

Deep Reinforcement Learning-Based Robotic Puncturing Path Planning of Flexible Needle


Abstract
1. Introduction
2. Related Work
- Dealing with high-dimensional state and action spaces;
- Automatically extracting features;
- Learning complex policies;
- Improving environment perception and decision-making capabilities;
- Better interpretability.
3. Path Planning of Flexible Needle in Robotic Puncturing
3.1. Definition of the Internal Human Environment
3.1.1. Obstacle Situation
3.1.2. Lesion Target Location
3.1.3. Hierarchical Model of the Human Body
3.2. Modeling of the Flexible Needle Puncture Problem
3.2.1. Kinematic Modeling
3.2.2. Mathematical Path Planning Model
4. Deep Reinforcement Learning-Based Path Planning
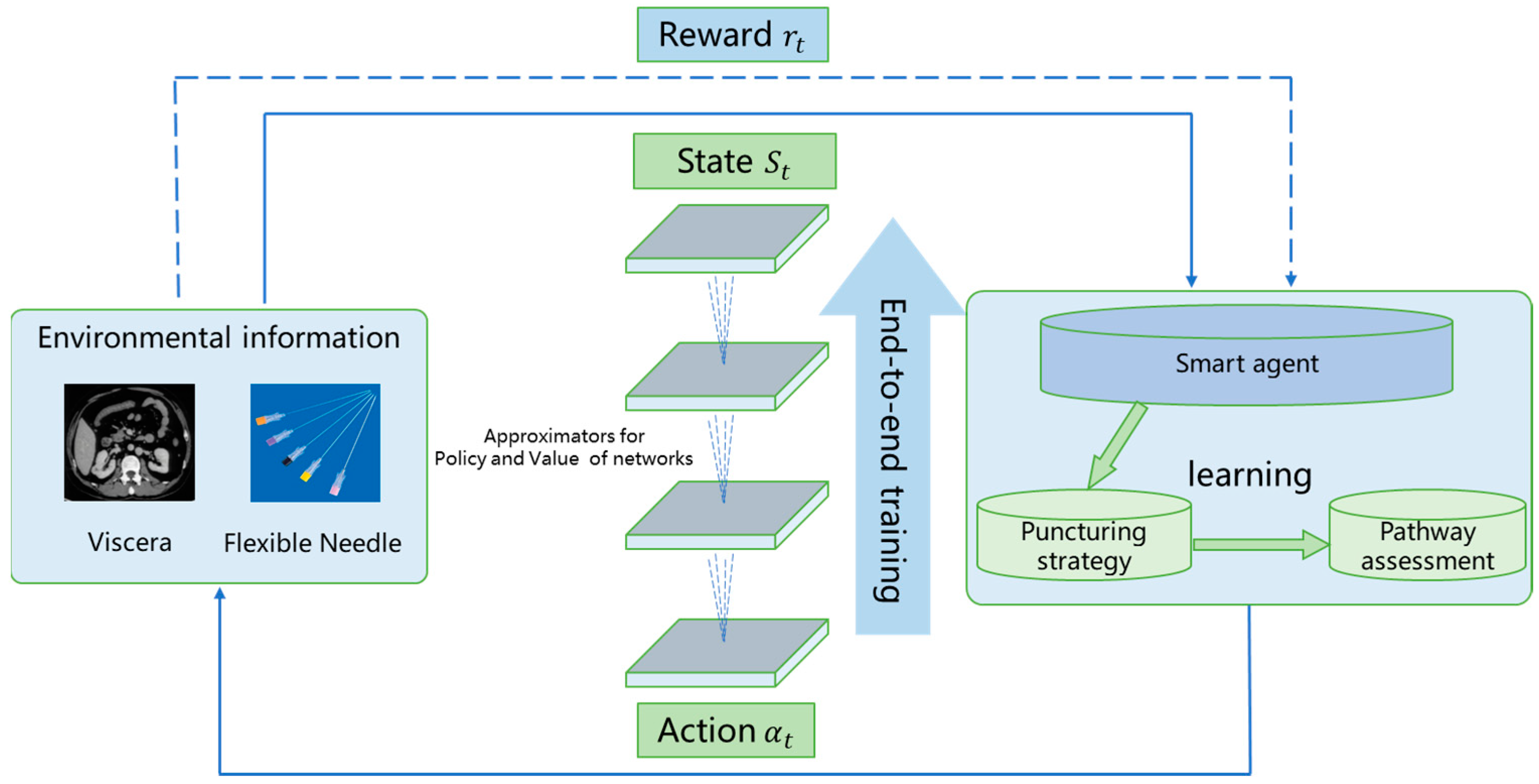
4.1. Framework of DRL-Based Path Planning
4.2. Reinforcement Learning Modeling
4.2.1. State Features
- Position information: this includes the absolute and relative position of the needle tip and the degree of bending of the needle to ensure that the needle can accurately reach the target position;
- Tissue information: this includes the density and hardness information of the surrounding tissues to ensure that no important tissues are damaged during the puncture process;
- Obstacle information: this identifies the location and size of obstacles (e.g., other organs, blood vessels) in the path to avoid collision.
- Able to describe the features and variations in the puncture environment, including global and local features;
- Applicable to puncture problems in different environments, contained within the state space;
- Provides a numerical representation of the information about the agent to enable the description of different problems in a uniform manner through formalization.
4.2.2. Action Space
4.2.3. Reward Function
- Tissue damage: negative rewards are imposed for any tissue damage incurred during needle insertions or rotations, thereby discouraging harmful maneuvers.
- Proximity to target: positive rewards are awarded as the needle draws nearer to the target, incentivizing accurate navigation.
- Distance from obstacles: negative rewards are imposed when the agent ventures too near an obstacle, promoting obstacle avoidance.
- Success rate: positive rewards are granted for successfully reaching the target location, reinforcing successful completion of the task.
- Obstacle avoidance: negative rewards are applied for any collisions with obstacles or boundary infringements within the exploration space, emphasizing the importance of safe navigation.
- Path efficiency: negative rewards are given for reaching the target via a convoluted path, encouraging the adoption of more direct routes.
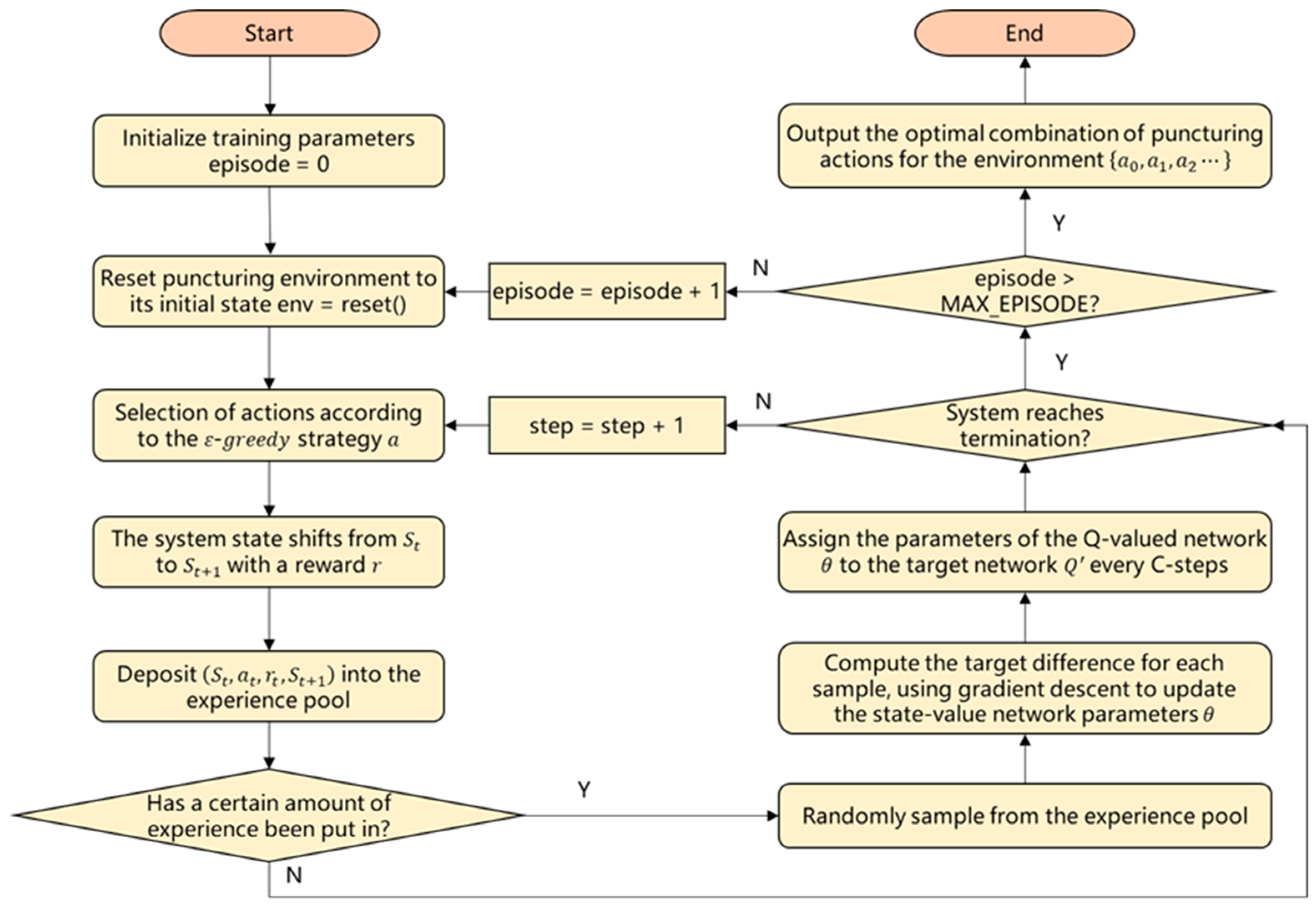
4.3. Algorithms for Agent Training
4.3.1. DQN Algorithm
| Algorithm 1. DQN Algorithm | |
| Hyper-Parameter: experience pool capacity , reward discount factor , delay step for target state-action value function update in the | |
| Input: empty experience pool , Initialize the state-action value function Q function with parameters θ | |
| Initialize the target state-action value function using the parameter | |
| 1: | for episode = 0, 1, 2, …… do |
| 2: | Initialize the environment and acquire observations |
| 3: | Initialization sequence and preprocess the sequence |
| 4: | for t = 0, 1, 2, …… do |
| 5: | Select a random action by probability , otherwise select the action: |
| 6: | Perform action and obtain observation data and reward data |
| 7: | Set if the council is over, otherwise |
| 8: | Set and pre-processing |
| 9: | Store the state transfer data into D |
| 10: | Random sampling of small batches of state transfer data from D |
| 11: | If , set , otherwise, set |
| 12: | Perform a gradient descent step on for θ |
| 13: | Synchronize the target network every C steps |
| 14: | Jump out of the loop if the segment ends |
| 15: | end for |
| 16: | end for |
4.3.2. Training Process
- MEMORY_SIZE: the capacity of the experience pool, storing more data as the size increases.
- BATCH_SIZE: the number of experiences sampled for gradient computation.
- MAX_EPISODES: the limit on the episodes per training cycle, with each episode consisting of a series of actions.
- LEARNING_RATE: the step size for weight updates during learning.
- Q_UPDATE_FREQ: the frequency at which the target network’s parameters are updated from the prediction network.
- INITIAL_PARAMETERS: initialize the Q network’s parameters (θ), the target network’s parameters (θ^), and the reward discount factor (γ).
5. Simulation Experiment Results
5.1. Sensitivity Analysis
- (1)
- Learning rate
- (2)
- Discount factor
- (3)
- Batch size
- (4)
- Update frequency of the target Q-network
5.2. DQN-Based Simulation Experiments for the PPFNP Problem
5.2.1. Different Space Dimensions
5.2.2. Number of Different Intelligences
5.2.3. Model Comparison
5.3. Discussion
- Managing high-dimensional spaces: deep reinforcement learning autonomously distills essential features from raw data, adeptly handling complex, nonlinear interactions and alleviating the feature engineering burden.
- Crafting sophisticated strategies: it surpasses conventional approaches by crafting more nuanced strategies, thereby boosting performance and efficiency.
- Enhancing environmental awareness: it bolsters the agent’s environmental perception, aiding in collision avoidance and optimal path identification.
- Adaptive strategy optimization: the dynamic strategy adjustment in response to performance feedback facilitates an ongoing refinement of goal-oriented planning and exploration.
- Behavioral clarity: the agent’s behavior, shaped by environmental interactions, becomes more transparent and understandable, fostering usability and trust.
- Addressing practical application challenges: Integrating path planning algorithms with medical equipment for precise navigation while ensuring needle stability, safety, and ease of use, presents significant challenges. Cross-disciplinary collaboration is crucial to merge these algorithms with practical applications, advancing flexible needle path planning in digital healthcare.
- Incorporating dynamic needle characteristics: The kinematic model of a unicycle, which assumes quasi-static needle motion and neglects external forces, often deviates from reality due to factors like needle deformation and tissue friction. Future research could address these biases by integrating the needle’s dynamic properties into the model. Combining mechanical analysis with real-time feedback control—using force sensors, visual feedback, or other intelligent perception techniques—can improve path accuracy and system robustness. This fusion of data-driven and physical models holds promise for enhancing practical performance.
- Integrating medical imaging: Existing medical imaging technologies, such as MRI, CT, and ultrasound, offer detailed anatomical insights that can be leveraged to guide needle path planning. Future work may focus on the seamless integration of these imaging modalities with real-time navigation systems, allowing for more accurate needle placement and adaptive path adjustments based on real-time visual feedback. This combination of imaging and path planning is key to advancing minimally invasive procedures and improving patient outcomes.
- Insights from recent research: Recent studies on needle path planning have provided valuable insights into the optimization of puncture trajectories. One study highlights the use of machine learning to predict tissue properties and improve the adaptability of needle insertion paths. Another explores biomechanical modeling to simulate tissue deformation, helping refine path planning under different operational conditions [27,28,29]. These advancements suggest that combining predictive models with real-time sensor feedback could enhance the precision and reliability of needle navigation in complex medical scenarios.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, K.; Li, B.; Zhang, Y.; Dai, X. Review of research on path planning and control methods of flexible steerable needle puncture robot. Comput. Assist. Surg. 2022, 27, 91–112. [Google Scholar] [CrossRef]
- Aggarwal, S.; Kumar, N. Path planning techniques for unmanned aerial vehicles: A review, solutions, and challenges. Comput. Commun. 2020, 149, 270–299. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Peng, L. Multi-robot path planning based on a deep reinforcement learning DQN algorithm. CAAI Trans. Intell. Technol. 2020, 5, 177–183. [Google Scholar]
- Momen, A.; Roesthuis, R.J.; Reilink, R.; Misra, S. Integrating deflection models and image feedback for real-time flexible needle steering. IEEE Trans. Robot. 2012, 29, 542–553. [Google Scholar]
- Zhao, Y.J.; Joseph, F.O.M.; Yan, K.; Datla, N.V.; Zhang, Y.D.; Podder, T.K.; Hutapea, P.; Dicker, A.; Yu, Y. Path planning for robot-assisted active flexible needle using improved Rapidly-Exploring Random trees. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 380–383. [Google Scholar]
- Xiong, J.; Li, X.; Gan, Y.; Xia, Z. Path planning for flexible needle insertion system based on Improved Rapidly-Exploring Random Tree algorithm. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 1545–1550. [Google Scholar]
- Hong, A.; Boehler, Q.; Moser, R.; Zemmar, A.; Stieglitz, L.; Nelson, B.J. 3D path planning for flexible needle steering in neurosurgery. Int. J. Med. Robot. Comput. Assist. Surg. 2019, 15, e1998. [Google Scholar]
- Zhang, Y.; Ju, Z.; Zhang, H.; Qi, Z. 3-d path planning using improved RRT* algorithm for robot-assisted flexible needle insertion in multilayer tissues. IEEE Can. J. Electr. Comput. Eng. 2021, 45, 50–62. [Google Scholar]
- Cai, C.; Sun, C.; Han, Y.; Zhang, Q. Clinical flexible needle puncture path planning based on particle swarm optimization. Comput. Methods Programs Biomed. 2020, 193, 105511. [Google Scholar]
- Tan, Z.; Liang, H.G.; Zhang, D.; Wang, Q.G. Path planning of surgical needle: A new adaptive intelligent particle swarm optimization method. Trans. Inst. Meas. Control. 2021, 44, 766–774. [Google Scholar]
- Tan, Z.; Zhang, D.; Liang, H.G.; Wang, Q.G.; Cai, W. A new path planning method for bevel-tip flexible needle insertion in 3D space with multiple targets and obstacles. Control. Theory Technol. 2022, 20, 525–535. [Google Scholar]
- Tan, X.; Yu, P.; Lim, K.B.; Chui, C.K. Robust path planning for flexible needle insertion using Markov decision processes. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1439–1451. [Google Scholar]
- Lee, Y.; Tan, X.; Chng, C.B.; Chui, C.K. Simulation of robot-assisted flexible needle insertion using deep Q-network. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 342–346. [Google Scholar]
- Hu, W.; Jiang, H.; Wang, M. Flexible needle puncture path planning for liver tumors based on deep reinforcement learning. Phys. Med. Biol. 2022, 67, 195008. [Google Scholar] [CrossRef]
- Milovancev, M.; Townsend, K.L. Current Concepts in Minimally Invasive Surgery of the Abdomen. Vet. Clin. Small Anim. Pract. 2015, 45, 507–522. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Yu, L.; Zhang, F. A survey on puncture models and path planning algorithms of bevel-tipped flexible needles. Heliyon 2024, 10, e25002. [Google Scholar] [CrossRef]
- Webster, R.J., III; Kim, J.S.; Cowan, N.J.; Chirikjian, G.S.; Okamura, A.M. Nonholonomic modeling of needle steering. Int. J. Robot. Res. 2006, 25, 509–525. [Google Scholar] [CrossRef]
- Abolhassani, N.; Patel, R. Deflection of a flexible needle during insertion into soft tissue. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 3858–3861. [Google Scholar]
- Yan, K.G.; Podder, T.; Yu, Y.; Liu, T.I.; Cheng, C.W.; Ng, W.S. Flexible needle–tissue interaction modeling with depth-varying mean parameter: Preliminary study. IEEE Trans. Biomed. Eng. 2008, 56, 255–262. [Google Scholar] [CrossRef]
- Płaskonka, J. The path following control of a unicycle based on the chained form of a kinematic model derived with respect to the Serret-Frenet frame. In Proceedings of the 2012 17th International Conference on Methods & Models in Automation & Robotics (MMAR), Miedzyzdroje, Poland, 27–30 August 2012; pp. 617–620. [Google Scholar]
- Liu, F.; Guo, H.; Li, X.; Tang, R.; Ye, Y.; He, X. End-to-end deep reinforcement learning based recommendation with supervised embedding. In Proceedings of the 13th International Conference on Web Search and Data Mining 2020, Houston, TX, USA, 3–7 February 2020; pp. 384–392. [Google Scholar]
- Kriegeskorte, N.; Golan, T. Neural network models and deep learning. Curr. Biol. 2019, 29, R231–R236. [Google Scholar] [CrossRef]
- Gulde, R.; Tuscher, M.; Csiszar, A.; Riedel, O.; Verl, A. Deep Reinforcement Learning using Cyclical Learning Rates. In Proceedings of the 2020 Third International Conference on Artificial Intelligence for Industries (AI4I), Irvine, CA, USA, 21–23 September 2020; p. 32. [Google Scholar]
- Amit, R.; Meir, R.; Ciosek, K. Discount factor as a regularizer in reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Chendu, China, 18–20 October 2024; pp. 269–278. [Google Scholar]
- Smith, S.L. Don’t decay the learning rate, increase the batch size. arXiv 2017, arXiv:1711.00489. [Google Scholar]
- Wang, J.; Gou, L.; Shen, H.W.; Yang, H. Dqnviz: A visual analytics approach to understand deep q-networks. IEEE Trans. Vis. Comput. Graph. 2018, 25, 288–298. [Google Scholar] [CrossRef]
- Mao, Z.; Kobayashi, R.; Nabae, H.; Suzumori, K. Multimodal Strain Sensing System for Shape Recognition of Tensegrity Structures by Combining Traditional Regression and Deep Learning Approaches. IEEE Robot. Autom. Lett. 2024, 9, 10050–10056. [Google Scholar] [CrossRef]
- Mao, Z.; Hosoya, N.; Maeda, S. Flexible Electrohydrodynamic Fluid-Driven Valveless Water Pump via Immiscible Interface. Cyborg Bionic Syst. 2024, 5, 91. [Google Scholar] [CrossRef]
- Peng, Y.; He, M.; Hu, F.; Mao, Z.; Huang, X.; Ding, J. Predictive modeling of flexible EHD pumps using Kolmogorov–Arnold Networks. Biomim. Intell. Robot. 2024, 4, 100184. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Implications | |
|---|---|---|
| Path Information | Number of path planning | |
| Pathway set | ||
| th path | ||
| from target point | ||
| Obstacle Information | Number of obstacles | |
| Obstacle course | ||
| th obstacle | ||
| Other Information | α | Precision factor |
| β | Length factor | |
| γ | Obstacle avoidance factor | |
| λ | Time factor | |
| Notations | Implications |
|---|---|
| -axis direction | |
| y | -axis direction |
| -axis direction | |
| -axis direction | |
| -axis direction | |
| -axis direction | |
| Manhattan distance between the current position of the needle and its initial position | |
| Manhattan distance between the current state of the needle and the target point | |
| Manhattan distance of the initial point from the target point | |
| Manhattan distance of the needle from the obstacle | |
| Number of needle rotations |
| Classes | Reward Functions | Implications |
|---|---|---|
| Single-step reward | Negative reward for damage to normal tissue per step | |
| Negative reward per needle rotation | ||
| Negative reward for approaching an obstacle | ||
| Positive rewards for approaching the target position | ||
| Multiple reward | Negative reward for collision with obstacles | |
| Negative reward to reach space boundaries | ||
| Negative reward for exceeding the worst step | ||
| Positive rewards for reaching the target location |
| Cumulative Reward | Implications |
|---|---|
| Normal puncture procedure | |
| Collision with obstacles | |
| Outside the model boundary | |
| Reach target position | |
| Exceeding the worst possible step size |
| Parameters | Settings |
|---|---|
| Spatial extent | 50 × 50 × 50 |
| Obstacle radius | 3 |
| Flexible needle curvature | 0.0069 |
| Number of intelligences per turn | 1 |
| Initial point position | [25, 25, 0] |
| Location of the target | [25, 25, 50] |
| Maximum number of steps | 50 |
| Maximum number of revolutions | 5 |
| Parameters | Settings |
|---|---|
| Neural network layers | 3 |
| Number of neurons in the hidden layer | 20 |
| Number of neural networks | 2 |
| Hidden layer activation function | ReLU |
| Output layer activation function | linear function |
| Gradient descent optimizer | RMSProp |
| Discovery strategy | ε-greedy |
| Experience pool size | 5000 |
| Learning rate | [0.001, 0.005, 0.01, 0.05, 0.1] |
| Discount factor | [0.80, 0.85, 0.90, 0.95, 0.99] |
| Batch size | [16, 32, 64, 128, 256] |
| Q-target update frequency | [10, 20, 30, 40, 50] |
| Number of training iterations | 8000 |
| Category | Original DRL | Improved DRL | ||||
|---|---|---|---|---|---|---|
| Goals | Learning Rate | Discount Factor | Batch Size | Update Frequency | ||
| Average | 45 | −4 | 134 | 3 | 246 | |
| Max | 161 | 212 | 186 | 43 | 332 | |
| Min | −6 | −64 | 64 | −51 | 197 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.; Huang, Z.; Zhu, T.; Leng, J.; Huang, K. Deep Reinforcement Learning-Based Robotic Puncturing Path Planning of Flexible Needle. Processes 2024, 12, 2852. https://doi.org/10.3390/pr12122852
Lin J, Huang Z, Zhu T, Leng J, Huang K. Deep Reinforcement Learning-Based Robotic Puncturing Path Planning of Flexible Needle. Processes. 2024; 12(12):2852. https://doi.org/10.3390/pr12122852
Chicago/Turabian StyleLin, Jun, Zhiqiang Huang, Tengliang Zhu, Jiewu Leng, and Kai Huang. 2024. "Deep Reinforcement Learning-Based Robotic Puncturing Path Planning of Flexible Needle" Processes 12, no. 12: 2852. https://doi.org/10.3390/pr12122852
APA StyleLin, J., Huang, Z., Zhu, T., Leng, J., & Huang, K. (2024). Deep Reinforcement Learning-Based Robotic Puncturing Path Planning of Flexible Needle. Processes, 12(12), 2852. https://doi.org/10.3390/pr12122852