1. Introduction
Fault detection constitutes a fundamental method in modern engineering practice, with critical applications spanning industrial manufacturing, aerospace systems, and energy production sectors. This systematic approach enables continuous evaluation of equipment operational status through comprehensive monitoring protocols, facilitates early identification of potential abnormalities, and initiates preventive actions to avert critical failures and safety-related emergencies. The implementation of such detection frameworks significantly enhances operational safety parameters, improves system reliability metrics, and optimizes cost efficiency in complex industrial environments [
1]. Over recent decades, substantial research efforts have been devoted to developing sophisticated data-driven methodologies for this purpose. Principal component analysis (PCA) projects the original data into principal component and residual subspaces and monitors variations in these subspaces [
2]. Partial least squares (PLS) focuses on establishing the relationship between process and quality variables by extracting latent variables that maximize the covariance between them [
3]. Considering the dynamics and nonlinearity in data, various variants of PCA and PLS have been developed, including dynamic PCA (DPCA) [
4], kernel PCA [
5], dynamic PLS [
6], and kernel PLS [
7].
In recent years, deep learning (DL) has emerged as a prominent technique for fault detection, owing to its powerful capabilities for automatic feature extraction [
8]. Among various deep learning frameworks, CNNs have been widely applied in image-based fault detection tasks due to their ability to capture spatial hierarchical features [
9]. Recurrent neural networks, especially long short-term memory networks, have demonstrated outstanding performance in time-series fault detection due to their capability to capture temporal dependencies within sequences [
10]. Autoencoders are widely used in anomaly detection by learning the reconstruction of normal operating states, identifying deviations, and marking them as potential faults [
11]. Deep belief networks have been widely researched due to their ability to learn hierarchical representations of data [
12]. These deep learning methods have shown significantly superior performance compared to traditional approaches, particularly when dealing with complex nonlinear relationships in industrial systems.
However, traditional deep learning methods generally assume that the training and testing datasets follow the same distribution [
13]. Furthermore, for the problem of fault detection, fault data in industrial environments are often scarce and costly to obtain, limiting the applicability of these methods in real-world scenarios [
14]. To tackle the problem of data scarcity and distributional mismatch in fault detection, transfer learning (TL) has emerged as a promising solution. By transferring knowledge from a source to a target domain, TL reduces reliance on labeled data and enhances model generalization. It leverages experience gained from source tasks to improve learning for target tasks. Additionally, it boosts learning efficiency by utilizing existing models or features, thus lowering the computational cost of training from scratch. Transfer learning shows significant potential in incipient fault detection across varying conditions, devices, and environments, making it increasingly vital for intelligent fault detection systems [
15].
TL has been effectively utilized in various fields, particularly in fault detection through methods such as parameter and feature transfer, along with domain adaptation [
16]. Parameter transfer focuses on fine-tuning model parameters using target domain data. Shao et al. [
17] applied pre-trained models for machine fault detection by converting sensor data into time–frequency images via wavelet transform and extracting low-level features with pre-trained networks. Zhang et al. [
18] introduced a TL-based method that utilizes neural networks to learn from large-scale source data and adjust network parameters accordingly. Feature-based transfer learning aims to establish a function that maps features between the source and target domains. Wen et al. [
19] developed a deep transfer learning approach based on a sparse autoencoder to mitigate performance degradation in traditional fault detection when training and testing data distributions differ. Wang et al. [
20] proposed probabilistic transfer FA, which employs factor analysis to facilitate autonomous fault detection across varying operational conditions by identifying cross-domain feature spaces. Domain adaptation is an essential aspect of transfer learning, focusing on knowledge transfer from the source domain to the target domain by exploring domain-invariant features that address distributional divergences [
21]. Lu et al. [
22] proposed a deep model called a deep neural network for domain adaptation in fault detection, which utilizes MMD to tackle domain shift issues in machine fault detection under varying operating conditions. Li et al. [
23] introduced a two-stage transfer adversarial network for detecting new faults in rotating machinery. Zhang et al. [
24] developed a domain adaptation method using a geodesic flow kernel to address fault detection challenges in mechanical equipment like gears and bearings across different operational scenarios. An et al. [
25] presented a multi-layer, multi-kernel maximum mean discrepancy approach for bearing fault detection under diverse working conditions.
Despite the encouraging achievements obtained in previous research, the practical implementation of transfer learning still faces several challenges. Firstly, discrepancies in data distribution between source and target domains significantly affect model performance due to variations in operating modes. Secondly, the negative transfer problem arises when excessive differences between domains lead to adverse effects on learning performance. Additionally, transfer learning models must demonstrate robust generalization capabilities for stable performance across various devices and conditions. Therefore, feature alignment during migration is crucial for minimizing inter-domain differences and enhancing generalization.
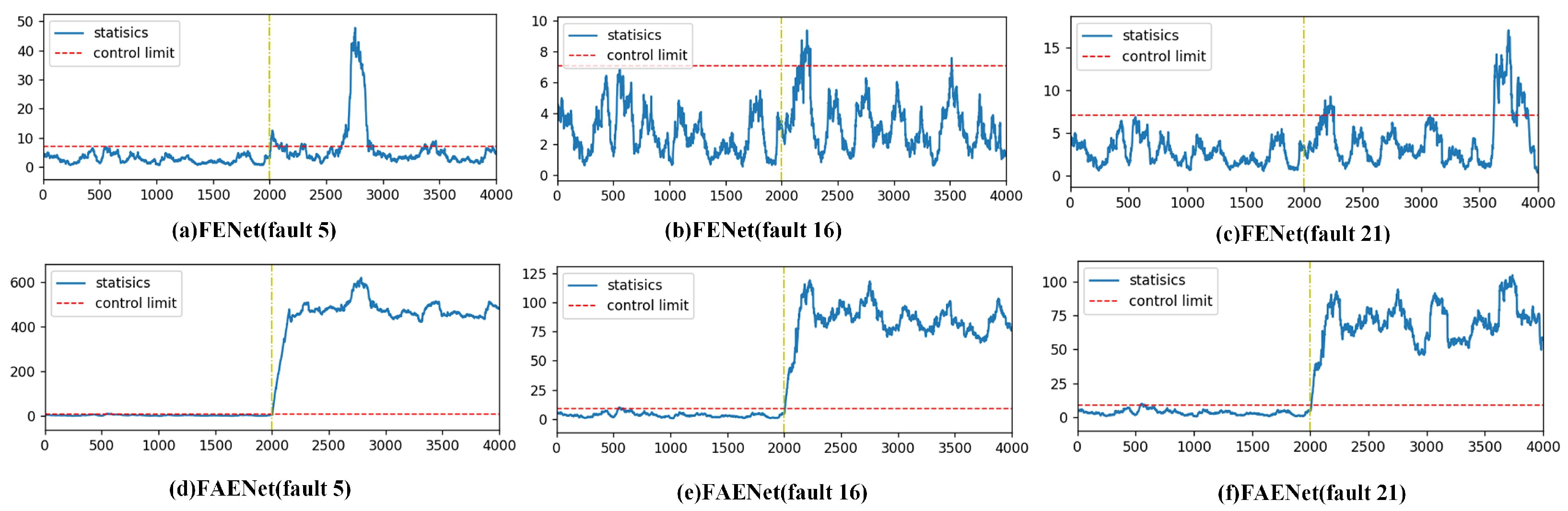
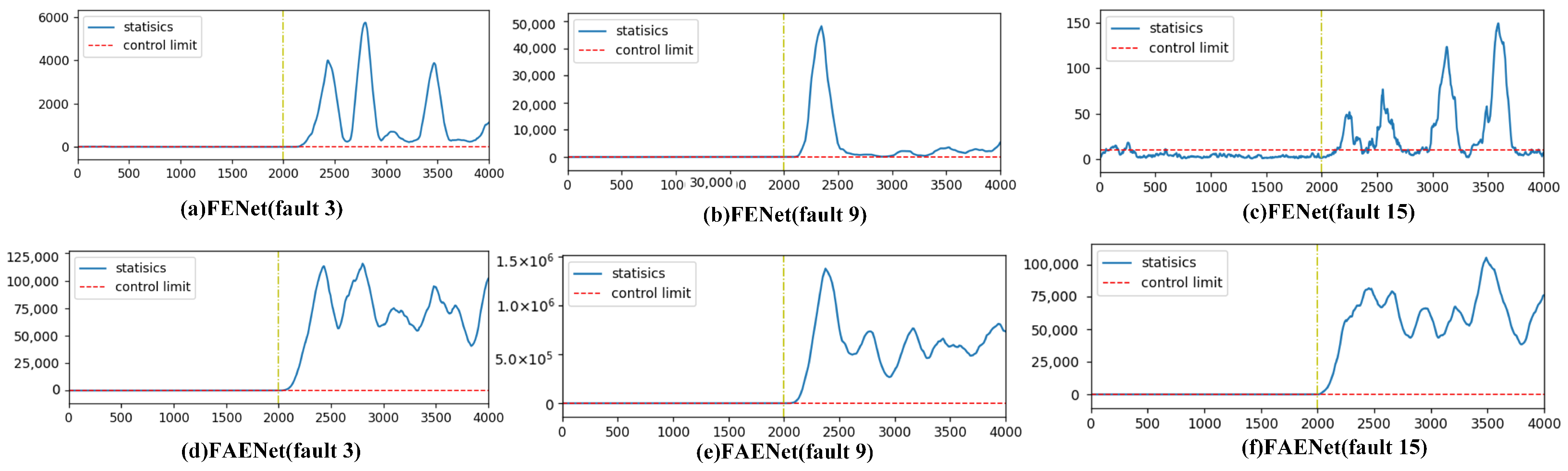
In the field of fault detection, the detection of incipient faults is of paramount importance. Over several decades of development, researchers have proposed numerous methods, including multivariate statistical analysis methods, machine learning approaches, and deep learning techniques. However, the detection of incipient faults is still a difficult task. Taking faults 3, 9, and 15 in TEP as examples, these faults are commonly regarded as incipient faults. Due to their small amplitudes, they are easily contaminated by noise or interference, making them difficult to detect effectively. Even when DL and TL are used, the detection of incipient faults is still difficult. Recently, a feature ensemble net (FENet) [
26] was proposed based on a deep feature ensemble framework, which can detect notorious incipient faults (such as faults 3, 9, and 15 in TEP). Central to FENet is its feature transformer layer, which processes feature matrices through sliding window operations and PCA to extract deep-level information, thereby improving detection capability. FENet demonstrates superior performance in detecting incipient faults through its dual strategy of multi-source feature integration and singular value derivation via sliding window mechanisms.
Although FENet exhibits enhanced detection performance through its deep feature ensemble framework, its principal limitation remains unaddressed: insufficient cross-domain generalization capacity. The constraint underscores the necessity for architectural refinements that prioritize the incorporation of transfer learning mechanisms and domain-agnostic feature encoding strategies within the ensemble framework, thereby optimizing its adaptive capabilities across heterogeneous environments. Crucially, this limitation is rooted in the inherent design of FENet’s feature ensemble matrix, which aggregates statistical and temporal patterns from base detectors like PCA and DPCA. While effective within homogeneous domains, this matrix lacks mechanisms to align cross-domain feature spaces or mitigate negative transfer caused by irrelevant source domain features. Such shortcomings are exacerbated in incipient fault scenarios, where weak signals are further masked by domain shifts.
In the context of fault detection, feature adaptive ensemble net (FAENet) is developed in this article, which consists of two modules, namely, feature adaptive extraction (FAE) and information entropy gain-based feature screening. The FAE framework integrates convolutional neural networks with MMD-based domain adaptation, incorporating information entropy gain-driven feature screening to establish a cross-domain fault detection paradigm with dual technical merits. This framework combines the CNN’s hierarchical pattern recognition capacity with the MMD’s domain-invariant feature alignment mechanism while strategically eliminating redundant features and mitigating negative transfer effects through entropy-based feature selection. The developed FAENet embeds transfer learning within an ensemble learning framework, simultaneously capturing multi-fault correlations in homogeneous conditions and cross-environment stable representations for individual faults. This synthesis produces an optimized transferable feature matrix that substantially improves detection accuracy and enhances model generalization across diverse operational environments.
This paper is organized as follows.
Section 2 provides a formulation of the problem. The detailed description of FAENet is presented in
Section 3. The experimental performances for TEP and CWRU are analyzed and discussed in
Section 4. The implications and limitations of the proposed framework are discussed in
Section 5. Finally, conclusions are given in
Section 6.
2. Problem Formulation
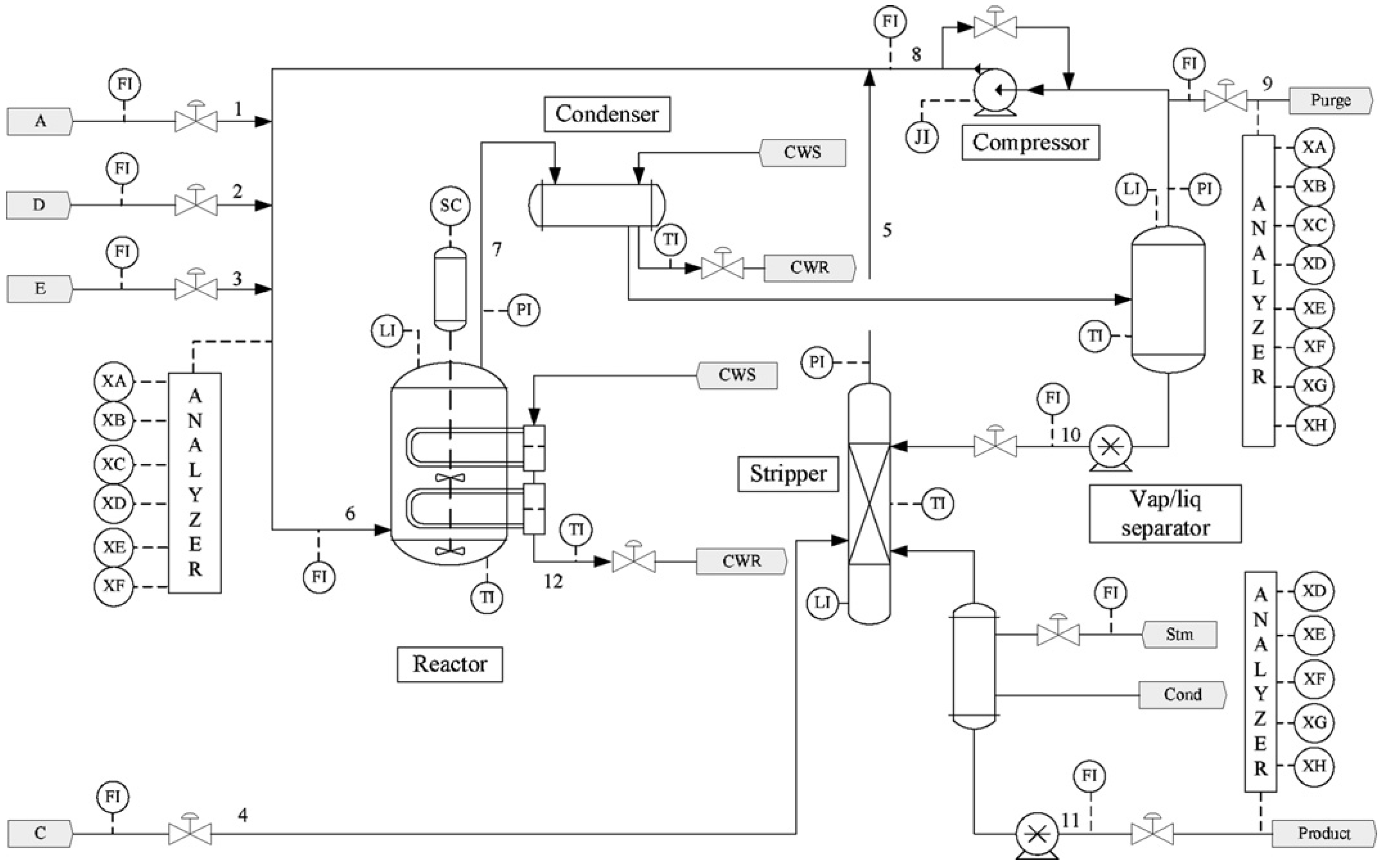
The escalating complexity of modern industrial systems has amplified the operational risks posed by incipient faults, necessitating heightened research focus on these latent system threats. These incipient faults typically manifest through inconspicuous characteristic changes, presenting formidable detection challenges. Contemporary methods of fault detection, ranging from multivariate statistical process monitoring to advanced neural architectures, continue to face persistent limitations in reliably detecting incipient faults, particularly notorious incipient faults 3, 9, and 15 in TEP.
FENet demonstrates improved detection capabilities through the deep feature ensemble framework, yet the principal limitation remains unaddressed: insufficient cross-domain generalization capacity. The operational limitation highlights the imperative for framework enhancements focused on integrating transfer learning paradigms and domain-invariant feature representations within FENet’s ensemble matrix to bolster its generalization potential.
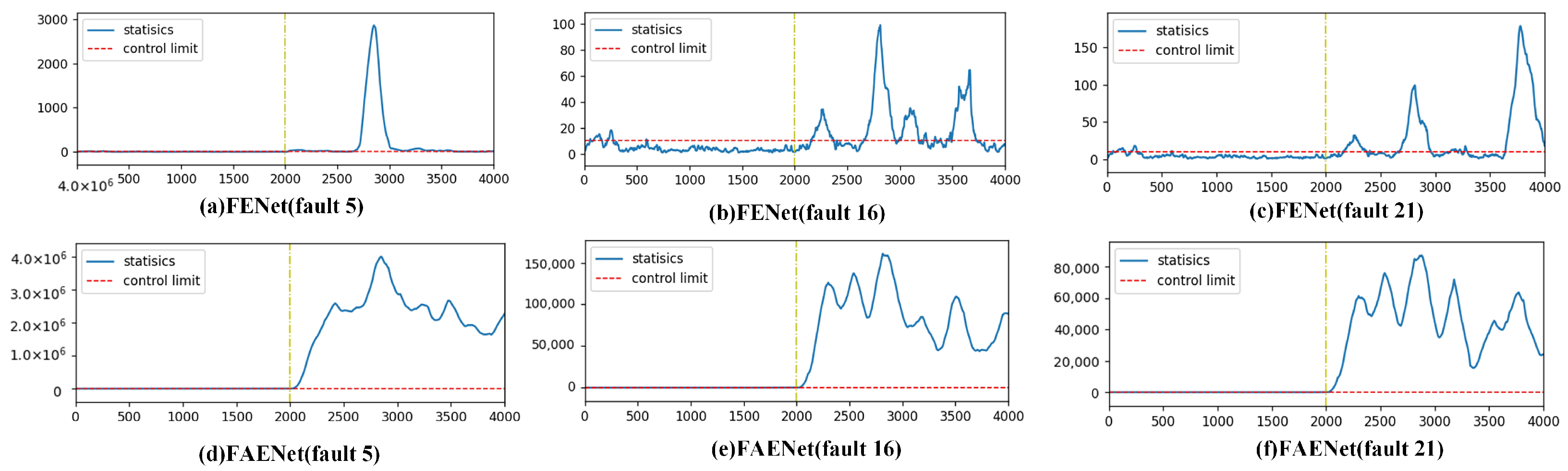
To solve this critical limitation, FAENet is proposed in this article. Compared to FENet, FAENet advances traditional ensemble frameworks through domain-transferable feature integration. While FENet primarily extract within-domain features, FAENet’s feature ensemble matrix systematically encodes domain-invariant features that retain information about faults across heterogeneous operating conditions. This structural innovation significantly improves fault detection accuracy under both data scarcity and cross-domain fault detection, particularly for incipient faults such as faults 3, 5, 9, 15, 16, and 21 in the TEP. The framework’s technical superiority originates from its synergistic combination of FAE and information entropy gain-based feature screening, effectively resolving the balance between stability and adaptability in traditional transfer learning implementations.
In this paper, the problem of incipient fault detection is considered. Here, transfer learning is incorporated within the framework of FENet. Compared to existing ensemble learning approaches, an incipient fault detection method based on FAENet is developed, which is constructed by two key components: FAE and information entropy gain-based feature screening. The key innovation lies in the integration of transfer learning into the ensemble learning framework, which significantly outperforms traditional methods and enhances fault detection accuracy, particularly for faults 3, 5, 9, 15, 16, and 21 in the TEP.
3. Feature Adaptive Ensemble Net
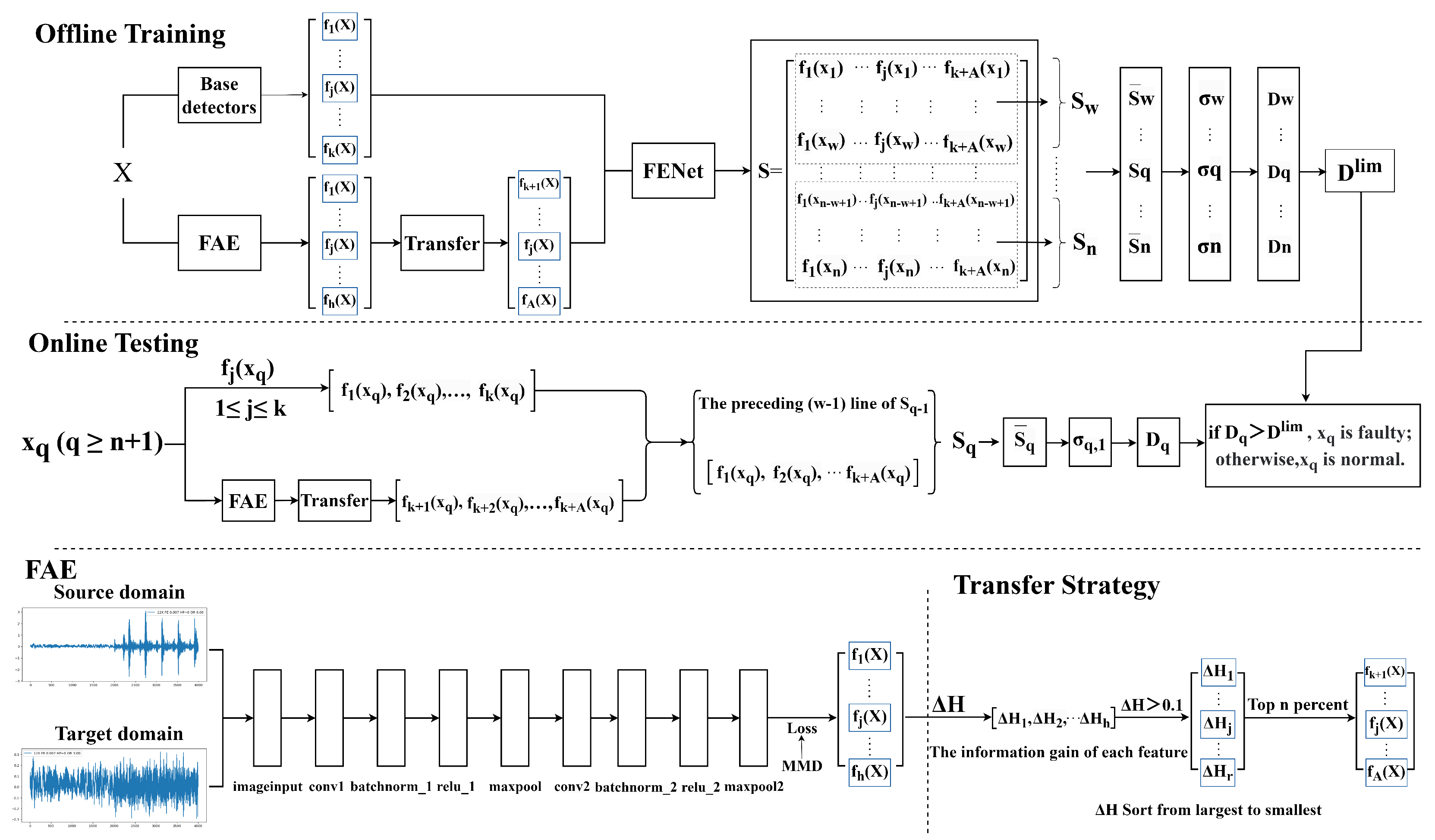
FAENet is proposed for incipient fault detection to address the critical challenge of insufficient cross-domain generalization capacity through a synergistic integration of transfer learning and ensemble learning. As shown in
Figure 1, the overall framework of FAENet is given in three components:
- (1)
A feature adaptive extractor (FAE) leverages a CNN combined with an MMD [
27] to extract domain-invariant features, aligning source and target domain distributions to minimize cross-domain discrepancies.
- (2)
An information entropy gain-driven feature screening module dynamically filters redundant features and mitigates negative transfer effects by evaluating the information gain of each feature relative to fault labels, thereby retaining only discriminative features critical for accurate detection.
- (3)
A deep multi-feature ensemble framework module integrates raw features from statistical detectors (such as PCA, DPCA, and MDs) with transfer features, constructing an adaptive ensemble matrix. This matrix is further processed via sliding window techniques and singular value decomposition (SVD) to capture multi-scale temporal patterns, ultimately generating a detection index.
The specific implementation details of offline training and online detection are respectively presented in Algorithms 1 and 2.
3.1. Feature Adaptive Extractor (FAE)
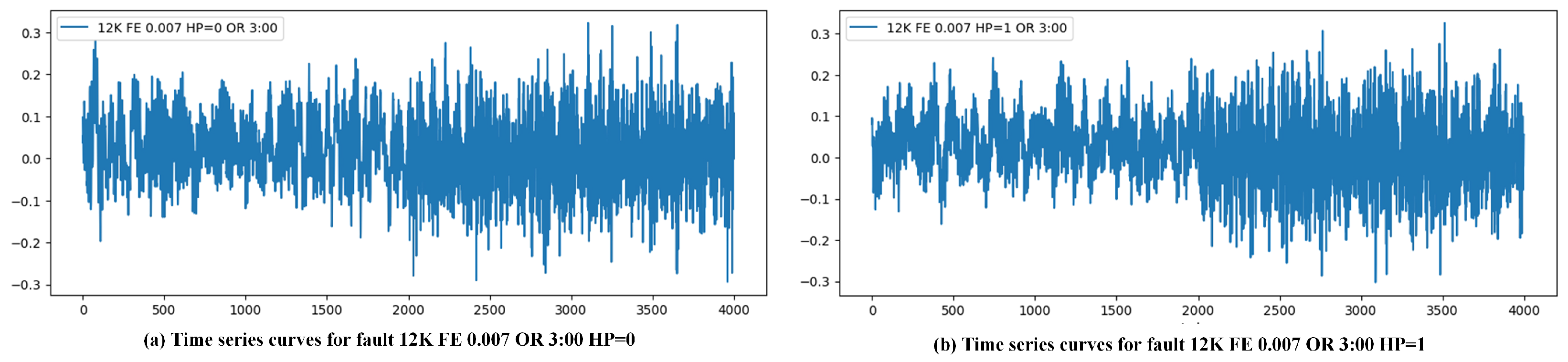
Here, a CNN is utilized for feature extraction. The network consists of an input layer and two convolutional and pooling layers that progressively extract and downsample features. Each convolutional layer is followed by batch normalization and ReLU activation layers to improve network stability and nonlinearity. Finally, a fully connected layer generates the output, and the MMD loss layer is employed for optimization, enhancing model performance of the task.
The network architecture includes two convolutional layers. The first convolutional layer employs a kernel size of 64 to capture broad spatial patterns in the input data, which is particularly effective for extracting high-level fault features from complex industrial signals. The second convolutional layer uses a smaller kernel size of 3 to refine these features and capture more localized patterns [
28]. This hierarchical approach ensures that both global and local features are effectively captured, enhancing the model’s ability to detect incipient faults. The detailed framework of the FAE is shown in
Table 1.
To minimize the discrepancy between the data distributions of the source and target domains, an MMD is adopted as the loss function for the feature extractor. This maps both the source and target domains into a reproducing kernel Hilbert space (RKHS) [
29] using the same mapping and then optimizes the mean discrepancy between the two sets of data in the mapped space to reduce the domain shift.
where H represents the RKHS,
is the feature mapping function that maps the data into the RKHS, and
X and
Y denote the distributions of the source and target domains, respectively, with
n and
m representing the sample sizes of the two distributions.
3.2. Information Entropy Gain-Based Feature Screening
During the transfer process, the problem of negative transfer may arise. Therefore, this paper leverages information entropy gain to select features extracted by FAE, aiming to eliminate redundant features that contribute minimally to fault detection as well as transfer features that negatively impact fault detection accuracy. Information gain measures the extent to which a feature contributes to the label. As the information gain value of a feature increases, its contribution to the label also increases. A higher information gain value indicates a more important feature [
30].
As stated, the difference in information content is referred to as information gain, which is defined as the difference between the original entropy and the conditional entropy under that feature, representing the amount of information gained. The mathematical expression for information entropy is shown in Equation (
2).
Assume that the original dataset obtained through multi-feature optimization combination is denoted as
D, and
A represents the features extracted by the feature extractor. The dataset after adding feature
A is denoted as
D|
A. The information gain is computed by subtracting the entropy of the two datasets. The information obtained is described by Equation (
3).
After the computation, the corresponding entropy matrix
is obtained. To eliminate redundant features with minimal contribution to label detection, features with an information gain
less than 0.1 are filtered out, resulting in the information entropy matrix after feature selection
[
31].
To prevent the negative transfer effects that may arise from the inclusion of multiple features, which could negatively impact fault detection accuracy, an optimization of different information entropy combinations is performed on the filtered information entropy matrix. By selecting and adding different features iteratively, the information entropy for multiple feature sets is computed and ranked. The top-ranked features are then retained as key features, thereby achieving the purpose of feature selection. Ultimately, the features selected through the information entropy gain-based feature screening are obtained.
3.3. Deep Multi-Feature Ensemble Framework
Similarly to FENet, various data-driven fault detection methods, such as PCA and DPCA, are employed as base detectors in FAENet. Using these detectors, an original feature ensemble matrix is created. However, this kind of original feature ensemble matrix may contain a large number of redundant features that contribute minimally to the detection task. These features not only increase computational complexity but also introduce noise, thereby reducing model generalization ability. Additionally, FENet fails to effectively handle situations involving the scarcity of failure samples and under cross-domain detection challenges. The selected feature-based information entropy gain-based feature screening is then incorporated into this original matrix, resulting in the final adaptive feature ensemble matrix. The resulting FENet framework, constructed upon this architecture, demonstrates dual capabilities: precise detection of incipient faults under data scarcity conditions and cross-domain fault detection performance. These distinctive characteristics warrant its designation as FAENet in technical nomenclature.
Let the process measurement data be represented by , where m denotes the number of sensors corresponding to each sample. The training dataset, consisting of n samples under normal operating conditions, is represented as . The mapping from the process data x to the corresponding detection metric for each detector is defined as . For detectors based on multivariate statistical analysis, this function is commonly represented as , where M is the linear projection matrix. For a given sample , after evaluation by k fundamental detectors, the resulting k detection metrics are compiled into a detection feature vector .
Thus, the detection feature vectors corresponding to all training samples
(
i = 1, 2, …,
n) are computed and assembled to represent the input feature matrix
S [
26]:
By incorporating the
A extracted features into Equation (
4), we obtain the proposed adaptive feature matrix:
The adaptive feature ensemble matrix
S obtained is then fed into the feature transformer layer. In each layer, a sliding window technique with a window size of
w is applied to the adaptive feature ensemble matrix from Equation (
5). This results in a sliding window matrix
with a window width of
:
Subsequently, the matrix
undergoes standardization processing:
where
,
represents the mean value of the
detection features corresponding to the
n samples and the diagonal matrix
represents the standard deviation.
After obtaining the normalized matrix
, the SVD is applied as follows:
where
,
, and
are the left singular matrix, diagonal matrix of singular values, and right singular matrix. After SVD, the singular values of the matrix are
.
Further, the singular value matrix
corresponding to the different samples can be obtained:
Similarly to the feature transformation layer in [
26], then, PCA is performed on each
to obtain
corresponding to the
statistics and the
Q statistics:
Then, the output of the
th transformer layer is expressed as:
In the final () feature transformation layer, all output feature matrices corresponding to different sliding window sizes are fused into a large feature matrix based on the sample sampling moments. This fused matrix is denoted as . The matrix , as the feature matrix of the output feature layer, serves as a crucial foundation for the decision layer.
In the decision layer, the input is the feature matrix
from the output feature layer. Based on the feature matrix
, a full sliding window is applied along the row direction, with a sliding window size of
, encompassing all columns of the feature matrix. For the sample
, the corresponding sliding window matrix is represented as
where
.
Then, is normalized to . Applying SVD, the singular values are denoted as .
For the standardized sliding window matrix
, the corresponding maximum singular value is calculated as
, and then the detection index of
can be designed as [
26]:
where
and
represent the mean and standard deviation of
, respectively.
Given the confidence level, the corresponding control limits of the detection index
can be calculated by the empirical method or kernel density estimation (KDE). If
exceeds
,
represents the fault data.
| Algorithm 1 Offline Training |
- Input:
Input data X, number of basic detectors k, width of sliding windows w, number of feature transformer layers , significance level , source domain data , target domain data . - Output:
Control limit , detectors , structure of FENet.
- 1:
Construct k detectors as - 2:
Stack into S via (1) - 3:
Features_s = CNN() - 4:
Features_t = CNN() - 5:
MMD_loss = MMD(Features_s, Features_t) - 6:
Total_loss = Classification_loss + * MMD_loss - 7:
Optimizer.minimize(Total_loss) - 8:
Extract candidate features F = [, , …, ] from FAE output - 9:
Compute information entropy gain for each feature - 10:
for
do - 11:
if then - 12:
Add to matrix F_selected - 13:
end if - 14:
end for - 15:
F_selected = [, , …, ] - 16:
F_selected are ranked in descending order of their information entropy gain - 17:
if
then - 18:
Set , proceed to 26 - 19:
else - 20:
Set - 21:
for do - 22:
Set - 23:
Calculate via (6)–(12) as the output feature matrix in the -th feature transformer layer; - 24:
end for - 25:
end if - 26:
Obtain feature matrix in the output feature layer - 27:
for
do - 28:
Obtain sliding window matrix - 29:
Normalize as - 30:
Calculate singular values of as - 31:
end for - 32:
Calculate detection indices via Equation ( 14) - 33:
Compute with significance level
|
| Algorithm 2 Online Detection |
- Input:
New sample , control limit , detectors , structure of FENet, real-time data stream , trained FAENet model. - Output:
Status (normal or faulty) of .
- 1:
Obtain feature vector for new sample - 2:
= FAE() - 3:
for
do - 4:
if then - 5:
Add to - 6:
end if - 7:
end for - 8:
if
then - 9:
Set - 10:
else - 11:
Set - 12:
Update with and - 13:
for do - 14:
Calculate in the output of the -th feature transformer layer - 15:
end for - 16:
end if - 17:
Update with and in the output feature layer - 18:
Normalize as - 19:
Calculate singular values of as - 20:
Compute detection index via (14) - 21:
Determine status of according to and
|
5. Discussion
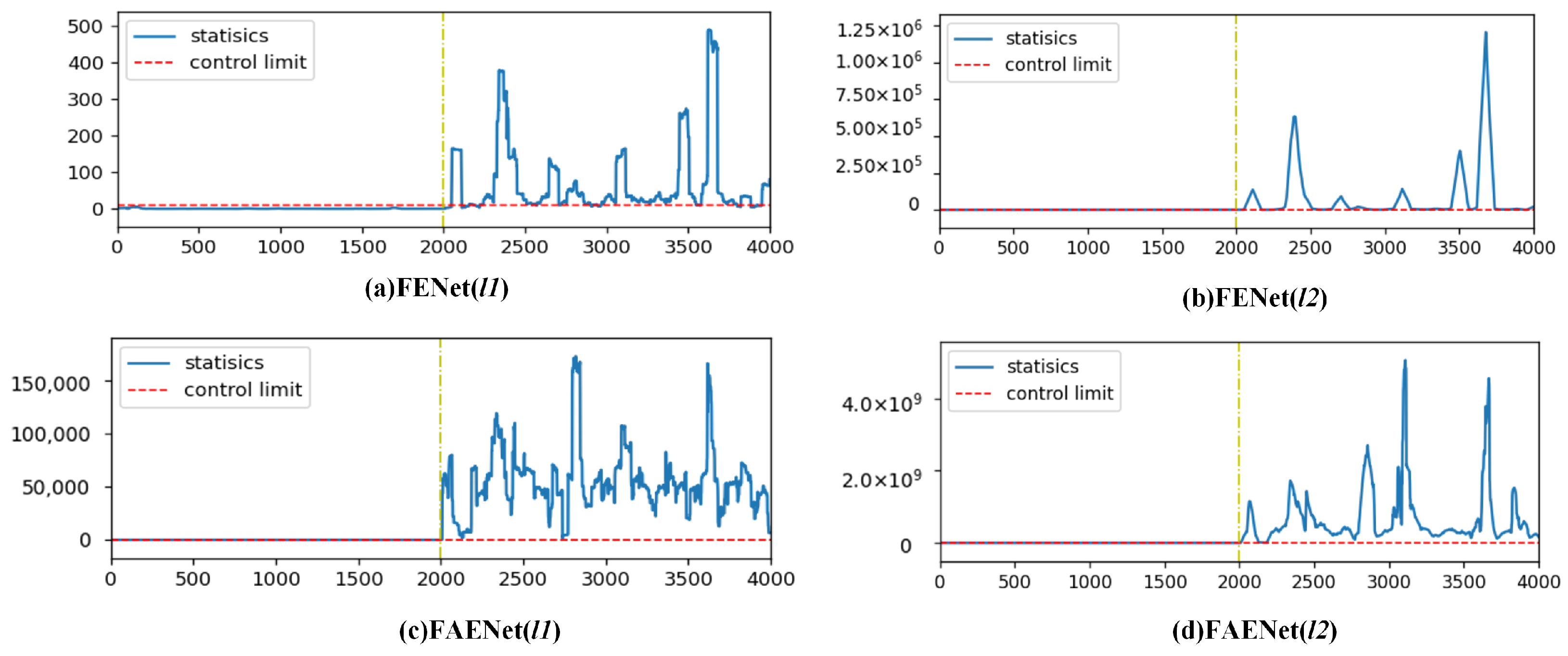
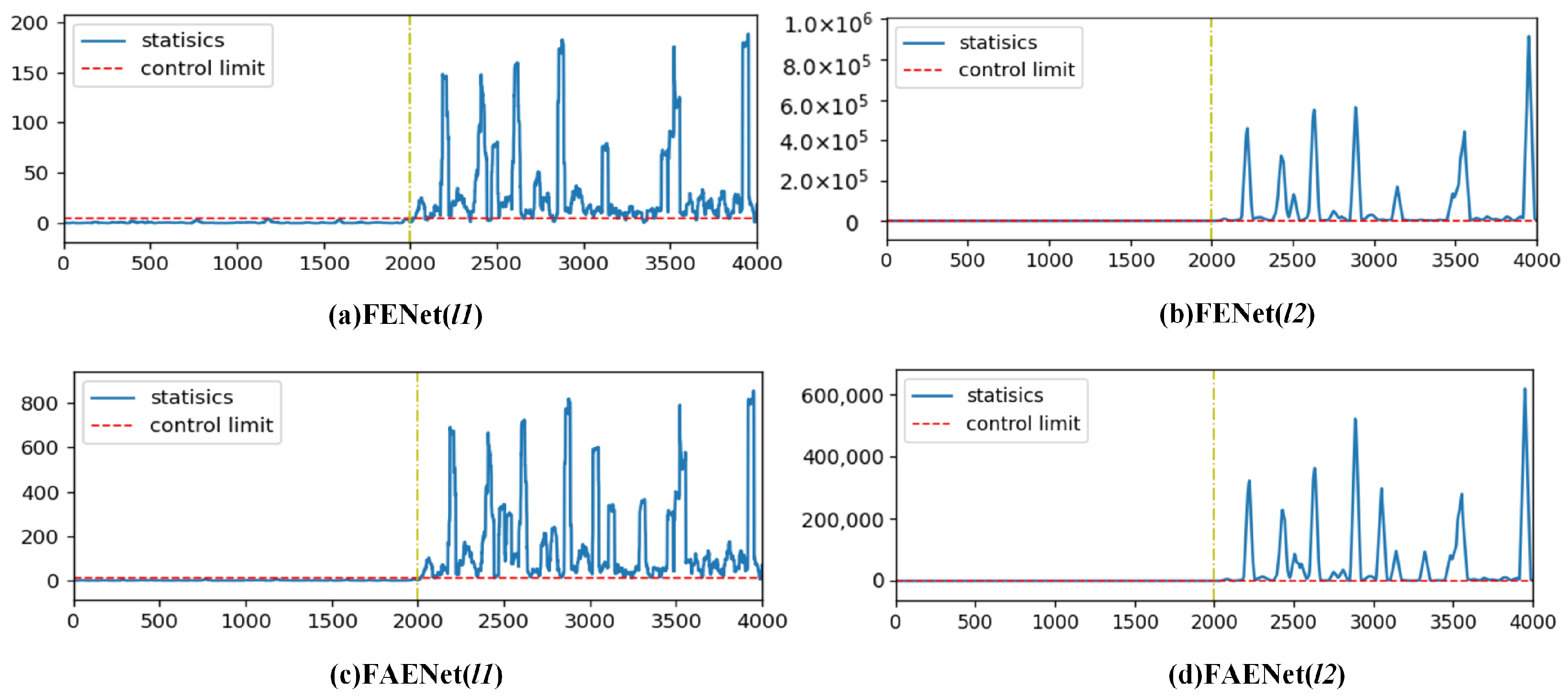
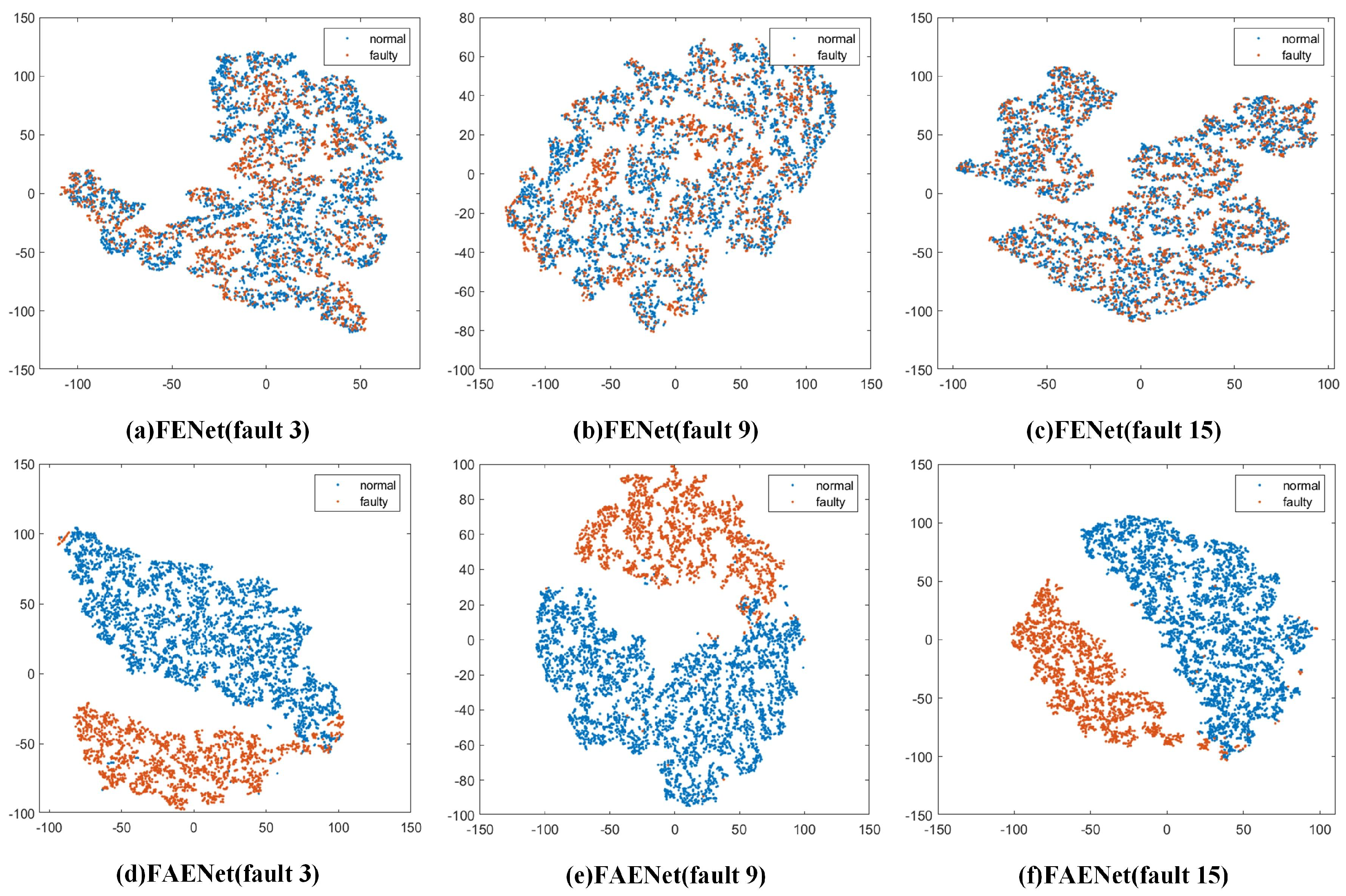
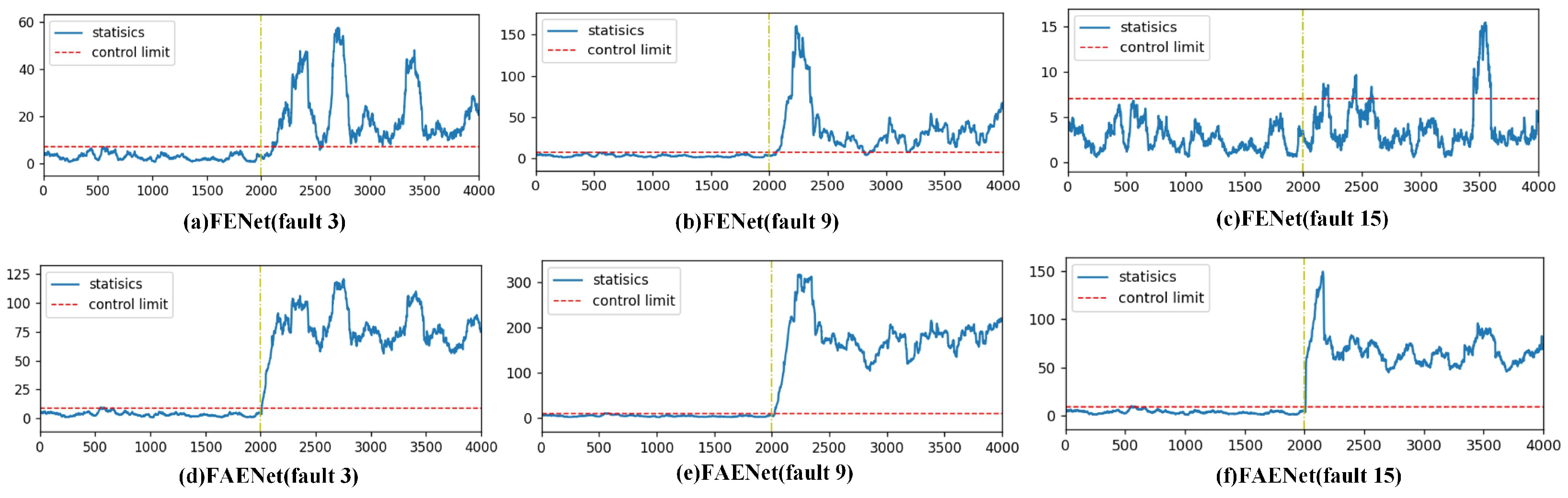
Despite advancements in fault detection technologies, a critical challenge persists: the insufficient cross-domain generalization capacity of existing methods for incipient faults. Traditional approaches, including deep learning frameworks, exhibit limited adaptability under distribution shifts across operational domains. For instance, detecting notoriously challenging TEP faults 3, 9, and 15, even with FENet, remains inefficient due to misaligned feature distributions between the source and target domains. To address this, we integrate transfer learning into the ensemble framework. Through feature adaptive extraction and information entropy gain-based feature screening, FAENet significantly reduces domain discrepancies, aligns marginal distributions, and enhances detection robustness in cross-domain scenarios.
As the number of transformation layers increases, the computational cost of FENet significantly rises due to the increased computational load of SVD. The main contribution of the proposed FAENet method lies in effectively integrating transfer learning into the ensemble learning framework. This method enables successful detection of incipient faults 3, 5, 9, 15, 16, and 21 in the TEP with fewer transformation layers. Therefore, when facing the detection of incipient faults, FAENet proves to be a powerful tool for intelligent fault detection, offering promising applications in practical mechanical detection.
However, in the proposed deep network framework, PCA is employed for feature transformation in the transformation layer. Given the diversity of detection methods, the feature transformer layer should not be limited to PCA; instead, various detectors can be utilized for feature transformation to extract deeper fault detection information. Furthermore, as the dataset grows, the deep network framework can be enhanced into a distributed structure to improve its capacity for handling large-scale data.
While the proposed FAENet demonstrates significant efficacy in detecting single-fault scenarios, the potential for multiple concurrent faults in industrial systems warrants further investigation. In cases where multiple faults occur simultaneously, the superposition of fault signals can amplify the overall impact on system data. This amplification often leads to more pronounced changes in the mean and variance of relevant process variables, potentially enhancing fault detectability. However, the interaction between multiple faults may also introduce complex nonlinearities that challenge traditional detection methods. Future research should explore the performance of FAENet in multi-fault scenarios, particularly focusing on its ability to distinguish and identify individual faults within composite signals. This investigation would provide valuable insights into the method’s robustness and applicability in real-world industrial settings where multiple faults may co-occur.
6. Conclusions
In this paper, FAENet based on a deep learning framework is proposed for incipient fault detection. To improve the cross-domain generalization capacity of FENet while effectively mitigating discrepancies in data distribution between the source domain and target domain, a feature adaptive extractor is developed. Subsequently, information entropy gain-based feature screening is proposed to eliminate redundant features that contribute minimally to fault detection as well as transfer features that negatively affect FDR; this approach facilitates enhanced fault detection. In the simulations, the FDR of FAENet improved by 13.67% and 5.59%, correspondingly, for TEP and CWRU compared to FENet, thereby demonstrating the efficacy of the proposed method.
However, as industrial systems grow increasingly complex, future research should further explore multimodal fusion techniques to enhance the model’s feature representation capability for incipient fault patterns by integrating multi-source heterogeneous data (such as sensor measurements, visual inputs, and time-series signals). Concurrently, combining parallel computing and distributed training strategies could optimize computational efficiency and scalability for industrial big-data scenarios, thereby addressing real-time monitoring demands. Moreover, adaptive modeling frameworks should be developed to capture the time-varying characteristics of dynamic industrial processes, improving the model’s robustness and real-time responsiveness under non-stationary conditions. Advances in these directions will propel intelligent fault detection toward greater efficiency and generalizability, ultimately providing more comprehensive safeguards for industrial safety and reliability.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}