In this section, we describe the results of evaluating the algorithm’s performance in predicting the value by applying regression. First, we describe the setting of the evaluation and the applied metrics. Second, we present the results of the algorithms for the three metrics RMSE, MAE, and score. Third, we analyze the importance of the different features for the prediction of the value. In the previous section, we explained the results of the regression models for predicting the value that our tested algorithms generated. Last, we describe potential threats to validity.
5.1. Evaluation Setting and Metrics
We analyzed the performance of the six mentioned algorithms (cf.
Section 4.2.5) in predicting the
value through regression using a regular working laptop—with an Intel(R) Core(TM) i7-12700H CPU at 2300 MHz, 32 GB RAM, and Microsoft Windows 10 Education as the operating system—for both model training (learning) and model testing (evaluation). This showed lightweight implementation and low resource consumption, even for the more sophisticated machine learning algorithms.
As described in the pipeline of analysis steps (cf.
Section 4.2), we focused on five different temperature values: 4.0
C, 7.0
C, 30.0
C, 37.0
C, and 40.0
C. For each of these temperatures, we generated a dedicated dataset composed of measurement data for solely the specified temperature. For each temperature, we compared the data in the original form with the data resulting from the pre-processing steps (i.e., log-based transformation and normalization). Additionally, we applied all six algorithms to the combination of temperature and data variants. Consequently, this resulted in 60 different scenarios for the evaluation. We applied three metrics commonly used for regression problems to evaluate the algorithms’ performance: RMSE, MAE, and
score.
MSE is a common metric used for measuring the accuracy of a regression model. It calculates the average of the squares of the errors or deviations, i.e., the difference between the estimator and what is estimated. MSE gives a relatively high weight to large errors (since it squares the errors), which means it can be particularly useful in situations where large errors are undesirable. The Root-Mean-Squared Error (RMSE) is the square root of MSE. It converts the metric back to the same scale as the original data. Like MSE, RMSE gives more weight to larger errors, but its scale is the same as the data, making it more interpretable and easier to relate to the magnitude of the errors. RMSE is often preferred when the goal is to understand the error in terms of the original units of measurement. As we had partly log-based data, we applied RMSE instead of MSE as it gives a performance more interpretable in terms of the original units of the data.
A lower MSE or RMSE value indicates a better fit of the model to the data.
As an additional metric, we used the MAE as it does not penalize large errors disproportionately, making it less sensitive to the influence of outliers. Consequently, the MAE is a metric that gives equal weight to all errors, regardless of their direction or magnitude and allows comparison of the RMSE.
The metric, also known as the coefficient of determination, is a statistical measure that represents the proportion of the variance for the dependent variable that is explained by the independent variables in a regression model. It indicates the goodness of fit of a set of predictions to the actual values. An score of 1 indicates that the regression predictions perfectly fit the data. Values of outside the range of 0 to 1 can occur when the model does not follow the trend of the data, leading to negative values or values greater than 1.
5.2. Machine Learning Regression
The following two tables describe the results of the performance measurements for the six algorithms—LR, RFR, GBR, XGB, SVR, and NNR—for the different temperatures, i.e., 4.0 C, 7.0 C, 30.0 C, 37.0 C, and 40.0 C. Further, we compared the performance of the algorithms using two variants of the datasets, the original data and the data that are pre-processed by applying log-based transformation and normalization (indicated by the appendix “_Proc”).
Next,
Table 2 presents the measured
scores. As can be seen, we have a wide range of scores from negative values to positive ones close to +1. This indicates that sometimes the algorithms provide very low performance, especially those configurations with a negative
score. However, over all scenarios and configurations, we can see that all temperature configurations, except 30.0
C, have an
score of at least 0.880, achieving up to almost perfect prediction with
.
This indicates that our principal approach works for the prediction of the value.
Additionally to the
scores, we analyzed the RMSE as a description of the size of the error terms.
Table 3 shows the measured RMSE scores. As can be seen, the RMSE scores lie in general between 13 and 2856. However, one can see that the ranges are highly different depending on the temperature. For example, the temperature of 7.0
C has the most extreme range, with RMSE scores between 792 and 2856; especially, the minimum RMSE value of 792 exceeds the maximum RMSE for all other temperatures. Additionally, the differences between the minimum and maximum RMSE scores for the temperatures 30.0
C and 37.0
C are both around 100. However, the numbers completely differ, with ranges of 13–132 (for 37.0
C) and 301–416 (for 30.0
C). The ranges for 4.0
C and 40.0
C integrate both acceptable values with minimum RMSE scores of 22 (for 4.0
C) and 65 (for 40.0
C) but high maximum RMSE scores of 297 (for 4.0
C) and 335 (for 40.0
C).
Additionally, we also report the measured values for the MAE. While MAE measures the average magnitude of errors in a set of predictions without considering their direction, RMSE penalizes larger errors more severely by squaring the residuals before averaging, thus often highlighting larger discrepancies more prominently. As can be seen in
Table 4, the results are pretty similar, epsecially when focusing on the best configurations for each temperature. Except for the temperature of 37.0
C, the same configuration is superior for RMSE and MAE. In the case of 37.0
C, for MAE, the RFR algorithm in the processed variant is superior than the RFR in the non-processed variant—this is vice versa for the RMSE score.
RMSE is preferred over MAE in many scenarios because it is more sensitive to large errors, as it squares the errors before averaging, thus giving greater weight to larger discrepancies. Additionally, RMSE aligns well with many machine learning algorithms that minimize quadratic loss functions, making it more compatible with common optimization techniques used in predictive modeling. As it can further be seen that the results are pretty similar for MAE and RMSE, we decide to focus on RMSE in the following. For interpretation of the RMSE, it makes sense to have an understanding of the range of the values for the
value as the target variable for the prediction. Accordingly, we report the minimum and maximum values for the
for each temperature as well as the standard deviation in
Table 5. Especially, we compare the RMSE values with the standard deviation of the analyzed variable as the standard deviation is a measure of the amount of variation or dispersion in a set of values, and a high standard deviation means the values are spread out over a wider range. Comparing the RMSE to the standard deviation can give an idea of how much of the variability in the data can be explained by the model. As can be seen, the standard deviation and the range between the minimal and maximal RMSE scores for a temperature are often pretty close. However, we can see small differences. If the RMSE of the model is significantly lower than the standard deviation of the data, it suggests that the model has good predictive accuracy. This is achieved for the temperatures 37.0
C and 40.0
C; especially for the temperature of 37.0
C, this indicates a very good fit of the model to the data as the standard deviation is low. In contrast, if the RMSE is close to or greater than the standard deviation, it indicates that your model may not be performing well and is not adding much value over a simple mean-based prediction. This is the case for the temperature of 30.0
C, where the standard deviation is smaller than the RMSE. Further, for the temperature of 4.0
C, the standard deviation (284) is smaller than the largest RMSE score (297); however, the range is wide, with values between 22 and 297. For the temperature of 7.0
C, the standard deviation lies in the range for the RMSE.
It is important to note that this comparison, while useful, has limitations. RMSE is influenced by outliers and can be disproportionately large if the prediction errors have a skewed distribution. Still, it is a first indicator that, especially for the temperature of 37 C, the model delivers good predictions of the value.
In the following, we will analyze in detail two scenarios. First, we compare the performance of the algorithms when the food items have the temperature of a common household fridge, i.e., 7.0 C. Second, we detail how the algorithms perform when the food is heated up to the temperature of the human mouth, i.e., 37.0 C. We decided to focus on these scenarios as (i) both are relevant from a practical point of view for food consumption, and (ii) if the quality of the algorithms varies, it allows us to draw interesting insights to further improve the prediction.
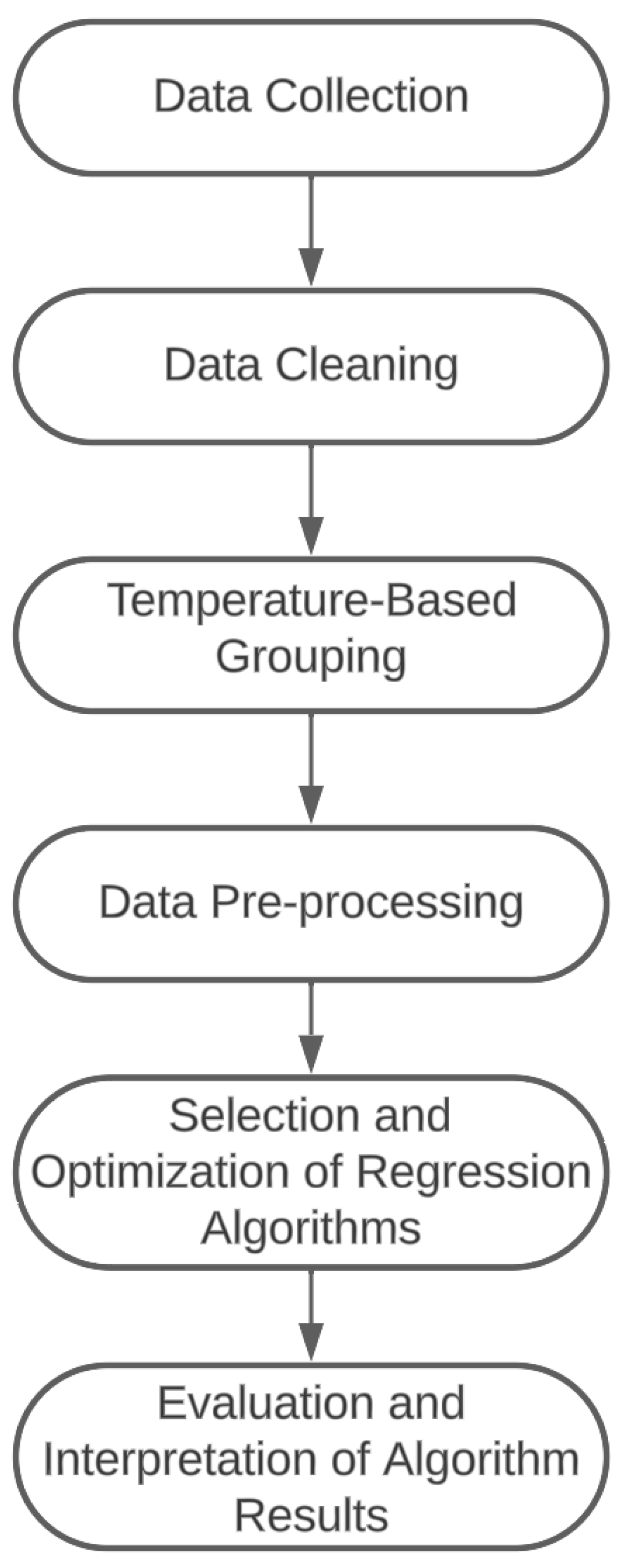
5.2.1. Analyzing the Performance for Chilled Food (at 7.0 C)
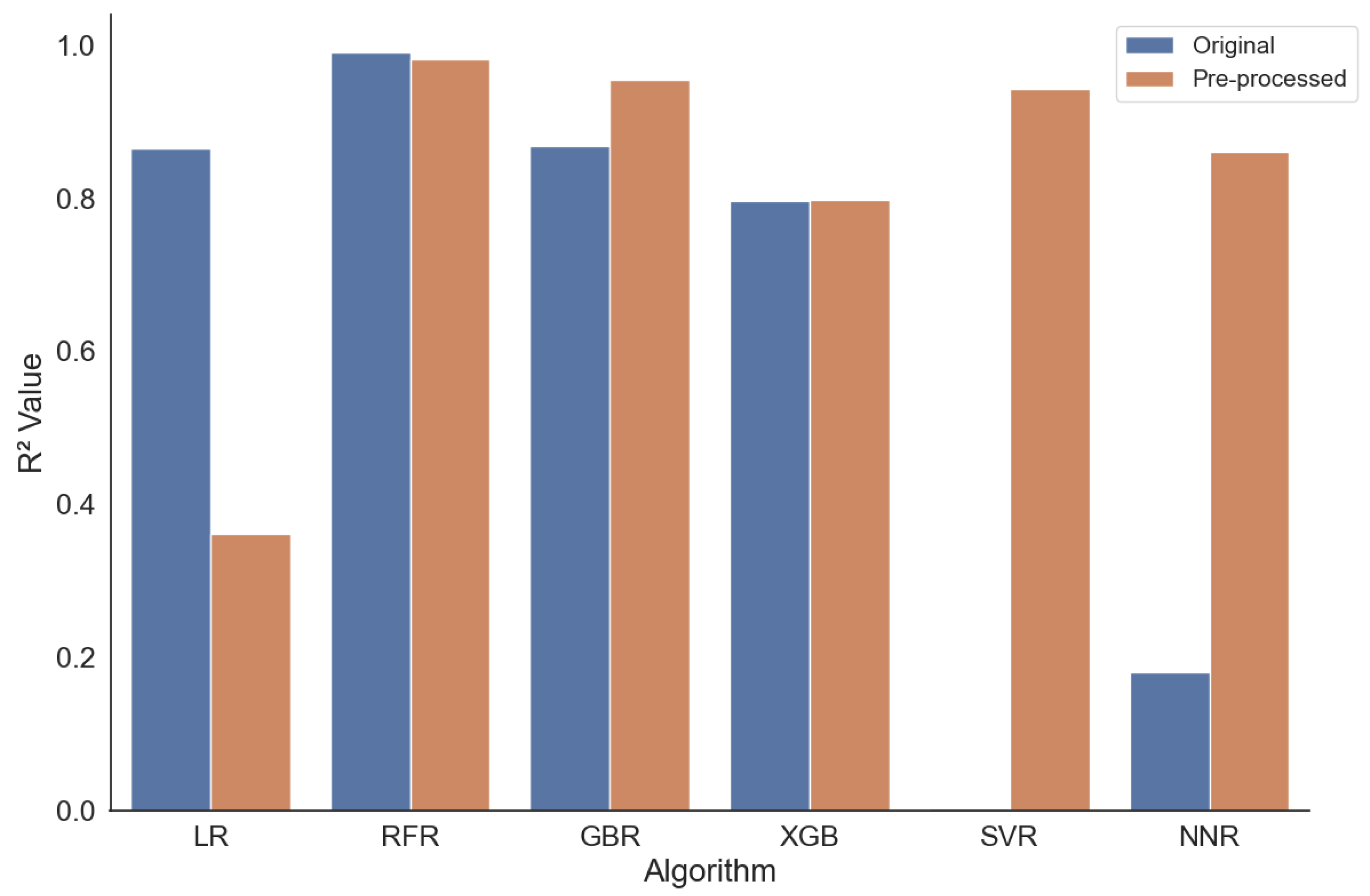
Figure 3 shows the measured
score for the six algorithms given the temperature of 7.0
C. The detailed results show interesting insights, which we elaborate on in the following.
First, the approach with NNs does not work at all, as can be seen by the negative scores, which indicate that the model does not follow the trend of the data. However, it can be observed that the data pre-processing improves the results. Second, the best results are returned for XGBoost (XGB) with and the Support Vector (SVR) algorithm with . Interestingly, the XGB performs very well on the non-processed dataset and worse on the pre-processed one; for the SVR, the situation is reversed. In general, it can be seen that, apart from the NN approach, all approaches perform well with an for at least one of the two tested variants of the data. However, the pre-processing of the data does not improve the results for most of the algorithms. Here, we need to test and identify further techniques which might improve the results. Still, the two best-performing configurations—SVR on the pre-processed data and XGB on the original data—deliver a very good performance based on the scores.
Another perspective provides the RMSE, which is visible in
Table 3. RMSE calculates the root of the average of the squares of the errors or deviations. The minimal values are in line with the
scores present for the XGB (non-processed data) and the SVR (pre-processed data). As can be seen, these values seem large, with 792 and 853 as the minimum values of all configurations for the XGB on the non-processed data and the SVR on the processed data, respectively. One explanation for those relatively large errors lies in the data. Some of the variables follow a log distribution and scale. Hence, taking this into account, the large measured error is relieved. Still, for a practical application of the prediction, we need to find approaches to reduce this error, e.g., with additional pre-processing techniques.
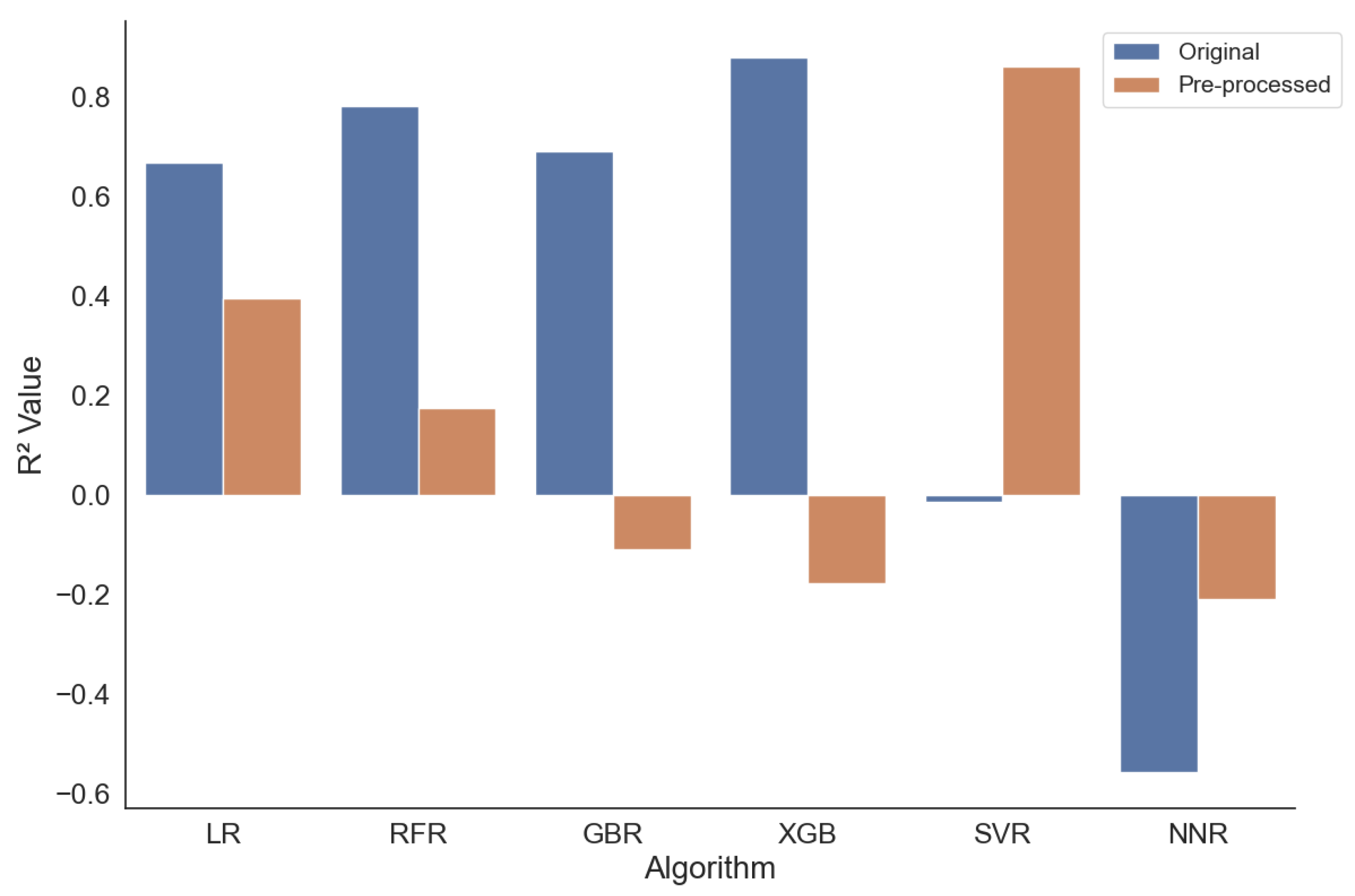
5.2.2. Analyzing the Performance for Mouth Temperature (at 37.0 C)
As a second detailed analysis, we focus on the temperature of 37.0
C.
Figure 4 compares the measured
scores.
As a first observation, it can be stated that all the algorithms work—this time, we have no negative scores. Further, we can observe that, for each algorithm, at least one configuration has a score of . This means that all algorithms are capable of finding a model that explains almost 80% of the variations in the datasets. This is a very impressive result and underlines the fact that the prediction of the value works at a temperature of 37 C, i.e., the temperature of the human mouth, and, hence, predicts the consumers’ impression of the food’s taste.
In detail, we observe very high scores between 0.92 and 0.99 for five configurations. The Random Forest approach performs best with for the non-processed data and for the pre-processed data. Also, the GBR (pre-processed) with , the SVR (pre-processed) with , and the neural network (pre-processed) with deliver a very good performance. The trained/learned models for all of the mentioned configurations explain the variance in the data by at least 92%, especially the performance of the models derived by the RFR algorithms, explaining the variance by 99% and 98%, almost completely.
It is interesting to note that, except for in the case of the RFR, for the mentioned top results, the pre-processed dataset works much better. This is contrary to the observations for the temperature of 7 C, for which the pre-processing mostly does not significantly improve the results. Further, it can be seen that the neural network and SVR approaches benefit from the pre-processing; however, this is not surprising, as neural networks require normalization to work well, and, also, for the SVR, it is known that normalization improves the calculation procedures.
The RMSE for the temperature of 37 C is, in general, relatively low, with values between 13 and 132. Specifically, the error values for the mentioned top-performing algorithms—RFR and RFR (pre-processed), GBR (pre-processed), SVR (pre-processed), and the neural networks (pre-processed)—are very low, with RMSE values of 13, 18, 28, 31, and 37, respectively, which are very good results and support the observation of high prediction quality, which is already indicated by the corresponding scores of these algorithms.
5.2.3. Performance Analysis of the Machine Learning Regression
The described machine learning pipeline (cf.
Section 4) represents a comprehensive approach to handling and analyzing data with a focus on addressing specific characteristics of the dataset (like missing values and temperature variations) and evaluating multiple models to find the best fit for the data. The use of pre-processing techniques like log transformation and normalization is particularly important for ensuring that the data are well suited for the modeling process.
We analyze the applied algorithms from different perspectives, resulting in different metrics (cf.
Section 5.1). Each of these applied metrics offers a different perspective on the performance of a regression model, and the choice of which to use can depend on the specific context and objectives of the modeling effort. For instance, if large errors are particularly undesirable in a given application, MSE or RMSE might be the preferred metric. If the goal is to simply measure the average error magnitude, MAE might be more appropriate.
is useful for understanding the proportion of variance explained by the model in the context of the data. Hence, it is important to understand the use case for the regression and, depending on that, to choose the fitting algorithm and corresponding model. This corresponds to the idea of adaptive software systems, which can integrate adaptive and learning behavior in software to adjust to dynamics [
49].
The results (cf.
Section 5.2) indicate three important insights. First, the results perform with
scores of up to 0.99, which means an explanation of the variance in the data of up to 99%. This is an outstanding result and definitely proves the applicability of our approach for predicting the
value.
Second, no algorithm performs best for all settings (e.g., temperatures). This is in line with the “No Free Lunch Theorem” [
50], which states that no single algorithm performs best for all problems. For this application domain, this means that the best algorithm/model depends on the temperature of the food. In practice, this insight might be a real challenge, as the food temperature changes, e.g., chilled food will be warmed up in the mouth or, vice versa, hot food will be cooled in the mouth. Hence, food designers who want to use our approach have to take those possible changes into account and need to define the temperature range of interest to identify the fitting regression algorithm. Potentially, a digital food twin might take those changes into account [
51]. However, in a current analysis of the digital food twin research, we can see that there are still many research challenges for achieving this [
52]. Additionally, the range of tested temperature covers the most important ones—human/mouth temperature and cooling temperature—however, this is limited due to data sparsity. This must be improved for future work.
Third, we applied variants for each algorithm, without optimization and with optimization of the data in the form of pre-processing. However, we have seen that, depending on the configuration and temperature, the pre-processing does not improve the results. For example, for 7.0 C, the best variant is the XGB with the non-processed data. However, there are other settings in which both dataset configurations perform equally well (e.g., temperatures of 37.0 C and 40.0 C) or the pre-processed ones are superior. Especially for the neural network, the pre-processing improves the performance significantly. In contrast, for example, the RFR does not improve much. Consequently, we need further experiments to identify working pre-processing techniques that find the data but also the algorithm’s characteristics.
5.3. Explainable Artificial Intelligence
The objective of the analysis for the value is not only the identification of a prediction of this value, but also the understanding of the influence of the measured factors for describing the value. This understanding is necessary as the results of the prediction will help to reformulate food recipes. Hence, we describe in the following the application of an analysis of the importance of the different factors. We focused in this analysis on the following algorithms: RF, GBR, XGB, and SVR. We excluded the linear regression as those models do not perform best in any of the settings. Further, we excluded the neural networks because they are more difficult to analyze concerning the importance of the variables. We excluded the scenario with a temperature of 30.0 C, as none of the algorithms returns satisfying results.
The method of calculating feature importance can vary. Some common methods include (i) impurity-based feature importance—which measures the decrease in node impurity when a feature is used for splitting—or (ii) permutation feature importance, which involves randomly shuffling each feature and measuring the change in the model’s performance. For the RFR and GBR algorithms, we applied the functions integrated in scikit-learn, which implement an impurity-based feature importance. For XGB, we applied the get_score() method with the parameter gain for the setting importance_type to obtain feature importance scores from an XGBoost model. This method calculates the feature importance scores based on the gain metric. Gain refers to the average improvement in accuracy brought by a feature to the branches it is on. This metric considers both the number of times a feature is used and how much it contributes to making more accurate predictions when it is used. For the SVR algorithm, we applied a weight-based scoring approach. Hence, we manually extracted the scores for each feature from the corresponding model and sorted them from large (more important) to small (less important) values.
Using the described integrated functions for calculating the feature importance of the four mentioned algorithms, we analyzed the ten most important features. First, we present the appearance of specific features in all 16 settings. Hence,
Table 6 presents the frequency of the different features appearing in all analyzed settings. The analyzed settings include the four different temperatures of 4.0
C, 7.0
C, 37.0
C, and 40.0
C (excluding 30.0
C). For each temperature, we looked at the applied four algorithms—as mentioned, we excluded the linear regression and the neural network approaches in this analysis. For the temperatures of 4.0
C, 37.0
C, and 40.0
C, we looked at the algorithms using the pre-processed data; for the temperature of 7.0
C, we analyzed the data without pre-processing as, at this temperature, the
scores of the data without pre-processing are superior. Consequently, a feature might be named 16 times at maximum in the feature frequency table.
It can be seen that the features log P (100%), specific gravity (93.75%), molecular weight (93.75%), water solubility (87.50%), boiling point (75%), concentration (68.75%), water (68.75%), whey protein (50%), and casein (50%) are the most common features. Their share is determined by how often they are counted as one of the top ten features for the different algorithm and temperature settings. Each feature identified for at least 50% of the setting is marked as being one of the top 10 features for the total 22 analyzed features.
Please note that the frequency shown in
Table 6 does not necessarily relate to the features’ importance as it might be possible that features are often named but have low importance. Hence, in the following, we perform a detailed analysis of the importance of the specific features of the algorithms that performed best for each temperature based on the
score. We use the
seaborn library to plot the results. Feature importance plots are a valuable tool in machine learning for understanding the contribution of each feature (input variable) to the predictive power of a model. These plots help in interpreting the model by quantifying the extent to which each feature contributes to the model’s predictions. The most important features are those that have the greatest impact on the model’s predictions. Please note that, for the different algorithms, the feature importance values are in different scales. Hence, it is not possible to directly compare the absolute values across algorithms.
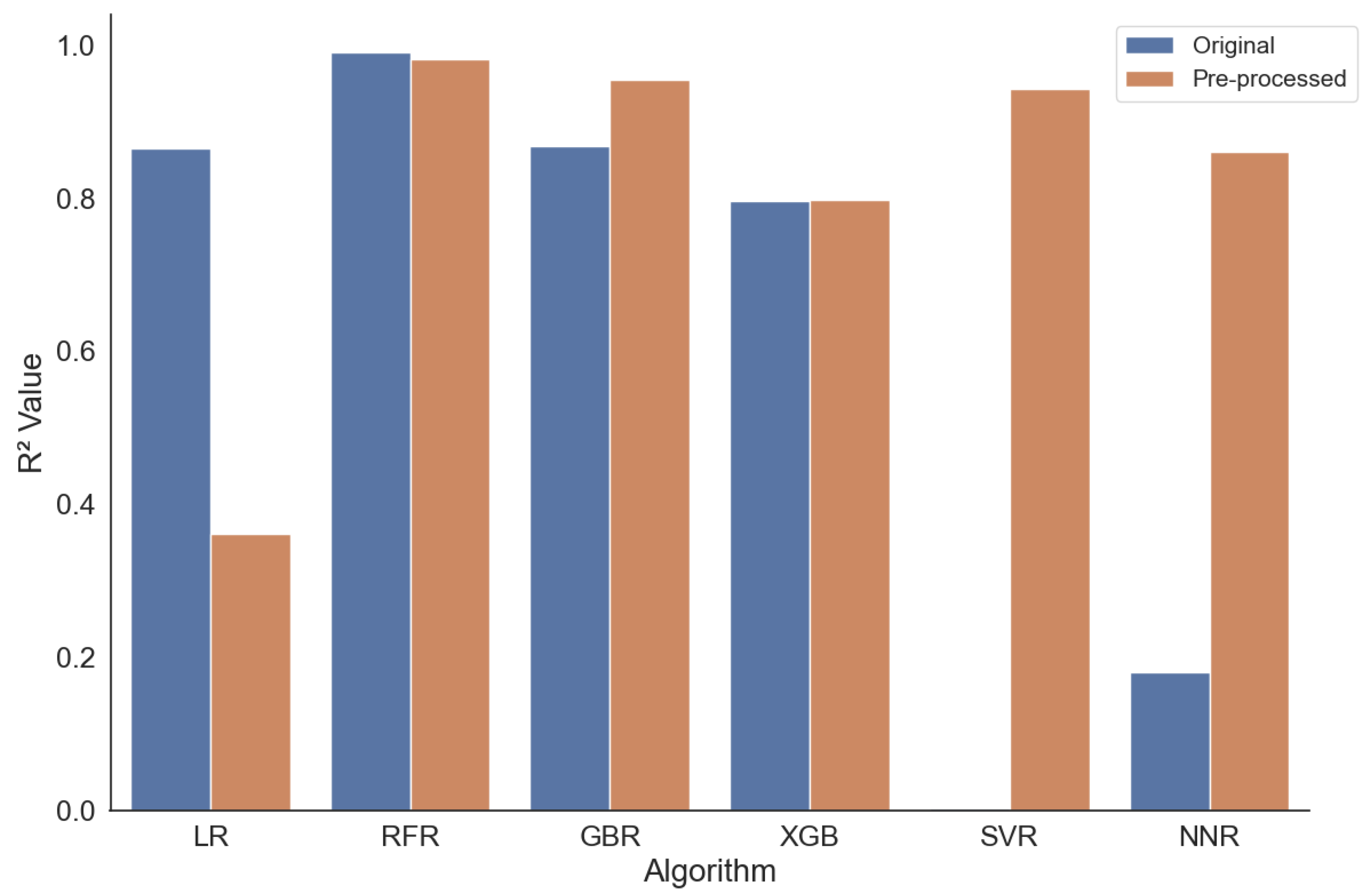
5.3.1. Explainability in the Best Configurations
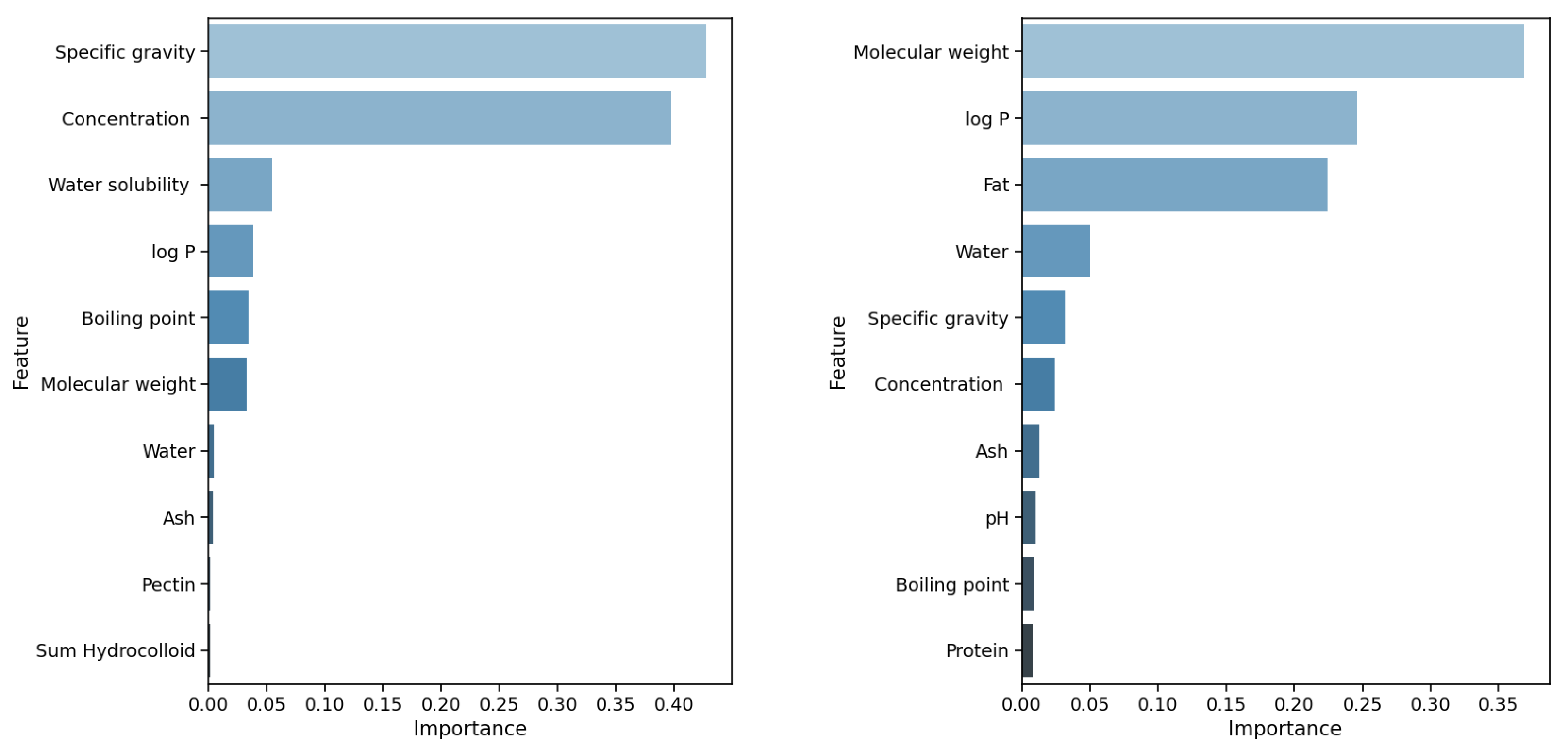
First, we analyze the best-performing configurations (according to their
score). These are the RFR algorithms with and without pre-processing for the temperature of 37
C. As can be seen from the plots in
Figure 5, the most important feature is the
specific gravity for both configurations. Interestingly, the feature achieves a score of 0.72 for the setting with the original data, i.e., it contributes 72% to the prediction of the
value; all others contribute less than 5% each. For the pre-processed data, the importance of the
specific gravity is reduced to 0.53; however, the importance of the feature
concentration is 0.27. For both settings, all ten features are identical; however, the importance scores slightly differ.
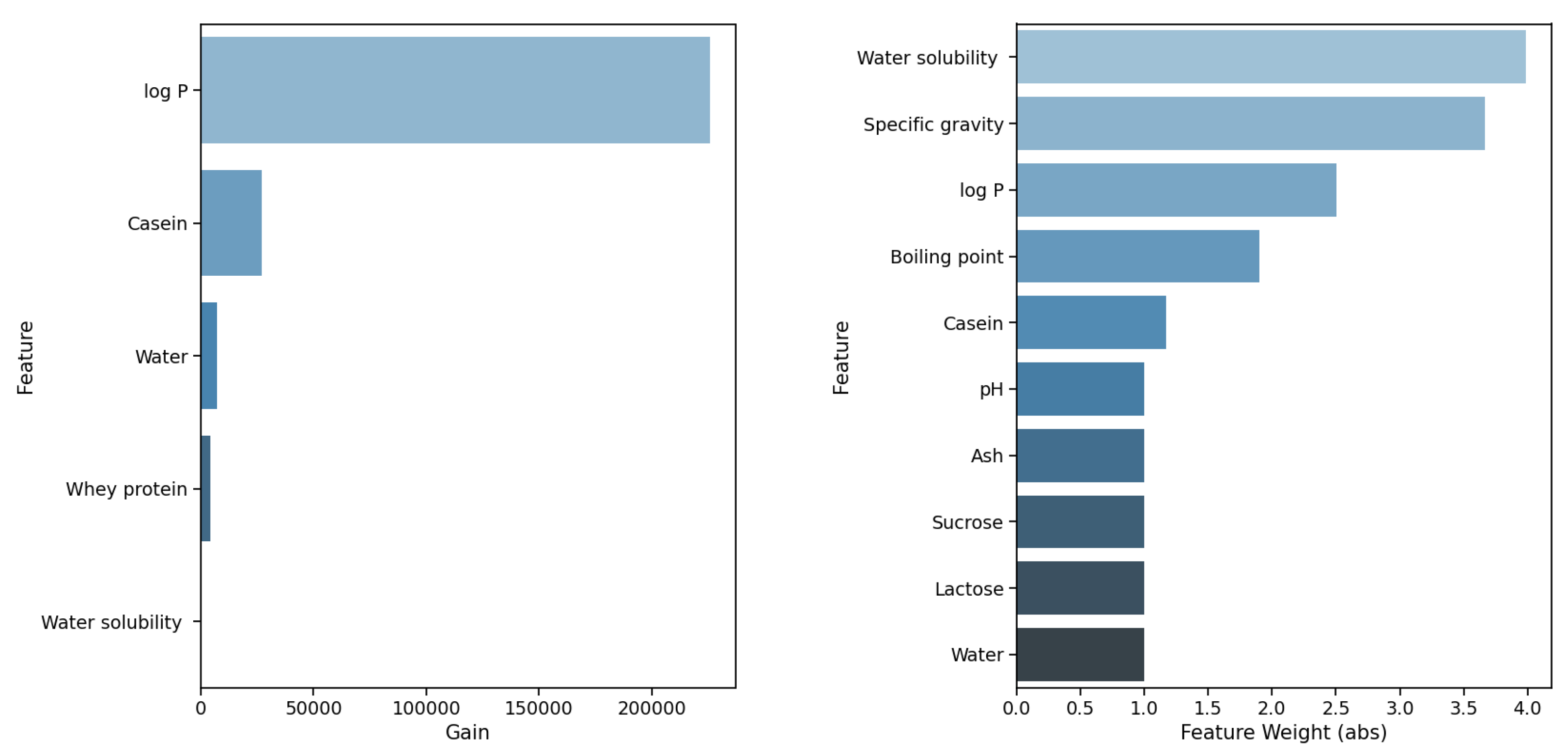
Other interesting insights are made for the GBR algorithm. For the temperatures of 37.0
C and 40.0
C, the achieved
scores are almost the same, both around 0.95; however, different feature sets contribute to the prediction (see
Figure 6). In the configuration for the temperature of 37.0
C, the top five most important features are:
specific gravity (0.4283),
concentration (0.3973),
water solubility (0.0550),
log P (0.3456), and
boiling point (0.0327). In the configuration for the temperature of 40.0
C, the top five most important features are:
molecular weight (importance score of 0.3687),
log P (0.2461),
fat (0.2241),
water (0.0502), and
specific gravity (0.0320). The top three features are completely different for both settings. Looking at the top five features with the highest importance, both settings share only one common feature; however, the importance of feature
log P differs between 0.2461 for the temperature of 40.0
C and 0.3456 for 37.0
C.
For both configurations, we use the pre-processed data; still, there are such differences visible in the feature importance while very good prediction performance is achieved. This underlines the importance of a thorough analysis and interpretation of the models. Further, it indicates the importance of the temperature and the suitability of the temperature-based analysis as we performed it.
5.3.2. Explainability Comparing Pre-Processing Techniques
When focusing on different algorithms for predicting the
value for the same temperature, we can see interesting effects. We do not include plots for all of the following settings; however, the results can be found in the online appendix: [
48].
For the temperature of 40.0
C, the algorithms RFR, XGB, and GBR all have the two features
fat and
log P within the top three features; RFR and GBR even have the same top three features. The same effects can be seen for the temperature of 37.0
C, where SVR, RFR, and GBR all have the same top feature,
specific gravity, and all three have
concentration as the second or third important feature. GBR and RFR have the same top three features in the same relevance order. In contrast to the more homogenous results for the temperatures of 37.0
C and 40.0
C, the picture changes for the temperature of 7.0
C.
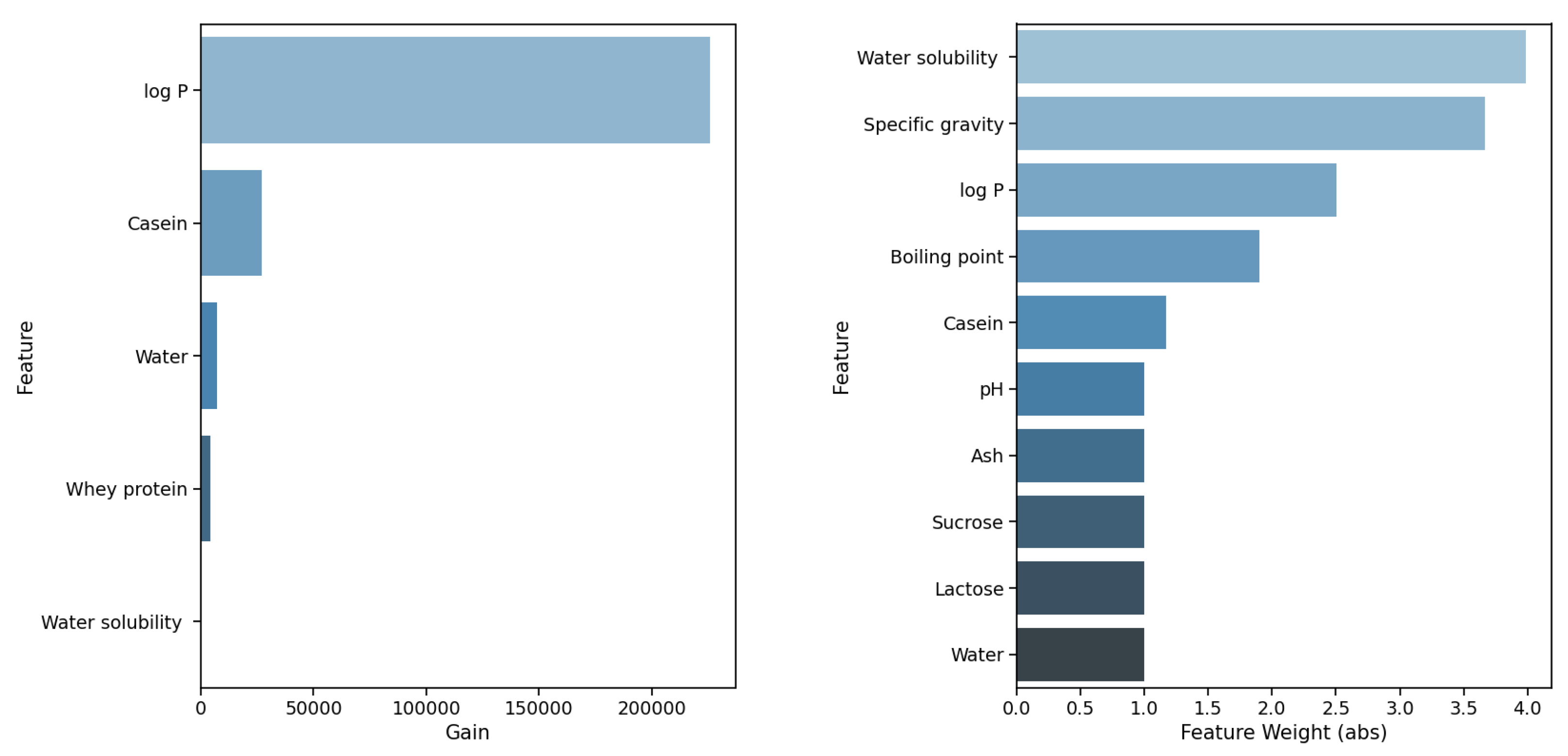
Figure 7 shows the result. Please note that, due to the difference in the calculation of the feature importance scores, these scores cannot be compared to the ones in
Figure 5 and
Figure 6. When focusing on the two best-performing algorithms, XGB and SVR, the first difference that can be observed is the fact that, for XGB, only five features contribute to the result. When comparing both algorithms in detail, it is interesting to note that the most important features completely differ; only the feature
log P shows similar importance. Again, this underlines the importance and need for a detailed analysis and interpretation of the models.
5.3.3. Performance Analysis of the Explainable Artificial Intelligence
Explainable artificial intelligence (XAI) refers to methods and techniques in the field of artificial intelligence that make the results and operations of AI systems more understandable to humans. The goal of XAI is to create AI models that are transparent and interpretable, allowing users to comprehend and trust the results and outputs they produce. This is particularly important in this application domain because the main objective is not solely the prediction of the value, but also the understanding of the underlying prediction model so that the model characteristics can help to improve the food reformulation.
In our analysis of the XAI of the tested algorithms (cf.
Section 5.3), we had to focus on specific settings for several reasons. First, we omitted the temperature of 30.0
C degrees as the regression results are too low. However, we might still apply XAI to find out why the algorithms do not perform as expected in future work. For this study, this was out of scope as we wanted to learn about the feature that can help to explain the regression of the
value. Second, we omitted the linear regression due to its performance. This was also observed by Heilig [
41] as they evaluated the model performance for linear regression. Additionally, we plan for the future to transfer the learned model to other food categories in addition to dairy matrices; this does not seem promising with linear regression. Third, artificial neural networks pose significant challenges to XAI due to their inherent complexity and opacity. These challenges primarily stem from the way these neural networks are structured and how they learn to make decisions. Hence, the analysis of the features’ importance is complicated, and, as the NN algorithms also do not outperform the other algorithms, we ignored them for the XAI analysis.
It can be seen that the features log P (100%), specific gravity (93.75%), molecular weight (93.75%), water solubility (87.50%), boiling point (75%), concentration (68.75%), water (68.75%), whey protein (50%), and casein (50%) are the features mostly present, each being identified for at least 50% of the setting as one of the top ten features of the total 22 analyzed features. Further, in the following detailed analysis, we see that the frequently mentioned features often have high feature importance scores; hence, these have relevant effects on the composition of the value.
When comparing the best performers as judged by their scores for the 37 C temperature setting, namely, the RFR both with and without pre-processing, it can be seen that, while the top ten features remain the same in both settings, their respective importance scores vary. This might be an important insight when reformulating food matrices and adjusting recipes.
We can further see that, for the same algorithm, even if the regression performance is very similar in terms of the scores, the temperature plays an important role. The GBR algorithm achieves scores around 0.95 at 37.0 C and 40.0 C yet relies on different feature sets for predictions. While the top three features differ for each temperature, only one feature, log P, is common in the top five, with varying importance between 0.2461 at 40.0 C and 0.3456 at 37.0 C, which confirms our model selection of the important features from the literature. Despite using pre-processed data for both scenarios, the distinct differences in feature importance, coupled with high prediction accuracy, highlight the need for in-depth model analysis and underscore the relevance of temperature in such analyses and also for practical usage.
When analyzing different algorithms for predicting the
value at the same temperature, interesting patterns emerge. At 40.0
C, RFR, XGB, and GBR algorithms rank
fat and
log P among their top three features, with RFR and GBR sharing the same top three. Similar trends are observed at 37.0
C, where SVR, RFR, and GBR all prioritize
specific gravity as the top feature and
concentration as the second or third. However, at 7.0
C, the results diverge, with XGB and SVR showing distinct differences in feature importance, except for in the case of
log P. This emphasizes the need for detailed model analysis and interpretation. Consequently, it is essential to enhance the machine learning process with an XAI component, which can either derive explanations from transparent models or decipher the decision-making process of more complex, opaque models. We describe such an approach in [
18]. Its implementation is part of our future work.
Furthermore, the XAI-based analysis shows one obstacle to the data-driven approach. When following a purely data-driven approach, the machine learning algorithm does not take into account specific constraints, for example, from scientific models. In our results, we identify that the feature
concentration for the Random Forest with pre-processing at 37
C has a higher importance, as can be explained with scientific knowledge about the chemical interrelationships. Hence, it is important to use the explanations and interpretations from XAI and combine them with domain knowledge for validation. Furthermore, it might be feasible to avoid such wrong conclusions from the machine learning algorithm by integrating the relevant scientific models in advance to set the relevant constraints for the learning process. This could be made possible by integrating surrogate models [
53]. Surrogate models are simplified models that are used to approximate more complex and computationally expensive models. They are often employed in various fields such as engineering, simulation, optimization, and machine learning. The primary purpose of a surrogate model is to reduce the computational cost associated with the evaluation of complex models while still providing a reasonably accurate approximation. However, the validation of the XAI or the integration of scientific models into the machine learning process is part of future work.
5.4. Threats to Validity
In evaluating the validity of our scientific study, it is important to acknowledge several limitations and potential threats to the robustness of our findings. We will describe those limitations in the following.
Pre-processing: The use of only basic pre-processing techniques may not adequately address complex data characteristics such as non-linearity, high dimensionality, or hidden patterns, potentially leading to suboptimal model performance and biased results. The inclusion of additional pre-processing techniques is part of our future work. However, the results indicate that the applied techniques work well with the dataset.
Limited number of data: The scarcity of data points, particularly at higher temperature ranges above 40 C, could lead to a lack of representativeness in the dataset, resulting in models that are not well generalized and potentially less accurate in their predictions for these specific conditions. We currently plan further measurements with additional temperature ranges.
Limited set of algorithms: Employing a restricted set of machine learning algorithms may limit the exploration of diverse modeling approaches, potentially overlooking algorithms that could be more effective or suitable for the specific characteristics of the dataset. In this first exploratory study, we focused on only six algorithms. Even though the applied set of algorithms shows good performance, the application of further algorithms is part of future work.
No hyperparameter tuning: The scope of this exploratory study was to identify the applicability of different ML algorithms for prediction of the value using regression; hence, we used the default configurations for these algorithms. Additional hyperparameter tuning can result in models that are better configured for the given data, potentially leading to better performance as compared to models where hyperparameters are not adjusted to enhance their predictive capabilities. It is common practice to rely on the default parameters in a first exploratory study. Further, hyperparameter tuning might also lead to overfitting and reduce the transferability of the machine learning models. However, we plan to integrate hyperparameter tuning in future work for comparison.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}