
Optimizing Product Quality Prediction in Smart Manufacturing Through Parameter Transfer Learning: A Case Study in Hard Disk Drive Manufacturing


Abstract
1. Introduction
2. Preliminaries
2.1. Transfer Learning
- Inductive transfer learning target is where domain labels are provided.
- Transductive transfer learning is where only the source domain labels are available.
- Unsupervised transfer learning is where neither source nor target domain labels are available.
- Instance transfer learning describes approaches that add (weighted) instances from the source domain(s) to the target domain to improve training on the target task.
- Feature representation transfer learning involves mapping instances from both the source and target domains into a shared feature space. This approach can enhance training for the target task.
- Parameter transfer learning involves sharing parameters or priors between source and target domain models to enhance the initial model before training on the target task. In deep transfer learning, this is achieved through the partial reuse of deep neural networks pre-trained on the source domain(s).
- Relational knowledge transfer learning maps relational knowledge from the source to the target domains, which usually requires domain expertise. However, deep transfer learning using generative adversarial networks or end-to-end approaches can alleviate this issue by integrating domain adaptation into the decision-making function.
2.2. Virtual Metrology
2.3. Problem Formulation: Transfer Learning in Seagate Factories
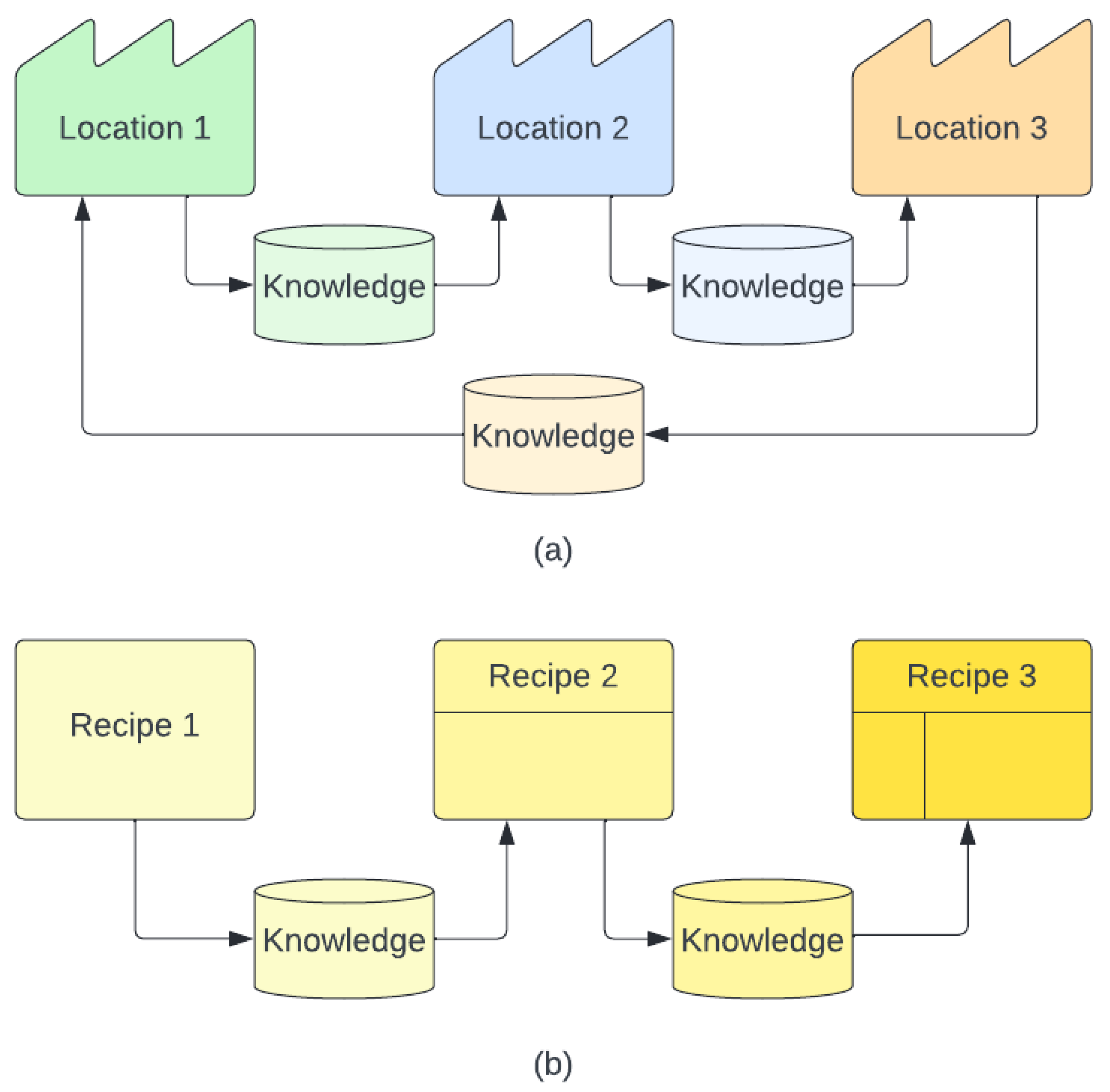
- Cross-factory refers to the transfer of knowledge and expertise from one location to another, as illustrated in Figure 1a. This practice involves leveraging the knowledge gained from one factory or site and applying it to other similar entities located elsewhere. This allows the dissemination of valuable knowledge and the sharing of best practices across different sites, ultimately improving overall performance and efficiency. In the realm of semiconductor manufacturing, a diverse range of deposition tools are utilized to create electronic components via the deposition of a thin film of material onto a substrate. They have the same process parameters, i.e., , while tools vary from each other and are located in different sites, resulting in different performance, i.e., ;
- Cross-recipe refers to the transfer of knowledge from one distinct manufacturing process recipe to another, for instance, from the processing of one product to a different one, , as illustrated in Figure 1b. A recipe in wafer manufacturing typically refers to a set of instructions detailing the specific steps and parameters required to fabricate a component at a given operation in the process flow. In this case, and .
2.4. Manufacturing Data Acquisition
3. Materials and Methods
3.1. Virtual Metrology Base Model Architecture
- Convolutional neural network (CNN), which is described in Section 3.1.1
- Batch Normalization [19], which is a layer to normalize activations in-between deep neural network layers. It also aims to improve deep learning model performance and speed up model training convergence.
- Fully connected layer (also known as a dense layer), which is expressed in Equation (4)where W denotes weight parameters associated with input i, and denotes a bias parameter.
3.1.1. Convolutional Neural Network (CNN)


3.1.2. Multi-Head Self-Attention
- The query (Q), matrix, where is a matrix, as a result, Q is a matrix.
- The key (K), matrix, where is a matrix, and K is a matrix. The scaled dot product between Q and K requires .
- The value (V), matrix where is a matrix, with a size of V.
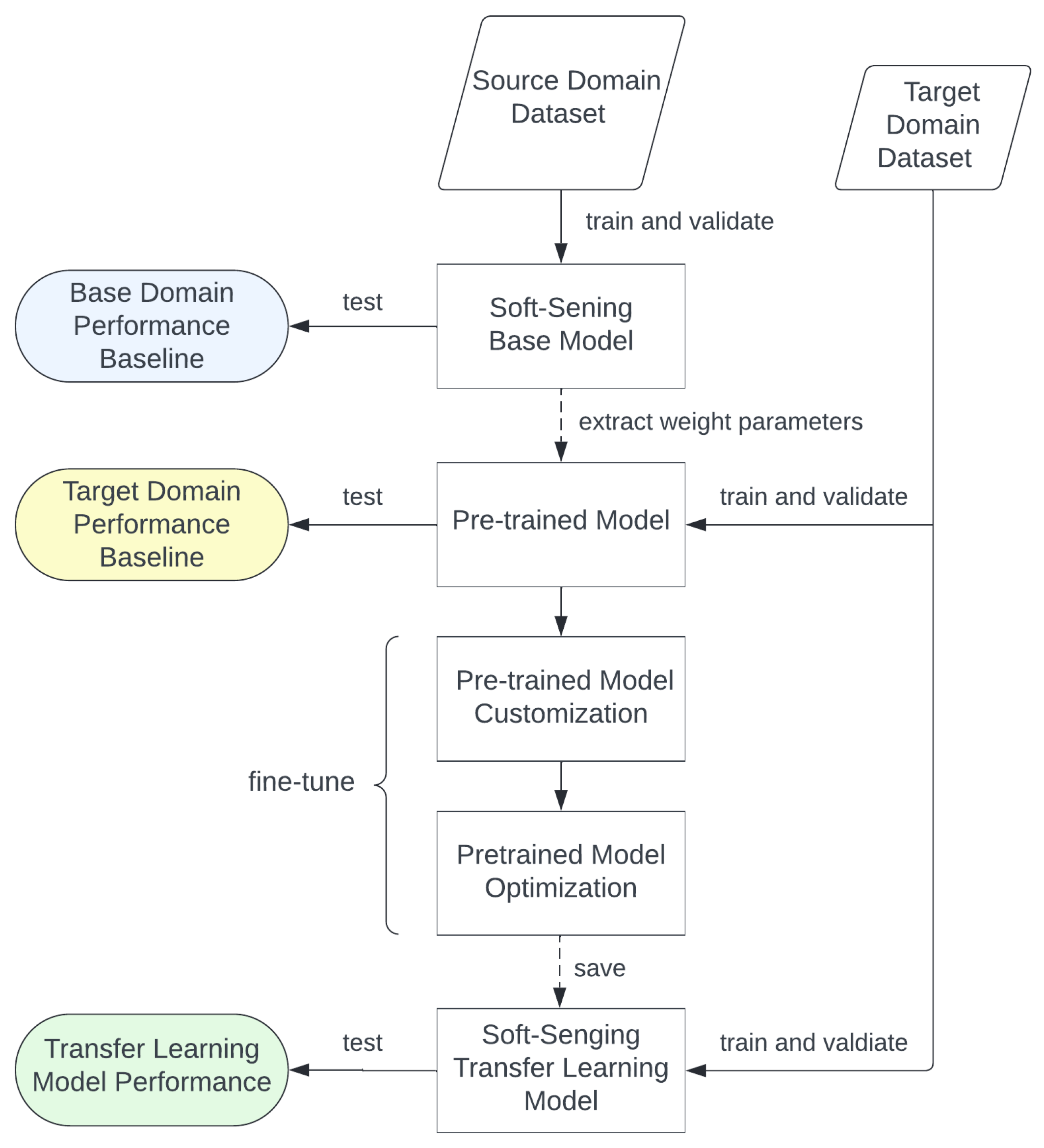
3.2. Parameter Transfer Learning Architecture
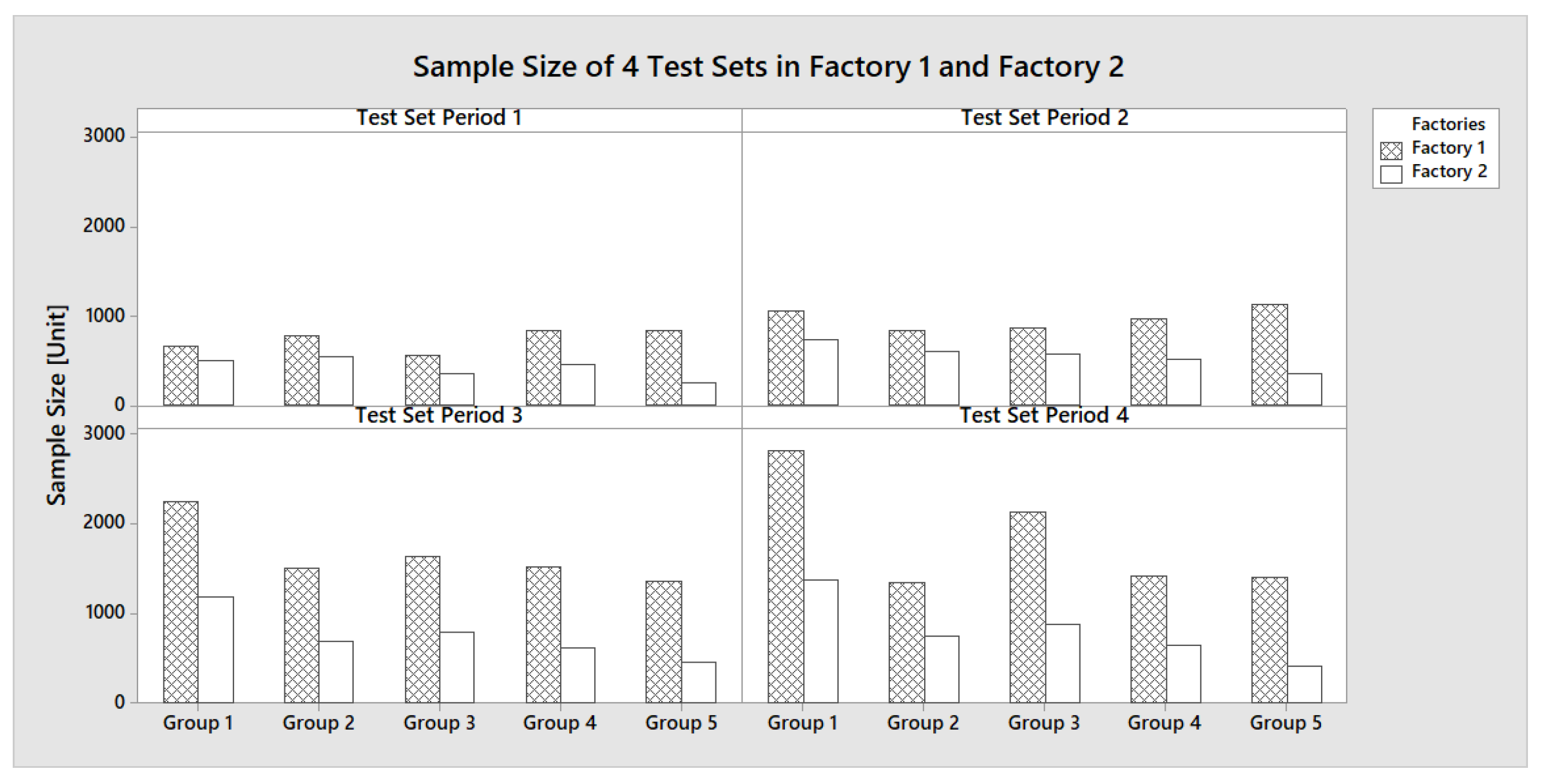
3.3. Experiment Setting
3.3.1. Design of Experiments
3.3.2. Evaluation Metrics
3.3.3. Implementation Details
- Source domain training and evaluation: The base model was trained on data from the source domain, from which the weight parameters of the model were preserved. In this step, the maximum epoch number is set as 2000. The increase in the number of epochs determines the model performance improvement [25]. The initial learning rate is set as 0.001. This pre-trained model serves as a pre-trained baseline.
- Target domain training and evaluation: the base model was trained separately on the target domain dataset using hyperparameter settings identical to those of the source domain.
- Parameter transfer and evaluation: The base model was initialized using the weights from the pre-trained baseline. The weight parameters of the three CNN layers discussed in Section 3.1 are frozen, which restricts learning and prevents weight parameter updates. Conversely, the input layer of a pre-trained model is unfrozen and it may be necessary to modify the input dimensions in cases where the data shapes of the source and target domains differ. A dense layer is appended to the final layer, creating a transfer learning model through fine-tuning. The partially frozen model is re-trained on the target domain, where the epoch is limited to 200, while the initial learning rate is reduced to . Thus, reducing the number of epochs not only decreases training time but also minimizes computational power consumption.
4. Results
4.1. Cross-Factory Transfer Learning Results
4.2. Cross-Recipe Transfer Learning Results


5. Conclusions
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | Area Under the Curve |
| CNN | Convolutional Neural Network |
| FPR | False Positive Rate |
| PTL | Parameter Transfer Learning |
| TPR | True Positive Rate |
| TL | Transfer Learning |
| VM | Virtual Metrology |
References
- Göke, S.; Staight, K.; Vrijen, R. Scaling AI in the Sector That Enables It: Lessons for Semiconductor-Device Makers; Article, McKinsey & Company: New York, NY, USA, 2021. [Google Scholar]
- Petrov, S.; Zhang, C.; Yella, J.; Huang, Y.; Qian, X.; Bom, S. IEEE BigData 2021 Cup: Soft sensing at scale. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 5780–5785. [Google Scholar]
- Symeonidis, G.; Nerantzis, E.; Kazakis, A.; Papakostas, G.A. MLOps-definitions, tools and challenges. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 0453–0460. [Google Scholar]
- Hirai, T.; Kano, M. Adaptive virtual metrology design for semiconductor dry etching process through locally weighted partial least squares. IEEE Trans. Semicond. Manuf. 2015, 28, 137–144. [Google Scholar] [CrossRef]
- Wan, J.; McLoone, S. Gaussian process regression for virtual metrology-enabled run-to-run control in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 2017, 31, 12–21. [Google Scholar] [CrossRef]
- Yella, J.; Zhang, C.; Petrov, S.; Huang, Y.; Qian, X.; Minai, A.A.; Bom, S. Soft-sensing conformer: A curriculum learning-based convolutional transformer. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 1990–1998. [Google Scholar]
- Maschler, B.; Weyrich, M. Deep transfer learning for industrial automation: A review and discussion of new techniques for data-driven machine learning. IEEE Ind. Electron. Mag. 2021, 15, 65–75. [Google Scholar] [CrossRef]
- Tercan, H.; Guajardo, A.; Heinisch, J.; Thiele, T.; Hopmann, C.; Meisen, T. Transfer-learning: Bridging the gap between real and simulation data for machine learning in injection molding. Procedia CIRP 2018, 72, 185–190. [Google Scholar]
- Liang, P.; Yang, H.D.; Chen, W.S.; Xiao, S.Y.; Lan, Z.Z. Transfer learning for aluminium extrusion electricity consumption anomaly detection via deep neural networks. Int. J. Comput. Integr. Manuf. 2018, 31, 396–405. [Google Scholar] [CrossRef]
- Hsieh, R.J.; Chou, J.; Ho, C.H. Unsupervised online anomaly detection on multivariate sensing time series data for smart manufacturing. In Proceedings of the 2019 IEEE 12th conference on service-oriented computing and applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019; pp. 90–97. [Google Scholar]
- Gentner, N.; Kyek, A.; Yang, Y.; Carletti, M.; Susto, G.A. Enhancing scalability of virtual metrology: A deep learning-based approach for domain adaptation. In Proceedings of the 2020 Winter Simulation Conference (WSC), Orlando, FL, USA, 14–18 December 2020; pp. 1898–1909. [Google Scholar]
- Kang, P.; Kim, D.; Cho, S. Semi-supervised support vector regression based on self-training with label uncertainty: An application to virtual metrology in semiconductor manufacturing. Expert Syst. Appl. 2016, 51, 85–106. [Google Scholar] [CrossRef]
- Clain, R.; Borodin, V.; Juge, M.; Roussy, A. Virtual metrology for semiconductor manufacturing: Focus on transfer learning. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1621–1626. [Google Scholar]
- Hsieh, Y.M.; Wang, T.J.; Lin, C.Y.; Peng, L.H.; Cheng, F.T.; Shang, S.Y. Convolutional neural networks for automatic virtual metrology. IEEE Robot. Autom. Lett. 2021, 6, 5720–5727. [Google Scholar] [CrossRef]
- Hsieh, Y.M.; Wang, T.J.; Lin, C.Y.; Tsai, Y.F.; Cheng, F.T. Convolutional Autoencoder and Transfer Learning for Automatic Virtual Metrology. IEEE Robot. Autom. Lett. 2022, 7, 8423–8430. [Google Scholar] [CrossRef]
- Zhang, C.; Yella, J.; Huang, Y.; Qian, X.; Petrov, S.; Rzhetsky, A.; Bom, S. Soft sensing transformer: Hundreds of sensors are worth a single word. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 1999–2008. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding batch normalization. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Anaya-Isaza, A.; Mera-Jiménez, L.; Zequera-Diaz, M. An overview of deep learning in medical imaging. Inform. Med. Unlocked 2021, 26, 100723. [Google Scholar] [CrossRef]
- Zhang, C.; Bis, D.; Liu, X.; He, Z. Biomedical word sense disambiguation with bidirectional long short-term memory and attention-based neural networks. BMC Bioinform. 2019, 20, 502. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, J.; Han, J. Multi-head or Single-head? An Empirical Comparison for Transformer Training. arXiv 2021, arXiv:2106.09650. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Ajayi, O.G.; Ashi, J. Effect of varying training epochs of a Faster Region-Based Convolutional Neural Network on the Accuracy of an Automatic Weed Classification Scheme. Smart Agric. Technol. 2023, 3, 100128. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Groups | Factory 1 Baseline | Factory 2 Baseline | Transfer Learning | Performance Improvement | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TPR | FPR | AUC | TPR | FPR | AUC | TPR | FPR | AUC | TPR | FPR | AUC | |
| Group 1 Train | 0.93201 | 0.10800 | 0.97113 | 0.88554 | 0.08318 | 0.96831 | 0.93820 | 0.05142 | 0.96720 | 5.95% | 38.18% | −0.11% |
| Group 1 Validate | 0.70629 | 0.11295 | 0.85057 | 0.63462 | 0.09050 | 0.86057 | 0.80000 | 0.06798 | 0.90522 | 26.06% | 24.88% | 5.19% |
| Group 1 Test Period 1 | 0.67398 | 0.10550 | 0.86864 | 0.56369 | 0.10275 | 0.79409 | 0.88621 | 0.05657 | 0.96594 | 57.22% | 44.94% | 21.64% |
| Group 1 Test Period 2 | 0.92121 | 0.10061 | 0.96872 | 0.68571 | 0.09773 | 0.83002 | 0.86333 | 0.05568 | 0.93467 | 25.90% | 43.03% | 12.61% |
| Group 1 Test Period 3 | 0.95015 | 0.18340 | 0.93859 | 0.72783 | 0.14003 | 0.85951 | 0.85172 | 0.05846 | 0.96448 | 17.02% | 58.25% | 12.21% |
| Group 1 Test Period 4 | 0.80059 | 0.10215 | 0.93714 | 0.83333 | 0.13264 | 0.90021 | 0.96667 | 0.09797 | 0.96113 | 16.00% | 26.14% | 6.77% |
| Group 2 Train | 0.93409 | 0.11528 | 0.97415 | 0.94842 | 0.05319 | 0.98210 | 0.88152 | 0.05926 | 0.93433 | −7.05% | −11.43% | −4.86% |
| Group 2 Validate | 0.61000 | 0.11607 | 0.75931 | 0.71000 | 0.06187 | 0.86621 | 0.95000 | 0.06630 | 0.95063 | 33.80% | −7.16% | 9.75% |
| Group 2 Test Period 1 | 0.75909 | 0.11886 | 0.85305 | 0.47826 | 0.05971 | 0.77913 | 0.66522 | 0.06060 | 0.90365 | 39.09% | −1.50% | 15.98% |
| Group 2 Test Period 2 | 0.86522 | 0.11623 | 0.91393 | 0.90909 | 0.06180 | 0.97580 | 0.95000 | 0.07753 | 0.98087 | 4.50% | −25.46% | 0.52% |
| Group 2 Test Period 3 | 0.85455 | 0.13802 | 0.91420 | 0.82609 | 0.07526 | 0.87500 | 0.82609 | 0.06124 | 0.93577 | 0.00% | 18.63% | 6.94% |
| Group 2 Test Period 4 | 0.84545 | 0.12663 | 0.92936 | 0.85217 | 0.07244 | 0.94098 | 0.91304 | 0.06530 | 0.95695 | 7.14% | 9.85% | 1.70% |
| Group 3 Train | 0.89352 | 0.04240 | 0.98279 | 0.91161 | 0.02756 | 0.99365 | 0.80991 | 0.01586 | 0.94794 | −11.16% | 42.43% | −4.60% |
| Group 3 Validate | 0.68333 | 0.04118 | 0.82259 | 0.75000 | 0.03240 | 0.87674 | 0.83333 | 0.02041 | 0.93287 | 11.11% | 37.01% | 6.40% |
| Group 3 Test Period 1 | 0.73571 | 0.04196 | 0.83895 | 0.80000 | 0.02920 | 0.92838 | 0.84615 | 0.01580 | 0.99339 | 5.77% | 45.87% | 7.00% |
| Group 3 Test Period 2 | 0.86429 | 0.04168 | 0.98271 | 0.76923 | 0.04006 | 0.96515 | 0.57692 | 0.02505 | 0.92206 | −25.00% | 37.46% | −4.47% |
| Group 3 Test Period 3 | 0.80588 | 0.08444 | 0.92772 | 0.96000 | 0.04666 | 0.98552 | 0.93333 | 0.04873 | 0.99147 | −2.78% | −4.42% | 0.60% |
| Group 3 Test Period 4 | 0.72941 | 0.05041 | 0.95821 | 0.82857 | 0.02601 | 0.92222 | 0.78571 | 0.01300 | 0.94119 | −5.17% | 50.00% | 2.06% |
| Group 4 Train | 0.95660 | 0.02760 | 0.99066 | 0.98889 | 0.03744 | 0.99164 | 0.93670 | 0.02269 | 0.97884 | −5.28% | 39.39% | −1.29% |
| Group 4 Validate | 0.75833 | 0.03079 | 0.90862 | 0.75000 | 0.03889 | 0.89917 | 0.83333 | 0.02602 | 0.90209 | 11.11% | 33.10% | 0.33% |
| Group 4 Test Period 1 | 0.78462 | 0.03438 | 0.91987 | 1.00000 | 0.04249 | 0.99548 | 1.00000 | 0.02875 | 0.99634 | 0.00% | 32.33% | 0.09% |
| Group 4 Test Period 2 | 0.85385 | 0.03801 | 0.97279 | 0.96923 | 0.03265 | 0.98558 | 1.00000 | 0.01986 | 0.99885 | 3.17% | 39.16% | 1.35% |
| Group 4 Test Period 3 | 0.86429 | 0.09857 | 0.93350 | 0.94286 | 0.06368 | 0.96600 | 1.00000 | 0.02785 | 0.99525 | 6.06% | 56.27% | 3.03% |
| Group 4 Test Period 4 | 0.72667 | 0.03707 | 0.89895 | 0.95714 | 0.05412 | 0.95541 | 0.92857 | 0.02163 | 0.97827 | −2.99% | 60.04% | 2.39% |
| Group 5 Train | 0.96456 | 0.11689 | 0.97999 | 0.95556 | 0.04223 | 0.99388 | 0.85062 | 0.01805 | 0.96464 | −10.98% | 57.25% | −2.94% |
| Group 5 Validate | 0.71111 | 0.05238 | 0.87560 | 0.73333 | 0.03164 | 0.91117 | 0.88889 | 0.02222 | 0.99342 | 21.21% | 29.76% | 9.03% |
| Group 5 Test Period 1 | 0.59000 | 0.11687 | 0.81431 | 0.80000 | 0.03235 | 0.91209 | 0.75556 | 0.01846 | 0.99007 | −5.56% | 42.93% | 8.55% |
| Group 5 Test Period 2 | 0.76364 | 0.12612 | 0.88361 | 0.82000 | 0.03294 | 0.90490 | 0.70000 | 0.02950 | 0.86829 | −14.63% | 10.46% | −4.05% |
| Group 5 Test Period 3 | 0.87000 | 0.08823 | 0.95611 | 0.83636 | 0.03217 | 0.93341 | 0.90909 | 0.01783 | 0.91890 | 8.70% | 44.56% | −1.55% |
| Group 5 Test Period 4 | 0.91818 | 0.14869 | 0.95935 | 0.97778 | 0.03656 | 0.99774 | 1.00000 | 0.01895 | 0.99599 | 2.27% | 48.17% | −0.17% |
| Groups | Source Recipe Group Baseline | ||
|---|---|---|---|
| TPR | FPR | AUC | |
| Source Recipe Group Train | 0.86458 | 0.15097 | 0.93659 |
| Source Recipe Group Validate | 0.72516 | 0.14726 | 0.85814 |
| Source Recipe Group Test Period 1 | 0.71519 | 0.15521 | 0.84321 |
| Source Recipe Group Test Period 2 | 0.81882 | 0.15440 | 0.90256 |
| Source Recipe Group Test Period 3 | 0.81758 | 0.18887 | 0.85617 |
| Source Recipe Group Test Period 4 | 0.80371 | 0.15542 | 0.88162 |
| Groups | Target Recipe Group Baseline | Transfer Learning | Performance Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|
| TPR | FPR | AUC | TPR | FPR | AUC | TPR | FPR | AUC | |
| Group 1 Train | 0.77044 | 0.22518 | 0.86848 | 0.85151 | 0.09789 | 0.93316 | 10.52% | 56.53% | 7.45% |
| Group 1 Validate | 0.55652 | 0.22767 | 0.70558 | 0.85932 | 0.09372 | 0.95082 | 54.41% | 58.84% | 34.76% |
| Group 1 Test Period 1 | 0.57600 | 0.23694 | 0.69810 | 0.84621 | 0.09345 | 0.92758 | 46.91% | 60.56% | 32.87% |
| Group 1 Test Period 2 | 0.64615 | 0.22997 | 0.79149 | 0.84504 | 0.09677 | 0.92687 | 30.78% | 57.92% | 17.11% |
| Group 1 Test Period 3 | 0.68571 | 0.22463 | 0.80887 | 0.83282 | 0.09268 | 0.92132 | 21.45% | 58.74% | 13.90% |
| Group 1 Test Period 4 | 0.62857 | 0.23274 | 0.76081 | 0.85038 | 0.09796 | 0.93269 | 35.29% | 57.91% | 22.59% |
| Group 2 Train | 0.82561 | 0.15326 | 0.92443 | 0.85751 | 0.10418 | 0.93781 | 3.86% | 32.03% | 1.45% |
| Group 2 Validate | 0.84444 | 0.15816 | 0.92170 | 0.86780 | 0.09495 | 0.95482 | 2.77% | 39.97% | 3.59% |
| Group 2 Test Period 1 | 0.39000 | 0.16171 | 0.63282 | 0.85308 | 0.10428 | 0.94622 | 118.74% | 35.52% | 49.52% |
| Group 2 Test Period 2 | 0.81000 | 0.15680 | 0.89111 | 0.86183 | 0.10449 | 0.93526 | 6.40% | 33.36% | 4.95% |
| Group 2 Test Period 3 | 0.66667 | 0.16279 | 0.81847 | 0.82443 | 0.10696 | 0.94029 | 23.66% | 34.30% | 14.88% |
| Group 2 Test Period 4 | 0.70909 | 0.18538 | 0.87006 | 0.88538 | 0.10634 | 0.93933 | 24.86% | 42.64% | 7.96% |
| Group 3 Train | 0.84516 | 0.18762 | 0.91333 | 0.86249 | 0.10833 | 0.93528 | 2.05% | 42.26% | 2.40% |
| Group 3 Validate | 0.65714 | 0.17379 | 0.82062 | 0.87034 | 0.09511 | 0.95759 | 32.44% | 45.27% | 16.69% |
| Group 3 Test Period 1 | 0.55652 | 0.20530 | 0.76141 | 0.82137 | 0.11008 | 0.92161 | 47.59% | 46.38% | 21.04% |
| Group 3 Test Period 2 | 0.67826 | 0.17845 | 0.83246 | 0.88779 | 0.10504 | 0.95808 | 30.89% | 41.14% | 15.09% |
| Group 3 Test Period 3 | 0.71852 | 0.21638 | 0.84151 | 0.87481 | 0.10673 | 0.93662 | 21.75% | 50.68% | 11.30% |
| Group 3 Test Period 4 | 0.69231 | 0.18294 | 0.82349 | 0.89313 | 0.11340 | 0.95149 | 29.01% | 38.01% | 15.54% |
| Group 4 Train | 0.79363 | 0.29263 | 0.85537 | 0.86276 | 0.10677 | 0.93883 | 8.71% | 63.52% | 9.76% |
| Group 4 Validate | 0.60000 | 0.23741 | 0.75515 | 0.85043 | 0.10095 | 0.94609 | 41.74% | 57.48% | 25.28% |
| Group 4 Test Period 1 | 0.69474 | 0.29447 | 0.77176 | 0.85191 | 0.10246 | 0.94022 | 22.62% | 65.20% | 21.83% |
| Group 4 Test Period 2 | 0.72222 | 0.30188 | 0.79792 | 0.84462 | 0.10409 | 0.92466 | 16.95% | 65.52% | 15.88% |
| Group 4 Test Period 3 | 0.65000 | 0.26328 | 0.77420 | 0.83206 | 0.10741 | 0.93382 | 28.01% | 59.20% | 20.62% |
| Group 4 Test Period 4 | 0.78947 | 0.31724 | 0.86429 | 0.88923 | 0.10638 | 0.95566 | 12.64% | 66.47% | 10.57% |
| Group 5 Train | 0.92308 | 0.02060 | 0.99582 | 0.85469 | 0.09876 | 0.93944 | −7.41% | −379.49% | −5.66% |
| Group 5 Validate | 0.50000 | 0.02586 | 0.81466 | 0.91207 | 0.09390 | 0.95903 | 82.41% | −263.07% | 17.72% |
| Group 5 Test Period 1 | 0.30000 | 0.03594 | 0.62656 | 0.82016 | 0.10111 | 0.94309 | 173.39% | −181.35% | 50.52% |
| Group 5 Test Period 2 | 0.50000 | 0.02000 | 0.82385 | 0.80000 | 0.09482 | 0.92558 | 60.00% | −374.12% | 12.35% |
| Group 5 Test Period 3 | 0.80000 | 0.05113 | 0.89398 | 0.85736 | 0.10059 | 0.94645 | 7.17% | −96.75% | 5.87% |
| Group 5 Test Period 4 | 0.60000 | 0.02754 | 0.97971 | 0.81719 | 0.09835 | 0.92863 | 36.20% | −257.15% | −5.21% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaitwanidvilai, S.; Sittisombut, C.; Huang, Y.; Bom, S. Optimizing Product Quality Prediction in Smart Manufacturing Through Parameter Transfer Learning: A Case Study in Hard Disk Drive Manufacturing. Processes 2025, 13, 962. https://doi.org/10.3390/pr13040962
Kaitwanidvilai S, Sittisombut C, Huang Y, Bom S. Optimizing Product Quality Prediction in Smart Manufacturing Through Parameter Transfer Learning: A Case Study in Hard Disk Drive Manufacturing. Processes. 2025; 13(4):962. https://doi.org/10.3390/pr13040962
Chicago/Turabian StyleKaitwanidvilai, Somyot, Chaiwat Sittisombut, Yu Huang, and Sthitie Bom. 2025. "Optimizing Product Quality Prediction in Smart Manufacturing Through Parameter Transfer Learning: A Case Study in Hard Disk Drive Manufacturing" Processes 13, no. 4: 962. https://doi.org/10.3390/pr13040962
APA StyleKaitwanidvilai, S., Sittisombut, C., Huang, Y., & Bom, S. (2025). Optimizing Product Quality Prediction in Smart Manufacturing Through Parameter Transfer Learning: A Case Study in Hard Disk Drive Manufacturing. Processes, 13(4), 962. https://doi.org/10.3390/pr13040962