1. Introduction
Recently, predictive analytics has been considered a key field within data science through the use of statistical models and machine learning algorithms to forecast future occurrences or behaviors in many applications such as fault diagnosis, customer segmentation, demand estimation, risk management, and healthcare improvement, among others.
The advancements in recent technologies such as the Internet of Things (IoT), cloud computing (CC), machine learning (ML), and Cyber–Physical Systems (CPSs), coupled with developments in telecommunication, have revolutionized information transmission. This revolution, attributed to digitalization, has permeated all aspects of life and given rise to the concept of digital twins (DTs) in the context of Industry 4.0. The DT represents a virtual replica of a physical product within the framework of Cyber–Physical Systems, mimicking the behavior of the real system throughout its lifecycle. By integrating digital and physical twins, efficient management, control, and decision-making processes are enabled during the operation of the real system. The DT captures data from physical sensors to monitor the system’s response and predicts and diagnoses its behavior to anticipate faults, enabling proactive maintenance actions. However, the performance and reliability of predictive maintenance models may be affected greatly by the unavailability of enough data or by the existence of imbalanced datasets. This lack of data may ultimately cause performance bias, misclassification, or poor analysis, thus causing the breakdown of maintenance systems.
Across various industries, including the manufacturing, healthcare, and automotive fields, the DT has become an invaluable asset [
1,
2,
3]. DT technology supports data fusion, modeling, and technology integration by simulating physical systems, enabling effective problem-solving for complex interdisciplinary challenges. Central to the DT concept is the exchange of data streams from learning components and remote sensors in simulation, which are crucial for developing intricate processes and exploring “what-if” scenarios. Notably, the field of environmental sciences has also recognized the importance of the DT, encompassing areas such as hydrology, agriculture, smart farming, animal farming, remote sensing, and earth sciences [
4,
5,
6,
7,
8,
9,
10,
11].
Digital twins are increasingly being integrated with ML algorithms for fault diagnosis schemes based on machine learning and digital twins for fault-tolerant systems. However, there are a lack of available industrial data, so there is a serious need to provide a promising approach for solving the scarcity of fault data by generating synthetic data with better adaptability like Conditional Generative Adversarial Networks (CGANs). CGANs are considered an advanced deep learning model capable of generating realistic data samples based on provided criteria. CGANs generate highly convincing outputs by combining generative models and adversarial training.
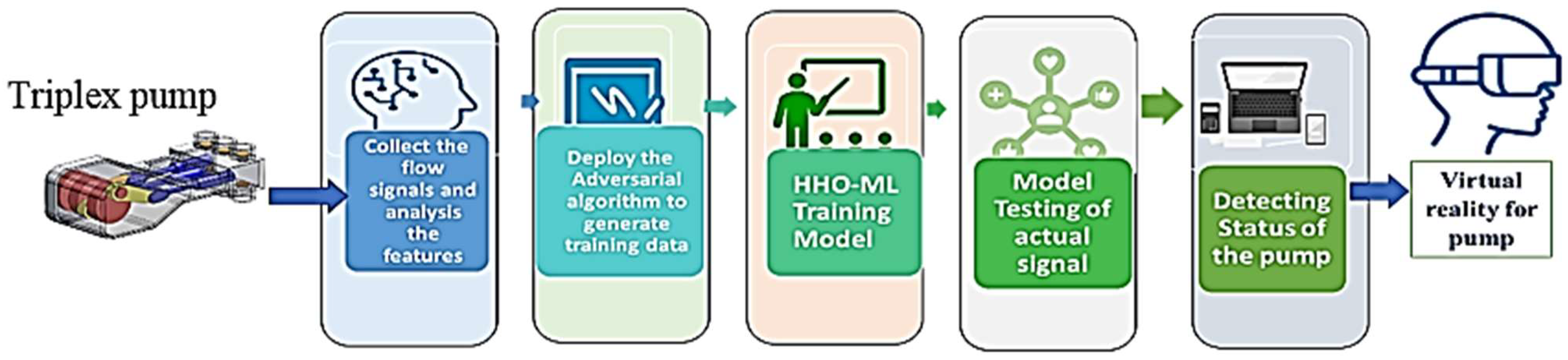
Figure 1 shows the general steps of the Fault Diagnosis Model for industrial control systems.
Nevertheless, the development of effective fault detection and diagnosis models remains challenging due to the lack of comprehensive datasets. To address this issue, we propose the use of Generative Adversarial Networks (GANs) to generate synthetic data that replicate real-world data, capturing essential features indicative of health-related information without directly referencing actual industrial DT systems. This paper introduces an intelligent fault detection and diagnosis framework for industrial triplex pumps, enhancing fault recognition capabilities and offering a robust solution for real-time industrial applications within the DT paradigm.
Therefore, this paper introduces an efficient fault diagnosis framework for industrial digital twin systems. The framework aims to achieve accurate and efficient fault detection and diagnosis by incorporating Conditional Generative Adversarial Networks (CGANs) for generating synthesis industrial pump data and hybrid-optimized machine learning methods with Harris Hawk Optimization (HHO). The novelty of the work is in the combination of CGAN with the HHO for the feature selection process in machine learning models. This approach renders a significant improvement in the performance of models used in fault detection systems. This resolves a very typical challenge in industrial fault detection where such datasets are often unbalanced, enhancing the generalization and performance of the model. Therefore, the key contributions of this paper can be summarized as follows:
Develop a smart and vigorous fault detection and diagnosis framework for industrial triplex pumps, enhancing fault recognition capabilities and offering a robust solution for real-time industrial applications within the DT paradigm.
The proposed framework leverages Conditional GANs (CGANs) alongside the Harris Hawk Optimization (HHO) metaheuristic method to optimize feature selection from input data effectively for machine learning (ML) models such as Bagged Ensemble (BE), AdaBoost (AD), Support Vector Machine (SVM), K-Nearest Neighbors (KNNs), Decision Tree (DT), and Naive Bayes (NB). The efficacy of the approach is evaluated using key performance metrics such as accuracy, precision, recall, and F-measure on a triplex pump dataset.
From the experimental results, the suggested hybrid-optimized ML algorithms outperform or match their classical counterparts across various metrics. BE-HHO achieves the highest accuracy at 95.24%, slightly surpassing BE’s 95.17%. SVM-HHO attains 94.86% accuracy, marginally higher than SVM’s 94.48%. KNN-HHO outperforms KNNs with an accuracy of 94.73% compared to 93.14%. Both DT-HHO and DT achieve 94.73% accuracy, with DT-HHO displaying slightly better precision and recall. NB-HHO and NB show nearly equivalent performance, with NB-HHO at 94.73% accuracy versus NB’s 94.6%. Although AD-HHO and AD have lower accuracies at 92.57% and 92.06%, respectively, AD achieves higher recall.
Hybrid-optimized machine learning models using the HHO will outperform classical models in terms of accuracy, precision, and recall in diagnosing faults in industrial pump systems.
Thus, this research proposes an innovative approach that successfully exploits both the features optimization and the synthetic data production to fit the needs of typical dynamic industrial environments based on the digital twin.
The structure of the paper is as follows: In
Section 2, relevant work on the paper’s theme is explored, while a brief overview of Conditional GAN (CGAN) and Harris Hawk Optimization (HHO) as they pertain to the proposed system is provided in
Section 3. The suggested framework is explained and clarified in
Section 4, while a high-level proposed framework for remote fault monitoring and detection in smart industrial IoT systems is delivered in
Section 5.
Section 6 shows the experimental findings and comparative effectiveness of the suggested approaches in comparison with classical ML models, while the paper’s conclusion and future scope of this innovative topic are explored in
Section 8.
2. Previous Studies
To identify and diagnose defective equipment, this study intends to develop and use a digital twin system for the triplex pump. For several industrial processes, fault detection and diagnosis have been carried out to boost effectiveness, safety, and continuous production. In recent decades, numerous Artificial Intelligence techniques for failure diagnosis have been introduced to increase the reliability and security of sophisticated equipment. One of the effective machine learning techniques used is Generative Adversarial Networks (GANs). GANs have shown promising results in various fields, including fault diagnosis [
12,
13,
14,
15]. These studies show how GANs can be used to diagnose faults in a range of sectors, including manufacturing, energy, and transportation. However, there are still several issues and open research paths in this field, including how to deal with imbalanced data, how to deal with the absence of labeled data, and how to use other GAN techniques in fault diagnosis.
One of the well-known and effective methods for defect diagnosis is the model-based approach, in which an accurate complicated apparatus model is built by different analytic terms [
16,
17,
18]. Physically and mathematically informed approaches have been effectively employed to tackle the intricacies of sophisticated industrial machinery, leveraging established model-based methodologies. Nevertheless, the profound complexity of certain equipment often necessitates a thorough comprehension of the underlying physical principles to create an accurate model. Due to its potential to revolutionize several industries, including gaming, education, healthcare, and manufacturing, the ideas of industrial digital twins have attracted significance recently.
On the other hand, digital twins are virtual representations of actual things, systems, or settings that can be used for testing, simulation, and monitoring. Numerous industries, including engineering, architecture, urban planning, and healthcare, use them. The publication by Grieves et al. [
19], which presents the idea of digital twins and explores their potential advantages and disadvantages, is one of the foundational works on this topic. The authors contend that digital twins can enhance consumer experience, lower expenses, and improve product development. Although the present DT schemes and executions are still in their initial phases and require significant effort, they have been successfully integrated into various applications such as healthcare systems, various industries including aviation and farming, smart cities, and climate prediction [
20,
21].
Designing a competent digital twin system for any physical system requires the expertise of specialized engineers and computer scientists. Their duties comprise constructing and proposing the necessary product model and creating a comprehensive description of the virtual system. The authors demonstrate the effectiveness of their approach in reducing costs and improving transparency. Also, Wang et al. [
22] create a digital twin platform for smart cities that combines data from several sources to offer in-the-moment monitoring and optimization of municipal infrastructure. However, they also note the difficulties in managing data, scaling, and cybersecurity that come with building and sustaining digital twins. A framework for building digital twins of the triplex pump and using hybrid machine learning for fault diagnosis in the industrial system is given in [
23]. Fault diagnosis becomes faster, more accurate, and more cost-effective, leading to improved operational efficiency and reduced downtime in various industries, such as manufacturing, energy, and transportation [
24,
25].
The current state of the art in industrial IoT applications is characterized by a scarcity of contributions focused on the integration of digital twins and machine learning algorithms. In response to this gap, this study proposes a novel fault prediction framework comprising four phases, namely (1). a Data Acquisition Step (DAS), (2). a Data Synthesizing Step (DSS), (3). ML-based Model Training and Testing (MLMT2), and finally (4). a Failure Diagnosis Step (FDS). The proposed framework seeks to develop an advanced powerful forecast digital twin-assisted AI framework that leverages Generative Adversarial Networks (GANs) in combination with diverse HHO-based optimized machine learning techniques, such as Bagged Ensemble (BE), AdaBoost (AD), Support Vector Machine (SVM), K-Nearest Neighbors (KNNs), Decision Tree (DT), and Naive Bayes (NB) to identify and classify faults effectively.
In conclusion, this section presents a critical review of the literature on fault detection and diagnosis (
Table 1) using digital twins and Artificial Intelligence techniques, specifically Generative Adversarial Networks (GANs) and machine learning algorithms. Various studies are summarized, highlighting their objectives, methodologies, key findings, and their pros and cons.
3. Background
This section discusses the topics of Conditional GAN (CGAN) and Harris Hawk Optimization (HHO) as they pertain to the proposed system.
3.1. Conditional GAN (CGAN)
A new kind of deep learning network model called a Generative Adversarial Network directly generates similar distributions from real data. Due to GAN’s powerful data-generating capabilities, data imbalance is a common problem that it is utilized to solve. The Generative Adversarial Network (GAN), which is used as a machine learning framework for training generative models, is extended to create the conditional generative adversarial network (CGAN). Therefore, to simulate real data input to the networks, synthetic data can be produced using conditional Generative Adversarial Networks (CGANs).
The CGAN uses a conditional setting, which contains two networks: generator and discriminator, as shown in
Figure 2. New data generated by the generator network have the same structure as the real data and correspond to the same label. By the discriminator network, on the other hand, observations are categorized as “real” or “generated.” When presented with batches containing both actual and created labeled data, the discriminator’s goal is to avoid being “fooled” by the generator. The discriminator and generator both rely on additional data, such as class labels or details from different modalities [
26].
Consequently, the detailed explanation of how a CGAN operates is summarized as follows: First, it is necessary to have a sizable collection of genuine data samples that fit the desired criteria. This dataset will act as our CGAN’s “teacher”. The next step is to construct a generator network that outputs a synthetic data sample from an input random noise vector. The instructor dataset’s real data samples are used to train the generator network to reduce the difference between its output and those samples. Then, a discriminator network is constructed to produce a probability score that indicates whether each sample of real and synthetic data is real or fraudulent. The discriminator network is skilled at telling the difference between true samples and false ones. Two loss functions—one for the generator and one for the discriminator—are specified during training. The discriminator loss function promotes the discriminator to accurately distinguish between real and false samples, whereas the generator loss function encourages the generator to create synthetic samples that are comparable to the real data samples. The generator and discriminator networks are optimized with each training cycle. Fixing the discriminator network will allow the model to assess the generator network’s loss. The generator network is then updated to reduce this loss. After the generator network has been fixed, it is used to calculate the discriminator network’s loss. The discriminator network is then updated to maximize this loss. Subsequently, we carry out the generator and discriminator networks’ optimizations once more until they reach a stable conclusion.
3.2. Harris Hawk Optimization (HHO)
A metaheuristic algorithm called the Harris Hawks Optimization (HHO) algorithm is a bio-inspired optimization technique that mimics the behavior of hawks to optimize a problem [
27]. Its purpose was to solve issues with non-linear objectives and many local optima. Utilizing a set of prey items that serve as potential solutions to the problem, the algorithm searches iteratively for better alternatives. Each prey item has a fitness rating assigned to it that describes how it stacks up against other prey items. The algorithm searches for fresh prey items and gradually increases their fitness values by combining exploration and exploitation tactics. The HHO has been successfully applied in various domains such as power systems, control engineering, biomedical applications, and communication systems. In the context of feature selection, the HHO can be used to identify the most relevant features in a dataset. The following is a high-level overview of how the HHO works for feature selection:
Initialize the population: Start by randomly selecting a subset of features from the original dataset. This initial population represents the first generation of hawks.
Evaluate the fitness: Assess the fitness of each individual in the population based on its ability to predict the target variable. In this case, the fitness function would evaluate the accuracy of the model built using the selected features.
Mating Pool: Select the fittest individuals from the current population to form the mating pool. The size of the mating pool determines the number of offspring produced in the next generation.
Crossover and Mutation: Apply crossover and mutation operators to the members of the mating pool to generate new offspring. Crossover involves combining two parent individuals to produce a single offspring, while mutation involves introducing random changes to an individual.
Replacement: Replace the least fit individuals in the current population with the newly generated offspring. This maintains the diversity of the population and prevents the algorithm from getting stuck in the local optimum.
Repeat: Go back to step 2 and repeat the process until a stopping criterion is met, such as reaching a maximum number of generations or achieving a desired level of accuracy.
Selection of final features: Once the algorithm converges, select the top-ranked features from the final population as the optimal set of features for the given dataset.
The key advantage of the HHO is its ability to handle complex, non-linear problems and its robustness against noise and outliers in the data. Additionally, the HHO can be easily parallelized, making it suitable for large datasets. However, the algorithm requires careful parameter tuning for optimal performance.
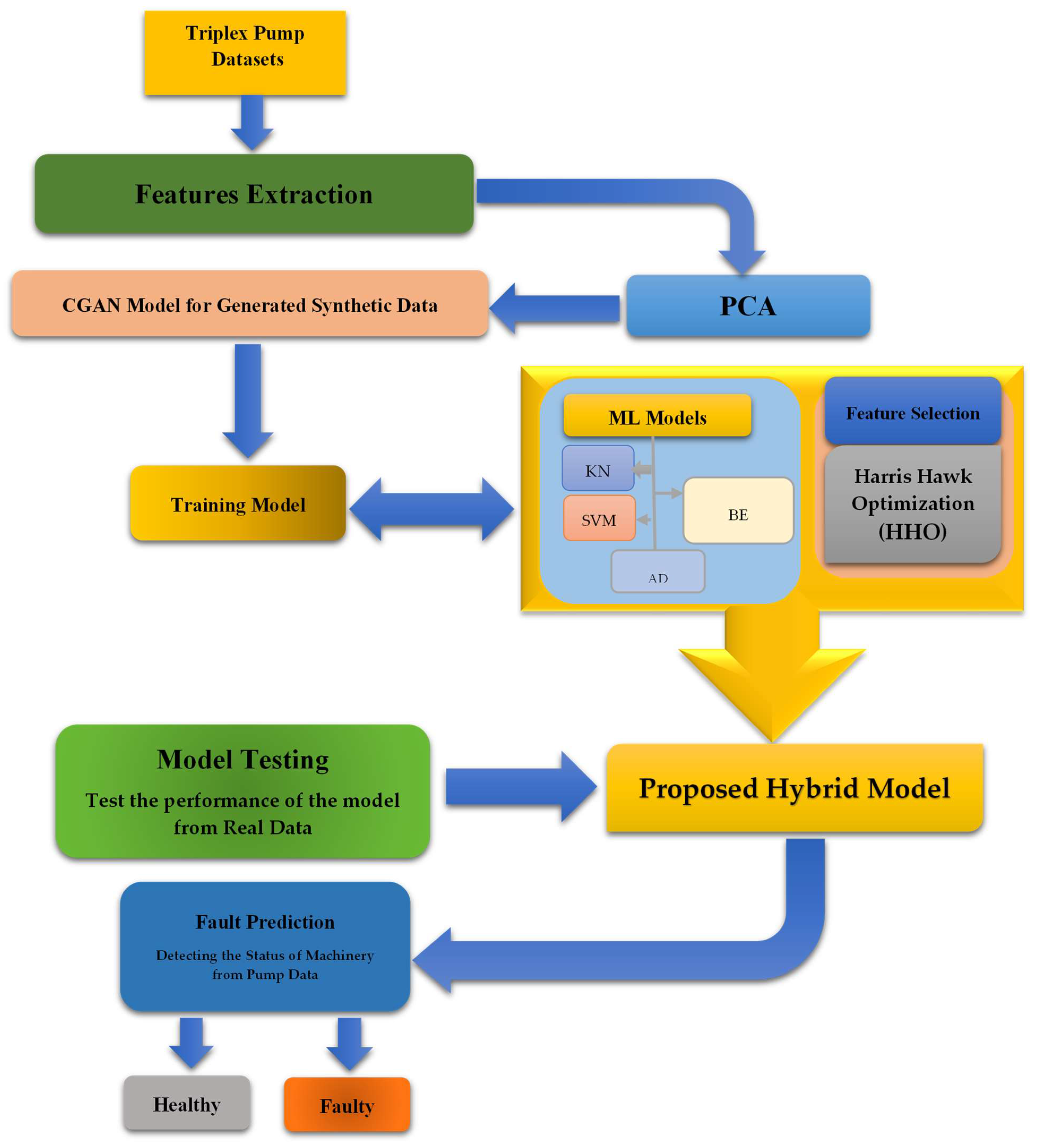
4. Proposed Framework
In this work, we present a powerful scheme for automatically recognizing faults in industrial DT systems. The proposed framework is demonstrated, which consists of a hybrid-optimized ML model through the HHO method with different machine learning methods such as Bagged Ensemble (BE), AdaBoost (AD), Support Vector Machine (SVM), K-Nearest Neighbors (KNNs), Decision Tree (DT), and Naive Bayes (NB) on the CGANS-based generated dataset. Furthermore, the detailed suggested framework comprises five significant steps, as follows, to achieve the diagnostic procedure explained in
Figure 3:
Stage 1: (Gaining and Gathering of Data): in this phase, the data will be gathered from digital twin sources to handle the subsequent steps in the proposed system.
Stage 2: (Generating Synthetic Data): In this stage, the CGAN is utilized to create synthetic data that resemble actual networks’ input. By utilizing labeled data, Conditional GANs (CGANs) can generate synthetic samples that belong to specific, predefined categories.
Stage 3: (Generated Data Validation): In this phase, the principal component analysis (PCA) is applied to assess the properties of both the created and actual signals. PCA enables a complex dataset to be transformed into a set of uncorrelated variables, which are referred to as the principal components. The goal of PCA is to use the numerical structures of the actual data and assign the features of the created data to the same PCA subspace.
Stage 4: (Training/Testing the proposed model): At this point, the data generated in phase one are used to train an effective ML model that diagnoses the fault of the optimized ML methods to organize all the input data generated from the digital twin model. Then, the HHO technique is applied to enhance the performance of the machine learning algorithm. Finally, the data collected in real-time digital twins of machinery data are used to test different machine learning algorithms. Therefore, the performing assessment indices are applied to assess the suggested framework.
Stage 5: (Cloud-based Monitoring System for Fault Classification and Prediction): To monitor machine data from their industrial systems, the supervisor operators in this step use a cloud-based industrial monitoring tool of the proposed framework. To optimize operations, operators can use this system to identify patterns and trends indicative of impending failures, enabling proactive remediation before issues arise.
5. High-Level Proposed Industrial IoT-Based DT Framework
The proposed framework aims to revolutionize the field of machinery fault diagnosis by leveraging cutting-edge technologies such as digital twins, Cyber–-Physical Systems, cloud computing, and Artificial Intelligence. By harnessing these innovations, the suggested framework offers real-time fault diagnosis and monitoring of industrial systems, thereby significantly improving their overall efficiency. The proposed framework comprises three distinct phases that collaboratively work towards achieving the desired outcomes. Each phase has a defined set of tasks and operations that coordinate with the others to deliver a seamless and effective solution.
Figure 4 explains the suggested system with the three phases as follows:
Phase 1: industrial IoT can be used for real-time digital twin generated data gathering, as shown in
Figure 5.
Phase 2: For storing and processing user data, the cloud infrastructure will serve as a centralized repository and data will be transmitted remotely via the Internet. Once received, the data will be sorted and organized, making it readily accessible for comprehensive analysis and thorough assessment.
Phase 3: The industrial supervisor employs a cloud-based monitoring system to track vital signs of their machinery in real-time. This intuitive dashboard provides supervisors with simple access to critical data, allowing them to examine detailed reports generated by the system’s advanced analytics capabilities. Armed with this information, the supervisor can make informed decisions to optimize their equipment’s performance and maintain maximum uptime.
6. Experimental Study
The generated pump dataset and the experimental setup are provided in this section. In conclusion, this section provides an analysis of the findings and a discussion of the suggested framework.
6.1. Experiment Setup
The machine learning classifiers were developed in MATLAB on an AMD Ryzen-5000 series (7) CPU with 8 GB RAM running Windows 11; tests were conducted to assess the suggested framework for problem diagnosis based on a triplex pump dataset.
6.2. Triplex Pump Dataset
To develop an automated fault diagnosis algorithm for the triplex pump, a simulated model of the pump was introduced [
28]. This allowed for the generation of 1575 pump output flow measurements, with 760 healthy signals and 815 faulty signals. The statistical characteristics of these real signals were analyzed using principal component analysis (PCA) to compare them to the created signals from the CGAN. Next, different machine learning models were trained based on the generated signals from the CGAN and tested on the real signals to determine their ability to accurately classify healthy and faulty signals. The trained models were then used to obtain predicted labels for the actual signals. The following steps were taken to train different machine learning models based on the generated signals from CGAN and then predict whether a real signal was healthy or faulty:
Create a training dataset using the generated signals.
Create a test dataset using the real signals.
Train the model using the training dataset.
Obtain the predicted labels for the actual signals using the trained model under the test.
6.3. Assessment Criteria
The proposed framework blends ML with a Conditional GAN to enhance the classification accuracy of fault detection in industrial control systems. We evaluate proposed ML different classifiers using precision, recall, and F-measure as our primary performance metrics. On each classifier, these metrics are computed for both positive (‘P’) and negative (‘N’) categorized documents, as depicted in the confusion matrix presented in
Table 2. This table provides a comprehensive overview of four crucial parameters—true positive (TrueP), true negative (TrueN), false positive (FalseP), and false negative (FalseN)—that are essential in evaluating the performance of a classification model. TP represents the accurate identification of anomalies, whereas TN refers to the incorrect estimation of regular instances. On the other hand, FP signifies the misclassification of regular instances as anomalies, while FN denotes the failure to identify actual anomalies. By carefully considering these parameters, we can gain effective perceptions of the robustness and weaknesses of each classifier and optimize our framework for enhanced reliability and accuracy in fault detection.
Assessment metrics like accuracy, precision, recall, and F1-Score can be processed after finding the parameters in the confusion matrix as follows [
29,
30,
31,
32]:
Accuracy: To ensure the reliability and accuracy of our system, it is imperative to determine certain key parameters that influence the quality of the model. Specifically, we must evaluate the symmetry of the datasets and the balance between false positive and false negative rates, as expressed in Equation (1). A well-balanced dataset with minimal disparity between these rates will enable us to achieve the highest possible F1-Score, thereby validating the efficacy of our proposed approach.
Recall: Recall, as quantified by the ratio of anticipated true positive values to submitted expected true positive values minus predicted false negative values (Equation (3)), serves as a vital metric for evaluating the performance of our proposed approach. A higher recall value indicates a greater likelihood of detecting actual anomalies within the data, thereby underscoring the effectiveness of our methodology.
6.4. Results Analysis
To thoroughly assess the effectiveness of the proposed classification framework, it is crucial to investigate the individual performance of each classifier in distinguishing between normal and problematic states in machinery pump data. The CGAN generates the synthetic data for the triplex pump to be utilized as the training set for our model to judge the validity and accuracy of the proposed framework. The CGAN model used in the proposed model is depicted in
Figure 6. Then, we test different ML models including Bagged Ensemble, Support Vector Machine (SVM), K-Nearest Neighbors (KNNs), AdaBoost, Decision Tree (DT), and Naïve Bias (NB) models using the real data gained from the actual system.
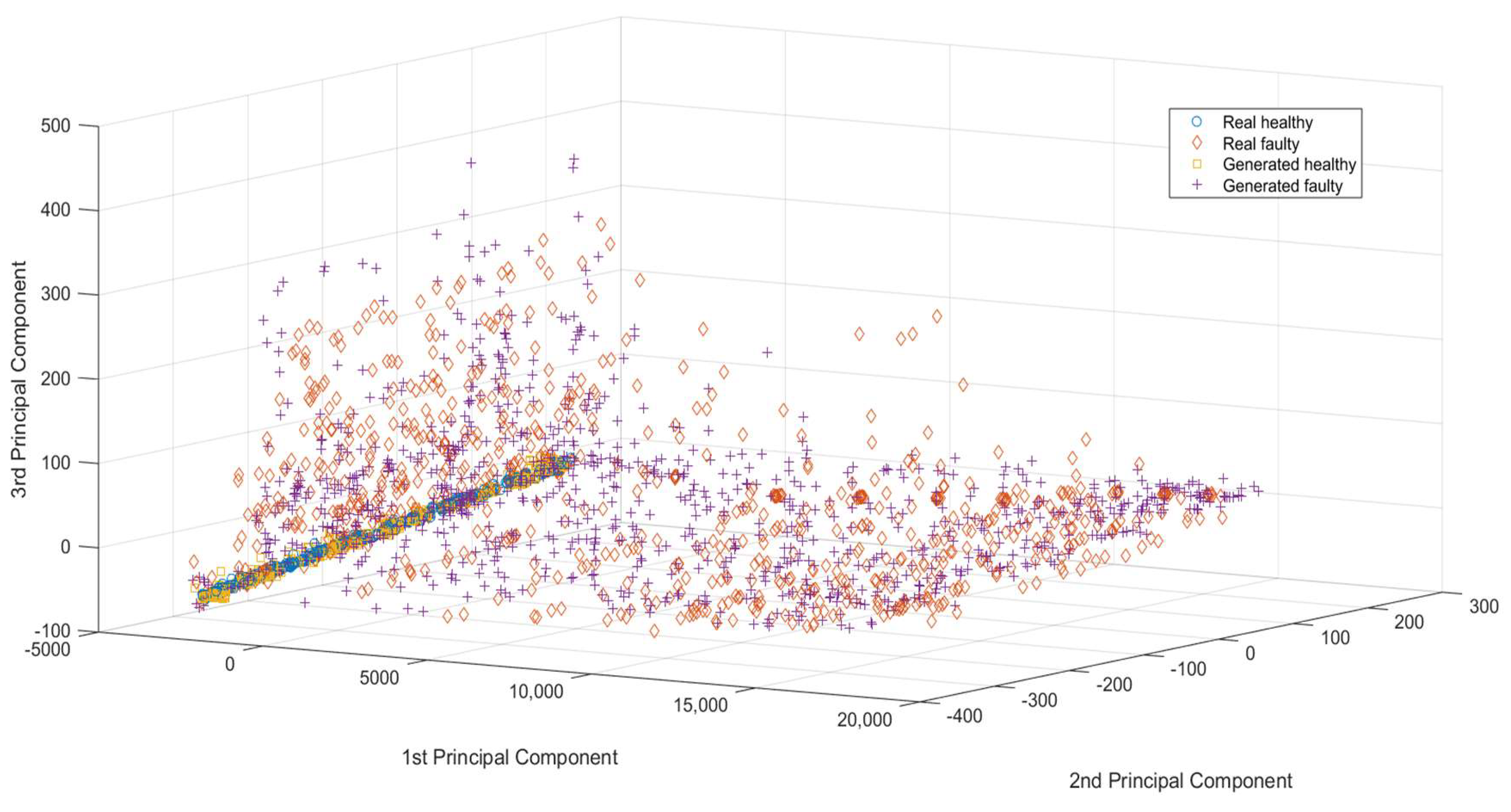
Therefore, the data generated from CGAN are used to train the different algorithms, and then the real data are used to examine the performance of the proposed algorithm. The advantage of this technique is that there is no need for splitting the actual data and one can test the proposed algorithm on whole actual data. We can grasp its capabilities due to this approach. From
Figure 7, the distribution of the generated signals is like the distribution of the real signals. Both faulty and healthy signals, whether generated or real, lie in the same region of the PCA subspace, indicating that the properties of the generated signals are equivalent to those of the real signals.
Table 3 shows a comparison of the results and these are also depicted in
Figure 8.
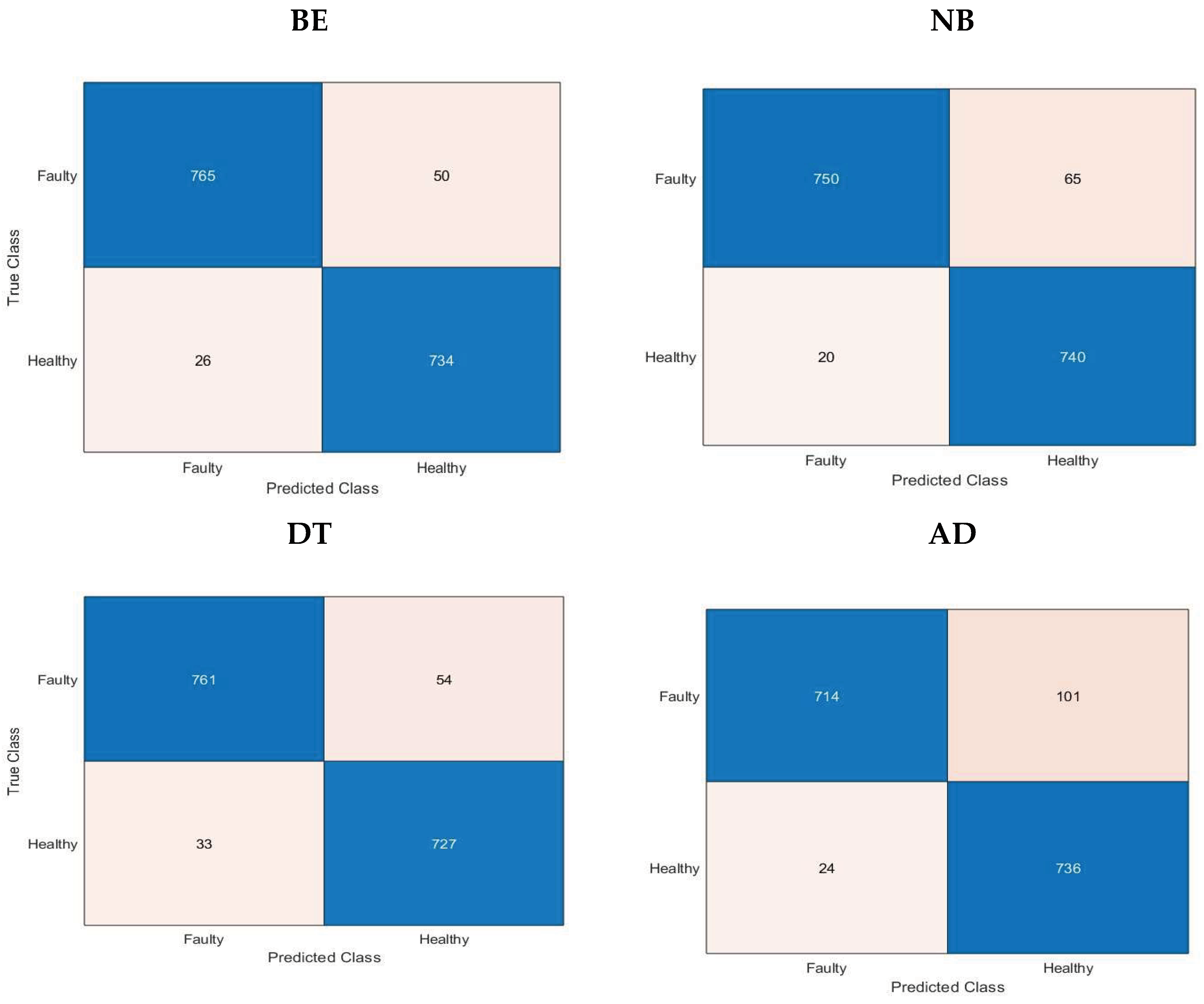
Figure 9 shows a confusion matrix for different ML methods and
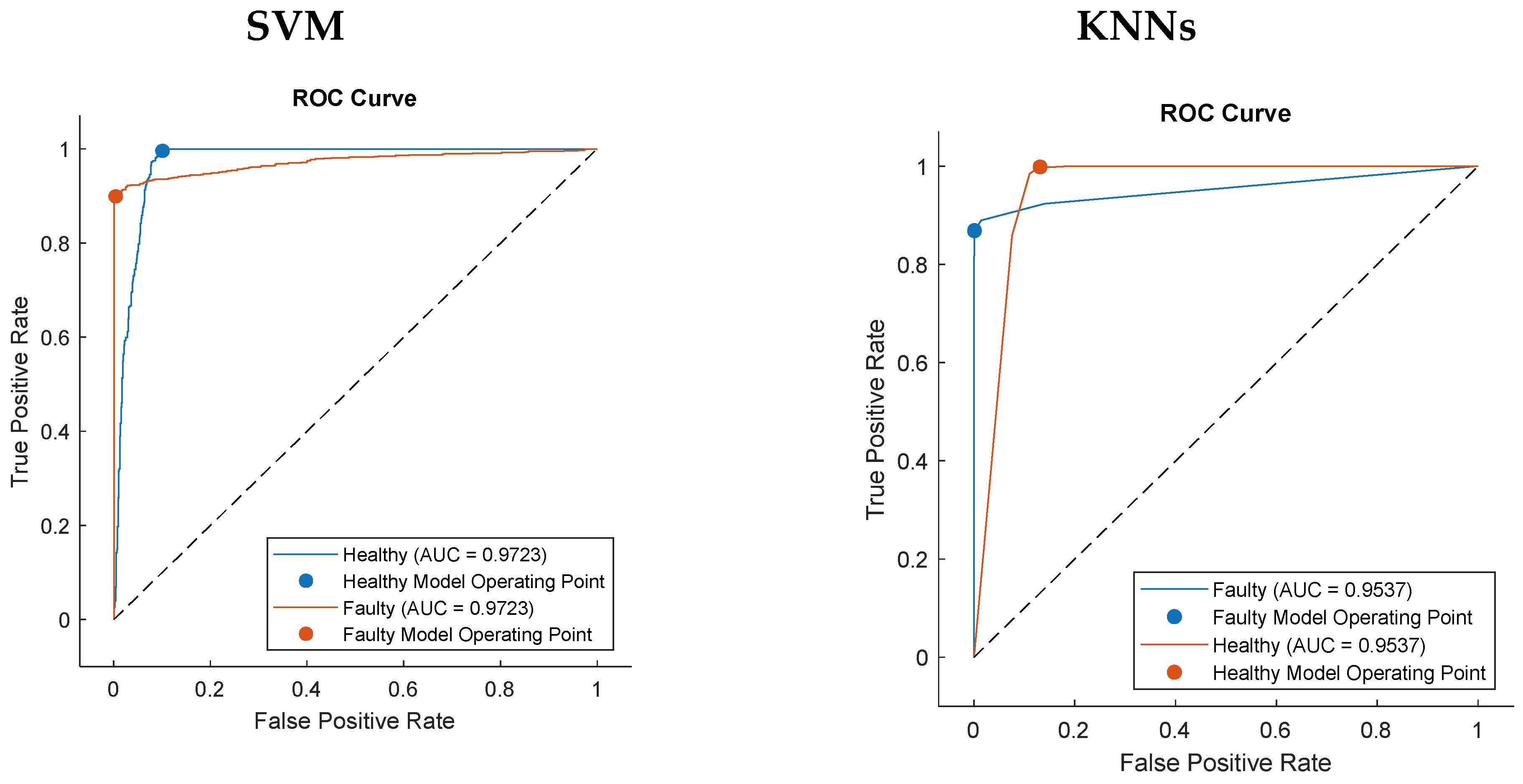
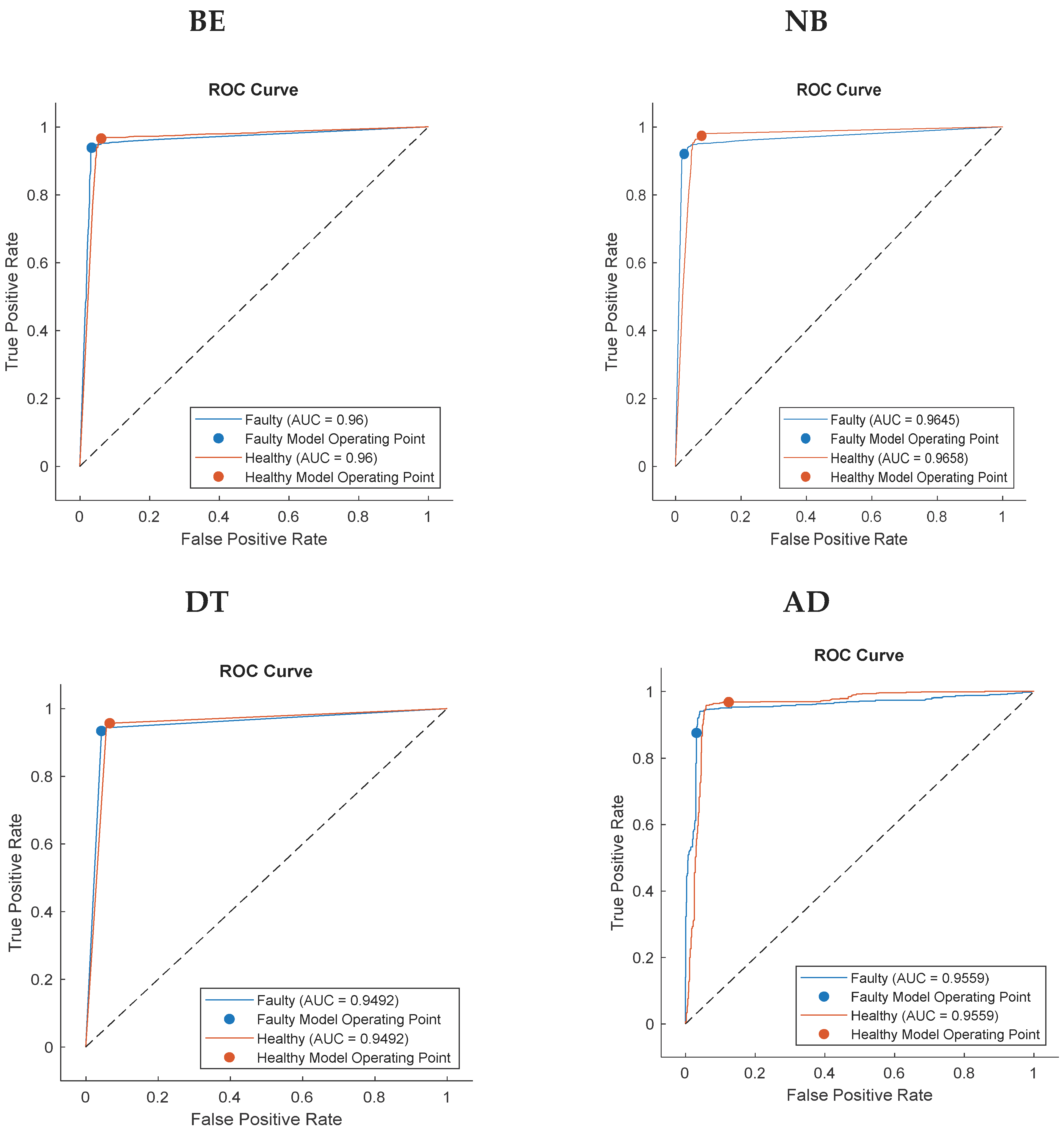
Figure 10 displays the confusion ROC curve for all algorithms in the ML framework.
For the mentioned ML models, the resulting confusion matrices are indicated in
Figure 8 and
Figure 9 for the triplex model. Likewise, the ROC curves of the proposed system are illustrated in
Figure 10. The Harris Hawk Optimization (HHO) is applied to machine learning algorithms to enhance the performance and boost the accuracy of the system. The HHO is performed in a highly competitive manner in terms of the caliber of its exploration and exploitation. The optimization algorithm is used for feature selection. The results in
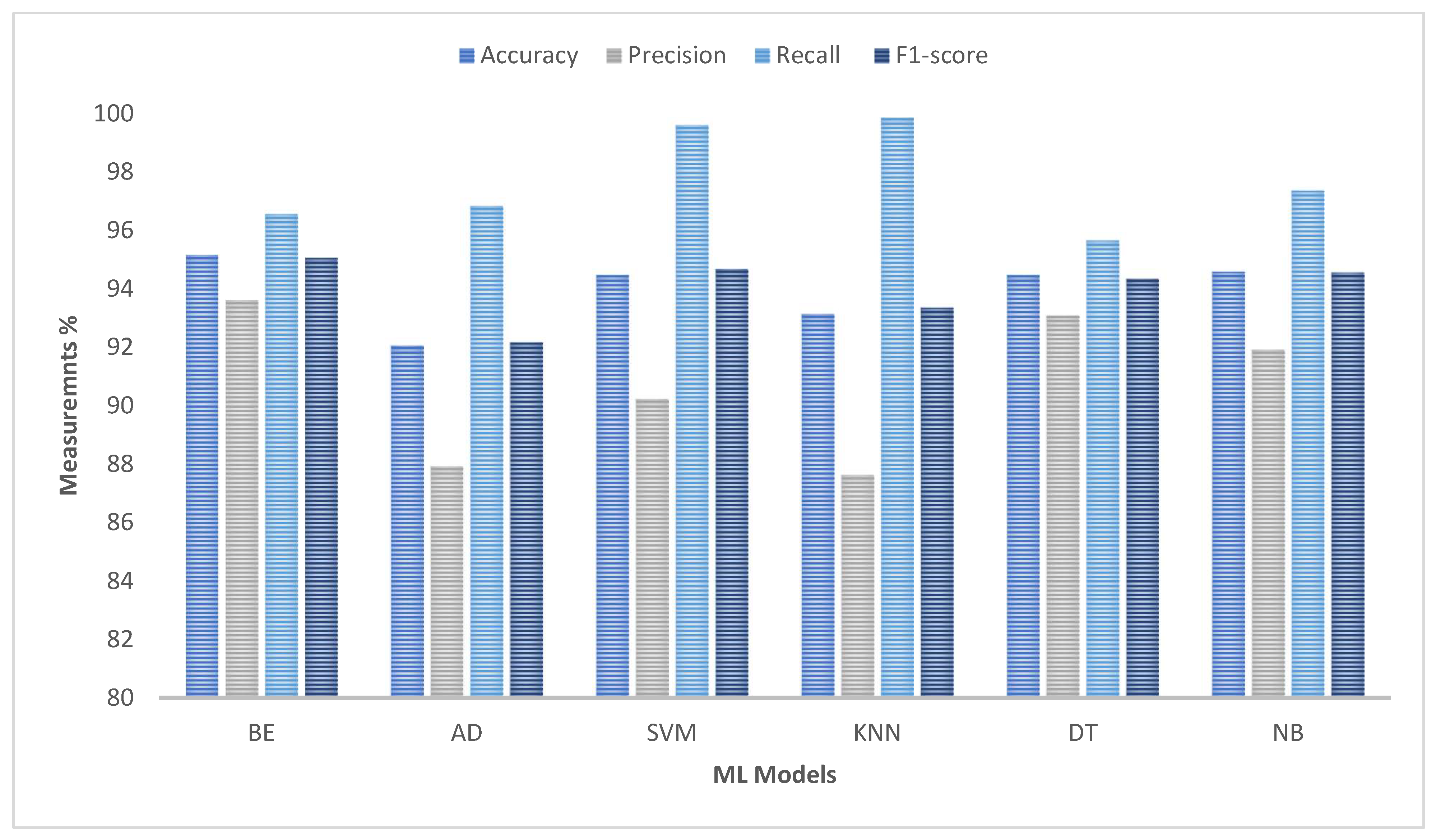
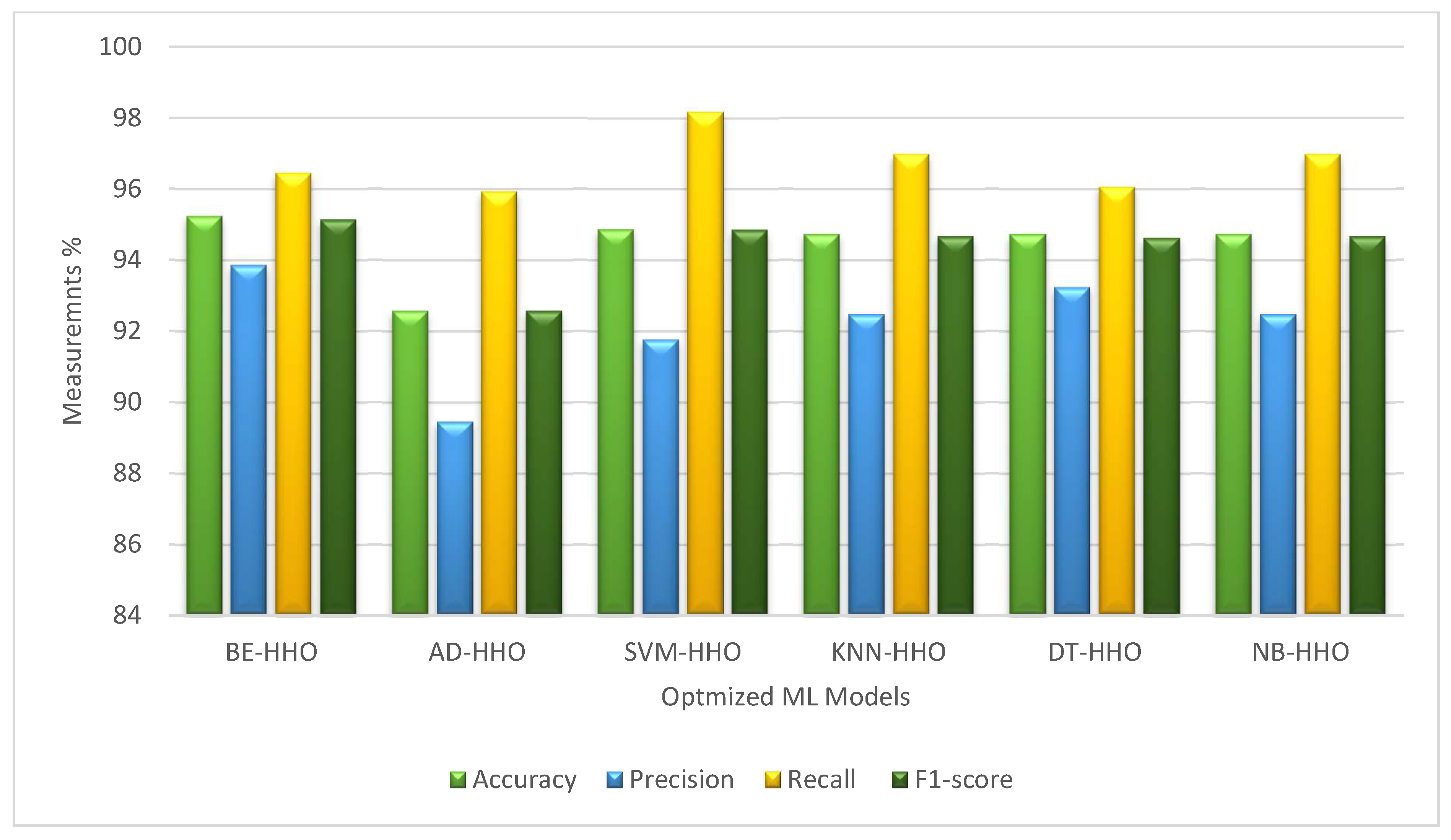
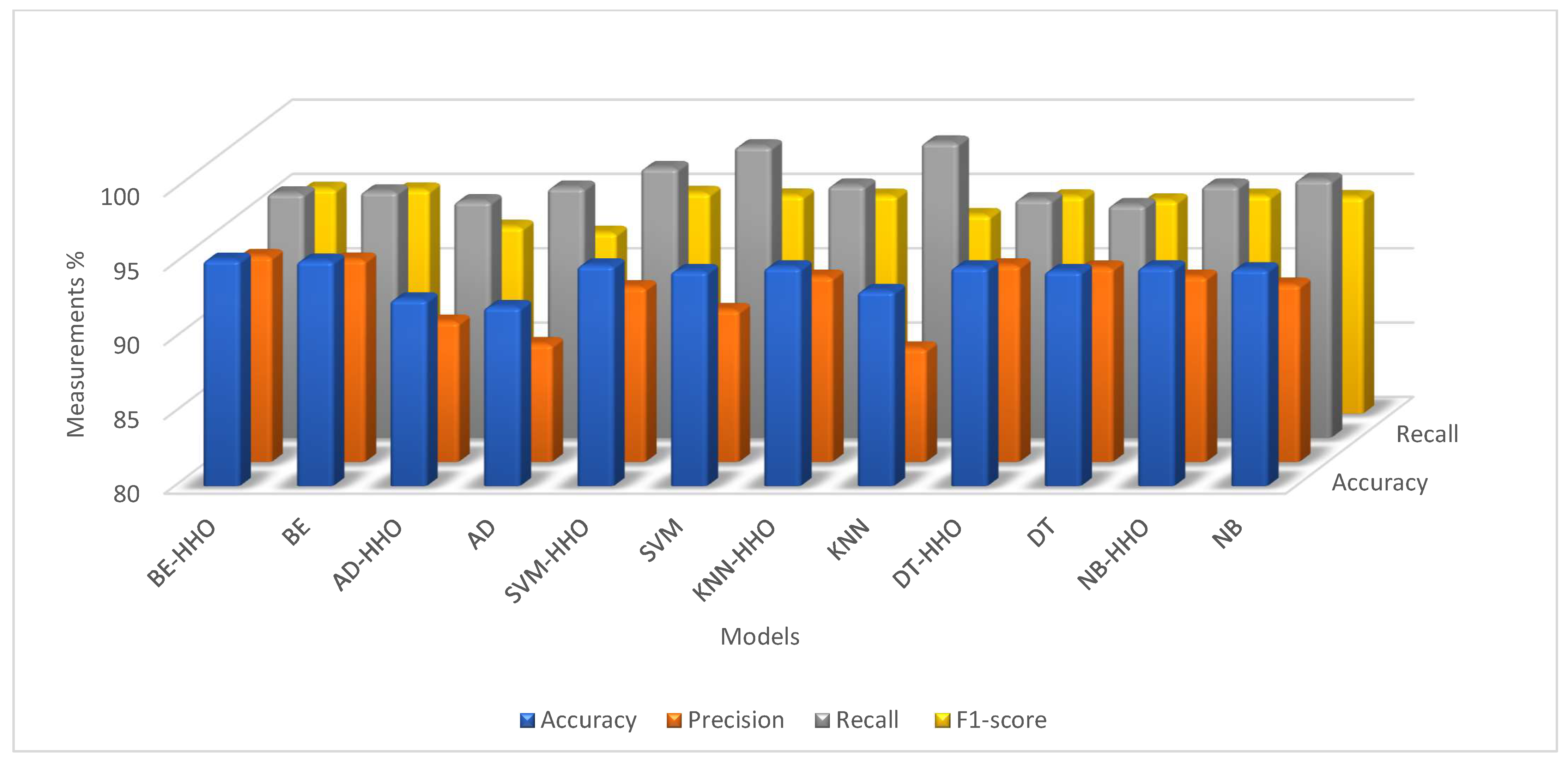
Figure 11 show that the HHO reserves and enhances the performance of all the models.
Figure 11 and
Table 4 show the performance of various machine learning (ML) algorithms in their optimized and classical forms across four metrics: accuracy, precision, recall, and F1-Score. The optimized versions are indicated with the suffix “-HHO” and consistently outperform or closely match their classical counterparts.
The BE-HHO shows slightly higher performance than BE, with an accuracy of 95.24% compared to 95.17%, and similarly high precision, recall, and F1-Scores. AD-HHO and AD have a notable difference in accuracy, with AD-HHO at 92.57% and AD at 92.06%, though AD achieves higher recall. The SVM-HHO variant exhibits an accuracy of 94.86%, slightly higher than the classical SVM at 94.48%, with both showing high recall values. KNN-HHO surpasses KNNs in accuracy (94.73% vs. 93.14%) and demonstrates improved precision and recall. DT-HHO and DT both have an accuracy of 94.73%, but DT-HHO has marginally better precision and recall. NB-HHO and NB are almost equivalent, with NB-HHO having a slightly higher accuracy of 94.73% compared to 94.6%. Overall, the optimized algorithms demonstrate marginal but consistent improvements over their classical versions in most metrics, as clarified in
Figure 12.
From the results above, it is evident that different models have their own strengths, with the best-performing ones being evaluated based on key metrics such as accuracy, precision, recall, and F1-Score. These metrics provide a more general view of model performance, beyond just accuracy. The BE-HHO model leads with the highest accuracy at 95.24%, followed closely by the BE model at 95.17%. Next, the SVM-HHO model has an accuracy of 94.86%, slightly outperforming the classical SVM at 94.48%. KNN-HHO and DT-HHO both have an accuracy of 94.73%, with KNN-HHO marginally outperforming classical KNNs (93.14%) and DT-HHO closely matching classical DT (94.48%). The NB-HHO model also has an accuracy of 94.73%, slightly higher than the classical NB at 94.6%. AD-HHO and AD have the lowest accuracies at 92.57% and 92.06%, respectively, but AD achieves the highest recall among all models. Therefore, the ranking of models based on their performance is as follows: BE-HHO, BE, SVM-HHO, DT-HHO, KNN-HHO, NB-HHO, SVM, DT, NB, KNN, AD-HHO, and AD. Small improvements in recall, accuracy, or precision can have a significant impact on predictive maintenance, fault detection quality, and system reliability in industrial applications.. Any improvement, no matter how little, helps to increase operational efficiency, lower risk, and improve decision-making in real-world systems where faulty or inaccurate diagnostics can cause expensive disruptions. So, the total cost of maintenance will be reduced.
Table 5 provides a comparative analysis of different optimization strategies that can be used to improve the accuracy of the Support Vector Machine (SVM) algorithm based on accuracy, precision, recall, and F1-Score. Among the different methods evaluated, the Harris Hawk Optimization (HHO) method emerges as the leader with a remarkable accuracy of 94.86%, a precision of 91.76%, and an F1-Score of 94.85 for this task, clearly demonstrating its ability in the detection of faults. Considering the results of all covered methods, the HHO appears to be the most successful optimization approach for enhancing ML-based fault detection.
7. Limitation
While the research shows good prospects with using the HHO with CGANs in digital twins for fault detection, some limitations have to be addressed to improve the robustness and scalability of the proposed approach:
Computation complexity and cost: The use of the HHO along with CGANs would increase the computational complexity and cost. Both methods would involve heavy computational loads—both the optimization for the HHO and CGANs, like any other generative model, tend to require power-intensive calculations because of the need to fit an auxiliary conditional variable in between, creating generator and discriminator networks. When these two are put together, the computational burden could increase even more, thus inhibiting real-time applications of digital twins in fast fault detection processes.
Overfitting and biases in fault: As in the case of every other machine learning model, there might be tendency of overfitting with the CGAN model, especially if it is trained on small or unbalanced datasets. When the training data do not cover enough fault types or some operating regimes, the learning algorithm may ‘overfit’ and learn to always favor certain types of failures/diminish the importance of failures that are less treated or are deemed rare. Such risk is more pronounced in large-scale complex industrial systems where there are tendencies of faults happening frequently and the amount of training data is small. Although the HHO is useful for the purpose of finding the optimal parameter values, it is not a solution to the problem of limited data.
Parameter sensitivity of HHO: In the absence of the self tuning nature of the HHO and other metaheuristic algorithms, initialization parameter values in those cases tend to impact the success of the HHO. With a small change in some parameters such as the population size or even the number of iterations, the performance experienced may be totally different. Such sensitivity probably causes the results obtained in different scenarios of fault detection tasks to be quite different, most probably when real-time data processing is involved, in particular in manufacturing systems.
Data quality and representation: The effectiveness of Generative Artificial Intelligence such as the CGAN heavily relies on the quality of the data used for training. Inaccurate, incomplete, or biased datasets can lead to poor fault detection performance, particularly when digital twins are expected to simulate real-world operational conditions.
These constraints can also be addressed and further researched to enhance the integration of the HHO with Generative Artificial Intelligence in digital twins for enhanced fault detection, making it more effective, efficient, and applicable to more industries.
8. Conclusions and Future Scope
In recent years, fault detection has emerged as a pivotal component within industrial DT systems, crucial for ensuring operational reliability and efficiency. This process involves identifying deviations from expected behavior or performance in physical assets mirrored by their digital representations. Furthermore, fault detection facilitates the implementation of predictive maintenance strategies, enabling targeted repairs and the optimization of asset performance in the industrial DT. This study proposes an efficient fault detection framework leveraging conditional Generative Adversarial Networks (GANs) and metaheuristic machine learning for fault detection. The experimental results demonstrate that hybrid-optimized ML algorithms, denoted as “ML-HHO”, consistently outperform or closely match their classical counterparts across various performance metrics. Particularly, BE-HHO achieves the highest accuracy at 95.24%, slightly surpassing BE’s 95.17%. Similarly, SVM-HHO achieves an accuracy of 94.86%, marginally exceeding SVM’s 94.48%. KNN-HHO exhibits superior performance with 94.73% accuracy compared to KNN’s 93.14%. DT-HHO and DT both achieve 94.73% accuracy, with DT-HHO showing slightly better precision and recall. NB-HHO and NB demonstrate comparable performance, with NB-HHO achieving 94.73% accuracy against NB’s 94.6%. Despite lower accuracies, AD-HHO and AD achieve higher recall rates at 92.57% and 92.06%, respectively. Overall, the optimized algorithms consistently deliver marginal enhancements over their classical counterparts. With respect to synthetic data generation, the framework employs CGANs and feature selection is carried out using the HHO, which makes the framework a powerful and adaptable architecture for continuous monitoring and diagnosis. As a result, operational efficiency is enhanced, downtime is reduced, and enhanced system uptime is observed. In addition, the ability of this approach to fit various industrial applications indicates greater prospects for enhancing predictive maintenance and improvement strategies in several applications over time.
Future research could explore the integration of other machine learning methods for anomaly detection techniques such as Autoencoders, Deep Belief Networks, deep reinforcement learning, or Recurrent Neural Networks and incorporate them into real-time data streams for continuous monitoring and adaptive fault detection in dynamic industrial DT systems. Expanding the framework beyond pumps opens up exciting avenues for research in a range of industries that rely on dynamic equipment such as turbines, compressors, and other industrial processes. Furthermore, efforts could be directed toward improving CGANs’ performances by fine-tuning the hyperparameters, such as learning rates, batch sizes, and the architecture of the generator and discriminator.
Author Contributions
Conceptualization and methodology, A.S. and E.E.-D.H.; software, validation and formal analysis A.S.; investigation, E.E.-D.H.; writing—original draft preparation A.S., writing—review and editing, S.A., E.E.-D.H. and A.S.; project administration and funding acquisition, S.A. All authors have read and agreed to the published version of the manuscript.
Funding
this project is funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R197), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Acknowledgments
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R197), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
References
- Bin, B.; Jian, K. Digital twin-based sustainable intelligent manufacturing: A review. Adv. Manuf. 2021, 9, 1–21. [Google Scholar]
- Liu, Y.; Zhang, L.; Yuan, Y.; Zhou, L.; Ren, L.; Wang, F.; Liu, R.; Pang, Z.; Jamal Deen, M. A novel cloud- based framework for elderly healthcare Services using a digital twin. IEEE Access 2019, 7, 49088–49101. [Google Scholar] [CrossRef]
- Caputo, F.; Greco, A.; Fera, M.; Macchiaroli, R. Digital twins to enhance the integration of ergonomics in workplace design. Int. J. Ind. Ergon. 2019, 71, 20–31. [Google Scholar] [CrossRef]
- Zayed, S.M.; Attiya, G.; El-Sayed, A.; Sayed, A.; Hemdan, E.E.-D. An Efficient Fault Diagnosis Framework for Digital Twins Using Optimized Machine Learning Models in Smart Industrial Control Systems. Int. J. Comput. Intell. Syst. 2023, 16, 69. [Google Scholar] [CrossRef]
- Hemdan, E.E.-D.; El-Shafai, W.; Sayed, A. Integrating Digital Twins with IoT-Based Blockchain: Concept, Architecture, Challenges, and Future Scope. Wirel. Pers. Commun. 2023, 131, 2193–2216. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, A.N.; Borup, M.; Brink-Kjær, A.; Christiansen, L.E.; Mikkelsen, P.S. Living and prototyping digital twins for urban water systems: Towards multi-purpose value creation using models and sensors. Water 2021, 13, 592. [Google Scholar] [CrossRef]
- Pylianidis, C.; Osinga, S.; Athanasiadis, I.N. Introducing digital twins to agriculture. Comput. Electron. Agric. 2021, 184, 105942. [Google Scholar] [CrossRef]
- Verdouw, C.; Tekinerdogan, B.; Beulens, A.; Wolfert, S. Digital twins in smart farming. Agric. Syst. 2021, 189, 103046. [Google Scholar] [CrossRef]
- Neethirajan, S.; Kemp, B. Digital Twins in Livestock Farming. Animals 2021, 4, 1008. [Google Scholar] [CrossRef]
- Nativi, S.; Mazzetti, P.; Craglia, M. Digital ecosystems for developing digital twins of the earth: The destination earth case. Remote Sens. 2021, 13, 2119. [Google Scholar] [CrossRef]
- Guo, H.; Nativi, S.; Liang, D.; Craglia, M.; Wang, L.; Schade, S.; Corban, C.; He, G.; Pesaresi, M.; Li, J.; et al. Big Earth Data science: An information framework for a sustainable planet. Int. J. Digit. Earth 2020, 13, 743–767. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Xu, Y.; Zheng, Y.; Peng, X.; Jiang, W. Unsupervised fault diagnosis of rolling bearings using a deep neural network based on generative adversarial networks. Neurocomputing 2018, 315, 412–424. [Google Scholar] [CrossRef]
- Sabuhi, M.; Zhou, M.; Bezemer, C.-P.; Musilek, P. Applications of generative adversarial networks in anomaly detection: A systematic literature review. IEEE Access 2021, 9, 161003–161029. [Google Scholar] [CrossRef]
- Lian, Y.; Geng, Y.; Tian, T. Anomaly Detection Method for Multivariate Time Series Data of Oil and Gas Stations Based on Digital Twin and MTAD-GAN. Appl. Sci. 2023, 13, 1891. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, H.; Wang, J.; Yuan, S.; Feng, W. LSTM-GAN-AE: A promising approach for fault diagnosis in machine health monitoring. IEEE Trans. Instrum. Meas. 2021, 71, 1–13. [Google Scholar] [CrossRef]
- Li, W.; Li, H.; Gu, S.; Chen, T. Process fault diagnosis with model-and knowledge-based approaches: Advances and opportunities. Control Eng. Pract. 2020, 105, 104637. [Google Scholar] [CrossRef]
- Syed, M.M.; Lemma, T.A.; Vandrangi, S.K.; Ofei, T.N. Recent developments in model-based fault detection and diagnostics of gas pipelines under transient conditions. J. Nat. Gas Sci. Eng. 2020, 83, 103550. [Google Scholar] [CrossRef]
- Costamagna, P.; De Giorgi, A.; Magistri, L.; Moser, G.; Pellaco, L.; Trucco, A. A classification approach for model-based fault diagnosis in power generation systems based on solid oxide fuel cells. IEEE Trans. Energy Convers. 2015, 31, 676–687. [Google Scholar] [CrossRef]
- Grieves, M. Digital Twin: Manufacturing Excellence Through Virtual Factory Replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Rasheed, A.; San, O.; Kvamsdal, T. Digital Twin: Values, Challenges and Enablers from a Modeling Perspective. IEEE Access 2020, 8, 21980–22012. [Google Scholar] [CrossRef]
- Jones, D.; Snider, C.; Nassehi, A.; Yon, J.; Hicks, B. Characterising the Digital Twin: A Systematic Literature Review. CIRP J. Manuf. Sci. Technol. 2020, 29, 36–52. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Jia, F.; Cheng, X. Digital twin-supported smart city: Status, challenges and future research directions. Expert Syst. Appl. 2023, 217, 119531. [Google Scholar] [CrossRef]
- Alshathri, S.; Hemdan, E.E.-D.; El-Shafai, W.; Sayed, A. Digital twin-based automated fault diagnosis in industrial IoT applications. Comput. Mater. Contin. 2023, 75, 183–196. [Google Scholar] [CrossRef]
- Rachmawati, S.M.; Putra, M.A.P.; Lee, J.M.; Kim, D.S. Digital twin-enabled 3D printer fault detection for smart additive manufacturing. Eng. Appl. Artif. Intell. 2023, 124, 106430. [Google Scholar] [CrossRef]
- Kuru, K. MetaOmniCity: Towards immersive urban metaverse cyberspaces using smart city digital twins. IEEE Access 2023, 11, 43844–43868. [Google Scholar] [CrossRef]
- Mirza, M.; Simon, O. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Multi-Class Fault Detection Using Simulated Data. Available online: https://ssd.mathworks.com/supportfiles/SPT/data/PumpSignalGAN.zip (accessed on 14 August 2024).
- El-Naby, A.A.; Hemdan, E.E.-D.; El-Sayed, A. An efficient fraud detection framework with credit card imbalanced data in financial services. Multimed. Tools Appl. 2023, 82, 4139–4160. [Google Scholar] [CrossRef]
- Rezk, N.G.; Attia, A.-F.; El-Rashidy, M.A.; El-Sayed, A.; Hemdan, E.E.-D. An Efficient Plant Disease Recognition System Using Hybrid Convolutional Neural Networks (CNNs) and Conditional Random Fields (CRFs) for Smart IoT Applications in Agriculture. Int. J. Comput. Intell. Syst. 2022, 15, 65. [Google Scholar] [CrossRef]
- Sharaf, M.; Hemdan, E.E.; El-Sayed, A.; El-Bahnasawy, N.A. An efficient hybrid stock trend prediction system during COVID-19 pandemic based on stacked-LSTM and news sentiment analysis. Multimed. Tools Appl. 2023, 82, 23945–23977. [Google Scholar] [CrossRef]
- Abd El Naby, A.; Hemdan, E.E.D.; El-Sayed, A. Deep learning approach for credit card fraud detection. In Proceedings of the 2021 International Conference on Electronic Engineering (ICEEM), Menouf, Egypt, 3–4 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}