In supervised learning, the network must be trained so that the last layer outputs a desired signal for a given input signal in the first layer. To do this, a training database containing pairs of input and output vectors of values is used. An input vector is propagated through the network, and the error between the observed and expected output vector is measured via a loss function. The weights of the networks are subsequently modified by back-propagation so that the loss function is minimized.
Recently, some works have been conducted to use artificial neural networks to address the image reconstruction problem of ECT devices. The ANN takes the capacitance measurements as input, and it aims to predict 2D volume fraction distribution. This technique has been very successful, with results that can be compared with the most performant algorithm already found in the literature. As we mentioned, machine learning algorithms require a training database from which to learn. In our case, this database should be composed of pairs of capacitance measurements and their corresponding solid volume fraction. Nevertheless, previous studies on the topic do not offer a satisfactory methodology to build this training database. Some works have proposed the use of images reconstructed with classical algorithms [
7]. However, using this approach, the ANN risks learning the shortcomings of the algorithm used. Another approach is to build a piece of software that creates random 2D volume fraction distributions resembling the patterns found in liquid-gas systems (stratified, annular, and core flows) [
8]. Then, using electrodynamics simulation software, they calculated the capacitance values associated with the volume fraction distribution. The main drawback of this approach is that generating random volume fraction distribution for fluidized bed applications is much more difficult. Unlike the liquid-gas patterns, the 3D solid volume fraction distribution inside a fluidized bed is much more complex and unpredictable. Moreover, we would need an additional piece of software as well as knowledge to perform the electrodynamics simulations.
In the following sections, we will propose two different strategies to generate a training database to train an artificial neural network that can be easily implemented in any ECVT device if the sensitivity matrix is known: supervised learning and reinforcement learning. The choice of keeping the sensitivity matrix approach makes our strategy much simpler, and it is also based on the fact that classical reconstruction algorithms can achieve very good results even with the simplification of the sensitivity matrix.
3.1. CFD-Generated Training Database
The first strategy we used to generate the training data required us to train our ANN based on computer simulations; this is supervised learning. Previous works [
8] have already built and trained ANNs using computer-generated data. However, their strategy consisted of generating artificial data that looked like the patterns found inside a two-phase flow (annular flow, stratified flow, single bar, and two bars). This allows us to generate a large number of different images to train our neural network. Nevertheless, we might not be able to accurately generate images corresponding to a 3D fluidized bed because the flow patterns are much more complex.
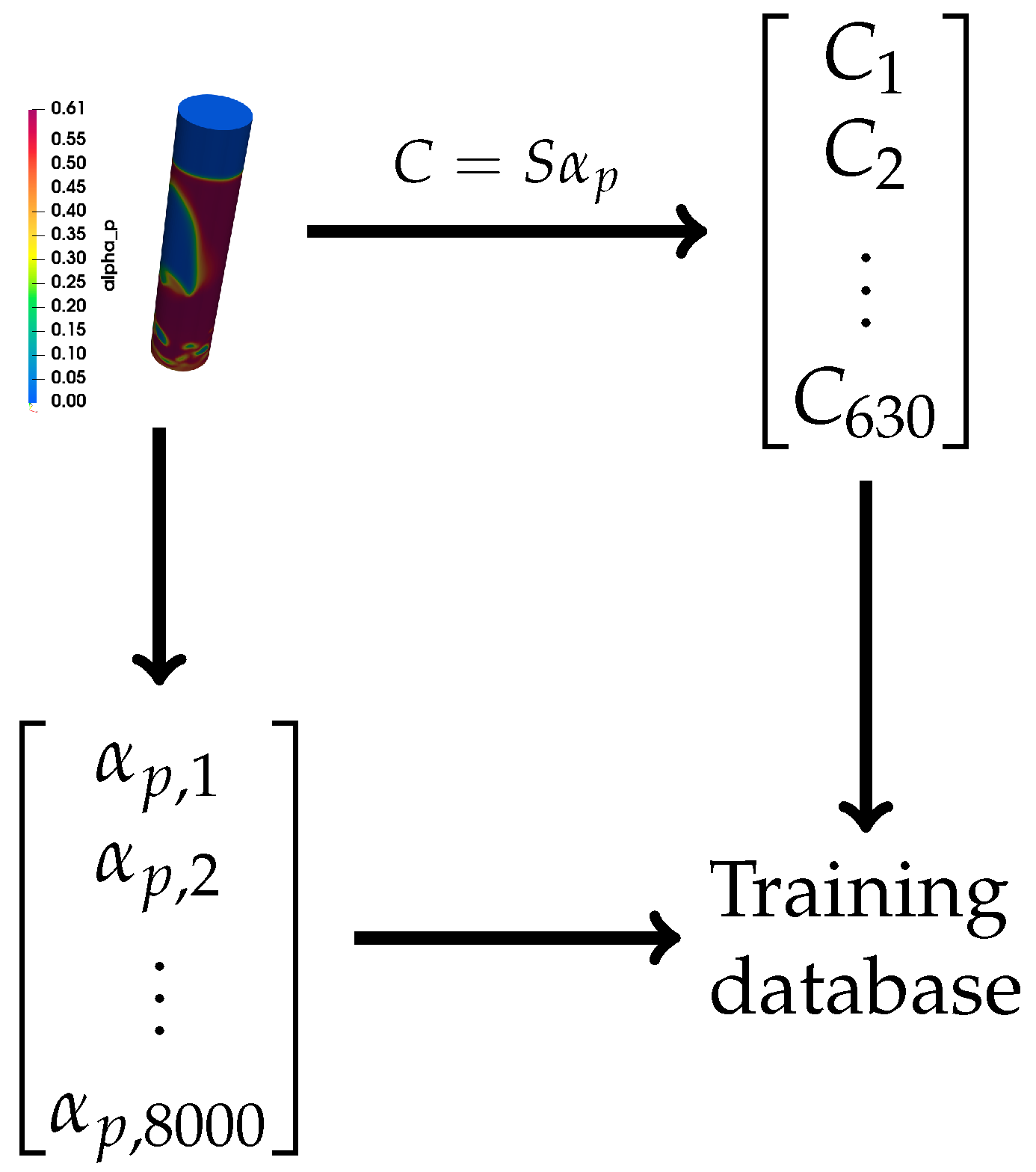
Nowadays, many CFD packages are very capable of accurately reproducing the general behavior of many different flow configurations (combustion, gas-solid flow, porous systems, etc.). These simulations give us information about the instantaneous solid volume fraction as a function of time. This information, combined with the sensitivity matrix, could allow us to simulate the capacitance measures associated with such distribution (Equation (
1)). With the simulated solid volume fraction distribution and the simulated capacitance measurements, we can build an input/output database that can be used in the training process of an artificial neural network (
Figure 6 and
Figure 7). An advantage of this method is that it can be easily applied to other fields that also have accurate simulation tools.
In this work, we will be focused on fluidized bed reactors. These systems can present different regimes depending on the types of particles and the fluidization velocity [
20]. Difference regimes present different hydrodynamic and thermal properties, and identifying them correctly is very important for many industrial applications. Especially the transition between the bubbling regime and the turbulent regime [
21,
22]. However, the turbulent regime is characterized by very chaotic and complex behavior, particularly for solid volume fraction distribution. It is for these reasons that a training database consisting of only simple and structured patterns might not be suitable for an ECVT system used in a fluidized bed. However, the current CFD software and mathematical models allow for the accurate prediction of these complex regimes. Therefore, we could use this information to build our training database for an artificial neural network.
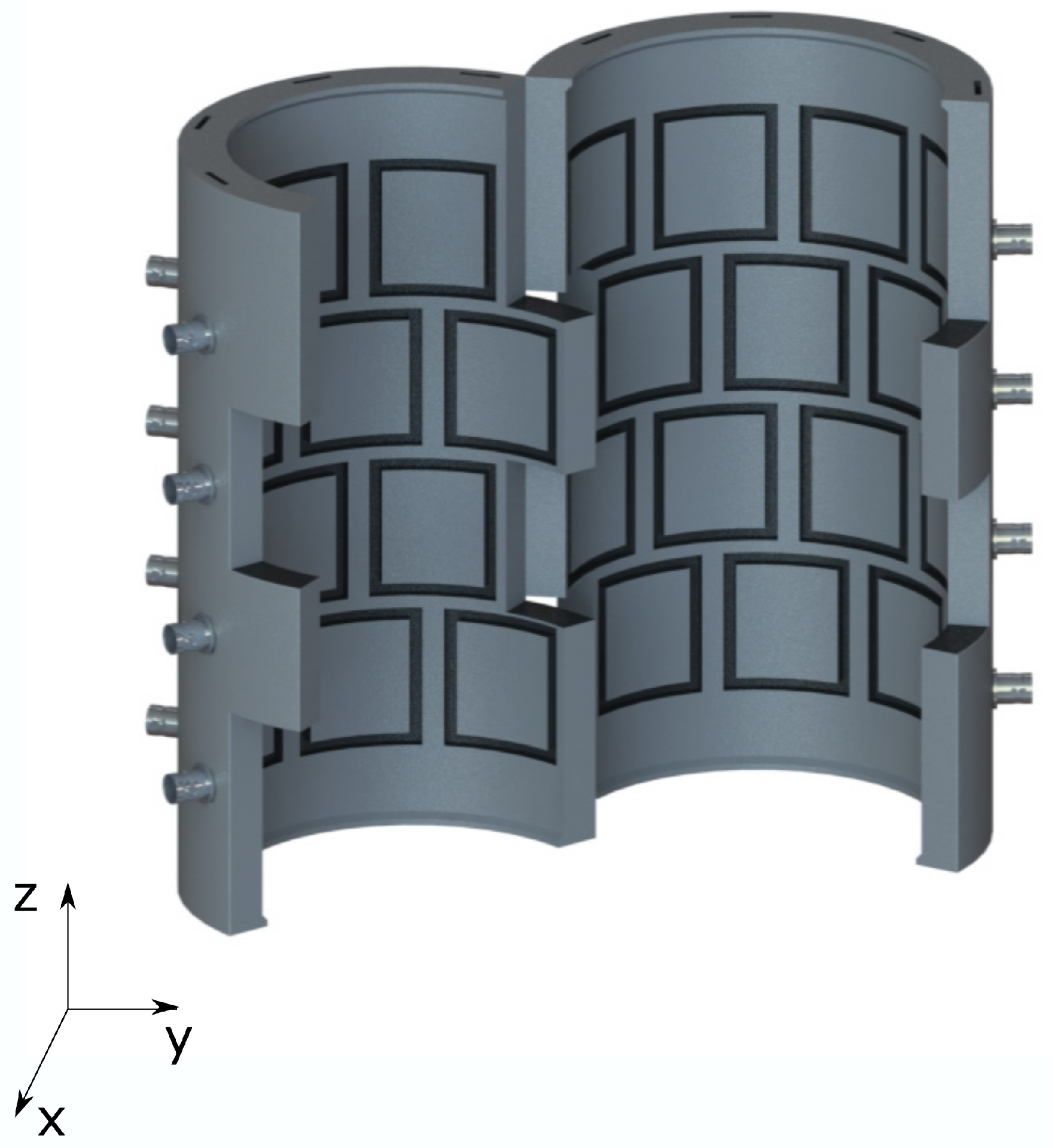
In order to simulate our fluidized bed reactor, we used the CFD software neptune_cfd. This is a multiphase Euler fluid code developed in the framework of the neptune project, financially supported by CEA, EDF, IRSN, and Framatome. It is capable of solving particle-laden flow problems in complex geometries using structured and non-structured meshes. This code has been extensively validated for a fluidized bed configuration using very accurate experimental techniques, such as positron emission particle tracking (PEPT) and radioactive particle tracking (RPT) [
23,
24,
25,
26]. neptune_cfd is a massively parallel code [
27]; this allows for the obtainment of a large training database very quickly. The simulated geometry is a column 10 cm in internal diameter and 1 m in height in the Z direction. We used an O-grid mesh with 400,000 cells, approximately 3 mm in length. For the solid phase, we used glass beads 250μm in diameter with a density equal to 2700 kg/m
3. The gas phase is air at 20 °C and atmospheric pressure. The initial height of the fluidized bed was set to 17 cm. The interested reader can consult [
24] for more details on the mathematical models used by neptune_cfd.
As we wanted to obtain the most diverse database possible, we used different gas velocities at the inlet. We performed simulations for four different inlet velocities (
,
,
, and
), where
= 6.3 cm/s is the minimum fluidization velocity obtained using Ergun’s correlation [
28]. For each simulation, we recorded the solid volume fraction distribution in the 8000 voxels corresponding to the exact location of the voxels reconstructed by the ECVT system. For each case, we simulated 30 s of physical time. We extracted the solid volume fraction inside a
height region between
and
, where
represents the column inlet. The acquisition frequency was set to 100 images per second. Given that the expected bubble frequency is about 1.5–2.5 Hz, this acquisition frequency is high enough to capture the bubbles passing through the sensing region. The final database is, therefore, composed of 12,000 pairs of capacitance/solid volume fraction vectors. The size of this database was chosen after a sensitivity analysis of the results by varying the size of the training database.
In order to build our ANN, we used Keras. This is a open source Python library designed to build artificial neural networks quickly [
29]. In the back end, Keras uses the symbolic mathematical library TensorFlow [
30].
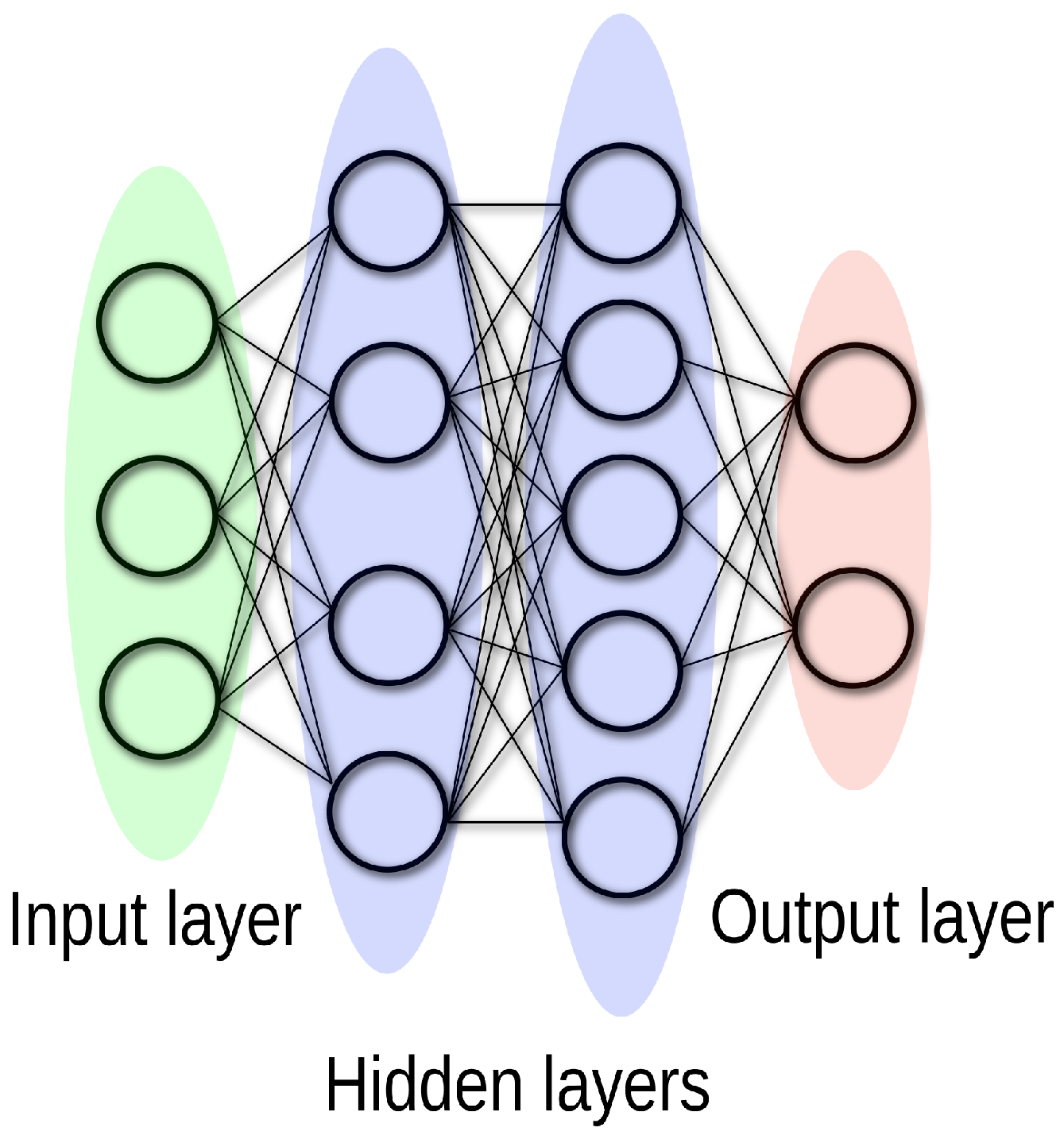
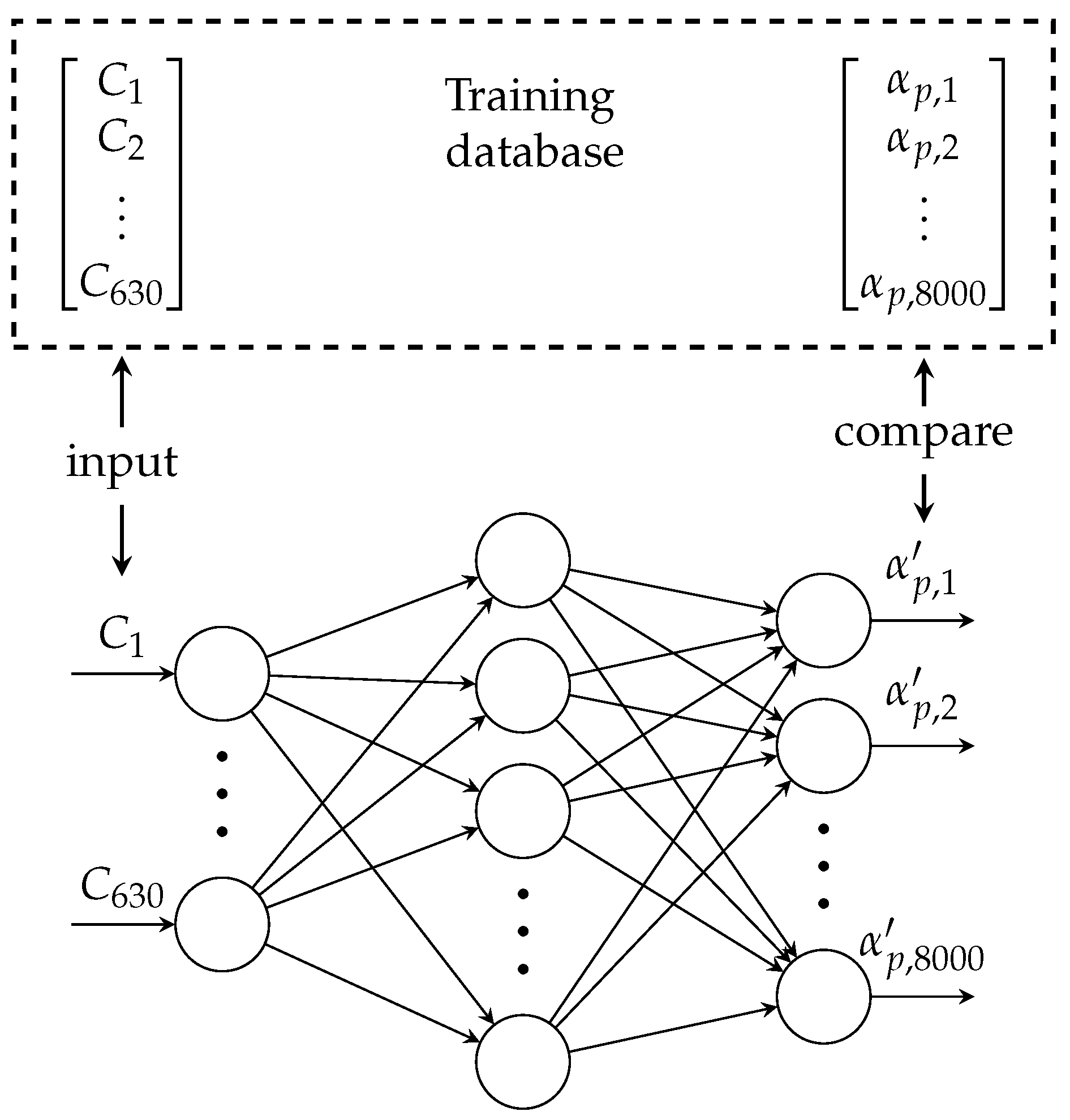
The artificial neural network used is composed of an input layer of 630 neurons (corresponding to the 630 capacitance measurements) followed by three hidden layers of 1024, 2048, and 4096 neurons, respectively, and a final output layer of 8000 neurons corresponding to the 8000 values of solid volume fraction. The choice of these parameters was made after analyzing different configurations with different numbers of hidden layers and numbers of neurons per hidden layer. This final configuration was chosen as it was the most performant ANN for the supervised learning approach and the reinforcement learning approach presented later. In order to ensure that the solid volume fraction predicted by the neural network is bounded between 0 and 0.64 (the solid volume fraction at maximum packing), we enforced a scaled sigmoid activation function for the output layer of the ANN:
where
is the sum of all inputs of the
i-th neuron in the output layer.
Before the training phase, we shuffled the training database so two consecutive entries were not correlated. We also randomly removed 25% of the entries of the training database for validation purposes. In this way, our ANN was trained with 75% of the available data, and the remaining 25% was used to quantify the precision of the algorithm during the training. For the training phase, there are two key parameters to specify: the batch size and the number of epochs. The first one refers to the number of samples of the training database that will be used to compute the loss function before updating the ANN weights. For example, if our training database consists of 9000 samples, and if we choose a batch size equal to 20, first, the entries 1–20 in the training database will be fed to our neural network, and the loss function of these 20 entries will be used to change the weights, . Then, we will feed the entries 21–40 to the updated ANN, and the new loss function value is used to change the weight values. This process is repeated until all 9000 entries are used. A small batch size could allow us to train the database faster because the weights are updated more frequently. However, choosing a very small batch size could generate important fluctuations that could harm the convergence rate. The second parameter that has to be specified is the number of epochs. The epochs are the number of times the whole database is used during the training phase. If the number of epochs is set to 10, this means that the learning algorithm will go over the 9000 samples 10 times. A high number of epochs can improve the quality of the ANN, but this could also be very time-consuming. In our example, we chose the batch size to be equal to 20, and we trained over 600 epochs.
In order to monitor the convergence of the ANN, we can calculate the root mean squared error (RMSE) between the predicted (
) and the expected (
) solid volume fraction values (Equation (
4)).
where
n is the total number of voxels in the sensing region.
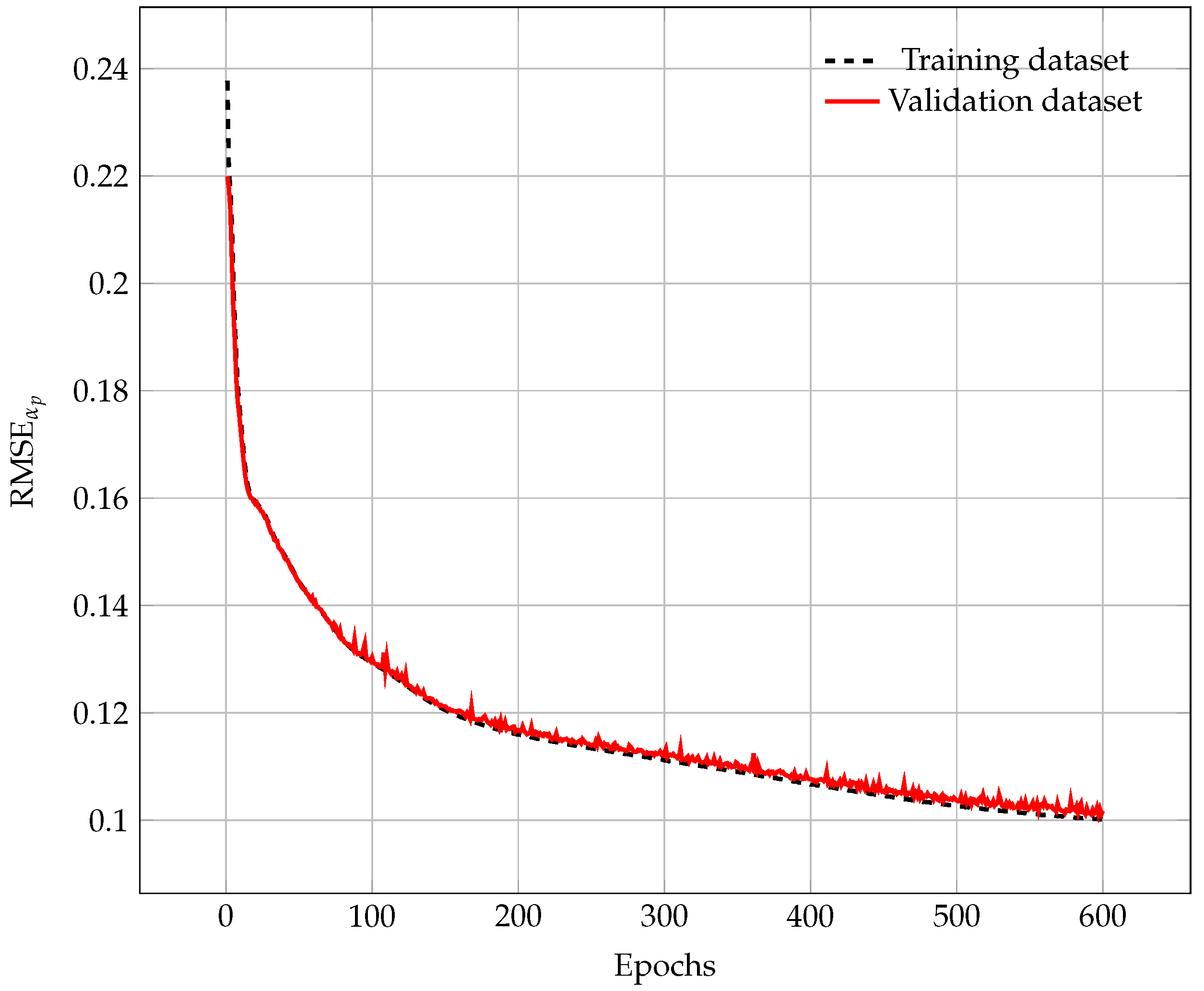
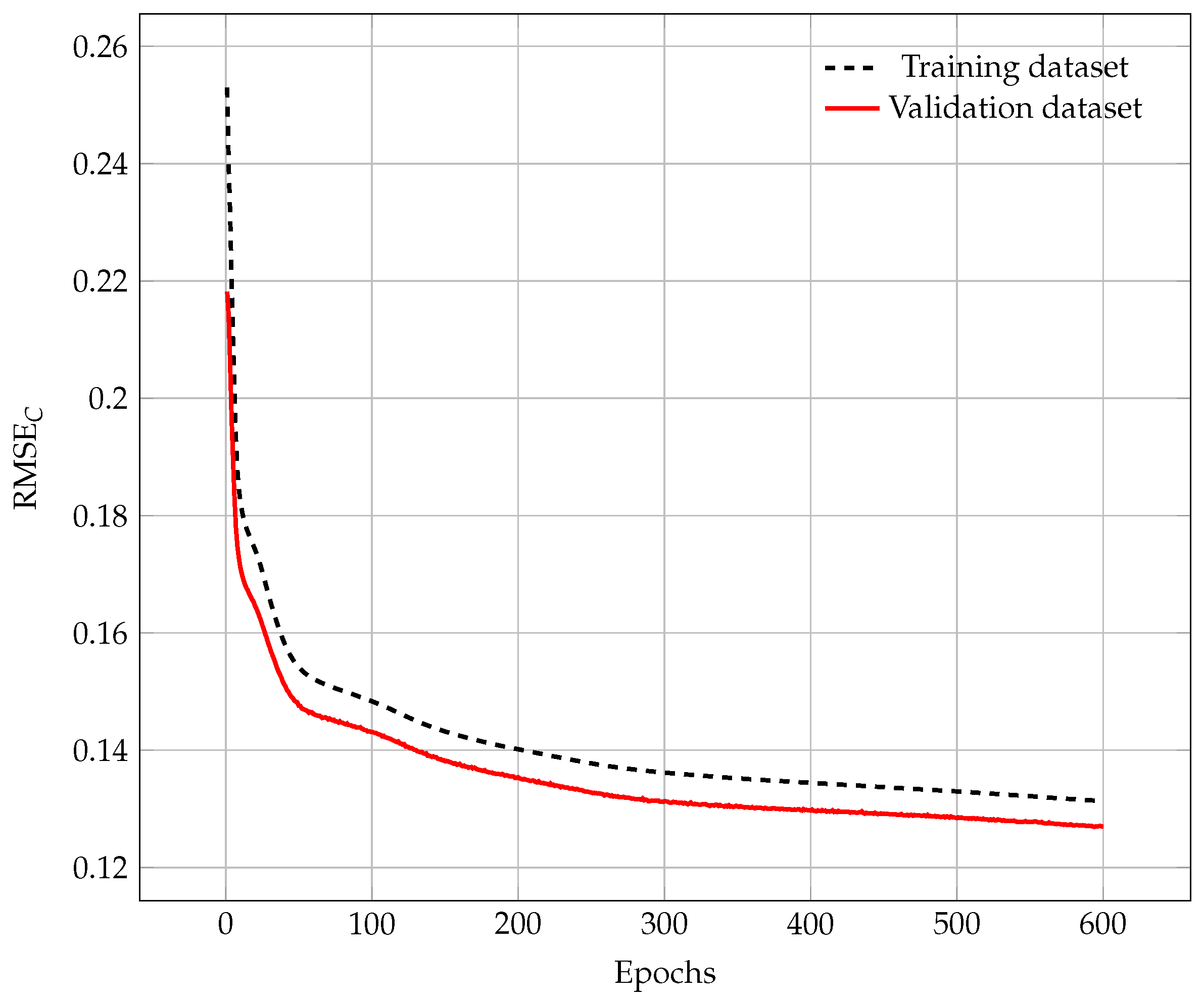
In
Figure 8, we can see the RMSE during the training phase when using the training and validation databases. As we can observe, the RMSE decreases as the number of epochs increases for the training database. This means that for each epoch, the output predicted by the neural network is closer to the expected output. We observe the same trend when we evaluate the accuracy of the neural network using the validation database (which is not used to update the internal weights of the ANN). This highlights that the ANN is also capable of predicting good values for inputs that are not present in the training database. This is a good sign because it shows that the neural network can also provide accurate results for data outside the training database (unseen data). After 600 epochs, we see that RMSE is decreasing slowly, which means that the training algorithm has converged, and the reconstructed images do not change if we keep training the ANN. Now, we can take the neural network obtained in the last epoch and use it to reconstruct images using new data.
In order to evaluate the quality of our trained ANN, we can feed it with new simulated data generated using a different inlet velocity than the ones used during the training phase (5
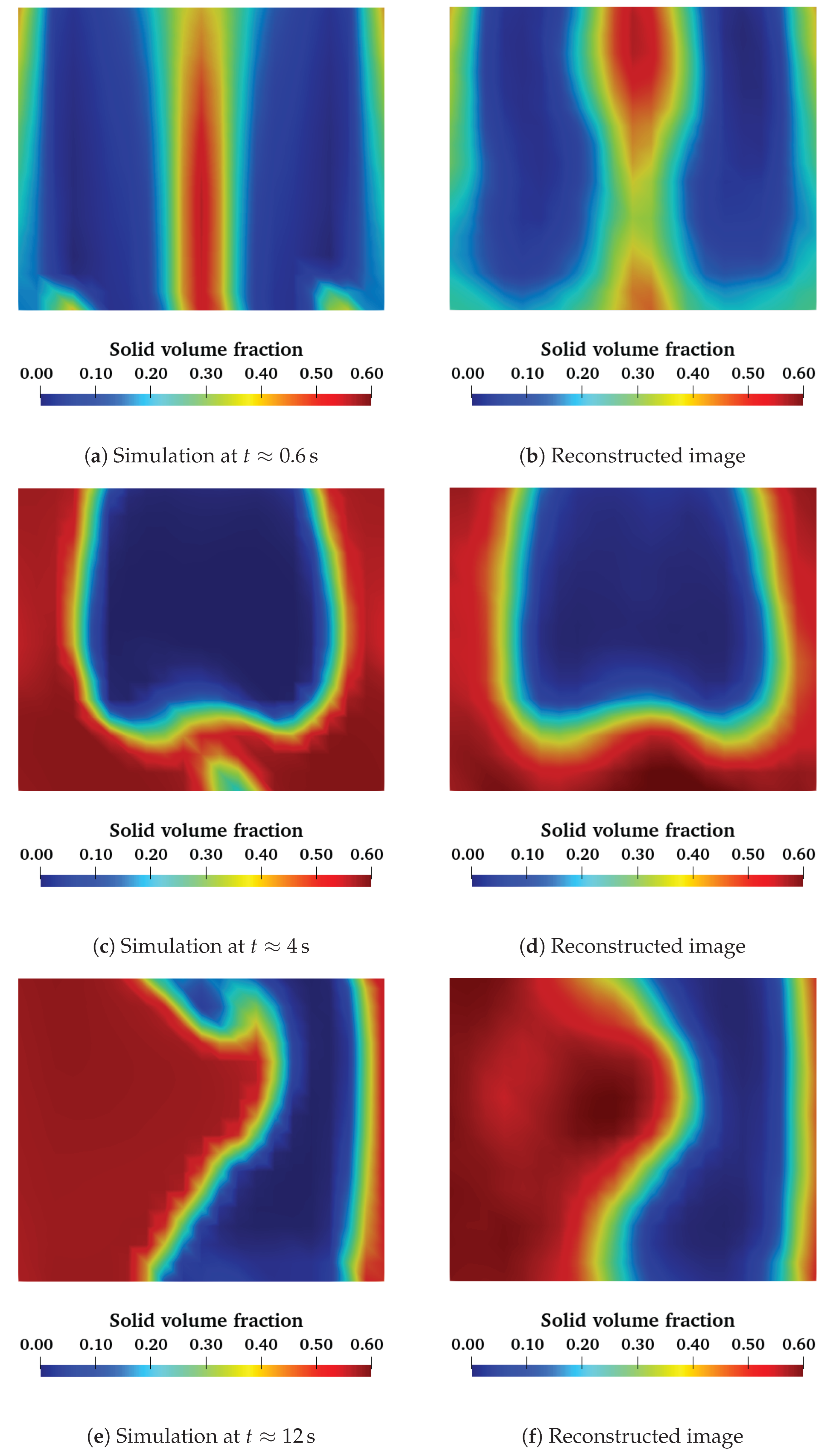
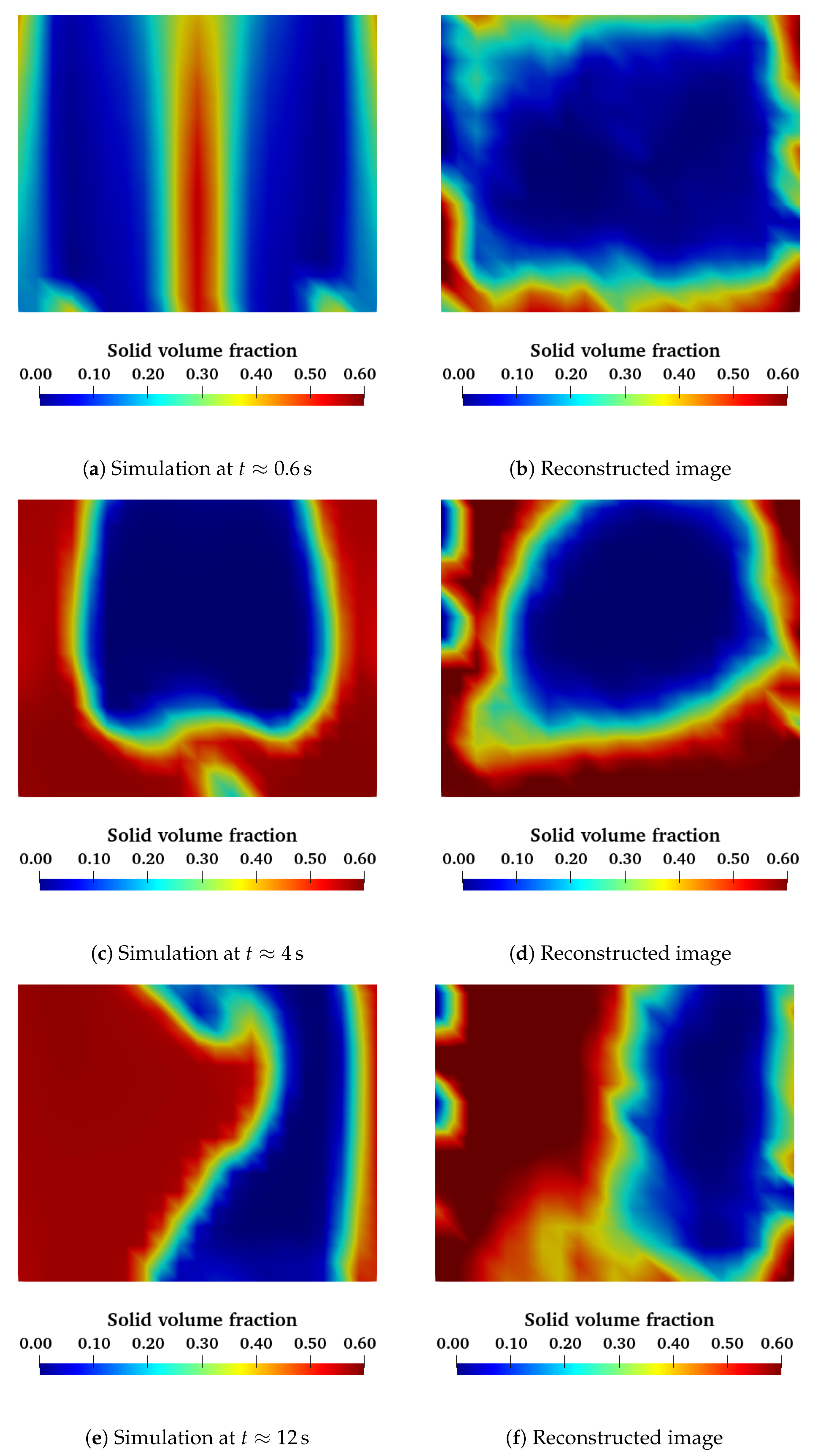
). For this simulation, we can extract the solid volume fraction and the capacitance values, as we did to construct the training database. Then, we pass the capacitance values as input to our ANN, and we compare the output solid volume fraction distribution with the simulation results. In
Figure 9, we compare the simulation output with the reconstructed image from the ANN for a 2D slice XZ plane in the middle of the column at three different moments in time. The first image corresponds to the first moments after fluidization started, where we have two symmetrical bubbles rising. The second image is the moment where a big air bubble rises, and the third image corresponds to a more complex structure appearing in the reactor. We remark that for all three cases, the reconstructed images are very close to the output of the simulation. These images show that the ANN is capable of reconstructing the 3D representation of a fluidized bed using simulated capacitance data as well as the global topology of the flow.
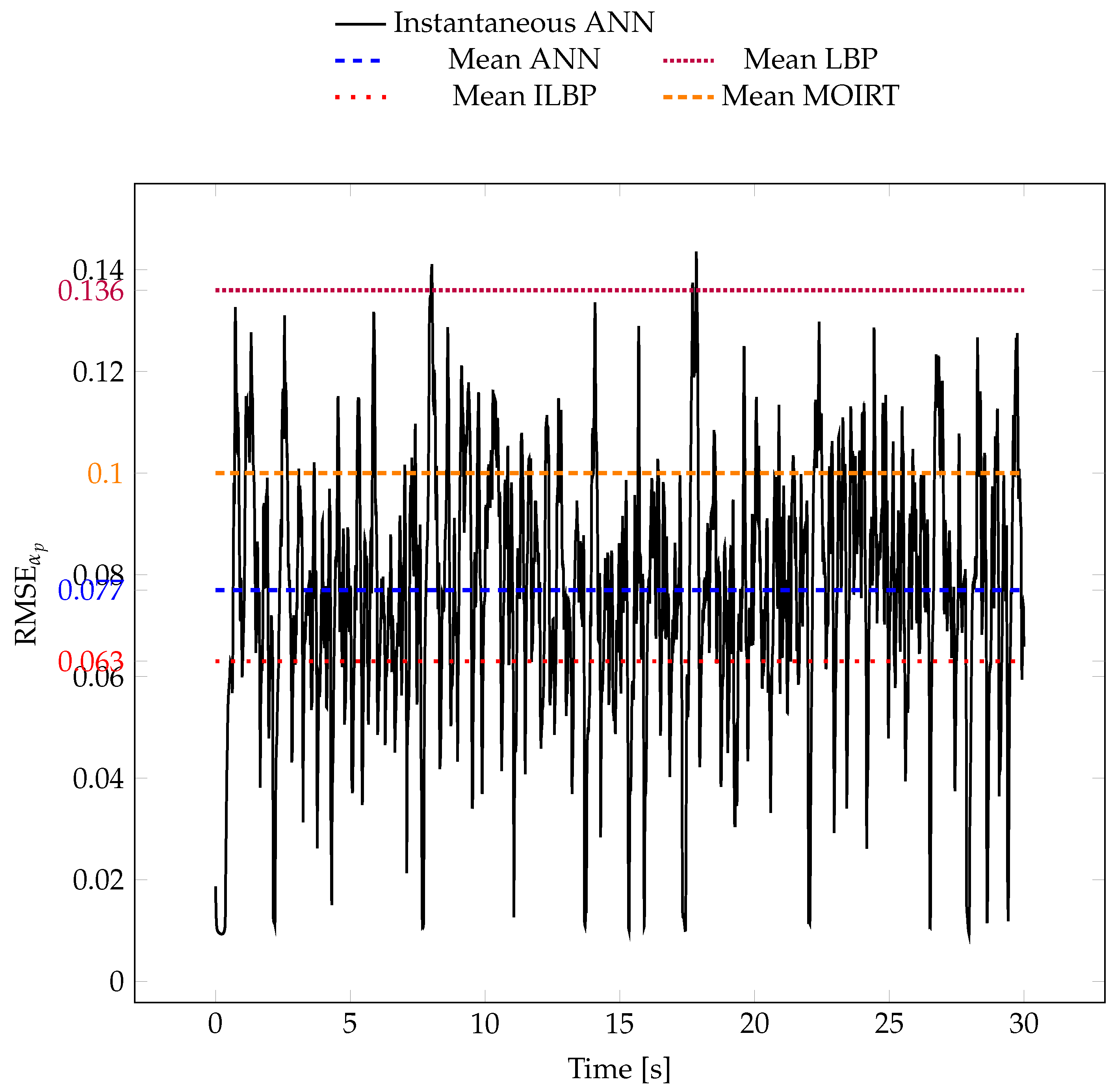
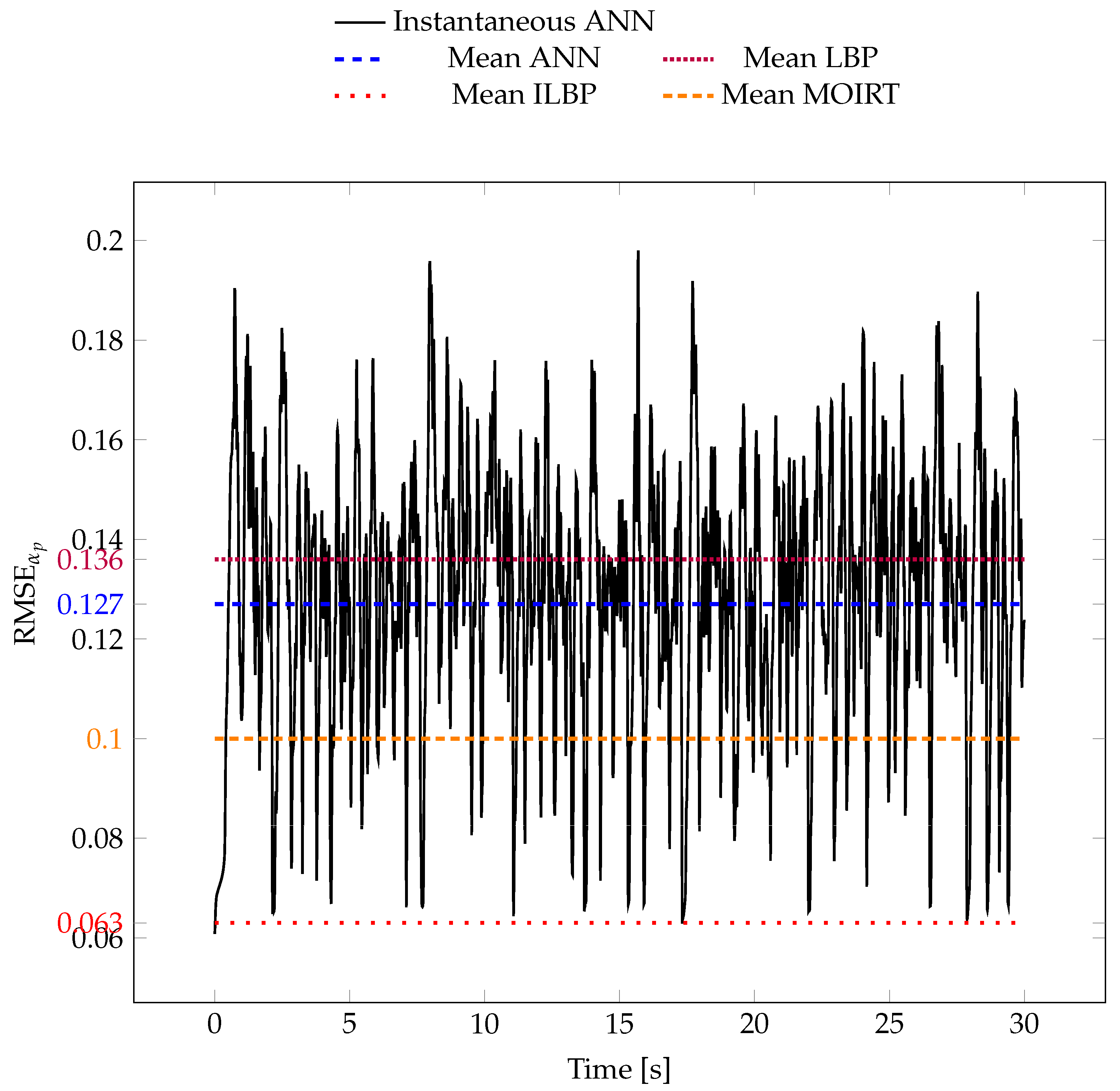
We can also compare the RMSE between the reconstructed images and the simulation for each time step (
Figure 10). For ANN, the black line represents the RMSE as a function of time, while the dashed blue line is its mean value over time. As a comparison, we also drew (in dashed lines) the mean RMSE of the images obtained with the classical reconstruction algorithms. This shows that the ANN is very close to the most performant algorithms. If we compute the mean absolute error between the simulated values and the predicted values, we get that the ANN predictions have an error in
of 0.06. Given that the average
value in a fluidized bed is of the order of 0.40, our ANN model has a prediction error of 15%. This error is low enough to allow us to capture the large structures developing inside the reactor accurately.
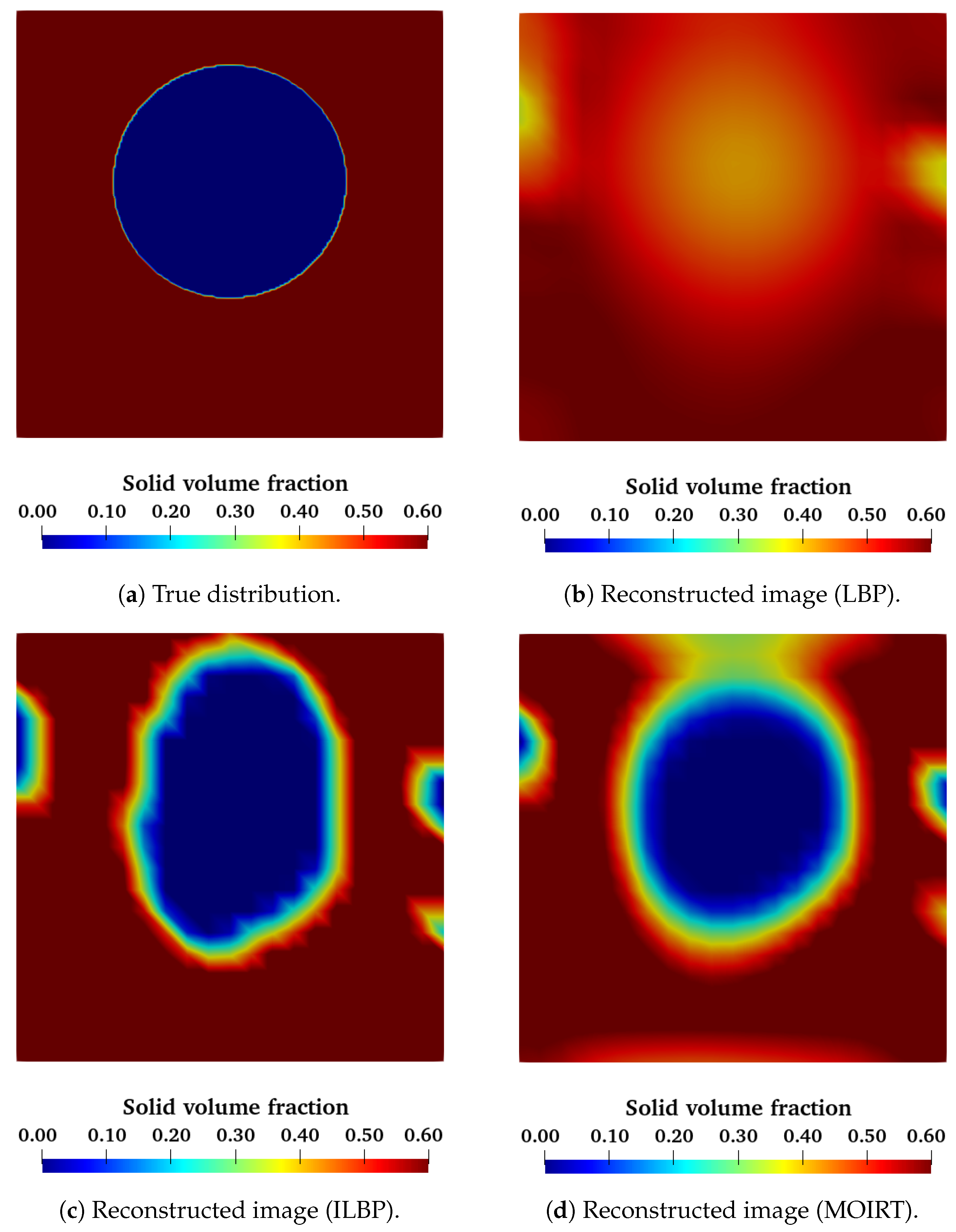
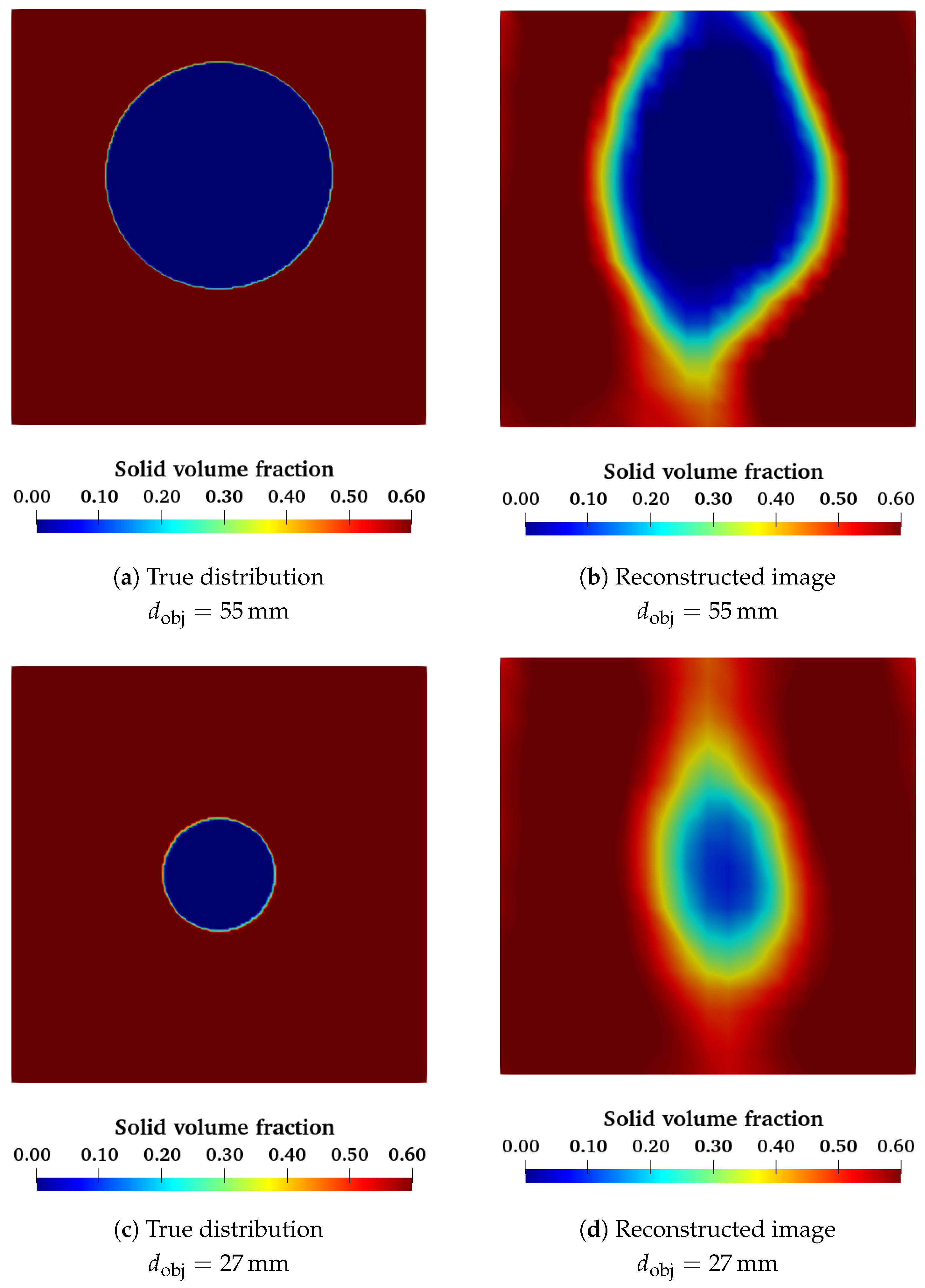
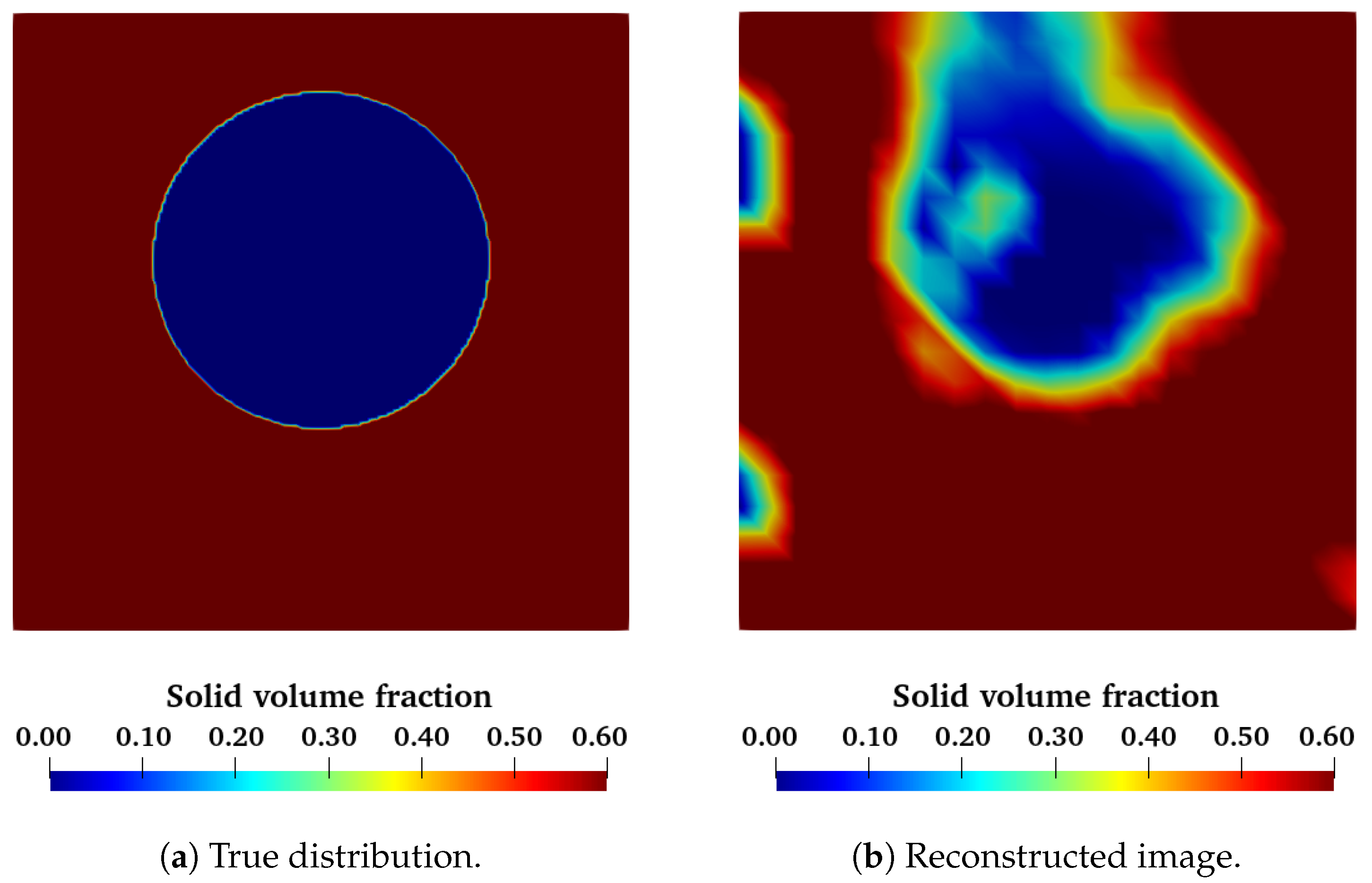
We can also test this neural network using the experimental data obtained with the void spheres in a fixed bed of glass beads.
Figure 11 shows a slice of the reconstructed volume for both the small and the big spheres. These images show that the ANN was able to detect a spherical object inside the volume. As with the classical algorithms, the big sphere is much easier to recognize than the small sphere. We can characterize the diameter of all test spheres using the same criteria as before (see
Table 2). As we can see, we have an overestimation for every object. However, these values are still close to the real expected value.
Once the neural network has been trained, the reconstruction process is very fast because it only requires propagating the capacitance signal through the network. This makes this strategy much more efficient than the classical iterative algorithms. However, the training phase can be computationally expensive depending on the size and complexity of the network, the number of training epochs, and the size of the training database. Our neural network took around 10 h to perform the entire training phase for the same computing power described above. Nevertheless, this neural network can reconstruct one image in around 45 ms. This makes this strategy as fast as the fastest algorithm, LBP, and as accurate as the most complex algorithm (MOIRT) but much faster.
This makes this approach suitable for a system where accurate and instantaneous post-processing is needed, or a large amount of data needs to be processed. However, an important drawback is the necessity of a way to generate simulated data. This means that this approach depends on other simulation tools. In addition to this, we need to make sure that the simulated data represents the physical phenomenon accurately; any bias or error present in the simulated data could also be reproduced by the neural network. In the next section, we present a different approach to making a standalone artificial neural network.
3.2. Experimental Generated Training Database
We propose a second strategy to build the training database needed for the training phase of the ANN: reinforcement learning. In this approach, we no longer need a database composed of input/outputs (). Instead, we can directly use experimental data even without any previous knowledge of the solid volume distribution.
The key aspect of this approach is that we know how to estimate the capacitance measurements given a solid volume fraction distribution (Equation (
1)). During the training phase, we can feed experimental data,
C, directly into the ANN. Instead of comparing the AAN’s output
to some true
distribution, we are going to use Equation (
1) to transform our predicted
into predicted capacitance values
. If the neural network is well-trained, the values
C and
must be similar (
Figure 12). This will mean that the generated 3D image corresponds to the original input capacitance data. If this is not the case, then the internal weights have to be adjusted. Hence, our neural network will be trained so it minimizes the RMSE between
C and
(Equation (
5)).
This approach has the advantage of not needing computer-simulated data to train itself. We can now directly use experimental data, even without having previous knowledge of the true solid volume fraction distribution. This makes this technique completely independent of any external tool. Another advantage is that we can use any new experimental data to simultaneously reconstruct the solid volume fraction and to train the neural network even further, which is in contrast to the previous approach, where the experimental data cannot be used to improve the neural network. Therefore, this technique allows us to have a self-sufficient ANN that can be in a constant learning process.
In order to test this approach, we built the same neural network used in the previous section—an input layer of 630 neurons, three hidden layers of 1024, 2048, and 4096 neurons, and one output layer with 8000 neurons—with the same sigmoid activation function used before (Equation (
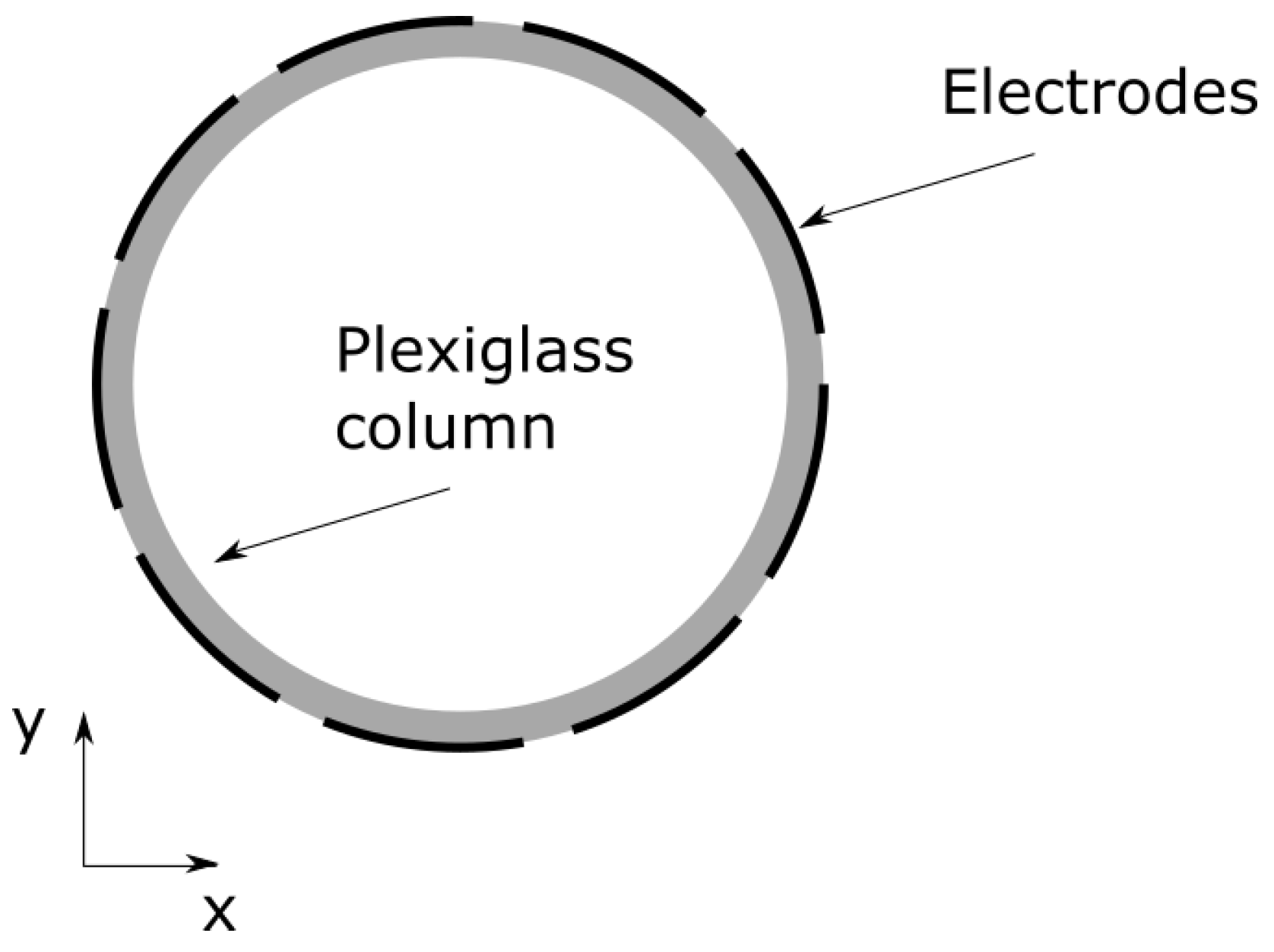
3)). In order to obtain the experimental data, we placed our ECVT electrodes around a plexiglas column
in internal diameter and 1 m in height (see
Figure 13). These are the exact same dimensions of the geometry used in the numerical simulations. The ECVT device is placed at the same location as in the simulation, between
and
. The solid phase is composed of glass beads
in mean diameter. The gas phase is air at ambient pressure and ambient temperature, with 50% relative humidity, to ensure that the electrostatic effects do not appear in the solid phase. Similar to the previous approach, we used different inlet velocities between 3
and 7
. The bottom of the ECVT system was placed
above the inlet to match the settings used in our simulations exactly. The acquisition frequency was set to 50 frames per second, and we took 3000 frames for each inlet velocity. We also used the exact training parameters for this ANN, with a batch size equal to 20, and we trained the neural network over 600 epochs.
Figure 14 shows the evolution of the RMSE as a function of the training epochs. We remark that the RMSE decreases when the number of training epochs increases. This means that the neural network is converging to a better solution. This behavior is true for both the training and the validation databases. This shows that this ANN can also be used for data that were not present in the training database.
With this trained artificial neural network, we can perform the same analysis as we did for the previous one. First, we can feed our ANN with simulated data and compare the reconstructed images with the numerical simulation. In
Figure 15, we can see that, qualitatively, the results produced by this approach are in good agreement with the expected results. However, they are not as good as the results produced by the CFD-trained ANN. The two symmetrical bubbles rising at the start of the simulation are not well captured (
Figure 15a,b). For the big bubble (
Figure 15c,d) and the complex structure near the wall (
Figure 15e,f), we obtained a more accurate reconstruction. Nevertheless, the results are worse than the previous ANN strategy.
Figure 16 represents the root mean squared error between the numerical simulation and the reconstructed image as a function of the simulation time. We can see that the mean RMSE value is around 0.13, which is worse than the previous ANN. This curve also shows that this ANN is also not as good as the ILBP and MOIRT algorithms. However, it does perform better than the LBP scheme. For this approach, the mean absolute error between the predicted and the expected solid volume fraction values is equal to 0.08. This means that this approach has an error of 22% compared to the mean solid volume fraction found in a fluidized bed.
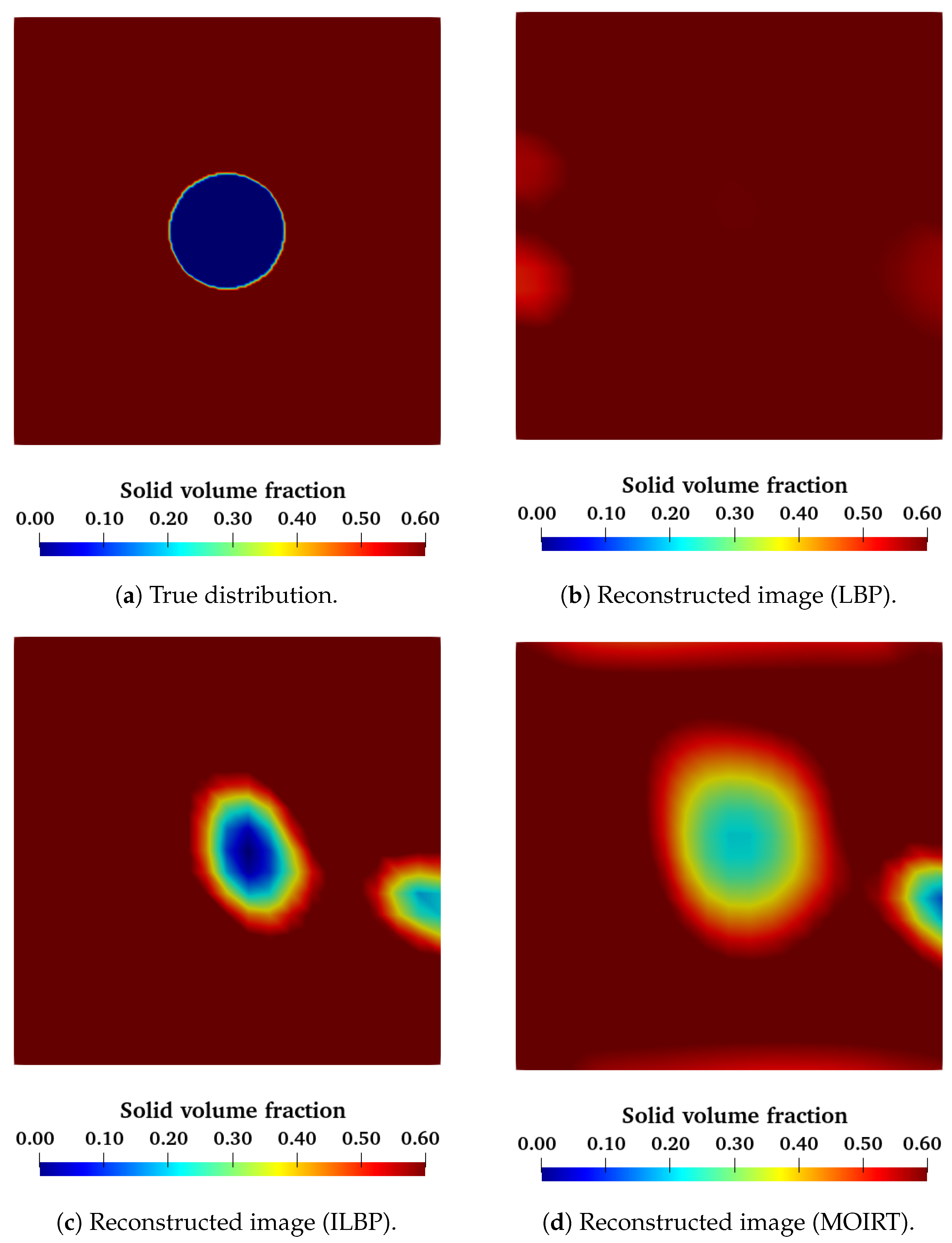
This ANN can also be used to compare against the experimental data obtained with the void spheres in the fixed bed. A visual comparison is made in
Figure 17 and
Figure 18. These images reveal that our ANN has no problem detecting big void objects inside a fixed bed of glass particles. It does, however, fail to reconstruct the smallest of our test objects. The equivalent diameters of the reconstructed objects are shown in
Table 3. We can see that the equivalent diameters are very close to the real diameters for large objects, but smaller objects are not detected at all. This shows that for a similar training database and network architecture, the reinforcement approach does not perform as well as the supervised approach.
The computational cost of using this neural network is almost the same as the previous one. The training phase took around 10 h, and the reconstruction of one image takes about 50 ms. Despite the fact that we obtained a less performant ANN, this strategy showed some promising results. We are able to reconstruct simulated data with acceptable spatial accuracy. Moreover, the algorithm is capable of detecting big objects inside the sensing regions. However, further research is needed to improve the network for capturing small objects.
These results prove that we can train an artificial neural network using solely experimental data in order to address the image reconstruction problem for 3D ECVT systems. Our ANN was tested against both simulated and real data. The results highlight that this approach is also suitable as an image reconstruction algorithm. Although the results were slightly worse compared to the first strategy, this approach is completely self-sufficient and does not need any external tool. This strategy will also benefit from any new experimental data to learn and increase its quality.
Despite the fact that this training technique did not perform as well as the previous one, it is worth noting that there are some fundamental differences between these two approaches. The CFD data used to train our first artificial neural network was totally free from noise, while the experimental data are always convoluted with the noise generated by the acquisition configuration. At this stage, it is unknown if this noise has an effect on the quality of the training process. This is something that should be taken into account when working with this approach; however, it is unclear how this effect could be modeled. Despite this, reinforcement learning has shown promising results and should be further investigated.
It is also worth noting that both approaches gave results that are of the same order of magnitude as the error obtained using the classical reconstruction algorithms. This might be due to the use of the sensitivity matrix approximation to solve the forward problem (Equation (
1)), which is the core of classical reconstruction algorithms and also our ANN-based approach. This approximation assumes that the sensitivity distribution of the ECVT is independent of solid volume fraction distribution. This hypothesis is not true in electric tomography. However, the sensitivity matrix approach has proven to be a valid strategy to tackle the reconstruction problem, both for the classical reconstruction algorithms and, now, for an ANN-based approach. Nevertheless, more accurate results are to be expected if the exact formulation of a forward problem is incorporated into the methodology. This would, however, add an extra layer of complexity.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}