

Novel Multi-Criteria Group Decision Making Method for Production Scheduling Based on Group AHP and Cloud Model Enhanced TOPSIS


Abstract
1. Introduction
2. Preliminaries
2.1. Cloud Model Theory
- (1)
- If Ex1 > Ex2, then T1 > T2;
- (2)
- If Ex1 = Ex2 and En1 < En2, then T1 > T2;
- (3)
- If Ex1 = Ex2, En1 = En2, and He1 < He2, then T1 > T2;
- (4)
- If Ex1 = Ex2, En1 = En2, and He1 = He2, then T1 = T2.
2.2. Linguistic Terms
2.3. Conversion of Heterogeneous Data
3. Methods
3.1. Indicator System
3.2. Weighting Algorithm Based on Group AHP
| Algorithm 1: Group AHP for Production Scheduling Evaluation Indicators Weighting. |
| 1: Collect PCMs {(Ad)n×n} on n indicators from m decision makers (d = 1,2, …, m). 2: for d = 1 to m do 3: Calculate the largest eigenvalue and its normalized eigenvector wd of Ad. 4: Calculate CRd of Ad by Equation (28). 5: end for 6: for d = 1 to m do 7: Calculate each decision maker’s weight by Equation (30). 8: end for 9: for i = 1 to n do 10: Calculate the weight of indicator ci represented as wi by Equation (31). 11: end for 12: Output the weight vector of n indicators as w = {w1, w2, …, wn}. |
3.3. Cloud Model Enhanced TOPSIS
3.3.1. Problem Description
3.3.2. Main Steps of the Proposed Method
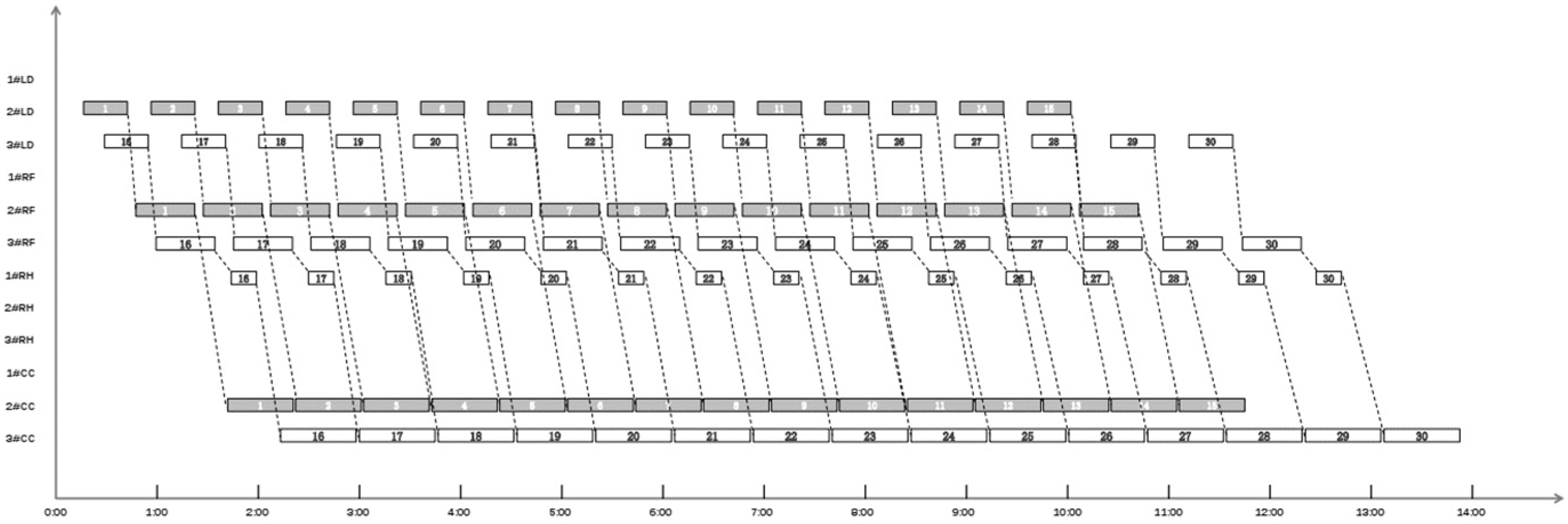
4. An Application Example
4.1. Obtain the Evaluation Matrix
4.2. Calculate the Weights of Indicators
4.3. Prioritize Alternative Schemes
5. Discussion
- (1)
- We propose a systematic evaluation system for steel production scheduling, which is more reasonable, flexible, practical, and effective in evaluating and ranking steel production scheduling schemes in an uncertain environment. It can also provide some guidance for the optimization direction of scheduling schemes according to indicator performance.
- (2)
- The evaluation indicators include both qualitative and quantitative indicators, which are built from the entire production scheduling process, simultaneously considering key factors that affect the production process and results from multiple dimensions of economic, environmental, and social aspects, breaking through the limitations of most evaluation indicators that are limited to a single production process or a single indicator dimension.
- (3)
- We present diverse statistical methods and evaluation functions to evaluate quantitative indicators to accurately reflect their real benefits, and develop a hybrid decision method integrating Group AHP, a cloud model, and the TOPSIS method to evaluate qualitative indicators. The hybrid method has good data capabilities of managing uncertainties of heterogeneous data, achieving better multi-indicator trade-offs, enhancing group decision-making rationality, and obtaining a more effective full and distinguishing ranking of schemes; hence, enhancing the effectiveness of evaluation.
- (4)
- The proposed hybrid MCGDM method is transparent with well-defined problem descriptions and implementation procedures and is evaluated on a real practical steel production scheduling dataset.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, J.; Liu, M.; Hao, J.; Jiang, S. A multi-objective optimization approach for integrated production planning under interval uncertainties in the steel industry. Comput. Oper. Res. 2016, 72, 189–203. [Google Scholar] [CrossRef]
- Li, Q.; Wang, X.; Zhang, X. A Scheduling Method Based on NSGA2 for Steelmaking and Continuous Casting Production Process. IFAC—PapersOnLine 2018, 51, 174–179. [Google Scholar] [CrossRef]
- Jiang, S.-L.; Liu, M.; Lin, J.-H.; Zhong, H.-X. A prediction-based online soft scheduling algorithm for the real-world steelmaking-continuous casting production. Knowl.-Based Syst. 2016, 111, 159–172. [Google Scholar] [CrossRef]
- Jiang, S.-L.; Peng, G.; Bogle, I.D.L.; Zheng, Z. Two-stage robust optimization approach for flexible oxygen distribution under uncertainty in integrated iron and steel plants. Appl. Energy 2021, 306, 118022. [Google Scholar] [CrossRef]
- Pacciarelli, D.; Pranzo, M. Production scheduling in a steelmaking-continuous casting plant. Comput. Chem. Eng. 2004, 28, 2823–2835. [Google Scholar] [CrossRef]
- Long, J.-Y.; Zheng, Z.; Gao, X.-Q.; Gong, Y.-M. Production Planning System for the Whole Steelmaking Process of Panzhihua Iron and Steel Corporation. J. Iron Steel Res. Int. 2014, 21, 44–50. [Google Scholar] [CrossRef]
- Thenarasu, M.; Rameshkumar, K.; Rousseau, J.; Anbuudayasankar, S. Development and analysis of priority decision rules using MCDM approach for a flexible job shop scheduling: A simulation study. Simul. Model. Pract. Theory 2021, 114, 102416. [Google Scholar] [CrossRef]
- Zhang, P.; Qiao, F.; Wang, J.; Sutherland, J.W. Novel Multi-Criteria Sustainable Evaluation for Production Scheduling Based on Fuzzy Analytic Network Process and Cumulative Prospect Theory-Enhanced VIKOR. IEEE Robot. Autom. Lett. 2022, 7, 9969–9976. [Google Scholar] [CrossRef]
- Nakhaeinejad, M.; Nahavandi, N. An interactive algorithm for multi-objective flow shop scheduling with fuzzy processing time through resolution method and TOPSIS. Int. J. Adv. Manuf. Technol. 2012, 66, 1047–1064. [Google Scholar] [CrossRef]
- Carlucci, D.; Renna, P.; Materi, S. A Job-Shop Scheduling Decision-Making Model for Sustainable Production Planning with Power Constraint. IEEE Trans. Eng. Manag. 2021, 70, 1923–1932. [Google Scholar] [CrossRef]
- Gharoun, H.; Hamid, M.; Torabi, S.A. An integrated approach to joint production planning and reliability-based multi-level preventive maintenance scheduling optimisation for a deteriorating system considering due-date satisfaction. Int. J. Syst. Sci.—Oper. Logist. 2022, 9, 489–511. [Google Scholar] [CrossRef]
- Joshi, D.K.; Kumar, S. Trapezium cloud TOPSIS method with interval-valued intuitionistic hesitant fuzzy linguistic information. Granul. Comput. 2017, 3, 139–152. [Google Scholar] [CrossRef]
- Morente-Molinera, J.; Wu, X.; Morfeq, A.; Al-Hmouz, R.; Herrera-Viedma, E. A novel multi-criteria group decision-making method for heterogeneous and dynamic contexts using multi-granular fuzzy linguistic modelling and consensus measures. Inf. Fusion 2019, 53, 240–250. [Google Scholar] [CrossRef]
- Liu, H.-C.; Wang, L.-E.; Li, Z.; Hu, Y.-P. Improving Risk Evaluation in FMEA with Cloud Model and Hierarchical TOPSIS Method. IEEE Trans. Fuzzy Syst. 2018, 27, 84–95. [Google Scholar] [CrossRef]
- Lourenzutti, R.; Krohling, R.A. A generalized TOPSIS method for group decision making with heterogeneous information in a dynamic environment. Inf. Sci. 2016, 330, 1–18. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Anjum, F.; Ullah, I.; Senapati, T.; Moslem, S. Priority Degrees and Distance Measures of Complex Hesitant Fuzzy Sets with Application to Multi-Criteria Decision Making. IEEE Access 2022, 11, 13647–13666. [Google Scholar] [CrossRef]
- Zheng, X.; Hao, T.; Wang, H.; Xu, K. Quantification study of mental load state based on AHP–TOPSIS integration extended with cloud model: Methodological and experimental research. Complex Intell. Syst. 2023, 9, 5501–5525. [Google Scholar] [CrossRef]
- Li, D.Y.; Du, Y. Artificial Intelligence with Uncertainty; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Yang, X.J.; Zeng, L.; Zhang, R. Cloud Delphi method. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2012, 20, 77–97. [Google Scholar] [CrossRef]
- Yang, X.J.; Zeng, L.; Luo, F.; Wang, S.X. Cloud hierarchical analysis. J. Inf. Comput. Sci. 2010, 7, 2468–2477. [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Zadeh, L. Fuzzy logic = computing with words. IEEE Trans. Fuzzy Syst. 1996, 4, 103–111. [Google Scholar] [CrossRef]
- Peng, G.; Xu, D.; Zhou, J.; Yang, Q.; Shen, W. A Novel Curve Pattern Recognition Framework for Hot-Rolling Slab Camber. IEEE Trans. Ind. Inform. 2022, 19, 1270–1278. [Google Scholar] [CrossRef]
- Peng, G.; Cheng, Y.; Zhang, Y.; Shao, J.; Wang, H.; Shen, W. Industrial big data-driven mechanical performance prediction for hot-rolling steel using lower upper bound estimation method. J. Manuf. Syst. 2023, 65, 104–114. [Google Scholar] [CrossRef]
- Peng, G.; Cheng, Y.; Wang, H.; Shen, W. Industrial IoT-enabled prediction interval estimation of mechanical performances for hot-rolling steel. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Huang, K.; Wu, Y.; Yang, C.; Peng, G.; Shen, W. Structure Dictionary Learning-Based Multimode Process Monitoring and its Application to Aluminum Electrolysis Process. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1989–2003. [Google Scholar] [CrossRef]
- Wang, H.L.; Feng, Y.Q. On multiple attribute group decision making with linguistic assessment information based on cloud model. Control Decis. 2005, 20, 679–685. [Google Scholar]
- Wang, P.; Xu, X.; Huang, S.; Cai, C. A Linguistic Large Group Decision Making Method Based on the Cloud Model. IEEE Trans. Fuzzy Syst. 2018, 26, 3314–3326. [Google Scholar] [CrossRef]
- Yang, X.; Yan, L.; Peng, H.; Gao, X. Encoding words into Cloud models from interval-valued data via fuzzy statistics and membership function fitting. Knowl.-Based Syst. 2014, 55, 114–124. [Google Scholar] [CrossRef]
- Yang, X.; Xu, Z.; Xu, J. Large-scale group Delphi method with heterogeneous decision information and dynamic weights. Expert Syst. Appl. 2023, 213, 118782. [Google Scholar] [CrossRef]
- Huang, H.-C.; Yang, X. Representation of The Pairwise Comparisons in AHP Using Hesitant Cloud Linguistic Term Sets. Fundam. Informaticae 2016, 144, 349–362. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Yang, X.J.; Xu, Z.F.; He, R.M.; Xue, F.X. Credibility assessment of complex simulation models using cloud models to represent and aggregate diverse evaluation results. In Intelligent Computing Methodologies; Huang, D.S., Huang, Z.K., Hussain, A., Eds.; ICIC 2019; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11645, pp. 306–317. [Google Scholar]
- Zhang, B.; Dong, Y.; Herrera-Viedma, E. Group Decision Making with Heterogeneous Preference Structures: An Automatic Mechanism to Support Consensus Reaching. Group Decis. Negot. 2019, 28, 585–617. [Google Scholar] [CrossRef]
- Chiclana, F.; Herrera, F.; Herrera-Viedma, E. Integrating multiplicative preference relations in a multipurpose decision-making model based on fuzzy preference relations. Fuzzy Sets Syst. 2001, 122, 277–291. [Google Scholar] [CrossRef]
- Xu, Z. Multiple-Attribute Group Decision Making with Different Formats of Preference Information on Attributes. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2007, 37, 1500–1511. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Ossadnik, W.; Schinke, S.; Kaspar, R.H. Group Aggregation Techniques for Analytic Hierarchy Process and Analytic Network Process: A Comparative Analysis. Group Decis. Negot. 2016, 25, 421–457. [Google Scholar] [CrossRef]
- Dong, Q.; Cooper, O. A peer-to-peer dynamic adaptive consensus reaching model for the group AHP decision making. Eur. J. Oper. Res. 2016, 250, 521–530. [Google Scholar] [CrossRef]
- Grošelj, P.; Dolinar, G. Group AHP framework based on geometric standard deviation and interval group pairwise comparisons. Inf. Sci. 2023, 626, 370–389. [Google Scholar] [CrossRef]
- Yang, X.; Yan, L.; Zeng, L. How to handle uncertainties in AHP: The Cloud Delphi hierarchical analysis. Inf. Sci. 2013, 222, 384–404. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef]
- Pant, S.; Kumar, A.; Ram, M.; Klochkov, Y.; Sharma, H.K. Consistency Indices in Analytic Hierarchy Process: A Review. Mathematics 2022, 10, 1206. [Google Scholar] [CrossRef]
- Correa Machado, A.M.; Ekel, P.I.; Libório, M.P. Goal-based participatory weighting scheme: Balancing objectivity and subjectivity in the construction of composite indicators. Qual. Quant. 2023, 57, 4387–4407. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Cabrerizo, F.J.; Kacprzyk, J.; Pedrycz, W. A review of soft consensus models in a fuzzy environment. Inf. Fusion 2014, 17, 4–13. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Linguistic Terms | NCMs |
|---|---|
| T0: none (n) | (0.00, 0.100, 0.020) |
| T1: very low (vl) | (0.197, 0.457, 0.022) |
| T2: low | (1.246, 1.062, 0.034) |
| T3: slightly low (sl) | (3.083, 1.030, 0.033) |
| T4: medium (med) | (5.058, 1.109, 0.056) |
| T5: slightly high (sh) | (7.105, 1.027, 0.041) |
| T6: high | (8.743, 1.242, 0.041) |
| T7: very high (vh) | (9.775, 1.054, 0.027) |
| T8: maximum (m) | (10.00, 0.100, 0.020) |
| Level I | Level II | Unit | Direction | Type |
|---|---|---|---|---|
| economy | total processing time (C1) | minute | − | quantitative |
| order production delay time (C2) | day | − | quantitative | |
| number of furnaces in the same casting plan (C3) | amount | + | quantitative | |
| change in steel grade between adjacent furnaces (C4) | amount | − | quantitative | |
| furnace residual capacity (C5) | ton | − | quantitative | |
| balance of production capacity between processes (C6) | ton | − | quantitative | |
| bottleneck process planning (C7) | ton | − | quantitative | |
| penalties for jumping production specifications (C8) | amount | − | quantitative | |
| environment | total energy consumption (C9) | score | − | qualitative |
| consumption of tools (C10) | score | − | qualitative | |
| waste discharge (C11) | score | − | qualitative | |
| society | job satisfaction (C12) | score | + | qualitative |
| worker workload balance (C13) | score | + | qualitative | |
| hazard exposure (C14) | score | − | qualitative |
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RI | 0 | 0 | 0.52 | 0.89 | 1.11 | 1.25 | 1.35 | 1.40 | 1.45 | 1.49 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | |
| A1 | 1366 | 1.85 | 0.85 | 8 | 166 | 3250 | 785 | 2356 |
| A2 | 1278 | 0 | 0.78 | 7 | 138 | 2886 | 904 | 1968 |
| A3 | 1445 | 0.86 | 0.66 | 11 | 155 | 3763 | 1048 | 2087 |
| A4 | 1210 | 0 | 0.82 | 6 | 147 | 2596 | 816 | 1789 |
| A5 | 1312 | 0.42 | 0.72 | 9 | 176 | 3015 | 953 | 2523 |
| C9 | C10 | C11 | ||||||
| A1 | DM1: between med and high | DM1: med | DM1: sl | |||||
| DM2: at least med | DM2: at least med | DM2: med | ||||||
| DM3: 5.5 | DM3: med | DM3: sl | ||||||
| A2 | DM1: low | DM1: sl | DM1: low | |||||
| DM2: between low and med | DM2: med | DM2: sl | ||||||
| DM3: 3.5 | DM3: med | DM3: low | ||||||
| A3 | DM1: high | DM1: med | DM1: med | |||||
| DM2: [8.5,9.5] | DM2: sh | DM2: med | ||||||
| DM3: 7 | DM3: sh | DM3: sh | ||||||
| A4 | DM1: sl | DM1: low | DM1: low | |||||
| DM2: med | DM2: sl | DM2: sl | ||||||
| DM3: sl | DM3: sl | DM3: sl | ||||||
| A5 | DM1: at least sh | DM1: med | DM1: sl | |||||
| DM2: med | DM2: med | DM2: sl | ||||||
| DM3: between med and vh | DM3: med | DM3: med | ||||||
| C12 | C13 | C14 | ||||||
| A1 | DM1: between med and high | DM1: med | DM1: low | |||||
| DM2: at least med | DM2: at least med | DM2: sl | ||||||
| DM3: med | DM3: 6.5 | DM3: low | ||||||
| DM4: med | DM4: at least med | DM4: 2 | ||||||
| A2 | DM1: 8 | DM1: med | DM1: low | |||||
| DM2: [7,9] | DM2: [6,7] | DM2: low | ||||||
| DM3: greater than med | DM3: greater than med | DM3: vl | ||||||
| DM4: med | DM4: [7,9] | DM4: 1 | ||||||
| A3 | DM1: [5,6] | DM1: sl | DM1: sl | |||||
| DM2: [4.5,5.5] | DM2: low | DM2: low | ||||||
| DM3: between low and med | DM3: between low and med | DM3: sl | ||||||
| DM4: low | DM4: [6.5,7.5] | DM4: sl | ||||||
| A4 | DM1: sh | DM1: sh | DM1: n | |||||
| DM2: med | DM2: med | DM2: vl | ||||||
| DM3: [6,8] | DM3: [6,8] | DM3: n | ||||||
| DM4: high | DM4: med | DM4: vl | ||||||
| A5 | DM1: at least sh | DM1: at least sh | DM1: low | |||||
| DM2: [7,8] | DM2: med | DM2: n | ||||||
| DM3: sh | DM3: between med and vh | DM3: low | ||||||
| DM4: between med and vh | DM4: [7,8] | DM4: 1.5 | ||||||
| C1 | C2 | C3 | C4 | C5 | |
| A1 | (1366.0000, 0, 0) | (1.8500, 0, 0) | (0.8500, 0, 0) | (8.0000, 0, 0) | (166.0000, 0, 0) |
| A2 | (1278.0000, 0, 0) | (0.0000, 0, 0) | (0.7800, 0, 0) | (7.0000, 0, 0) | (138.0000, 0, 0) |
| A3 | (1445.0000, 0, 0) | (0.8600, 0, 0) | (0.6600, 0, 0) | (11.0000, 0, 0) | (155.0000, 0, 0) |
| A4 | (1210.0000, 0, 0) | (0.0000, 0, 0) | (0.8200, 0, 0) | (6.0000, 0, 0) | (147.0000, 0, 0) |
| A5 | (1312.0000, 0, 0) | (0.4200, 0, 0) | (0.7200, 0, 0) | (9.0000, 0, 0) | (176.0000, 0, 0) |
| C6 | C7 | C8 | C9 | C10 | |
| A1 | (3250.0000, 0, 0) | (785.0000, 0, 0) | (2356.0000, 0, 0) | (6.8683, 0.8622, 0.0396) | (6.0841, 0.8129, 0.0393) |
| A2 | (2886.0000, 0, 0) | (904.0000, 0, 0) | (1968.0000, 0, 0) | (2.6250, 0.6741, 0.0270) | (4.3997, 0.6254, 0.0286) |
| A3 | (3763.0000, 0, 0) | (1048.0000, 0, 0) | (2087.0000, 0, 0) | (8.2477, 0.4177, 0.0137) | (6.4227, 0.6091, 0.0269) |
| A4 | (2596.0000, 0, 0) | (816.0000, 0, 0) | (1789.0000, 0, 0) | (3.7413, 0.6103, 0.0243) | (2.4707, 0.6009, 0.0192) |
| A5 | (3015.0000, 0, 0) | (953.0000, 0, 0) | (2523.0000, 0, 0) | (7.2113, 0.8772, 0.0406) | (5.0580, 0.6403, 0.0323) |
| C11 | C12 | C13 | C14 | ||
| A1 | (3.7413, 0.6103, 0.0243) | (6.3052, 0.7563, 0.0357) | (6.9576, 0.7162, 0.0339) | (1.8938, 0.4553, 0.0146) | |
| A2 | (1.8583, 0.6071, 0.0194) | (7.4909, 0.4709, 0.0218) | (7.1159, 0.4727, 0.0218) | (0.9223, 0.3925, 0.0132) | |
| A3 | (5.7403, 0.6249, 0.0297) | (3.7188, 0.5090, 0.0202) | (3.6145, 0.5689, 0.0218) | (2.6238, 0.5190, 0.0166) | |
| A4 | (2.4707, 0.6009, 0.0192) | (6.9765, 0.4961, 0.0202) | (6.0553, 0.4760, 0.0223) | (0.0985, 0.1654, 0.0105) | |
| A5 | (3.7413, 0.6103, 0.0243) | (7.7953, 0.6508, 0.0289) | (7.2835, 0.6592, 0.0305) | (0.9980, 0.3763, 0.0130) |
| 1 | 3 | 5 | 1 | 2 | 4 | 1 | 3 | 4 | 1 | 2 | 5 | 1 | 3 | 4 | 1 | 2 | 4 |
| 1/3 | 1 | 2 | 1/2 | 1 | 2 | 1/3 | 1 | 1.5 | 1/2 | 1 | 2 | 1/3 | 1 | 1 | 1/2 | 1 | 2 |
| 1/5 | 1/2 | 1 | 1/4 | 1/2 | 1 | 1/4 | 1/1.5 | 1 | 1/5 | 1/2 | 1 | 1/4 | 1 | 1 | 1/4 | 1/2 | 1 |
| C1 | C2 | C3 | C4 | C5 | |
| A1 | (0.3362, 0, 0) | (0, 0, 0) | (1.0000, 0, 0) | (0.6000, 0, 0) | (0.2632, 0, 0) |
| A2 | (0.7106, 0, 0) | (1.0000, 0, 0) | (0.6316, 0, 0) | (0.8000, 0, 0) | (1.0000, 0, 0) |
| A3 | (0, 0, 0) | (0.5351, 0, 0) | (0, 0, 0) | (0, 0, 0) | (0.5526, 0, 0) |
| A4 | (1.0000, 0, 0) | (1.0000, 0, 0) | (0.8421, 0, 0) | (1.0000, 0, 0) | (0.7632, 0, 0) |
| A5 | (0.5660, 0, 0) | (0.7730, 0, 0) | (0.3158, 0, 0) | (0.4000, 0, 0) | (0, 0, 0) |
| C6 | C7 | C8 | C9 | C10 | |
| A1 | (0.4396, 0, 0) | (1.0000, 0, 0) | (0.2275, 0, 0) | (0.2453, 0.1739, 0.0076) | (0.0857, 0.2577, 0.0121) |
| A2 | (0.7515, 0, 0) | (0.5475, 0, 0) | (0.7561, 0, 0) | (1.0000, 0.1995, 0.0076) | (0.5119, 0.2471, 0.0108) |
| A3 | (0, 0, 0) | (0, 0, 0) | (0.5940, 0, 0) | (0, 0.1051, 0.0034) | (0, 0.2180, 0.0096) |
| A4 | (1.0000, 0, 0) | (0.8821, 0, 0) | (1.0000, 0, 0) | (0.8015, 0.1734, 0.0066) | (1.0000, 0.3062, 0.0118) |
| A5 | (0.6410, 0, 0) | (0.3612, 0, 0) | (0, 0, 0) | (0.1843, 0.1747, 0.0077) | (0.3453, 0.2358, 0.0110) |
| C11 | C12 | C13 | C14 | ||
| A1 | (0.5149, 0.2530, 0.0109) | (0.6345, 0.2580, 0.0115) | (0.9112, 0.3300, 0.0144) | (0.2891, 0.2804, 0.0090) | |
| A2 | (1.0000, 0.3174, 0.0129) | (0.9253, 0.2532, 0.0108) | (0.9543, 0.3032, 0.0129) | (0.6738, 0.2958, 0.0099) | |
| A3 | (0, 0.2277, 0.0108) | (0, 0.1766, 0.0070) | (0, 0.2193, 0.0084) | (0, 0.2906, 0.0093) | |
| A4 | (0.8422, 0.2926, 0.0119) | (0.7991, 0.2380, 0.0098) | (0.6652, 0.2565, 0.0109) | (1.0000, 0.3051, 0.0110) | |
| A5 | (0.5149, 0.2530, 0.0109) | (1.0000, 0.2866, 0.0122) | (1.0000, 0.3356, 0.0145) | (0.6438, 0.2894, 0.0097) |
| C1 | C2 | C3 | C4 | C5 | |
| A1 | (0.0175, 0, 0) | (0, 0, 0) | (0.0656, 0, 0) | (0.0316, 0, 0) | (0.0279, 0, 0) |
| A2 | (0.0370, 0, 0) | (0.0917, 0, 0) | (0.0414, 0, 0) | (0.0421, 0, 0) | (0.1062, 0, 0) |
| A3 | (0, 0, 0) | (0.0491, 0, 0) | (0, 0, 0) | (0, 0, 0) | (0.0587, 0, 0) |
| A4 | (0.0520, 0, 0) | (0.0917, 0, 0) | (0.0552, 0, 0) | (0.0526, 0, 0) | (0.0810, 0, 0) |
| A5 | (0.0294, 0, 0) | (0.0709, 0, 0) | (0.0207, 0, 0) | (0.0210, 0, 0) | (0, 0, 0) |
| C6 | C7 | C8 | C9 | C10 | |
| A1 | (0.0346, 0, 0) | (0.0814, 0, 0) | (0.0181, 0, 0) | (0.0329, 0.0233, 0.0010) | (0.0063, 0.0190, 0.0009) |
| A2 | (0.0591, 0, 0) | (0.0446, 0, 0) | (0.0603, 0, 0) | (0.1340, 0.0267, 0.0010) | (0.0378, 0.0183, 0.0008) |
| A3 | (0, 0, 0) | (0, 0, 0) | (0.0473, 0, 0) | (0, 0.0141, 0.0005) | (0, 0.0161, 0.0007) |
| A4 | (0.0786, 0, 0) | (0.0718, 0, 0) | (0.0797, 0, 0) | (0.1074, 0.0232, 0.0009) | (0.0739, 0.0226, 0.0009) |
| A5 | (0.0504, 0, 0) | (0.0294, 0, 0) | (0, 0, 0) | (0.0247, 0.0234, 0.0010) | (0.0255, 0.0174, 0.0008) |
| C11 | C12 | C13 | C14 | ||
| A1 | (0.0210, 0.0103, 0.0004) | (0.0286, 0.0116, 0.0005) | (0.0264, 0.0096, 0.0004) | (0.0200, 0.0194, 0.0006) | |
| A2 | (0.0407, 0.0129, 0.0005) | (0.0417, 0.0114, 0.0005) | (0.0277, 0.0088, 0.0004) | (0.0467, 0.0205, 0.0007) | |
| A3 | (0, 0.0093, 0.0004) | (0, 0.0080, 0.0003) | (0, 0.0064, 0.0002) | (0, 0.0201, 0.0006) | |
| A4 | (0.0343, 0.0119, 0.0005) | (0.0360, 0.0107, 0.0004) | (0.0193, 0.0074, 0.0003) | (0.0693, 0.0211, 0.0008) | |
| A5 | (0.0210, 0.0103, 0.0004) | (0.0451, 0.0129, 0.0006) | (0.0290, 0.0097, 0.0004) | (0.0446, 0.0201, 0.0007) |
| Schemes | Distance from CPIS () | Distance from CNIS () |
|---|---|---|
| A1 | (0.5879, 0.0610, 0.0024) | (0.4119, 0.0517, 0.0021) |
| A2 | (0.1889, 0.0628, 0.0024) | (0.8109, 0.0538, 0.0021) |
| A3 | (0.8447, 0.0562, 0.0022) | (0.1551, 0.0459, 0.0017) |
| A4 | (0.0969, 0.0626, 0.0024) | (0.9029, 0.0535, 0.0020) |
| A5 | (0.5881, 0.0610, 0.0024) | (0.4117, 0.0517, 0.0021) |
| Indicator | Ranking | Indicator | Ranking |
|---|---|---|---|
| C1 | C8 | ||
| C2 | C9 | ||
| C3 | C10 | ||
| C4 | C11 | ||
| C5 | C12 | ||
| C6 | C13 | ||
| C7 | C14 |
| Methods | Performance Calculations | Data Types | Weight Assignments | Ranking Algorithms |
|---|---|---|---|---|
| Thenarasu et al. (2022) [1] | Statistical calculations | Exact numbers | Fuzzy AHP | TOPSIS |
| Zhang et al. (2022) [8] | Statistical calculations and cumulative prospect theory | Exact numbers | Fuzzy ANP | VIKOR |
| Proposed method | Quantitative indicators: Statistical calculations or/and evaluation functions Qualitative indicators: Group decision making | Exact numbers Interval numbers Linguistic terms Linguistic expressions | Group AHP | Cloud model enhanced TOPSIS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Lv, Z.; Liu, Y.; Xiao, X.; Xu, D. Novel Multi-Criteria Group Decision Making Method for Production Scheduling Based on Group AHP and Cloud Model Enhanced TOPSIS. Processes 2024, 12, 305. https://doi.org/10.3390/pr12020305
Zhang X, Lv Z, Liu Y, Xiao X, Xu D. Novel Multi-Criteria Group Decision Making Method for Production Scheduling Based on Group AHP and Cloud Model Enhanced TOPSIS. Processes. 2024; 12(2):305. https://doi.org/10.3390/pr12020305
Chicago/Turabian StyleZhang, Xuejun, Zhimin Lv, Yang Liu, Xiong Xiao, and Dong Xu. 2024. "Novel Multi-Criteria Group Decision Making Method for Production Scheduling Based on Group AHP and Cloud Model Enhanced TOPSIS" Processes 12, no. 2: 305. https://doi.org/10.3390/pr12020305
APA StyleZhang, X., Lv, Z., Liu, Y., Xiao, X., & Xu, D. (2024). Novel Multi-Criteria Group Decision Making Method for Production Scheduling Based on Group AHP and Cloud Model Enhanced TOPSIS. Processes, 12(2), 305. https://doi.org/10.3390/pr12020305