

Multi-Step Prediction of Wind Power Based on Hybrid Model with Improved Variational Mode Decomposition and Sequence-to-Sequence Network

Abstract
1. Introduction
- In order to solve the problem of VMD parameter setting, the average envelope entropy is introduced as an evaluation index, and the squirrel search algorithm is used to automatically find the optimal decomposition parameters of VMD to improve the decomposition effect. The original wind power sequence is preprocessed through SSA-VMD to enhance predictability.
- A novel Seq2Seq model is proposed to be applied to the multi-step power prediction. The encoder encodes the hidden representation of the wind power time series data into context vectors, and the decoder progressively decodes the output prediction sequence. Through this end-to-end process, we can better learn the implicit correlation features of multidimensional time series data and achieve effective prediction of wind power power fluctuation trends in future time periods.
- Different from the traditional use of recurrent neural networks as the encoder and decoder of Seq2Seq, CNN-BiGRU is used as the encoder to extract the coupling information and timing information between the input data for encoding; the other GRU is used as the decoder to output predictions. The deep correlation information between the different features and the dependence between the time series data are fully explored.
- Finally, the effectiveness and robustness of the proposed model are proved by testing with the measured data set. The experimental results show that our model has the best prediction performance compared with the baseline method.
2. SSA-VMD Algorithm
2.1. Variational Modal Decomposition
2.1.1. Variational Problem Construction
2.1.2. Variational Problem Solving
2.2. Decomposition Performance Evaluation Criteria
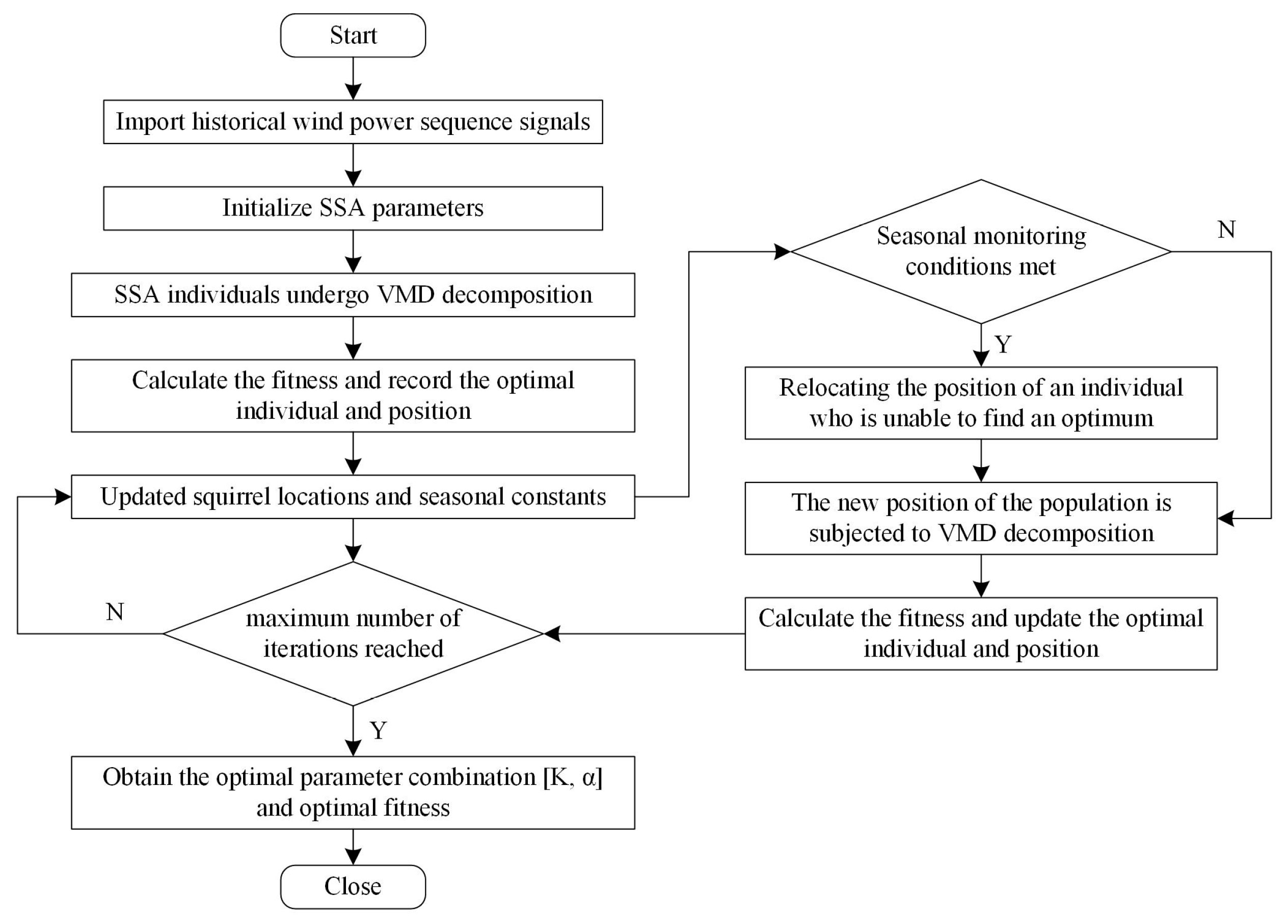
2.3. Squirrel Search Algorithm Optimized Variational Modal Decomposition
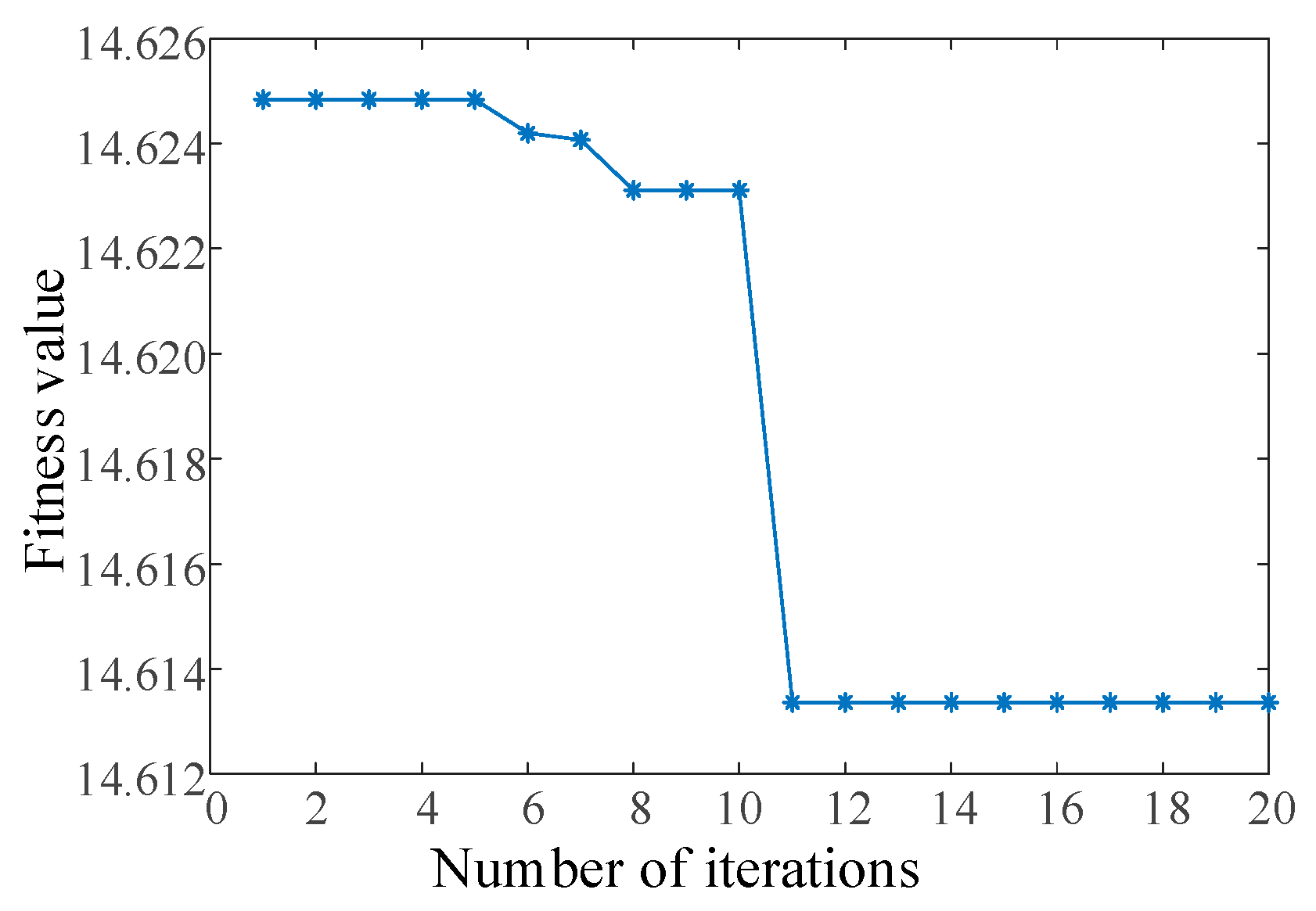
- Set the algorithm parameters and initialize the population position. The optimization dimension is 2, K and are used as squirrel locations, and the two optimization search ranges are set to [3, 15] and [800, 2500], respectively. The population size is set to 20 and the maximum number of iterations is set to 20.
- Perform a VMD decomposition of the power sequence based on the location of each squirrel. Calculate the fitness of each individual and rank them. Assign the individual squirrels to the hickory tree (optimal food source), the oak tree (normal food source), and the common tree (no food source) in order to save the optimal individual squirrel positions.
- Update the individual squirrel locations. Three situations will occur based on the dynamic foraging behavior of squirrels: Situation 1, squirrels with normal food sources move to the optimal food source; Situation 2, squirrels with no food sources move to normal food sources; Situation 3, squirrels with no food sources move toward optimal food sources.
- Update the seasonal detection value, and when the seasonal detection value is less than the minimum seasonal constant, then randomly adjust the location of squirrels without a food source to re-forage.
- Calculate and rank the fitness of the new population and update the global optimal solution and the best fitness.
- Judge whether the maximum number of iterations is reached; if the judgement is no, repeat steps 3 to 5 until the maximum number of iterations is reached to end the optimization process. The location of squirrels on the optimal food source is the final optimal solution.
3. Principles of Predictive Modeling
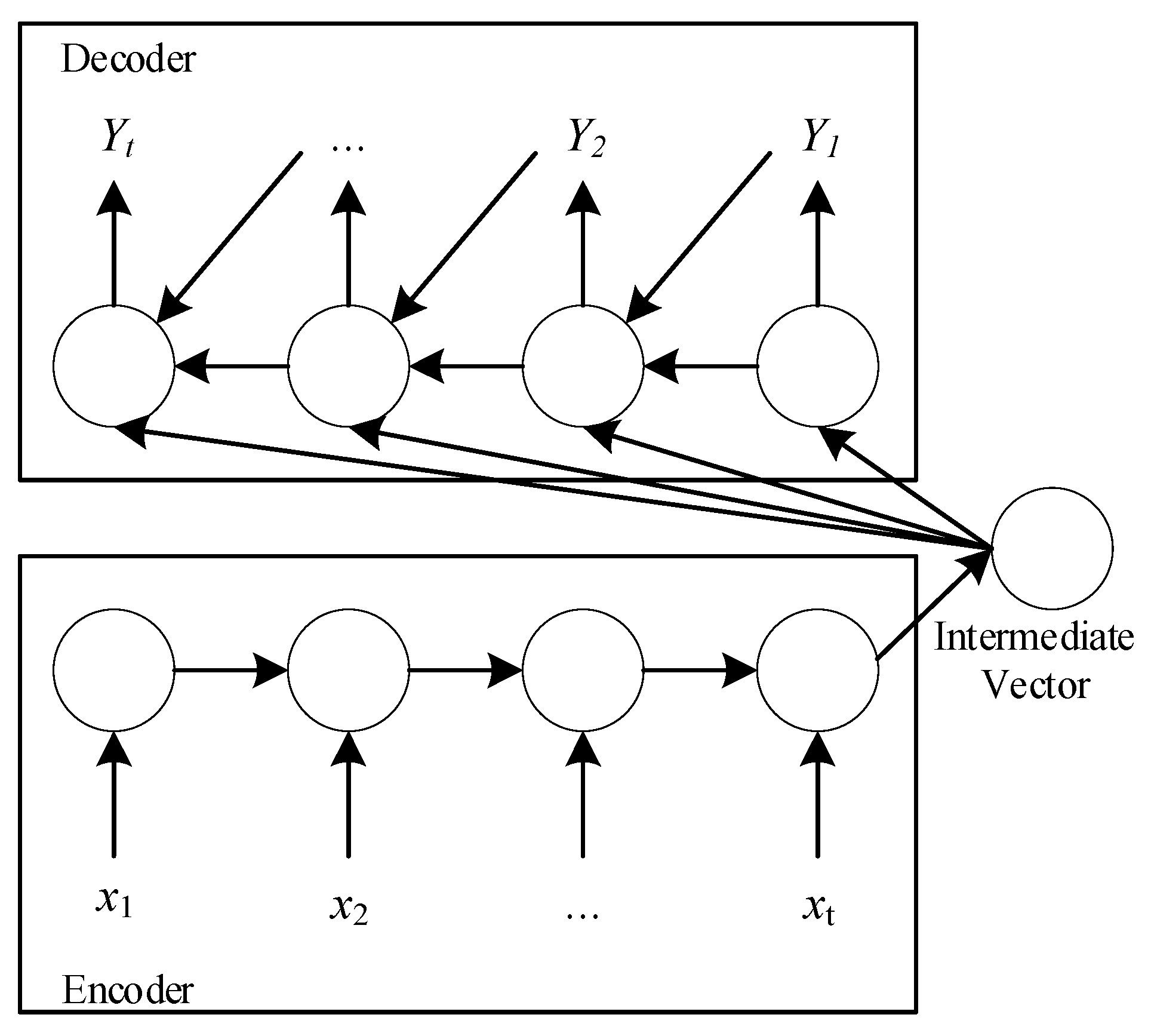
3.1. Sequence-to-Sequence Fundamentals
3.2. Convolutional Neural Network
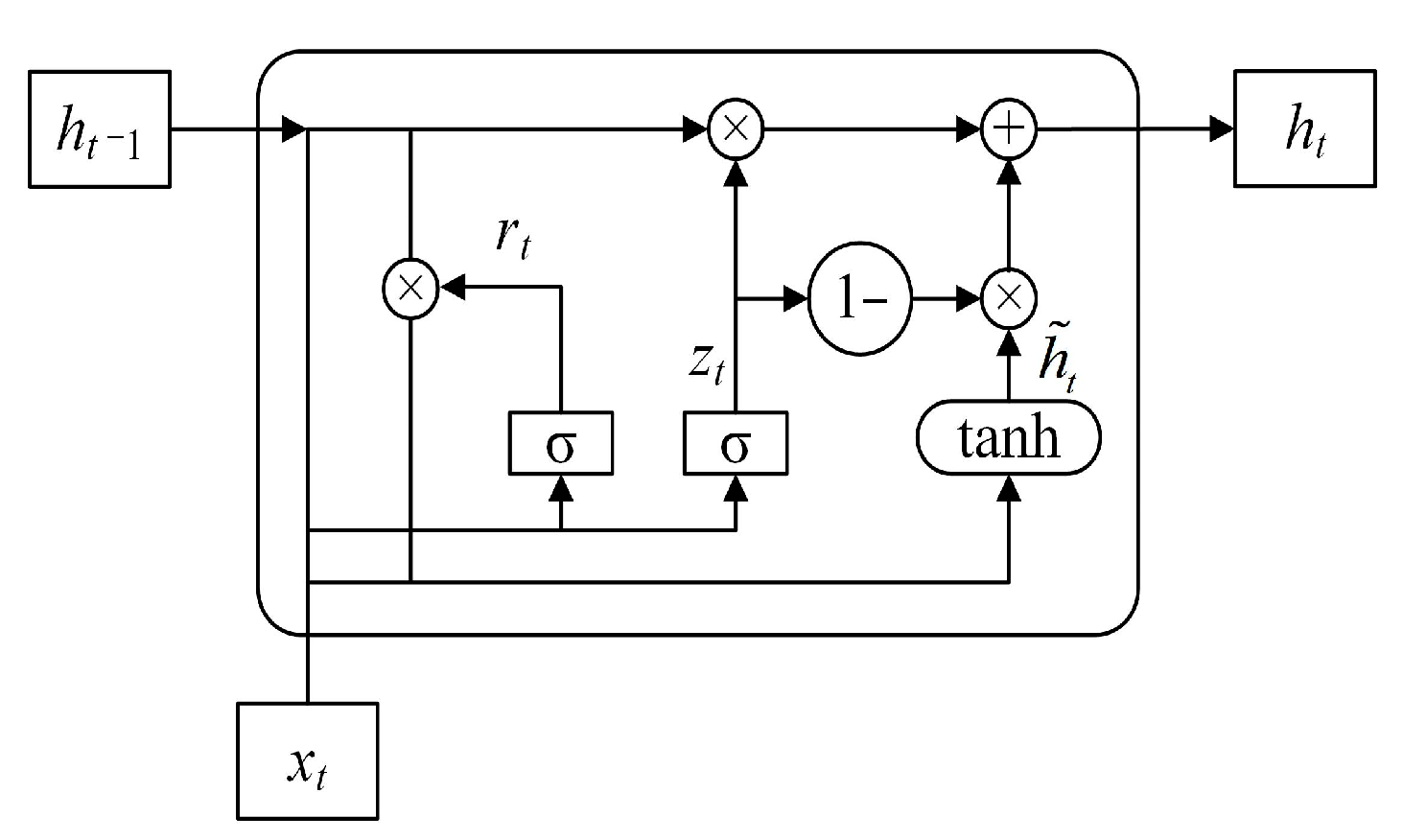
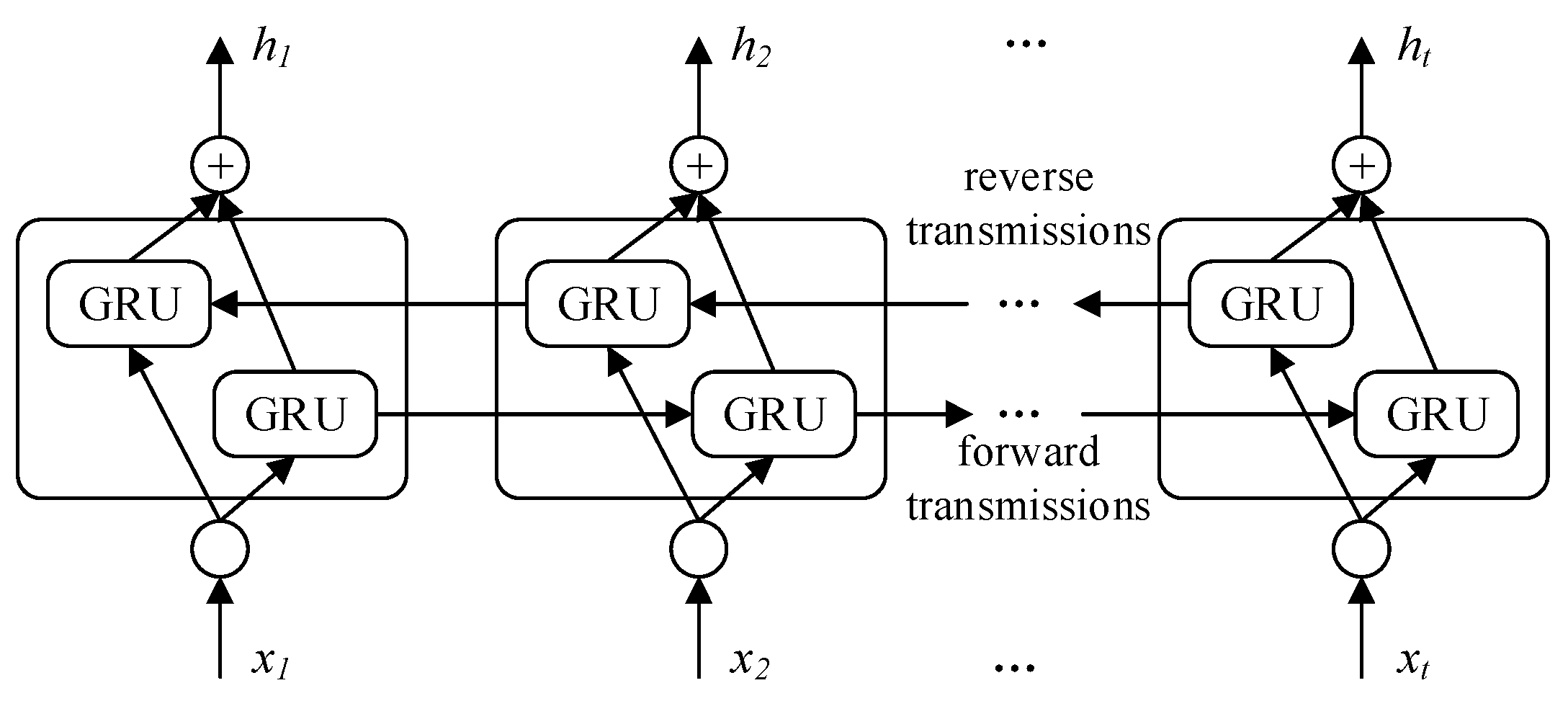
3.3. Bidirectional Gated Recurrent Unit
4. SSA-VMD-Seq2Seq Prediction Model
4.1. Constructing Input Features
4.2. Encoding
4.3. Decoding
5. Case Study
5.1. Description of the Experiment
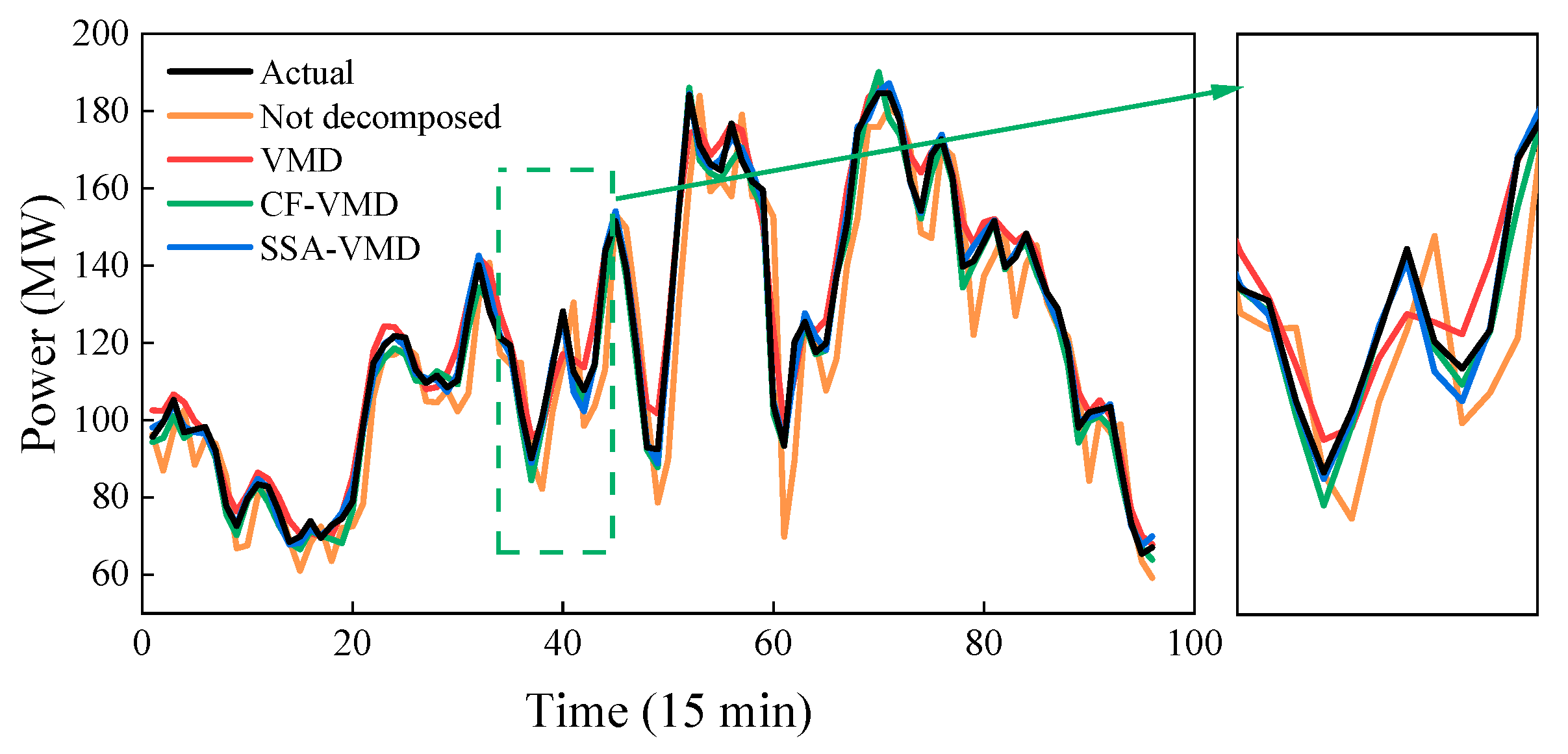
5.2. SSA-VMD Effect and Prediction Experiments
5.3. Seq2Seq Encoding–Decoding Structure Ablation Experiments
5.4. Experiments on Multi-Step Prediction Performance of the Seq2Seq Model
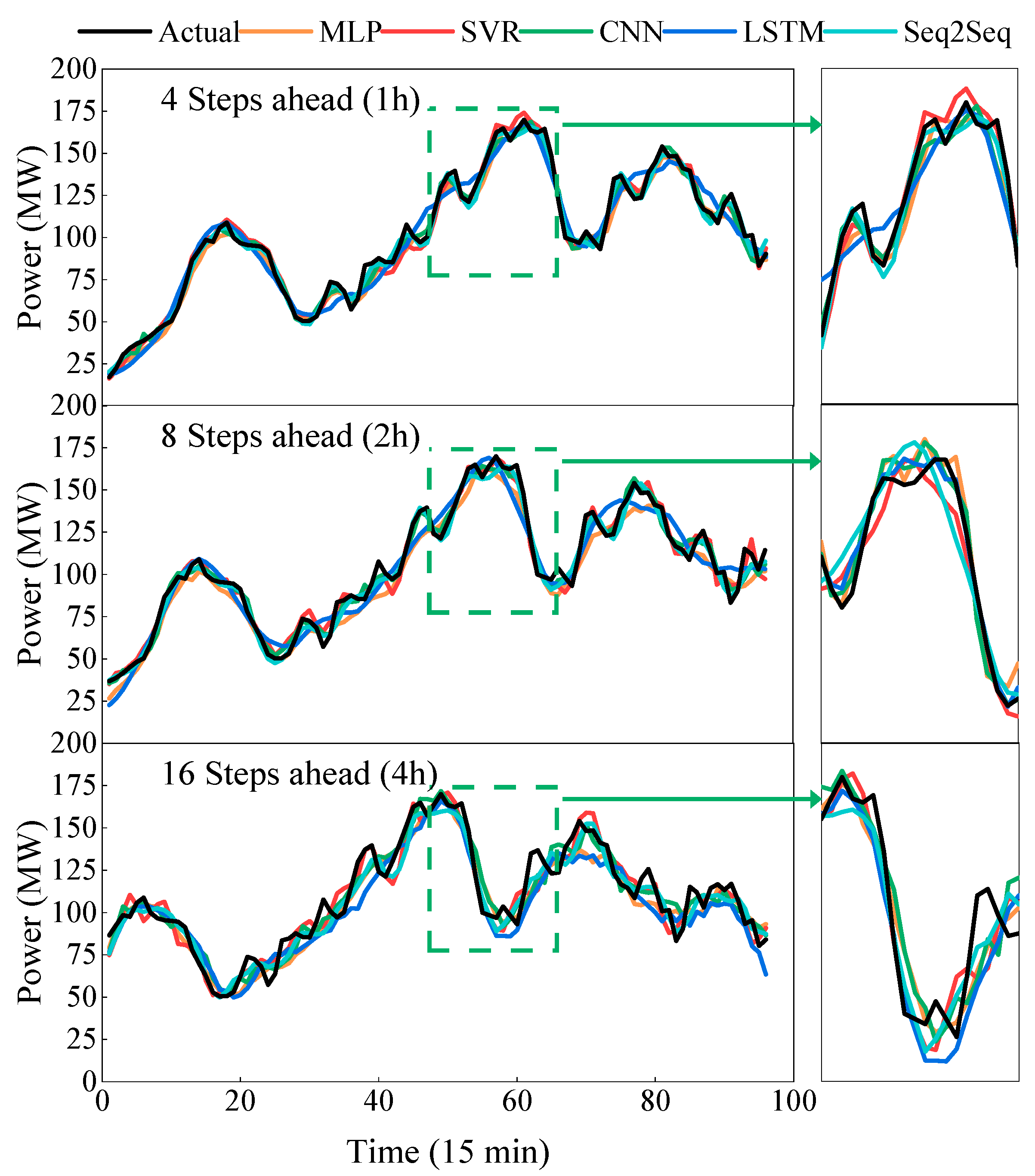
- As the prediction step size increases, the error metrics of all models increase. This shows that the longer the prediction time step is, the more obvious the cumulative error of the model will be, and the more difficult the prediction will be. Among them, the Seq2Seq model is least affected. The MAE, RMSE, and MAPE of the 16-step-ahead prediction are increased by 50.10%, 45.77%, and 63.06%, respectively, compared with the 8-step-ahead prediction. The prediction error increases minimally compared with the baseline method.
- When wind power generation experiences non-stationary fluctuations, the prediction curves of MLP, SVR, and CNN exhibit pronounced oscillations, indicating unstable predictive performance. In contrast, the prediction curves of LSTM and Seq2Seq are relatively smooth. Specifically, Seq2Seq demonstrates MAPE values of 10.73, 12.589, and 20.527 for lead time predictions of 4, 8, and 16 steps, respectively. This suggests that the Seq2Seq model is less affected by data fluctuations, resulting in more stable predictive performance and a closer fit to actual power fluctuations.
- The Seq2Seq model has the lowest MAE, RMSE, and MAPE at 4 steps, 8 steps, and 16 steps in advance, and the advantages become more obvious as the prediction step size increases; the prediction accuracy is the highest. Experimental results show that the Seq2Seq model can maintain the lowest prediction error compared with the baseline method, and the prediction results are more accurate.
6. Conclusions
- The optimization of VMD decomposition parameters through SSA successfully improves the decomposition effectiveness for wind power sequences. The resulting subsequences exhibited stronger representation capabilities of the feature information. In comparison with the traditional approach of determining VMD decomposition parameters using the central frequency method, SSA-VMD reduced the randomness associated with empirical settings and led to higher accuracy in predictions.
- The introduction of CNN-BiGRU as the encoder for the Seq2Seq model fully utilized CNN to extract coupling information between multivariate time series and further exploited deep temporal features through BiGRU. This improvement enhances the model’s encoding capabilities, making it more sensitive to changes in key features.
- The Seq2Seq model proposed in this paper demonstrates significant advantages in multi-step predictions, particularly as the time step increases. Owing to its unique compression–encoding–decoding mechanism, the model delves deeply into uncovering the changing characteristics of wind power. Additionally, the decoder adopts an output feedback mode to predict continuous power sequences, reducing the impact of error accumulation.
- Compared with other benchmark models, the proposed hybrid prediction approach performs best in advance predictions at various lead times, with optimal values achieved for RMSE, MAE, and MAPE metrics. This indicates that the proposed method significantly enhances prediction accuracy and robustness, demonstrating a certain level of applicability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kisvari, A.; Lin, Z.; Liu, X. Wind power forecasting—A data-driven method along with gated recurrent neural network. Renew. Energy 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, Z.H.; Liu, L.J. Short-term wind power prediction analysis of complicated topography in abandoned wind power conditions. Acta Energiae Solaris Sin. 2017, 38, 3376–3384. [Google Scholar]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. A novel hybrid model based on Bernstein polynomial with mixture of Gaussians for wind power forecasting. Appl. Energy 2021, 286, 116545. [Google Scholar] [CrossRef]
- Yang, M.; Zhou, Y. Ultra-short-term prediction of wind power considering wind farm status. Proc. CSEE 2019, 39, 1259–1268. [Google Scholar]
- Hossain, M.A.; Chakrabortty, R.K.; Elsawah, S.; Ryan, M.J. Very short-term forecasting of wind power generation using hybrid deep learning model. J. Clean. Prod. 2021, 296, 126564. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, C.; Luo, Y.; Wu, B.; Dong, N.; Xiao, T.; Zhou, H. Wind power forecast based on variational mode decomposition and long short term memory attention network. Energy Rep. 2022, 8, 922–931. [Google Scholar] [CrossRef]
- Qian, Z.; Pe, Y.; Cao, L.X.; Wang, J.Y.; Jing, B. Review of wind power forecasting method. High Volt. Eng. 2016, 42, 1047–1060. [Google Scholar]
- Feng, S.L.; Wang, W.S.; Liu, C.; Dai, H.Z. Study on the physical approach to wind power prediction. Proc. CSEE 2010, 30, 1–6. [Google Scholar]
- Wang, H.; Han, S.; Liu, Y.; Yang, J.; Li, L. Sequence transfer correction algorithm for numerical weather prediction wind speed and its application in a wind power forecasting system. Appl. Energy 2019, 237, 1–10. [Google Scholar] [CrossRef]
- Liu, S.; Zhu, Y.L.; Zhang, K.; Gao, J.C. Short term wind power forecasting based on error correction ARMA-GARCH model. Acta Energiae Solaris Sin. 2020, 41, 268–275. [Google Scholar]
- Guan, C.; Luh, P.B.; Michel, L.D.; Chi, Z. Hybrid Kalman filters for very short-term load forecasting and prediction interval estimation. IEEE Trans. Power Syst. 2013, 28, 3806–3817. [Google Scholar] [CrossRef]
- Song, J.; Wang, J.; Lu, H. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, B.; Liu, C.; Wang, W. Improved BP neural network algorithm to wind power forecast. J. Eng. 2017, 2017, 940–943. [Google Scholar] [CrossRef]
- Lu, P.; Ye, L.; Tang, Y.; Zhao, Y.; Zhong, W.; Qu, Y.; Zhai, B. Ultra-short-term combined prediction approach based on kernel function switch mechanism. Renew. Energy 2021, 164, 842–866. [Google Scholar] [CrossRef]
- Khodayar, M.; Wang, J.; Manthouri, M. Interval deep generative neural network for wind speed forecasting. IEEE Trans. Smart Grid 2018, 10, 3974–3989. [Google Scholar] [CrossRef]
- Peng, X.; Li, Y.; Dong, L.; Cheng, K.; Wang, H.; Xu, Q.; Wang, B.; Liu, C.; Che, J.; Yang, F.; et al. Short-term wind power prediction based on wavelet feature arrangement and convolutional neural networks deep learning. IEEE Trans. Ind. Appl. 2021, 57, 6375–6384. [Google Scholar] [CrossRef]
- He, J.J.; Yu, C.J.; Li, Y.L.; Xiang, H.Y. Ultra-short term wind prediction with wavelet transform, deep belief network and ensemble learning. Energy Convers. Manag. 2020, 205, 112418. [Google Scholar]
- Shi, X.; Lei, X.; Huang, Q.; Huang, S.Z.; Ren, K.; Hu, Y.Y. Hourly day-ahead wind power prediction using the hybrid model of variational model decomposition and long short-term memory. Energies 2018, 11, 3227. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Xie, X.Y.; Zhou, J.H.; Zhang, Y.J.; Wang, J.; Su, J.Y. W-BilSTM based ultra-short-term generation power predictionmethod of renewable energy. Autom. Electr. Power Syst. 2021, 45, 175–184. [Google Scholar]
- Wang, J.X.; Deng, B.; Wang, J. Short-term wind power prediction based on empirical mode decomposition and RBF neural network. J. Electr. Power Syst. Autom. 2020, 32, 109–115. [Google Scholar]
- Duan, J.; Wang, P.; Ma, W.; Tian, X.; Fang, S.; Cheng, Y.; Chang, Y.; Liu, H. Short-term wind power forecasting using the hybrid model of improved variational mode decomposition and Correntropy Long Short-term memory neural network. Energy 2021, 214, 118980. [Google Scholar] [CrossRef]
- Yildiz, C.; Acikgoz, H.; Korkmaz, D.; Budak, U. An improved residual-based convolutional neural network for very short-term wind power forecasting. Energy Convers. Manag. 2021, 228, 113731. [Google Scholar] [CrossRef]
- Aksan, F.; Suresh, V.; Janik, P.; Sikorski, T. Load Forecasting for the Laser Metal Processing Industry Using VMD and Hybrid Deep Learning Models. Energies 2023, 16, 5381. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, H.; Zhang, J.; Yan, Y.; Zhang, L.; Wu, C.; Hua, X.; Wang, Y. Wind power prediction based on variational mode decomposition multi-frequency combinations. J. Mod. Power Syst. Clean Energy 2019, 7, 281–288. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, R.; Zhang, J. Optimization scheme of wind energy prediction based on artificial intelligence. Environ. Sci. Pollut. Res. 2021, 28, 39966–39981. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wu, L. On practical challenges of decomposition-based hybrid forecasting algorithms for wind speed and solar irradiation. Energy 2016, 112, 208–220. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Li, C.; Tan, J. Multi-step short-term wind speed forecasting approach based on multi-scale dominant ingredient chaotic analysis, improved hybrid GWO-SCA optimization and ELM. Energy Convers. Manag. 2019, 187, 356–377. [Google Scholar] [CrossRef]
- Bao, Y.; Xiong, T.; Hu, Z. Multi-step-ahead time series prediction using multiple-output support vector regression. Neurocomputing 2014, 129, 482–493. [Google Scholar] [CrossRef]
- Tang, J.; Hou, H.J.; Chen, H.G.; Wang, S.J.; Sheng, G.H.; Jiang, C.X. Concentration prediction method based on Seq2Seg network improved by BI-GRU for dissolved gas intransformer oil. Electr. Power Autom. Equip. 2022, 42, 196–202+217. [Google Scholar]
- Deng, Y.; Wang, L.; Jia, H.; Tong, X.; Li, F. A sequence-to-sequence deep learning architecture based on bidirectional GRU for type recognition and time location of combined power quality disturbance. IEEE Trans. Ind. Inform. 2019, 15, 4481–4493. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Jing, X.; Luo, J.; Zhang, S.; Wei, N. Runoff forecasting model based on variational mode decomposition and artificial neural networks. Math. Biosci. Eng. 2022, 19, 1633–1648. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.X.; Zhang, S.; Liu, J.C.; Liu, J.Y.; Xiang, Y.; Han, X.Y. Short-term photo-voltaic power prediction based on variational mode decomposition and long short term memory with dual-stage attention mechanism. Autom. Electr. Power Syst. 2021, 45, 174–182. [Google Scholar]
- Li, H.; Fan, B.; Jia, R.; Zhai, F.; Bai, L.; Luo, X.Q. Research on multi-domain fault diagnosis of gearbox of wind turbine based on adaptive variational mode decomposition and extreme learning machine algorithms. Energies 2020, 13, 1375. [Google Scholar] [CrossRef]
- Yao, J.; Xiang, Y.; Qian, S.; Wang, S.; Wu, S. Noise source identification of diesel engine based on variational mode decomposition and robust independent component analysis. Appl. Acoust. 2017, 116, 184–194. [Google Scholar] [CrossRef]
- Jain, M.; Singh, V.; Rani, A. A novel nature-inspired algorithm for optimization: Squirrel search algorithm. Swarm Evol. Comput. 2019, 44, 148–175. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Kuznetsov, V.; Mariet, Z. Foundations of sequence-to-sequence modeling for time series. arXiv 2018, arXiv:1805.03714. [Google Scholar]
- Chen, Y.C.; Zhang, D.H.; Yu, H.; Wang, Y.Q. Short-term Bus Load Forecasting of Multi Feature Based on Seq2seq Model. J. Electr. Power Syst. Autom. 2023, 35, 1–6+35. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Ghosh, A.; Sufian, A.; Sultana, F.; Chakrabarti, A.; De, D. Fundamental concepts of convolutional neural network. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Springer: Cham, Switzerland, 2020; pp. 519–567. [Google Scholar]
- Aslam, S.; Herodotou, H.; Mohsin, S.M.; Javaid, N.; Ashraf, N.; Aslam, S. A survey on deep learning methods for power load and renewable energy forecasting in smart microgrids. Renew. Sustain. Energy Rev. 2021, 144, 110992. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Yang, M.; Bai, Y.Y. Ultra-short-term prediction of wind power based on multi-location numerical weather prediction and gated recurrent unit. Autom. Electr. Power Syst. 2021, 45, 177–183. [Google Scholar]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]
- Kumari, P.; Toshniwal, D. Deep Learning Models for Solar Irradiance Forecasting: A Comprehensive Review. J. Clean. Prod. 2021, 318, 128566. [Google Scholar] [CrossRef]
- Suresh, V.; Aksan, F.; Janik, P.; Sikorski, T.; Sri Revathi, B. Probabilistic LSTM-Autoencoder Based Hour-Ahead Solar Power Forecasting Model for Intra-Day Electricity Market Participation: A Polish Case Study. IEEE Access 2022, 10, 110628–110638. [Google Scholar] [CrossRef]
- Velasco, L.C.P.; Arnejo, K.A.S.; Macarat, J.S.S. Performance Analysis of Artificial Neural Network Models for Hour-Ahead Electric Load Forecasting. Procedia Comput. Sci. 2021, 197, 16–24. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decomposition Methods | MAE/MW | RMSE/MW | MAPE/% |
|---|---|---|---|
| Undecomposed | 4.155 | 6.985 | 15.886 |
| VMD | 2.19 | 3.174 | 12.508 |
| CF-VMD | 1.865 | 2.274 | 12.89 |
| SSA-VMD | 1.104 | 1.542 | 9.662 |
| Modeling | Predicted Step Length | MAE /MW | RMSE /MW | MAPE /% | |
|---|---|---|---|---|---|
| Encoders | Decoders | ||||
| LSTM | LSTM | 4 steps | 2.726 | 4.36 | 15.031 |
| 8 steps | 3.023 | 4.703 | 17.345 | ||
| 16 steps | 4.382 | 6.401 | 31.514 | ||
| GRU | GRU | 4 steps | 2.819 | 4.036 | 23.809 |
| 8 steps | 2.552 | 3.916 | 15.455 | ||
| 16 steps | 5.176 | 6.99 | 47.67 | ||
| BiGRU | GRU | 4 steps | 2.036 | 3.199 | 11.252 |
| 8 steps | 2.543 | 3.832 | 13.279 | ||
| 16 steps | 4.709 | 6.368 | 39.765 | ||
| CNN- BiGRU | GRU | 4 steps | 1.902 | 3.02 | 10.73 |
| 8 steps | 2.409 | 3.681 | 12.589 | ||
| 16 steps | 3.616 | 5.366 | 20.527 | ||
| Modeling | Predicted Step Length | MAE/MW | RMSE/MW | MAPE/% |
|---|---|---|---|---|
| MLP | 4 steps | 3.451 | 4.811 | 25.005 |
| 8 steps | 6.44 | 8.024 | 59.391 | |
| 16 steps | 7.782 | 10.816 | 68.974 | |
| SVR | 4 steps | 5.081 | 6.777 | 59.782 |
| 8 steps | 5.881 | 7.504 | 71.971 | |
| 16 steps | 6.538 | 8.525 | 68.155 | |
| CNN | 4 steps | 2.673 | 3.884 | 19.553 |
| 8 steps | 3.628 | 5.106 | 30.979 | |
| 16 steps | 6.531 | 9.059 | 58.595 | |
| LSTM | 4 steps | 3.51 | 4.88 | 29.026 |
| 8 steps | 3.01 | 4.626 | 15.439 | |
| 16 steps | 5.465 | 7.712 | 22.924 | |
| Seq2Seq | 4 steps | 1.902 | 3.02 | 10.73 |
| 8 steps | 2.409 | 3.681 | 12.589 | |
| 16 steps | 3.616 | 5.366 | 20.527 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, W.; Jin, M.; Li, W.; Zhao, J.; Feng, B.; Xie, T.; Li, S.; Li, H. Multi-Step Prediction of Wind Power Based on Hybrid Model with Improved Variational Mode Decomposition and Sequence-to-Sequence Network. Processes 2024, 12, 191. https://doi.org/10.3390/pr12010191
Bai W, Jin M, Li W, Zhao J, Feng B, Xie T, Li S, Li H. Multi-Step Prediction of Wind Power Based on Hybrid Model with Improved Variational Mode Decomposition and Sequence-to-Sequence Network. Processes. 2024; 12(1):191. https://doi.org/10.3390/pr12010191
Chicago/Turabian StyleBai, Wangwang, Mengxue Jin, Wanwei Li, Juan Zhao, Bin Feng, Tuo Xie, Siyao Li, and Hui Li. 2024. "Multi-Step Prediction of Wind Power Based on Hybrid Model with Improved Variational Mode Decomposition and Sequence-to-Sequence Network" Processes 12, no. 1: 191. https://doi.org/10.3390/pr12010191
APA StyleBai, W., Jin, M., Li, W., Zhao, J., Feng, B., Xie, T., Li, S., & Li, H. (2024). Multi-Step Prediction of Wind Power Based on Hybrid Model with Improved Variational Mode Decomposition and Sequence-to-Sequence Network. Processes, 12(1), 191. https://doi.org/10.3390/pr12010191