S. Reinforcement Learning Applied to Linear Quadratic Regulation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; Hanson, S., Cowan, J., Giles, C., Eds.; Morgan-Kaufmann: Burlington, MA, USA, 1992; Volume 5. [Google Scholar]
- Alhazmi, K.; Albalawi, F.; Sarathy, M.S. A reinforcement learning-based economic model predictive control framework for autonomous operation of chemical reactors. Chem. Eng. J. 2022, 428, 130993. [Google Scholar] [CrossRef]
- Oh, T.H.; Park, H.M.; Kim, J.W.; Lee, J.M. Integration of reinforcement learning and model predictive control to optimize semi-batch bioreactor. AIChE J. 2022, 68, e17658. [Google Scholar] [CrossRef]
- Kim, J.W.; Park, B.J.; Oh, T.H.; Lee, J.M. Model-based reinforcement learning and predictive control for two-stage optimal control of fed-batch bioreactor. Comput. Chem. Eng. 2021, 154, 107465. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, S. Enhanced reinforcement learning in two-layer economic model predictive control for operation optimization in dynamic environment. Chem. Eng. Res. Des. 2023, 196, 133–143. [Google Scholar] [CrossRef]
- Kordabad, A.B.; Reinhardt, D.; Anand, A.S.; Gros, S. Reinforcement Learning for MPC: Fundamentals and Current Challenges. IFAC-PapersOnLine 2023, 56, 5773–5780. [Google Scholar] [CrossRef]
- Mesbah, A.; Wabersich, K.P.; Schoellig, A.P.; Zeilinger, M.N.; Lucia, S.; Badgwell, T.A.; Paulson, J.A. Fusion of Machine Learning and MPC under Uncertainty: What Advances Are on the Horizon? In Proceedings of the 2022 American Control Conference (ACC), Atlanta, GA, USA, 8–10 June 2022; pp. 342–357. [Google Scholar] [CrossRef]
- Hedrick, E.; Hedrick, K.; Bhattacharyya, D.; Zitney, S.E.; Omell, B. Reinforcement learning for online adaptation of model predictive controllers: Application to a selective catalytic reduction unit. Comput. Chem. Eng. 2022, 160, 107727. [Google Scholar] [CrossRef]
- Spielberg, S.; Tulsyan, A.; Lawrence, N.P.; Loewen, P.D.; Bhushan Gopaluni, R. Toward self-driving processes: A deep reinforcement learning approach to control. AIChE J. 2019, 65, e16689. [Google Scholar] [CrossRef]
- Alves Goulart, D.; Dutra Pereira, R. Autonomous pH control by reinforcement learning for electroplating industry wastewater. Comput. Chem. Eng. 2020, 140, 106909. [Google Scholar] [CrossRef]
- Bangi, M.S.F.; Kwon, J.S.I. Deep reinforcement learning control of hydraulic fracturing. Comput. Chem. Eng. 2021, 154, 107489. [Google Scholar] [CrossRef]
- Siraskar, R. Reinforcement learning for control of valves. Mach. Learn. Appl. 2021, 4, 100030. [Google Scholar] [CrossRef]
- Panjapornpon, C.; Chinchalongporn, P.; Bardeeniz, S.; Makkayatorn, R.; Wongpunnawat, W. Reinforcement Learning Control with Deep Deterministic Policy Gradient Algorithm for Multivariable pH Process. Processes 2022, 10, 2514. [Google Scholar] [CrossRef]
- Patel, K.M. A practical Reinforcement Learning implementation approach for continuous process control. Comput. Chem. Eng. 2023, 174, 108232. [Google Scholar] [CrossRef]
- Bao, Y.; Zhu, Y.; Qian, F. A Deep Reinforcement Learning Approach to Improve the Learning Performance in Process Control. Ind. Eng. Chem. Res. 2021, 60, 5504–5515. [Google Scholar] [CrossRef]
- Elmaz, F.; Di Caprio, U.; Wu, M.; Wouters, Y.; Van Der Vorst, G.; Vandervoort, N.; Anwar, A.; Leblebici, M.E.; Hellinckx, P.; Mercelis, S. Reinforcement Learning-Based Approach for Optimizing Solvent-Switch Processes. Comput. Chem. Eng. 2023, 176, 108310. [Google Scholar] [CrossRef]
- Hong, X.; Shou, Z.; Chen, W.; Liao, Z.; Sun, J.; Yang, Y.; Wang, J.; Yang, Y. A reinforcement learning-based temperature control of fluidized bed reactor in gas-phase polyethylene process. Comput. Chem. Eng. 2024, 183, 108588. [Google Scholar] [CrossRef]
- Beahr, D.; Bhattacharyya, D.; Allan, D.A.; Zitney, S.E. Development of algorithms for augmenting and replacing conventional process control using reinforcement learning. Comput. Chem. Eng. 2024, 190, 108826. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Z. Physics-informed reinforcement learning for optimal control of nonlinear systems. AIChE J. 2024, 70, e18542. [Google Scholar] [CrossRef]
- Faridi, I.K.; Tsotsas, E.; Kharaghani, A. Advancing Process Control in Fluidized Bed Biomass Gasification Using Model-Based Deep Reinforcement Learning. Processes 2024, 12, 254. [Google Scholar] [CrossRef]
- Croll, H.C.; Ikuma, K.; Ong, S.K.; Sarkar, S. Systematic Performance Evaluation of Reinforcement Learning Algorithms Applied to Wastewater Treatment Control Optimization. Environ. Sci. Technol. 2023, 57, 18382–18390. [Google Scholar] [CrossRef] [PubMed]
- Oh, T.H. Quantitative comparison of reinforcement learning and data-driven model predictive control for chemical and biological processes. Comput. Chem. Eng. 2024, 181, 108558. [Google Scholar] [CrossRef]
- Bradley, W.; Kim, J.; Kilwein, Z.; Blakely, L.; Eydenberg, M.; Jalvin, J.; Laird, C.; Boukouvala, F. Perspectives on the integration between first-principles and data-driven modeling. Comput. Chem. Eng. 2022, 166, 107898. [Google Scholar] [CrossRef]
- Pistikopoulos, E.N.; Tian, Y. Advanced modeling and optimization strategies for process synthesis. Annu. Rev. Chem. Biomol. Eng. 2024, 15. [Google Scholar] [CrossRef] [PubMed]
- Popova, M.; Isayev, O.; Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 2018, 4, eaap7885. [Google Scholar] [CrossRef] [PubMed]
- Ståhl, N.; Falkman, G.; Karlsson, A.; Mathiason, G.; Bostrom, J. Deep reinforcement learning for multiparameter optimization in de novo drug design. J. Chem. Inf. Model. 2019, 59, 3166–3176. [Google Scholar] [CrossRef]
- Nikita, S.; Tiwari, A.; Sonawat, D.; Kodamana, H.; Rathore, A.S. Reinforcement learning based optimization of process chromatography for continuous processing of biopharmaceuticals. Chem. Eng. Sci. 2021, 230, 116171. [Google Scholar] [CrossRef]
- Benyahia, B.; Anandan, P.D.; Rielly, C. Control of batch and continuous crystallization processes using reinforcement learning. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2021; Volume 50, pp. 1371–1376. [Google Scholar]
- Manee, V.; Baratti, R.; Romagnoli, J.A. Learning to navigate a crystallization model with deep reinforcement learning. Chem. Eng. Res. Des. 2022, 178, 111–123. [Google Scholar]
- Anandan, P.D.; Rielly, C.D.; Benyahia, B. Optimal control policies of a crystallization process using inverse reinforcement learning. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2022; Volume 51, pp. 1093–1098. [Google Scholar]
- Lu, M.; Rao, S.; Yue, H.; Han, J.; Wang, J. Recent advances in the application of machine learning to crystal behavior and crystallization process control. Cryst. Growth Des. 2024, 24, 5374–5396. [Google Scholar] [CrossRef]
- Xiouras, C.; Cameli, F.; Quilló, G.L.; Kavousanakis, M.E.; Vlachos, D.G.; Stefanidis, G.D. Applications of artificial intelligence and machine learning algorithms to crystallization. Chem. Rev. 2022, 122, 13006–13042. [Google Scholar] [CrossRef]
- Yoo, H.; Byun, H.E.; Han, D.; Lee, J.H. Reinforcement learning for batch process control: Review and perspectives. Annu. Rev. Control 2021, 52, 108–119. [Google Scholar] [CrossRef]
- Ma, Y.; Zhu, W.; Benton, M.G.; Romagnoli, J. Continuous control of a polymerization system with deep reinforcement learning. J. Process Control 2019, 75, 40–47. [Google Scholar] [CrossRef]
- Li, H.; Collins, C.R.; Ribelli, T.G.; Matyjaszewski, K.; Gordon, G.J.; Kowalewski, T.; Yaron, D.J. Tuning the molecular weight distribution from atom transfer radical polymerization using deep reinforcement learning. Mol. Syst. Des. Eng. 2018, 3, 496–508. [Google Scholar] [CrossRef]
- Cassola, S.; Duhovic, M.; Schmidt, T.; May, D. Machine learning for polymer composites process simulation—A review. Compos. Part B Eng. 2022, 246, 110208. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, J.; Zhang, Y.; Bevan, M.A. Controlling colloidal crystals via morphing energy landscapes and reinforcement learning. Sci. Adv. 2020, 6, eabd6716. [Google Scholar] [CrossRef]
- Whitelam, S.; Tamblyn, I. Learning to grow: Control of material self-assembly using evolutionary reinforcement learning. Phys. Rev. E 2020, 101, 052604. [Google Scholar] [CrossRef]
- Li, R.; Zhang, C.; Xie, W.; Gong, Y.; Ding, F.; Dai, H.; Chen, Z.; Yin, F.; Zhang, Z. Deep reinforcement learning empowers automated inverse design and optimization of photonic crystals for nanoscale laser cavities. Nanophotonics 2023, 12, 319–334. [Google Scholar] [CrossRef] [PubMed]
- Tovey, S.; Zimmer, D.; Lohrmann, C.; Merkt, T.; Koppenhoefer, S.; Heuthe, V.L.; Bechinger, C.; Holm, C. Environmental effects on emergent strategy in micro-scale multi-agent reinforcement learning. arXiv 2023, arXiv:2307.00994. [Google Scholar]
- Chatterjee, S.; Jacobs, W.M. Multiobjective Optimization for Targeted Self-Assembly among Competing Polymorphs. Phys. Rev. X 2025, 15, 011075. [Google Scholar] [CrossRef]
- Lieu, U.T.; Yoshinaga, N. Dynamic control of self-assembly of quasicrystalline structures through reinforcement learning. Soft Matter 2025, 21, 514–525. [Google Scholar] [CrossRef]
- Yang, Q.; Cao, W.; Meng, W.; Si, J. Reinforcement-learning-based tracking control of waste water treatment process under realistic system conditions and control performance requirements. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 5284–5294. [Google Scholar] [CrossRef]
- Chen, M.; Cui, Y.; Wang, X.; Xie, H.; Liu, F.; Luo, T.; Zheng, S.; Luo, Y. A reinforcement learning approach to irrigation decision-making for rice using weather forecasts. Agric. Water Manag. 2021, 250, 106838. [Google Scholar] [CrossRef]
- Sundui, B.; Ramirez Calderon, O.A.; Abdeldayem, O.M.; Lázaro-Gil, J.; Rene, E.R.; Sambuu, U. Applications of machine learning algorithms for biological wastewater treatment: Updates and perspectives. Clean Technol. Environ. Policy 2021, 23, 127–143. [Google Scholar] [CrossRef]
- Bonny, T.; Kashkash, M.; Ahmed, F. An efficient deep reinforcement machine learning-based control reverse osmosis system for water desalination. Desalination 2022, 522, 115443. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, J.; Yang, X.; Zhang, Y.; Zhang, L.; Ren, H.; Wu, B.; Ye, L. A review of the application of machine learning in water quality evaluation. Eco-Environ. Health 2022, 1, 107–116. [Google Scholar] [CrossRef] [PubMed]
- Croll, H.C.; Ikuma, K.; Ong, S.K.; Sarkar, S. Reinforcement learning applied to wastewater treatment process control optimization: Approaches, challenges, and path forward. Crit. Rev. Environ. Sci. Technol. 2023, 53, 1775–1794. [Google Scholar] [CrossRef]
- Alvi, M.; Batstone, D.; Mbamba, C.K.; Keymer, P.; French, T.; Ward, A.; Dwyer, J.; Cardell-Oliver, R. Deep learning in wastewater treatment: A critical review. Water Res. 2023, 245, 120518. [Google Scholar] [CrossRef]
- Taqvi, S.A.A.; Zabiri, H.; Tufa, L.D.; Uddin, F.; Fatima, S.A.; Maulud, A.S. A review on data-driven learning approaches for fault detection and diagnosis in chemical processes. ChemBioEng Rev. 2021, 8, 239–259. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, Z.; Yuan, X.; Yang, C.; Gui, W. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Trans. 2020, 96, 457–467. [Google Scholar] [CrossRef]
- Baldea, M.; Georgiou, A.T.; Gopaluni, B.; Mercangöz, M.; Pantelides, C.C.; Sheth, K.; Zavala, V.M.; Georgakis, C. From automated to autonomous process operations. Comput. Chem. Eng. 2025, 196, 109064. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Zare, R.N. Optimizing Chemical Reactions with Deep Reinforcement Learning. Acs Cent. Sci. 2017, 3, 1337–1344. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Lapkin, A. Searching for optimal process routes: A reinforcement learning approach. Comput. Chem. Eng. 2020, 141, 107027. [Google Scholar] [CrossRef]
- Park, S.; Han, H.; Kim, H.; Choi, S. Machine learning applications for chemical reactions. Chem.-Asian J. 2022, 17, e202200203. [Google Scholar] [CrossRef] [PubMed]
- Neumann, M.; Palkovits, D.S. Reinforcement learning approaches for the optimization of the partial oxidation reaction of methane. Ind. Eng. Chem. Res. 2022, 61, 3910–3916. [Google Scholar] [CrossRef]
- Zhang, C.; Lapkin, A.A. Reinforcement learning optimization of reaction routes on the basis of large, hybrid organic chemistry–synthetic biological, reaction network data. React. Chem. Eng. 2023, 8, 2491–2504. [Google Scholar] [CrossRef]
- Hoque, A.; Surve, M.; Kalyanakrishnan, S.; Sunoj, R.B. Reinforcement Learning for Improving Chemical Reaction Performance. J. Am. Chem. Soc. 2024, 146, 28250–28267. [Google Scholar] [CrossRef]
- Meuwly, M. Machine learning for chemical reactions. Chem. Rev. 2021, 121, 10218–10239. [Google Scholar] [CrossRef]
- He, Z.; Tran, K.P.; Thomassey, S.; Zeng, X.; Xu, J.; Yi, C. A deep reinforcement learning based multi-criteria decision support system for optimizing textile chemical process. Comput. Ind. 2021, 125, 103373. [Google Scholar] [CrossRef]
- Hubbs, C.D.; Li, C.; Sahinidis, N.V.; Grossmann, I.E.; Wassick, J.M. A deep reinforcement learning approach for chemical production scheduling. Comput. Chem. Eng. 2020, 141, 106982. [Google Scholar] [CrossRef]
- Jitchaiyapoom, T.; Panjapornpon, C.; Bardeeniz, S.; Hussain, M.A. Production Capacity Prediction and Optimization in the Glycerin Purification Process: A Simulation-Assisted Few-Shot Learning Approach. Processes 2024, 12, 661. [Google Scholar] [CrossRef]
- Zhu, Z.; Yang, M.; He, W.; He, R.; Zhao, Y.; Qian, F. A deep reinforcement learning approach to gasoline blending real-time optimization under uncertainty. Chin. J. Chem. Eng. 2024, 71, 183–192. [Google Scholar] [CrossRef]
- Powell, K.M.; Machalek, D.; Quah, T. Real-time optimization using reinforcement learning. Comput. Chem. Eng. 2020, 143, 107077. [Google Scholar] [CrossRef]
- Quah, T.; Machalek, D.; Powell, K.M. Comparing Reinforcement Learning Methods for Real-Time Optimization of a Chemical Process. Processes 2020, 8, 1497. [Google Scholar] [CrossRef]
- Panzer, M.; Bender, B. Deep reinforcement learning in production systems: A systematic literature review. Int. J. Prod. Res. 2022, 60, 4316–4341. [Google Scholar] [CrossRef]
- Rajasekhar, N.; Radhakrishnan, T.K.; Samsudeen, N. Exploring reinforcement learning in process control: A comprehensive survey. Int. J. Syst. Sci. 2025, 1–30. [Google Scholar] [CrossRef]
- Garcıa, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning. arXiv 2021. [Google Scholar] [CrossRef]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained policy optimization. In Proceedings of the International conference on machine learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Gu, S.; Yang, L.; Du, Y.; Chen, G.; Walter, F.; Wang, J.; Knoll, A. A Review of Safe Reinforcement Learning: Methods, Theory and Applications. arXiv 2024, arXiv:2205.10330. [Google Scholar] [CrossRef]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained Policy Optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Feinberg, E.A. Constrained Discounted Markov Decision Processes and Hamiltonian Cycles. Math. Oper. Res. 2000, 25, 130–140. [Google Scholar] [CrossRef]
- Leveson, N.G.; Stephanopoulos, G. A system-theoretic, control-inspired view and approach to process safety. AIChE J. 2013, 60, 2–14. [Google Scholar] [CrossRef]
- Wu, Z.; Christofides, P.D. Process Operational Safety and Cybersecurity; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Braniff, A.; Akundi, S.S.; Liu, Y.; Dantas, B.; Niknezhad, S.S.; Khan, F.; Pistikopoulos, E.N.; Tian, Y. Real-time process safety and systems decision-making toward safe and smart chemical manufacturing. Digit. Chem. Eng. 2025, 15, 100227. [Google Scholar] [CrossRef]
- Savage, T.; Zhang, D.; Mowbray, M.; Río Chanona, E.A.D. Model-free safe reinforcement learning for chemical processes using Gaussian processes. IFAC-PapersOnLine 2021, 54, 504–509. [Google Scholar] [CrossRef]
- Pan, E.; Petsagkourakis, P.; Mowbray, M.; Zhang, D.; del Rio-Chanona, A. Constrained Q-learning for batch process optimization. IFAC-PapersOnLine 2021, 54, 492–497. [Google Scholar] [CrossRef]
- Petsagkourakis, P.; Sandoval, I.O.; Bradford, E.; Galvanin, F.; Zhang, D.; Rio-Chanona, E.A.D. Chance constrained policy optimization for process control and optimization. J. Process Control 2022, 111, 35–45. [Google Scholar] [CrossRef]
- Kim, Y.; Oh, T.H. Model-based safe reinforcement learning for nonlinear systems under uncertainty with constraints tightening approach. Comput. Chem. Eng. 2024, 183, 108601. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, J.M. Model-based reinforcement learning for nonlinear optimal control with practical asymptotic stability guarantees. AIChE J. 2020, 66, e16544. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Z. Control Lyapunov-barrier function-based safe reinforcement learning for nonlinear optimal control. AIChE J. 2024, 70, e18306. [Google Scholar] [CrossRef]
- Bo, S.; Agyeman, B.T.; Yin, X.; Liu, J. Control invariant set enhanced safe reinforcement learning: Improved sampling efficiency, guaranteed stability and robustness. Comput. Chem. Eng. 2023, 179, 108413. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, M.; Wu, Z. Safe Transfer-Reinforcement-Learning-Based Optimal Control of Nonlinear Systems. IEEE Trans. Cybern. 2024, 54, 7272–7284. [Google Scholar] [CrossRef]
- Mehta, S.; Ricardez-Sandoval, L.A. Integration of Design and Control of Dynamic Systems under Uncertainty: A New Back-Off Approach. Ind. Eng. Chem. Res. 2016, 55, 485–498. [Google Scholar] [CrossRef]
- Rafiei, M.; Ricardez-Sandoval, L.A. Stochastic Back-Off Approach for Integration of Design and Control Under Uncertainty. Ind. Eng. Chem. Res. 2018, 57, 4351–4365. [Google Scholar] [CrossRef]
- Bradford, E.; Imsland, L.; Zhang, D.; Del Rio Chanona, E.A. Stochastic data-driven model predictive control using gaussian processes. Comput. Chem. Eng. 2020, 139, 106844. [Google Scholar] [CrossRef]
- Ames, A.D.; Xu, X.; Grizzle, J.W.; Tabuada, P. Control Barrier Function Based Quadratic Programs for Safety Critical Systems. IEEE Trans. Autom. Control 2017, 62, 3861–3876. [Google Scholar] [CrossRef]
- Artstein, Z. Stabilization with relaxed controls. Nonlinear Anal. Theory Methods Appl. 1983, 7, 1163–1173. [Google Scholar] [CrossRef]
- Wieland, P.; Allgöwer, F. Constructive Safety Using Control Barrier Functions. Ifac Proc. Vol. 2007, 40, 462–467. [Google Scholar] [CrossRef]
- Clark, A. Control barrier functions for complete and incomplete information stochastic systems. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 2928–2935. [Google Scholar]
- Kim, Y.; Kim, J.W. Safe model-based reinforcement learning for nonlinear optimal control with state and input constraints. AIChE J. 2022, 68, e17601. [Google Scholar] [CrossRef]
- Blanchini, F. Set invariance in control. Automatica 1999, 35, 1747–1767. [Google Scholar] [CrossRef]
- Towers, M.; Terry, J.K.; Kwiatkowski, A.; Balis, J.U.; De Cola, G.; Deleu, T.; Goulão, M.; Kallinteris, A.; KG, A.; Krimmel, M.; et al. Gymnasium, version v0.28.1; Zenodo: Geneva, Switzerland, 2023. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- Lange, R.T. gymnax: A JAX-based Reinforcement Learning Environment Library. Version 0.0 2022, 4. Available online: https://pypi.org/project/gymnax/ (accessed on 27 May 2025).
- Freeman, C.D.; Frey, E.; Raichuk, A.; Girgin, S.; Mordatch, I.; Bachem, O. Brax–a differentiable physics engine for large scale rigid body simulation. arXiv 2021, arXiv:2106.13281. [Google Scholar]
- Bonnet, C.; Luo, D.; Byrne, D.; Surana, S.; Abramowitz, S.; Duckworth, P.; Coyette, V.; Midgley, L.I.; Tegegn, E.; Kalloniatis, T.; et al. Jumanji: A Diverse Suite of Scalable Reinforcement Learning Environments in JAX. arXiv 2024. [Google Scholar] [CrossRef]
- Koyamada, S.; Okano, S.; Nishimori, S.; Murata, Y.; Habara, K.; Kita, H.; Ishii, S. Pgx: Hardware-accelerated parallel game simulators for reinforcement learning. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Bloor, M.; Torraca, J.; Sandoval, I.O.; Ahmed, A.; White, M.; Mercangöz, M.; Tsay, C.; Chanona, E.A.D.R.; Mowbray, M. PC-Gym: Benchmark Environments For Process Control Problems. arXiv 2024. [Google Scholar] [CrossRef]
- OpenAI; Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar] [CrossRef]
- OpenAI; Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar] [CrossRef]
- Swan, J.; Nivel, E.; Kant, N.; Hedges, J.; Atkinson, T.; Steunebrink, B. Challenges for Reinforcement Learning. In The Road to General Intelligence; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2022; Volume 1049, pp. 33–38. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, C.; Zhang, Z.; Meng, X.; Hong, S.; Li, W.; Wang, Z.; Wang, Z.; Yin, F.; Zhao, J.; et al. Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects. arXiv 2024, arXiv:2401.03428. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:1511.05952. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. arXiv 2017, arXiv:1703.06907. [Google Scholar]
- Taylor, M.E.; Stone, P. Transfer Learning for Reinforcement Learning Domains: A Survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Lazaric, A. Transfer in Reinforcement Learning: A Framework and a Survey. In Reinforcement Learning: State-of-the-Art; Wiering, M., van Otterlo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 143–173. [Google Scholar] [CrossRef]
- Zhu, Z.; Lin, K.; Jain, A.K.; Zhou, J. Transfer Learning in Deep Reinforcement Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13344–13362. [Google Scholar] [CrossRef] [PubMed]
- Ada, S.E.; Ugur, E.; Akin, L.H. Generalization in Transfer Learning. arXiv 2024, arXiv:1909.01331. [Google Scholar]
- Gao, Q.; Yang, H.; Shanbhag, S.M.; Schweidtmann, A.M. Transfer learning for process design with reinforcement learning. Comput. Aided Chem. Eng. 2023, 52, 2005–2010. [Google Scholar] [CrossRef]
- Alam, M.F.; Shtein, M.; Barton, K.; Hoelzle, D. Reinforcement Learning Enabled Autonomous Manufacturing Using Transfer Learning and Probabilistic Reward Modeling. IEEE Control Syst. Lett. 2023, 7, 508–513. [Google Scholar] [CrossRef]
- Mowbray, M.; Smith, R.; Del Rio-Chanona, E.A.; Zhang, D. Using process data to generate an optimal control policy via apprenticeship and reinforcement learning. AIChE J. 2021, 67, e17306. [Google Scholar] [CrossRef]
- Lin, R.; Chen, J.; Xie, L.; Su, H. Facilitating Reinforcement Learning for Process Control Using Transfer Learning: Overview and Perspectives. arXiv 2024, arXiv:2404.00247. [Google Scholar]
- Zhu, Z.; Lin, K.; Dai, B.; Zhou, J. Learning Sparse Rewarded Tasks from Sub-Optimal Demonstrations. arXiv 2020, arXiv:2004.00530. [Google Scholar]
- Oh, J.; Hessel, M.; Czarnecki, W.M.; Xu, Z.; Hasselt, H.v.; Singh, S.; Silver, D. Discovering Reinforcement Learning Algorithms. arXiv 2020, arXiv:2007.08794. [Google Scholar]
- McClement, D.G.; Lawrence, N.P.; Backström, J.U.; Loewen, P.D.; Forbes, M.G.; Gopaluni, B.R. Meta-reinforcement learning for the tuning of PI controllers: An offline approach. J. Process Control 2022, 118, 139–152. [Google Scholar] [CrossRef]
- Kirsch, L.; van Steenkiste, S.; Schmidhuber, J. Improving Generalization in Meta Reinforcement Learning using Learned Objectives. arXiv 2019, arXiv:1910.04098. [Google Scholar]
- Rakelly, K.; Zhou, A.; Quillen, D.; Finn, C.; Sergey, L. Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables. arXiv 2019, arXiv:1903.08254. [Google Scholar]
- Korkmaz, E. A Survey Analyzing Generalization in Deep Reinforcement Learning. arXiv 2024, arXiv:2401.02349v1. [Google Scholar]
- Lockwood, O.; Si, M. A Review of Uncertainty for Deep Reinforcement Learning. In Proceedings of the Eighteenth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Pomona, CA, USA, 24–28 October 2022; Volume 18. [Google Scholar]
- Zhao, X.; Hu, S.; Cho, J.H.; Chen, F. Uncertainty-based Decision Making Using Deep Reinforcement Learning. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, P.; Escontrela, A.; Hafner, D.; Abbeel, P.; Goldberg, K. Daydreamer: World models for physical robot learning. In Proceedings of the Conference on Robot Learning, PMLR, Atlanta, GA, USA, 6–9 November 2023; pp. 2226–2240. [Google Scholar]
- Diehl, C.; Sievernich, T.S.; Krüger, M.; Hoffmann, F.; Bertram, T. Uncertainty-Aware Model-Based Offline Reinforcement Learning for Automated Driving. IEEE Robot. Autom. Lett. 2023, 8, 1167–1174. [Google Scholar] [CrossRef]
- Ghavamzadeh, M.; Mannor, S.; Pineau, J.; Tamar, A. Bayesian Reinforcement Learning: A Survey. arXiv 2016, arXiv:1609.04436. [Google Scholar]
- O’Donoghue, B. Variational bayesian reinforcement learning with regret bounds. Adv. Neural Inf. Process. Syst. 2021, 34, 28208–28221. [Google Scholar]
- Rana, K.; Dasagi, V.; Haviland, J.; Talbot, B.; Milford, M.; Sünderhauf, N. Bayesian controller fusion: Leveraging control priors in deep reinforcement learning for robotics. Int. J. Robot. Res. 2023, 42, 123–146. [Google Scholar] [CrossRef]
- Kang, P.; Tobler, P.N.; Dayan, P. Bayesian reinforcement learning: A basic overview. Neurobiol. Learn. Mem. 2024, 211, 107924. [Google Scholar] [CrossRef]
- Roy, S.S.; Everitt, R.G.; Robert, C.P.; Dutta, R. Generalized Bayesian deep reinforcement learning. arXiv 2024, arXiv:2412.11743. [Google Scholar]
- Gan, Y.; Dai, Z.; Wu, L.; Liu, W.; Chen, L. Deep Reinforcement Learning and Dempster-Shafer Theory: A Unified Approach to Imbalanced Classification. In Proceedings of the 2023 IEEE 3rd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Wuhan, China, 15–17 December 2023; pp. 67–72. [Google Scholar]
- Tang, Y.; Zhou, Y.; Zhou, Y.; Huang, Y.; Zhou, D. Failure Mode and Effects Analysis on the Air System of an Aero Turbofan Engine Using the Gaussian Model and Evidence Theory. Entropy 2023, 25. [Google Scholar] [CrossRef]
- Tang, Y.; Fei, Z.; Huang, L.; Zhang, W.; Zhao, B.; Guan, H.; Huang, Y. Failure Mode and Effects Analysis Method on the Air System of an Aircraft Turbofan Engine in Multi-Criteria Open Group Decision-Making Environment. Cybern. Syst. 2025, 1–32. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, Y.; Jiang, W.; He, Y.; Deng, X. Intelligent information fusion for conflicting evidence using reinforcement learning and Dempster-Shafer theory. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 190–195. [Google Scholar]
- Anyszka, W. Towards an Approximation Theory of Observable Operator Models. arXiv 2024, arXiv:2404.12070. [Google Scholar]
- Ha, D.; Schmidhuber, J. World models. arXiv 2018, arXiv:1803.10122. [Google Scholar]
- Matsuo, Y.; LeCun, Y.; Sahani, M.; Precup, D.; Silver, D.; Sugiyama, M.; Uchibe, E.; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Netw. 2022, 152, 267–275. [Google Scholar] [CrossRef]
- Chen, C.; Wu, Y.F.; Yoon, J.; Ahn, S. Transdreamer: Reinforcement learning with transformer world models. arXiv 2022, arXiv:2202.09481. [Google Scholar]
- Singh, G.; Peri, S.; Kim, J.; Kim, H.; Ahn, S. Structured world belief for reinforcement learning in pomdp. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 9744–9755. [Google Scholar]
- Subramanian, J.; Sinha, A.; Seraj, R.; Mahajan, A. Approximate Information State for Approximate Planning and Reinforcement Learning in Partially Observed Systems. J. Mach. Learn. Res. 2022, 23, 1–83. [Google Scholar]
- Hafner, D.; Pasukonis, J.; Ba, J.; Lillicrap, T. Mastering diverse domains through world models. arXiv 2023, arXiv:2301.04104. [Google Scholar]
- Luo, F.M.; Xu, T.; Lai, H.; Chen, X.H.; Zhang, W.; Yu, Y. A survey on model-based reinforcement learning. Sci. China Inf. Sci. 2024, 67, 121101. [Google Scholar] [CrossRef]
- Uehara, M.; Sekhari, A.; Lee, J.D.; Kallus, N.; Sun, W. Provably Efficient Reinforcement Learning in Partially Observable Dynamical Systems. Adv. Neural Inf. Process. Syst. 2022, 35, 578–592. [Google Scholar]
- Uehara, M.; Kiyohara, H.; Bennett, A.; Chernozhukov, V.; Jiang, N.; Kallus, N.; Shi, C.; Sun, W. Future-Dependent Value-Based Off-Policy Evaluation in POMDPs. In Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Wang, R.; Du, S.S.; Yang, L.; Salakhutdinov, R.R. On reward-free reinforcement learning with linear function approximation. Adv. Neural Inf. Process. Syst. 2020, 33, 17816–17826. [Google Scholar]
- Jin, C.; Yang, Z.; Wang, Z.; Jordan, M.I. Provably efficient reinforcement learning with linear function approximation. In Proceedings of the Conference on Learning Theory, PMLR, Graz, Austria, 9–12 July 2020; pp. 2137–2143. [Google Scholar]
- Long, J.; Han, J. Reinforcement Learning with Function Approximation: From Linear to Nonlinear. arXiv 2022, arXiv:2302.09703. [Google Scholar]
- Zhao, H.; He, J.; Gu, Q. A nearly optimal and low-switching algorithm for reinforcement learning with general function approximation. Adv. Neural Inf. Process. Syst. 2024, 37, 94684–94735. [Google Scholar]
- Shanahan, M. Talking About Large Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Adv. Neural Inf. Process. Syst. 2023, 36, 11809–11822. [Google Scholar]
- Besta, M.; Blach, N.; Kubicek, A.; Gerstenberger, R.; Podstawski, M.; Gianinazzi, L.; Gajda, J.; Lehmann, T.; Niewiadomski, H.; Nyczyk, P.; et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 17682–17690. [Google Scholar]
- Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Sunderhauf, N.; Reid, I.; Gould, S.; Van Den Hengel, A. Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3674–3683. [Google Scholar] [CrossRef]
- Jiang, Y.; Gu, S.; Murphy, K.; Finn, C. Language as an Abstraction for Hierarchical Deep Reinforcement Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Cao, Y.; Zhao, H.; Cheng, Y.; Shu, T.; Chen, Y.; Liu, G.; Liang, G.; Zhao, J.; Yan, J.; Li, Y. Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Yang, X.; Wang, Z.; Zhu, X.; Zhou, J.; Qiao, Y.; Wang, X.; Li, H.; Lu, L.; Dai, J. Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft. arXiv 2024. [Google Scholar] [CrossRef]
- Chakraborty, S.; Weerakoon, K.; Poddar, P.; Elnoor, M.; Narayanan, P.; Busart, C.; Tokekar, P.; Bedi, A.S.; Manocha, D. RE-MOVE: An Adaptive Policy Design for Robotic Navigation Tasks in Dynamic Environments via Language-Based Feedback. arXiv 2023. [Google Scholar] [CrossRef]
- Pang, J.C.; Yang, X.Y.; Yang, S.H.; Yu, Y. Natural Language-conditioned Reinforcement Learning with Inside-out Task Language Development and Translation. arXiv 2023. [Google Scholar] [CrossRef]
- Vyas, J.; Mercangöz, M. Autonomous Industrial Control using an Agentic Framework with Large Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Vouros, G.A. Explainable deep reinforcement learning: State of the art and challenges. Acm. Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Canese, L.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Spanó, S. Multi-agent reinforcement learning: A review of challenges and applications. Appl. Sci. 2021, 11, 4948. [Google Scholar] [CrossRef]
- Wong, A.; Bäck, T.; Kononova, A.V.; Plaat, A. Deep multiagent reinforcement learning: Challenges and directions. Artif. Intell. Rev. 2023, 56, 5023–5056. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Levine, N.; Mankowitz, D.J.; Li, J.; Paduraru, C.; Gowal, S.; Hester, T. Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis. Mach. Learn. 2021, 110, 2419–2468. [Google Scholar] [CrossRef]
- Hutsebaut-Buysse, M.; Mets, K.; Latré, S. Hierarchical reinforcement learning: A survey and open research challenges. Mach. Learn. Knowl. Extr. 2022, 4, 172–221. [Google Scholar] [CrossRef]
- Srinivasan, A. Reinforcement Learning: Advancements, Limitations, and Real-world Applications. Int. J. Sci. Res. Eng. Manag. (IJSREM) 2023, 7, 8. [Google Scholar] [CrossRef]
- Casper, S.; Davies, X.; Shi, C.; Gilbert, T.K.; Scheurer, J.; Rando, J.; Freedman, R.; Korbak, T.; Lindner, D.; Freire, P.; et al. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv 2023, arXiv:2307.15217. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Reference | Key Features | Year |
|---|---|---|---|
| DQN | Mnih et al. [28] | Addressed issues of bias and variance in Q-learning algorithms by introducing target Q-networks and exploiting experience replay | 2013 |
| DPG | Silver et al. [29] | A representative departure from stochastic policies that provides the theoretical foundation for deterministic policies in modern RL | 2014 |
| DDPG | Lillicrap et al. [30] | Leveraged the tools from DQN to provide a stable and efficient deterministic policy algorithm for continuous action spaces | 2015 |
| TRPO | Schulman et al. [31] | Policy update by minimizing the KL-divergence between new and old policies | 2015 |
| PPO | Schulman et al. [32] | Clipped surrogate objective to avoid the expensive computation of KL-divergence | 2017 |
| TD3 | Fujimoto et al. [33] | Twin independent Q-networks, target policy smoothing with clipped noise, delayed policy update | 2018 |
| SAC | Haarnoja et al. [34] | Entropy term added for soft Bellman equation, stochastic policy | 2018 |
| RND | Burda et al. [35] | Introduces an exploration bonus using the prediction error of a fixed initial neural network for policy improvement | 2018 |
| CQL | Kumar et al. [36] | Learns a conservative Q-function to address limitations in standard off-policy RL methods | 2020 |
| Distributional SAC | Duan et al. [37], Ma et al. [38] | Leverages distribution function to mitigate Q-value overestimation | 2020, 2020 |
| Diffusion-QL | Wang et al. [39] | Represents the policy as a diffusion model to address challenges associated with function approximation on out-of-distribution actions | 2023 |
| Offline-to-online RL | Zheng et al. [40] | Considers the difference between offline and online data for adaptive policy learning | 2023 |
| PQN | Gallici et al. [41] | Uses LayerNorm to accelerate and simplify temporal difference policy training | 2025 |
| Publication | Algorithm | Key features | Year |
|---|---|---|---|
| Dogru et al. [49] | Contextual bandit | Constrained-RL; Offline training using approximate step-response model; Online fine tuning | 2022 |
| Lakhani et al. [50] | DPG | PID tuning with stability consideration; Episodic tuning; Layer normalization | 2022 |
| Fujii et al. [51] | Policy-gradient-type AC | MIMO process; Complex process with input coupling and input–output lag | 2021 |
| Mate et al. [52] | DDPG | Single DRL agent used to tune multiple PID controllers; Inverting gradients to integrate interval constraints on tuning parameters | 2023 |
| Wang and Ricardez-Sandoval [47] | Modified IDDPG | Nonlinear MIMO; Time-varying uncertainty | 2024 |
| Li and Yu [53] | TGSL-TD3PG | Multiple agents trained via imitation learning and curriculum learning | 2021 |
| Li and Yu [54] | FSSL-TD3 | Improved exploration using fittest survival strategy | 2021 |
| Lawrence et al. [55] | Modified TD3 | Implementation in a real physical process; Software-hardware interplay; Interpretability | 2022 |
| Chowdhury et al. [56] | EMTD3 | Entropy-maximizing stochastic actor for environment exploration, followed by deterministic actor for local exploitation | 2023 |
| Veerasamy et al. [57] | TD3 and SAC | Comparison of discrete and Gaussian reward functions; Nonlinear process | 2024 |
| Shuprajhaa et al. [58] | Modified PPO | Unstable processes with unbounded output; Action repeat; Early stopping | 2022 |
| Publication | Algorithm | Key Features | Year |
|---|---|---|---|
| Spielberg et al. [72] | AC | Discrete-time SISO, MIMO, and nonlinear processes; Set-point tracking and disturbance rejection | 2019 |
| Goulart & Pereira [73] | AC | Particle swarm optimization for RL hyperparameter tuning | 2020 |
| Petsagkourakis et al. [9] | REINFORCE | Batch process with plant-model mismatch; Offline training followed by transfer learning and online deployment | 2020 |
| Bangi and Kwon [74] | DDPG | Principal component analysis for dimensionality reduction; Transfer learning for online deployment | 2021 |
| Siraskar [75] | DDPG | Graded learning technique; MATLAB (R2019a) RL Toolbox and Simulink | 2021 |
| Panjapornpon et al. [76] | DDPG | Multi-agent RL with gated recurrent unit layer; Grid search for hyperparameter tuning | 2022 |
| Patel [77] | DDPG | Problem formulation with domain knowledge | 2023 |
| Bao et al. [78] | DDACP | Immediate reward to provide gradient information to actor; Expectation form of policy gradient | 2021 |
| Elmaz et al. [79] | PPO | Combining two separate process phases; Constraints implemented via logarithmic barrier functions | 2023 |
| Hong et al. [80] | DDPG | DRL-PID cascade control | 2024 |
| Beahr et al. [81] | TD3 | RL-PID in parallel | 2024 |
| Wang and Wu [82] | Physics-informed RL | Integrating Lyapunov stability and policy iteration convergence conditions | 2024 |
| Faridi et al. [83] | Model-based DRL | Deep NN to learn process dynamics | 2024 |
| Croll et al. [84] | – | Comparison of DQN; ppO, TD3, etc. | 2023 |
| Oh [85] | – | Comparison of data-driven MPC using N4SID, NNARX, LSTM vs. model-free RL control using DDPG, TD3, SAC | 2024 |
| Publication | Safety Additions | Key Features | Year |
|---|---|---|---|
| Savage et al. [140] | Constraint tightening with backoffs | GPs to approximate action–value function; Analytical uncertainty; GP-based backoffs | 2021 |
| Pan et al. [141] | Constraint tightening with backoffs | “Oracle”-assisted constrained Q-learning; Self-tuning backoffs using Broyden’s method | 2021 |
| Petsagkourakis et al. [142] | Constraint tightening with Backoffs | Chance constrained policy optimization; GP-based backoffs for policy gradient algorithm | 2022 |
| Kim and Oh [143] | Backoffs and control barrier function | GP-based backoffs; Plant-model mismatches and stochastic disturbances | 2024 |
| Kim and Lee [144] | Control Lyapunov functions | Value function restricted to control Lyapunov function; Asymptotic stability | 2022 |
| Wang and Wu [145] | Control Lyapunov-barrier functions | Value network trained to approximate the control Lyapunov-barrier function; Input constraints | 2024 |
| Bo et al. [146] | Controlled invariant sets | CIS-based initial state sampling, reward design, state reset; Safety supervisor algorithm for online training | 2023 |
| Wang et al. [147] | Controlled invariant sets & Lyapunov functions | Lyapunov neural network trained using data from controlled invariant sets; Transfer learning | 2024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devarakonda, V.S.; Sun, W.; Tang, X.; Tian, Y. Recent Advances in Reinforcement Learning for Chemical Process Control. Processes 2025, 13, 1791. https://doi.org/10.3390/pr13061791
Devarakonda VS, Sun W, Tang X, Tian Y. Recent Advances in Reinforcement Learning for Chemical Process Control. Processes. 2025; 13(6):1791. https://doi.org/10.3390/pr13061791
Chicago/Turabian StyleDevarakonda, Venkata Srikar, Wei Sun, Xun Tang, and Yuhe Tian. 2025. "Recent Advances in Reinforcement Learning for Chemical Process Control" Processes 13, no. 6: 1791. https://doi.org/10.3390/pr13061791
APA StyleDevarakonda, V. S., Sun, W., Tang, X., & Tian, Y. (2025). Recent Advances in Reinforcement Learning for Chemical Process Control. Processes, 13(6), 1791. https://doi.org/10.3390/pr13061791