


An Untargeted Gas Chromatography–Ion Mobility Spectrometry Approach for the Geographical Origin Evaluation of Dehydrated Apples


Abstract
1. Introduction
2. Materials and Methods
2.1. Dehydration Process
- -
- Single-process steps: (i) washing, (ii) calibration and selection, (iii) de-peeling/peeling, (iv) cubing, (v) drying, (vi) packaging.
- -
- Shape and size in typically applied cubing/dicing process: irregular cubes ranging from 5 mm to 12.5 mm.
- -
- Drying temperature: <40°.
- -
- Average duration of drying treatment: 6–36 h (dryers created “ad hoc” in company design).
- -
- Final humidity after drying: 3–25%.
2.2. Sampling
2.3. Sample Preparation
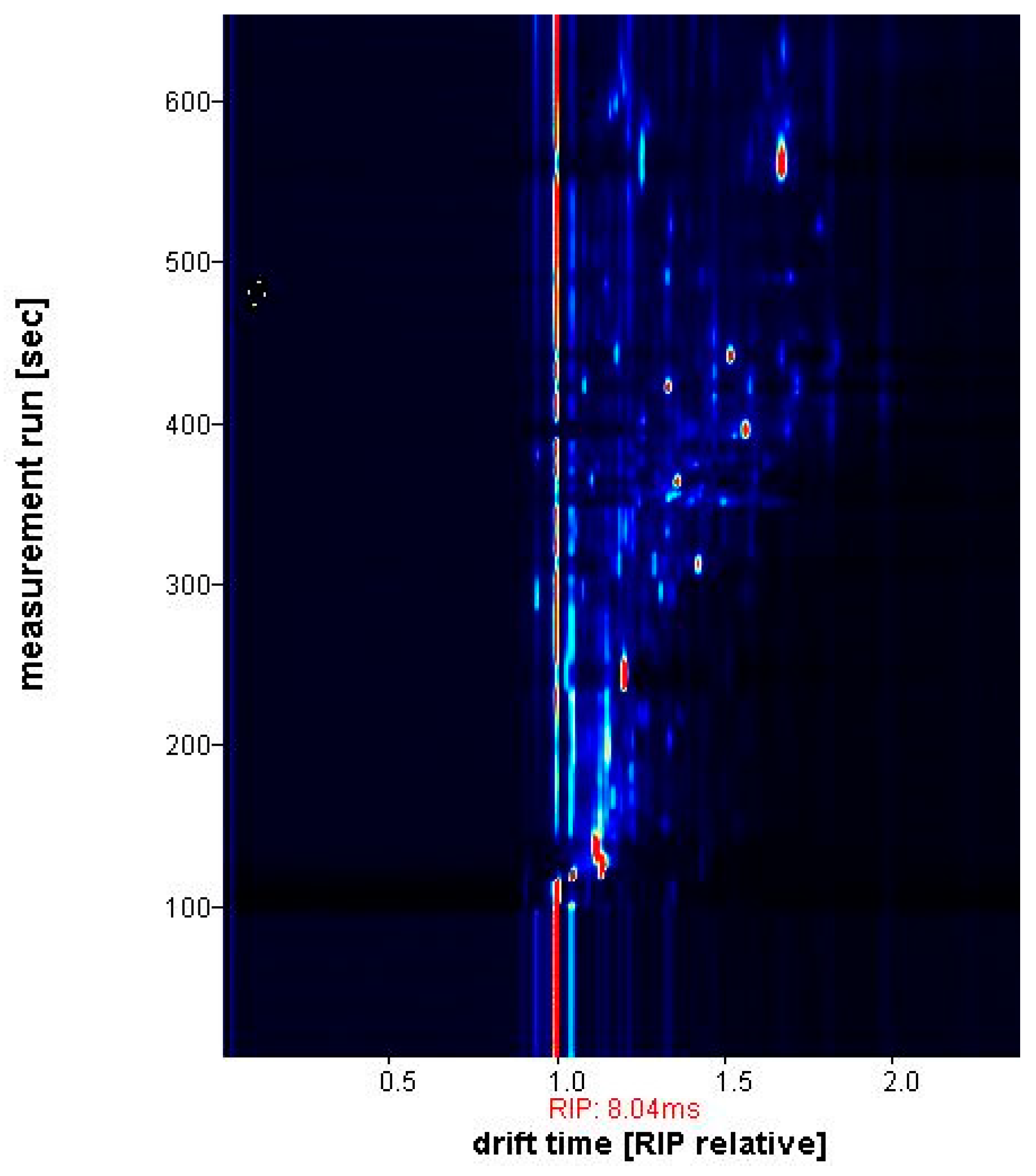
2.4. Instrumental Parameters
2.5. Data Elaboration
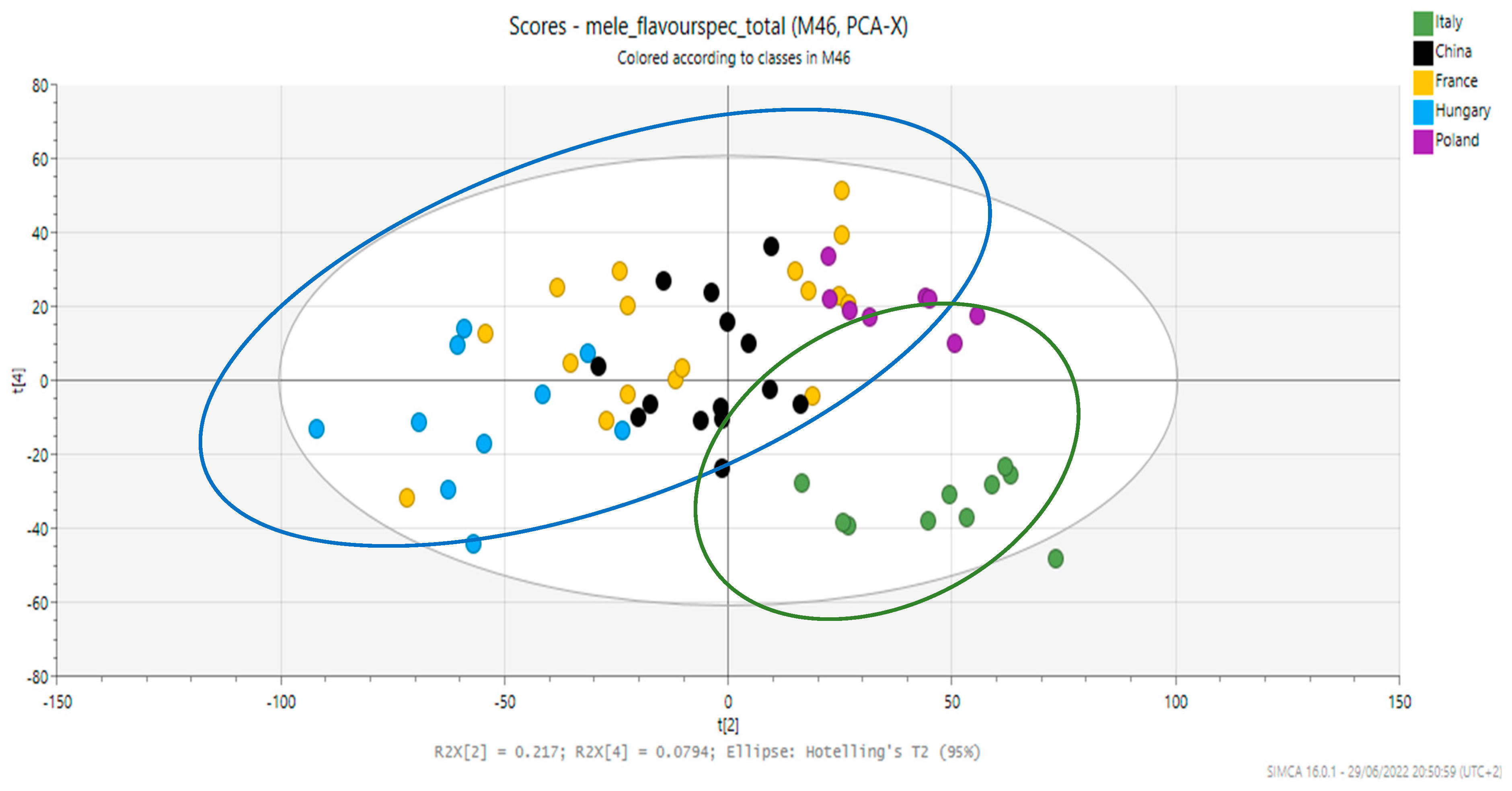
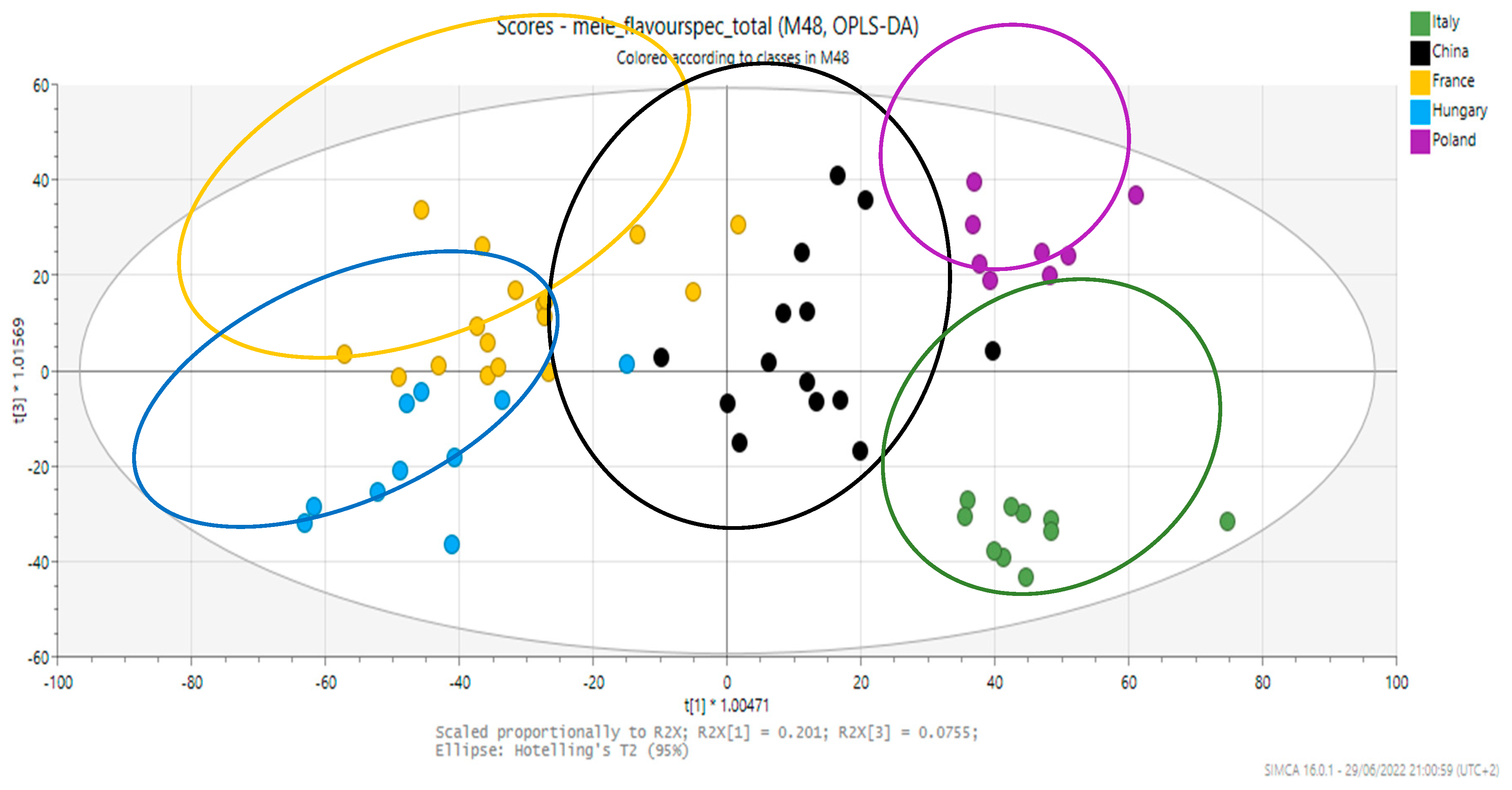
3. Results and Discussion
- -
- If <0.35: the samples did not belong to the class.
- -
- Between 0.35 and 0.65: the samples were borderline.
- -
- If >0.65: the samples belonged to the class.
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, L.; Wu, B.; Zhu, S.; He, Y.; Zhang, C. Application of Visible/Infrared Spectroscopy and Hyperspectral Imaging with Machine Learning Techniques for Identifying Food Varieties and Geographical Origins. Front. Nutr. 2021, 8, 680357. [Google Scholar] [CrossRef] [PubMed]
- Atlas Big. World Apple Production by Country. 2021. Available online: https://au.atlasbig.com/countries-by-apple-production (accessed on 13 January 2023).
- World’s Top Exports. Apples Exports by Country Plus Average Prices. Top Exports. 2021. Available online: https://www.worldstopexports.com/apples-exports-by-country/ (accessed on 23 February 2021).
- Aguzzoni, A.; Bassi, M.; Pignotti, E.; Robatscher, P.; Scandellari, F.; Tirler, W.; Tagliavini, M. Sr isotope composition of Golden Delicious apples in Northern Italy reflects the soil 87Sr/86Sr ratio of the cultivation area. J. Sci. Food Agric. 2020, 100, 3666–3674. [Google Scholar] [CrossRef] [PubMed]
- Global Product Prices. Apples—Prices by Country, Around the World, June 2022. Available online: https://www.globalproductprices.com/rankings/apple_prices/ (accessed on 13 January 2023).
- Li, C.; Li, L.; Wu, Y.; Lu, M.; Yang, Y.; Li, L. Apple Variety Identification Using Near-Infrared Spectroscopy. J. Spectrosc. 2018, 2018, 6935197. [Google Scholar] [CrossRef]
- Schmutzler, M.; Huck, C. Automatic sample rotation for simultaneous determination of geographical origin and quality characteristics of apples based on near infrared spectroscopy (NIRS). Vib. Spectrosc. 2014, 72, 97–104. [Google Scholar] [CrossRef]
- Bat, K.; Vidrih, R.; Necemer, N.; Vodopivec, B.; Mulic, I.; Kump, P.; Ogrinc, N. Characterization of Slovenian Apples with Respect to Their Botanical and Geographical Origin and Agricultural Production Practice. Food Technol. Biotechnol. 2012, 50, 107–116. [Google Scholar]
- Guo, J.; Yue, T.; Yuan, Y. Feature selection and recognition from nonspecific volatile profiles for discrimination of apple juices according to variety and geographical origin. J. Food Sci. 2012, 77, 1090–1096. [Google Scholar] [CrossRef] [PubMed]
- Ruszkiewicz, D.; Myers, R.; Henderson, B.; Yusof, H.; Meister, A.; Moreno, S.; Thomas, C. Peppermint protocol: First results for gas chromatography-ion mobility spectrometry. J. Breath Res. 2022, 16, 036004. [Google Scholar] [CrossRef] [PubMed]
- Gerhardt, N.; Birkenmeier, M.; Schwolow, S.; Rohn, S.; Weller, P. Volatile-Compound Fingerprinting by Headspace-Gas-Chromatography Ion-Mobility Spectrometry (HS-GC-IMS) as a Benchtop Alternative to 1H NMR Profiling for Assessment of the Authenticity of Honey. Anal. Chem. 2018, 90, 1777–1785. [Google Scholar] [CrossRef] [PubMed]
- Gerhardt, N.; Birkenmeier, M.; Sanders, D.; Rohn, S.; Weller, P. Resolution-optimized headspace gas chromatography-ion mobility spectrometry (HS-GC-IMS) for non-targeted olive oil profiling. Anal. Bioanal. Chem. 2017, 409, 3933–3942. [Google Scholar] [CrossRef]
- Schwolow, S.; Gerhardt, N.; Rohn, S.; Weller, P. Data fusion of GC-IMS data and FT-MIR spectra for the authentication of olive oils and honeys—Is it worth to go the extra mile? Anal. Bioanal. Chem. 2019, 411, 6005–6019. [Google Scholar] [CrossRef] [PubMed]
- Feng, T.; Sun, J.; Song, S.; Wang, H.; Yao, L.; Sun, M.; Chen, D. Geographical differentiation of Molixiang table grapes grown in China based on volatile compounds analysis by HS-GC-IMS coupled with PCA and sensory evaluation of the grapes. Food Chem. X 2022, 15, 100423. [Google Scholar] [CrossRef]
- Feng, X.; Wang, H.; Wang, Z.; Huang, P.; Kan, J. Discrimination and characterization of the volatile organic compounds in eight kinds of huajiao with geographical indication of China using electronic nose, HS-GC-IMS and HS-SPME-GC–MS. Food Chem. 2022, 375, 131671. [Google Scholar] [CrossRef] [PubMed]
- Vera, L.; Companioni, E.; Meacham, A.; Gygax, H. Real Time Monitoring of VOC and Odours Based on GC-IMS at Wastewater Treatment Plants. Chem. Eng. Trans. 2016, 54, 79–84. [Google Scholar]
- Kumar, A. PCA Explained Variance Concepts with Python Example. 2023. Available online: https://vitalflux.com/pca-explained-variance-concept-python-example/ (accessed on 15 January 2023).
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury/Thomson Learning: Pacific Groove, CA, USA, 2001. [Google Scholar]
- Ghojogh, B.; Crowley, M. Unsupervised and Supervised Principal Component Analysis: Tutorial. arXiv 2022, arXiv:1906.03148. [Google Scholar]
- Nepomuceno, G.; Cruz Junho, C.V.; Carneiro-Ramos, M.S.; da Silva Martinho, H. Partial Least Squares—Discriminant Analysis (PLS-DA); Scientific Reports; 2021; Available online: https://www.metabolon.com/bioinformatics/pls-da/ (accessed on 15 January 2023).
- Beckwith-Hall, B.M.; Brindle, J.T.; Barton, R.H.; Coen, M.; Holmes, E.; Nicholson, J.K.; Antti, H. Application of orthogonal signal correction to minimise the effects of physical and biological variation in high resolution 1H NMR spectra of biofluids. Analyst 2002, 10, 1283–1288. [Google Scholar] [CrossRef] [PubMed]
- Triba, M.N.; Le Moyec, L.; Amanthieu, R.; Goossens, C.; Bouchemal, N.; Nahon, P.; Savarin, P. PLS/OPLS models in metabolomics: The impact of permutation of dataset rows on the K-fold cross-validation quality parameters. Mol. BioSyst. 2015, 1, 13–19. [Google Scholar] [CrossRef] [PubMed]
- MKS Umetrics. Dynacentrix. 2015. Available online: https://www.dynacentrix.com/telecharg/SimcaP/SIMCA14_User_Guide.pdf (accessed on 15 January 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Members | Correct | Italy | China | France | Hungary | Poland | No Class | |
|---|---|---|---|---|---|---|---|---|
| Italy | 4 | 100% | 4 | 0 | 0 | 0 | 0 | 0 |
| China | 3 | 100% | 0 | 3 | 0 | 0 | 0 | 0 |
| France | 5 | 100% | 0 | 0 | 5 | 0 | 0 | 0 |
| Hungary | 3 | 66.67% | 0 | 0 | 1 | 2 | 0 | 0 |
| Poland | 2 | 100% | 0 | 0 | 0 | 0 | 2 | 0 |
| No class | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Total | 17 | 94.12% | 4 | 3 | 6 | 2 | 2 | 0 |
| Sample ID | Class ID | YVarPS (ITA) | YPredPS (ITA) | YVarPS (NOT ITA) | YPredPS (NOT ITA) |
|---|---|---|---|---|---|
| Chile 1 A | Not Italy | 0 | 0.465 | 1 | 0.535 |
| Chile 1 B | Not Italy | 0 | 0.334 | 1 | 0.666 |
| Chile 2 A | Not Italy | 0 | 0.351 | 1 | 0.649 |
| Chile 2 B | Not Italy | 0 | 0.561 | 1 | 0.439 |
| Chile 3 A | Not Italy | 0 | 0.598 | 1 | 0.402 |
| Chile 3 B | Not Italy | 0 | 0.742 | 1 | 0.258 |
| Chile 4 A | Not Italy | 0 | 0.524 | 1 | 0.476 |
| Chile 4 B | Not Italy | 0 | 0.607 | 1 | 0.393 |
| Italy 1 A | Italy | 1 | 1.107 | 0 | −0.107 |
| Italy 1 B | Italy | 1 | 1.080 | 0 | −0.080 |
| Italy 2 A | Italy | 1 | 1.306 | 0 | −0.306 |
| Italy 2 B | Italy | 1 | 1.229 | 0 | −0.229 |
| Italy 3 A | Italy | 1 | 1.180 | 0 | −0.180 |
| Italy 3 B | Italy | 1 | 1.258 | 0 | −0.258 |
| Italy 4 A | Italy | 1 | 1.317 | 0 | −0.317 |
| Italy 4 B | Italy | 1 | 1.379 | 0 | −0.379 |
| Hungary 1 A | Not Italy | 0 | 1.163 | 1 | −0.163 |
| Hungary 1 B | Not Italy | 0 | 0.993 | 1 | 0.007 |
| Hungary 2 A | Not Italy | 0 | 0.004 | 1 | 0.996 |
| Hungary 2 B | Not Italy | 0 | −0.048 | 1 | 1.048 |
| Hungary 3 A | Not Italy | 0 | 0.102 | 1 | 0.898 |
| Hungary 3 B | Not Italy | 0 | 0.118 | 1 | 0.882 |
| Hungary 4 A | Not Italy | 0 | 0.168 | 1 | 0.832 |
| Hungary 4 B | Not Italy | 0 | 0.142 | 1 | 0.858 |
| Members | Correct | Italy | Not Italy | No Class | |
|---|---|---|---|---|---|
| Italy | 8 | 100% | 8 | 0 | 0 |
| Not Italy | 16 | 56.25% | 3 | 7 | 6 |
| No class | 0 | 0 | 0 | 0 | |
| Total | 17 | 78.12% | 11 | 7 | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sammarco, G.; Dall’Asta, C.; Suman, M. An Untargeted Gas Chromatography–Ion Mobility Spectrometry Approach for the Geographical Origin Evaluation of Dehydrated Apples. Processes 2025, 13, 1373. https://doi.org/10.3390/pr13051373
Sammarco G, Dall’Asta C, Suman M. An Untargeted Gas Chromatography–Ion Mobility Spectrometry Approach for the Geographical Origin Evaluation of Dehydrated Apples. Processes. 2025; 13(5):1373. https://doi.org/10.3390/pr13051373
Chicago/Turabian StyleSammarco, Giuseppe, Chiara Dall’Asta, and Michele Suman. 2025. "An Untargeted Gas Chromatography–Ion Mobility Spectrometry Approach for the Geographical Origin Evaluation of Dehydrated Apples" Processes 13, no. 5: 1373. https://doi.org/10.3390/pr13051373
APA StyleSammarco, G., Dall’Asta, C., & Suman, M. (2025). An Untargeted Gas Chromatography–Ion Mobility Spectrometry Approach for the Geographical Origin Evaluation of Dehydrated Apples. Processes, 13(5), 1373. https://doi.org/10.3390/pr13051373