
High-Performance Defect Detection Methods for Real-Time Monitoring of Ceramic Additive Manufacturing Process Based on Small-Scale Datasets

 ,
,
Abstract
:1. Introduction
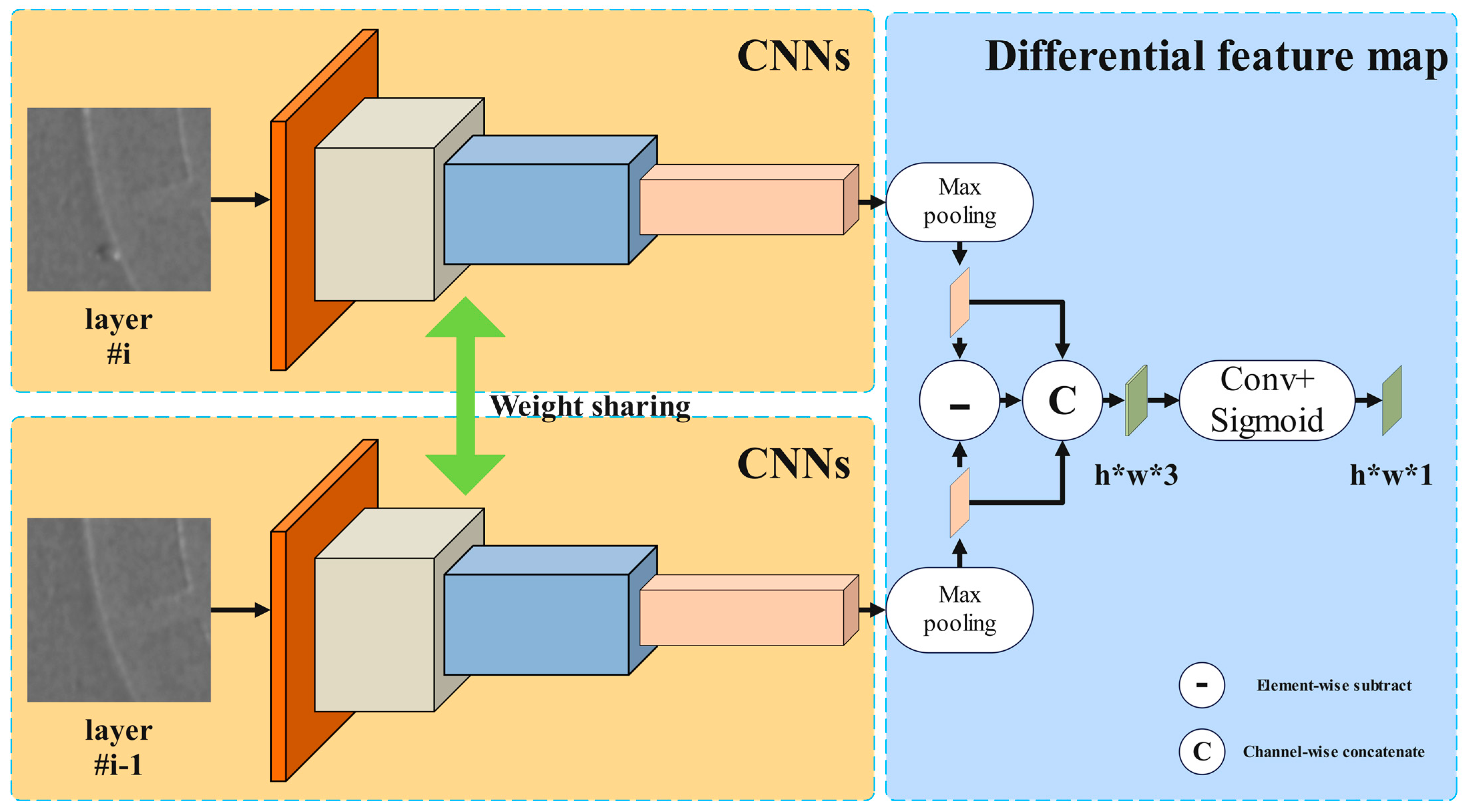
- A dual-branch object detection model is proposed based on the characteristics of multi-image fusion. In the first branch, two layers of recoating images are put into a differential Siamese network to extract images differences. Two layers of recoating images and one layer of slice image are fused as a three-channel image and put into another branch. Through this operation, multiple feature extraction is achieved.
- By employing the approach of parallel prediction with multiple prediction heads in this task, each prediction head is responsible for predicting defect targets of different scales. Subsequently, duplicate results are filtered through the non-maximum suppression principle. This method significantly improves the efficiency of the framework.
- Based on the detection results and 3D reconstruction technology, quality close-up control of the DLP manufacturing process is achieved, which can be used to guide the subsequent processes.
2. Related Work
- Insufficient research: Currently, there is a lack of comprehensive research on defect detection of ceramic AM. Most of the existing literature focuses primarily on material modification or non-destructive testing of finished components, with limited emphasis on direct monitoring of the DLP printing process.
- Inapplicability of techniques: Despite the similarity of metal AM and DLP, the majority of techniques used for process monitoring in metal AM cannot be directly applied to DLP. Considering the specific materials and process characteristics of ceramic AM, the applicability of existing techniques to DLP process monitoring may be limited.
3. Methodology
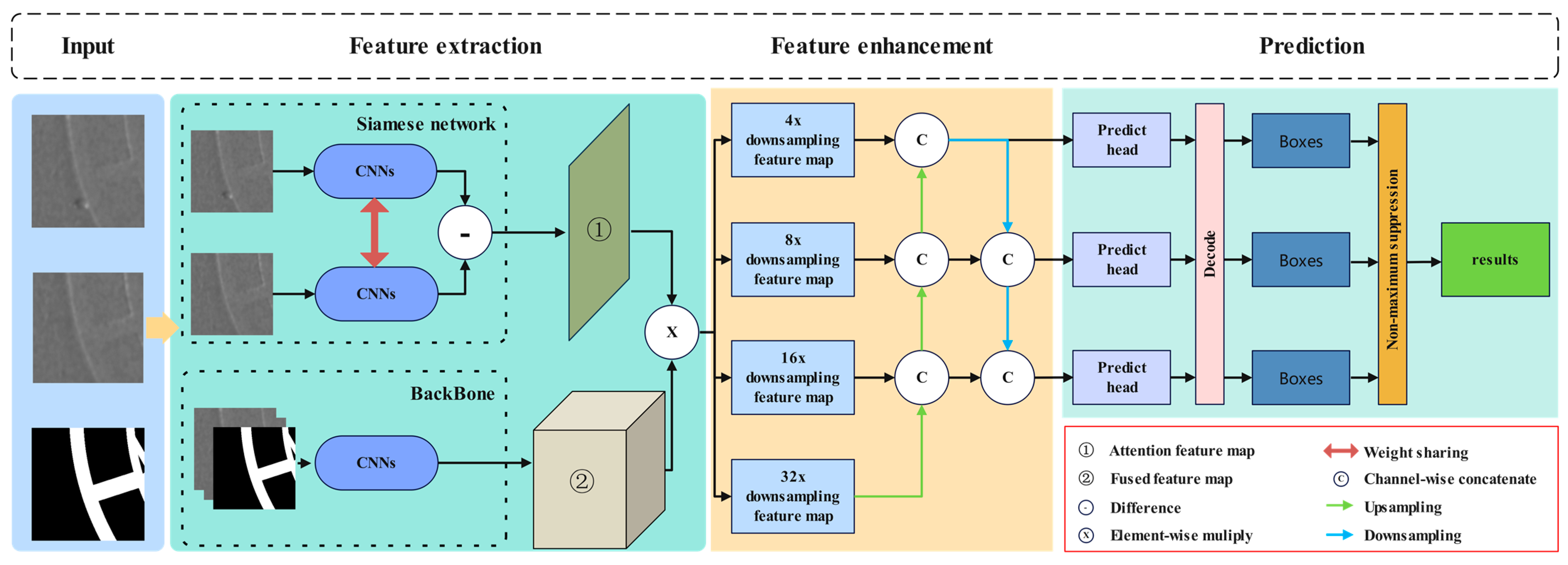
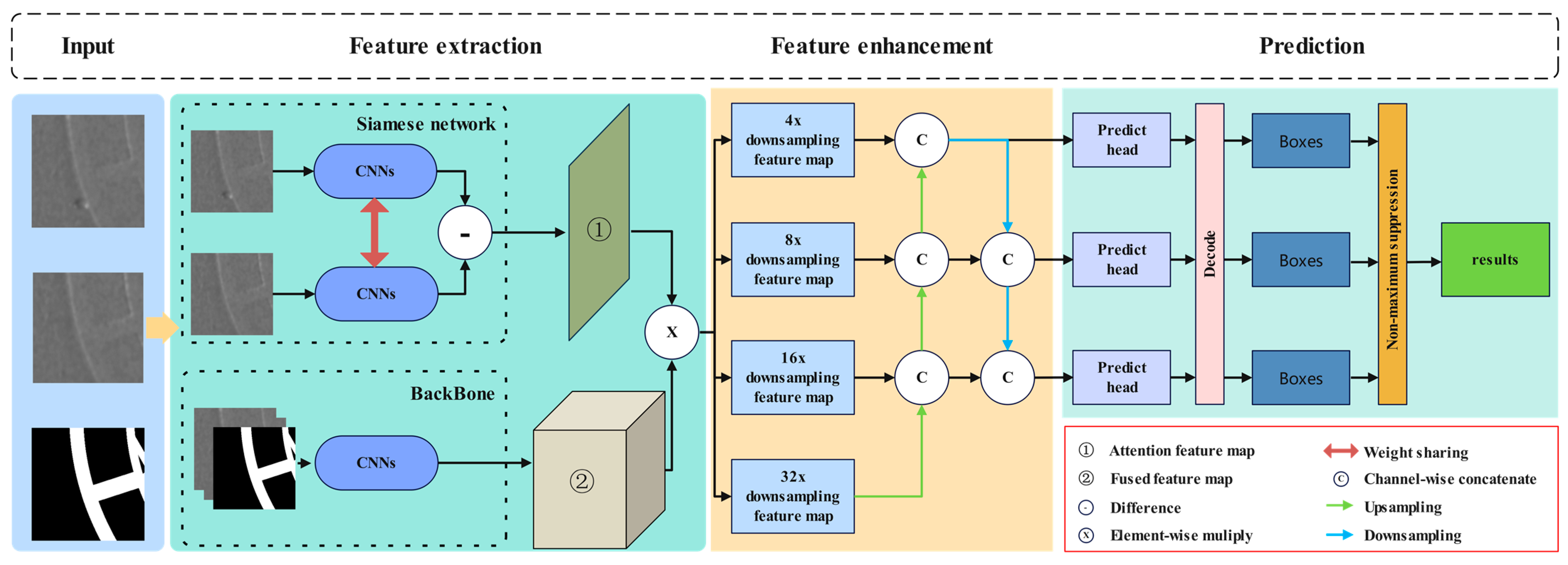
3.1. Model Overview
3.2. Serial Branch
3.3. Dual Branch
3.4. Feature Pyramid
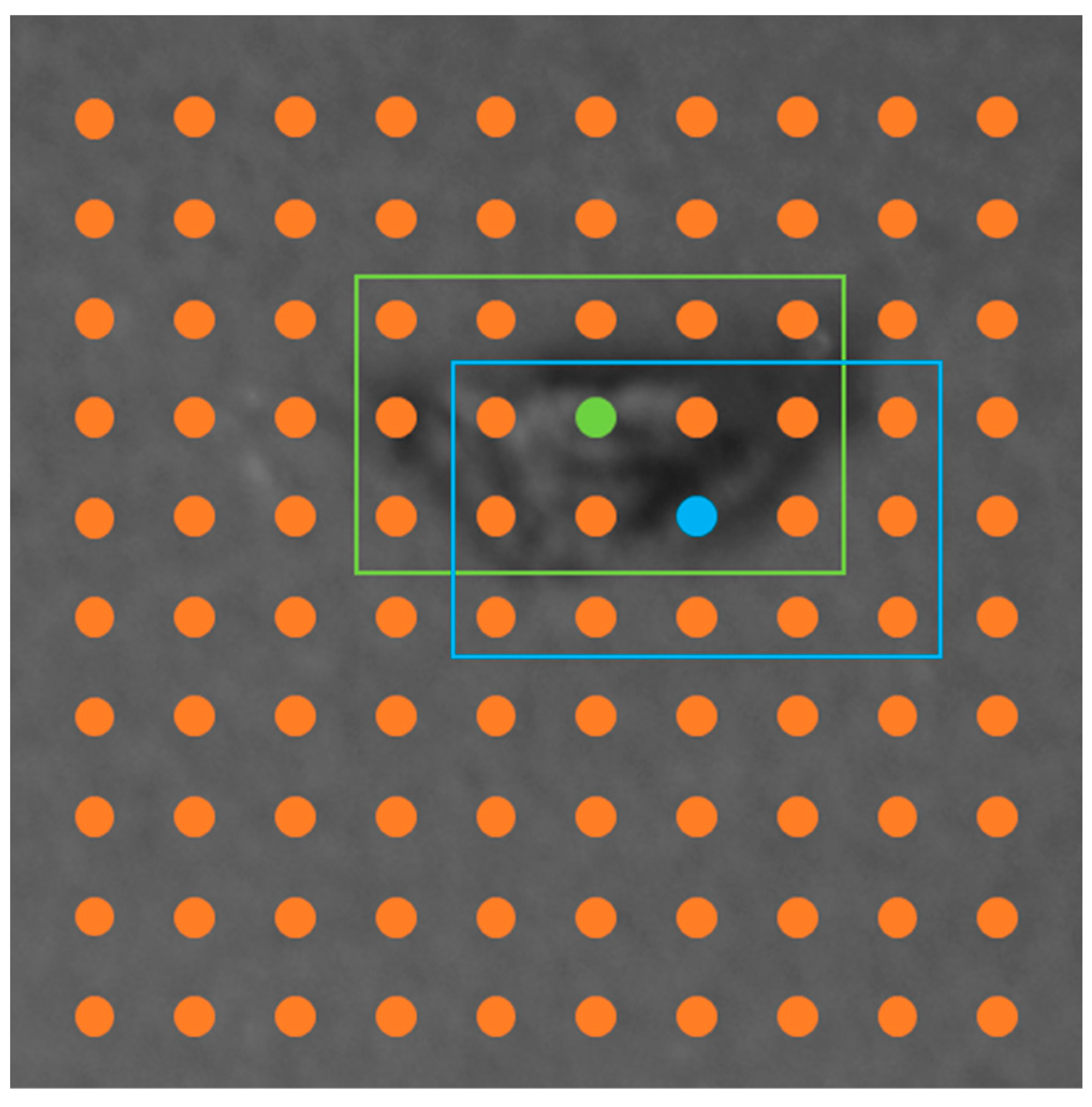
3.5. Prediction Heads
3.6. Loss Function
4. Experiments and Discussion
4.1. Environment and Datasets
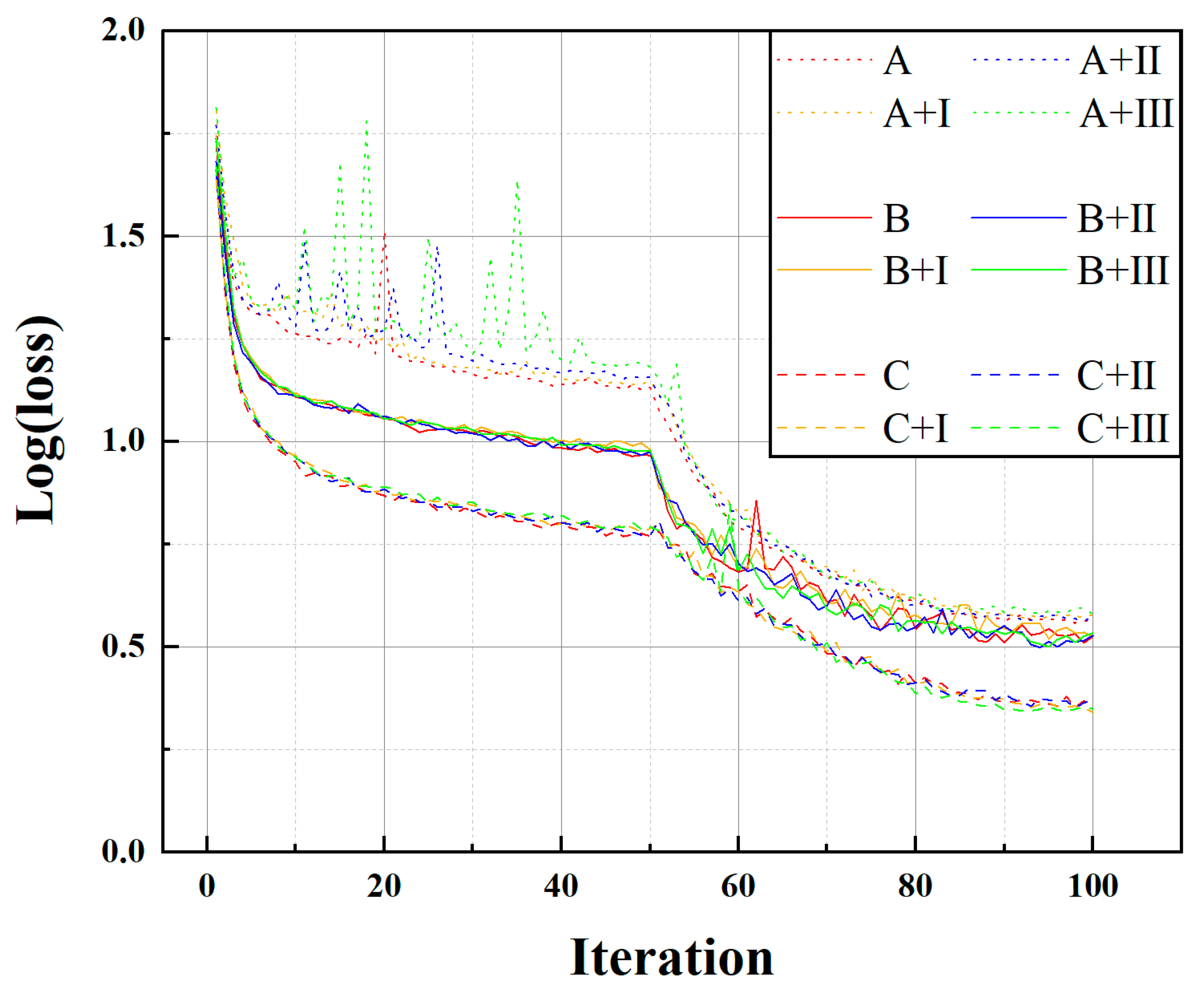
4.2. Analysis of the Model
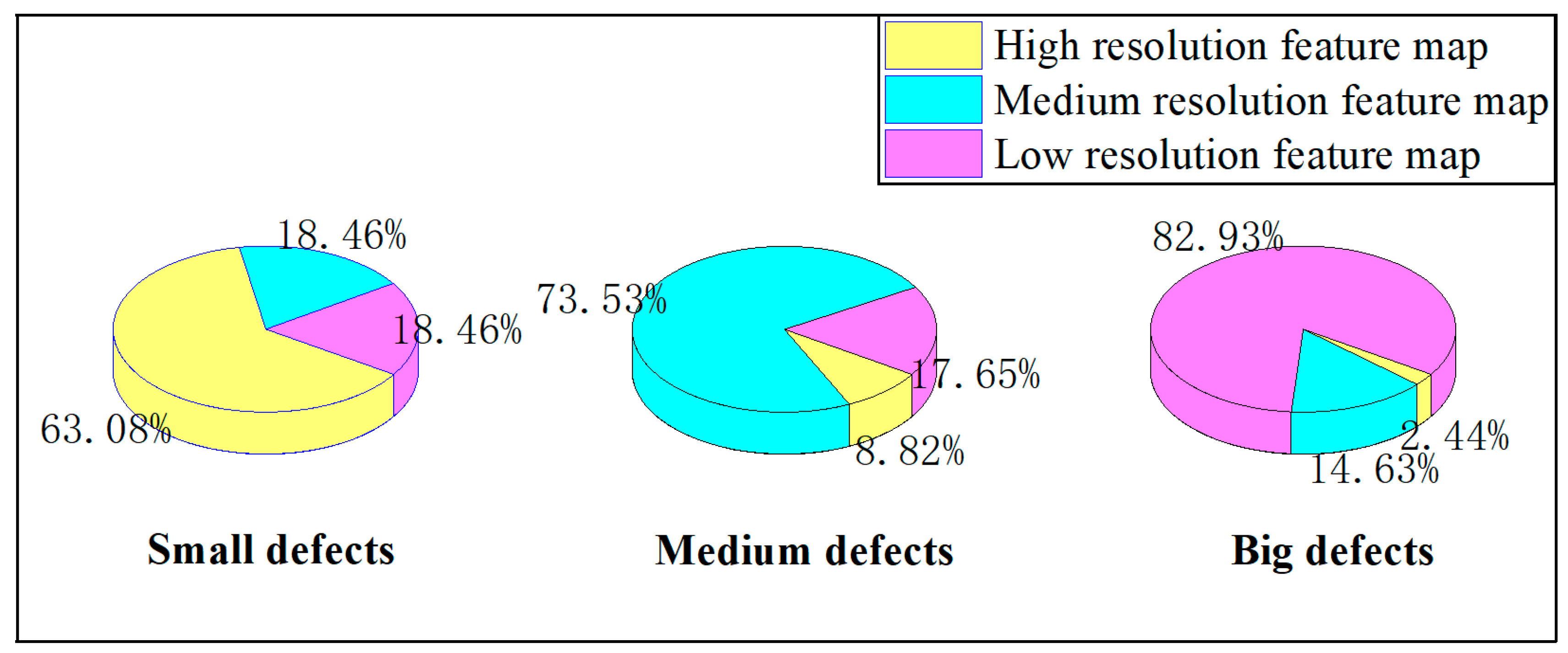
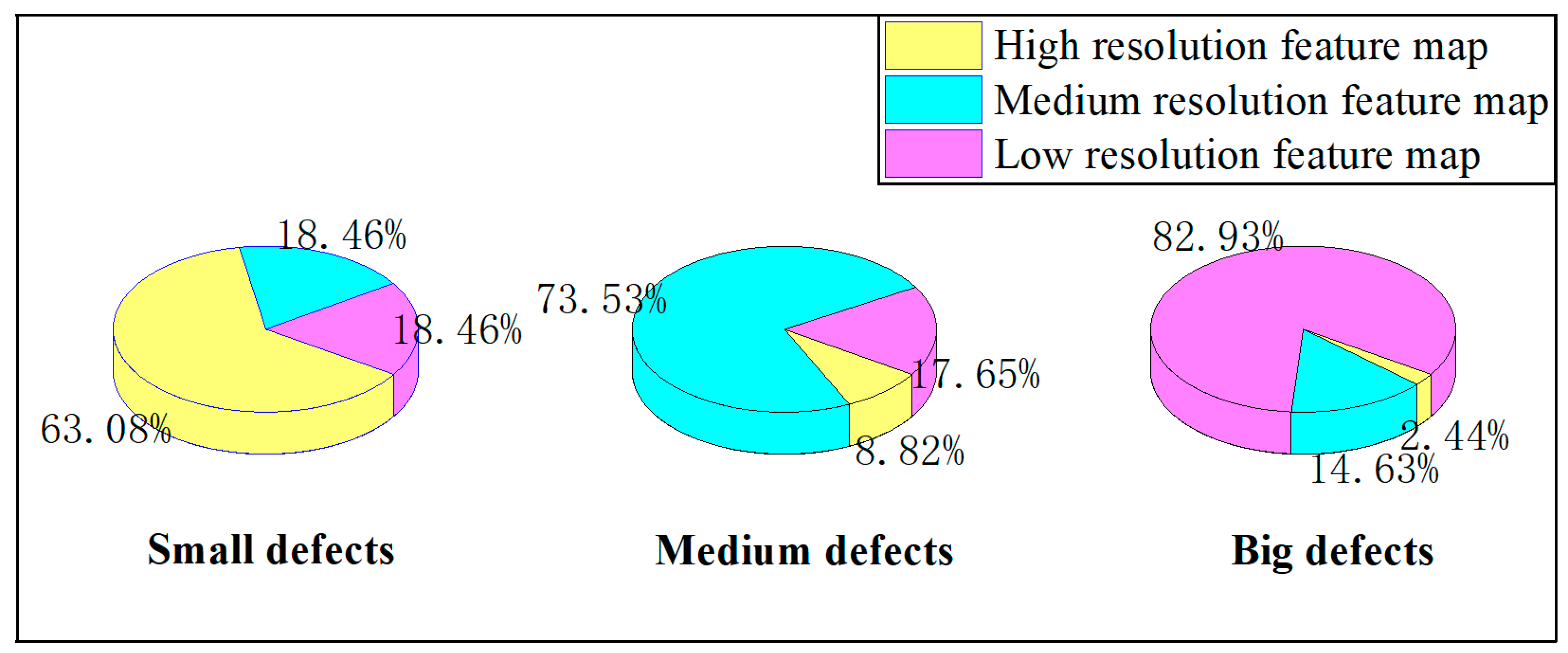
4.3. Analysis of Multiple Heads
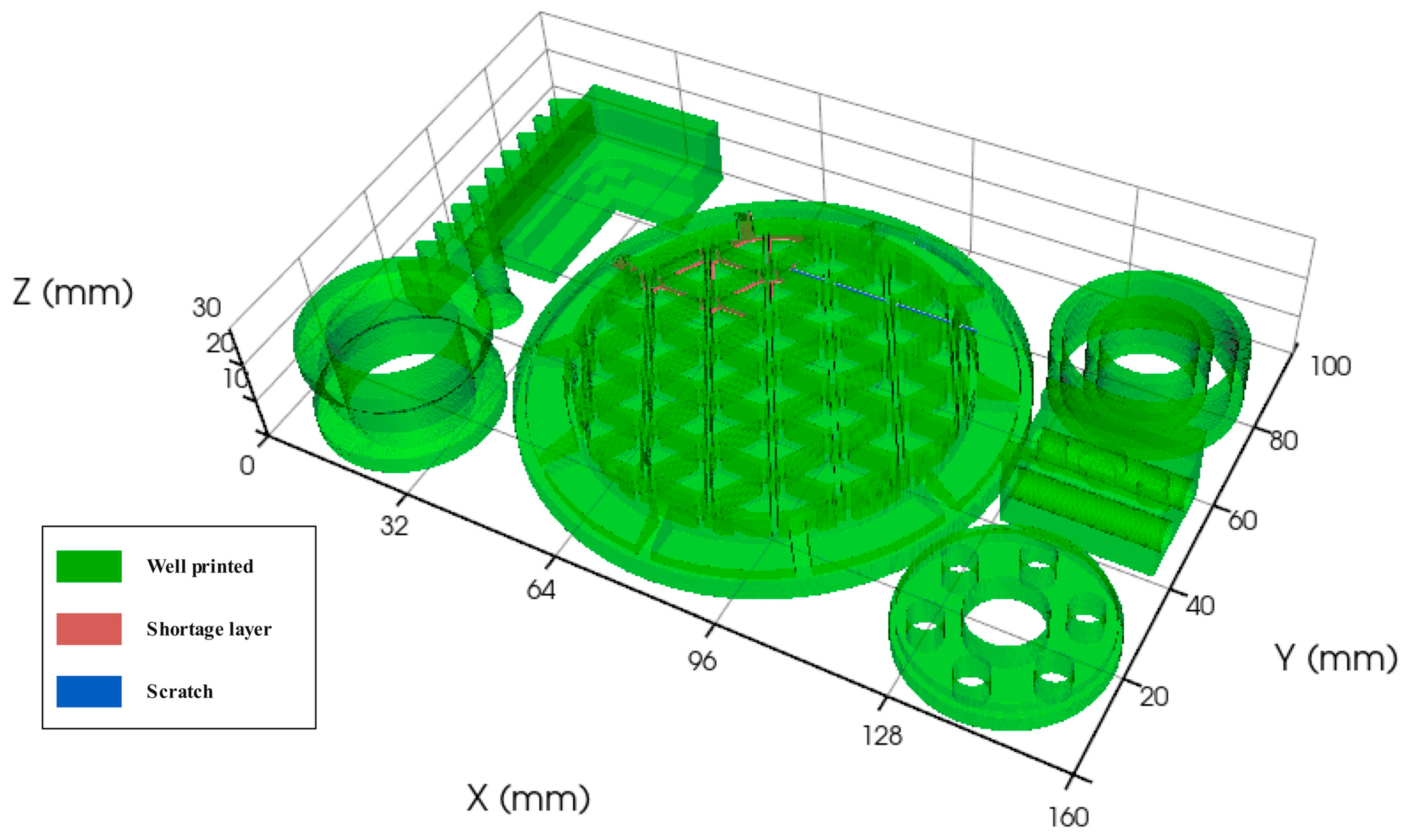
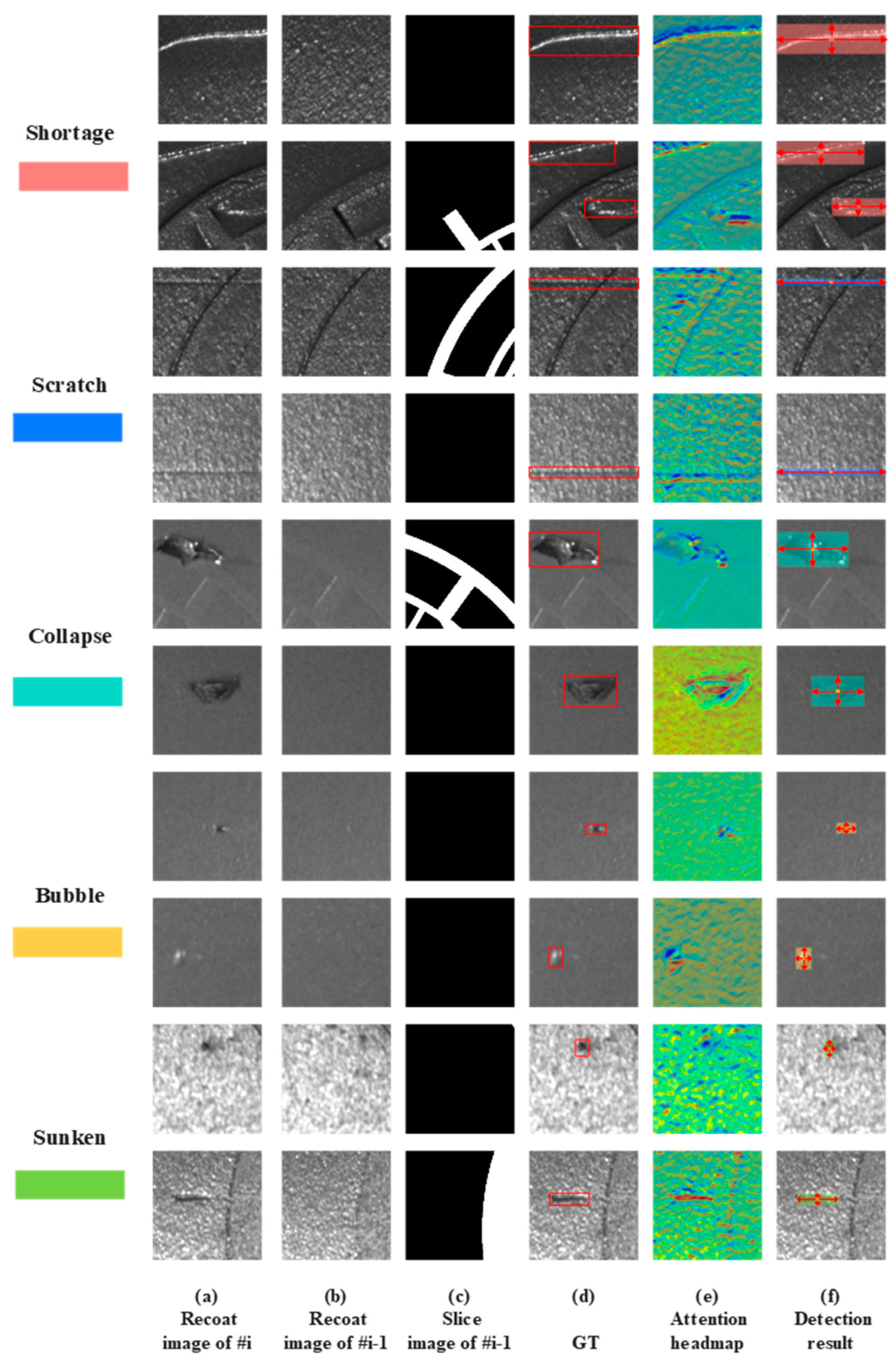
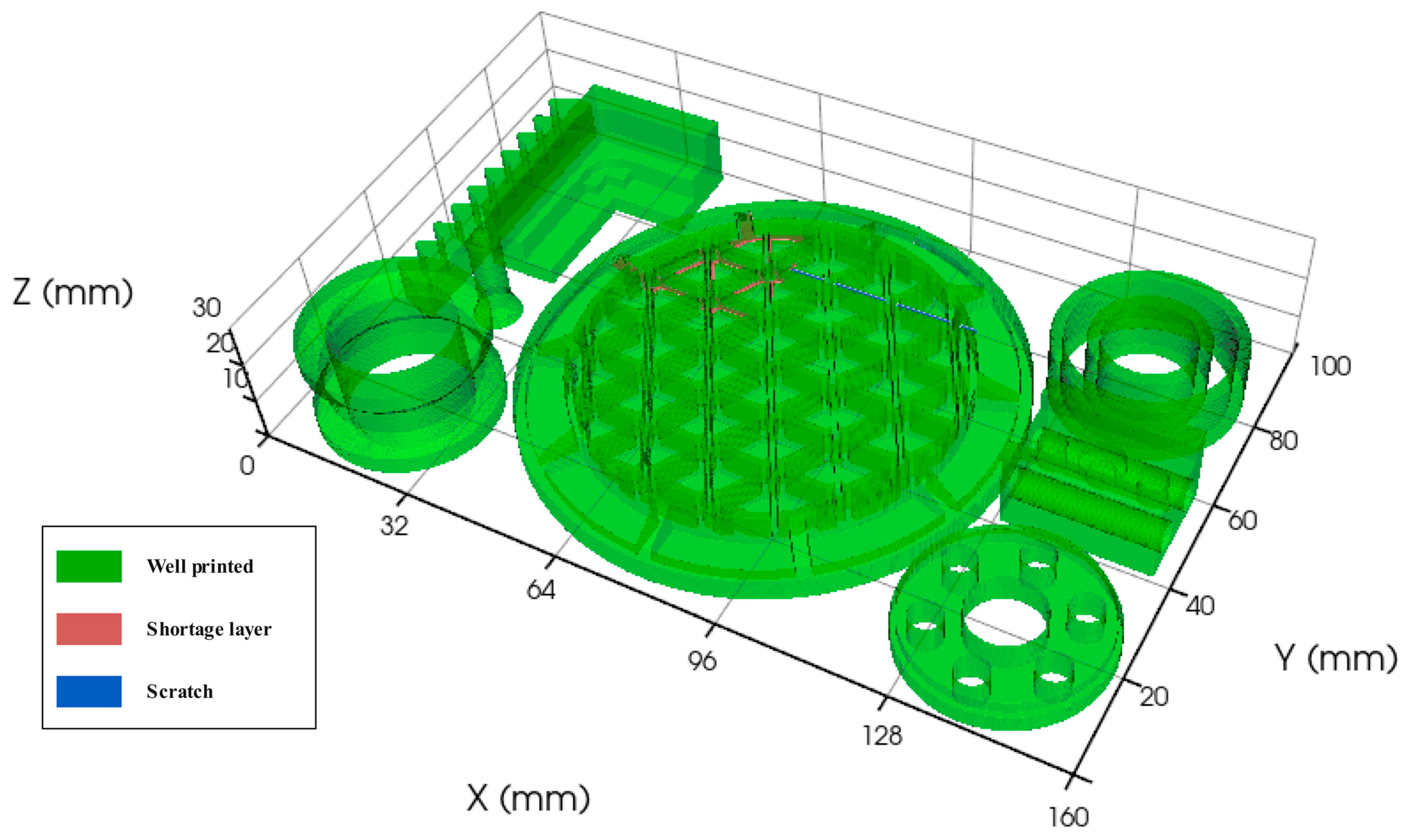
4.4. Analysis of a Build
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, R.; Zhou, N.; Zhang, K.; Zhang, X.; Zhang, L.; Wang, W.; Fang, D. Progress and Challenges towards Additive Manufacturing of Sic Ceramic. J. Adv. Ceram. 2021, 10, 637–674. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, B.; Li, H.; Li, X.; Wang, G.; Li, S. A nesting optimization method based on digital contour similarity matching for additive manufacturing. J. Intell. Manuf. 2022, 34, 2825–2847. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Cui, Y.; Guo, D.; Shao, Y.; Wang, Z.; Shen, C.; Zhang, L.; Chen, S. Joint Classification and Regression for Visual Tracking with Fully Convolutional Siamese Networks. Int. J. Comput. Vis. 2022, 130, 550–566. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Z.; Demir, K.; Gu, G.X. Machine learning for advanced additive manufacturing. Matter 2020, 3, 1541–1556. [Google Scholar] [CrossRef]
- Grierson, D.; Rennie, A.E.W.; Quayle, S.D. Machine learning for additive manufacturing. Encyclopedia 2021, 1, 576–588. [Google Scholar] [CrossRef]
- Abdallah, M.; Joung, B.-G.; Lee, W.J.; Mousoulis, C.; Raghunathan, N.; Shakouri, A.; Sutherland, J.W.; Bagchi, S. Anomaly detection and inter-sensor transfer learning on smart manufacturing datasets. Sensors 2023, 23, 486. [Google Scholar] [CrossRef]
- Abdallah, M.; Lee, W.J.; Raghunathan, N.; Mousoulis, C.; Sutherland, J.W.; Bagchi, S. Anomaly detection through transfer learning in agriculture and manufacturing IoT systems. arXiv 2021, arXiv:2102.05814. [Google Scholar]
- Jacobsmuhlen, J.Z.; Kleszczynski, S.; Witt, G.; Merhof, D. Elevated Region Area Measurement for Quantitative Analysis of Laser Beam Melting Process Stability. In Proceedings of the 26th International Solid Free Form Fabrication (SFF), Austin, TX, USA, 10–12 August 2015. [Google Scholar] [CrossRef]
- Zhang, B.; Ziegert, J.; Farahi, F.; Davies, A. In situ surface topography of laser powder bed fusion using fringe projection. Addit. Manuf. 2016, 12, 100–107. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Wen, S.; He, P.; Zhong, K.; Wei, Q.; Shi, Y.; Liu, S. In Situ 3D Monitoring of Geometric Signatures in the Powder-Bed-Fusion Additive Manufacturing Process via Vision Sensing Methods. Sensors 2018, 18, 1180. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zhang, Q.; Li, Q.; Wu, Z.; Chen, C.; Xu, J.; Xue, J. Research on Morphology Detection of Metal Additive Manufacturing Process Based on Fringe Projection and Binocular Vision. Appl. Sci. 2022, 12, 9232. [Google Scholar] [CrossRef]
- Xiong, J.; Shi, M.; Liu, Y.; Yin, Z. Virtual binocular vision sensing and control of molten pool width for gas metal arc additive manufactured thin-walled components. Addit. Manuf. 2020, 33, 101121. [Google Scholar] [CrossRef]
- Scime, L.; Beuth, J. A Multi-Scale Convolutional Neural Network for Autonomous Anomaly Detection and Classification in a Laser Powder Bed Fusion Additive Manufacturing Process. Addit. Manuf. 2018, 24, 273–286. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Gaikwad, A.; Imani, F.; Yang, H.; Reutzel, E.; Rao, P. In Situ Monitoring of Thin-Wall Build Quality in Laser Powder bed Fusion Using Deep Learning. Smart Sustain. Manuf. Syst. 2019, 3, 98–121. [Google Scholar] [CrossRef]
- Liu, C.; Wang, R.R.; Ho, I.; Kong, Z.J.; Williams, C.; Babu, S.; Joslin, C. Toward online layer-wise surface morphology measurement in additive manufacturing using a deep learning-based approach. J. Intell. Manuf. 2022, 34, 2673–2689. [Google Scholar] [CrossRef]
- Bevans, B.; Barrett, C.; Spears, T.; Gaikwad, A.; Riensche, A.; Smoqi, Z.; Halliday, H.; Rao, P. Heterogeneous sensor data fusion for multiscale, shape agnostic flaw detection in laser powder bed fusion additive manufacturing. Virtual Phys. Prototyp. 2023, 18, e2196266. [Google Scholar] [CrossRef]
- Nguyen, N.V.; Hum, A.J.W.; Do, T.; Tran, T. Semi-Supervised Machine Learning of Optical in-Situ Monitoring Data for Anomaly Detection in Laser Powder bed Fusion. Virtual Phys. Prototyp. 2022, 18, e2129396. [Google Scholar] [CrossRef]
- Repossini, G.; Laguzza, V.; Grasso, M.; Colosimo, B.M. On the use of spatter signature for in-situ monitoring of Laser Powder Bed Fusion. Addit. Manuf. 2017, 16, 35–48. [Google Scholar] [CrossRef]
- Rodriguez, E.; Mireles, J.; Terrazas, C.A.; Espalin, D.; Perez, M.A.; Wicker, R.B. Approximation of absolute surface temperature measurements of powder bed fusion additive manufacturing technology using in situ infrared thermography. Addit. Manuf. 2015, 5, 31–39. [Google Scholar] [CrossRef]
- Li, Q.; Qiu, Y.; Hou, W.; Liang, J.; Mei, H.; Li, J.; Zhou, Y.; Sun, X. Slurry flow characteristics control of 3D printed ceramic core layered structure: Experiment and simulation. J. Mater. Sci. Technol. 2023, 164, 215–228. [Google Scholar] [CrossRef]
- Zhao, D.; Su, H.; Hu, K.; Lu, Z.; Li, X.; Dong, D.; Liu, Y.; Shen, Z.; Guo, Y.; Liu, H.; et al. Formation mechanism and controlling strategy of lamellar structure in 3D printed alumina ceramics by digital light processing. Addit. Manuf. 2022, 52, 102650. [Google Scholar] [CrossRef]
- Chen, L.; Cikalova, U.; Muench, S.; Roellig, M.; Bendjus, B. Stress Characterization of Ceramic Substrates by Laser Speckle Photometry. In Proceedings of the 2019 42nd International Spring Seminar on Electronics Technology (ISSE), Wroclaw, Poland, 15–19 May 2019; pp. 1–6. [Google Scholar]
- Liu, W.; Chen, C.; Shuai, S.; Zhao, R.; Liu, L.; Wang, X.; Hu, T.; Xuan, W.; Li, C.; Yu, J.; et al. Study of pore defect and mechanical properties in selective laser melted Ti6Al4V alloy based on X-ray computed tomography. Mater. Sci. Eng. A 2020, 797, 139981. [Google Scholar] [CrossRef]
- Su, R.; Kirillin, M.; Chang, E.W.; Sergeeva, E.; Yun, S.H.; Mattsson, L. Perspectives of mid-infrared optical coherence tomography for inspection and micrometrology of industrial ceramics. Opt. Express 2014, 22, 15804–15819. [Google Scholar] [CrossRef]
- Saâdaoui, M.; Khaldoun, F.; Adrien, J.; Reveron, H.; Chevalier, J. X-ray tomography of additive-manufactured zirconia: Processing defects—Strength relations. J. Eur. Ceram. Soc. 2020, 40, 3200–3207. [Google Scholar] [CrossRef]
- Diener, S.; Franchin, G.; Achilles, N.; Kuhnt, T.; Rösler, F.; Katsikis, N.; Colombo, P. X-ray microtomography investigations on the residual pore structure in silicon nitride bars manufactured by direct ink writing using different printing patterns. Open Ceram. 2020, 5, 100042. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar] [CrossRef]
- Karpathy, A. CS231n Convolutional Neural Networks for Visual Recognition. 2017. Available online: https://cs231n.github.io/convolutional-networks/#overview (accessed on 5 February 2018).
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; Lecun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 737–744. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Yang, K.; He, Z.; Zhou, Z.; Fan, N. SiamAtt: Siamese attention network for visual tracking. Knowl.-Based Syst. 2020, 203, 106079. [Google Scholar] [CrossRef]
- Marino, F.; Distante, A.; Mazzeo, P.L.; Stella, E. A Real-Time Visual Inspection System for Railway Maintenance: Automatic Hexagonal-Headed Bolts Detection. IEEE Trans. Syst. Man Cybern. Part C 2007, 37, 418–428. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Pu, M.; Huang, Y.; Liu, Y.; Guan, Q.; Ling, H. EDTER: Edge Detection with Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1392–1402. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems (NIPS) 27, Montreal, QC, Canada, 8–13 December 2014. [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar] [CrossRef]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2015, 125, 3–18. [Google Scholar] [CrossRef]
- Su, Z.; Liu, W.; Yu, Z.; Hu, D.; Liao, Q.; Tian, Q.; Pietikainen, M.; Liu, L. Pixel Difference Networks for Efficient Edge Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5097–5107. [Google Scholar] [CrossRef]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. Bi-Directional Cascade Network for Perceptual Edge Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3823–3832. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contributor | Material | Method | Target |
|---|---|---|---|
| Jacobsmühlen [10] | Inconel 625, Inconel 718 | SVM, RF, SGD | Structure defects |
| Zhang [11] | Inconel 625 | Topography analysis | Flatness of powder bed |
| Wang [13] | 30CrMnSiNi2A | Topography analysis | Flatness of powder bed |
| Xiong [14] | / | Visual binocular vision | Thin-walled components |
| Scime [15] | Inconel 718 | MsCNN | Flatness of powder bed |
| Li [12] | Metal | Topography analysis | Flatness of powder bed |
| Gaikwrad [17] | Ti-6Al-4V | CNN | Geometric integrity |
| Liu [18] | Ti-6Al-4 V alloy | CNN | EBM powder bed |
| Bevans [19] | Inconel 718 | Multi-sensor fusion | Part-level and micro defects |
| Repossini [21] | Nickel alloy | Statistics | Melt pool |
| Rodriguez [22] | Ti-6Al-4V | Regression | Melt pool |
| Li [23] | ZrO2, SiO2 | Finite element simulation | Slurry flow |
| Zhao [24] | Alumina ceramics | Finite element simulation | lamellar structure |
| Chen [25] | ZrO2 | LSP | Internal defects of ceramic parts |
| Su [27] | Alumina ceramics | OCT | Morphology of ceramic parts |
| Saâdaoui [28] | Zirconia | XCT | Strength of parts |
| Diener [29] | silicon nitride | XCT | Residual pore structure |
| Indicator | Definition |
|---|---|
| TP | The target is identified as a defect, and the true value is the defect target. |
| FP | The target is identified as a defect, but the true value is the background. |
| TN | Target recognition is the background, and the true value is the background. |
| FN | Target recognition is background, but the true value is the defect target. |
| Serial | Siamese | Bubble | Sunken | Scratch | Shortage | Collapse | Mean | FPS |
|---|---|---|---|---|---|---|---|---|
| darknet | / | 0.4842 | 0.4546 | 0.8318 | 0.7680 | 0.9647 | 0.7293 | 115.95 |
| HED | 0.5000 | 0.4686 | 0.8372 | 0.8300 | 0.9765 | 0.7558 | 64.33 | |
| pidinet | 0.4946 | 0.4571 | 0.8357 | 0.7296 | 0.9704 | 0.7225 | 69.65 | |
| BDCN | 0.4946 | 0.4546 | 0.8318 | 0.7935 | 0.9647 | 0.7378 | 67.22 | |
| mobilenet | / | 0.4090 | 0.4081 | 0.8407 | 0.9281 | 0.9586 | 0.7775 | 104.42 |
| HED | 0.5208 | 0.4605 | 0.8800 | 0.9319 | 0.9647 | 0.8047 | 62.15 | |
| pidinet | 0.3838 | 0.4161 | 0.8348 | 0.8351 | 0.9586 | 0.7422 | 65.22 | |
| BDCN | 0.4509 | 0.4026 | 0.8778 | 0.9291 | 0.9643 | 0.7378 | 63.11 | |
| resnet50 | / | 0.5000 | 0.5294 | 0.9322 | 0.9315 | 0.9823 | 0.8252 | 91.51 |
| HED | 0.6538 | 0.6742 | 0.9705 | 0.9722 | 0.9823 | 0.8853 | 54.01 | |
| pidinet | 0.6200 | 0.5749 | 0.9231 | 0.9614 | 0.9823 | 0.8524 | 63.25 | |
| BDCN | 0.5631 | 0.6067 | 0.9250 | 0.9517 | 0.9823 | 0.8469 | 60.12 |
| Defect | Precision | Recall | F1 |
|---|---|---|---|
| Bubble | 0.9444 | 0.5000 | 0.6538 |
| Sunken | 0.9678 | 0.5172 | 0.6742 |
| Scratch | 0.9746 | 0.9664 | 0.9705 |
| Shortage | 0.9859 | 0.9589 | 0.9722 |
| Collapse | 0.9881 | 0.9765 | 0.9822 |
| Algorithm | Bubble | Sunken | Scratch | Shortage | Collapse | Mean |
|---|---|---|---|---|---|---|
| Faster RCNN | 0.5859 | 0.6171 | 0.8559 | 0.9178 | 0.8293 | 0.7796 |
| YOLOv7 | 0.5941 | 0.6012 | 0.8507 | 0.9010 | 0.8313 | 0.7735 |
| Ous (resnet50+HED) | 0.6538 | 0.6742 | 0.9705 | 0.9722 | 0.9823 | 0.8853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, X.; Li, S.; Wang, T.; Liu, B.; Cui, C.; Li, W.; Wang, G. High-Performance Defect Detection Methods for Real-Time Monitoring of Ceramic Additive Manufacturing Process Based on Small-Scale Datasets. Processes 2024, 12, 633. https://doi.org/10.3390/pr12040633
Jia X, Li S, Wang T, Liu B, Cui C, Li W, Wang G. High-Performance Defect Detection Methods for Real-Time Monitoring of Ceramic Additive Manufacturing Process Based on Small-Scale Datasets. Processes. 2024; 12(4):633. https://doi.org/10.3390/pr12040633
Chicago/Turabian StyleJia, Xinjian, Shan Li, Tongcai Wang, Bingshan Liu, Congcong Cui, Wei Li, and Gong Wang. 2024. "High-Performance Defect Detection Methods for Real-Time Monitoring of Ceramic Additive Manufacturing Process Based on Small-Scale Datasets" Processes 12, no. 4: 633. https://doi.org/10.3390/pr12040633
APA StyleJia, X., Li, S., Wang, T., Liu, B., Cui, C., Li, W., & Wang, G. (2024). High-Performance Defect Detection Methods for Real-Time Monitoring of Ceramic Additive Manufacturing Process Based on Small-Scale Datasets. Processes, 12(4), 633. https://doi.org/10.3390/pr12040633