
Improved Vehicle Object Detection Algorithm Based on Swin-YOLOv5s

Abstract
1. Introduction
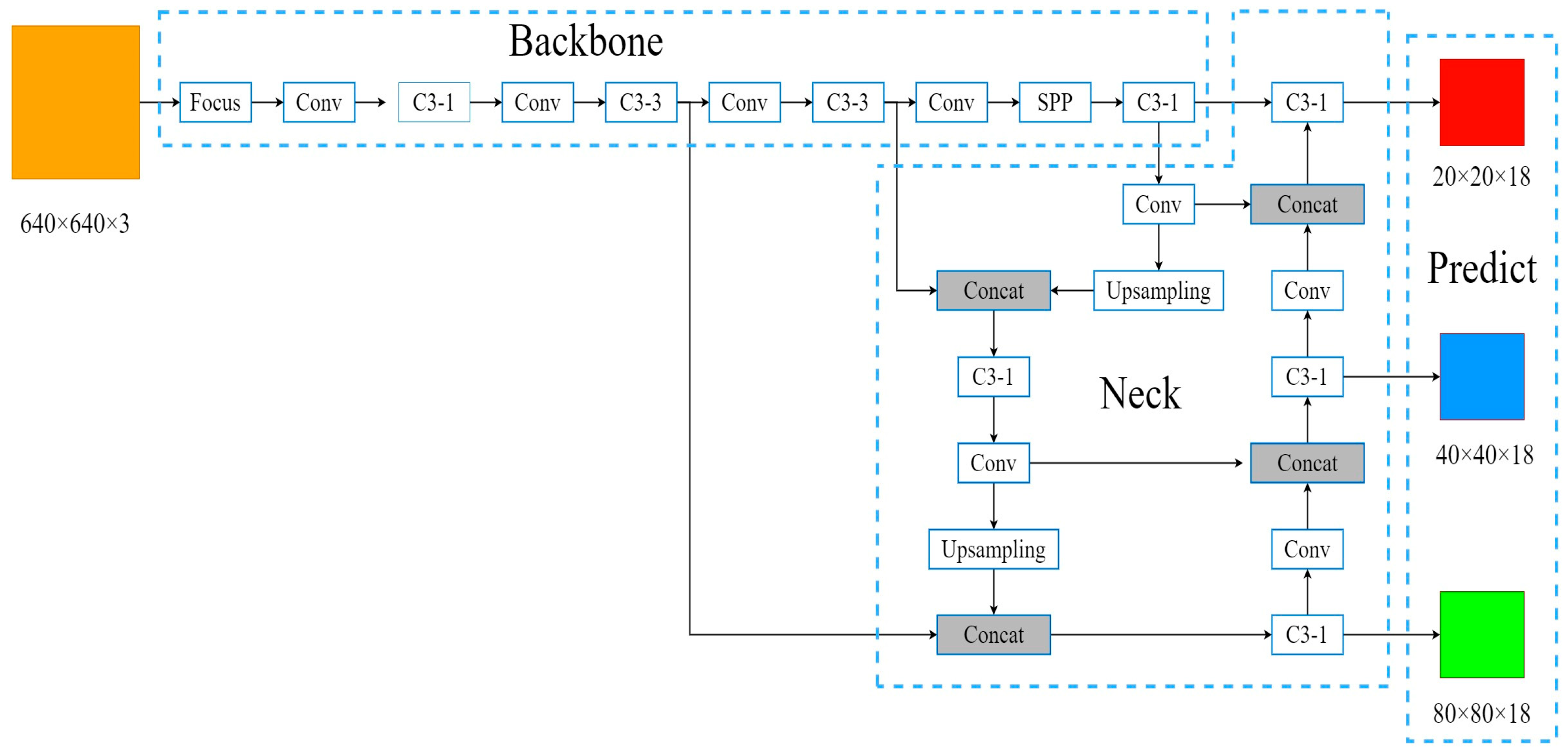
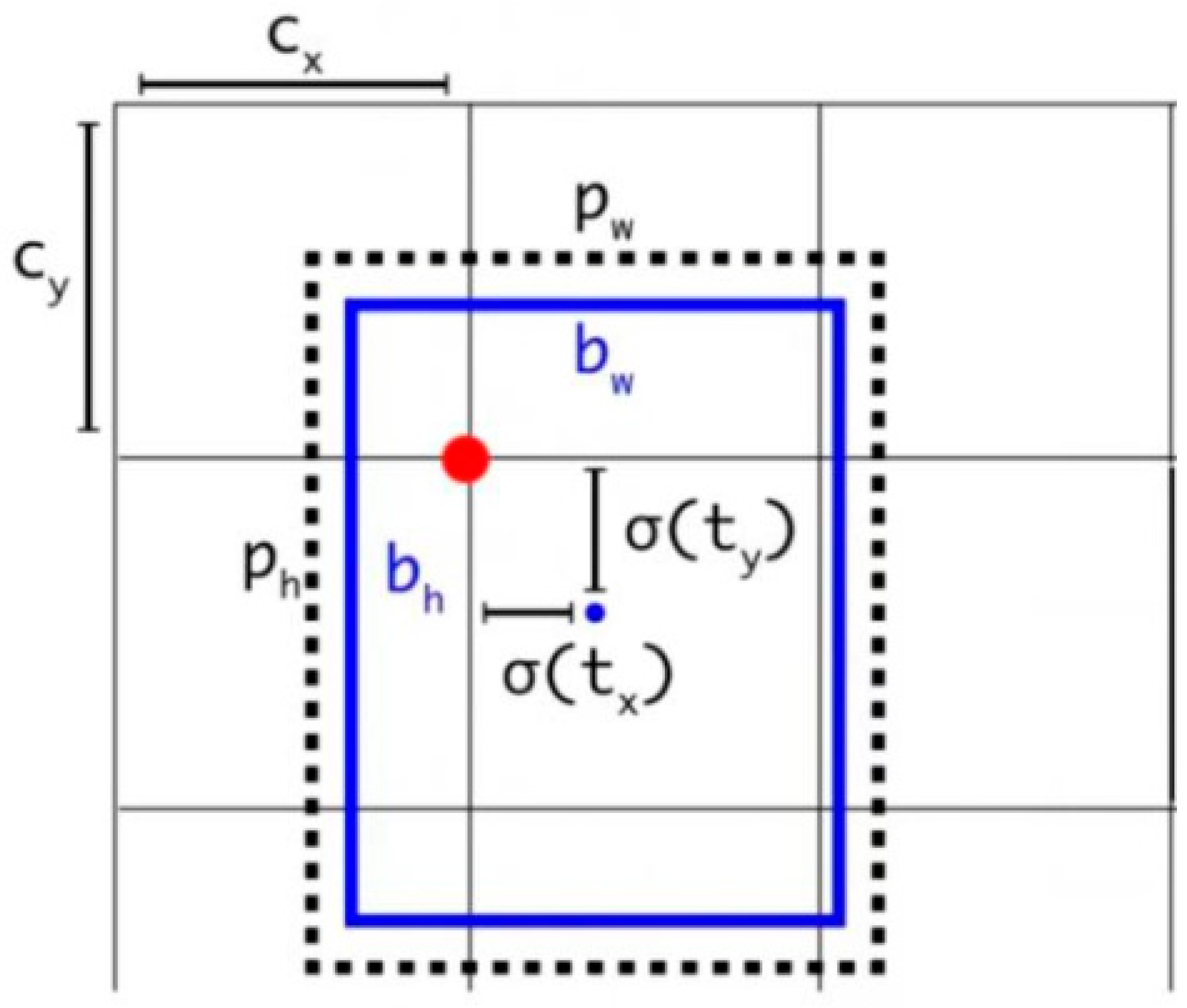
2. Analysis of the Principles Behind the YOLOv5s Algorithm
3. Algorithm Enhancement
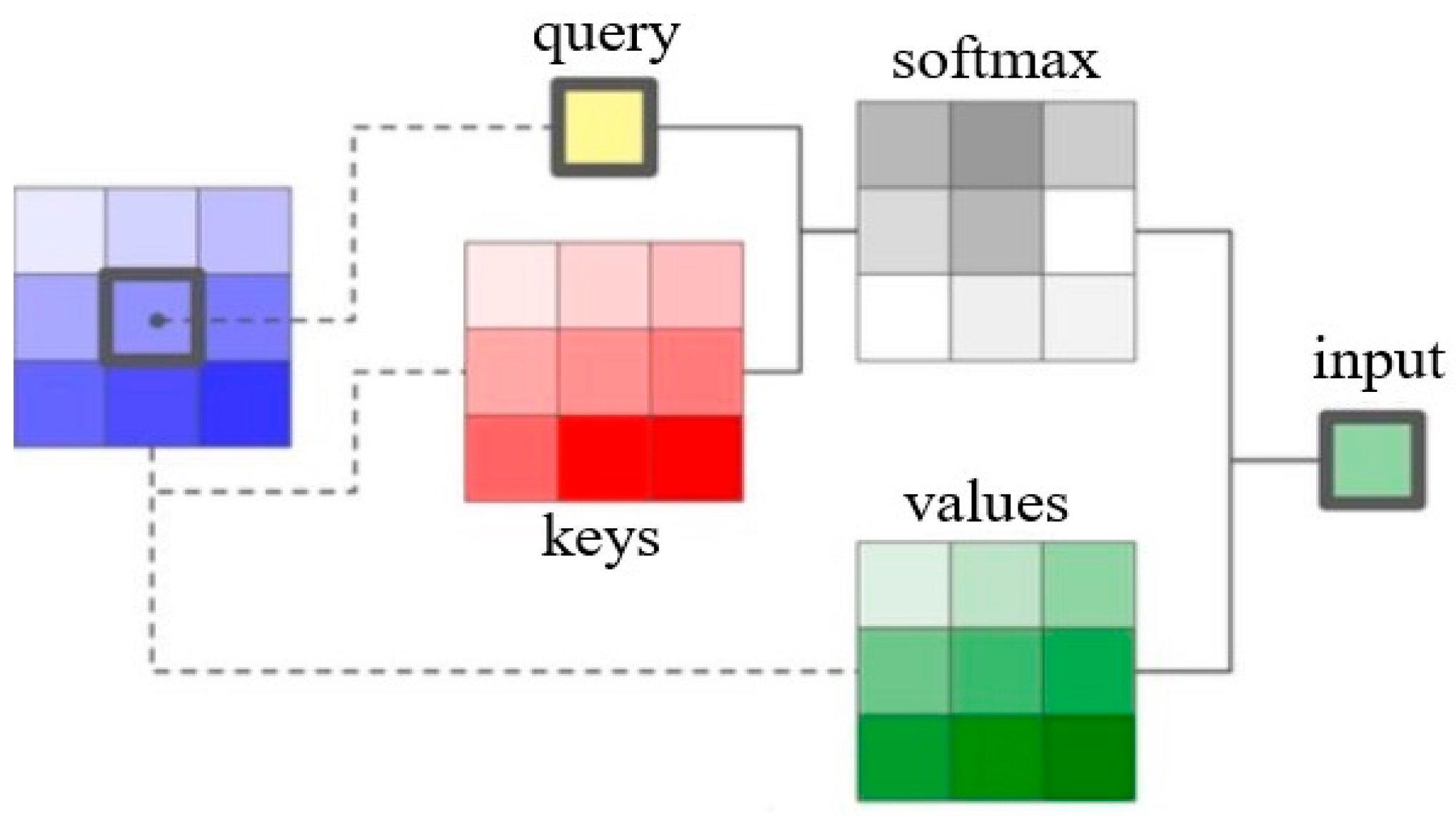
3.1. Introduction of the Swin Transformer Module
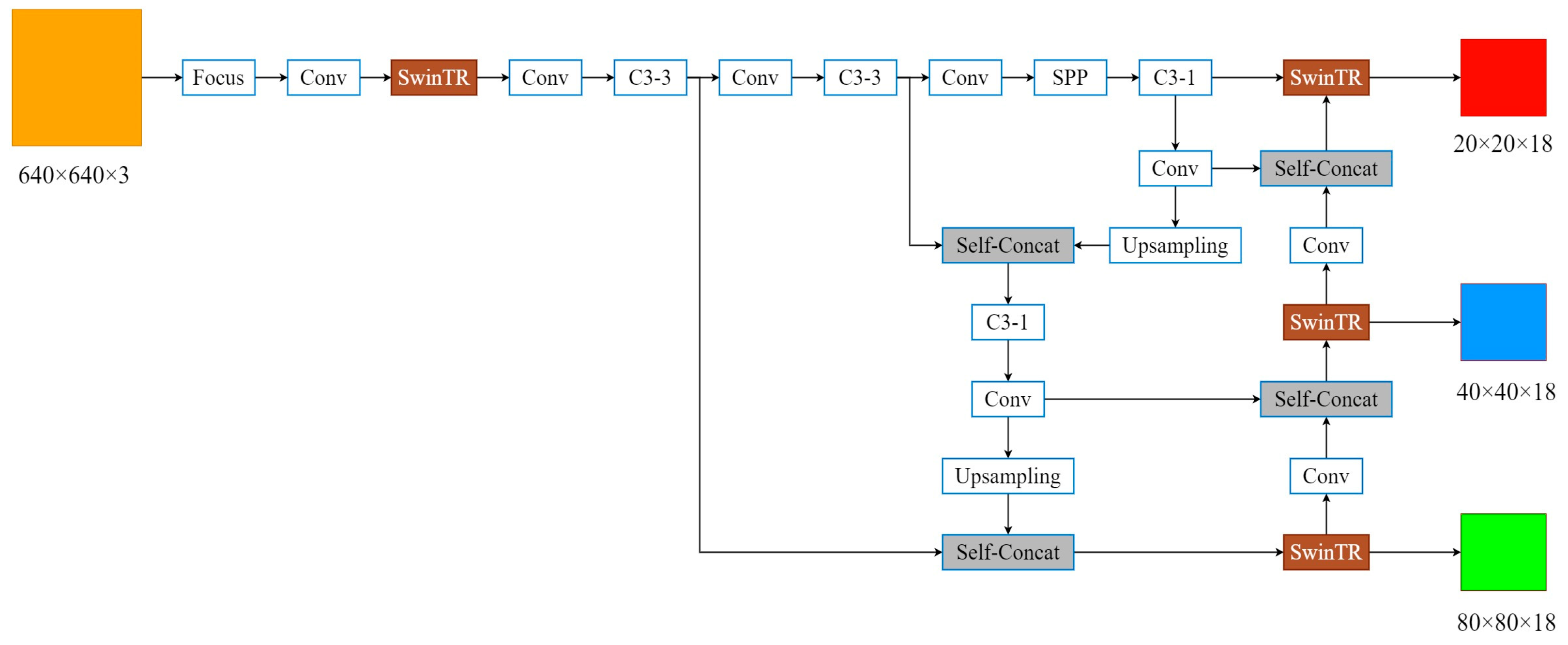
3.2. Self-Concat Feature Fusion
3.3. Improved Structure of the Swin-YOLOv5s Algorithm
4. Experimental Analysis and Validation
4.1. Dataset and Experimental Environment
4.2. Performance Evaluation Metrics
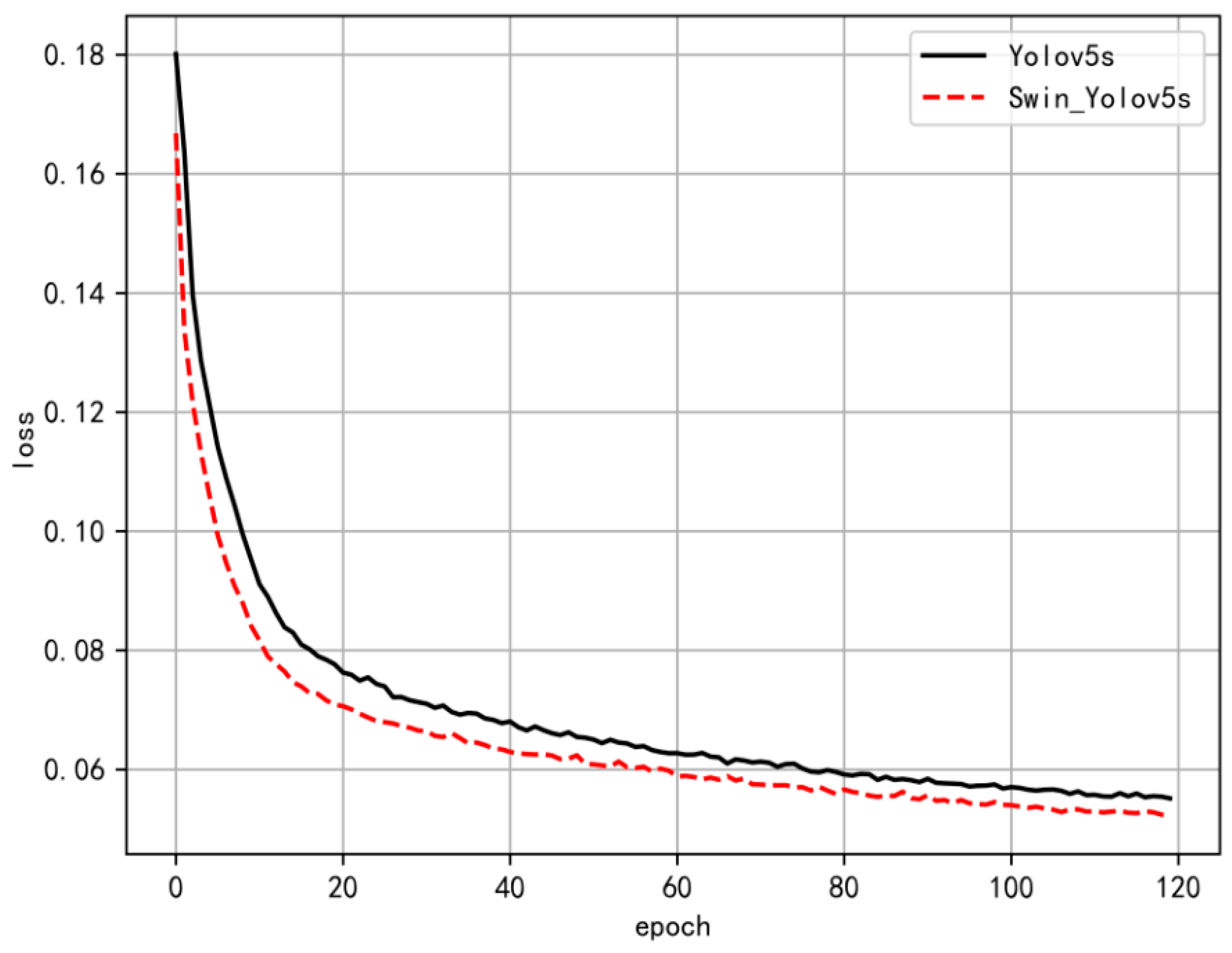
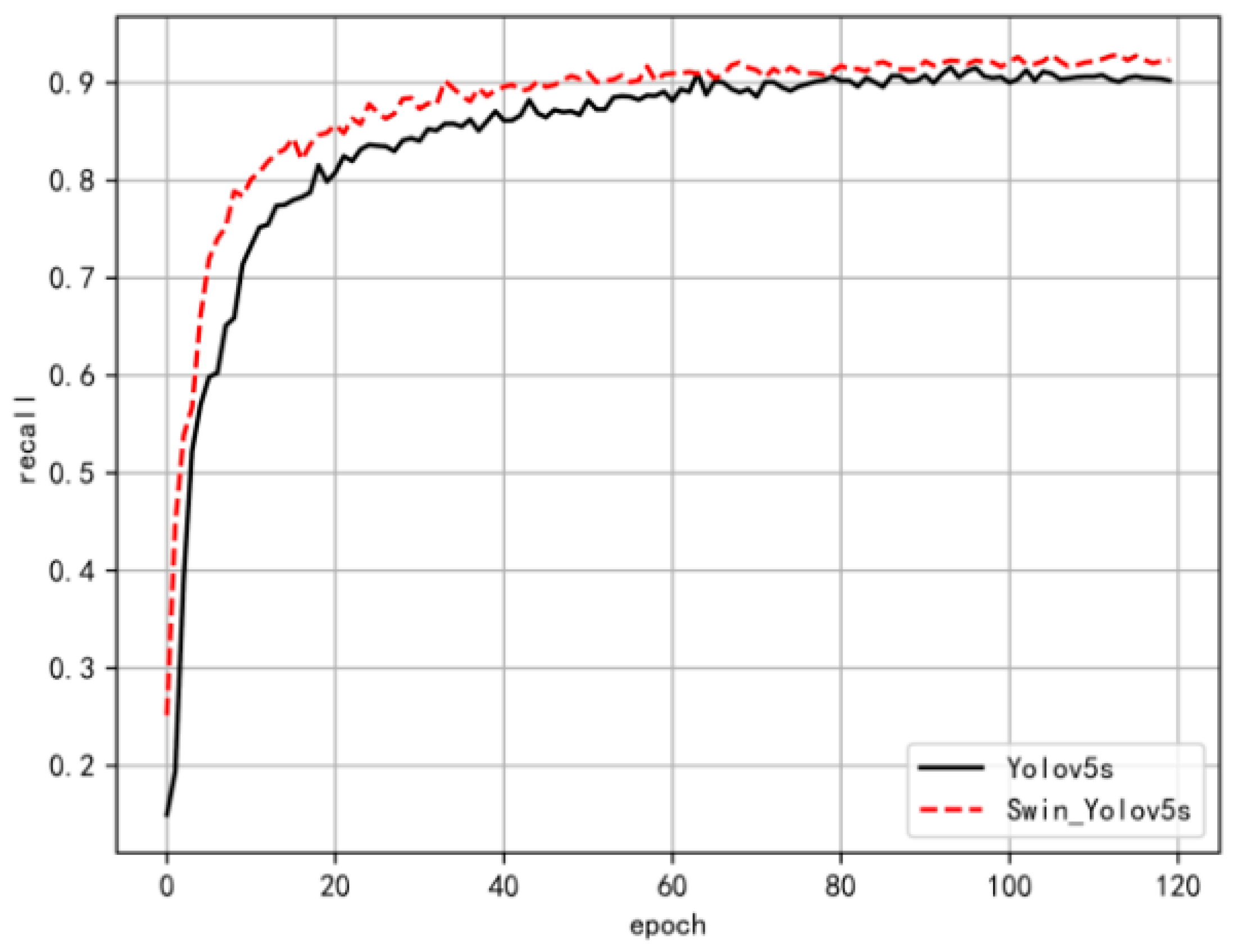
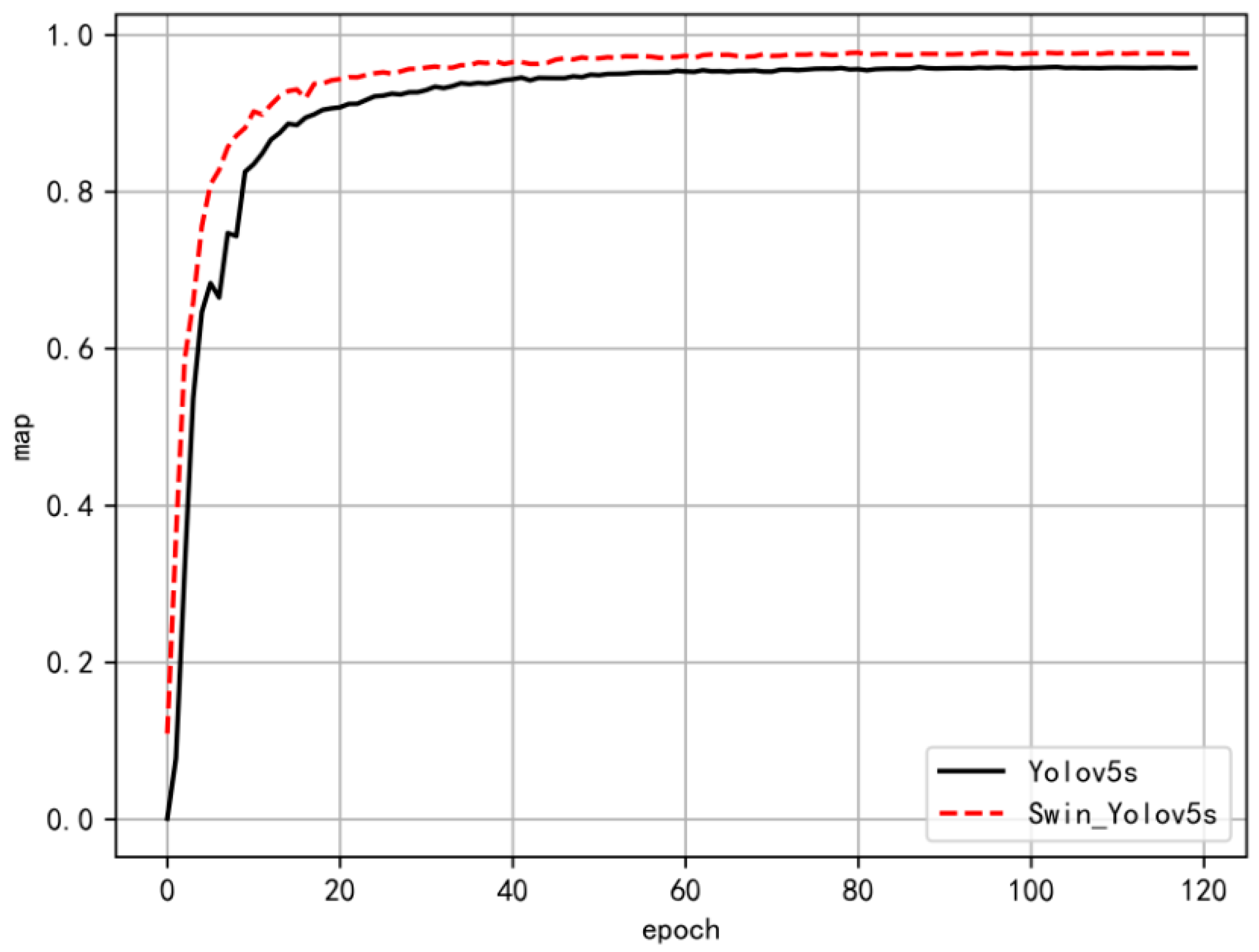
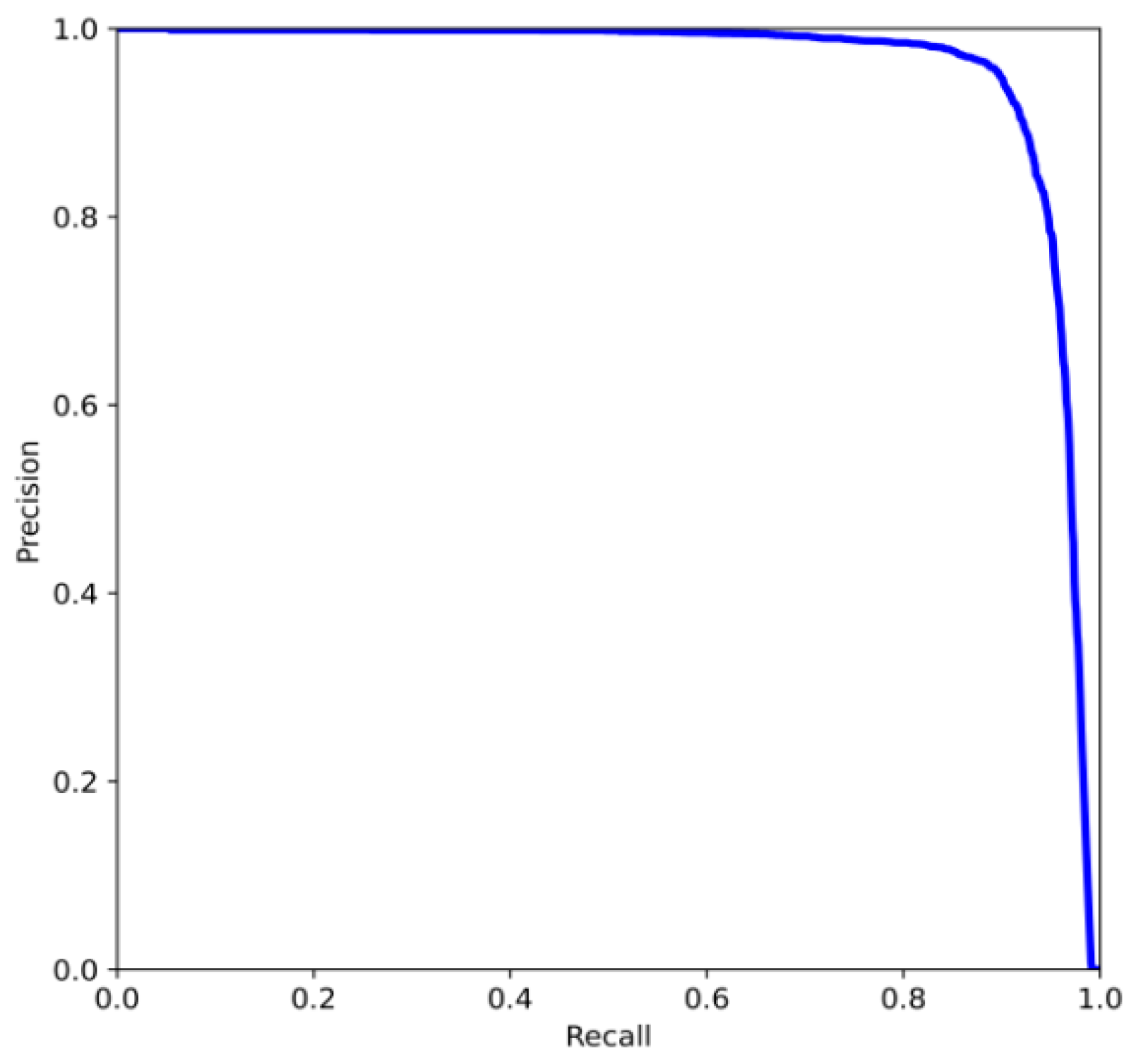
4.3. Experimental Validation and Analysis
5. Conclusions
- (1)
- In response to the issues of low detection accuracy, slow speed, and high rates of false positives and missed detections in the existing YOLOv5s vehicle detection model, an improved Swin-YOLOv5s vehicle target detection algorithm was proposed by incorporating a Swin Transformer attention mechanism along with a novel feature fusion approach based on Self-Concat. The proposed algorithm was capable of extracting vehicle information at a deeper level and adaptively adjusting the weights of feature maps to suppress the negative characteristics of the target.
- (2)
- The proposed algorithm was effectively trained and tested using the KITTI dataset. The improved Swin-YOLOv5s model achieved a 1.6% increase in mean average precision compared to the YOLOv5s model, along with a 0.56% enhancement in the F1 score. Additionally, the inference speed for a single image increased by 1.11%, while the overall detection speed measured in frames per second (FPS) improved by 12.5%. The ablation experiments and comparative experiments with various network models both validated the efficiency and accuracy of this model, which also demonstrated strong generalization capabilities and rapid detection speeds.
- (3)
- The results of the test set image detection indicated that the proposed Swin-YOLOv5s vehicle detection algorithm demonstrated a significantly higher confidence level across various scenarios compared to the YOLOv5s algorithm. Furthermore, even in cases of severe vehicle occlusion, it maintained effective detection capabilities, thereby addressing the issue of missed detections inherent to the YOLOv5s algorithm.
- (4)
- In future research, it is essential to test the algorithm on various hardware platforms. Additionally, training and validation should be conducted using other datasets as well as self-constructed augmented datasets under diverse conditions. Furthermore, comparisons with more advanced network models are necessary for improvement, aiming to enhance the effectiveness of this method.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, S.K.; Shiwakoti, N.; Stasinopoulos, P.; Chen, Y.L.; Warren, M. The impact of perceived cyber-risks on automated vehicle acceptance: Insights from a survey of participants from the United States, the United Kingdom, New Zealand, and Australia. Transp. Policy 2024, 152, 87–101. [Google Scholar]
- Bengamra, S.; Mzoughi, O.; Bigand, A.; Zagrouba, E. A comprehensive survey on object detection in Visual Art: Taxonomy and challenge. Multimed. Tools Appl. 2023, 83, 14637–14670. [Google Scholar] [CrossRef]
- Xiao, Z.; Luo, L.; Chen, M.; Wang, J.; Lu, Q.; Luo, S. Detection of grapes in orchard environment based on improved YOLO-V4. J. Intel. Agri. Mech. 2023, 4, 35–43. [Google Scholar]
- Mozumder, M.; Biswas, S.; Vijayakumari, L.; Naresh, R.; Kumar, C.N.S.V.; Karthika, G. An Hybrid Edge Algorithm for Vehicle License Plate Detection. In Proceedings of the International Conference on Intelligent Sustainable Systems, Bangalore, India, 26–27 September 2023; Springer: Singapore, 2023. [Google Scholar]
- Mei, S.; Ding, W.; Wang, J. Research on the real-time detection of red fruit based on the you only look once algorithm. Processes 2024, 12, 15. [Google Scholar]
- Dai, Y.; Fang, X. An armature defect self-adaptation quantitative assessment system based on improved YOLO11 and the degment anything model. Processes 2025, 13, 532. [Google Scholar]
- Othman, K.M.; Alfraihi, H.; Nemri, N.; Miled, A.B.; Alruwais, N.; Mahmud, A. Exploiting remote sensing imagery for vehicle detection and classification using robust competitive algorithm with deep convolutional neural network. Fractals 2024, 32, 1–16. [Google Scholar]
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar]
- Tang, M.J.; Cai, S.F.; Lau, V.K.N. Over-the-Air aggregation with multiple shared channels and graph-based state estimation for industrial IoT systems. IEEE Internet Things J. 2021, 8, 14638–14657. [Google Scholar] [CrossRef]
- Geetha, A.S. Comparing YOLOv5 variants for vehicle detection: A Performance Analysis. arXiv 2024, arXiv:2408.12550. [Google Scholar]
- Bakirci, M. Real-time vehicle detection using YOLOv8-nano for intelligent transportation systems. Trait. Signal 2024, 41, 1727. [Google Scholar] [CrossRef]
- Vasavi, S.; Raj, G.H.; Suhitha, T.S. Onboard processing of drone imagery for military vehicles classification using enhanced YOLOv5. J. Adv. Inf. Technol. 2023, 14, 1221–1229. [Google Scholar]
- Hao, Y.; Geng, C. Improved pedestrian vehicle detection for small objects based on attention mechanism. Int. J. Adv. Netw. Monit. Control. 2024, 9, 80–89. [Google Scholar] [CrossRef]
- Hong, T.S.; Ma, Y.J.; Jiang, H. Vehicle identification and analysis based on lightweight YOLOv5 on edge computing platform. Meas. Sci. Technol. 2025, 36, 16–44. [Google Scholar] [CrossRef]
- Wang, C.L.; Zhou, Y.Q.; Lv, Z.G.; Ye, C.Q.; Xiang, X.J. Research on tunnel vehicle detection based on GCM-YOLOv5s. J. Beijing Jiaotong Univ. 2025, 2, 1–16. [Google Scholar]
- Deng, C.; Ma, J.J.; Yan, Y.; Wang, Y.F.; Li, Y.Q. Vehicle identification algorithms based on lightweight neural networks. J. Chongqing Jiaotong Univ. 2024, 43, 80–87. [Google Scholar]
- Hu, P.F.; Wang, Y.G.; Zhai, Q.Q.; Yan, J.; Bai, Q. Night vehicle detection algorithm based on YOLOv5s and bistable stochastic resonance. Comput. Sci. 2024, 51, 173–181. [Google Scholar]
- Zhao, L.L.; Wang, X.Y.; Zhang, Y.; Zhang, M.Y. Vehicle target detection based on YOLOv5s fusion SENet. J. Graph. 2022, 43, 776–782. [Google Scholar]
- Fan, J.X.; Zhang, W.H.; Zhang, L.L.; Yu, T.; Zhong, L.C. Vehicle detection method of UAV imagery based on improved YOLOv5. Remote Sens. Inf. 2023, 38, 114–121. [Google Scholar]
- Chen, D.D.; Ren, X.M.; Li, D.P.; Chen, J. Research on binocular vision vehicle detection and ranging method based on improved YOLOv5s. J. Optoelectron. Laser 2024, 35, 311–319. [Google Scholar]
- Mishra, S.; Yadav, D. Vehicle detection in high density traffic surveillance data using YOLO.v5. Recent Adv. Electr. Electron. Eng. 2024, 17, 216–227. [Google Scholar] [CrossRef]
- Wu, C.x.; Hu, J. Efficient image super-resolution reconstruction via symmetric visual attention network. Softw. Guide 2025, 2, 1–6. [Google Scholar]
- Jiang, T.Y.; Hu, C.J.; Zheng, L.Z. Cable detection method with modified DeepLabV3+ network based on attention mechanism. J. Transp. Sci. Eng. 2025, 2, 1–11. [Google Scholar]
- Wang, K.; Chen, H.; Chen, L.M.; Huang, H.P.; Chen, X.L. Two-stage point cloud reconstruction based on improved attention mechanism and surface differential geometry. ACTA Metrol. Sin. 2024, 45, 952–963. [Google Scholar]
- Hüseyin, F.; Hüseyin, Z.; Atila, O.; Engür, A. Automated efficient traffic gesture recognition using swin transformer-based multi-input deep network with radar image. Signal Image Video Process. 2025, 19, 1–11. [Google Scholar]
- Tayaranian, M.; Mozafari, S.H.; Clark, J.J.; Meyer, B.; Gross, W. Faster inference of integer SWIN transformer by removing the GELU activation. arXiv 2024, arXiv:2402.01169. [Google Scholar]
- Subburaj, K.; Mazroa, A.A.; Alotaibi, F.A.; Alnfiai, M.M. DBCW-YOLO: An advanced yolov5 framework for precision detection of surface defects in steel. Matéria 2024, 29, e20240549. [Google Scholar]
- Vítor, C. A Novel Deep Learning Approach for Yarn Hairiness Characterization Using an Improved YOLOv5 Algorithm. Appl. Sci. 2024, 15, 149. [Google Scholar] [CrossRef]
- Qureshi, A.M.; Butt, A.H.; Alazeb, A.; Mudawi, N.A.; Alonazi, M.; Almujally, N.A.; Jalal, A.; Liu, H. Semantic segmentation and YOLO detector over aerial vehicle Images. Comput. Mater. Contin. 2024, 80, 3315–3332. [Google Scholar]
- Abdallah, S.M. Real-time vehicles detection using a tello drone with YOLOv5 algorithm. Cihan Univ.-Erbil Sci. J. 2024, 8, 1–7. [Google Scholar]
- Lv, J.M.; Zhang, F.; Luo, Y.B. Improved YOLOv5s based target detection algorithm for tobacco stem material. J. Zhejiang Univ. 2024, 58, 2438–2446. [Google Scholar]
- Tian, D.; Wei, X.; Yuan, J. Vehicle target detection algorithm based on improved YOLOv5 lightweight. Comput. Appl. Softw. 2024, 41, 240–246. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | |
|---|---|
| YOLOv3 | The introduction of three predictions at different scales enhances small object detection by leveraging both deep and shallow features. |
| YOLOv4 | The introduction of techniques such as the Mish activation function, feature pyramid networks, and adaptive anchor boxes has further enhanced accuracy. |
| YOLOv5 | Using the pytorch framework, we incorporate techniques such as Focus, CSP, and SPP to further enhance accuracy. |
| YOLOv7 | The introduction of transformer modules or similar attention mechanisms has led to the adoption of deeper and more complex network architectures for the extraction of high-level features. |
| YOLOv8 | The C2f module has been utilized, and the incorporation of a decoupled head has significantly enhanced performance. |
| Parameter | Initialize Learning Rate | Momentum | Weight Decay | Refinement of Training Epochs | Batch Size | Image Size | Learning Rate Decay Strategies |
|---|---|---|---|---|---|---|---|
| Value | 0.001 | 0.937 | 0.0005 | 120 | 50 | 640 × 640 | cosine |
| Model | mAP@0.5 (%) | F1 (%) | Precision (%) | Recall (%) | Time Consumption for a Single Image (ms) | Detection Speed (FPS) |
|---|---|---|---|---|---|---|
| Swin-YOLOv5s | 95.7 | 93.01 | 96.02 | 90.24 | 3.2 | 312.5 |
| YOLOv5s | 94.1 | 92.45 | 95.51 | 89.62 | 3.6 | 277.7 |
| Algorithm | Swin TR | Self-Concat | Parameter Count (M) | GFLOPS | mAP@0.5 (%) | Time Consumption for a Single Image (ms) | FPS |
|---|---|---|---|---|---|---|---|
| 1 | × | × | 7.31 | 51.5 | 94.1 | 3.6 | 277.7 |
| 2 | √ | × | 5.63 | 30.4 | 95.2 | 3.2 | 296.4 |
| 3 | √ | √ | 5.03 | 21.8 | 95.7 | 3.2 | 312.5 |
| Algorithm | Precision (%) | Recall (%) | mAP@0.5 (%) | F1 (%) | Parameter Count (M) |
|---|---|---|---|---|---|
| YOLOv3 | 92.94 | 86.83 | 92.1 | 89.78 | 61.56 |
| YOLOv3-Tiny | 89.73 | 68.81 | 78.5 | 77.89 | 8.63 |
| YOLOv7 | 95.72 | 84.75 | 95.5 | 89.90 | 20.94 |
| Faster R-CNN | 96.66 | 90.57 | 96.3 | 93.52 | 38.4 |
| YOLOv5s | 95.51 | 89.62 | 94.1 | 92.45 | 7.31 |
| Swin-YOLOv5s | 96.02 | 90.24 | 95.7 | 93.01 | 5.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, H.; Tang, J.; Fan, Y.; Liu, M. Improved Vehicle Object Detection Algorithm Based on Swin-YOLOv5s. Processes 2025, 13, 925. https://doi.org/10.3390/pr13030925
An H, Tang J, Fan Y, Liu M. Improved Vehicle Object Detection Algorithm Based on Swin-YOLOv5s. Processes. 2025; 13(3):925. https://doi.org/10.3390/pr13030925
Chicago/Turabian StyleAn, Haichao, Jianhua Tang, Ying Fan, and Meiqin Liu. 2025. "Improved Vehicle Object Detection Algorithm Based on Swin-YOLOv5s" Processes 13, no. 3: 925. https://doi.org/10.3390/pr13030925
APA StyleAn, H., Tang, J., Fan, Y., & Liu, M. (2025). Improved Vehicle Object Detection Algorithm Based on Swin-YOLOv5s. Processes, 13(3), 925. https://doi.org/10.3390/pr13030925